从数据集到 XIAO ESP32S3 的模型部署
欢迎来到这个综合教程,我们将踏上一段旅程,将您的数据集转化为可在 XIAO ESP32S3 上部署的功能完整的模型。在本指南中,我们将使用 Roboflow 的直观工具完成数据集标注的初始步骤,然后在 Google Colab 的协作环境中进行模型训练。
接下来,我们将使用 SenseCraft Model Assistant 部署训练好的模型,这个过程连接了训练和实际应用之间的桥梁。在本教程结束时,您不仅将拥有一个在 XIAO ESP32S3 上运行的自定义模型,还将掌握解释和利用模型预测结果的知识。
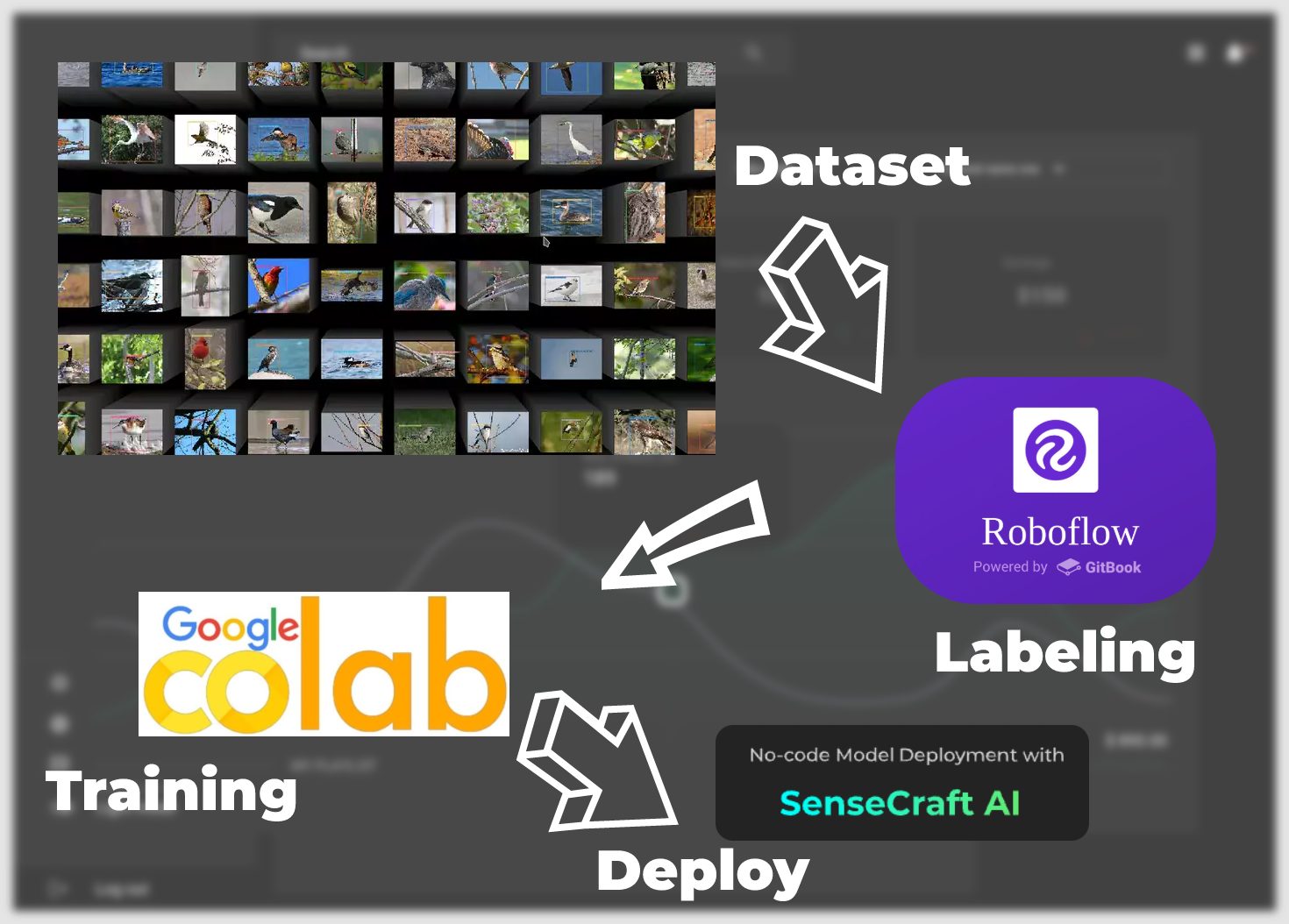
从数据集到模型落地,我们将有以下主要步骤。
-
标注数据集 —— 本章重点介绍如何获取可以训练成模型的数据集。主要有两种方式。第一种是使用 Roboflow 社区提供的标注数据集,另一种是使用您自己特定场景的图像作为数据集,但您需要手动进行标注。
-
训练数据集导出模型 —— 本章重点介绍如何基于第一步获得的数据集,通过使用 Google Colab 平台进行训练,获得可以部署到 XIAO ESP32S3 的模型。
-
通过 SenseCraft Model Assistant 上传模型 —— 本节描述如何使用导出的模型文件,通过 SenseCraft Model Assistant 将模型上传到 XIAO ESP32S3。
-
模型的通用协议和应用 —— 最后,我们将介绍 SenseCraft AI 的统一数据通信格式,以便您可以利用设备和模型的最大潜力来制作适合您场景的应用程序。
让我们开始这个令人兴奋的数据赋能过程吧。
所需材料
在开始之前,您可能需要准备以下设备。


XIAO ESP32S3 标准版和 Sense 版都可以用于本教程,但由于标准版产品不支持使用摄像头扩展板,我们建议您使用 Sense 版。
标注数据集
