在 NVIDIA Jetson 上使用 TensorRT 部署 YOLOv8
本 wiki 指南介绍如何将 YOLOv8 模型部署到 NVIDIA Jetson 平台并使用 TensorRT 进行推理。这里我们使用 TensorRT 来最大化 Jetson 平台上的推理性能。
这里将介绍不同的计算机视觉任务,例如:
- 目标检测
- 图像分割
- 图像分类
- 姿态估计
- 目标跟踪

先决条件
- Ubuntu 主机 PC(原生或使用 VMware Workstation Player 的虚拟机)
- reComputer Jetson 或任何其他运行 JetPack 5.1.1 或更高版本的 NVIDIA Jetson 设备
本 wiki 已在 reComputer J4012 和 reComputer Industrial J4012[https://www.seeedstudio.com/reComputer-Industrial-J4012-p-5684.html] 上进行了测试和验证,这些设备由 NVIDIA Jetson orin NX 16GB 模块驱动
将 JetPack 刷写到 Jetson
现在您需要确保 Jetson 设备已刷写了 JetPack 系统。您可以使用 NVIDIA SDK Manager 或命令行将 JetPack 刷写到设备。
对于 Seeed Jetson 驱动设备的刷写指南,请参考以下链接:
- reComputer J1010 | J101
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 载板
- A205 载板
- Jetson Xavier AGX H01 套件
- Jetson AGX Orin 32GB H01 套件
确保刷写 JetPack 版本 5.1.1,因为这是我们为本 wiki 验证过的版本
一行代码将 YOLOV8 部署到 Jetson!
在您将 Jetson 设备刷写了 JetPack 后,您可以简单地运行以下命令来运行 YOLOv8 模型。这将首先下载并安装必要的包、依赖项,设置环境并从 YOLOv8 下载预训练模型来执行目标检测、图像分割、姿态估计和图像分类任务!
wget files.seeedstudio.com/YOLOv8-Jetson.py && python YOLOv8-Jetson.py
上述脚本的源代码可以在这里找到
使用预训练模型
开始使用 YOLOv8 的最快方法是使用 YOLOv8 提供的预训练模型。但是,这些是 PyTorch 模型,因此在 Jetson 上进行推理时只会使用 CPU。如果您希望这些模型在 Jetson 上运行时获得最佳性能并在 GPU 上运行,您可以按照本 wiki 的这一部分将 PyTorch 模型导出为 TensorRT。
- Object Detection
- Image Classification
- Image Segmentation
- 姿态估计
- 目标跟踪
YOLOv8 为目标检测提供了 5 个预训练的 PyTorch 模型权重,在输入图像尺寸为 640x640 的 COCO 数据集上训练。您可以在下面找到它们
| 模型 | 尺寸 (像素) | mAPval 50-95 | 速度 CPU ONNX (ms) | 速度 A100 TensorRT (ms) | 参数 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
参考:https://docs.ultralytics.com/tasks/detect
您可以从上表中选择并下载您所需的模型,然后执行以下命令对图像进行推理
