智能零售语音 AI
利用 Seeed 的智能零售语音 AI 解决方案来捕获和分析店内客户对话。我们的边缘 AI 技术支持设备端语音转文本处理,将语音数据转化为可操作的洞察,无需依赖云服务。通过我们专为零售环境定制的离线 AI 驱动语音分析,提升客户体验、优化店铺运营并获得宝贵反馈。
| 智能零售语音 AI |
|---|
 |
智能零售语音 AI
使用边缘设备和 SenseCraft Voice 构建店内语音分析管道,现场捕获对话,运行设备端语音转文本,将客户语音转化为结构化数据。
边缘设备端语音转文本
SenseCraft Voice 直接在店内边缘设备上运行,本地处理语音活动检测和语音识别。所有语音都在边缘处理,大大减少了对云连接的依赖,实现实时转录生成。
远场零售就绪音频捕获
该解决方案专为嘈杂零售环境中的远场音频捕获而设计。支持麦克风阵列、波束成形和噪声抑制,即使在背景音乐和周围聊天声中也能专注于真实的客户-员工对话。
隐私优先的边缘架构
由于音频在边缘设备上本地转录,只有文本和元数据被发送到上游,零售商可以更好地控制隐私和合规风险,同时保持较低的云成本和网络需求。
从对话到数据驱动决策
SenseCraft Voice 生成的转录成为结构化、可分析的数据。零售商可以衡量服务质量,识别常见问题和痛点,持续改进脚本、政策和整体店铺体验。
入门指南
在本节中,我们将指导您完成使用 Seeed 的 reRouter 和 reSpeaker XVF3800 麦克风阵列设置智能零售语音 AI 解决方案的步骤。
1. 硬件要求
本指南使用 Seeed 的 reRouter 和 reSpeaker XVF3800 麦克风阵列来演示如何构建智能零售语音 AI 解决方案。
| reRouter(边缘计算) | reSpeaker XVF3800(音频捕获) |
|---|---|
 |  |
角色:处理单元
| 角色:语音捕获
|
硬件设置

1.1 获取 reRouter 固件
reRouter 有两个版本的 OpenWrt 固件可用:
一个适用于全球用户,另一个针对中国大陆用户进行了优化。
当前固件基于OpenWrt 24.10.3(构建版本 r28872)。
请参考reRouter 刷机指南了解刷机程序的详细说明。
请注意:您应该使用上面提供的固件,而不是指南页面中的固件。
1.2. 硬件连接
请按以下方式连接 reRouter:
- 互联网接入:将网线从您的路由器/调制解调器连接到WAN端口。
- 主机连接:无线连接到名为
OpenWrt-XXXX的 Wi-Fi 热点,或通过网线将您的计算机连接到LAN端口。

- WAN 端口:连接到互联网。
- LAN 端口:连接到您的主机计算机进行配置。
1.3. reSpeaker XVF3800 设置
通过 USB 将 reSpeaker XVF3800 麦克风阵列连接到您的主机设备进行配置。
- Linux/MacOS
- Windows
- 克隆仓库并导航到控制文件夹:
根据您的设备,将<YOUR_HOST_DIR>替换为与您系统匹配的文件夹(例如,linux_x86_64、rpi_64bit、mac_arm64或jetson)。
git clone https://github.com/respeaker/reSpeaker_XVF3800_USB_4MIC_ARRAY.git
cd reSpeaker_XVF3800_USB_4MIC_ARRAY/host_control/<YOUR_HOST_DIR>
- 执行配置序列:
授予执行权限并运行以下三个命令来初始化设备(在 Linux 上如需要请使用 sudo):
chmod +x ./xvf_host
# 1. Clear existing configuration
sudo ./xvf_host clear_configuration 1
# 2. Enable specific audio manager setting
sudo ./xvf_host audio_mgr_op_r 8 0
# 3. Save configuration
sudo ./xvf_host save_configuration 1
- 克隆仓库并导航到控制文件夹:
打开命令提示符(cmd)或 PowerShell 并运行:
git clone https://github.com/respeaker/reSpeaker_XVF3800_USB_4MIC_ARRAY.git
cd reSpeaker_XVF3800_USB_4MIC_ARRAY\host_control\win32
- 执行配置序列:
运行以下三个命令来初始化设备:
# 1. Clear existing configuration
.\xvf_host.exe clear_configuration 1
# 2. Enable specific audio manager setting
.\xvf_host.exe audio_mgr_op_r 8 0
# 3. Save configuration
.\xvf_host.exe save_configuration 1
2. 软件安装
2.1. 前提条件
开始之前,请确保满足以下条件:
- 访问权限: 通过 SSH 对您的 OpenWrt 设备具有 root 访问权限(例如,
ssh [email protected])。 - 网络: OpenWrt 设备具有稳定的互联网连接。
- 音频: reSpeaker XVF3800 已连接到 reRouter。
2.2 访问设备
一旦您的计算机连接到 reRouter(通过 LAN 或 Wi-Fi),您可以使用以下默认设置访问系统:
- SSH 访问:
默认情况下,root 用户未设置密码。
您也可以使用 OpenWrt Web 界面来配置网络设置,包括将 reRouter 连接到您的 Wi-Fi 或以太网网络以获得互联网访问。
- 打开浏览器并访问:http://192.168.49.1
- 用户名:root
- 密码:(默认为空)
如果您需要其他语言支持,例如中文,您可以通过 Web 界面或 SSH 安装 luci-i18n-base-zh-cn 包。
opkg update
opkg install luci-i18n-base-zh-cn
在继续执行以下安装步骤之前,请验证 reRouter 可以访问互联网 (例如,在 SSH 终端中运行 ping google.com 或 ping openwrt.org)。
2.3 分步安装
在建立与您的 OpenWrt 设备的 SSH 连接后,按顺序执行以下命令。
步骤 1:安装 Docker 和依赖项
此步骤安装容器运行时环境和必要工具,包括用于文件验证的 SHA-256 校验和实用程序。
- 全球
- 中国大陆
# 1. Update the local package list
opkg update
# 2. Install Docker core components
# Note: On some systems, you might need to install these separately: dockerd, docker, containerd, runc
opkg install dockerd docker containerd runc
# 3. Install utility packages
opkg install wget-ssl unzip ca-certificates
# 4. Enable and start the Docker daemon service
/etc/init.d/dockerd enable
/etc/init.d/dockerd start
# Optional: verify downloaded files
# sha256sum <filename>
# For users in Mainland China, switch to Tsinghua University mirror for faster package downloads
sed -i 's_https\?://downloads.openwrt.org_https://mirrors.tuna.tsinghua.edu.cn/openwrt_' /etc/opkg/distfeeds.conf
# 1. Update the local package list
opkg update
# 2. Install Docker core components
# Note: On some systems, you might need to install these separately: dockerd, docker, containerd, runc
opkg install dockerd docker containerd runc
# 3. Install utility packages
opkg install wget-ssl unzip ca-certificates
# 4. Enable and start the Docker daemon service
/etc/init.d/dockerd enable
/etc/init.d/dockerd start
# Optional: verify downloaded files
# sha256sum <filename>
步骤 2.2:准备数据目录和配置
创建 SenseCraft 容器所需的持久存储目录并下载默认配置文件。
# 1. Create required application data directories
mkdir -p /data-iot/respeaker/recordings \
/data-iot/respeaker/models \
/data-iot/respeaker/voiceprints \
/data-iot/respeaker/logs
# 2. Navigate to the base directory
cd /data-iot/respeaker
# 3. Download the configuration file
wget -q -O config.yaml 'https://appstore.seeed-fleet.com/config.yaml'
步骤 2.3:下载和提取模型
我们将直接从 Seeed Studio 服务器下载预训练的 ASR 模型包,使用 SHA-256 验证其完整性,并提取它。
| 文件 | URL |
|---|---|
models.zip | https://files.seeedstudio.com/wiki/solution/ai-sound/reRouter-firmware-backup/models.zip |
| 预期 SHA-256 哈希值 | 7b9e7606a2ddcad56f3f72a77b16eb2c60437ae4bfc3f1423bd33db177385c9d |
通过 SSH 在 OpenWrt 主机上执行以下命令:
# 1. Navigate to the base directory
cd /data-iot/respeaker
# 2. Define the Model URL
MODEL_URL="https://files.seeedstudio.com/wiki/solution/ai-sound/reRouter-firmware-backup/models.zip"
# 3. Download the large model package.
# -c allows the download to resume if interrupted.
wget -O models.zip -c "$MODEL_URL"
echo "Model package download completed. Check file size is approximately 500MB."
