在本地部署 Watcher 的 AI 功能

SenseCAP Watcher 是一个 AI 监控器,帮助您监控空间内的异常情况并采取相应行动。虽然 Watcher 可以利用 SenseCraft AI 服务,但它也提供了在您自己的设备上本地部署 AI 功能的选项,为您提供更大的控制权、隐私保护和灵活性。
在这个全面的指南中,我们将引导您完成在本地设备上设置和部署 Watcher AI 服务的过程。无论您使用的是 Windows PC、MacOS 机器还是 NVIDIA® Jetson AGX Orin,我们都将提供逐步说明,帮助您在自己的环境中利用 Watcher AI 功能的强大能力。
在本指南中,我们将涵盖必要的软件和硬件准备、每个支持平台的部署过程,以及如何有效利用 Watcher 的本地 AI 服务来解锁新的可能性并提高您的生产力。在本指南结束时,您将对如何在自己的设备上利用 Watcher 的 AI 功能有深入的了解,使您能够创建适合您需求的智能化和个性化解决方案。
软件准备
要使用 Watcher 的本地部署功能,用户首先需要下载必要的软件。软件包包括 Watcher 应用程序和设备 AI 服务组件,这些组件使用户能够设置和配置他们的本地 AI 服务。
用户可以通过以下下载链接下载 Watcher APP:
- 适用于 Windows:
- 适用于 macOS:
- 适用于 Linux:
请根据您的操作系统选择合适的下载链接。Watcher APP 兼容 Windows、macOS 和主要的 Linux 发行版,确保在不同平台上的无缝体验。
硬件准备
