Getting Started with Roboflow Inference on NVIDIA® Jetson Devices
This wiki guide explains how to easily deploy AI models using Roboflow inference server running on NVIDIA Jetson devices. Here we will use Roboflow Universe to select an already trained model, deploy the model to the Jetson device and perform inference on a live webcam stream!
Roboflow Inference is the easiest way to use and deploy computer vision models, providing an HTTP Roboflow API used for running inference. Roboflow inference supports:
- Object detection
- Image Segmentation
- Image Classification
and foundation models like CLIP and SAM.
Prerequisites
- Ubuntu Host PC (native or VM using VMware Workstation Player)
- reComputer Jetson or any other NVIDIA Jetson device
This wiki has been tested and verified on a reComputer J4012 and reComputer Industrial J4012 powered by NVIDIA Jetson Orin NX 16GB module
Flash JetPack to Jetson
Now you need to make sure that the Jetson device is flashed with a JetPack system. You can either use NVIDIA SDK Manager or command-line to flash JetPack to the device.
For Seeed Jetson-powered devices flashing guides, please refer to the below links:
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 Carrier Board
- A205 Carrier Board
- A206 Carrier Board
- A603 Carrier Board
- A607 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
- reComputer Indsutrial
- reServer Industrial
Make sure to Flash JetPack version 5.1.1 because that is the version we have verified for this wiki
Tap into 50,000+ Models at Roboflow Universe
Roboflow offers 50,000+ ready-to-use AI models for everyone to get started with computer vision deployment in the fastest way. You can explore them all at Roboflow Universe. Roboflow Universe also offers 200,000+ datasets where you can use these datasets to train a model on Roboflow cloud servers or else bring your own dataset, use Roboflow online image annotation tool and start training.
-
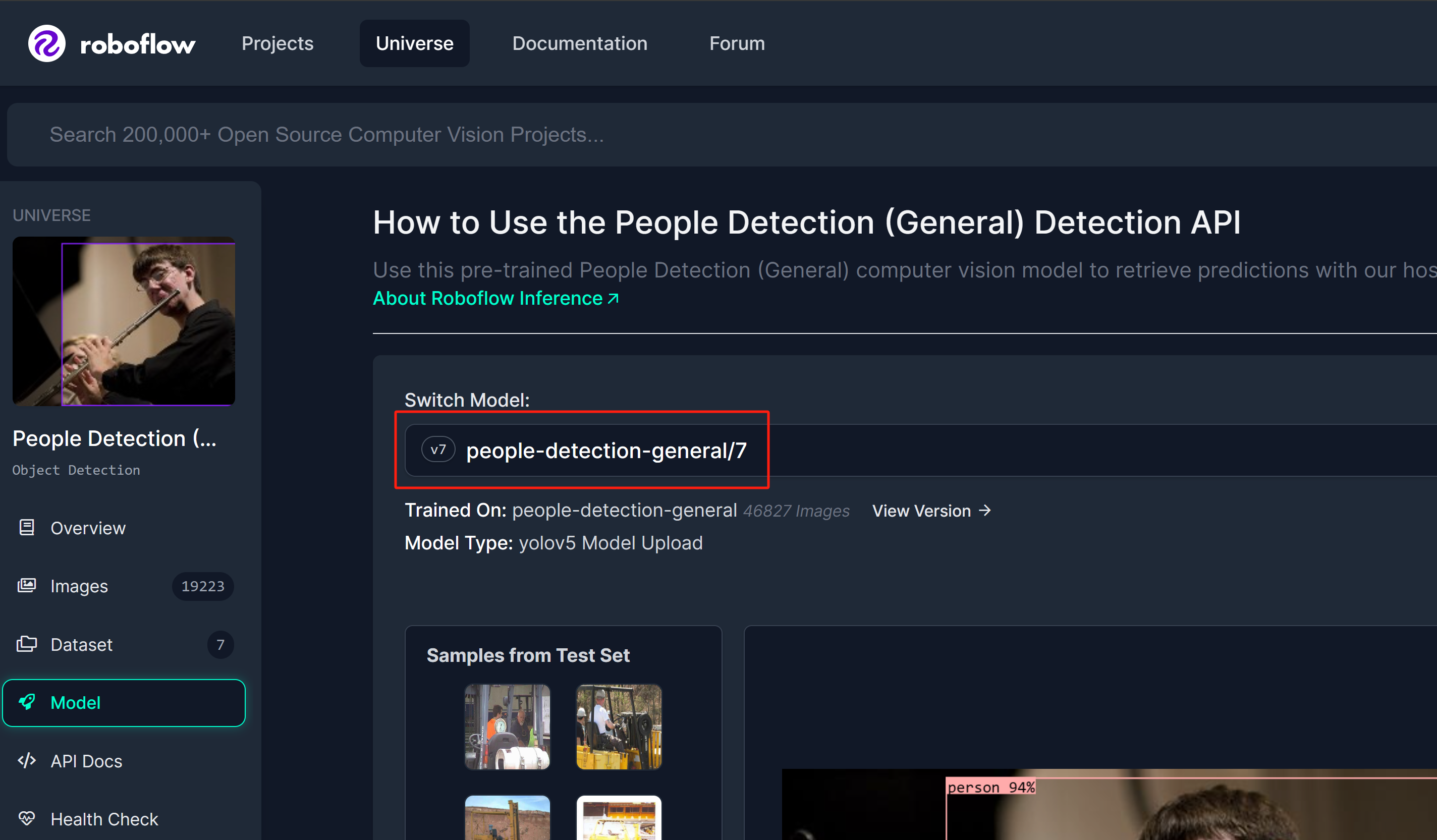
Step 1: We will use a people detection model from Roboflow Universe as reference
-
Step 2: Here the model name will follow the format "model_name/version". In this case, it is people-detection-general/7. We will use this model name later in this wiki when we start inferencing.