# 4. Verify the file integrity using SHA-256 Checksum
# The result MUST match the expected hash above.
sha256sum models.zip
# 5. Extract the model package into the 'models' directory
unzip -o models.zip
# 6. Clean up the temporary ZIP file
# rm -f models.zip
# 7. Verify the model files are present
ls -l /data-iot/respeaker/models/
步骤 2.4:配置音频设备权限
语音客户端容器需要对音频设备的特权访问。确保设备文件具有适当的权限。
# 1. Check for audio devices
ls -l /dev/snd/
# 2. Set read/write permissions for all users on audio device nodes
chmod -R 666 /dev/snd/*
步骤 2.5:部署 Docker 容器
定义镜像变量并启动三个必需的服务:sensecraft-voice-client、sensecraft-asr-server 和 watchtower。
# Define Image Variables
VOICE_CLIENT_IMAGE="sensecraft-missionpack.seeed.cn/respeaker/sensecraft-voice-client:v0.0.2"
ASR_SERVER_IMAGE="sensecraft-missionpack.seeed.cn/respeaker/sensecraft-asr-server:latest"
WATCHTOWER_IMAGE="sensecraft-missionpack.seeed.cn/respeaker/containrrr/watchtower:latest"
# 1. Pull Images
docker pull $VOICE_CLIENT_IMAGE
docker pull $ASR_SERVER_IMAGE
docker pull $WATCHTOWER_IMAGE
# 2. Stop and remove any containers with the same names
docker rm -f sensecraft-voice-client sensecraft-asr-server watchtower
# 3. Launch sensecraft-voice-client
docker run -d --name sensecraft-voice-client \
--restart=unless-stopped \
--privileged \
--device /dev/snd \
--network host \
--group-add audio \
--group-add video \
--cap-add SYS_ADMIN \
--cap-add SYS_RAWIO \
-e TZ=Asia/Shanghai \
-e AUDIO_CARD_ID=1 \
-e AUDIO_DEVICE_ID=0 \
-v /etc/wpa_supplicant:/etc/wpa_supplicant \
-v /etc/network:/etc/network \