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' show=True
在这里,对于模型,你可以更改为 yolov8s.pt、yolov8m.pt、yolov8l.pt、yolov8x.pt 中的任何一个,它将下载相关的预训练模型
你也可以连接网络摄像头并执行以下命令
yolo detect predict model=yolov8n.pt source='0' show=True
如果您在执行上述命令时遇到任何错误,请尝试在命令末尾添加"device=0"

以上运行在 reComputer J4012/ reComputer Industrial J4012 上,使用在 640x640 输入下训练的 YOLOv8s 模型,并使用 TensorRT FP16 精度。
YOLOv8 为图像分类提供了 5 个预训练的 PyTorch 模型权重,在 ImageNet 上以 224x224 输入图像尺寸进行训练。您可以在下面找到它们
| Model | size (pixels) | acc top1 | acc top5 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) at 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
参考:https://docs.ultralytics.com/tasks/classify
您可以选择所需的模型并执行以下命令在图像上运行推理
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' show=True
在这里,对于模型,你可以更改为 yolov8s-cls.pt、yolov8m-cls.pt、yolov8l-cls.pt、yolov8x-cls.pt 中的任何一个,它将下载相关的预训练模型
你也可以连接网络摄像头并执行以下命令
yolo classify predict model=yolov8n-cls.pt source='0' show=True
如果您在执行上述命令时遇到任何错误,请尝试在命令末尾添加"device=0"
(使用224推理更新)
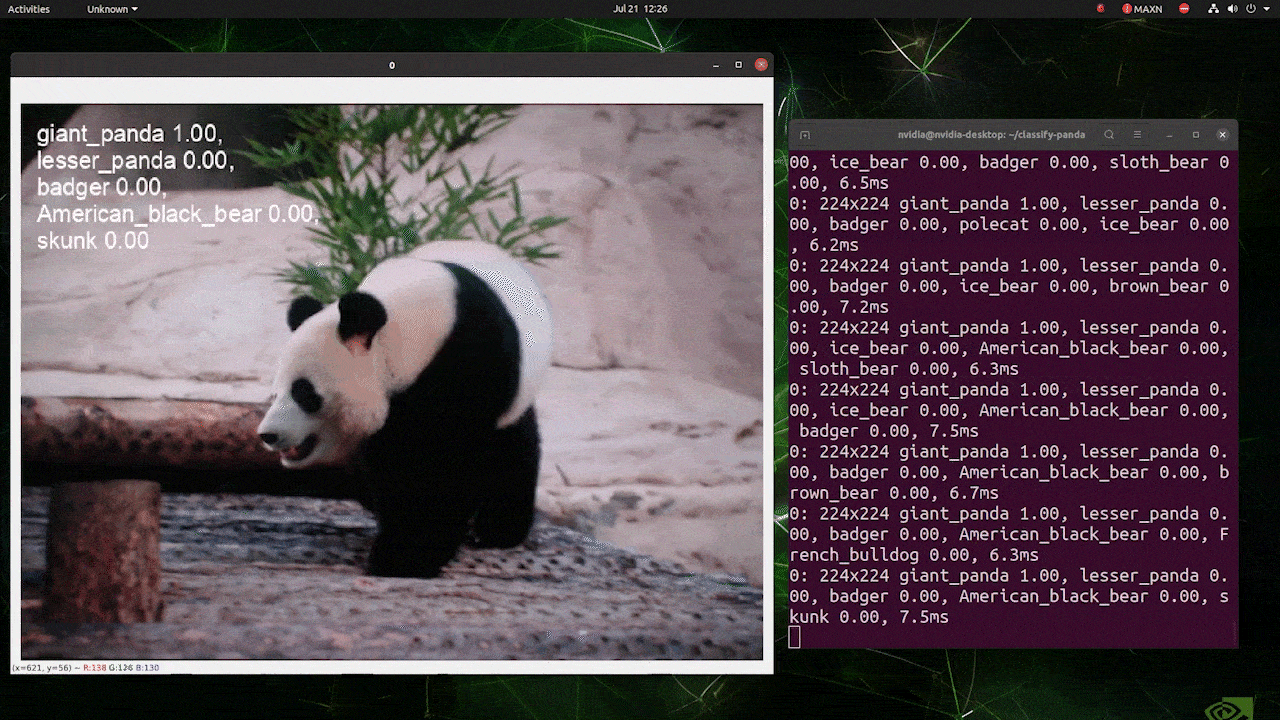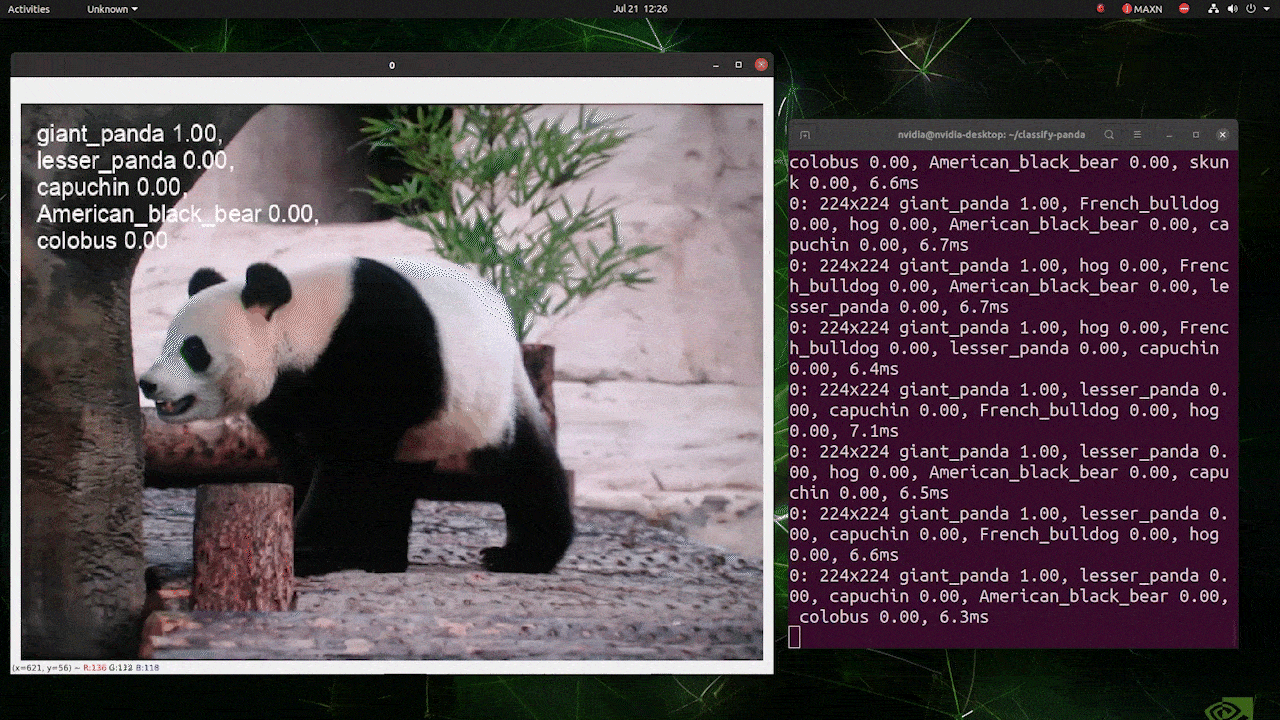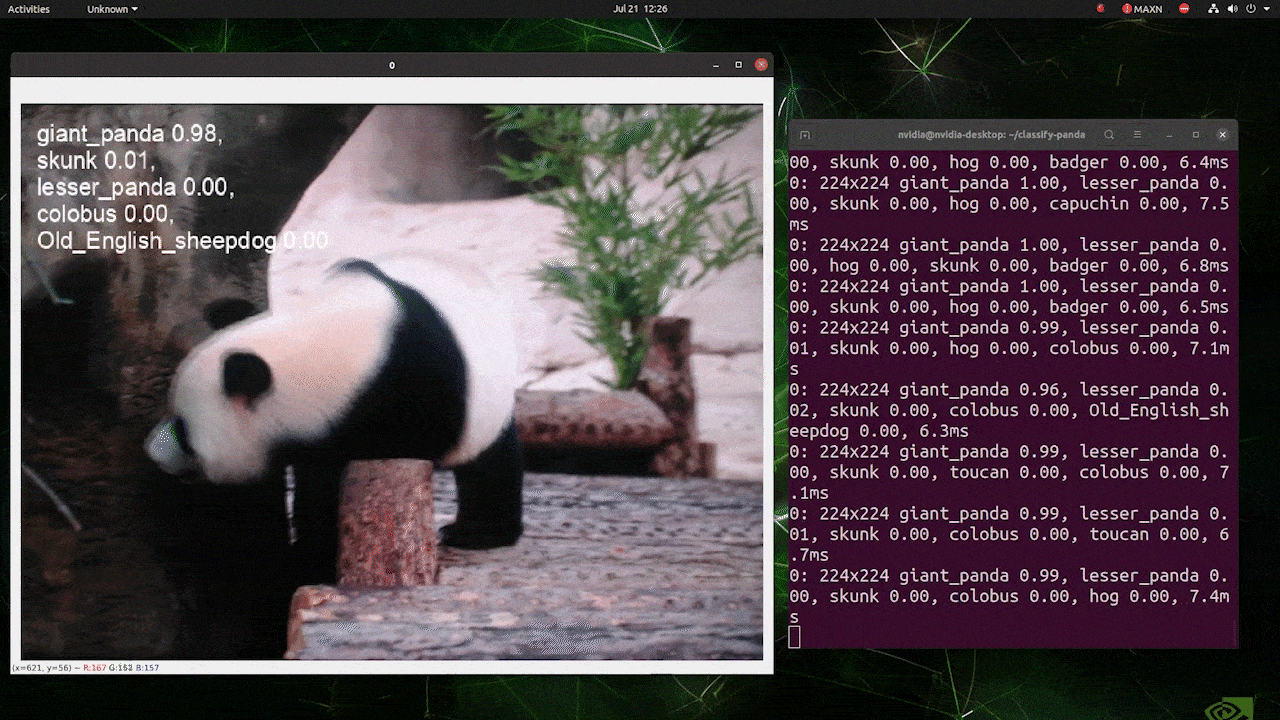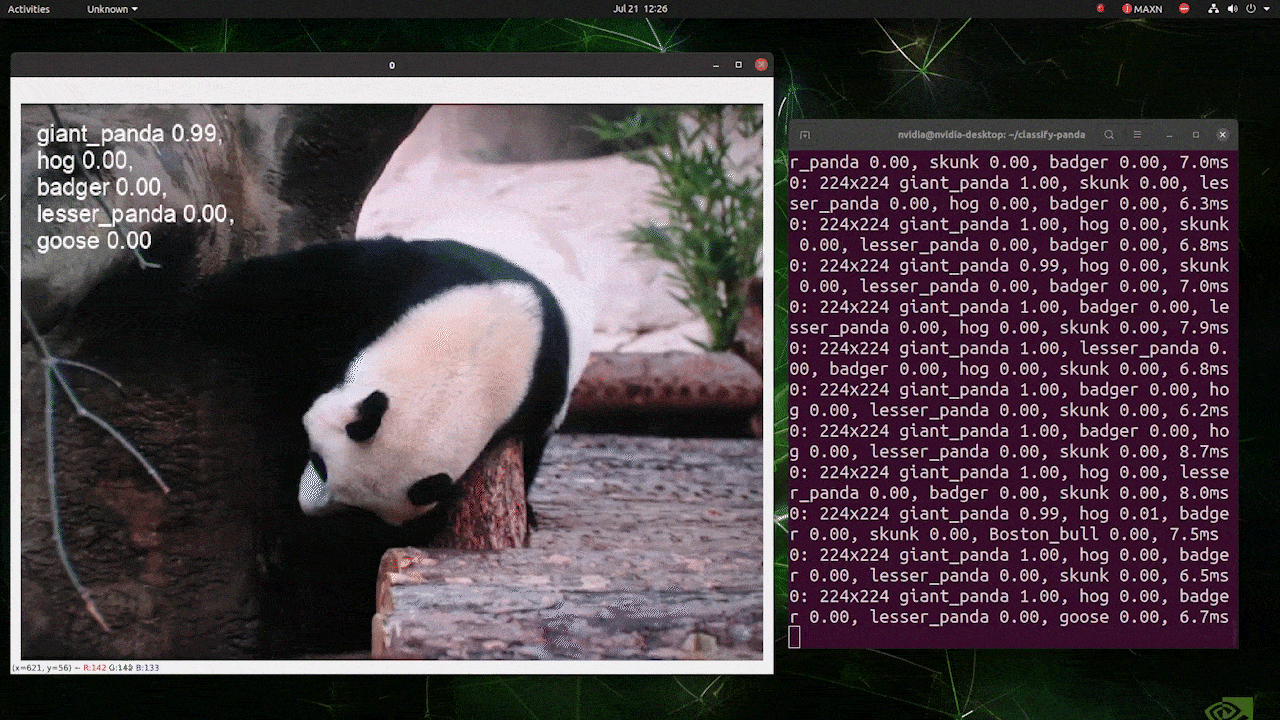
上述运行在reComputer J4012/reComputer Industrial J4012上,使用了以224x224输入训练的YOLOv8s-cls模型,并使用TensorRT FP16精度。另外,在使用TensorRT导出时,请确保在推理命令中传递参数imgsz=224,因为推理引擎在使用TensorRT模型时默认接受640图像尺寸。
YOLOv8为图像分割提供了5个预训练的PyTorch模型权重,在COCO数据集上以640x640输入图像尺寸进行训练。您可以在下面找到它们
| 模型 | 尺寸 (像素) | mAPbox 50-95 | mAPmask 50-95 | 速度 CPU ONNX (ms) | 速度 A100 TensorRT (ms) | 参数 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
参考:https://docs.ultralytics.com/tasks/segment
您可以选择所需的模型并执行以下命令在图像上运行推理
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' show=True
