如何在 reComputer 上训练和部署 YOLOv8
介绍
面对日益复杂和动态的挑战,人工智能的应用为解决问题提供了新的途径,并为全球社会的可持续发展和人们生活质量的改善做出了重大贡献。通常,在部署人工智能算法之前,AI 模型的设计和训练在高性能计算服务器上进行。一旦模型训练完成,就会导出到边缘计算设备进行边缘推理。实际上,所有这些过程都可以直接在边缘计算设备上进行。具体来说,准备数据集、训练神经网络、验证神经网络和部署模型等任务都可以在边缘设备上执行。这不仅确保了数据安全,还节省了购买额外设备的成本。

在本文档中,我们在 reComputer J4012 上训练和部署一个用于交通场景的目标检测模型。本文档以 YOLOv8 目标检测算法为例,详细介绍了整个过程。请注意,下面描述的所有操作都在 Jetson 边缘计算设备上进行,确保 Jetson 设备安装了 JetPack 5.0 或更高版本的操作系统。
数据集
机器学习的过程涉及在给定数据中寻找模式,然后使用函数来捕获这些模式。因此,数据集的质量直接影响模型的性能。一般来说,训练数据的质量和数量越好,训练出的模型就越好。因此,数据集的准备至关重要。
收集训练数据集有多种方法。这里介绍两种方法:1. 下载预标注的开源公共数据集。2. 收集和标注训练数据。最后,整合所有数据为后续的训练阶段做准备。
下载公共数据集
公共数据集是在机器学习和人工智能研究中广泛使用的共享标准化数据资源。它们为研究人员提供标准基准来评估算法性能,促进该领域的创新和协作。这些数据集推动 AI 社区朝着更加开放、创新和可持续的方向发展。
有许多平台可以免费下载数据集,如 Roboflow、 Kaggle 等。在这里,我们从 Kaggle 下载一个与交通场景相关的标注数据集, Traffic Detection Project。
解压后的文件结构如下:
archive
├── data.yaml
├── README.dataset.txt
├── README.roboflow.txt
├── test
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.jpg
│ │ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.txt
│ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.txt
│ ├── ...
├── train
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.jpg
│ │ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.txt
│ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.txt
│ ├── ...
└── valid
├── images
│ ├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.jpg
│ ├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.jpg
│ ├── ...
└── labels
├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.txt
├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.txt
├──...
每个图像都有一个对应的文本文件,其中包含该图像的完整标注信息。data.json 文件记录了训练集、测试集和验证集的位置,您需要修改路径:
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 5
names: ['bicycle', 'bus', 'car', 'motorbike', 'person']
收集和标注数据
当公共数据集无法满足用户需求时,需要考虑收集和创建针对特定需求的自定义数据集。这可以通过收集、标注和组织相关数据来实现。 为了演示目的,我从 YouTube 捕获并保存了三张图像,并尝试使用 Label Studio 来标注这些图像。
步骤 1. 收集原始数据:

步骤 2. 安装并运行标注工具:
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
sudo chmod a+rw /var/run/docker.sock
mkdir label_studio_data
sudo chmod -R 776 label_studio_data
docker run -it -p 8080:8080 -v $(pwd)/label_studio_data:/label-studio/data heartexlabs/label-studio:latest
步骤 3. 创建一个新项目并按照提示完成标注: Label Studio 参考文档
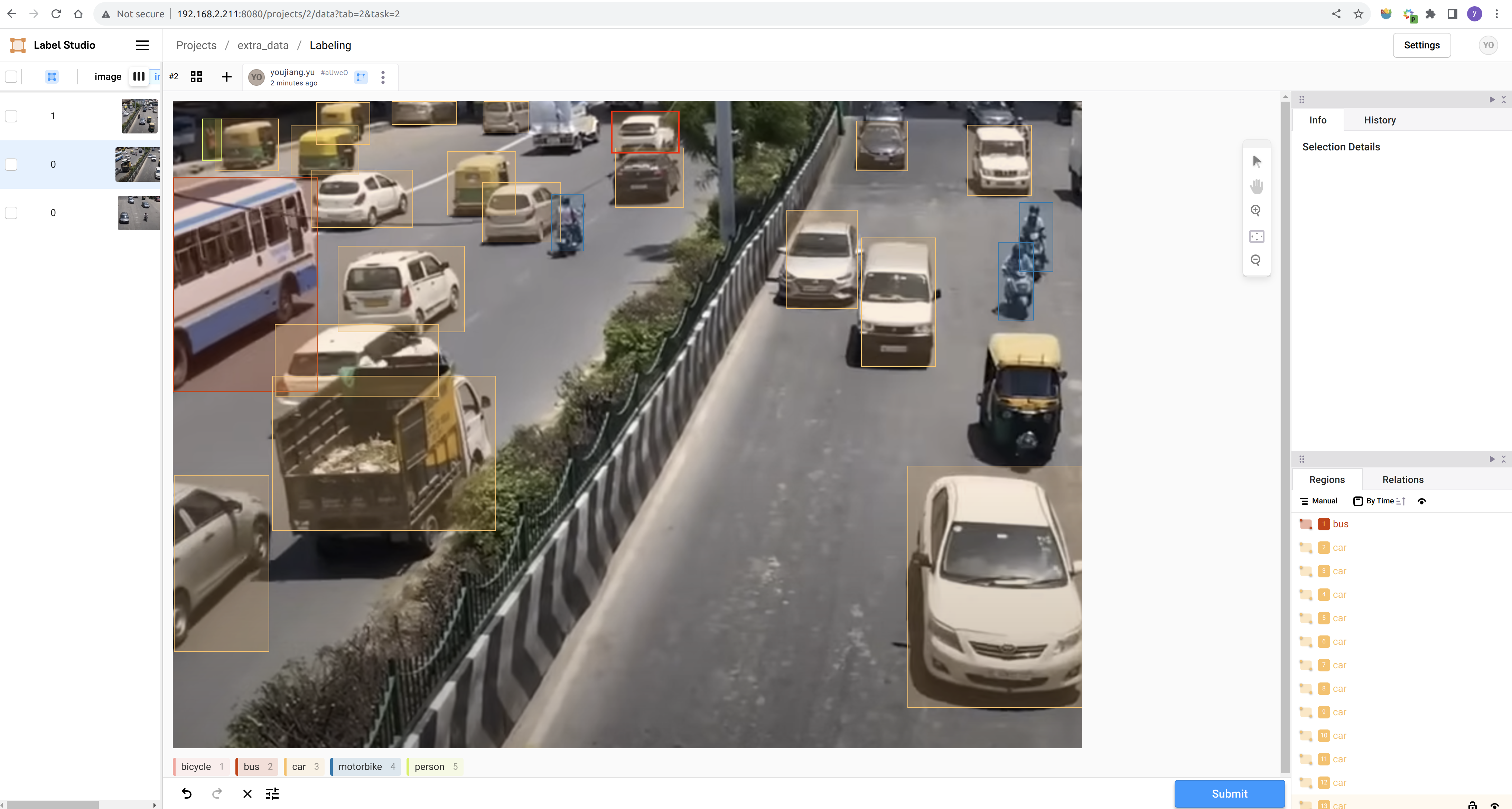
完成标注后,您可以导出 YOLO 格式的数据集,并将标注数据与下载的数据一起整理。最简单的方法是将所有图像复制到公共数据集的 train/images 文件夹中,将生成的标注文本文件复制到公共数据集的 train/labels 文件夹中。
至此,我们通过两种不同的方法获得了训练数据并将它们整合在一起。如果您想要更高质量的训练数据,还有许多额外的步骤需要考虑,例如数据清洗、类别平衡等等。由于我们的任务相对简单,我们现在将跳过这些步骤,直接使用上面获得的数据进行训练。
模型
在本节中,我们将在 reComputer 上下载 YOLOv8 源代码并配置运行环境。
步骤 1. 使用以下命令下载源代码:
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
步骤 2. 打开 requirements.txt 并修改相关内容:
# Use the `vi` command to open the file
vi requirements.txt
# Press `a` to enter edit mode, and modify the following content:
torch>=1.7.0 --> # torch>=1.7.0
torchvision>=0.8.1 --> # torchvision>=0.8.1
# Press `ESC` to exit edit mode, and finally input `:wq` to save and exit the file.
步骤 3. 运行以下命令来下载 YOLO 所需的依赖项并安装 YOLOv8:
pip3 install -e .
cd ..
步骤 4. 安装 Jetson 版本的 PyTorch:
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.cn/compute/redist/jp/v512/pytorch/torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl -O torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
步骤 5. 安装相应的 torchvision:
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.16.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
cd ..
步骤 6. 使用以下命令确保已成功安装 YOLO:
yolo detect predict model=yolov8s.pt source='https://ultralytics.com/images/bus.jpg'
训练
模型训练是更新模型权重的过程。通过训练模型,机器学习算法可以从数据中学习识别模式和关系,从而能够对新数据进行预测和决策。
步骤 1. 创建一个用于训练的 Python 脚本:
vi train.py
按 a 进入编辑模式,并修改以下内容:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8s.pt')
# Train the model
results = model.train(
data='/home/nvidia/Everything_Happens_Locally/Dataset/data.yaml',
batch=8, epochs=100, imgsz=640, save_period=5
)
按 ESC 退出编辑模式,最后输入 :wq 保存并退出文件。
YOLO.train() 方法有许多配置参数;详情请参考
文档。
此外,您可以使用更简化的 CLI 方法根据您的具体需求开始训练。
步骤 2. 使用以下命令开始训练:
python3 train.py
接下来是漫长的等待过程。考虑到等待期间可能会关闭远程连接窗口,本教程使用了 Tmux 终端复用器。因此,我在过程中看到的界面如下所示:
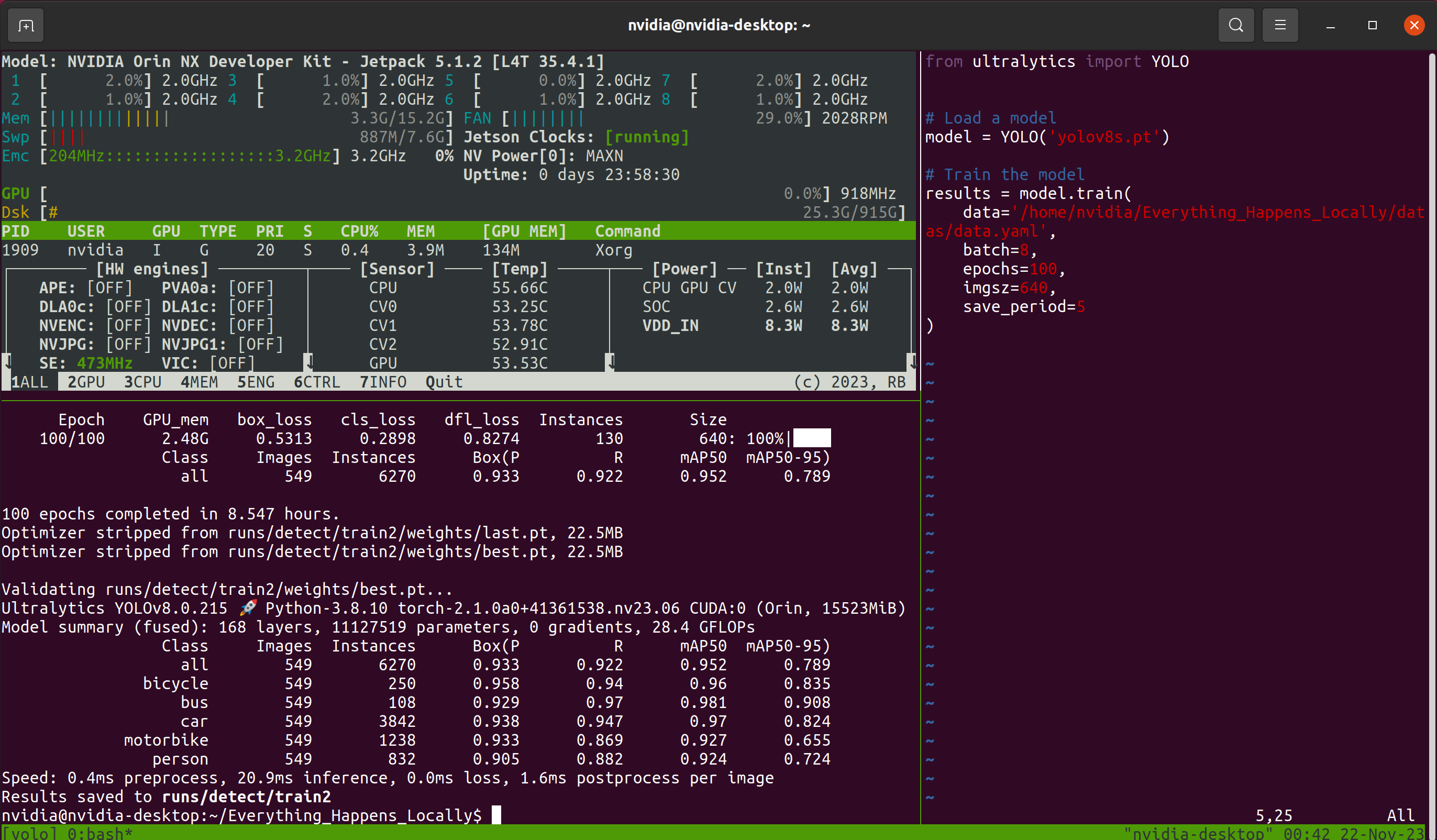
Tmux 是可选的;只要模型正常训练即可。训练程序完成后,您可以在指定文件夹中找到训练过程中保存的模型权重文件:

