训练并部署您自己的AI模型到SenseCAP A1101
概述
在本教程中,我们将教您如何为特定应用训练自己的AI模型,然后轻松地将其部署到SenseCAP A1101 - LoRaWAN视觉AI传感器上。让我们开始吧!
硬件介绍
我们将在本教程中主要使用SenseCAP A1101 - LoRaWAN视觉AI传感器。首先,让我们熟悉一下这个硬件。
SenseCAP A1101 - LoRaWAN视觉AI传感器结合了TinyML AI技术和LoRaWAN长距离传输,为户外使用提供了低功耗、高性能的AI设备解决方案。该传感器采用海思的高性能、低功耗AI视觉解决方案,支持Google TensorFlow Lite框架和多个TinyML AI平台。不同的模型可以实现不同的AI功能,例如害虫检测、人员计数、物体识别。用户可以采用Seeed提供的模型,通过AI训练工具生成自己的模型,或从Seeed的合作伙伴模型提供商处获取可部署的商业模型。

软件介绍
我们将在本教程中使用以下软件技术
- Roboflow - 用于标注
- YOLOv5 - 用于训练
- TensorFlow Lite - 用于推理

什么是Roboflow?
Roboflow是一个基于在线的标注工具。该工具允许您轻松标注所有图像,对这些图像添加进一步处理,并将标记的数据集导出为不同格式,如YOLOV5 PyTorch、Pascal VOC等!Roboflow还为用户提供了现成的公共数据集。
什么是YOLOv5?
YOLO是"You Only Look Once"的缩写。它是一种实时检测和识别图像中各种物体的算法。Ultralytics YOLOv5是基于PyTorch框架的YOLO版本。
什么是TensorFlow Lite?
TensorFlow Lite是一个开源的、产品就绪的、跨平台的深度学习框架,它将TensorFlow中的预训练模型转换为可以针对速度或存储进行优化的特殊格式。这种特殊格式的模型可以部署在边缘设备上,如使用Android或iOS的移动设备,或基于Linux的嵌入式设备如Raspberry Pi或微控制器,以在边缘进行推理。
Wiki 结构
本 wiki 将分为三个主要部分
第一部分将是以最少步骤构建您自己的 AI 模型的最快方法。第二部分需要花费一些时间和精力来构建您自己的 AI 模型,但绝对值得学习。第三部分关于部署 AI 模型可以在第一或第二部分之后进行。
因此有两种方式来遵循本 wiki:
但是,我们鼓励首先遵循第一种方式,然后再转向第二种方式。
1. 使用公共数据集训练您自己的 AI 模型
目标检测项目的第一步是获取用于训练的数据。您可以下载公开可用的数据集或创建您自己的数据集!
但是开始目标检测的最快最简单的方法是什么呢?嗯...使用公共数据集可以为您节省大量时间,否则您需要自己收集数据并对其进行标注。这些公共数据集已经开箱即用地进行了标注,为您提供更多时间专注于您的 AI 视觉应用。
硬件准备
- SenseCAP A1101 - LoRaWAN Vision AI Sensor
- USB Type-C 数据线
- 具有互联网访问的 Windows/ Linux/ Mac
软件准备
- 无需准备额外软件
使用公开可用的标注数据集
