Wio Terminal Edge Impulse 使用内置麦克风进行音频场景识别
在这个项目中,我们将学习如何使用 Wio Terminal 和 Edge Impulse 训练和部署音频场景分类器。 更多详细信息和视频教程,请观看相应的视频!
计算机中的声音处理
音频场景分类是一项任务,机器学习模型需要为音频片段预测一个类别,例如"婴儿哭声"、"咳嗽声"、"狗叫声"等。
声音是一种振动,以声波的形式通过传输介质(如气体、液体或固体)传播。

声源推动周围介质分子,它们推动相邻的分子,如此循环往复。当它们到达其他物体时,该物体也会轻微振动——我们在麦克风中使用这一原理。麦克风膜片被介质分子向内推动,然后回到原始位置。
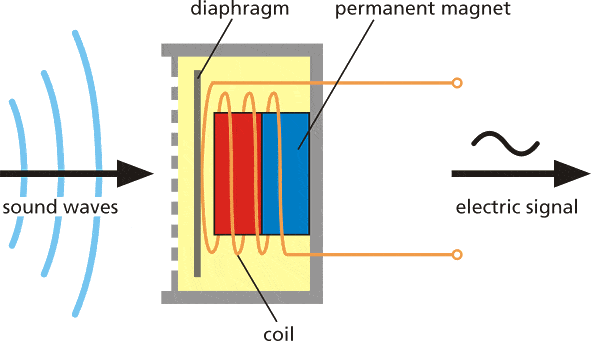
这在电路中产生交流电,其中电压与声音振幅成正比——声音越大,对膜片的推动越强,从而产生更高的电压。然后我们用模数转换器读取这个电压,并以相等的间隔记录——我们每秒测量声音的次数称为采样率,例如 8000 Hz 采样率是每秒测量 8000 次。采样率显然对声音质量很重要——如果我们采样太慢,可能会错过重要的部分。用于数字录音的数字范围也很重要——使用的数字范围越大,我们能从原始声音中保留的"细节"就越多。这称为音频位深度——你可能听过 8 位声音和 16 位声音这样的术语。嗯,这正如字面意思——对于 8 位声音,使用无符号 8 位整数,范围从 0 到 255。对于 16 位声音,使用有符号 16 位整数,即 -32768 到 32767。好的,最终我们得到一串数字,较大的数字对应声音的响亮部分,我们可以这样可视化它——这是以 8000 Hz 频率、8 位深度(0-255)录制的 1 秒枪声。

不过,我们无法对这种原始声音表示做太多处理——是的,我们可以剪切和粘贴部分或使其更安静或更响亮,但对于分析声音来说,它太原始了。这就是傅里叶变换、梅尔刻度、频谱图和倒谱系数发挥作用的地方。在这个项目中,我们将傅里叶变换定义为一种数学变换,它允许我们将信号分解为其各个频率和频率的振幅。
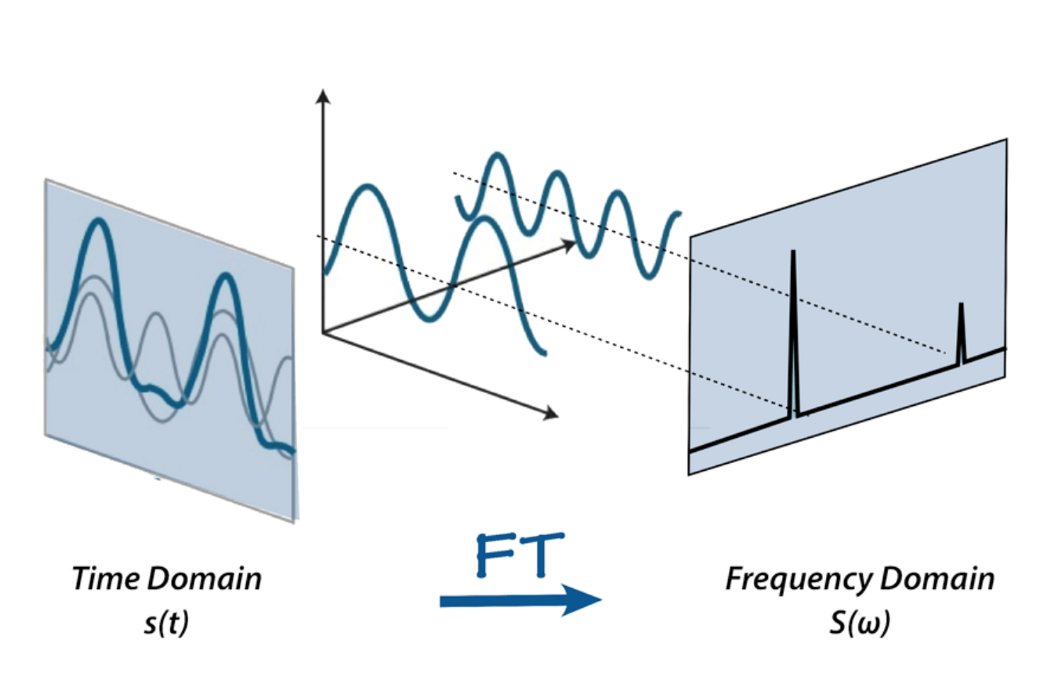
或者,如果你想用一个比喻——给定奶昔,它输出配方。
互联网上有很多关于傅里叶变换的材料,例如betterexplained.com 的这篇文章和3Blue1Gray 的视频——查看它们以了解更多关于 FFT 的信息。
这是我们的声音应用傅里叶变换后的样子——较高的条形对应较大振幅的频率。

太好了!现在我们可以对音频信号做更有趣的事情——例如消除最不重要的频率来压缩音频文件,或者去除噪音,或者可能是语音声音等。但这对于音频和语音识别仍然不够好——通过进行傅里叶变换,我们失去了所有时域信息,这对于非周期信号(如人类语音)不好。不过我们很聪明,只是在信号样本上多次进行傅里叶变换,本质上是切片,然后以频谱图的形式将来自多个傅里叶变换的数据重新拼接在一起。
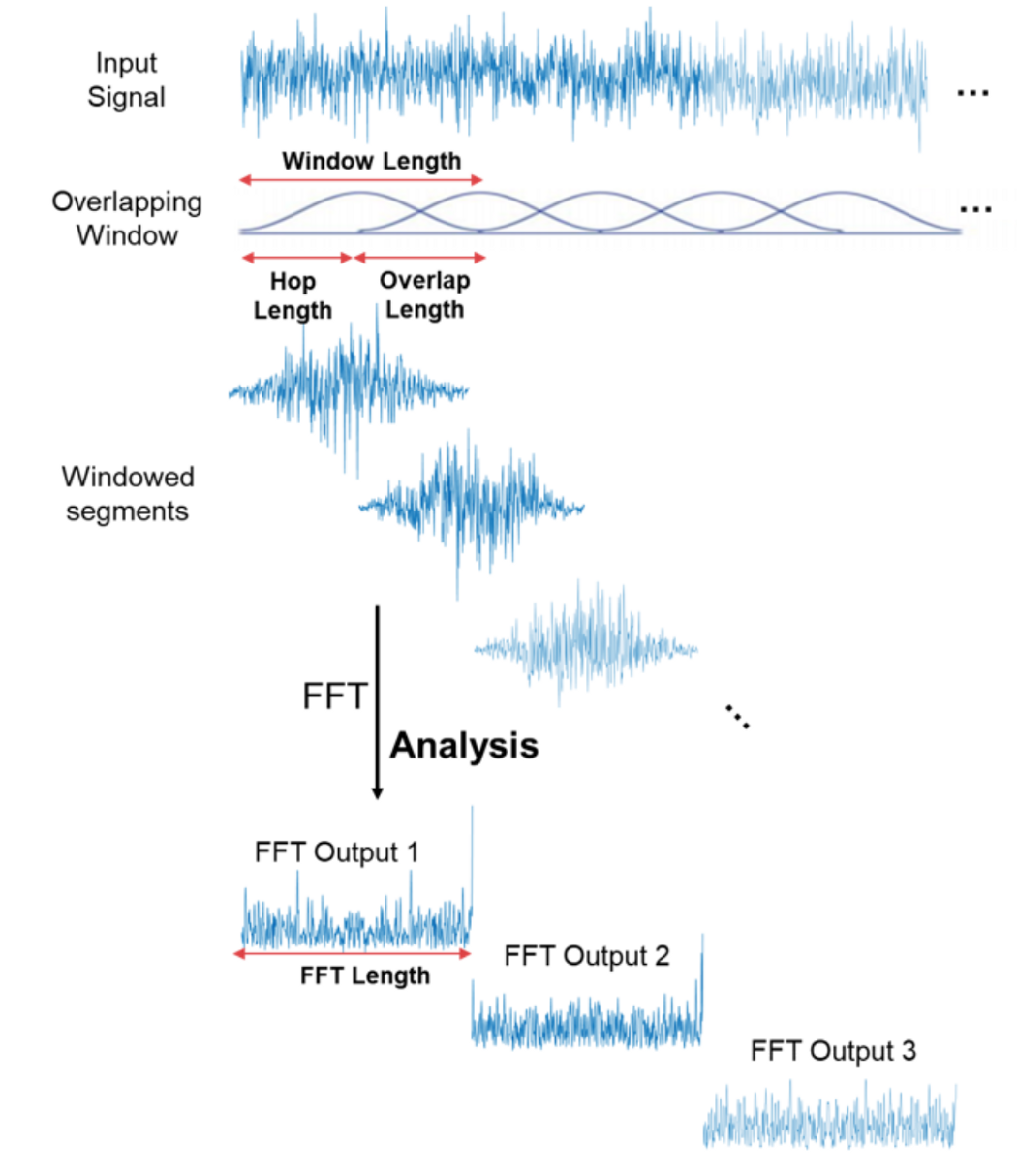
这里 x 轴是时间,y 轴是频率,频率的振幅通过颜色表达,较亮的颜色对应较大的振幅。

