Wio Terminal Edge Impulse 入门指南

Edge Impulse 使开发者能够通过嵌入式机器学习创建下一代智能设备解决方案。边缘机器学习将能够有效利用目前由于成本、带宽或功耗限制而被丢弃的 99% 传感器数据。
现在,Wio Terminal 已正式得到 Edge Impulse 的支持。让我们看看如何让 Wio Terminal 开始使用边缘机器学习!
安装依赖项
要在 Edge Impulse 中设置 Wio Terminal,您需要安装以下软件:
- Node.js v12 或更高版本。
- Arduino CLI
- Edge Impulse CLI 和串口监视器。通过打开命令提示符或终端并运行以下命令进行安装:
npm install -g edge-impulse-cli
安装 CLI 时遇到问题?请查看安装和故障排除获取更多参考。
连接到 Edge Impulse
安装好所有软件后,现在是时候将开发板连接到 Edge Impulse 了。
1. 将开发板连接到您的计算机
将 Wio Terminal 连接到您的计算机。通过快速滑动电源开关两次进入引导加载程序模式。更多参考信息,请参见这里。

您的 PC 中应该会出现一个名为 Arduino 的外部驱动器。将下载的 Edge Impulse uf2 固件文件 拖拽到 Arduino 驱动器中。现在,Edge Impulse 已加载到 Seeeduino Wio Terminal 上!
