搭配 reSpeaker 使用 SenseCraft AI
介绍
SenseCraft AI 是 Seeed Studio 推出的零代码/低代码 AI 平台,可简化将预训练人工智能模型部署到诸如 reSpeaker 等边缘设备上的流程。本指南重点介绍如何将 reSpeaker 配置为使用自定义触发词 "Lumio" 进行唤醒词检测,从而在无需编写复杂代码的情况下,为你的项目实现语音激活控制。借助 SenseCraft AI,你可以快速测试、预览并将唤醒词事件集成到硬件工作流中。该平台还允许你创建并上传自己的自定义模型,用于检测特定声音事件和自定义唤醒词,为你量身定制语音交互提供充分的灵活性,以满足独特的应用需求。


部署现有模型
步骤 1:更新设备固件
在部署唤醒词模型之前,请确保你的 reSpeaker XVF3800 正在运行正确的固件版本。
所需的固件文件为:
respeaker_xvf3800_i2s_master_dfu_firmware_v1.0.7_48k_test5.bin
按照设备的标准 DFU(设备固件升级)流程将此文件烧录到 reSpeaker XVF3800。
如果你使用的是 reSpeaker Lite,请确保其也在运行正确的固件版本。
所需的固件文件为:
respeaker_lite_i2s_dfu_firmware_v1.0.9.bin
按照设备的标准 DFU(设备固件升级)流程将此文件烧录到 reSpeaker Lite。
步骤 2:进入 SenseCraft AI 平台
打开你的网页浏览器并访问:
步骤 3:进入训练页面
在主导航菜单中:
- 点击 Products
- 选择 SenseCraft AI
- 选择 Training AI Models
步骤 4:打开你的工作区
- 进入你的 Workspace

- 确认工作区中已将 reSpeaker 设置为当前设备类型
- 在设备列表中选择 reSpeaker
