使用 YOLOv5 和 Roboflow 进行少样本目标检测
介绍
YOLO 是目前最著名的目标检测算法之一。它只需要少量样本进行训练,同时提供更快的训练时间和高精度。我们将在本教程中逐一演示这些特性,同时逐步解释完整的机器学习流水线,您将收集数据、标注数据、训练数据,最后通过在边缘设备(如 NVIDIA Jetson 平台)上运行训练好的模型来检测目标。此外,我们还将比较使用自定义数据集和公共数据集之间的差异。
什么是 YOLOv5?
YOLO 是"You Only Look Once"的缩写。它是一种能够实时检测和识别图像中各种目标的算法。Ultralytics YOLOv5 是 YOLO 的最新版本,现在基于 PyTorch 框架。

什么是少样本目标检测?
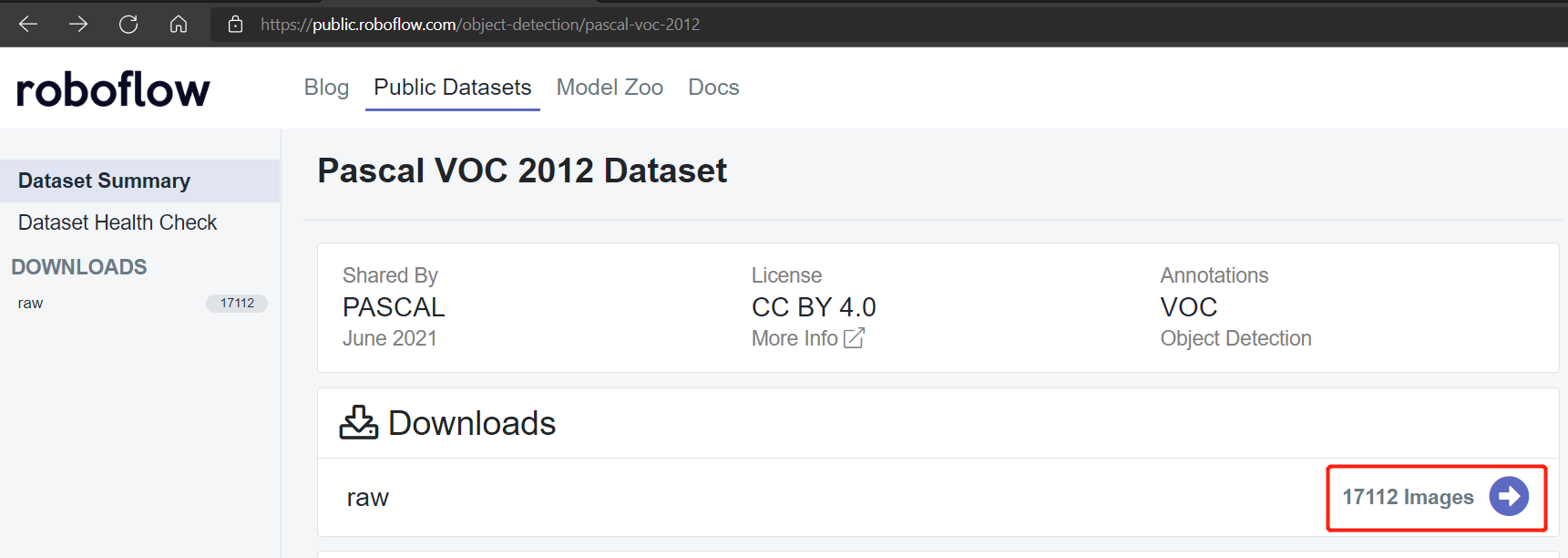
传统上,如果您想训练机器学习模型,您会使用公共数据集,如包含约 17112 张图像的 Pascal VOC 2012 数据集。然而,我们将使用迁移学习来实现 YOLOv5 的少样本目标检测,这只需要非常少的训练样本。我们将在本教程中演示这一点。
支持的硬件
YOLOv5 支持以下硬件:
-
NVIDIA 官方开发套件:
- NVIDIA® Jetson Nano Developer Kit
- NVIDIA® Jetson Xavier NX Developer Kit
- NVIDIA® Jetson AGX Xavier Developer Kit
- NVIDIA® Jetson TX2 Developer Kit
-
NVIDIA 官方 SoM:
- NVIDIA® Jetson Nano module
- NVIDIA® Jetson Xavier NX module
- NVIDIA® Jetson TX2 NX module
- NVIDIA® Jetson TX2 module
- NVIDIA® Jetson AGX Xavier module
-
Seeed 载板:
- Jetson Mate
- Jetson SUB Mini PC
- Jetson Xavier AGX H01 Kit
- A203 Carrier Board
- A203 (Version 2) Carrier Board
- A205 Carrier Board
- A206 Carrier Board
先决条件
-
运行最新 JetPack v4.6.1 并安装所有 SDK 组件的上述任一 Jetson 设备(安装参考请查看此教程)
-
主机 PC
- 本地训练需要 Linux PC(最好是 Ubuntu)
- 云端训练可以从任何操作系统的 PC 执行
入门指南
在边缘设备(如 Jetson 平台)上运行您的第一个目标检测项目只需要 4 个主要步骤!
-
收集数据集或使用公开可用的数据集
- 手动收集数据集
- 使用公开可用的数据集
-
使用 Roboflow 标注数据集
-
在本地 PC 或云端训练
- 在本地 PC 上训练(Linux)
- 在 Google Colab 上训练
-
在 Jetson 设备上推理
收集数据集或使用公开可用的数据集
目标检测项目的第一步是获取用于训练的数据。您可以下载公开可用的数据集或创建自己的数据集!通常公共数据集用于教育和研究目的。但是,如果您想构建特定的目标检测项目,而公共数据集中没有您想要检测的对象,您可能需要构建自己的数据集。
手动收集数据集
建议您首先录制想要识别的对象的视频素材。您必须确保覆盖对象的所有角度(360度),将对象放置在不同的环境、不同的光照和不同的天气条件下。 我们录制的总视频长度为9分钟,其中4.5分钟是花朵,剩余4.5分钟是叶子。录制可以分解如下:

- 早晨正常天气
- 早晨有风天气
- 早晨雨天
- 中午正常天气
- 中午有风天气
- 中午雨天
- 傍晚正常天气
- 傍晚有风天气
- 傍晚雨天
注意: 稍后,我们将把这个视频素材转换为一系列图像,以构成用于训练的数据集。
使用公开可用的数据集
您可以下载许多公开可用的数据集,如 COCO dataset、Pascal VOC dataset 等等。Roboflow Universe 是一个推荐的平台,它提供广泛的数据集,拥有 90,000+ 个数据集和 66+ 百万张图像 可用于构建计算机视觉模型。此外,您也可以在 Google 上简单搜索开源数据集,从各种可用的数据集中进行选择。
使用 Roboflow 标注数据集
接下来我们将继续标注我们拥有的数据集。标注意味着简单地在我们想要检测的每个对象周围绘制矩形框并为它们分配标签。我们将解释如何使用 Roboflow 来完成这项工作。
Roboflow 是一个基于在线的标注工具。在这里我们可以直接将之前录制的视频素材导入到 Roboflow 中,它将被导出为一系列图像。这个工具非常方便,因为它可以帮助我们将数据集分配到"训练、验证和测试"中。此外,这个工具还允许我们在标记这些图像后对其进行进一步处理。而且,它可以轻松地将标记的数据集导出为 YOLOV5 PyTorch 格式,这正是我们所需要的!
-