Obtain Roboflow API Key
Now we need to obtain a Roboflow API key for the Roboflow inference server to work.
-
Step 1: Sign up for a new Roboflow account by entering your credentials
-
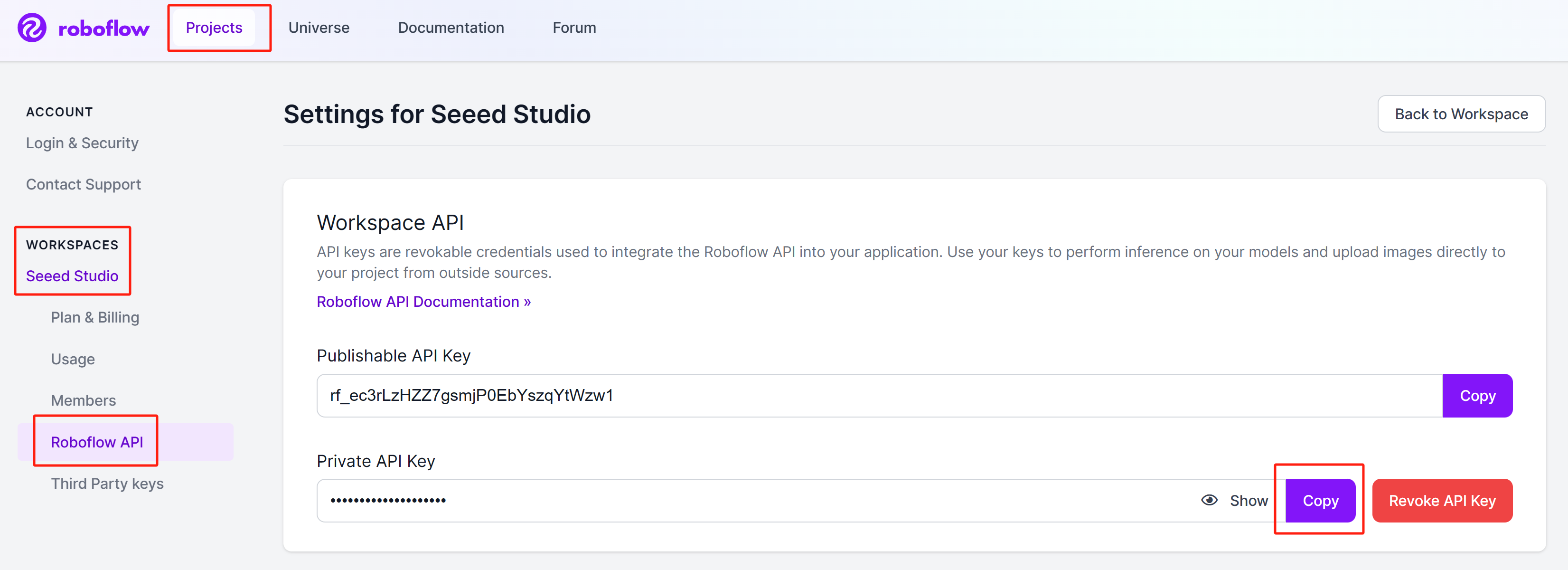
Step 2: Sign in to the account, navigate to
Projects > Workspaces > <your_workspace_name> > Roboflow API, and click Copy next to "Private API Key" section
Keep this private key because we will be needing it later.
Running Roboflow Inference Server
You can get started with Roboflow inference on NVIDIA Jetson in 3 different ways.
- Using pip package - Using pip package will be the fastest way to get started, however you will need to install SDK components (CUDA, cuDNN, TensorRT) along with JetPack.
- Using Docker hub - Using Docker hub will be a little slow because it will first pull a Docker image which is around 19GB. however you do not need to install SDK components because the Docker image will already have those.
- Using local Docker build - Using local Docker build is an extension of Docker hub method where you can change the source code for the Docker image according to your desired application (such as enable TensorRT precision with INT8).
Before moving on to running Roboflow inference server, you need to obtain an AI model to inference on, and a Roboflow API key. We will first go through that.