在这里,对于模型,你可以更改为 yolov8s-seg.pt、yolov8m-seg.pt、yolov8l-seg.pt、yolov8x-seg.pt 中的任何一个,它将下载相关的预训练模型
你也可以连接网络摄像头并执行以下命令
yolo segment predict model=yolov8n-seg.pt source='0' show=True
如果您在执行上述命令时遇到任何错误,请尝试在命令末尾添加"device=0"

以上运行在 reComputer J4012/ reComputer Industrial J4012 上,使用在 640x640 输入下训练的 YOLOv8s-seg 模型,并使用 TensorRT FP16 精度。
YOLOv8 为姿态估计提供了 6 个预训练的 PyTorch 模型权重,在 COCO 关键点数据集上以 640x640 输入图像尺寸进行训练。您可以在下面找到它们
| 模型 | 尺寸 (像素) | mAPpose 50-95 | mAPpose 50 | 速度 CPU ONNX (ms) | 速度 A100 TensorRT (ms) | 参数 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-pose | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-pose | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-pose | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-pose | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-pose | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
参考:https://docs.ultralytics.com/tasks/pose
您可以选择所需的模型并执行以下命令在图像上运行推理
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg'
在这里,对于模型,你可以更改为 yolov8s-pose.pt、yolov8m-pose.pt、yolov8l-pose.pt、yolov8x-pose.pt、yolov8x-pose-p6 中的任意一个,它将下载相关的预训练模型
你也可以连接网络摄像头并执行以下命令
yolo pose predict model=yolov8n-pose.pt source='0'
如果您在执行上述命令时遇到任何错误,请尝试在命令末尾添加 "device=0"

目标跟踪是一项涉及识别对象位置和类别,然后在视频流中为该检测分配唯一ID的任务。
基本上,目标跟踪的输出与目标检测相同,只是增加了对象ID。
参考:https://docs.ultralytics.com/modes/track
您可以根据目标检测/图像分割选择所需的模型,并执行以下命令在视频上运行推理
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc"
在这里,对于模型,你可以更改为 yolov8n.pt、yolov8s.pt、yolov8m.pt、yolov8l.pt、yolov8x.pt、yolov8n-seg.pt、yolov8s-seg.pt、yolov8m-seg.pt、yolov8l-seg.pt、yolov8x-seg.pt 中的任意一个,它将下载相关的预训练模型
你也可以连接网络摄像头并执行以下命令