步骤 1. 点击 这里 注册 Roboflow 账户
-
步骤 2. 点击 Create New Project 开始我们的项目
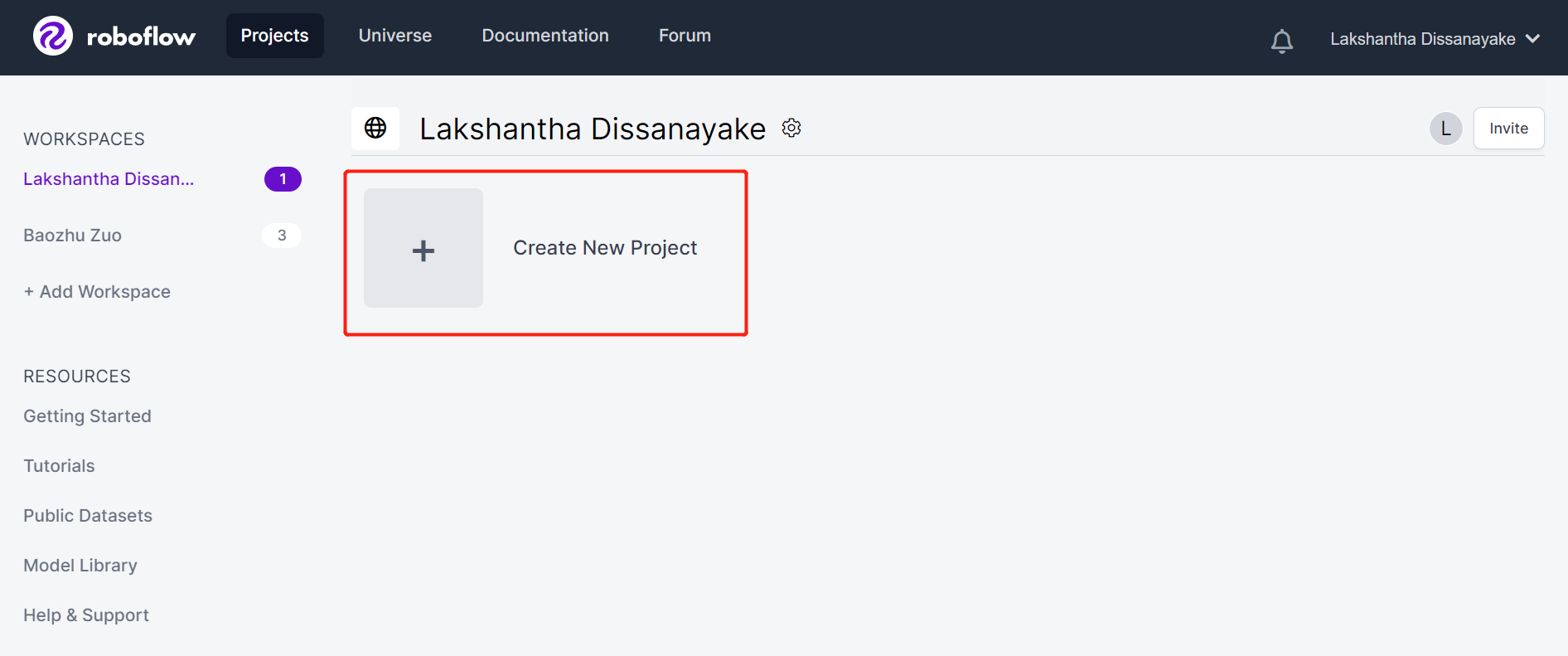
- 步骤 3. 填写 Project Name,保持 License (CC BY 4.0) 和 Project type (Object Detection (Bounding Box)) 为默认设置。在 What will your model predict? 列下,填写一个标注组名称。例如,在我们的案例中,我们选择 plants。这个名称应该突出显示数据集的所有类别。最后,点击 Create Public Project。
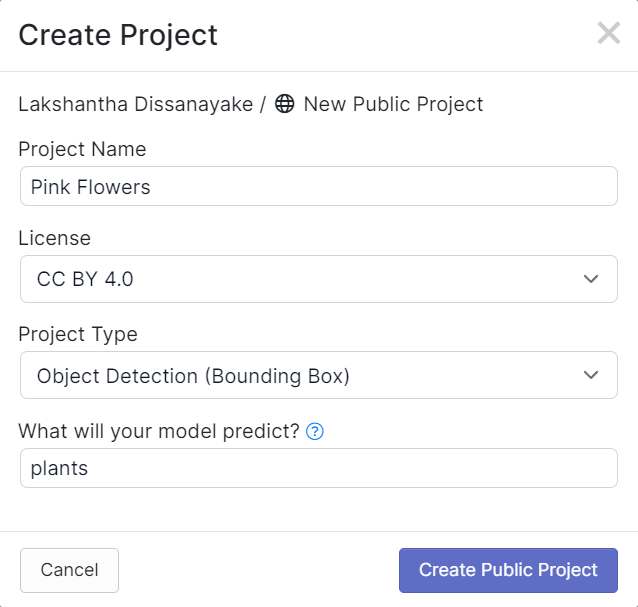
- 步骤 4. 拖放您之前录制的视频素材
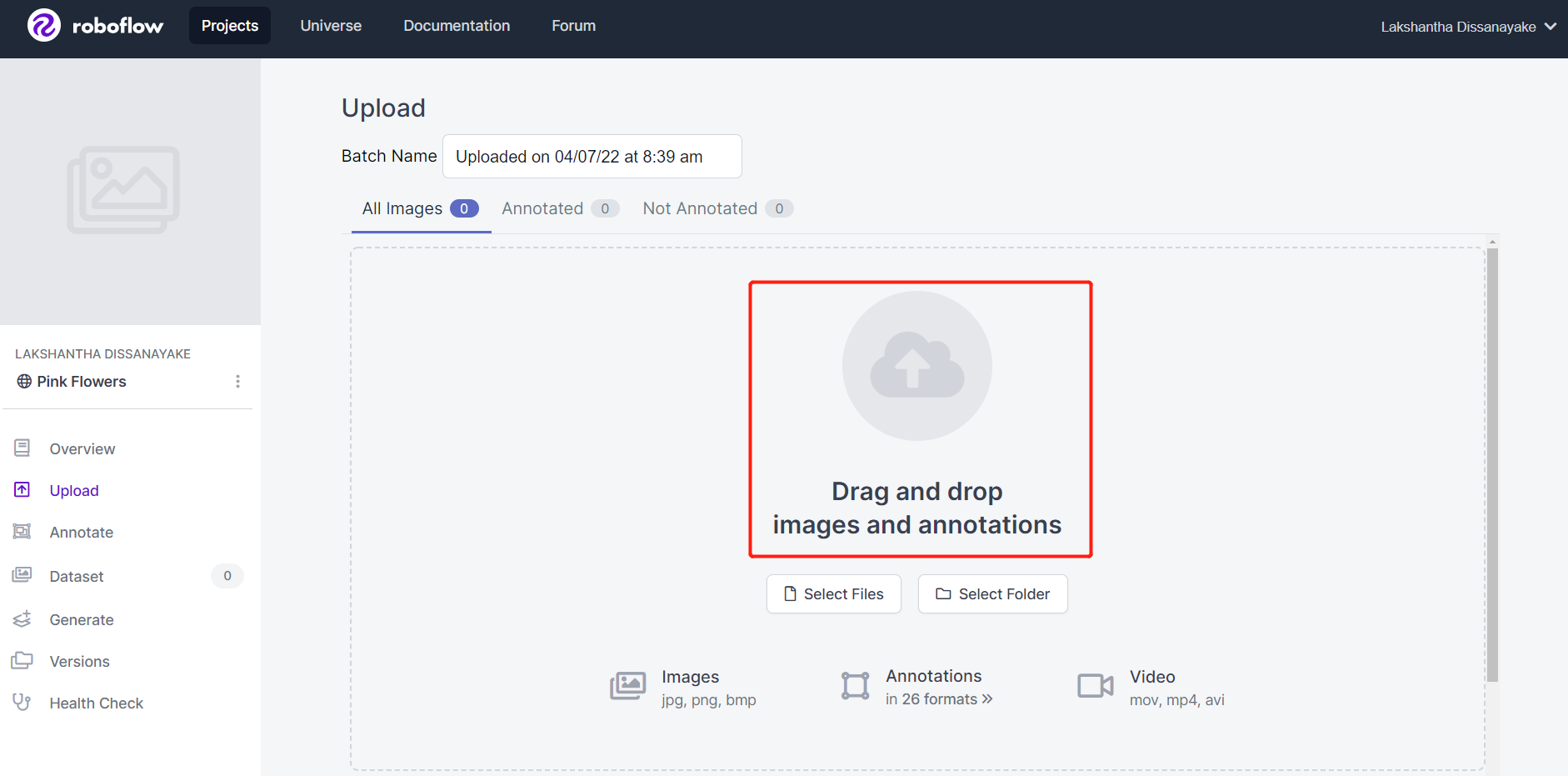
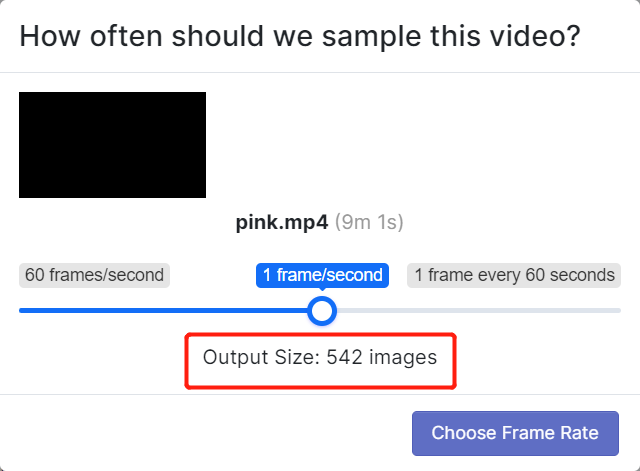
- 步骤 5. 选择一个帧率,以便将视频分割成一系列图像。这里我们将使用默认帧率,即 1 帧/秒,这将总共生成 542 张图像。通过滑动滑块选择帧率后,点击 Choose Frame Rate。完成此过程需要几秒钟到几分钟(取决于视频长度)。
- 步骤 6. 图像处理完成后,点击 Finish Uploading。耐心等待直到图像上传完成。
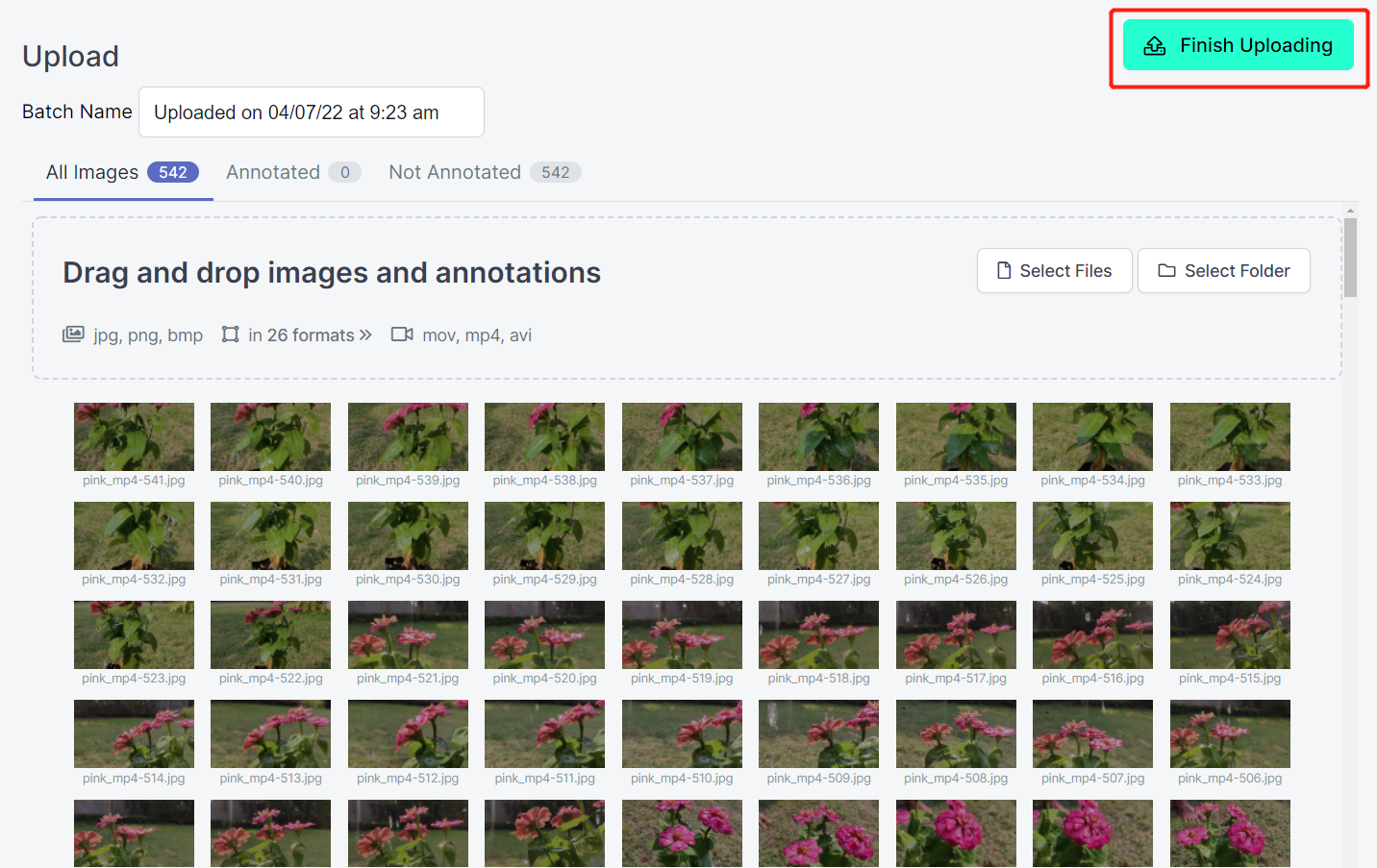
- 步骤 7. 图像上传完成后,点击 Assign Images
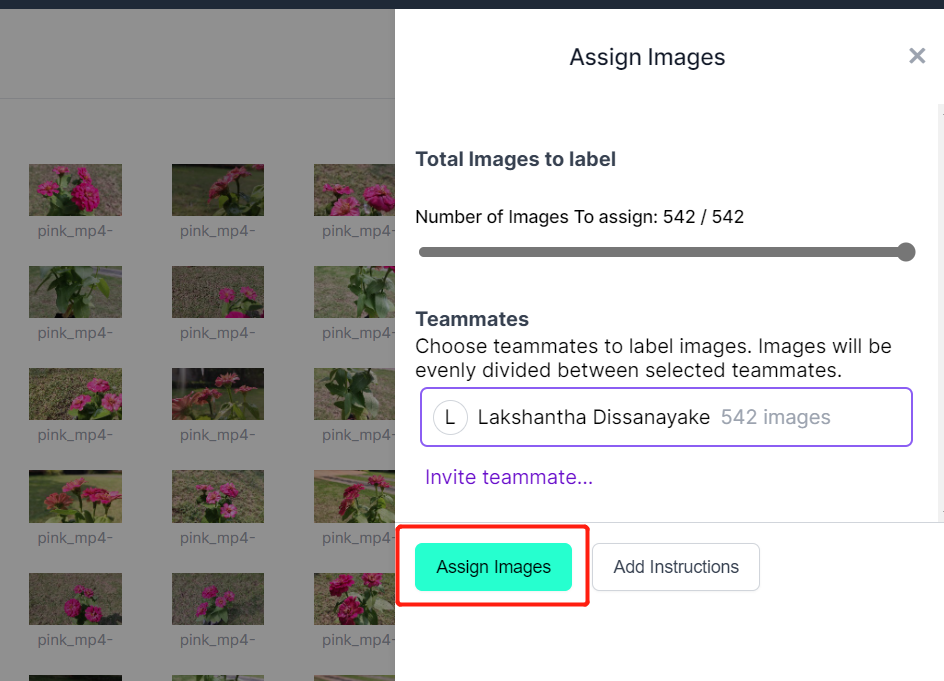
- 步骤 8. 选择一张图像,在花朵周围绘制一个矩形框,选择标签为 pink flower 并按 ENTER
- 步骤 9. 对剩余的花朵重复相同操作
- 步骤 10. 在叶子周围绘制一个矩形框,选择标签为 leaf 并按 ENTER
- 步骤 11. 对剩余的叶子重复相同操作
注意: 尽量标记图像中看到的所有对象。如果只有对象的一部分可见,也要尝试标记它。
- 步骤 12. 继续标注数据集中的所有图像
Roboflow 有一个名为 Label Assist 的功能,它可以预先预测标签,使您的标记工作更快。但是,它不适用于所有对象类型,而是选定类型的对象。要启用此功能,您只需按 Label Assist 按钮,选择一个模型,选择类别,然后浏览图像以查看带有边界框的预测标签
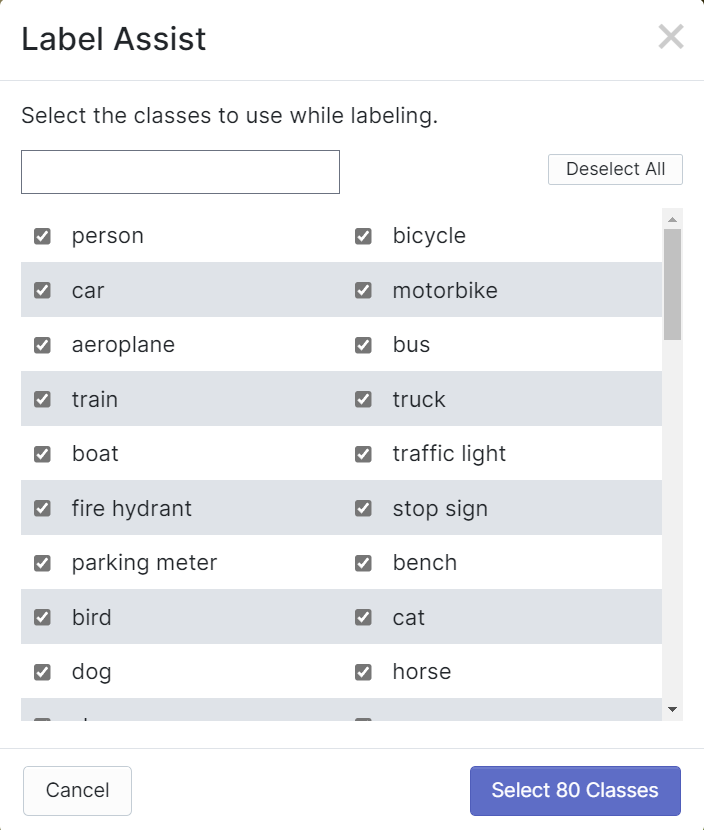
如上所示,它只能帮助预测上述提到的80个类别的标注。如果您的图像不包含上述对象类别,您就无法使用标签辅助功能。
- 步骤 13. 标注完成后,点击 Add images to Dataset

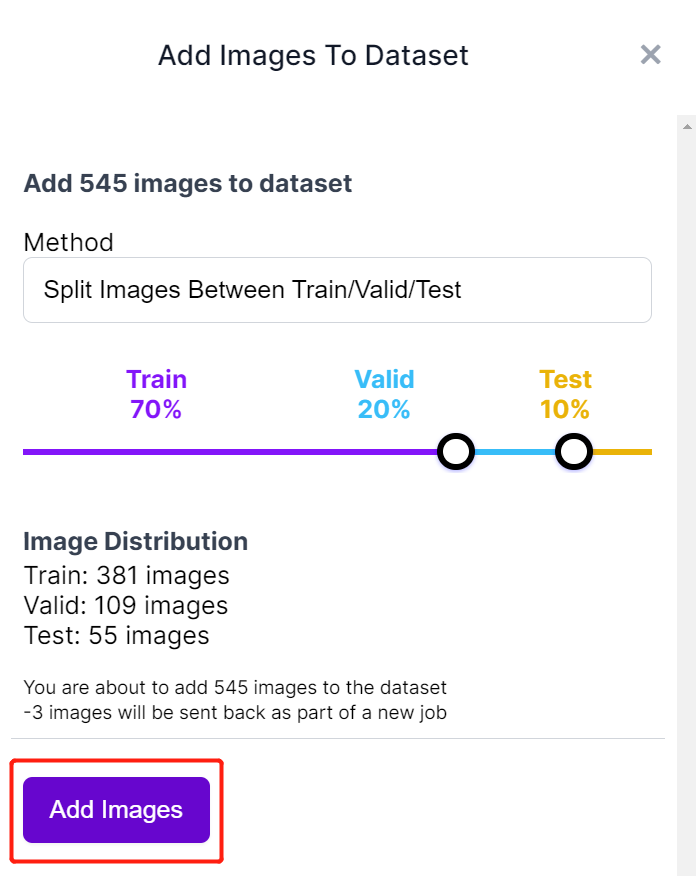
- 步骤 14. 接下来我们将在"Train, Valid and Test"之间分割图像。保持分布的默认百分比并点击 Add Images
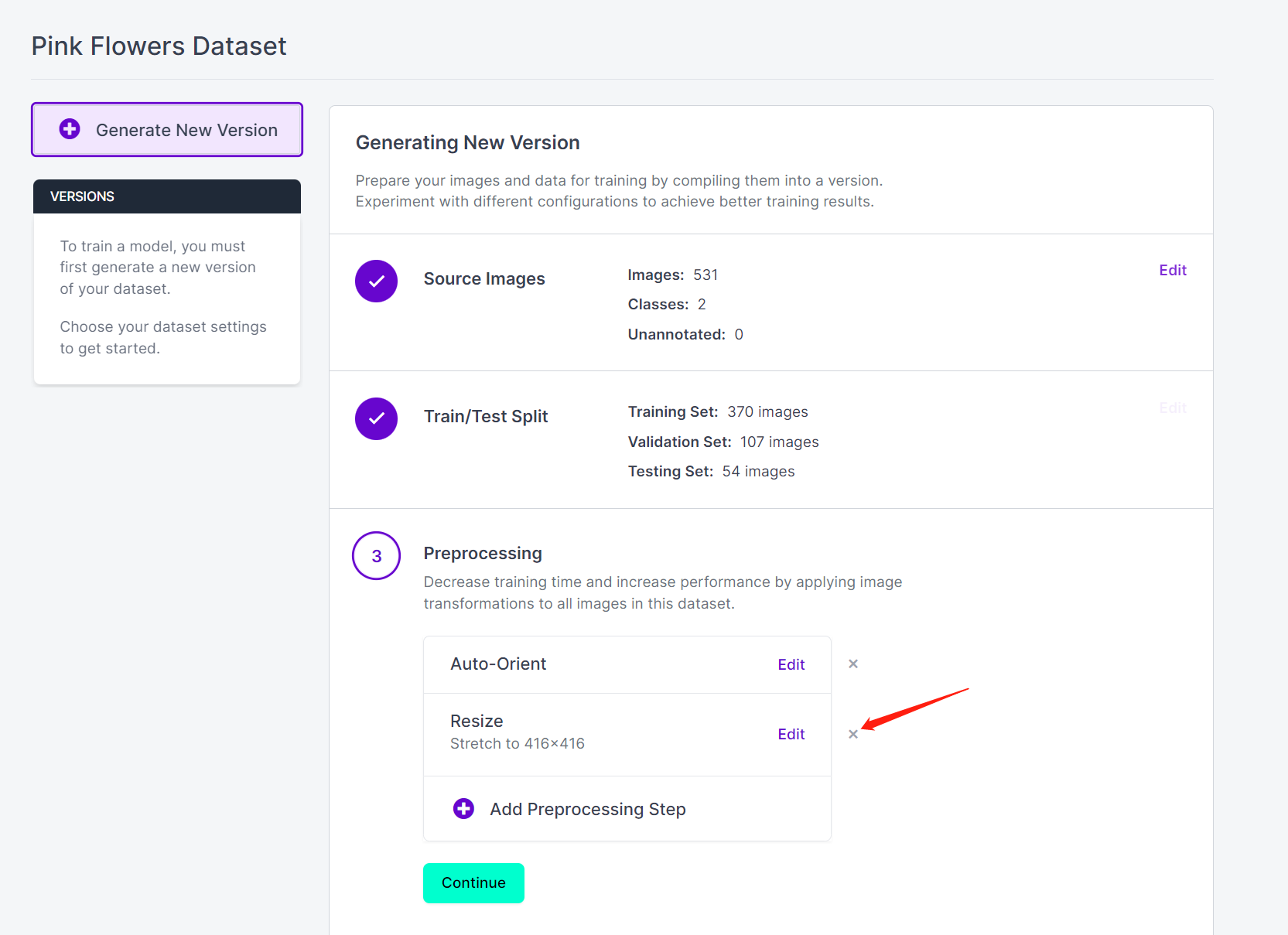
- 步骤 15. 点击 Generate New Version

- 步骤 16. 现在您可以根据需要添加 Preprocessing 和 Augmentation。这里我们将 删除 Resize 选项并保持原始图像尺寸
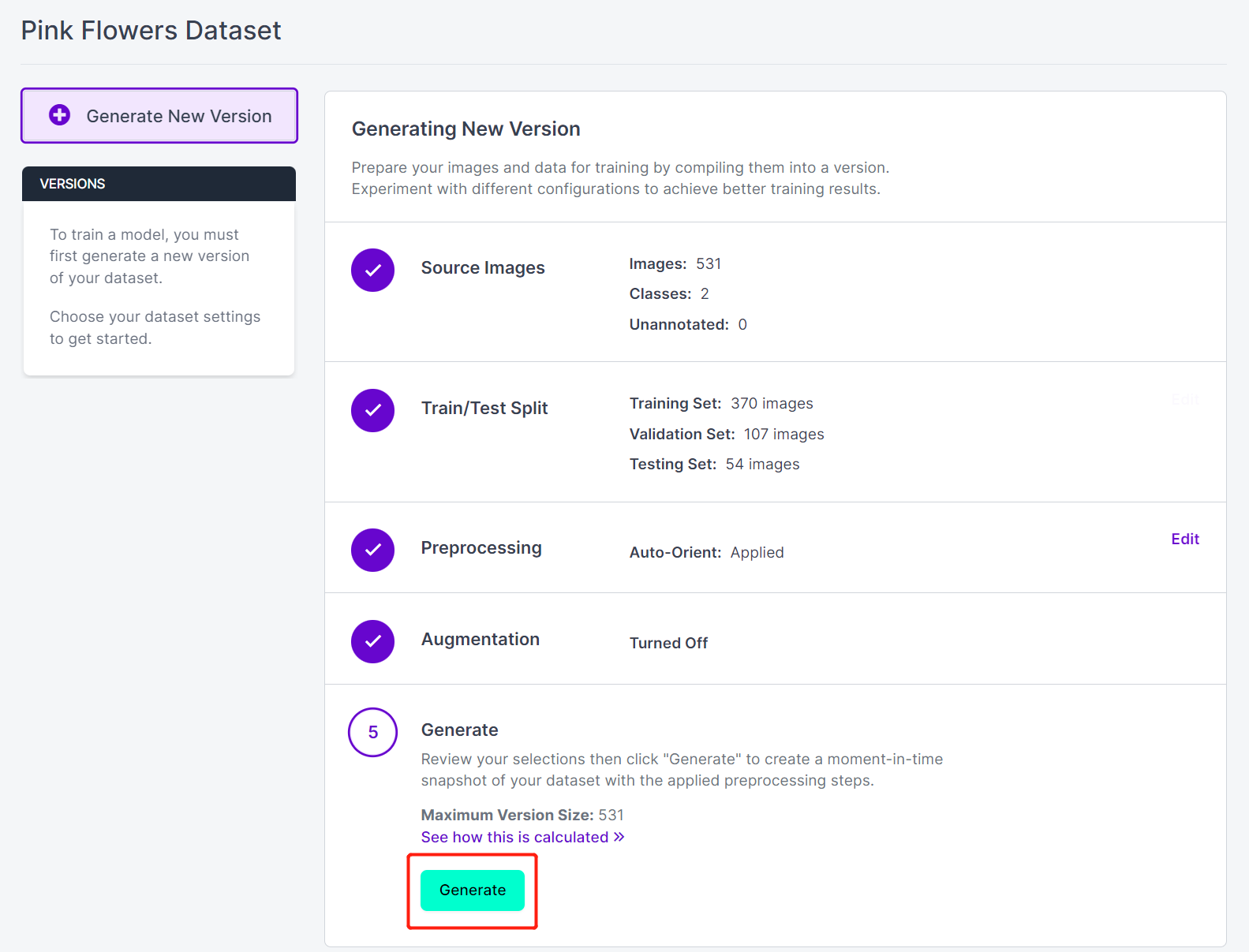
- 步骤 17. 接下来,继续使用其余默认设置并点击 Generate
- 步骤 18. 点击 Export
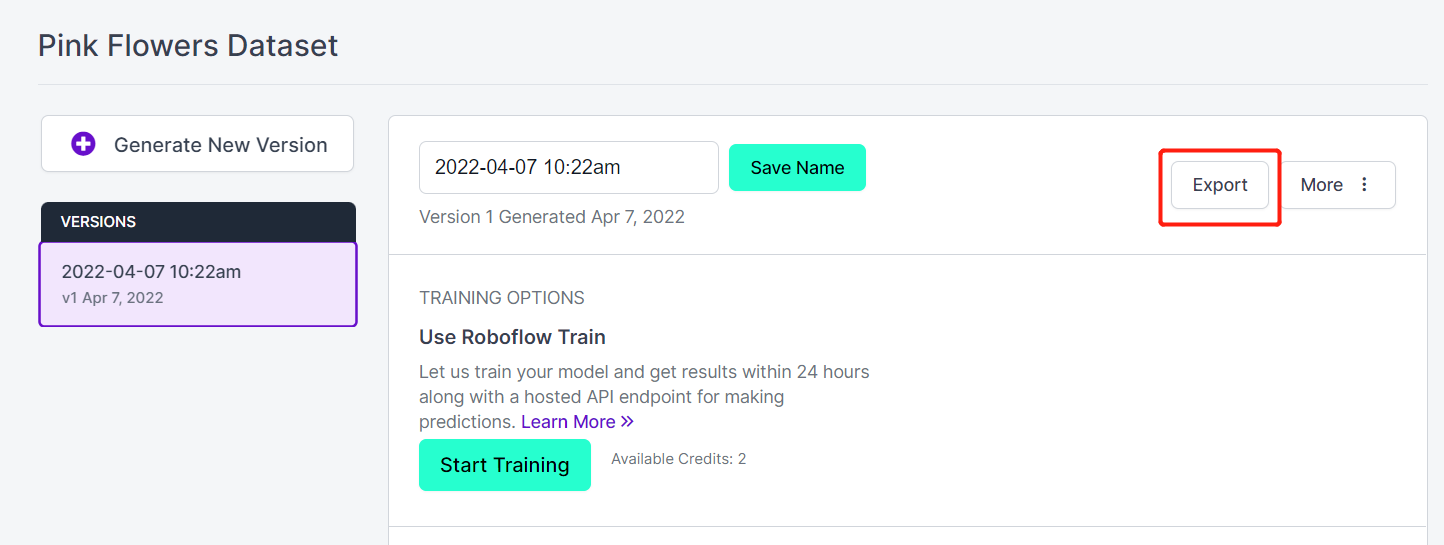
- 步骤 19. 选择 download zip to computer,在"Select a Format"下选择 YOLO v5 PyTorch 并点击 Continue
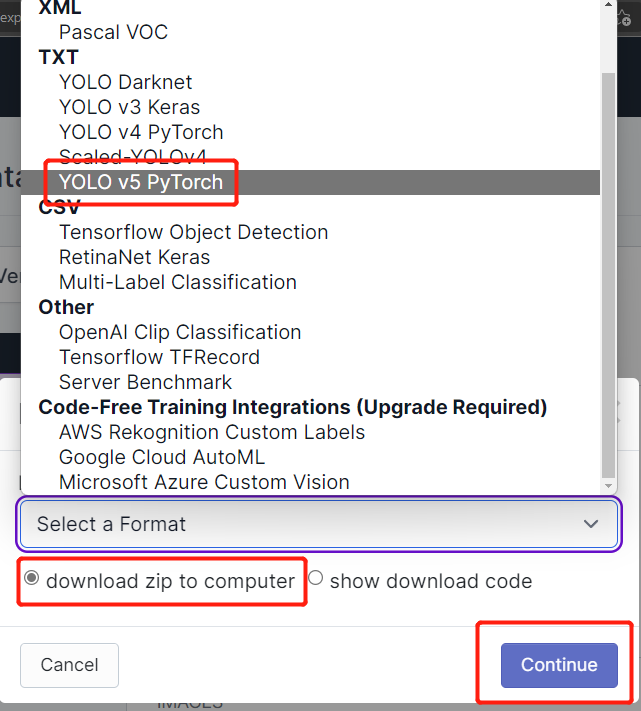
- 步骤 20. 之后,一个 .zip 文件 将下载到您的计算机。我们稍后训练时需要这个 .zip 文件。
在本地PC或云端训练
完成数据集标注后,我们需要训练数据集。对于训练,我们将介绍两种方法。一种方法基于在线(Google Colab),另一种方法基于本地PC(Linux)。
对于Google Colab训练,我们将使用两种方法。在第一种方法中,我们将使用Ultralytics HUB上传数据集,在Colab上设置训练,监控训练并获取训练好的模型。在第二种方法中,我们将通过Roboflow api从Roboflow获取数据集,训练并从Colab下载模型。
使用Google Colab与Ultralytics HUB
Ultralytics HUB 是一个平台,您可以在不需要了解任何代码的情况下训练您的模型。只需将您的数据上传到Ultralytics HUB,训练您的模型并将其部署到现实世界中!它快速、简单且易于使用。任何人都可以开始使用!
