在 NVIDIA Jetson 上使用 TensorRT 和 DeepStream SDK 支持部署 YOLOv8
本指南介绍如何将训练好的 AI 模型部署到 NVIDIA Jetson 平台上,并使用 TensorRT 和 DeepStream SDK 进行推理。这里我们使用 TensorRT 来最大化 Jetson 平台上的推理性能。

先决条件
- Ubuntu 主机 PC(原生或使用 VMware Workstation Player 的虚拟机)
- reComputer Jetson 或任何其他运行 JetPack 4.6 或更高版本的 NVIDIA Jetson 设备
DeepStream 版本对应的 JetPack 版本
为了让 YOLOv8 与 DeepStream 协同工作,我们使用这个 DeepStram-YOLO 仓库,它支持不同版本的 DeepStream。因此请确保根据正确的 DeepStream 版本使用相应的 JetPack 版本。
| DeepStream 版本 | JetPack 版本 |
|---|---|
| 6.2 | 5.1.1 |
| 5.1 | |
| 6.1.1 | 5.0.2 |
| 6.1 | 5.0.1 DP |
| 6.0.1 | 4.6.3 |
| 4.6.2 | |
| 4.6.1 | |
| 6.0 | 4.6 |
为了验证这个wiki,我们在运行于reComputer J4012上的JetPack 5.1.1系统上安装了DeepStream SDK 6.2。
将JetPack刷写到Jetson
现在您需要确保Jetson设备已刷写了包含SDK组件(如CUDA、TensorRT、cuDNN等)的JetPack系统。您可以使用NVIDIA SDK Manager或命令行将JetPack刷写到设备。
对于Seeed Jetson驱动设备的刷写指南,请参考以下链接:
- reComputer J1010 | J101
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203载板
- A205载板
- Jetson Xavier AGX H01套件
- Jetson AGX Orin 32GB H01套件
安装DeepStream
有多种方式可以将DeepStream安装到Jetson设备上。您可以参考这个指南了解更多信息。但是,我们建议您通过SDK Manager安装DeepStream,因为它可以保证成功且简便的安装。
如果您使用SDK manager安装DeepStream,在系统启动后,您需要执行以下命令,这些是DeepStream的额外依赖项
sudo apt install \
libssl1.1 \
libgstreamer1.0-0 \
gstreamer1.0-tools \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly \
gstreamer1.0-libav \
libgstreamer-plugins-base1.0-dev \
libgstrtspserver-1.0-0 \
libjansson4 \
libyaml-cpp-dev
Install Necessary Packages
- 步骤 1. 访问 Jetson 设备的终端,安装 pip 并升级
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- 步骤 2. 克隆以下仓库
git clone https://github.com/ultralytics/ultralytics.git
- 步骤 3. 打开 requirements.txt
cd ultralytics
vi requirements.txt
- 步骤 4. 编辑以下行。这里你需要先按
i进入编辑模式。按ESC,然后输入:wq保存并退出
# torch>=1.7.0
# torchvision>=0.8.1
注意: torch 和 torchvision 目前被排除在外,因为它们将在稍后安装。
- 步骤 5. 安装必要的软件包
pip3 install -r requirements.txt
如果安装程序报告 python-dateutil 包过时,请通过以下方式升级它
pip3 install python-dateutil --upgrade
安装 PyTorch 和 Torchvision
我们无法从 pip 安装 PyTorch 和 Torchvision,因为它们不兼容运行在基于 ARM aarch64 架构的 Jetson 平台上。因此我们需要手动安装预构建的 PyTorch pip wheel 并从源码编译/安装 Torchvision。
访问此页面获取所有 PyTorch 和 Torchvision 链接。
以下是 JetPack 5.0 及以上版本支持的一些版本。
PyTorch v1.11.0
支持 JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) 与 Python 3.8
文件名: torch-1.11.0-cp38-cp38-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/ssf2v7pf5i245fk4i0q926hy4imzs2ph.whl
PyTorch v1.12.0
支持 JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) 与 Python 3.8
文件名: torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- 步骤 1. 根据您的 JetPack 版本按以下格式安装 torch
wget <URL> -O <file_name>
pip3 install <file_name>
例如,这里我们运行的是 JP5.0.2,因此我们选择 PyTorch v1.12.0
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl -O torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
pip3 install torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- 步骤 2. 根据您已安装的 PyTorch 版本安装 torchvision。例如,我们选择了 PyTorch v1.12.0,这意味着我们需要选择 Torchvision v0.13.0
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.13.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
以下是根据 PyTorch 版本需要安装的对应 torchvision 版本列表:
- PyTorch v1.11 - torchvision v0.12.0
- PyTorch v1.12 - torchvision v0.13.0
如果您需要更详细的列表,请查看此链接。
DeepStream YOLOv8 配置
- 步骤 1. 克隆以下仓库
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- 步骤 2. 将仓库检出到以下提交
cd DeepStream-Yolo
git checkout 68f762d5bdeae7ac3458529bfe6fed72714336ca
- 步骤 3. 将 gen_wts_yoloV8.py 从 DeepStream-Yolo/utils 复制到 ultralytics 目录
cp utils/gen_wts_yoloV8.py ~/ultralytics
- 步骤 4. 在 ultralytics 仓库内,从 YOLOv8 releases 下载 pt 文件(以 YOLOv8s 为例)
wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt
注意: 您可以使用自定义模型,但重要的是在您的 cfg 和 weights/wts 文件名中保持 YOLO 模型引用 (yolov8_),以便正确生成引擎。
- 步骤 5. 生成 cfg、wts 和 labels.txt(如果可用)文件(YOLOv8s 示例)
python3 gen_wts_yoloV8.py -w yolov8s.pt
**注意:**要更改推理大小(默认值:640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280
- 步骤 6. 将生成的 cfg、wts 和 labels.txt(如果生成)文件复制到 DeepStream-Yolo 文件夹中
cp yolov8s.cfg ~/DeepStream-Yolo
cp yolov8s.wts ~/DeepStream-Yolo
cp labels.txt ~/DeepStream-Yolo
- 步骤 7. 打开 DeepStream-Yolo 文件夹并编译库
cd ~/DeepStream-Yolo
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
- 步骤 8. 根据您的模型编辑 config_infer_primary_yoloV8.txt 文件(YOLOv8s 80 类的示例)
[property]
...
custom-network-config=yolov8s.cfg
model-file=yolov8s.wts
...
num-detected-classes=80
...
- 步骤 9. 编辑 deepstream_app_config.txt 文件
...