-v /var/run/dbus:/var/run/dbus \
-v /dev:/dev \
-v /run/udev:/run/udev:ro \
-v /proc:/proc:ro \
-v /sys:/sys:ro \
-v /data-iot/respeaker/recordings:/app/recordings \
-v /data-iot/respeaker/voiceprints:/app/voiceprints \
-v /data-iot/respeaker/logs:/app/logs \
-e WIFI_INTERFACE=wlan0 \
-e WIFI_CONFIG_PATH=/etc/wpa_supplicant \
$VOICE_CLIENT_IMAGE
# 4. Launch sensecraft-asr-server (model server)
docker run -d --network host \
-v /data-iot/respeaker/models:/app/models \
-v /data-iot/respeaker/voiceprints:/app/data \
--restart=always \
--name=sensecraft-asr-server \
$ASR_SERVER_IMAGE
# 5. Launch watchtower (for continuous container monitoring and update)
docker run -d --name watchtower \
--restart always \
-v /var/run/docker.sock:/var/run/docker.sock \
$WATCHTOWER_IMAGE \
--cleanup -i 60 sensecraft-asr-server sensecraft-voice-client
3. 验证
检查部署的最终状态。
# Check container status (All three should show Status: Up)
docker ps
# Check the voice client logs for successful initialization and audio device detection
docker logs sensecraft-voice-client
如果日志显示成功启动且没有严重错误,则 SenseCraft 服务已成功部署。
强烈建议重启设备以确保所有设置、权限和网络配置都被系统完全加载和识别。
reboot
重启后,您可以导航到 http://192.168.49.1:8090 访问边缘客户端界面,进行实时 ASR 转录和设备配置。有关 SenseCraft Voice 平台的详细使用方法,请参考下面的用户指南部分。
SenseCraft Voice:边缘到云端平台概述
SenseCraft Voice 是一个尖端平台,旨在通过强大的 AI 分析和集中管理,将在边缘(reRouter)捕获的原始音频数据转换为可操作的商业智能。
该平台独特的边缘-云端架构为企业级音频监控解决方案提供了无与伦比的可靠性、速度和分析深度。
| 功能 | 价值主张 | 主要优势 |
|---|---|---|
| 弹性边缘处理 | 保证持续运行和低延迟。 | 语音 ASR 和识别在 reRouter 上本地运行,确保实时响应和数据收集,即使在网络中断期间也能正常工作。 |
