使用 YOLOv8 训练和部署自定义分类模型
介绍
在本指南中,我们将解释如何使用 YOLOv8 训练和部署自定义分类模型
概述
我们将创建一个虚拟环境,在其中安装 YOLOv8,从 roboflow 下载分类模型,训练并部署它。
图像分类
图像分类是计算机视觉最简单的任务,涉及将图像分类到预定义类别之一。 我们得到的输出是单个类别标签和置信度分数。
当我们不需要知道对象在图像中的位置,只需要知道图像属于哪个类别时,图像分类非常有用。
材料要求
硬件设置
对于本教程,我们需要一个 Nvidia Jetson Orin NX 16GB。

软件设置
- 在 reComputer 中安装 JetPack 6.0
- 一个 Roboflow 账户来下载数据集
准备 reComputer
Seeed Studio 的 reComputer J4012 是一个 Jetson Orin NX 16GB。 它是一台强大的机器,但 Tegra Linux 带有很多东西,并且启动到图形模式。让我们改变这一点。
我将使用 VScode 和启用 X 转发的 SSH 终端远程运行示例和编程。 X 转发是 SSH 的一个选项,可以在我们连接的这一端运行一些图形应用程序,而不是在远程计算机上。
如果您要使用显示器、键盘和鼠标连接到您的 reComputer,请跳过下一步。
更改启动模式

这很好,但我们不需要图形界面,在空闲模式下,它消耗大约 1.5GB 的内存。

我们将让它启动到命令行界面。
sudo systemctl set-default multi-user
目前,我们的 reComputer 在启动时会启动到 CLI。 如果您愿意,可以现在重启,或者我们可以用一个命令进入 CLI。
sudo systemctl isolate multi-user
我们现在已经从使用 1.5GB 内存降低到 700MB。在使用机器学习时,每一个内存字节都很重要。
更改功耗模式
默认情况下,我们的 reComputer 应该运行在级别 2 - 15W。 在训练甚至推理机器学习模型时,如果我们能以全功率运行,效果应该会更好。
让我们学习如何更改它。
在文件 /etc/nvpmodel.conf 中,我们有可用的功耗模式。
< POWER_MODEL ID=0 NAME=MAXN >
< POWER_MODEL ID=1 NAME=10W >
< POWER_MODEL ID=2 NAME=15W >
< POWER_MODEL ID=3 NAME=25W >
然后我们可以使用 sudo nvpmodel -m <power model number> 来更改电源模式。并且,根据这个论坛帖子,这些设置在重启后仍会保持。
要查看我们当前处于什么电源级别,
sudo nvpmodel -q

