在 Jetpack6.2 上部署 TensorRT Edge-LLM
什么是 TensorRT Edge-LLM?
TensorRT Edge-LLM 是 NVIDIA 面向嵌入式平台的大型语言模型(LLM)和视觉语言模型(VLM)的高性能 C++ 推理运行时。它能够在诸如 NVIDIA Jetson 和 NVIDIA DRIVE 等资源受限设备上高效部署最新的语言模型。
TensorRT Edge-LLM 支持广泛的前沿模型:
-
大型语言模型:Llama 3.x、Qwen 2/2.5/3、DeepSeek-R1 Distilled
-
视觉语言模型:Qwen2/2.5/3-VL、InternVL3-1B-hf、InternVL3-2B-hf、Phi-4-Multimodal
-
量化:FP16、FP8(SM89+)、INT4 AWQ/GPTQ、NVFP4(SM100+)
有关支持的完整模型列表、精度要求和平台兼容性,请参阅 Supported Models。https://nvidia.github.io/TensorRT-Edge-LLM/0.6.0/user_guide/getting_started/supported-models.html
TensorRT Edge-LLM 主要针对 JetPack 7.x 软件栈设计。然而,NVIDIA 通过专门的兼容版本在官方文档中提供了对 JetPack 6.2 的兼容性支持。本指南介绍在 JetPack 6.2 上部署和验证 TensorRT Edge-LLM 的工作流程。
对于 JetPack 6.2 系统,推荐并已验证使用 TensorRT Edge-LLM v0.6.0 版本。
部署流程由两个阶段组成:
-
在 x86 Linux 主机上进行模型准备
