Wio Terminal Tensorflow Lite Micro Intelligent meteostation with BME280
In this project we’re going to use Wio Terminal and Tensorflow Lite for Microcontrollers to create an intelligent meteostation, able to predict the weather and precipitation for next 24 hours based on local data from BME280 environmental sensor.

For more details and visuals, watch the corresponding video!
You will learn how to apply model optimization techniques, that will allow not only to run medium-sized Convolutional neural network, but also to have this sleeky GUI and WiFi connection all running at the same time for days and month at the time!

This is the end result, you can see there are current temperature, humidity and atmospheric pressure values displayed on the screen, together with city name, predicted weather type and predicted precipitation chance – and in the bottom of the screen there is a log output field, which you can easily re-purpose for displaying extreme weather information or other relevant information. While it looks good and useful as it is, there is a lot of things you can add yourself – for example above mentioned news/tweets output on the screen or using deep sleep mode to conserve energy and make it battery powered and so on.
In this project we will be dealing with time series data, as we did multiple times before - the only big difference this time is that the time period is much larger for weather prediction. We are going to take a measurement every hour and perform prediction on 24 hours of data. Also since we're going to predict the average weather type for next 24 hours, additionally we will predict a precipitation chance for next 24 hours, with the same model. In order to do that we will utilize Keras Functional API and multi-output model.
Within multi-output model there is going to be "a stem", common for both outputs, which going to "branch out" to two different outputs. Main benefit of using multi-output model as compared to two independent models here is that the data and learned features used for predicting weather type and precipitation chance are highly related.
If you are making this project on Windows, first thing you’ll need to do is to download nightly version of Arduino IDE, since current stable version 1.18.3 will not compile sketches with a lot of library dependencies (the issue is that linker command during compilation exceeds maximum length on Windows).
Second, you need to make sure you have 1.8.2 version of Seeed SAMD board definitions in Arduino IDE.
Finally, since we’re using a Convolutional neural network and build it with Keras API, it contains an operation not supported by current stable version of Tensorflow Micro. Browsing Tensorflow issues on Github I found that there is a pull request for adding this op (EXPAND_DIMS) to list of available ops, but it was not merged into master at the time of making this video. You can git clone the Tensorflow repository, switch to PR branch and compile Arduino library by executing./tensorflow/lite/micro/tools/ci_build/test_arduino.sh on Linux machine – the resulting library can be found in tensorflow/lite/micro/tools/make/gen/arduino_x86_64/prj/tensorflow_lite.zip. Alternatively, you can download already compiled library from this project Github repository and place it into your Arduino sketches libraries folder – just make sure you only have one Tensorflow lite library at the time!
Understanding the data
It all starts with data of course. For this tutorial we will use a readily available weather dataset from Kaggle, Historical Hourly Weather Data 2012-2017. Seeed EDU headquarters are located in Shenzhen, a city in Southern China – and that city is absent from the dataset, so we picked a city that is located on the similar latitude and also has a subtropical climate – Miami.
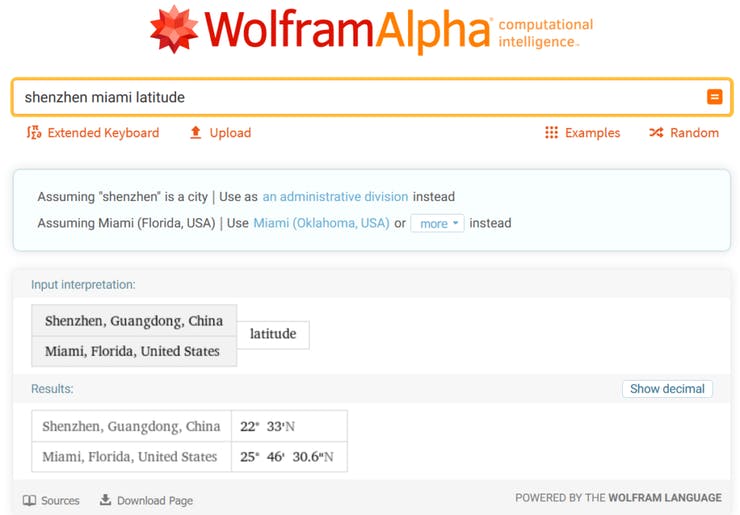
You’ll need to pick a city that at least resembles the climate where you live – it goes without saying that the model trained on data from Miami and then deployed in Chicago in winter is not going to output correct predictions.