| 深度 AI 定制 | 使平台适应特定的业务需求和术语。 | 管理员可以定义自定义关键词、同义词和 AI 提示来指导 AI 分析,确保准确检测特定于其业务语言的事件。 |
| 精细位置映射 | 简化大规模部署管理。 | 支持按商店、位置和设备名称对数千个边缘设备进行分层组织,摆脱令人困惑的 MAC 地址,便于过滤和报告。 |
| 可操作的仪表板 | 提供即时的业务洞察和性能跟踪。 | 集中式仪表板具有多商店过滤、实时设备在线率和关键词热点分析功能,可即时监控运营状态和业务事件。 |
SenseCraft Voice 解决方案基于强大的边缘-云端架构构建,确保实时本地处理和集中管理。该服务由两个主要组件组成:运行在 reRouter 上的边缘端客户端,以及云端/服务器端管理平台。
用户指南
边缘端客户端(reRouter)访问
边缘客户端对于实时验证和本地设置至关重要。
- 访问: 打开您的网络浏览器,导航到 reRouter 的 IP 地址的 8090 端口:
http://192.168.49.1:8090。 - 核心功能: 该界面提供实时 ASR 转录(用于验证音频输入)、声纹识别控制(说话人识别)和设备配置(网络设置、上游服务器地址)。
| 模块名称 | 描述 | 界面截图 |
|---|---|---|
| 语音 ASR | 描述: 显示本地自动语音识别(ASR)服务的当前运行状态。 目的: 提供检测到的语音的实时转录,对于验证本地音频输入和识别准确性至关重要。 | 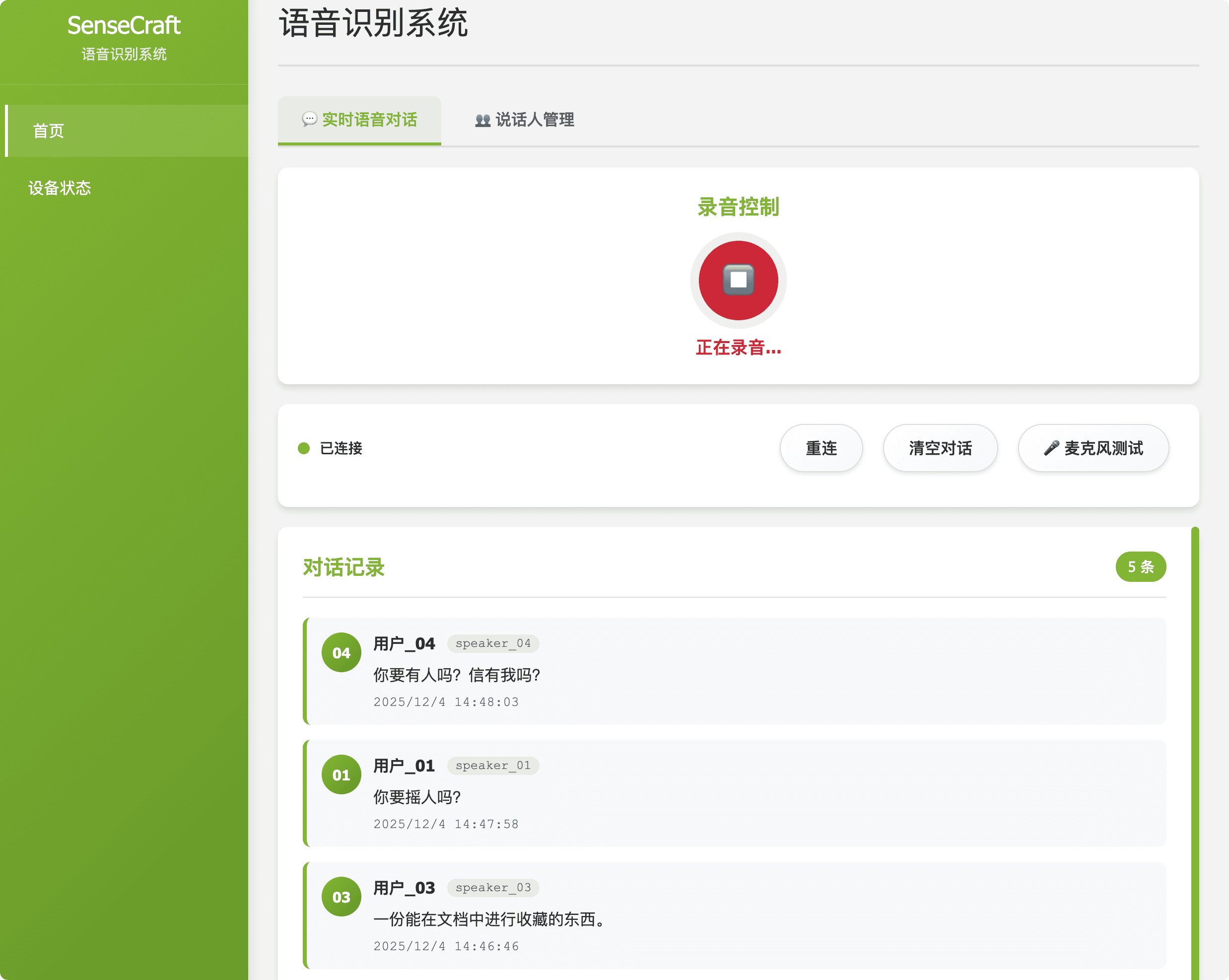 图 1:语音 ASR 模块 |
| 声纹识别 | 描述: 管理和监控声纹识别系统。 目的: 从音频录音中自动生成独特的声纹,以实现说话人区分和识别。 | 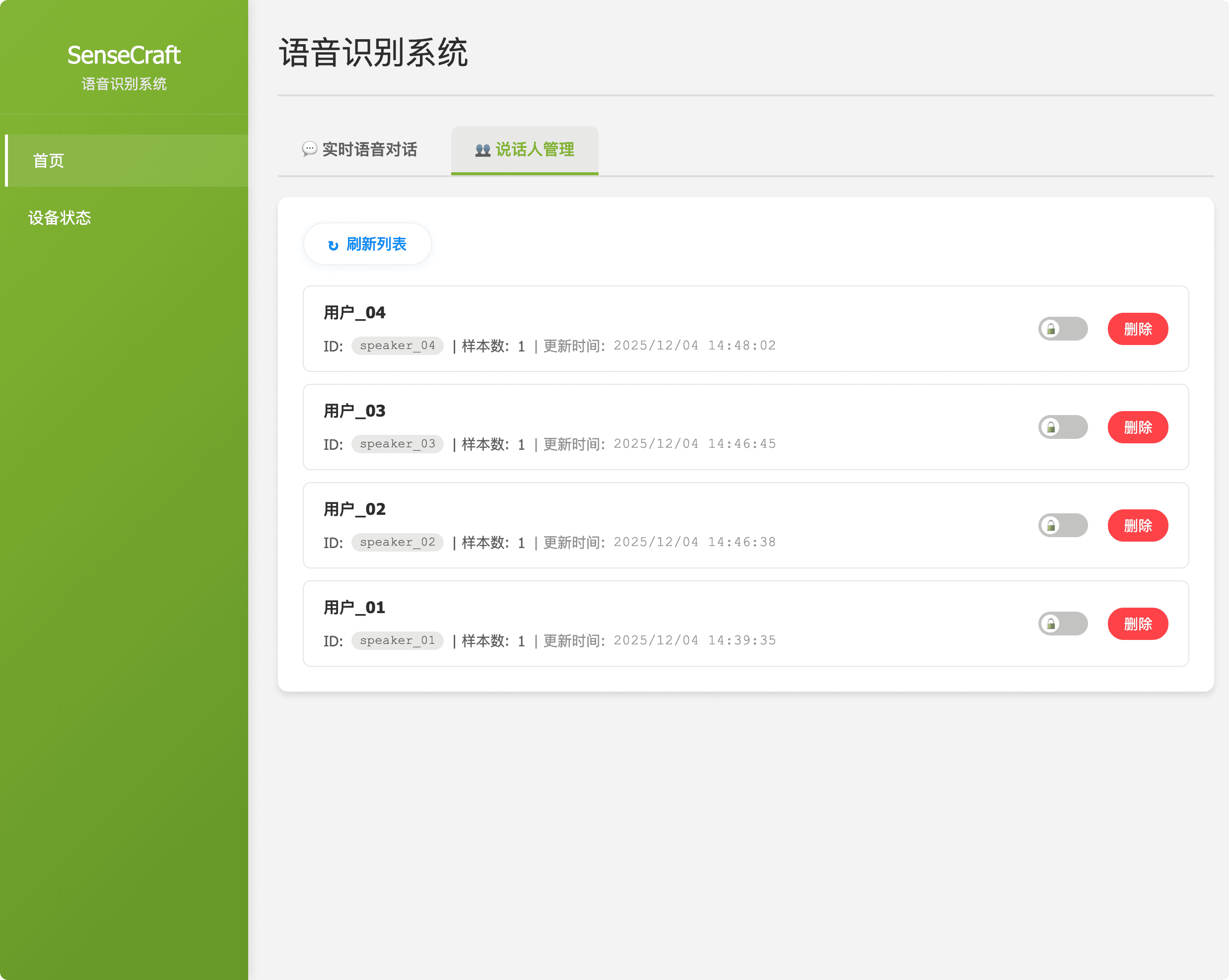 图 2:声纹识别模块 |