在配备 NVIDIA GPU 的 x86 Linux 工作站上,使用 TensorRT Edge-LLM 工具链对目标大型语言模型(LLM)进行量化,并导出为 ONNX 格式。
-
在 Jetson 上生成引擎
将导出的 ONNX 模型传输到 Jetson 设备上,由 TensorRT Edge-LLM 生成优化的 TensorRT 推理引擎,用于部署和运行时执行。
第 1 部分:模型准备(带 GPU 的 x86 主机)
Python 导出流水线负责转换和量化模型。该流程必须在带有 NVIDIA GPU 的 x86 Linux 系统上运行。
系统要求
-
平台:x86-64 Linux 系统
-
推荐操作系统:Ubuntu 22.04、24.04
-
GPU:计算能力 8.0+ 的 NVIDIA GPU(Ampere 或更新架构)
-
CUDA:12.x 或 13.x
-
Python:3.10+
内存要求(取决于你要部署的模型大小)
GPU 显存(VRAM):
-
一般规则:大多数操作需要约模型大小的 2-3 倍,FP8 ONNX 导出需要约模型大小的 5-6 倍
-
小模型(0.6B-3B):8-16GB
-
大模型(7B-8B):20-48GB
-
超大模型(13B+):48GB+
CPU 内存(RAM):
-
一般规则:大多数操作需要约模型大小的 2-3 倍,FP8 ONNX 导出需要约 18-20 倍 模型大小
-
小模型(0.6B-3B):8-16GB(FP8 ONNX 导出需 48GB+)
-
大模型(7B-8B):20-48GB(FP8 ONNX 导出需 128GB+)
-
超大模型(13B+):48GB+
注意: 由于内部处理流程,目前 FP8 ONNX 导出在 CPU(最高可达模型大小的 20 倍)和 GPU(最高可达模型大小的 6 倍)内存方面有显著更高的需求。这是已知问题,正在积极优化中。