您可以下载许多公开可用的数据集,如 COCO 数据集、Pascal VOC 数据集等等。Roboflow Universe 是一个推荐的平台,它提供广泛的数据集,拥有90,000+ 个数据集和 66+ 百万张图像可用于构建计算机视觉模型。此外,您可以简单地在 Google 上搜索开源数据集并从各种可用的数据集中选择。
-
步骤 1. 访问此 URL 以访问 Roboflow Universe 上公开可用的苹果检测数据集
-
步骤 2. 点击Create Account创建 Roboflow 账户
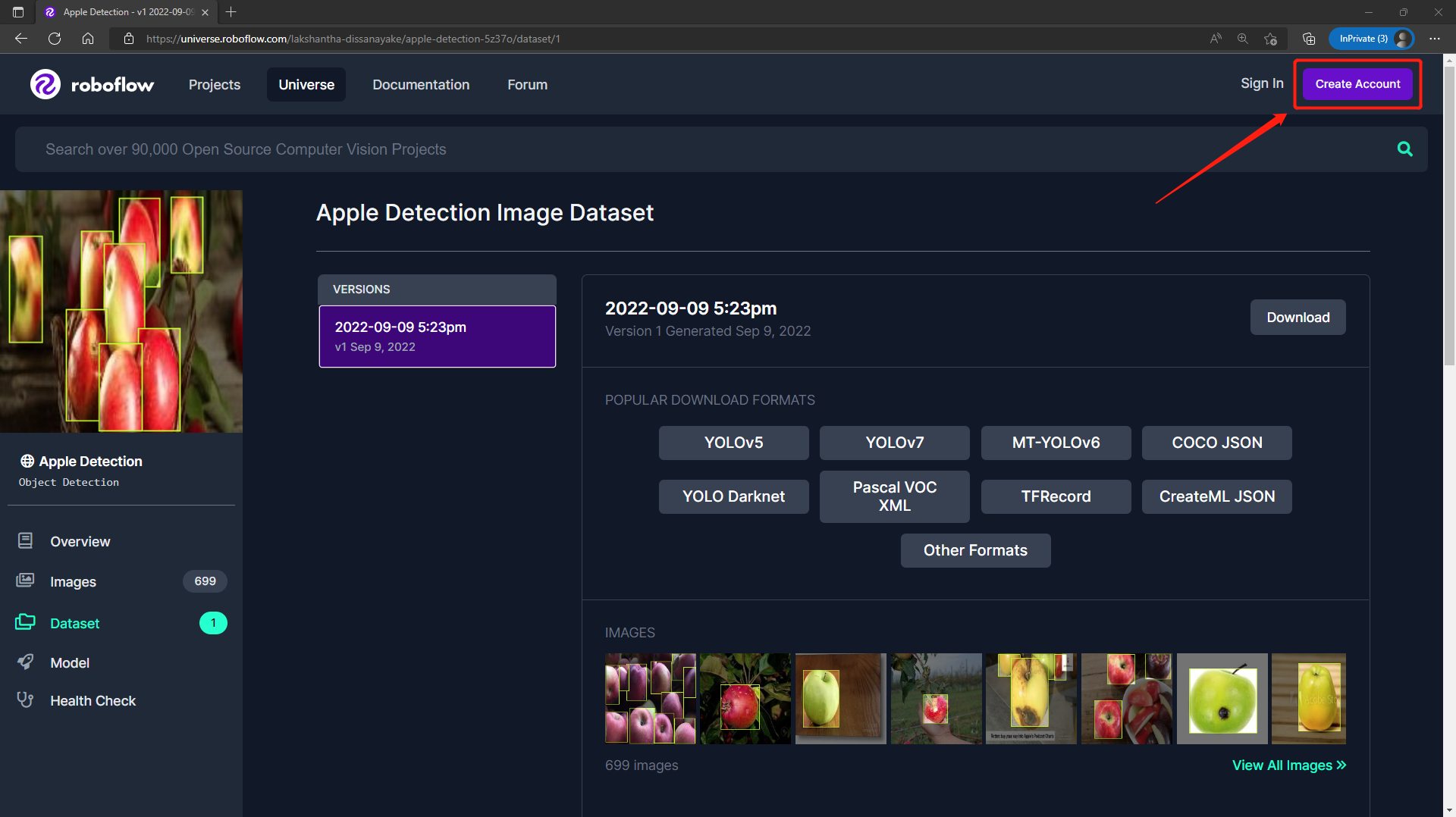
- 步骤 3. 点击Download,选择YOLO v5 PyTorch作为Format,点击show download code并点击Continue
这将生成一个代码片段,我们稍后将在 Google Colab 训练中使用。所以请保持此窗口在后台打开。
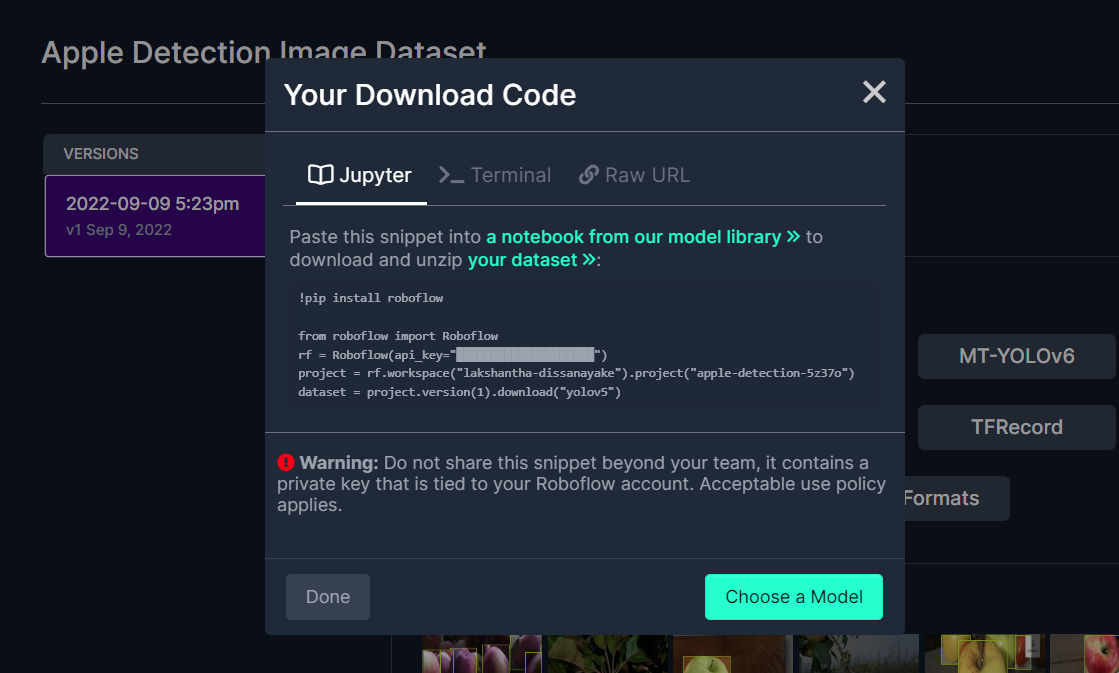
在 Google Colab 上使用 YOLOv5 进行训练
在我们选择了公共数据集之后,我们需要训练数据集。这里我们使用 Google Colaboratory 环境在云端执行训练。此外,我们在 Colab 中使用 Roboflow api 来轻松下载我们的数据集。
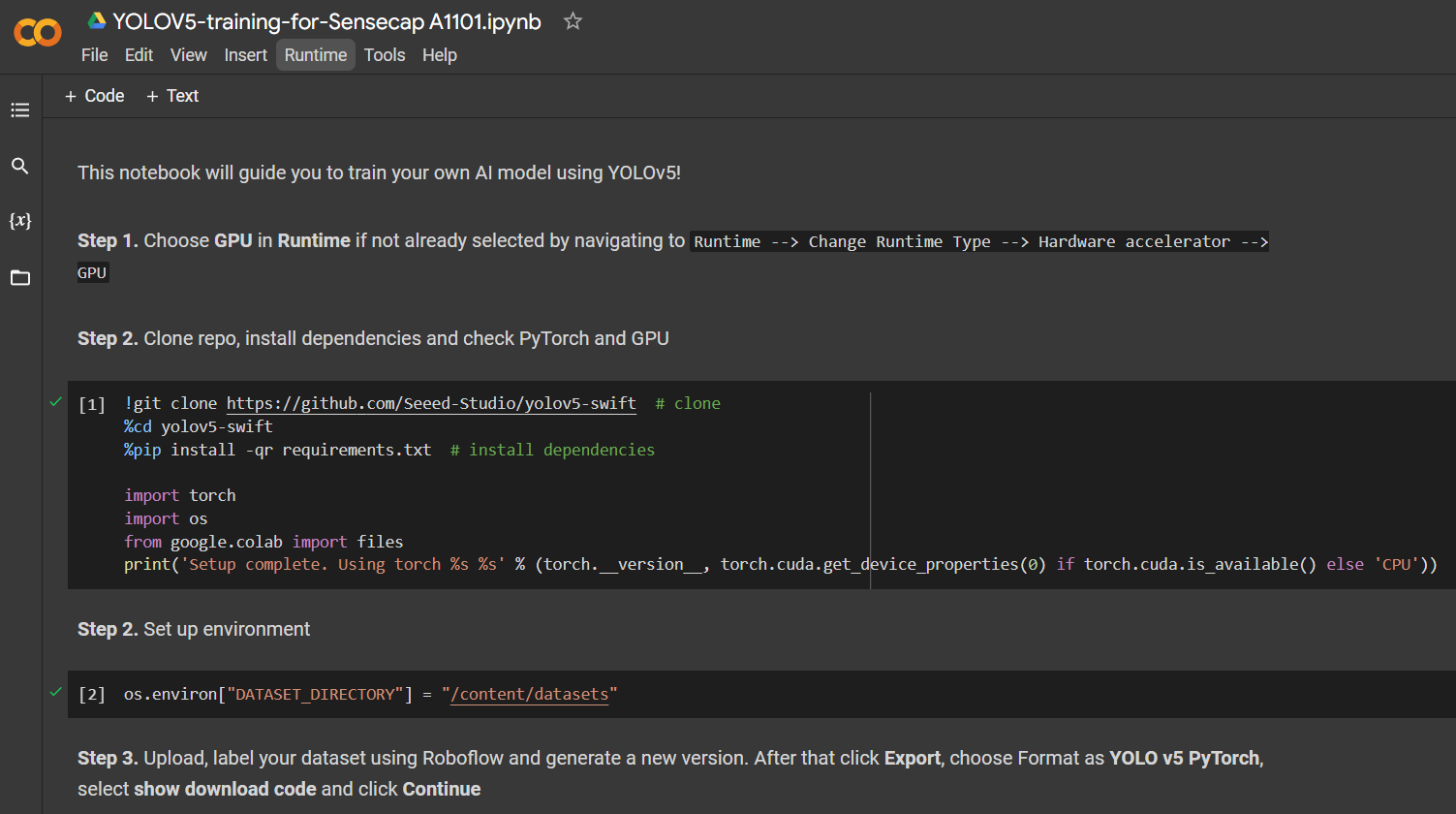
点击这里打开一个已经准备好的 Google Colab 工作空间,按照工作空间中提到的步骤进行操作,并逐个运行代码单元。
注意: 在 Google Colab 上,在步骤 4下的代码单元中,您可以直接复制上面提到的来自 Roboflow 的代码片段
它将演示以下内容:
- 设置训练环境
- 下载数据集
- 执行训练
- 下载训练好的模型
对于包含 699 张图像的苹果检测数据集,在运行 NVIDIA Tesla T4 GPU 和 16GB GPU 内存的 Google Colab 上完成训练过程大约需要 7 分钟。
如果您遵循了上述 Colab 项目,您知道可以一次将 4 个模型加载到设备上。但是,请注意一次只能加载一个模型。这可以由用户指定,稍后将在本 wiki 中解释。
部署和推理
如果您想直接跳转到第三部分,该部分解释如何将训练好的 AI 模型部署到 SenseCAP A1101 并执行推理,点击这里。
2. 使用自己的数据集训练自己的AI模型
如果您想构建特定的目标检测项目,而公共数据集中没有您想要检测的对象,您可能需要构建自己的数据集。当您为自己的数据集记录数据时,您必须确保覆盖对象的所有角度(360度),将对象放置在不同的环境中,不同的光照和不同的天气条件下。记录自己的数据集后,您还必须对数据集中的图像进行标注。本节将涵盖所有这些步骤。
尽管有不同的数据收集方法,如使用手机摄像头,但收集数据的最佳方式是使用SenseCAP A1101上的内置摄像头。这是因为当我们在SenseCAP A1101上执行推理时,颜色、图像质量和其他细节将相似,这使得整体检测更加准确。
硬件准备
- SenseCAP A1101 - LoRaWAN视觉AI传感器
- USB Type-C数据线
- 具有互联网访问的Windows/Linux/Mac
软件准备
现在让我们设置软件。Windows、Linux和Intel Mac的软件设置将相同,而M1/M2 Mac的设置将有所不同。