- pip Package
- Docker Hub
- Local Docker Build
Using pip Package
- Step 1: If you only flash the Jetson device with Jetson L4T, you need to install SDK components first
sudo apt update
sudo apt install nvidia-jetpack -y
- Step 2: Execute the below commands on the terminal to install Roboflow inference server pip package
sudo apt update
sudo apt install python3-pip -y
pip install inference-gpu
- Step 3: Execute the below and replace with your Roboflow Private API Key that you obtained before
export ROBOFLOW_API_KEY=your_key_here
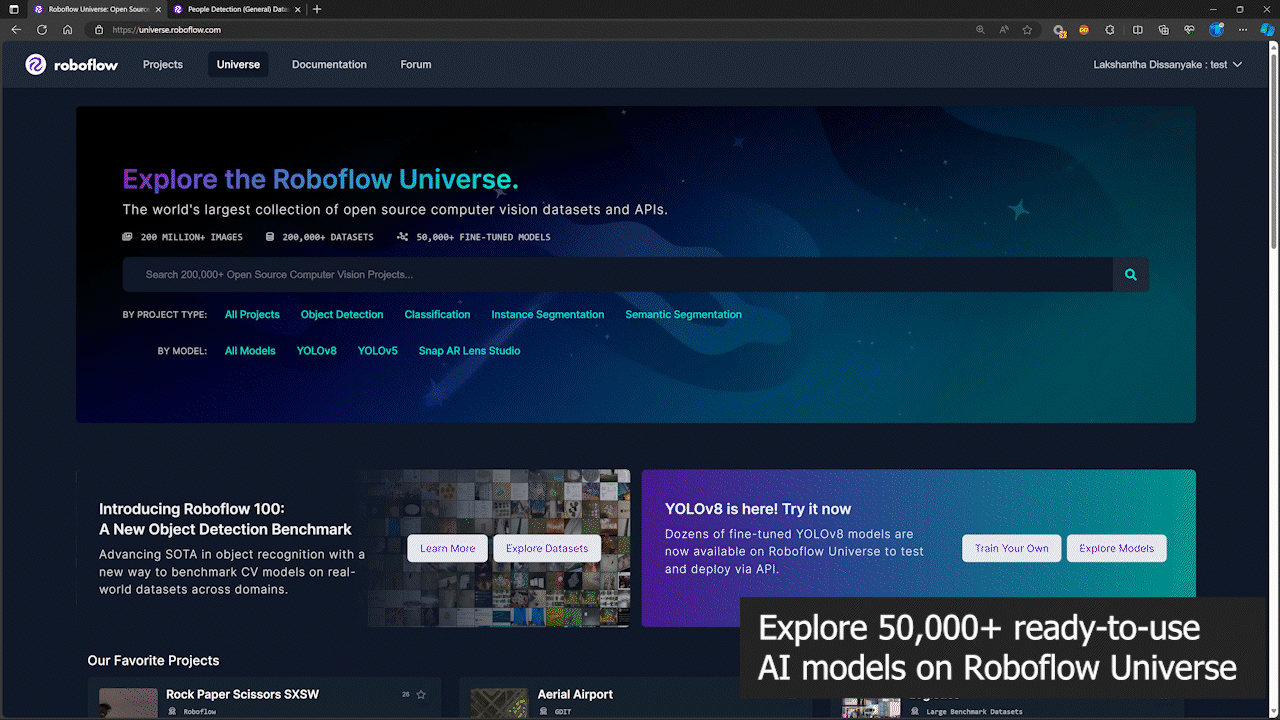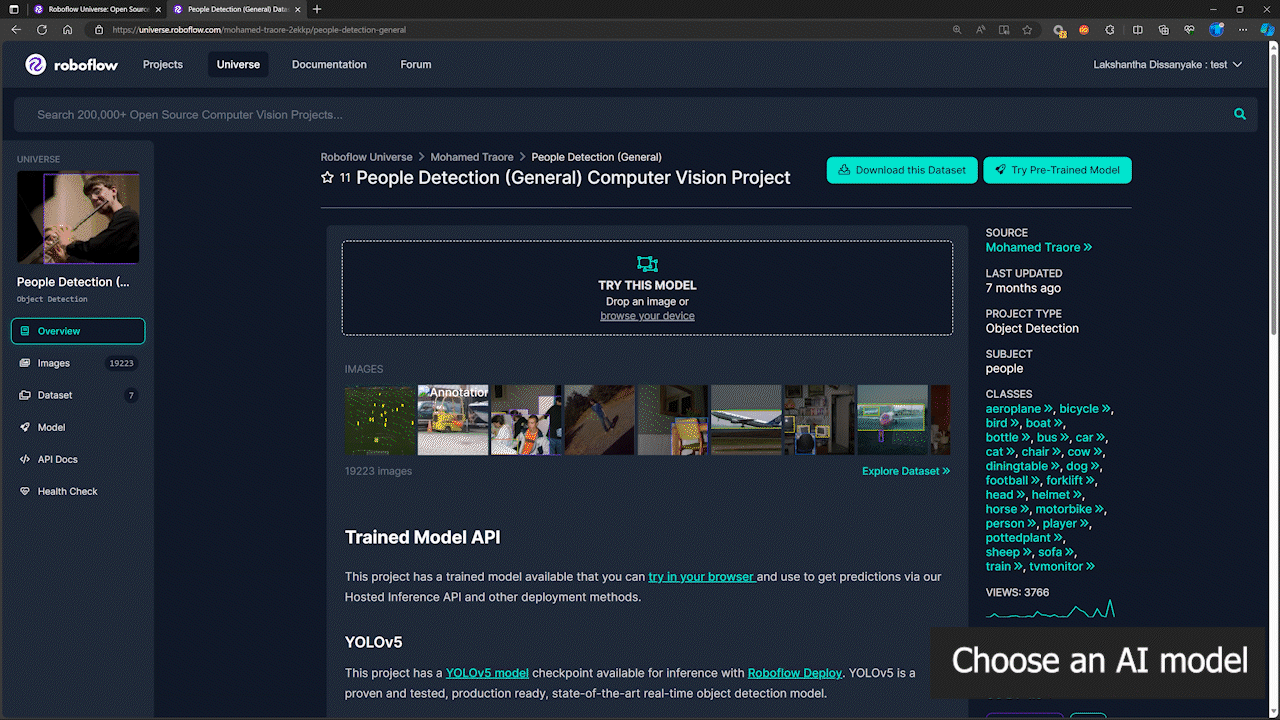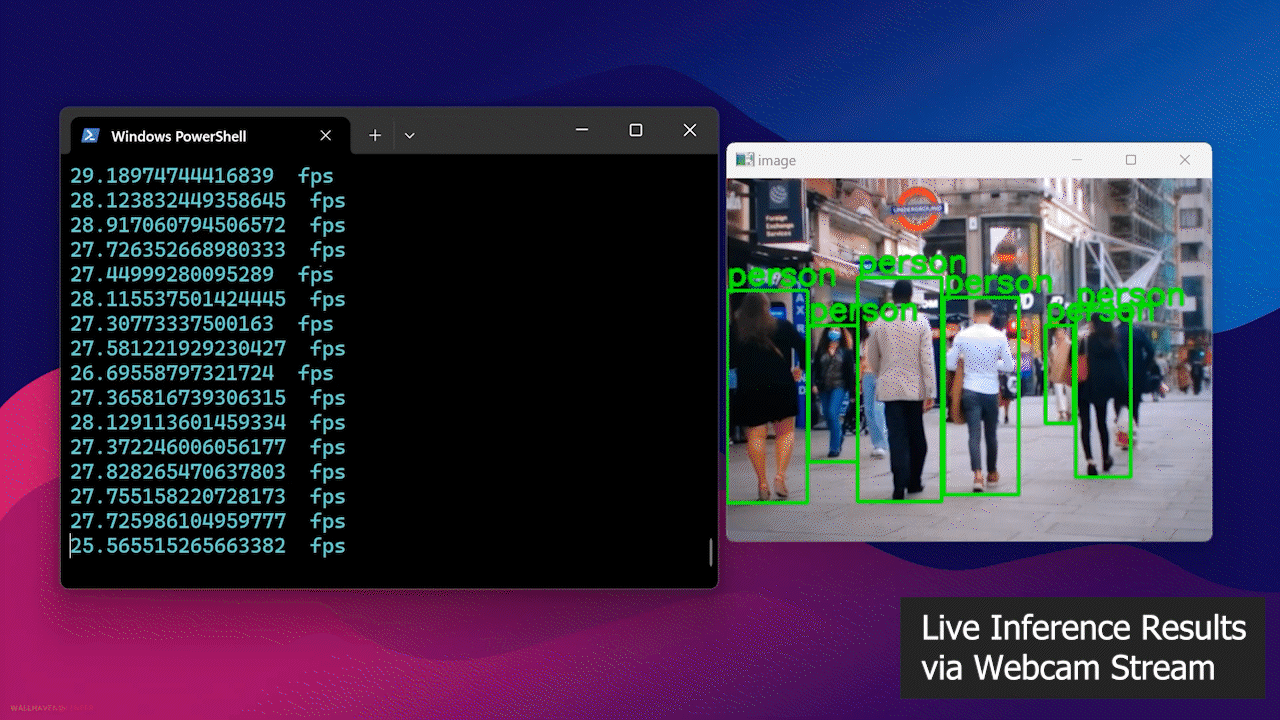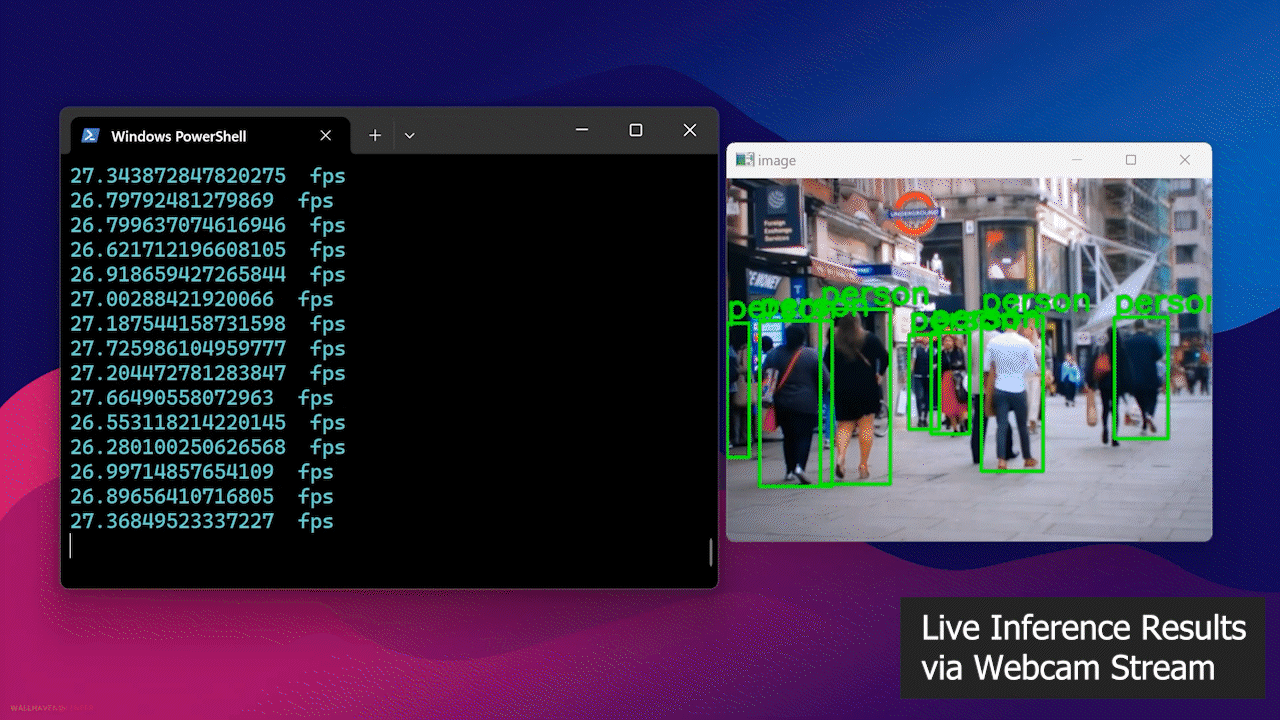
