本教程的内容可能不再有效,不再提供新的软件维护和技术支持。
使用 XIAO nRF52840 基于 Edge Impulse 的语音识别
在本教程中,我将展示如何使用 Edge Impulse 结合 Seeed Studio XIAO nRF52840 的机器学习功能进行语音识别。我们将使用 XIAO nRF52840 Sense 上已有的麦克风。
项目前置知识
XIAO nRF52840 并未得到 Edge Impulse 的官方支持,也不作为数据收集设备出现,但我将演示如何使用它通过设备麦克风运行推理。
入门指南
要学习本教程,您需要以下硬件
| Seeed Studio XIAO nRF52840-Sense |
|---|
 |
硬件准备
我们不需要任何硬件准备。XIAO nRF52840 已经具备了这个项目所需的一切。我们只需要 PDM 麦克风。
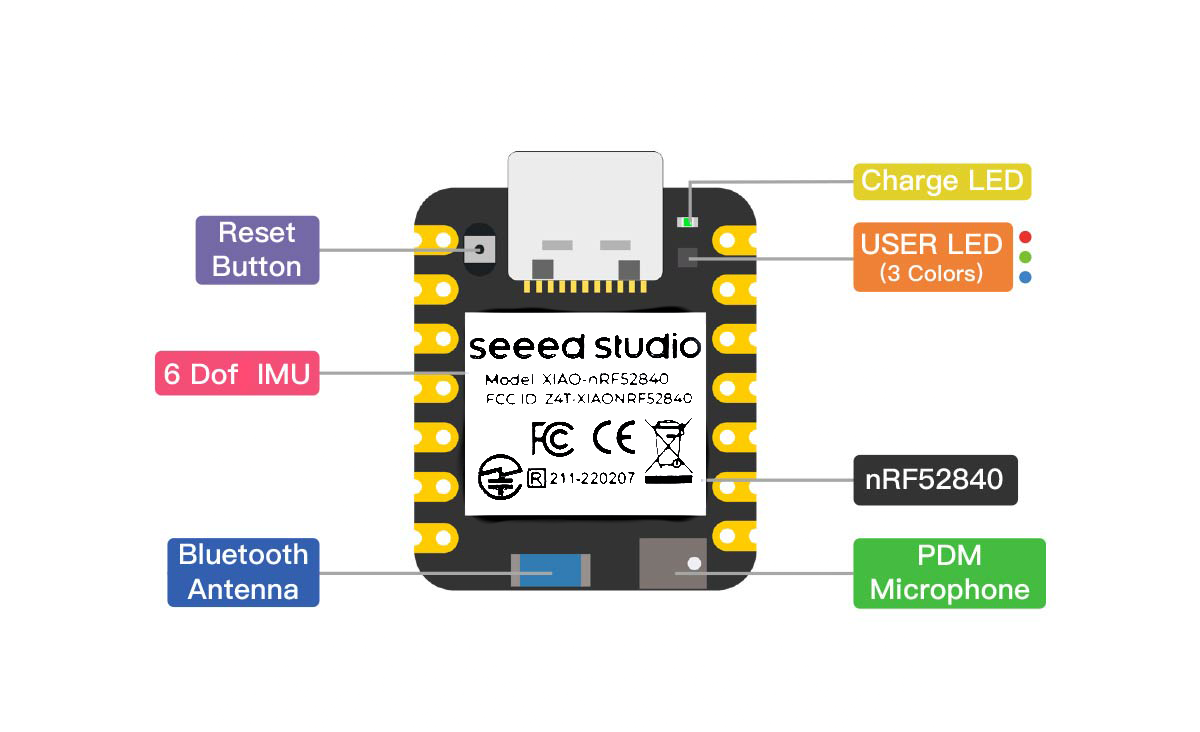
这是 XIAO nRF52840 Sense 的硬件引脚图
软件准备
要尝试这个项目,我们只需要三样东西:
- Google 语音命令数据集(见下文)
- Edge Impulse 账户
- Arduino IDE
数据集
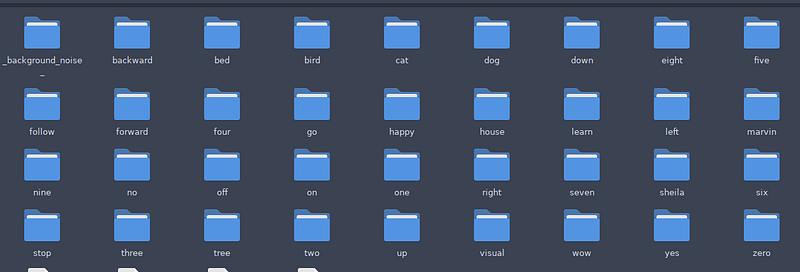
- 我将使用 Google 语音命令数据集。不是全部数据集,只是其中的一些词汇。
- 现在,下载数据集并解压。完整的数据集有 2.3GB。
- 这个 Google 语音命令数据集 被 Google 用于他们的 TensorFlow Lite for MicroControllers 微语音示例中。
- 你可以在这里找到代码。