为了确保在本地部署 Watcher AI 功能时获得流畅和最佳的体验,您的设备必须满足最低硬件要求。这些要求因您的操作系统而异。以下是每个支持平台的硬件要求:
| Windows | Mac | Linux (arm64) | |
|---|---|---|---|
| 显卡(推荐配置) | GeForece RTX2070 | Apple M1 16 GB | GeForece RTX2070 |
| 内存(最低配置) | 8 GB | 16 GB | 8 GB |
| 存储空间(最低配置) | 20 GB | 20 GB | 20 GB |
需要注意的是,这些是最低要求,拥有更高的规格可以显著提高 Watcher AI 服务的性能和响应速度。如果您计划同时部署多个 AI 服务或处理大量数据,我们建议使用具有更先进硬件配置的设备。
性能考虑
Watcher 本地部署的 AI 服务的性能可能会根据您设备的硬件规格而有所不同。以下是一些一般性能指导原则:
- 内存:更大的内存容量允许更流畅的多任务处理,并且可以处理更复杂的 AI 模型和更大的数据集。
- 显卡:像 RTX2070 这样的专用显卡可以大大加速 AI 计算,特别是涉及计算机视觉和深度学习的任务。
- 存储空间:充足的存储空间对于存储 AI 模型、数据集和生成的输出至关重要。推荐的 20 GB 存储空间确保为 Watcher 的 AI 服务提供充足的空间。
在本地部署 Watcher 的 AI 服务时,考虑您的具体用例和您打算使用的 AI 模型的复杂性至关重要。如果您需要实时处理或计划处理资源密集型任务,建议选择更高端的硬件配置以确保最佳性能。
通过满足硬件要求并考虑上述性能因素,您可以确保在本地设备上顺利高效地部署 Watcher 的 AI 功能。
设备基准测试