Building a machine learning model
For data processing and model training step, let’s open Jupyter Notebook you can find in course materials. The easiest way to run this notebook is to upload it to Google Colab, since it already has all the packages installed and ready to run.
Alternatively you can execute the notebook locally - to do that first install all the required dependencies in the virtual environment by running
pip install -r requirements.txt
with ml virtual environment you have created before activated. Then run jupyter notebook command in the same environment, which will open notebook server in your default browser. Jupyter Notebooks are great way to explore and present data, since they allow having both text and executable code in the same environment. The general workflow is explained in the Notebook text sections.
Deploying to Wio Terminal
The model you have trained in the last step was converted to a byte array, which contains model structure and wights and can now be loaded to Wio Terminal together with C++ code.
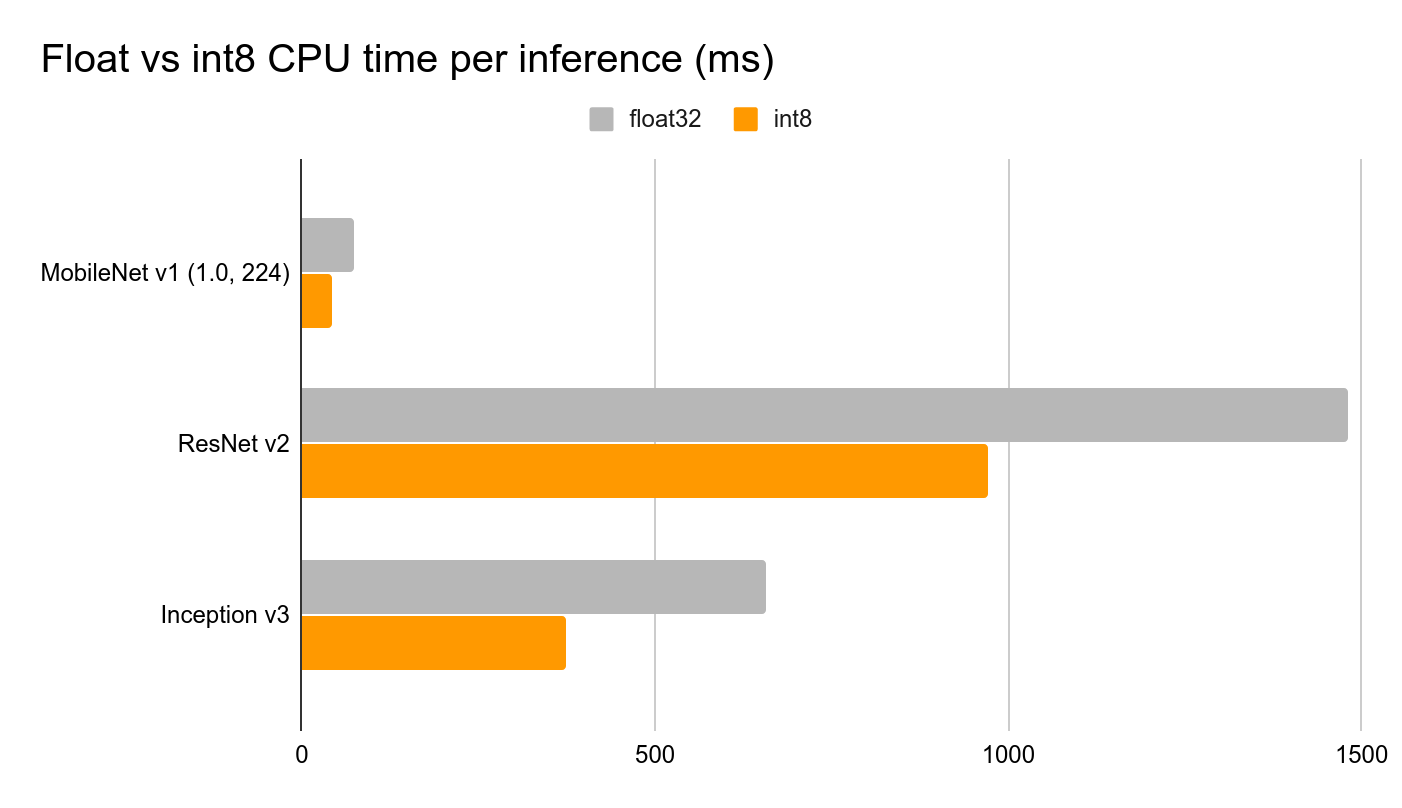
Tensorflow Lite for Microcontrollers includes model Interpreter, which is designed to be lean and fast. The interpreter uses a static graph ordering and a custom (less-dynamic) memory allocator to ensure minimal load, initialization, and execution latency. The data placed in input buffers is fed to the model graph and then after inference is finished results are placed in the output buffer. In order to reduce the size of the model and decrease inference time, we perform two important optimizations: • Perform full-integer quantization, changing model weights, inputs and outputs from floating point 32 numbers (each one occupying 32 bits of memory) to integer 8 numbers (each occupying only 8 bits), thus reducing size by factor of 4.
• Use micro_mutable_op_resolver and specify operations that we have in neural network, to compile our code only with the operations needed to run the model, as opposed to using all_ops_resolver, which includes all operations supported by current Tensorflow Lite for Microcontrollers interpreter.
Once the model training is finished, create an empty sketch and save it. Then copy the model you trained to the sketch folder and re-open the sketch. Change the variable name of model and model length to something shorter. Then use the code from wio_terminal_tfmicro_weather_prediction_static.ino, which you can find in course materials for testing.