注意: 这里是 Wio Terminal Edge Impulse 源代码,您也可以从这里构建固件。
2. 设置密钥
从命令提示符或终端运行:
edge-impulse-daemon
注意: 连接到新设备时,运行 edge-impulse-daemon --clean 来清除之前的缓存。
3. 验证设备已连接
就是这样!您的设备现在已连接到 Edge Impulse。要验证这一点,请转到您的 Edge Impulse 项目,然后点击设备。设备将在这里列出。
对于您的第一个项目,让我们快速训练和部署一个简单的神经网络,仅使用单个光传感器来分类石头剪刀布手势。更多详细信息和视频教程,请观看相应的视频!
训练数据获取
转到数据获取选项卡。将样本长度设置为约 10000 毫秒或 10 秒,为每个手势创建 10 个样本,在 Wio terminal 附近挥动手部。

这是一个小数据集,但我们也有一个微型神经网络,所以在这种特殊情况下,欠拟合比过拟合更有可能发生。
欠拟合: 当统计模型或机器学习算法无法捕获数据的潜在趋势时,就称为欠拟合,这种情况发生在(除其他情况外)模型大小太小,无法为具有大量变化和噪声的数据制定通用规则时。
过拟合: 当统计模型开始从我们数据集中的噪声和不准确数据条目中学习时,就称为过拟合。这种情况发生在你有大模型和相对较小的数据集时——模型可以"死记硬背"所有数据点而不进行泛化。