以下是我们在一些设备上部署 AI 服务后的响应时间线。
| 设备 | Windows 10 32GB 配 GeForce RTX4060 显卡 | Windows 10 16GB 无显卡 | Mac Mini M1 (16 GB) | NVIDIA® Jetson AGX Orin 32GB |
|---|---|---|---|---|
| 任务分析时间 | 5s | 17m14s | 36s | 18s |
| 图像分析时间 | 4s | 4m10s | 8s | 7s |
在将 NVIDIA Jetson AGX 系列产品与消费级显卡(如 RTX 4090)进行 AI 相关任务比较时,Jetson AGX 系列提供了几个关键优势:
-
工业级可靠性:Jetson AGX 系列产品专为工业和商业应用而设计,这意味着它们具有更长的平均故障间隔时间(MTBF)。它们被设计为连续运行,24/7 全天候工作而不会遇到问题。相比之下,像 RTX 4090 这样的消费级显卡并非为如此苛刻的全天候运行而设计,可能无法提供相同级别的可靠性。
-
紧凑尺寸和低功耗:Jetson AGX 系列产品专为嵌入式和边缘计算应用而设计。与高端消费级显卡相比,它们具有更小的外形尺寸和更低的功耗。这使得它们更适合在空间受限的环境中部署,并降低了整体运营成本。较低的功耗也意味着更少的热量产生,这对嵌入式系统至关重要,有助于最小化冷却需求。
除了这些优势外,Jetson AGX 系列还提供了针对 AI 工作负载优化的全面软件堆栈,使开发人员更容易高效地创建和部署 AI 应用程序。工业级可靠性、紧凑尺寸、低功耗和优化软件堆栈的结合,使 Jetson AGX 系列成为 AI 相关项目和应用的引人注目的选择,特别是与像 RTX 4090 这样的消费级显卡相比。