Windows、Linux、Intel Mac
-
步骤1. 确保计算机上已安装Python。如果没有,请访问此页面下载并安装最新版本的Python
-
步骤2. 安装以下依赖项
pip3 install libusb1
M1/ M2 Mac
- 步骤 1. 安装 Homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 步骤 2. 安装 conda
brew install conda
- 步骤 3. 下载 libusb
wget https://conda.anaconda.org/conda-forge/osx-arm64/libusb-1.0.26-h1c322ee_100.tar.bz2
- 步骤 4. 安装 libusb
conda install libusb-1.0.26-h1c322ee_100.tar.bz2
收集数据集
- 步骤 1. 使用 USB Type-C 线缆将 SenseCAP A1101 连接到 PC

- 步骤 2. 双击启动按钮进入启动模式

之后您将在文件资源管理器中看到一个名为 SENSECAP 的新存储驱动器
- 步骤 3. 将此 .uf2 文件拖放到 SENSECAP 驱动器
一旦 uf2 文件完成复制到驱动器中,驱动器将消失。这意味着 uf2 已成功上传到模块。
-
步骤 4. 复制并粘贴此 Python 脚本到您 PC 上新创建的名为 capture_images_script.py 的文件中
-
步骤 5. 执行 Python 脚本开始捕获图像
python3 capture_images_script.py
默认情况下,它会每 300ms 捕获一张图像。如果你想改变这一点,可以按以下格式运行脚本
python3 capture_images_script.py --interval <time_in_ms>
例如,每秒捕获一张图像
python3 capture_images_script.py --interval 1000
执行上述脚本后,SenseCAP A1101 将开始从内置摄像头连续捕获图像,并将所有图像保存在名为 save_img 的文件夹中
同时,在录制过程中会打开一个预览窗口
当您捕获了足够的图像后,点击终端窗口并按下以下组合键来停止捕获过程
- Windows: Ctrl + Break
- Linux: Ctrl + Shift + \
- Mac: CMD + Shift + \
图像收集后更改设备固件
完成数据集图像录制后,您需要确保将 SenseCAP A1101 内的固件更改回原始版本,这样您就可以再次加载目标检测模型进行检测。现在让我们来了解具体步骤。
-
步骤 1. 如前所述,让 SenseCAP A1101 进入 Boot 模式
-
步骤 2. 根据您的设备,将此 .uf2 文件拖放到 SENSECAP 驱动器中
一旦 uf2 文件完成复制到驱动器中,驱动器就会消失。这意味着 uf2 已成功上传到模块。
使用 Roboflow 标注数据集
如果您使用自己的数据集,您需要标注数据集中的所有图像。标注意味着简单地在我们想要检测的每个对象周围绘制矩形框并为它们分配标签。我们将解释如何使用 Roboflow 来完成此操作。
