使用 reCamera 实现 AI 语音交互
介绍
本项目展示了一种通过自然语言与 reCamera 进行交互的方式。在视觉推理触发音频录制后,reCamera 将录音发送到服务器,通过完整的 STT(语音转文本)→ LLM(大语言模型推理)→ TTS(文本转语音) 流程进行处理,合成后的语音再返回到 reCamera 播放,从而实现自然语言对话。
你是否曾经希望有一台不仅能“看见”,还能“理解”和“说话”的相机?通过本项目的架构,利用 reCamera 的麦克风和扬声器,设备不再只是一个视觉工具,而是一个能够自然对话的智能助手。这包括但不限于以下场景:
-
智能门禁助手:将 reCamera 安装在出入口,访客仅通过语音即可完成身份登记、留言或询问路线,无需额外的交互屏幕。
-
工厂安全巡检伙伴:在工业环境中,当工人双手被占用时,可以通过手势触发语音交互,向 AI 助手询问设备状态、操作手册,或上报异常情况。
-
无障碍辅助交互:为视障或行动不便用户提供语音控制入口,通过简单的手势触发,与设备进行自然语言对话,以获取环境信息或发送指令。
-
教育与展览讲解:在博物馆或展览馆中,参观者可以通过手势触发语音交互,向 AI 助手询问展品信息,并获得个性化讲解。
演示视频
系统架构
整个系统由两部分协同完成:reCamera 端 和 PC 服务器端。架构如下:
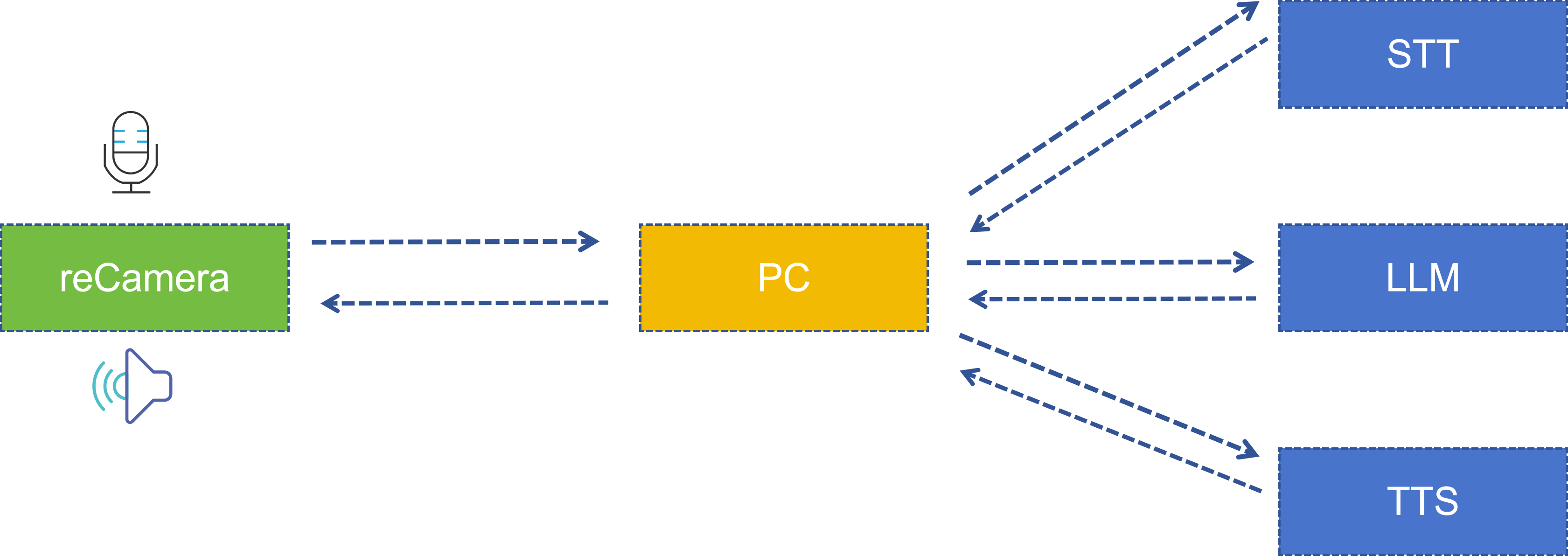
| 阶段 | 执行位置 | 使用的技术/模型 | 描述 |
|---|---|---|---|