[primary-gie]
...
config-file=config_infer_primary_yoloV8.txt
- 步骤 10. 在 deepstream_app_config.txt 文件中更改视频源。这里加载了一个默认视频文件,如下所示
...
[source0]
...
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
运行推理
deepstream-app -c deepstream_app_config.txt
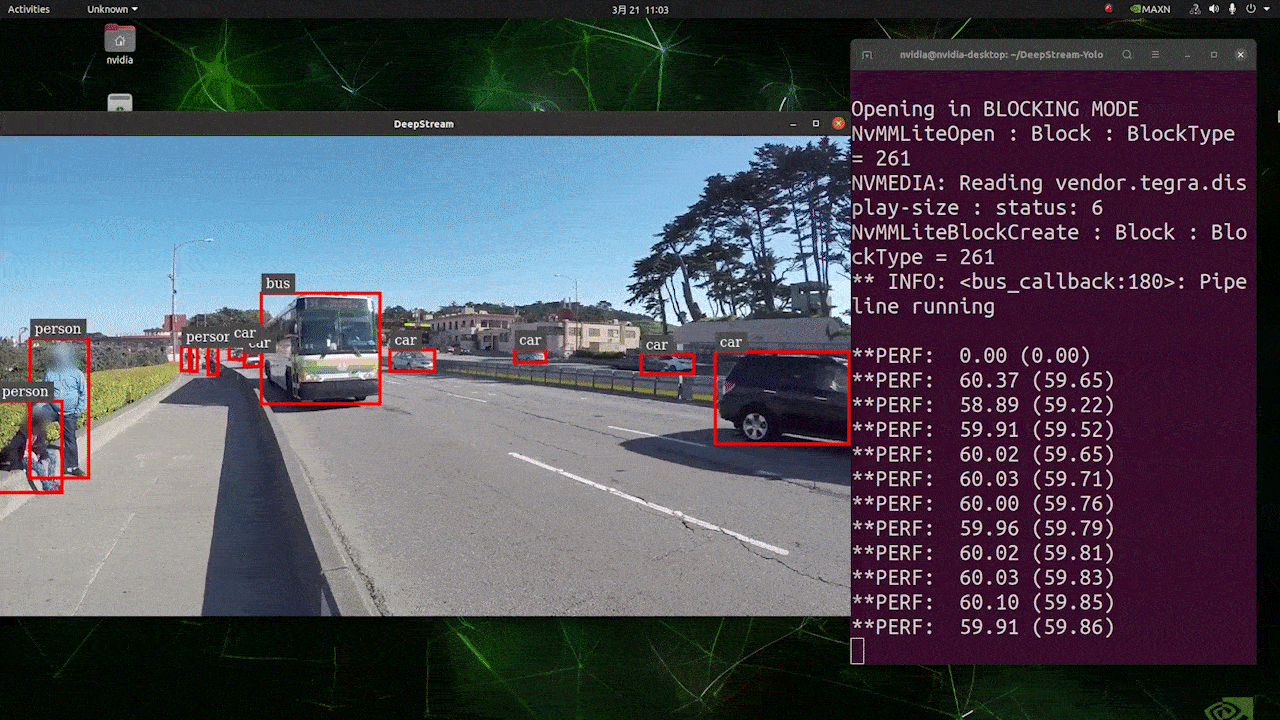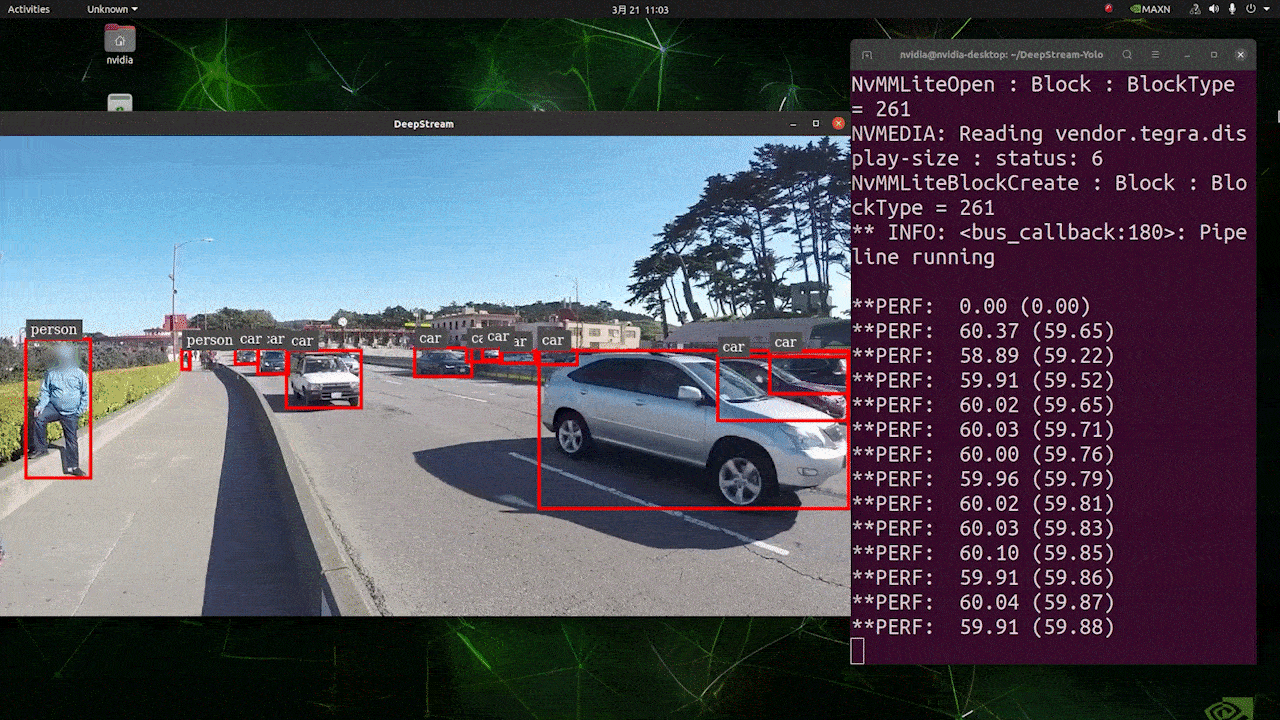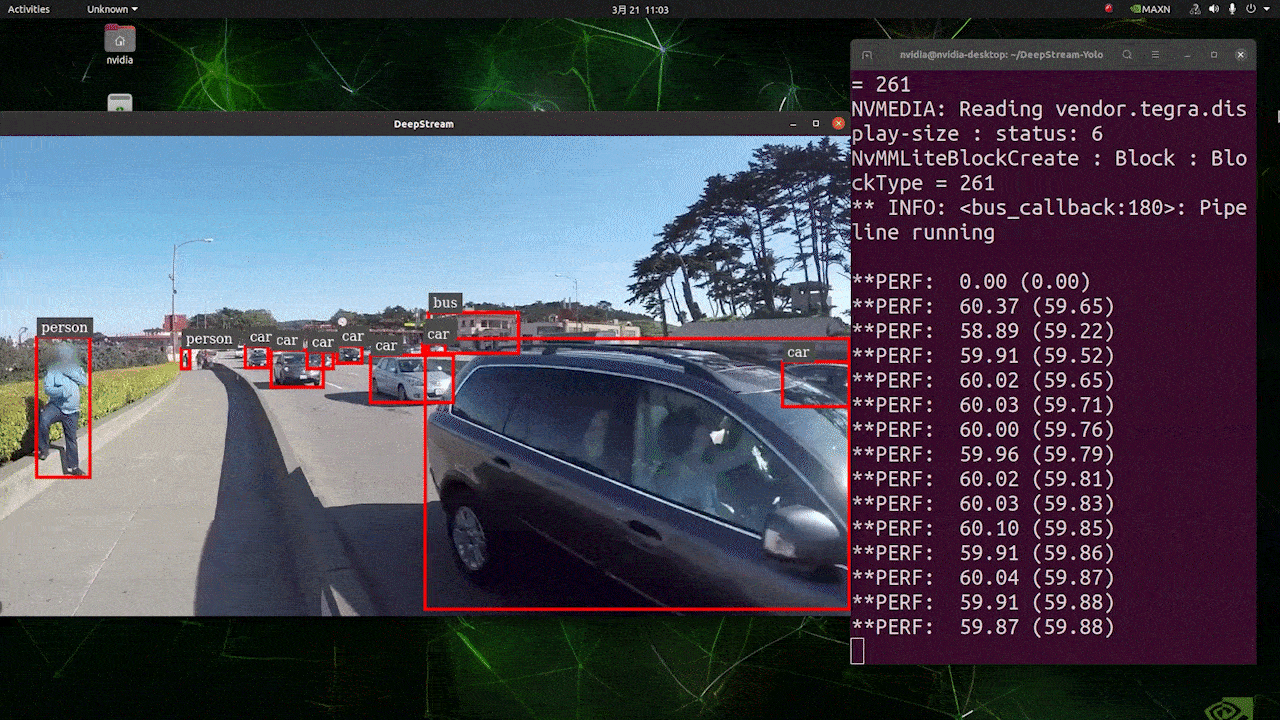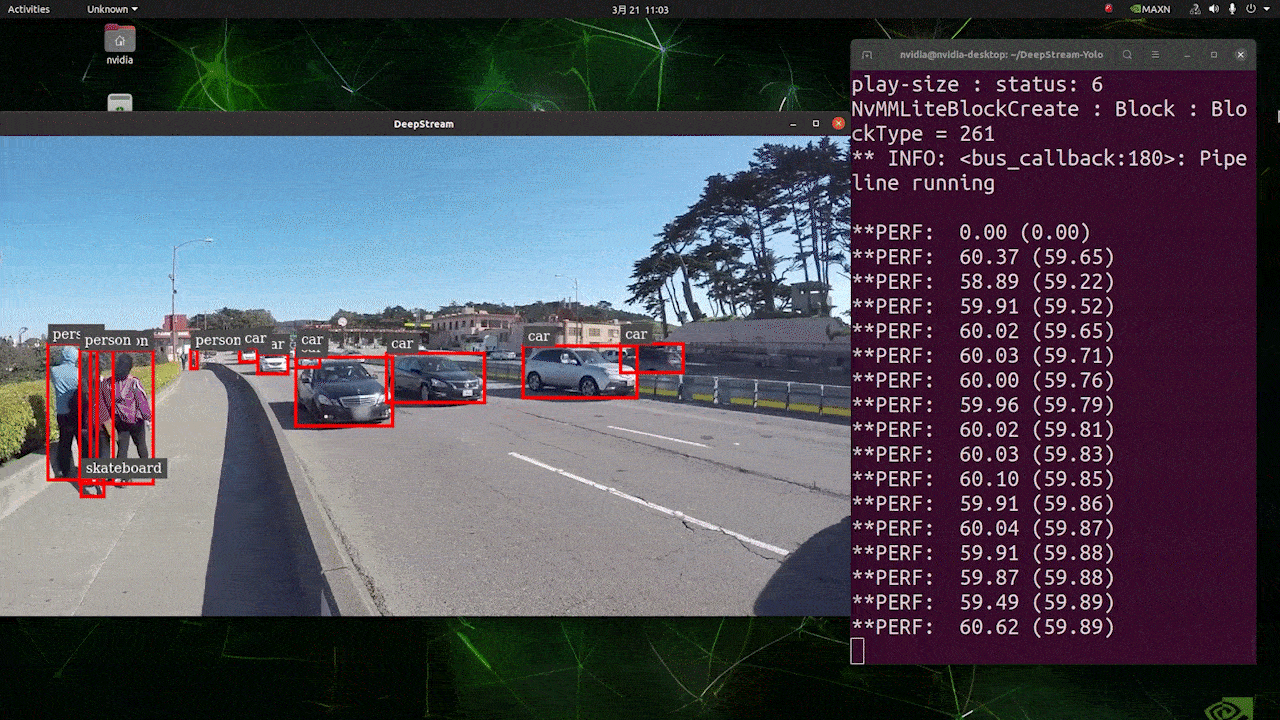
上述结果是在 Jetson AGX Orin 32GB H01 套件上使用 FP32 和 YOLOv8s 640x640 运行的。我们可以看到 FPS 大约为 60,但这不是真实的 FPS,因为当我们在 deepstream_app_config.txt 文件中的 [sink0] 下设置 type=2 时,FPS 会被限制为显示器的 fps,而我们用于此次测试的显示器是 60Hz 显示器。但是,如果您将此值更改为 type=1,您将能够获得最大 FPS,但不会有实时检测输出。