Roboflow 是一个基于在线的标注工具。在这里我们可以直接将录制的视频素材导入到 Roboflow 中,它将被导出为一系列图像。这个工具非常方便,因为它可以帮助我们将数据集分配到"训练、验证和测试"中。此外,这个工具还允许我们在标记图像后对这些图像进行进一步处理。而且,它可以轻松地将标记的数据集导出为 YOLOV5 PyTorch 格式,这正是我们所需要的!
在本教程中,我们将使用包含苹果图像的数据集,这样我们稍后就可以检测苹果并进行计数。
-
步骤 1. 点击这里注册 Roboflow 账户
-
步骤 2. 点击 Create New Project 开始我们的项目
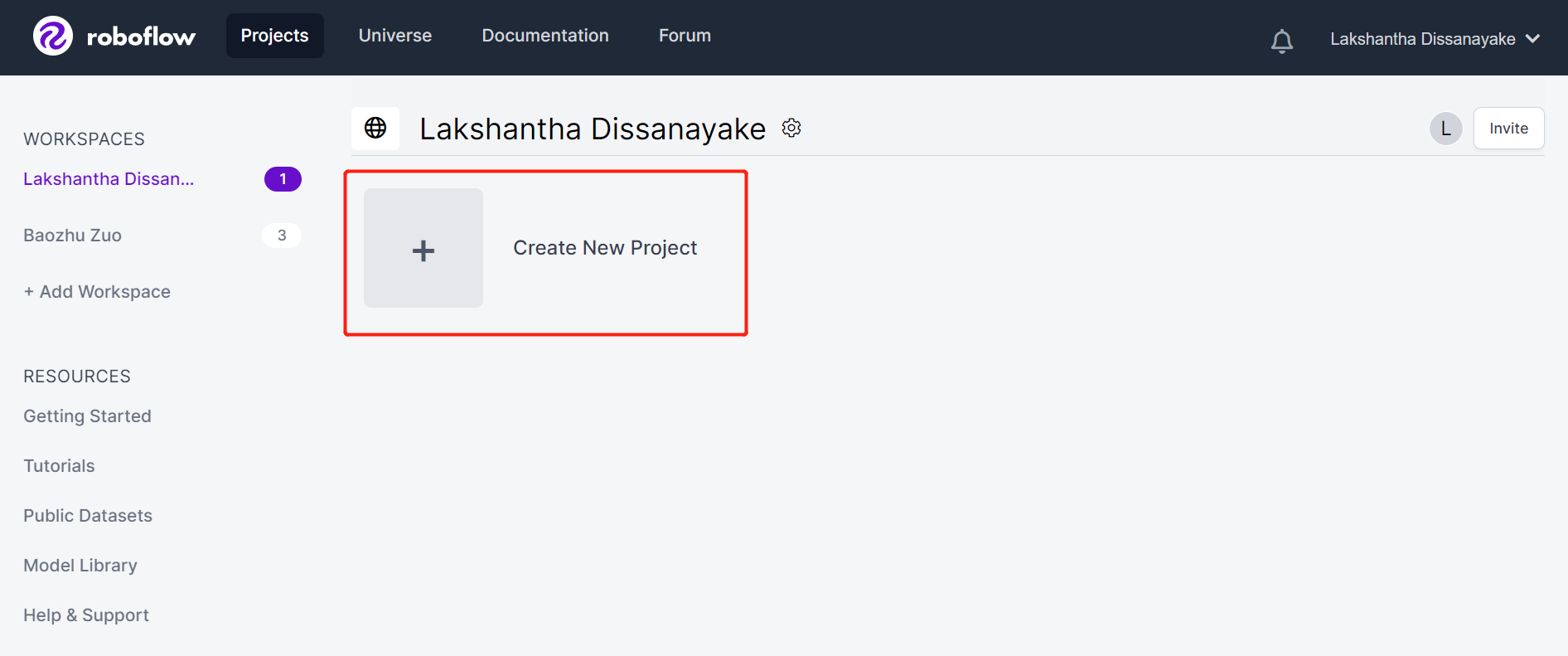
- 步骤 3. 填写 Project Name,保持 License (CC BY 4.0) 和 Project type (Object Detection (Bounding Box)) 为默认设置。在 What will your model predict? 列下,填写标注组名称。例如,在我们的案例中选择 apples。这个名称应该突出显示数据集的所有类别。最后,点击 Create Public Project。
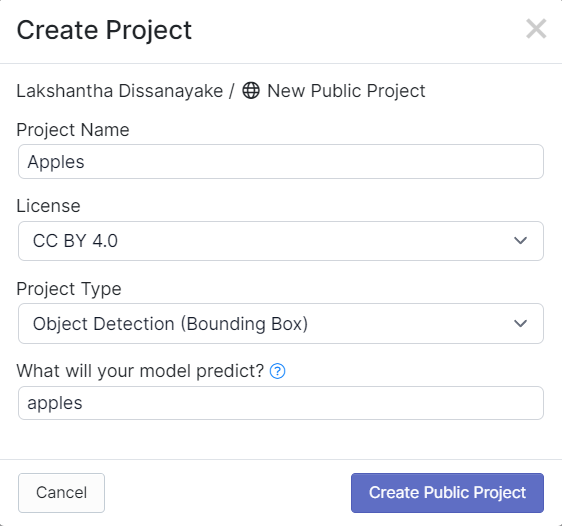
- 步骤 4. 拖放您使用 SenseCAP A1101 捕获的图像
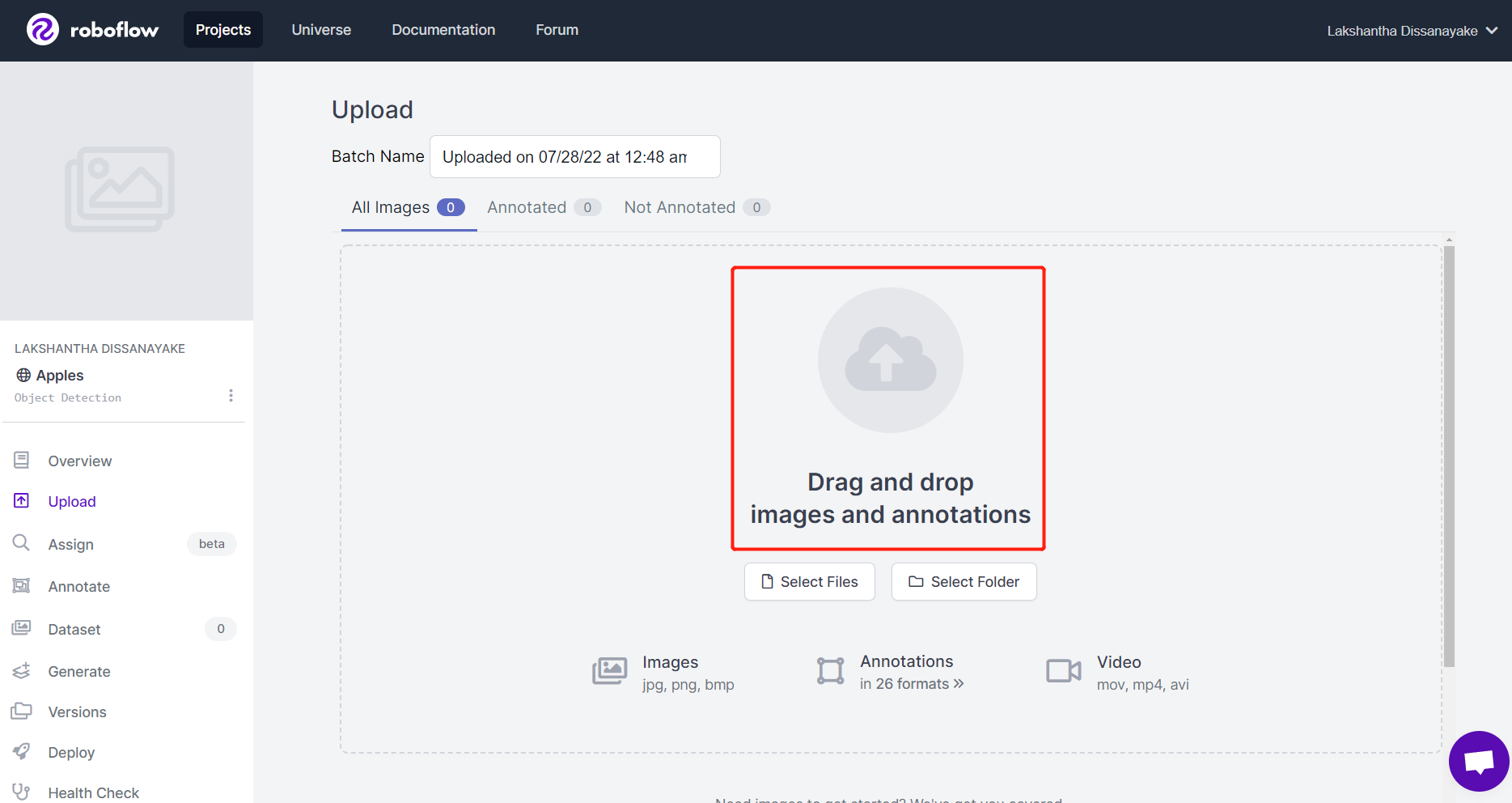
- 步骤 5. 图像处理完成后,点击 Finish Uploading。耐心等待直到图像上传完成。
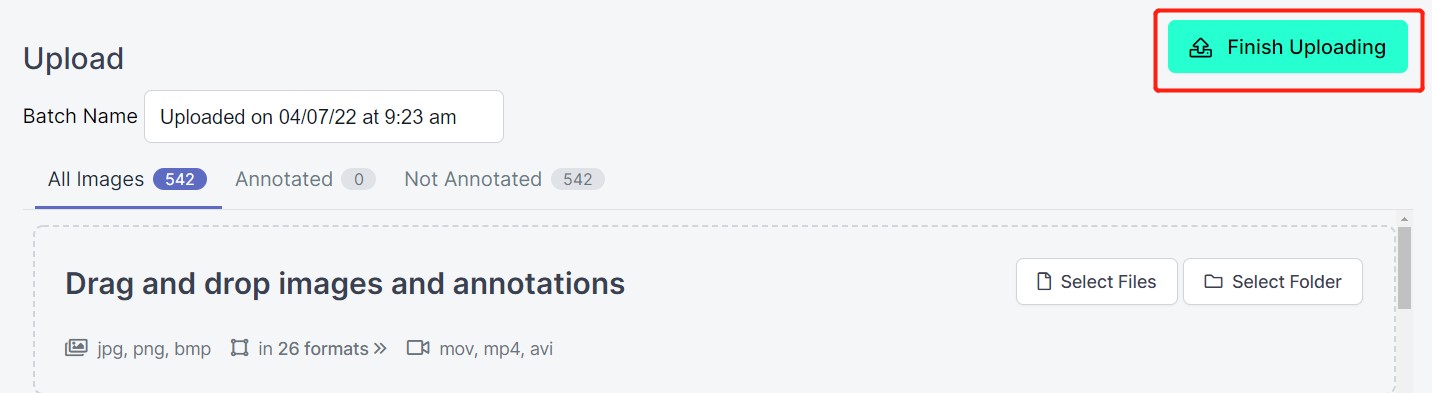
- 步骤 6. 图像上传完成后,点击 Assign Images
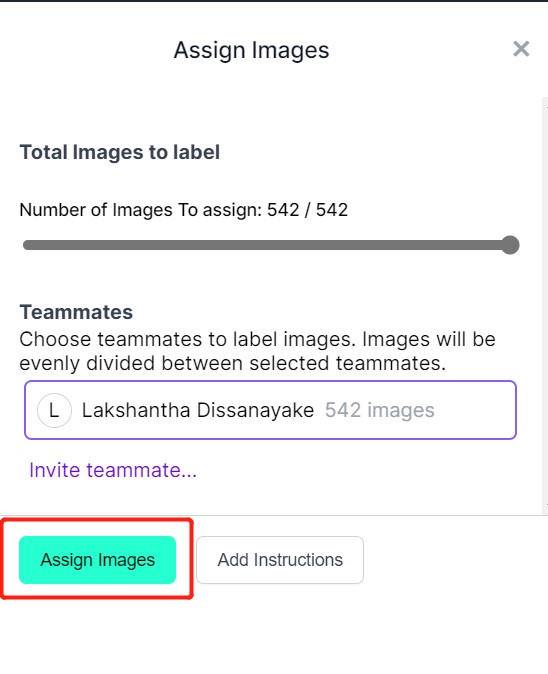
- 步骤 7. 选择一张图像,在苹果周围绘制矩形框,选择标签为 apple 并按 ENTER
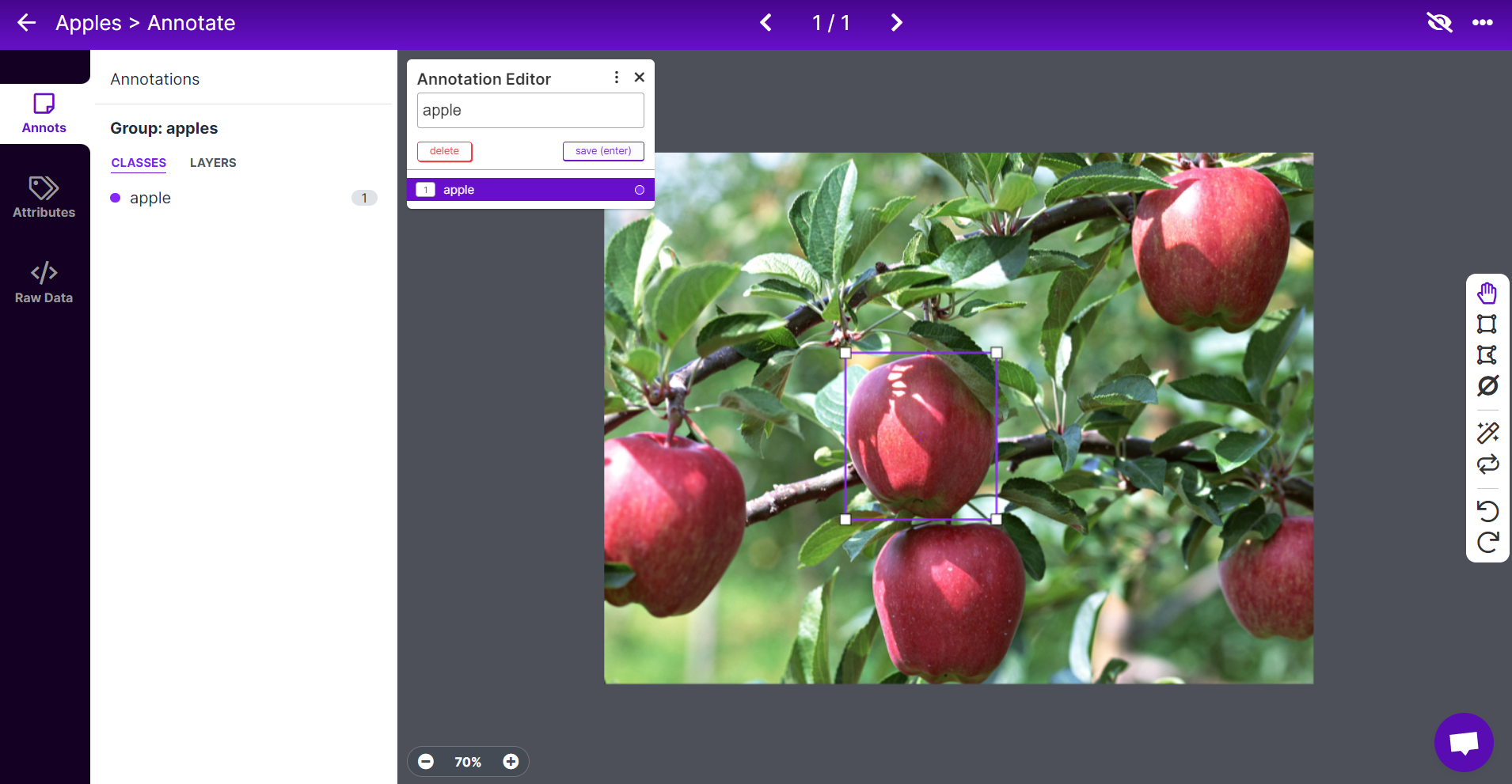
- 步骤 8. 对其余苹果重复相同操作
注意: 尽量标记您在图像中看到的所有苹果。如果只有苹果的一部分可见,也要尝试标记它。
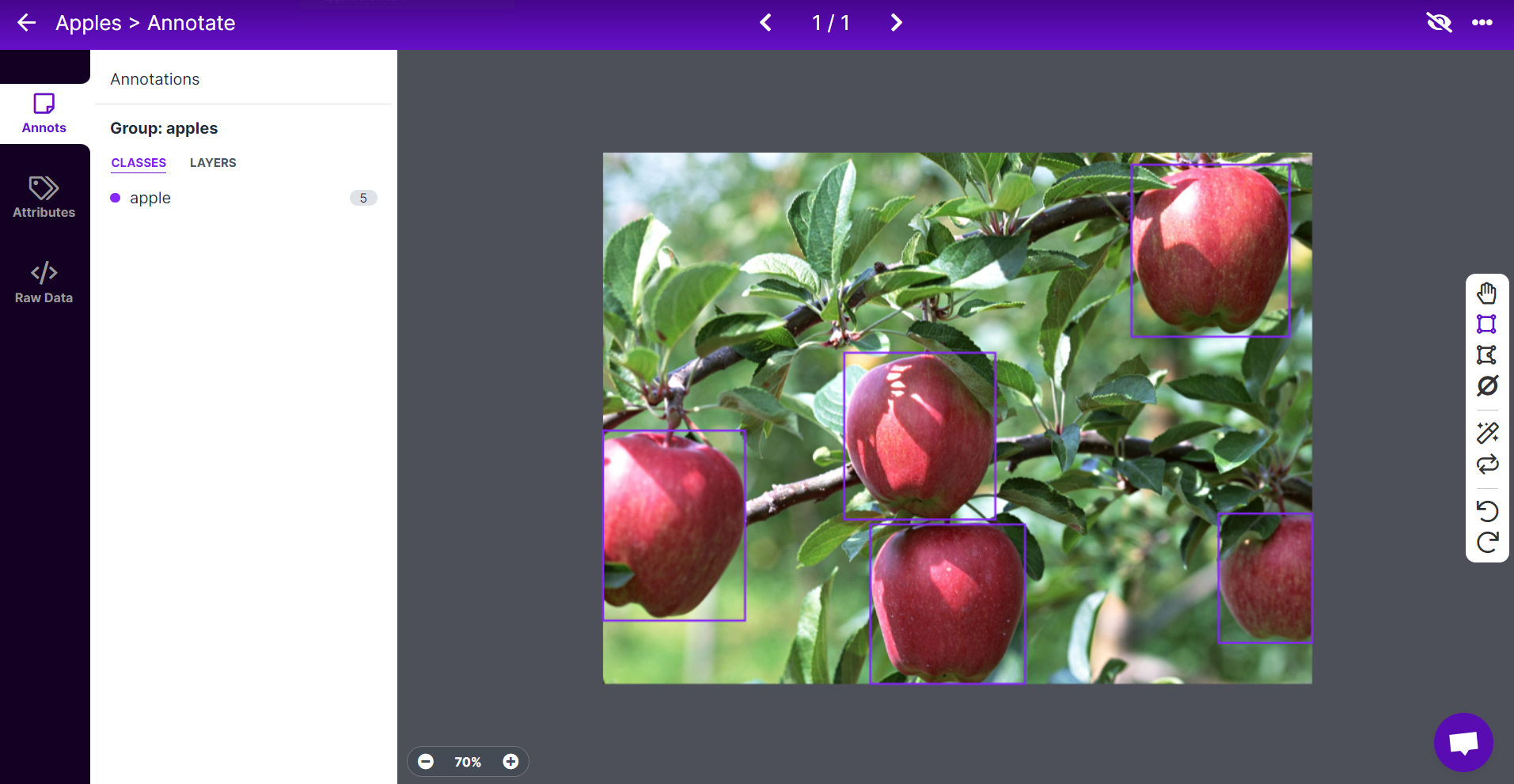
- 步骤 9. 继续标注数据集中的所有图像
Roboflow 有一个名为 Label Assist 的功能,它可以预先预测标签,这样您的标记工作会快得多。但是,它不适用于所有对象类型,而是选定类型的对象。要启用此功能,您只需按下 Label Assist 按钮,选择一个模型,选择类别,然后浏览图像以查看带有边界框的预测标签
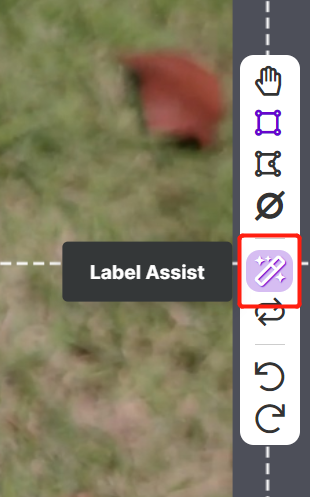
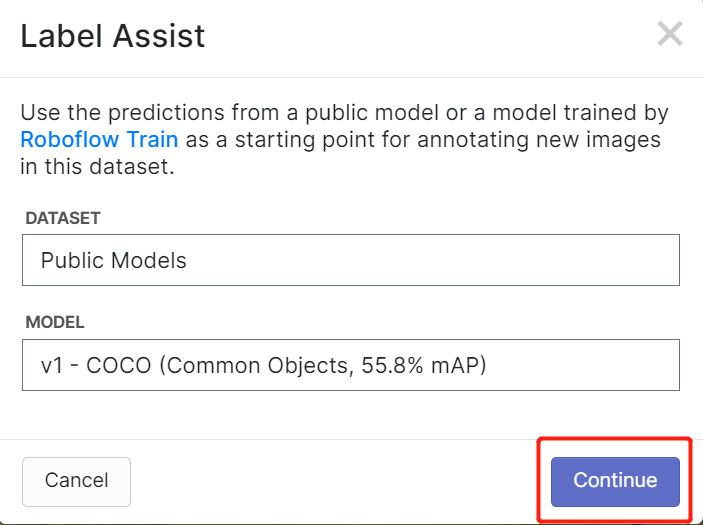
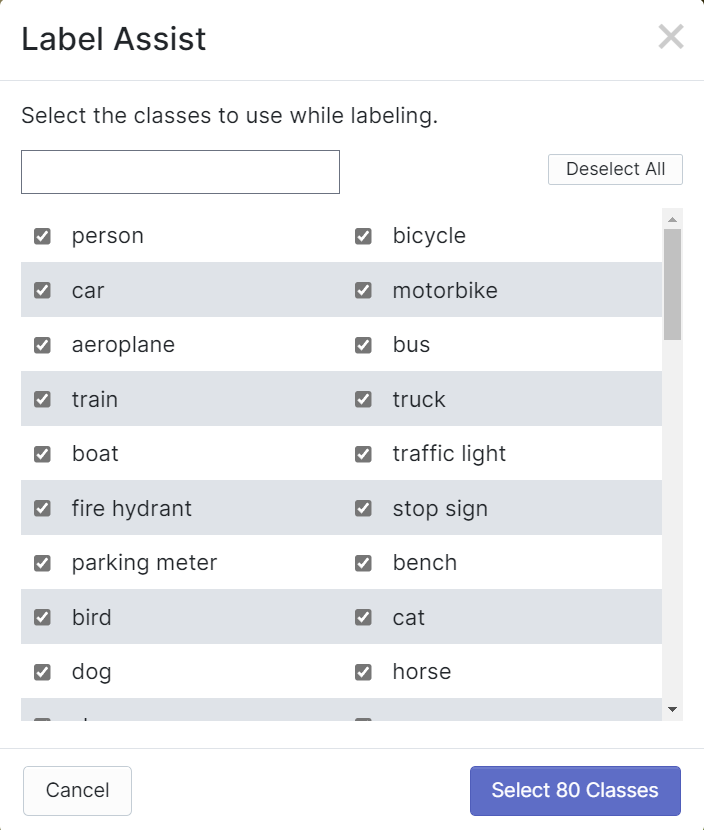
如上所示,它只能帮助预测上述 80 个类别的标注。如果您的图像不包含上述对象类别,则无法使用标签辅助功能。
- 步骤 10. 标记完成后,点击 Add images to Dataset