| 姿态检测 | reCamera | YOLO11n Pose | 检测 17 个人体关键点 |
| 姿态判断 | reCamera(Node-RED Function) | 自定义逻辑 | 比较肩部与肘部关键点距离 |
| 录音/播放 | reCamera | arecord / aplay | 16kHz 单声道 PCM |
| 语音识别(STT) | PC 服务器 | 讯飞语音听写 API | 音频转文本 |
| 大模型推理(LLM) | PC 服务器 | 星火大模型 Spark Lite | 生成智能回复 |
| 文本转语音(TTS) | PC 服务器 | 讯飞语音合成 API | 文本转音频 |
硬件准备
要运行本演示,你需要以下硬件:
- 一台 reCamera 设备(支持所有 reCamera 型号)
- 一台 PC 电脑(用于运行语音处理服务,必须与 reCamera 处于同一局域网)
你可以根据部署需求选择 任意版本的 reCamera:
- reCamera 2002 系列(Wi-Fi)
- reCamera Gimbal
- reCamera HQ PoE(以太网 + PoE)
注意: PoE 版本不支持 Wi-Fi,必须通过支持 PoE 的交换机接入同一局域网。
| reCamera 2002 系列 | reCamera Gimbal | reCamera HQ PoE |
|---|---|---|
 |  |  |
演示环境配置
步骤 1:配置 reCamera
首先,按照官方入门指南完成 reCamera 的基础配置:reCamera 入门指南