在收集样本时,重要的是为模型提供多样性以便能够更好地泛化,例如具有不同方向、速度和距离传感器的样本。一般来说,网络只能从数据集中存在的数据中学习——所以如果你拥有的唯一样本是在传感器上方从左到右移动的手势,你不应该期望训练好的模型能够识别从右到左或上下移动的手势。
构建机器学习模型
收集样本后,是时候设计一个"脉冲"了。脉冲在这里是 Edge Impulse 用来表示数据处理——训练管道的词汇。按下创建脉冲并将窗口长度设置为 1000 毫秒,窗口长度增加设置为 50 毫秒。
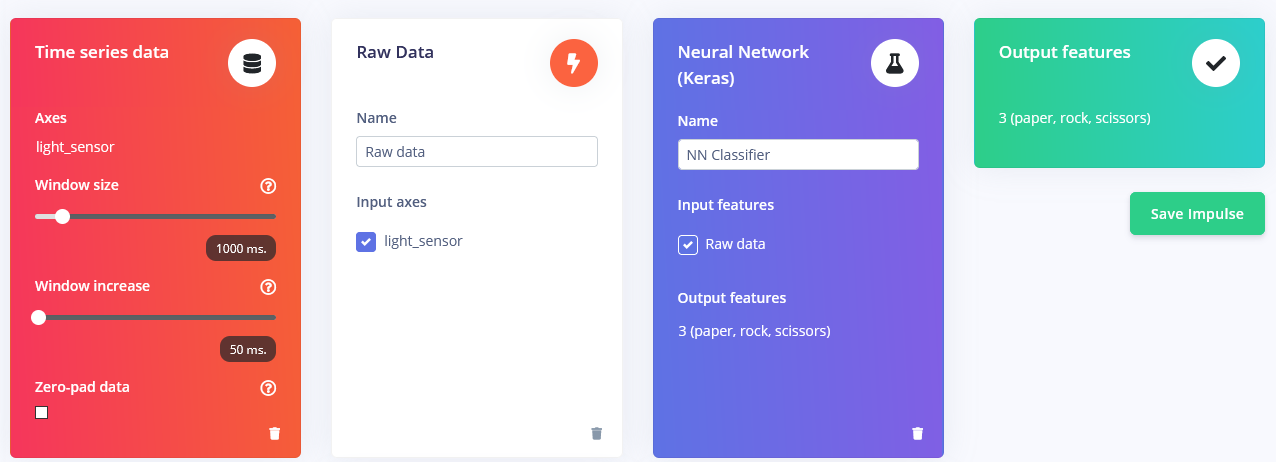
这些设置意味着每次执行推理时,我们将在 1000 毫秒内进行传感器测量——你的设备将进行多少次测量取决于频率。在数据收集期间,你将采样频率设置为 40 Hz,或每秒 40 次。因此,总结一下,你的设备将在 1000 毫秒时间窗口内收集 40 个数据样本,然后获取这些值,对其进行预处理并将其输入神经网络以获得推理结果。当然,我们在训练期间使用相同的窗口大小。 对于这个概念验证项目,我们将尝试三种不同的预处理块,使用默认参数(除了添加缩放)—— Flatten 块,它计算时间窗口内原始数据的平均值、最小值、最大值和其他函数。
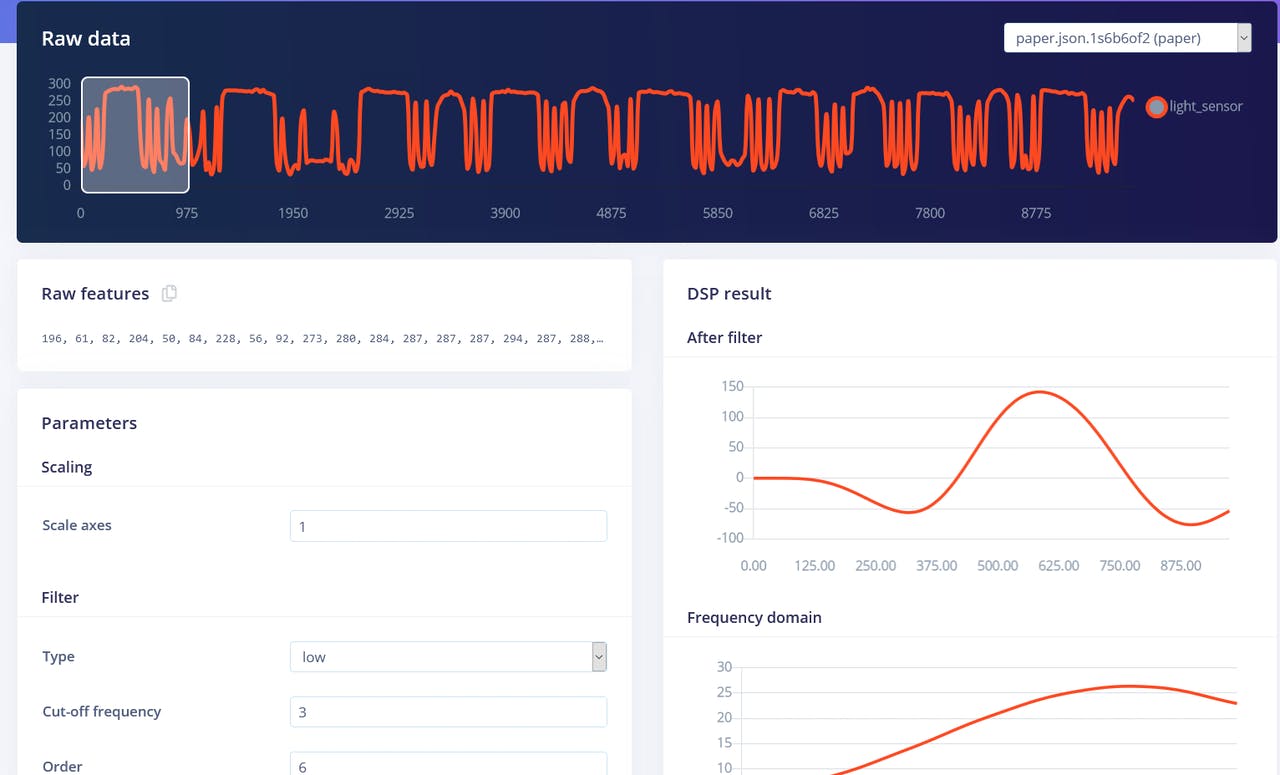
