基于 LeRobot 的 SO-ARM100 and SO-ARM101 机械臂入门教程
SO-10xARM 是由 TheRobotStudio 发起的一个完全开源的机器人手臂项目。它包括从动臂和领导臂手臂,并提供详细的3D打印文件和操作指南。LeRobot 致力于为真实世界的机器人提供 PyTorch 中的模型、数据集和工具。其目标是降低机器人学的入门门槛,使每个人都能通过共享数据集和预训练模型进行贡献和受益。LeRobot 集成了经过验证的前沿方法,专注于模仿学习和强化学习。它提供了一套预训练模型、包含人类收集的示范数据集和仿真环境,使用户无需进行机器人组装即可开始使用。未来几周,计划在当前最具成本效益和性能的机器人上增强对真实世界机器人的支持。
项目介绍
SO-ARM10x 和 reComputer Jetson AI 智能机器人套件无缝结合了高精度的机器人手臂控制与强大的 AI 计算平台,提供了全面的机器人开发解决方案。该套件基于 Jetson Orin 或 AGX Orin 平台,结合 SO-ARM10x 机器人手臂和 LeRobot AI 框架,为用户提供适用于教育、科研和工业自动化等多种场景的智能机器人系统。
本维基提供了 SO ARM10x 的组装和调试教程,并在 Lerobot 框架内实现数据收集和训练。

Seeed Studio 仅对硬件质量负责。教程严格按官方文档更新,如遇无法解决的软件或环境问题,请先查阅文末FAQ,或者联系客服加入SeeedStudio Lerobot交流群询问,也可以在这里询问:LeRobot GitHub 或 Discord频道。
🔧 SO-ARM10x 系列特点:
-
开源 & 低成本
本系列由 TheRobotStudio 提供,是一套开源、低成本的机器人臂解决方案。 -
支持 LeRobot 平台集成
专为与 LeRobot 平台 集成而设计。该平台提供 PyTorch 模型、数据集与工具,面向现实机器人任务的模仿学习(包括数据采集、仿真、训练与部署)。 -
丰富的学习资源
提供全面的开源学习资源,包括组装与校准指南、测试与数据采集教程、训练与部署文档,帮助用户快速上手并开发机器人应用。 -
兼容 Nvidia 平台
支持通过 reComputer Mini J4012 Orin NX 16GB 平台进行部署。
🆕 更新内容:
- 布线优化:与 SO-ARM100 相比,SO-ARM101 在布线方面进行了改进,解决了先前第3关节处可能出现断线的问题。新的布线设计也不再限制关节的活动范围。
- 主臂齿轮比优化:主臂现在采用了经过优化的齿轮比电机,无需外部减速机构,同时提升了性能。
- 新增功能支持:主臂现在可以实时跟随从臂动作,这对即将引入的策略尤为关键,可实现人类实时干预并修正机器动作。
规格参数
本教程硬件由矽递科技Seeed Studio提供
| 类型 | SO-ARM100 | SO-ARM101 | ||
|---|---|---|---|---|
| 标准版 | 专业版 | 标准版 | 专业版 | |
| Leader Arm | 12个 ST-3215- C001 (7.4V) 1:345 齿轮比电机,适用于所有关节 | 12个 ST-3215-C018/ST-3215-C047 (12V) 1:345 齿轮比电机,适用于所有关节 | 1个 ST-3215- C001 (7.4V) 1:345 齿轮比电机,仅用于第2号关节 | |
| Follower Arm | 与SO-ARM100相同 | |||
| 电源 | 5.5 mm×2.1 mm DC 5 V 4 A | 5.5 mm×2.1 mm DC 12 V 2 A | 5.5 mm×2.1 mm DC 5 V 4 A | 5.5 mm×2.1 mm DC 12 V 2 A(从臂Follower) |
| 角度传感器 | 12位磁编码器 | |||
| 推荐工作温度范围 | 0 °C ~ 40 °C | |||
| 通信方式 | UART | |||
| 控制方式 | PC | |||
若购买 SO101 Arm Kit 标准版,所有电源均为5V。若购买 SO101 Arm Kit Pro 版,Leader机械臂的校准及每一步骤均使用5V电源,Follower机械臂的校准及每一步骤均使用12V电源。
材料清单(BOM)
| 部件 | 数量 | 是否包含 |
|---|---|---|
| 舵机 | 12 | ✅ |
| 舵机驱动板 | 2 | ✅ |
| USB-C线缆(2条) | 1 | ✅ |
| 电源适配器 | 2 | ✅ |
| 3D打印桌面夹具 | 4 | ✅ |
| 手臂的3D打印部件 | 1 | Option |
初始系统环境
For Ubuntu X86:
- Ubuntu 22.04
- CUDA 12+
- Python 3.10
- Troch 2.6
For Jetson Orin:
- Jetson Jetpack 6.0 和 6.1,暂不支持6.2
- Python 3.10
- Torch 2.3+
步骤目录
- A. 3D打印指南
- B. 安装Lerobot
- C. 校准舵机并组装机械臂
- D. 校准机械臂
- E. 遥操作
- F. 添加摄像头
- G. 数据集制作采集
- H. 可视化数据集
- I. 重播一个回合
- J. 训练
- K. 评估
3D打印参考参数
随着2025年4月28日官方发布 SO101,SO100 将不再支持打印指导,但源文件仍可在我们的 Makerworld 找到。不过,对于之前购买了SO100 的用户,教程和安装方法以及代码依然兼容。SO101 的打印件也完全兼容 SO100 的电机套件安装。
第一步:选择打印机
提供的 STL 文件可以直接在许多 FDM 打印机上打印。以下是经过测试并推荐的设置,但其他设置也可能适用。
- 材料:PLA+
- 喷嘴直径与精度:0.4mm 喷嘴直径,层高 0.2mm,或 0.6mm 喷嘴直径,层高 0.4mm。
- 填充密度:15%
第二步:设置打印机
- 确保打印机已校准且打印床水平调整正确,具体操作请参考打印机说明书。
- 清洁打印床,确保无灰尘或油污。如果使用水或其他液体清洁打印床,请确保彻底干燥。
- 如果打印机建议,使用标准胶棒在打印区域涂抹一层薄薄的均匀胶水,避免结块或涂抹不均。
- 按照打印机说明书装载打印机耗材(线材)。
- 确保打印机设置与上述推荐参数匹配(大多数打印机有多种设置选项,请选择最接近的)。
- 设置支撑:支撑应设置为“处处需要”,但忽略与水平面小于 45 度的倾斜面。
- 水平轴方向的螺丝孔内不应有支撑结构。
第三步:打印零件
所有关于 Leader 或 Follower 的零件都已经排版好,方便 3D 打印,且朝 Z 轴正方向摆放,以最小化支撑需求。
-
对于打印床尺寸为 220mm x 220mm(如 Ender)的打印机,请打印以下文件:
-
对于打印床尺寸为 205mm x 250mm(如 Prusa/Up)的打印机,请打印以下文件:
安装 LeRobot
需要根据你的 CUDA 版本安装 pytorch 和 torchvision 等环境。
- 安装 Miniconda: 对于 Jetson:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
或者,对于 X86 Ubuntu 22.04:
mkdir -p ~/miniconda3
cd miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
source ~/miniconda3/bin/activate
conda init --all
- 创建并激活一个新的 conda 环境用于 lerobot
conda create -y -n lerobot python=3.10 && conda activate lerobot
- 克隆 Lerobot 仓库:
git clone https://github.com/Seeed-Projects/lerobot.git ~/lerobot
- 使用 miniconda 时,在环境中安装 ffmpeg:
conda install ffmpeg -c conda-forge
这通常会为你的平台安装使用 libsvtav1 编码器编译的 ffmpeg 7.X。如果不支持 libsvtav1(可以通过 ffmpeg -encoders 查看支持的编码器),你可以:
- 【适用于所有平台】显式安装 ffmpeg 7.X:
conda install ffmpeg=7.1.1 -c conda-forge
- 【仅限 Linux】安装 ffmpeg 的构建依赖并从源码编译支持 libsvtav1 的 ffmpeg,并确保使用的 ffmpeg 可执行文件是正确的,可以通过
which ffmpeg确认。
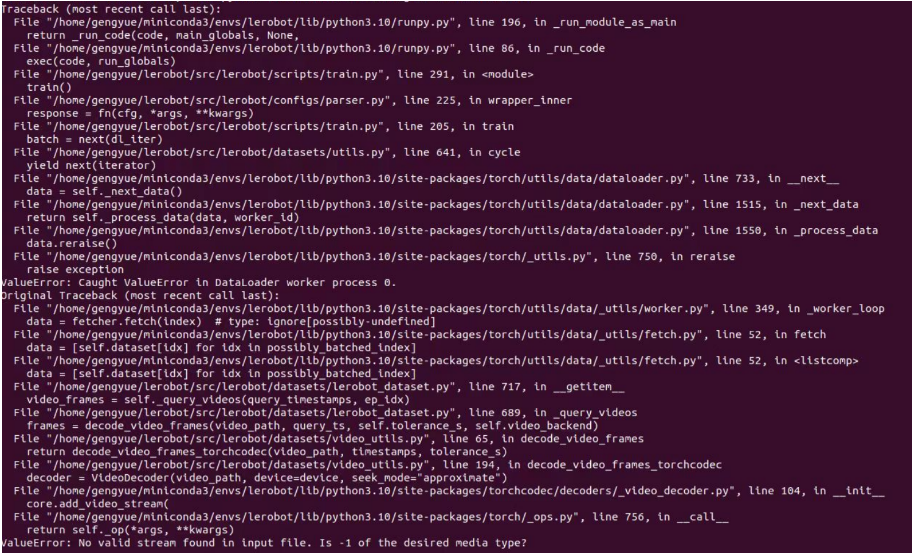
如果你遇到以下报错,也可以使用上述命令解决。
- 安装带有 feetech 电机依赖的 LeRobot:
cd ~/lerobot && pip install -e ".[feetech]"
- (电脑端可跳过这一步) 对于 Jetson Jetpack 6.0+ 设备(请确保在执行此步骤前按照此链接教程的第 5 步安装了 Pytorch-gpu 和 Torchvision):
conda install -y -c conda-forge "opencv>=4.10.0.84" # 通过 conda 安装 OpenCV 和其他依赖,仅适用于 Jetson Jetpack 6.0+
conda remove opencv # 卸载 OpenCV
pip3 install opencv-python==4.10.0.84 # 使用 pip3 安装指定版本 OpenCV
conda install -y -c conda-forge ffmpeg
conda uninstall numpy
pip3 install numpy==1.26.0 # 该版本需与 torchvision 兼容
- 检查 Pytorch 和 Torchvision
由于通过 pip 安装 lerobot 环境时会卸载原有的 Pytorch 和 Torchvision 并安装 CPU 版本,因此需要在 Python 中进行检查。
import torch
print(torch.cuda.is_available())
如果输出结果为 False,需要根据官网教程重新安装 Pytorch 和 Torchvision。
如果你使用的是 Jetson 设备,请根据此教程安装 Pytorch 和 Torchvision。
校准舵机并组装机械臂
- SO101
SO101 的舵机校准初始化与 SO100 方法和代码一致,只是需要注意:SO101 的 Leader 机械臂前三个关节减速比与 SO100 不同,因此需要仔细区分并校准。