我们可以从上面的第一个链接下载数据集,解压后如下所示:
开始使用
现在让我们开始使用 Edge Impulse 基于数据集创建一个机器学习模型。
步骤 1 - 打开 Edge Impulse
- Edge Impulse 是一个机器学习(ML)开发平台,使开发者能够创建和部署自定义机器学习模型到边缘设备,如微控制器和智能手机。
- 它提供了各种工具和资源来帮助构建和优化特定任务的机器学习模型,如关键词识别、异常检测和分类。
让我们创建一个新项目。给它起个名字。
创建新项目后,转到数据采集页面。
步骤 2 - 添加数据
因为我们要使用 Google 语音命令数据集,选择"添加现有数据"。 接下来,选择"上传数据"
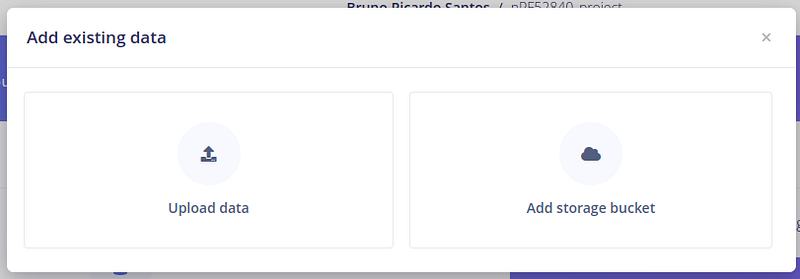
接下来,我们需要选择数据 - 让我们从语音数据集中选择一个文件夹。
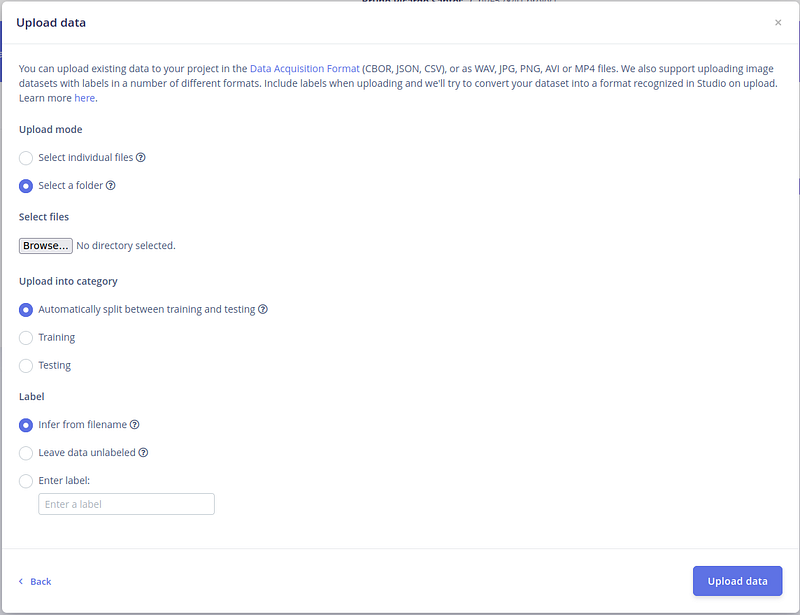
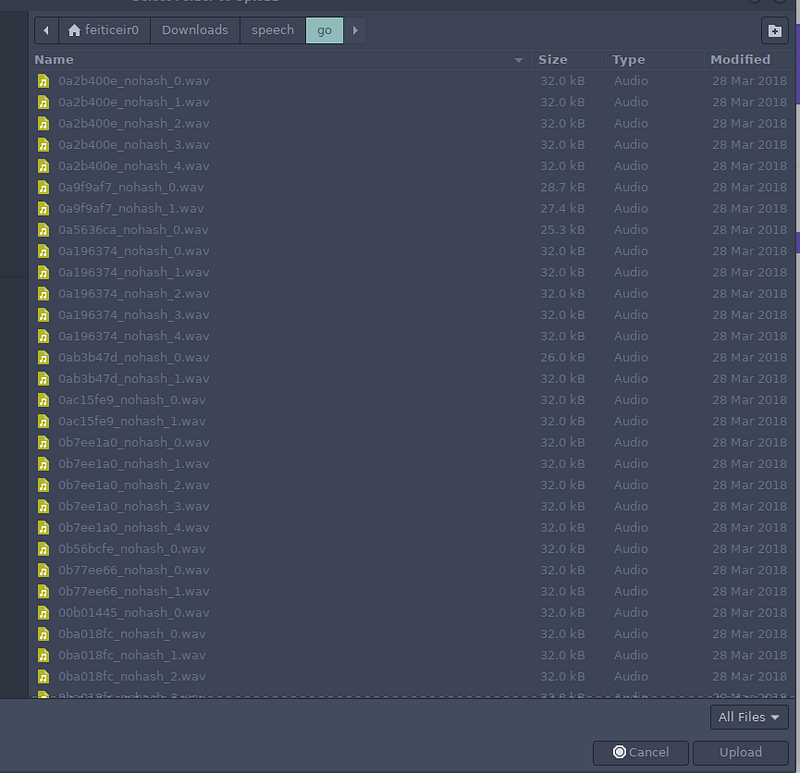
数据集有很多词汇可以用来训练。让我们选择 3 个文件夹(我们的标签)来训练,以及背景噪声。我们得到 4 个标签。 按下"浏览"按钮。 第一个是"go"。选择文件夹 - 你可以看到所有的 .wav 文件 - 然后按"上传"。
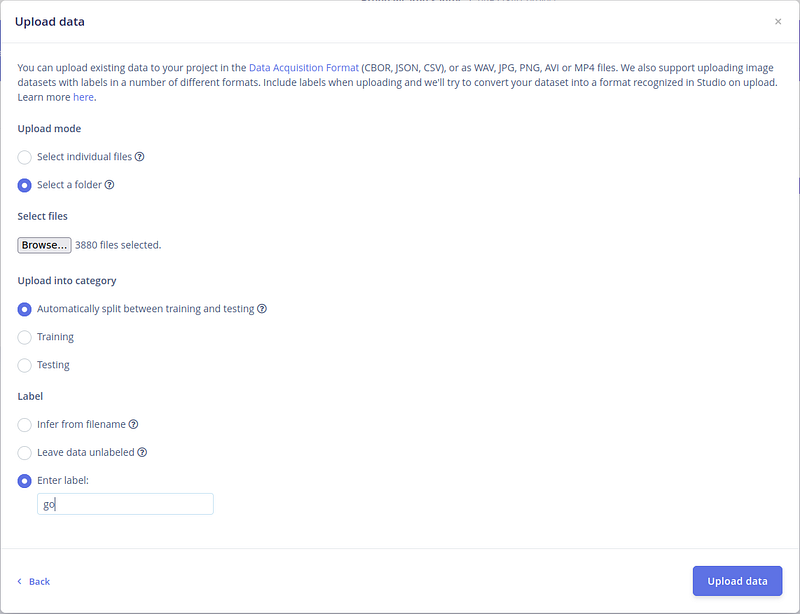
接下来,让我们保持类别的默认选项。让 Edge Impulse 分割数据。 对于标签,自己写标签。完成这些后,按"上传数据"。
在右侧,你会看到文件正在上传。这可能需要一段时间,因为文件很多。
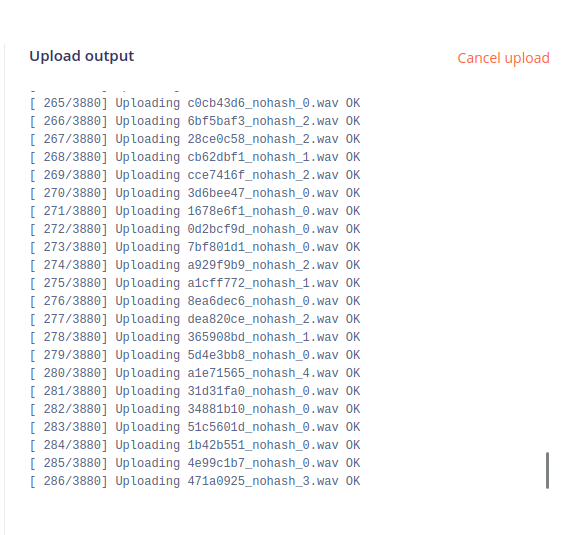