yolo track model=yolov8n.pt source="0"
如果您在执行上述命令时遇到任何错误,请尝试在命令末尾添加 "device=0"

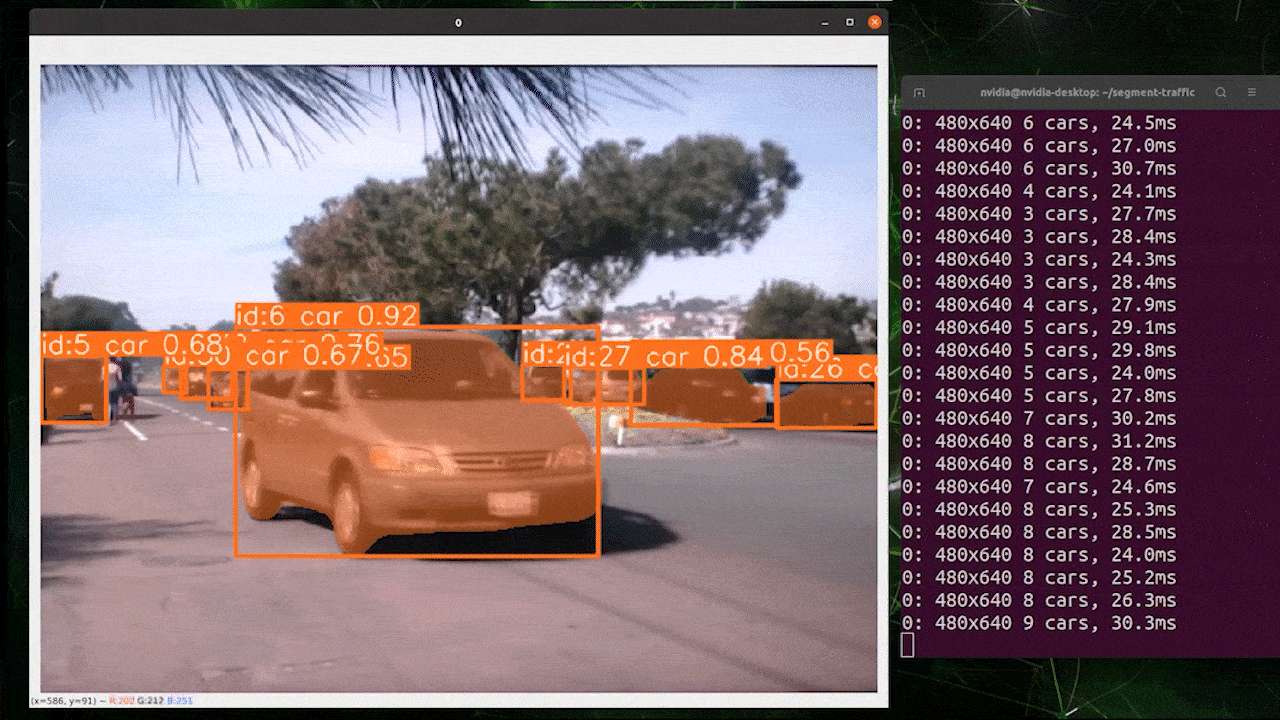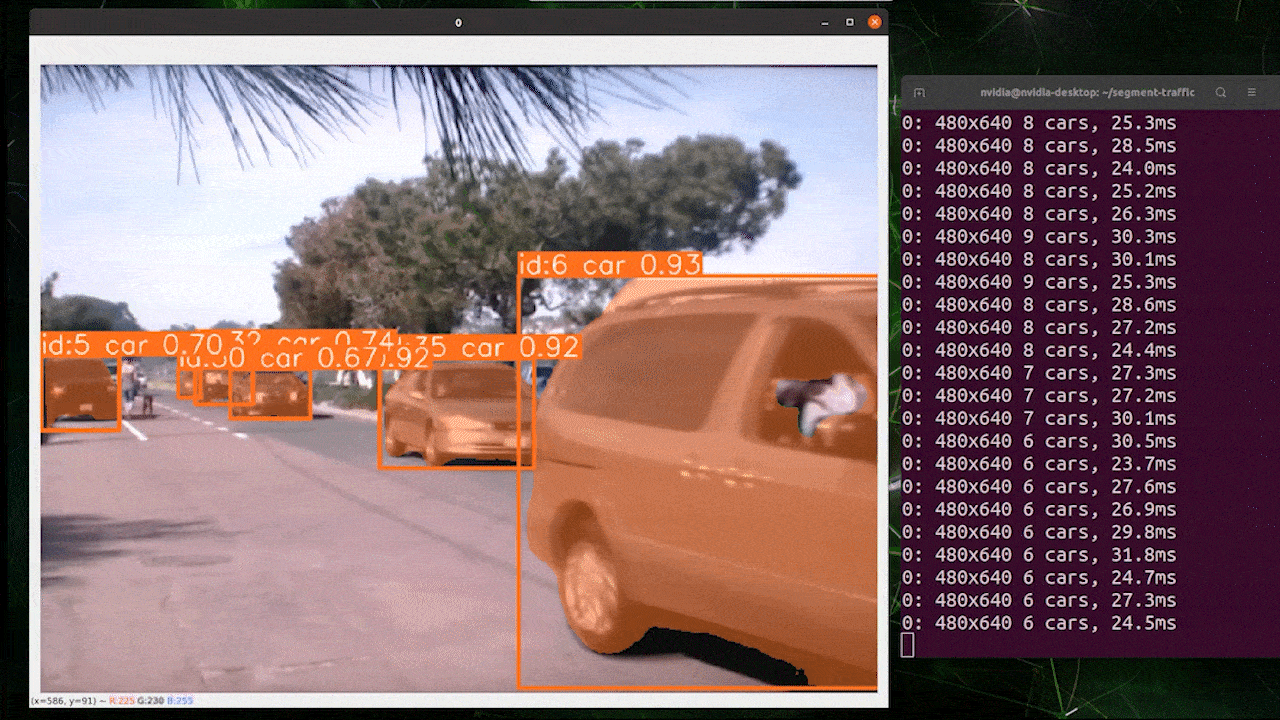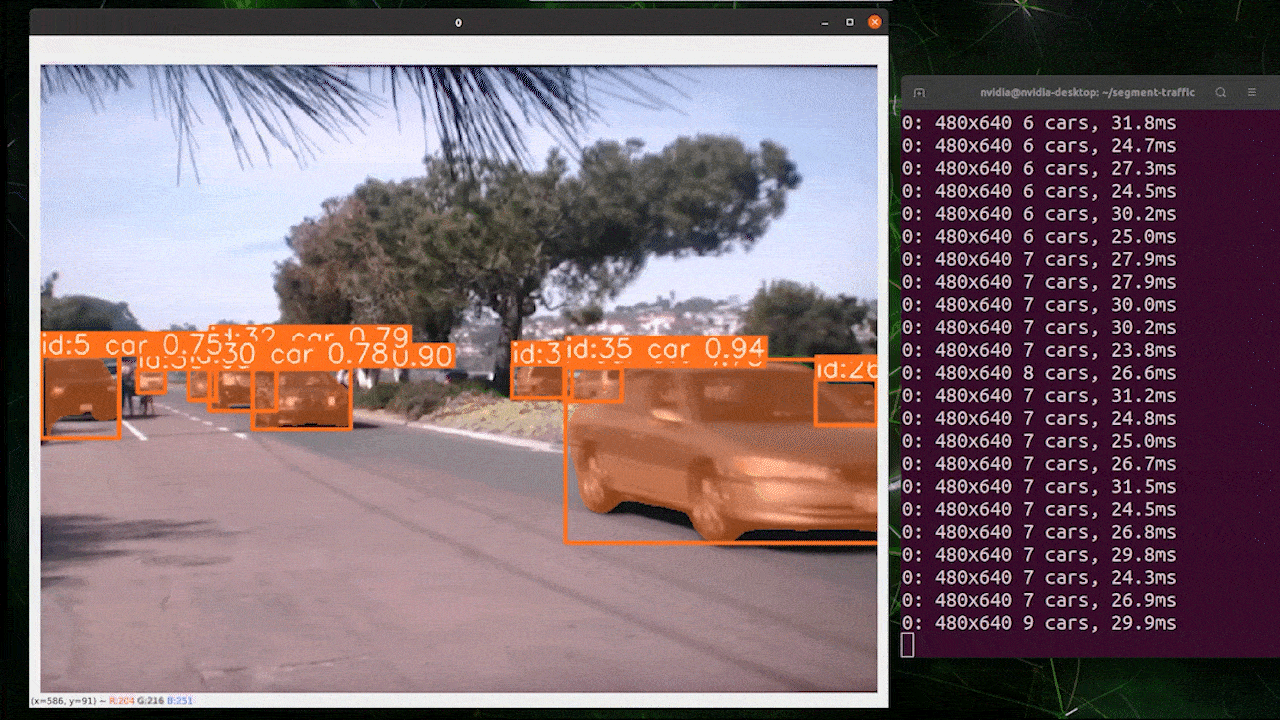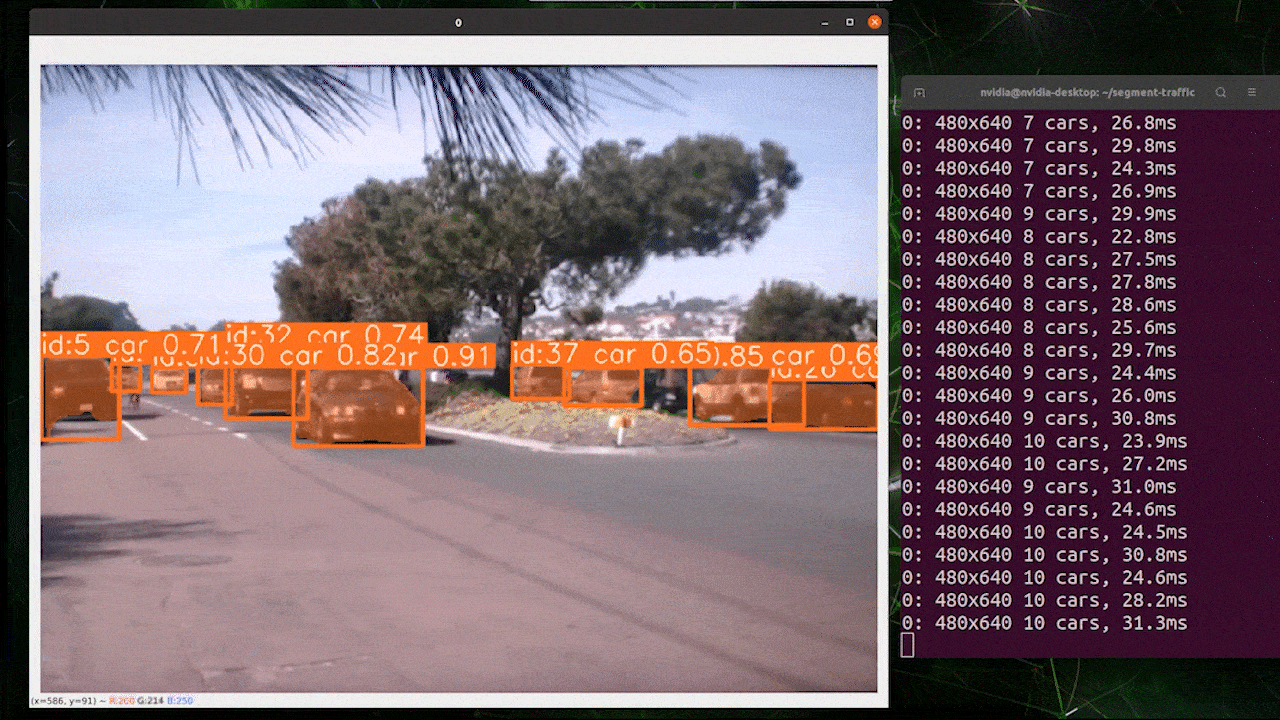
使用 TensorRT 提升推理速度
正如我们之前提到的,如果您想要提升在 Jetson 上运行 YOLOv8 模型的推理速度,您首先需要将原始的 PyTorch 模型转换为 TensorRT 模型。
按照以下步骤将 YOLOv8 PyTorch 模型转换为 TensorRT 模型。
这适用于我们之前提到的所有四个计算机视觉任务
- 步骤 1. 通过指定模型路径执行导出命令
yolo export model=<path_to_pt_file> format=engine device=0
例如:
yolo export model=yolov8n.pt format=engine device=0
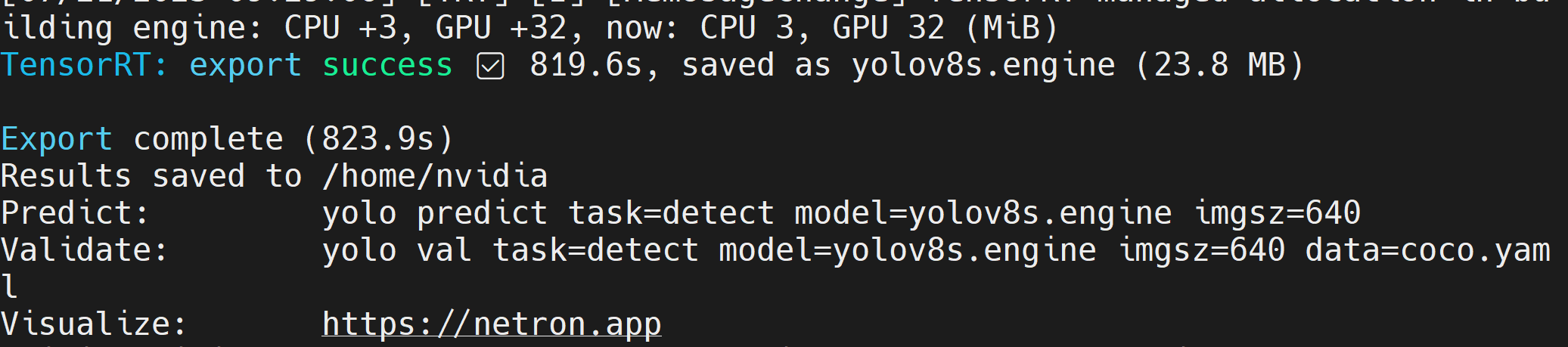
如果您遇到关于 cmake 的错误,可以忽略它。请耐心等待直到 TensorRT 导出完成。这可能需要几分钟时间
在创建 TensorRT 模型文件(.engine)后,您将看到如下输出
- 步骤 2. 如果您想传递额外的参数,可以按照下表进行操作
| 键 | 值 | 描述 |
|---|---|---|
| imgsz | 640 | 图像大小,可以是标量或 (h, w) 列表,例如 (640, 480) |
| half | False | FP16 量化 |
| dynamic | False | 动态轴 |
| simplify | False | 简化模型 |
| workspace | 4 | 工作空间大小(GB) |
例如,如果您想将 PyTorch 模型转换为使用 FP16 量化的 TensorRT 模型,请执行
yolo export model=yolov8n.pt format=engine half=True device=0
一旦模型成功导出,您可以在运行检测、分类、分割、姿态估计这4个任务时,直接在yolo的predict命令中用**model=**参数替换此模型。
例如,对于目标检测:
yolo detect predict model=yolov8n.engine source='0' show=True
使用您自己的AI模型
数据收集和标注
如果您有特定的AI应用程序并希望使用适合您应用程序的自己的AI模型,您可以收集自己的数据集,对其进行标注,然后使用YOLOv8进行训练。
如果您不想自己收集数据,您也可以选择现成可用的公共数据集。您可以下载许多公开可用的数据集,如COCO数据集、Pascal VOC数据集等等。Roboflow Universe是一个推荐的平台,它提供了广泛的数据集,拥有90,000+个数据集和6600万+张图像可用于构建计算机视觉模型。此外,您也可以简单地在Google上搜索开源数据集,从各种可用的数据集中进行选择。
如果您有自己的数据集并想要标注图像,我们建议您使用Roboflow提供的标注工具。请参考wiki的这一部分了解更多信息。您也可以参考Roboflow的这个指南来了解标注。
训练
这里我们有3种方法来训练模型。
-