Spectral Features 块,它提取信号随时间的频率和功率特征。
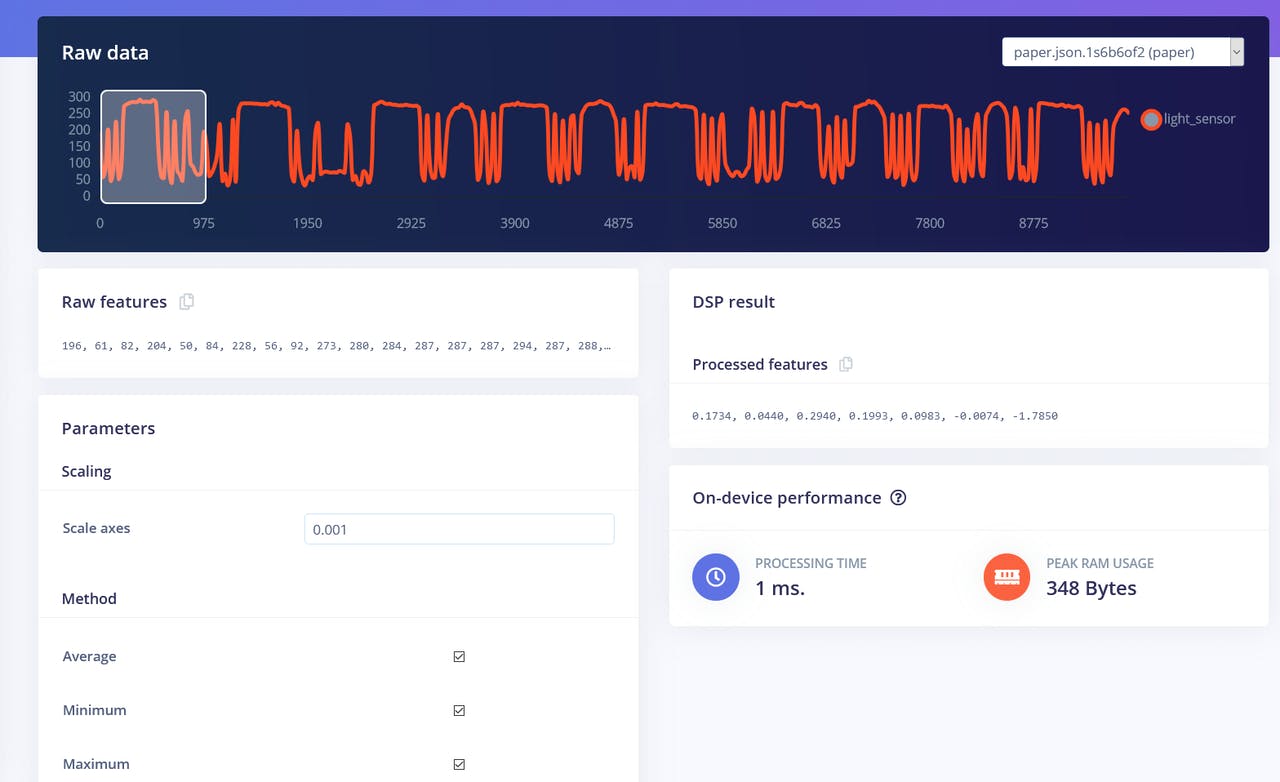
以及 Raw data 块,正如你可能猜到的那样,它只是将原始数据输入到神经网络学习块(可选择对数据进行归一化)。
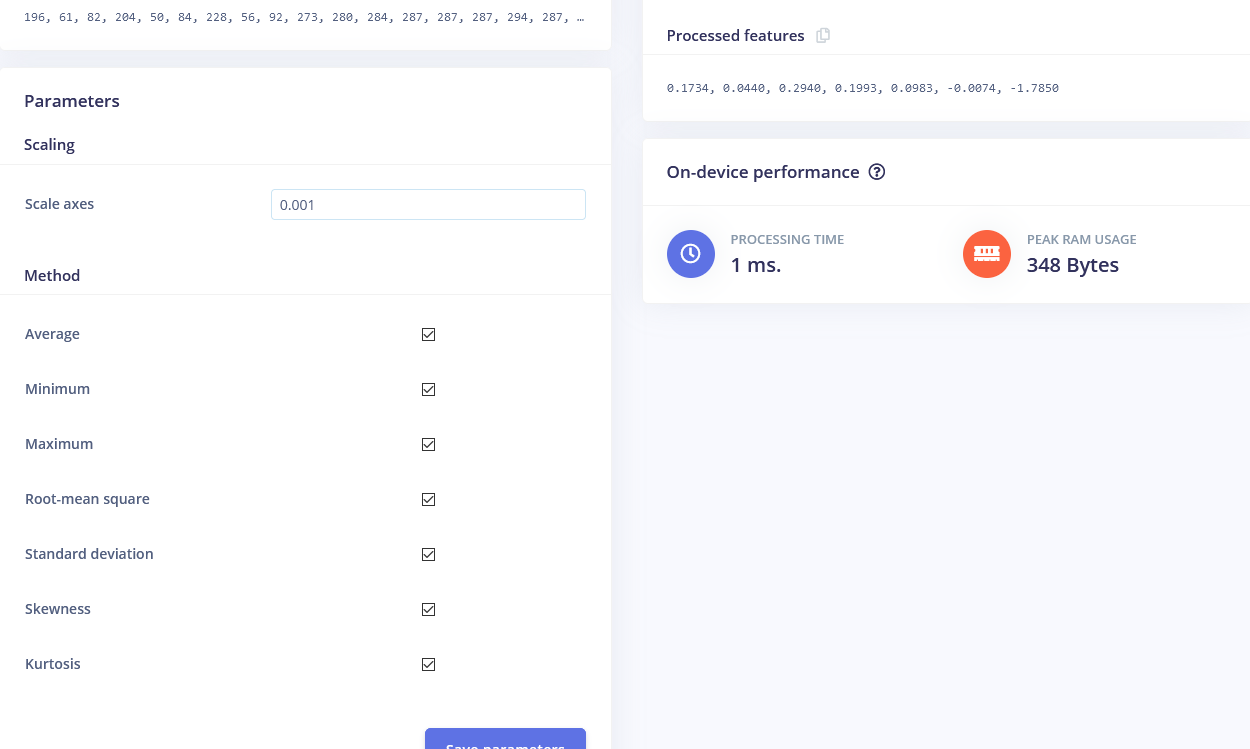
我们将从 Flatten 块开始。添加此块,然后添加神经网络(Keras)作为学习块,选中 Flatten 作为输入特征,然后点击保存脉冲。转到下一个选项卡,该选项卡的名称是你选择的处理块——Flatten。在那里输入 0.001 作为缩放值,其他参数保持不变。按下保存参数,然后生成特征。
特征可视化是 Edge Impulse Web 界面中特别有用的工具,因为它允许用户获得预处理后数据外观的图形洞察。例如,这是经过 Flatten 处理块后的数据:
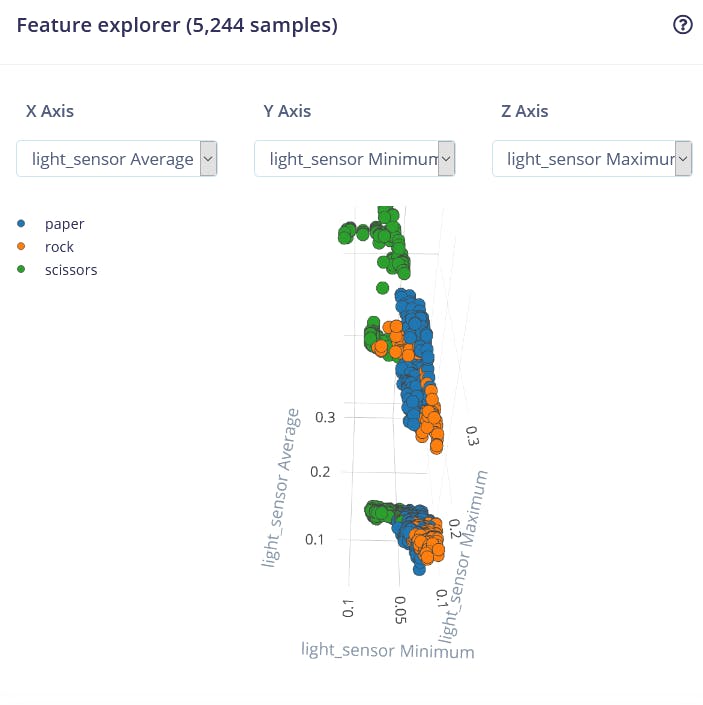
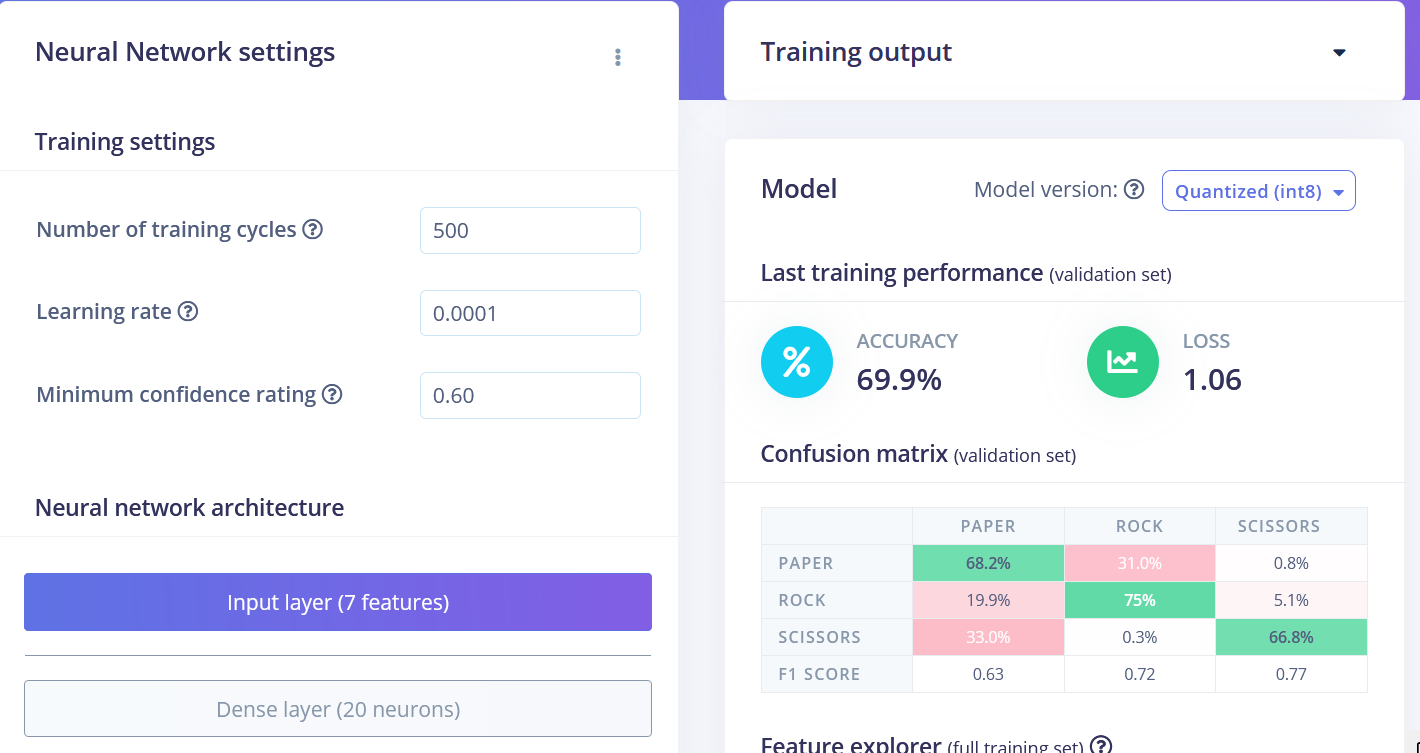
我们可以看到不同类别的数据点大致分开,但 rock 和其他类别之间有很多重叠,这将导致这两个类别出现问题和低准确性。生成并检查特征后,转到神经网络分类器选项卡。 训练一个简单的全连接网络,具有 2 个隐藏层,每个隐藏层分别有 20 和 10 个神经元,训练 500 个周期,学习率为 1e-4。训练完成后,你将在混淆矩阵中看到测试结果,类似于这样:
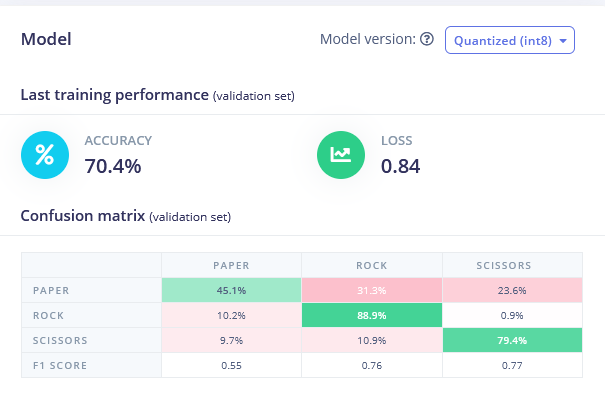
回到创建脉冲选项卡,删除 Flatten 块并选择 Spectral Features 块,生成特征(记住将缩放设置为 0.001!)并在 Spectral features 数据上训练神经网络。你应该看到轻微的改进。
Flatten 和 Spectral Features 块实际上都不是石头剪刀布手势识别任务的最佳处理方法。如果我们考虑一下,为了分类石头剪刀布手势,我们只需要计算光传感器接收到"低于正常"值的次数和持续时间。如果是一次相对较长的时间——那么它是石头(拳头经过传感器上方)。如果是两次,那么它是剪刀。超过这个数量的任何情况都是布。听起来很简单,但保持时间序列数据对于神经网络能够学习数据点中的这种关系非常重要。 Flatten 和 Spectral Features 处理块都移除了每个窗口内的时间关系——Flatten 块简单地将最初按顺序排列的原始值转换为在时间窗口内所有值上计算的平均值、最小值、最大值等值,而不考虑它们的顺序。Spectral Features 块提取频率和功率特征,它在这个特定任务上效果不佳的原因可能是每个手势的持续时间太短。 