过一段时间后,上传完成并显示已上传文件的简要摘要。
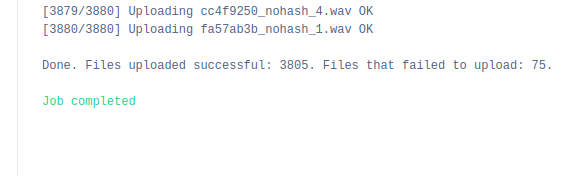
之后,这是屏幕显示
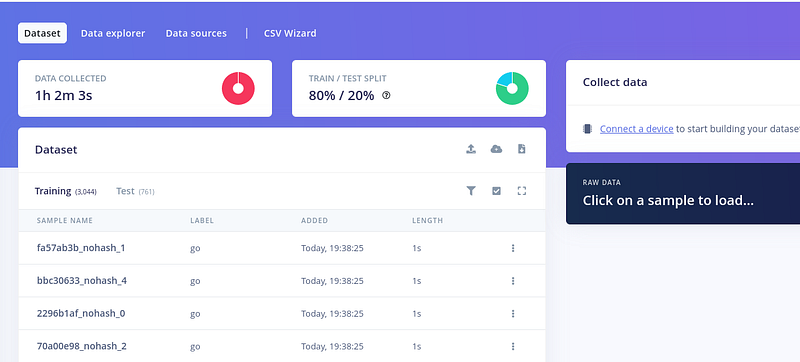
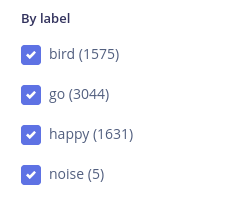
要上传更多数据,按右侧文件列表上方的小上传按钮。 重复这个过程 3 次 - 再添加 2 个标签和背景噪声。 我将选择 happy、bird 和标签为"noise"的"background noise"文件夹。 最后,这些是我们拥有的所有标签
接下来,让我们创建网络来学习我们的词汇。点击 Impulse design 来创建脉冲
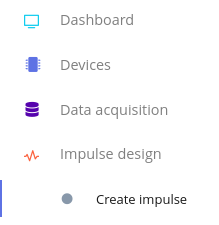
步骤 3 - 选择训练方法
因为音频片段每个都是 1 秒且 16Khz,让我们保持相同的窗口大小和频率。现在,让我们添加一个处理块。
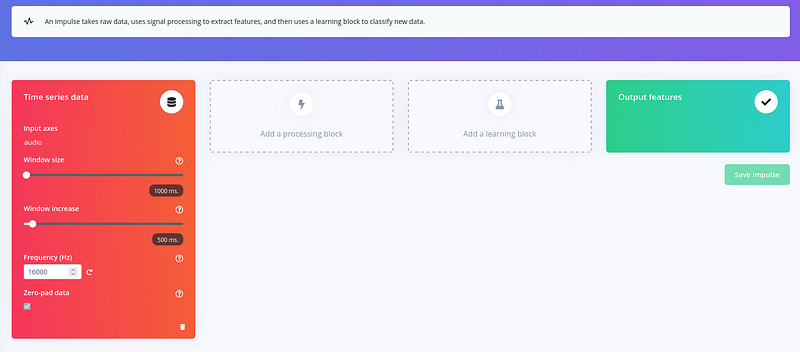
Edge Impulse 在这里也为我们提供了很大帮助。点击"Add a processing block"并选择 Audio (MFCC)。
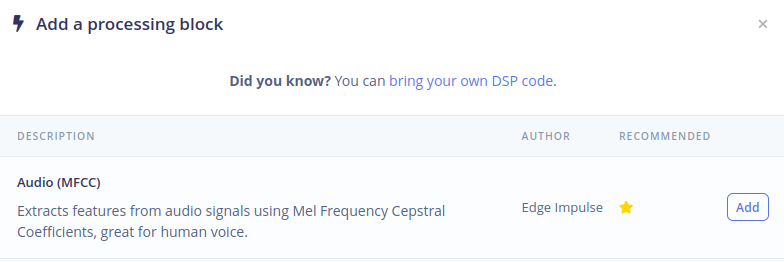
接下来,点击"Add learning block"并选择 Classification。
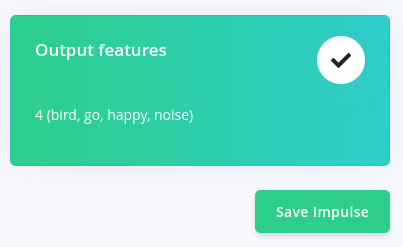
现在,我们的最后一列 - Output features - 有了我们的 4 个标签(bird、go、happy、noise)。 按"Save Impulse"保存我们目前的工作。
