Wio Terminal Edge Impulse 使用内置加速度计进行连续动作识别
在本教程中,您将使用机器学习构建一个在 Wio Terminal 上运行的手势识别系统。这是一个使用基于规则的编程很难解决的任务,因为人们每次执行手势的方式都不完全相同。但机器学习可以轻松处理这些变化。您将学习如何从真实传感器收集高频数据,使用信号处理清理数据,构建神经网络分类器,以及如何将模型部署回设备。在本教程结束时,您将对使用 Edge Impulse 在嵌入式设备中应用机器学习有深入的理解。
本教程还有视频版本:
1. 先决条件
对于本教程,您需要一个受支持的设备。请先按照 Wio Terminal Edge Impulse 教程进行操作,然后再进行以下步骤。
除了 Wio Terminal,以下是其他受支持的设备。
如果您的设备在工作室的设备下已连接,您可以继续:
Edge Impulse 可以从任何设备摄取数据 - 包括您已经在生产中使用的嵌入式设备。有关更多信息,请参阅 摄取服务 的文档。
2. 收集您的第一个数据
连接设备后,我们可以收集一些数据。在工作室中转到 数据采集 选项卡。这是存储所有原始数据的地方,如果您的设备连接到远程管理 API,也是您可以开始采样新数据的地方。
在 记录新数据 下,选择您的设备,将标签设置为 idle,采样长度设置为 5000,传感器设置为 内置加速度计,频率设置为 62.5Hz。这表示您想要记录 10 秒的数据,并将记录的数据标记为 idle。如果需要,您可以稍后编辑这些标签。
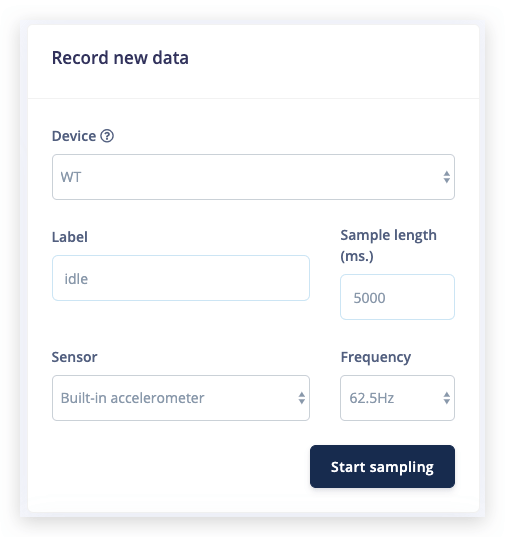
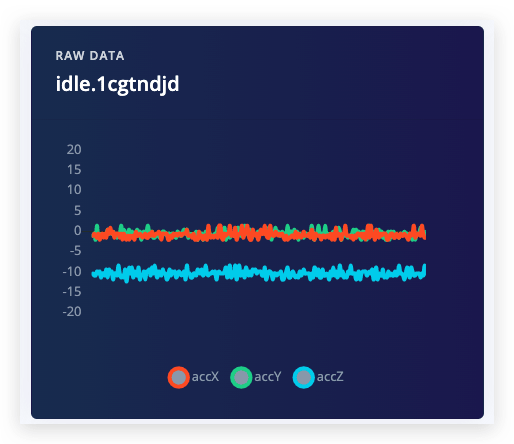
点击开始采样后,以连续动作上下移动您的设备。大约十二秒后,设备应该完成采样并将文件上传回 Edge Impulse。您会看到工作室中"已收集数据"下出现新的一行。当您点击它时,您现在会看到原始数据的图形显示。由于开发板上的加速度计有三个轴,您会注意到三条不同的线,每个轴一条。
进行连续动作很重要,因为我们稍后会将数据切片成更小的窗口。