很好!我们现在可以进行声音识别了吗?不!是的!也许! 如果我们只关心识别人耳能听到的声音,普通频谱图包含太多信息。研究表明,人类不会在线性尺度上感知频率。我们更善于检测低频率的差异而不是高频率的差异。例如,我们可以轻易分辨 500 和 1000 Hz 之间的差异,但我们几乎无法分辨 10000 和 10500 Hz 之间的差异,尽管两对之间的距离相同。 1937 年,Stevens、Volkmann 和 Newmann 提出了一个音调单位,使得音调中相等的距离对听者来说听起来同样遥远。这称为梅尔刻度。
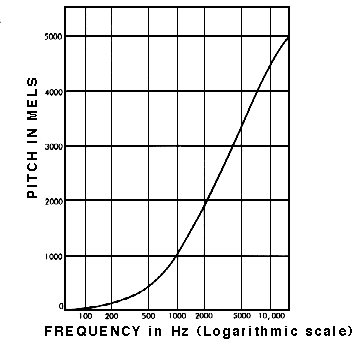
梅尔频谱图是将频率转换为梅尔刻度的频谱图。

语音识别涉及更多步骤——例如我们上面提到的倒谱系数——我们将在后续项目中讨论它们。现在是时候开始实际实现了。
训练数据采集
音频信号需要以非常高的采样率进行采样,8000 Hz 或理想情况下 16000 Hz。Edge Impulse 数据转发器工具太慢,无法处理这种采样率,因此我们需要使用专用的数据收集固件来获取此项目的数据。下载支持麦克风的新版本 Wio Terminal Edge Impulse 固件并将其刷入您的设备,如Edge Impulse 入门页面所述。之后在 Edge Impulse 平台上创建一个新项目,启动 edge-impulse 摄取服务
edge-impulse-daemon
如果您之前使用过 edge-impulse-daemon,您需要在上述命令中添加 --clean 来清理项目数据。
然后使用您的凭据登录并选择您刚刚创建的项目。转到数据采集选项卡,您就可以开始获取数据样本了。
我们将有三类数据:
• background(背景)
• coughing(咳嗽)
• crying(哭泣)
为每个类别录制 10 个样本,每个持续时间为 5000 毫秒。您可以录制从计算机扬声器播放的声音(背景类别除外),但如果您有机会录制真实的声音,那会更好。
对于背景类别,录制不应被分类为咳嗽或哭泣的声音,例如人们说话、无声音、空调/风扇等等。

30 个样本数量极少,所以我们还要上传更多数据。只需从互联网下载声音,将它们重新采样到 16000 Hz,并使用此转换器脚本将它们保存为 .wav 格式
import librosa
import sys
import soundfile as sf
input_filename = sys.argv[1]
output_filename = sys.argv[2]
data, samplerate = librosa.load(input_filename, sr=16000)
print(data.shape, samplerate)
sf.write(output_filename, data, samplerate, subtype='PCM_16')
复制代码并将其粘贴到文本文档中(使用 Notepad++、IDLE IDE 或其他合适的 IDE。不要使用 Windows 默认记事本)。
将文档保存为 converter.py,然后从 Anaconda 环境运行
python converter.py name-of-the-downloaded-file class_name.number.wav

您可以在此项目的 Github 仓库中找到已转换为正确格式的示例声音文件。 然后分割所有声音样本,只保留"有趣"的片段——对每个类别都这样做,除了背景类别。
数据收集完成后,就该选择处理块并定义我们的神经网络模型了。
构建机器学习模型