验证
验证过程涉及使用一部分数据来验证模型的可靠性。这个过程有助于确保模型能够在实际应用中准确且稳健地执行任务。如果您仔细查看训练过程中输出的信息,您会注意到在整个训练过程中穿插了许多验证。本节不会分析每个评估指标的含义,而是通过检查预测结果来分析模型的可用性。
步骤 1. 使用训练好的模型对特定图像进行推理:
yolo detect predict \
model='./runs/detect/train2/weights/best.pt' \
source='./datas/test/images/ant_sales-2615_png_jpg.rf.0ceaf2af2a89d4080000f35af44d1b03.jpg' \
save=True show=False
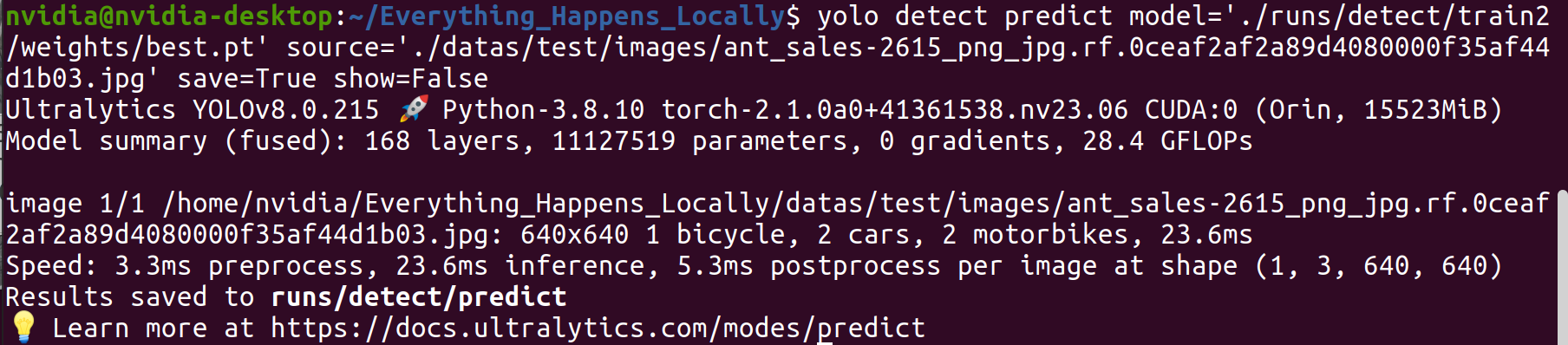
步骤 2. 检查推理结果。
从检测结果可以观察到,训练的模型达到了预期的检测性能。