-
步骤 1. 访问 此链接 注册免费的Ultralytics HUB账户
-
步骤 2. 输入您的凭据并 sign up with email 或直接使用 Google、GitHub或Apple账户 注册
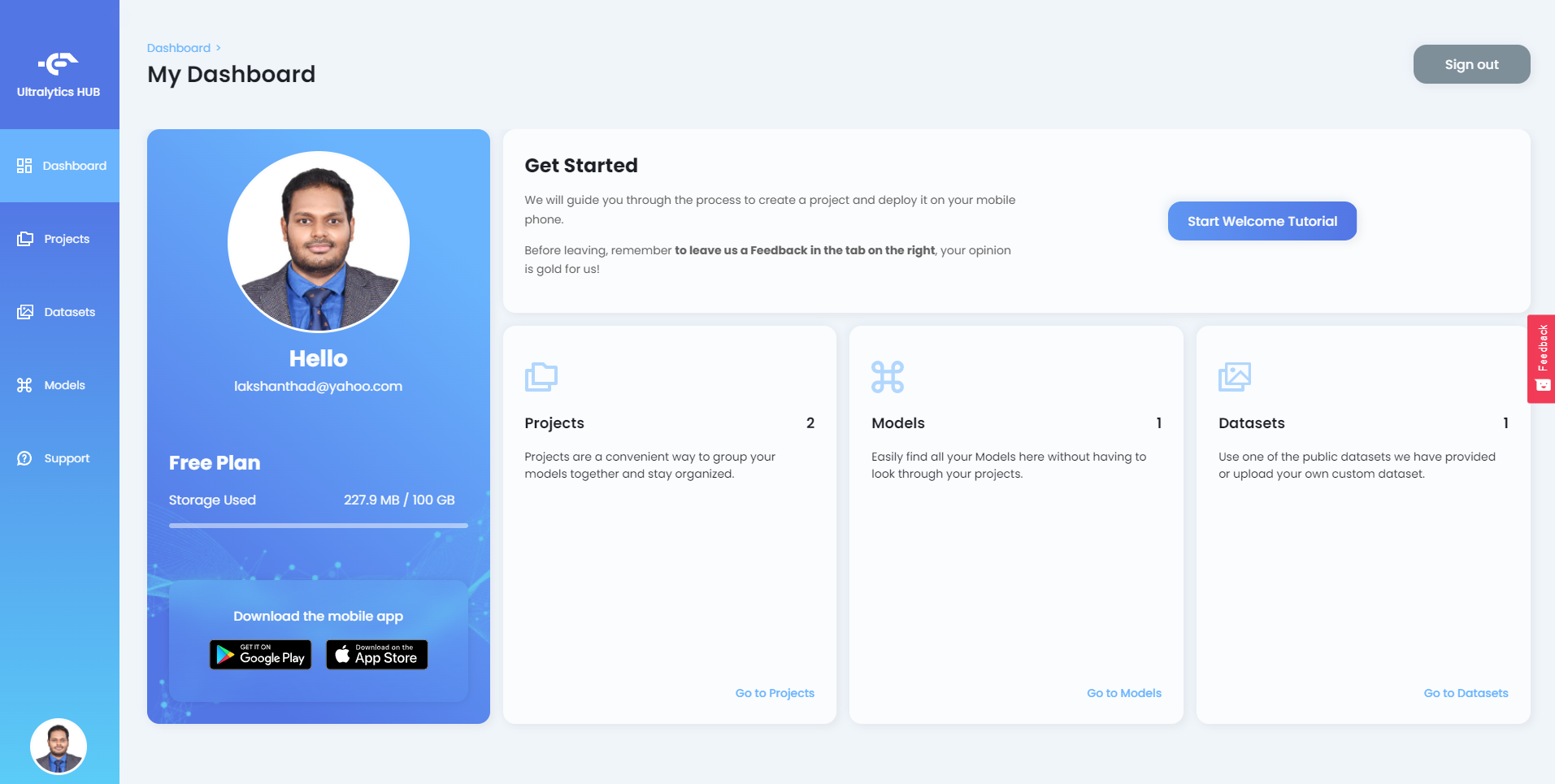
登录Ultralytics HUB后,您将看到如下仪表板
-
步骤 3. 解压我们之前从Roboflow下载的zip文件,并将所有包含的文件放入一个新文件夹中
-
步骤 4. 确保您的 dataset yaml 和 根文件夹(我们之前创建的文件夹)共享相同的名称。例如,如果您将yaml文件命名为 pinkflowers.yaml,根文件夹应命名为 pinkflowers。
-
步骤 5. 打开 pinkflowers.yaml 文件并按如下方式编辑 train 和 val 目录
train: train/images
val: valid/images
- 步骤 6. 将根文件夹压缩为 .zip 格式,并将其命名为与根文件夹相同的名称(在此示例中为 pinkflowers.zip)
现在我们已经准备好了可以上传到 Ultalytics HUB 的数据集。
- 步骤 7. 点击 Datasets 选项卡,然后点击 Upload Dataset
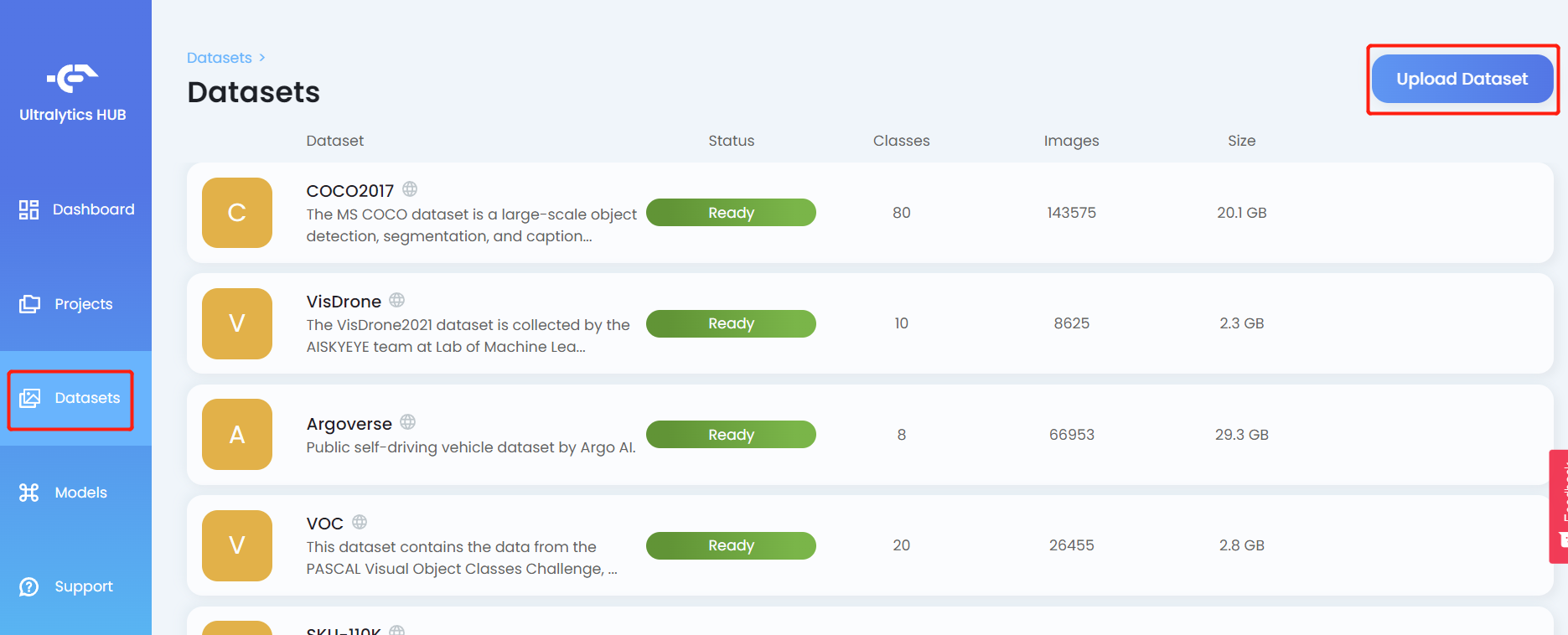
- 步骤 8. 为数据集输入一个 Name,如果需要的话输入 Description,在 Dataset 字段下拖放我们之前创建的 .zip 文件,然后点击 Upload Dataset
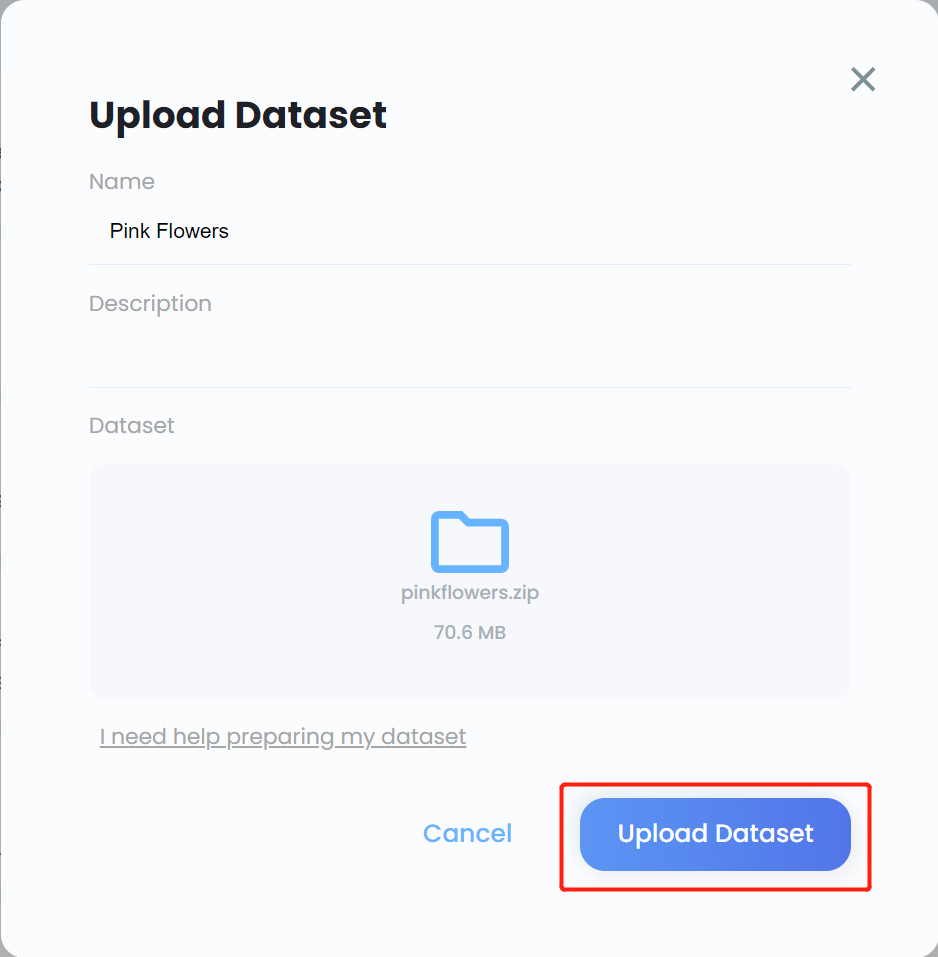
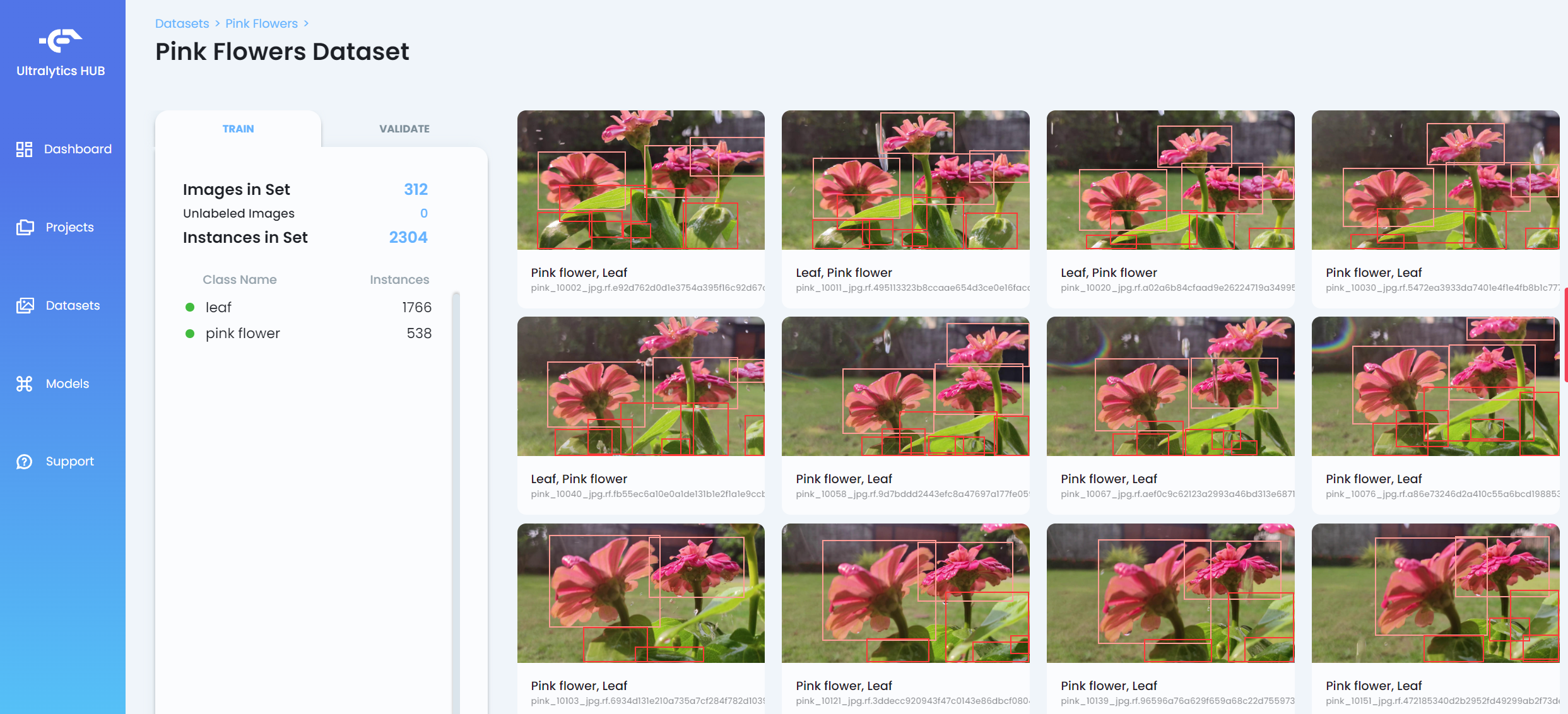
- 步骤 9. 数据集上传后,点击数据集以查看数据集的更多详细信息
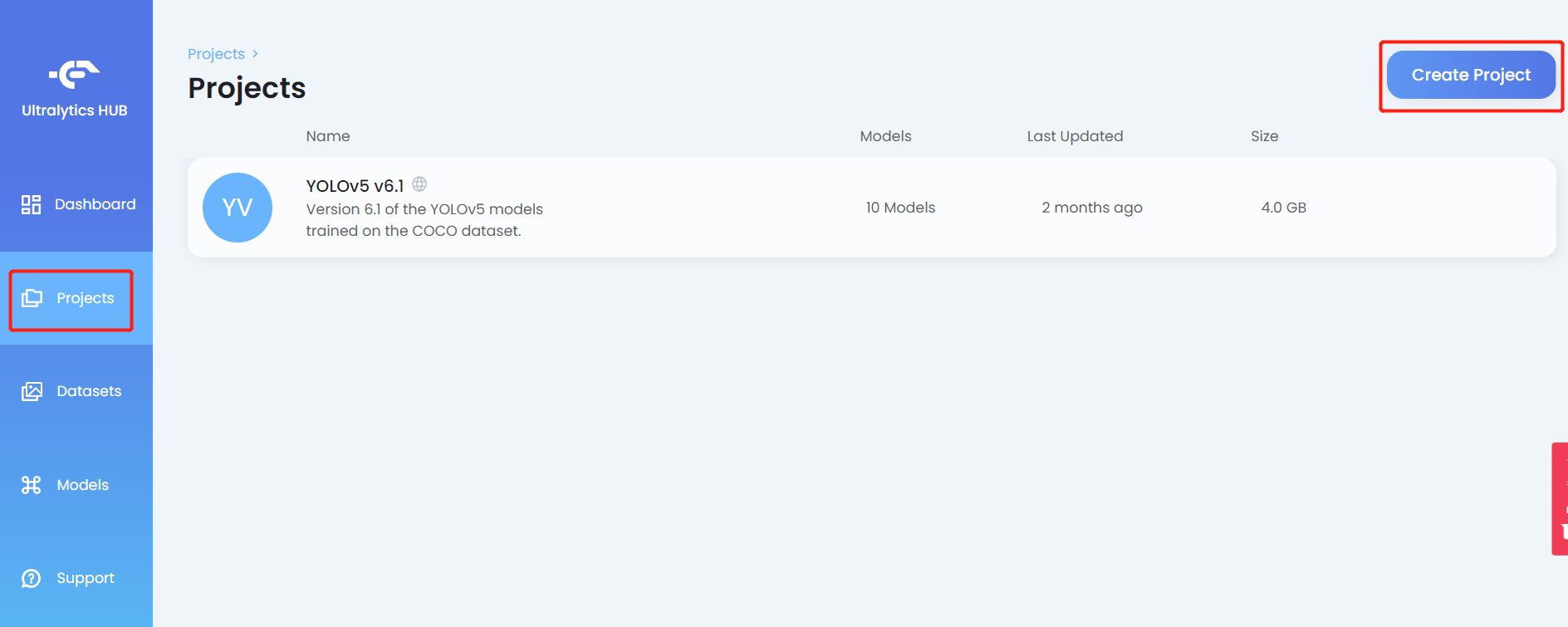
- 步骤 10. 点击 Projects 选项卡,然后点击 Create Project
- 步骤 11. 为项目输入一个 Name,如果需要的话输入 Description,如果需要的话添加 cover image,然后点击 Create Project
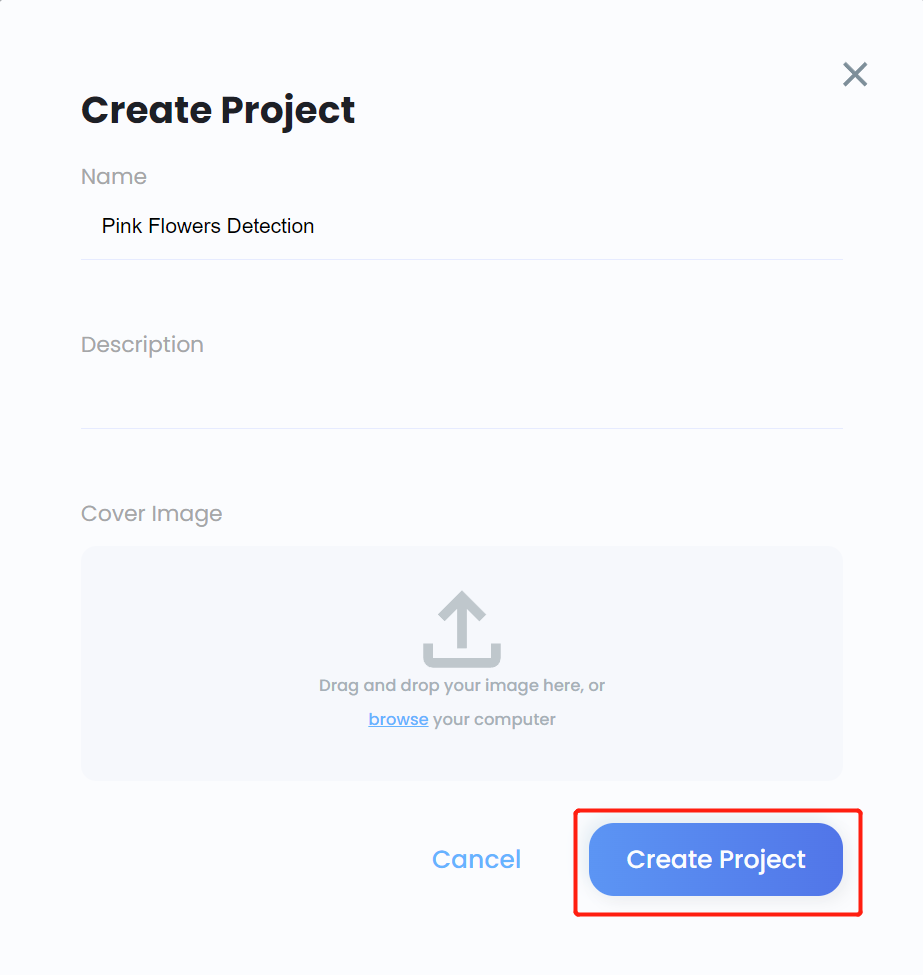
- 步骤 12. 进入新创建的项目,点击 Create Model

- 步骤 13. 输入 Model name,选择 YOLOv5n 作为预训练模型,然后点击 Next
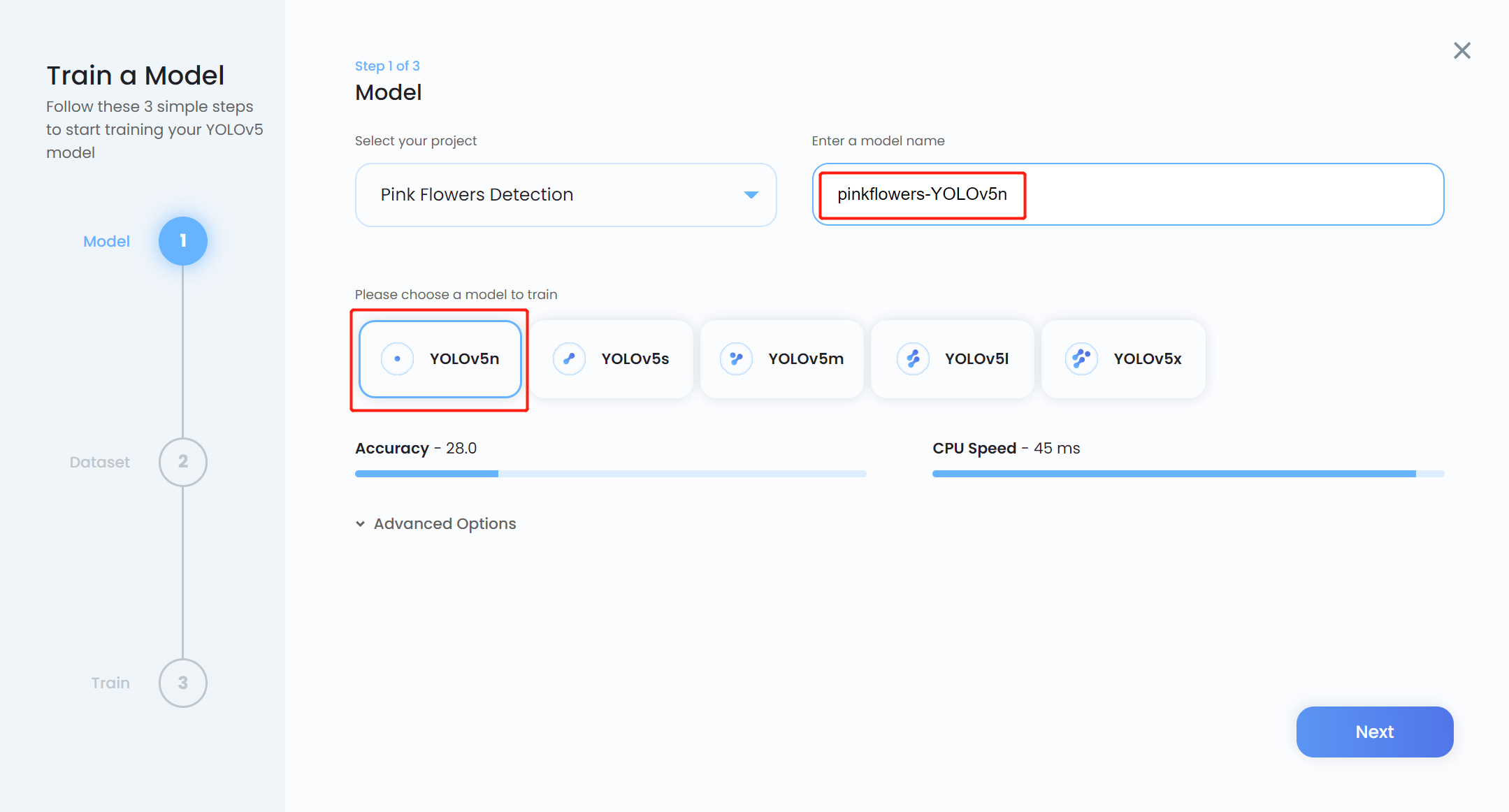
注意: 通常 YOLOv5n6 是首选的预训练模型,因为它适合用于边缘设备,如 Jetson 平台。但是,Ultralytics HUB 仍然不支持它。所以我们使用 YOLOv5n,这是一个稍微相似的模型。
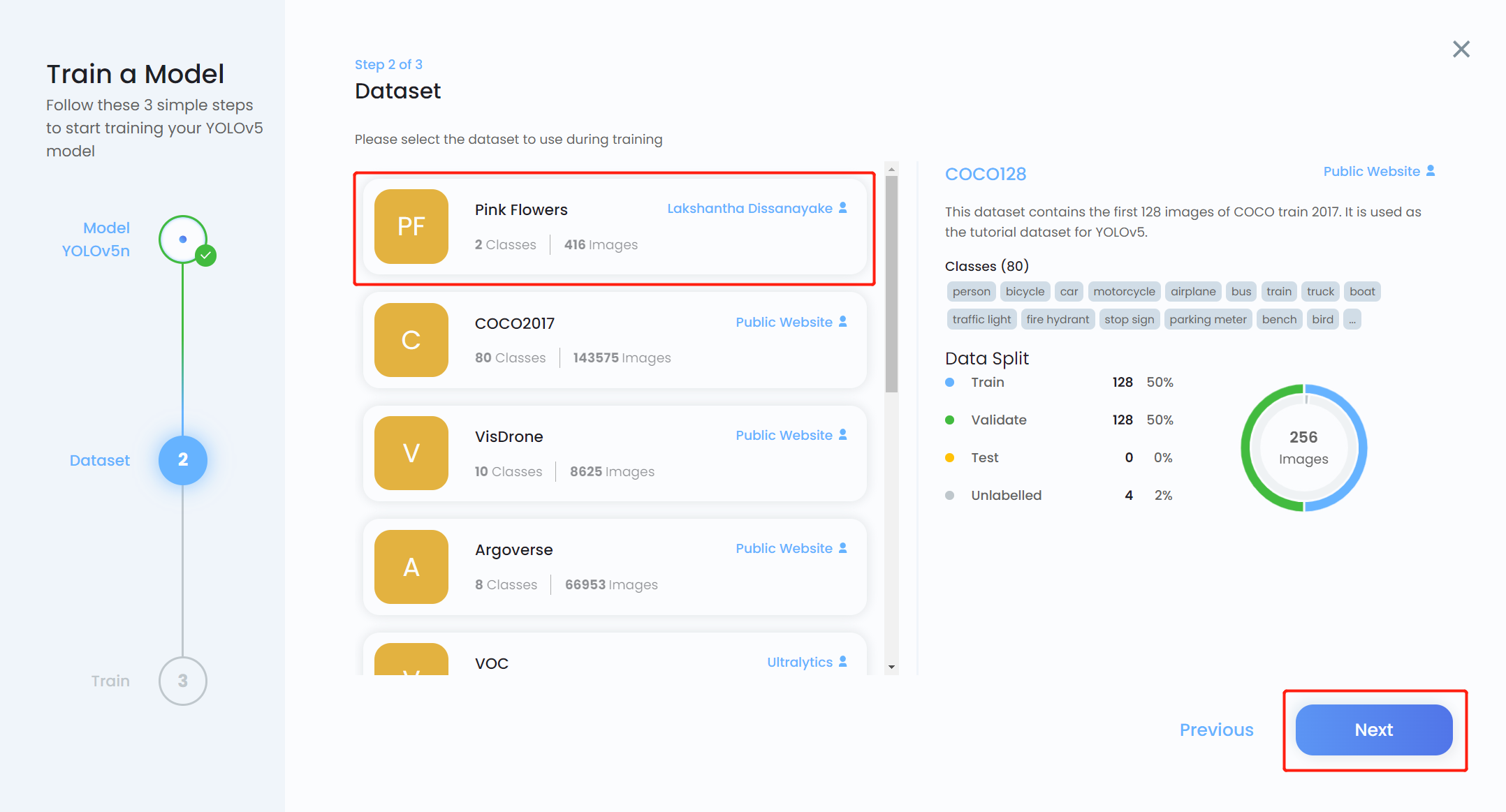
- 步骤 14. 选择我们之前上传的数据集,然后点击 Next
- 步骤 15. 选择 Google Colab 作为训练平台,点击 Advanced Options 下拉菜单。在这里我们可以更改一些训练设置。例如,我们将训练轮数从 300 改为 100,其他设置保持不变。点击 Save
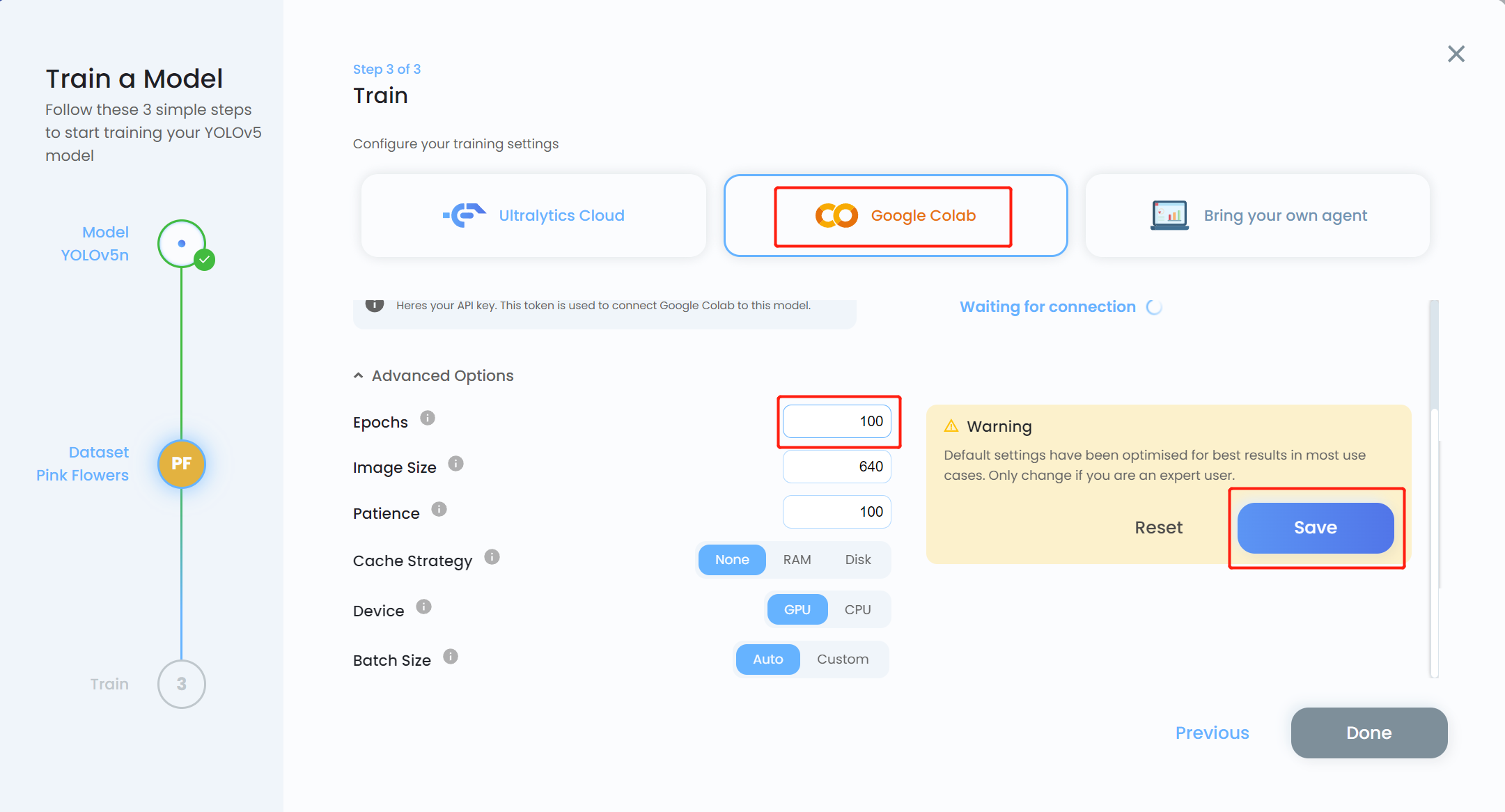
注意: 如果您计划进行本地训练,也可以选择 Bring your own agent
- 步骤 16. 复制 API key,然后点击 Open Colab
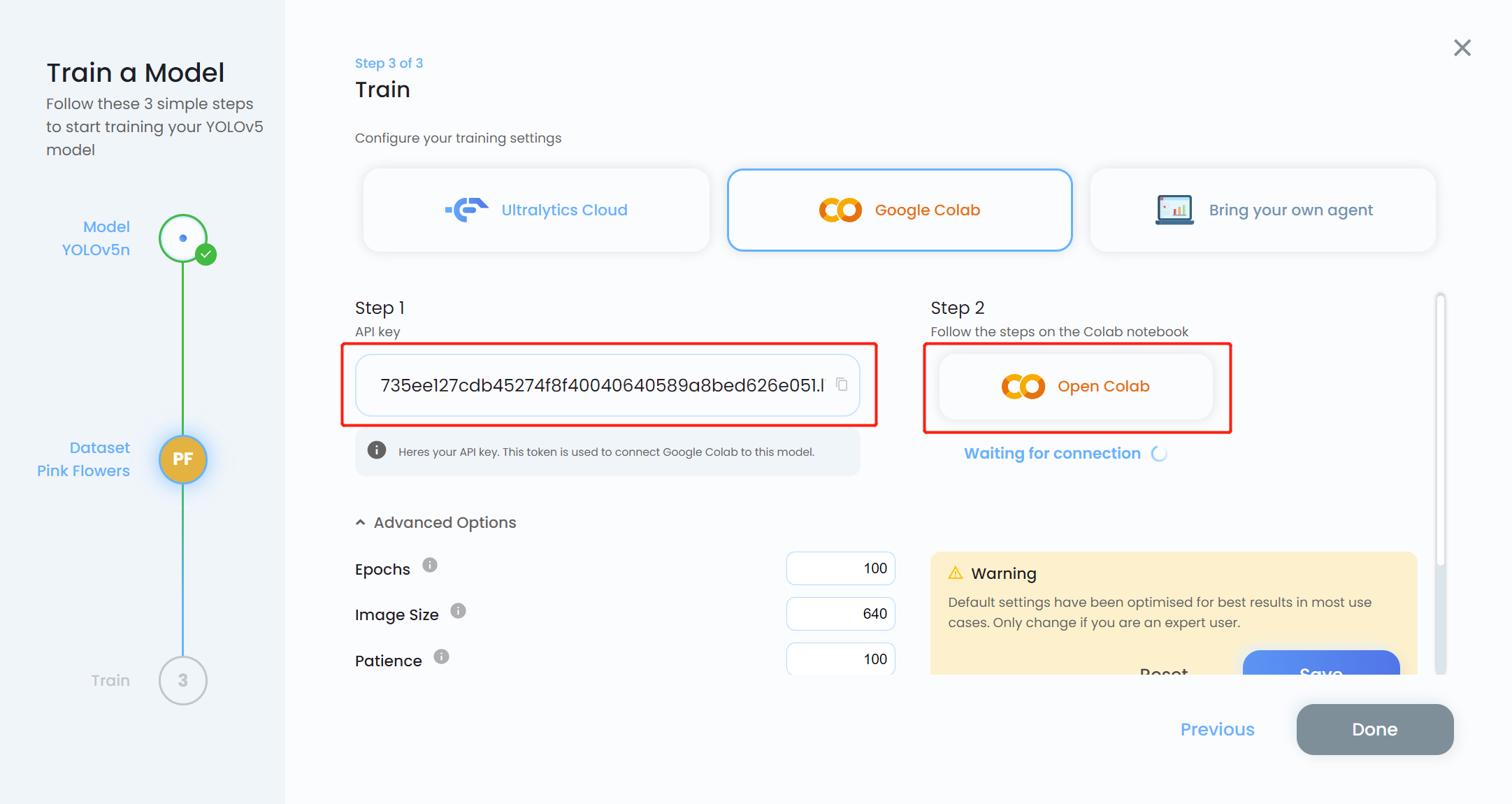
- 步骤 17. 用我们之前复制的 API key 替换 MODEL_KEY
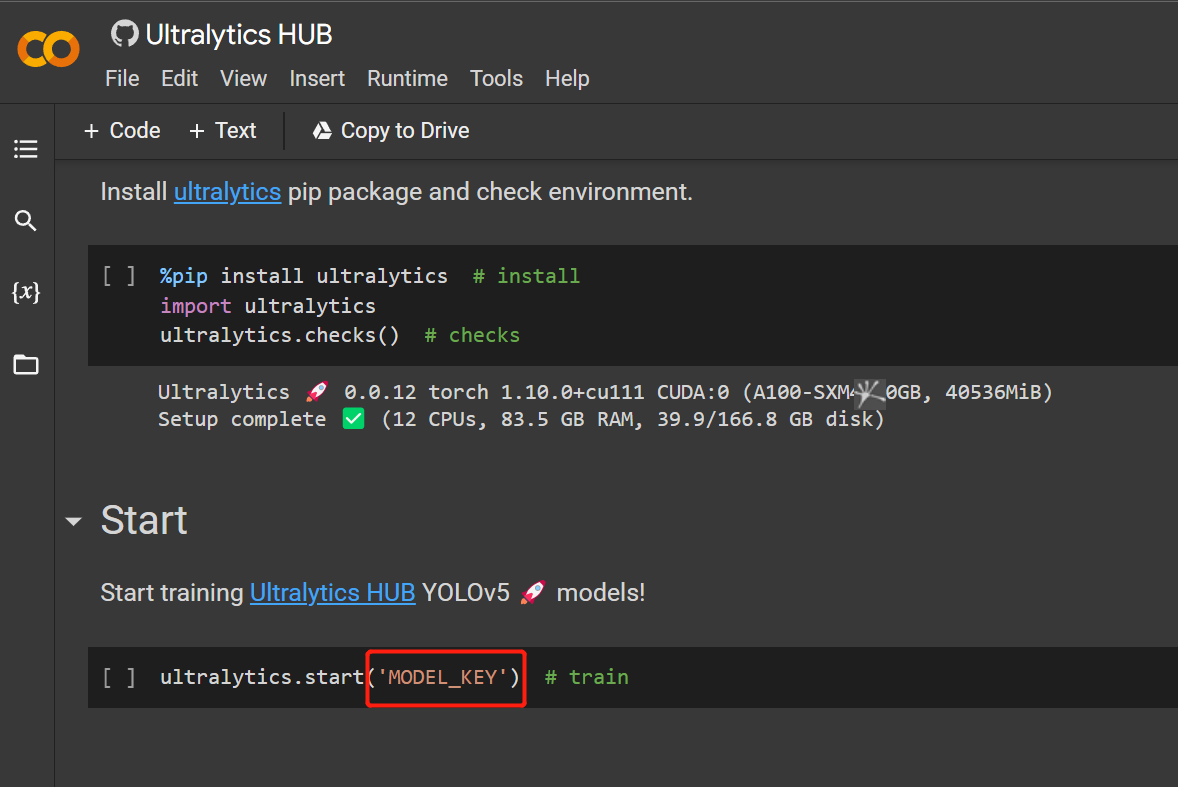
- 步骤 18. 点击
Runtime > Rull All运行所有代码单元并开始训练过程
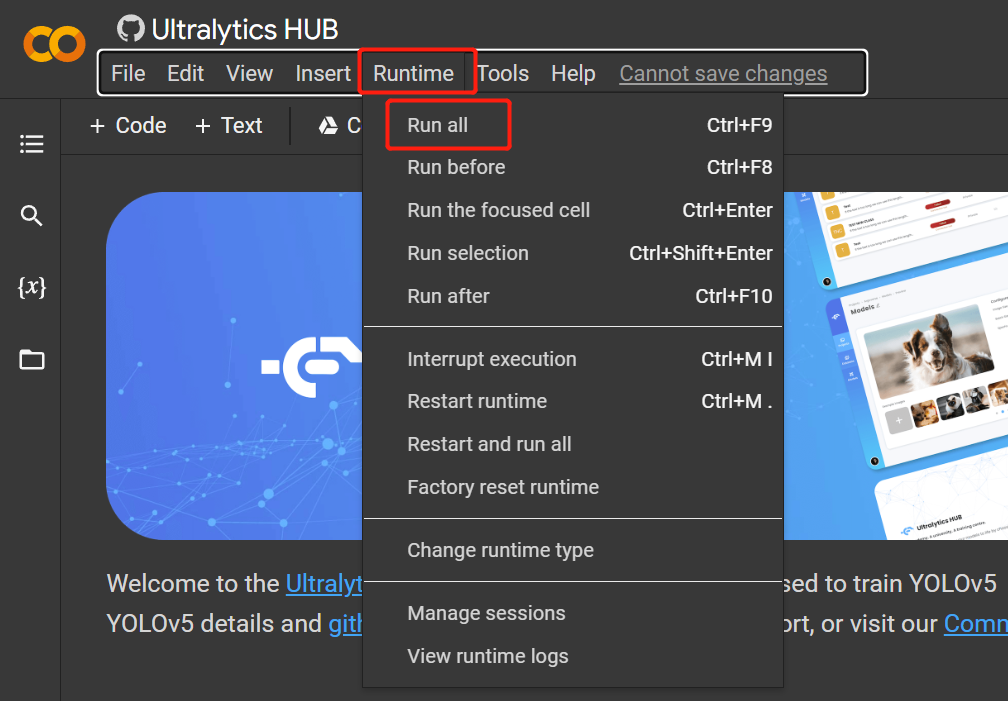
- 步骤 19. 回到 Ultralytics HUB,当按钮变为蓝色时点击 Done。您还会看到 Colab 显示为 Connected。
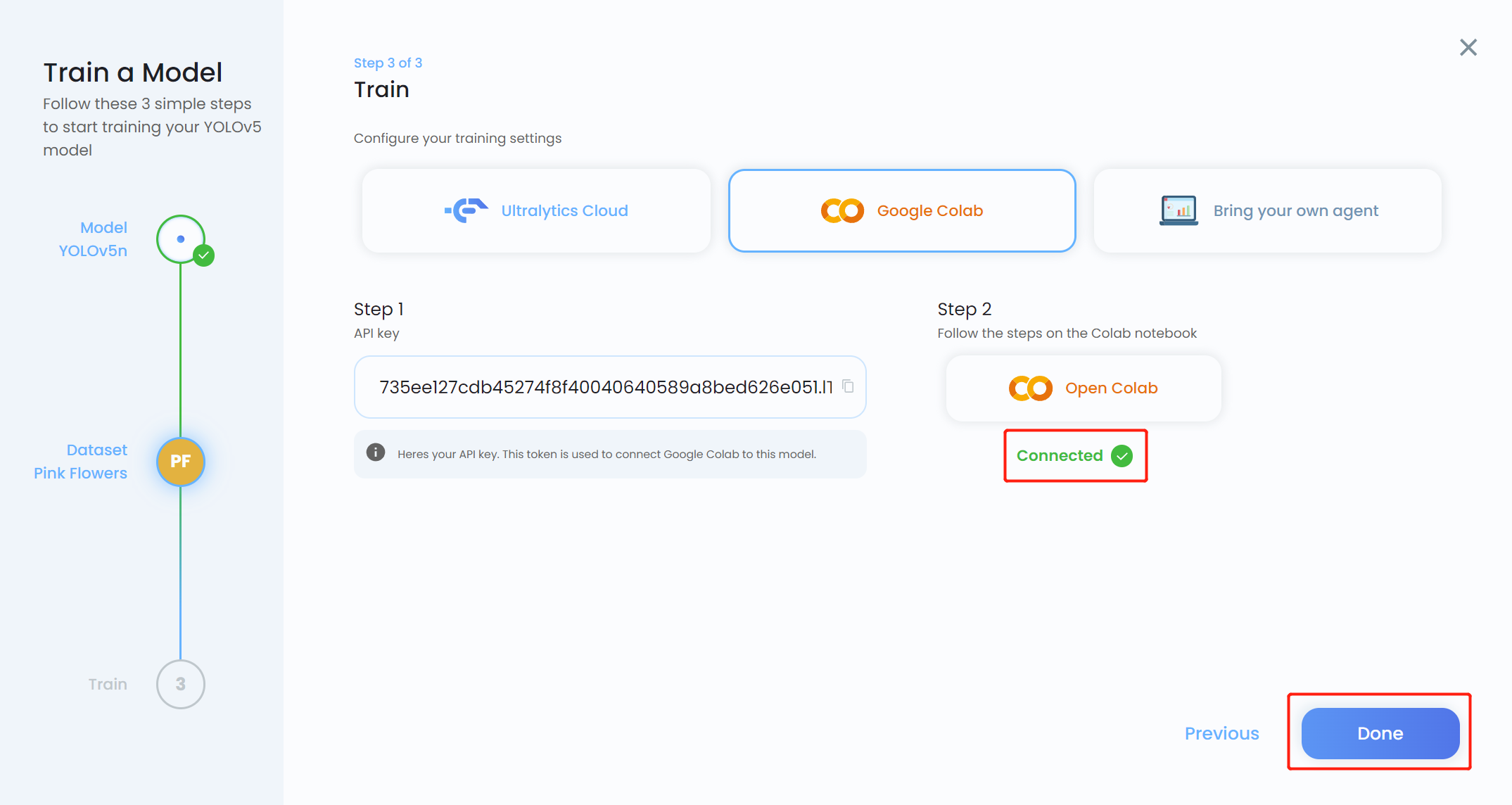