| 设备状态与配置 | 描述: 提供关于 reRouter 运行状态的详细信息,并允许更改核心参数。 目的: 启用配置更新,如网络设置(Wi-Fi)和更改用于云端通信的上游服务器地址。 | 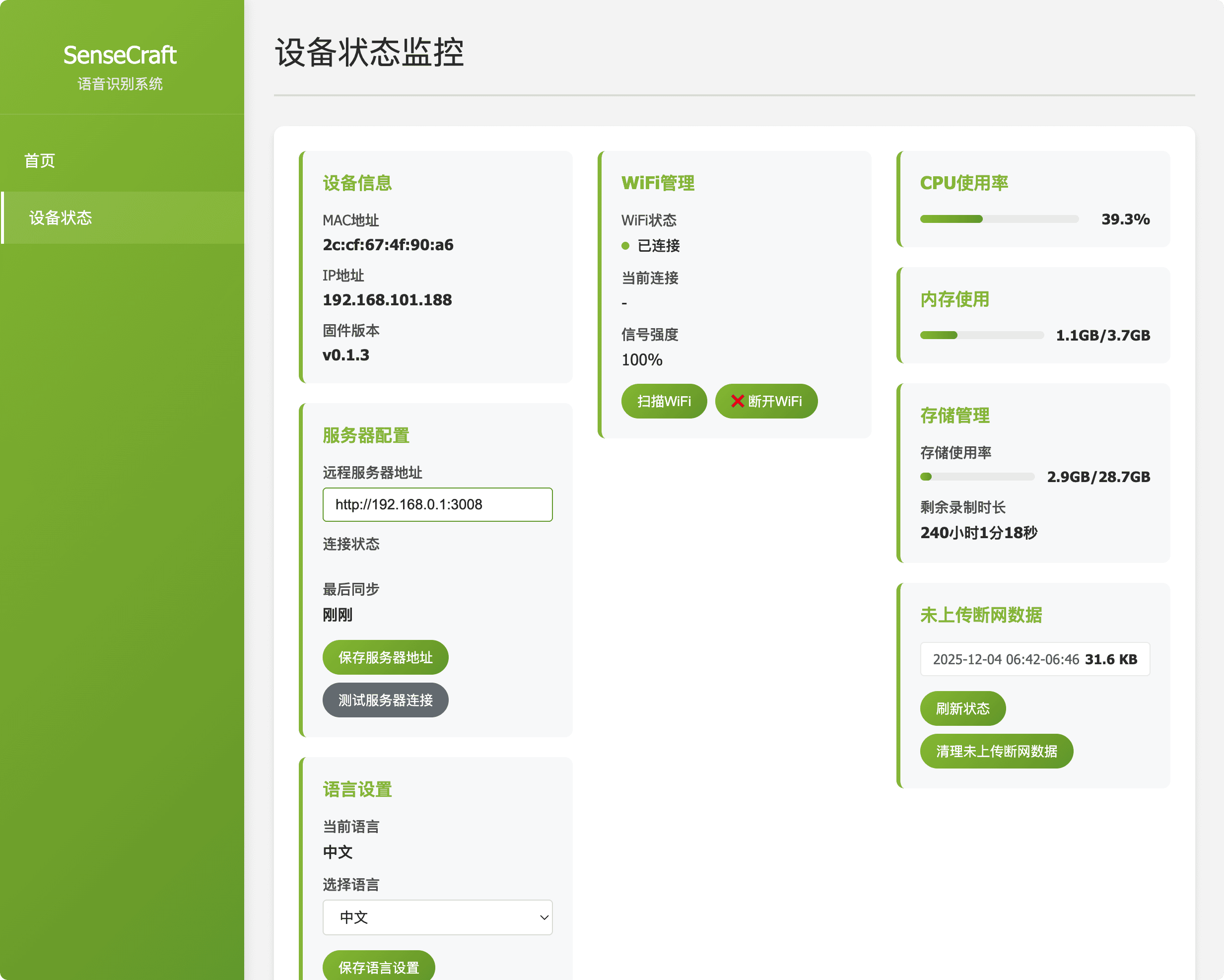 图 3:设备状态与配置 |
云端管理平台
云端平台分为五个主要导航区域,提供强大的数据分析和系统配置工具。
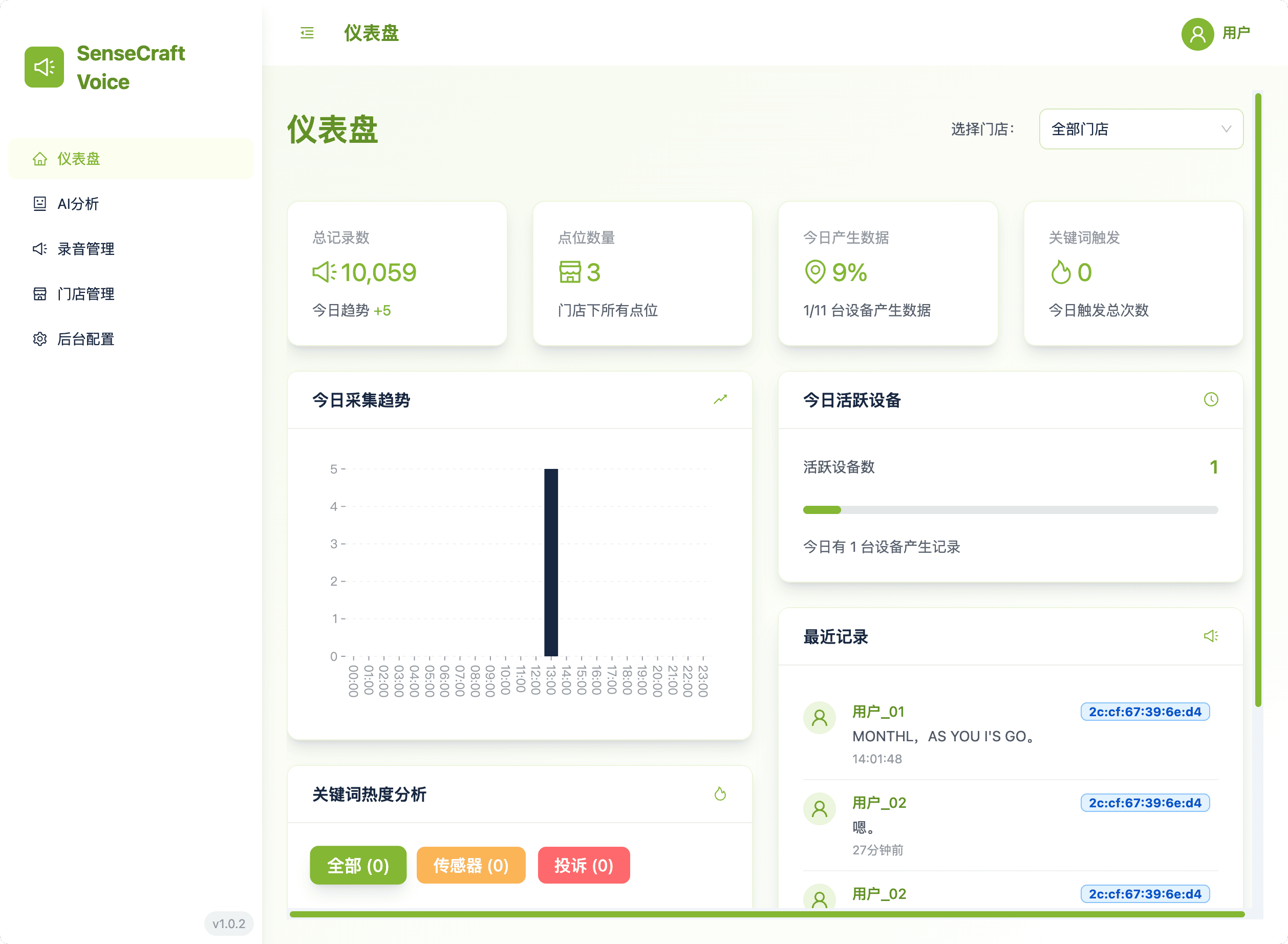
1. 仪表板:一目了然的洞察
仪表板是您的运营指挥中心,提供聚合指标和性能趋势:
- 门店筛选: 通过选择一个或多个门店轻松切换视图,所有图表会立即更新。
- 分析: 监控每日收集趋势(按小时记录)和关键词热点分析(显示哪些关键词被频繁触发以及相关的设备名称)。
2. 记录管理:数据审计与导出
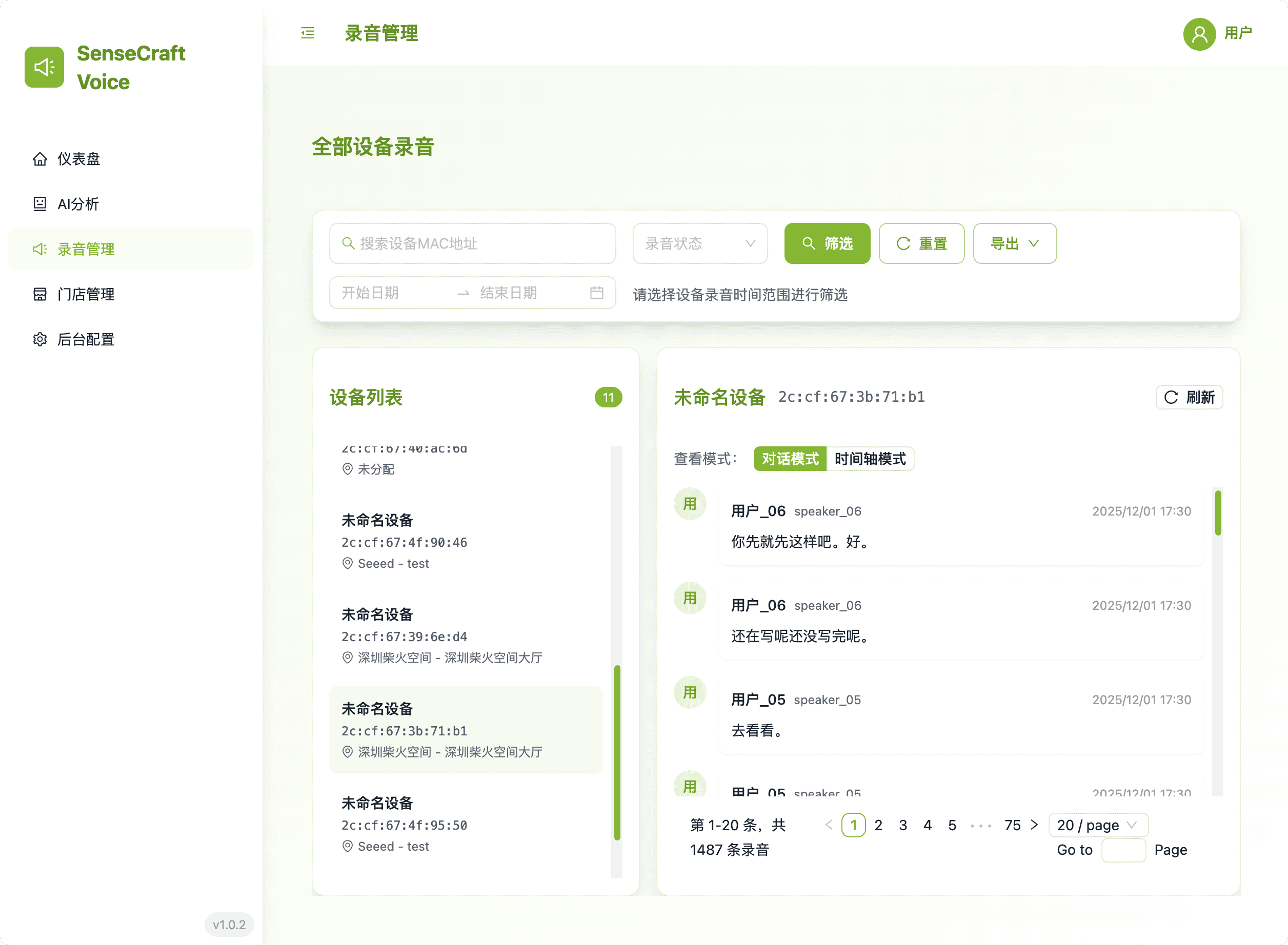
此模块提供所有收集的语音记录的权威视图。
- 高级筛选: 使用设备名称、门店名称、位置名称或 MAC 地址进行精确数据检索。搜索仅在点击**"Filter"**按钮后执行,让用户完全控制。
- 导出功能: 选择并以三种格式导出筛选的数据供外部使用(一次选择一种):Markdown、纯文本(.txt)或原始音频文件。
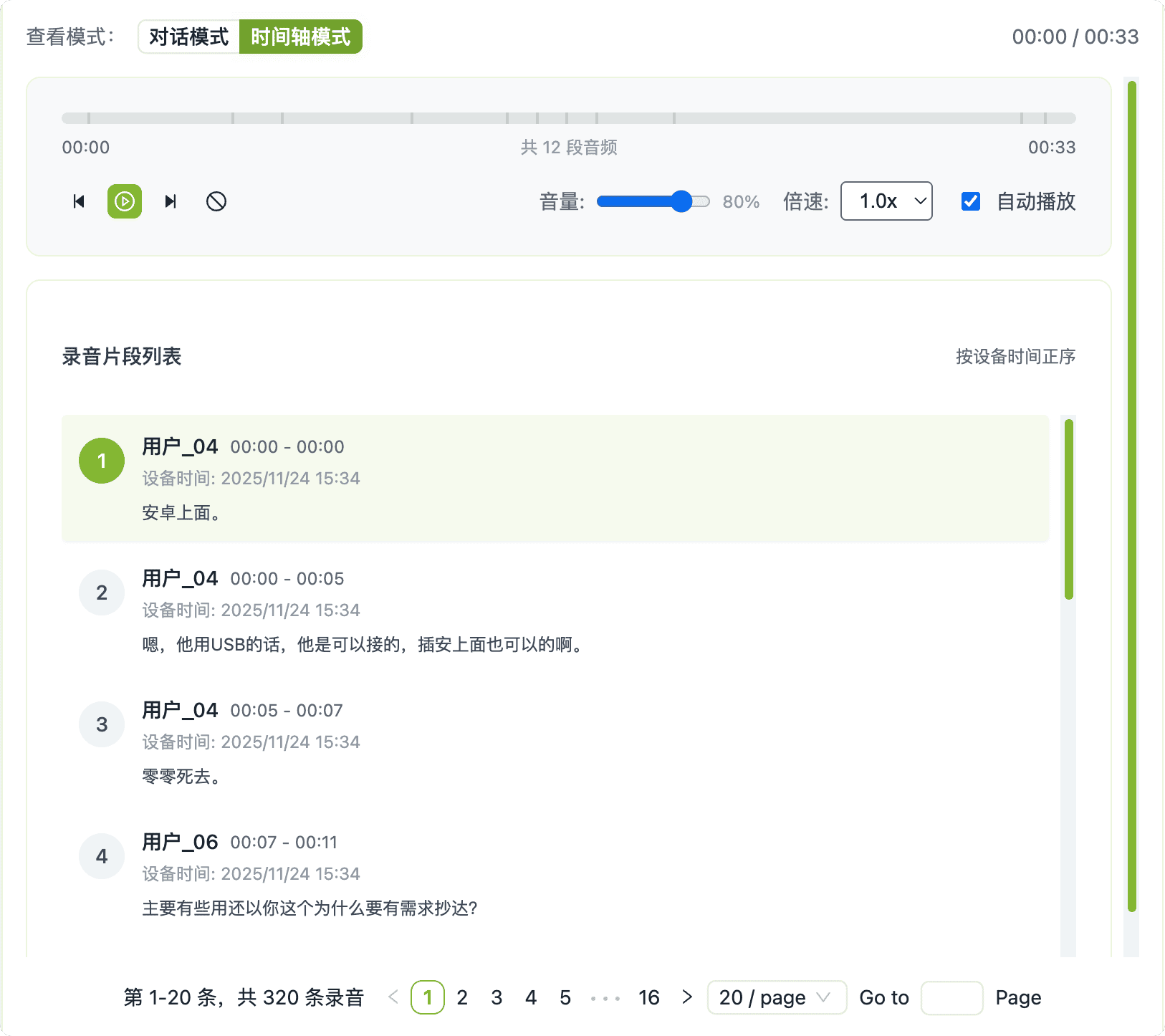
- 双视图审计: 轻松在对话模式(查看转录的对话)和时间线模式(收听原始音频回放)之间切换。这种双重方法允许快速验证转录准确性并更深入地理解交互的上下文。
- 清晰度: 所有记录视图都优先显示易于识别的设备名称而非 MAC 地址。