在 Windows 上部署
要在 Windows 设备上部署 Watcher 的 AI 功能,请按照以下简单步骤操作。
步骤 1. 在您计算机的下载文件夹或指定位置找到下载的 .exe 文件。双击 .exe 文件开始安装过程。安装向导将引导您完成设置过程。在安装过程中,您无需进行任何额外的选择或配置。
步骤 2. 安装完成后,启动 Watcher 应用程序。首次启动应用程序时,系统会提示您选择要使用的 AI 模型。Watcher 提供两个选项。
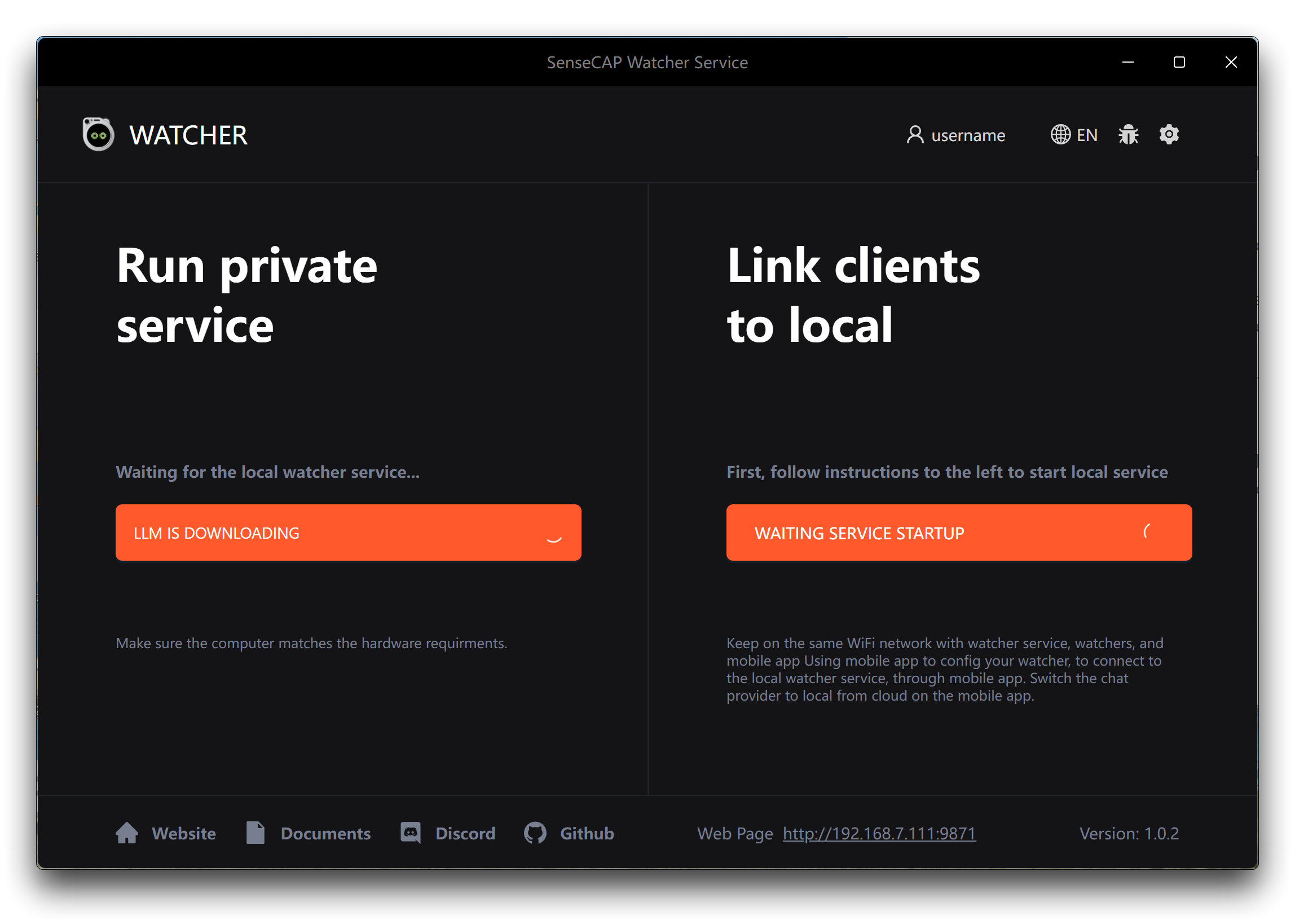
- Llama 3.1 + LLaVA:如果您选择此选项,请点击下方的应用按钮开始下载所需的 AI 模型和相关文件。这些额外的下载可能需要一些时间,因为它们的大小约为 10 GB。确保在模型下载过程中拥有稳定快速的互联网连接,以避免任何中断或下载不完整。
- OpenAI:如果您更喜欢使用 OpenAI 的模型,您需要提前准备好您的 OpenAI API 密钥。确保您有一个有效的 API 密钥和足够的积分来使用 OpenAI 模型。当提示时,输入您的 API 密钥来配置 Watcher 使用 OpenAI 的服务。
选择最适合您需求和资源的选项。如果您有充足的存储空间和可靠的互联网连接,Llama 3.1 + LLaVA 选项提供了一个自包含的解决方案。如果您更喜欢 OpenAI 模型的灵活性和强大功能,并且已经准备好 API 密钥,请选择 OpenAI 选项。
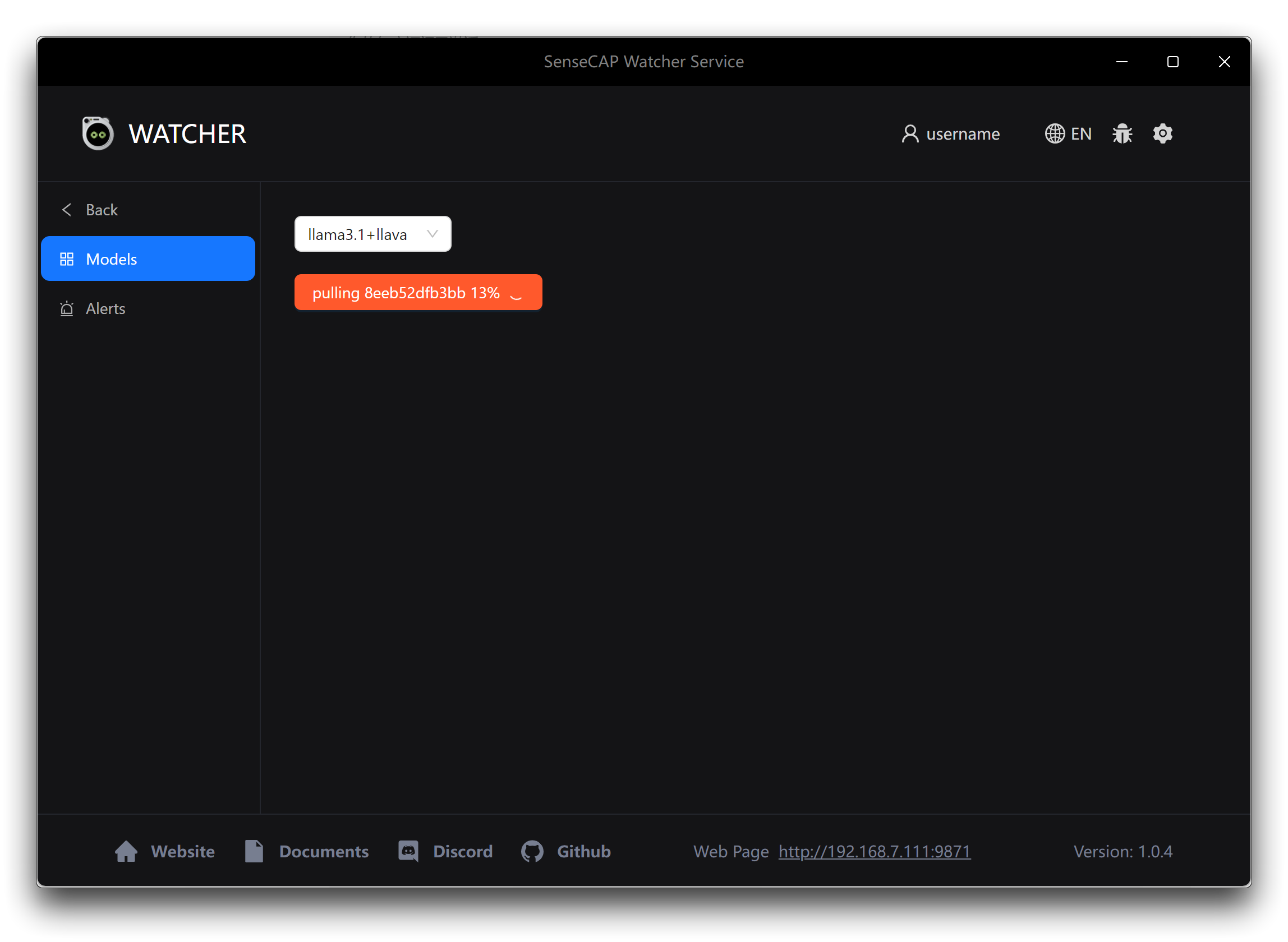