- 步骤 11. 接下来我们将在"Train, Valid and Test"之间分割图像。保持分布的默认百分比并点击 Add Images
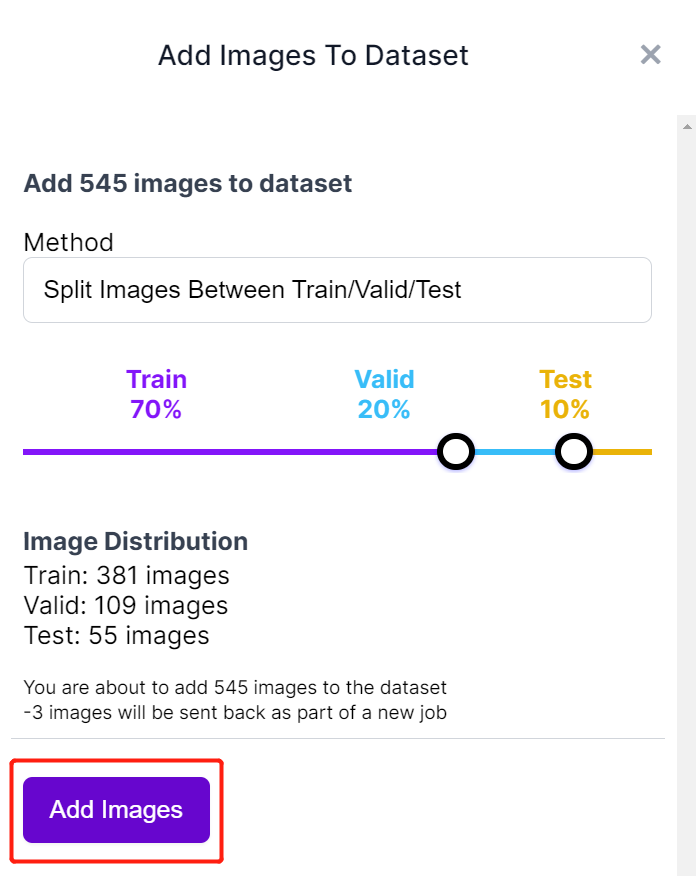
- 步骤 12. 点击 Generate New Version

- 步骤 13. 现在您可以根据需要添加 Preprocessing 和 Augmentation。在这里我们将 Resize 选项 更改 为 192x192
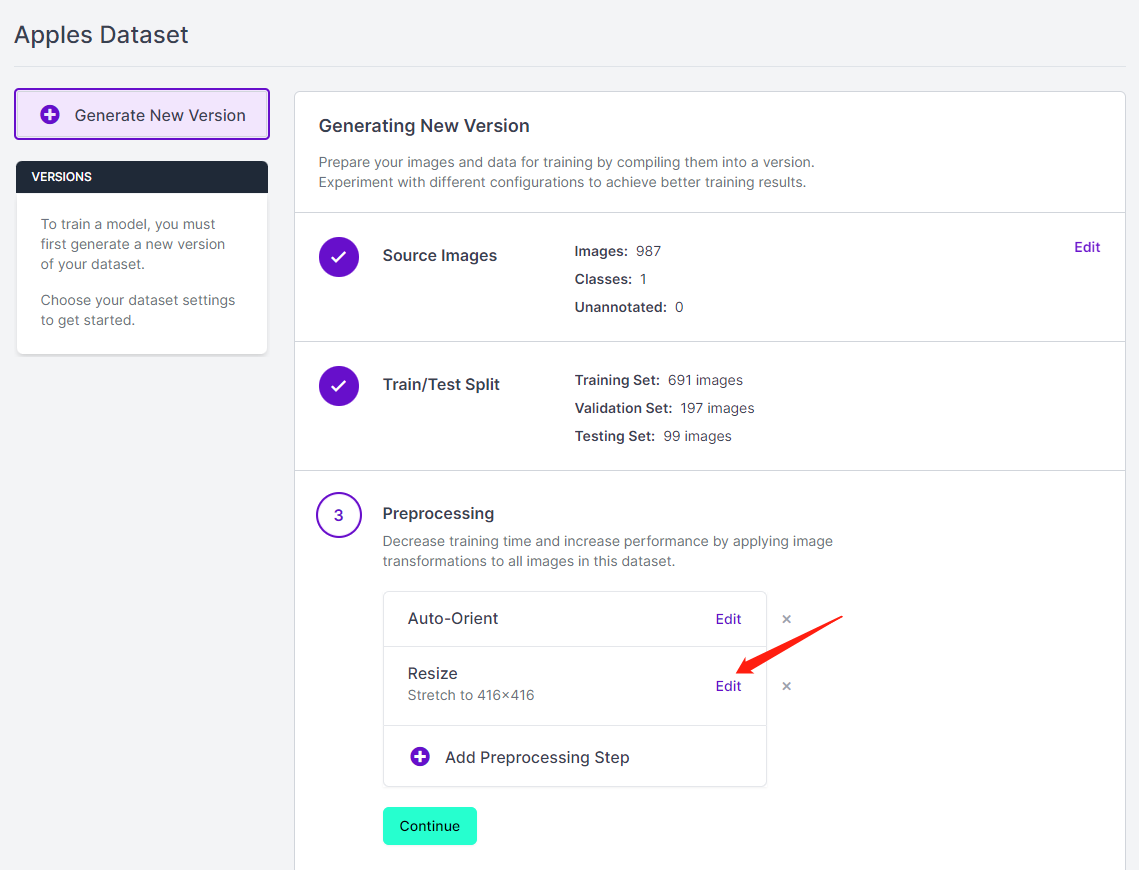
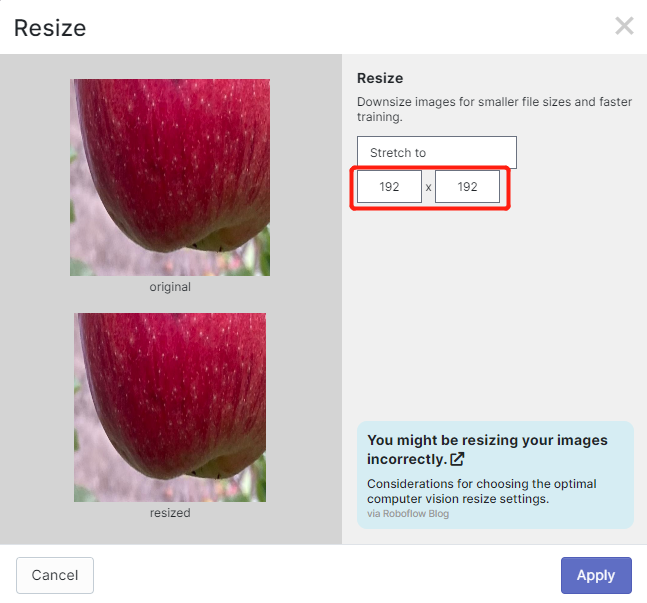
这里我们将图像尺寸更改为 192x192,因为我们将使用该尺寸进行训练,这样训练会更快。否则,在训练过程中必须将所有图像转换为 192x192,这会消耗更多的 CPU 资源并使训练过程变慢。
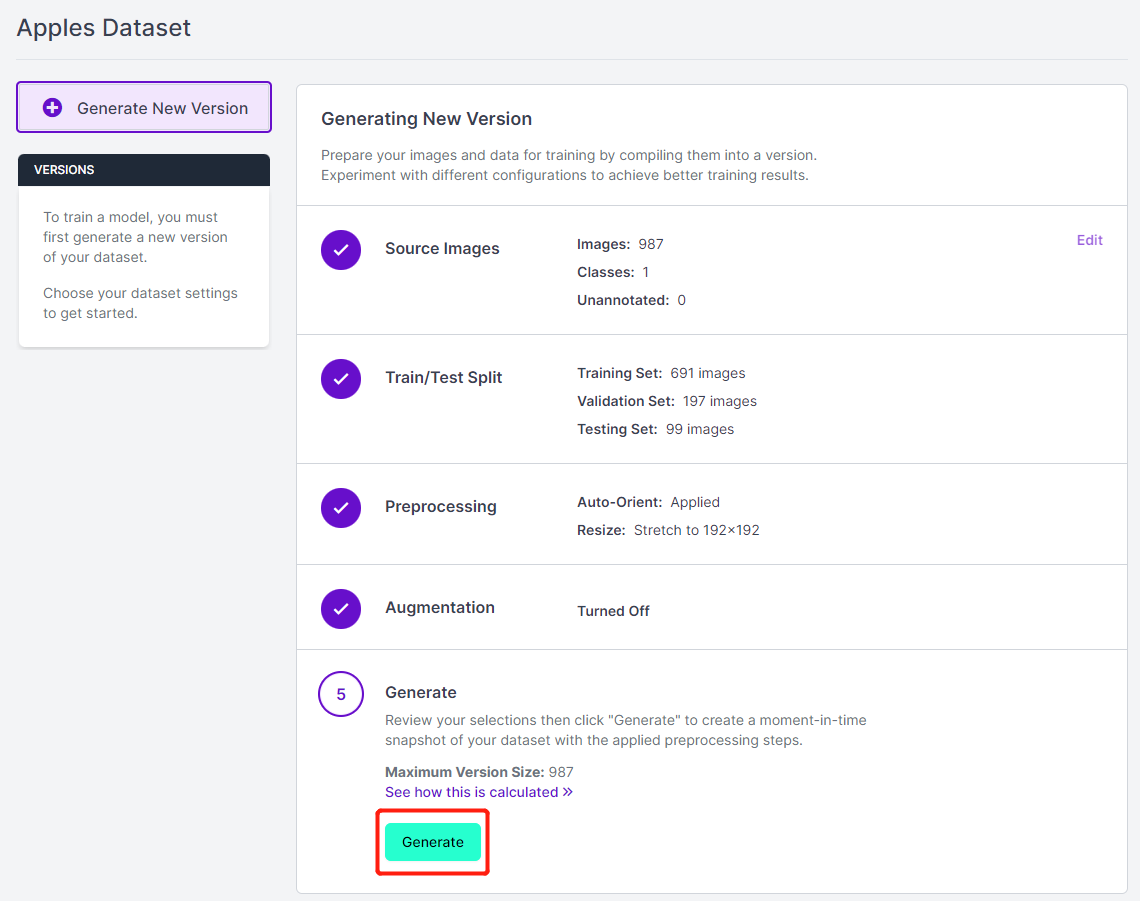
- 步骤 14. 接下来,继续使用其余默认设置并点击 Generate
- 步骤 15. 点击 Export,选择 Format 为 YOLO v5 PyTorch,选择 show download code 并点击 Continue
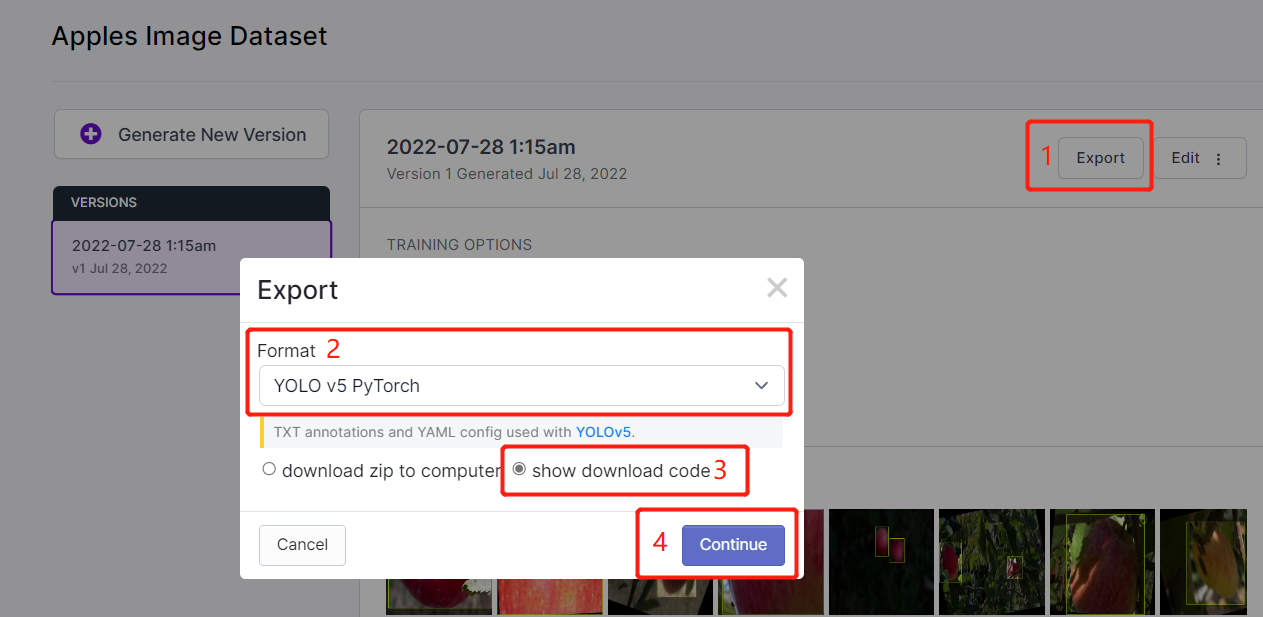
这将生成一个代码片段,我们稍后将在 Google Colab 训练中使用。所以请保持此窗口在后台打开。
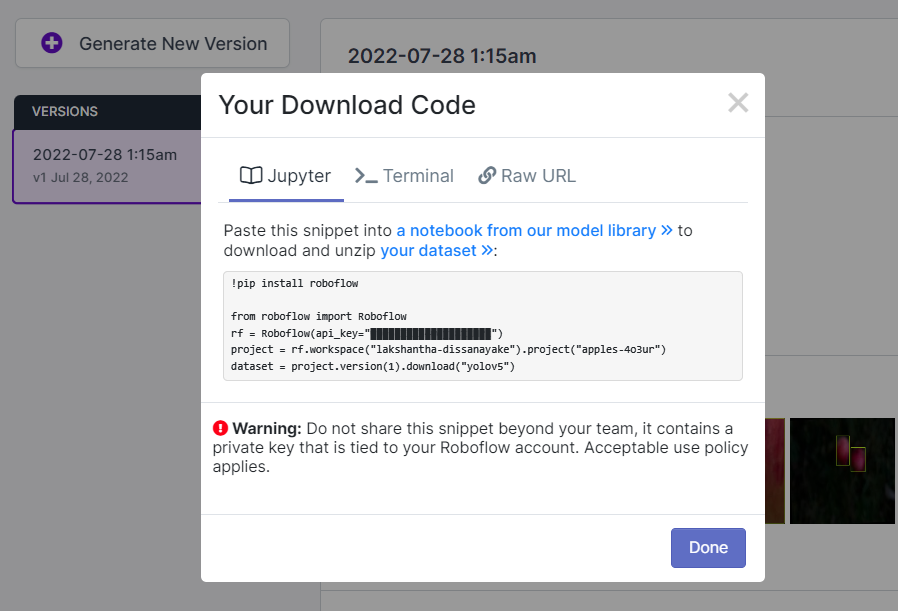
在 Google Colab 上使用 YOLOv5 进行训练
完成数据集标注后,我们需要训练数据集。跳转到这一部分,其中解释了如何使用在 Google Colab 上运行的 YOLOv5 训练 AI 模型。
3. 部署训练好的模型并执行推理
现在我们将把在训练结束时获得的 model-1.uf2 移动到 SenseCAP A1101 中。
-
步骤 1. 安装最新版本的 Google Chrome 或 Microsoft Edge 浏览器 并打开它
-
步骤 2. 通过 USB Type-C 线缆将 SenseCAP A1101 连接到您的 PC
- 步骤 3. 双击 SenseCAP A1101 上的启动按钮以进入大容量存储模式
之后,您将在文件资源管理器中看到一个新的存储驱动器显示为 SENSECAP
- 步骤 4. 将 model-1.uf2 文件拖放到 SENSECAP 驱动器
一旦 uf2 完成复制到驱动器,驱动器将消失。这意味着 uf2 已成功上传到模块。
注意: 如果您有 4 个模型文件准备就绪,您可以逐个拖放每个模型。先放第一个模型,等待它完成复制,再次进入启动模式,放第二个模型,依此类推。如果您只将一个模型(索引为 1)加载到 SenseCAP A1101 中,它将加载该模型。
-
步骤 5. 打开 SenseCAP Mate App。如果您没有,请根据您的操作系统在手机上下载并安装
-
步骤 6. 打开应用,在 Config 屏幕下,选择 Vision AI Sensor

- 步骤 7. 按住 SenseCap A1101 上的配置按钮 3 秒钟以进入蓝牙配对模式

- 步骤 8. 点击 Setup,它将开始扫描附近的 SenseCAP A1101 设备