第一种方法是使用Ultralytics HUB。您可以轻松地将Roboflow集成到Ultralytics HUB中,这样您所有的Roboflow项目都可以随时用于训练。这里它提供了一个Google Colab笔记本来轻松开始训练过程,并实时查看训练进度。
-
第二种方法是使用我们创建的Google Colab工作空间来简化训练过程。这里我们使用Roboflow API从Roboflow项目下载数据集。
-
第三种方法是使用本地PC进行训练过程。这里您需要确保您有足够强大的GPU,并且需要手动下载数据集。
- Ultralytics HUB + Roboflow + Google Colab
- Roboflow + Google Colab
- Roboflow + 本地PC
这里我们使用Ultralytics HUB加载Roboflow项目,然后在Google Colab上进行训练。
-
步骤1. 访问此URL并注册Ultralytics账户
-
步骤2. 使用新创建的账户登录后,您将看到以下仪表板
-
步骤3. 访问此URL并注册Roboflow账户
-
步骤4. 使用新创建的账户登录后,您将看到以下仪表板
-
步骤5. 创建一个新的工作空间,并按照我们准备的这个wiki指南在工作空间下创建一个新项目。您也可以查看这里从官方Roboflow文档了解更多信息。
-
步骤6. 一旦您的工作空间中有几个项目,它将如下所示
- 步骤7. 转到Settings并点击Roboflow API
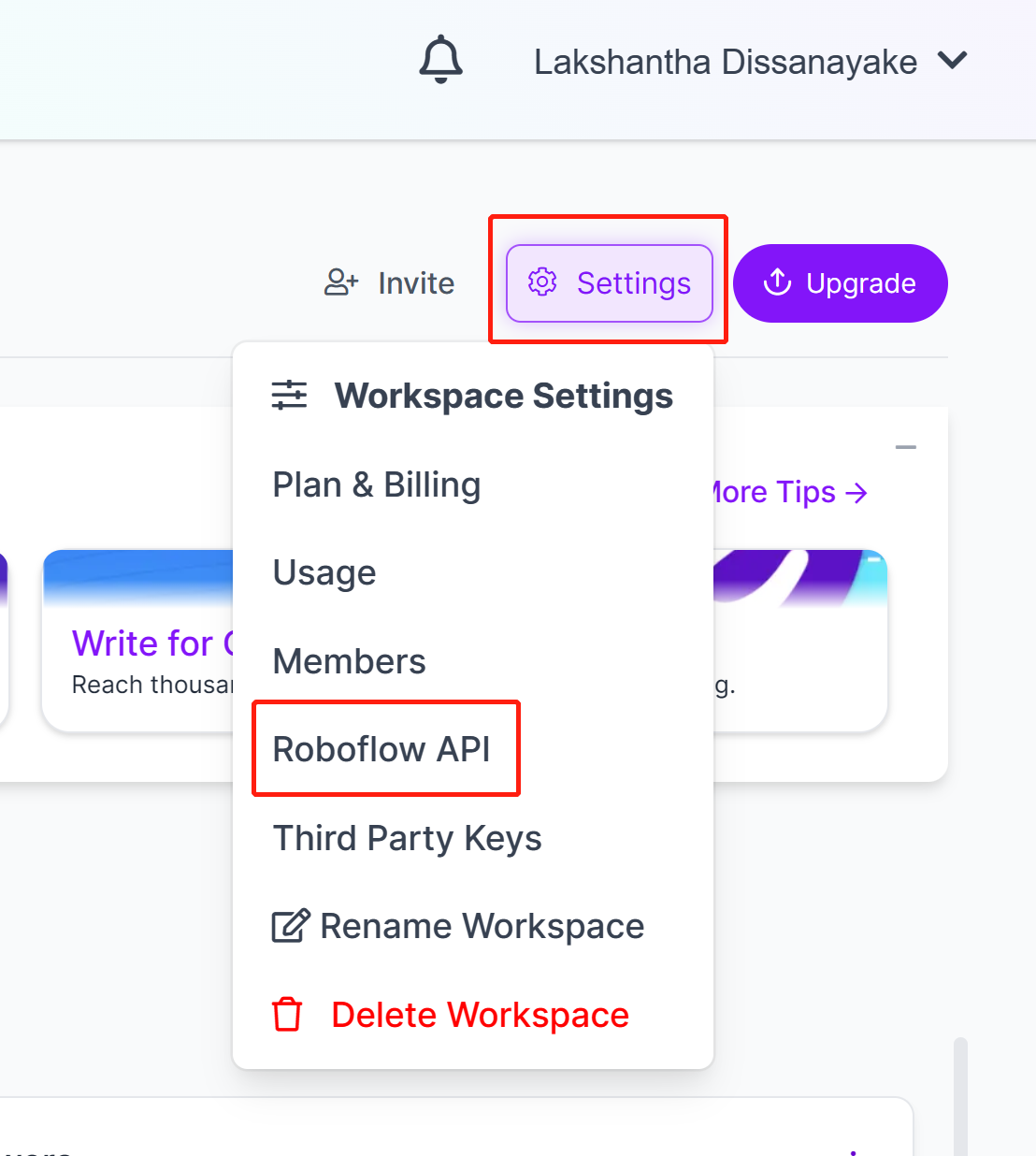
- 步骤8. 点击copy按钮复制Private API Key
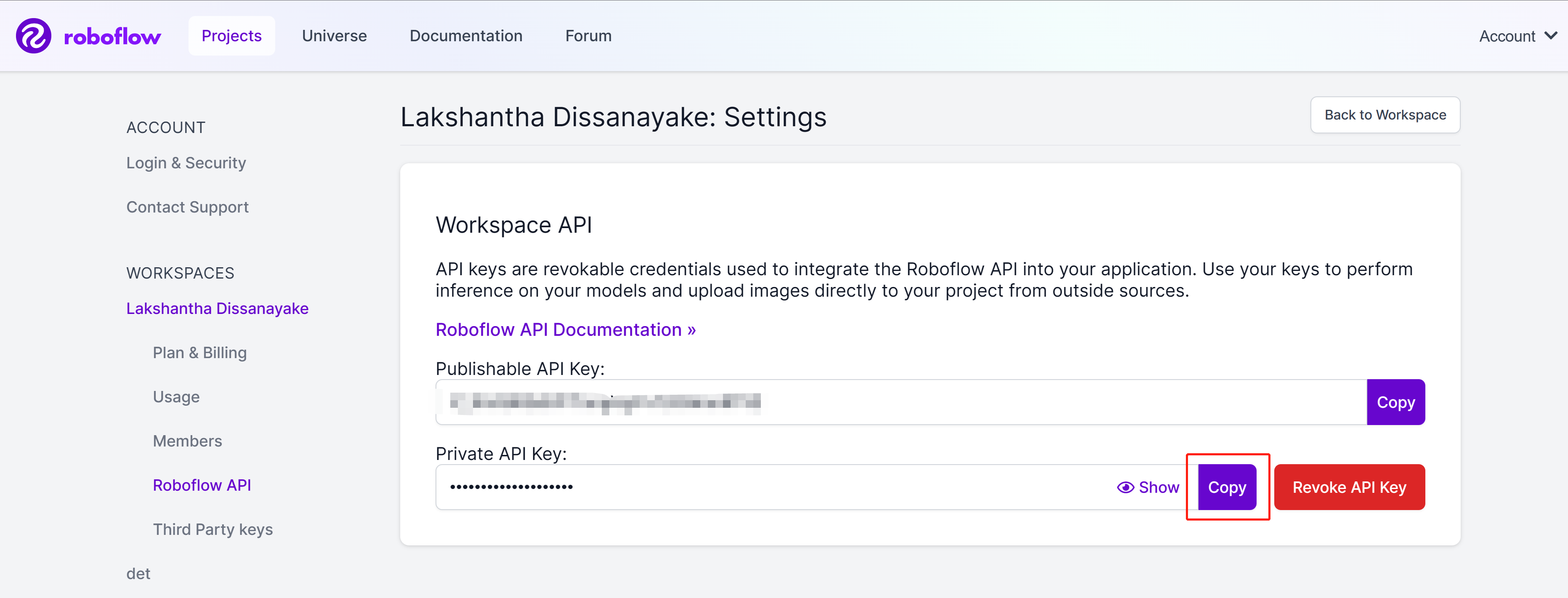
- 步骤9. 回到Ultralytics HUB仪表板,点击Integrations,将我们之前复制的API Key粘贴到空白栏中,然后点击Add
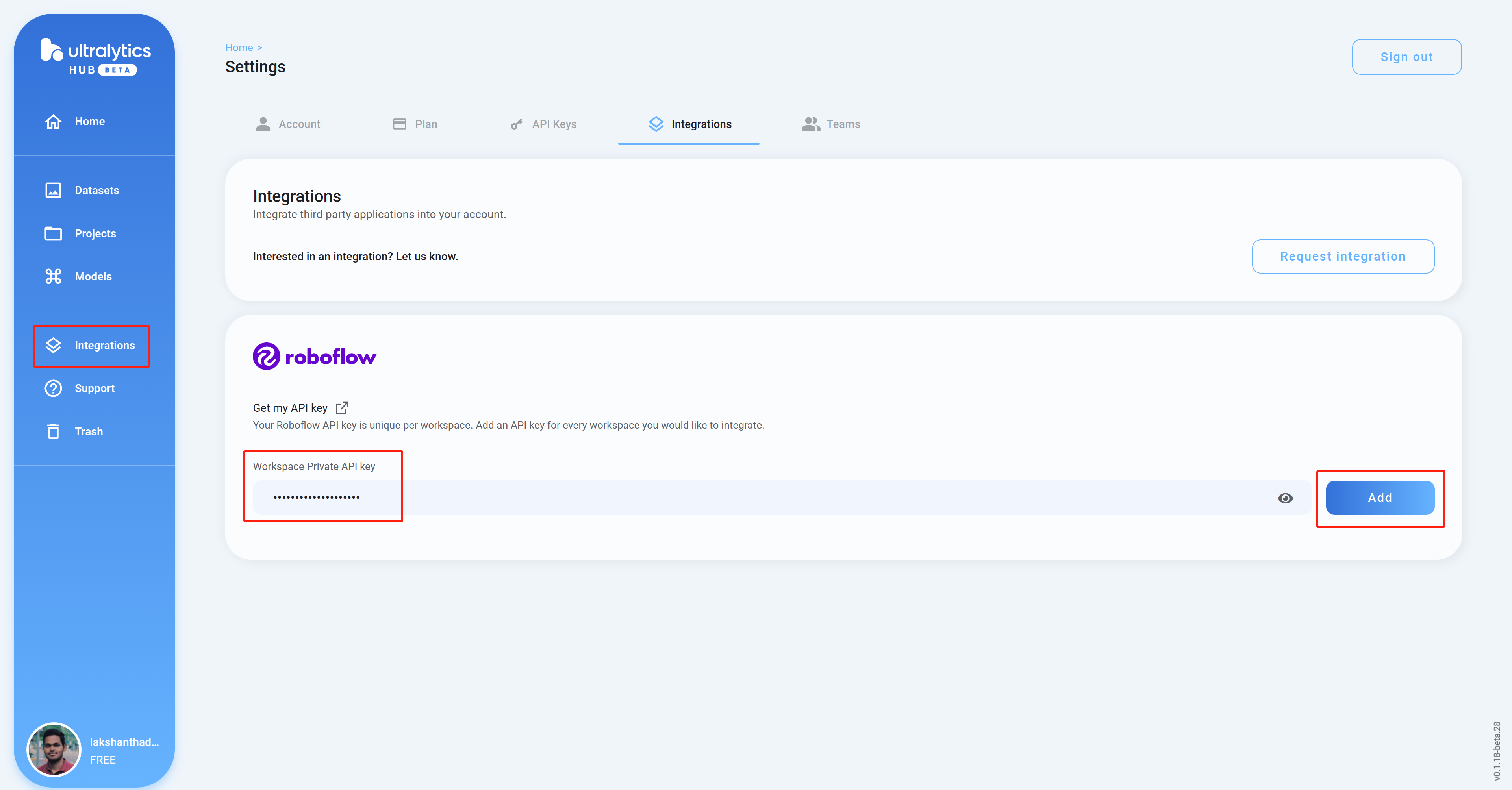
- 步骤10 如果您看到您的工作空间名称被列出,这意味着集成成功
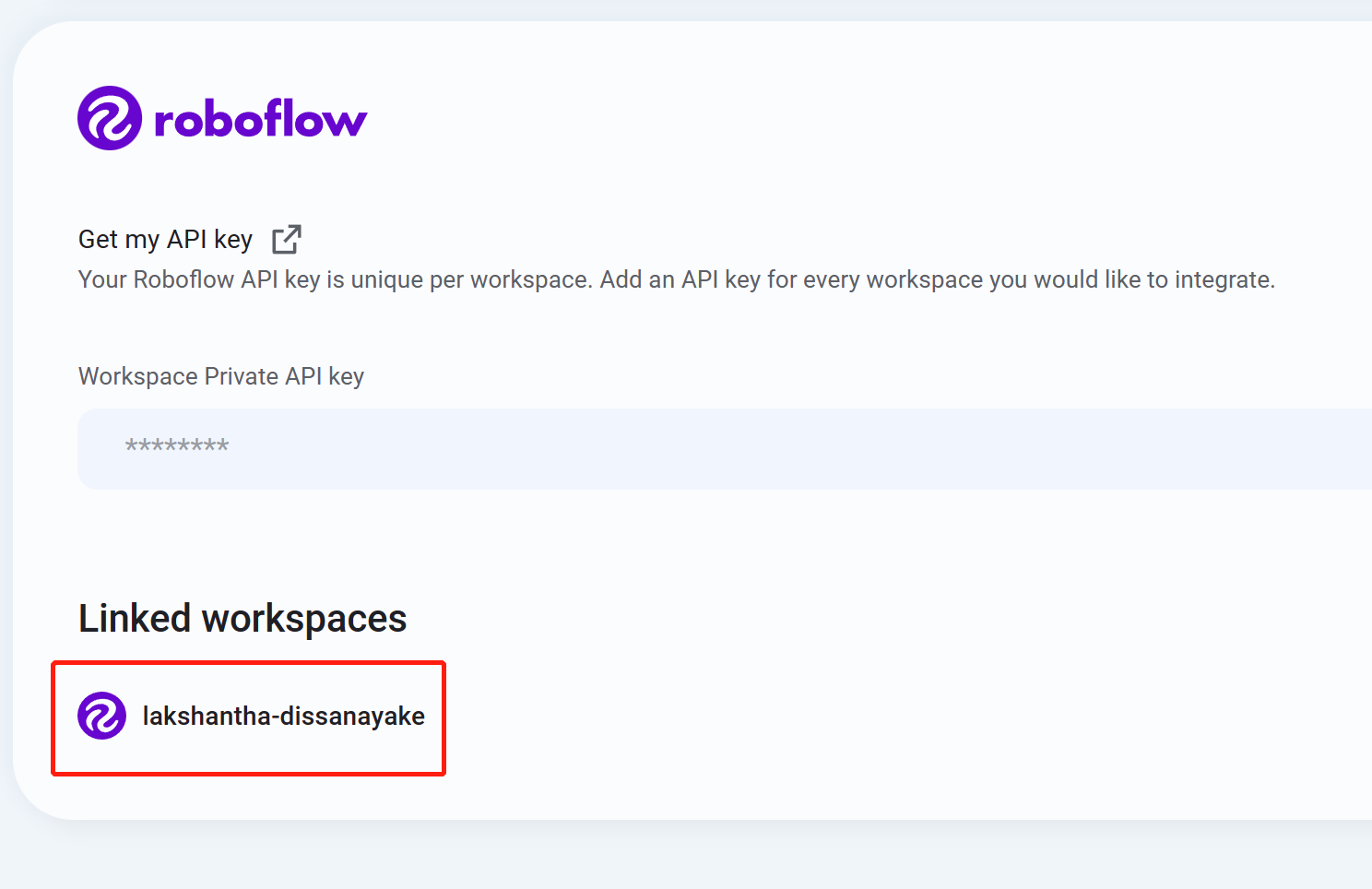
- 步骤11 导航到Datasets,您将在这里看到您所有的Roboflow项目
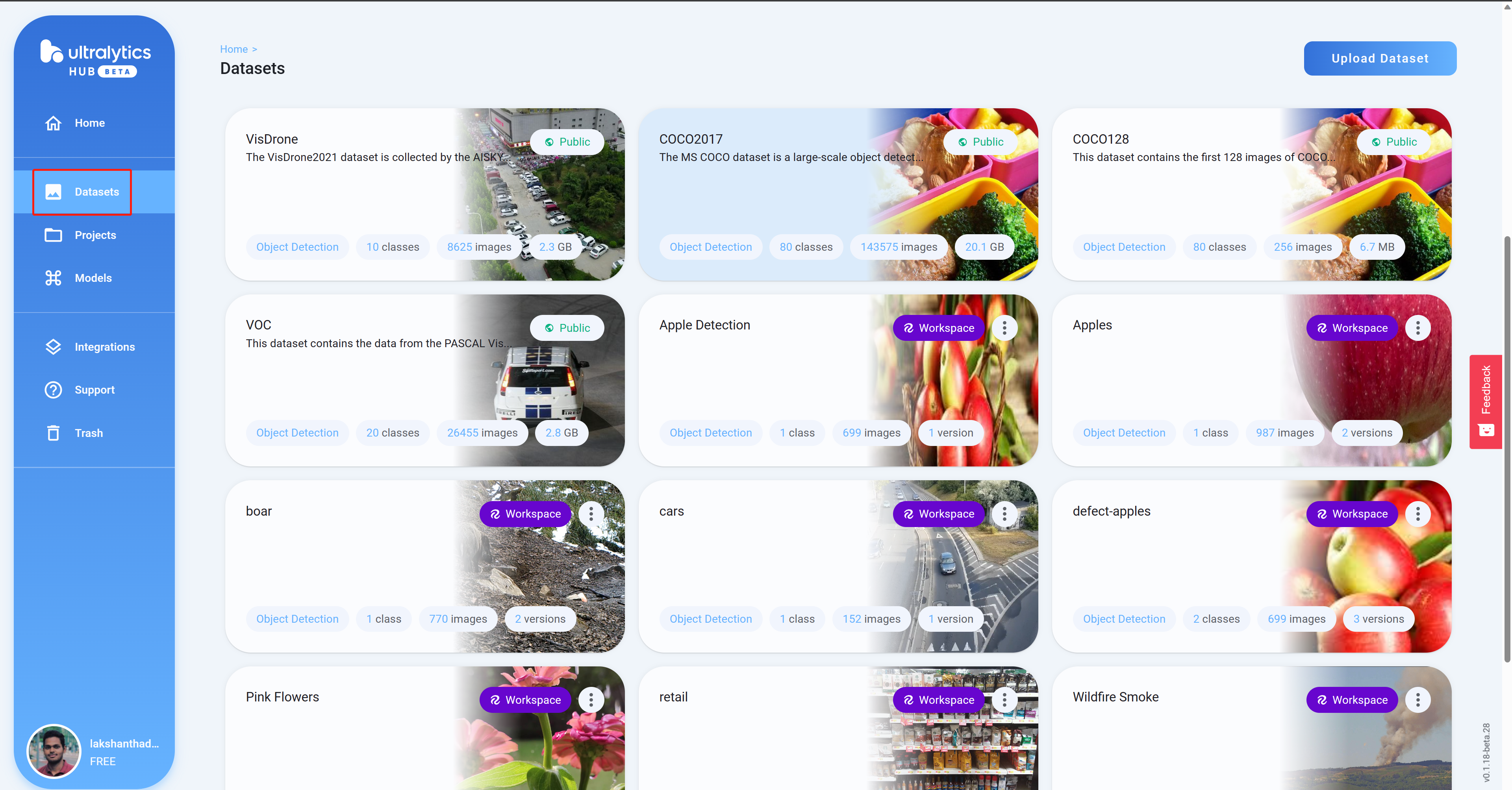
- 步骤12 点击一个项目来查看更多关于数据集的信息。这里我选择了一个可以检测健康和损坏苹果的数据集
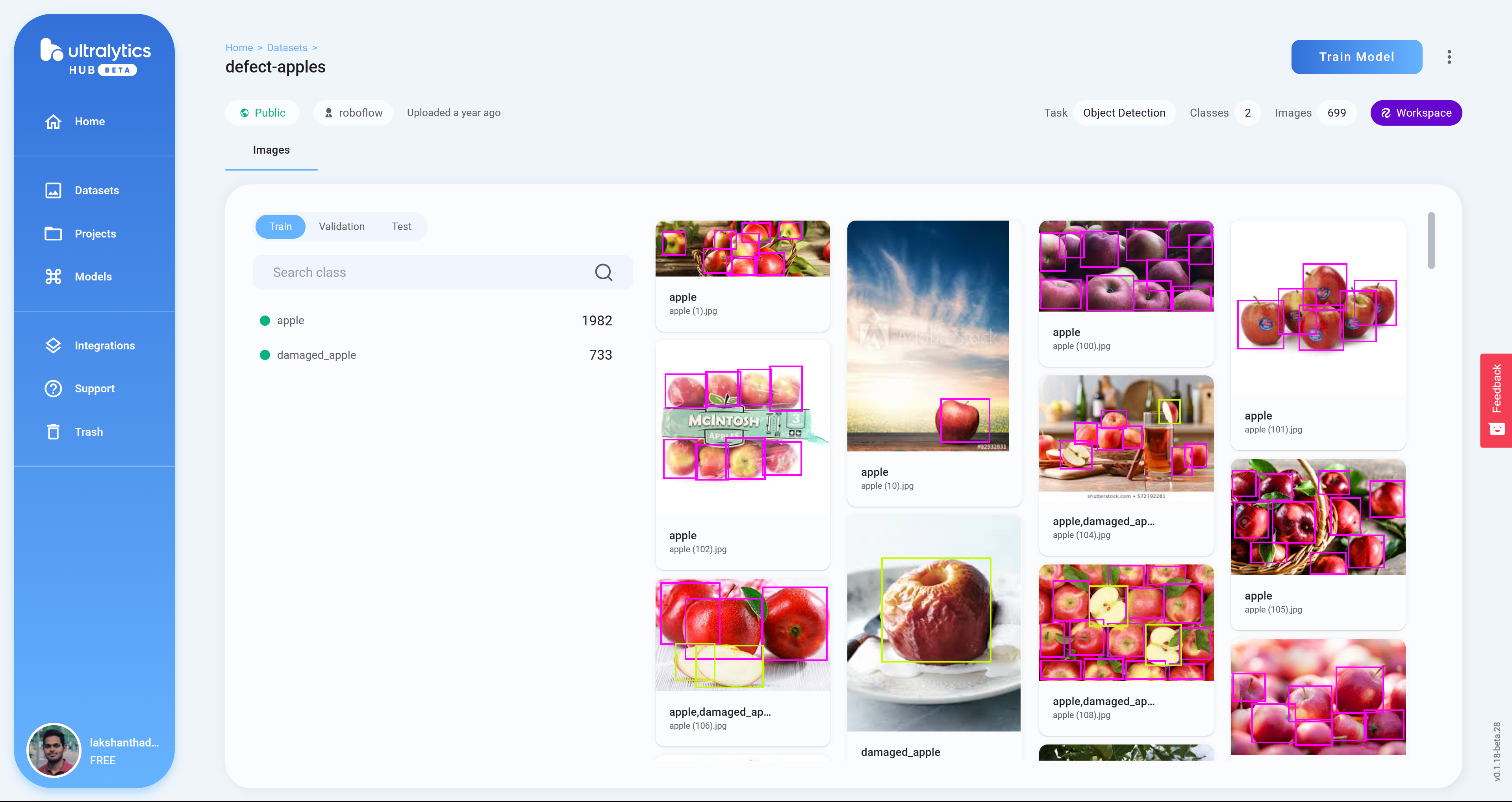
- 步骤13 点击Train Model
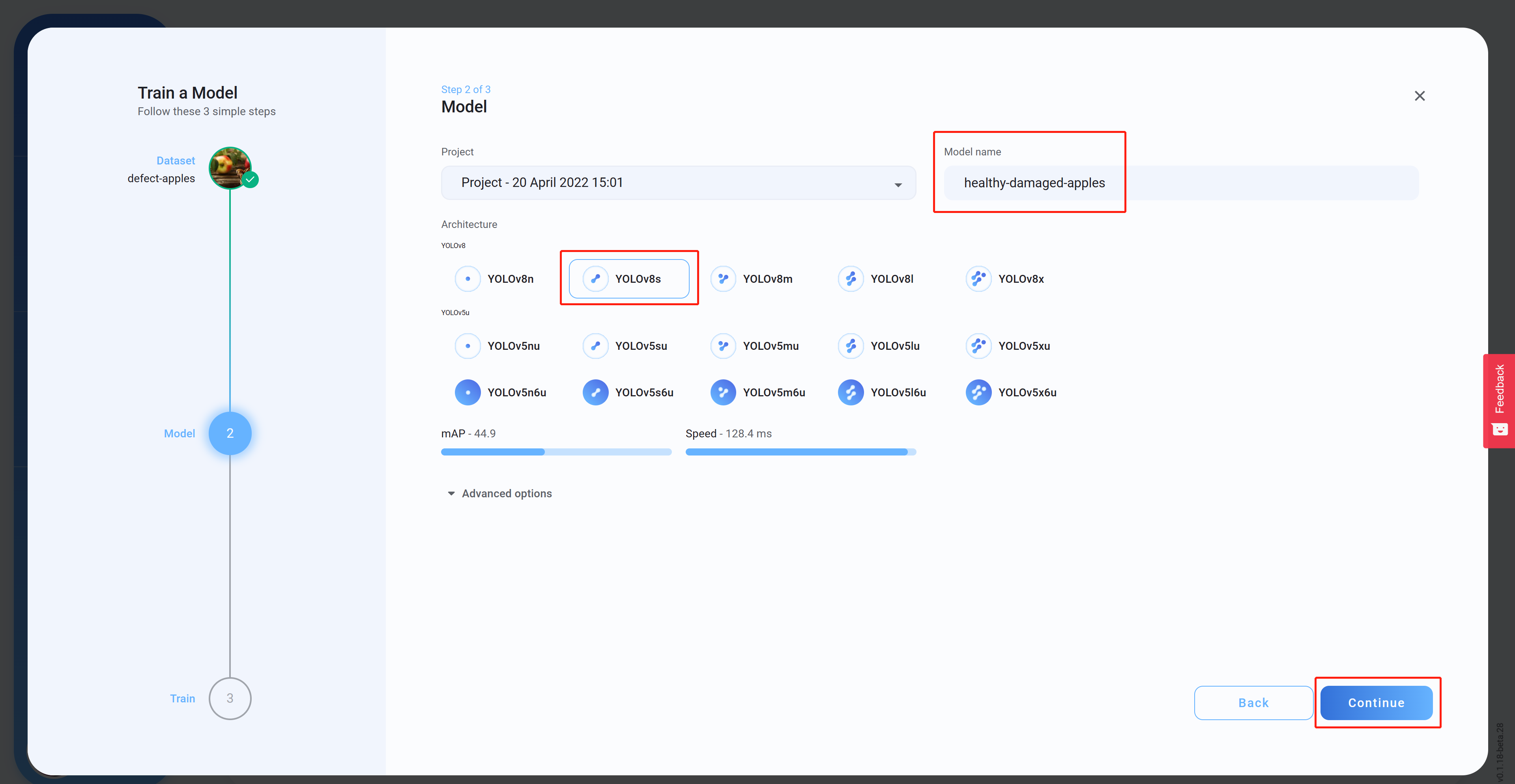
- 步骤14 选择Architecture,设置Model name(可选),然后点击Continue。这里我们选择了YOLOv8s作为模型架构
- 步骤15 在Advanced options下,根据您的偏好配置设置,复制并粘贴Colab代码(这将稍后粘贴到Colab工作空间中),然后点击Open Google Colab
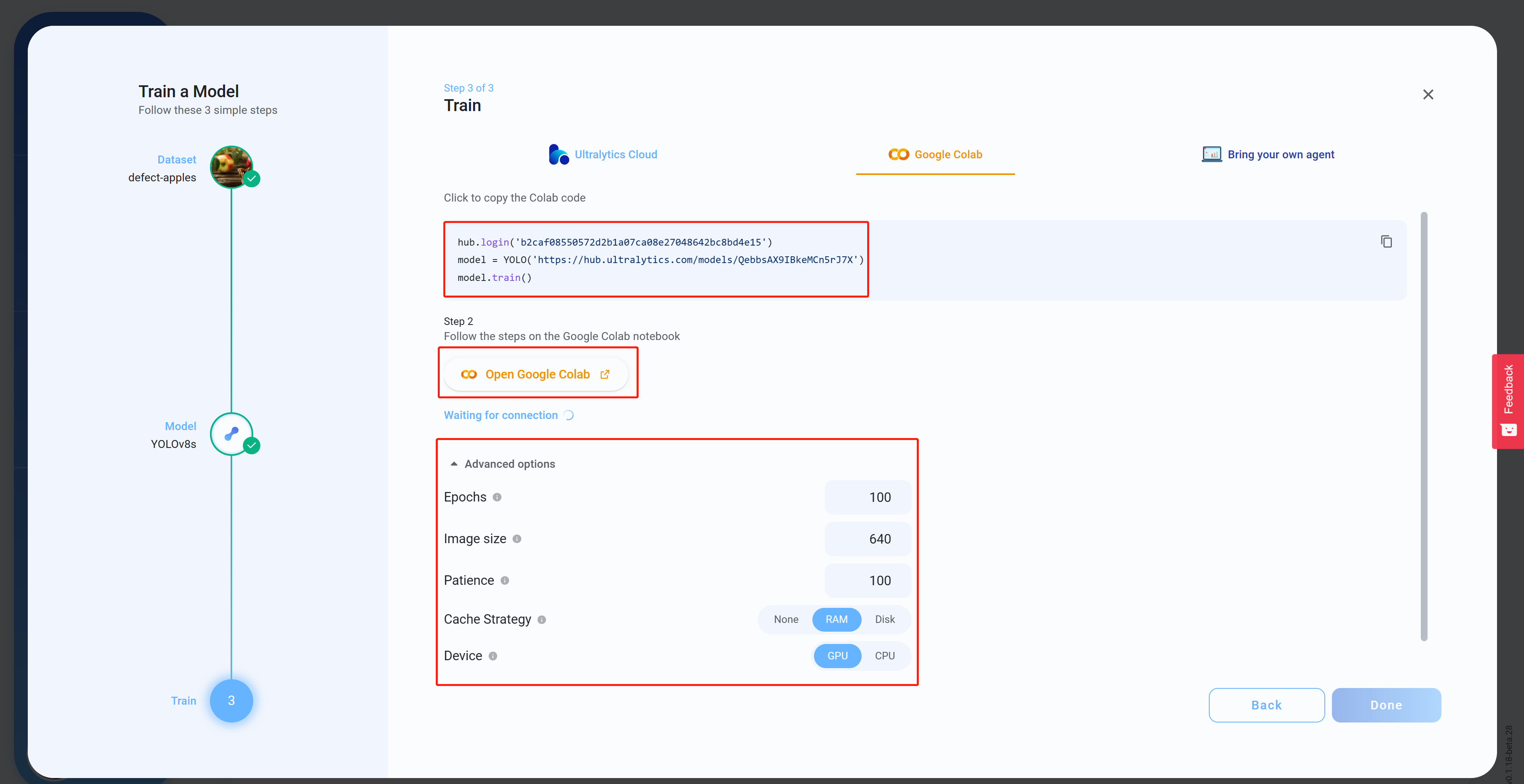
- 步骤16 如果您尚未登录,请登录您的Google账户
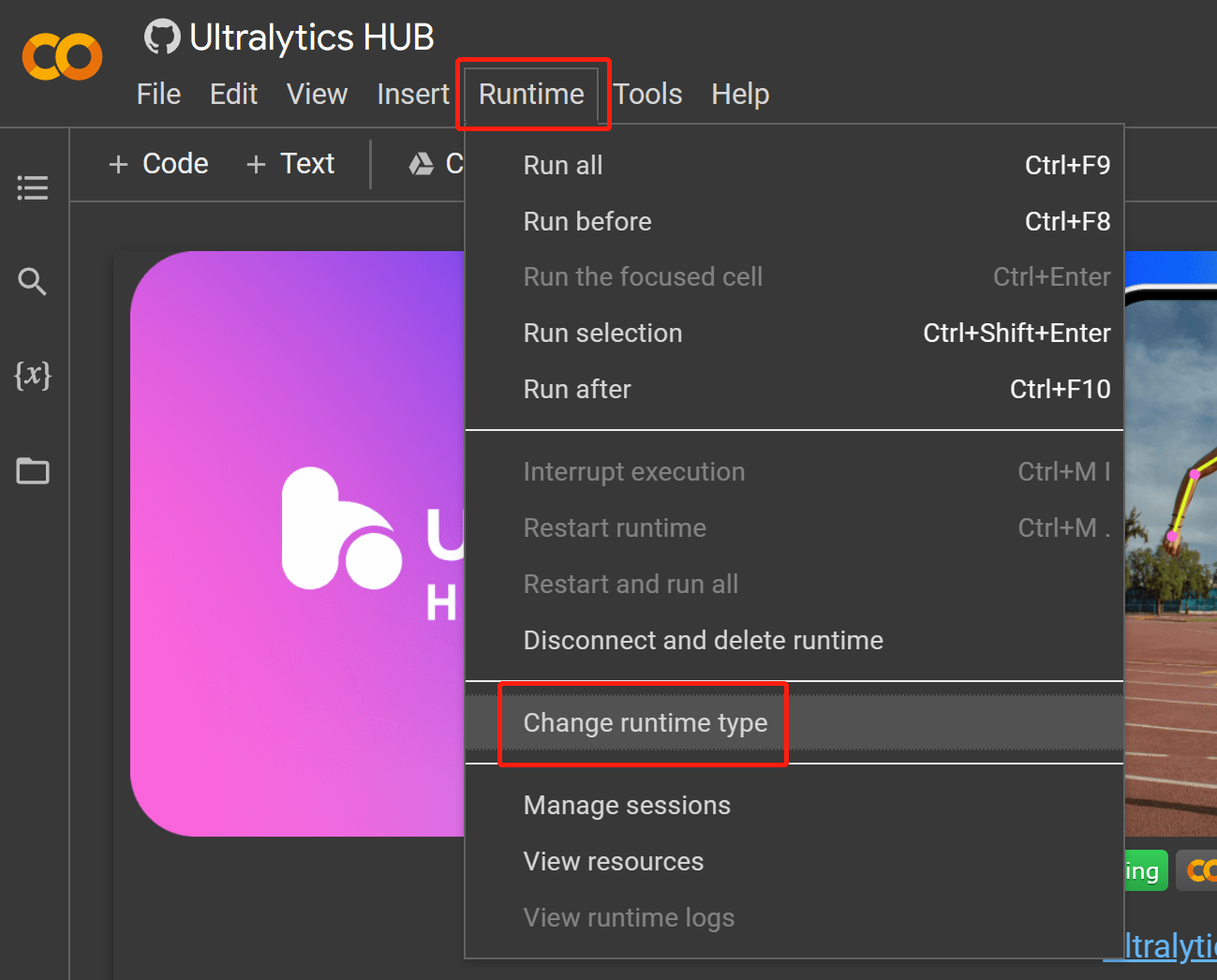
- 步骤 17 导航到
Runtime > Change runtime type
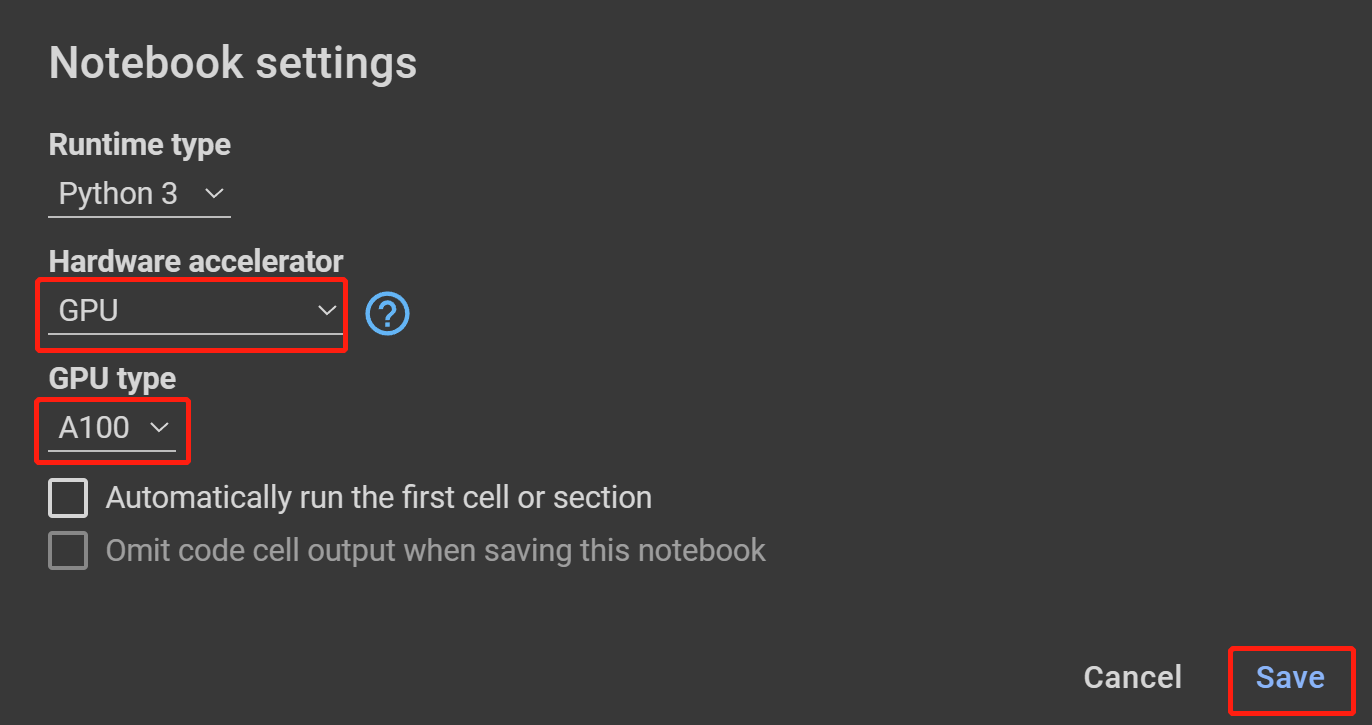
- 步骤 18 在 Hardware accelerator 下选择 GPU,在 GPU type 下选择最高可用选项,然后点击 Save
- 步骤 19 点击 Connect
- 步骤 20 点击 RAM, Disk 按钮来检查硬件资源使用情况