部署
部署是将训练好的机器学习或深度学习模型应用到实际场景中的过程。上面介绍的内容已经验证了模型的可行性,但没有考虑模型的推理效率。在部署阶段,需要在检测精度和效率之间找到平衡。可以使用 TensorRT 推理引擎来提高模型的推理速度。
步骤 1. 为了直观地展示轻量化模型与原始模型的对比,使用 vi 工具创建一个新的 inference.py 文件来实现视频文件推理。您可以通过修改第 8 行和第 9 行来替换推理模型和输入视频。本文档中的输入是我用手机拍摄的视频。
from ultralytics import YOLO
import os
import cv2
import time
import datetime
model = YOLO("/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt")
cap = cv2.VideoCapture('./sample_video.mp4')
save_dir = os.path.join('runs/inference_test', datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S'))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
output = cv2.VideoWriter(os.path.join(save_dir, 'result.mp4'), fourcc, fps, size)
while cap.isOpened():
success, frame = cap.read()
if success:
start_time = time.time()
results = model(frame)
annotated_frame = results[0].plot()
total_time = time.time() - start_time
fps = 1/total_time
cv2.rectangle(annotated_frame, (20, 20), (200, 60), (55, 104, 0), -1)
cv2.putText(annotated_frame, f'FPS: {round(fps, 2)}', (30, 50), 0, 0.9, (255, 255, 255), thickness=2, lineType=cv2.LINE_AA)
print(f'FPS: {fps}')
cv2.imshow("YOLOv8 Inference", annotated_frame)
output.write(annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cv2.destroyAllWindows()
cap.release()
output.release()
步骤 2. 运行以下命令并记录模型量化前的推理速度:
python3 inference.py

结果表明,量化前模型的推理速度为 21.9 FPS
步骤 3. 生成量化模型:
pip3 install onnx
yolo export model=/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt format=engine half=True device=0
程序完成后(大约10-20分钟),将在输入模型的同一目录中生成一个.engine文件。该文件就是量化后的模型。

步骤 4. 使用量化模型测试推理速度。
在这里,您需要修改步骤1中创建的脚本第8行的内容。
model = YOLO(<path to .pt>) --> model = YOLO(<path to .engine>)
然后,重新运行推理命令:
python3 inference.py

从推理效率的角度来看,量化模型在推理速度方面显示出显著的改进。
总结
本文为读者提供了一个全面的指南,涵盖了从数据收集和模型训练到部署的各个方面。重要的是,所有过程都在 reComputer 中进行,无需用户额外的 GPU。
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。