在本节内容中,我们允许用户自由选择他们拥有的数据集。这包括社区或他们自己拍摄的场景照片。本教程将介绍两种主要场景。第一种是使用 Roboflow 社区提供的现成标注数据集。另一种是使用您拍摄的高分辨率图像并标注数据集。请根据您的需求阅读下面的不同教程。
步骤 1:创建免费的 Roboflow 账户
Roboflow 提供标注、训练和部署计算机视觉解决方案所需的一切。首先,创建一个免费的 Roboflow 账户。
在审阅并接受服务条款后,系统会要求您在两个计划中选择一个:公共计划和入门计划。
然后,系统会要求您邀请协作者到您的工作空间。这些协作者可以帮助您标注图像或管理工作空间中的视觉项目。一旦您邀请了人员到工作空间(如果您想要的话),您就可以创建项目了。
选择获取数据集的方式
- 使用 Roboflow 下载标注数据集
- 使用您自己的图像作为数据集
从 Roboflow 选择合适的数据集直接使用涉及确定最符合项目要求的数据集,考虑数据集大小、质量、相关性和许可等方面。
步骤 2. 探索 Roboflow Universe
Roboflow Universe 是一个可以找到各种数据集的平台。访问 Roboflow Universe 网站并探索可用的数据集。
Roboflow 提供过滤器和搜索功能来帮助您找到数据集。您可以按领域、类别数量、标注类型等过滤数据集。利用这些过滤器缩小符合您条件的数据集范围。
步骤 3. 评估单个数据集
一旦您有了候选列表,请逐个评估每个数据集。查看:
标注质量:检查标注是否准确和一致。
数据集大小:确保数据集足够大以便您的模型有效学习,但又不会太大而难以处理。
类别平衡:数据集理想情况下应该为每个类别提供平衡数量的示例。
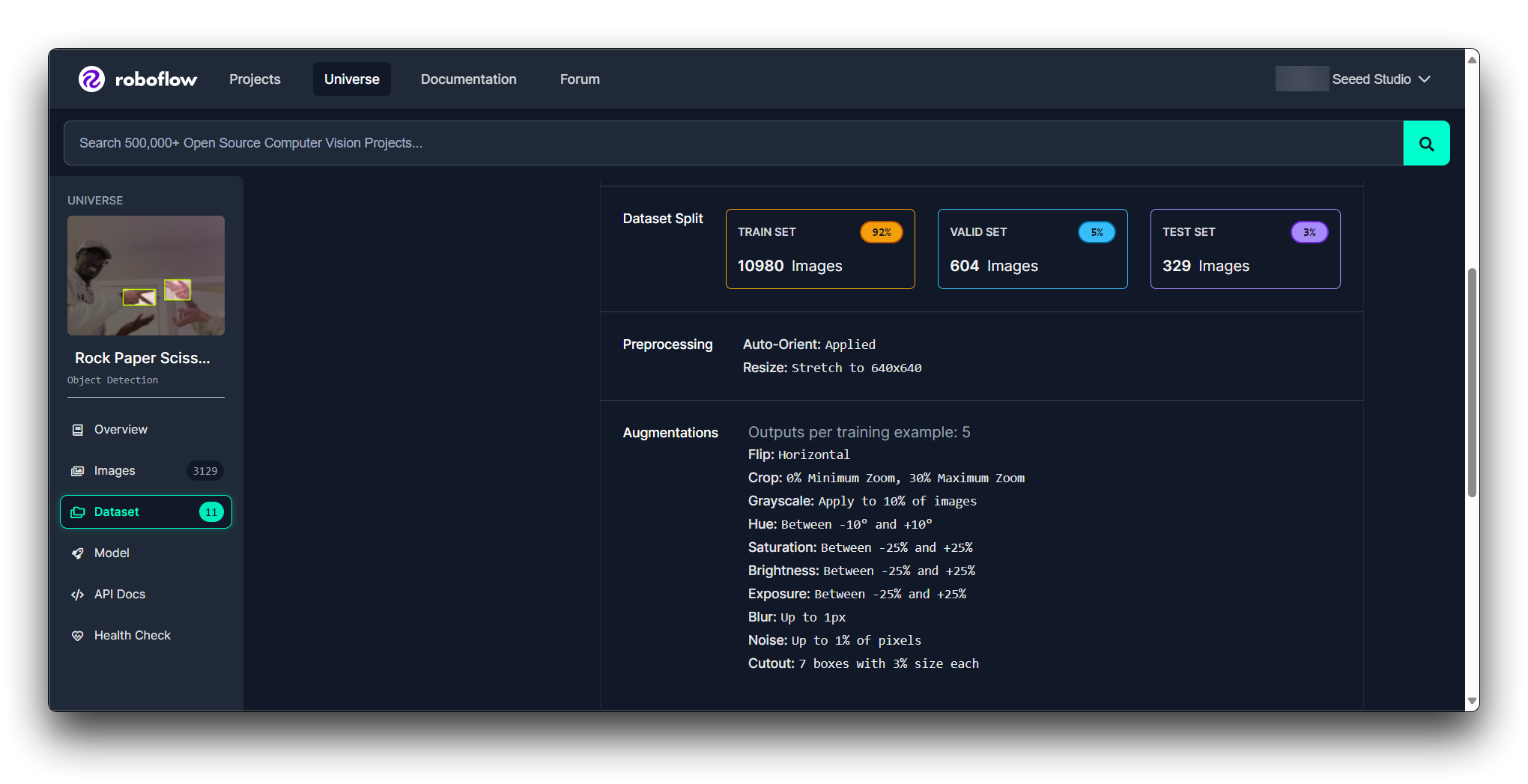
许可证:查看数据集的许可证以确保您可以按预期使用它。
文档:查看数据集附带的任何文档或元数据,以更好地了解其内容和已应用的任何预处理步骤。
您可以通过 Roboflow Health Check 了解模型的状况。
步骤 4. 下载样本