让我们为模型训练选择最大功率模式
sudo nvpmodel -m 0

重启后,我们可以确认正在以全功率运行

训练模型
对于模型训练,我们将使用 YOLOv8。以下是安装它并支持 CUDA 所需的步骤。 我们还需要一个 roboflow 账户。
模型
我将创建一个用于分类鸟类的模型。 这是我将放置在花园中的智能鸟类喂食器项目的一部分,我想知道在那里觅食的鸟类是什么。
因为这是一个分类任务,我们不需要知道鸟类在照片中的位置。
您可以使用您选择的其他数据集,只要它是分类数据集或模型
我已经获得了 12 类我知道生活在我所在地区并且在我附近很常见的鸟类,并在 Roboflow 中创建了一个分类数据集。
我将尝试识别的鸟类类别有:
- 家燕
- 欧金冠戴菊
- 欧夜莺
- 苍头燕雀
- 欧岩燕
- 欧洲金翅雀
- 欧洲绿金翅雀
- 欧丝雀
- 家麻雀
- 西班牙麻雀
- 白腰雨燕
- 白鹡鸰
选择您的数据集并从 roboflow 下载。 选择数据集后,选择"Download Dataset"。- 您需要一个账户。
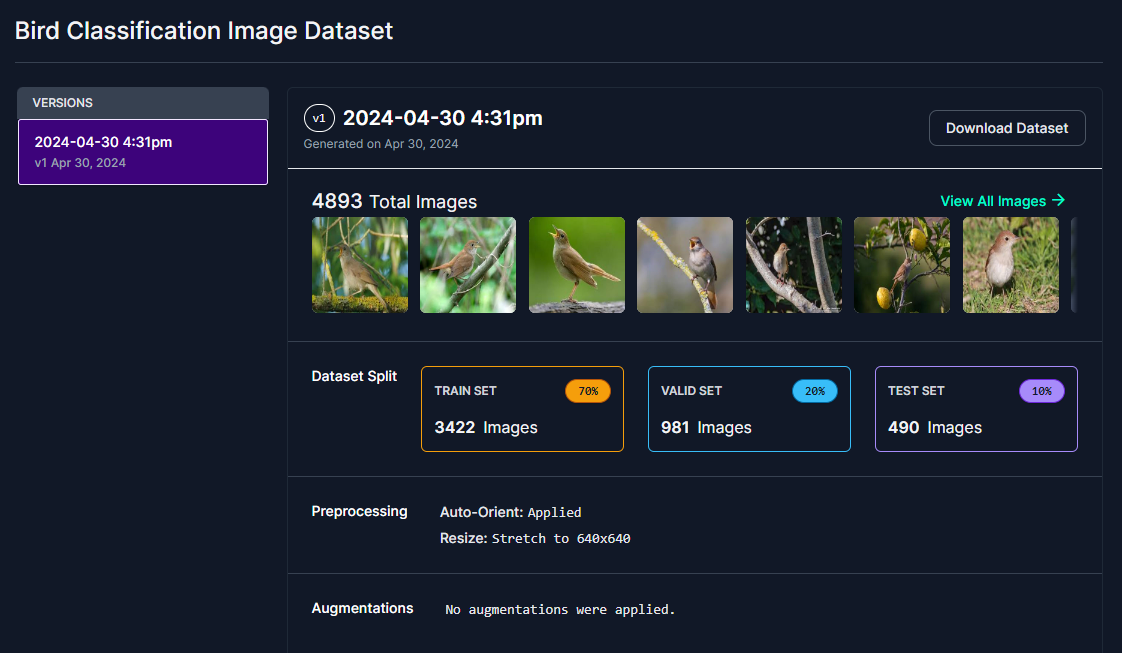
接下来,在格式中选择 Folder Structure,然后选择 show download code。
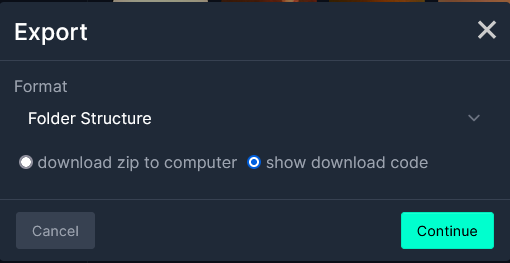
接下来,如果您要使用 Jupyter Notebook,请选择 Jupyter,如果您计划在终端中执行此操作,请选择 Terminal。
我选择了 Jupyter,在 Jupyter notebook 中使用。复制代码。
创建环境
我们将创建一个虚拟环境,安装 PyTorch 并安装 YOLOv8。 根据 YOLOv8 文档提示,最好先安装 PyTorch,然后再安装 ultralytics。
另外,我正在安装 jupyterlab 包以与 VSCode 一起使用。本教程附带了 notebook。
让我们先安装一些依赖项。
注意: 因为我们要使用 YOLOv8,我们需要执行一些通常不需要的步骤。
只需按照 NVIDIA 深度学习文档 安装 Torch 就足以拥有支持 CUDA 的 Torch。
如果我们使用 PIP 正常安装 PyTorch,它将不支持 CUDA。
依赖项
sudo apt install libopenblas-dev cuda-toolkit libcudnn8 tensorrt python3-libnvinfer nvidia-l4t-dla-compiler
创建 Python 虚拟环境
python -m venv birdClassificationModel
如果您遇到错误,是因为没有安装 python3-venv 包。让我们安装它并重复上述命令。
sudo apt install python3-venv
Activate the virtual environment
source birdClassificationModel/bin/activate
您可以确认它是活动的,因为它的名称放在您的提示之前。
YOLOv8
在此之前,为了遵循文档提示,让我们首先安装 PyTorch。
我正在使用 JetPack 6.0,它附带 NVIDIA Jetson Linux 36.3 和 CUDA 12.2。 让我们首先升级 PIP
pip install -U pip
