Wio Terminal Tensorflow Lite Micro 在MCU上的语音识别 – 语音转意图
传统的使用语音进行设备控制/用户请求处理的方法是,首先将语音转录为文本,然后将文本解析为合适格式的命令/查询。虽然这种方法在词汇量和/或应用场景方面提供了很大的灵活性,但语音识别模型和专用解析器的组合不适合微控制器的受限资源。
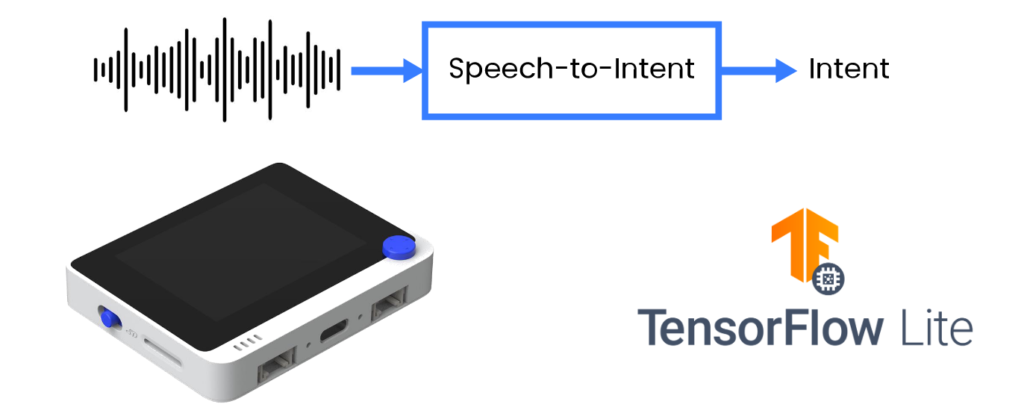
来源:Wio Terminal、Picovoice、Tensorflow Lite
在这个项目中,我们将采用一种更高效的方法,直接将用户话语解析为意图/槽位形式的可操作输出。我们将分享训练特定领域语音转意图模型的技术,并将其部署到基于Cortex M4F的开发板上,该开发板内置麦克风,即来自Seeed Studio的Wio Terminal。
更多详细信息和视觉效果,请观看相应的视频!
有不同类型的语音识别任务——我们可以大致将它们分为三组:
- 大词汇量连续语音识别(LVCSR)
- 关键词检测
- 语音转意图
关键词检测在微控制器上运行良好,使用各种可用的无代码开源工具(如Edge Impulse)相当容易训练,但无法很好地处理大词汇量。
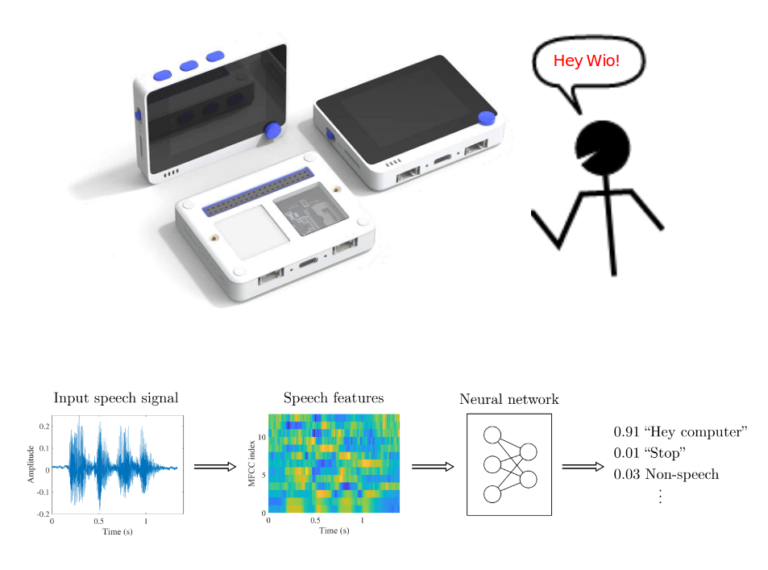
如果我们希望设备基于语音输入执行有用的操作,我们需要结合LVCSR模型和基于文本的自然语言解析器——这种方法是稳健的,并且由于公开可用的ASR引擎丰富,实现起来相对容易,但即使在单板计算机上运行也不合适,更不用说微控制器了。
还有第三种方法,基于特定领域词汇直接将语音转换为解析的意图。让我们以智能洗衣机或智能灯为例。语音转意图模型在处理话语"Normal cycle with low-spin"时会输出解析的意图,例如
{ Intent: washClothes },
{ Slots: cycle: normal,
spin: low,
water: default }
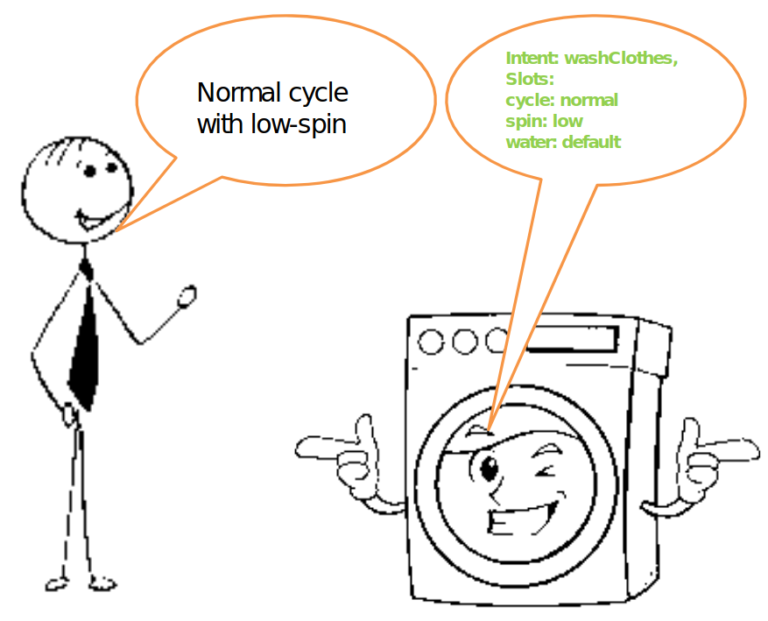
这确实是我们能够用语音控制所述智能洗衣机所需要的全部。
语音转意图在研究中有很好的代表性,但缺乏适用于微控制器的广泛可用的开源实现。 生产就绪,非开源:
- Picovoice
- Fluent.ai
生产就绪,FOSS,不适用于微控制器:
- Speechbrain.io
对于模型训练,您可以使用我们准备的Jupyter Notebook或来自Github仓库的训练脚本(在文章末尾的参考部分找到它们)。Jupyter Notebook包含一个非常基本的参考模型实现,并且对每个单元格都有解释。
模型训练完成后,将其复制到包含Wio Terminal代码的文件夹中,并在第106行中将模型名称更改为您的模型名称。让我们回顾代码中最重要的部分。它可以大致分为三个部分:
- 音频采集
- MFCC计算
- 在MFCC特征上进行推理
音频采集

为了使用 Wio Terminal 内置麦克风录制声音进行处理,我们使用 Cortex M4F MCU 的 DMA ADC 功能。DMA 代表直接内存访问,正如其名称所示——MCU 的一个特定部分称为 DMAC 或直接内存访问控制器,预先设置用于将数据从一个位置(例如内部内存、SPI、I2C、ADC 或其他接口)"传输"到另一个位置。这样,传输可以在 MCU 很少参与的情况下进行,除了初始设置。我们在这里设置传输的源和目标
descriptor.descaddr = (uint32_t)&descriptor_section[1]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_0 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_0 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[0], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
descriptor.descaddr = (uint32_t)&descriptor_section[0]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_1 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_1 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[1], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