如果您找到了选择的数据集,那么您可以选择下载并使用它。Roboflow 通常允许您下载数据集的样本。测试样本以查看它是否与您的工作流程良好集成,以及是否适合您的模型。
要继续后续步骤,我们建议您按照下图所示的格式导出数据集。
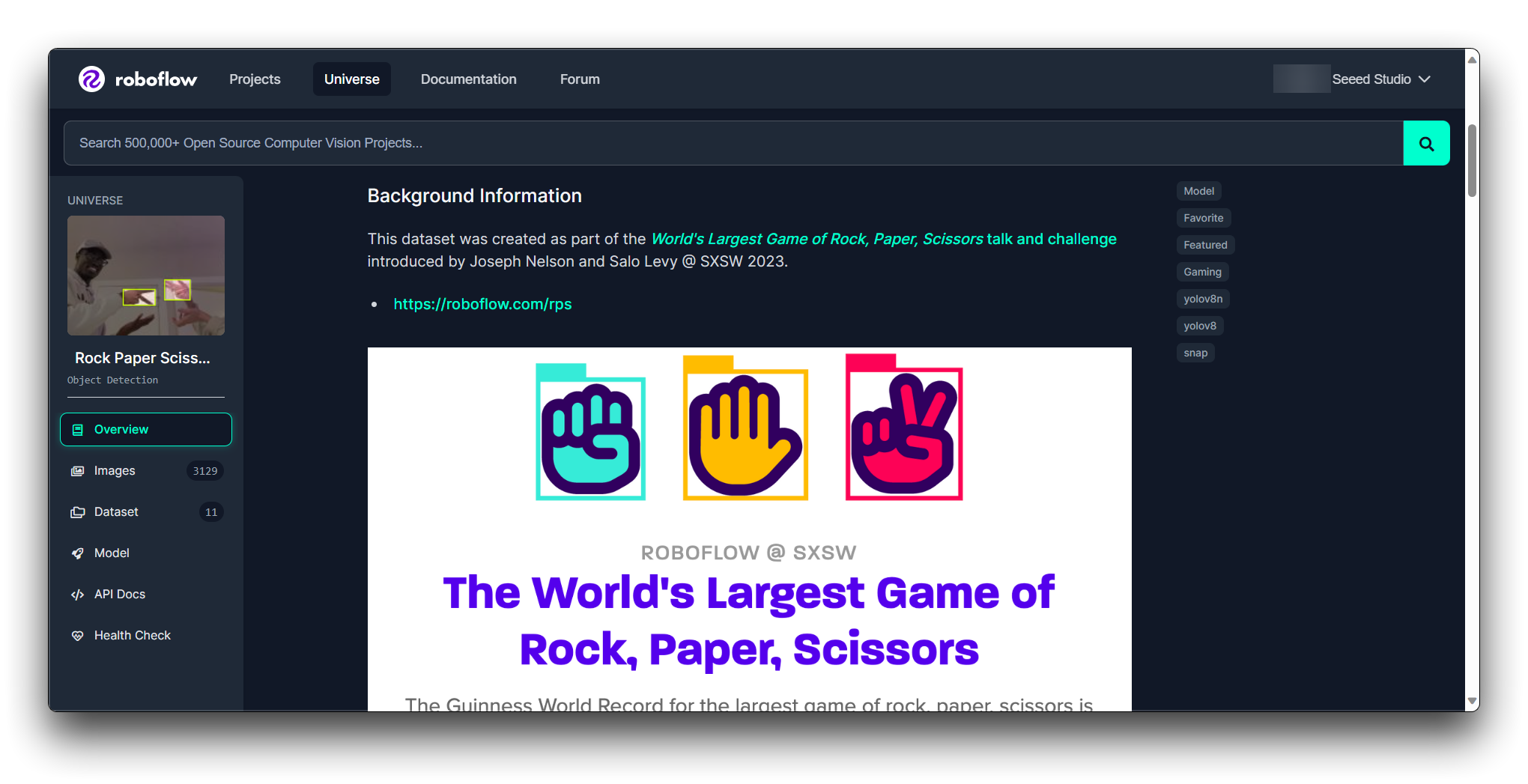
然后您将获得此模型的 Raw URL,请妥善保存,我们稍后在模型训练步骤中会使用该链接。
如果您是第一次使用 Roboflow 并且对数据集的选择完全没有判断,那么使用数据集训练模型进行初始测试以查看性能的步骤可能是必不可少的。这可以帮助您评估数据集是否满足您的要求。
如果数据集满足您的要求并在初始测试中表现良好,那么它很可能适合您的项目。否则,您可能需要继续搜索或考虑用更多图像扩展数据集。
在这里,我将使用石头剪刀布手势图像作为演示,指导您完成在 Roboflow 上传图像、标注和导出数据集的任务。
我们强烈建议您使用 XIAO ESP32S3 拍摄数据集照片,这对 XIAO ESP32S3 来说是最佳选择。XIAO ESP32S3 Sense 拍照的示例程序可以在下面的 Wiki 链接中找到。
步骤 2. 创建新项目并上传图片
登录 Roboflow 后,点击 Create Project。
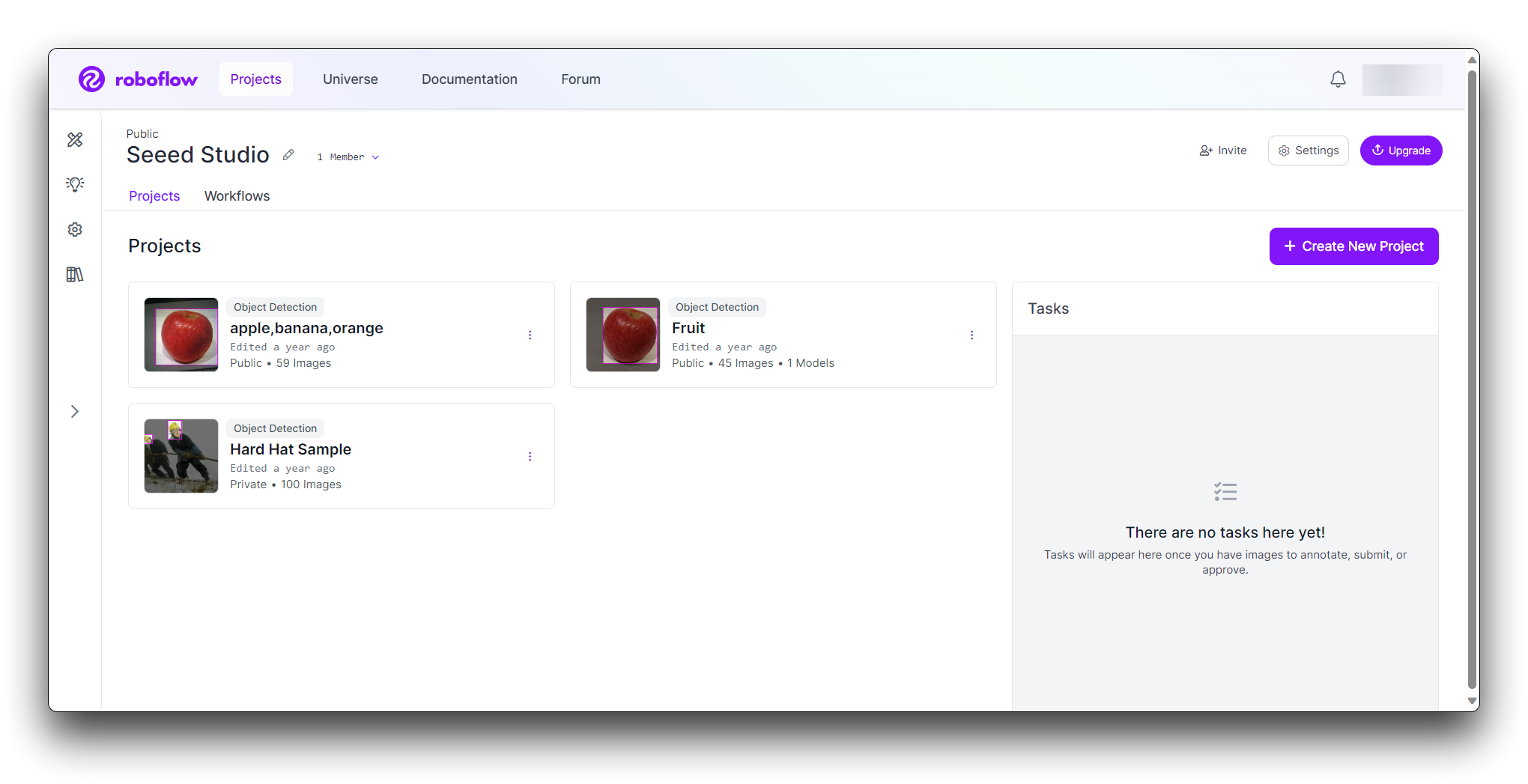
为您的项目命名(例如,"Rock-Paper-Scissors")。将您的项目定义为 Object Detection。将 Output Labels 设置为 Categorical(因为石头、布、剪刀是不同的类别)。
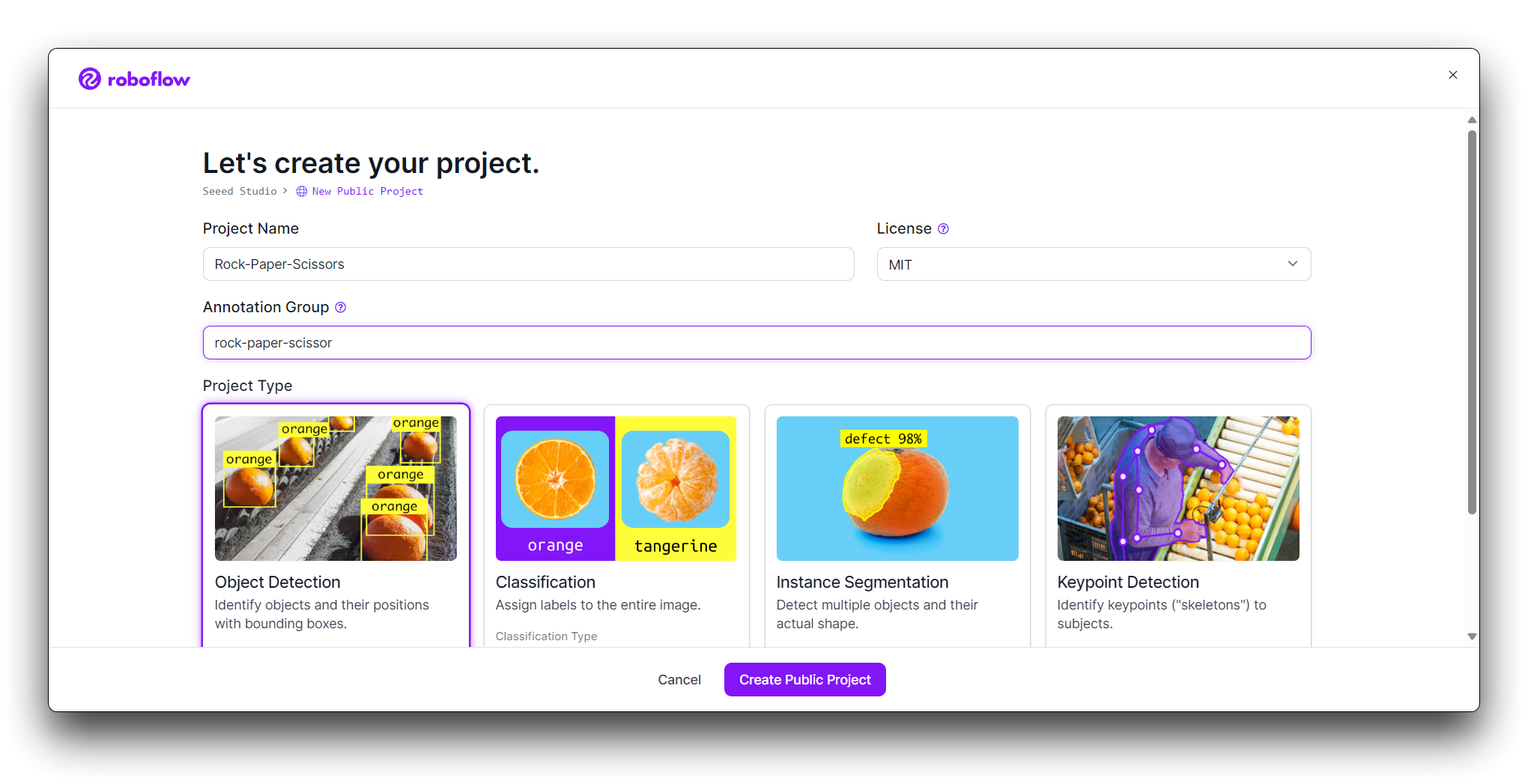
现在是时候上传您的手势图片了。
收集石头、布和剪刀手势的图片。确保您有各种背景和光照条件。在您的项目页面上,点击"Add Images"。
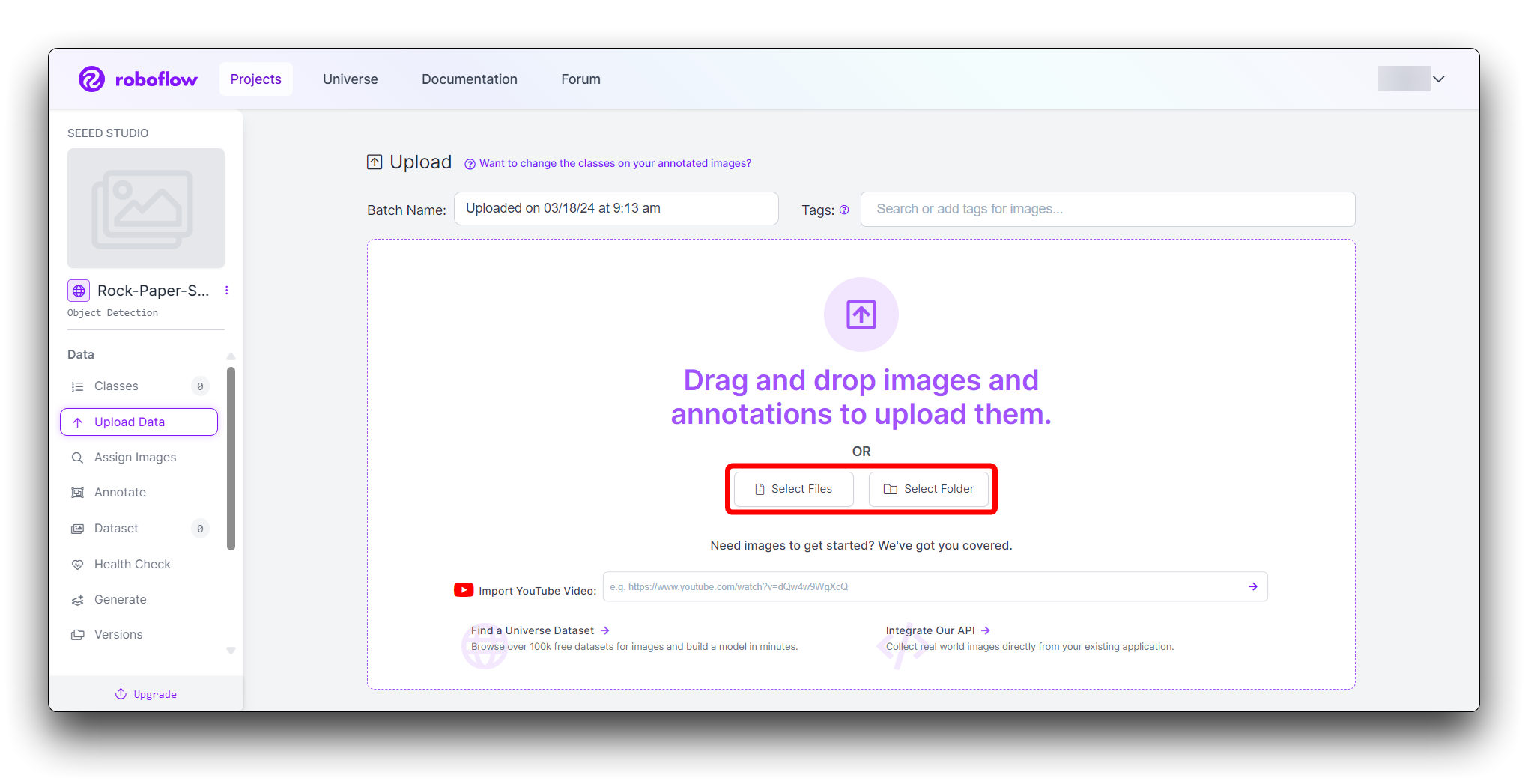
您可以拖放图片或从计算机中选择它们。为了构建一个强大的数据集,请为每个手势至少上传 100 张图片。
数据集大小如何确定?