- 点击 Connect 按钮,与设备建立连接
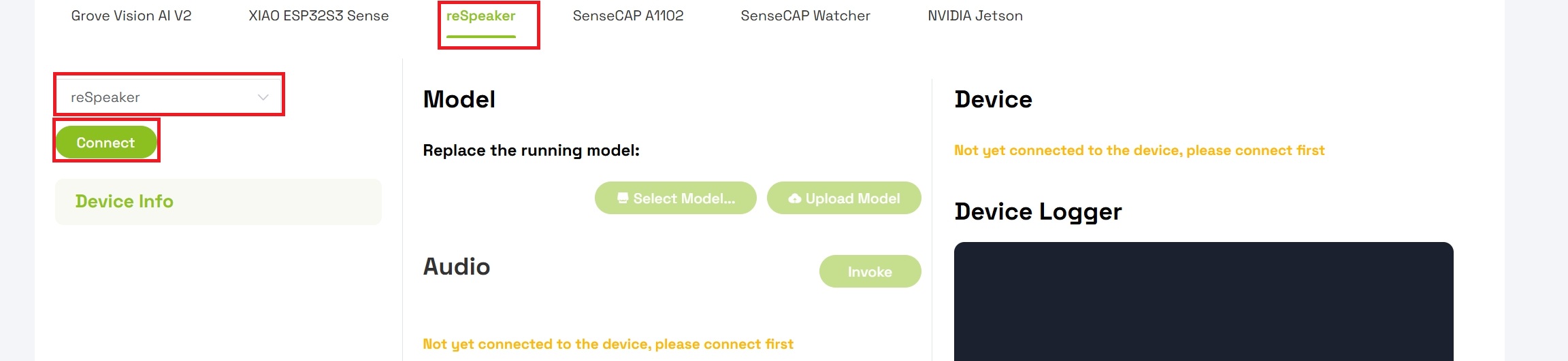
步骤 5:替换正在运行的模型
连接成功后,你将替换设备上现有的模型:
- 在 “Replace the device running model” 下找到 Model 区域
- 点击 Select Model
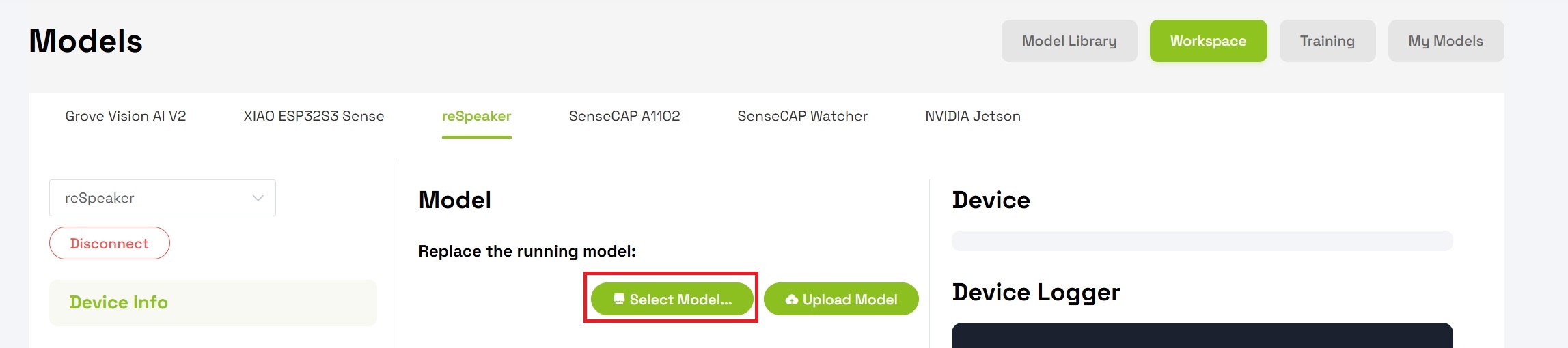
- 在可用选项中选择 Keyword Spotting- Lumos Keyword recognition
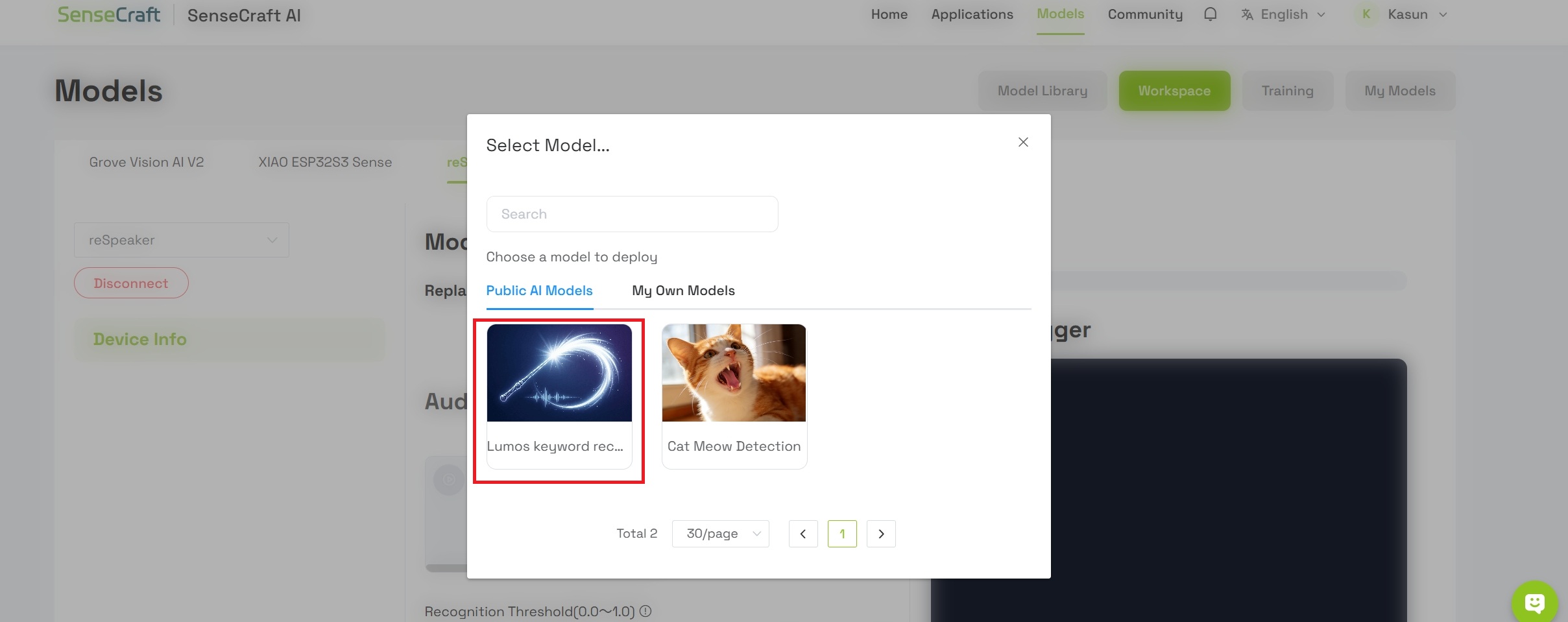
你正在部署的模型名为 Lumos。它是一款轻量级语音识别模型,旨在为边缘设备提供高效、低延迟的语音交互能力。通过分析音频的频谱特征,该模型即使在复杂的环境背景噪声中,也能准确检测到特定唤醒词 "Lumos"。
