GPT-OSS在reComputer Jetson上实时运行!
介绍
这远不仅仅是一个简单的技术移植练习——它是对边缘设备可能性的探索。在本文中,我将演示一个200亿参数的开源大语言模型如何在Nvidia Jetson Orin Nx等边缘设备上运行。

NVIDIA Jetson系列是一个顶级的边缘计算平台,以其卓越的功耗效率和紧凑的外形因子而闻名。与此同时,GPT-OSS-20B代表了免费开源大语言模型的前沿技术。它们的融合不仅展示了边缘设备的未开发潜力,还为离线AI应用开创了新的可能性。
前提条件
- reComputer Super J4012
在本wiki中,我们将使用reComputer Super J4012完成以下任务,但您也可以尝试使用其他Jetson设备。

后续步骤将涉及在Jetson上设置多个Python环境。我们建议在Jetson设备上安装Conda:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
安装 llama.cpp
首先,我们需要在 Jetson 上安装 llama.cpp 推理引擎。请在 Jetson 的终端窗口中执行以下命令。
sudo apt update
sudo apt install -y build-essential cmake git
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --parallel
编译完成后,llama.cpp 的所有可执行文件将在 build/bin 中生成。
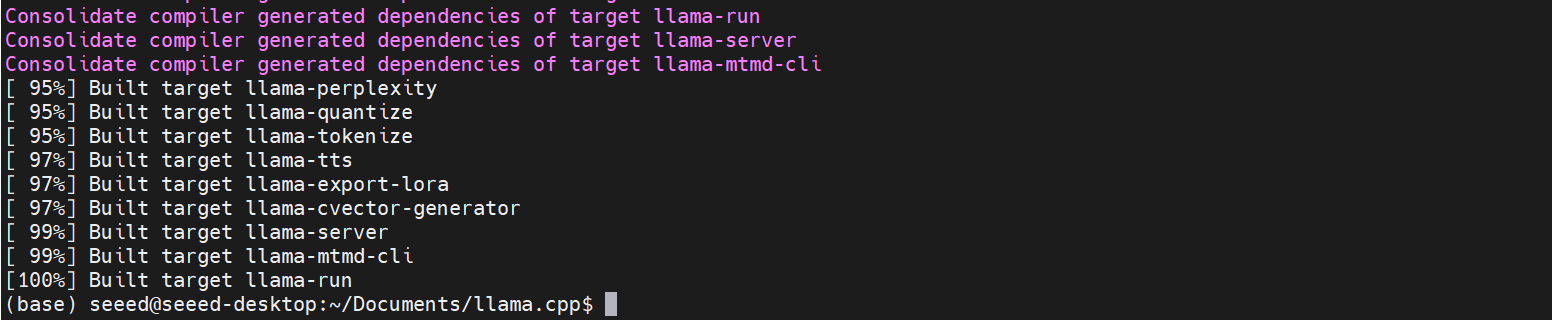
构建过程通常需要大约 2 小时。
准备 GPT-OSS 模型
步骤1. 从 Huggingface 下载 GPT-OSS-20B 并上传到 Jetson。

步骤2. 安装模型转换所需的依赖项。
conda create -n gpt-oss python=3.10
conda activate gpt-oss
cd /home/seeed/Documents/llama.cpp # cd `path_of_llama.cpp`
pip install .