安装
-
克隆仓库
git clone https://github.com/NVIDIA/TensorRT-Edge-LLM.git
cd TensorRT-Edge-LLM
git submodule update --init --recursive -
安装 Python 包
建议使用虚拟环境:
python3 -m venv venv
source venv/bin/activate然后安装软件:
pip3 install . -
验证安装
tensorrt-edgellm-export-llm --help
tensorrt-edgellm-quantize-llm --help
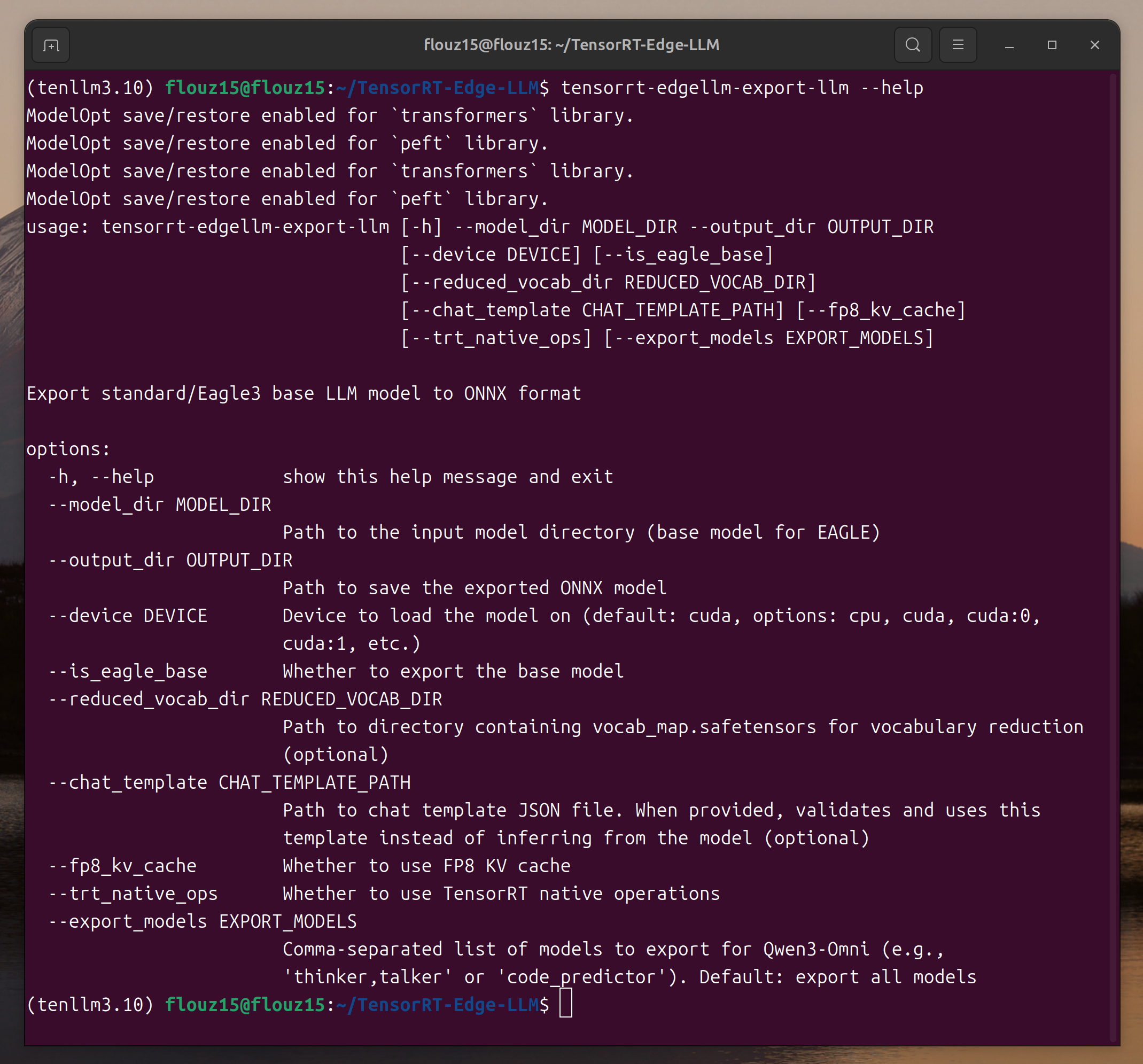
如果显示了参数说明,则表示 TensorRT Edge-LLM 已成功安装。
导出与量化
我们以 Qwen3-0.6B 作为轻量级示例:
注意:实际命令可能会根据你具体的文件夹结构有所不同。
# Set up workspace directory
export WORKSPACE_DIR=$HOME/tensorrt-edgellm-workspace
export MODEL_NAME=Qwen3-0.6B
mkdir -p $WORKSPACE_DIR
cd $WORKSPACE_DIR
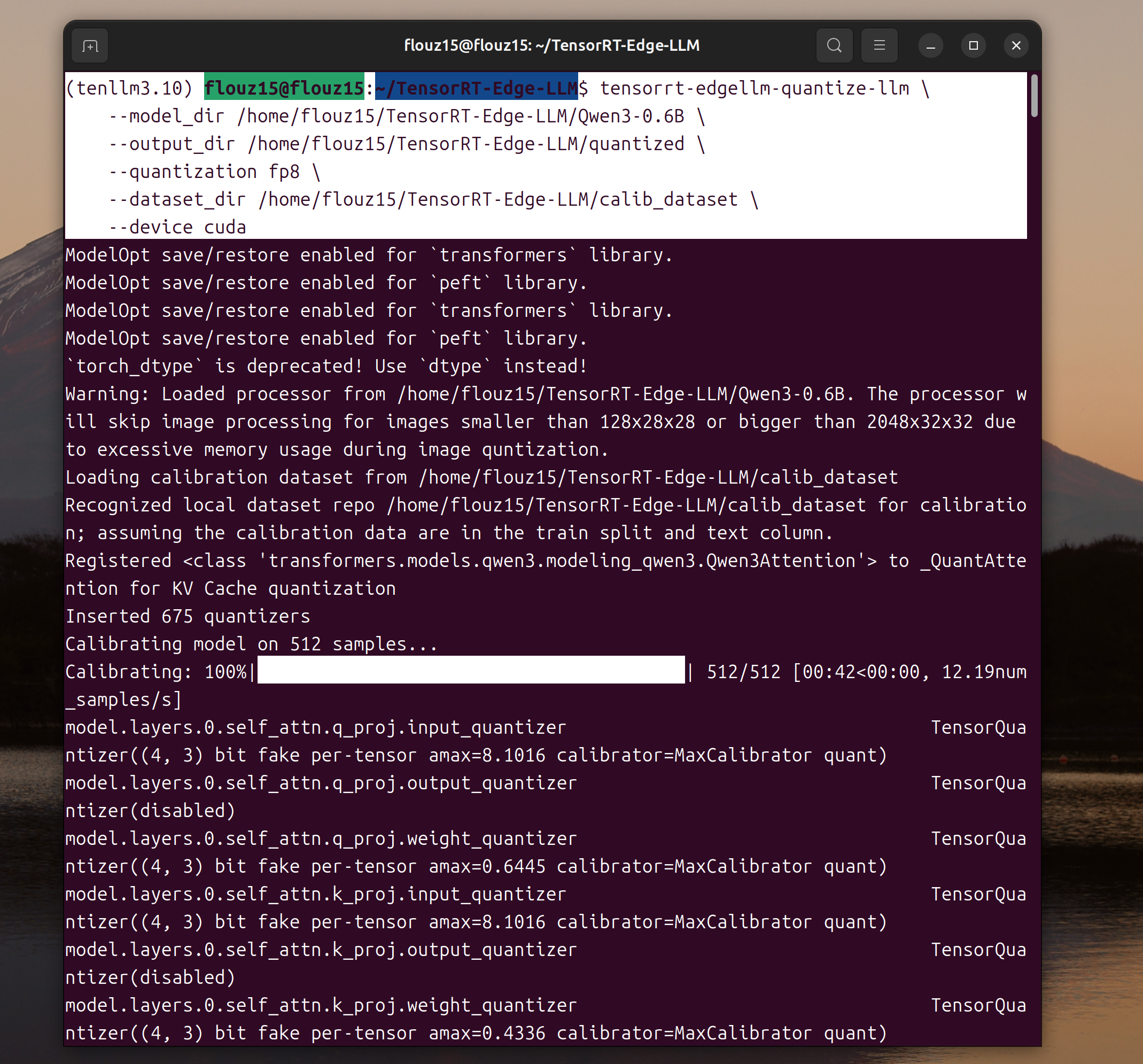
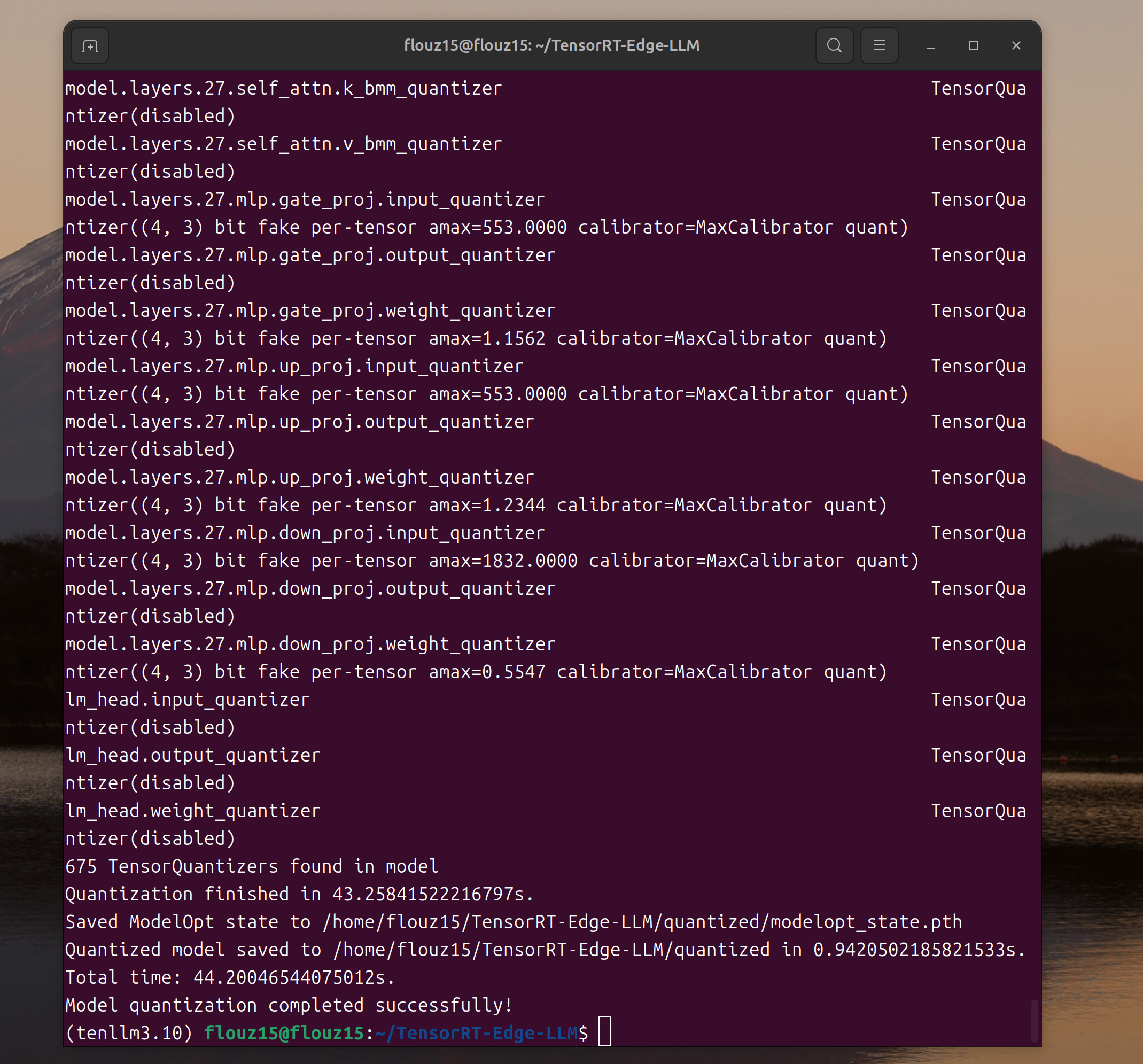
# Step 1: Quantize to FP8 (downloads model automatically)
tensorrt-edgellm-quantize-llm \
--model_dir Qwen/Qwen3-0.6B \