在处理块中,我们看到三个熟悉的选项——即原始数据、频谱分析(本质上是信号的傅里叶变换)、频谱图和 MFE(梅尔频率能量库)——这对应于我们之前描述的音频处理的四个阶段!
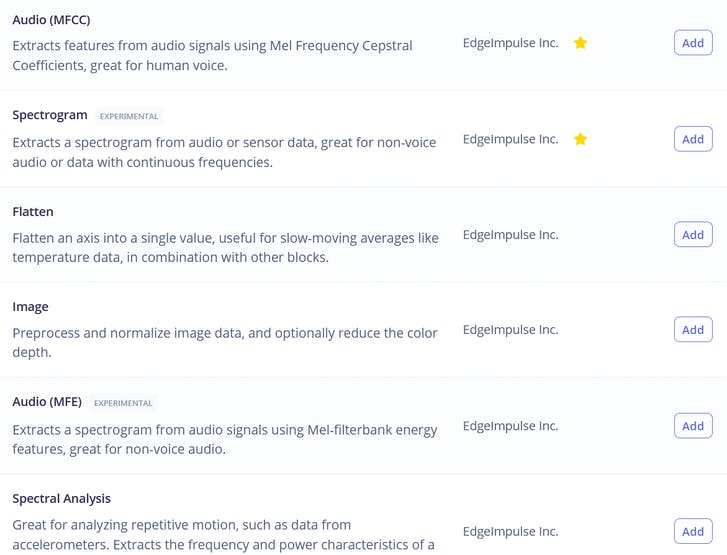
如果您喜欢实验,可以尝试在您的数据上使用所有这些选项,除了可能的原始数据,因为对于我们相对较小的神经网络来说,原始数据会有太多数据。在本课程中,我们将选择最适合此任务的选项,即 MFE 或梅尔频率能量库。计算特征后,转到 NN 分类器选项卡并选择合适的模型架构。我们有两个选择:使用 1D 卷积和 2D 卷积。两者都可以工作,但如果可能的话,我们应该始终选择较小的模型,因为我们希望将其部署到嵌入式设备上。在编写本课程材料时,我们进行了 4 个不同的实验,使用 MFE 和 MFCC 特征的 1D 卷积/2D 卷积,结果如下表所示。

最佳模型是使用 MFE 处理块的 1D 卷积网络。通过调整 MFE 参数(即将步长增加到 0.02 并将低频降低到 0),我们在验证数据集上达到了 89.4% 的准确率。
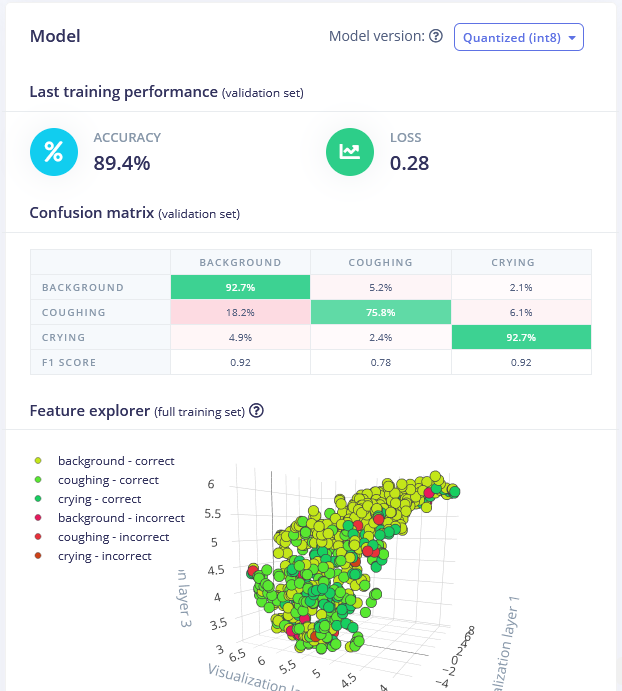
您可以在这里找到训练好的模型并自己测试。虽然它很擅长区分哭声和背景声音,但咳嗽声检测的准确率有点低,可能需要获取更多样本。
部署到 Wio Terminal
在我们有了模型并对其训练准确率满意后,我们可以在实时分类选项卡中用新数据测试它,然后将其部署到 Wio Terminal。我们将其下载为 Arduino 库,放入 Arduino 库文件夹,并打开示例 -> 您的项目名称 -> nano_33_ble_sense_microphone_continuous。该演示基于 Arduino Nano 33 BLE 并使用 PDM 库。对于 Wio Terminal,我们将依靠 DMA 或直接内存访问控制器从 ADC(模数转换器)获取样本并将其保存到推理缓冲区,而无需 MCU 参与。
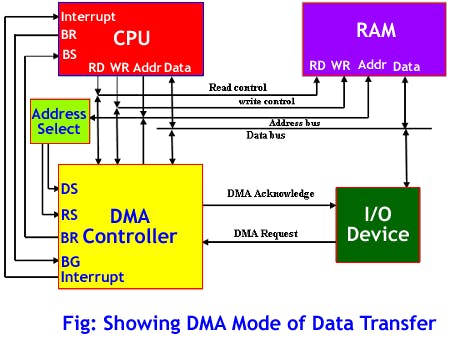
这将允许我们同时收集声音样本和执行推理。为了将声音数据收集从 PDM 库更改为 DMA,我们需要进行相当多的更改,如果您在解释过程中感到有点迷失,请查看完整的示例代码,您可以在课程材料中找到它。 从草图中删除 PDM 库
#include <PDM.h>
在最后一个include语句之后添加DMA描述符结构和其他设置常量
// 设置
#define DEBUG 1 // 在 ISR 期间启用引脚脉冲
enum {ADC_BUF_LEN = 4096}; // DMA 双缓冲区之一的大小
static const int debug_pin = 1; // 每次 DAC ISR 时切换(如果 DEBUG 设置为 1)
// DMAC 描述符结构
typedef struct {
uint16_t btctrl;
uint16_t btcnt;
uint32_t srcaddr;
uint32_t dstaddr;
uint32_t descaddr;
} dmacdescriptor;
然后在 setup 函数之前创建缓冲区数组的变量、用于在 ISR 回调和主代码之间传递值的 volatile 变量,以及高通巴特沃斯滤波器,我们将应用它来消除麦克风信号中的大部分直流分量。
// 全局变量 - DMA 和 ADC
volatile uint8_t recording = 0;