安装 Torch 以便能够与 YOLOv8 一起使用,我们需要按照 NVIDIA 论坛中的步骤进行操作。
这将在虚拟环境激活的状态下完成,以便将其安装在虚拟环境中。 从 NVIDIA 下载 Torch 版本 2.3
wget https://nvidia.box.com/shared/static/mp164asf3sceb570wvjsrezk1p4ftj8t.whl -O torch-2.3.0-cp310-cp310-linux_aarch64.whl
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev libomp-dev
pip3 install 'Cython<3'
pip install numpy torch-2.3.0-cp310-cp310-linux_aarch64.whl
接下来,让我们编译 torchvision。如果我们从 wheels 安装它,它将不会有 CUDA 支持。
分支版本是针对已安装的 Torch 版本。您可以在论坛页面中查看更多详细信息。
记住,您需要激活虚拟环境,这样所有内容都会安装在其中。
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libopenblas-dev libavcodec-dev libavformat-dev libswscale-dev
git clone --branch v0.18.0 https://github.com/pytorch/vision torchvision
cd torchvision/
export BUILD_VERSION=0.18.0
python setup.py install
一段时间后,它将被编译和安装。
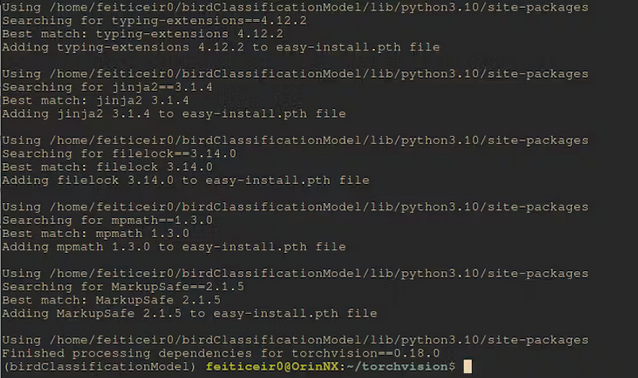
安装完成后,让我们看看 Cuda 是否可用。
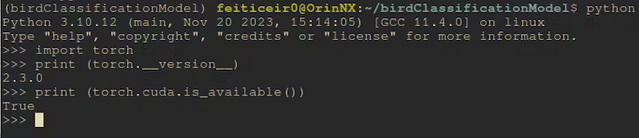
从命令行
python -c "import torch;print (torch.cuda.is_available())"
这应该返回 True
安装 YOLOv8
现在我们已经安装了支持 CUDA 的 PyTorch,当我们安装 YOLOv8 时,它将使用已安装的版本,而不是尝试安装一个新的包(尽管是相同版本)但不支持 CUDA。
pip install ultralytics
让我们安装 roboflow 和 jupyterlab
pip install roboflow jupyterlab
现在,让我们下载数据集。 如果你正在使用笔记本,只需替换那里的代码。
rf = Roboflow(api_key="<your_api_key>")
project = rf.workspace("bruno-santos-omqsq").project("bird-classification-19z7c")
version = project.version(1)
dataset = version.download("folder")
下载模型后,我们现在有了一组三个目录(test、train、valid),每个目录都包含来自每个类别的一定数量的图像。每个类别的每张图像都在其自己的目录中。 因为这是用于图像分类的,我们不需要标记图像。 YOLOv8 将知道类别,不仅从我们稍后创建的配置文件中,还从目录中。