这通常取决于多种因素:任务模型、任务复杂性、数据纯度等等。例如,人体检测模型涉及大量的人、范围广泛,任务更加复杂,因此需要收集更多数据。 另一个例子是手势检测模型,它只需要检测"石头"、"剪刀"和"布"三种类型,需要的类别较少,因此收集的数据集大约是 500 张。
步骤 3:标注图片
上传后,您需要通过标记手势来标注图片。
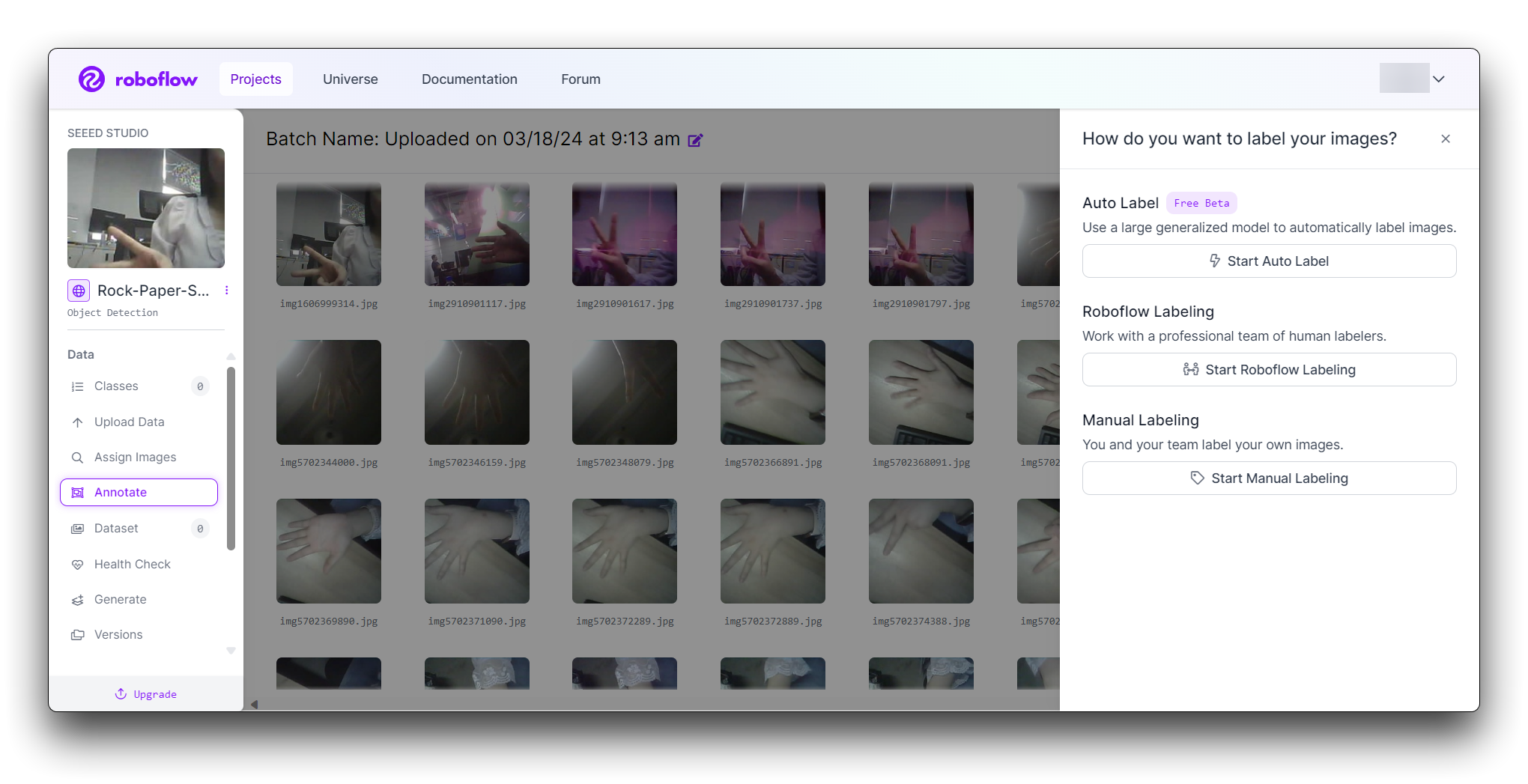
Roboflow 提供三种不同的图片标记方式:Auto Label、Roboflow Labeling 和 Manual Labeling。
- Auto Label:使用大型通用模型自动标记图片。