为便于校准与后续排查,建议在舵机校准前对每个电机做好标记:
- 标注该舵机属于 Follower(用 F 表示)还是 Leader(用 L 表示)
- 标注编号从 1 到 6(例如 F1...F6、L1...L6)
- 编号规则:从底座开始为 1 号,向上依次为 2、3...,直到夹爪为 6 号
后续我们用 F1–F6 表示 Follower 机械臂的 1–6 号关节舵机,用 L1–L6 表示 Leader 机械臂的 1–6 号关节舵机。对应的舵机型号、关节与减速比信息如下。
| 舵机型号 | 减速比 | 对应机械臂关节 |
|---|---|---|
| ST-3215-C044(7.4V) | 1:191 | L1 |
| ST-3215-C001(7.4V) | 1:345 | L2 |
| ST-3215-C044(7.4V) | 1:191 | L3 |
| ST-3215-C046(7.4V) | 1:147 | L4–L6 |
| ST-3215-C001(7.4V) / C018(12V) / C047(12V) | 1:345 | F1–F6 |
现在你需要将 5V 或 12V 电源连接到电机总线上。对于 STS3215 7.4V 电机使用 5V 电源,对于 STS3215 12V 电机使用 12V 电源。请注意,Leader 机械臂始终使用 7.4V 电机,因此如果你同时有 12V 和 7.4V 电机,一定要使用正确的电源,否则可能会烧坏电机!然后,通过 USB 将电机总线连接到你的电脑。请注意,USB 不会为电机供电,因此电源和 USB 都必须连接。

以下是代码校准步骤,请参照上图中接线舵机进行校准
查找机械臂对应的 USB 端口 为了找到每个机械臂正确的端口,请运行实用脚本两次:
lerobot-find-port
示例输出:
Finding all available ports for the MotorBus.
['/dev/ttyACM0', '/dev/ttyACM1']
Remove the usb cable from your MotorsBus and press Enter when done.
[...Disconnect corresponding leader or follower arm and press Enter...]
The port of this MotorsBus is /dev/ttyACM0
Reconnect the USB cable.
请记住要拔出 USB 接头,否则将无法检测到接口。
识别从动臂端口时的示例输出(例如,在 Mac 上为 /dev/tty.usbmodem575E0031751,或在 Linux 上可能为 /dev/ttyACM0):
识别领导臂端口时的示例输出(例如,在 Mac 上为 /dev/tty.usbmodem575E0032081,或在 Linux 上可能为 /dev/ttyACM1):
故障排除:在 Linux 上,你可能需要通过运行以下命令来赋予 USB 端口访问权限:
sudo chmod 666 /dev/ttyACM0
sudo chmod 666 /dev/ttyACM1
配置舵机
如果你买的是SO101的标准版,则使用5V电源进行Leader舵机校准(ST-3215-C046, C044, C001).
| Leader机械臂6号舵机校准 | Leader机械臂5号舵机校准 | Leader机械臂4号舵机校准 | Leader机械臂3号舵机校准 | Leader机械臂2号舵机校准 | Leader机械臂1号舵机校准 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
如果你买的是SO101的Pro版,则使用12V电源进行Follower舵机校准(ST-3215-C047/ST-3215-C018),如果是SO101标准版则使用5V进行舵机校准(ST-3215-C001).
| Follower机械臂6号舵机校准 | Follower机械臂5号舵机校准 | Follower机械臂4号舵机校准 | Follower机械臂3号舵机校准 | Follower机械臂2号舵机校准 | Follower机械臂1号舵机校准 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
再次提醒,请确保舵机关节 ID 和齿轮比与 SO-ARM101 的严格对应。
将 USB 线从电脑连接到从动臂的舵机驱动板,并接通电源。然后,运行以下命令。
lerobot-setup-motors \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0
您会看到以下输出。
Connect the controller board to the 'gripper' motor only and press enter.
依照指示,将驱动板单独连接夹爪舵机(即 6 号舵机)。请确保它现在是唯一连接到舵机驱动板的舵机:电脑 → USB 线 → 驱动板 → 三针线 → 6 号舵机,并且舵机本身没有连接到任何其他舵机。当您按下 [Enter] 键后,脚本将自动设置该舵机的 ID 和波特率。
之后,您应该会看到以下信息:
'gripper' motor id set to 6
接着是下一条输出是:
Connect the controller board to the 'wrist_roll' motor only and press enter.
与之前的舵机一样,请确保它是唯一连接到驱动板的舵机,并且舵机本身没有连接到任何其他舵机。
根据指示,对每个舵机重复上述操作。
在每次按 Enter 键之前,请务必检查您的线缆连接。例如,在操作电路板时,电源线可能会断开。
当您完成所有步骤后,脚本将自动结束,此时舵机即可投入使用。现在,您可以将每根舵机的 3 针接口依次连接,并将第一个舵机(ID 为 1 的“shoulder pan”舵机)的线缆连接到驱动板。现在可以将驱动板安装到机械臂的底座上。
对领导臂重复相同的步骤。
lerobot-setup-motors \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM0
组装教程
- SO-ARM101 双臂的组装过程与 SO-ARM100 相同。唯一的区别在于 SO-ARM101 增加了线缆夹,且主机械臂(Leader Arm)关节舵机的齿轮比不同。因此,SO100 和 SO101 都可以参考以下内容进行安装。
- 组装前,请再次检查您的电机型号和减速比。如果您购买的是 SO100,可以忽略此步骤。如果您购买的是 SO101,请参考下表区分 F1 至 F6 和 L1 至 L6。
| Servo Model | Gear Ratio | Corresponding Joints |
|---|---|---|
| ST-3215-C044(7.4V) | 1:191 | L1 |
| ST-3215-C001(7.4V) | 1:345 | L2 |
| ST-3215-C044(7.4V) | 1:191 | L3 |
| ST-3215-C046(7.4V) | 1:147 | L4–L6 |
| ST-3215-C001(7.4V) / C018(12V) / C047(12V) | 1:345 | F1–F6 |
如果您购买的是 SO101 机械臂套件标准版,所有电源均为 5V。如果您购买的是 SO101 机械臂套件专业版,则主机械臂(Leader Arm)在每个校准和操作步骤中应使用 5V 电源,而随动臂(Follower Arm)在每个校准和操作步骤中应使用 12V 电源。
组装领导臂
| 步骤 1 | 步骤 2 | 步骤 3 | 步骤 4 | 步骤 5 | 步骤 6 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| 步骤 7 | 步骤 8 | 步骤 9 | 步骤 10 | 步骤 11 | 步骤 12 |
 |  |  |  |  |  |
| 步骤 13 | 步骤 14 | 步骤 15 | 步骤 16 | 步骤 17 | 步骤 18 |
 |  |  |  |  |  |
| 步骤 19 | 步骤 20 | ||||
 |  |
组装从动臂
- 从动臂的组装步骤与领导臂基本相同。唯一的区别在于第12步之后,末端执行器(夹爪和手柄)的安装方式有所不同。
| 步骤 1 | 步骤 2 | 步骤 3 | 步骤 4 | 步骤 5 | 步骤 6 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| 步骤 7 | 步骤 8 | 步骤 9 | 步骤 10 | 步骤 11 | 步骤 12 |
 |  |  |  |  |  |
| 步骤 13 | 步骤 14 | 步骤 15 | 步骤 16 | 步骤 17 | |
 |  |  |  |  |
校准机械臂
SO100 和 SO101 的代码是兼容的。SO100 用户可以直接使用 SO101 的参数和代码进行操作。
若购买 SO101 Arm Kit 标准版,所有电源均为5V。若购买 SO101 Arm Kit Pro 版,Leader机械臂的校准及每一步骤均使用5V电源,Follower机械臂的校准及每一步骤均使用12V电源。
接下来,你需要对你的 SO-10x 机器人接上电源和数据线进行校准,以确保在相同的物理位置时,Leader 臂和 Follower 臂的位置信息一致。这个校准过程至关重要,因为它可以让在一个 SO-10x 机器人上训练的神经网络在另一个机器人上也能正常工作。如果需要重新校准机械臂,请完全删除~/.cache/huggingface/lerobot/calibration/robots或者~/.cache/huggingface/lerobot/calibration/teleoperators下的文件并重新校准机械臂,否则会出现报错提示,校准的机械臂信息会存储该目录下的json文件中。
请通过 3 针接口连接 6 个机器人舵机的接口,并将底盘舵机连接到舵机驱动板,然后运行以下命令或 API 示例来校准机械臂:
以PC(linux)和jetson板卡为例,第一个插入usb接口会映射为ttyACM0,第二个插入usb接口会映射为ttyACM1。
在运行代码前请注意leader和follower的映射接口。
首先,您需要授予接口权限,运行以下命令:
sudo chmod 666 /dev/ttyACM*
校准从动臂
接下来,通过运行以下 Python 命令来校准从动臂:
lerobot-calibrate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm
下面的视频演示了如何执行校准。首先,您需要将机器人移动到所有关节都位于其活动范围中间的位置。然后,按下回车键后,您必须将每个关节在其完整的运动范围内移动。
校准领导臂
对主机械臂进行校准的步骤与上述相同,请运行以下命令或 API 示例:
lerobot-calibrate \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm
使用 Seeed Studio SoARM 系列快捷校准工具进行中位校准(可选)
当校准或运行过程中出现类似报错:
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)
通常表示某个舵机的当前位置/零点偏移异常,导致读到的角度值超出正常范围。此时可以使用 Seeed Studio 提供的 SoARM 快捷工具对舵机进行中位校准(将当前位置设为中位值 2048),然后再重新进行整臂校准。
1)从 GitHub 拉取工具并安装依赖
git clone https://github.com/Seeed-Projects/Seeed_RoboController.git
cd Seeed_RoboController
pip install -r requirements.txt
2)中位校准与验证
工具脚本位置:
src/tools/servo_middle_calibration.py:舵机中位校准(将当前位置写为中位 2048)src/tools/servo_disable.py:关闭舵机力矩(便于手动旋转关节)src/tools/servo_center_test.py:移动到 2048 以验证校准效果
按顺序执行(命令会交互式让你选择端口):
1.(可选)关闭力矩,便于手动调整关节:
python -m src.tools.servo_disable
2.执行中位校准(将当前位置设为 2048):
python -m src.tools.servo_middle_calibration
3.验证:将舵机移动到 2048,检查是否回到预期中位:
python -m src.tools.servo_center_test
测试流程:
- 扫描舵机
- 读取当前位置
- 启动力矩
- 移动到中位(2048)
- 显示位移结果
完成中位校准后,请回到本节上方的 lerobot-calibrate 流程重新进行机械臂整臂校准。
遥控操作
现在,您就可以遥控操作您的机器人了!运行这个简单的脚本(它不会连接和显示摄像头):
请注意,与机器人关联的 ID 用于存储校准文件。在使用相同设置进行遥控操作、录制和评估时,使用相同的 ID 至关重要。
先对串口给予权限:
sudo chmod 666 /dev/ttyACM*
运行遥操作:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm
遥控操作命令将自动执行以下步骤:
- 识别任何缺失的校准文件并启动校准程序。
- 连接机器人和遥控设备,并开始遥控操作。
添加摄像头
如果使用 RealSense D435i/D405
RealSense 深度相机可为 LeRobot 提供 RGB-D 感知能力,适用于目标识别、点云重建与桌面抓取等场景。这里推荐使用 RealSense D405 与 RealSense D435i。
RealSense D405

RealSense D405 是一款近距离双目深度相机,适合机械臂桌面操作等高精度近场视觉任务,典型工作范围为 7 cm 到 50 cm。
RealSense D435i

RealSense D435i 集成深度感知、RGB 成像和 IMU,适合三维重建、SLAM 与机器人环境感知等中近距离应用。
1. 切换到相机分支
当前相机支持位于 DepthCameraSupport 分支上:
git checkout DepthCameraSupport
git pull origin DepthCameraSupport
确认当前分支:
git branch --show-current
预期输出:
DepthCameraSupport
2. 检测相机
2. 以可编辑模式安装 LeRobot
如果你只使用 RealSense:
pip install -e ".[realsense]"
3. 检测相机
lerobot-find-cameras realsense
该命令会输出以下信息:
- 相机型号
- 序列号
- USB 信息
- 默认流配置
4. RealSense 示例
双 RealSense 测试:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{
d435i_color: {
type: realsense_d435i_color,
serial_number_or_name: "419522072950",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
color_stream_format: rgb8,
rotation: 0,
warmup_s: 1
},
d435i_depth: {
type: realsense_d435i_depth,
serial_number_or_name: "419522072950",
width: 640,
height: 480,
fps: 30,
max_depth_m: 2.0,
depth_alpha: 0.2,
rotation: 0,
warmup_s: 5
},
d405_color: {
type: realsense_d405_color,
serial_number_or_name: "409122273421",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
color_stream_format: rgb8,
rotation: 0,
warmup_s: 1
},
d405_depth: {
type: realsense_d405_depth,
serial_number_or_name: "409122273421",
width: 640,
height: 480,
fps: 30,
depth_alpha: 0.03,
rotation: 0,
warmup_s: 5
}
}' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
5. 参数建议
depth_alpha用于控制深度图的缩放比例;可以根据画面显示效果和目标距离范围进行调整。- 如果需要连接三个及以上深度相机,建议将
fps降低到15,以减轻 USB 带宽与系统负载压力。 - 建议优先保持
640x480分辨率,以兼顾稳定性与实时性。
如果使用 Orbbec Gemini2/Gemini336 相机

Orbbec Gemini 2 是一款适用于机器人场景的高性能 RGB-D 相机,提供同步的 RGB 与深度数据流,并支持精确的深度到彩色对齐。结合双目深度感知与 6 轴 IMU,它非常适合物体检测、三维感知、建图、导航等机器人任务。相机体积紧凑,易于部署,并完整支持 Orbbec SDK,适合研究和实际应用。

Gemini 336 是 Gemini 330 系列中的新成员,继承了 Gemini 335 出色的深度性能,并进一步优化了在室内反光区域、高动态暗部区域以及户外强光环境下的深度成像表现。对于机器人应用来说,它能够提供更稳定的高质量深度数据,适合感知、定位与操作等任务。
1. 切换到相机分支
当前相机支持位于 DepthCameraSupport 分支上:
git checkout DepthCameraSupport
git pull origin DepthCameraSupport
确认当前分支:
git branch --show-current
预期输出:
DepthCameraSupport
2. 以可编辑模式安装 LeRobot
如果你只使用 Orbbec:
pip install -e ".[orbbec]"
3. 检测相机
lerobot-find-cameras orbbec
该命令会输出以下信息:
- 相机型号
- 序列号
- USB 信息
- 默认流配置
4. Orbbec 示例
单 Orbbec 测试:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{
orbbec_color: {
type: orbbec_color,
serial_number_or_name: "CP9JA530003A",
width: 640,
height: 480,
fps: 30,
color_mode: rgb,
rotation: 0,
warmup_s: 1
},
orbbec_depth: {
type: orbbec_depth,
serial_number_or_name: "CP9JA530003A",
width: 640,
height: 400,
fps: 30,
depth_alpha: 0.2,
rotation: 0,
warmup_s: 5
}
}' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
5. 参数建议
depth_alpha用于控制深度图的缩放比例;通常可以从0.2开始测试,再根据显示效果进行微调。- 如果需要连接三个及以上深度相机,建议将
fps降低到15,以提升整体稳定性。 - 建议优先保持
640x480分辨率,以获得更稳定的显示与传输效果。
6. 常见问题
出现以下报错时:
No Orbbec camera found for 'XXXX'
通常说明配置中的序列号与当前在线设备不一致。请先运行:
lerobot-find-cameras orbbec
确认实际 serial 后,再更新命令中的 serial_number_or_name。
如果使用普通相机
为了实例化摄像头,您需要一个摄像头标识符。这个标识符可能会在您重启电脑或重新插拔摄像头时发生变化,这主要取决于您的操作系统。
要查找连接到您系统的摄像头的摄像头索引,请运行以下脚本:
lerobot-find-cameras opencv # or realsense for Intel Realsense cameras
终端会打印相关摄像头信息。
--- Detected Cameras ---
Camera #0:
Name: OpenCV Camera @ 0
Type: OpenCV
Id: 0
Backend api: AVFOUNDATION
Default stream profile:
Format: 16.0
Width: 1920
Height: 1080
Fps: 15.0
--------------------
(more cameras ...)