对于与上述相同的视频源和相同的模型,在 [sink0] 下更改为 type=1 后,可以获得以下结果。
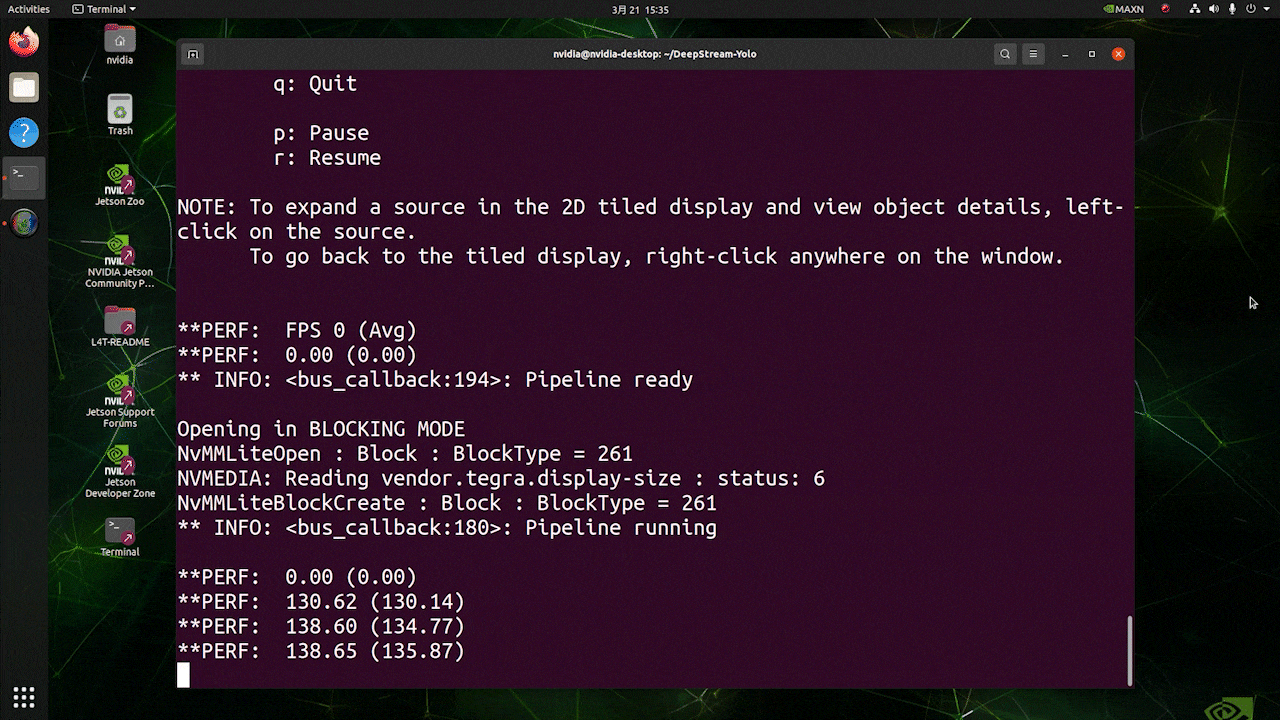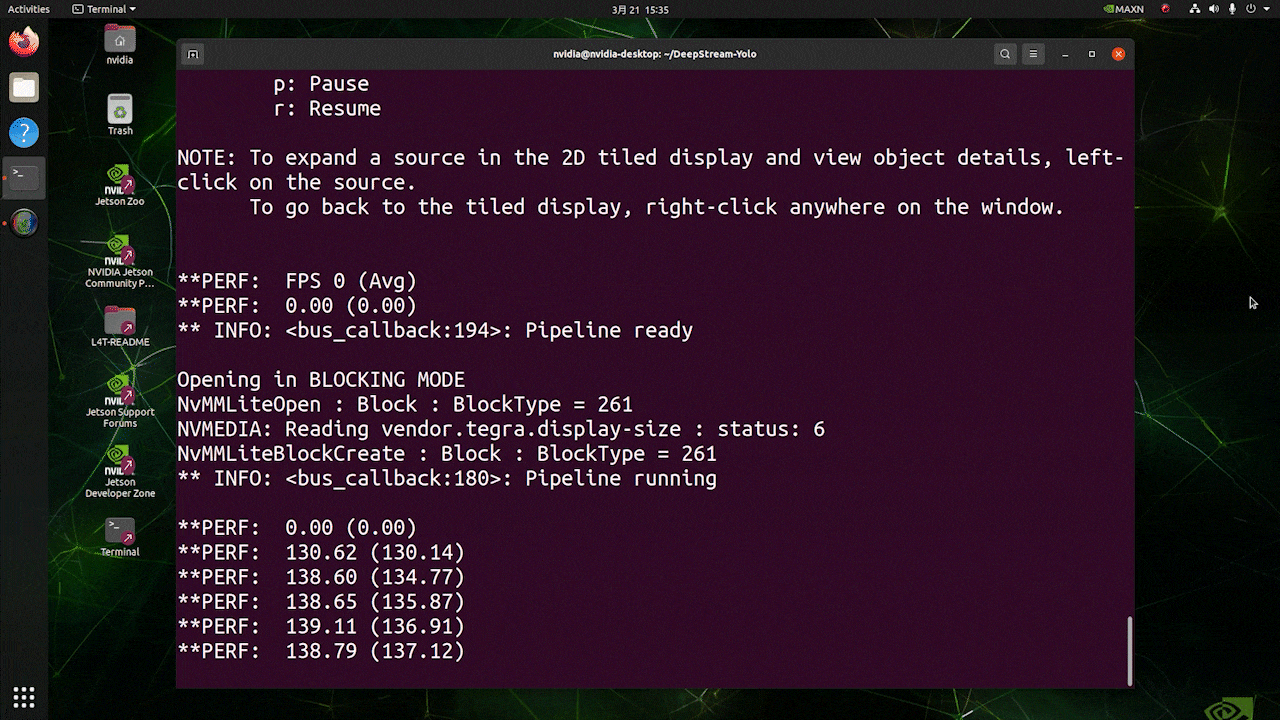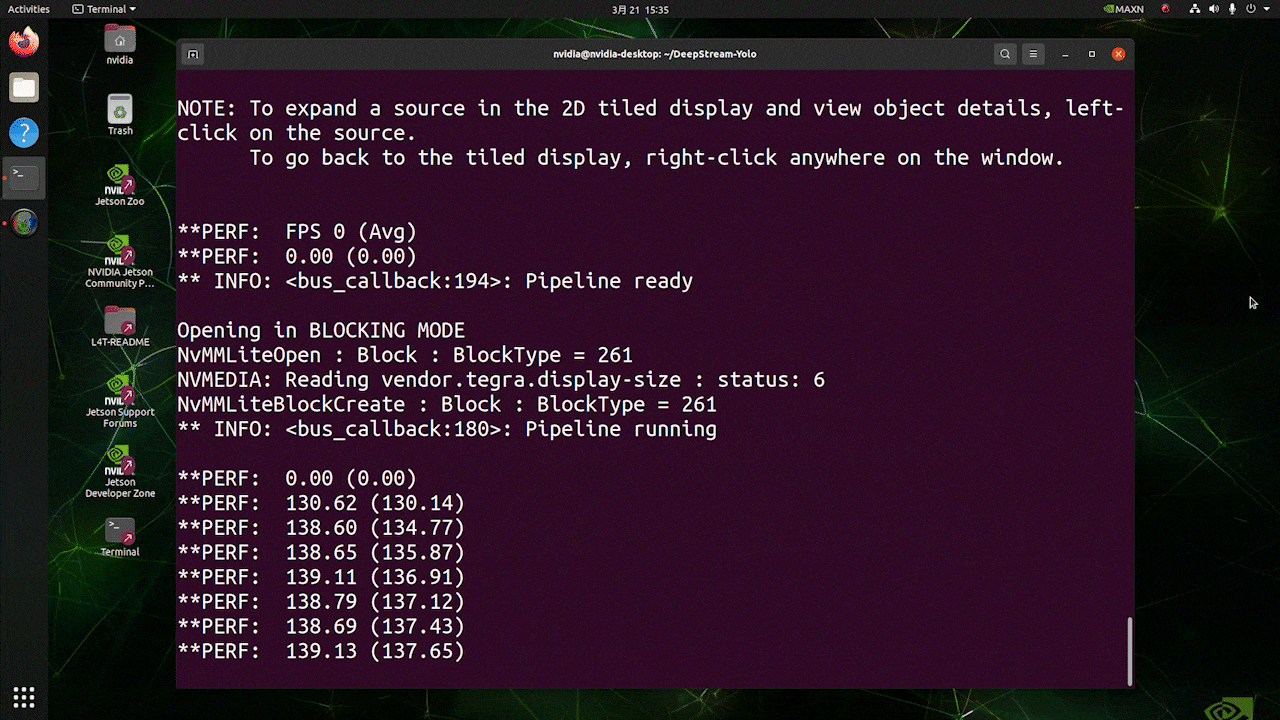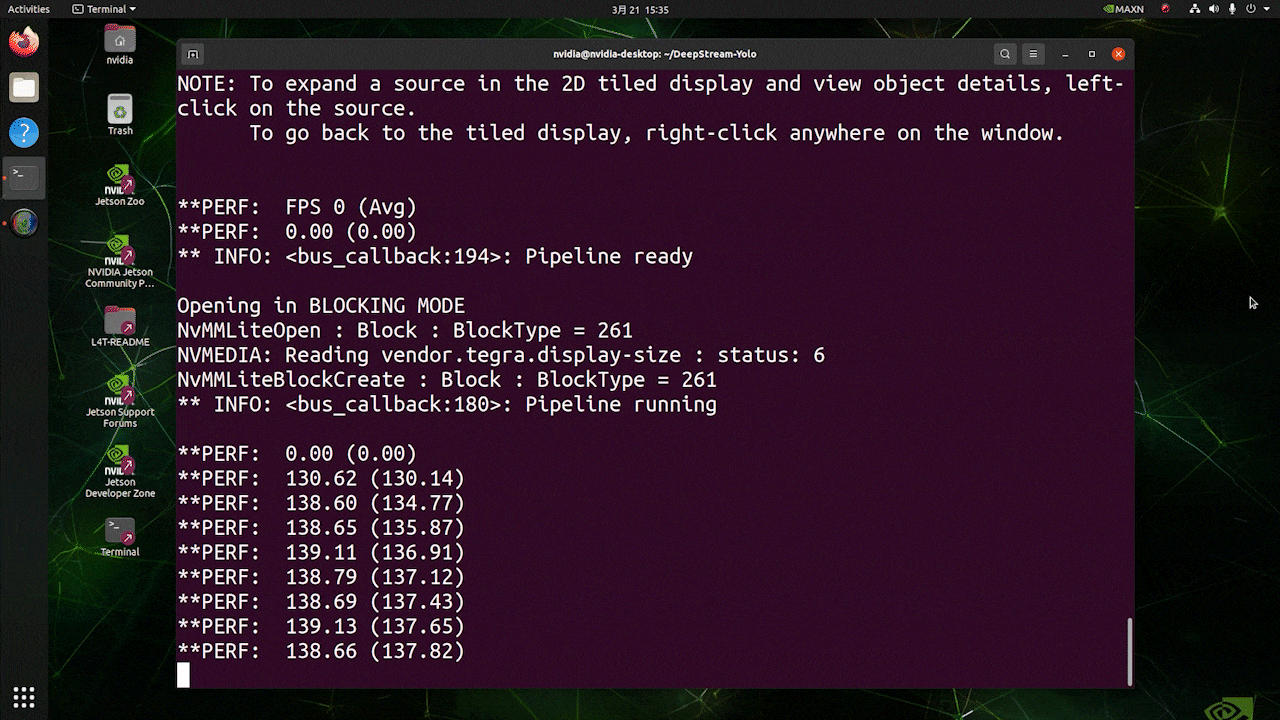
如您所见,我们可以获得大约 139 的 fps,这与真实的 fps 值相关。
INT8 校准
如果您想使用 INT8 精度进行推理,您需要按照以下步骤操作
- 步骤 1. 安装 OpenCV
sudo apt-get install libopencv-dev
- 步骤 2. 使用 OpenCV 支持编译/重新编译 nvdsinfer_custom_impl_Yolo 库
cd ~/DeepStream-Yolo
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
-
步骤 3. 对于 COCO 数据集,下载 val2017,解压,并移动到 DeepStream-Yolo 文件夹
-
步骤 4. 为校准图像创建一个新目录
mkdir calibration