机器学习在大量数据下效果最佳,所以单个样本是不够的。现在是开始构建您自己的数据集的时候了。例如,使用以下三个类别,每个类别记录大约 3 分钟的数据:
- Idle - 当您工作时只是放在桌子上。
- Wave - 从左到右挥动设备。
- Circle - 画圆圈。
确保对动作进行变化。例如,进行慢速和快速动作,并改变板子的方向。您永远不知道用户会如何使用设备。最好收集每个约 10 秒的样本。
3. 设计脉冲
有了训练集,您就可以设计脉冲了。脉冲获取原始数据,将其切分为更小的窗口,使用信号处理块提取特征,然后使用学习块对新数据进行分类。信号处理块对相同输入总是返回相同值,用于使原始数据更易于处理,而学习块则从过去的经验中学习。
在本教程中,我们将使用"频谱分析"信号处理块。该块应用滤波器,对信号执行频谱分析,并提取频率和频谱功率数据。然后我们将使用"神经网络"学习块,它获取这些频谱特征并学习区分三个(空闲、圆圈、挥手)类别。
在工作室中转到 Create impulse,将窗口大小设置为 2000(您可以点击 2000 ms. 文本来输入精确值),窗口增量设置为 80,并添加 Spectral Analysis 和 Neural Network (Keras) 块。然后点击 Save impulse。
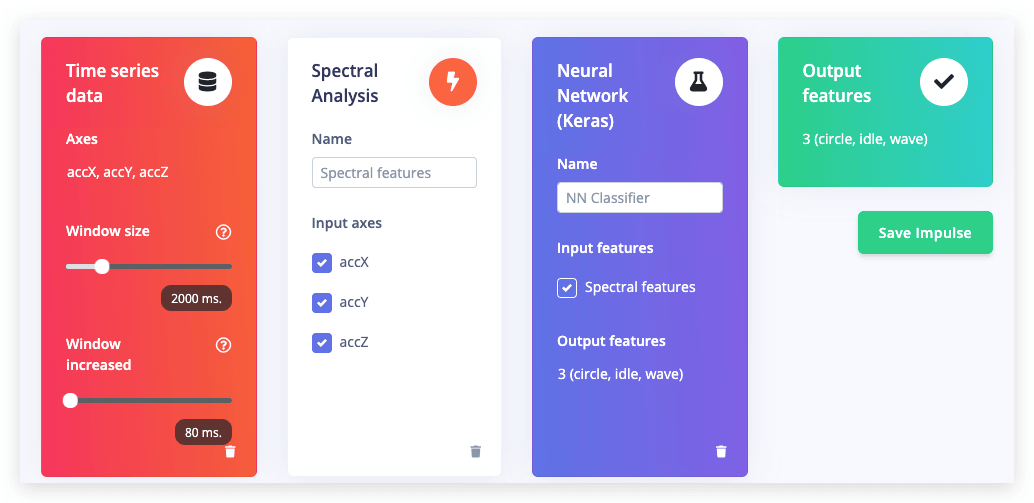
配置频谱分析块
要配置您的信号处理块,请点击左侧菜单中的 Spectral features。这将在屏幕顶部显示原始数据(您可以通过下拉菜单选择其他文件),并在右侧通过图表显示信号处理的结果。对于频谱特征块,您将看到以下图表:
- After filter - 应用低通滤波器后的信号。这将去除噪声。
- Frequency domain - 信号重复的频率(例如,每秒做一次挥手动作将在 1 Hz 处显示峰值)。
- Spectral power - 在每个频率处信号中投入的功率量。
良好的信号处理块对相似数据会产生相似结果。如果您移动滑动窗口(在原始数据图上),图表应该保持相似。此外,当您切换到具有相同标签的另一个文件时,即使设备方向不同,您也应该看到相似的图表。