- Step 4: Connect a webcam to the Jetson device and execute the following Python script to run an open-source people detection model on your webcam stream
webcam.py
import cv2
import inference
import supervision as sv
annotator = sv.BoxAnnotator()
inference.Stream(
source="webcam",
model=" people-detection-general/7",
output_channel_order="BGR",
use_main_thread=True,
on_prediction=lambda predictions, image: (
print(predictions),
cv2.imshow(
"Prediction",
annotator.annotate(
scene=image,
detections=sv.Detections.from_roboflow(predictions)
)
),
cv2.waitKey(1)
)
)
Finally, you will see the result as follows
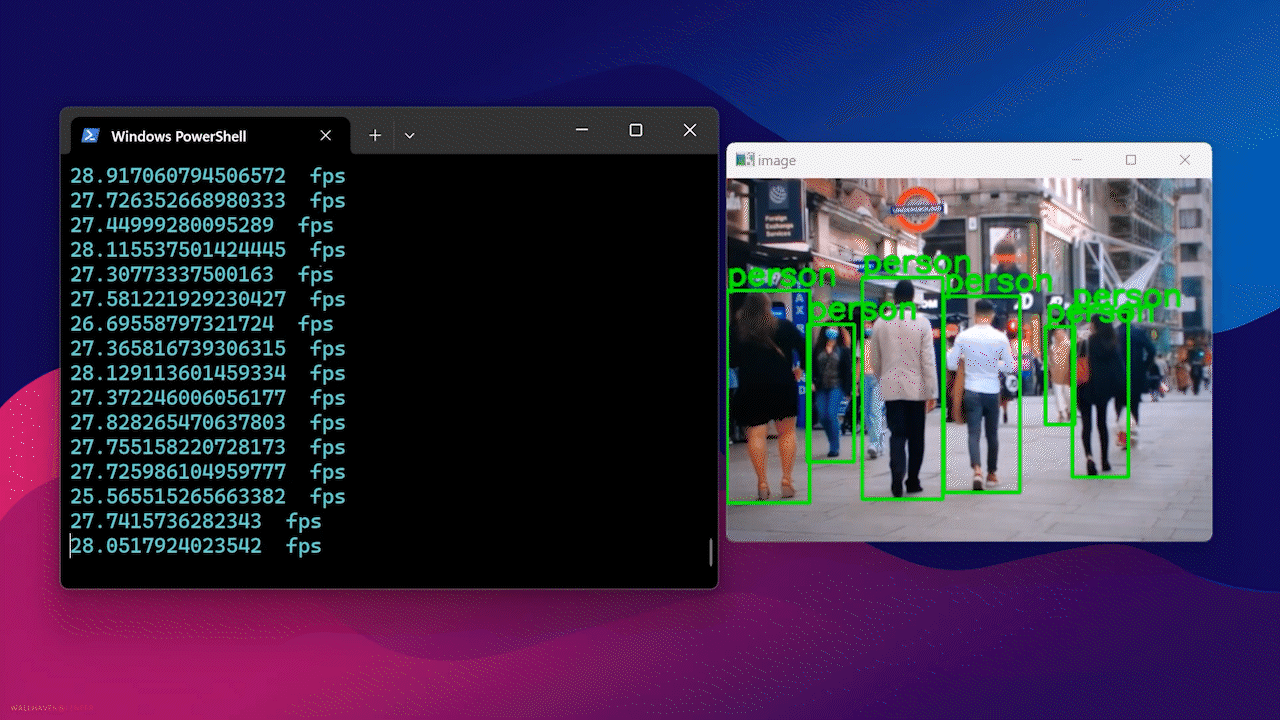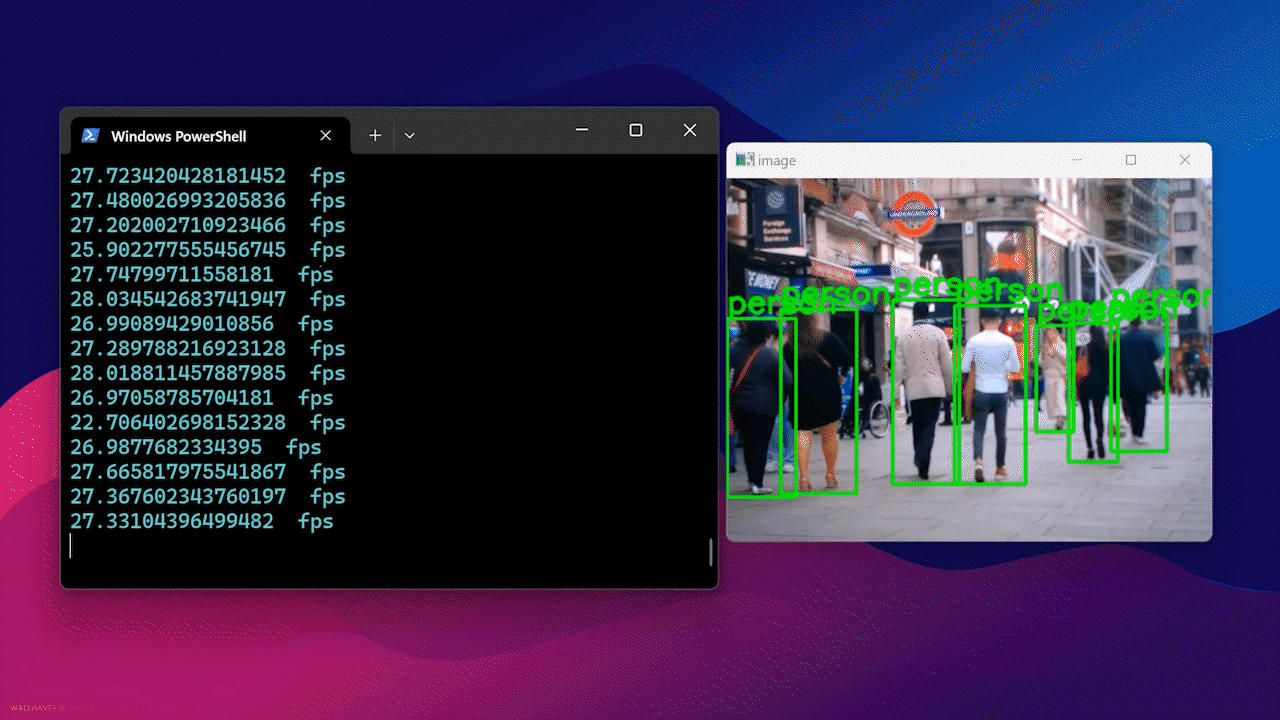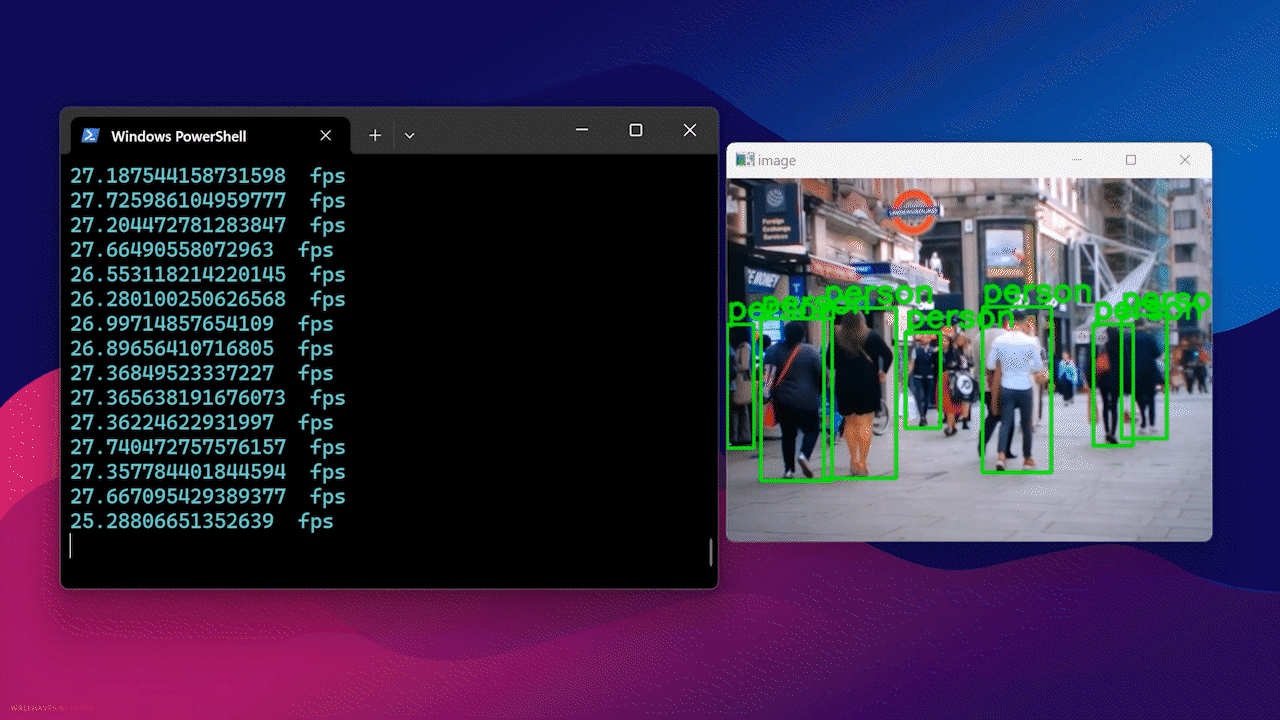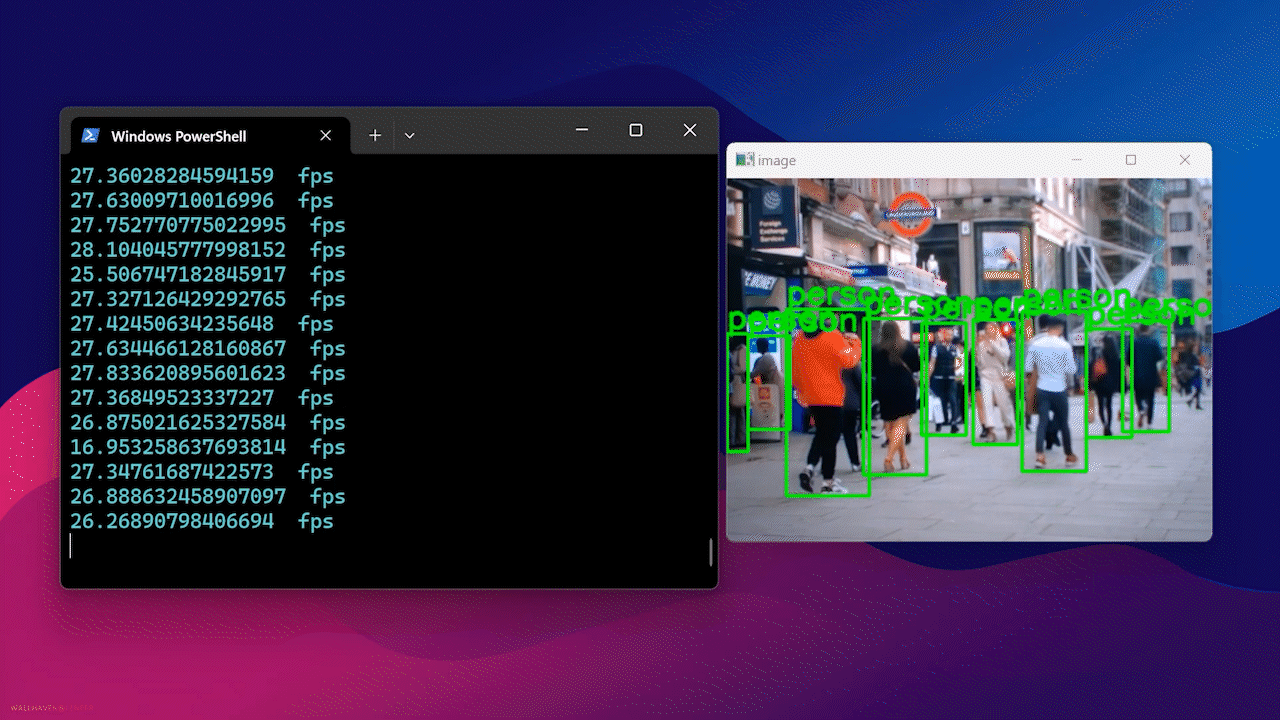
Using Docker Hub
To use this method, flashing the device with Jetson L4T is enough. This uses a client-server architecture where Roboflow inference server will run on a specific network port on the Jetson and you will be able to access this inference server using any PC on the same network or even use the Jetson itself as server and client both.