volatile boolean results0Ready = false;
volatile boolean results1Ready = false;
uint16_t adc_buf_0[ADC_BUF_LEN]; // ADC 结果数组 0
uint16_t adc_buf_1[ADC_BUF_LEN]; // ADC 结果数组 1
volatile dmacdescriptor wrb[DMAC_CH_NUM] __attribute__ ((aligned (16))); // 写回 DMAC 描述符
dmacdescriptor descriptor_section[DMAC_CH_NUM] __attribute__ ((aligned (16))); // DMAC 通道描述符
dmacdescriptor descriptor __attribute__ ((aligned (16))); // 占位符描述符
//高通巴特沃斯滤波器 order=1 alpha1=0.0125
class FilterBuHp1
{
public:
FilterBuHp1()
{
v[0]=0.0;
}
private:
float v[2];
public:
float step(float x) //class II
{
v[0] = v[1];
v[1] = (9.621952458291035404e-1f * x)
+ (0.92439049165820696974f * v[0]);
return
(v[1] - v[0]);
}
};
FilterBuHp1 filter;
在此之后添加三个代码块 - 第一个是回调函数,每当两个缓冲区之一被填满时由 ISR(中断服务程序)调用。在该函数内部,我们从录音缓冲区(刚刚被填满的那个)读取元素,处理它们并放入推理缓冲区。
/*******************************************************************************
* 中断服务程序 (ISRs)
*/
/**
* @brief 在选定的缓冲区中复制采样数据,当缓冲区满时发出就绪信号
*
* @param[in] *buf 指向源缓冲区的指针
* @param[in] buf_len 从缓冲区复制的采样数量
*/
static void audio_rec_callback(uint16_t *buf, uint32_t buf_len) {
static uint32_t idx = 0;
// 从DMA缓冲区复制采样到推理缓冲区
if (recording) {
for (uint32_t i = 0; i < buf_len; i++) {
// 将12位无符号ADC值转换为16位PCM(有符号)音频值
inference.buffers[inference.buf_select][inference.buf_count++] = filter.step(((int16_t)buf[i] - 1024) * 16);
// 必要时交换双缓冲区
if (inference.buf_count >= inference.n_samples) {
inference.buf_select ^= 1;
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
}