训练
通常数据集包含图像和标签(或注释)以及对象坐标。由于这是一个分类任务,我们不需要任何这些。只需要图像位于以类别名称命名的每个目录中。
准备配置文件
我们仍然需要一个配置文件让 YOLOv8 识别类别。 这个文件应该放在数据集目录内,扩展名为 .yaml。名称并不重要。
cd <dataset_directory>
vi birdClassificationModel.yaml
在文件中插入以下文本
train: train/
valid: valid/
test: test/
# number of classes
nc: 12
# class names
names: ["Barn Swallow","Common Firecrest","Common Nightingale","Eurasian Chaffinch","Eurasian Crag Martin","European Goldfinch","European Greenfinch","European Serin","House Sparrow","Spanish Sparrow","Western House Martin","white Wagtail"]
对于分类,我们将使用 Ultralytics 已经提供的预训练模型 之一。
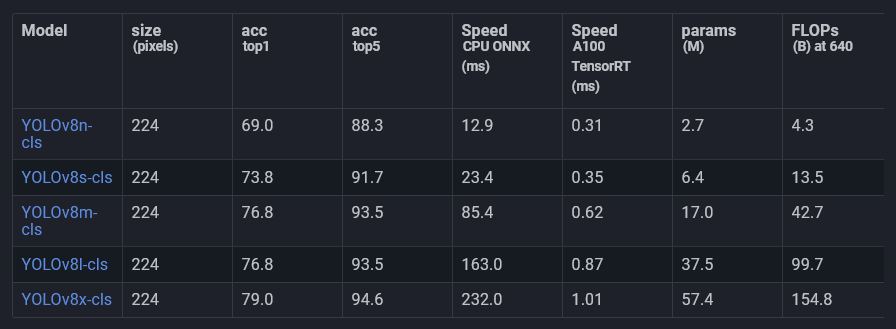
这些模型已经在 ImageNet 上进行了训练,并针对分类任务进行了微调。 我们将使用它并在我们的数据上进行训练。
这就是所谓的迁移学习。
我将使用模型 YOLOv8l-cls。可能其他模型也能很好地工作,但因为我们不需要实时性,这是速度和准确性之间的权衡。
然后让我们使用 YOLOv8 CLI 接口来训练模型
yolo task=classify mode=train model=yolov8l-cls.pt data=Bird-Classification-1 epochs=100
- task=classify : 我们将对图像进行分类
- mode=train : 我们正在训练模型
- model=yolov8l-cls.pt : 我们使用预训练的分类模型
- data=Bird-Classification-1 : 我们数据集所在的目录
- epochs=100 : 我们训练模型的时长。
现在它正在运行,这里是使用 jtop (tegra-stats) 的一些统计信息
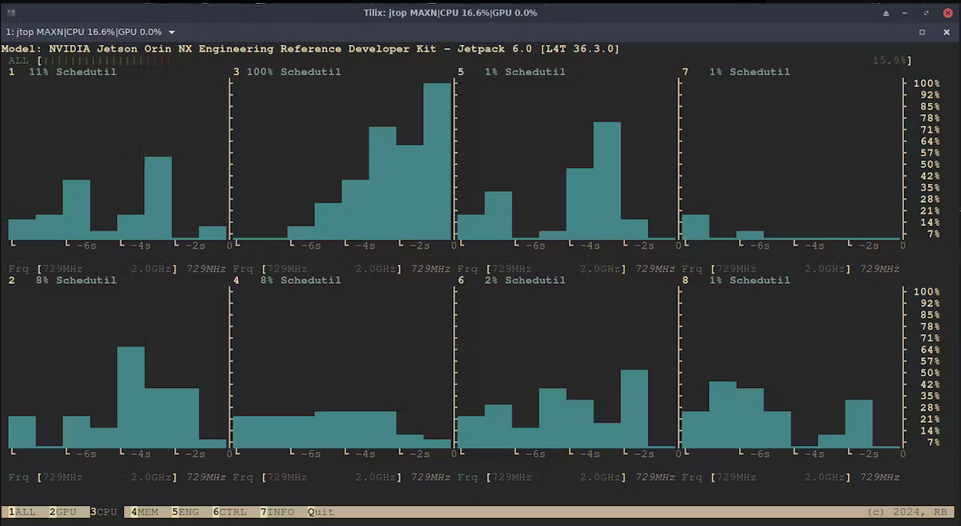
几个小时后,训练完成了。
现在,让我们看看模型的表现如何。让我们测试一下。
yolo task=classify mode=predict model='./runs/classify/train6/weights/best.pt' source=Bird-Classification-1/test/**/*.jpg
这将使 yolo 进入测试目录并尝试预测每个
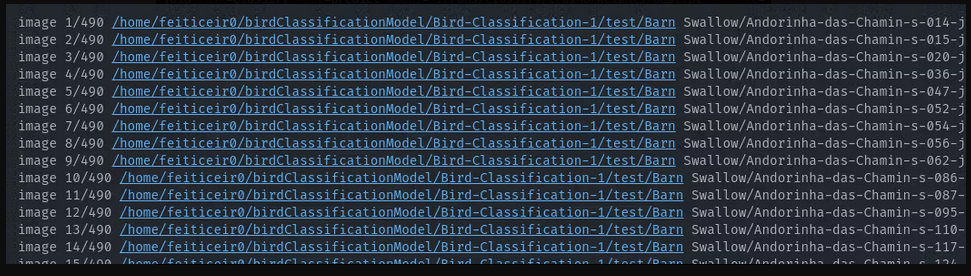