一旦您对结果满意,点击 Save parameters。这将带您到 Feature generation 屏幕。在这里您将:
- 将所有原始数据分割为窗口(基于窗口大小和窗口增量)。
- 在所有这些窗口上应用频谱特征块。
点击 Generate features 开始该过程。
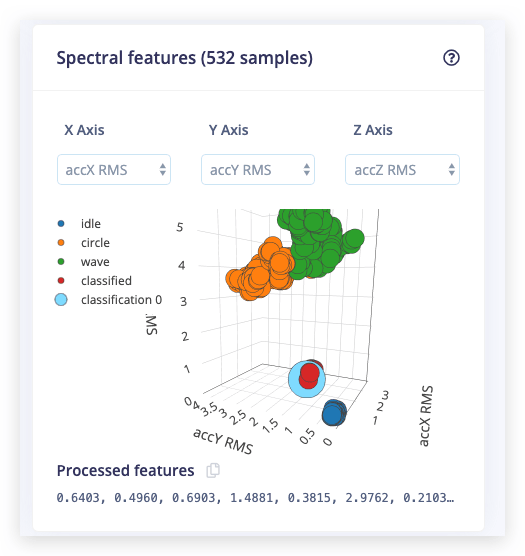
之后将加载 Feature explorer。这是所有提取特征与所有生成窗口的对比图。您可以使用此图表比较完整的数据集。例如,通过在 X 轴上绘制第一个峰值的高度,在 Y 轴上绘制 0.5 Hz 和 1 Hz 之间的频谱功率。一个好的经验法则是,如果您可以在多个轴上视觉分离数据,那么机器学习模型也能够做到这一点。
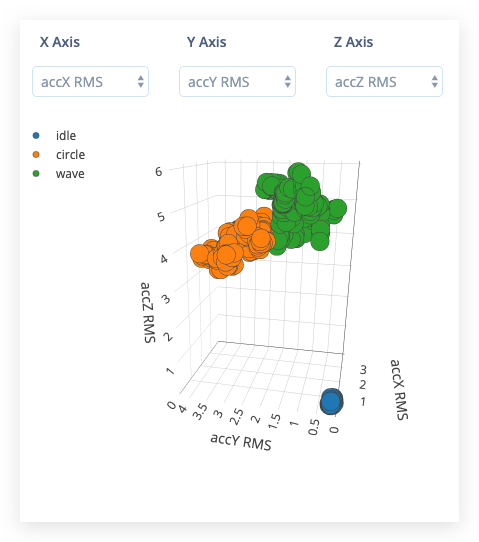
配置神经网络
处理完所有数据后,是时候开始训练神经网络了。神经网络是一组算法,松散地模仿人脑,旨在识别模式。我们在这里训练的网络将以信号处理数据作为输入,并尝试将其映射到三个类别之一。
那么神经网络如何知道要预测什么呢?神经网络由神经元层组成,全部相互连接,每个连接都有一个权重。输入层中的一个这样的神经元可能是 X 轴第一个峰值的高度(来自信号处理块);输出层中的一个这样的神经元可能是挥手(类别之一)。在定义神经网络时,所有这些连接都是随机初始化的,因此神经网络将做出随机预测。在训练期间,我们获取所有原始数据,要求网络做出预测,然后根据结果对权重进行微小调整(这就是为什么标记原始数据很重要)。
这样,经过大量迭代后,神经网络学习;并最终在预测新数据方面变得更好。让我们通过点击菜单中的 NN Classifier 来尝试这个。
将 Number of training cycles 设置为 1。这将限制训练为单次迭代。然后点击 Start training。
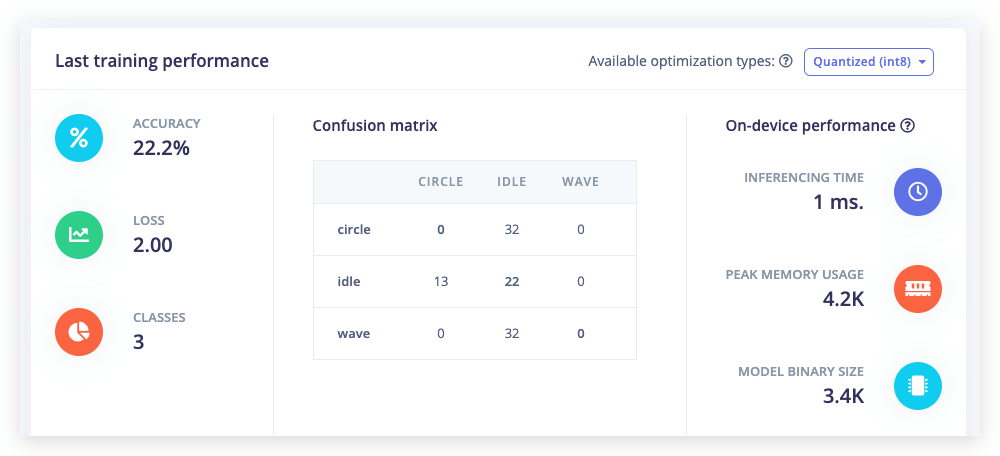
现在将 Number of training cycles 更改为 2,您将看到性能提升。最后,将 Number of training cycles 更改为 100 或更多,让训练完成。您刚刚训练了您的第一个神经网络!