下一个代码块包含ISR本身 - 它由定时器在特定时间周期执行,在该函数内部我们检查DMAC通道1是否已被挂起 - 如果已被挂起,这意味着麦克风数据的其中一个缓冲区已满,我们需要从中复制数据,切换到另一个缓冲区并重启DMAC ADC。
/**
* DMAC 1 的中断服务程序 (ISR)
*/
void DMAC_1_Handler() {
static uint8_t count = 0;
// 检查 DMAC 通道 1 是否已被挂起 (SUSP)
if (DMAC->Channel[1].CHINTFLAG.bit.SUSP) {
// 调试:在复制缓冲区之前将引脚设为高电平
#if DEBUG
digitalWrite(debug_pin, HIGH);
#endif
// 重启 DMAC 通道 1 并清除 SUSP 中断标志
DMAC->Channel[1].CHCTRLB.reg = DMAC_CHCTRLB_CMD_RESUME;
DMAC->Channel[1].CHINTFLAG.bit.SUSP = 1;
// 查看哪个缓冲区已满,并将结果转储到大缓冲区中
if (count) {
audio_rec_callback(adc_buf_0, ADC_BUF_LEN);
} else {
audio_rec_callback(adc_buf_1, ADC_BUF_LEN);
}
// 切换到下一个缓冲区
count = (count + 1) % 2;
// 调试:在复制缓冲区后将引脚设为低电平
#if DEBUG
digitalWrite(debug_pin, LOW);
#endif
}
}
下一个代码块包含 ADC DMAC 和控制 ISR(中断服务程序)的定时器的配置数据
// 配置DMA以定期从ADC采样
void config_dma_adc() {
// 配置DMA以定期从ADC采样(由定时器/计数器触发)
DMAC->BASEADDR.reg = (uint32_t)descriptor_section; // 指定描述符的位置
DMAC->WRBADDR.reg = (uint32_t)wrb; // 指定写回描述符的位置
DMAC->CTRL.reg = DMAC_CTRL_DMAENABLE | DMAC_CTRL_LVLEN(0xf); // 启用DMAC外设
DMAC->Channel[1].CHCTRLA.reg = DMAC_CHCTRLA_TRIGSRC(TC5_DMAC_ID_OVF) | // 设置DMAC在TC5定时器溢出时触发
DMAC_CHCTRLA_TRIGACT_BURST; // DMAC突发传输
descriptor.descaddr = (uint32_t)&descriptor_section[1]; // 设置循环描述符
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // 从ADC0 RESULT寄存器获取结果
descriptor.dstaddr = (uint32_t)adc_buf_0 + sizeof(uint16_t) * ADC_BUF_LEN; // 将其放入adc_buf_0数组
descriptor.btcnt = ADC_BUF_LEN; // 节拍计数
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // 节拍大小为HWORD(16位)