3. AI 分析:历史与自定义处理
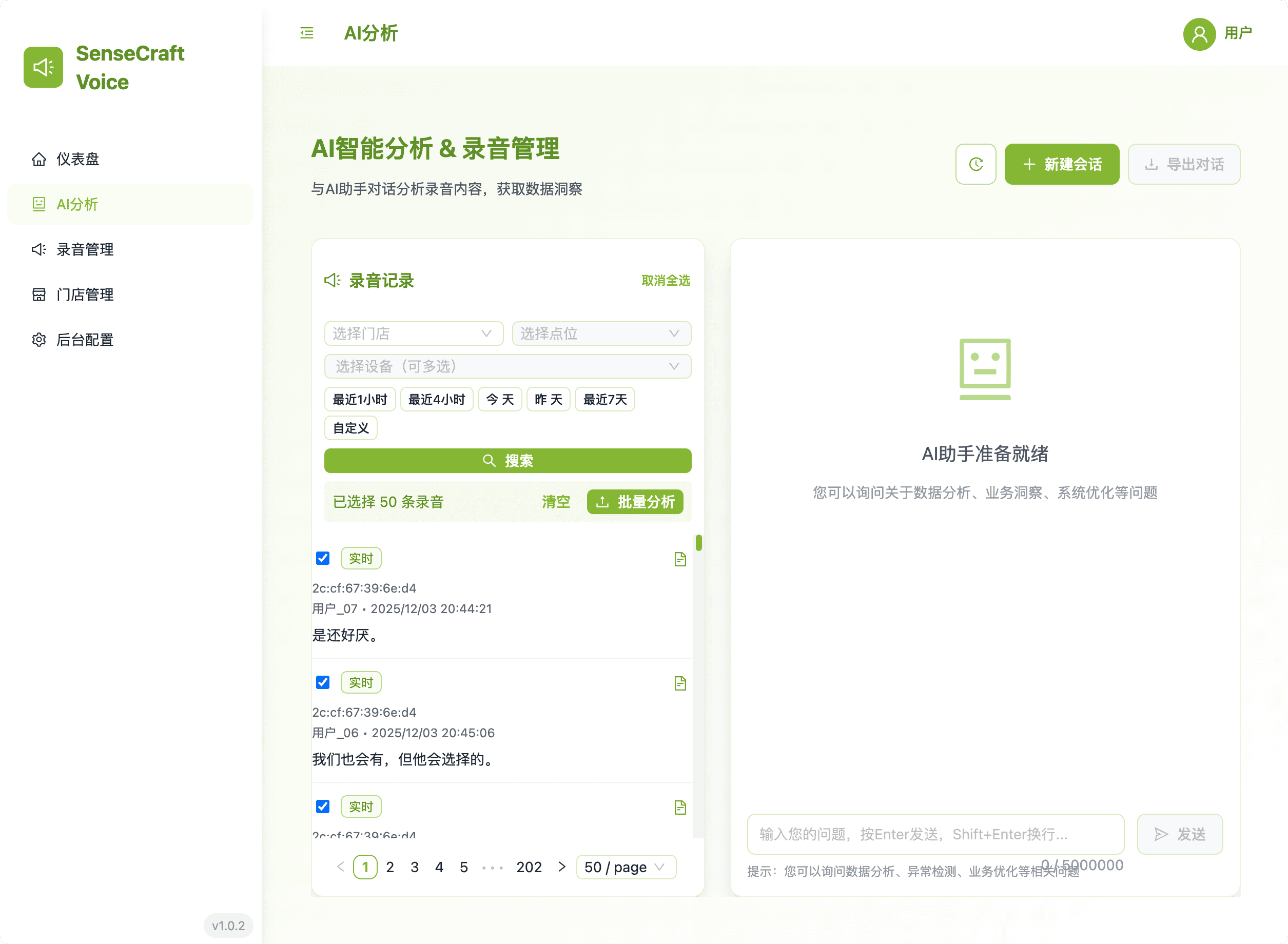
此区域处理向 AI 引擎提交语音记录以进行高级处理。
- 历史会话: 查看您与 AI 分析引擎的过往交互。历史窗口按时间顺序显示对话,点击会话会立即加载之前的对话线程供查看。
- 处理: 基于当前选择的 AI Prompt 提交筛选的记录进行 AI 处理。
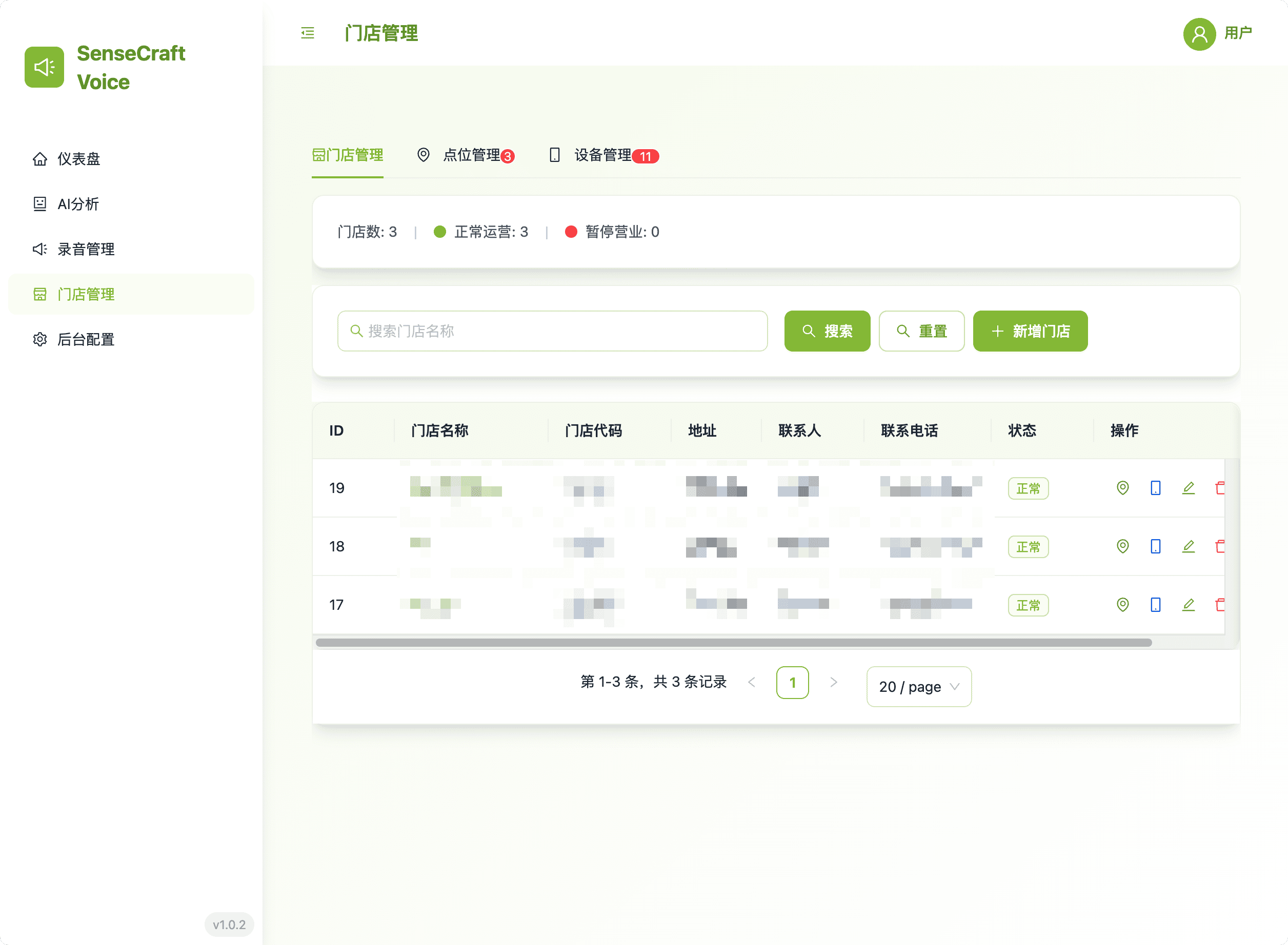
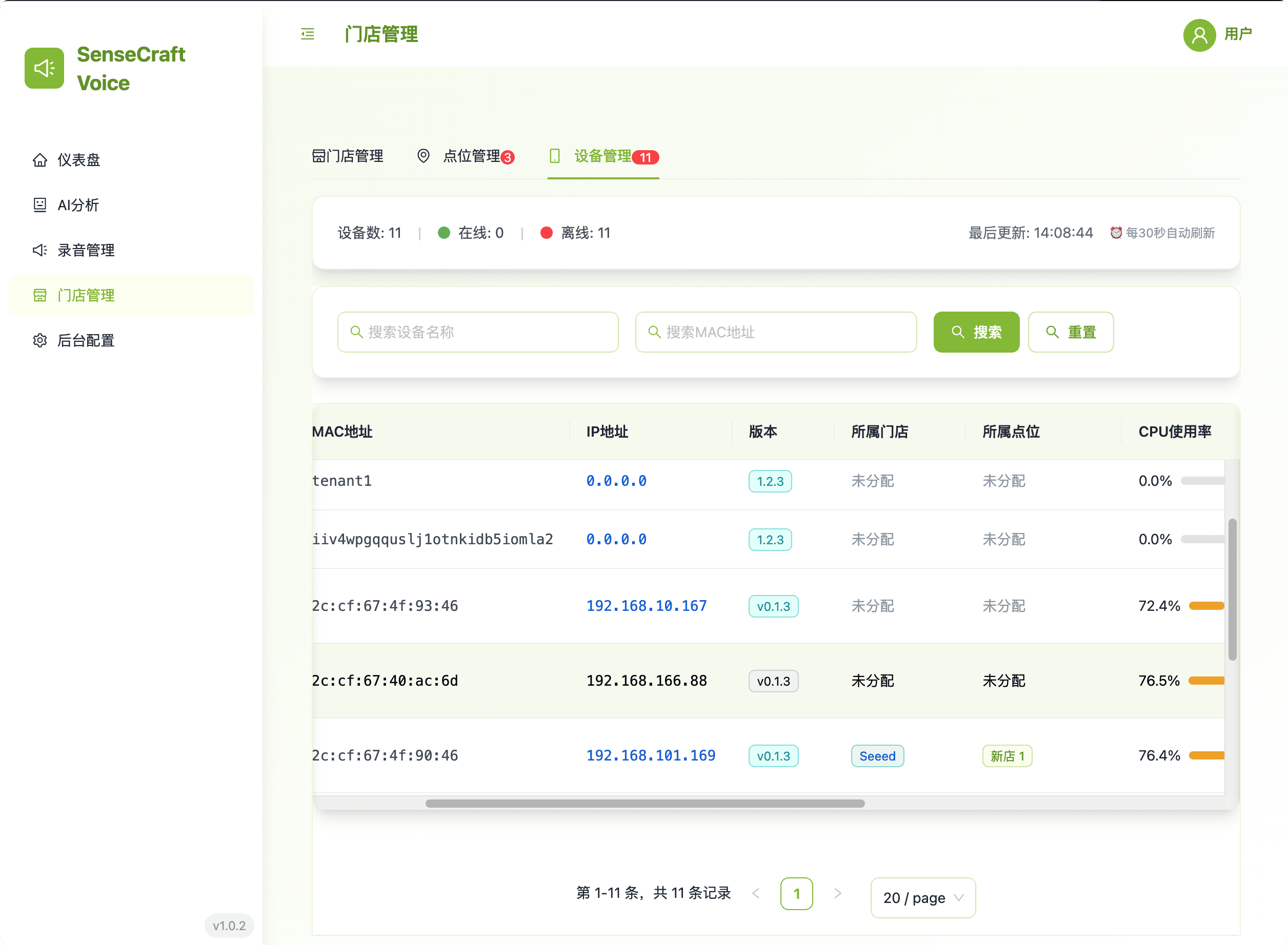
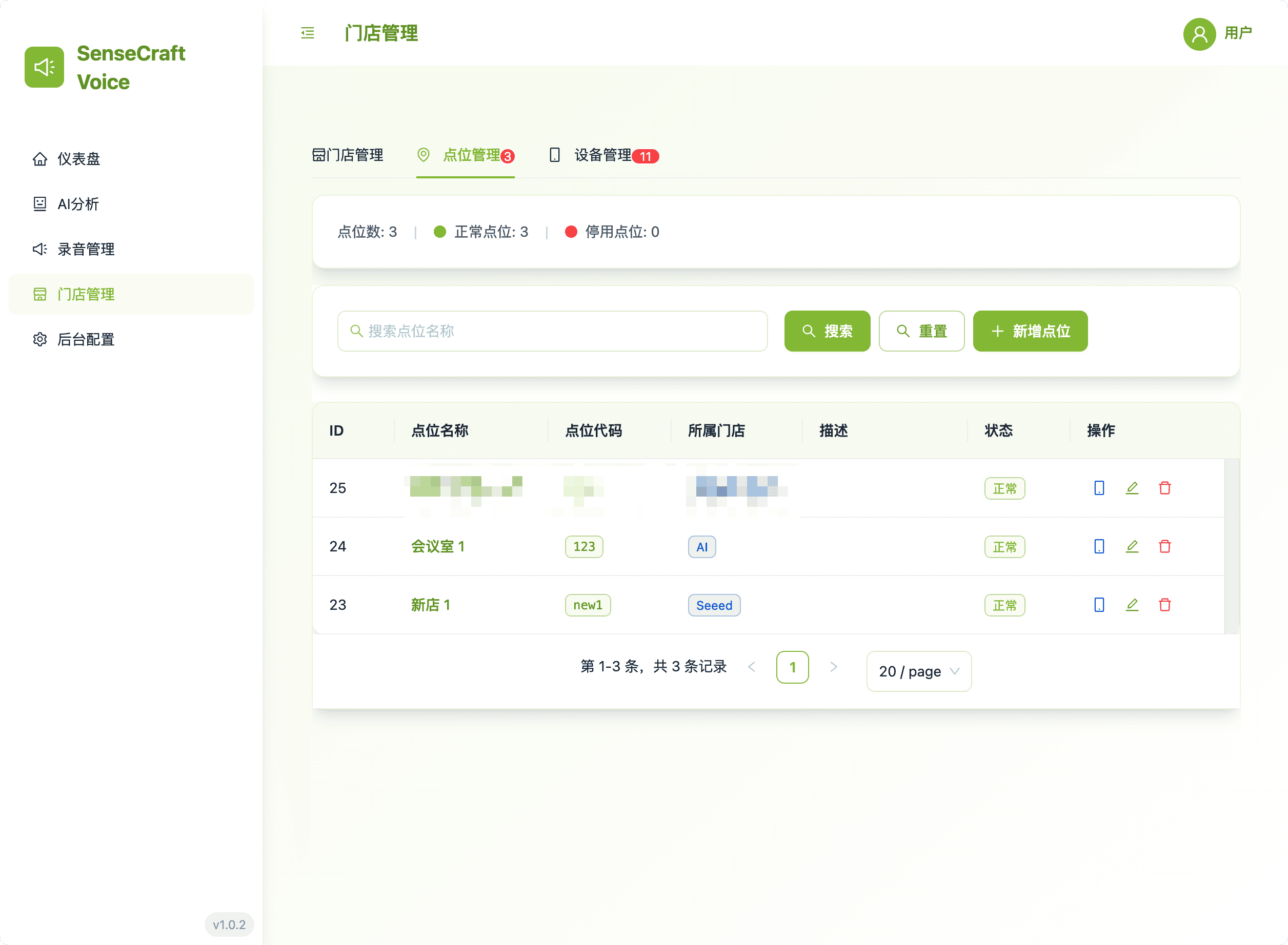
4. 门店管理:设备与位置层次结构
此区域提供设置和维护所有边缘设备组织层次结构的必要工具。
- 层次视图: 轻松管理门店、其特定的店内位置以及相关的 reRouter 设备。
- 集中控制: 通过逻辑分组设备来简化设备部署和配置。
5. 后端配置:系统控制与自定义
此部分允许管理员定义 AI 处理和事件触发的系统级参数。
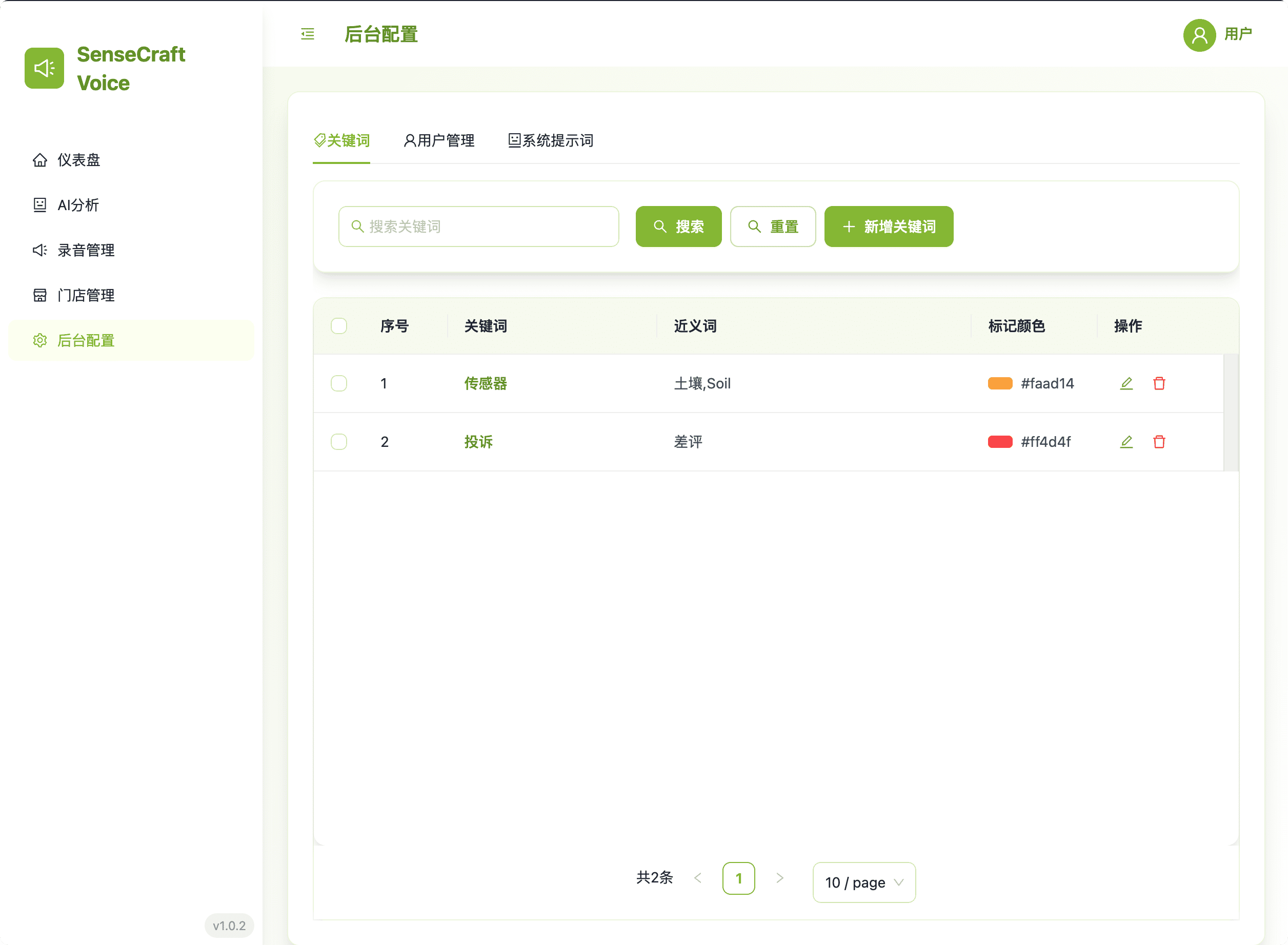
5.1. 关键词设置
定义自定义关键词和同义词以识别录音中的特定业务事件。
- 自定义: 定义用于事件检测的关键词及其同义词。
- 可视化: 分配标记颜色以在仪表板上进行视觉区分。
- 管理: 支持添加、编辑、删除和批量删除。
5.3. 用户管理
用户管理模块控制平台访问和权限。
5.2. AI 提示设置
创建和管理自定义 AI 提示以指导 AI 如何处理选定的语音记录。
- 控制: 定义提示名称、标签和内容。一次只有一个启用的提示处于活动状态供使用。
- 管理: 支持添加、编辑、删除和批量删除。