在 reComputer Jetson 上的分布式 llama.cpp(RPC 模式)

在 NVIDIA Jetson 等边缘设备上运行大型语言模型(LLM)可能因内存和计算限制而具有挑战性。本指南演示了如何使用 llama.cpp 的 RPC 后端在多个 reComputer Jetson 设备上分布 LLM 推理,从而为更苛刻的工作负载实现水平扩展。
前提条件
- 两台安装了 JetPack 6.x+ 且 CUDA 驱动程序正常工作的 reComputer Jetson 设备
- 两台设备在同一本地网络中,能够相互
ping通 - 本地机器(客户端)具有 ≥ 64 GB RAM,远程节点具有 ≥ 32 GB RAM
1. 克隆源代码
步骤 1. 克隆 llama.cpp 仓库:
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
2. 安装构建依赖项
步骤 1. 更新软件包列表并安装所需依赖项:
sudo apt update
sudo apt install -y build-essential cmake git libcurl4-openssl-dev python3-pip
3. 使用 RPC + CUDA 后端构建
步骤 1. 配置 CMake 以支持 RPC 和 CUDA:
cmake -B build \
-DGGML_CUDA=ON \
-DGGML_RPC=ON \
-DCMAKE_BUILD_TYPE=Release
步骤 2. 使用并行作业编译:
cmake --build build --parallel # Multi-core parallel compilation
4. 安装 Python 转换工具
步骤 1. 以开发模式安装 Python 包:
pip3 install -e .
5. 下载并转换模型
此示例使用 TinyLlama-1.1B-Chat-v1.0:
模型链接: https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