DMAC_BTCTRL_DSTINC | // 递增目标地址
DMAC_BTCTRL_VALID | // 描述符有效
DMAC_BTCTRL_BLOCKACT_SUSPEND; // 块传输后挂起DMAC通道0
memcpy(&descriptor_section[0], &descriptor, sizeof(descriptor)); // 将描述符复制到描述符段
descriptor.descaddr = (uint32_t)&descriptor_section[0]; // 设置循环描述符
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // 从ADC0 RESULT寄存器获取结果
descriptor.dstaddr = (uint32_t)adc_buf_1 + sizeof(uint16_t) * ADC_BUF_LEN; // 将其放入adc_buf_1数组
descriptor.btcnt = ADC_BUF_LEN; // 节拍计数
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // 节拍大小为HWORD(16位)
DMAC_BTCTRL_DSTINC | // 递增目标地址
DMAC_BTCTRL_VALID | // 描述符有效
DMAC_BTCTRL_BLOCKACT_SUSPEND; // 块传输后挂起DMAC通道0
memcpy(&descriptor_section[1], &descriptor, sizeof(descriptor)); // 将描述符复制到描述符段
// 配置NVIC
NVIC_SetPriority(DMAC_1_IRQn, 0); // 将嵌套向量中断控制器(NVIC)的DMAC1优先级设置为0(最高)
NVIC_EnableIRQ(DMAC_1_IRQn); // 将DMAC1连接到嵌套向量中断控制器(NVIC)
// 激活DMAC通道1上的挂起(SUSP)中断
DMAC->Channel[1].CHINTENSET.reg = DMAC_CHINTENSET_SUSP;
// 配置ADC
ADC1->INPUTCTRL.bit.MUXPOS = ADC_INPUTCTRL_MUXPOS_AIN12_Val; // 将模拟输入设置为ADC0/AIN2(PB08 - Metro M4上的A4)
while(ADC1->SYNCBUSY.bit.INPUTCTRL); // 等待同步
ADC1->SAMPCTRL.bit.SAMPLEN = 0x00; // 将最大采样时间长度设置为ADC时钟脉冲的一半(2.66us)
while(ADC1->SYNCBUSY.bit.SAMPCTRL); // 等待同步
ADC1->CTRLA.reg = ADC_CTRLA_PRESCALER_DIV128; // 将ADC GCLK时钟除以128(48MHz/128 = 375kHz)
ADC1->CTRLB.reg = ADC_CTRLB_RESSEL_12BIT | // 将ADC分辨率设置为12位
ADC_CTRLB_FREERUN; // 将ADC设置为自由运行模式
while(ADC1->SYNCBUSY.bit.CTRLB); // 等待同步