- Roboflow Labeling:与专业的人工标记团队合作。无最小数量要求。无预付承诺。边界框标注起价 $0.04,多边形标注起价 $0.08。
- Manual Labeling:您和您的团队自己标记图片。
以下描述最常用的手动标记方法。
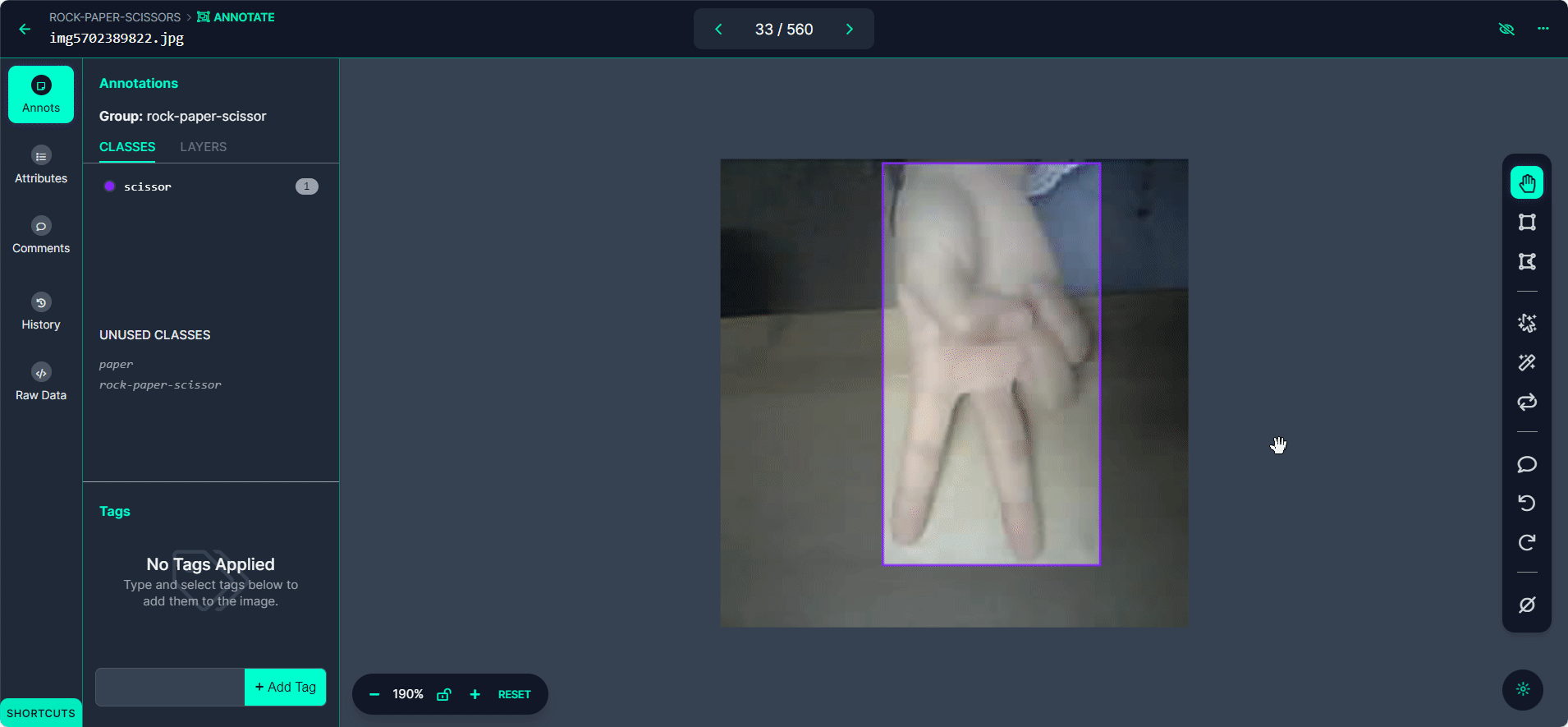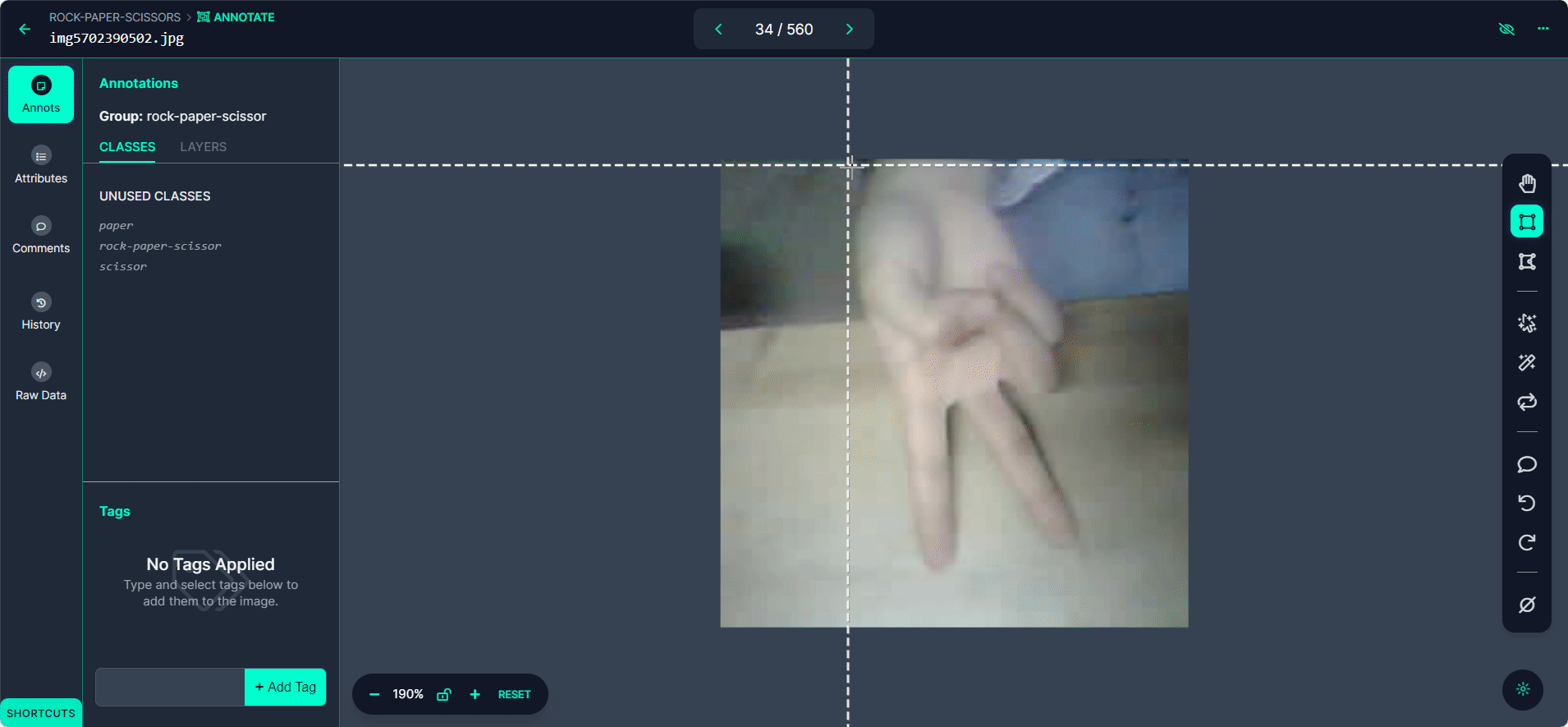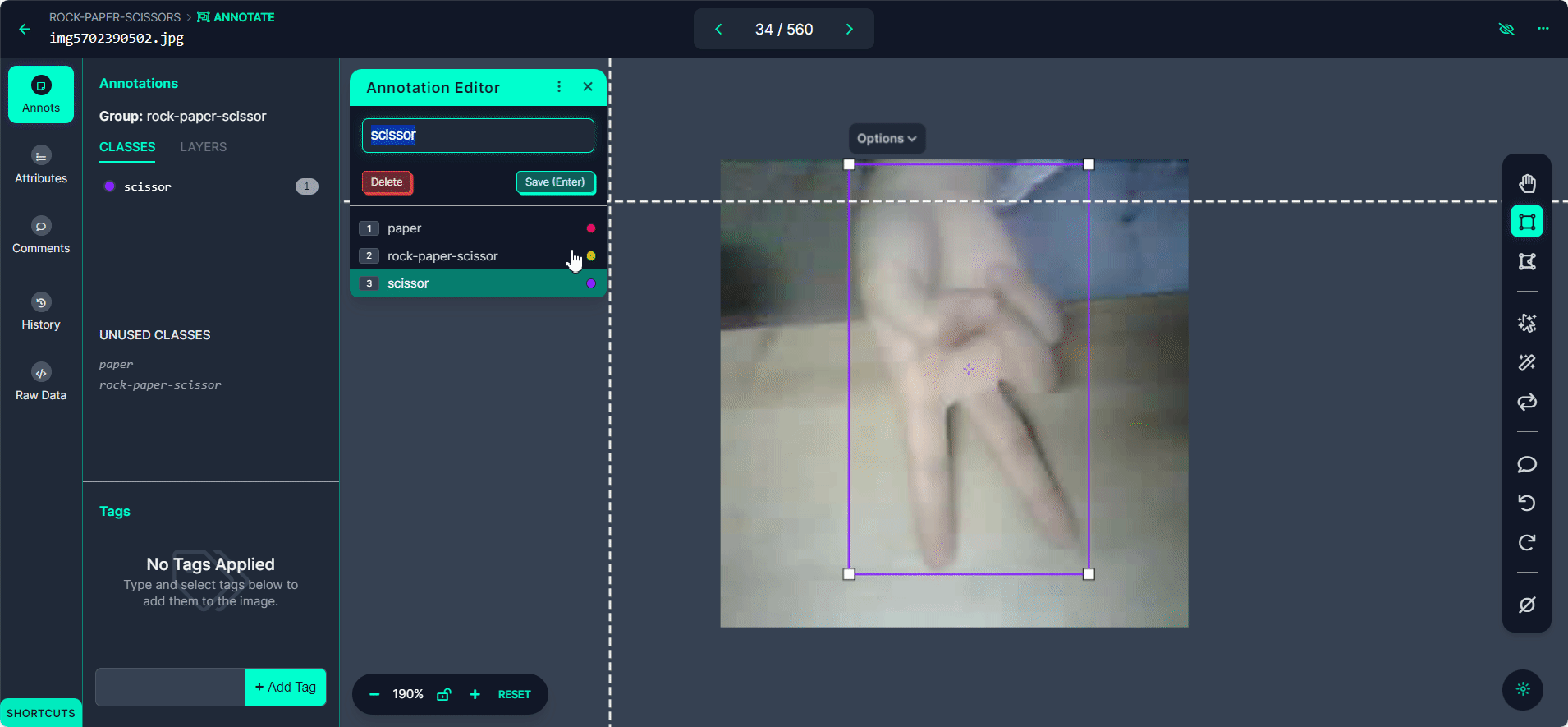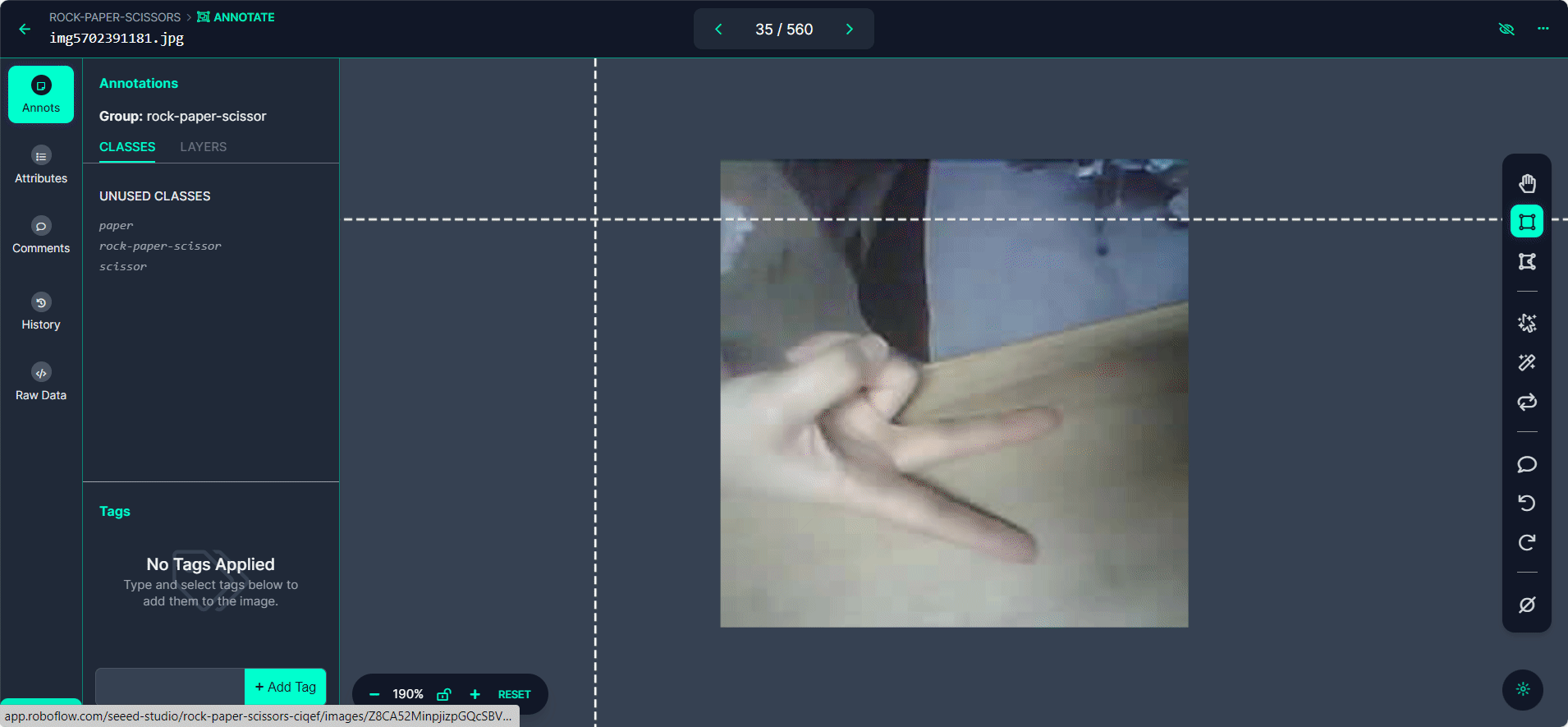
点击"Manual Labeling"按钮。Roboflow 将加载标注界面。