Let’s go over the main steps we have in C++ code We include the headers for Tensorflow library and the file with model flatbuffer
#include <TensorFlowLite.h>
//#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/micro/all_ops_resolver.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/system_setup.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "model_Conv1D.h"
Notice how I have micro_mutable_op_resolver.h commented out and all_ops_resolver.h enabled – all_ops_resolver.h header compiles all the operations currently present in Tensorflow Micro and convenient for testing, but once you finished testing it is much better to switch to micro_mutable_op_resolver.h to save devices memory – it does make a big difference. Next we define the pointers for error reporter, model, input and output tensors and interpreter. Notice how our model has two outputs – one for precipitation amount and another one for weather type. We also define tensor arena, which you can think of as a scratch board, holding input, output, and intermediate arrays – size required will depend on the model you are using, and may need to be determined by experimentation.
// Globals, used for compatibility with Arduino-style sketches.
namespace {
tflite::ErrorReporter* error_reporter = nullptr;
const tflite::Model* model = nullptr;
tflite::MicroInterpreter* interpreter = nullptr;
TfLiteTensor* input = nullptr;
TfLiteTensor* output_type = nullptr;
TfLiteTensor* output_precip = nullptr;
constexpr int kTensorArenaSize = 1024*25;
uint8_t tensor_arena[kTensorArenaSize];
} // namespace
Then in setup function, there is more boilerplate stuff, such as instantiating error reporter, op resolver, interpreter, mapping the model, allocating tensors and finally checking the tensor shapes after allocation. Here is when code might throw an error during runtime, if some of model operations are not supported by current version of Tensorflow Micro library. In case you have unsupported operations, you can either changed the model architecture or add the support for the operator yourself, usually by porting it from Tensorflow Lite.
void setup() {
Serial.begin(115200);
while (!Serial) {delay(10);}
// Set up logging. Google style is to avoid globals or statics because of
// lifetime uncertainty, but since this has a trivial destructor it's okay.