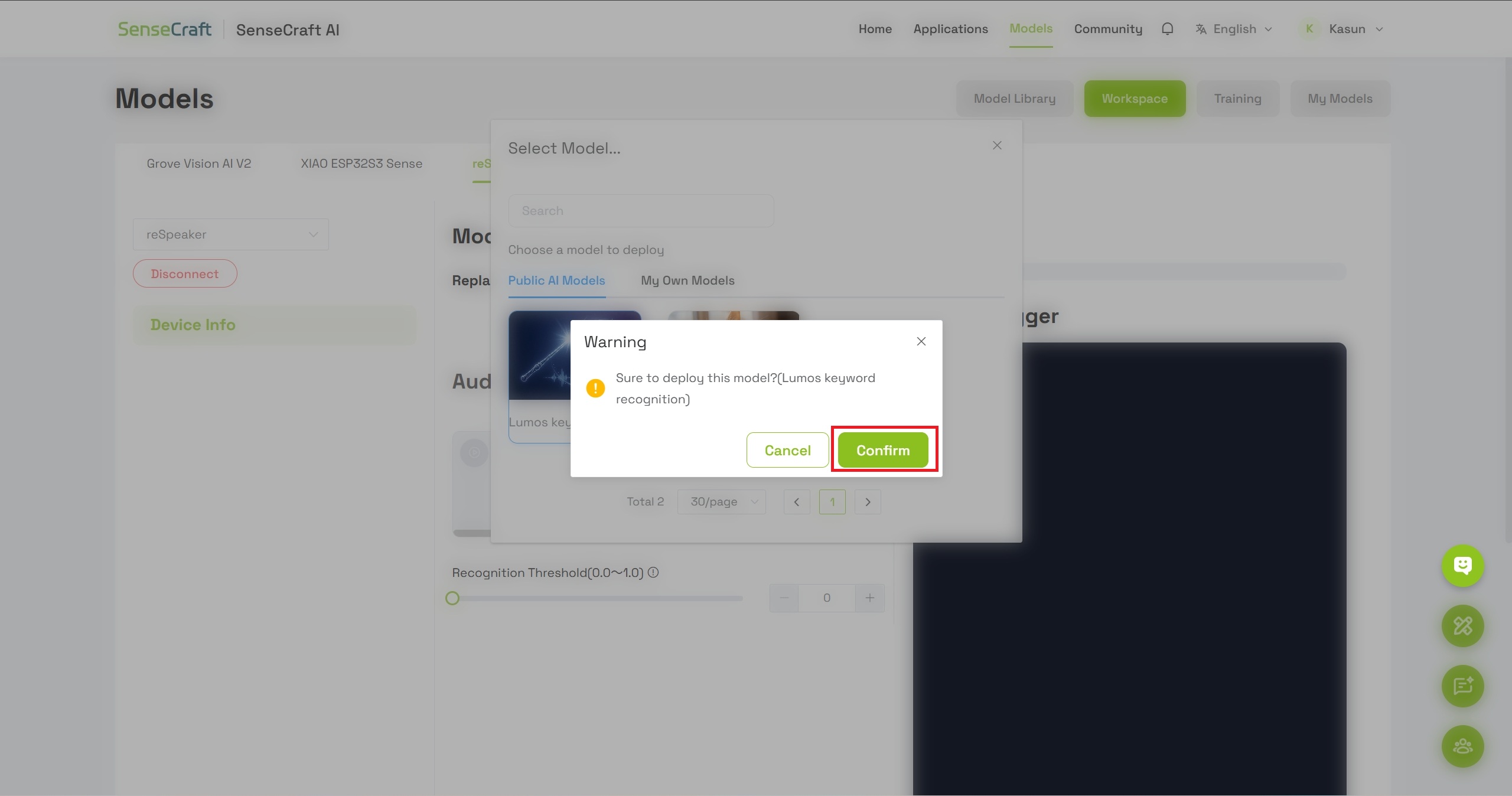
步骤 6:确认模型部署
- 将弹出一个对话框,显示模型的详细信息
- 点击 Confirm 以继续将模型烧录到设备
- 等待片刻,直至模型烧录到 reSpeaker 完成
步骤 8:测试唤醒词检测
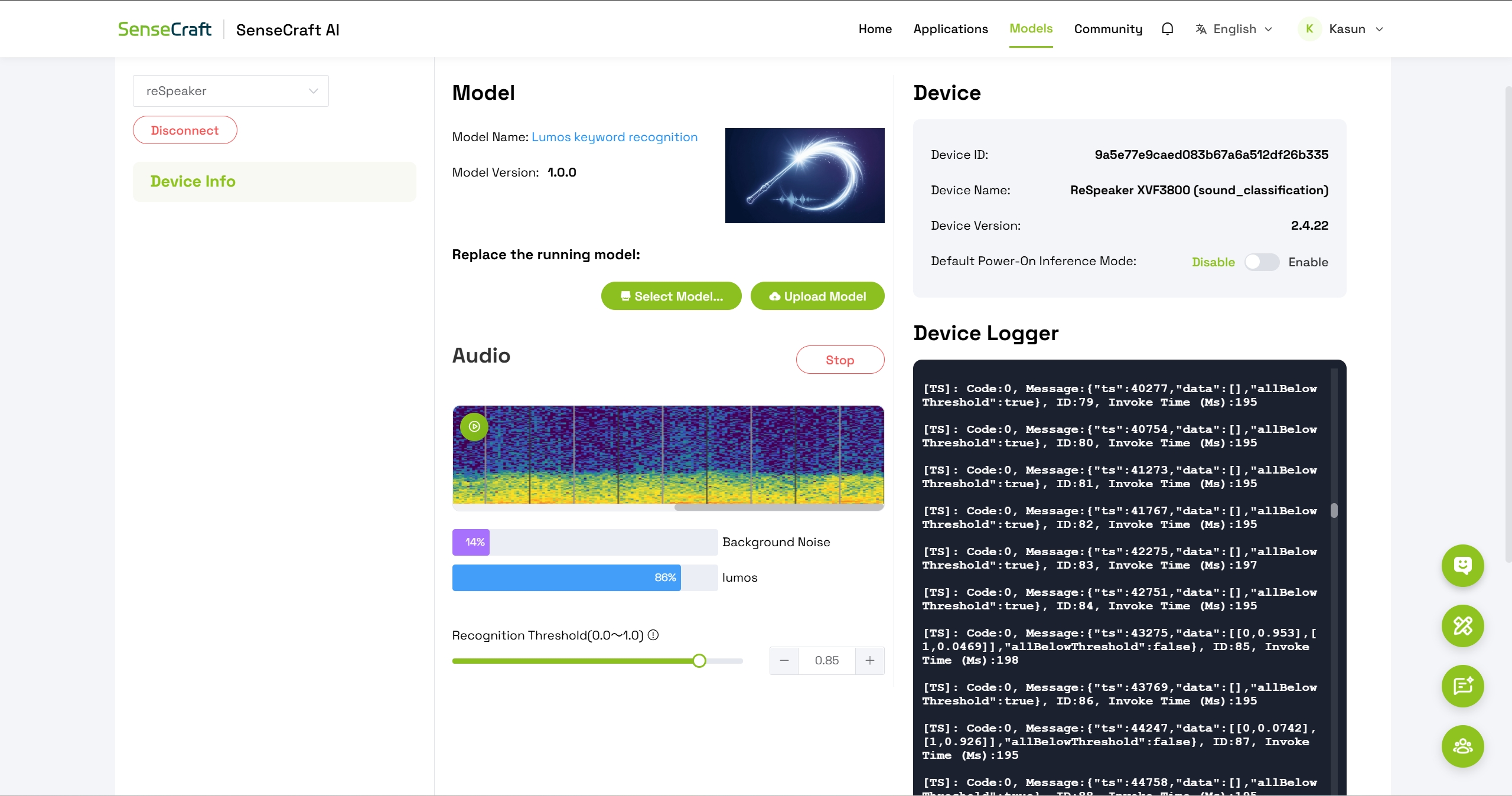
部署成功后,你将看到:
- 音频频谱可视化 – 显示实时声音输入
- 两个检测类别:
- 背景噪声
- Lumos
测试唤醒词的方法:
- 对着 reSpeaker 麦克风清晰地说出 "Lumos"
- 观察 Lumos 类别的置信度水平是否上升
- 根据需要调整 threshold parameter,以微调检测灵敏度
训练并部署你自己的音频分类器
步骤 1:打开 Training 选项卡
- 访问 https://sensecraft.seeed.cc/