您可以在 ~/lerobot/outputs/captured_images 目录中找到每台摄像头拍摄的图片。
在 macOS 中使用 Intel RealSense 摄像头时,您可能会遇到 “Error finding RealSense cameras: failed to set power state” 的错误。这可以通过使用 sudo 权限运行相同的命令来解决。请注意,在 macOS 中使用 RealSense 摄像头是不稳定的。
之后,您就可以在遥控操作时在电脑上显示摄像头画面了,只需运行以下代码即可。这对于在录制第一个数据集之前准备您的设置非常有用。
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"} }' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
fourcc: "MJPG"格式图像是经过压缩后的图像,你可以尝试更高分辨率,当然你可以尝试YUYV格式图像,但是这会导致图像的分辨率和FPS降低导致机械臂运行卡顿。目前MJPG格式下可支持3个摄像头1920*1080分辨率并且保持30FPS, 但是依然不推荐2个摄像头通过同一个USB HUB接入电脑。同时,如果摄像头接在 USB2.0 的接口,也可能会出现无法读取的问题,建议优先使用 USB3.0 接口并尽量直连设备。
如果您有更多摄像头,可以通过更改 --robot.cameras 参数来添加。您应该注意index_or_path 的格式,它由 python -m lerobot.find_cameras opencv 命令输出的摄像头 ID 的最后一位数字决定。
例如,如果你想添加摄像头:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"} }' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
fourcc: "MJPG"格式图像是经过压缩后的图像,你可以尝试更高分辨率,当然你可以尝试YUYV格式图像,但是这会导致图像的分辨率和FPS降低导致机械臂运行卡顿。目前MJPG格式下可支持3个摄像头1920*1080分辨率并且保持30FPS, 但是依然不推荐2个摄像头通过同一个USB HUB接入电脑。同时,如果摄像头接在 USB2.0 的接口,也可能会出现无法读取的问题,建议优先使用 USB3.0 接口并尽量直连设备。
数据集制作采集
- 如果你想数据集保存在本地,可以直接运行:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"} }' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=seeedstudio123/test \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black cube" \
--dataset.push_to_hub=false \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=30
其中repo_id可以自定义修改,push_to_hub=false,最后数据集会保存在主目录的~/.cache/huggingface/lerobot下会创建上述seeedstudio123/test文件夹
- 如果您想使用 Hugging Face Hub 的功能来上传您的数据集,并且您之前尚未这样做,请确保您已使用具有写入权限的令牌登录,该令牌可以从 Hugging Face 设置 中生成:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential
将您的 Hugging Face 仓库名称存储在一个变量中,以运行以下命令:
HF_USER=$(huggingface-cli whoami | head -n 1)
echo $HF_USER
记录 5 个回合并将您的数据集上传到 Hub:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras='{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"} }' \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=${HF_USER}/record-test \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black cube" \
--dataset.push_to_hub=true \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=30
你会看到类似如下数据:
INFO 2024-08-10 15:02:58 ol_robot.py:219 dt:33.34 (30.0hz) dtRlead: 5.06 (197.5hz) dtWfoll: 0.25 (3963.7hz) dtRfoll: 6.22 (160.7hz) dtRlaptop: 32.57 (30.7hz) dtRphone: 33.84 (29.5hz)
记录功能
record功能提供了一套工具,用于在机器人运行期间捕获和管理数据。
1. 数据存储
- 数据以
LeRobotDataset格式存储,并在记录过程中保存到磁盘中。 - 默认情况下,数据集在记录完成后会推送到你的 Hugging Face 页面。
- 若要禁用上传,请使用:
--dataset.push_to_hub=False。
2. 检查点与恢复
- 在记录过程中会自动创建检查点。
- 如果记录过程中断,可以通过重新运行相同的命令并添加
--resume=true来恢复记录。
⚠️ 重要提示:在恢复时,需将 --dataset.num_episodes 设置为要额外记录的剧集数量(而不是数据集中目标的总剧集数量)。
- 若要从头开始记录,请手动删除数据集目录。
3. 记录参数
通过命令行参数设置数据记录的流程:
| 参数 | 描述 | 默认值 |
|---|---|---|
| --dataset.episode_time_s | 每个数据剧集的持续时间(秒) | 60 |
| --dataset.reset_time_s | 每个剧集后环境重置时间(秒) | 60 |
| --dataset.num_episodes | 要记录的总剧集数量 | 50 |
4. 记录过程中的键盘控制
使用键盘快捷键控制数据记录流程:
| 键 | 动作 |
|---|---|
| →(右箭头) | 提前终止当前剧集/重置;进入下一个。 |
| ←(左箭头) | 取消当前剧集;重新录制。 |
| ESC | 立即停止会话,编码视频,并上传数据集。 |
如果你的键盘按下后没有反应,可能你需要降低你pynput的版本,例如安装个1.6.8版本的。
pip install pynput==1.6.8
假设你正在执行“将红色方块抓取并放入盒子”的任务:
- 如果在操作过程中不慎将方块弄掉,或出现任何可能导致该剧集数据质量较差的情况,可以先将机械臂操控至休息状态(即弯曲并折叠回初始位置),然后按下左箭头键。此时系统将返回到环境准备阶段,刚刚录制的动作数据会被直接舍弃。
- 如果本次任务完成得较快,机械臂已经成功完成操作并回到休息状态,而你不希望等待剩余时间结束,也可以按下右箭头键,以跳过剩余等待时间,直接进入下一个剧集前的环境准备阶段。
在录制过程中合理使用方向键,有助于避免失败动作污染数据集,并有效提升整体录制效率。
如果你想要了解如何删除或者改动已录制数据集,请参阅数据集工具。
数据收集技巧
- 任务建议:在不同位置抓取物体并将其放入箱子中。
- 规模:记录 ≥50 个剧集(每个位置 10 个剧集)。
- 一致性:
- 保持摄像头固定。
- 保持相同的抓取行为。
- 确保操作的物体在摄像头画面中可见。
- 逐步推进:
- 先从可靠的抓取开始,然后再增加变化(新位置、抓取技巧、摄像头调整)。
- 避免复杂性急剧增加,以防止失败。
💡 经验法则:仅使用摄像头画面作为指导,只根据屏幕反馈的视频图像,来控制机械臂完成任务。
如果你想要深入了解这个重要主题,可以查看我们撰写的关于什么是好的数据集的博客文章。
故障排除
Linux 问题: 如果在记录过程中右箭头/左箭头/ESC 键无响应:
- 验证
$DISPLAY环境变量是否已设置(参见 pynput 限制)。
可视化数据集
不稳定,可跳过,可尝试。
echo ${HF_USER}/so101_test
如果您没有使用 --dataset.push_to_hub=false ,并上传了数据,您也可以在本地通过以下命令进行可视化:
lerobot-dataset-viz \
--repo-id ${HF_USER}/so101_test \
如果您使用了 --dataset.push_to_hub=false ,没有上传数据,您也可以通过以下命令在本地进行可视化:
lerobot-dataset-viz \
--repo-id seeedstudio123/test \
这里,seeedstudio123 是数据收集时自定义的 repo_id 名称。
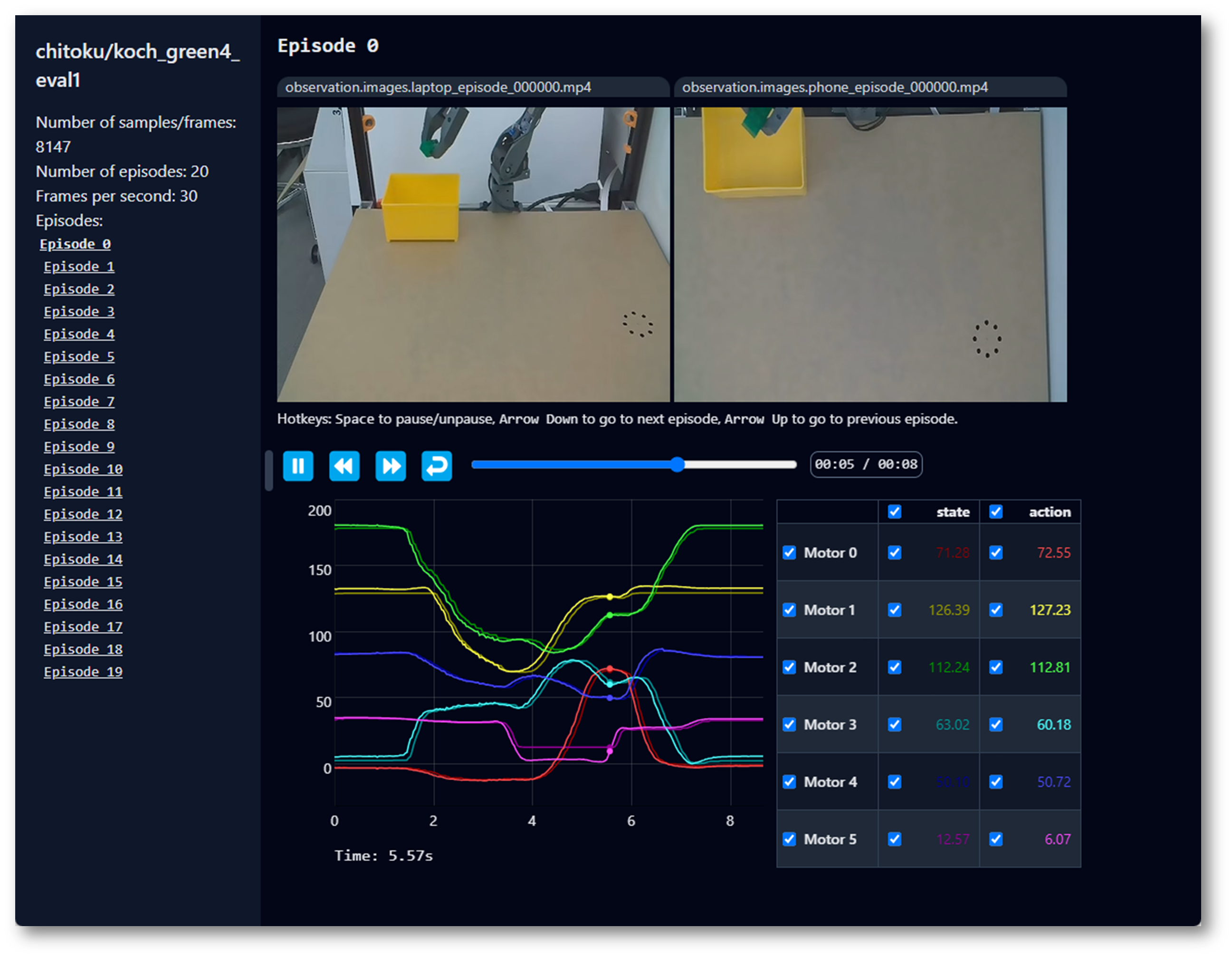
回放一个数据集
不稳定,可跳过,可尝试。
现在,尝试在您的机器人上重播第一个数据集:
lerobot-replay \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--dataset.repo_id=${HF_USER}/record-test \
--dataset.episode=0
此时,机器人应该做出与你遥操记录时一样的动作。
训练及评估
ACT
参考官方教程ACT
训练
要训练一个控制您机器人策略,使用 python -m lerobot.scripts.train 脚本。需要一些参数。以下是一个示例命令:
lerobot-train \
--dataset.repo_id=${HF_USER}/so101_test \
--policy.type=act \
--output_dir=outputs/train/act_so101_test \
--job_name=act_so101_test \
--policy.device=cuda \
--wandb.enable=false \
--steps=300000
如果您想在本地数据集上进行训练,请确保 repo_id 与数据收集时使用的名称匹配,并添加 --policy.push_to_hub=false。
lerobot-train \
--dataset.repo_id=seeedstudio123/test \
--policy.type=act \
--output_dir=outputs/train/act_so101_test \
--job_name=act_so101_test \
--policy.device=cuda \
--wandb.enable=false \
--policy.push_to_hub=false\
--steps=300000
命令解释
- 数据集指定:我们通过
--dataset.repo_id=${HF_USER}/so101_test参数提供了数据集。 - 训练步数:我们通过
--steps=300000修改训练步数,算法默认为800000,根据自己的任务难易程度,来进行调整,如果不确定,可以调高一些,因为训练过程中会生成检查点,评估可以从检查点开始。 - 策略类型:我们使用
policy.type=act提供了策略,同样你可以更换[act,diffusion,pi0,pi0fast,pi0fast,sac,smolvla]等策略,这将从configuration_act.py加载配置。重要的是,这个策略会自动适应您机器人(例如laptop和phone)的电机状态、电机动作和摄像头数量,这些信息已保存在您的数据集中。 - 设备选择:我们提供了