一旦模型文件下载并安装完成,Watcher 就可以在您的 Windows 设备上使用了。
在 MacOS 上部署
要在 macOS 设备上部署 Watcher 的 AI 功能,请按照以下步骤操作。
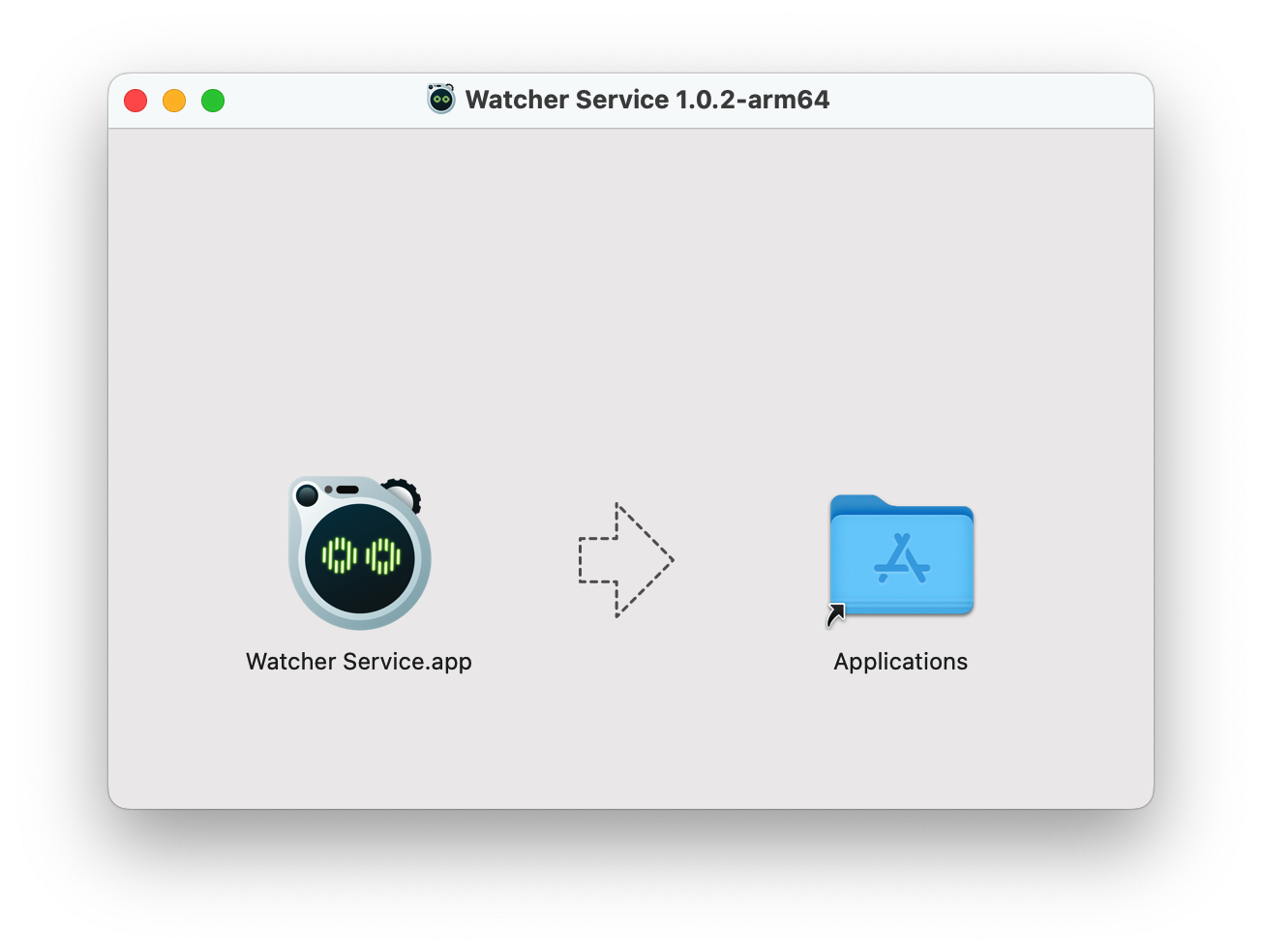
步骤 1。在您计算机的下载文件夹或指定位置找到下载的 .dmg 文件。双击 .dmg 文件打开它。将出现一个新窗口,显示安装包的内容。
步骤 2。在新窗口中,您将看到 Watcher 应用程序图标和应用程序文件夹的别名。点击并将 Watcher 应用程序图标拖拽到窗口内的应用程序文件夹别名上。此操作将把 Watcher 应用程序复制到您计算机的应用程序文件夹中。
复制过程完成后,您可以关闭 .dmg 窗口。
步骤 3。首次启动应用程序时,Watcher 将自动开始下载所需的 AI 模型和相关文件。这些额外的下载可能需要一些时间,因为它们的大小可能约为 10 GB。确保在模型下载过程中有稳定快速的互联网连接,以避免任何中断或下载不完整。
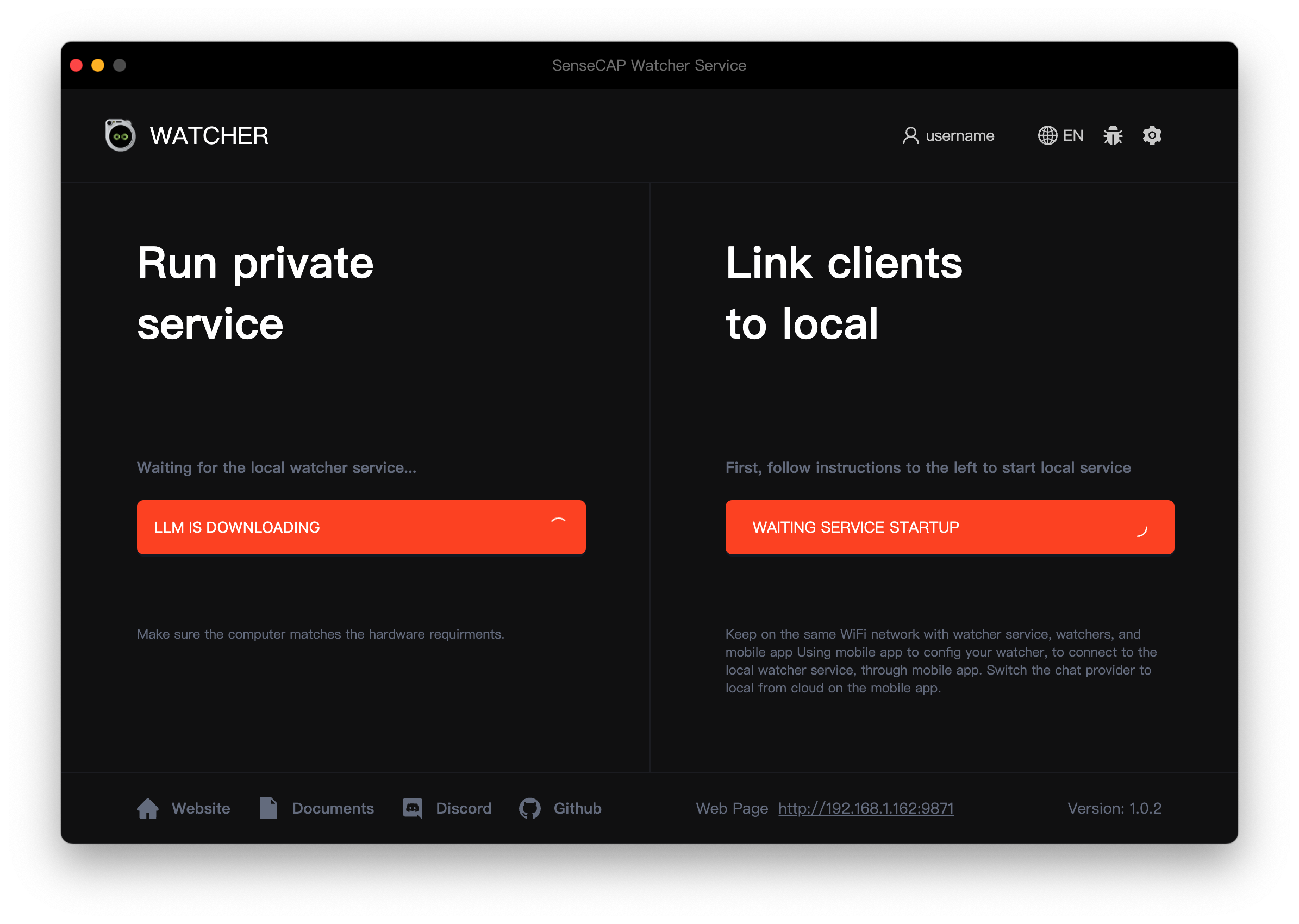
-
Llama 3.1 + LLaVA:如果您选择此选项,请点击下方的应用按钮开始下载所需的 AI 模型和相关文件。这些额外的下载可能需要一些时间,因为它们的大小可能约为 10 GB。确保在模型下载过程中有稳定快速的互联网连接,以避免任何中断或下载不完整。
-
OpenAI:如果您更喜欢使用 OpenAI 的模型,您需要提前准备好您的 OpenAI API 密钥。确保您有一个有效的 API 密钥和足够的积分来使用 OpenAI 模型。当提示时,输入您的 API 密钥来配置 Watcher 使用 OpenAI 的服务。