因此,实现最佳性能的方法是使用 Raw data 块,它将保持时间序列数据。看看我们使用 Raw data 和卷积 1D 网络的示例项目,这是一种更专业的网络类型,与全连接网络相比。我们能够在相同数据上实现 92.4% 的准确率!
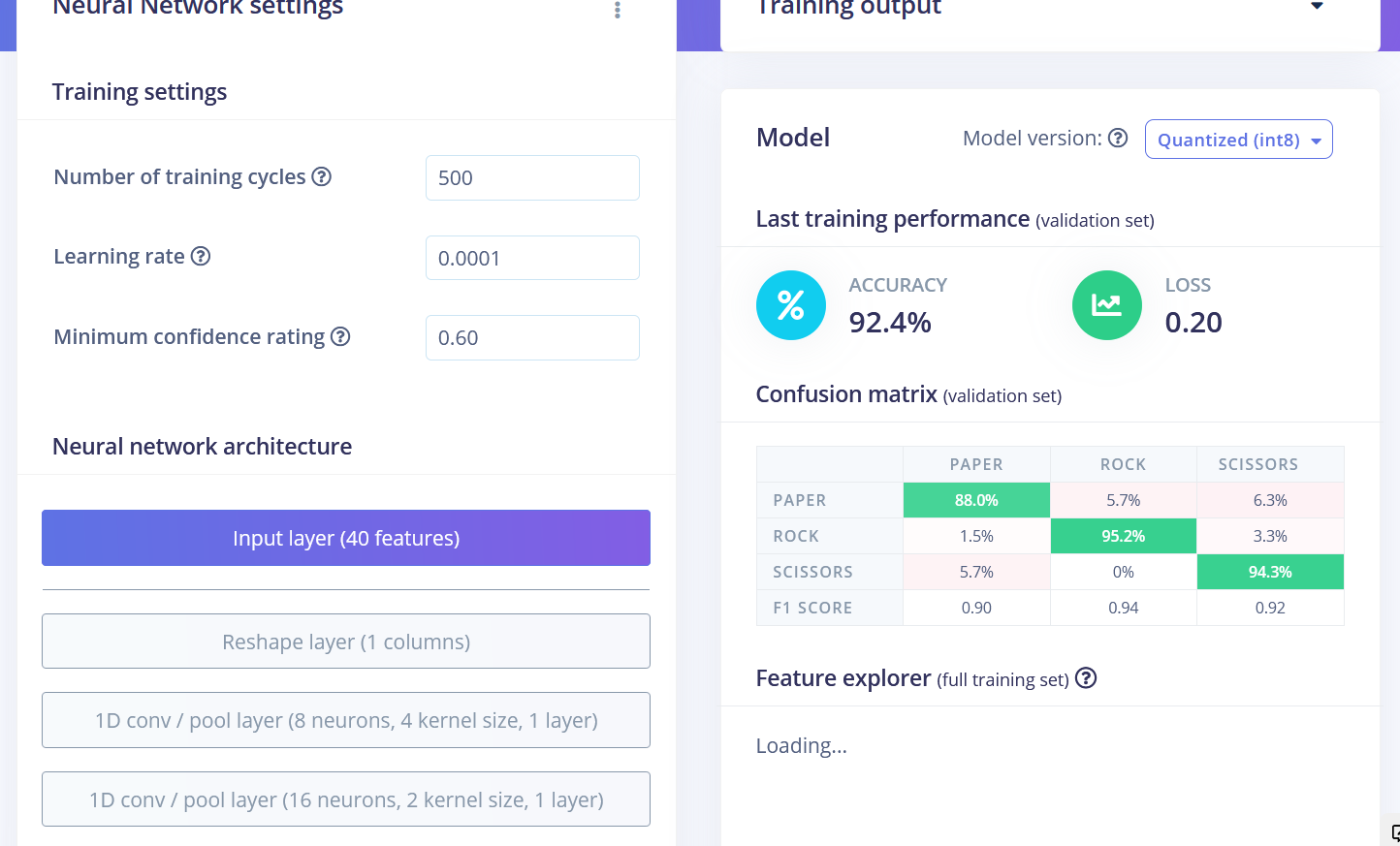
训练后的最终结果为:
• Flatten FC 69.9% 准确率
• Spectral Features FC 70.4% 准确率
• Raw Data Conv1D 92.4% 准确率
训练完成后,您可以使用实时分类选项卡测试模型,该选项卡将从设备收集数据样本并使用托管在 Edge Impulse 上的模型对其进行分类。我们测试了三种不同的手势,发现准确率在概念验证方面是令人满意的。
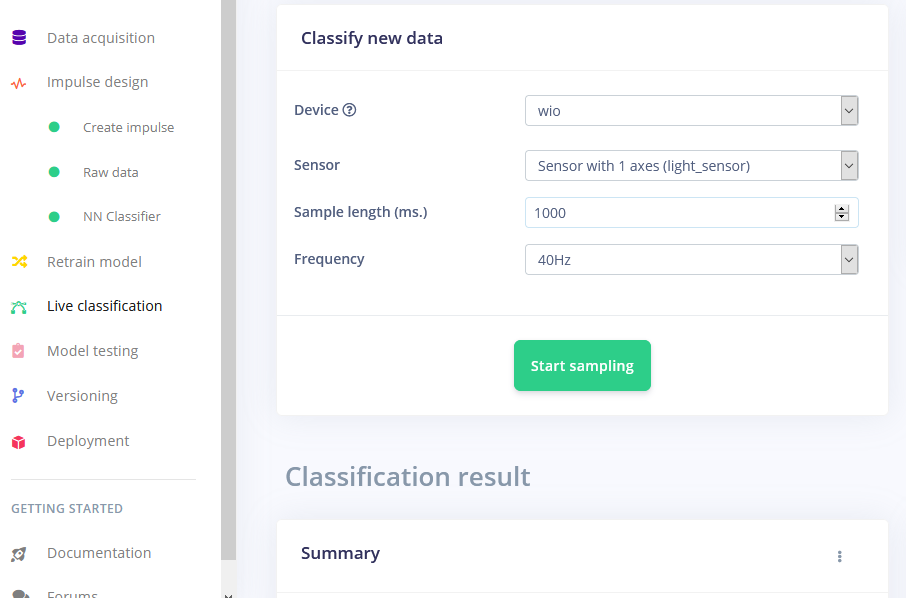
部署到 Wio Terminal
下一步是在设备上部署。点击部署选项卡后,选择 Arduino 库并下载。
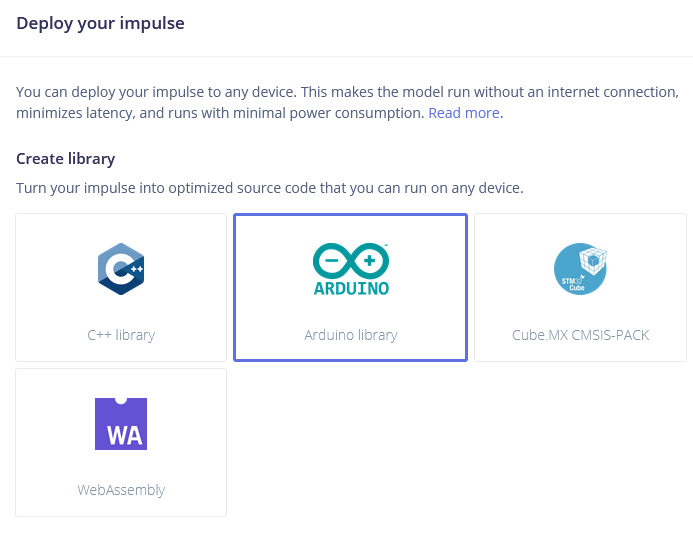
解压存档文件并将其放置在您的 Arduino 库文件夹中。打开 Arduino IDE 并选择静态缓冲区示例(位于文件 -> 示例 -> 您的项目名称 -> static_buffer),该示例已经包含了使用您的模型进行分类的所有样板代码。很棒!