现在您将在 HUB 上看到训练进度
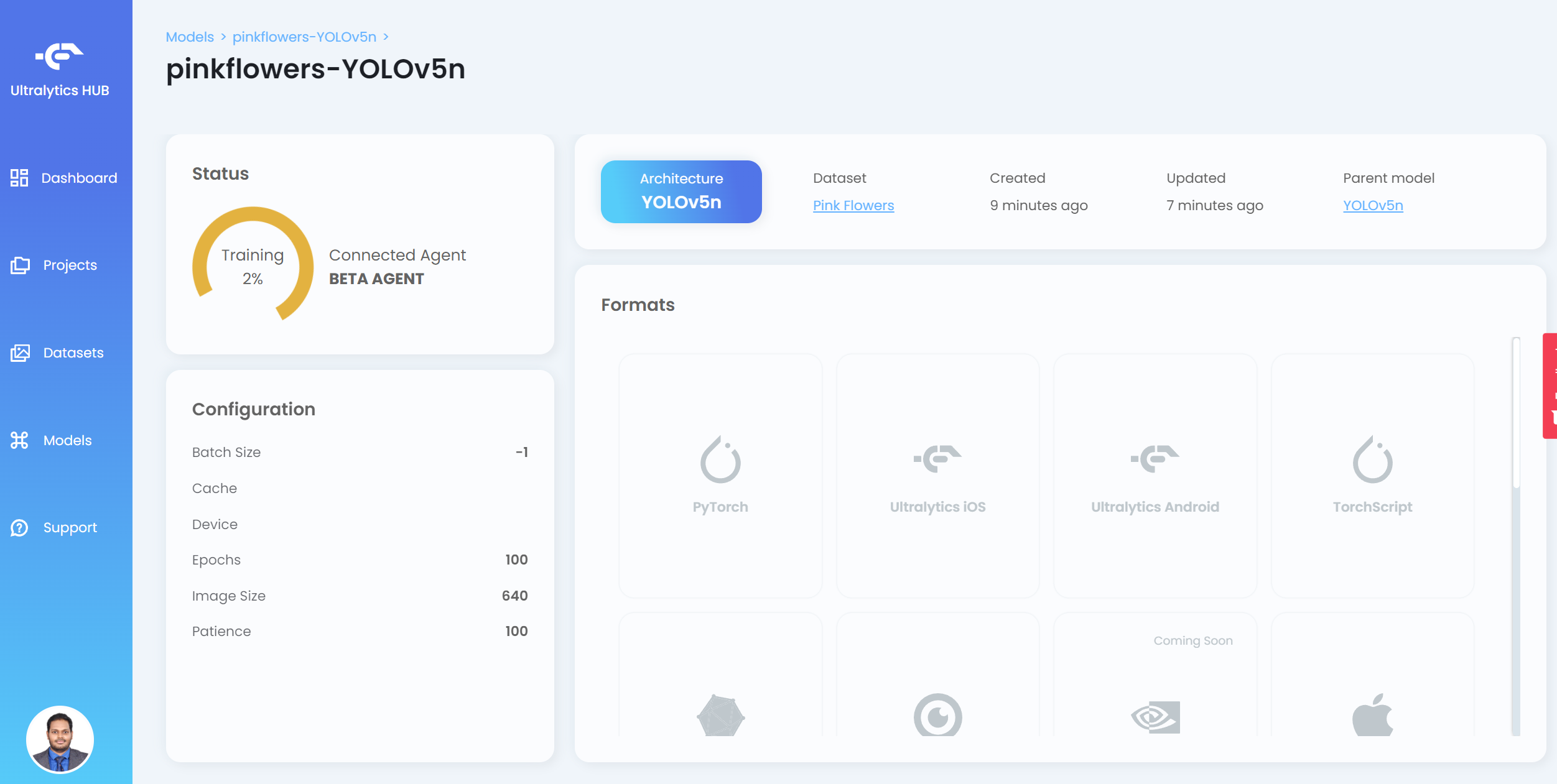
- 步骤 20. 训练完成后,点击 PyTorch 下载 PyTorch 格式的训练模型。PyTorch 是我们在 Jetson 设备上进行推理所需的格式
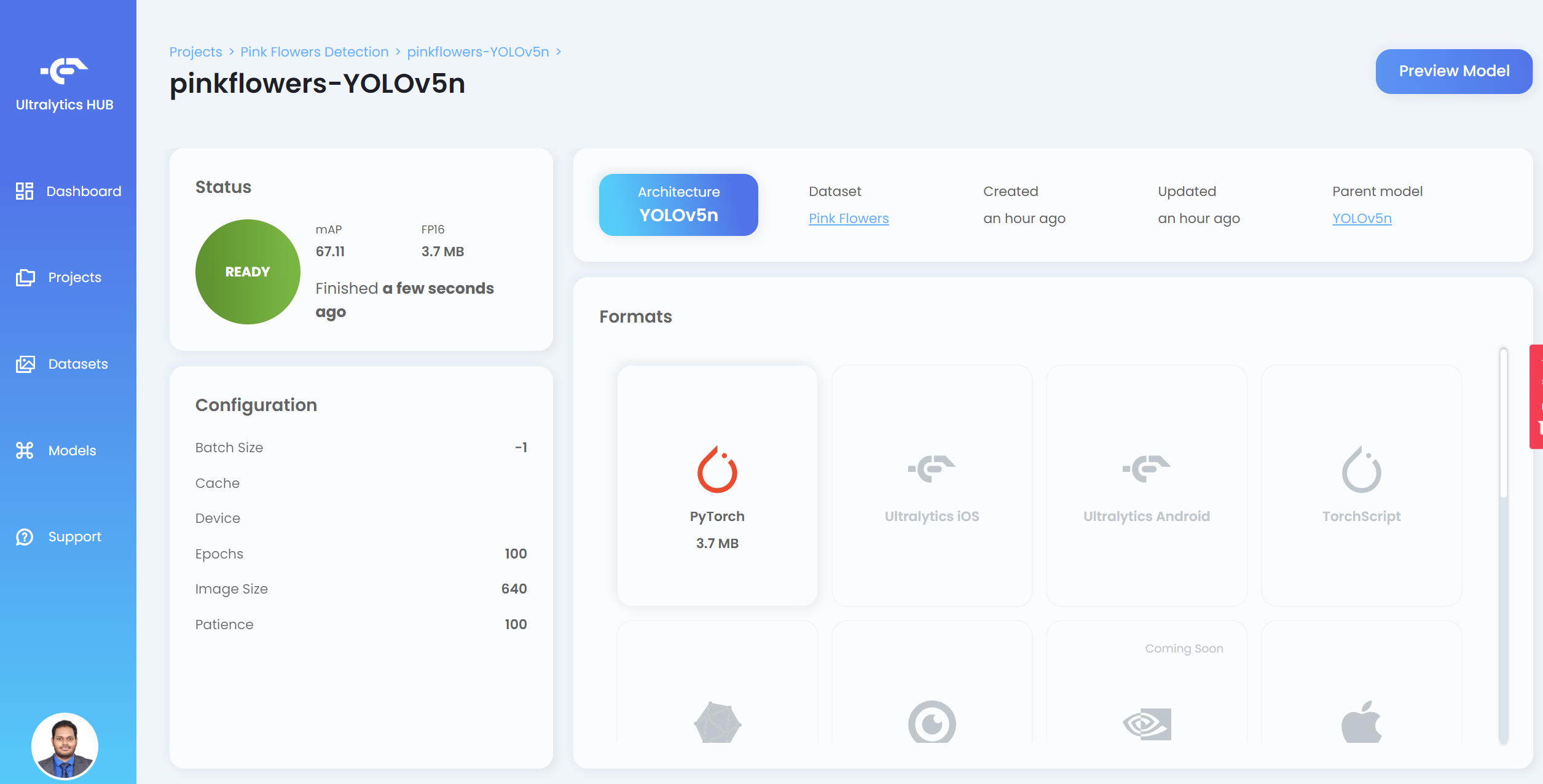
注意: 您也可以导出为其他格式,这些格式显示在 Formats 下
如果您回到 Google Colab,可以看到更多详细信息如下:
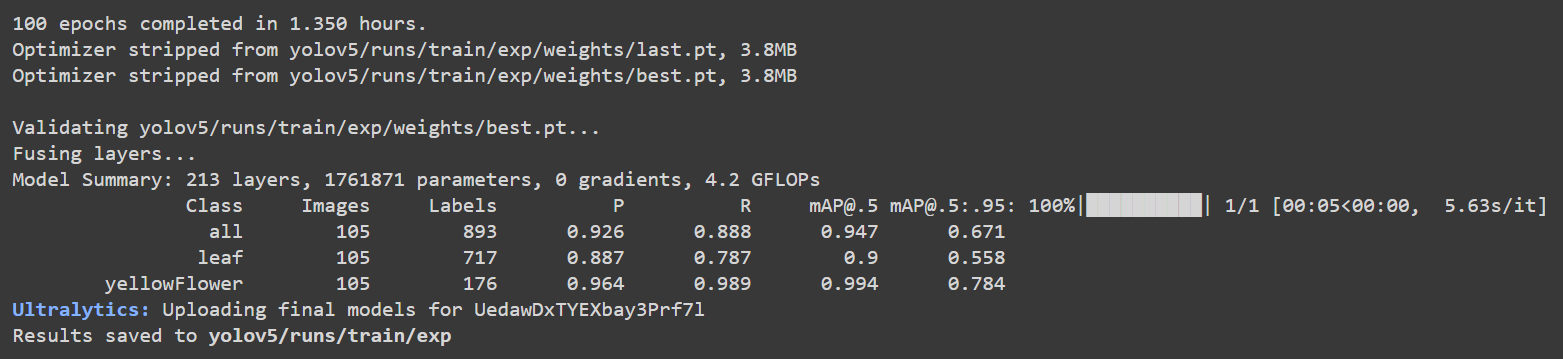
这里叶子和花朵的准确率 [email protected] 分别约为 90% 和 99.4%,而总准确率 [email protected] 约为 94.7%。
使用 Google Colab 与 Roboflow api
在这里我们使用 Google Colaboratory 环境在云端进行训练。此外,我们在 Colab 中使用 Roboflow api 来轻松下载我们的数据集。
- 步骤 1. 点击这里打开一个已经准备好的 Google Colab 工作空间,并按照工作空间中提到的步骤进行操作
训练完成后,您将看到如下输出:
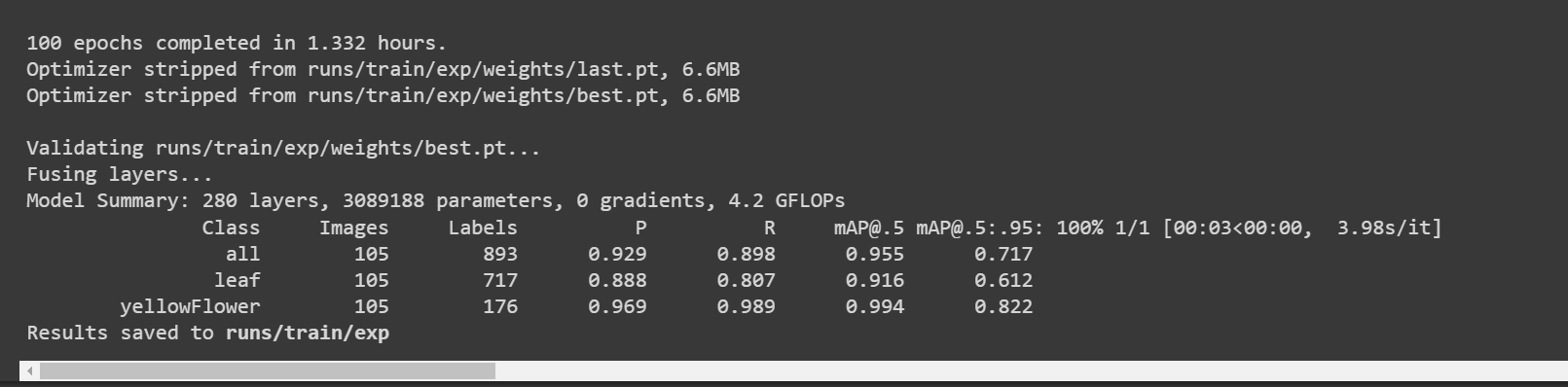
这里叶子和花朵的准确率 [email protected] 分别约为 91.6% 和 99.4%,而总准确率 [email protected] 约为 95.5%。
- 步骤 2. 在 Files 选项卡下,如果您导航到
runs/train/exp/weights,您将看到一个名为 best.pt 的文件。这是训练生成的模型。下载此文件并复制到您的 Jetson 设备,因为这是我们稍后在 Jetson 设备上进行推理时要使用的模型。
使用本地 PC
在这里您可以使用带有 Linux 操作系统的 PC 进行训练。我们在此 wiki 中使用了 Ubuntu 20.04 PC。
- 步骤 1. 在 Python>=3.7.0 环境中克隆 YOLOv5 repo 并安装 requirements.txt
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
- 步骤 2. 将我们之前从 Roboflow 下载的 .zip 文件复制并粘贴到 yolov5 目录中并解压
# example
cp ~/Downloads/pink-flowers.v1i.yolov5pytorch.zip ~/yolov5
unzip pink-flowers.v1i.yolov5pytorch.zip
- 步骤 3. 打开 data.yaml 文件并按如下方式编辑 train 和 val 目录
train: train/images
val: valid/images
- 步骤 4. 执行以下操作以开始训练
python3 train.py --data data.yaml --img-size 640 --batch-size -1 --epoch 100 --weights yolov5n6.pt
由于我们的数据集相对较小(约500张图像),迁移学习预计会比从头开始训练产生更好的结果。我们的模型使用预训练COCO模型的权重进行初始化,通过将模型名称(yolov5n6)传递给'weights'参数。这里我们使用yolov5n6,因为它非常适合边缘设备。这里图像尺寸设置为640x640。我们使用批处理大小为**-1**,因为这会自动确定最佳批处理大小。但是,如果出现"GPU内存不足"的错误,请选择批处理大小为32,甚至16。您也可以根据自己的偏好更改epoch。
训练完成后,您将看到如下输出:

这里叶子和花朵的准确率[email protected]分别约为90.6%和99.4%,而总准确率[email protected]约为95%。
- 步骤5. 如果您导航到
runs/train/exp/weights,您将看到一个名为best.pt的文件。这是训练生成的模型。将此文件复制并粘贴到您的Jetson设备上,因为这是我们稍后在Jetson设备上进行推理时要使用的模型。

在Jetson设备上进行推理
使用TensorRT
现在我们将使用Jetson设备在图像上执行推理(检测对象),借助我们之前训练生成的模型。这里我们将使用NVIDIA TensorRT来提高在Jetson平台上的推理性能