policy.device=cuda,因为我们正在 Nvidia GPU 上进行训练,但您可以使用policy.device=mps在 Apple Silicon 上进行训练。 - 可视化工具:我们提供了
wandb.enable=true来使用 Weights and Biases 可视化训练图表。这是可选的,但如果您使用它,请确保您已通过运行wandb login登录。
评估
您可以使用 lerobot/record.py 中的 record 功能,但需要将策略训练结果训练结果权重文件作为输入。例如,运行以下命令记录 10 个评估回合:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras='{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"} }' \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/train/act_so101_test/checkpoints/last/pretrained_model
--policy.path参数,指示您的策略训练结果权重文件的路径(例如outputs/train/act_so101_test/checkpoints/last/pretrained_model)。如果您将模型训练结果权重文件上传到 Hub,也可以使用模型仓库(例如${HF_USER}/act_so100_test)。- 数据集的名称
dataset.repo_id以eval_开头,这个操作会在你评估的时候为你单独录制评估时候的视频和数据,将保存在eval_开头的文件夹下,例如seeed/eval_test123。 - 如果评估阶段遇到
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'请先删除eval_开头的这个文件夹再次运行程序。 - 当遇到
mean is infinity. You should either initialize with stats as an argument or use a pretrained model请注意--robot.cameras这个参数中的front和side等关键词必须和采集数据集的时候保持严格一致。
SmolVLA
参考官方教程 SmolVLA。
SmolVLA 是 Hugging Face 提供的轻量级机器人基础模型(foundation model)。它的设计目标是:让你把自己录制的 LeRobot 数据集拿来快速微调(fine-tune),更快在真实机器人上跑出效果。
简单理解它的输入/输出:
- 输入:多路相机画面 + 机器人当前状态(传感器/关节等)+ 一句自然语言任务指令
- 输出:一段连续的动作(action chunk),用来驱动机械臂执行任务
pip install -e ".[smolvla]"
收集数据集(建议)
SmolVLA 是“底座模型”,要在你的桌面、你的相机、你的夹爪/物体上表现好,通常需要用你自己的数据做微调。
- 建议从 ~50 个 episode 开始(太少容易学不会/泛化差)。
- 如果你的任务有“变化项”(例如方块在桌面上的不同位置),请确保每一种变化都有足够示范:
- 例:5 个位置 × 每个位置 10 个 episode = 50 个 episode
- 经验:只录 25 个 episode 往往不够,数据质量和数量都很关键。
训练
使用 smolvla_base(预训练的 450M 模型)作为起点,在你的数据集上微调。官方示例是训练 20k steps;在一张 A100 上大约需要 4 小时(仅供参考,实际会因硬件而变)。
如果你没有可用的 GPU,可以考虑用 Colab 的 notebook 方式训练(见官方教程)。
lerobot-train \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=${HF_USER}/mydataset \
--batch_size=64 \
--steps=20000 \
--output_dir=outputs/train/my_smolvla \
--job_name=my_smolvla_training \
--policy.device=cuda \
--wandb.enable=true
提示:
- 显存不够就先把
--batch_size调小;能跑通后再慢慢加大。 - 想快速了解可用参数:
lerobot-train --help
验证
评估阶段会加载你微调后的模型,让机器人执行任务,并把评估过程录成一个新数据集(便于回看视频、复盘效果)。
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_blue_follower_arm \
--robot.cameras='{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"} }' \
--dataset.single_task="Grasp a lego block and put it in the bin." \
--dataset.repo_id=${HF_USER}/eval_DATASET_NAME_test \
--dataset.episode_time_s=50 \
--dataset.num_episodes=10 \
--policy.path=${HF_USER}/FINETUNE_MODEL_NAME
参数怎么填:
--robot.port:改成你自己机器上识别到的串口(常见是/dev/ttyACM0或/dev/ttyUSB0)。--robot.id:你的机器人 ID(要和你校准/录制时使用的保持一致)。--robot.cameras:改成你真实相机的index_or_path,并确保相机键名(比如front、side)和你录制数据集时完全一致。--dataset.single_task:建议与录制数据集时的任务描述一致。--dataset.repo_id:评估输出的数据集名;如果你登录了 Hugging Face,它会被创建/上传到你的账号下。--policy.path:- 如果模型在本地:填训练输出目录下的权重路径(例如
outputs/train/my_smolvla/checkpoints/last/pretrained_model) - 如果模型在 Hub:填
${HF_USER}/FINETUNE_MODEL_NAME
- 如果模型在本地:填训练输出目录下的权重路径(例如
可选:如果你想在评估的 episode 之间“手动遥操调整一下”,可以加入 teleop(按你的设备与配置填写):
--teleop.type=so100_leader \
--teleop.port=/dev/ttyACM0 \
--teleop.id=my_red_leader_arm \
Pi0
参考官方教程 Pi0。
π₀(Pi0)是 Physical Intelligence 提出的 Vision-Language-Action(视觉-语言-动作) 模型,用于更“通用”的机器人控制。你可以把它理解为:它既能看相机画面,也能读懂一句自然语言指令,然后输出控制机械臂的动作。
在 LeRobot 里使用它很简单:训练时把策略类型设为 --policy.type=pi0 即可(不重复赘述 ACT 里讲过的通用训练/评估概念)。
pip install -e ".[pi]"
如果你使用的是较旧的 LeRobot 版本(例如 0.4.0),安装 pi 依赖时可能需要从 GitHub 源安装(官方说明后续补丁会修复):
pip install "lerobot[pi]@git+https://github.com/huggingface/lerobot.git"
训练
lerobot-train \
--policy.type=pi0 \
--dataset.repo_id=${HF_USER}/my_dataset \
--job_name=pi0_training \
--output_dir=outputs/pi0_training \
--policy.pretrained_path=lerobot/pi0_base \
--policy.repo_id=${HF_USER}/my_pi0_policy \
--policy.compile_model=true \
--policy.gradient_checkpointing=true \
--policy.dtype=bfloat16 \
--policy.freeze_vision_encoder=false \
--policy.train_expert_only=false \
--steps=3000 \
--policy.device=cuda \
--batch_size=32 \
--wandb.enable=false
常用参数(只挑 Pi0 特有/最常调的):
--policy.pretrained_path=lerobot/pi0_base:基础模型。官方也提供lerobot/pi0_libero(更偏 Libero 数据集的版本),你可以按任务尝试切换。--policy.compile_model=true:启用编译优化,训练可能更快(首次编译会慢一点)。--policy.gradient_checkpointing=true:显著省显存,适合显存吃紧时开启。--policy.dtype=bfloat16:混合精度,速度/显存更友好(硬件支持时推荐)。--policy.train_expert_only=true(省显存技巧):冻结大模型(VLM)部分,只训练“动作专家”和投影层;更省显存,但可训练能力会更受限,适合先跑通或小数据快速试验。
验证
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras='{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"} }' \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=${HF_USER}/eval_my_pi0_test \
--dataset.single_task="Put lego brick into the transparent box" \
--dataset.episode_time_s=50 \
--dataset.num_episodes=10 \
--policy.path=outputs/pi0_training/checkpoints/last/pretrained_model
Pi0.5
参考官方教程 Pi0.5。
π₀.₅(Pi0.5)同样是 Physical Intelligence 提出的 Vision-Language-Action(视觉-语言-动作) 模型,可以理解为 π₀ 的“升级版”,重点增强了开放世界泛化能力:不只在训练时见过的固定场景里表现好,还要能在新的房间、新的物体、新的摆放方式下更稳地完成任务。
它要解决的“泛化”大致分三层(举例帮助理解):
- 物理层:没见过的勺子/盘子,也能知道该怎么抓(把手/边缘),并在杂乱环境中操作。
- 语义层:理解“该放哪里/用什么工具”,例如鞋子应该进鞋柜、衣服进洗衣篮。
- 环境层:适应更真实的“乱糟糟”场景,例如家庭、办公室、医院等。
在 LeRobot 里使用它:把策略类型设为 --policy.type=pi05 即可
pip install -e ".[pi]"
如果你使用的是较旧的 LeRobot 版本(例如 0.4.0),安装 pi 依赖时可能需要从 GitHub 源安装(官方说明后续补丁会修复):
pip install "lerobot[pi]@git+https://github.com/huggingface/lerobot.git"