步骤 4 - 生成特征
现在,让我们看一下 MFCC 参数。如果需要,您可以更改这些值。 现在,让我们保持默认值。点击"Save Parameters"。 保存参数后,我们会得到一个新窗口来"Generate features"。
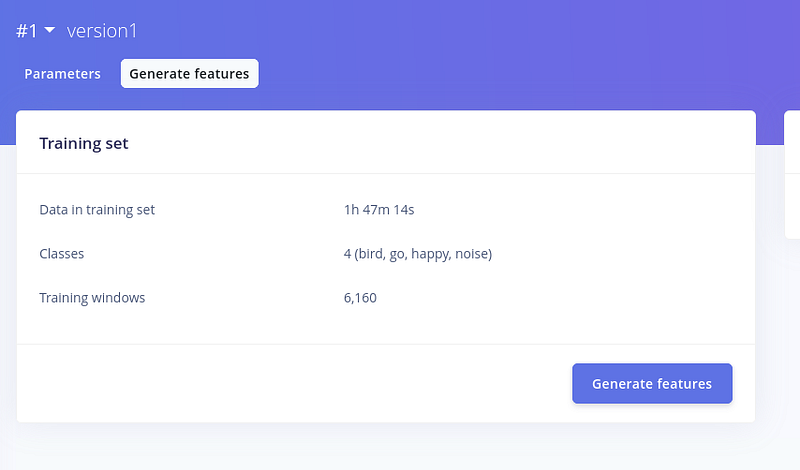
点击后,Edge Impulse 将开始生成特征。
一段时间后,我们的特征生成完成,我们可以将它们可视化
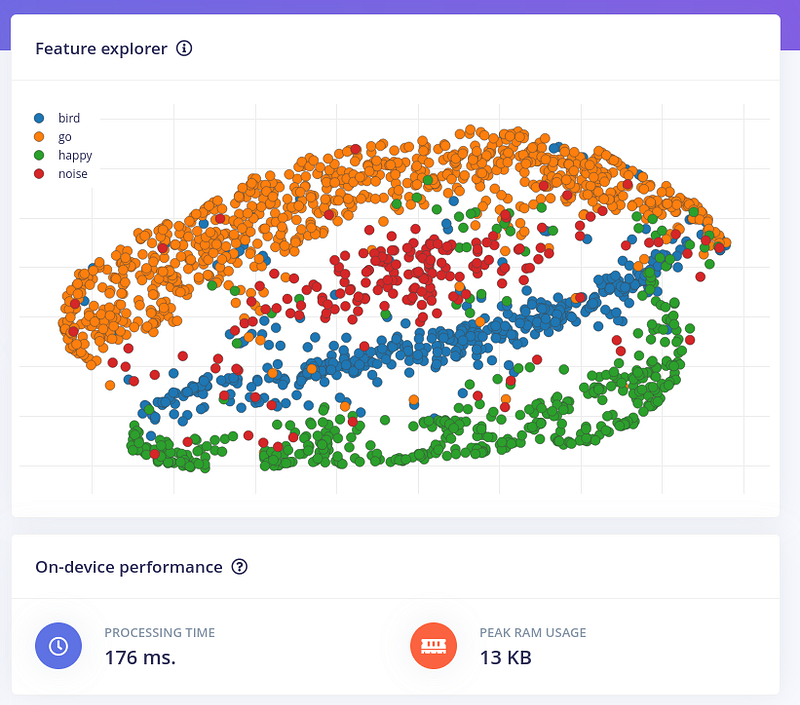
现在我们可以使用选择的参数来训练我们的网络。点击"Classifier"。
步骤 5 - 分类器

在这里我们可以调整网络设置,比如训练周期、是否需要数据增强等等。 Edge Impulse 为关键词识别提供了一个简单但有效的神经网络架构。该架构包含以下层:
- 输入层: 输入层将 MFCC 特征作为输入。
- 隐藏层: 隐藏层学习从 MFCC 特征中提取更高级别的特征。Edge Impulse 支持多种隐藏层类型,如卷积层和循环层。
- 输出层: 输出层预测音频输入包含关键词的概率。
我们可以更改默认参数,但默认值就足够了。点击"Start Training"。
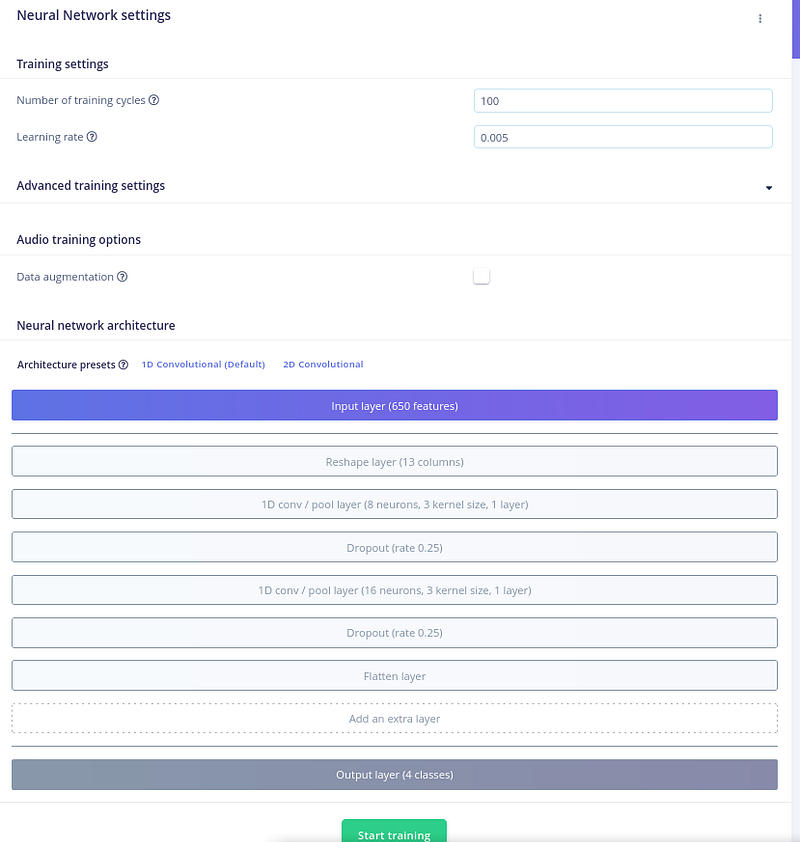
开始训练后,在屏幕右侧我们可以观看训练进度。
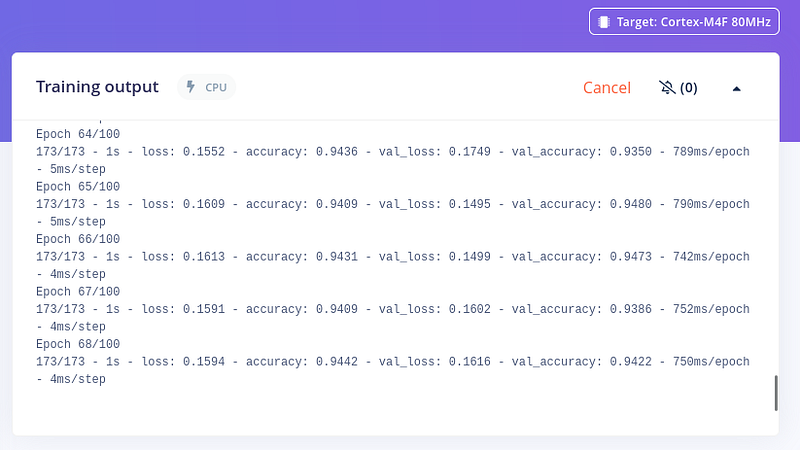
我们可以将目标设备更改为 nRF52840 - 就像我们的 XIAO nRF52840 Sense - 这样我们就可以看到性能计算和优化。
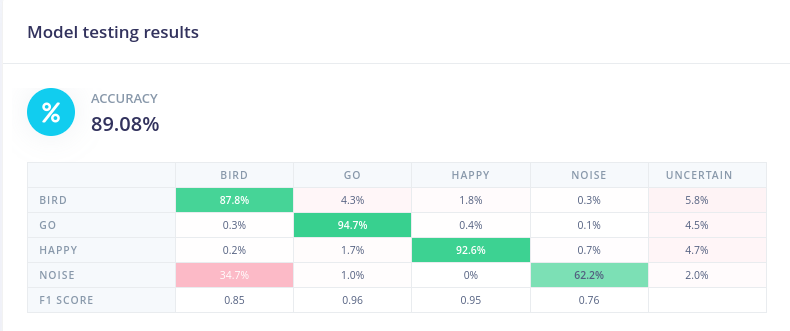