- 步骤1. 访问Jetson设备的终端,安装pip并升级它
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- 步骤 2. 克隆以下仓库
git clone https://github.com/ultralytics/yolov5
- 步骤 3. 打开 requirements.txt
cd yolov5
vi requirements.txt
- 步骤 4. 编辑以下行。这里你需要先按 i 进入编辑模式。按 ESC,然后输入 :wq 保存并退出
matplotlib==3.2.2
numpy==1.19.4
# torch>=1.7.0
# torchvision>=0.8.1
注意: 我们包含了 matplotlib 和 numpy 的固定版本,以确保稍后运行 YOLOv5 时不会出现错误。此外,torch 和 torchvision 暂时被排除,因为它们将在稍后安装。
- 步骤 5. 安装以下依赖项
sudo apt install -y libfreetype6-dev
- 步骤 6. 安装必要的软件包
pip3 install -r requirements.txt
- 步骤 7. 安装 torch
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- 步骤 8. 安装 torchvision
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
- 步骤 9. 克隆以下仓库
cd ~
git clone https://github.com/wang-xinyu/tensorrtx
-
步骤 10. 将之前训练的 best.pt 文件复制到 yolov5 目录中
-
步骤 11. 将 gen_wts.py 从 tensorrtx/yolov5 复制到 yolov5 目录中
cp tensorrtx/yolov5/gen_wts.py yolov5
- 步骤 12. 从带有 .pt 的 PyTorch 生成 .wts 文件
cd yolov5
python3 gen_wts.py -w best.pt -o best.wts
- 步骤 13。 导航到 tensorrtx/yolov5
cd ~
cd tensorrtx/yolov5
- 步骤 14。 使用 vi 文本编辑器打开 yololayer.h
vi yololayer.h
- 步骤 15. 将 CLASS_NUM 更改为你的模型训练的类别数量。在我们的示例中,它是 2
CLASS_NUM = 2
- 步骤 16. 创建一个新的 build 目录并进入其中
mkdir build
cd build
- 步骤 17. 将之前生成的 best.wts 文件复制到这个 build 目录中
cp ~/yolov5/best.wts .
- 步骤 18. 编译它
cmake ..
make
- 步骤 19. 序列化模型
sudo ./yolov5 -s [.wts] [.engine] [n/s/m/l/x/n6/s6/m6/l6/x6 or c/c6 gd gw]
#example
sudo ./yolov5 -s best.wts best.engine n6
这里我们使用 n6,因为这是推荐用于边缘设备(如 NVIDIA Jetson 平台)的版本。但是,如果您使用 Ultralytics HUB 来设置训练,您只能使用 n,因为 HUB 尚不支持 n6。
-
步骤 20. 将您希望模型检测的图像复制到新文件夹中,例如 tensorrtx/yolov5/images
-
步骤 21. 反序列化并对图像运行推理,如下所示
sudo ./yolov5 -d best.engine images
以下是在 Jetson Nano 与 Jetson Xavier NX 上运行推理时间的比较。
Jetson Nano
这里量化设置为 FP16
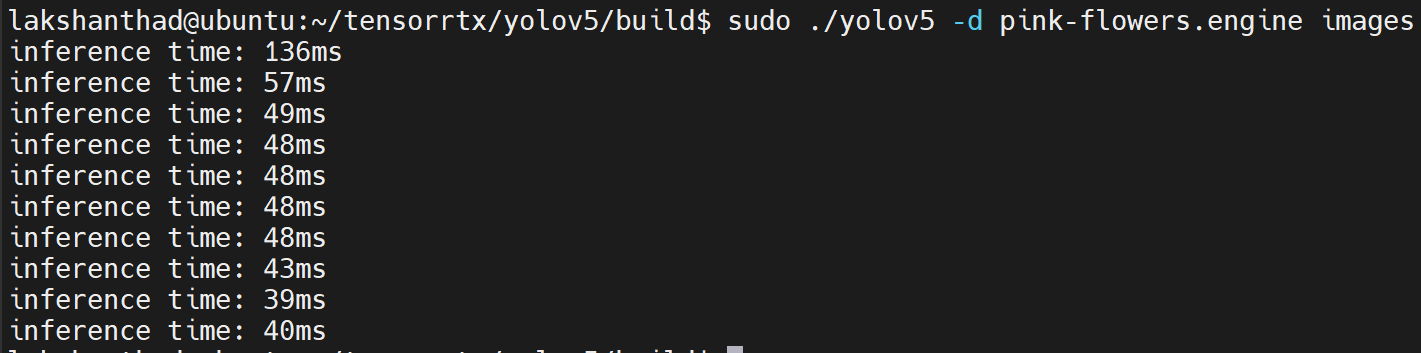
从上述结果中,我们可以取平均值约为 47ms。将此值转换为每秒帧数:1000/47 = 21.2766 = 21fps。
Jetson Xavier NX
这里量化设置为 FP16
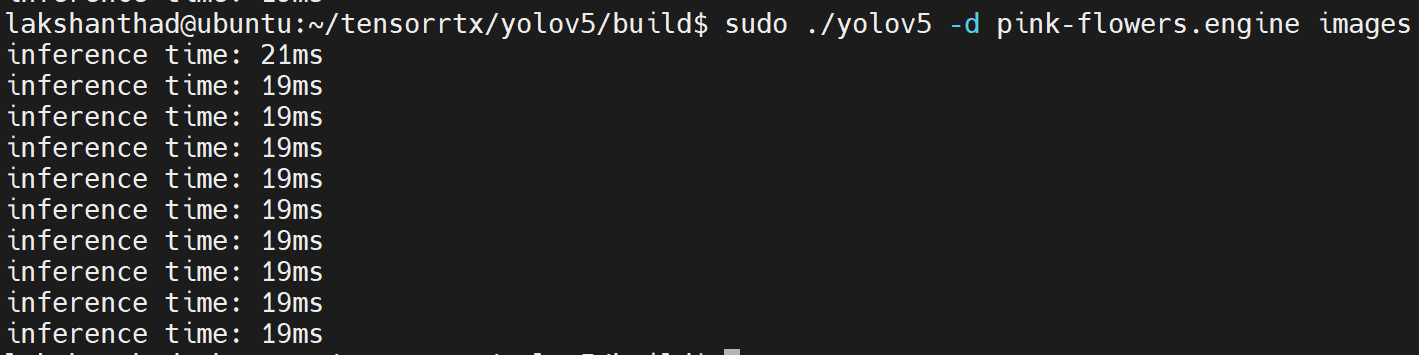