下载这些文件并将它们放在自创建的 TinyLlama-1.1B-Chat-v1.0 文件夹中。
步骤 1. 将 Hugging Face 模型转换为 GGUF 格式:
# Assuming the model is already downloaded to ~/TinyLlama-1.1B-Chat-v1.0 using git-lfs or huggingface-cli
python3 convert_hf_to_gguf.py \
--outfile ~/TinyLlama-1.1B.gguf \
~/TinyLlama-1.1B-Chat-v1.0
6. 验证单机推理
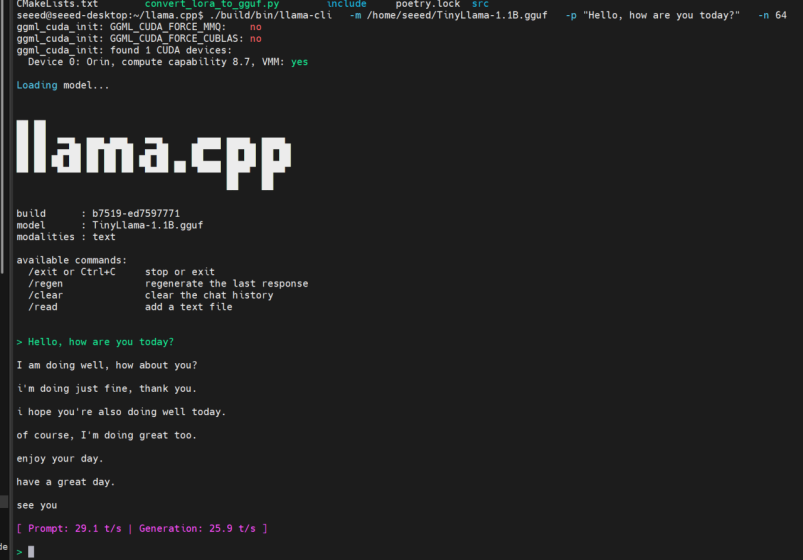
步骤 1. 使用简单提示测试模型:
./build/bin/llama-cli \
-m ~/TinyLlama-1.1B.gguf \
-p "Hello, how are you today?" \
-n 64
如果您收到响应,则模型工作正常。
7. 分布式 RPC 操作
7.1 硬件拓扑示例
| 设备 | RAM | 角色 | IP |
|---|---|---|---|
| 机器 A | 64 GB | 客户端 + 本地服务器 | 192.168.100.2 |
| 机器 B | 32 GB | 远程服务器 | 192.168.100.1 |
7.2 启动远程 RPC 服务器(机器 B)
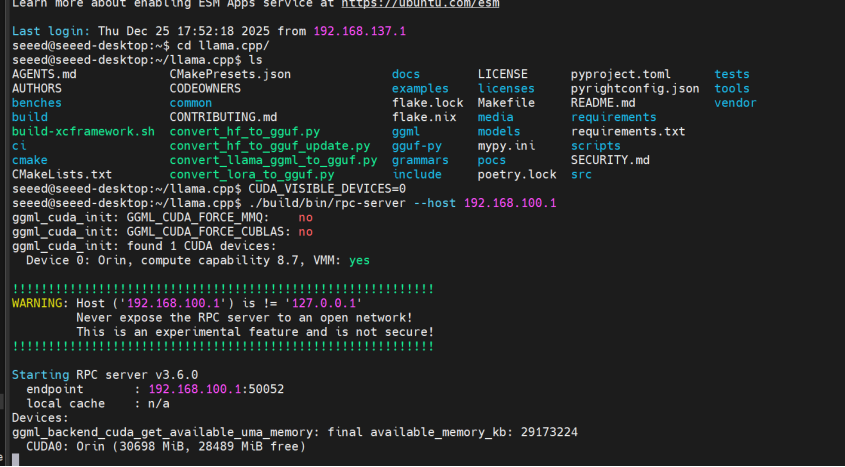
步骤 1. 连接到远程机器并启动 RPC 服务器:
ssh [email protected]
cd ~/llama.cpp
CUDA_VISIBLE_DEVICES=0 ./build/bin/rpc-server --host 192.168.100.1
服务器默认使用端口 50052。要自定义,请添加 -p <port>。
7.3 启动本地 RPC 服务器(机器 A)
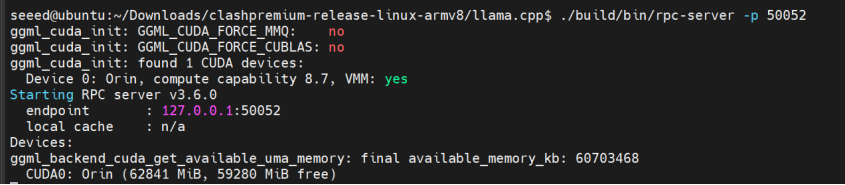
步骤 1. 启动本地 RPC 服务器:
cd ~/llama.cpp