- 在主菜单中依次进入 Products → SenseCraft AI → Training AI Models
- 点击 Training 选项卡,进入音频分类界面

步骤 2:连接你的 reSpeaker 设备
在 Audio Classification / Detection 下:
- 确认已选择 reSpeaker Microphone 作为输入设备
- 点击 Connect 按钮建立连接
- 等待平台确认连接成功

步骤 3:采集背景噪声数据
在训练自定义声音之前,你必须先为正常环境噪声建立一个基线。
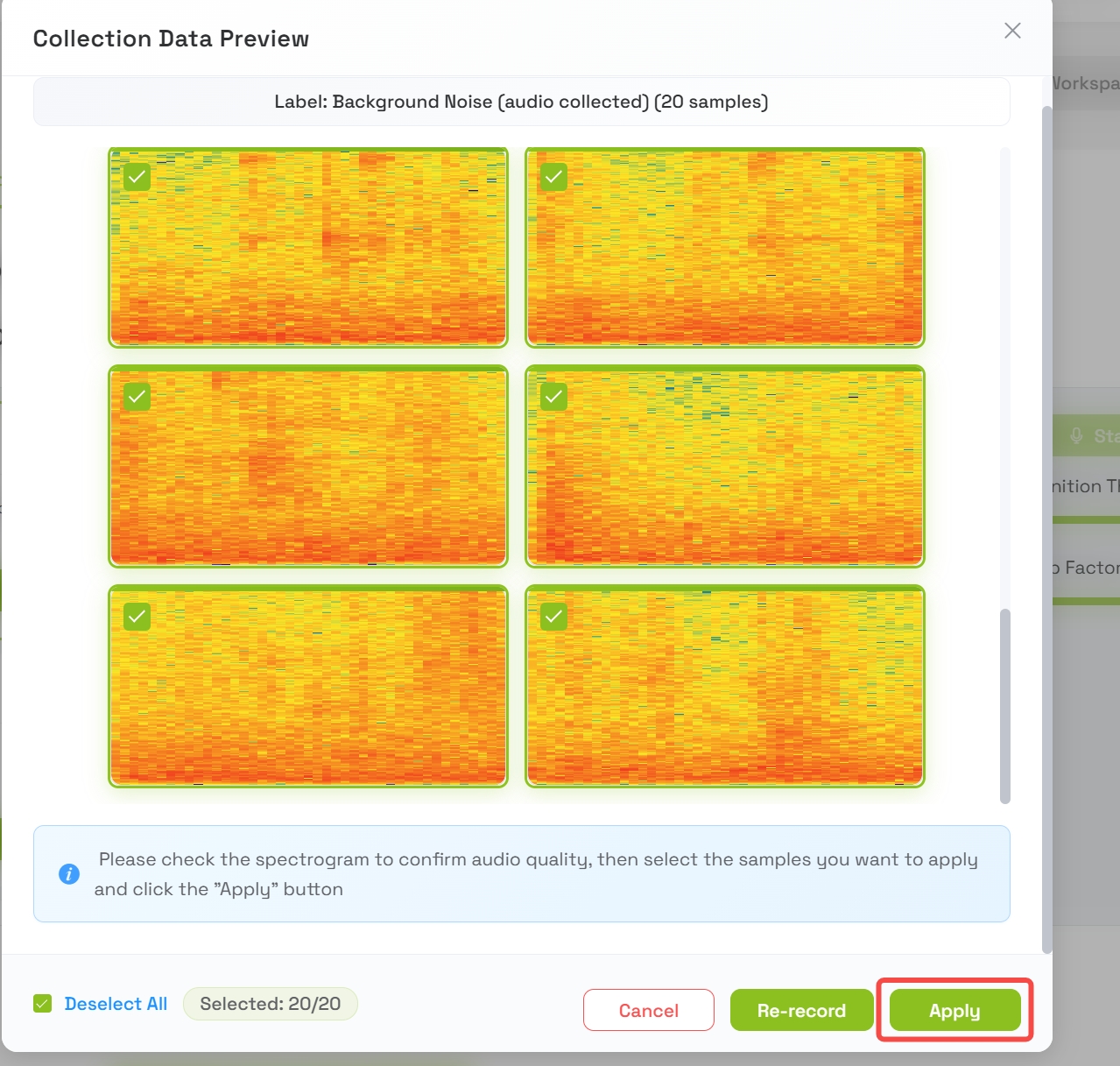
- 点击 Collect Training Data for Background Noise

- 平台会自动录制大约 20 秒
- 录音将被切分为 1 秒的样本
- 完成后,将显示背景数据样本的预览
- 检查这些样本,满意后点击 Apply
步骤 4:创建自定义声音类别