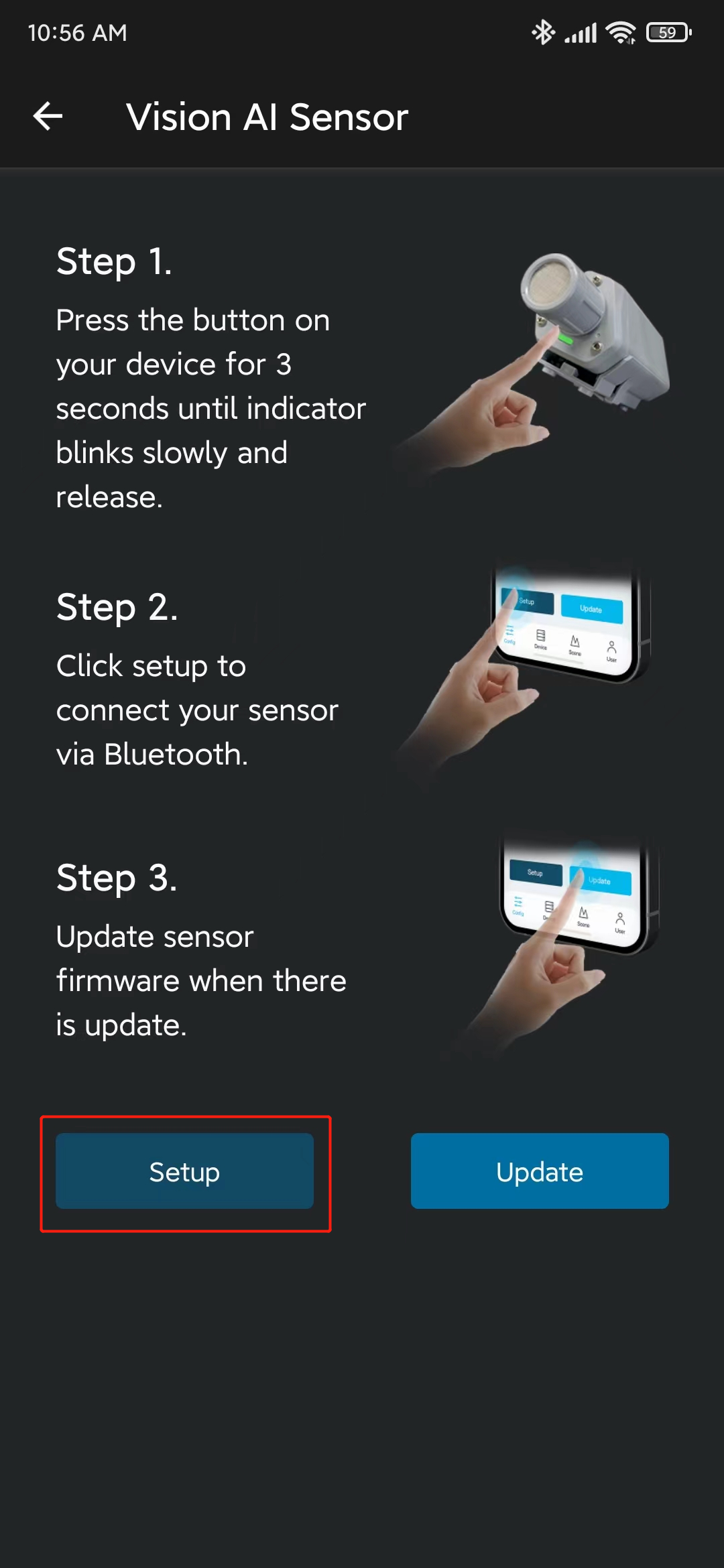
- 步骤 9. 点击找到的设备
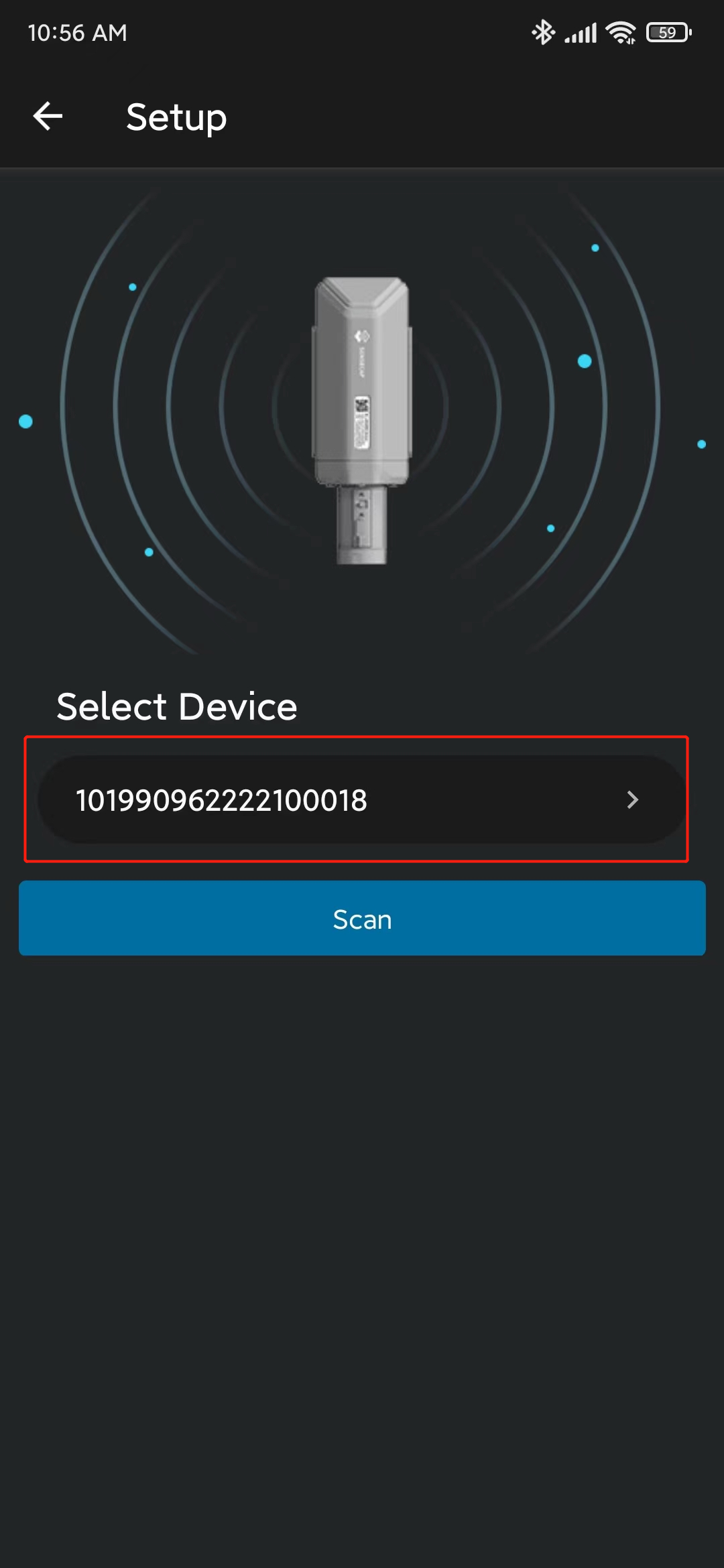
- 步骤 10. 转到 Settings 并确保选择了 Object Detection。如果没有,请选择它并点击 Send
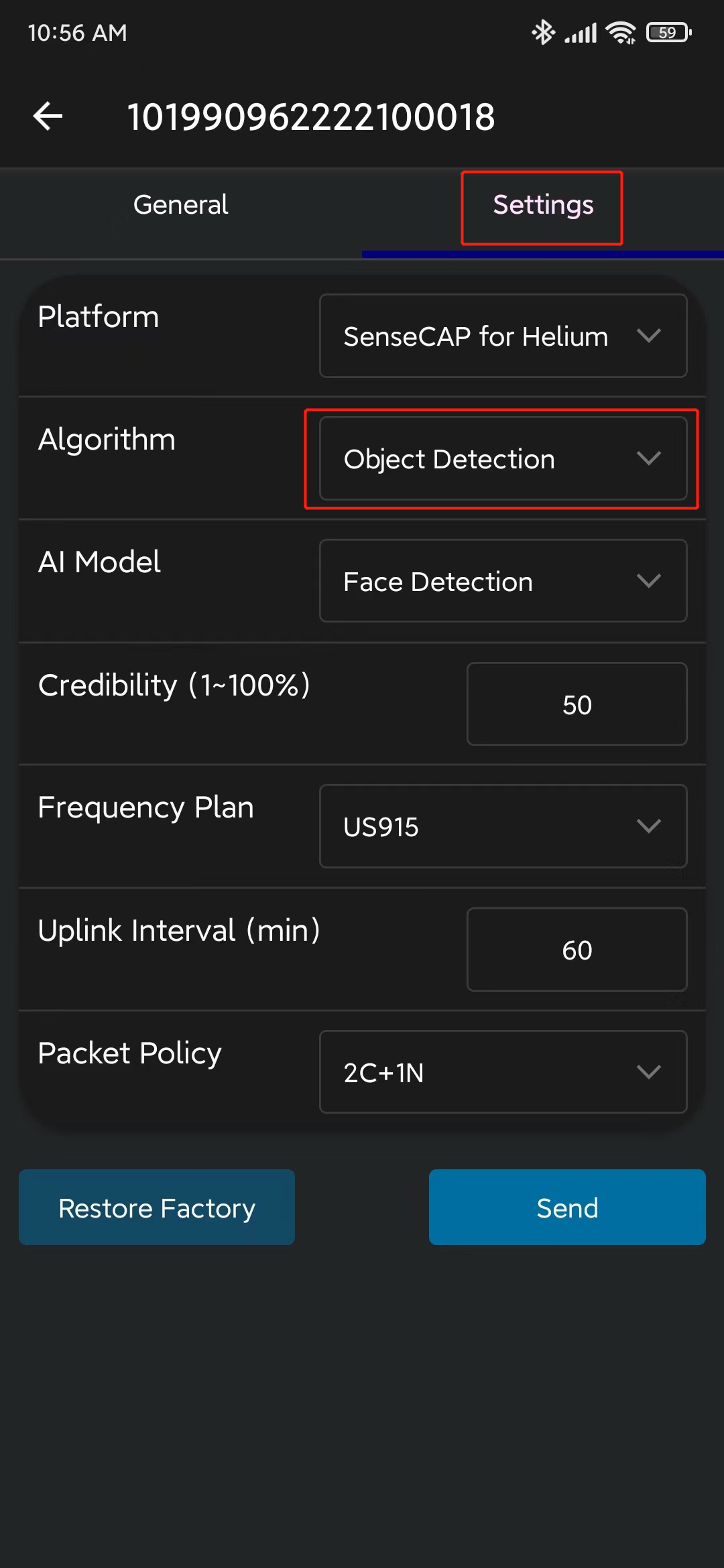
- 步骤 11. 转到 General 并点击 Detect
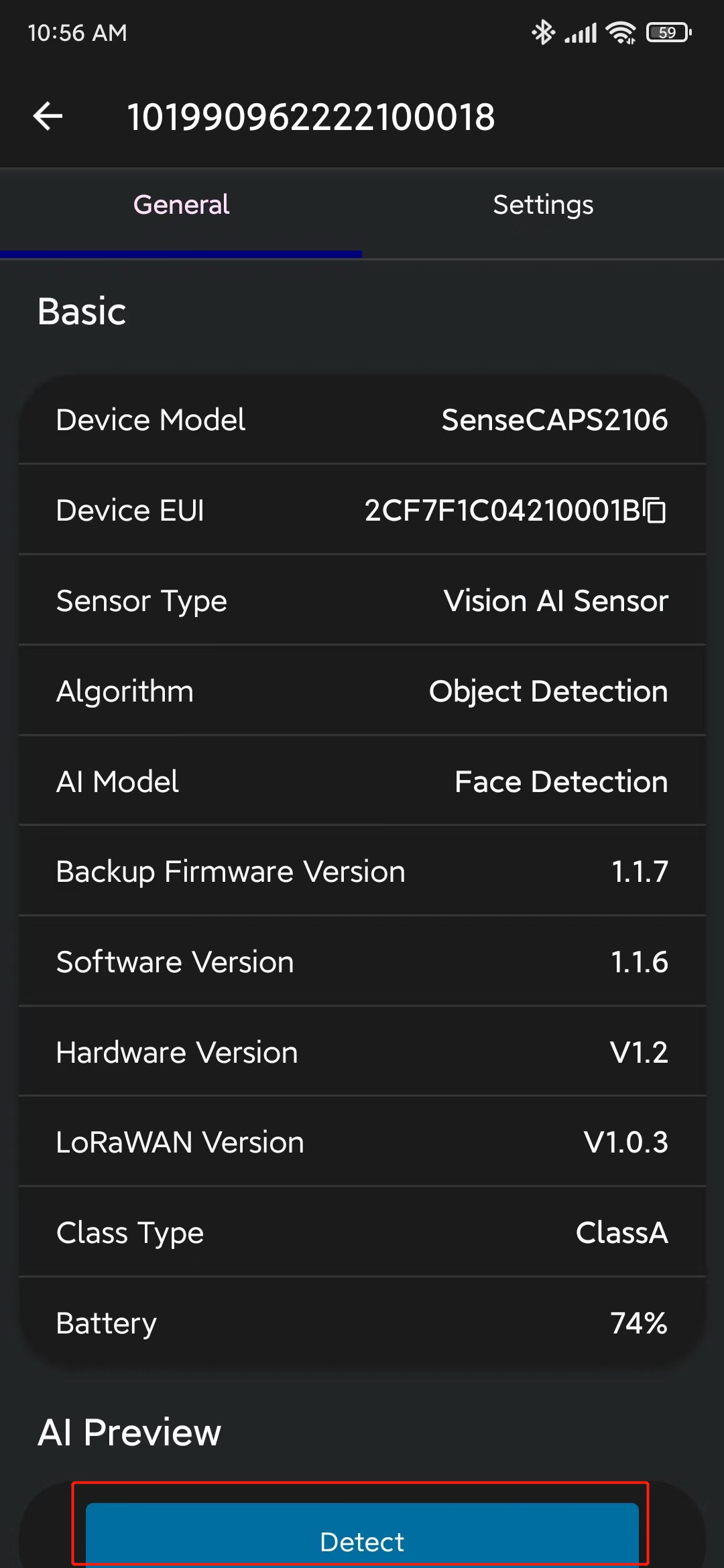
- 步骤 12. 点击这里 打开摄像头流的预览窗口

- 步骤 13. 点击 Connect 按钮。然后您将在浏览器上看到一个弹出窗口。选择 SenseCAP Vision AI - Paired 并点击 Connect
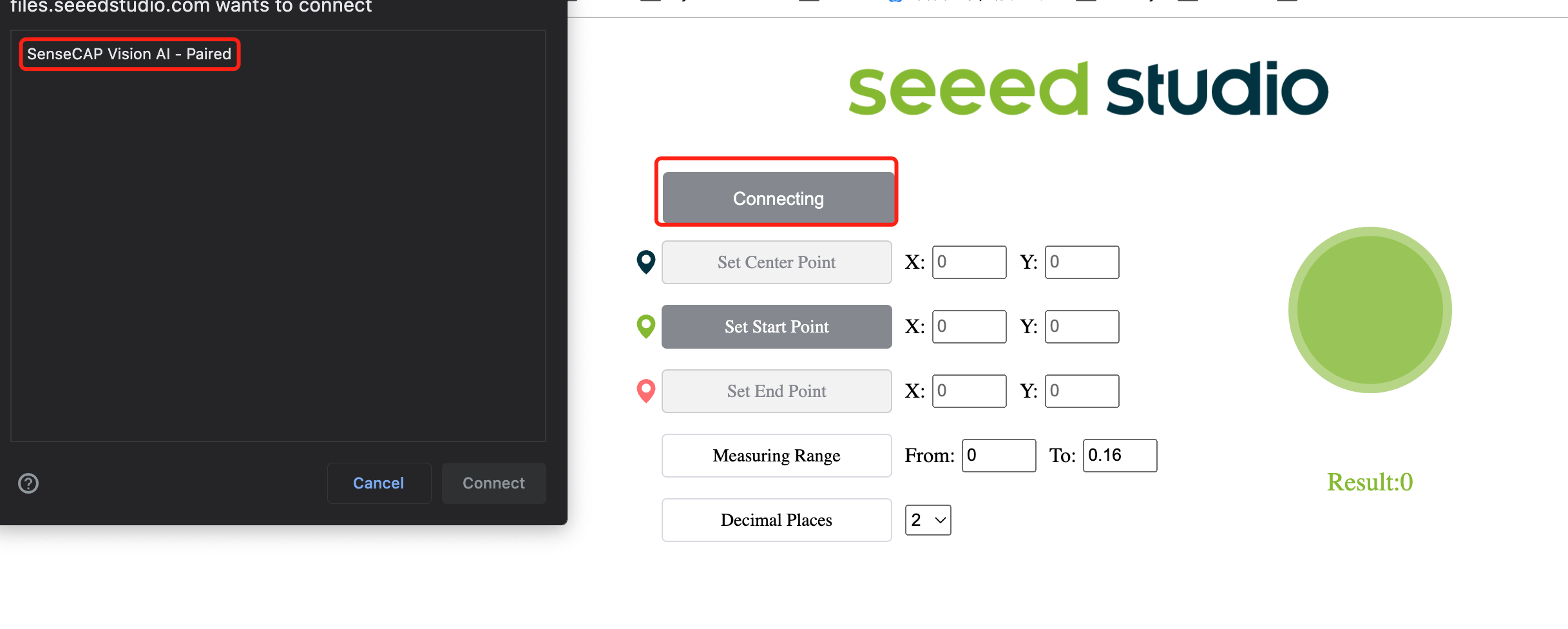
- 步骤 14. 使用预览窗口查看实时推理结果!

如上所示,苹果正在被检测到,周围有边界框。这里"0"对应于同一类别的每次检测。如果您有多个类别,它们将被命名为 0,1,2,3,4 等等。此外,每个检测到的苹果的置信度分数(上述演示中的 0.8 和 0.84)也在显示!
额外内容
如果您感觉更有冒险精神,可以继续遵循 wiki 的其余部分!
我可以在我的 PC 上训练 AI 模型吗?
您也可以使用自己的 PC 来训练目标检测模型。但是,训练性能将取决于您拥有的硬件。您还需要有一台运行 Linux 操作系统的 PC 进行训练。我们在此 wiki 中使用了 Ubuntu 20.04 PC。
- 步骤 1. 克隆 yolov5-swift 仓库 并在 Python>=3.7.0 环境中安装 requirements.txt
git clone https://github.com/Seeed-Studio/yolov5-swift
cd yolov5-swift
pip install -r requirements.txt
- 步骤 2. 如果您之前按照本 wiki 中的步骤操作过,您可能还记得我们在 Robolflow 中标注后导出了数据集。同样在 Roboflow Universe 中,我们下载了数据集。在这两种方法中,都有一个如下所示的窗口,询问要以什么格式下载数据集。所以现在,请选择 download zip to computer,在 Format 下选择 YOLO v5 PyTorch 并点击 Continue
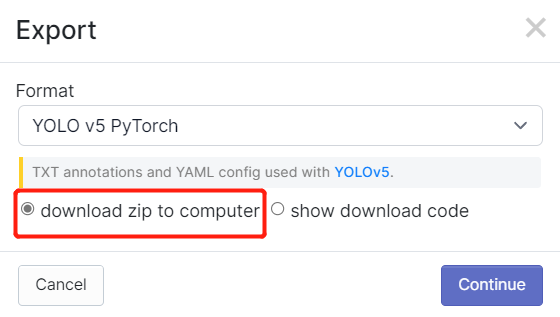
之后,一个 .zip 文件 将下载到您的计算机
- 步骤 3. 将我们下载的 .zip 文件复制并粘贴到 yolov5-swift 目录中并解压
# example
cp ~/Downloads/Apples.v1i.yolov5pytorch.zip ~/yolov5-swift
unzip Apples.v1i.yolov5pytorch.zip
- 步骤 4. 打开 data.yaml 文件并按如下方式编辑 train 和 val 目录
train: train/images
val: valid/images