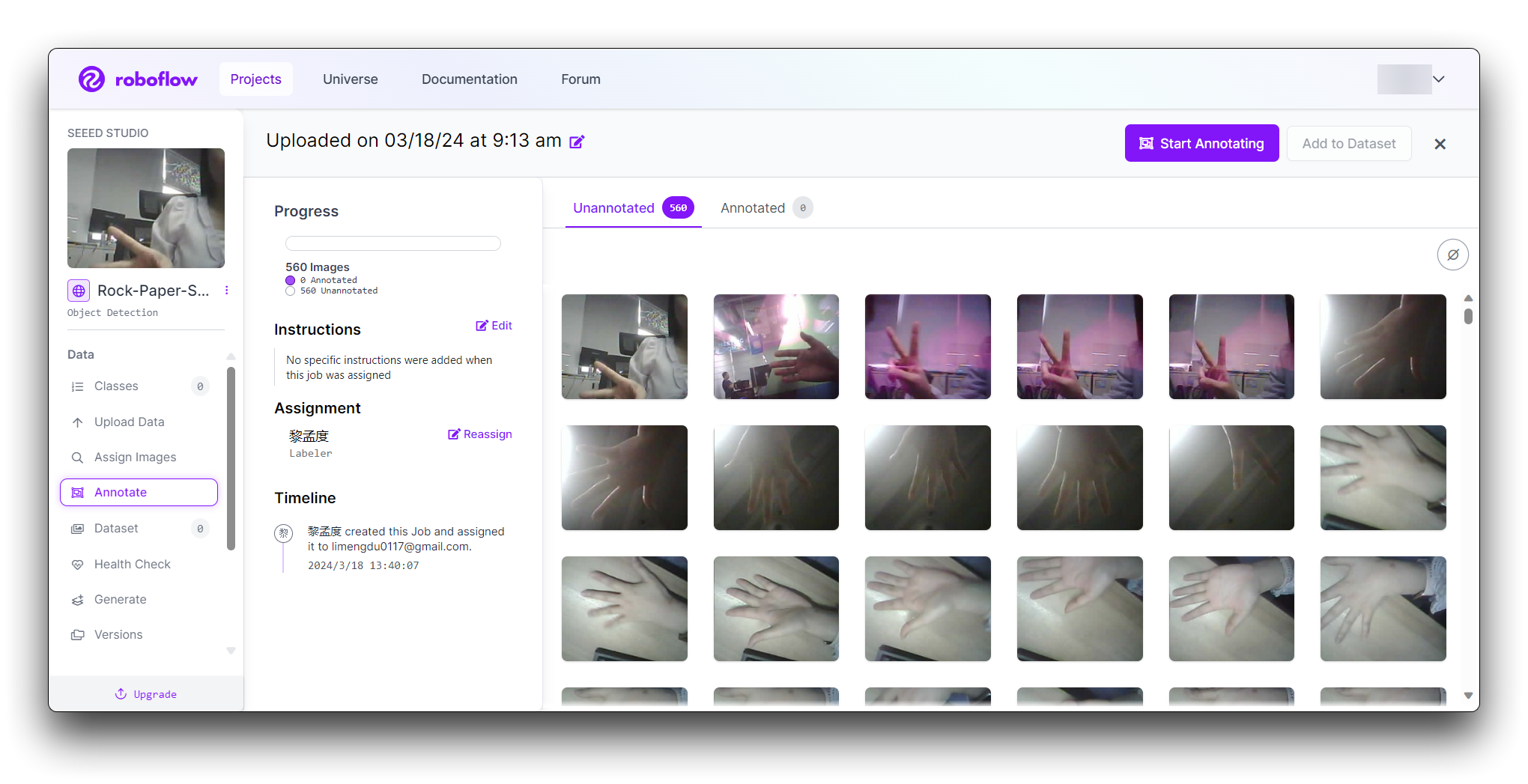
选择"Start Annotating"按钮。在每张图片中围绕手势绘制边界框。
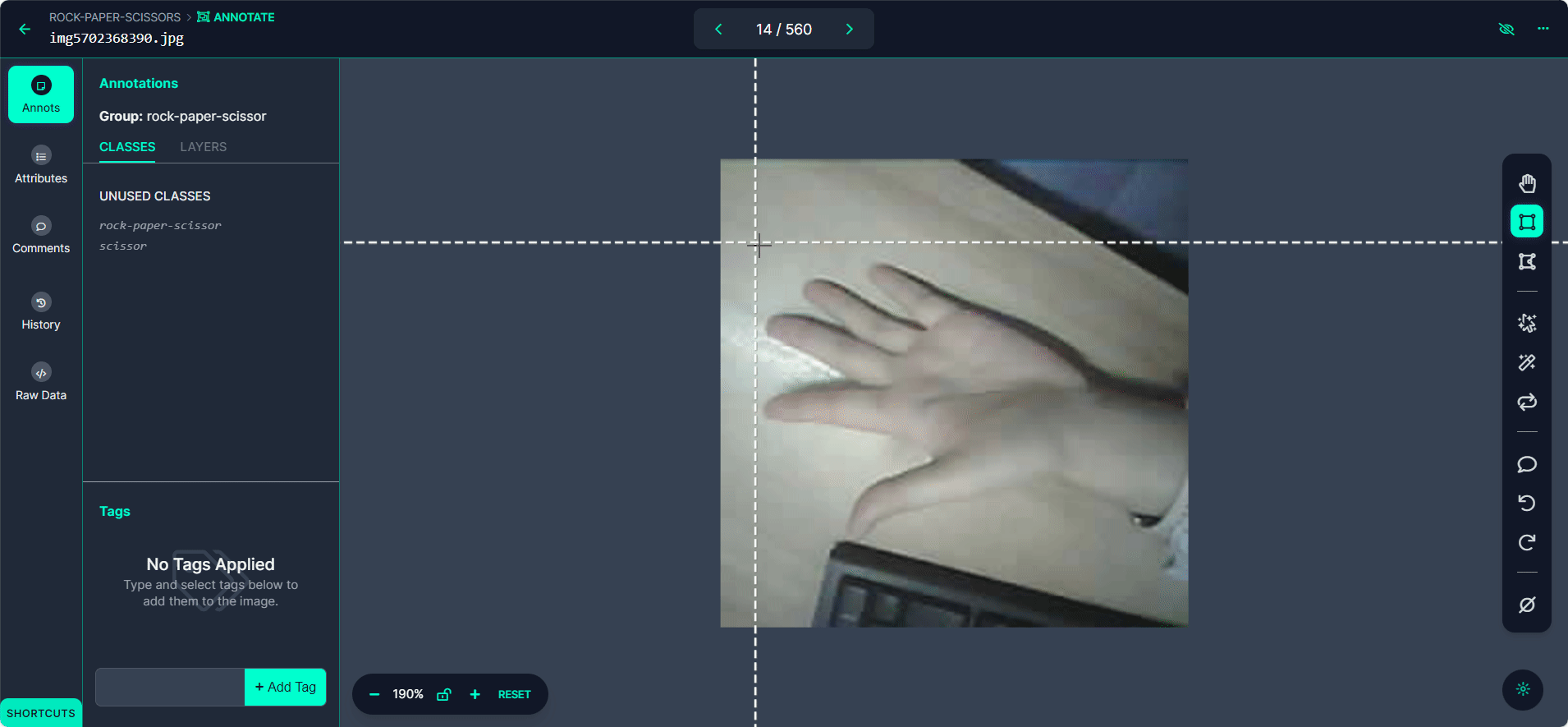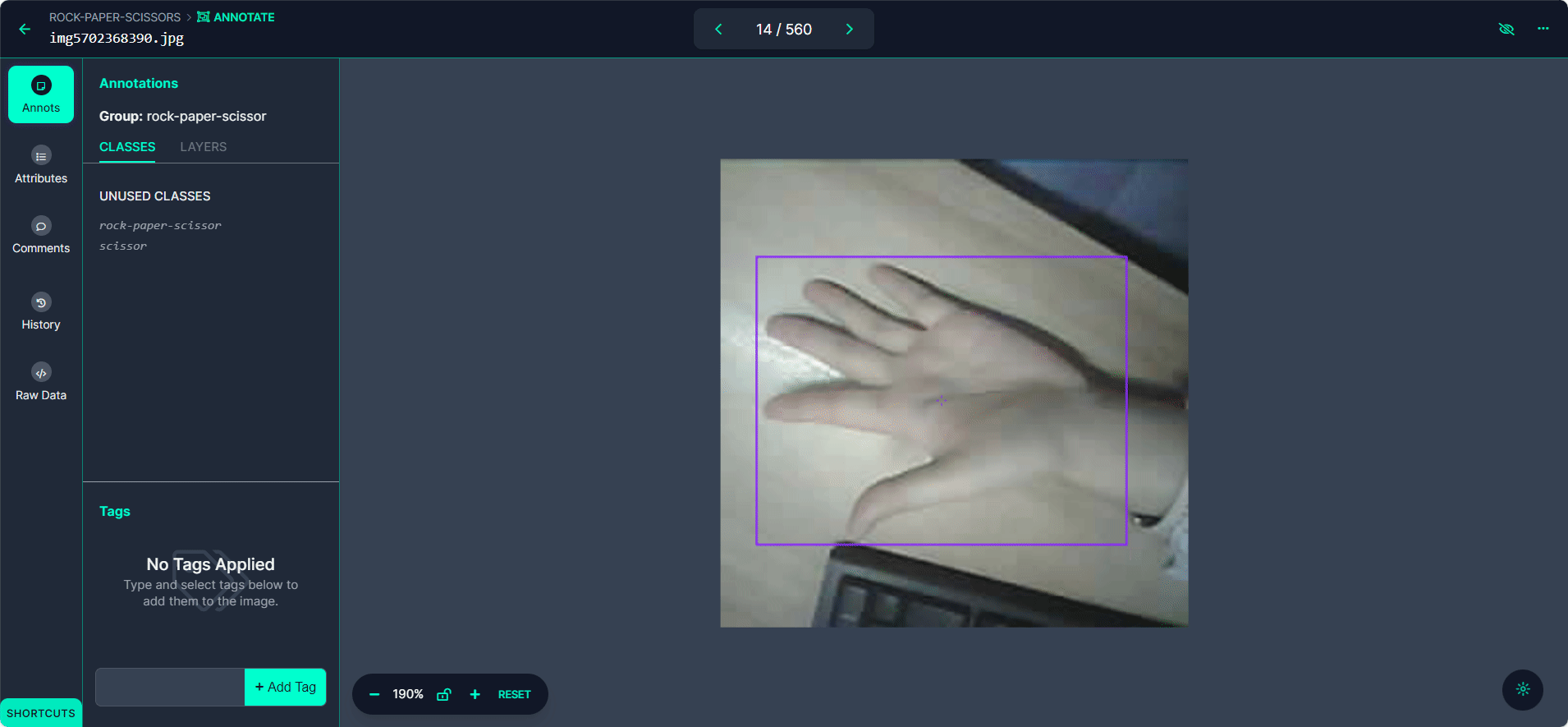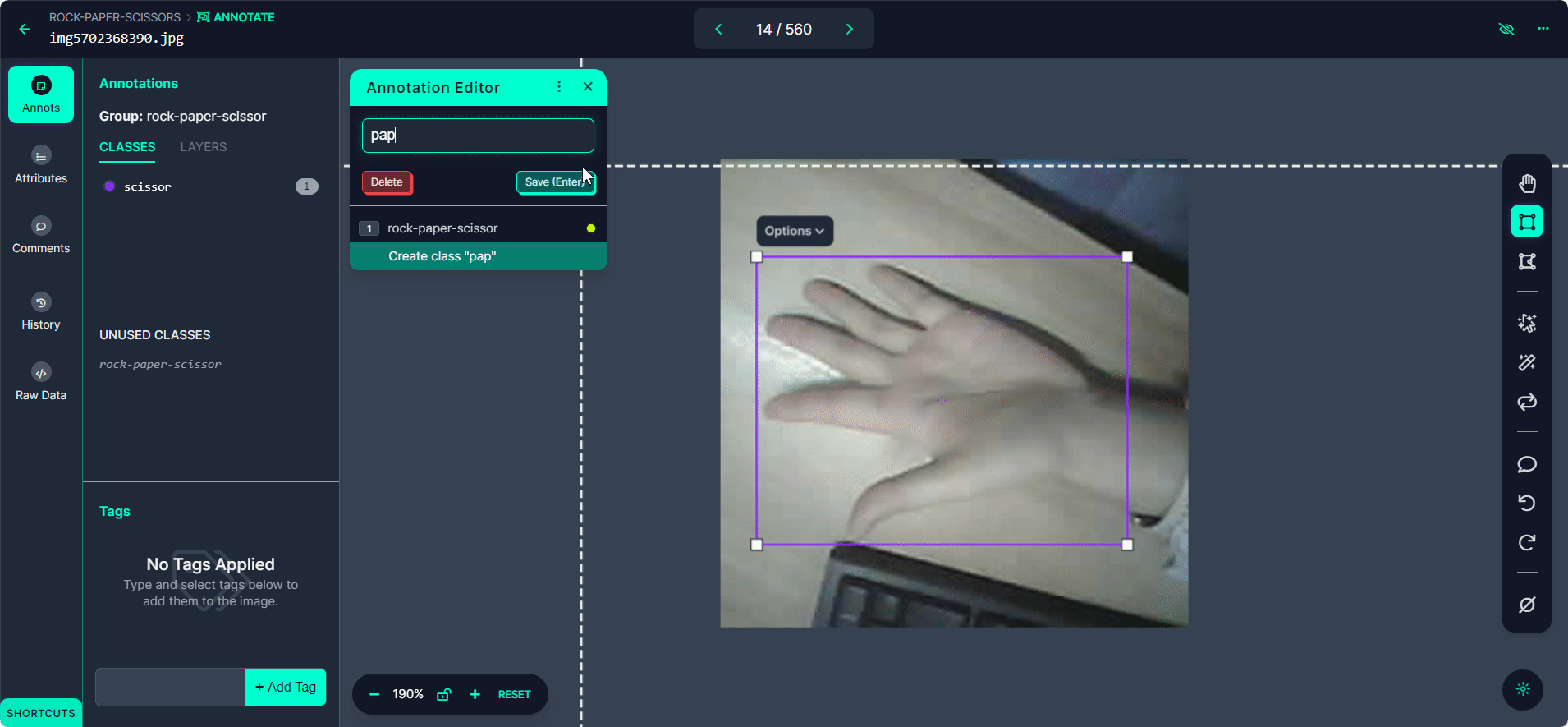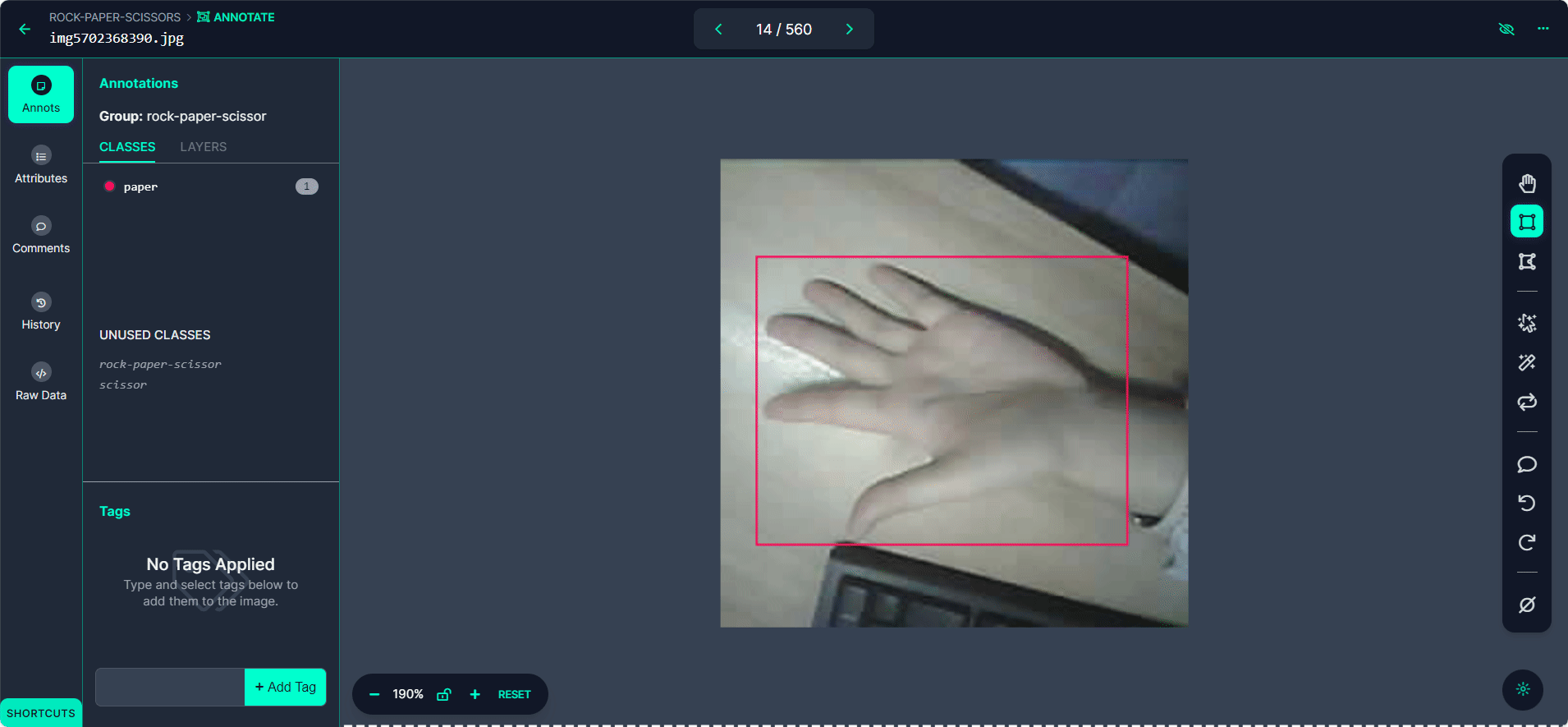
将每个边界框标记为"Rock"、"Paper"或"Scissors"。
使用">"按钮浏览您的数据集,为每张图片重复标注过程。
步骤 4:审查和编辑标注
确保标注准确性至关重要。