现在你将为希望模型检测的特定声音添加一个新类别。
4.1 为类别命名
- 点击 Add New Class
- 输入类别名称:Grassbreaking
- 点击 Create 或确认新类别
4.2 为自定义类别采集训练数据
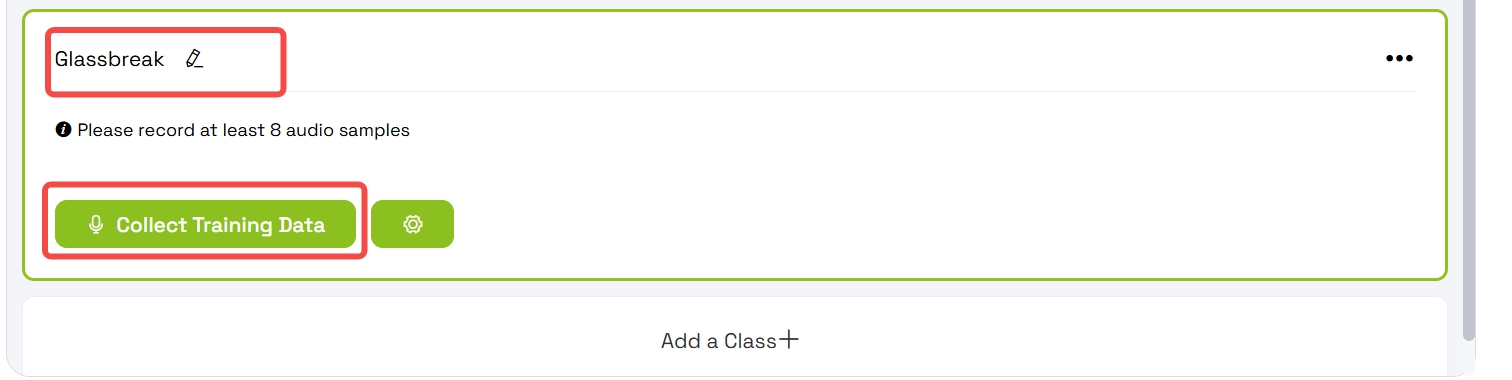
- 选择 Grassbreaking 类别
- 点击 Collect Training Data
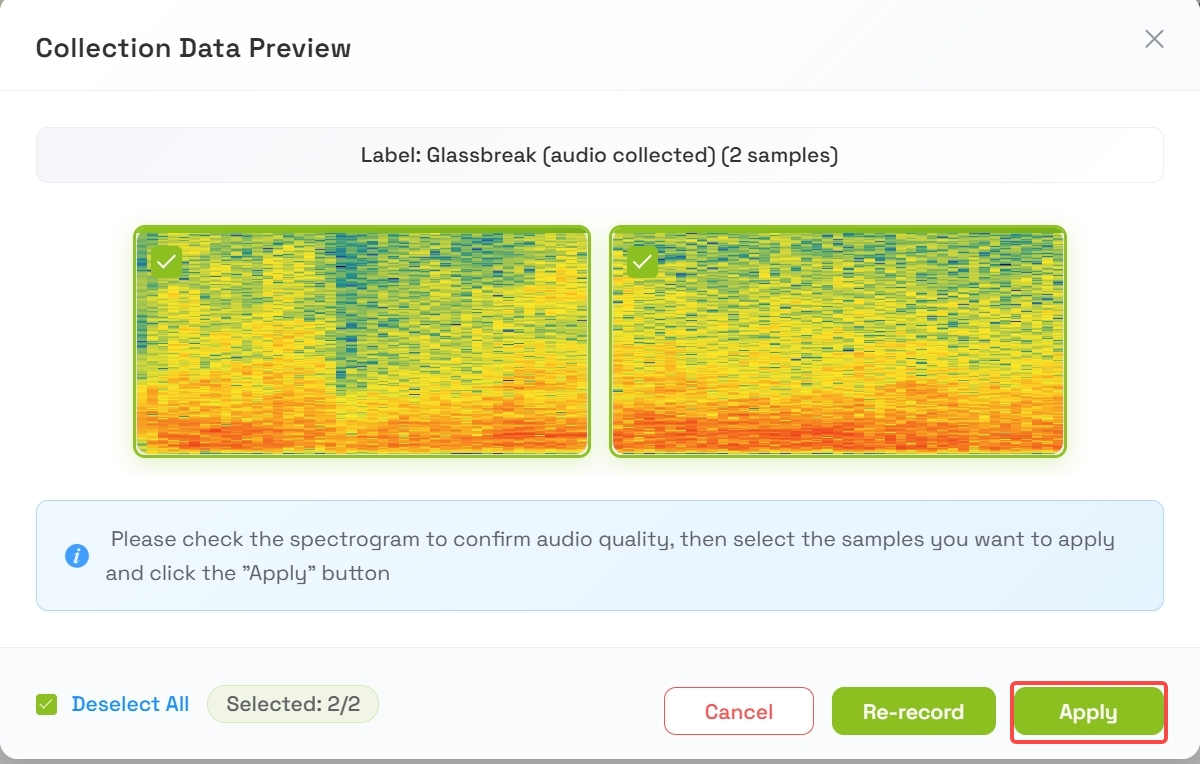
- 平台将录制大约 2 秒
- 录音将被切分为 1 秒的样本
4.3 查看并应用样本
- 采集完成后,将显示 2 个样本 的预览
- 试听或查看这些样本
- 当你对样本质量满意时,点击 Apply
4.4 重复采集更多样本
为获得可靠的检测效果,请重复数据采集流程,直到为 Grassbreaking 类别至少收集到 8 个样本。