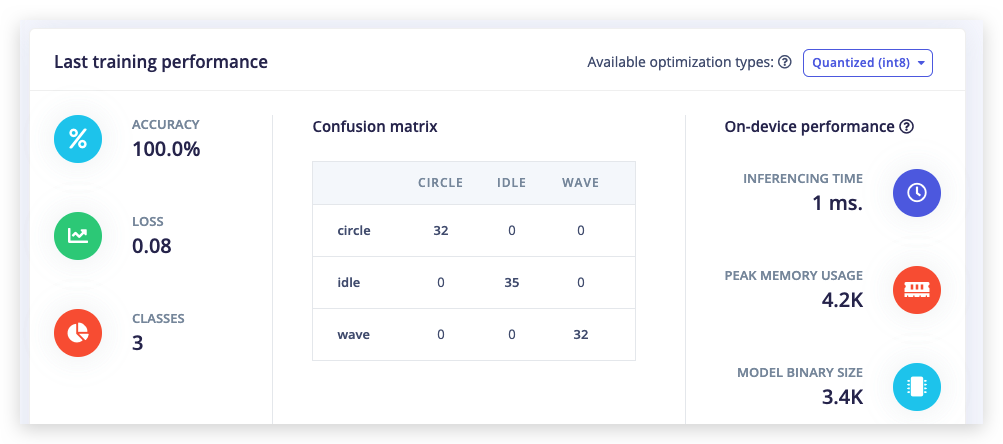
训练 100 个训练周期后,您可能最终获得 100% 的准确率。这不一定是好事,因为这可能表明神经网络过于针对特定测试集进行调优,在新数据上可能表现不佳(过拟合)。减少这种情况的最佳方法是添加更多数据或降低学习率。
4. 对新数据进行分类
从前面步骤的统计数据中我们知道模型对我们的训练数据有效,但网络在新数据上的表现如何呢?点击菜单中的 Live classification 来找出答案。您的设备应该(就像在步骤2中一样)在 Classify new data 下显示为在线状态。将 Sample length 设置为 5000(5秒),点击 Start sampling 并开始做动作。之后您将获得一份关于网络认为您做了什么的完整报告。
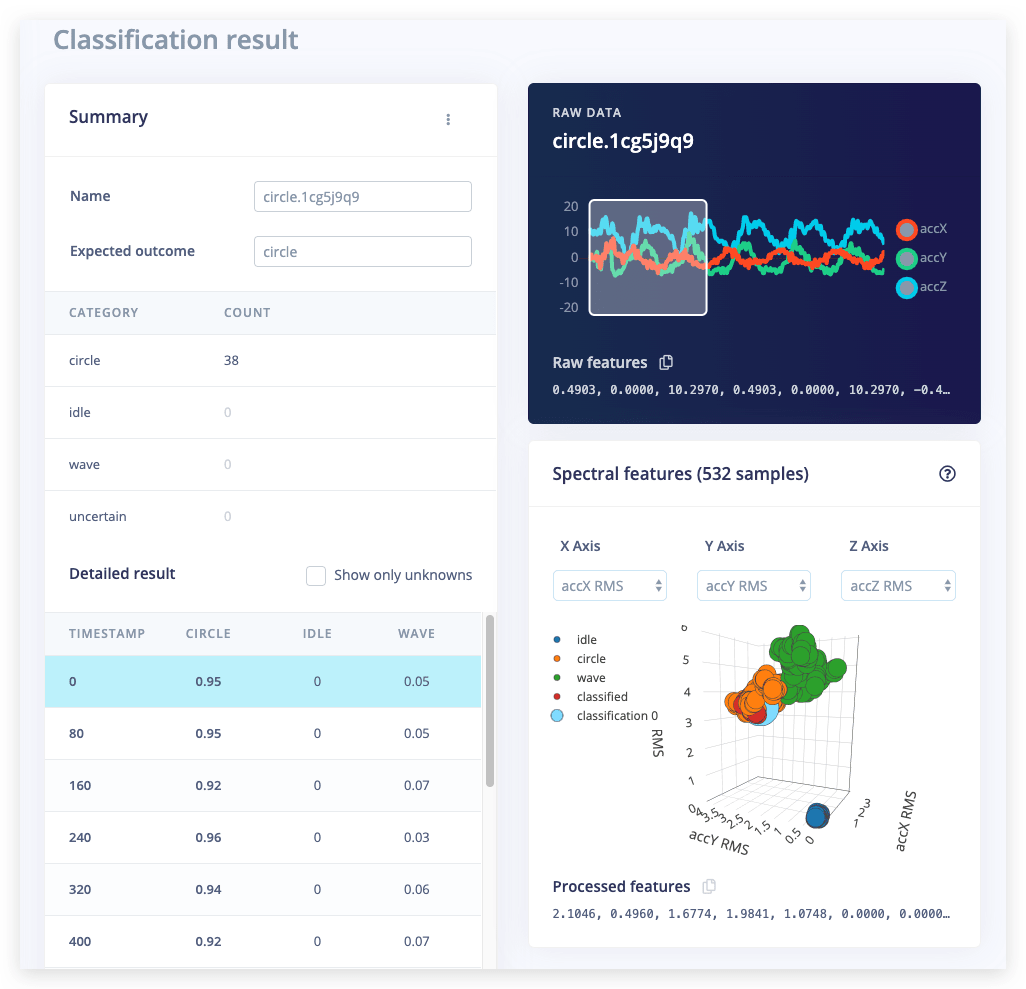
如果网络表现很好,那太棒了!但如果表现不佳怎么办?可能有多种原因,但最常见的是:
- 数据不够。神经网络需要学习数据集中的模式,数据越多越好。
- 数据看起来不像网络之前见过的其他数据。当有人以您没有添加到测试集中的方式使用设备时,这种情况很常见。您可以通过点击将当前文件添加到测试集,然后选择 Move to training set。确保在训练前在
Data acquisition下更新标签。 - 模型训练不够。将 epochs 数量增加到
200,看看性能是否提高(分类文件已存储,您可以通过Classify existing validation sample加载它)。 - 模型过拟合,因此在新数据上表现不佳。尝试降低学习率或添加更多数据。
- 神经网络架构不太适合您的数据。调整层数和神经元数量,看看性能是否改善。
如您所见,构建神经网络时仍然需要大量的试验和错误,但我们希望可视化能提供很大帮助。您还可以通过 Model validation 对完整的验证集运行网络。将模型验证页面视为您模型的一组单元测试!
有了一个可工作的模型,我们可以查看当前脉冲表现不佳的地方...
5. 异常检测
神经网络很棒,但它们有一个大缺陷。它们在处理从未见过的数据(如新手势)时表现糟糕。神经网络无法判断这一点,因为它们只知道训练数据。如果您给它一些与之前见过的任何东西都不同的东西,它仍然会分类为三个类别中的一个。
让我们看看这在实践中是如何工作的。转到 Live classification 并记录一些新数据,但现在剧烈摇晃您的设备。看看网络仍然会预测某些东西。
那么...我们如何做得更好?如果您查看 accX RMS、accY RMS 和 accZ RMS 轴上的特征浏览器,您应该能够在视觉上将分类数据与训练数据分开。我们可以利用这一点,训练一个新的(第二个)网络,该网络围绕我们之前见过的数据创建聚类,并将传入数据与这些聚类进行比较。如果与聚类的距离太大,您可以将样本标记为异常,并且不信任神经网络。