// NOLINTNEXTLINE(runtime-global-variables)
static tflite::MicroErrorReporter micro_error_reporter;
error_reporter = µ_error_reporter;
// Map the model into a usable data structure. This doesn't involve any
// copying or parsing, it's a very lightweight operation.
model = tflite::GetModel(Conv1D_tflite);
if (model->version() != TFLITE_SCHEMA_VERSION) {
TF_LITE_REPORT_ERROR(error_reporter,
"Model provided is schema version %d not equal "
"to supported version %d.",
model->version(), TFLITE_SCHEMA_VERSION);
return;
}
// This pulls in all the operation implementations we need.
// NOLINTNEXTLINE(runtime-global-variables)
//static tflite::MicroMutableOpResolver<1> resolver;
static tflite::AllOpsResolver resolver;
// Build an interpreter to run the model with.
static tflite::MicroInterpreter static_interpreter(model, resolver, tensor_arena, kTensorArenaSize, error_reporter);
interpreter = &static_interpreter;
// Allocate memory from the tensor_arena for the model's tensors.
TfLiteStatus allocate_status = interpreter->AllocateTensors();
if (allocate_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "AllocateTensors() failed");
return;
}
// Obtain pointers to the model's input and output tensors.
input = interpreter->input(0);
output_type = interpreter->output(1);
output_precip = interpreter->output(0);
Serial.println(input->dims->size);
Serial.println(input->dims->data[1]);
Serial.println(input->dims->data[2]);
Serial.println(input->type);
Serial.println(output_type->dims->size);
Serial.println(output_type->dims->data[1]);
Serial.println(output_type->type);
Serial.println(output_precip->dims->size);
Serial.println(output_precip->dims->data[1]);
Serial.println(output_precip->type);
}
Finally in the loop function we define a placeholder for quantized INT8 values and an array with float values, which you can copy paste from Colab notebook for comparison of model inference on device vs. in Colab.
void loop() {
int8_t x_quantized[72];
float x[72] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0};
We quantize the float values to INT8 in for loop and place them in the input tensor one by one:
for (byte i = 0; i < 72; i = i + 1) {
input->data.int8[i] = x[i] / input->params.scale + input->params.zero_point;
}
Then inference is performed by Tensorflow Micro interpreter and if no errors are reported, values are placed in the output tensors.
// Run inference, and report any error
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed");
return;
}
Similar to input, the output of the model is also quantized, so we need to perform the reverse operation and convert it from INT8 to float.
// Obtain the quantized output from model's output tensor
float y_type[4];
// Dequantize the output from integer to floating-point
int8_t y_precip_q = output_precip->data.int8[0];
Serial.println(y_precip_q);
float y_precip = (y_precip_q - output_precip->params.zero_point) * output_precip->params.scale;
Serial.print("Precip: ");
Serial.print(y_precip);
Serial.print("\t");
Serial.print("Type: ");
for (byte i = 0; i < 4; i = i + 1) {
y_type[i] = (output_type->data.int8[i] - output_type->params.zero_point) * output_type->params.scale;
Serial.print(y_type[i]);
Serial.print(" ");
}
Serial.print("\n");
}
Check and compare the values for the same data point, they should be the same for quantized Tensorflow Lite model in Colab notebook and Tensorflow Micro model running on your Wio Terminal.

LVGL Interface and WiFi
Now the next step is to make it from a demo into actually useful project. Open the sketch wio_terminal_tfmicro_weather_prediction_static.ino from course materials and have a look at its content.

The code is divided into main sketch, get_historical_data and GUI parts. Since our model requires the data for past 24 hours we would need to wait 24 hours to perform the first inference, which is a lot – to solve this problem we get the weather for past 24 hours from openweathermap.com API and can perform the first inference immediately after device boots up and then replace the values in the circular buffer with temperature, humidity and pressure from BME280 sensor connected to Wio Terminal I2C Grove socket. For GUI we used LVGL, a Little and Versatile Graphics Library.

Compile and upload the code, make sure you change WiFi credentials, your location and openweathermap.com API key in sketch before uploading. After upload the device will connect to the Internet, get the data for last 24 hours for your location and perform the first inference. Then it will wait for 1 hour before getting the values from BME280 sensor connected to Wio Terminal - if no sensor connected, the program will not initialize.