--output_dir $MODEL_NAME/quantized \
--quantization fp8
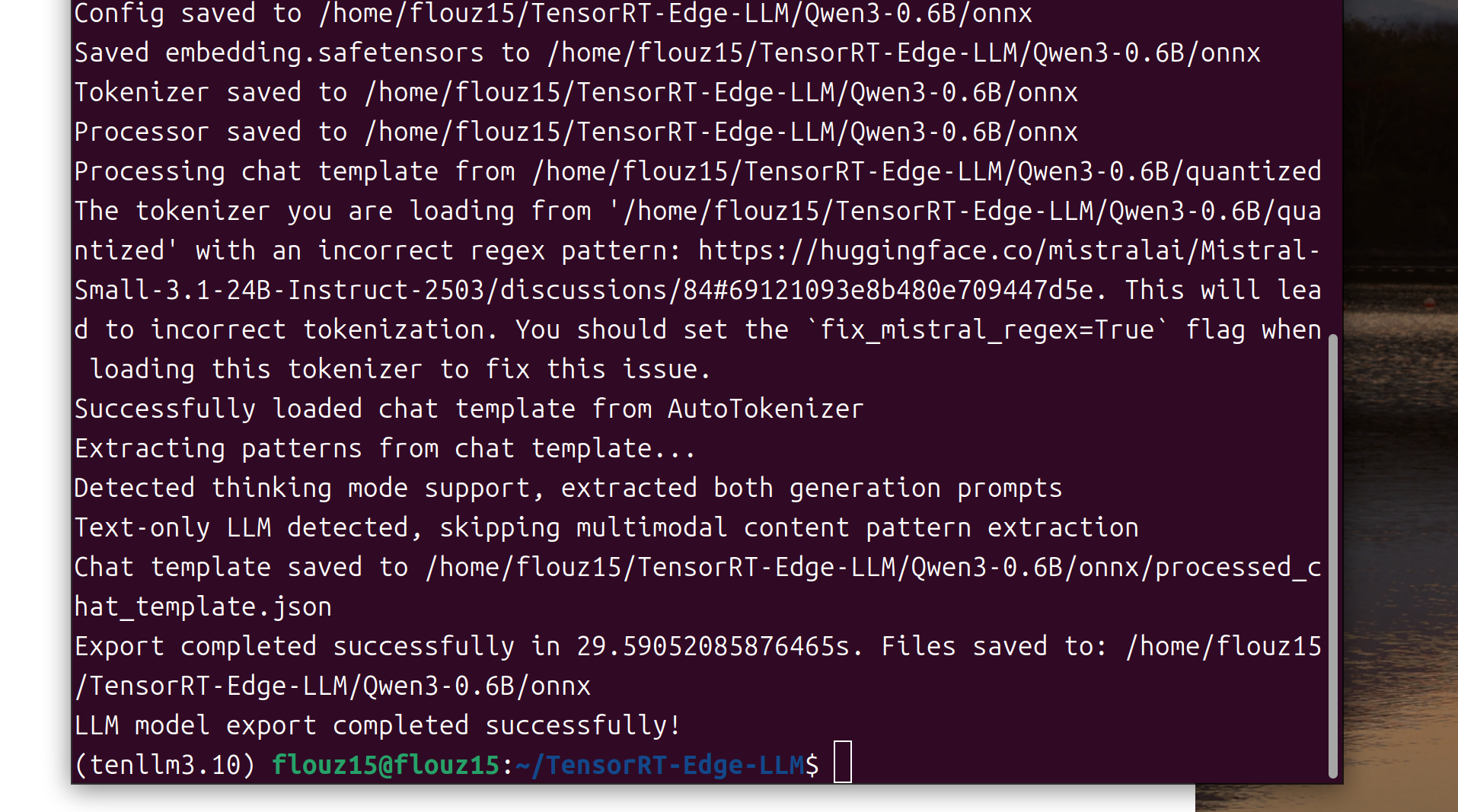
# Step 2: Export to ONNX
tensorrt-edgellm-export-llm \
--model_dir $MODEL_NAME/quantized \
--output_dir $MODEL_NAME/onnx
第 2 部分:引擎生成(边缘 Jetson 设备)
C++ 运行时在目标边缘设备上构建并执行模型。它必须在目标平台上或面向目标平台进行构建。
系统要求
目标平台:
-
NVIDIA Jetson Orin NX SUPER 16GB
-
JetPack 6.2
-
磁盘空间:20~50GB,用于存放 ONNX 文件和 TensorRT 引擎
安装与构建
-
安装系统依赖(在边缘设备上)
sudo apt update
sudo apt install -y \
cmake \
build-essential \
git -
验证 CUDA 和 TensorRT 安装
安装 JetPack 后,TensorRT 应该安装在 /usr 目录下
检查 CUDA 版本
nvcc --version # Should show CUDA 12.6 -
克隆仓库(在边缘设备上)
cd ~
git clone https://github.com/NVIDIA/TensorRT-Edge-LLM.git
cd TensorRT-Edge-LLM
git submodule update --init --recursive -
配置构建
在你的 Jetson Thor 设备上,使用以下命令配置构建:
mkdir build