训练完成后,我们得到混淆矩阵和数据浏览器
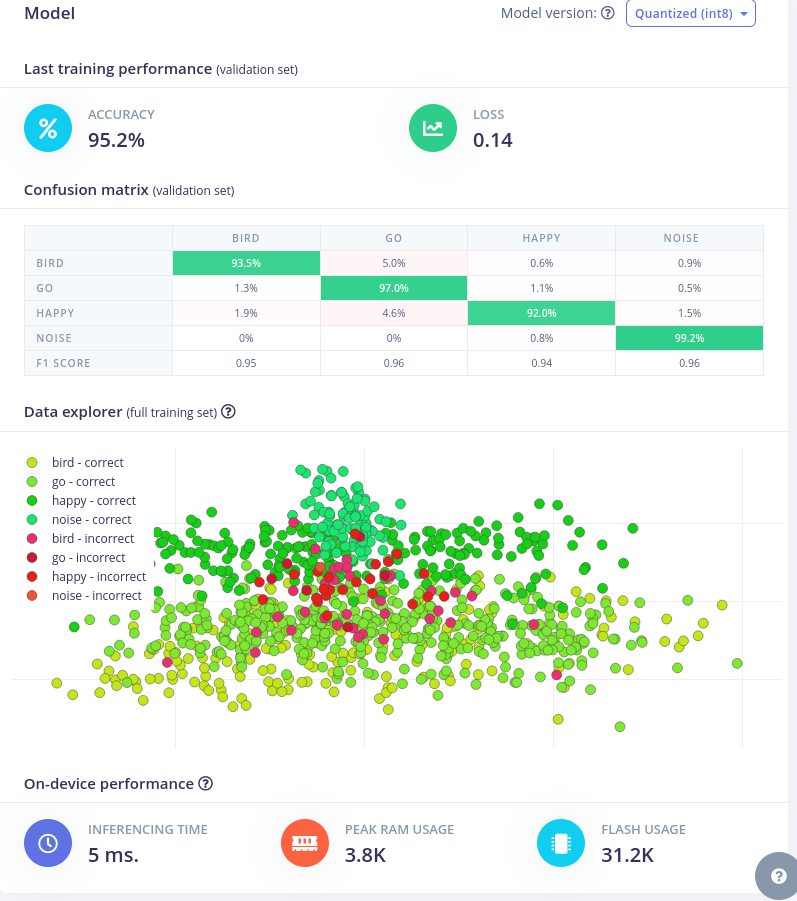
现在网络已经准备好了,让我们尝试一些样本并进行实时分类。 如果您转到实时分类,我们可以选择一个样本并查看分类结果。这里,对于一个鸟类示例,我们在结果中得到了 bird。太好了。模型正在工作。
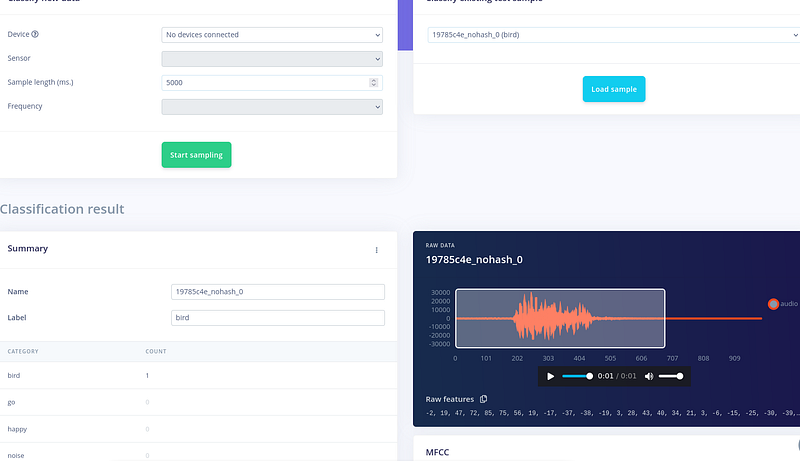
现在,让我们转到模型测试。 让我们使用分割的样本来测试模型。点击"Classify all"。
我们得到了将近 90% 的准确率。
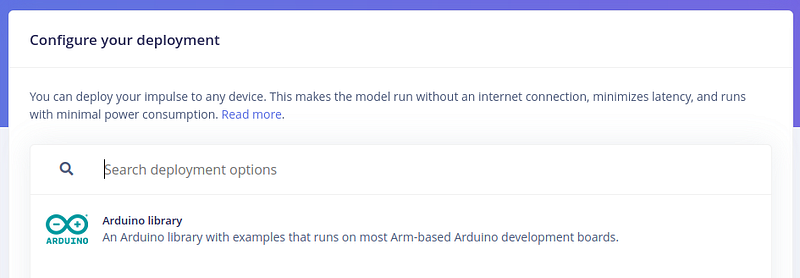
步骤 6 - 部署并获取 Arduino 库
现在,让我们转到部署来获取微控制器的文件。
部署选项
让我们选择 Arduino
接下来,让我们保持选择 Quantized(int8) 并点击"Build"下载文件以在 Arduino IDE 中使用 我们可以稍微调整一下优化设置。如果您发现准确率很低,请尝试关闭 EON 编译器并重试。
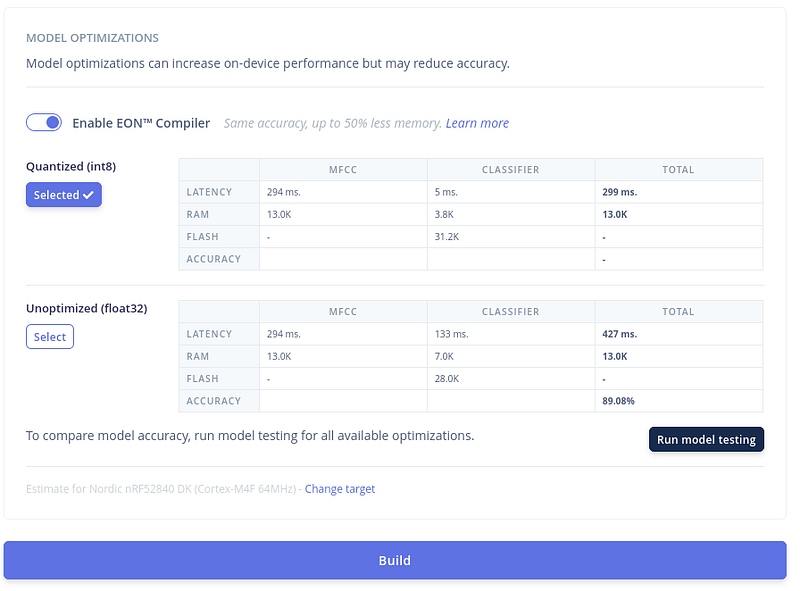
一段时间后,文件将自动下载。
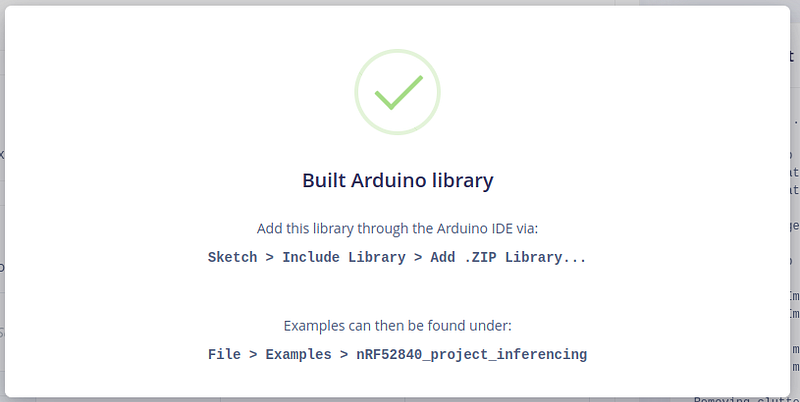
步骤 7 - 将库添加到 Arduino IDE
在 Arduino IDE 中,让我们添加新下载的文件。 转到 Sketch > Include Library > Add .ZIP Library
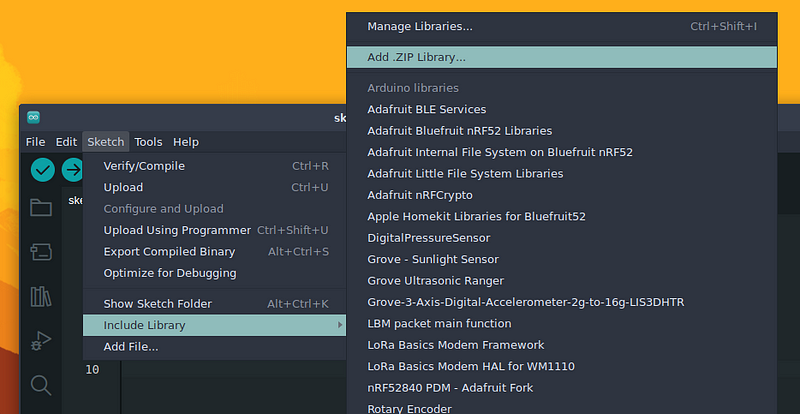
选择下载的文件。稍等片刻后,输出窗口会显示库已安装的消息。