从上述结果中,我们可以取平均值约为 20ms。将此值转换为每秒帧数:1000/20 = 50fps。
此外,输出图像将如下所示,其中检测到了对象:


使用 TensorRT 和 DeepStream SDK
这里我们将使用 NVIDIA TensorRT 以及 NVIDIA DeepStream SDK 对视频片段进行推理
- 步骤 1. 确保您已在 Jetson 设备上正确安装了所有 SDK 组件 和 DeepStream SDK。(请参考此 wiki 了解安装参考)
注意: 建议使用 NVIDIA SDK Manager 来安装所有 SDK 组件和 DeepStream SDK
- 步骤 2. 访问 Jetson 设备的终端,安装 pip 并升级它
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- 步骤 3. 克隆以下仓库
git clone https://github.com/ultralytics/yolov5
- 步骤 4. 打开 requirements.txt
cd yolov5
vi requirements.txt
- 步骤 5. 编辑以下行。这里你需要先按 i 进入编辑模式。按 ESC,然后输入 :wq 保存并退出
matplotlib==3.2.2
numpy==1.19.4
# torch>=1.7.0
# torchvision>=0.8.1
注意: 我们包含了 matplotlib 和 numpy 的固定版本,以确保稍后运行 YOLOv5 时不会出现错误。此外,torch 和 torchvision 暂时被排除,因为它们将在稍后安装。
- 步骤 6. 安装以下依赖项
sudo apt install -y libfreetype6-dev
- 步骤 7. 安装必要的软件包
pip3 install -r requirements.txt
- 步骤 8. 安装 torch
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- 步骤 9. 安装 torchvision
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
- 步骤 10。 克隆以下仓库
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- 步骤 11. 将 gen_wts_yoloV5.py 从 DeepStream-Yolo/utils 复制到 yolov5 目录
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5
- 步骤 12. 在 yolov5 仓库内,从 YOLOv5 发布中下载 pt 文件(以 YOLOv5s 6.1 为例)
cd yolov5
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
- 步骤 13。 生成 cfg 和 wts 文件
python3 gen_wts_yoloV5.py -w yolov5s.pt
注意:要更改推理大小(默认值:640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280
- 步骤 14. 将生成的 cfg 和 wts 文件复制到 DeepStream-Yolo 文件夹中
cp yolov5s.cfg ~/DeepStream-Yolo
cp yolov5s.wts ~/DeepStream-Yolo
- 步骤 15. 打开 DeepStream-Yolo 文件夹并编译库
cd ~/DeepStream-Yolo
# For DeepStream 6.1
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo
# For DeepStream 6.0.1 / 6.0
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo
- 步骤 16. 根据你的模型编辑 config_infer_primary_yoloV5.txt 文件
[property]
...
custom-network-config=yolov5s.cfg
model-file=yolov5s.wts
...