要添加此块,转到 Create impulse,点击 Add learning block,并选择 K-means Anomaly Detection。然后点击 Save impulse。
要配置聚类模型,点击菜单中的 Anomaly detection。这里我们需要指定:
- 聚类数量。这里使用
32。 - 我们想要在聚类期间选择的轴。由于我们可以在 accX RMS、accY RMS 和 accZ RMS 轴上视觉分离数据,选择这些轴。
点击 Start training 生成聚类。您可以使用下拉菜单将现有验证样本加载到异常浏览器中。
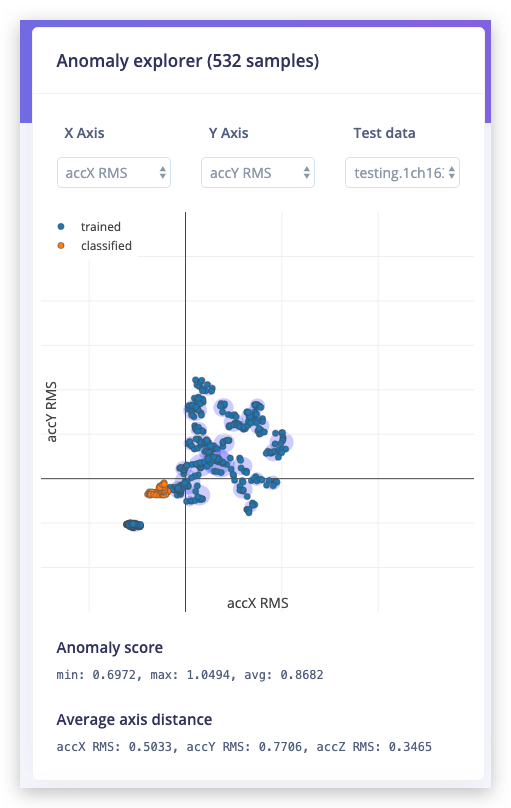
蓝色的已知聚类,橙色的摇晃数据。它明显在任何已知聚类之外,因此可以标记为异常。
异常浏览器一次只绘制两个轴。在 average axis distance 下,您可以看到验证样本距离每个轴有多远。使用下拉菜单更改轴。
6. 部署回设备
在脉冲设计、训练和验证完成后,您可以将此模型部署回您的设备。这使得模型可以在没有互联网连接的情况下运行,最小化延迟,并以最低功耗运行。Edge Impulse 可以将完整的脉冲 - 包括信号处理代码、神经网络权重和分类代码 - 打包成一个单独的 C++ 库,您可以将其包含在您的嵌入式软件中。
点击部署选项卡后,选择 Arduino 库并下载它。解压存档文件并将其放置在您的 Arduino 库文件夹中。打开 Arduino IDE 并选择示例-> 您的项目名称 Inferencing Edge Impulse -> nano_ble33_sense_accelerometer 草图。我们的板子类似于 Arduino Nano BLE33 Sense,但使用不同的加速度计(LIS3DHTR 而不是 LSM9DS1),所以我们需要相应地更改数据采集部分。另外,由于 Wio Terminal 有一个 LCD 屏幕,如果检测到的类别置信度值高于阈值,我们将在屏幕上显示该类别的名称。 首先更改头文件
#include <Arduino_LSM9DS1.h>
为
#include"LIS3DHTR.h"
#include"TFT_eSPI.h"
LIS3DHTR<TwoWire> lis;
TFT_eSPI tft;
然后在 setup 函数中更改初始化
if (!IMU.begin()) {
ei_printf("Failed to initialize IMU!\r\n");
}
else {
ei_printf("IMU initialized\r\n");
}
为
tft.begin();
tft.setRotation(3);
tft.fillScreen(TFT_WHITE);
lis.begin(Wire1);
if (!lis.available()) {
Serial.println("Failed to initialize IMU!");
while (1);
