在 Orin Nano / NX 8GB 上快速上手 Jetson-Claw
本文档将带你完成一个适用于 Jetson Orin Nano 8GB 和 Jetson Orin NX 8GB 的实用 Jetson-Claw 入门搭建。整个软件栈都在 Jetson 本地运行:我们会安装 nanobot,扩展交换分区以更安全地加载模型,用 CUDA 编译 llama.cpp,下载一个 Qwen3.5 4B GGUF 模型,将 nanobot 切换到本地 llama.cpp 后端,最后把机器人接入 飞书(Feishu),这样你就可以通过聊天来控制它。
与更大规模的 OpenClaw 部署相比,nanobot 更适合作为这个入门级 Jetson-Claw 方案的核心,因为它更轻量、启动更快、代码更易阅读和修改,并且已经支持 飞书 以及 兼容 OpenAI 的本地后端。在 8 GB 的 Jetson 上,更低的运行时开销可以为本地模型本身留出更多空间。如果你之后需要更大的插件生态或更复杂的多组件工作流,仍然可以升级到 OpenClaw。
你将搭建什么
- 一个基于
nanobot的轻量本地 AI 助手 - 一个运行在 Jetson 上、兼容 OpenAI 的
llama.cppHTTP 服务器 - 一个本地
Qwen3.5 4BGGUF 模型 - 一个接入飞书的 Jetson 机器人,可通过私聊或群聊 @ 控制
前置条件
- 1 台 Jetson Orin Nano 8GB 或 Jetson Orin NX 8GB
- 已安装 JetPack 6.x
- 可用于安装软件包和下载模型的互联网连接
- 建议至少预留 20 GB 可用存储空间
本指南以 reComputer Super J3011 作为参考 Jetson 平台:

nanobot 目前需要 Python 3.11 或更高版本,因此本指南使用 Miniconda 环境,而不是 Jetson 上默认的系统 Python。
步骤 1. 安装 nanobot
首先安装系统依赖和 Miniconda:
sudo apt update
sudo apt install -y git curl wget build-essential cmake libcurl4-openssl-dev python3-pip
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
创建一个干净的 Python 3.11 环境并安装 nanobot:
conda create -y -n jetson-claw python=3.11
conda activate jetson-claw