步骤 8 - 语音控制 XIAO nRF52840 Sense 上的 RGB 灯
让我们打开一个示例 转到 Examples > <your_files_names> > nano_ble33_sense > nano_ble33_sense_microphone
为什么是 Arduino BLE 33 Sense?它们使用相同的库 - PDM(脉冲密度调制)- 来控制麦克风。Arduino Nano BLE 33 Sense 有一个 MP34DT05,而 XIAO nRF52840 Sense 有 MSM261D3526H1CPM。 打开草图后,让我们编译它,看看是否有任何错误。
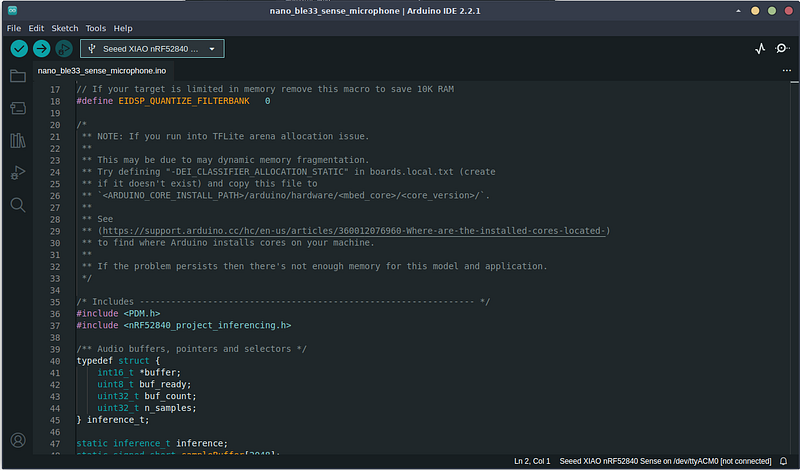
稍等片刻后,草图编译完成,没有报告错误。
现在,连接 XIAO nRF52840 Sense(如果您还没有连接的话)并将代码上传到开发板。
现在,打开串口监视器(Ctrl+Shift+M)并查看推理结果(开发板已经开始录音、进行推理和预测)
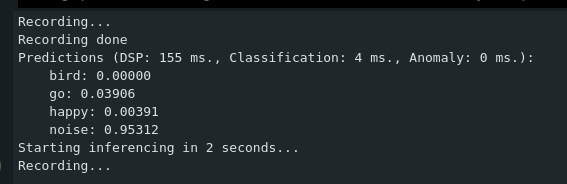
尝试说出选择的单词之一。我说了 go
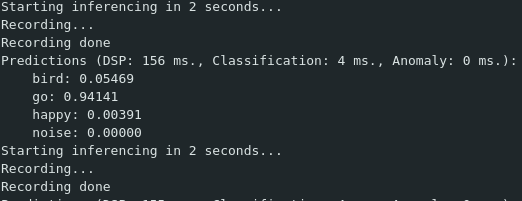
如果它正确检测到单词,最可能的单词将有一个接近 1.0 的结果,而其他单词的值接近 0.0 现在,让我们稍微修改一下代码,增加一些乐趣。 XIAO nRF52840 Sense 有一个内置 LED,具有 3 种颜色:
- 红色 - LED_BUILTIN 或 LED_RED

- 绿色 - LED_GREEN

- 蓝色 - LED_BLUE

由于我们有 3 个单词,让我们为每个单词分配一种颜色,并为相应的单词点亮相应的颜色。