- 步骤 5. 下载适合我们训练的预训练模型
sudo apt install wget
wget https://github.com/Seeed-Studio/yolov5-swift/releases/download/v0.1.0-alpha/yolov5n6-xiao.pt
- 步骤 6. 执行以下命令开始训练
在这里,我们可以传递多个参数:
- img: 定义输入图像大小
- batch: 确定批次大小
- epochs: 定义训练轮数
- data: 设置我们的 yaml 文件路径
- cfg: 指定我们的模型配置
- weights: 指定权重的自定义路径
- name: 结果名称
- nosave: 仅保存最终检查点
- cache: 缓存图像以加快训练速度
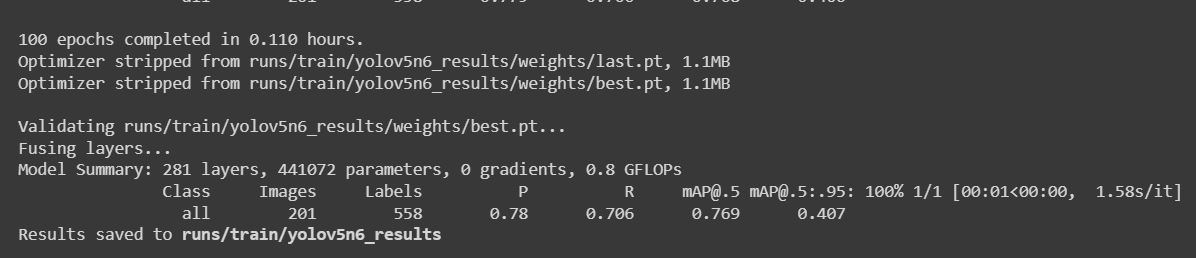
python3 train.py --img 192 --batch 64 --epochs 100 --data data.yaml --cfg yolov5n6-xiao.yaml --weights yolov5n6-xiao.pt --name yolov5n6_results --cache
对于一个包含987张图像的苹果检测数据集,在配备NVIDIA GeForce GTX 1660 Super GPU(6GB GPU内存)的本地PC上完成训练过程大约需要30分钟。

如果您按照上述Colab项目进行操作,您会知道可以一次性将4个模型加载到设备上。但是,请注意一次只能加载一个模型。这可以由用户指定,稍后将在本wiki中进行说明。
- 步骤7. 如果您导航到
runs/train/exp/weights,您将看到一个名为best.pt的文件。这是训练生成的模型。

- 步骤8. 将训练好的模型导出为TensorFlow Lite
python3 export.py --data {dataset.location}/data.yaml --weights runs/train/yolov5n6_results/weights/best.pt --imgsz 192 --int8 --include tflite
- 步骤 9. 将 TensorFlow Lite 转换为 UF2 文件
UF2 是由微软开发的一种文件格式。Seeed 使用这种格式将 .tflite 转换为 .uf2,允许 tflite 文件存储在 Seeed 推出的 AIoT 设备上。目前 Seeed 的设备最多支持 4 个模型,每个模型(.tflite)小于 1M。
您可以使用 -t 指定要放置在相应索引位置的模型。
例如:
-t 1:索引 1-t 2:索引 2
# Place the model to index 1
python3 uf2conv.py -f GROVEAI -t 1 -c runs//train/yolov5n6_results//weights/best-int8.tflite -o model-1.uf2
尽管您可以一次将4个模型加载到设备中,但请注意一次只能加载一个模型。这可以由用户指定,稍后将在本wiki中进行说明。
- 步骤 10. 现在将生成一个名为 model-1.uf2 的文件。这就是我们将加载到 SenseCAP A1101 模块中进行推理的文件!