- 步骤 17。编辑deepstream_app_config文件
...
[primary-gie]
...
config-file=config_infer_primary_yoloV5.txt
- 步骤 18. 运行推理
deepstream-app -c deepstream_app_config.txt
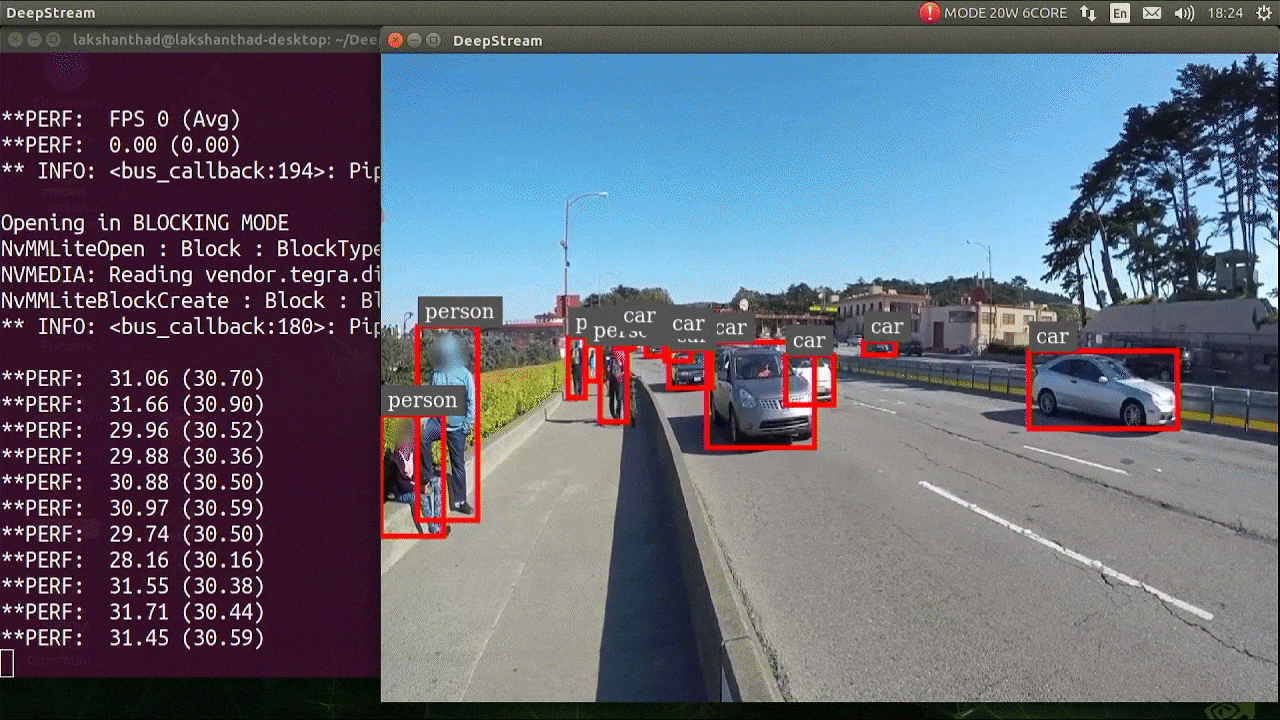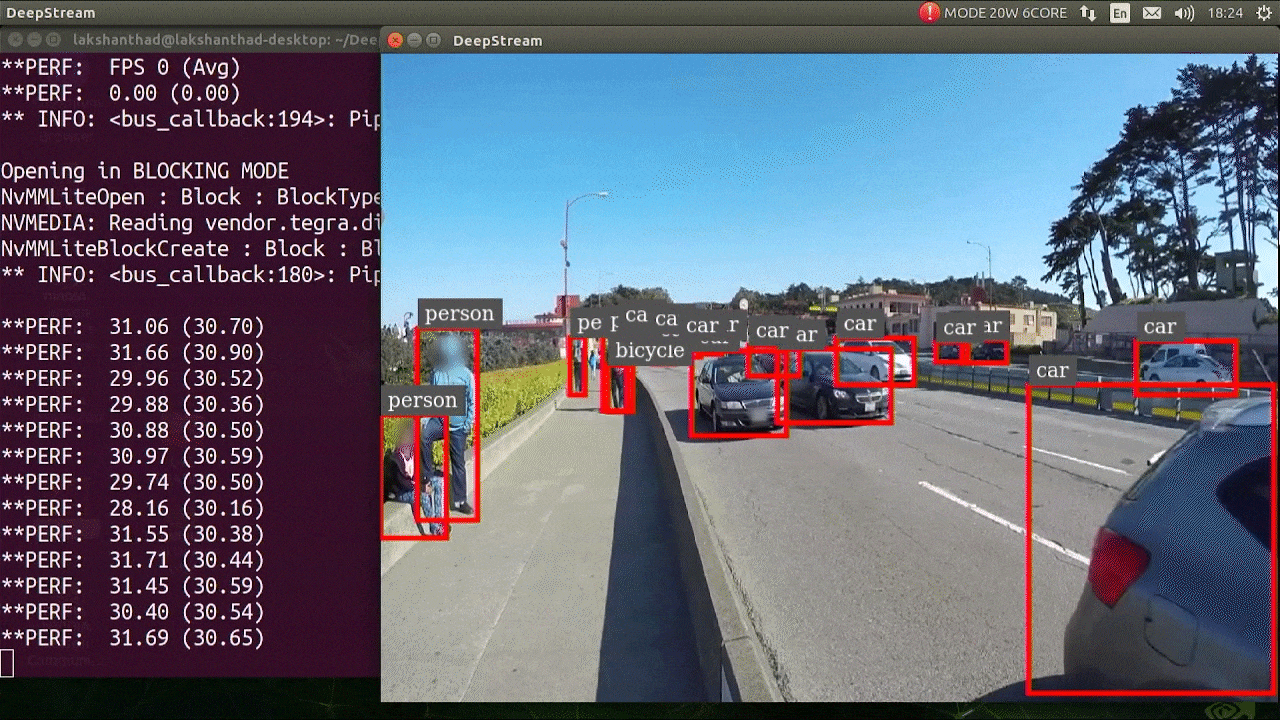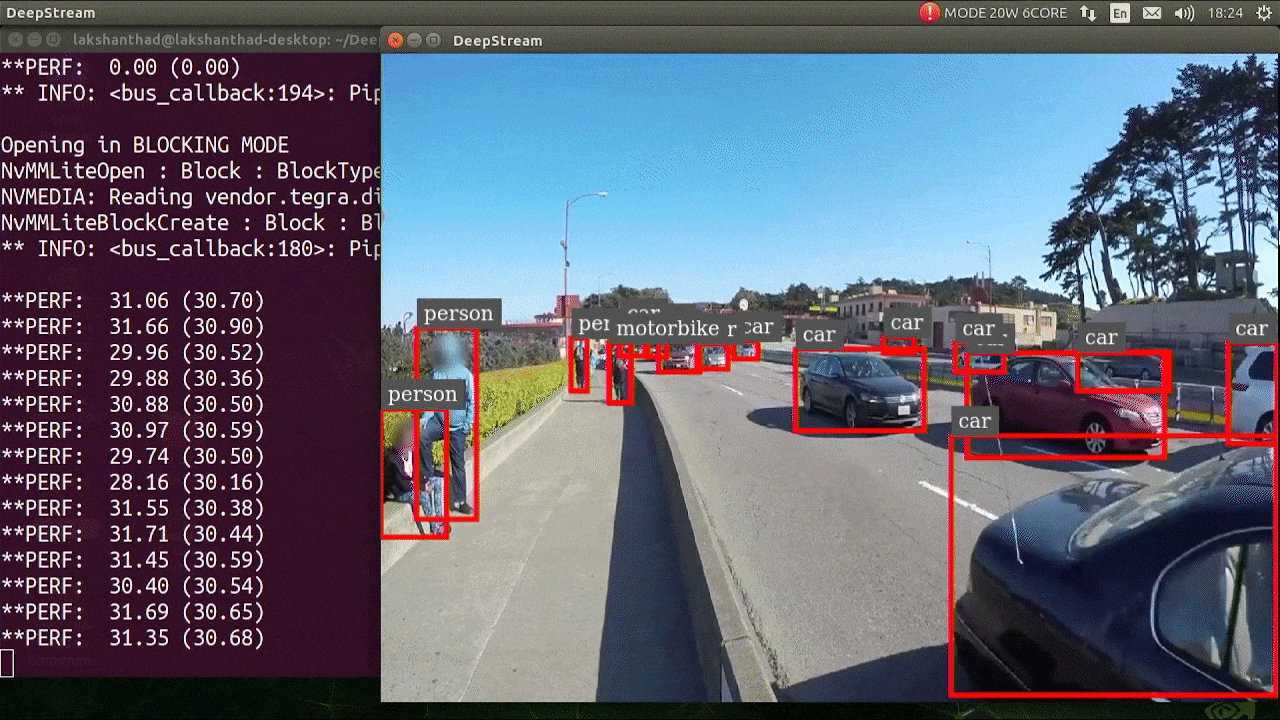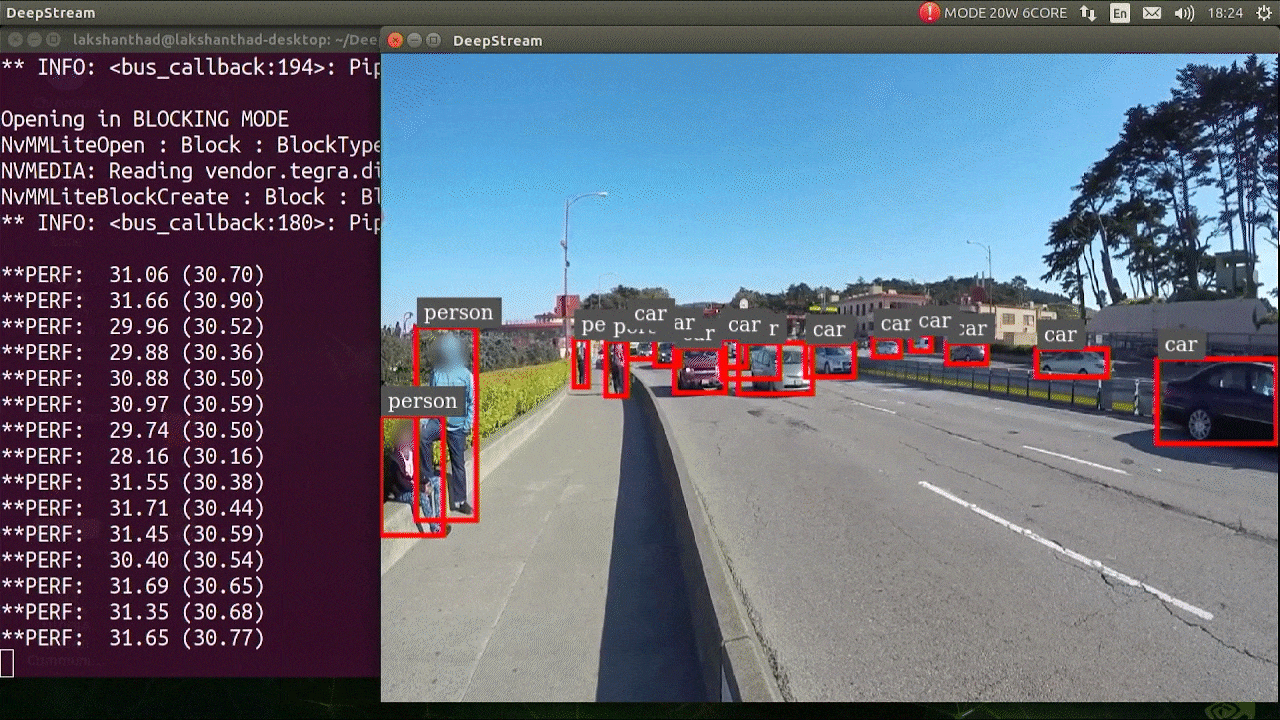
上述结果是在 Jetson Xavier NX 上使用 FP32 和 YOLOv5s 640x640 运行的。我们可以看到 FPS 大约为 30。
INT8 校准
如果您想使用 INT8 精度进行推理,您需要按照以下步骤操作
- 步骤 1. 安装 OpenCV
sudo apt-get install libopencv-dev
- 步骤 2. 使用 OpenCV 支持编译/重新编译 nvdsinfer_custom_impl_Yolo 库
cd ~/DeepStream-Yolo
# For DeepStream 6.1
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo
# For DeepStream 6.0.1 / 6.0
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo
-
步骤 3. 对于 COCO 数据集,下载 val2017,解压,并移动到 DeepStream-Yolo 文件夹
-
步骤 4. 为校准图像创建一个新目录
mkdir calibration
- 步骤 5. 运行以下命令从COCO数据集中选择1000张随机图像来进行校准
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
注意: NVIDIA 建议至少使用 500 张图像以获得良好的精度。在此示例中,选择了 1000 张图像以获得更好的精度(更多图像 = 更高精度)。更高的 INT8_CALIB_BATCH_SIZE 值将带来更高的精度和更快的校准速度。请根据您的 GPU 内存进行设置。您可以从 head -1000 进行设置。例如,对于 2000 张图像,使用 head -2000。此过程可能需要很长时间。
- 步骤 6. 使用所有选定的图像创建 calibration.txt 文件
realpath calibration/*jpg > calibration.txt
- 步骤 7. 设置环境变量
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- 步骤 8. 更新 config_infer_primary_yoloV5.txt 文件
From
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
To
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
- 步骤 9. 运行推理
deepstream-app -c deepstream_app_config.txt
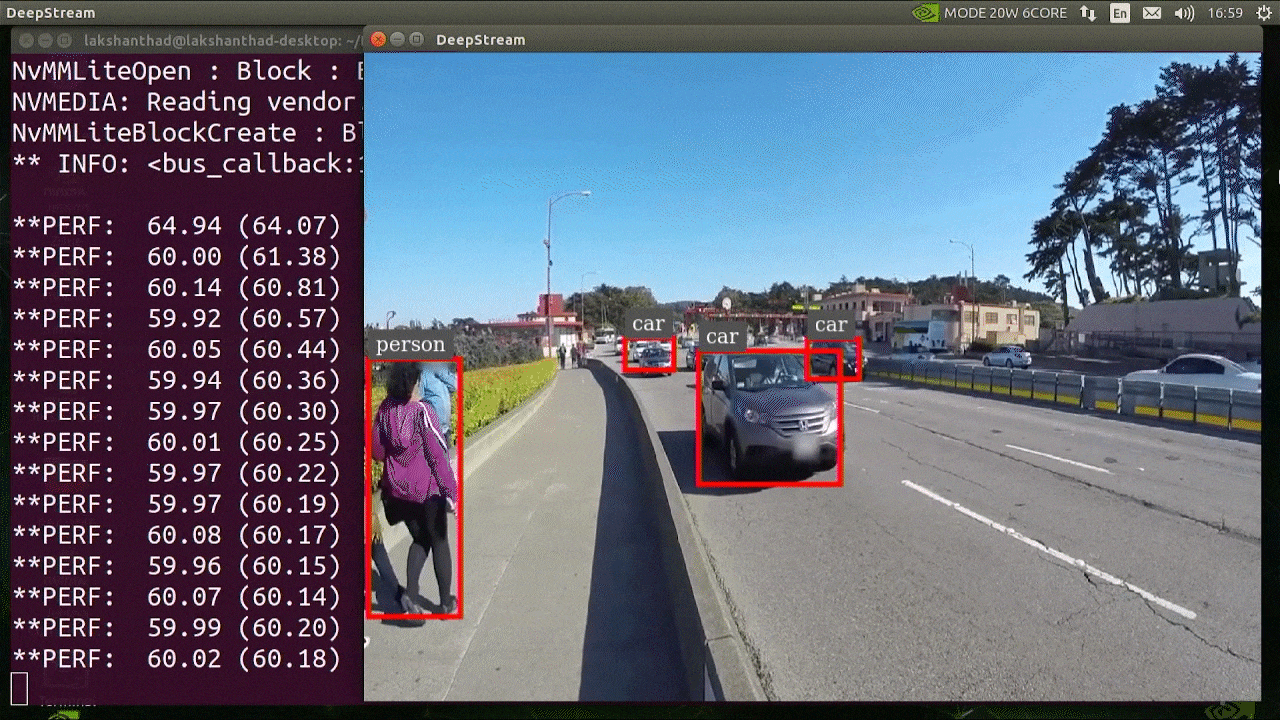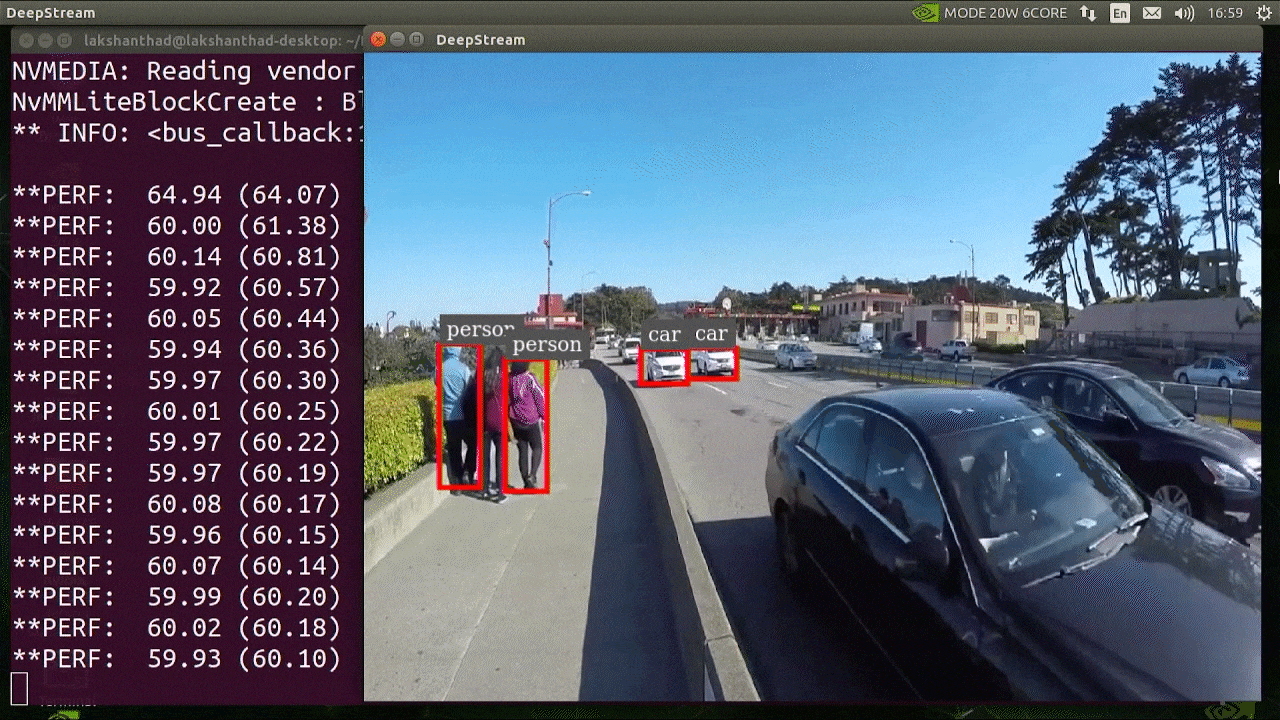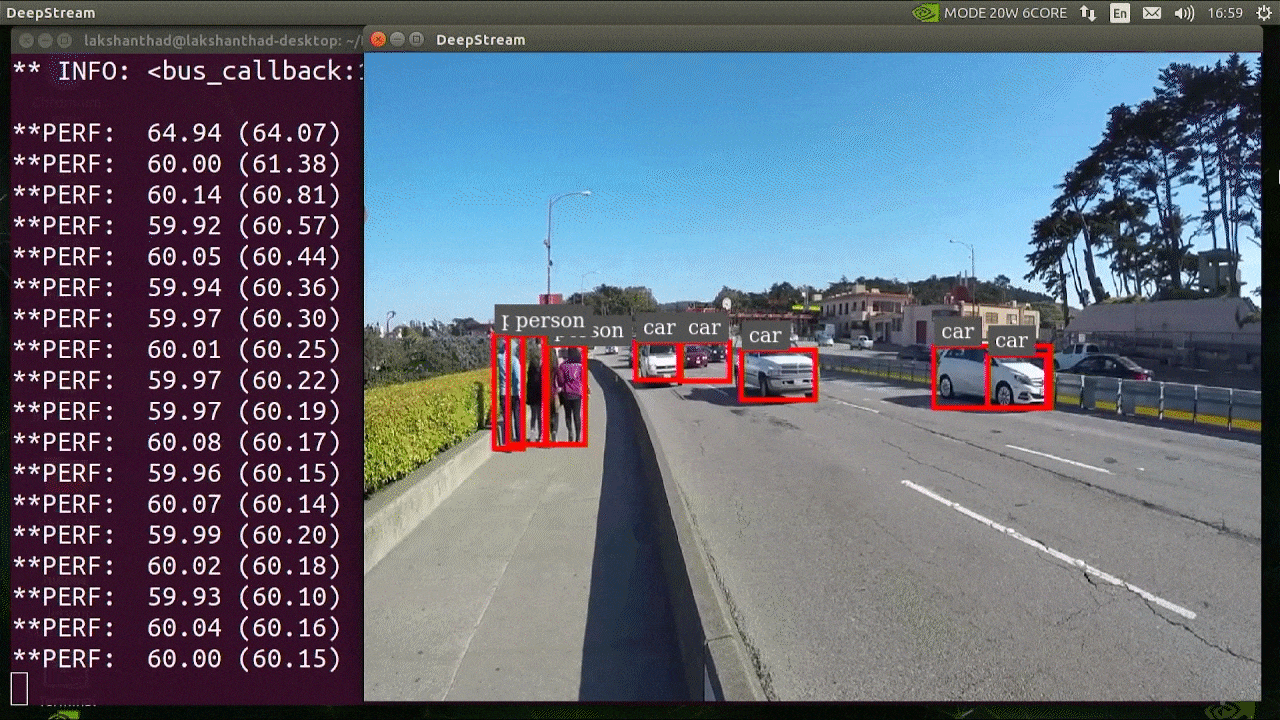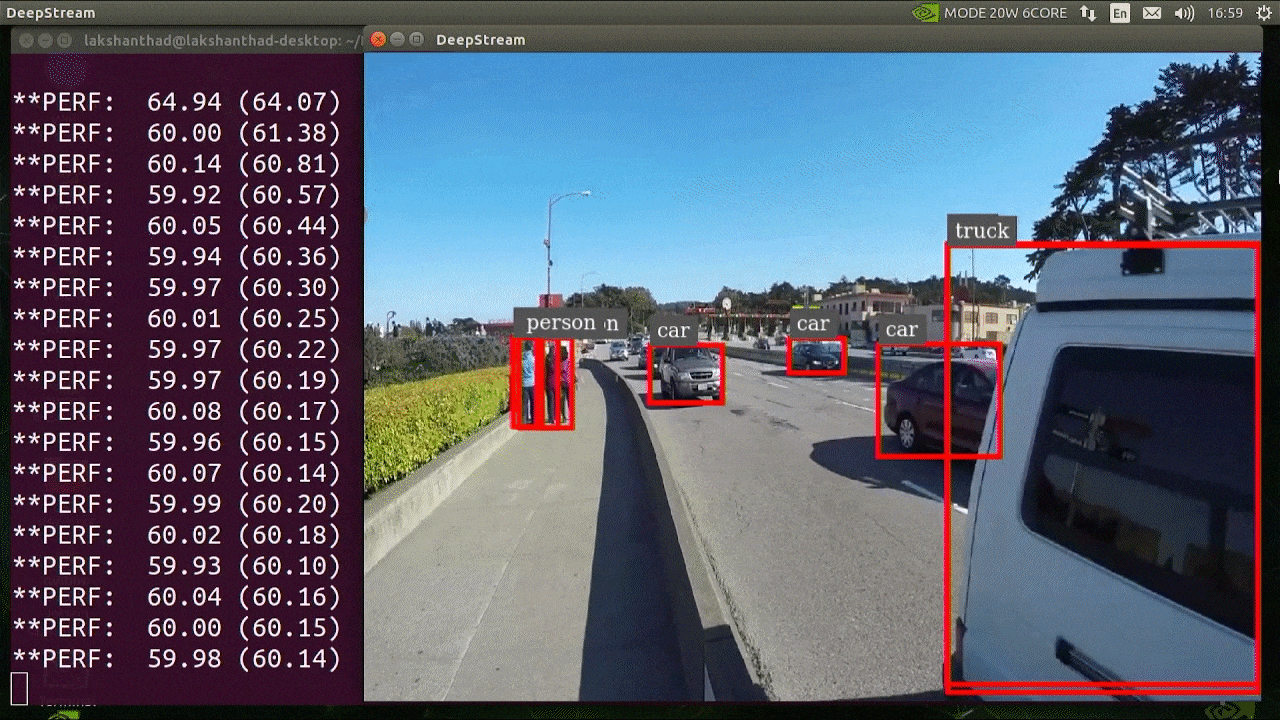
上述结果运行在 Jetson Xavier NX 上,使用 INT8 和 YOLOv5s 640x640。我们可以看到 FPS 大约为 60。
基准测试结果
下表总结了不同模型在 Jetson Xavier NX 上的性能表现。
| 模型名称 | 精度 | 推理尺寸 | 推理时间 (ms) | FPS |
|---|---|---|---|---|
| YOLOv5s | FP32 | 320x320 | 16.66 | 60 |
| FP32 | 640x640 | 33.33 | 30 | |
| INT8 | 640x640 | 16.66 | 60 | |
| YOLOv5n | FP32 | 640x640 | 16.66 | 60 |
使用公共数据集与自定义数据集的比较
现在我们将比较使用公共数据集和您自己的自定义数据集时训练样本数量和训练时间的差异
训练样本数量
自定义数据集
在本wiki中,我们首先以视频形式收集了植物数据集,然后使用Roboflow将视频转换为一系列图像。在这里我们获得了542张图像,与公共数据集相比,这是一个非常小的数据集。
公共数据集
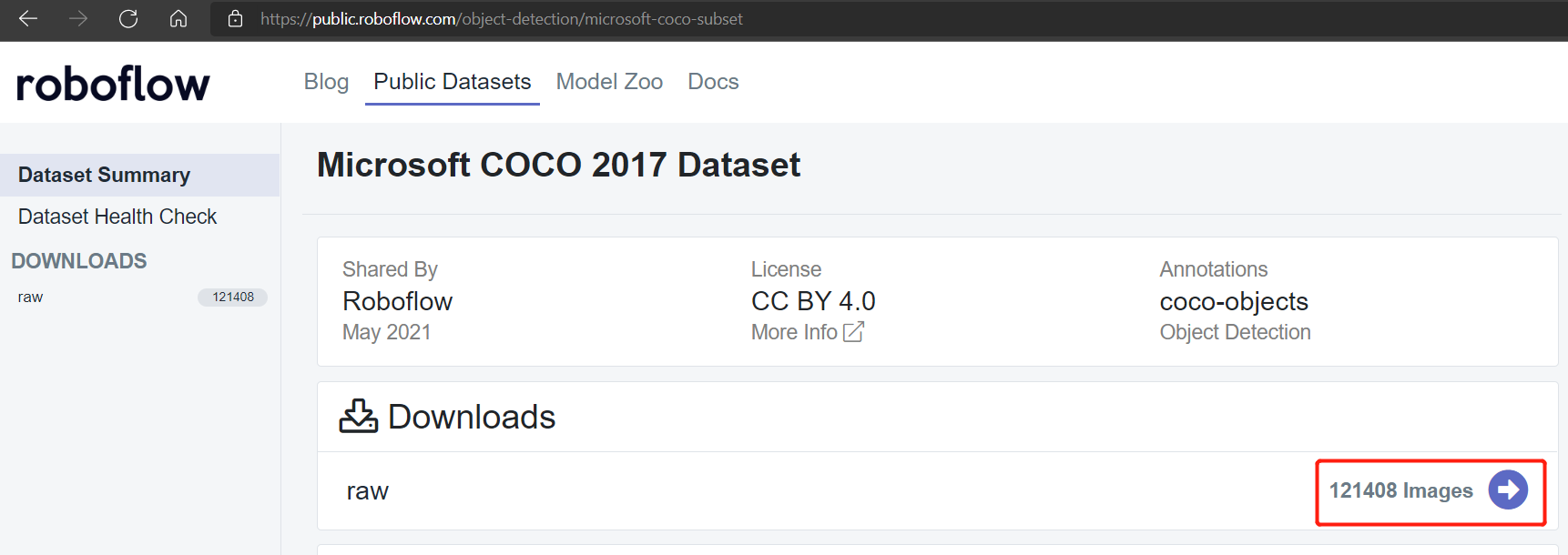
公共数据集如Pascal VOC 2012和Microsoft COCO 2017数据集分别有大约17112和121408张图像。
Pascal VOC 2012数据集
Microsoft COCO 2017数据集
训练时间
本地训练
训练在配备6GB内存的NVIDIA GeForce GTX 1660 Super显卡上进行
使用自定义数据集进行本地训练
540张图像数据集
根据我们之前对植物进行的本地训练,我们获得了以下结果
这里运行100个epoch只用了2.2小时。与使用公共数据集训练相比,这相对更快。
240张图像数据集
我们将数据集减少到240张图像并再次进行训练,获得了以下结果

这里运行100个epoch只用了大约1小时。与使用公共数据集训练相比,这相对更快。
使用Pascal VOC 2012数据集进行本地训练