结果都是正确的。让我们尝试两张它从未见过的图像。


yolo task=classify mode=predict model='./runs/classify/train6/weights/best.pt' source=house_sparrow.jpg

yolo task=classify mode=predict model='./runs/classify/train6/weights/best.pt' source=white_wagtail.jpg

我要说这些结果非常棒
导出模型
我们可以直接使用这个模型进行推理,只需要打开并使用它即可。 为了获得更快的推理时间,我们可以将其导出为 TensorRT,因为我们使用的是 NVIDIA Jetson Orin NX,或者甚至可以导出为 ONNX 格式等。
并不是说我们在这个项目中需要更快的推理时间——我不会在实时视频中使用它——但能够利用我们所在平台的优势是很好的。
不幸的是,由于虚拟环境的原因,我无法将其导出为 TensorRT。出于某种原因,我无法在 Python 中导入 tensorrt,但在虚拟环境之外,我使用 tensorrt 库没有任何问题。
ONNX
我们可以像这样将模型导出为 ONNX 格式
yolo export model='./runs/classify/train6/weights/best.pt' format=onnx imgsz=640
我们得到了一个可以用来运行推理的 best.onnx 文件。
要使用 ONNX 运行推理,我们需要安装 onnxruntime_gpu wheel。
要在 JetPack 6.0 上安装 onnxruntime-gpu,我们需要从 Jetson Zoo 下载它。
我们将下载 onnxruntime_gpu 1.18.0
为我们的 Python 版本(Python-3.10)下载 pip wheel
wget https://nvidia.box.com/shared/static/48dtuob7meiw6ebgfsfqakc9vse62sg4.whl -O onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl
and then, install it
pip install onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl
推理
照片
我使用以下代码运行 best.pt 模型的推理并查看结果
# running inference
from ultralytics import YOLO
# load the model
bird_model = YOLO("./runs/classify/train6/weights/best.pt")
#run inference
results = bird_model("house_sparrow.jpg")[0]
# get class names
class_names = results.names
# get top class with more probability
top1 = results.probs.top1
# print the class name with the highest probability
print (f" The detected bird is: {class_names[top1]}")
上面的代码所做的是加载模型,在图像上运行推理并将结果保存到 results 变量中。
因为 results 是 ultralytics.engine.results.Results 对象,类型为包含一个项目的列表,该项目是 Results 的一个实例。results 变量中的 [0] 用于保存推理结果,这将允许我们获取我们想要的结果。
results = bird_model("house_sparrow.jpg")[0]
接下来,我们使用结果来获取类名。不是说我们不知道它们,而是这样做可以让这段代码在其他模型中也能正常工作。
class_names = results.names
其中一个结果是一个 top1 变量,它保存着概率最高的 TOP 1 类别。这个 TOP1 是由 probs 列表给出的。
top1 = results.probs.top1
接下来,我们打印出概率最高的类别,这应该是鸟类的种类。
print (f" The detected bird is: {class_names[top1]}")
The detected bird is: House Sparrow
摄像头
现在,让我们使用摄像头来运行推理。
Jetson 可以使用 USB 摄像头或 RPI 摄像头。我将连接一个 USB 摄像头。