- 步骤 5. 运行以下命令从 COCO 数据集中选择 1000 张随机图像来进行校准
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
注意: NVIDIA 建议至少使用 500 张图像以获得良好的准确性。在此示例中,选择了 1000 张图像以获得更好的准确性(更多图像 = 更高准确性)。更高的 INT8_CALIB_BATCH_SIZE 值将带来更高的准确性和更快的校准速度。请根据您的 GPU 内存进行设置。您可以从 head -1000 进行设置。例如,对于 2000 张图像,使用 head -2000。此过程可能需要很长时间。
- 步骤 6. 使用所有选定的图像创建 calibration.txt 文件
realpath calibration/*jpg > calibration.txt
- 步骤 7. 设置环境变量
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- 步骤 8. 更新 config_infer_primary_yoloV8.txt 文件
From
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
To
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
-
步骤 9. 在运行推理之前,如前所述,在 deepstream_app_config.txt 文件中的 [sink0] 下设置 type=2 以获得最大 fps 性能。
-
步骤 10. 运行推理
deepstream-app -c deepstream_app_config.txt
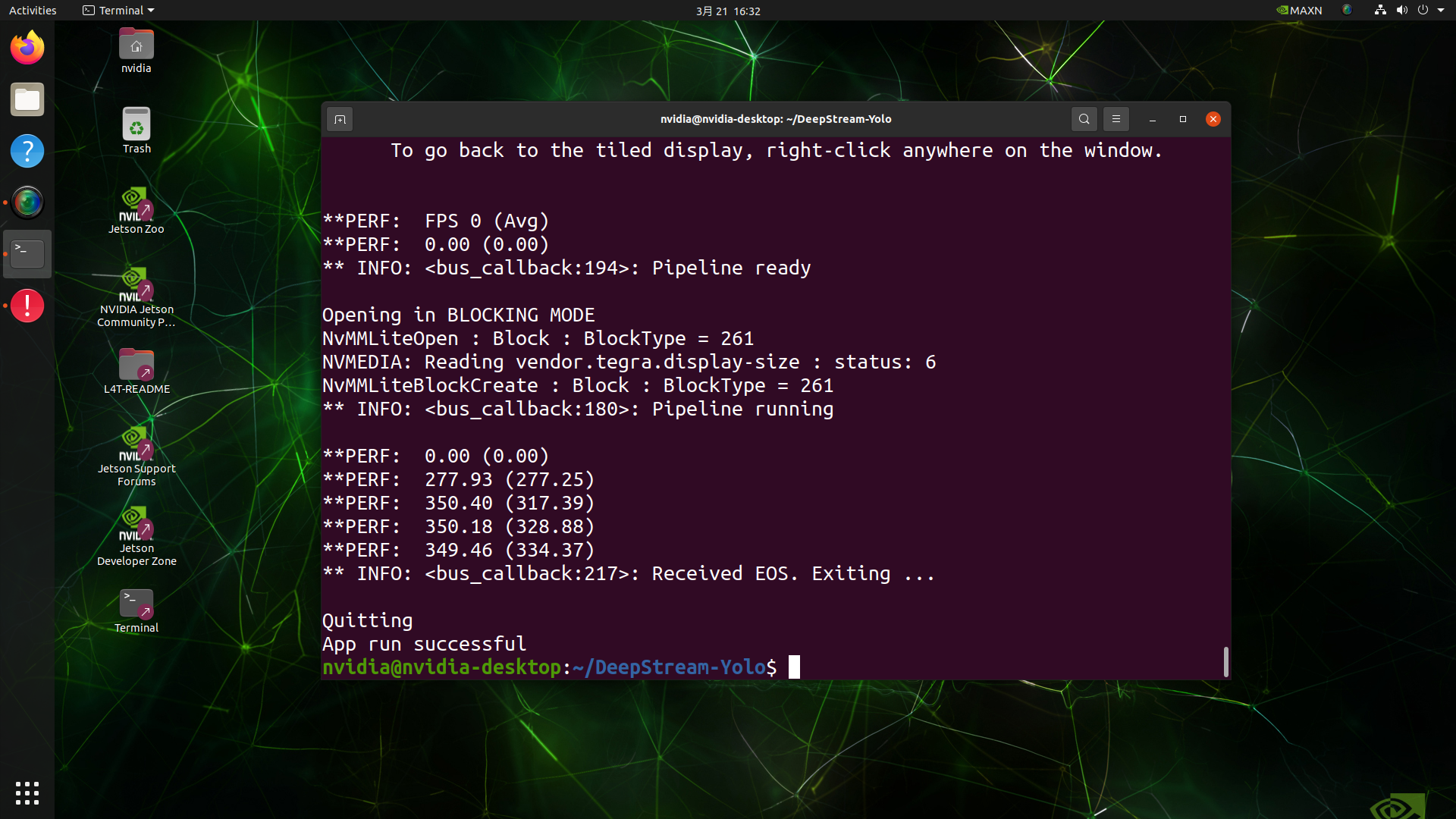
这里我们得到了大约 350 的 FPS 值!
多流配置
NVIDIA DeepStream 允许您在单个配置文件上轻松设置多个流,以构建多流视频分析应用程序。我们将在本 wiki 中稍后演示高 FPS 性能的模型如何真正帮助多流应用程序,并提供一些基准测试。
这里我们将以 9 个流为例。我们将修改 deepstream_app_config.txt 文件。
- 步骤 1. 在 [tiled-display] 部分内,将行数和列数更改为 3 和 3,这样我们就可以有一个 3x3 网格,包含 9 个流
[tiled-display]
rows=3
columns=3
- 步骤 2. 在 [source0] 部分内,设置 num-sources=9 并添加更多 uri。这里我们将简单地复制当前示例视频文件 8 次,总共组成 9 个流。但是,您可以根据您的应用程序更改为不同的视频流
[source0]
enable=1
type=3