pip install -U pip
pip install nanobot-ai
初始化运行时目录:
nanobot onboard
初始化完成后,主配置文件位于:
~/.nanobot/config.json
nanobot 受 OpenClaw 启发,但对于 Orin Nano / NX 8GB 来说,它通常是更好的起点:更低的内存开销、更快的启动速度,以及更少需要排查的组件。
步骤 2. 增加交换分区(Swap)
在 8 GB Jetson 上运行 4B 本地模型时,增加额外的交换分区会稳定得多。这在模型加载、编译以及长上下文推理时都会有所帮助。
sudo fallocate -l 8G /var/swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /var/swapfile
sudo swapon /var/swapfile
echo '/var/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
swapon --show
如果你计划尝试更大的上下文长度或其他模型,可以进一步增加交换分区大小。
步骤 3. 使用 CUDA 编译 llama.cpp
设置 CUDA 路径:
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
克隆并构建 llama.cpp:
git clone https://github.com/ggml-org/llama.cpp.git ~/llama.cpp
cd ~/llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build --parallel
编译完成后,主要可执行文件会放在以下目录下:
~/llama.cpp/build/bin
你可以通过下面的命令快速确认服务端二进制文件是否就绪:
~/llama.cpp/build/bin/llama-server --help
步骤 4. 下载 Qwen3.5 4B GGUF 权重
本指南使用 Q4_K_M GGUF 量化格式,因为在 8 GB Jetson 设备上,它在内存占用和响应质量之间达成了较好的平衡。
安装 Hugging Face CLI:
conda activate jetson-claw
pip install -U "huggingface_hub[cli]"
mkdir -p ~/llama.cpp/models/Qwen3.5-4B-GGUF
然后打开下面的模型页面,将 Q4_K_M GGUF 文件下载到 ~/llama.cpp/models/Qwen3.5-4B-GGUF/ 目录中:
在 Hugging Face 页面中选择 Qwen3.5-4B.Q4_K_M.gguf 文件:
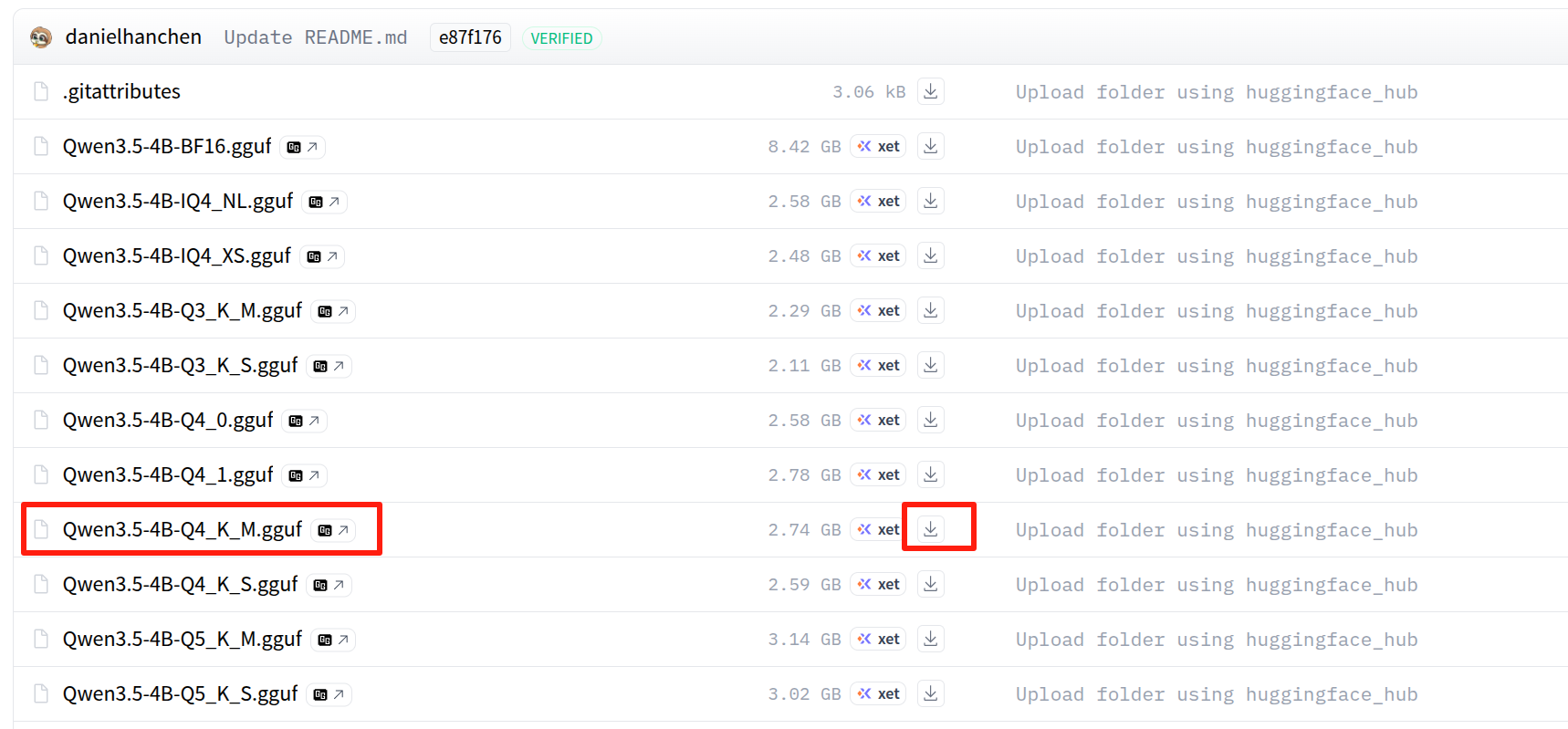
如果该仓库使用的文件名与本指南示例相同,你也可以通过以下方式下载:
huggingface-cli download \
unsloth/Qwen3.5-4B-GGUF \
Qwen3.5-4B.Q4_K_M.gguf \
--local-dir ~/llama.cpp/models/Qwen3.5-4B-GGUF
如果你的文件名不同,只需在后面的启动命令中更新路径即可。在本示例中,我们假设模型文件为:
~/llama.cpp/models/Qwen3.5-4B-GGUF/Qwen3.5-4B.Q4_K_M.gguf
步骤 5. 将 llama.cpp 作为本地后端启动
启动本地兼容 OpenAI 的 API 服务器:
conda activate jetson-claw
cd ~/llama.cpp
./build/bin/llama-server \
-m ~/llama.cpp/models/Qwen3.5-4B-GGUF/Qwen3.5-4B.Q4_K_M.gguf \
--alias qwen3.5-4b-local \
-t 6 \
-c 40960 \
--n-gpu-layers 40 \
--reasoning off \
--reasoning-format none \
--host 127.0.0.1 \
--port 8080
推荐参数说明:
--alias qwen3.5-4b-local:为本地模型设置一个干净的 API 模型名,供nanobot使用-t 6:在入门级 Jetson 设备上使用适中的 CPU 线程数-c 40960:提供较大的上下文窗口,如果内存吃紧可以适当调小--n-gpu-layers 40:尽可能多地将层数卸载到 Jetson GPU 上--reasoning off:让输出更简洁,同时降低对入门环境来说不必要的开销
如果服务器因为内存压力启动失败,先尝试将 -c 降到 16384,然后再逐步降低 --n-gpu-layers。
在另一个终端中验证 API:
curl http://127.0.0.1:8080/v1/models
步骤 6. 配置 nanobot 使用 llama.cpp
打开配置文件:
nano ~/.nanobot/config.json
然后将下面这些配置片段合并到你的配置文件中:
{
"agents": {
"defaults": {
"workspace": "~/.nanobot/workspace",