- 红色对应 bird
- 绿色对应 Go
- 蓝色对应 happy
为了更简单,我检查了开发板的引脚定义,以下引脚分配给 LED 颜色:
- RED - 引脚 11
- GREEN - 引脚 13
- BLUE - 引脚 12
首先,我们需要定义一个阈值。我们知道预测值从 0.0 到 1.0。越接近 1.0,我们对单词分类的确定性就越高。这个值可以稍后调整。我将其设置为 0.7。
首先,定义一些变量。我在包含的库之后定义了这些:
/* threshold for predictions */
float threshold = 0.7;
/**
LABELS INDEX:
0 - bird
1 - go
2 - happy
3 - noise
*/
// LED pin (defines color) to light up
/**
PIN 11 - RED
PIN 12 - BLUE
PIN 13 - GREEN
*/
int LED = 0;
int oldLED;
int oldLED 将定义之前点亮的LED,这样当没有预测或预测发生变化时我们可以将其关闭。
int LED 是我们将要点亮的当前LED。
接下来,在loop()函数中,在for循环指令内部,我们循环遍历CLASSIFIER_LABEL_COUNT的地方(大约第129行 - 已经包含上面的行):
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
我们使用 if 指令来检查分类值。如果它超过了定义的阈值,我们使用 switch 指令检查记录了哪个单词。
完整的 for 循环,加上我们的添加内容,是:
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: %.5f\n", result.classification[ix].label, result.classification[ix].value);
//lets light up some LEDS
if (result.classification[ix].value > threshold) {
//now let's see what label were in
switch (ix) {
case 0: LED = 11; break;
case 1: LED = 13; break;
case 2: LED = 12; break;
default: LED = 0;
}
//in Sense, LOW will light up the LED
if (LED != 0) {
digitalWrite (oldLED, HIGH); //if we enter a word right next to previous - we turn off the previous LED
digitalWrite (LED, LOW);
oldLED = LED;
}
else //turn off LED
digitalWrite (oldLED, HIGH);
}
}
更改后,只需将代码上传到您的微控制器并尝试说出训练的单词,看看LED是否根据单词亮起。
就是这样。虽然没有直接支持,但我们现在可以使用XIAO nRF52840 Sense通过Edge Impulse运行一些ML模型
✨ 贡献者项目
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。