优质样本的小贴士:
- 变化草折断声音的强度
- 从略有不同的位置或角度采集样本
- 确保该声音在背景噪声之上清晰可辨
步骤 5:训练模型
在收集到足够的数据后,就可以开始训练模型了。
5.1 进入训练步骤
在界面中进入 Step 2: Training。
5.2 确认设备选择
确认已选择 reSpeaker 作为训练的目标设备。
5.3 开始训练
- 点击 Train 按钮
- 等待几分钟,直至训练过程完成
- 训练期间不要关闭浏览器或断开设备连接

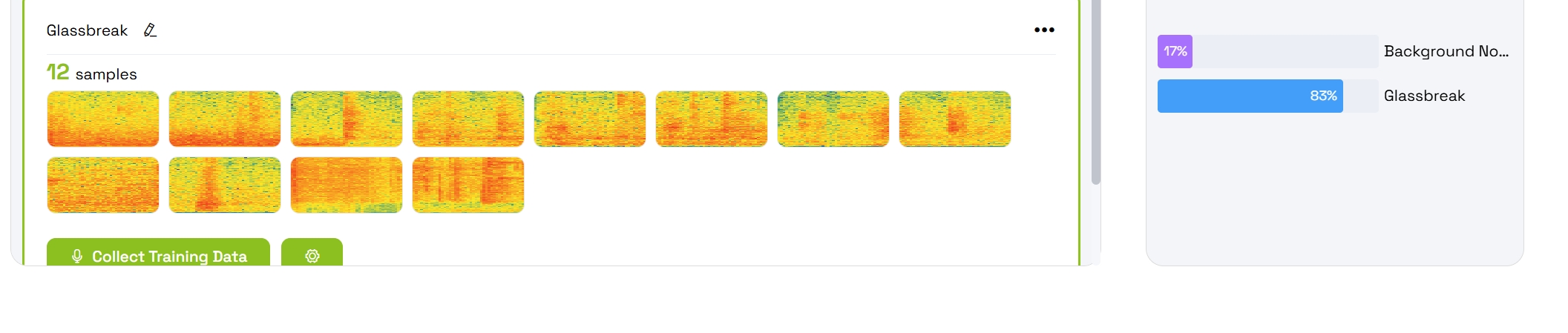
5.4 查看训练结果
训练完成后,你训练的类别将会显示以下内容:
- 动态概率条 显示置信度水平
- 基于实时音频输入的实时预测
步骤 6:将模型部署到 reSpeaker
6.1 前往部署步骤
在界面中导航到 Step 3: Deploy。
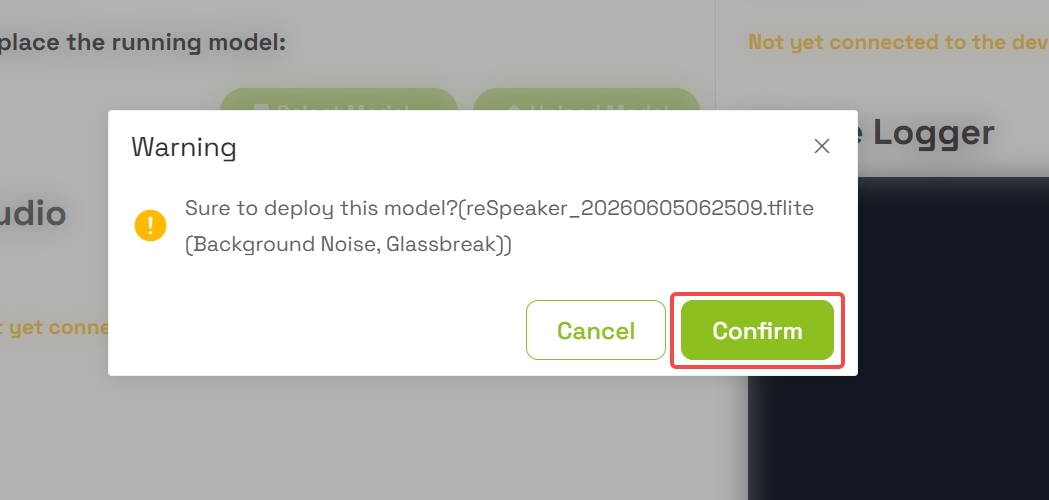