完成初始设置后,确保设备已上电并正确连接到网络。 然后通过浏览器访问 192.168.42.1 登录 reCamera,进入 Node-RED 工作空间。
如果你能够成功访问如下所示的 Node-RED 流程界面,则说明配置已完成。

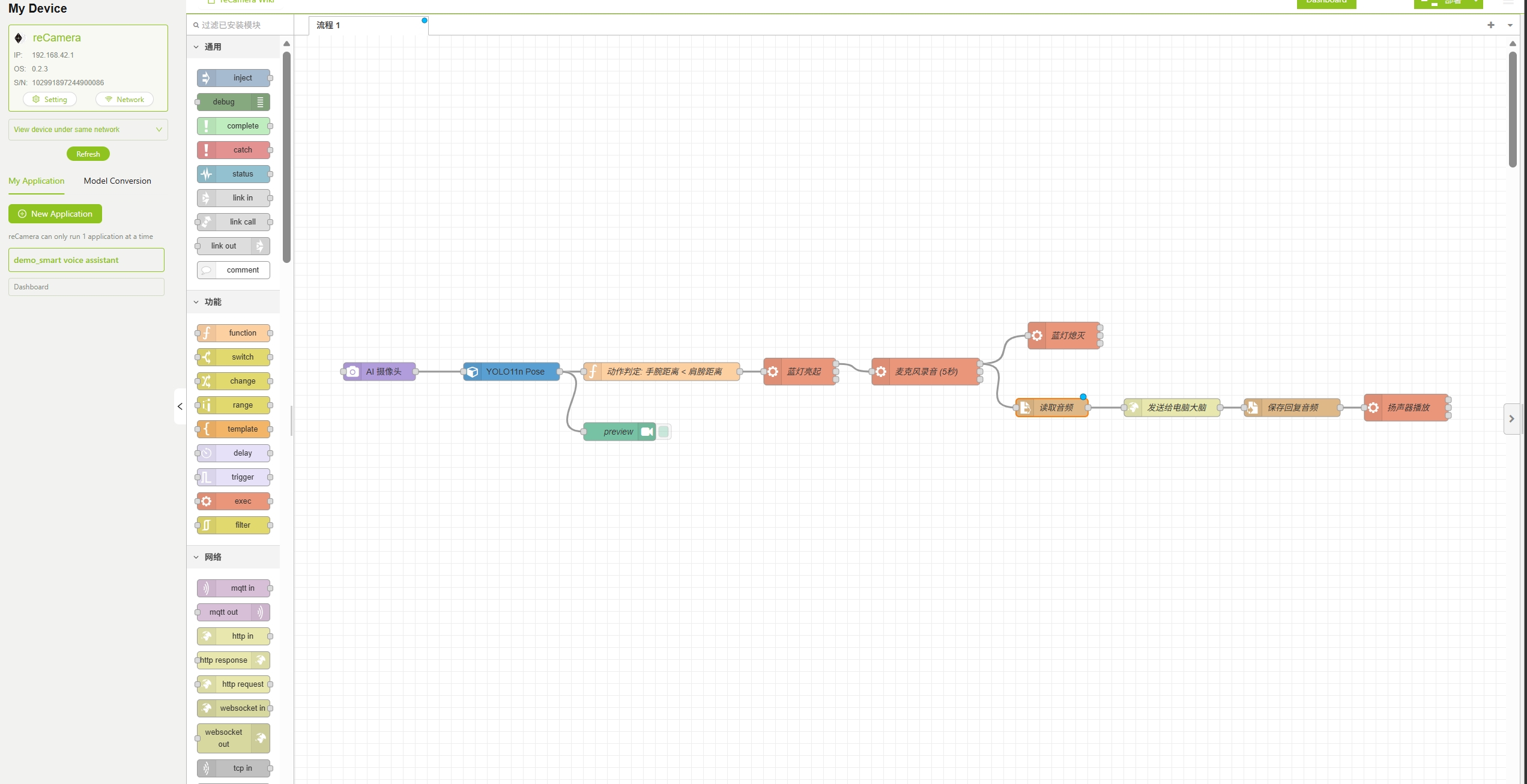
步骤 2:导入 Node-RED 工作流
本演示提供了一个预配置的工作流文件,其中已经包含智能语音助手所需的全部节点和连接。 你需要按照下面的步骤进行一些配置,以便正确运行本项目。
创建一个新应用,然后从 SenseCraft AI 平台 下载 AI Voice Assistant 工作流文件,并直接导入到 reCamera 中。关于 SenseCraft AI 的教程,请参考链接 访问 SenseCraft AI reCamera Dashboard。
如果你能够成功访问如下所示的 Node-RED 流程界面,则说明工作流已导入成功。
步骤 3:配置工作流参数
导入工作流后,你需要根据实际网络环境和系统设置,修改下文 3.1 至 3.5 小节中的参数。
3.1 Model 节点
工作流中的 Model 节点内置了多个预训练模型,你可以在此选择并配置各类模型参数。本演示使用 YOLO11n Pose 模型来检测人体姿态。
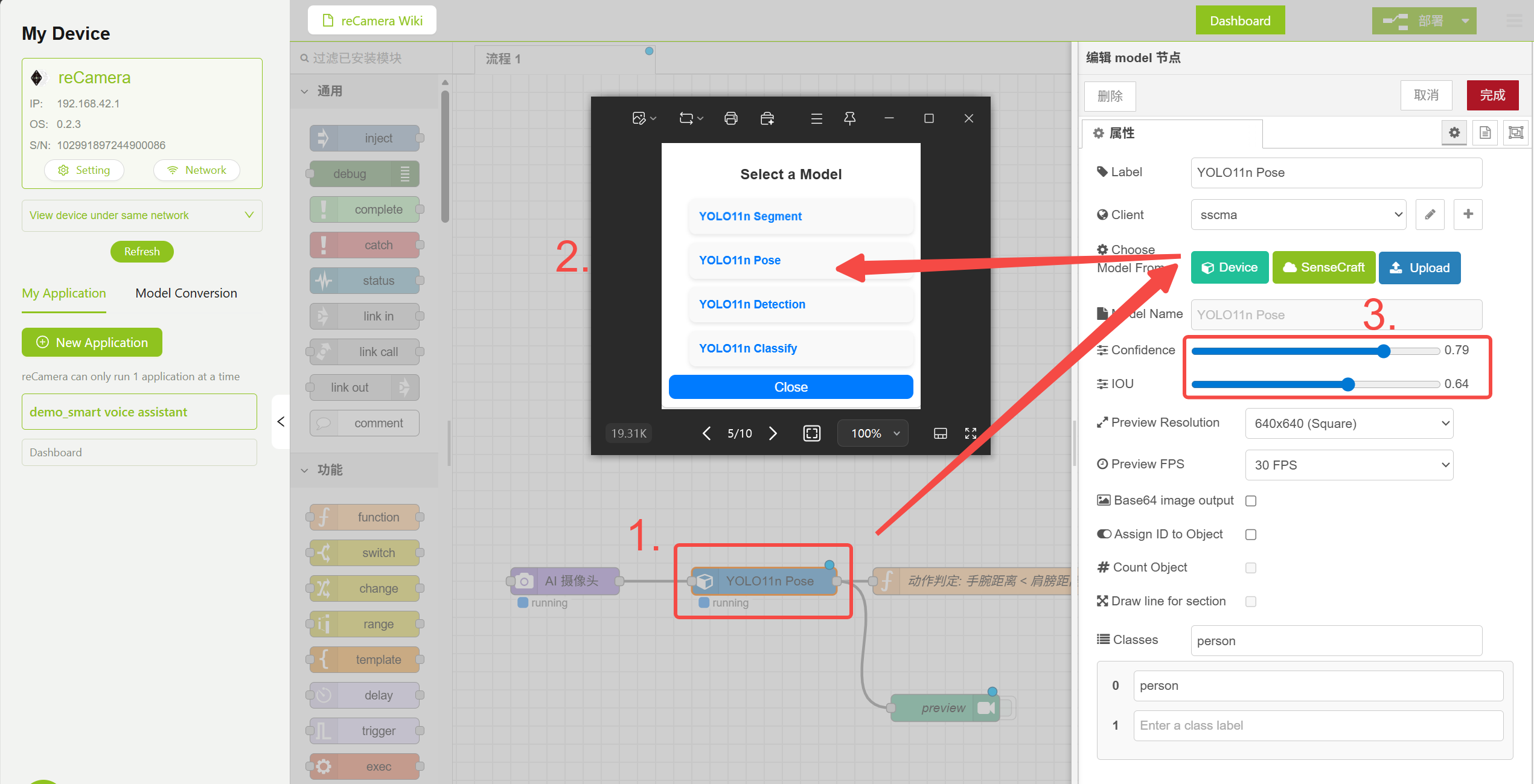
Model 节点配置
3.2 Model 节点 — 姿态判断逻辑