选择最适合您需求和资源的选项。如果您有充足的存储空间和可靠的互联网连接,Llama 3.1 + LLaVA 选项提供了一个自包含的解决方案。如果您更喜欢 OpenAI 模型的灵活性和强大功能,并且已经准备好 API 密钥,请选择 OpenAI 选项。
一旦模型文件下载并安装完成,Watcher 就可以在您的 macOS 设备上使用了。
在 NVIDIA® Jetson AGX Orin / Linux 上部署
要在 NVIDIA® Jetson AGX Orin 或 Linux 设备上部署 Watcher 的 AI 功能,请按照以下步骤操作。
步骤 1。在您的 Jetson AGX Orin 或 Linux 设备上打开终端窗口。
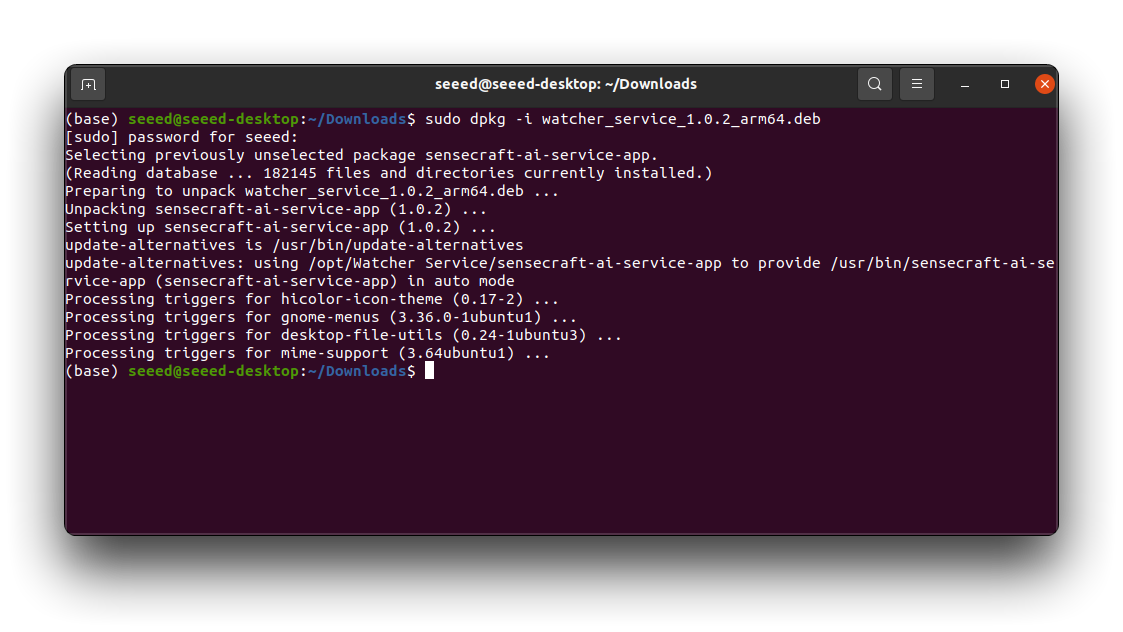
步骤 2。使用 cd 命令导航到下载的 .deb 文件所在的目录。运行以下命令来安装 Watcher。
sudo dpkg -i watcher_service_x.x.x_arm64.deb
将 watcher_service_x.x.x_arm64.deb 替换为下载的 .deb 文件的实际名称。安装过程将开始。您可能会被提示输入系统密码来授权安装。等待安装完成。终端将显示进度和任何其他信息。
步骤 3。安装完成后,您可以通过在终端中输入 watcher 或在应用程序启动器中找到它来启动 Watcher。
-
Llama 3.1 + LLaVA:如果您选择此选项,请点击下方的应用按钮开始下载所需的 AI 模型和相关文件。这些额外的下载可能需要一些时间,因为它们的大小可能约为 10 GB。确保在模型下载过程中有稳定快速的互联网连接,以避免任何中断或下载不完整。