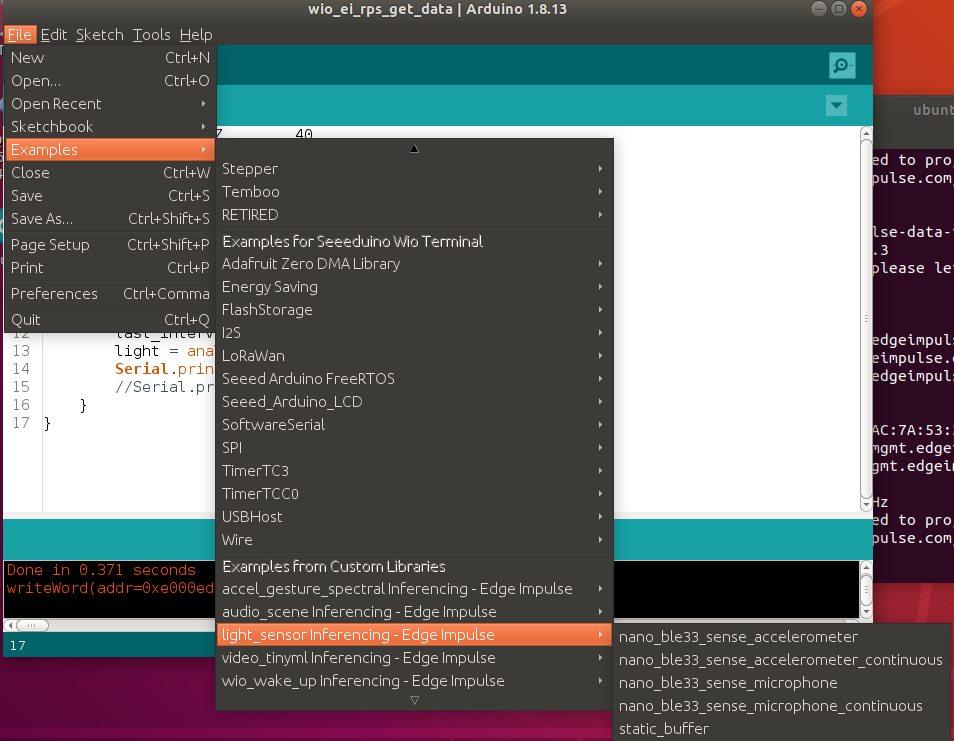
我们唯一需要填写的是设备上的数据采集。我们将使用一个简单的 for 循环和延迟来考虑频率(如果您还记得,我们在收集训练数据集时有 25 毫秒的延迟)。
int raw_feature_get_data(size_t offset, size_t length, float *out_ptr) {
float features[40];
for (byte i = 0; i < 40; i = i + 1)
{
features[i]=analogRead(WIO_LIGHT);
delay(25);
}
memcpy(out_ptr, features + offset, length * sizeof(float));