- 步骤 21 点击 Play 按钮运行第一个代码单元
- 步骤 22 将我们之前从 Ultralytics HUB 复制的代码单元粘贴到 Start 部分下方并运行它来开始训练
- 步骤 23 现在如果你回到 Ultralytics HUB,你会看到 Connected 消息。点击 Done
- 步骤 24 在这里你会看到模型在 Google Colab 上训练时的实时 Box Loss、Class Loss 和 Object Loss
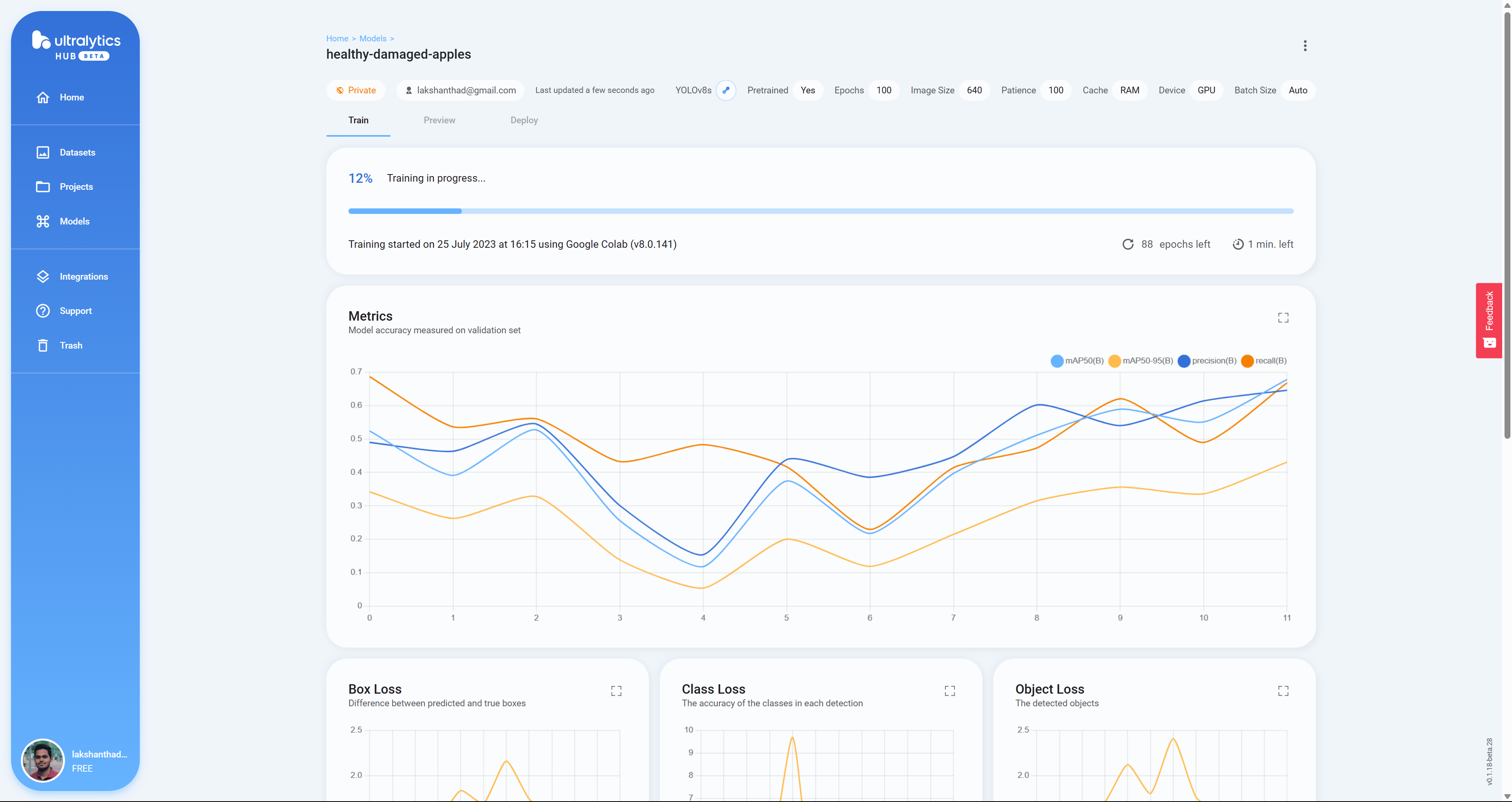
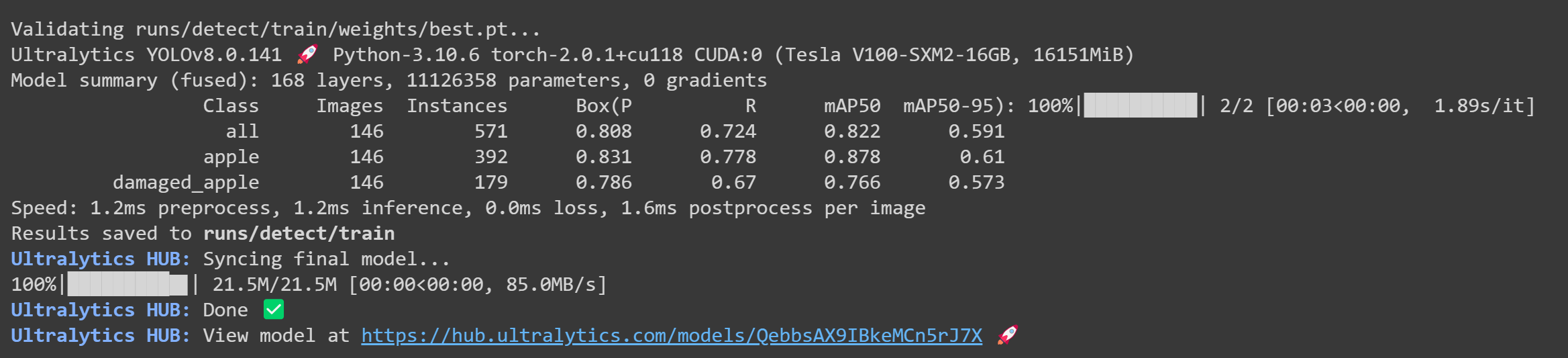
- 步骤 25 训练完成后,你会在 Google Colab 上看到以下输出
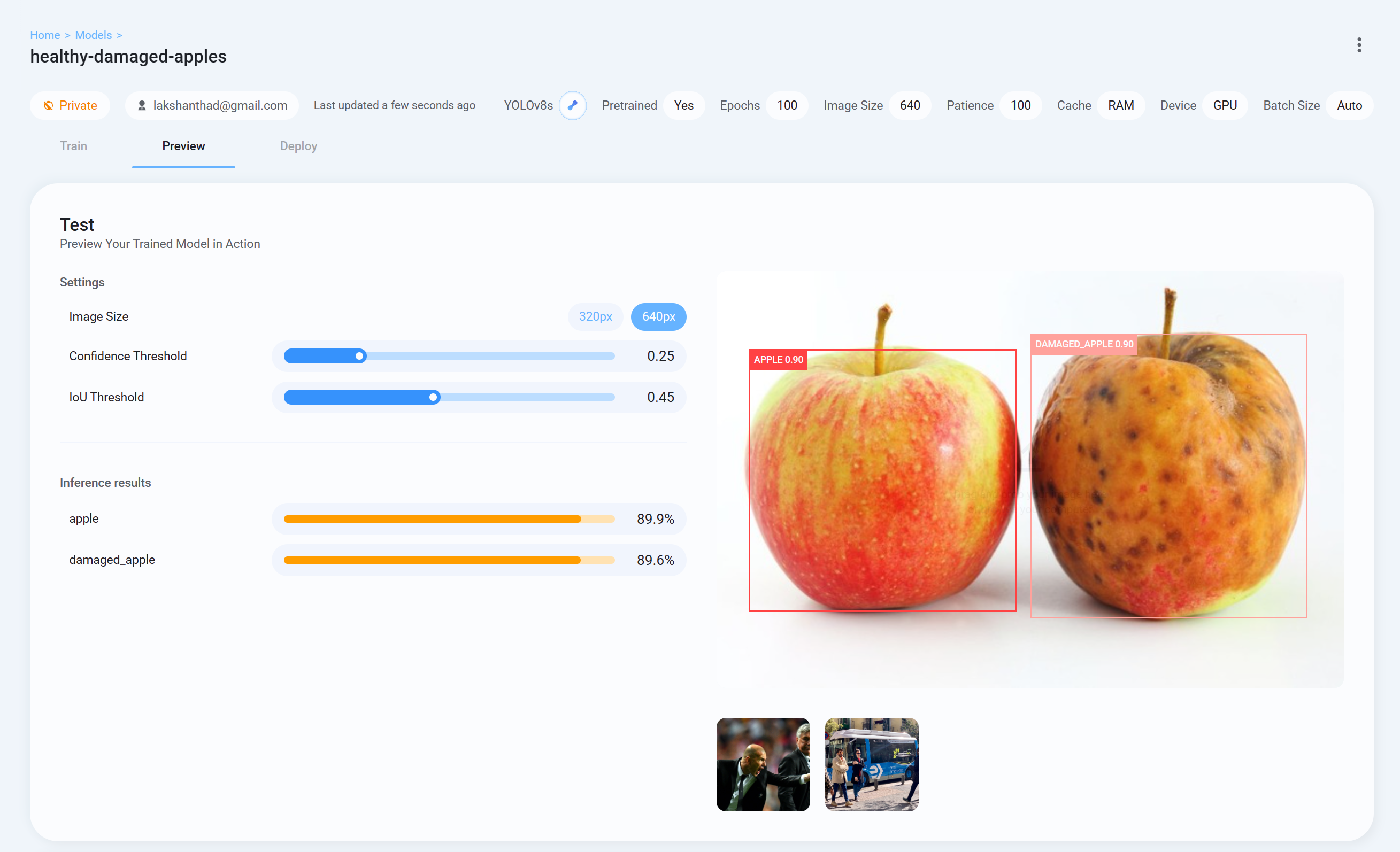
- 步骤 26 现在回到 Ultralytics HUB,转到 Preview 选项卡并上传一张测试图片来检查训练好的模型表现如何
- 步骤 26 最后转到 Deploy 选项卡,下载你希望用于 YOLOv8 推理的格式的训练好的模型。这里我们选择了 PyTorch。
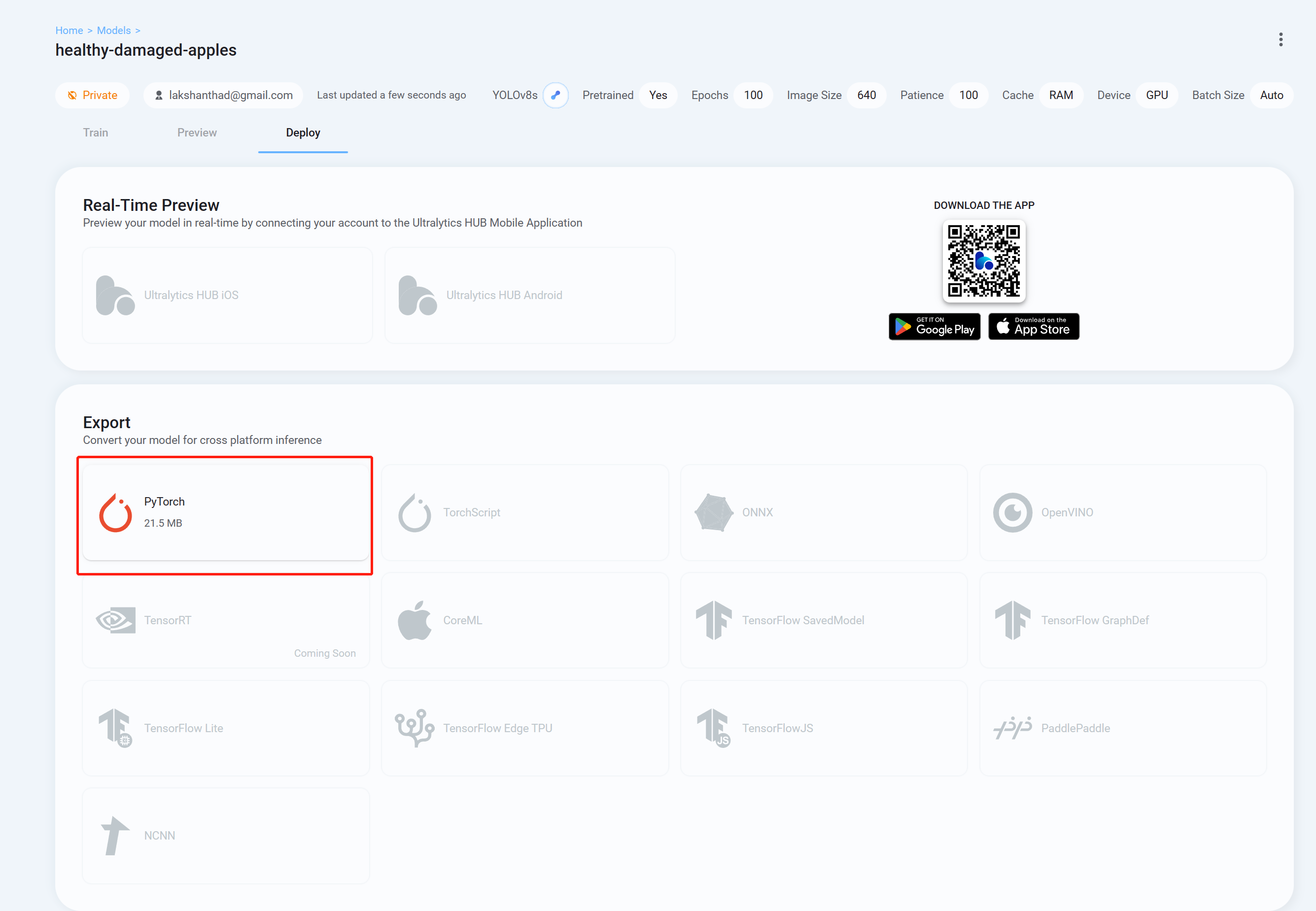
现在你可以将这个下载的模型用于我们之前在本 wiki 中解释的任务。你只需要将模型文件替换为你的模型。
例如:
yolo detect predict model=<your_model.pt> source='0' show=True
这里我们使用 Google Colaboratory 环境在云端执行训练。此外,我们在 Colab 中使用 Roboflow API 来轻松下载我们的数据集。
- 步骤 1. 点击这里打开一个已经准备好的 Google Colab 工作空间,并按照工作空间中提到的步骤进行操作
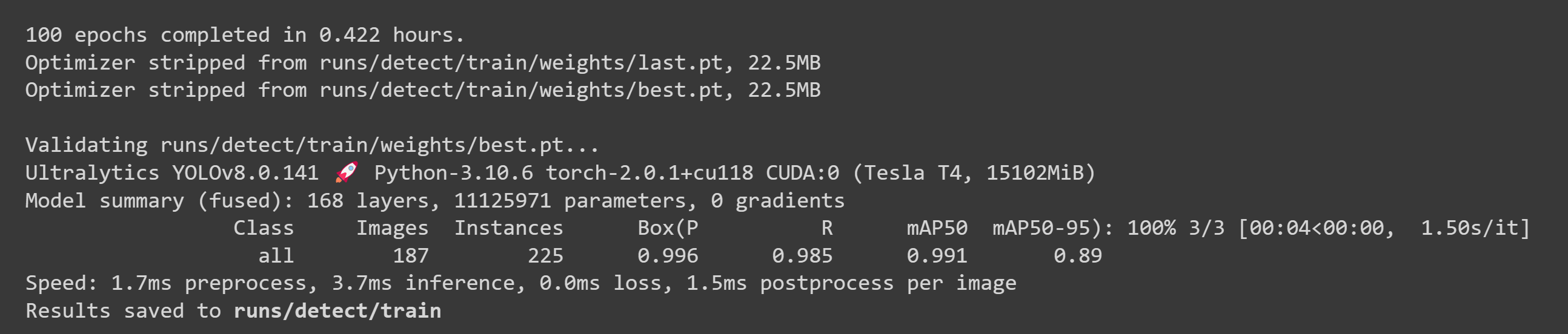
训练完成后,您将看到如下输出:
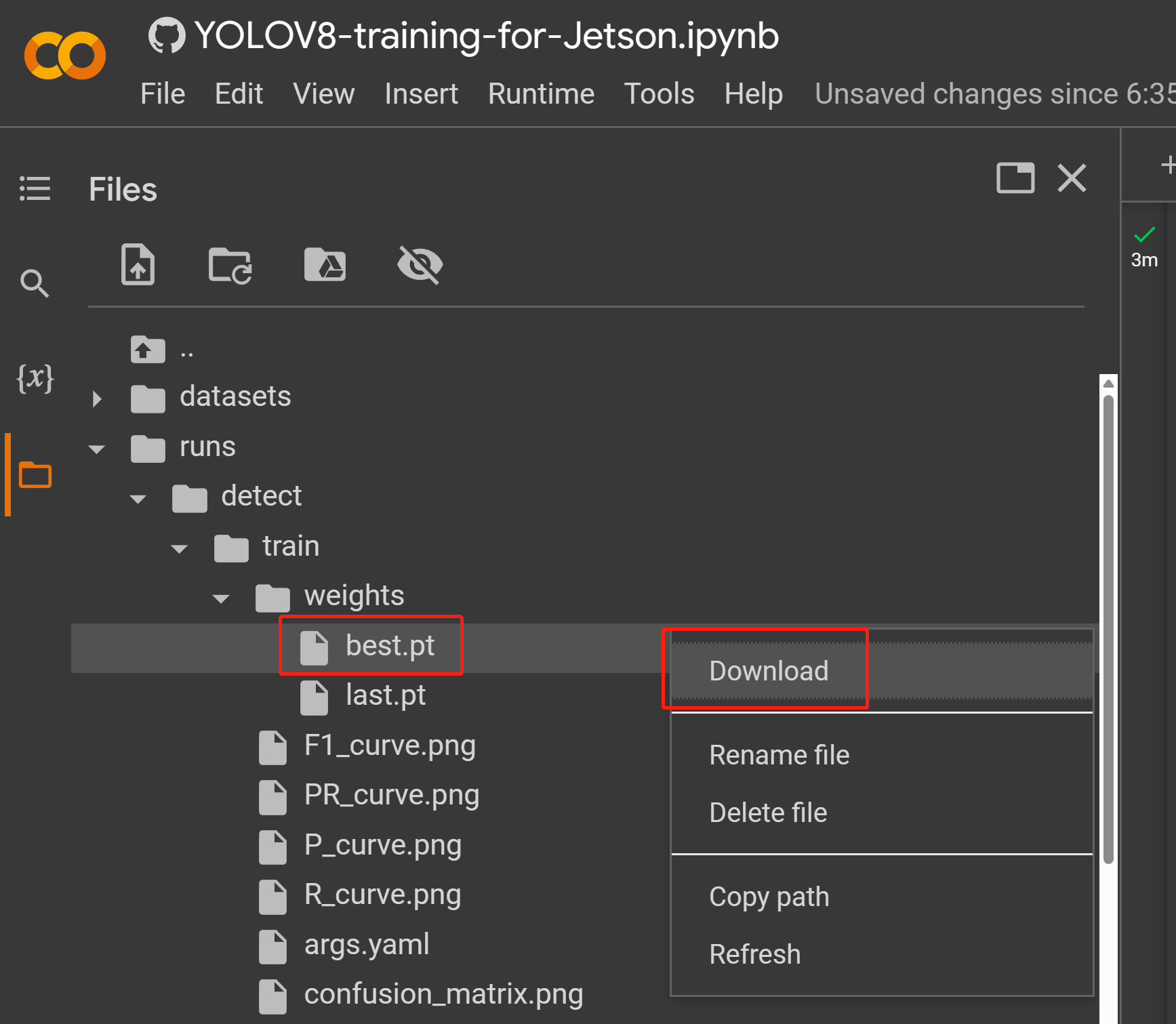
- 步骤 2. 在文件选项卡下,如果您导航到
runs/train/exp/weights,您将看到一个名为 best.pt 的文件。这是训练生成的模型。下载此文件并复制到您的 Jetson 设备上,因为这是我们稍后将在 Jetson 设备上用于推理的模型。
现在您可以将这个下载的模型用于我们之前在本 wiki 中解释的任务。您只需要用您的模型替换模型文件即可。
例如:
yolo detect predict model=<your_model.pt> source='0' show=True
这里你可以使用安装了Linux操作系统的PC进行训练。我们在这个wiki中使用了Ubuntu 20.04 PC。
- 步骤1. 如果你的系统中没有pip,请安装pip
sudo apt install python3-pip -y
- 步骤 2. 安装 Ultralytics 及其依赖项
pip install ultralytics
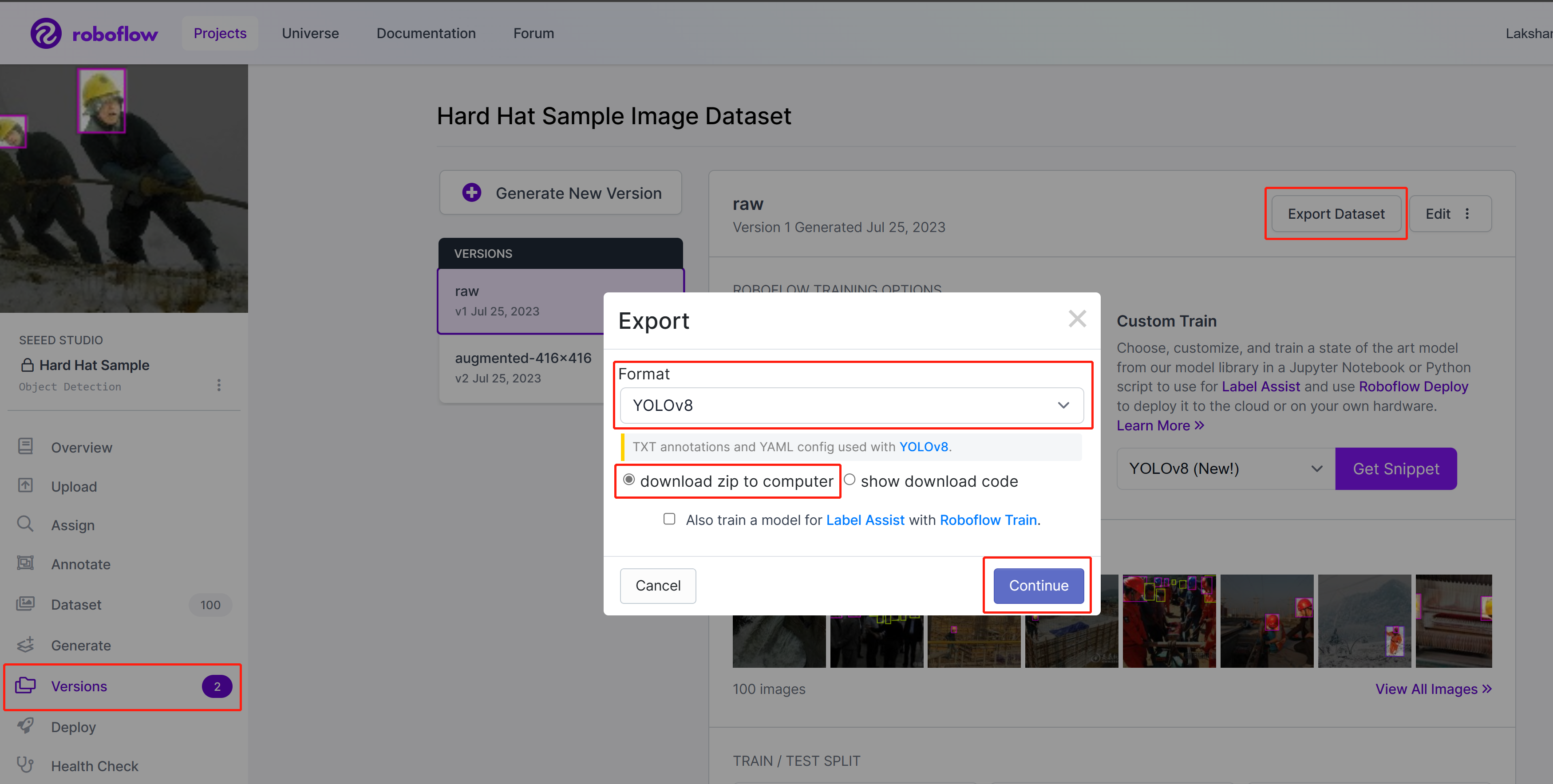
- 步骤 3. 在 Roboflow 上,进入您的项目,转到 Versions,选择 Export Dataset,选择 Format 为 YOLOv8,选择 download zip to computer 并点击 Continue
-
步骤 4. 解压下载的 zip 文件
-
步骤 5. 执行以下命令开始训练。这里您需要将 path_to_yaml 替换为之前解压的 zip 文件中的 .yaml 文件位置