Function 节点中包含姿态判断逻辑,通过比较肩部关键点距离与肘部关键点距离来决定是否触发语音交互。你可以在 Model 节点中调整 Confidence 和 IOU 参数以减少误触发,或修改下方 Function 节点中的逻辑代码以实现更多功能。
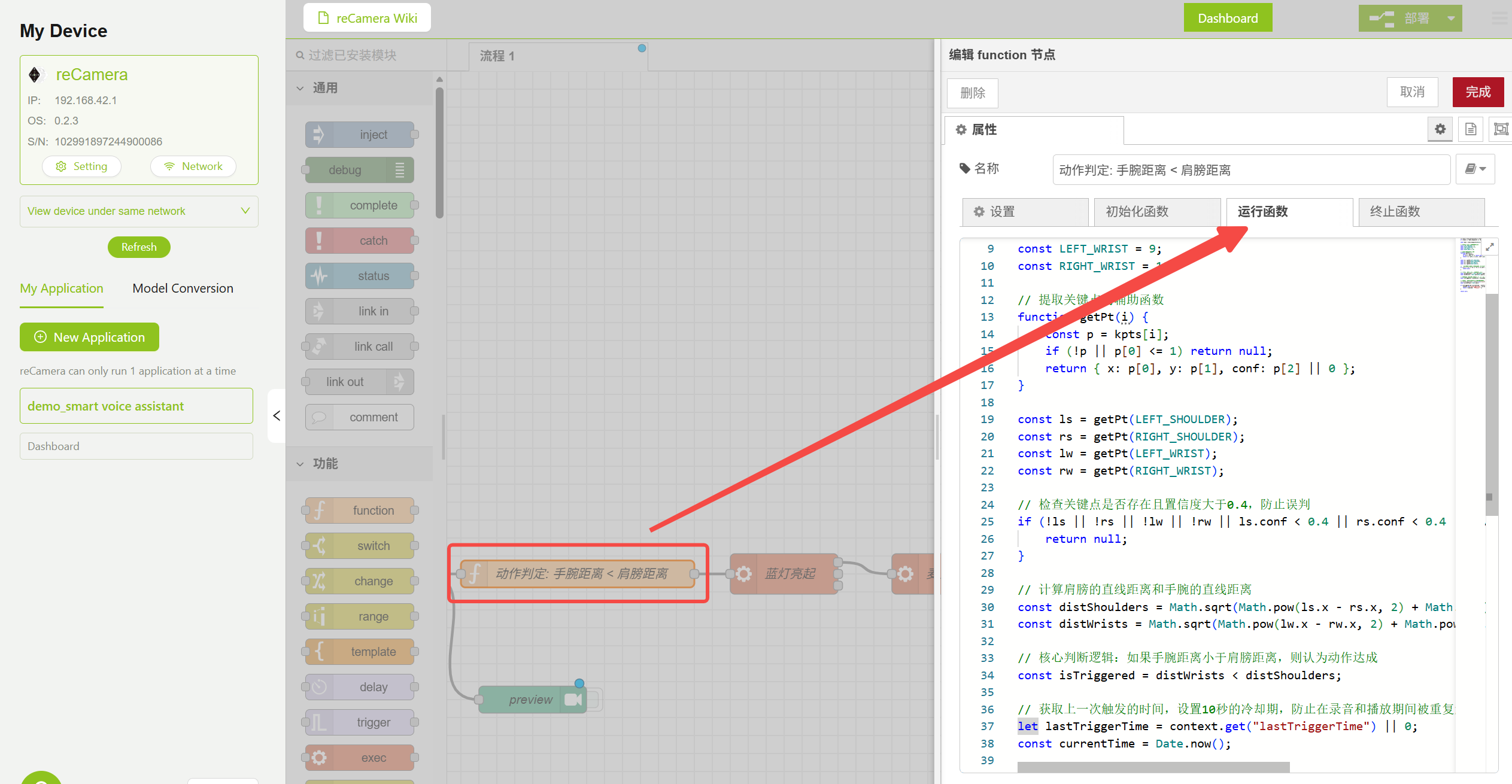
姿态判断 Function 节点配置
3.3 Exec 节点 — LED 控制与录音
工作流使用 Exec 节点 执行系统命令来控制 LED 和录音。双击对应节点,并根据你的实际设置修改 reCamera 的 root 密码:
echo "your_Password" | sudo -S sh -c 'echo 1 > /sys/class/leds/blue/brightness'
- 打开和关闭蓝色 LED(表示录音已开始)
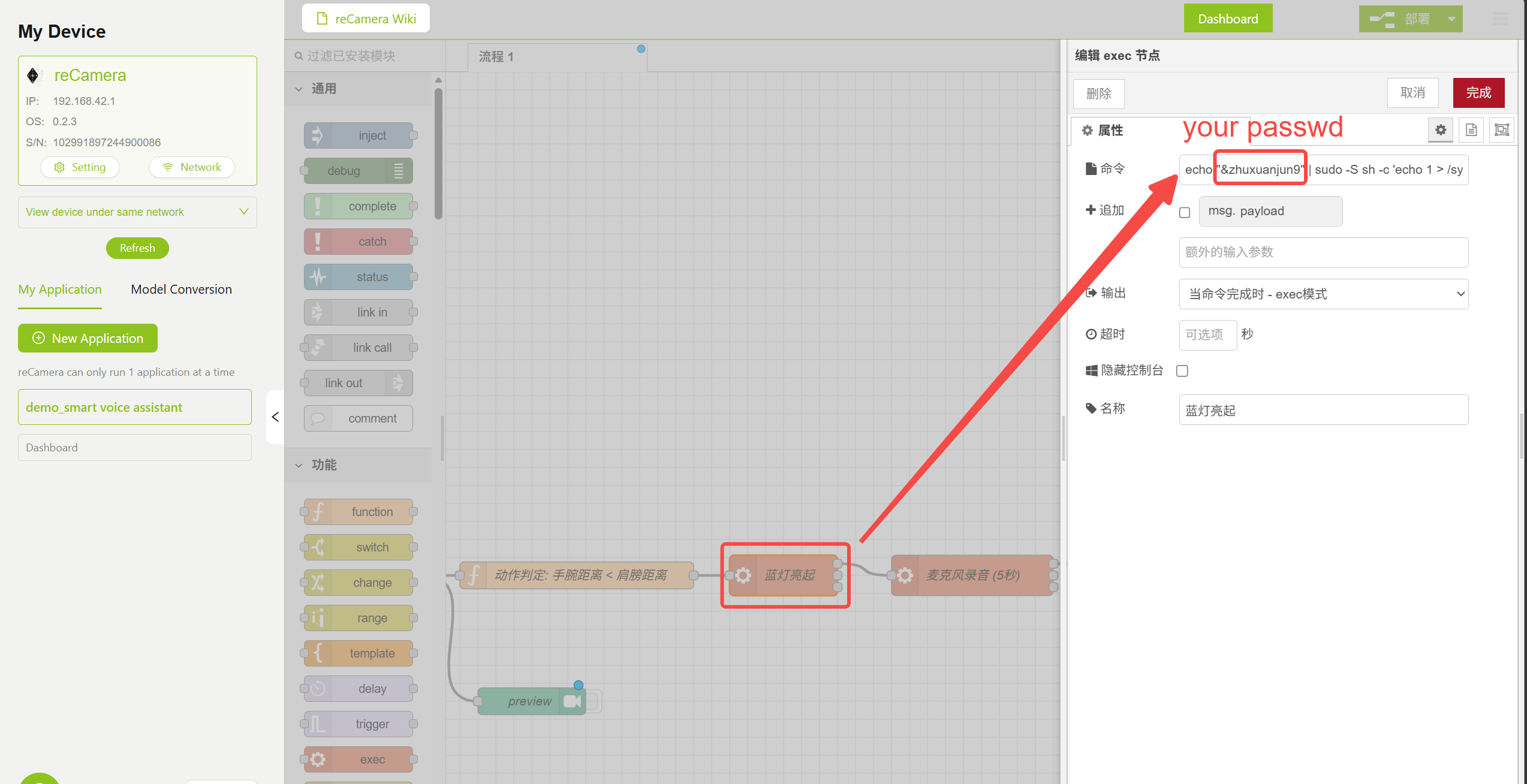
打开 LED 节点参数配置
3.4 HTTP Request 节点 — 音频发送地址
在工作流中找到 HTTP Request 节点,将 URL 修改为你的 PC 服务器地址。这需要你先完成步骤 4 并运行 server.py,然后将地址填写到下图所示的对应位置。
http://<PC_IP_ADDRESS>:5000/interact
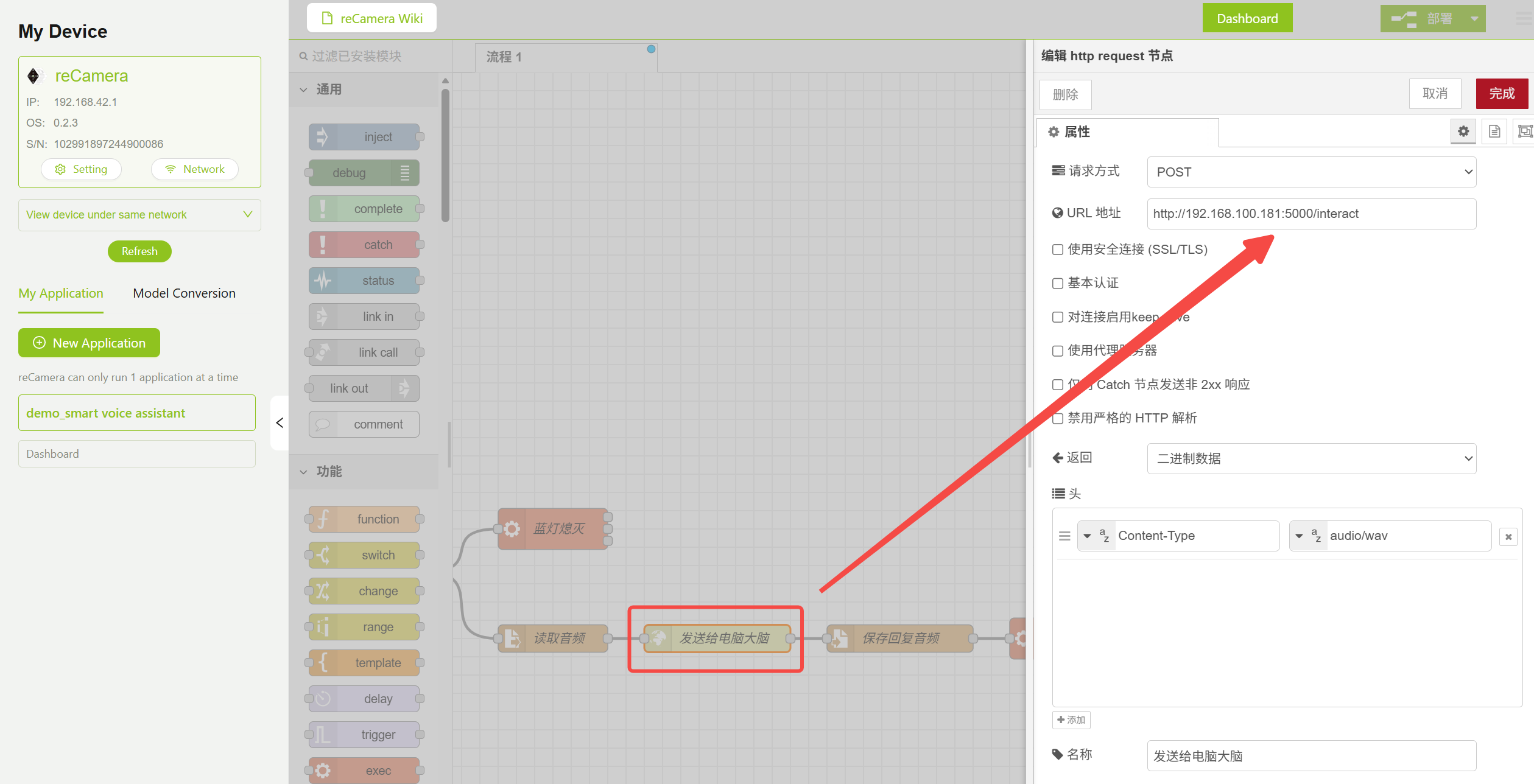
HTTP Request 节点参数配置
3.5 Exec 节点 — 音频播放
返回的音频通过 aplay 命令进行播放。你需要指定正确的音频参数,以匹配 TTS 模型的输出格式(16kHz、单声道、16 位):