审查每张图片以确保边界框正确绘制和标记。如果发现任何错误,选择标注以调整边界框或更改标签。
错误的标记会影响训练的整体性能,如果某些数据集不符合标记要求,可以丢弃。以下是一些错误标记的示例。

步骤 5:生成和导出数据集
所有图片标注完成后。在 Annotate 中点击右上角的 Add x images to Dataset 按钮。
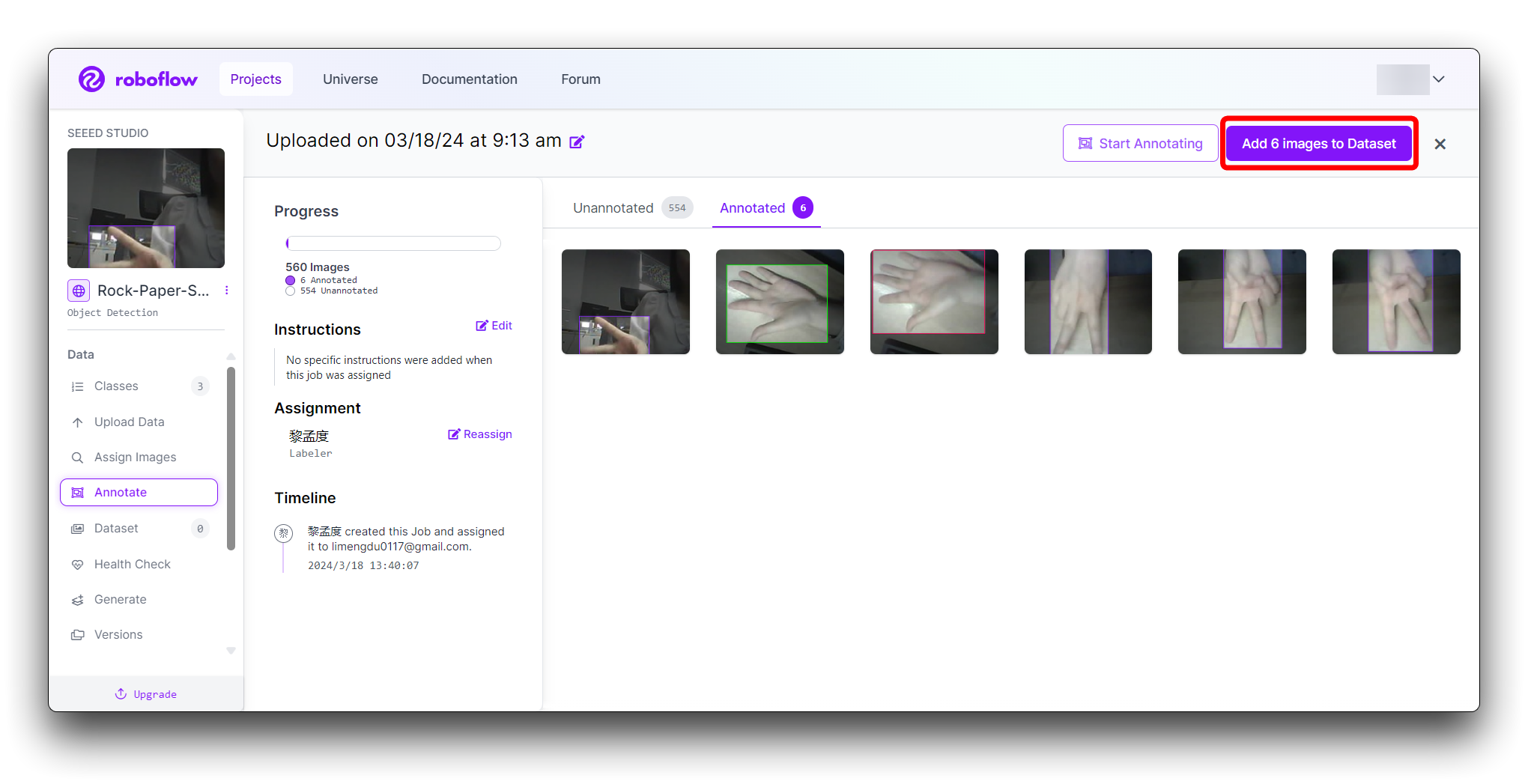
然后点击新弹出窗口底部的 Add Images 按钮。
点击左侧工具栏中的 Generate,并在第三个 Preprocessing 步骤中点击 Continue。
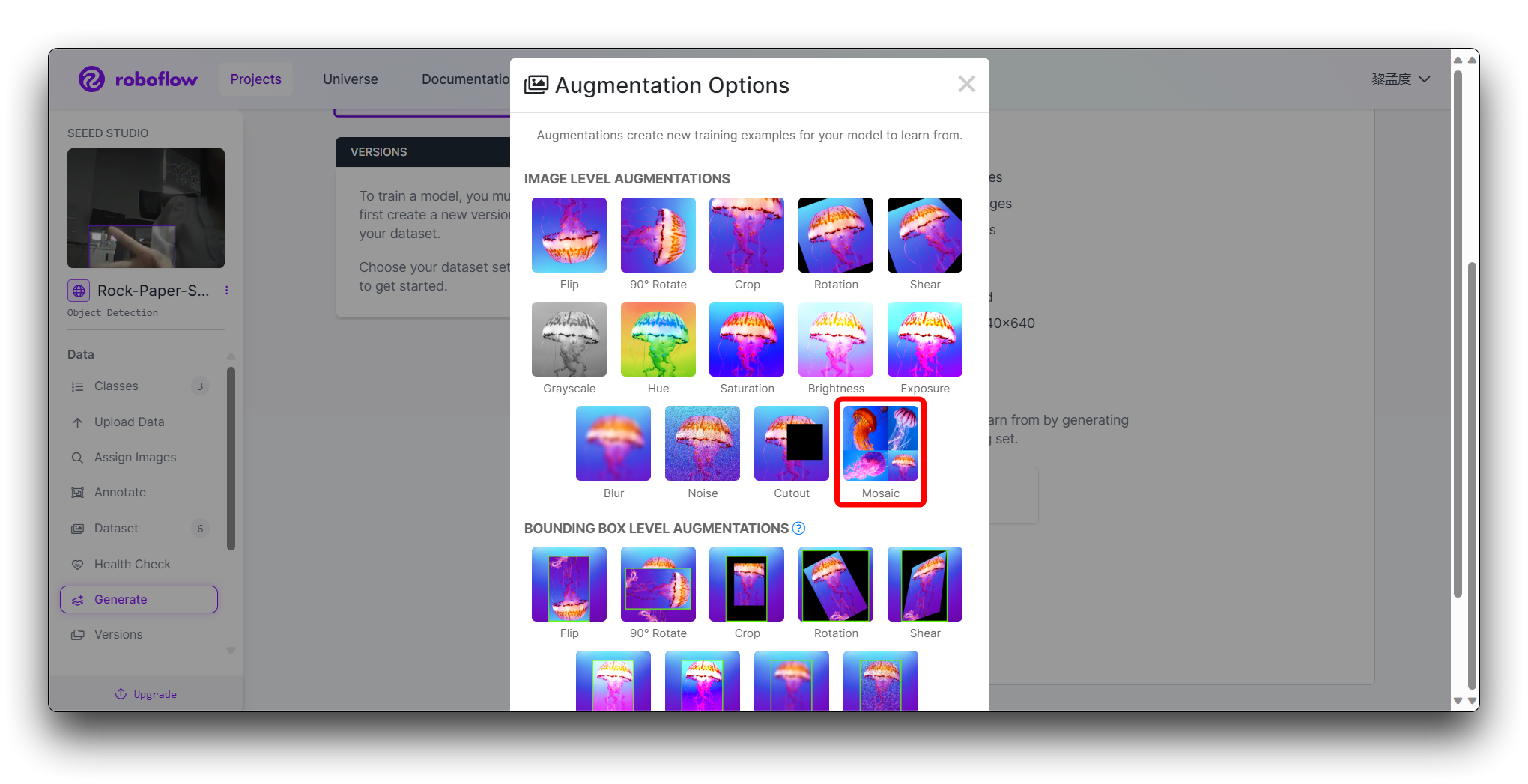