return 0;
}
当然有更好的方法来实现这一点,例如传感器数据缓冲区,这将允许我们更频繁地执行推理。但我们将在本系列的后续文章中讨论这个问题。
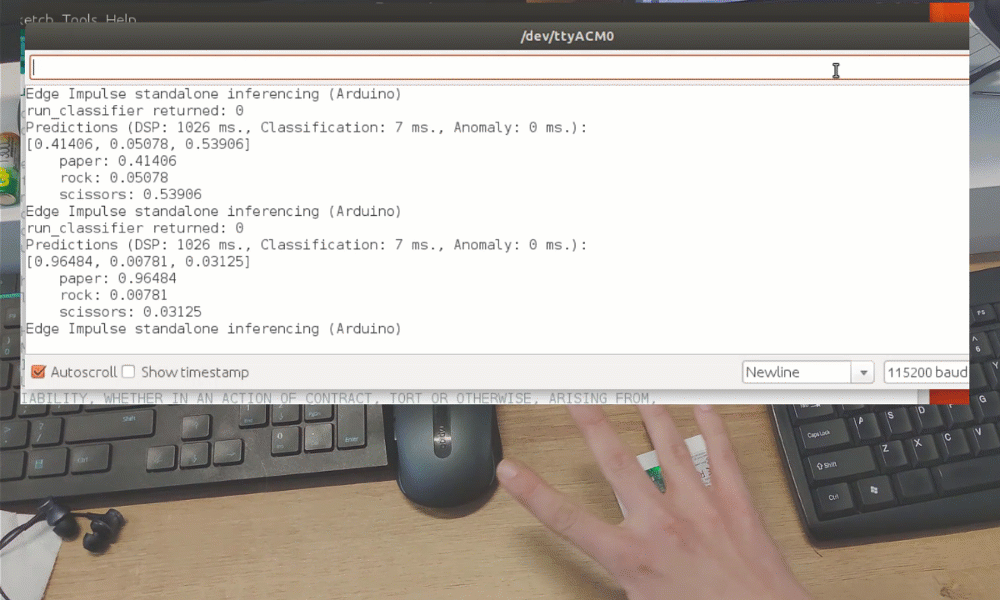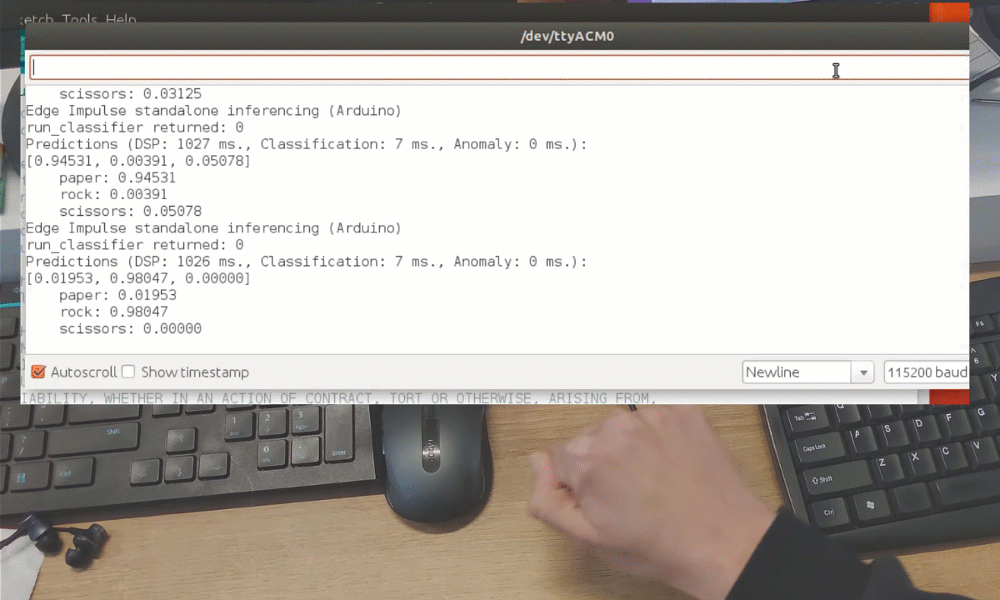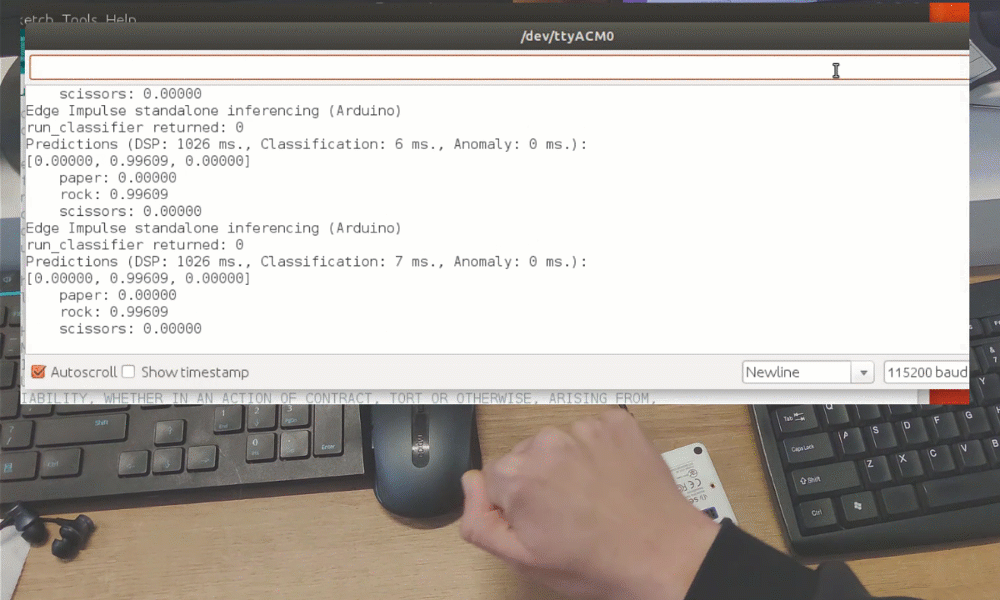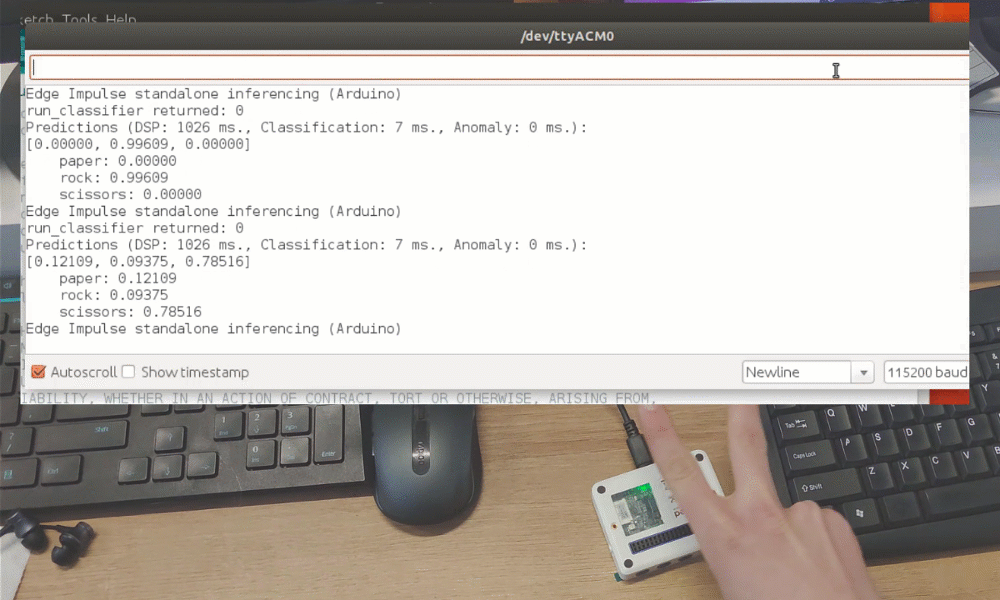
虽然这只是一个概念验证演示,但它真正展示了 TinyML 正在做一些重大的事情。您可能知道即使图像被大幅缩小,也可以使用摄像头传感器识别手势。但仅用 1 个像素识别手势完全是另一个层次!