正如我们在 DMA 描述符中使用参数 DMAC_BTCTRL_BLOCKACT_SUSPEND; 指定的那样,DMA 通道应在完整的块传输后被挂起。然后我们继续设置一个由 TC5 定时器触发的 ISR(中断服务例程):
// Configure Timer/Counter 5
GCLK->PCHCTRL[TC5_GCLK_ID].reg = GCLK_PCHCTRL_CHEN | // Enable perhipheral channel for TC5
GCLK_PCHCTRL_GEN_GCLK1; // Connect generic clock 0 at 48MHz
TC5->COUNT16.WAVE.reg = TC_WAVE_WAVEGEN_MFRQ; // Set TC5 to Match Frequency(MFRQ) mode
TC5->COUNT16.CC[0].reg = 3000 - 1; // Set the trigger to 16 kHz: (4Mhz / 16000) - 1
while (TC5->COUNT16.SYNCBUSY.bit.CC0); // Wait for synchronization
// Start Timer/Counter 5
TC5->COUNT16.CTRLA.bit.ENABLE = 1; // Enable the TC5 timer
while (TC5->COUNT16.SYNCBUSY.bit.ENABLE); // Wait for synchronization
ISR 将在由 TC5 定时器控制的等间隔时间调用特定函数。让我们看看那个函数。
/**
* Interrupt Service Routine (ISR) for DMAC 1
*/
void DMAC_1_Handler() {
static uint8_t count = 0;
// Check if DMAC channel 1 has been suspended (SUSP)
if (DMAC->Channel[1].CHINTFLAG.bit.SUSP) {
// Debug: make pin high before copying buffer
#ifdef DEBUG
digitalWrite(debug_pin, HIGH);
#endif
// Restart DMAC on channel 1 and clear SUSP interrupt flag
DMAC->Channel[1].CHCTRLB.reg = DMAC_CHCTRLB_CMD_RESUME;
DMAC->Channel[1].CHINTFLAG.bit.SUSP = 1;
// See which buffer has filled up, and dump results into large buffer
if (count) {
audio_rec_callback(adc_buf_0, ADC_BUF_LEN);
} else {
audio_rec_callback(adc_buf_1, ADC_BUF_LEN);
}
// Flip to next buffer
count = (count + 1) % 2;
// Debug: make pin low after copying buffer
#ifdef DEBUG
digitalWrite(debug_pin, LOW);
#endif
}
}
名为 DMAC1_Handler() 的 ISR 函数检查 DMAC 通道 1 是否被挂起——这在一个信息块完成录制时发生。如果是,它调用用户定义的函数 audio_rec_callback(),在这里我们将填充的 DMA ADC 缓冲区的内容复制到用于计算 MFCC 特征的(可能)更大的缓冲区中。可选地,我们还在此步骤中应用一些声音后处理。
MFCC 计算
用于匹配 TensorFlow MFCC Op 代码的 MFCC 特征提取借用了 ARM 仓库中用于 ARM 微控制器关键词搜索的代码。您可以在这里找到原始代码。
与 MFCC 特征计算相关的大部分工作都在 MFCC 类的 mfcc_compute(const int16_t audio_data, float mfcc_out) 方法中进行。该方法接收一个指向音频数据的指针,在我们的情况下是 320 个声音数据点,以及一个指向 MFCC 输出值数组中特定位置的指针。对于一个时间片,我们执行以下操作:
将数据标准化到 -1,1 并填充它(在我们的情况下不会发生填充,因为音频数据总是计算一个 MFCC 特征片所需的确切大小):
//TensorFlow way of normalizing .wav data to (-1,1)
for (i = 0; i < frame_len; i++) {
frame[i] = (float)audio_data[i]/(1<<15);
}