6.2 部署模型
- 点击 Deploy 按钮将模型推送到你的设备

- 将会弹出一个确认对话框
- 确认 部署,将 TFLM(TensorFlow Lite Micro)模型推送到 reSpeaker 的 XIAO ESP32-S3 上
6.3 等待完成
部署过程可能需要一点时间。请等待显示部署成功的确认消息。
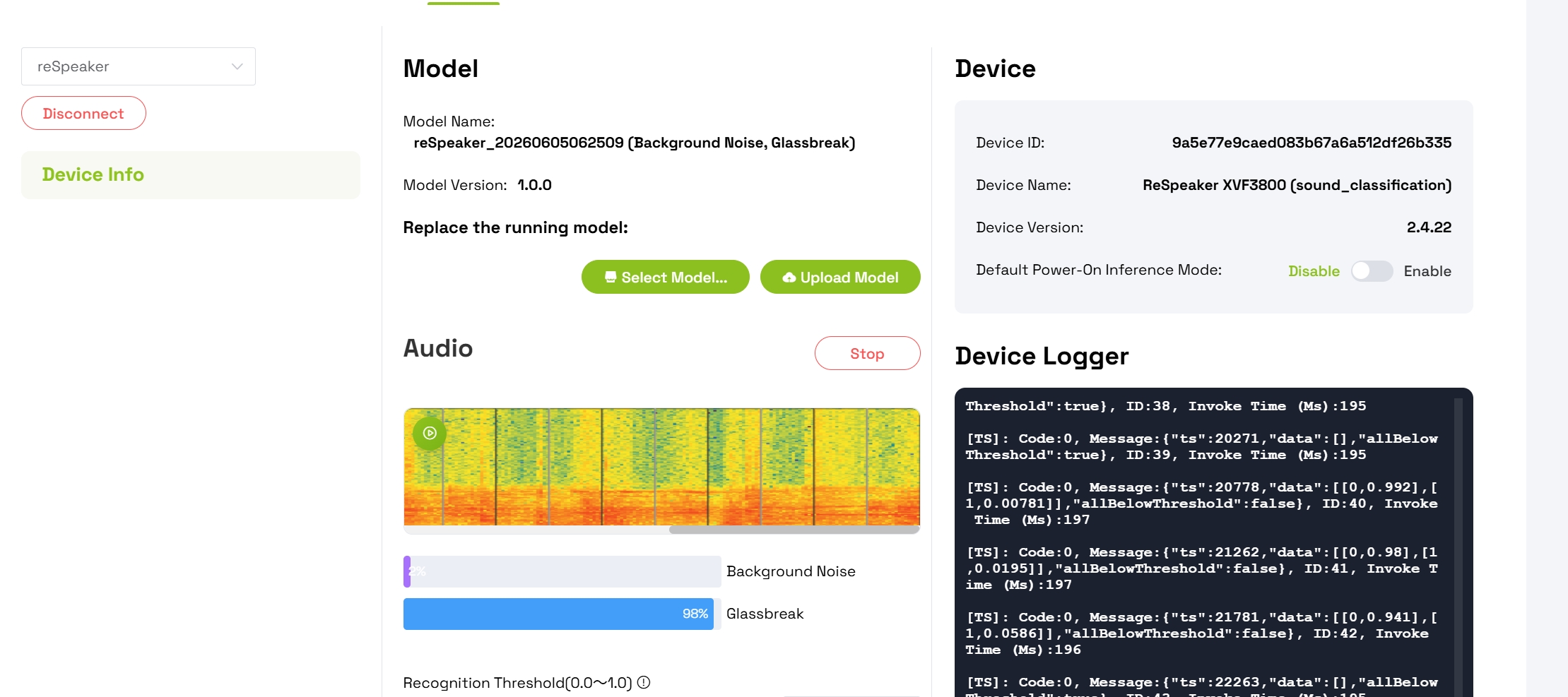
步骤 7:监控实时检测
成功部署后:
- 界面会为每个检测到的类别显示 动态置信度条
- 说话或发出玻璃破碎声来测试检测效果
- 观察 Grassbreaking 类别的置信度水平上升
- 当检测到自定义声音时,观察 Background Noise 的置信度下降
技术支持与产品讨论
感谢你选择我们的产品!我们将为你提供多种支持,确保你在使用我们产品的过程中尽可能顺利。我们提供多种沟通渠道,以满足不同的偏好和需求。