以下代码将检查是否可以显示摄像头画面。
#Lets test if we can use a USB camera
import cv2
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
cv2.imshow('Camera', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows
这是我在桌面计算机上的操作。只需使用 ssh -X username@jetson_ip,X11 窗口就会转发到你的桌面。这之所以有效是因为我也在使用 Linux。我认为 WSL 也可以工作。
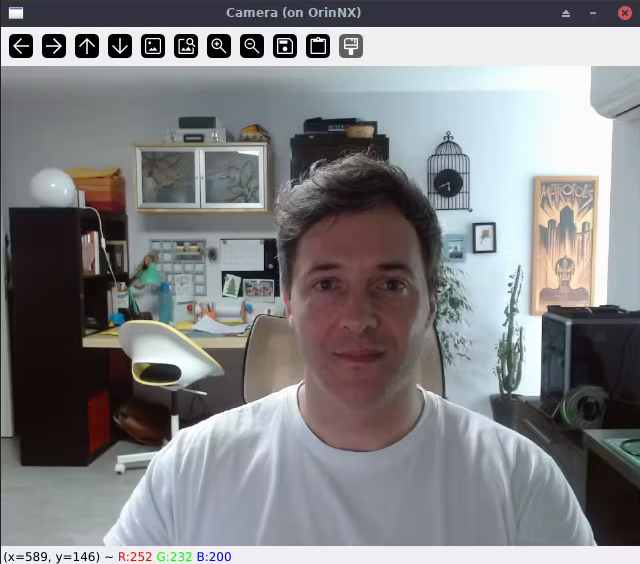
现在,让我们尝试在视频流上运行推理,显示概率较高的类别
代码如下
# again, save this code in a file a run it from the Jetson
import cv2
from ultralytics import YOLO
import time
#define confidence level
#only equal or above this level we say it's a class of bird
confidence = 0.95
# time when processed last frame
prev_frame = 0
# time processed current frame
cur_time = 0
# load the model
bird_model = YOLO("./runs/classify/train6/weights/best.pt")
# cv2 font
font = cv2.FONT_HERSHEY_SIMPLEX
# open camera
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
# to display fps
cur_frame = time.time()
fps = 1 / (cur_frame - prev_frame)
prev_frame = cur_frame
fps = int(fps)
fps = str(fps)
cv2.putText (img, fps, (550,50), font, 1, (124,10,120), 2, cv2.LINE_AA)
# inference current frame
results = bird_model(img, verbose=False)[0]
# get class names
class_names = results.names
# get top class with more probability
top1 = results.probs.top1
top1conf = results.probs.top1conf.tolist()
# we will only show the class name if the confidence is higher than defined level
# print the class name with the highest probability
if (top1conf >= confidence):
bird_class = class_names[top1]
print (f" The detected bird is: {class_names[top1]}")
# color is in BGR
confid = round(top1conf,2)
img = cv2.putText(img, bird_class, (50,50), font, 0.9, (0, 0, 255), 2, cv2.LINE_AA)
img = cv2.putText(img, "Conf: " + str(confid), (50,80), font, 0.6, (255, 0, 255), 1, cv2.LINE_AA)
cv2.imshow('Camera', img)
else:
img = cv2.imshow('Camera', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows
这里有一个视频展示了在视频流上进行推理的过程
✨ 贡献者项目
- 此项目由 Seeed Studio 贡献者项目支持。
- 感谢 Bruno 的努力,您的工作将被展示。
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。