步骤3. 运行模型转换过程。
python convert_hf_to_gguf.py --outfile /home/seeed/Downloads/gpt-oss /home/seeed/Documents/gpt-oss-gguf/
# python convert_hf_to_gguf.py --outfile <path_of_input_model> <path_of_output_model>
步骤4. 模型量化。
./build/bin/llama-quantize /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf /home/seeed/Documents/gpt-oss-gguf-Q4/Gpt-Oss-32x2.4B-Q4.gguf Q4_K
# ./build/bin/llama-quantize <path_of_f16_gguf_model> <path_of_output_model> <quantization_method>
通过 llama.cpp 启动 GPT-OSS
现在我们可以尝试在 Jetson 终端中启动推理程序。
./build/bin/llama-cli -m /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf -ngl 40
请根据需要替换模型路径。
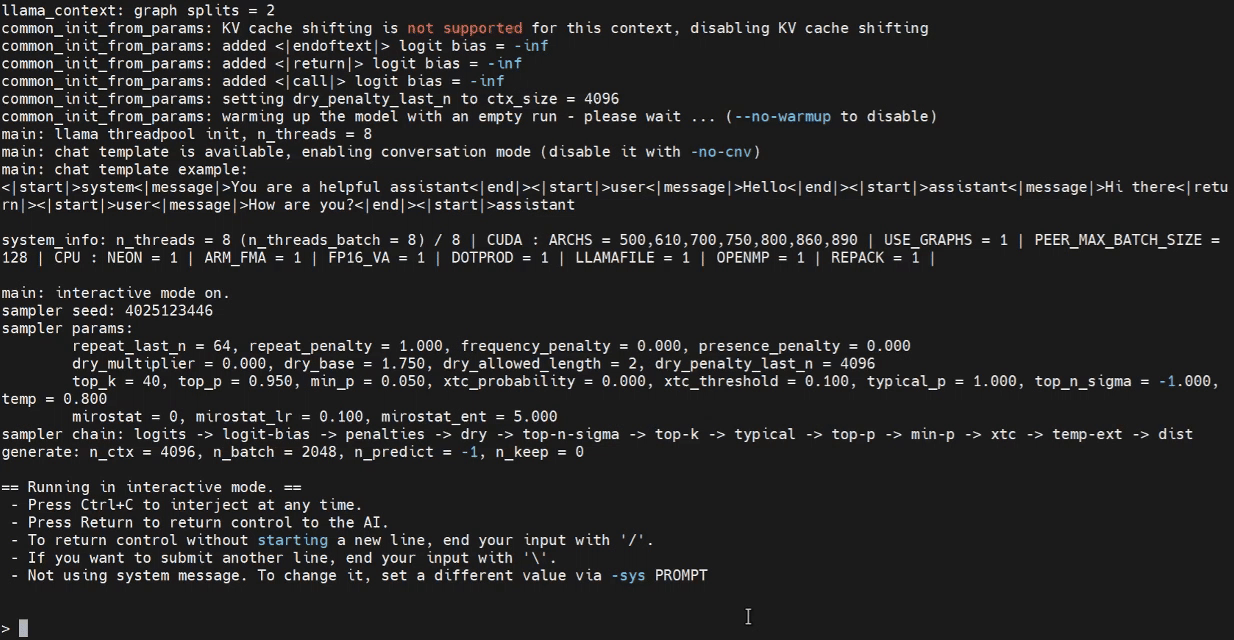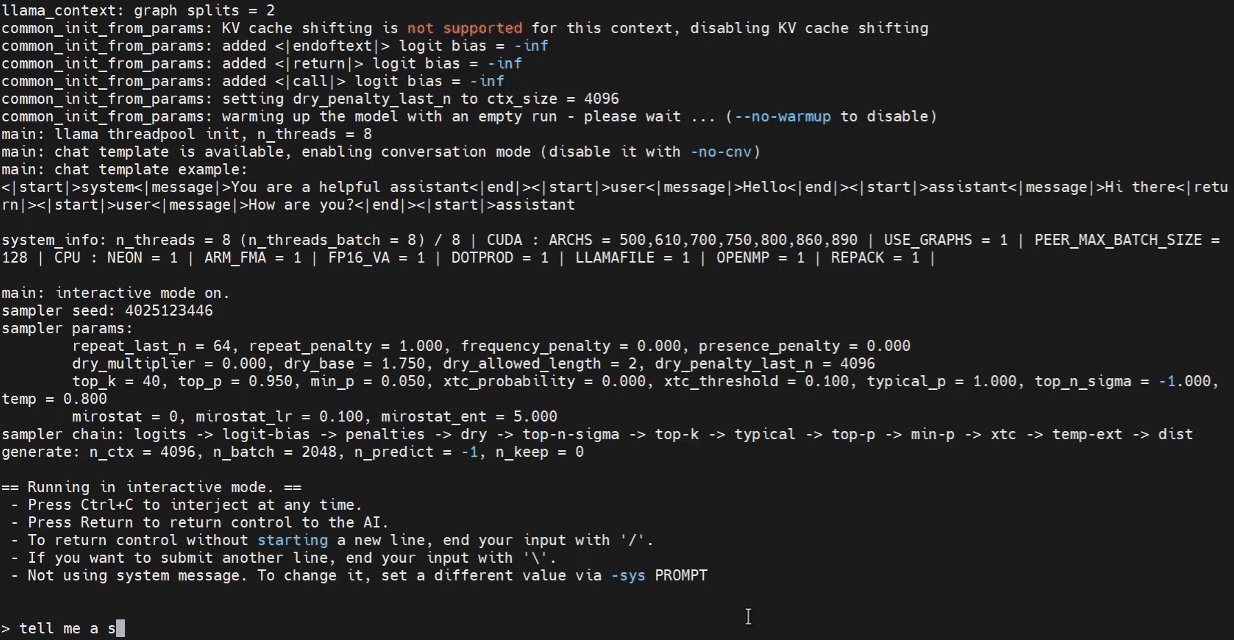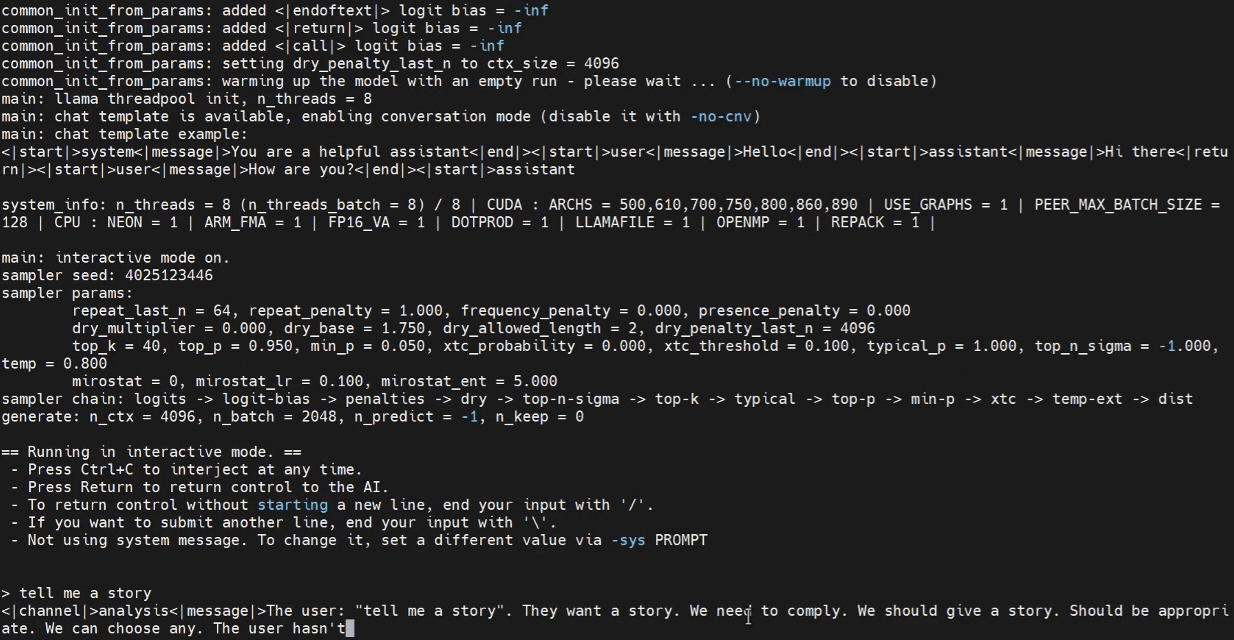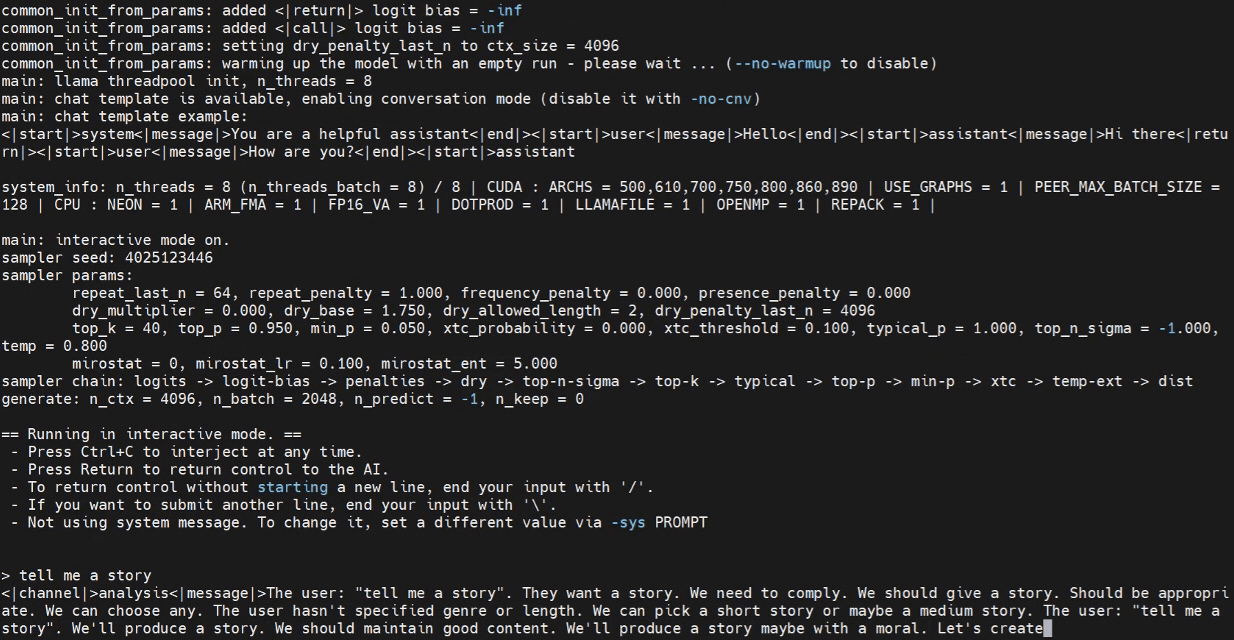
使用 WebUI 进行推理(可选)
如果您想通过 UI 界面访问模型,可以在 Jetson 上安装 OpenWebUI 来实现。 在 Jetson 中打开新的终端并输入以下命令:
conda create -n open-webui python=3.11
conda activate open-webui
pip install open-webui
open-webui serve
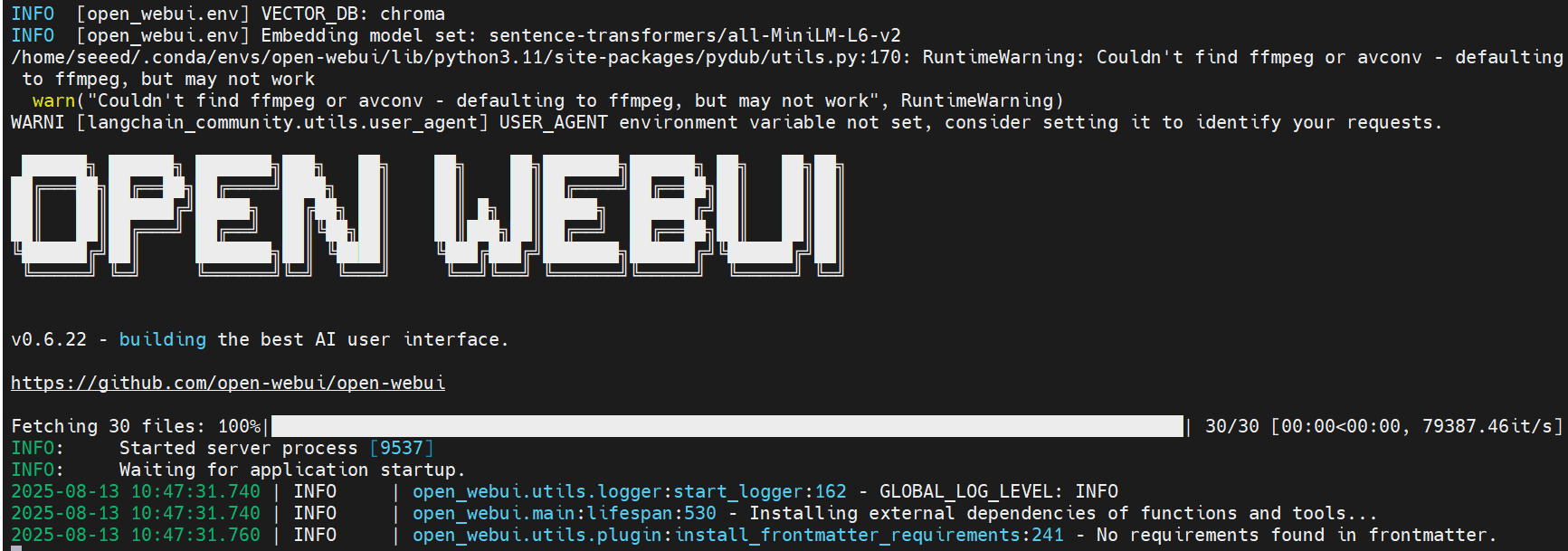
启动 OpenWebUI 将安装依赖项并下载模型——请耐心等待。
设置完成后,您应该在终端中看到类似的日志。
然后,打开浏览器并导航到 http://<jetson的ip地址>:8080 来启动 Open WebUI。
如果您是第一次打开,请按照说明设置您的账户。
转到 ⚙️ 管理员设置 → 连接 → OpenAI 连接,将 url 设置为:http://127.0.0.1:8081。保存后,Open WebUI 将开始使用您的本地 Llama.cpp 服务器作为后端!
效果演示
最后,我将通过视频演示来展示 GPT-OSS-20B 模型在 NVIDIA Jetson Orin NX 上的实际推理性能。
参考资料
- https://hyd.ai/2025/03/07/llamacpp-on-jetson-orin-agx/
- https://docs.openwebui.com/getting-started/quick-start/starting-with-llama-cpp
- https://github.com/open-webui/open-webui
- https://huggingface.co/openai/gpt-oss-20b
- https://www.seeedstudio.com/tag/nvidia.html
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。