训练类型 - 目标检测
目标检测的特性
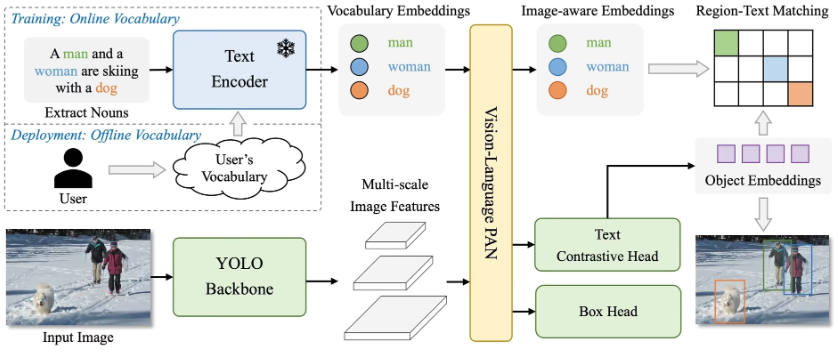
Seeed SenseCraft AI 平台是一个专为目标检测任务量身定制的高效 AI 训练工具。基于先进的 YOLO - World 目标检测模型构建,提供两种便捷的训练方法:
- 快速训练
特性:无需图像数据。只需输入目标名称即可快速生成单类目标检测模型。 优势:适用于简单场景,能够快速创建和部署模型。
- 图像收集训练
特性:结合目标名称和上传的图像数据进行训练。
优势:利用多样化的图像数据显著提高生成模型的检测精度,适用于需要高精度的应用。
通过这两种方法,SenseCraft 平台满足了多样化的目标检测模型训练需求,简化了 AI 开发的复杂性,同时确保了易用性和精确性。
快速训练
我们将创建一个简单的识别人类演示。快速训练功能利用了 YOLO – World 目标检测模型的以下核心特性:
快速训练功能利用 YOLO 的优势来高效创建单类检测模型。通过结合预训练权重、文本语义和高效特征提取,它生成定制模型,例如用于"人类"的模型,而无需图像数据。
步骤 1. 确定目标名称
在文本框中输入目标名称。然后点击**"开始训练"**。
训练会话将持续 1-3 分钟,请耐心等待!
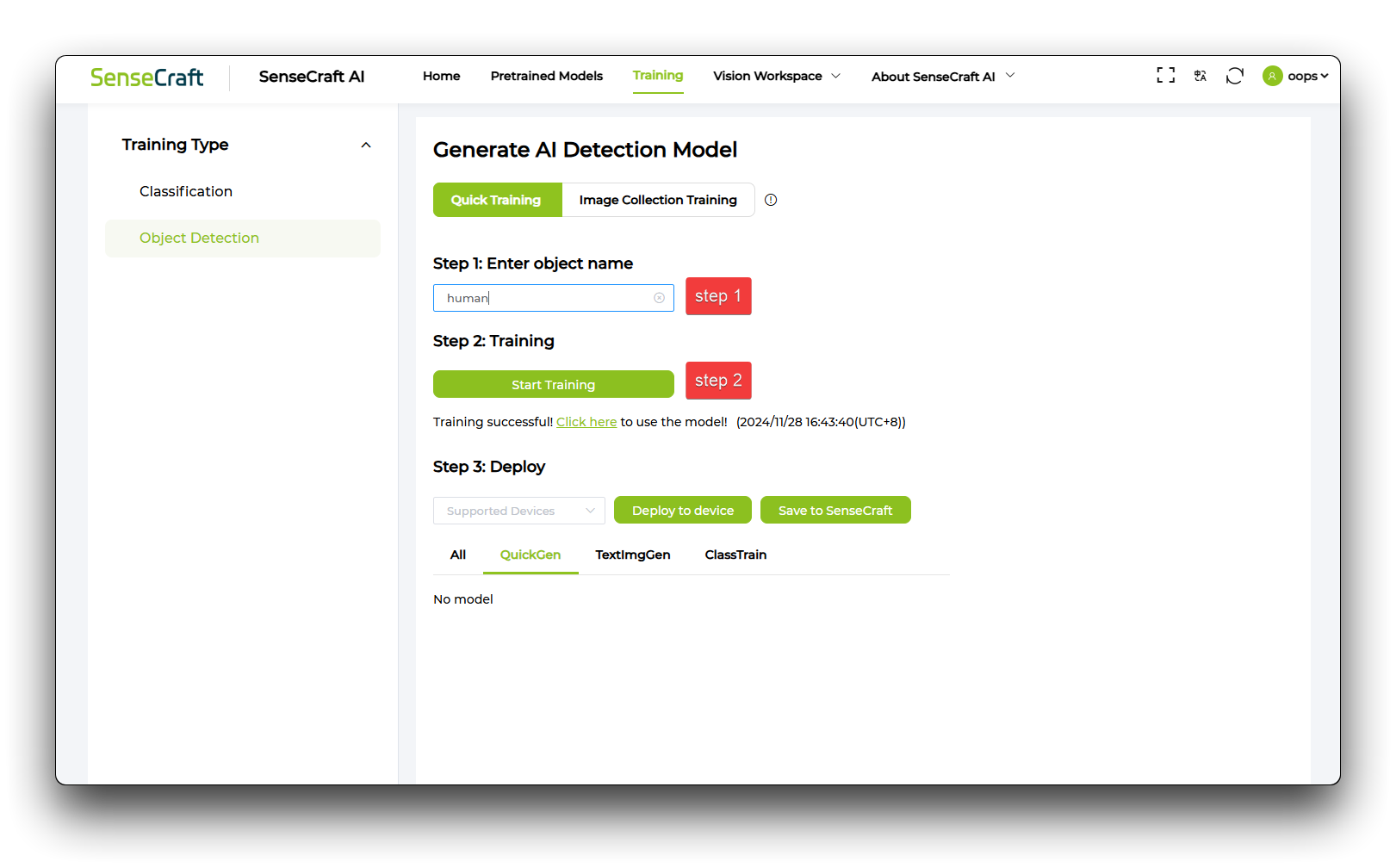
步骤 2. 训练和上传模型
完成模型训练后,模型将被部署,并选择 Grove Vision AI (V2) 进行部署。然后选择正确的串口进行连接,最后耐心等待 1-3 分钟直到模型训练完成!
目前目标检测中的设备选择只能支持 Grove Vision AI (V2)。