在这种情况下,我们使用Pascal VOC 2012数据集进行训练,同时保持相同的训练参数。我们发现运行1个epoch大约需要50分钟(0.846小时 * 60),因此我们在1个epoch后停止了训练。

如果我们计算100个epoch的训练时间,大约需要50 * 100分钟 = 5000分钟 = 83小时,这比自定义数据集的训练时间长得多。
使用Microsoft COCO 2017数据集进行本地训练
在这种情况下,我们使用Microsoft COCO 2017数据集进行训练,同时保持相同的训练参数。我们发现运行1个epoch估计需要大约7.5小时,因此我们在1个epoch完成之前停止了训练。

如果我们计算100个epoch的训练时间,大约需要7.5小时 * 100 = 750小时,这比自定义数据集的训练时间长得多。
Google Colab训练
训练在配备12GB内存的NVIDIA Tesla K80显卡上进行
自定义数据集
540张图像数据集
根据我们之前在Google Colab上对540张图像的植物进行的训练,我们获得了以下结果
这里运行100个epoch只用了大约1.3小时。与使用公共数据集训练相比,这也相对更快。
240张图像数据集
我们将数据集减少到240张图像并再次进行训练,获得了以下结果
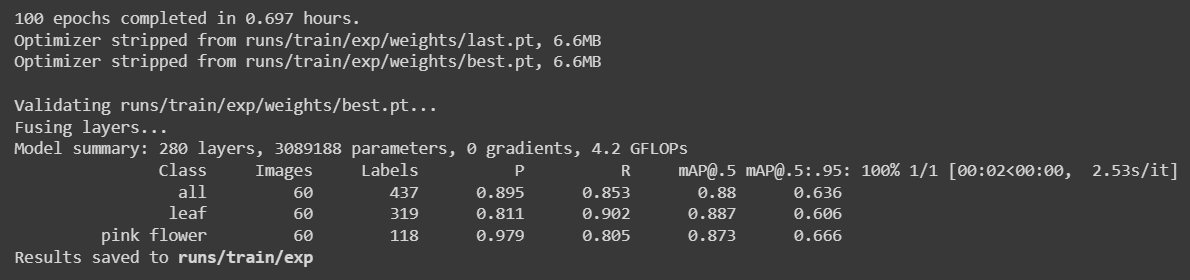
这里运行100个epoch只用了大约42分钟(0.697小时 * 60)。与使用公共数据集训练相比,这相对更快。
使用Pascal VOC 2012数据集进行Google Colab训练
在这种情况下,我们使用Pascal VOC 2012数据集进行训练,同时保持相同的训练参数。我们发现运行1个epoch大约需要9分钟(0.148小时 * 60),因此我们在1个epoch后停止了训练。
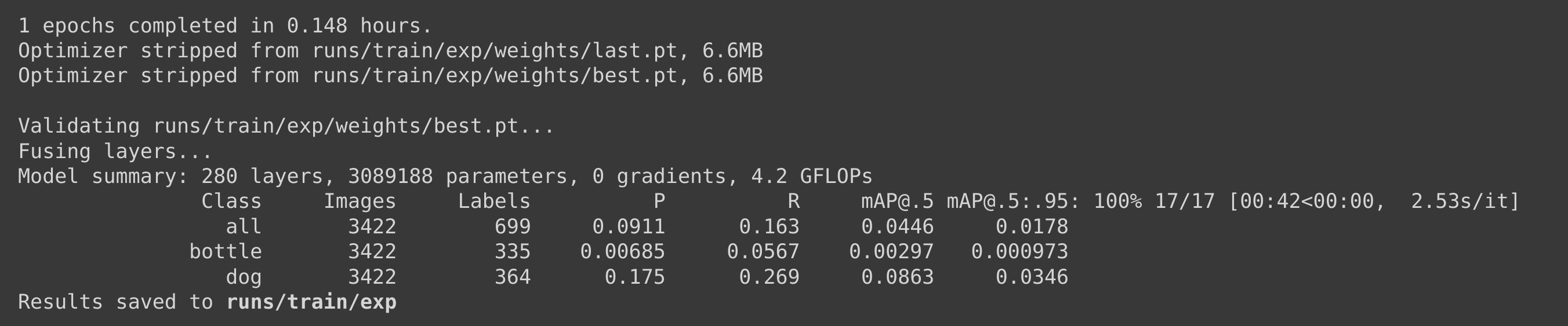
如果我们计算100个epoch的训练时间,大约需要9 * 100分钟 = 900分钟 = 15小时,这比自定义数据集的训练时间长得多。
使用Microsoft COCO 2017数据集进行Google Colab训练
在这种情况下,我们使用Microsoft COCO 2017数据集进行训练,同时保持相同的训练参数。我们发现运行1个epoch估计需要大约1.25小时,因此我们在1个epoch完成之前停止了训练。

如果我们计算100个epoch的训练时间,大约需要1.25小时 * 100 = 125小时,这比自定义数据集的训练时间长得多。
训练样本数量和训练时间总结
| 数据集 | 训练样本数量 | 本地PC训练时间(GTX 1660 Super) | Google Colab训练时间(NVIDIA Tesla K80) |
|---|---|---|---|
| 自定义 | 542 | 2.2小时 | 1.3小时 |
| 240 | 1小时 | 42分钟 | |
| Pascal VOC 2012 | 17112 | 83小时 | 15小时 |
| Microsoft COCO 2017 | 121408 | 750小时 | 125小时 |
预训练检查点比较
您可以从下表了解更多关于预训练检查点的信息。这里我们突出显示了使用 Google Colab 进行训练并在 Jetson Nano 和 Jetson Xavier NX 上使用 YOLOv5n6 作为预训练检查点进行推理的场景。
| Model | size (pixels) | mAPval 0.5:0.95 | mAPval 0.5 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | Speed Jetson Nano FP16 (ms) | Speed Jetson Xavier NX FP16 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 | ||
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 | ||
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 | ||
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 | ||
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 | ||
| YOLOv5n6 | 640 | 71.7 | 95.5 | 153 | 8.1 | 2.1 | 47 | 20 | 3.1 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 | ||
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 | ||
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 | ||
| YOLOv5x6 + [TTA] | 1280 1536 | 55.0 55.8 | 72.7 72.7 | 3136 - | 26.2 - | 19.4 - | 140.7 - | 209.8 - |
额外应用
由于我们上面解释的所有步骤对于任何类型的目标检测应用都是通用的,您只需要为自己的目标检测应用更换数据集即可!
道路标志检测
这里我们使用了来自 Roboflow 的道路标志数据集,并在 NVIDIA Jetson 上执行推理!

野火烟雾检测
这里我们使用了来自 Roboflow 的野火烟雾数据集,并在 NVIDIA Jetson 上执行推理!

资源
-
[网页] YOLOv5 文档
-
[网页] Ultralytics HUB
-
[网页] Roboflow 文档
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。