检查 BootLoader 版本
- 双击 BOOT 按钮并等待可移动驱动器挂载
- 在可移动驱动器中打开 INFO_UF2.TXT

更新 BootLoader
如果您的 SenseCAP A1101 无法被计算机识别并且表现为没有端口号,那么您可能需要更新 BootLoader。
- 步骤 1. 在 Windows PC 上下载 BootLoader
.bin文件。
请通过下面的链接下载最新版本的 BootLoader 文件。BootLoader 的名称通常是 tinyuf2-sensecap_vision_ai_vx.x.x.bin。
这是控制 BL702 芯片的固件,该芯片在计算机和 Himax 芯片之间建立连接。最新版本的 BootLoader 现在已经修复了 Vision AI 无法被 Mac 和 Linux 识别的问题。
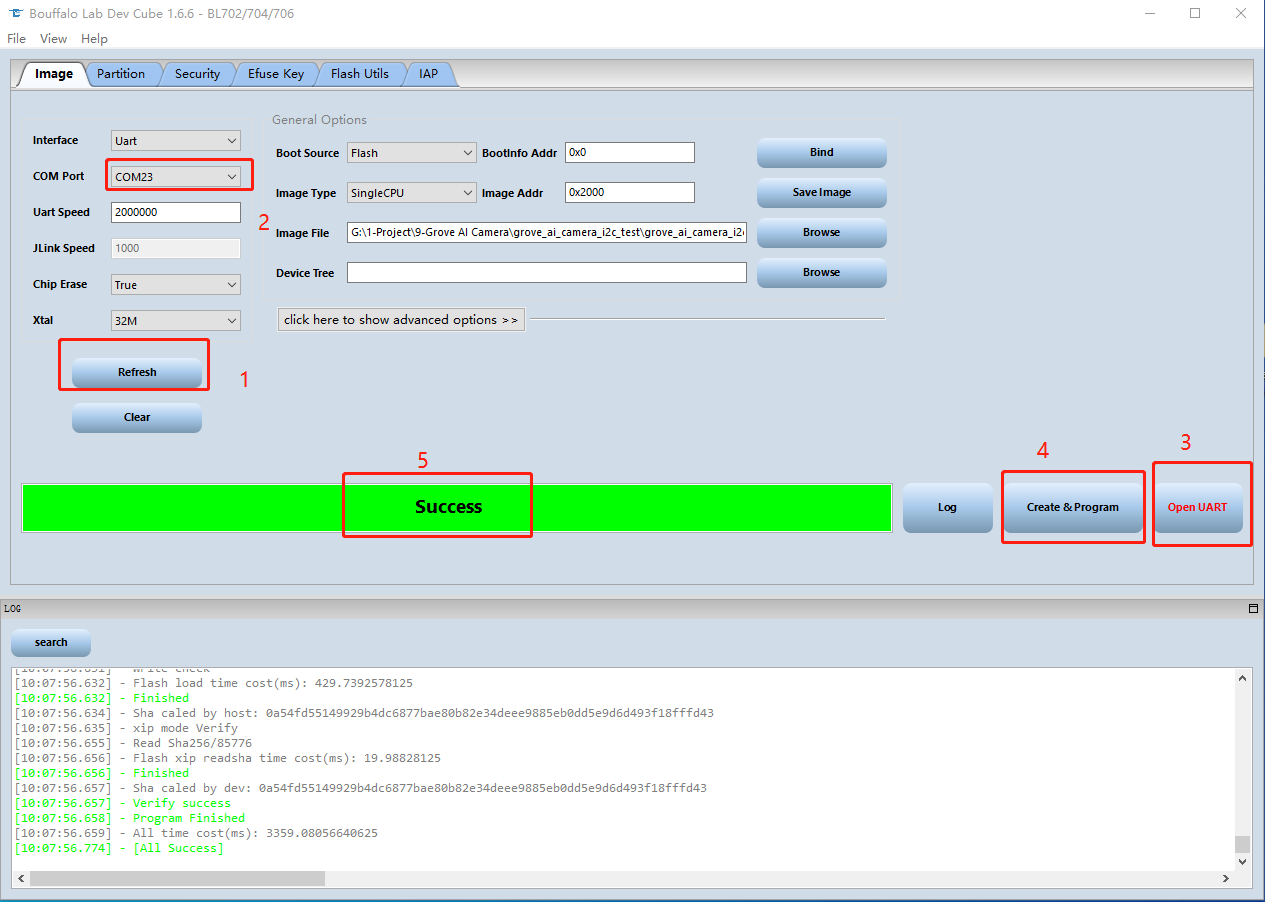
- 步骤 2. 下载并打开 BLDevCube.exe 软件,选择 BL702/704/706,然后点击 Finish。

- 步骤 3. 点击 View,首先选择 MCU。移动到 Image file,点击 Browse 并选择您刚刚下载的固件。
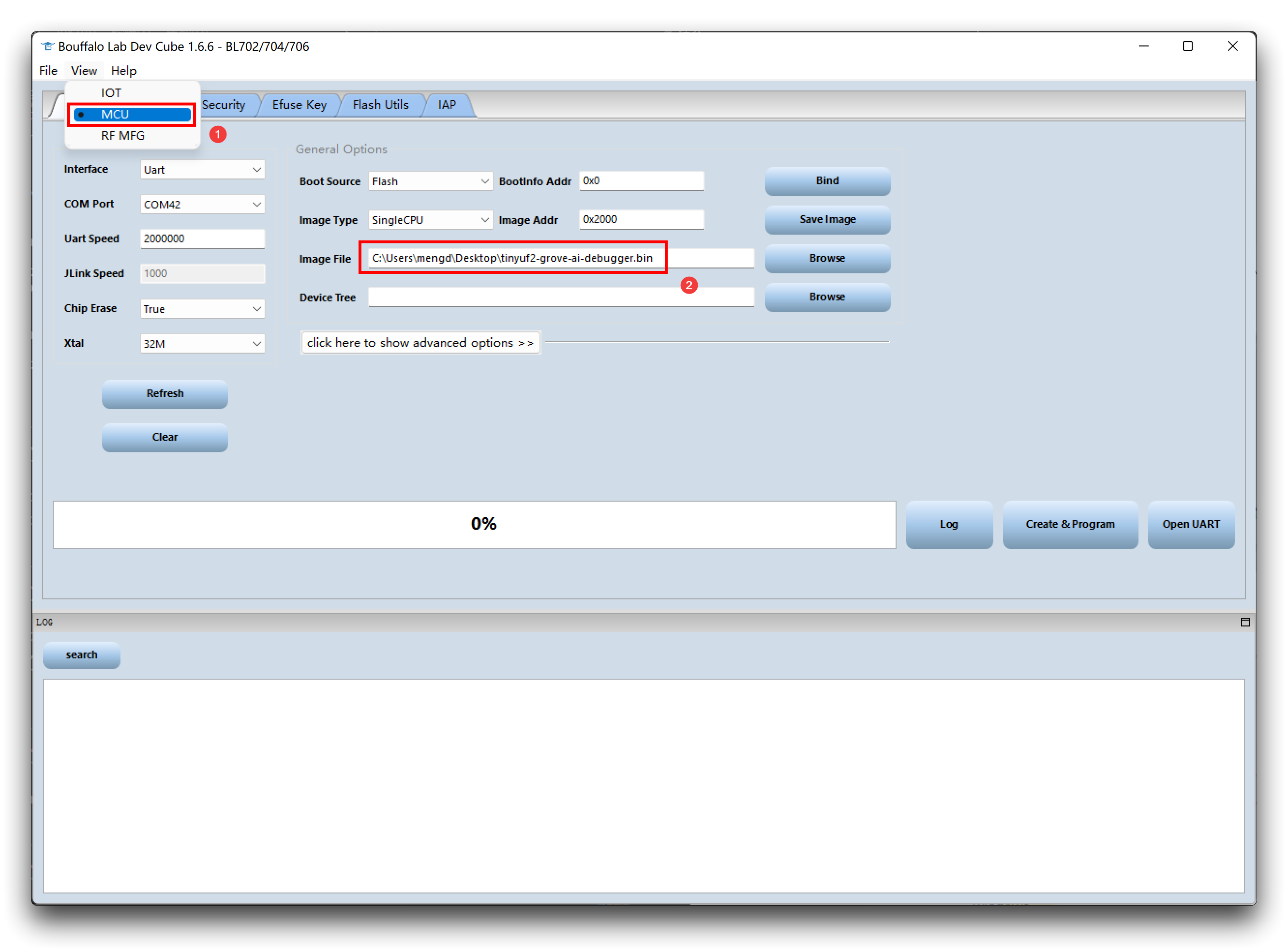
-
步骤 4. 确保没有其他设备连接到 PC。然后按住模块上的 Boot 按钮,将其连接到 PC。
-
步骤 5. 回到 PC 上的 BLDevCube 软件,点击 Refresh 并选择合适的端口。然后点击 Open UART 并将 Chip Erase 设置为 True,然后点击 Create&Program,等待过程完成。
资源
-
[网页] YOLOv5 文档
-
[网页] Ultralytics HUB
-
[网页] Roboflow 文档
-
[网页] TensorFlow Lite 文档
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。