-
OpenAI:如果您更喜欢使用 OpenAI 的模型,您需要提前准备好您的 OpenAI API 密钥。确保您有一个有效的 API 密钥和足够的积分来使用 OpenAI 模型。当提示时,输入您的 API 密钥来配置 Watcher 使用 OpenAI 的服务。
选择最适合您需求和资源的选项。如果您有充足的存储空间和可靠的互联网连接,Llama 3.1 + LLaVA 选项提供了一个自包含的解决方案。如果您更喜欢 OpenAI 模型的灵活性和强大功能,并且已经准备好 API 密钥,请选择 OpenAI 选项。
与 Windows 和 macOS 安装类似,Watcher 将自动开始下载所需的 AI 模型和相关文件。
在 SenseCraft APP 中配置使用本地 AI 服务
要在 SenseCraft APP 中使用 Watcher 提供的本地 AI 服务,请按照以下简洁步骤操作:
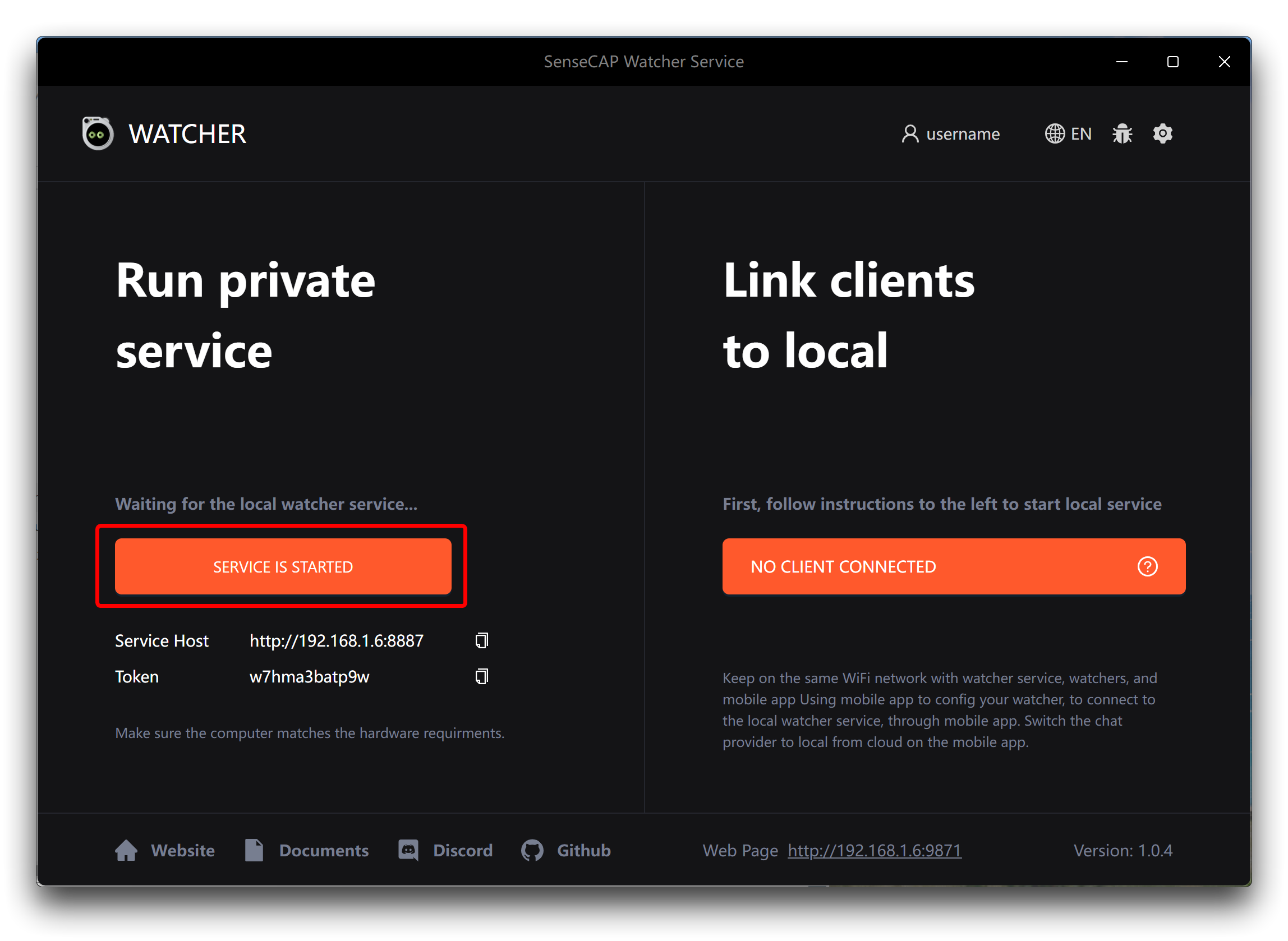
步骤 1。在您的设备上打开 Watcher APP,点击左下角的启动服务按钮。
步骤 2。在 SenseCraft APP 中,导航到 Watcher 界面,点击右上角的设置按钮。从设置菜单中选择设备 AI 服务。
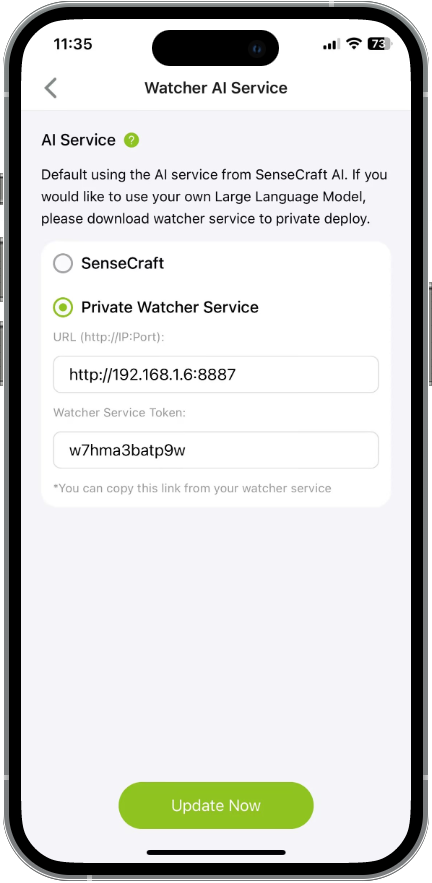
步骤 3。从 Watcher APP 主屏幕复制 URL 和 Token。
步骤 4。将 URL 和 Token 粘贴到 SenseCraft APP 中设备 AI 服务设置的相应字段中。