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
num-sources=9
现在如果您再次使用 deepstream-app -c deepstream_app_config.txt 命令运行应用程序,您将看到以下输出
trtexec 工具
在 samples 目录中包含了一个名为 trtexec 的命令行包装工具。trtexec 是一个无需开发自己的应用程序就能使用 TensorRT 的工具。trtexec 工具有三个主要用途:
- 在随机或用户提供的输入数据上对网络进行基准测试。
- 从模型生成序列化引擎。
- 从构建器生成序列化时序缓存。
在这里我们可以使用 trtexec 工具来快速对具有不同参数的模型进行基准测试。但首先,您需要有一个 onnx 模型,我们可以使用 ultralytics yolov8 来生成这个 onnx 模型。
- 步骤 1. 使用以下命令构建 ONNX:
yolo mode=export model=yolov8s.pt format=onnx
- 步骤 1. 使用trtexec构建引擎文件,步骤如下:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
For example:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine
这将输出性能结果以及生成的 .engine 文件。默认情况下,它会将 ONNX 转换为 FP32 精度的 TensorRT 优化文件,您可以看到如下输出
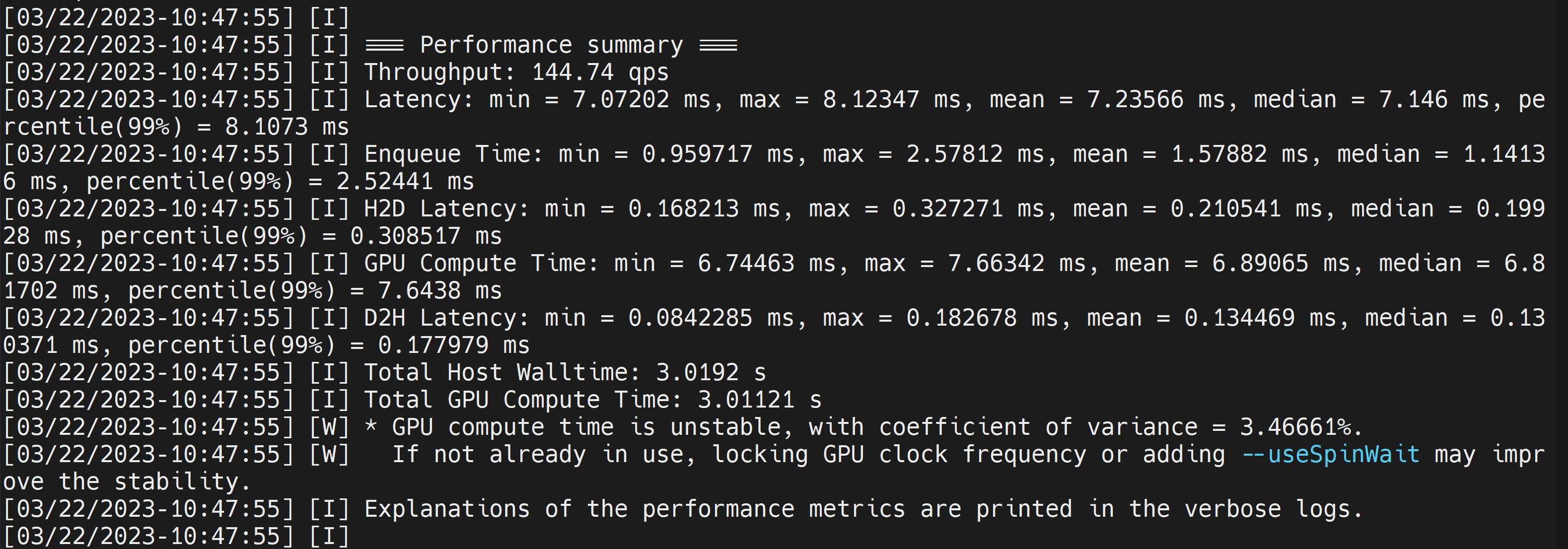
这里我们可以取平均延迟为 7.2ms,相当于 139FPS。这与我们在之前的 DeepStream 演示中获得的性能相同。
但是,如果您想要 INT8 精度以获得更好的性能,您可以按如下方式执行上述命令
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
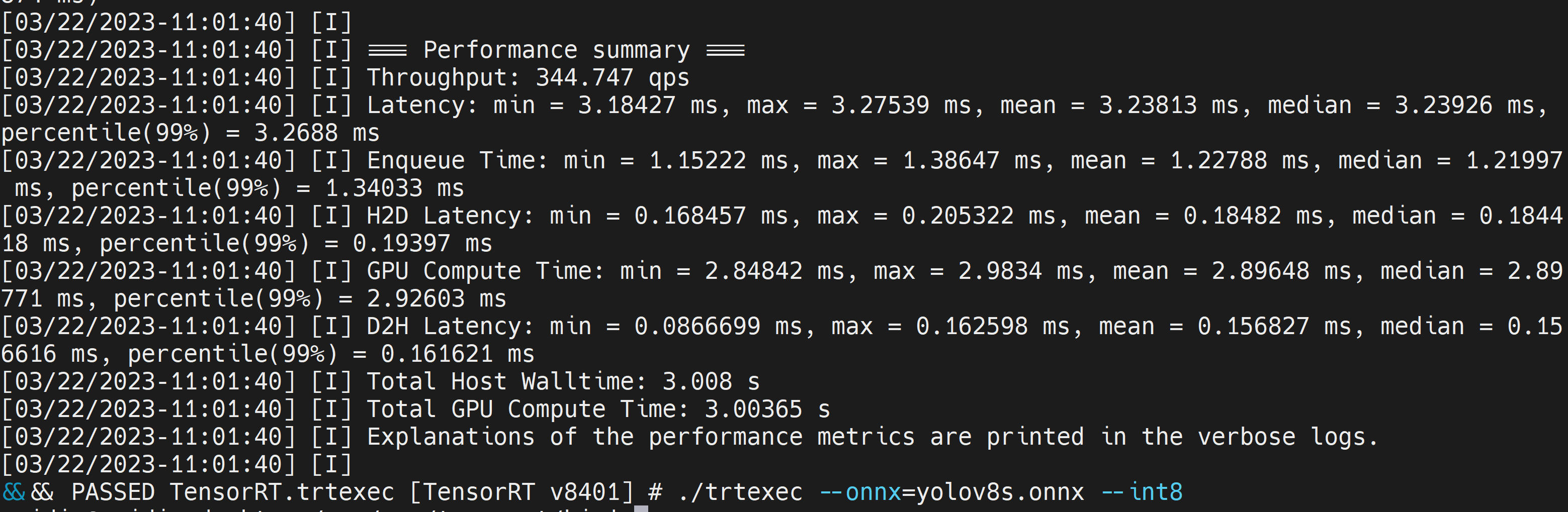
这里我们可以取平均延迟为 3.2ms,相当于 313FPS。
YOLOv8 基准测试结果
我们已经对在 reComputer J4012、AGX Orin 32GB H01 Kit 和 reComputer J2021 上运行的不同 YOLOv8 模型进行了性能基准测试
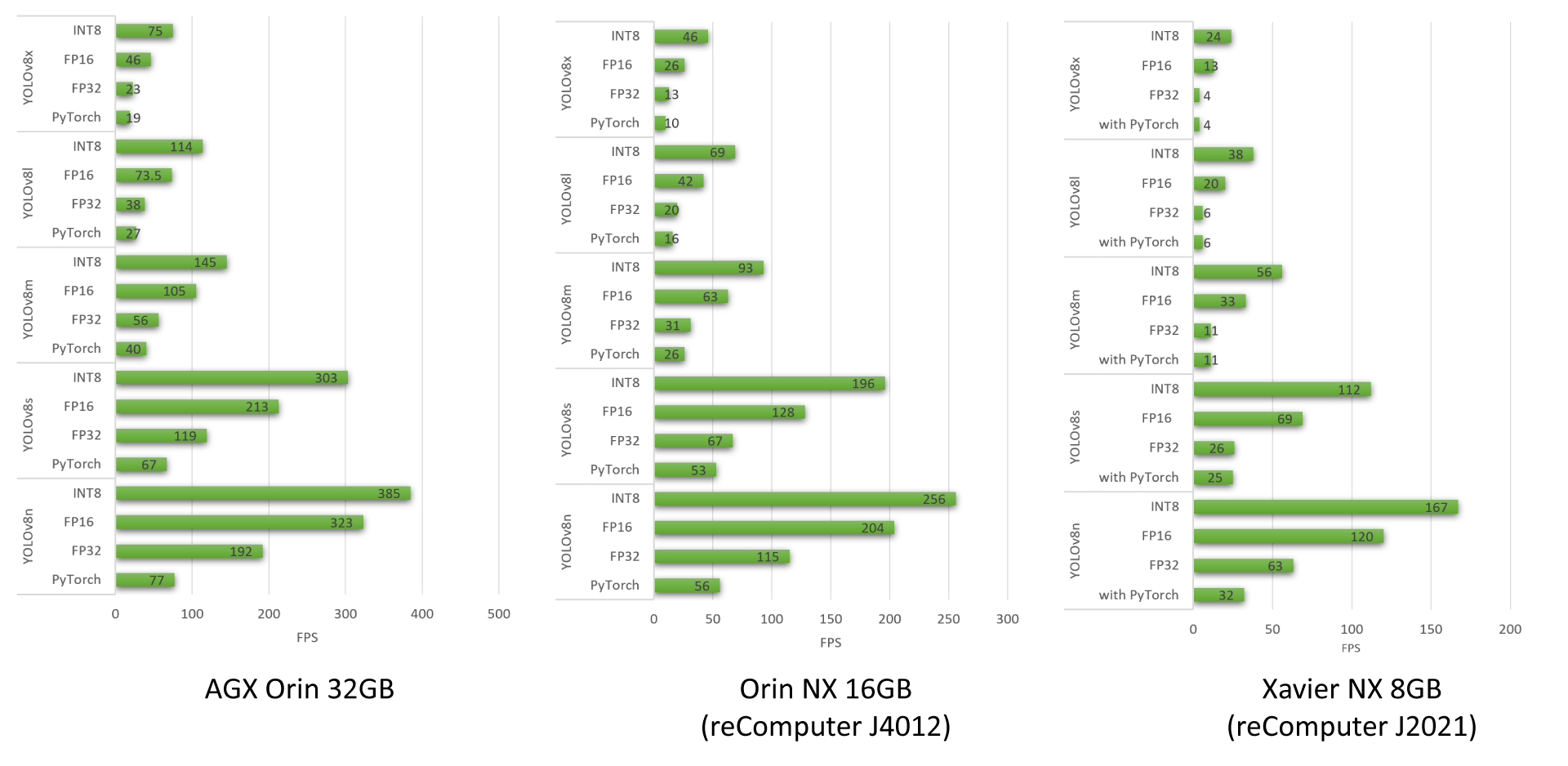
要了解更多我们使用 YOLOv8 模型进行的性能基准测试,请查看我们的博客。
多流模型基准测试
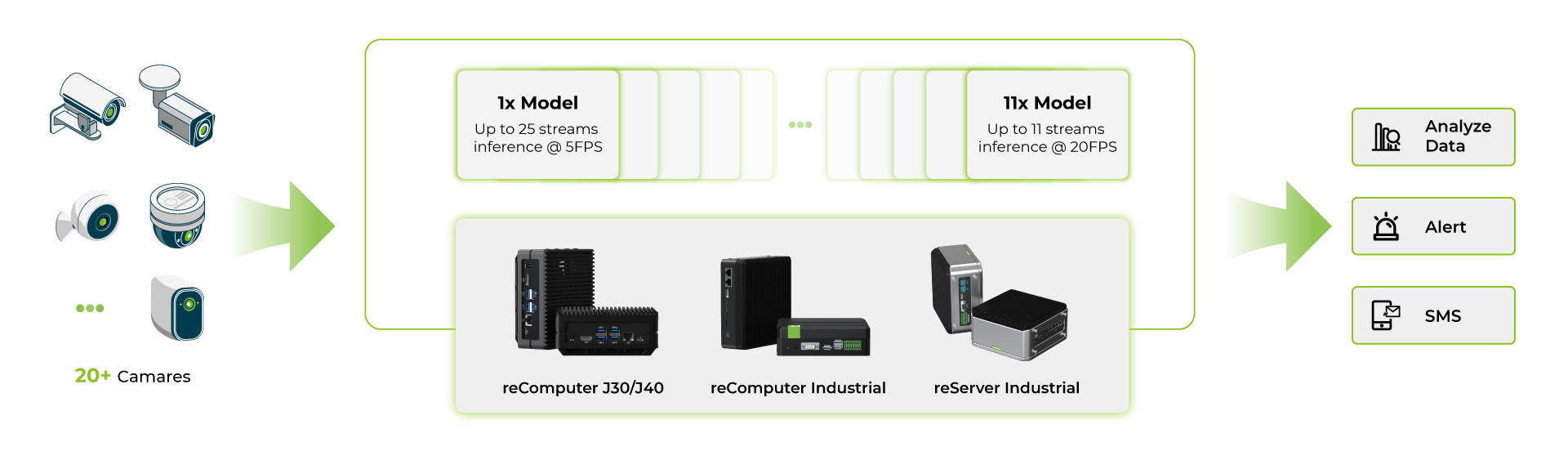