ADC1->CTRLA.bit.ENABLE = 1; // 启用ADC
while(ADC1->SYNCBUSY.bit.ENABLE); // 等待同步
ADC1->SWTRIG.bit.START = 1; // 启动软件触发以开始ADC转换
while(ADC1->SYNCBUSY.bit.SWTRIG); // 等待同步
// 启用DMA通道1
DMAC->Channel[1].CHCTRLA.bit.ENABLE = 1;
// 配置定时器/计数器5
GCLK->PCHCTRL[TC5_GCLK_ID].reg = GCLK_PCHCTRL_CHEN | // 为TC5启用外设通道
GCLK_PCHCTRL_GEN_GCLK1; // 连接48MHz的通用时钟0
TC5->COUNT16.WAVE.reg = TC_WAVE_WAVEGEN_MFRQ; // 将TC5设置为匹配频率(MFRQ)模式
TC5->COUNT16.CC[0].reg = 3000 - 1; // 将触发设置为16 kHz:(4Mhz / 16000) - 1
while (TC5->COUNT16.SYNCBUSY.bit.CC0); // 等待同步
// 启动定时器/计数器5
TC5->COUNT16.CTRLA.bit.ENABLE = 1; // 启用TC5定时器
while (TC5->COUNT16.SYNCBUSY.bit.ENABLE); // 等待同步
}
在setup函数顶部添加调试条件:
// 配置引脚在DMA中断时切换
#if DEBUG
pinMode(debug_pin, OUTPUT);
#endif
然后在setup函数中,在 run_classifier_init(); 之后添加以下代码,该代码创建推理缓冲区,配置DMA并通过将易失性全局变量recording设置为1来开始录制。
// 为推理创建双缓冲区
inference.buffers[0] = (int16_t *)malloc(EI_CLASSIFIER_SLICE_SIZE * sizeof(int16_t));
if (inference.buffers[0] == NULL) {
ei_printf("ERROR: Failed to create inference buffer 0");
return;
}
inference.buffers[1] = (int16_t *)malloc(EI_CLASSIFIER_SLICE_SIZE *
sizeof(int16_t));
if (inference.buffers[1] == NULL) {
ei_printf("ERROR: Failed to create inference buffer 1");
free(inference.buffers[0]);
return;
}
// 设置推理参数
inference.buf_select = 0;
inference.buf_count = 0;
inference.n_samples = EI_CLASSIFIER_SLICE_SIZE;
inference.buf_ready = 0;
// 配置DMA以16kHz从ADC采样(立即开始采样)
config_dma_adc();
// 开始录制到推理缓冲区
recording = 1;
}