"model": "qwen3.5-4b-local",
"provider": "custom",
"maxTokens": 8192,
"contextWindowTokens": 40960,
"temperature": 0.1,
"maxToolIterations": 40,
"reasoningEffort": null
}
},
"channels": {
"sendProgress": true,
"sendToolHints": false,
"feishu": {
"enabled": true,
"appId": "cli_xxx",
"appSecret": "xxx",
"encryptKey": "",
"verificationToken": "",
"allowFrom": ["*"],
"reactEmoji": "THUMBSUP",
"groupPolicy": "mention",
"replyToMessage": false
}
},
"providers": {
"custom": {
"apiKey": "no-key",
"apiBase": "http://127.0.0.1:8080/v1",
"extraHeaders": null
}
},
"gateway": {
"host": "0.0.0.0",
"port": 18790
}
}
这样配置的原因:
provider: "custom"告诉nanobot使用任意兼容 OpenAI 的后端apiBase: "http://127.0.0.1:8080/v1"指向本地的llama-servermodel: "qwen3.5-4b-local"与启动llama.cpp时使用的--alias值保持一致
在快速测试阶段,使用 allowFrom: ["*"] 很方便。但在生产环境中,请在验证后将其替换为你自己的飞书 open_id。
步骤 7. 将飞书接入 nanobot
在飞书开放平台中创建一个飞书应用:
- 打开 https://open.feishu.cn/app
- 创建或打开你的机器人应用
- 复制 App ID 和 App Secret
- 将它们填入
channels.feishu.appId和channels.feishu.appSecret
对于长连接模式,encryptKey 和 verificationToken 可以保持为空。
如果之后找不到这些凭据,可以前往:
- 飞书开放平台
- 你的应用
凭证与基础信息(Credentials & Basic Info)
导入飞书权限
为了让文件、图片和富文本消息处理正常工作,请在以下位置导入下面的权限集合:
- 飞书开放平台
- 你的应用
权限管理(Permission Management)批量导入(Bulk Import)
{
"scopes": {
"tenant": [
"aily:file:read",
"aily:file:write",
"application:application.app_message_stats.overview:readonly",
"application:application:self_manage",
"application:bot.menu:write",
"cardkit:card:write",
"contact:user.employee_id:readonly",
"corehr:file:download",
"docs:document.content:read",
"event:ip_list",
"im:chat",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.members:bot_access",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:message:readonly",
"im:message:send_as_bot",
"im:resource",
"sheets:spreadsheet",
"wiki:wiki:readonly"
],
"user": [
"aily:file:read",
"aily:file:write",
"im:chat.access_event.bot_p2p_chat:read"
]
}
}
导入权限后:
- 创建一个新的应用版本
- 发布该应用版本
否则新添加的权限可能不会生效。
步骤 8. 启动 nanobot 并测试飞书控制
在一个终端中保持 llama-server 运行,然后在另一个终端中启动 nanobot:
conda activate jetson-claw
nanobot gateway
一些有用的检查方式:
nanobot status
nanobot channels status
现在从飞书向机器人发送一条消息:
- 在私聊中发送一条直接消息
- 在群聊中,如果你保持
groupPolicy: "mention",请在消息中提及该机器人
如果你使用了 allowFrom: ["*"],机器人应该会立即回复。如果你之后想要收紧访问权限,先发送一条消息,在 nanobot 日志中查看你的 open_id,然后将 ["*"] 替换为该值。
可选:添加示例 Jetson-Claw 技能