yolo train data=<path_to_yaml> model=yolov8s.pt epochs=100 imgsz=640 batch=-1
这里图像尺寸设置为 640x640。我们使用 batch-size 为 -1,因为这会自动确定最佳批次大小。您也可以根据自己的偏好更改 epoch。在这里您可以将预训练模型更改为任何检测、分割、分类、姿态模型。
训练完成后,您将看到如下输出:
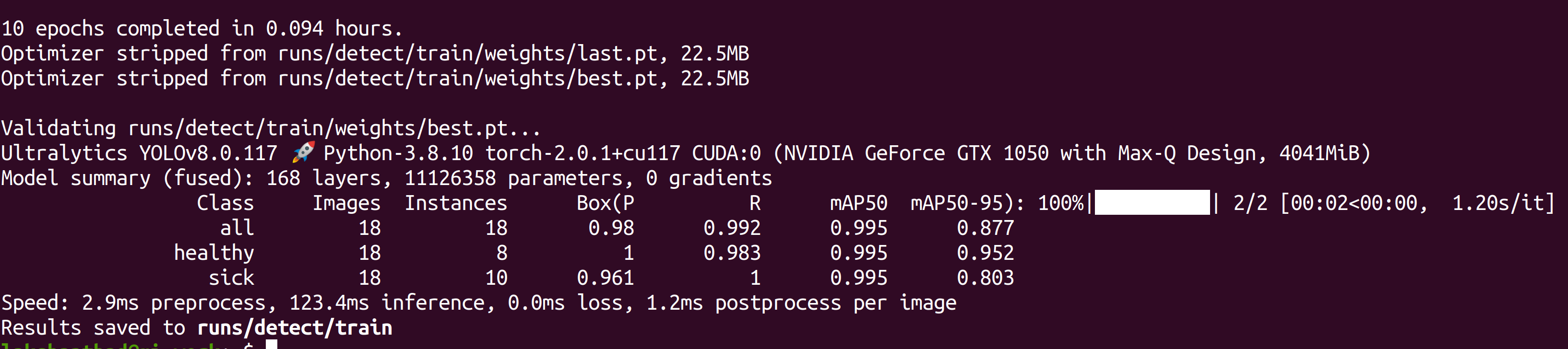
- 步骤 6. 在 runs/detect/train/weights 目录下,您将看到一个名为 best.pt 的文件。这是训练生成的模型。下载此文件并复制到您的 Jetson 设备上,因为这是我们稍后在 Jetson 设备上进行推理时要使用的模型。

现在您可以将这个下载的模型用于我们之前在本 wiki 中解释的任务。您只需要将模型文件替换为您的模型即可。
例如:
yolo detect predict model=<your_model.pt> source='0' show=True
性能基准测试
准备工作
我们已经对运行在 reComputer J4012/ reComputer Industrial J4012(搭载 NVIDIA Jetson Orin NX 16GB 模块)上的 YOLOv8 支持的所有计算机视觉任务进行了性能基准测试。
samples 目录中包含一个名为 trtexec 的命令行包装工具。trtexec 是一个无需开发自己的应用程序即可使用 TensorRT 的工具。trtexec 工具有三个主要用途:
- 使用随机或用户提供的输入数据对网络进行基准测试。
- 从模型生成序列化引擎。
- 从构建器生成序列化时序缓存。
在这里我们可以使用 trtexec 工具来快速对具有不同参数的模型进行基准测试。但首先,您需要有一个 onnx 模型,我们可以使用 ultralytics yolov8 来生成这个 onnx 模型。
- 步骤 1. 使用以下命令构建 ONNX:
yolo mode=export model=yolov8s.pt format=onnx
- 步骤 2. 使用trtexec构建引擎文件,步骤如下:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
For example:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine
这将输出性能结果以及生成的 .engine 文件。默认情况下,它将把 ONNX 转换为 FP32 精度的 TensorRT 优化文件,您可以看到如下输出
如果您想要 FP16 精度(比 FP32 提供更好的性能),您可以按如下方式执行上述命令
./trtexec --onnx=/home/nvidia/yolov8s.onnx --fp16 --saveEngine=/home/nvidia/yolov8s.engine
但是,如果您想要 INT8 精度,它比 FP16 提供更好的性能,您可以按如下方式执行上述命令
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
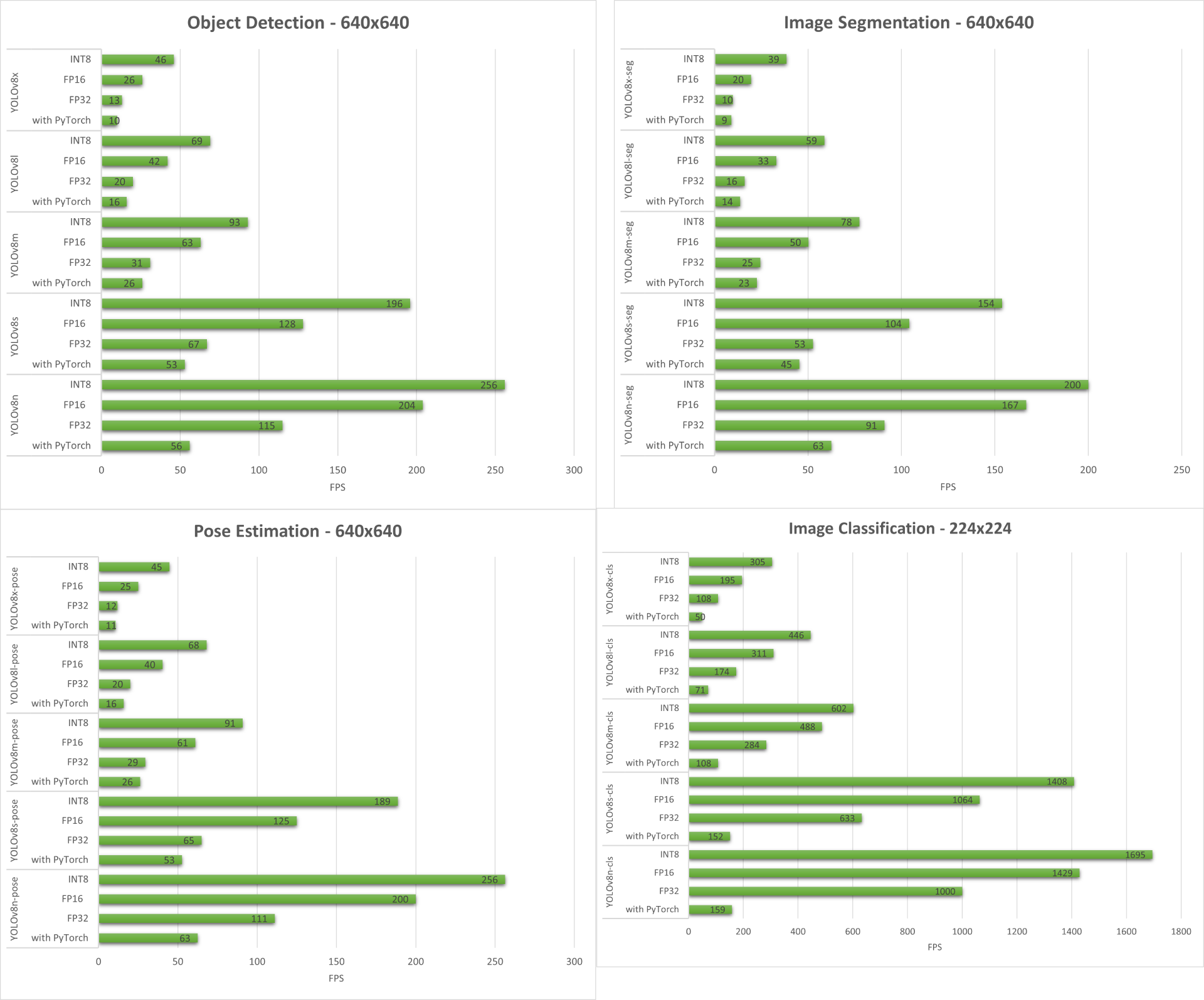
结果
下面我们总结了在 reComputer J4012/ reComputer Industrial J4012 上运行所有四个计算机视觉任务得到的结果。
额外演示:基于 YOLOv8 的运动检测和计数器
我们使用 YOLOv8-Pose 模型构建了一个基于 YOLOv8 的运动检测和计数姿态估计演示应用程序。您可以查看这里的项目来了解更多关于此演示的信息,并在您自己的 Jetson 设备上部署!