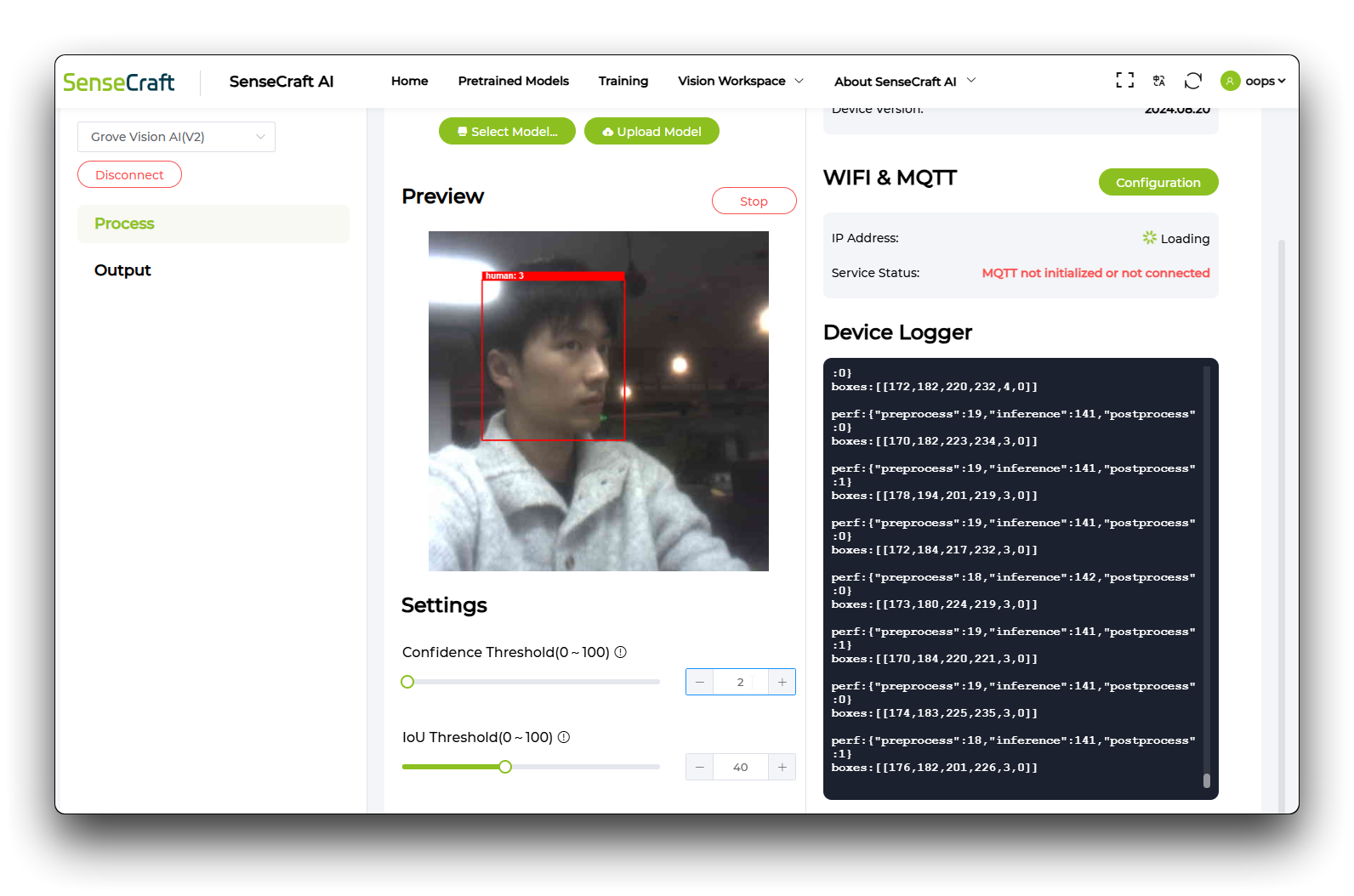
结果演示
完成上述步骤后,模型将成功部署并运行,但需要注意置信度阈值和IoU 阈值的设置,这将影响模型的识别能力。
置信度阈值: 模型必须具有的最小置信度分数才能将检测视为有效,过滤掉低置信度的预测。
IoU 阈值: 将预测边界框分类为真正例所需的最小交并比(IoU)值,确保预测框和真实框之间重叠测量的准确性。
图像收集训练
我们将制作一个识别耳机的演示。基于 YOLO – World 目标检测模型,您可以自定义文本和图像的训练,这可以提高生成模型的检测精度。
步骤 1. 确定目标名称
首先在文本框中输入目标名称,然后选择 Grove Vision AI (V2) 进行连接。

如果连接成功,右侧框中将出现摄像头的实时预览。

步骤 2. 捕获图像
然后将摄像头对准目标物体并点击 'Capture',接着用红色框框选目标物体,最后点击 'Confirm'。

图像素材越多,模型的识别效果越好。
步骤 3. 训练和上传模型
点击 'Training',然后耐心等待模型完成训练。

最后是模型部署的时间。

结果演示
完成上述步骤后,模型将成功训练并部署。

技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。