aplay -D hw:1,0 -f S16_LE -c 1 -r 16000 /tmp/reply.wav
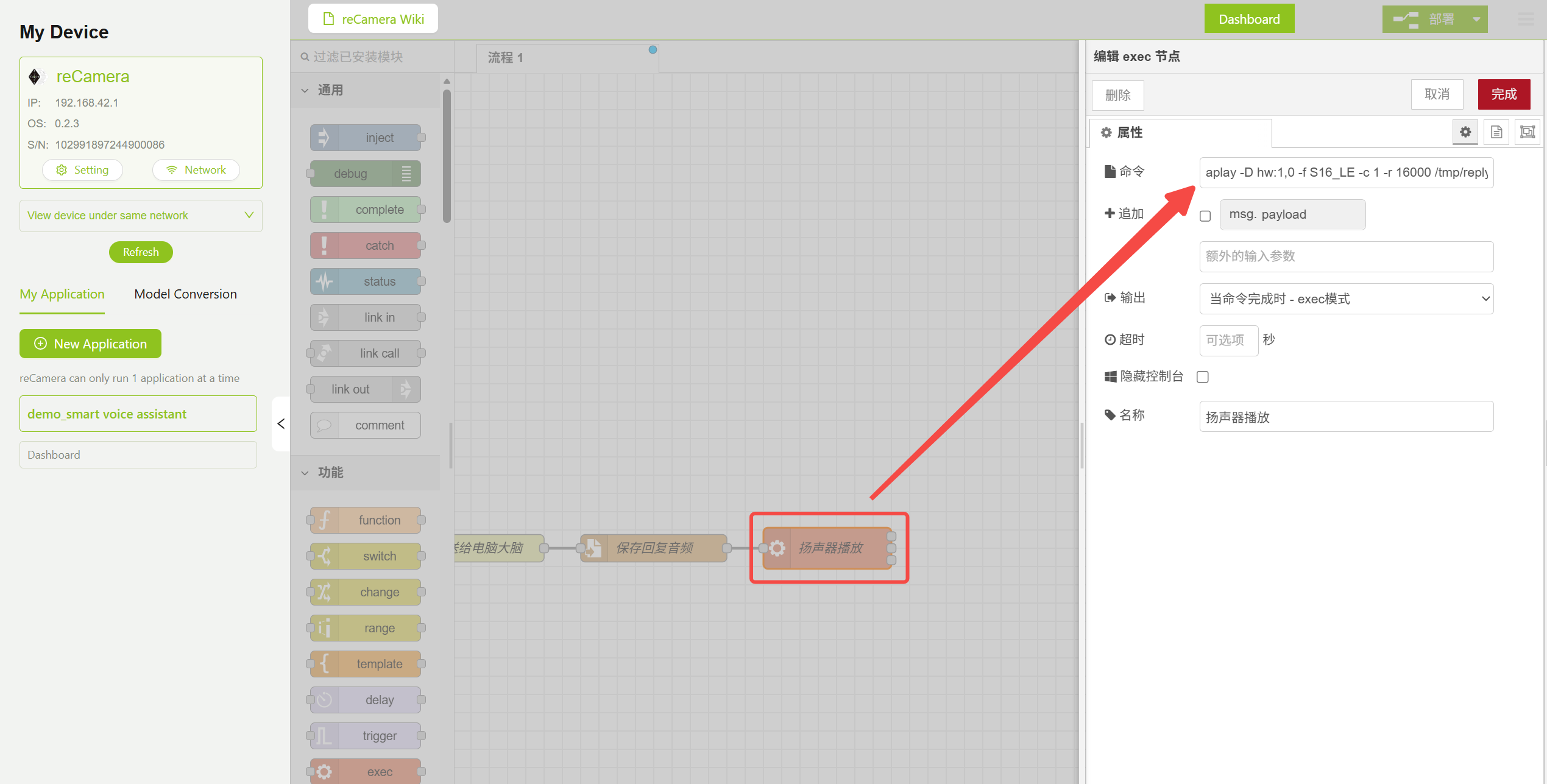
音频播放节点参数配置
步骤 4:在 PC 上部署语音处理服务
语音处理服务运行在 PC 上,负责完成整个 STT → LLM → TTS 语音处理流程。
4.1 前置条件
请确保在你的电脑上已安装以下环境:
- Python 3.8+
- pip 包管理器
4.2 获取代码并安装依赖
从代码仓库获取 AI 语音助手的服务端 Python 代码。将项目代码下载到电脑后,进入服务目录并安装 Python 依赖:
cd server/
pip install -r requirements.txt
主要依赖包括:
| Package | Purpose |
|---|---|
| Flask | HTTP 服务框架 |
| websocket-client | 与 iFlytek API 通信 |
| certifi | SSL 证书校验 |
| pydub | 音频处理 |
4.3 配置 API 密钥
在运行服务之前,你需要配置 iFlytek 的 API 密钥。请前往iFlytek 开放平台注册账号,并开通以下三项服务:
| Service | Purpose | Activation Link |
|---|---|---|
| 语音听写(STT) | 将用户语音转换为文本 | iFlytek 语音听写 |
| 星火大模型(LLM) | 基于文本生成智能回复 | iFlytek 星火大模型 |