训练
lerobot-train \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=pi05 \
--output_dir=outputs/pi05_training \
--job_name=pi05_training \
--policy.repo_id=${HF_USER}/my_pi05_policy \
--policy.pretrained_path=lerobot/pi05_base \
--policy.compile_model=true \
--policy.gradient_checkpointing=true \
--policy.dtype=bfloat16 \
--policy.freeze_vision_encoder=false \
--policy.train_expert_only=false \
--steps=3000 \
--policy.device=cuda \
--batch_size=32 \
--wandb.enable=false
常用参数(Pi0.5 相关):
--policy.pretrained_path=lerobot/pi05_base:基础模型。官方也提供lerobot/pi05_libero(更偏 Libero 数据集的版本),你可以按任务尝试切换。--policy.train_expert_only=true(省显存技巧):冻结大模型(VLM)部分,只训练“动作专家”和投影层;更省显存,适合先跑通或小数据试验。--policy.normalization_mapping=...:如果你的数据集归一化统计不匹配/缺失,可以用该映射强制指定归一化方式(见官方教程示例)。
如果你的数据集没有 quantile 统计(某些版本/格式需要),官方也提供了转换脚本思路:把数据集补齐/转换统计后再训练(具体以官方文档为准)。
验证
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras='{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"} }' \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=${HF_USER}/eval_my_pi05_test \
--dataset.single_task="Put lego brick into the transparent box" \
--dataset.episode_time_s=50 \
--dataset.num_episodes=10 \
--policy.path=outputs/pi05_training/checkpoints/last/pretrained_model
GR00T N1.5
请参考官方教程 GR00T N1.5。
GR00T N1.5 是 NVIDIA 提供的一个开放基础模型(foundation model),面向更通用的机器人推理与技能学习。它是跨机体(cross-embodiment)模型:可以同时接收语言与图像等多模态输入,在不同环境里执行操作任务。
在 LeRobot 中使用它的关键点是把策略类型设为 --policy.type=groot。不过需要注意:目前 GR00T N1.5 对环境要求更高(依赖 FlashAttention,且需要 CUDA GPU),建议先把 ACT / Pi0 跑通,再来尝试。
安装(重要)
截至官方文档目前的说明,GR00T N1.5 需要 flash-attn 才能工作,并且只能在支持 CUDA 的设备上使用。
建议步骤(按顺序执行):
- 按安装指南先把基础环境准备好(Python、CUDA、驱动等),这一步先不要安装
lerobot。 - 安装 PyTorch(版本范围以官方为准;下面是示例写法):
# 不同 CUDA 版本对应不同 index-url,请按你的系统参考 PyTorch 安装页
pip install "torch>=2.2.1,<2.8.0" "torchvision>=0.21.0,<0.23.0"
- 安装 flash-attn 依赖与 flash-attn 本体:
pip install ninja "packaging>=24.2,<26.0"
pip install "flash-attn>=2.5.9,<3.0.0" --no-build-isolation
python -c "import flash_attn; print(f'Flash Attention {flash_attn.__version__} imported successfully')"
- 安装 LeRobot 的 groot 依赖:
pip install "lerobot[groot]"
如果 flash-attn 安装失败,通常与(1)PyTorch/CUDA 版本不匹配、(2)编译依赖缺失或(3)环境过新/过旧有关。遇到这种情况优先对照官方 GR00T 文档与 PyTorch 安装说明排查。
训练(微调)
官方给了多 GPU 的训练示例(accelerate launch --multi_gpu ...)。如果你只有一张 GPU,也可以先用单进程方式跑通(是否支持/参数细节以官方文档为准)。
多 GPU(变量需要自己替换):
accelerate launch \
--multi_gpu \
--num_processes=$NUM_GPUS \
$(which lerobot-train) \
--output_dir=$OUTPUT_DIR \
--save_checkpoint=true \
--batch_size=$BATCH_SIZE \
--steps=$NUM_STEPS \
--save_freq=$SAVE_FREQ \
--log_freq=$LOG_FREQ \
--policy.push_to_hub=true \
--policy.type=groot \
--policy.repo_id=$REPO_ID \
--policy.tune_diffusion_model=false \
--dataset.repo_id=$DATASET_ID \
--wandb.enable=true \
--wandb.disable_artifact=true \
--job_name=$JOB_NAME
参数说明(最常需要修改的几项):
--dataset.repo_id:你的训练数据集(Hub 上的用户名/数据集名或本地缓存对应的repo_id)。--output_dir:训练输出目录(权重/检查点会放在这里)。--steps、--batch_size:训练步数与 batch,大模型对显存很敏感,跑不动就先减小batch_size。--policy.repo_id:如果你要把模型推到 Hub,填你希望创建的模型仓库名。
验证(上机运行/评估)
训练完成后可以像其它策略一样用 lerobot-record 做评估/录制回放。下面是官方给的“双臂”示例(仅供参考;SO101 单臂用户不需要 left_arm_port/right_arm_port 这类参数):
lerobot-record \
--robot.type=bi_so_follower \
--robot.left_arm_port=/dev/ttyACM1 \
--robot.right_arm_port=/dev/ttyACM0 \
--robot.id=bimanual_follower \
--robot.cameras='{ right: {"type": "opencv", "index_or_path": 0, "width": 640, "height": 480, "fps": 30}, left: {"type": "opencv", "index_or_path": 2, "width": 640, "height": 480, "fps": 30}, top: {"type": "opencv", "index_or_path": 4, "width": 640, "height": 480, "fps": 30} }' \
--display_data=true \
--dataset.repo_id=${HF_USER}/eval_groot_bimanual \
--dataset.num_episodes=10 \
--dataset.single_task="Grab and handover the red cube to the other arm" \
--policy.path=${HF_USER}/groot-bimanual \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=10
License:该模型遵循 Apache 2.0 许可证(与原始 GR00T 仓库一致)。
(可选)使用 PEFT 进行高效微调
PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)是一套“参数高效适配”方法与工具,用于在不更新全部模型参数的前提下,让大型预训练模型更快适配新任务。对于 LeRobot 的预训练策略(例如 SmolVLA、π₀ 等),通常可以只训练少量“适配器”参数(例如 LoRA),在降低显存占用与训练成本的同时获得接近全量微调的效果。
安装
安装 LeRobot 的 peft 可选依赖后即可使用 PEFT 相关参数:
# 方式一:源码安装(在 lerobot 仓库根目录)
pip install -e ".[peft]"
# 方式二:pip 安装
pip install "lerobot[peft]"
更多适配方法与概念说明可参考官方文档:
🤗 PEFT 文档
示例:用 LoRA 微调 SmolVLA(Libero 的 libero_spatial 子任务)
下面示例展示如何在 HuggingFaceVLA/libero 数据集上,对 lerobot/smolvla_base 进行 LoRA 微调。参数名称以当前 LeRobot 版本为准,建议同时参考 lerobot-train --help。
lerobot-train \
--policy.path=lerobot/smolvla_base \
--policy.repo_id=${HF_USER}/my_libero_smolvla_peft \
--dataset.repo_id=HuggingFaceVLA/libero \
--env.type=libero \
--env.task=libero_spatial \
--output_dir=outputs/train/my_libero_smolvla_peft \
--job_name=my_libero_smolvla_peft \
--policy.device=cuda \
--steps=10000 \
--batch_size=32 \
--optimizer.lr=1e-3 \
--peft.method_type=LORA \
--peft.r=64
PEFT 关键参数说明
--peft.method_type:选择要使用的 PEFT 方法。LoRA(Low-Rank Adapter)是最常用的方法之一。--peft.r:LoRA 的 rank。一般来说,rank 越大可表达能力越强,但参数量与显存占用也会增加。
指定要注入 LoRA 的层(可选)
默认情况下,PEFT 往往会针对模型中最关键的投影层(例如注意力的 q_proj、v_proj 等)注入 LoRA,并可能额外覆盖状态/动作相关的投影层。若需要针对不同层,可以使用 --peft.target_modules 指定目标层。
常见写法包括:
1)按模块名后缀列表指定(示例):
--peft.target_modules="['q_proj', 'v_proj']"
2)使用正则表达式指定(示例,需按模型实际模块名调整):