CUDA_VISIBLE_DEVICES=0 ./build/bin/rpc-server -p 50052
7.4 联合推理(多节点负载)
步骤 1. 使用本地和远程 RPC 服务器运行推理:
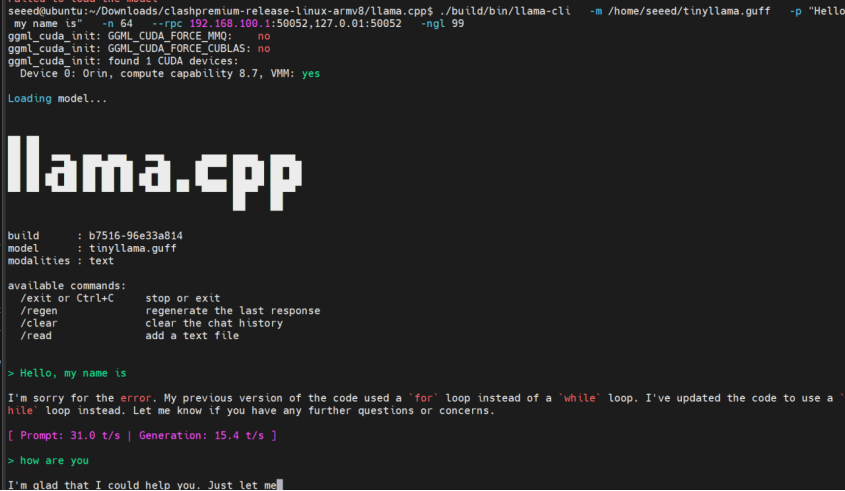
./build/bin/llama-cli \
-m ~/TinyLlama-1.1B.gguf \
-p "Hello, my name is" \
-n 64 \
--rpc 192.168.100.1:50052,127.0.0.1:50052 \
-ngl 99
-ngl 99 将 99% 的层卸载到 GPU(RPC 节点和本地 GPU)。
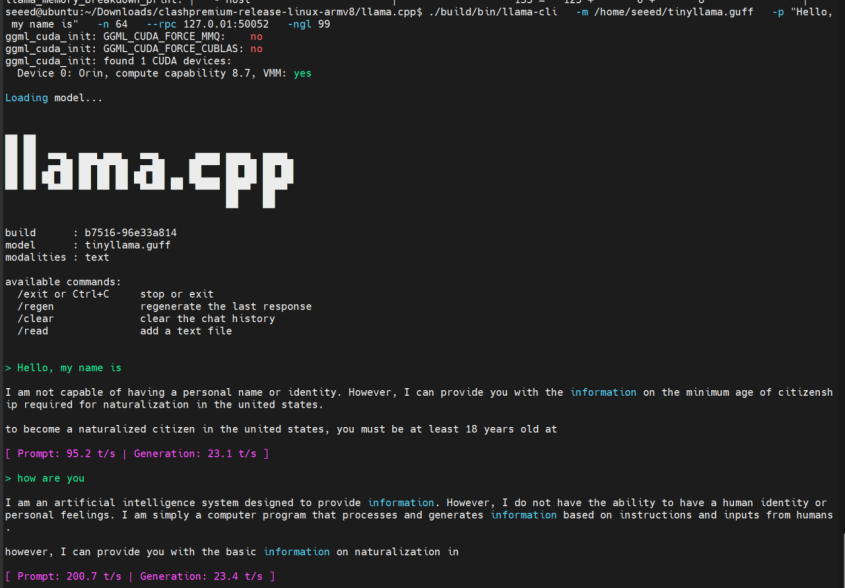
如果您只想在本地运行,请从 --rpc 中删除远程地址:
--rpc 127.0.0.1:50052
8. 性能比较
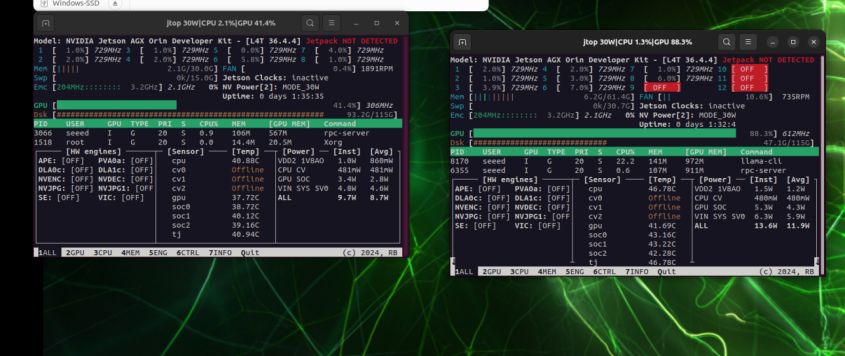
左:192.168.100.1 上的 GPU 利用率;右:192.168.100.2 上的 GPU 利用率
仅在本地运行时,GPU 压力集中在单张卡上
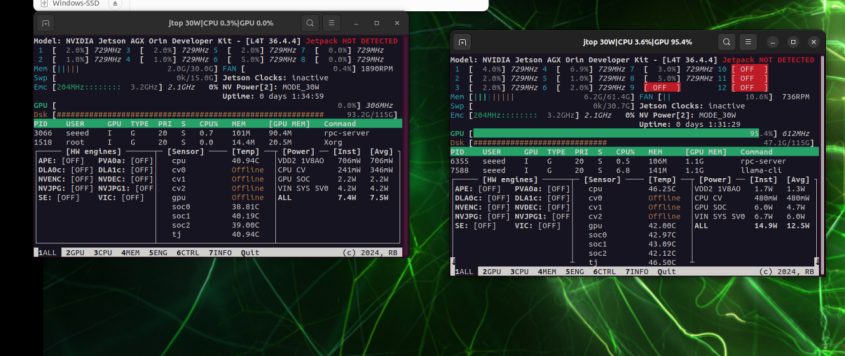
9. 故障排除
| 问题 | 解决方案 |
|---|---|
| rpc-server 启动失败 | 检查端口是否被占用或防火墙是否阻止了 50052/tcp |
| 推理速度较慢 | 模型太小,网络延迟 > 计算收益;尝试更大的模型或 Unix-socket 模式 |
| 内存不足错误 | 减少 -ngl 值以将更少的层卸载到 GPU,或将一些层保留在 CPU 上 |
通过此设置,您现在可以使用 llama.cpp 的 RPC 后端在多个 Jetson 设备上实现 LLM 推理的"水平扩展"。为了获得更高的吞吐量,您可以添加更多 RPC 节点或进一步将模型量化为 q4_0 或 q5_k_m 等格式。
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。