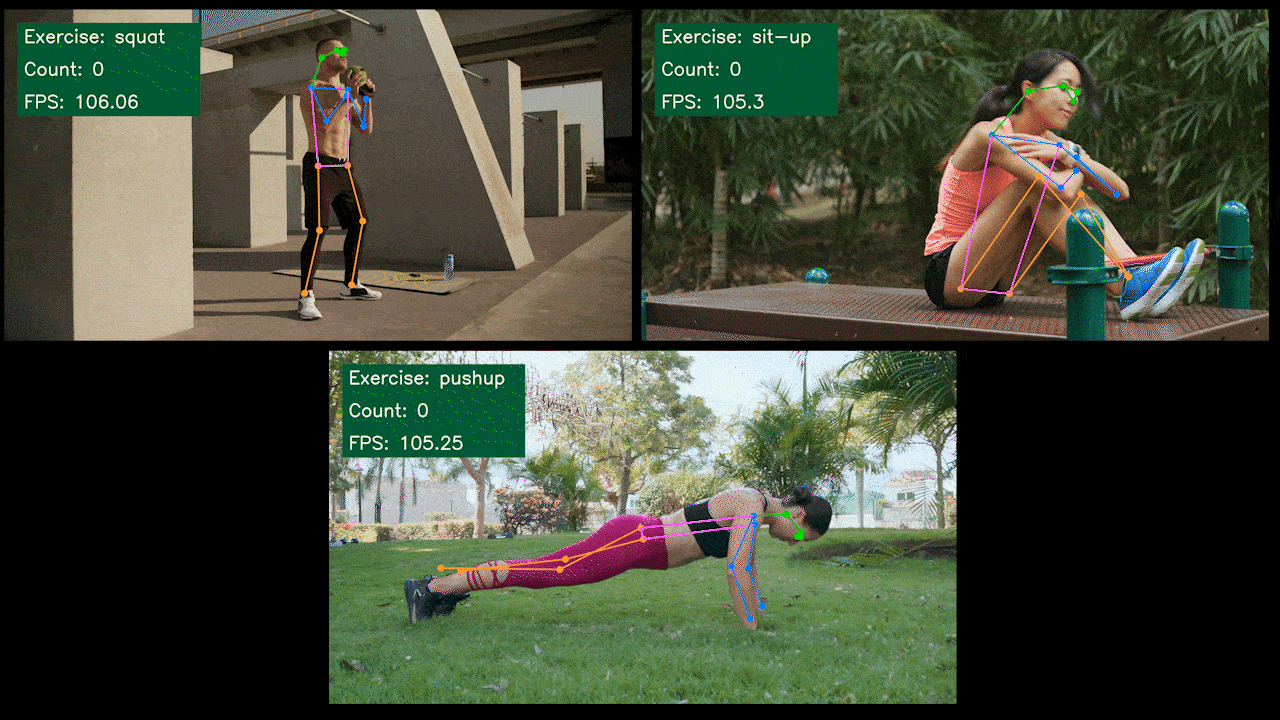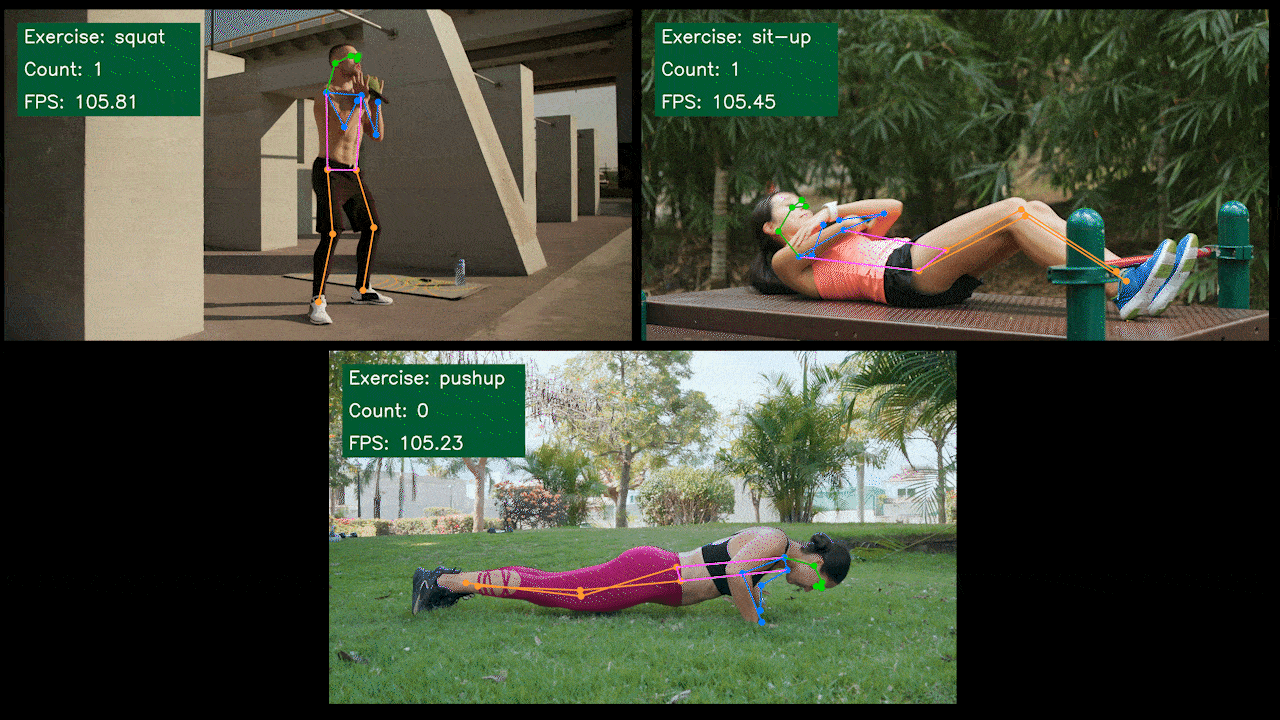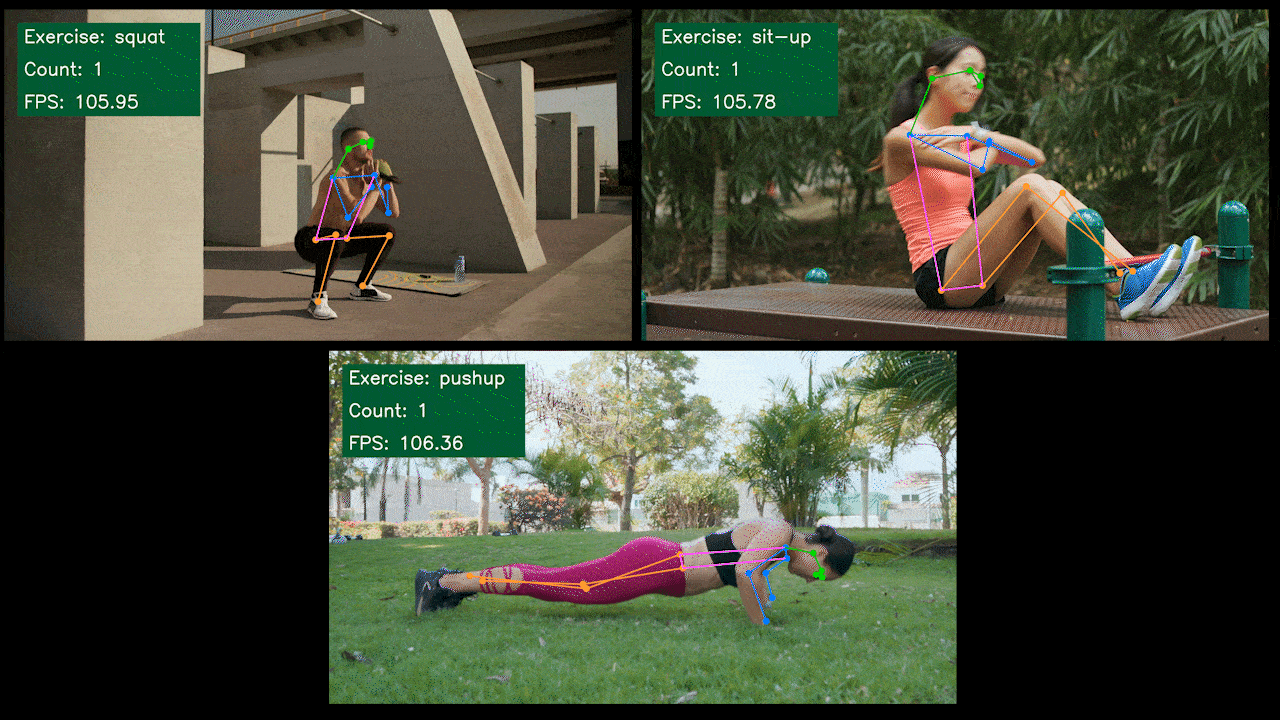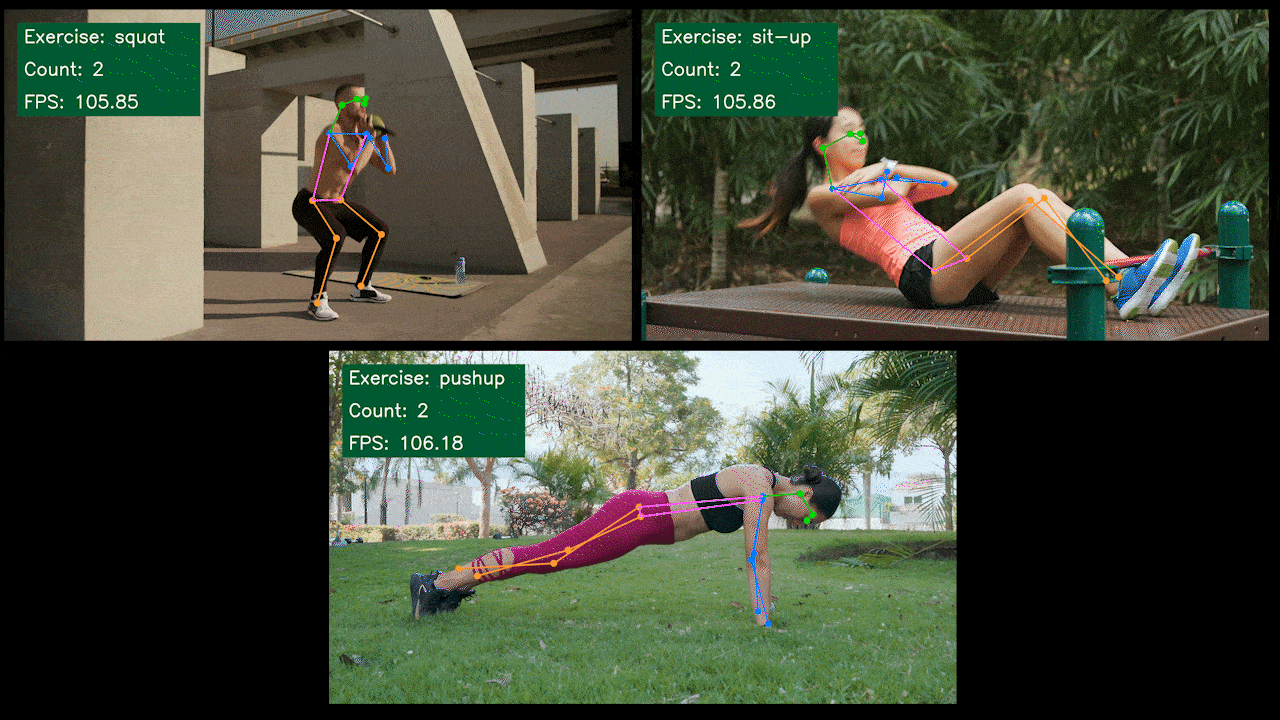
在 NVIDIA Jetson 上手动设置 YOLOv8
如果我们之前提到的一行脚本出现了一些错误,您可以逐步执行以下步骤来为 Jetson 设备准备 YOLOv8。
安装 Ultralytics 包
- 步骤 1. 访问 Jetson 设备的终端,安装 pip 并升级它
sudo apt update
sudo apt install -y python3-pip -y
pip3 install --upgrade pip
- 步骤 2. 安装 Ultralytics 包
pip3 install ultralytics
- 步骤 3. 将 numpy 版本升级到最新
pip3 install numpy -U
- 步骤 4. 重启设备
sudo reboot
卸载 Torch 和 Torchvision
上述 ultralytics 安装将会安装 Torch 和 Torchvision。然而,通过 pip 安装的这 2 个包与基于 ARM aarch64 架构的 Jetson 平台不兼容。因此我们需要手动安装预构建的 PyTorch pip wheel 并从源码编译/安装 Torchvision。
pip3 uninstall torch torchvision
安装 PyTorch 和 Torchvision
访问此页面获取所有 PyTorch 和 Torchvision 链接。
以下是 JetPack 5.0 及以上版本支持的一些版本。
PyTorch v2.0.0
支持 JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) 与 Python 3.8
文件名: torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl
PyTorch v1.13.0
支持 JetPack 5.0 (L4T R34.1) / JetPack 5.0.2 (L4T R35.1) / JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) 与 Python 3.8
文件名: torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v502/pytorch/torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl
- 步骤 1. 根据您的 JetPack 版本按以下格式安装 torch pip3
wget <URL> -O <file_name>
pip3 install <file_name>
例如,在这里我们运行的是 JP5.1.1,因此我们选择 PyTorch v2.0.0
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl -O torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
- 步骤 2. 根据您已安装的 PyTorch 版本安装 torchvision。例如,我们选择了 PyTorch v2.0.0,这意味着我们需要选择 Torchvision v0.15.2
sudo apt install -y libjpeg-dev zlib1g-dev
git clone https://github.com/pytorch/vision torchvision
cd torchvision
git checkout v0.15.2
python3 setup.py install --user
以下是根据 PyTorch 版本需要安装的对应 torchvision 版本列表:
- PyTorch v2.0.0 - torchvision v0.15
- PyTorch v1.13.0 - torchvision v0.14
如果您想要更详细的列表,请查看此链接。
安装 ONNX 并降级 Numpy
只有当您想要将 PyTorch 模型转换为 TensorRT 时才需要此步骤
- 步骤 1. 安装 ONNX,这是一个必需的依赖项
pip3 install onnx
- 步骤 2. 降级到较低版本的Numpy以修复错误
pip3 install numpy==1.20.3
资源
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。