--peft.target_modules='(model\\.vlm_with_expert\\.lm_expert\\..*\\.(down|gate|up)_proj|.*\\.(state_proj|action_in_proj|action_out_proj|action_time_mlp_in|action_time_mlp_out))'
指定某些层进行全量训练(可选)
如果希望某些模块“全量训练”(而不是只注入 LoRA),可以使用 --peft.full_training_modules 指定。例如仅全量训练 state_proj:
--peft.full_training_modules="['state_proj']"
学习率建议(经验值)
LoRA 的学习率通常可以比全量微调更大一个量级(常见经验:约 10×)。例如全量微调常用 1e-4,LoRA 可以从 1e-3 起步;若你启用了学习率衰减(scheduler),最终学习率也常设置在 1e-4 附近作为参考。
(可选)在训练时使用多GPU训练
1.训练步骤
方式一:使用命令行参数进行多卡训练
首先,在lerobot环境中安装训练加速系统
pip install accelerate
接着运行以下命令来开始多卡训练
accelerate launch \
--multi_gpu \
--num_processes=2 \
$(which lerobot-train) \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=act \
--policy.repo_id=${HF_USER}/my_trained_policy \
--output_dir=outputs/train/act_multi_gpu \
--job_name=act_multi_gpu \
--wandb.enable=true
关键的 accelerate 参数说明:
--multi_gpu:启用多 GPU 训练
--num_processes=2:使用的 GPU 数量(通常等于 GPU 张数)
--mixed_precision=fp16:使用 fp16 混合精度(如果硬件支持,也可以使用 bf16)
请注意,bf16 需要硬件支持,并非所有 GPU 都可以使用。
| 精度类型 | 硬件支持情况 |
|--|--|
| fp16 | 几乎所有 NVIDIA GPU 均支持 |
| bf16 | 仅部分较新的 GPU 支持(如 Ampere 及更新架构) |
如果你的 GPU 不支持 bf16,请在 accelerate 配置中选择 fp16,
或在命令行中显式指定 fp16。
方式二:使用 accelerate 配置文件(可选)
如果您经常进行多卡训练,也可以将上述的训练配置进行保存,从而避免繁琐的命令行输入。
提示:如果你不理解这一节的内容,或者只是想尽快跑起来训练,
可以直接跳过本节,使用方式一(命令行参数)即可。
accelerate config 的作用是:
**将您的硬件环境(GPU 数量、混合精度等)保存为一个配置文件,
以后运行 accelerate launch 时无需重复填写这些信息。**
它并不会改变 LeRobot 的训练逻辑,只是为了减少重复输入参数。
如果只是偶尔使用多 GPU,或你是第一次尝试,不使用它完全没有问题。
运行:
accelerate config
在交互式配置过程中,对于单机多 GPU 的常见场景,可以按如下方式选择:
Compute environment:This machine
Number of machines:1
Number of processes:使用的 GPU 数量(通常等于 GPU 张数)
GPU ids to use:直接回车(表示使用所有 GPU)
Mixed precision:
优先选择 fp16
若确认 GPU 支持 bf16,也可选择 bf16
完成配置后,可以直接使用一下命令进行训练:
accelerate launch $(which lerobot-train) \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=act \
--policy.repo_id=${HF_USER}/my_trained_policy \
--output_dir=outputs/train/act_multi_gpu \
--job_name=act_multi_gpu \
--wandb.enable=true
多 GPU 训练对于训练参数的影响以及调整策略
LeRobot 不会根据 GPU 数量自动调整学习率或训练步骤。以避免在用户在不知情的情况下改变训练行为。这与其他常用的分布式训练框架不同。
如果您希望在多 GPU 训练时调整超参数,需要按以下步骤手动完成。
对于步数的影响以及调整策略
由于多 GPU 会使 有效 batch size 增大(batch_size × num_gpus)
(可以通过以下例子直观理解,如果将训练比作走路,一张卡训练是一步迈出去一米,那么两张卡训练就是一步迈出两米,如果希望达到同等距离(模型学习到的数据总量),双卡训练应该将步数减少至单卡训练的二分之一。同理,n张卡是1/n)
因此在多 GPU 训练的时候,应该适当降低训练的步数(steps)
单卡训练时:
-
batch_size = 8
-
steps = 100000
双卡训练(有效 batch size 变为 16):
-
batch_size 如果仍然被您设定为 8
-
steps 可以减少为 50000
accelerate launch --num_processes=2 $(which lerobot-train) \
--batch_size=8 \
--steps=50000 \
--dataset.repo_id=lerobot/pusht \
--policy=act
对于学习率的影响以及调整策略
使用多块 GPU 时,每一步更新会使用更多样本。
如果你希望模型“学习速度”保持和单卡相近,
通常需要按 GPU 数量等比例增大学习率。
- 新的学习率 = 单卡学习率 × GPU 数量
例如:
单卡训练时学习率(optimizer.lr)为 1e-4,
使用 2 张 GPU 时,可以改为 2e-4:
accelerate launch --num_processes=2 $(which lerobot-train) \
--optimizer.lr=2e-4 \
--dataset.repo_id=lerobot/pusht \
--policy=act
注意:
这些调整并不是强制的规则,而是常见的经验做法。
如果你不确定如何调整,也可以先:
-
保持学习率不变
-
保持训练步数不变
只要训练过程稳定,结果依然是可用的。
如需更高级的配置和故障排除,请参见[Accelerate]https://huggingface.co/docs/accelerate/index 文档。如果你想了解更多如何在大量GPU上训练,可以看看这份超棒的指南:[Ultrascale Playbook]。
(可选)在部署时使用异步推理
在不启用异步推理时,LeRobot 的控制流程可以理解为常规的顺序式 / 同步式推理:策略先预测一段动作,再执行这段动作,之后再等待下一次预测。对于较大的模型,这会导致机器人在等待新动作块时出现明显停顿。异步推理的目标,就是让机器人一边执行当前动作块,一边提前计算下一块动作,从而减少空等并提升响应性。异步推理适用于 LeRobot 支持的策略;包括 ACT、OpenVLA、Pi0、SmolVLA 这类按 chunk 输出动作的策略。由于推理和实际控制解耦,异步推理也有助于利用具有更强算力的机器来为机器人进行推理。
你可以在 Hugging Face 提供的博客文章中阅读更多关于异步推理的信息。
先让我们介绍一些基本概念:
- 客户端:连接机械臂和相机,采集观测数据(如图像、机器人位姿等),把这些观测发送到服务器;同时接收服务器返回的动作块,并按顺序执行。
- 服务器端:提供算力的设备,接收相机数据和机械臂数据,推理(也就是计算)出动作块发回客户端。它可以是连接机械臂和摄像头的设备本身,也可以是局域网内的另一台电脑,或是网上租赁的云端服务器。
- 动作块:一系列的机械臂动作指令,由策略经过服务器端推理得到。
- 同步推理:预测一块动作块、执行一块动作块;机器人在等待下一块动作时会出现等待动作块推理的间隙,这时候机械臂不会移动。在模型参数量更大并且算力不足的时候,推理的时间间隙是显著的,这时候机械臂会运动一段时间,然后停滞一段时间(推理),然后继续运动。
- 异步推理:不同于同步推理,机器人执行当前动作块的同时,服务器已经在计算下一块动作;重叠部分会做聚合,以得到更及时的控制。
异步推理的三种部署场景
1. 单机部署
机器人、相机、客户端、服务器都在同一台设备上。
这是最简单的情况,服务器监听 127.0.0.1 即可,客户端也连接 127.0.0.1:端口。官方文档中的命令示例就是这个场景。
2. 局域网部署
机器人和相机接在一台轻量设备上,策略服务器运行在同一局域网中的另一台高算力设备上。
此时服务器必须监听一个可被其他机器访问的地址,客户端也必须连接服务器的局域网 IP,而不能再写 127.0.0.1。
3. 跨网络 / 云端部署
策略服务器运行在公网可访问的云主机上,客户端通过公网连接它。
这种方式可以使用云主机更强的 GPU。在网络状况良好的情况下,网络往返时间(网络延时)有时相对推理耗时较小,但这取决于你的实际网络环境。
安全提醒:LeRobot async inference 管线存在未认证 gRPC + pickle 反序列化的风险。如果服务器上有重要信息或者重要服务,公网部署时,不建议把服务直接裸露到互联网;更稳妥的做法是 VPN、SSH 隧道,或至少把安全组来源 IP 限制到你自己的客户端公网地址。
开始异步推理部署
Step1: 环境配置
首先,使用 pip 安装运行异步推理所需的额外依赖。客户端和服务器端均需要安装 lerobot 并安装额外依赖:
pip install -e ".[async]"
Step2: 网络配置与检查
1. 代理问题
如果你当前终端配置了代理,并且连接出现异常,可以临时取消代理环境变量:
unset http_proxy https_proxy ftp_proxy all_proxy HTTP_PROXY HTTPS_PROXY FTP_PROXY ALL_PROXY
注意:以上的命令只对一个终端生效,如果你重新开了另一个终端窗口,需要重新运行该命令。
2. 在防火墙 / 安全组放行端口
- 单机部署:通常可以跳过。
- 局域网部署:需要在服务器端放行监听端口。
局域网放行监听端口示例(在服务器端运行):
sudo ufw allow 8080/tcp
- 云端部署:需要在云服务器安全组中放行该端口,并尽量限制来源 IP。
如果是在云端服务器上运行:
在服务器管理页面的安全组放行 8080 端口,或使用其他已经放行的端口。不同云服务平台的方式并不统一,详见云平台服务商。
3. 确认 IP 地址
单机部署可以跳过这一步(单机的 IP 地址恒为 127.0.0.1)。
如果是局域网部署:
需要确认并记住服务器端的局域网 IP 地址。客户端连接时,填写的应当是运行 policy_server 的那台机器的局域网 IP,而不是客户端自己的 IP。
Linux / Jetson / 树莓派:
hostname -I
如果输出多个地址,一般选择当前局域网网卡对应的那个,例如 192.168.x.x。
也可以使用:
ip addr
查看当前联网网卡下的 inet 字段。
Windows:
ipconfig
找到类似 IPv4 地址 . . . . . . . . . . . : 192.168.14.140 的字段,它就是该机器的局域网 IP 地址。
macOS:
ifconfig
找到当前联网网卡对应的 inet 字段,它就是局域网 IP 地址。
我们需要将服务器端的局域网 IP 地址记住。我们将用<局域网IP地址>来指代它。