//Fill up remaining with zeros
memset(&frame[frame_len], 0, sizeof(float) * (frame_len_padded-frame_len));
使用 ARM Math 库函数计算 RFTT 或实数快速傅里叶变换:
//Compute FFT
arm_rfft_fast_f32(rfft, frame, buffer, 0);
将值转换为功率谱:
//frame is stored as [real0, realN/2-1, real1, im1, real2, im2, ...]
int32_t half_dim = frame_len_padded/2;
float first_energy = buffer[0] * buffer[0],
last_energy = buffer[1] * buffer[1]; // handle this special case
for (i = 1; i < half_dim; i++) {
float real = buffer[i*2], im = buffer[i*2 + 1];
buffer[i] = real*real + im*im;
}
buffer[0] = first_energy;
buffer[half_dim] = last_energy;
然后对上一步保存在缓冲区中的数据的平方根应用 Mel 滤波器组。Mel 滤波器组在 MFCC 类实例化时在 create_mel_fbank() 方法内创建。滤波器组的数量、最小和最大频率由用户预先指定——在训练脚本和推理代码之间保持它们的一致性非常重要,否则会出现显著的精度下降。
float sqrt_data;
//Apply mel filterbanks
for (bin = 0; bin < NUM_FBANK_BINS; bin++) {
j = 0;
float mel_energy = 0;
int32_t first_index = fbank_filter_first[bin];
int32_t last_index = fbank_filter_last[bin];
for (i = first_index; i <= last_index; i++) {
arm_sqrt_f32(buffer[i],&sqrt_data);
mel_energy += (sqrt_data) * mel_fbank[bin][j++];
}
mel_energies[bin] = mel_energy;
//avoid log of zero
if (mel_energy == 0.0)
mel_energies[bin] = FLT_MIN;
}
最后,我们对 Mel 能量数组进行离散余弦变换并将其写入 MFCC 特征输出数组。在原始脚本中,此步骤也执行了量化,但我选择使用 Tensorflow Lite for Microcontrollers 示例中的量化程序。
对 MFCC 特征进行推理
一旦一个样本(3 秒)内的所有音频都被处理并转换为 MFCC 特征,我们将整个 MFCC 特征数组从 FLOAT32 转换为 INT8 值并将其输入神经网络。TensorFlow Lite for Microcontrollers 的初始化和推理过程已经在我之前的一篇文章中描述过,所以我不会在这里重复。
在编译草图之前,请确保您已安装所有必要的库,并且 Seeed SAMD 板定义至少是 1.8.2 版本——这对于 TensorFlow Lite 库无错误编译非常重要。编译并上传草图——如果您将 DEBUG 参数设置为 false,代码将立即开始运行,您只需按下 Wio Terminal 顶部的 C 按钮并说出数据集中的一个句子。结果将显示在屏幕上,如果 Wio Terminal 连接到计算机,也会输出到串行监视器。
虽然本课程基于 Wio Terminal,因为它非常适合探索嵌入式机器学习,但绝对可以在其他设备上实现。最简单的方法是将代码移植到其他 Cortex M4F MCU,如 Nano33 BLE Sense——这只需要调整不同的麦克风。移植到其他 ARM MCU 也应该相当简单。

移植到其他架构,例如 ESP32 或 K210 或其他架构,需要重新实现 MFCC 计算,因为它们使用来自 CMSIS-DSP 的 ARM 特定函数。
项目中的基本神经网络架构可以进行多项改进。这些改进包括:
- 模型预训练
- seq2seq、LSTM、注意力机制
- 可训练滤波器
- AutoML、合成数据
查看这个关于此主题的TinyML演讲,了解更多信息并找到论文链接!
我们鼓励您分叉代码仓库,尝试在自己的数据集上进行训练,也许尝试实现更高级的架构或模型训练技术。如果您这样做,请不要犹豫在这里给我留言或在 Github 上提交 PR!