Server Setup - Jetson
Execute the following to download and run the Roboflow inference server Docker container
sudo docker run --network=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1
If you see the following output, the inference server has started successfully

Client Setup - Jetson/ PC
- Step 1: Install the necessary packages
sudo apt update
sudo apt install python3-pip -y
git clone https://github.com/roboflow/roboflow-api-snippets
cd Python/webcam
pip install -r requirements.txt
-
Step 2: Create a roboflow_config.json file in the same directory including your Roboflow API key, model name. You can refer to the sample roboflow_config.sample.json file included inside this GitHub repo
-
Step 3: On the same device on a different terminal window or on another PC on the same as the Jetson, execute the following Python script to run an open-source people detection model on your webcam stream
python infer-simple.py
Using Local Docker Build
Server Setup - Jetson
To use this method, flashing the device with Jetson L4T is enough. This uses a client-server architecture where Roboflow inference server will run on a specific network port on the Jetson and you will be able to access this inference server using any PC on the same network or even use the Jetson itself as server and client both.
- Step 1: Clone the Roboflow inference server repository
git clone https://github.com/roboflow/inference
- Step 2: Enter the "inference" directory and start compiling your own Docker image
cd inference
sudo docker build \
-f docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1 \
-t roboflow/roboflow-inference-server-jetson-5.1.1:seeed1 .
Here the text after "-t" is the name of the container we are building. You can give it any name.
- Step 3: Execute the below command to check whether the Docker image we compiled is listed
sudo docker ps

- Step 4: Start a Docker container based on the Docker image that you just built
docker run --privileged --net=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1:seeed1
If you see the following output, the inference server has started successfully

Client Setup - Jetson/ PC
Execute the following Python script to run an open-source people detection model on your webcam stream webcam.py
import cv2
import base64
import requests
import time
upload_url = ("http://<ip_address_of_jetson>:9001/"
"people-detection-general/7"
"?api_key=xxxxxxxx"
"&stroke=5")
video = cv2.VideoCapture(0)
while True:
start = time.time()
ret, img = video.read()
if ret:
# Resize (while maintaining the aspect ratio) to improve speed and save bandwidth
height, width, channels = img.shape
scale = 416 / max(height, width)
img = cv2.resize(img, (round(scale * width), round(scale * height)))
# Encode image to base64 string
retval, buffer = cv2.imencode('.jpg', img)
img_str = base64.b64encode(buffer)
# Get prediction from Roboflow Infer API
resp = requests.post(upload_url, data=img_str, headers={
"Content-Type": "application/x-www-form-urlencoded"
}, stream=True)
resp = resp.json()
for bbox in resp["predictions"]:
img = cv2.rectangle(
img,
(int(bbox['x']-(bbox['width']/2)), int(bbox['y']-(bbox['height']/2))),
(int(bbox['x']+(bbox['width']/2)), int(bbox['y']+(bbox['height']/2))),
(0, 255, 0),
2)
cv2.putText(
img, f"{bbox['class']}",
(int(bbox['x']-(bbox['width']/2)), int(bbox['y']-(bbox['height']/2)-5)),
0, 0.9,
(0, 255, 0), thickness=2, lineType=cv2.LINE_AA
)
cv2.imshow('image', img)
print((1/(time.time()-start)), " fps")
if cv2.waitKey(1) == ord('q'):
break
video.release()
cv2.destroyAllWindows()
Note that the elements that need to be included in the upload_url in the script are:
- IP address of roboflow inference srever
- The model you want to run
- roboflow api key
The model can be selected in the roboflow universe
Enable TensorRT
By default, Roboflow inference server is using CUDA runtime. However, if you want to change to TensorRT runtime to increase the inference speed, you can add the following inside the file "inference/docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1" and build the Docker image
ENV ONNXRUNTIME_EXECUTION_PROVIDERS=TensorrtExecutionProvider
Learn more
Roboflow offers very detailed and comprehensive documentation. So it is highly recommended to check them here.
Tech Support & Product Discussion
Thank you for choosing our products! We are here to provide you with different support to ensure that your experience with our products is as smooth as possible. We offer several communication channels to cater to different preferences and needs.