cd build
cmake .. \
-DCMAKE_BUILD_TYPE=Release \
-DTRT_PACKAGE_DIR=/usr \
-DCMAKE_TOOLCHAIN_FILE=cmake/aarch64_linux_toolchain.cmake \
-DEMBEDDED_TARGET=jetson-orin -
构建项目
make -j$(nproc)构建时间:约 1-2 分钟,具体取决于硬件。
验证构建
# Test C++ examples
./examples/llm/llm_build --help
./examples/llm/llm_inference --help
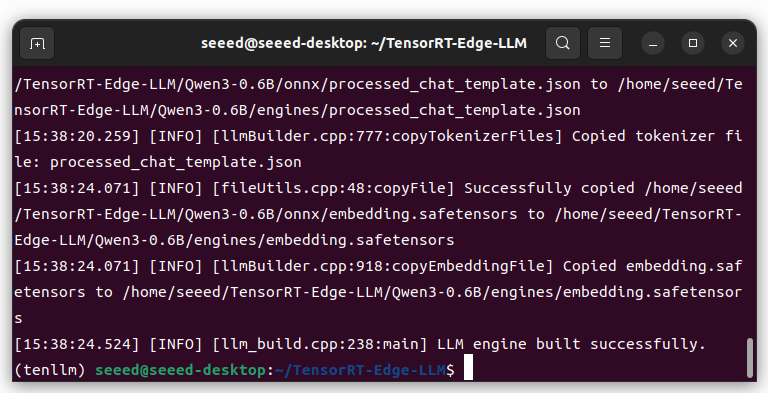
构建 TensorRT 引擎
将主机 PC 上生成的 ONNX 模型目录复制到 Jetson 设备。
在你的 Jetson 上:
# Set up workspace directory
export WORKSPACE_DIR=$HOME/tensorrt-edgellm-workspace
export MODEL_NAME=Qwen3-0.6B
cd ~/TensorRT-Edge-LLM
# Build engine
./build/examples/llm/llm_build \
--onnxDir $WORKSPACE_DIR/$MODEL_NAME/onnx \
--engineDir $WORKSPACE_DIR/$MODEL_NAME/engines \
--maxBatchSize 1 \
--maxInputLen 1024 \
--maxKVCacheCapacity 4096
运行推理
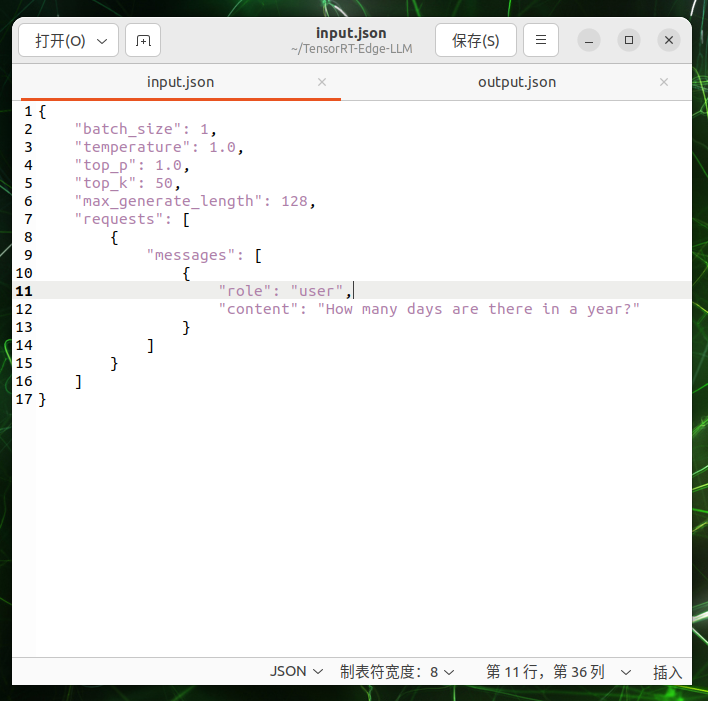
创建一个包含示例问题的输入文件:
cat > $WORKSPACE_DIR/input.json << 'EOF'
{
"batch_size": 1,
"temperature": 1.0,
"top_p": 1.0,
"top_k": 50,
"max_generate_length": 128,
"requests": [
{
"messages": [
{
"role": "user",
"content": "What is the capital of United States?"
}
]
}
]
}
EOF
"content"是输入给 LLM 的内容。运行引擎:
cd ~/TensorRT-Edge-LLM
./build/examples/llm/llm_inference \
--engineDir $WORKSPACE_DIR/$MODEL_NAME/engines \
--inputFile $WORKSPACE_DIR/input.json \
--outputFile $WORKSPACE_DIR/output.json
验证输出:
# View the model response
cat $WORKSPACE_DIR/output.json
你应该会看到一个包含模型回答的 JSON 响应,类似于:
{
"responses": [
{
"text": "The capital of the United States is Washington, D.C.",
"finish_reason": "stop"
}
]
}
成功!🎉 你已经在边缘设备上成功运行了 LLM 推理!
技术支持与产品讨论
感谢你选择我们的产品!我们将为你提供多种支持,确保你在使用我们产品的过程中尽可能顺利。我们提供多种沟通渠道,以满足不同的偏好和需求。