| 语音合成(TTS) | 将回复文本转换为语音 | iFlytek 语音合成 |
开通后,在 server.py 中填写你的 API 密钥:
# 1. STT Speech Recognition Configuration
STT_APPID = "your_APPID"
STT_APISecret = "your_APISecret"
STT_APIKey = "your_APIKey"
# 2. TTS Speech Synthesis Configuration
TTS_APPID = "your_APPID"
TTS_APISecret = "your_APISecret"
TTS_APIKey = "your_APIKey"
# 3. LLM Spark Large Model Configuration (Spark Lite)
LLM_APPID = "your_APPID"
LLM_APISecret = "your_APISecret"
LLM_APIKey = "your_APIKey"
本示例使用 Spark Lite 模型(免费)。你也可以根据需要切换到更高级的模型版本,或使用其他厂商的大模型。
4.4 启动服务
python server.py

服务启动日志
服务启动后,将等待来自 reCamera 的音频请求。请确保电脑防火墙允许 5000 端口的入站连接,并确保电脑与 reCamera 处于同一局域网中。步骤 5:运行 Demo
- 确保电脑上的
server.py已启动并在运行 - 在 Node-RED 中点击 Deploy 部署流程
- 站在 reCamera 前方,做出双臂交叉手势(肩膀间距小于手肘间距)
- reCamera 上的蓝色 LED 亮起,表示开始录音
- 对着麦克风说出你的问题
- 蓝色 LED 熄灭后,reCamera 会将音频发送到服务器,并在收到回复后播放。
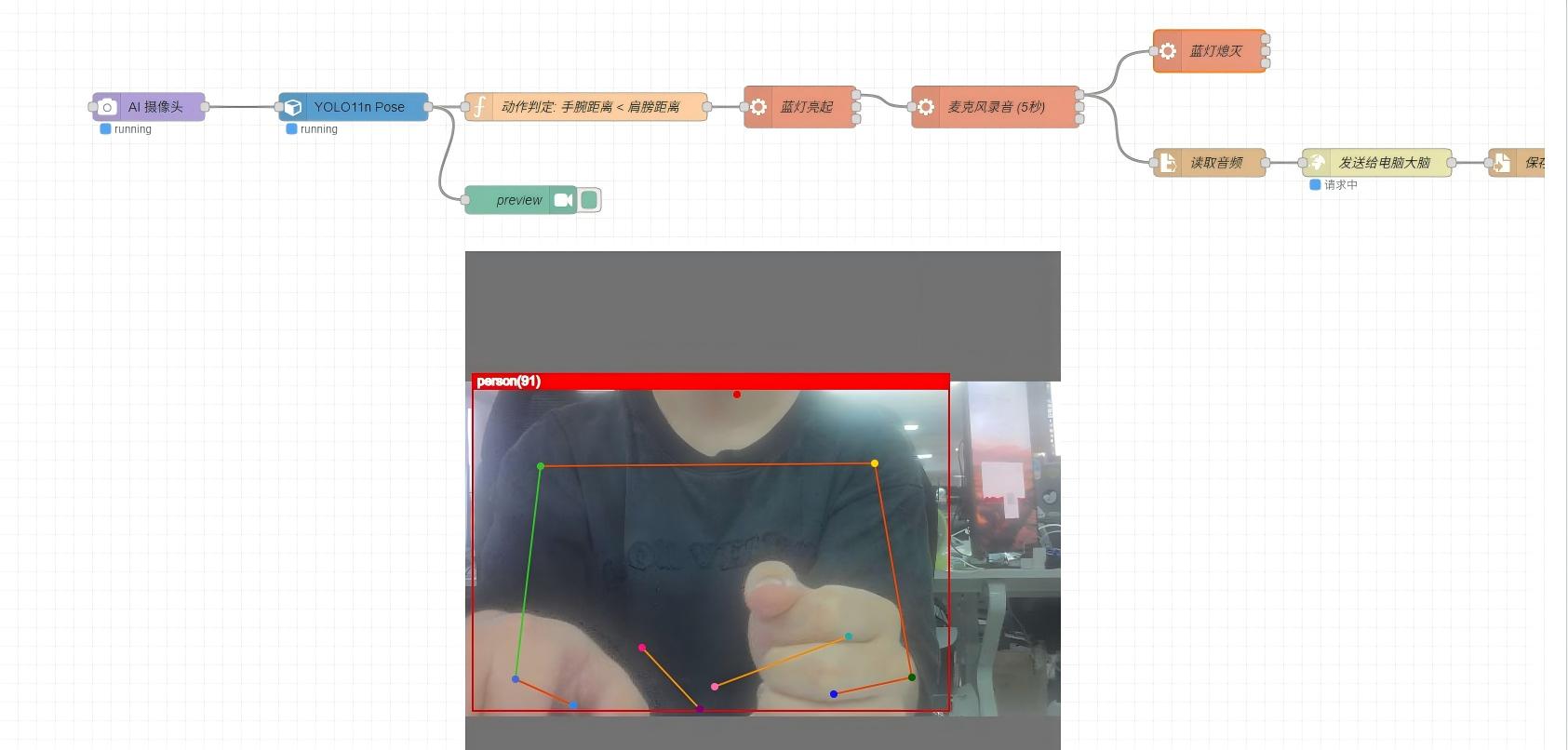
触发语音对话流程
Received reCamera audio,length:160044 bytes
User said:Hi,who are you?
LLM is thinking……
LLM reply:Hi,I′m the voice assistant on your smart camera reCamera.I'm here to help you with any questions or concerns you may have.
Generating speech……
Speech delivered! Waiting for next interaction.
192.168.4.53--[11/Jun/2026 16:38:14]"POST /interact HTTP/1.1" 200 -

服务日志
工作流详情
整个工作流的高层逻辑如下:
-
视频输入与姿态检测 摄像头持续采集视频帧,YOLO11 姿态估计模型检测人体关键点(共 17 个关键点,包括肩膀、手肘、手腕等)。
-