如果你想把这个入门配置变成一个更实用的 Jetson-Claw 演示,你可以添加一个示例技能集:
git clone https://github.com/jjjadand/JetsonClaw-SKILLS.git ~/JetsonClaw-SKILLS
mkdir -p ~/.nanobot/workspace/skills
cp -r ~/JetsonClaw-SKILLS/person-detection ~/.nanobot/workspace/skills/
然后重启 nanobot gateway,将 USB 摄像头连接到 Jetson,并在 Feishu 中让机器人检查摄像头前是否有人可见。
Feishu 监控流程示例
安装技能后,你可以从 Feishu 应用发送请求,让 Jetson-Claw 检查摄像头画面:
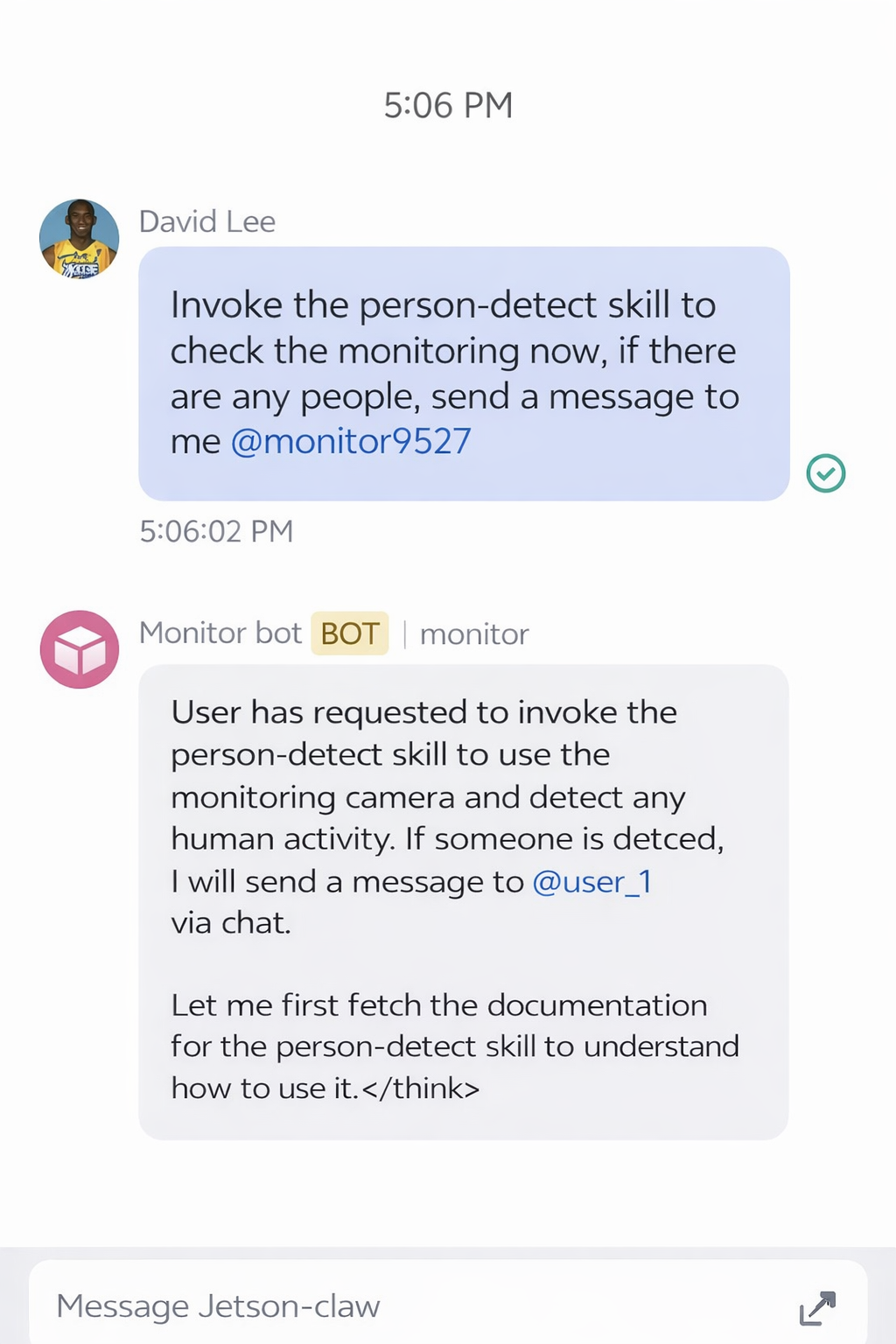
如果未检测到人,监控结果可能如下所示:
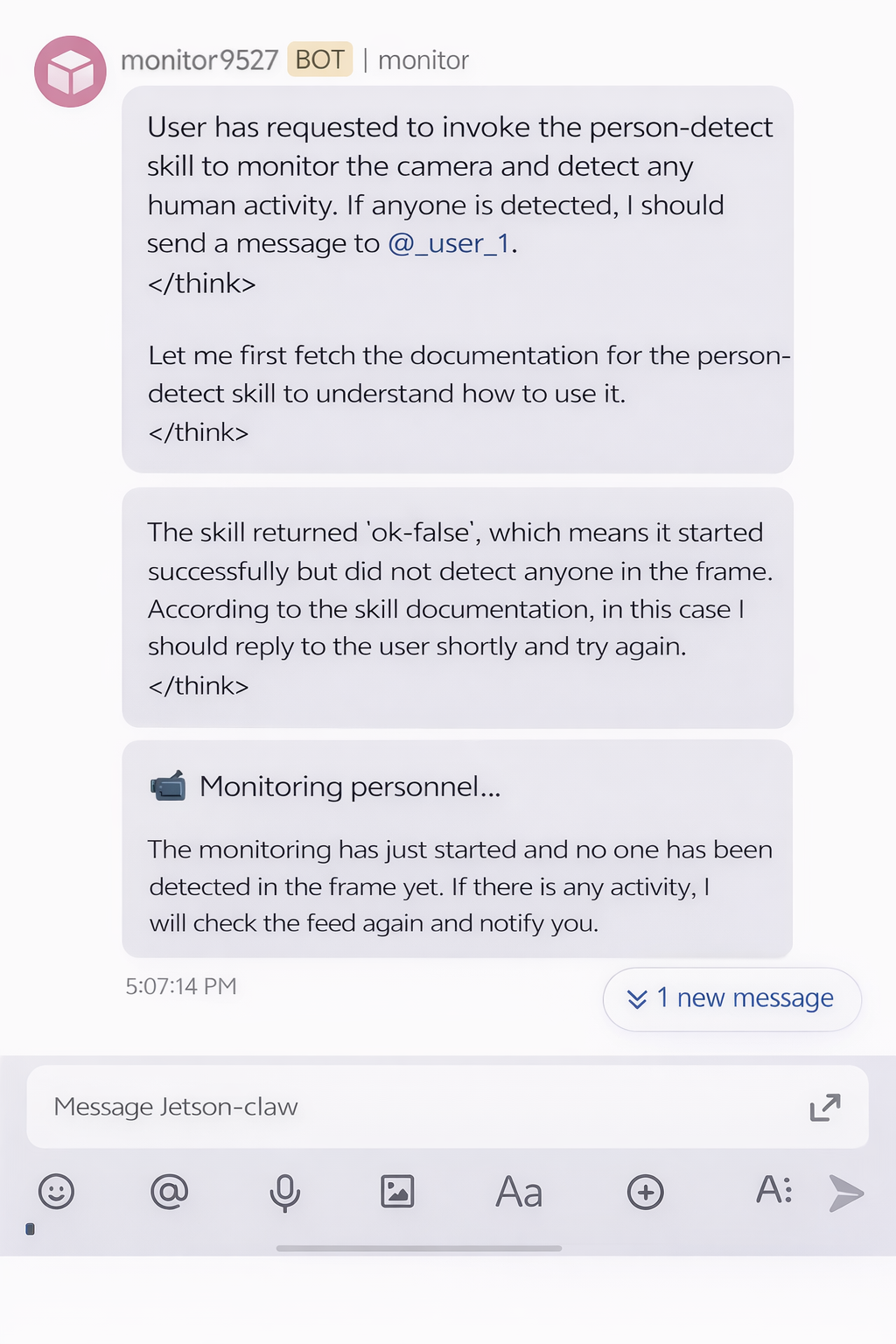
如果检测到有人,Jetson-Claw 可以通过 Feishu 返回告警:
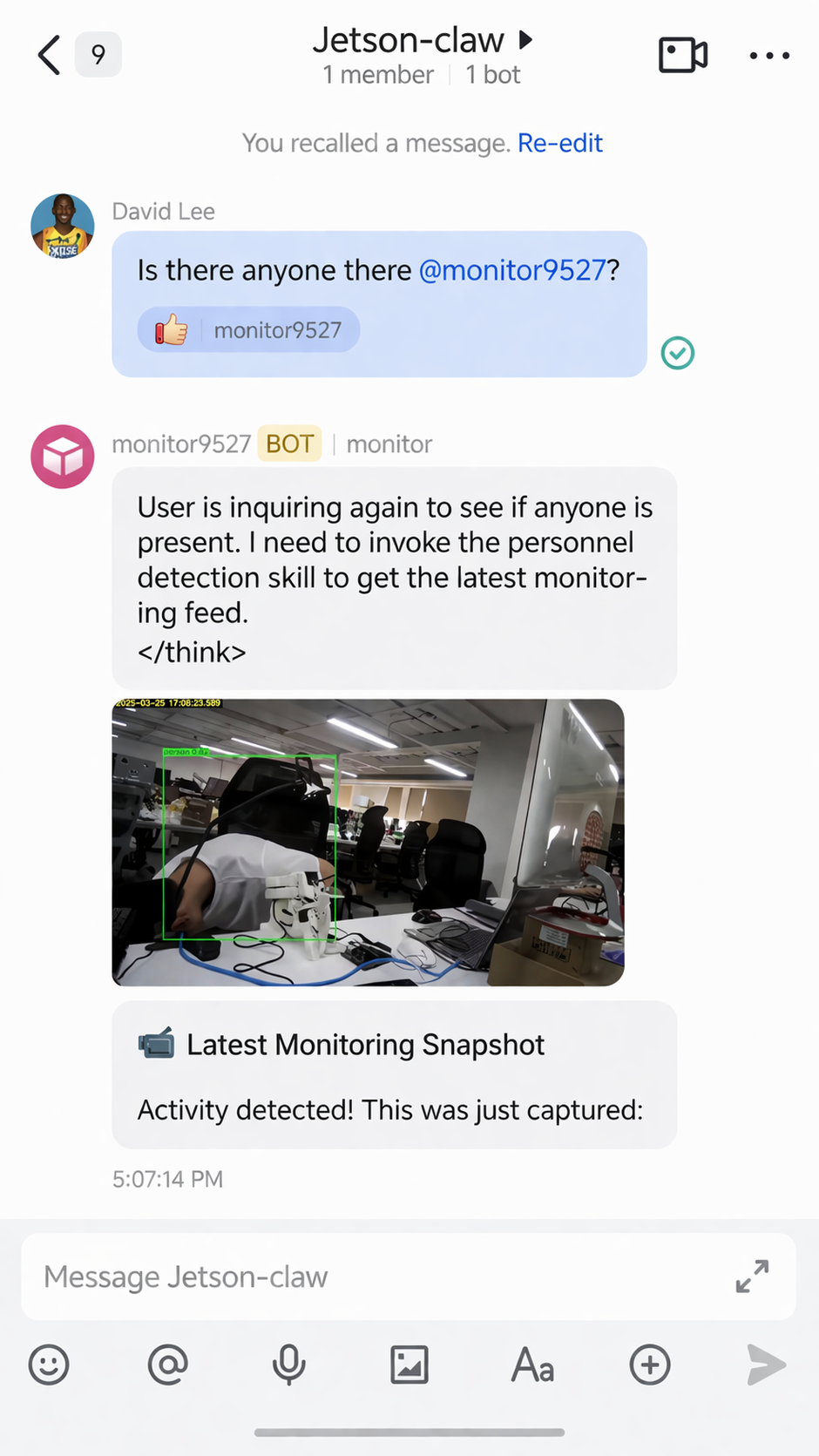
监控技能还可以回传捕获到的结果图像:

故障排查
nanobot安装失败:请确保你处于 Python 3.11 环境中llama-server在加载模型时退出:请增加交换分区或减小-c- Feishu 机器人没有回复:请核对 App ID、App Secret、已导入的权限以及已发布的应用版本
- 群消息没有触发机器人:请检查
groupPolicy并确保你在消息中提及了机器人 - 回复很慢:请降低上下文大小、减少并发使用,或使用更小的量化模型
参考资料
- https://github.com/HKUDS/nanobot
- https://github.com/ggml-org/llama.cpp
- https://huggingface.co/unsloth/Qwen3.5-4B-GGUF/tree/main
- https://open.feishu.cn/app
- https://github.com/jjjadand/JetsonClaw-SKILLS
- https://wiki.seeedstudio.com/cn/local_openclaw_on_recomputer_jetson/
技术支持与产品讨论
感谢你选择我们的产品!我们将为你提供多种支持,以确保你在使用我们产品时的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。