步骤 5。现在您可以通过 SenseCraft APP 为 Watcher 分配任务,Watcher 将使用其本地部署的 AI 功能来处理这些任务。
请注意,确保您的计算机满足**硬件准备**中推荐的计算机配置是很重要的。如果低于推荐配置,那么您可能无法及时收到识别结果和报警消息,因为您的计算机可能正在全力分析您的其中一张图像,此时 Watcher 将显示为持续观察状态。
通过完成这些步骤,您可以直接在设备上利用 Watcher 的 AI 服务的强大功能,确保增强隐私保护和方便地自定义您自己的集成系统的能力。通过 Watcher 的 AI 功能在本地运行,您可以安全高效地执行高级任务、分析和自动化,同时保持对数据的控制。
我们将继续在应用程序目录中添加关于在本地化部署后使用**HTTP 消息块**进行消息推送的教程,敬请关注!
常见问题
SenseCap Watcher 服务无法工作
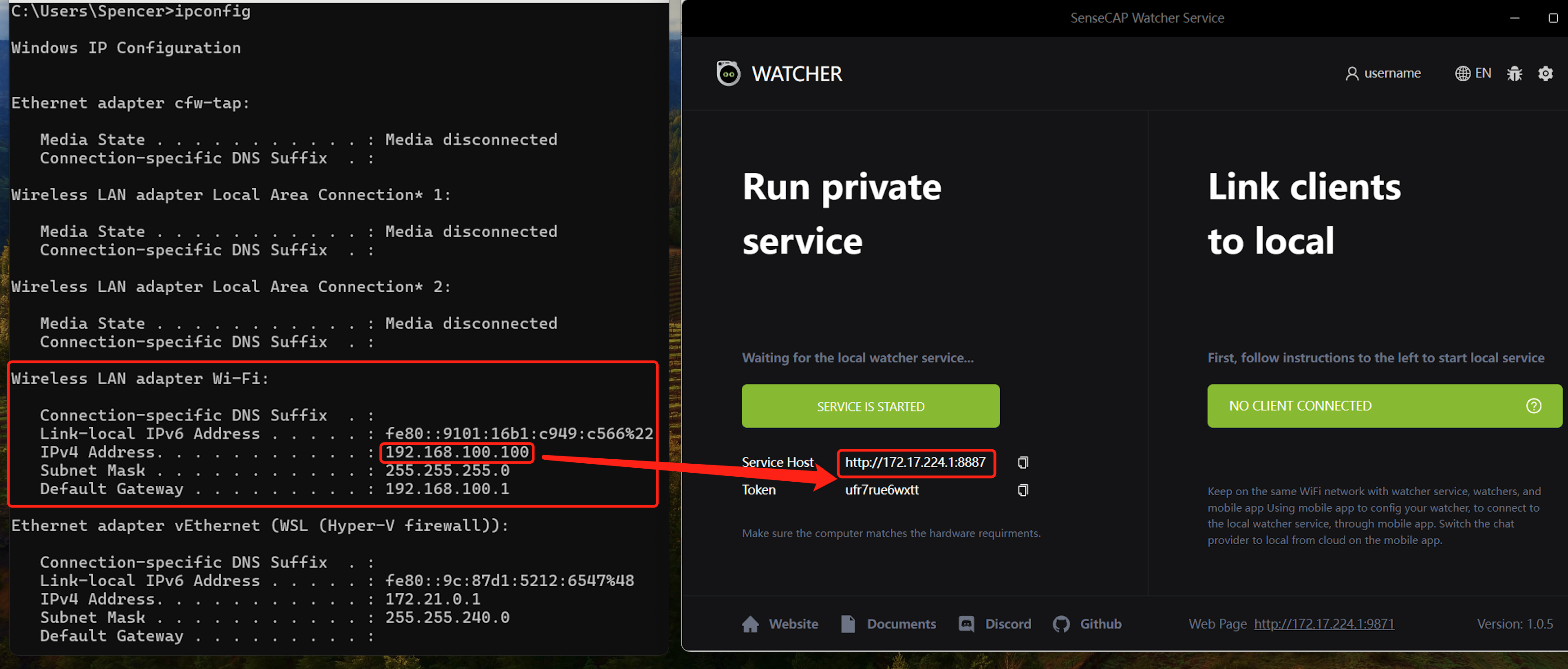
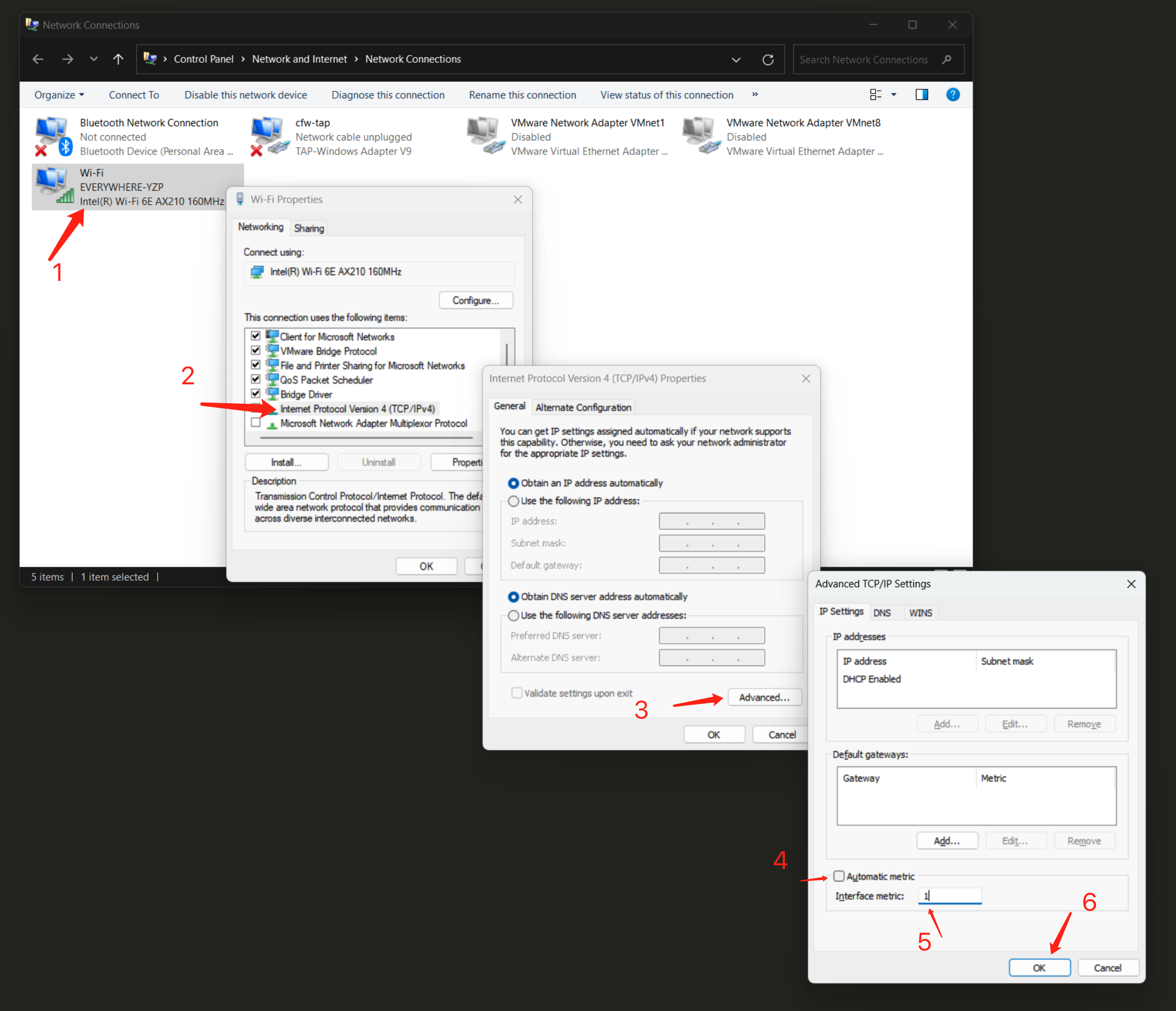
服务主机的 IP 应该是您的计算机 IP 地址,如果不是,SenseCAP Watcher 服务将无法工作。您需要按照以下步骤进行修复。
-
按 Win + R > 输入 "ncpa.cpl" > 回车。
-
右键点击 "Wi-Fi" 或以太网 > 选择 "属性"。
-
双击 IPv4 或 IPv6 > 点击 "高级"。
-
取消选中自动跃点数 > 输入 1(或您想要的数字)> 点击确定。
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。