在 reComputer Jetson Orin 系列产品上运行多个 deepstream 应用程序后,我们使用 YOLOv8s 模型进行了基准测试。
- 首先,我们使用单个 AI 模型并在同一个 AI 模型上运行多个流
- 其次,我们使用多个 AI 模型并在多个 AI 模型上运行多个流
所有这些基准测试都在以下条件下进行:
- YOLOv8s 640x640 图像输入
- 禁用 UI
- 开启最大功率和最大性能模式
从这些基准测试中,我们可以看到对于最高端的 Orin NX 16GB 设备,使用单个 YOLOv8s 模型在 INT8 精度下,您可以使用大约 40 个摄像头,帧率约为 5fps;而对于每个流使用多个 YOLOv8s 模型在 INT8 精度下,您可以使用大约 11 个摄像头,帧率约为 15fps。对于多模型应用,摄像头数量较少是因为设备上的 RAM 限制,每个模型都会占用大量的 RAM。
总结来说,当边缘设备仅运行 YOLOv8 模型而没有其他应用程序运行时,Jetson Orin Nano 8GB 可以支持 4-6 个流,而 Jetson Orin NX 16GB 在最大容量下可以管理 16-18 个流。然而,在实际应用中,随着 RAM 资源的使用,这些数字可能会减少。因此,建议将这些数字作为指导,并在您的特定条件下进行自己的测试。
资源
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。