如果是云端服务器部署:
在服务器控制台寻找公网 IP,一般是这些名字之一:
- Public IPv4
- External IP
- Public IP address
- EIP
- 公网 IP
我们需要将公网 IP 地址记住。我们将用<服务器公网IP>来指代它。
4. 连接测试
- 单机部署:可跳过这一步
- 局域网 / 云端部署:建议在客户端测试是否能访问服务器端口,测试例子如下:
局域网示例:在客户端运行
nc -vz <局域网IP地址> 8080
云端示例:在客户端运行
nc -vz <服务器公网IP> 8080
Step3: 启动服务
场景 A:单机部署
在一个终端中启动本地服务:
python -m lerobot.async_inference.policy_server \
--host=127.0.0.1 \
--port=8080
运行成功后,你需要保持这个终端打开,你需要新建新的终端才可以执行其他命令。
场景 B:局域网内部署
在服务器端运行:
python -m lerobot.async_inference.policy_server \
--host=0.0.0.0 \
--port=8080
此时客户端连接时,--server_address 中填写的应当是服务器端的局域网 IP 地址,即 <局域网IP地址>:8080。
场景 C:云端服务器部署
在服务器端运行:
python -m lerobot.async_inference.policy_server \
--host=0.0.0.0 \
--port=8080
此时客户端连接时,--server_address 中填写的应当是服务器的公网 IP 地址,即<服务器公网IP>:8080。
Step4: 选择推理参数
在客户端运行:
python -m lerobot.async_inference.robot_client \
--server_address=<ip地址>:8080 \
--robot.type=so100_follower \
--robot.port=/dev/tty.usbmodem585A0076841 \
--robot.id=follower_so100 \
--robot.cameras="{ laptop: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}, phone: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \
--task="dummy" \
--policy_type=your_policy_type \
--pretrained_name_or_path=user/model \
--policy_device=cuda \
--actions_per_chunk=50 \
--chunk_size_threshold=0.5 \
--aggregate_fn_name=weighted_average \
--debug_visualize_queue_size=True
参数解释:
-
--server_address
指定策略服务器的地址和端口。<ip地址>应该换为 127.0.0.1(本机)或<局域网IP地址>(局域网)或<服务器公网IP>(云服务器)。 -
--robot.type、--robot.port、--robot.id、--robot.cameras
硬件设备参数,与数据集采集时的参数保持一致。 -
--task
任务的描述,SmolVLA 等视觉语言策略可以根据任务文本决定动作目标。 -
--policy_type
替换成具体策略名,例如:- smolvla
- act
-
--pretrained_name_or_path
这个的值要替换为服务器端的模型路径,或者 Hugging Face 上的模型路径。 -
--policy_device
指定服务器端使用的推理设备。
可以是 cuda、mps 或 cpu。 -
--actions_per_chunk=50
指定每次推理输出多少个动作。
这个值越大:- 优点:动作缓存更充足,不容易断流
- 缺点:预测跨度更长,控制误差可能累计得更明显
-
--chunk_size_threshold=0.5
指定何时向服务器请求下一块动作。
这是一个阈值,范围通常在 0 到 1 之间。
可以理解为:当当前动作队列剩余比例低于这个阈值时,客户端就会提前发送新的观测,请求下一块动作。这里设置为 0.5,表示:
- 当当前动作块大约消耗到一半时
- 客户端就开始请求下一块动作
这个值越大,请求会越频繁,系统更灵敏,但服务器负载也更高。
这个值越小,就越接近同步推理的行为。 -
--aggregate_fn_name=weighted_average
指定重叠动作区间的聚合方式。在异步推理中,旧动作块还没完全执行完时,新动作块可能已经回来了。
这时两块动作会有一部分时间区间重叠,需要用一个聚合函数把它们合成最终执行动作。weighted_average 的含义就是:
对重叠部分使用加权平均的方式进行融合。这样通常能让动作切换更平滑,减少突变。
-
--debug_visualize_queue_size=True
是否在运行时可视化动作队列大小。
打开后可以更直观地看到队列是否频繁触底,从而帮助你调整 actions_per_chunk 和 chunk_size_threshold。
Step5: 根据机器人表现调整参数
在异步推理中,有两个同步推理没有的额外参数需要调整:
| 参数 | 建议初始值 | 说明 |
|---|---|---|
| actions_per_chunk | 50 | 策略一次输出多少动作。典型值:10-50。 |
| chunk_size_threshold | 0.5 | 当动作队列剩余比例 ≤ chunk_size_threshold 时,客户端会发送一个新的动作块。值的范围为 [0, 1]。 |
当 --debug_visualize_queue_size=True 时,会在运行时绘制动作队列大小的变化情况。
异步推理需要平衡的是:服务器生成动作块的速度必须大于等于客户端消耗动作块的速度,否则动作队列会空,机器人将重新出现卡顿(可以在队列可视化中看到曲线触底)。
服务器生成动作块的速度受模型大小、设备类型、显存/内存、GPU 算力等影响。
客户端消耗动作块的速度受设定的执行 fps 影响。
如果队列频繁空,需要加大 actions_per_chunk、chunk_size_threshold,或者减少 fps。
当队列曲线波动频繁,但是队列剩余动作一直充足时,可以适当降低 chunk_size_threshold。
一般来说:
- actions_per_chunk 经验值在 10-50
- chunk_size_threshold 经验值在 0.5-0.7,建议调整时从 0.5 开始,慢慢加大。
如果你遇到了以下报错:
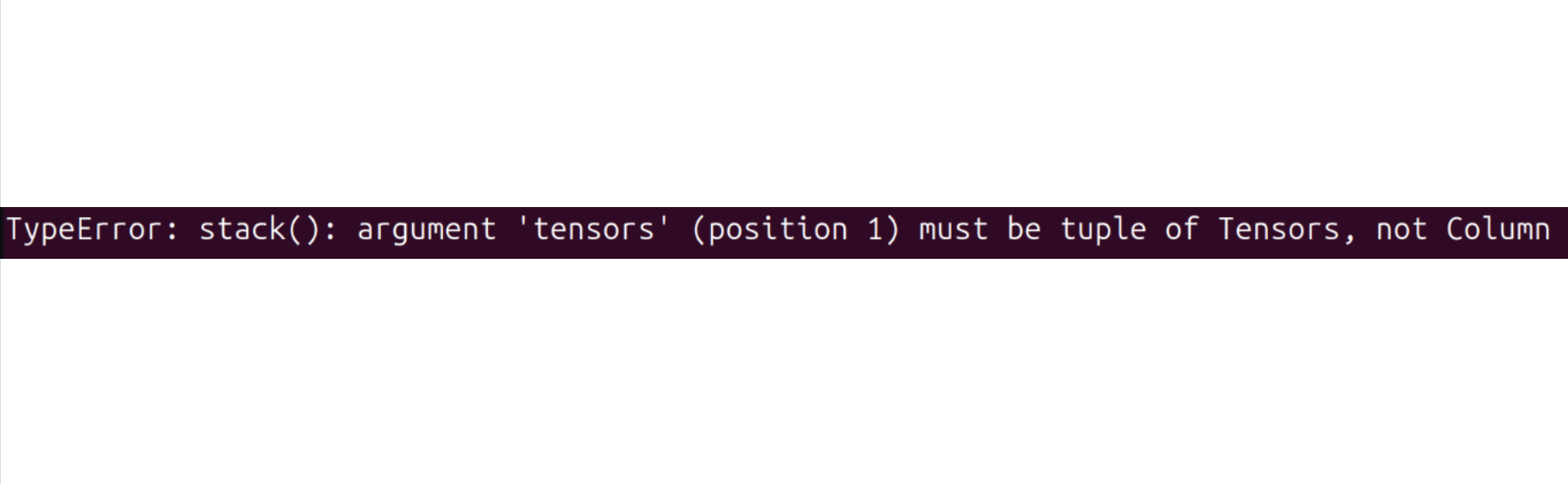
尝试运行以下命令来解决:
pip install datasets==2.19
训练可能需要几个小时。您将在 outputs/train/act_so101_test/checkpoints 目录中找到训练结果权重文件。
要从某个训练结果权重文件恢复训练,下面是一个从 act_so101_test 策略的最后一个训练结果权重文件恢复训练的示例命令:
lerobot-train \
--config_path=outputs/train/act_so101_test/checkpoints/last/pretrained_model/train_config.json \
--resume=true
FAQ
-
如果使用本文档教程,请git clone本文档推荐的github仓库
https://github.com/Seeed-Projects/lerobot.git,本文档推荐的仓库是验证过后的稳定版本,Lerobot官方仓库是实时更新的最新版本,会出现一些无法预知的问题,例如数据集版本不同,指令不同等。 -
如果校准舵机ID时候遇到
`Motor ‘gripper’ was not found, Make sure it is connected`请仔细检查通讯线是否与舵机连接正常,电源是否正确电压供电。”
-
如果遇到
Could not connect on port "/dev/ttyACM0"并且通过
ls /dev/ttyACM*看到是有ACM0存在的,则是忘记给串口权限了,终端输入sudo chmod 666 /dev/ttyACM*即可` -
如果遇到
No valid stream found in input file. Is -1 of the desired media type?请安装ffmpeg7.1.1,
conda install ffmpeg=7.1.1 -c conda-forge。
-
如果遇到
ConnectionError: Failed to sync read 'Present_Position' on ids=[1,2,3,4,5,6] after 1 tries. [TxRxResult] There is no status packet!需要检查对应端口号的机械臂是否接通电源,总线舵机是否出现数据线松动或者脱落,哪个舵机灯不亮就是前面那个舵机的线松了。
-
如果校准机械臂的时候遇到
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)对机械臂进行重新断电和上电,再次尝试校准机械臂。如果在校准过程中遇到 MAX 角度达到上万的值也可以使用这个方法;如果仍然无效,则需要对相应舵机重新进行舵机校准(中位校准和 ID 写入)。
-
如果评估阶段遇到
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'请先删除
eval_开头的这个文件夹再次运行程序。 -
如果评估阶段遇到
`mean` is infinity. You should either initialize with `stats` as an argument or use a pretrained model请注意--robot.cameras这个参数中的front和side等关键词必须和采集数据集的时候保持严格一致。
-
如果你维修或者更换过机械臂零件,请完全删除
~/.cache/huggingface/lerobot/calibration/robots或者~/.cache/huggingface/lerobot/calibration/teleoperators下的文件并重新校准机械臂,否则会出现报错提示,校准的机械臂信息会存储该目录下的json文件中。 -
在3060的8G笔记本上训练ACT的50组数据的时间大概为6小时,在4090和A100的电脑上训练50组数据时间大概为2~3小时。
-
数据采集过程中要确保摄像头位置和角度和环境光线的稳定,并且减少摄像头采集到过多的不稳定背景和行人,否则部署的环境变化过大会导致机械臂无法正常抓取。
-
数据采集命令的num-episodes要确保采集数据足够,不可中途手动暂停,因为在数据采集结束后才会计算数据的均值和方差,这在训练中是必要的数据。
-
如果程序提示无法读取USB摄像头图像数据,请确保USB摄像头不是接在Hub上的,USB摄像头必须直接接入设备,确保图像传输速率快。
如果你遇到无法解决的软件问题或环境依赖问题,除了查看本教程末尾的常见问题(FAQ)部分外,请及时在 LeRobot 平台 或 LeRobot Discord 频道 反馈问题。
参考文档
TheRobotStudio Project: SO-ARM10x
Huggingface Project: Lerobot
Dnsty: Jetson Containers
技术支持与产品讨论
感谢您选择我们的产品!我们在此为您提供多种支持,以确保您的产品体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。