}
else {
ei_printf("IMU initialized\r\n");
}
lis.setOutputDataRate(LIS3DHTR_DATARATE_100HZ); // Setting output data rage to 25Hz, can be set up tp 5kHz
lis.setFullScaleRange(LIS3DHTR_RANGE_16G); // Setting scale range to 2g, select from 2,4,8,16g
我们在 loop 函数中进行数据收集和推理,这里我们需要将使用 LSM9DS1 的数据采集更改为 LIS3DHTR 的数据采集函数
IMU.readAcceleration(buffer[ix], buffer[ix + 1], buffer[ix + 2]);
为
lis.getAcceleration(&buffer[ix], &buffer[ix + 1], &buffer[ix + 2]);
然后在 LCD 屏幕上显示类别名称,在
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: %.3f\n", result.anomaly);
#endif
之后添加以下代码块,在其中我们检查每个类别的置信度值,如果其中一个高于阈值,则更改屏幕颜色并显示该类别的名称。
if (result.classification[1].value > 0.7) {
tft.fillScreen(TFT_PURPLE);
tft.setFreeFont(&FreeSansBoldOblique12pt7b);
tft.drawString("Wave", 20, 80);
delay(1000);
tft.fillScreen(TFT_WHITE);
}
if (result.classification[2].value > 0.7) {
tft.fillScreen(TFT_RED);
tft.setFreeFont(&FreeSansBoldOblique12pt7b);
tft.drawString("Circle", 20, 80);
delay(1000);
tft.fillScreen(TFT_WHITE);
}
然后编译并上传 - 打开串口监视器并执行其中一个手势!您将能够在串口监视器和 LCD 屏幕上看到推理结果。
7. 结论
机器学习是一个超级有趣的领域:它允许您构建从过去经验中学习的复杂系统,自动在传感器数据中找到模式,并在不明确编程的情况下搜索异常。我们认为在嵌入式系统上的机器学习有巨大的机会。目前收集了大量的传感器数据,但由于成本、带宽或功耗限制,99%的数据目前被丢弃。
Edge Impulse 帮助您解锁这些数据。通过直接在设备上处理数据,您不再需要将原始数据发送到云端,而是可以直接在重要的地方得出结论。我们迫不及待地想看到您将构建什么!