从 microphone_inference_end(void) 函数中删除 PDM.end(); 和 free(sampleBuffer);,同时也从 microphone_inference_start(uint32_t n_samples) 和 pdm_data_ready_inference_callback(void) 函数中删除,因为我们不会使用它们。
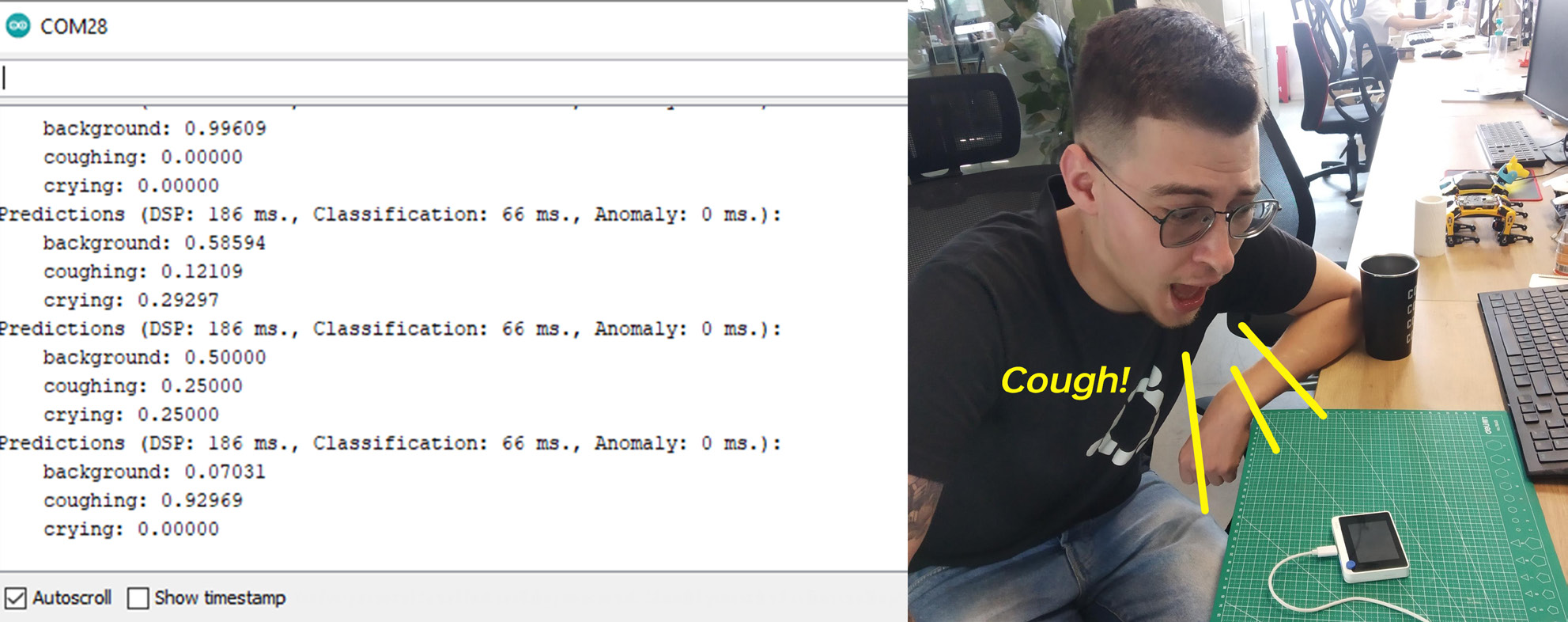
编译并上传代码后,打开串口监视器,你将看到每个类别的概率被打印出来。在 Wio Terminal 前播放一些声音或咳嗽来检查准确性!
Blynk 集成
由于 WioTerminal 可以连接到互联网,我们可以将这个简单的演示制作成一个真正的物联网应用程序,使用 Blynk。
Blynk 是一个平台,允许你快速构建界面来从你的 iOS 和 Android 设备控制和监控你的硬件项目。在这种情况下,我们将使用 Blink 向我们的智能手机推送通知,如果 Wio Terminal 检测到任何我们应该担心的声音。 要开始使用 Blink,请下载应用程序,注册一个新账户并创建一个新项目。向其中添加一个推送通知元素并按播放按钮。

然后确保你已经根据这里的指南设置了 Wio Terminal WiFi 库和固件。按照该教程中概述的方法下载 Blynk 库。
然后通过编译和上传简单的按钮示例来测试你的设置——确保你更改了 WiFi SSID、密码和你的 Blynk API 令牌,你可以在应用程序中获取它。
#define BLYNK_PRINT Serial
#include <rpcWiFi.h>
#include <WiFiClient.h>
#include <BlynkSimpleWioTerminal.h>
char auth[] = "token";
char ssid[] = "ssid";
char pass[] = "password";
void checkPin()
{
int isButtonPressed = !digitalRead(WIO_KEY_A);
if (isButtonPressed) {
Serial.println("按钮被按下。");
Blynk.notify("耶...按钮被按下了!");
}
}
void setup()
{
Serial.begin(115200);
Blynk.begin(auth, ssid, pass);
pinMode(WIO_KEY_A, INPUT_PULLUP);
}
void loop()
{
Blynk.run();
checkPin();
}
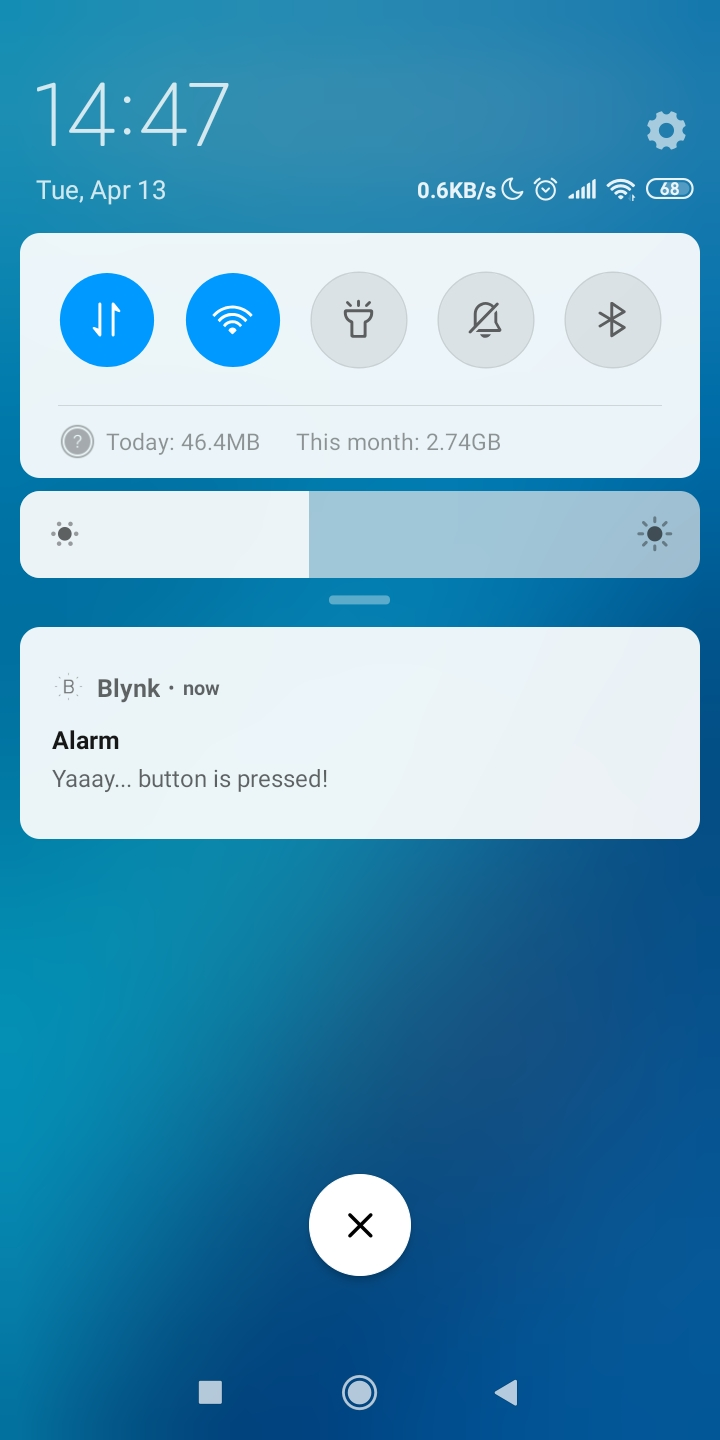
如果代码编译成功且测试成功(按下 Wio Terminal 左上角的按钮会在你的手机上出现推送通知),那么你可以进入下一阶段。
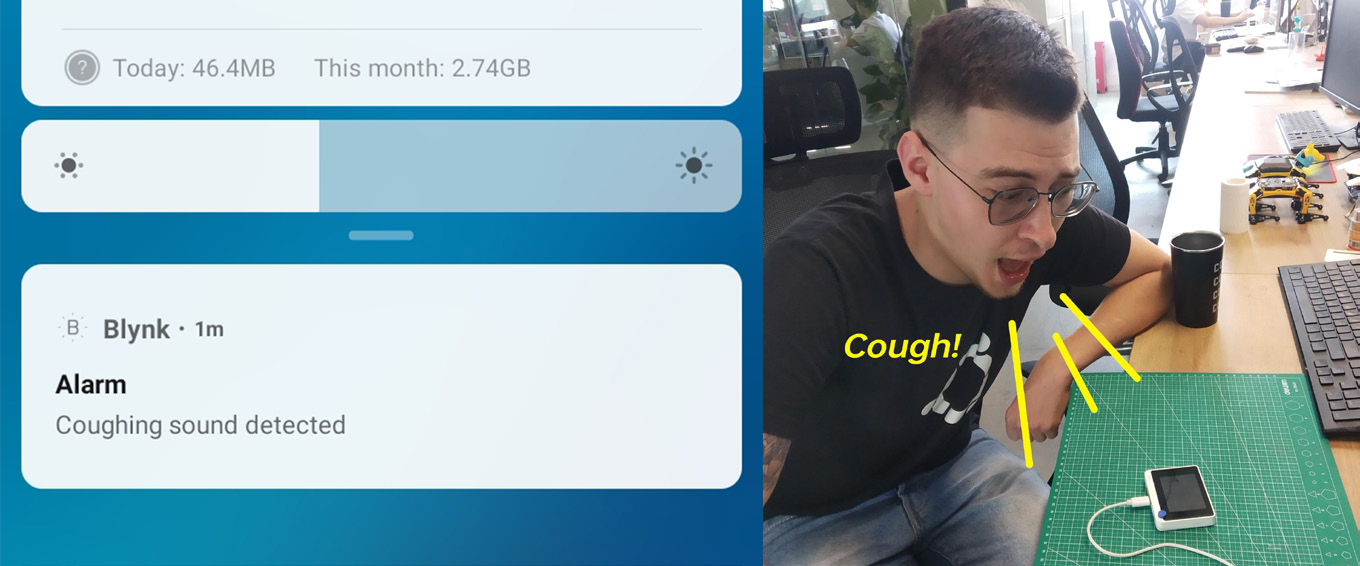
我们将把所有神经网络推理代码移到一个单独的函数中,并在 loop() 函数中紧接着 Blynk.run() 之后调用它。与我们之前所做的类似,我们检查神经网络预测概率,如果它们对于某个特定类别高于阈值,我们调用 Blynk.notify() 函数,正如你可能猜到的,它会向你的移动设备推送通知。
在此项目的 Github 仓库中找到 NN 推理 + Blynk 通知的完整代码。