手势触发判断 Function 节点计算左右肩关键点之间的距离以及左右手肘关键点之间的距离。当肩膀距离 < 手肘距离时,即判定为触发手势(即双臂交叉姿势)。
-
录音流程 触发后:点亮蓝色 LED → 录制音频 → 熄灭蓝色 LED。
-
音频处理与对话生成 录音完成后,通过 HTTP Request 将音频数据 POST 到电脑上的 Flask 服务,执行:
- STT:iFlytek 语音听写 API 将音频转换为文本
- LLM:星火大模型(Spark Lite)基于用户输入生成智能回复
- TTS:iFlytek 语音合成 API 将回复文本转换为音频
-
音频播放 电脑返回 WAV 音频,reCamera 通过
aplay命令播放回复语音。
注意事项
- 当前录音间隔设置为 10 秒。如果 STT → LLM → TTS 的处理时间超过该间隔,多次触发可能导致流水线拥塞。建议控制 LLM 回复字数(当前系统提示将其限制在 50 个单词以内),以减少处理时间。
- 如果因拥塞导致 CPU 无响应,你可以在 Model 节点中调整 Confidence 属性,以减少误触发并控制触发频率。
- 使用
aplay播放返回音频时,请指定正确的参数(-f S16_LE -c 1 -r 16000),否则可能无法正常播放。具体参数可参考 TTS 生成的音频。
技术支持与产品讨论
感谢你选择我们的产品!如果你在特定定制目标方面需要指导,或希望进一步扩展工作流,欢迎随时联系我们。我们将为你提供不同层级的支持,确保你在使用我们产品的过程中尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。