在步骤 4 的 Augmentation 中,选择 Mosaic,这可以增加泛化能力。
在最后的 Create 步骤中,请根据 Roboflow 的提升合理计算图片数量;一般来说,图片越多,训练模型所需的时间就越长。然而,图片越多并不一定会使模型更准确,这主要取决于数据集是否足够好。
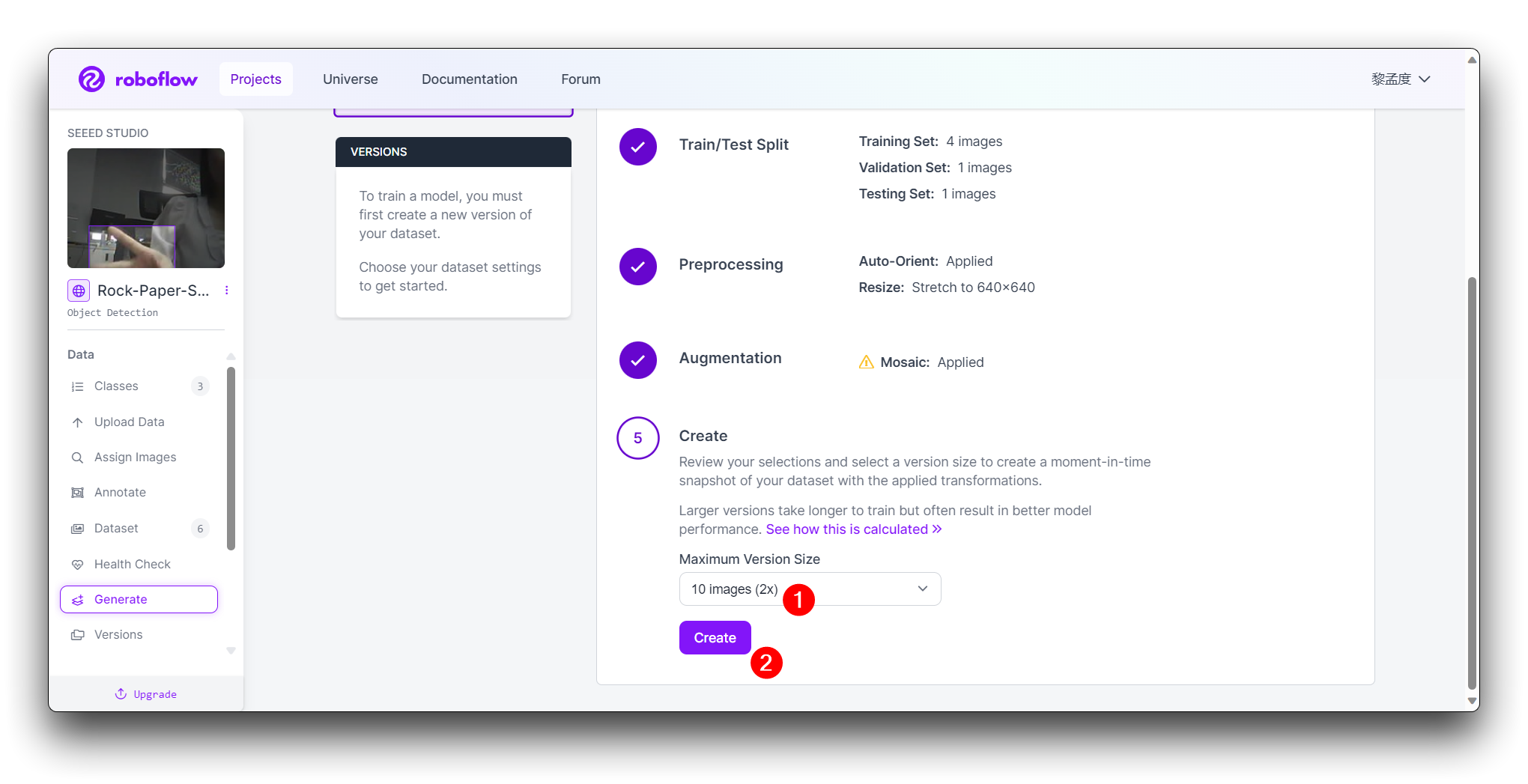
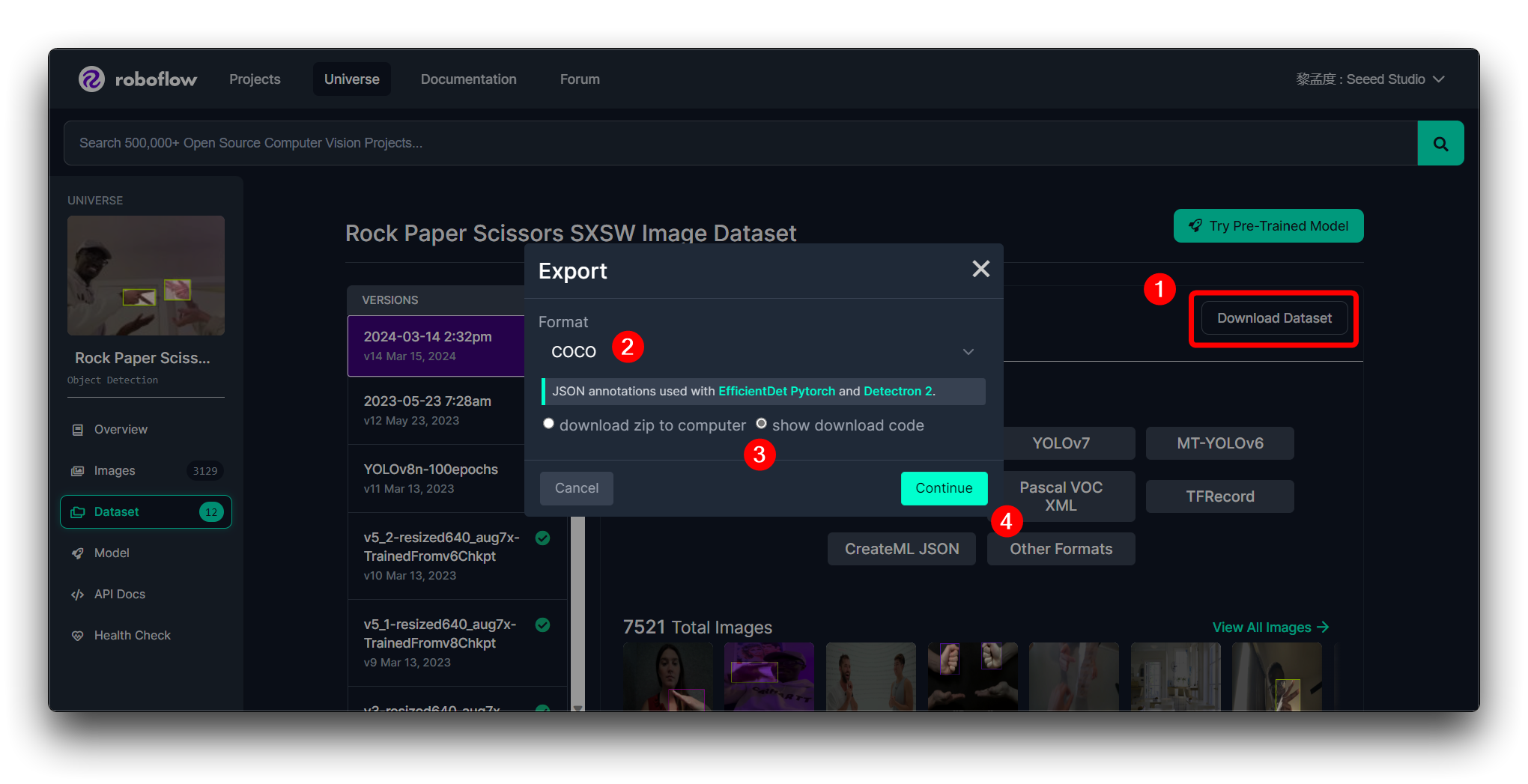
点击 Create 创建数据集版本。Roboflow 将处理图像和标注,创建一个版本化的数据集。数据集生成后,点击 Export Dataset。选择与您要训练的模型要求匹配的 COCO 格式。
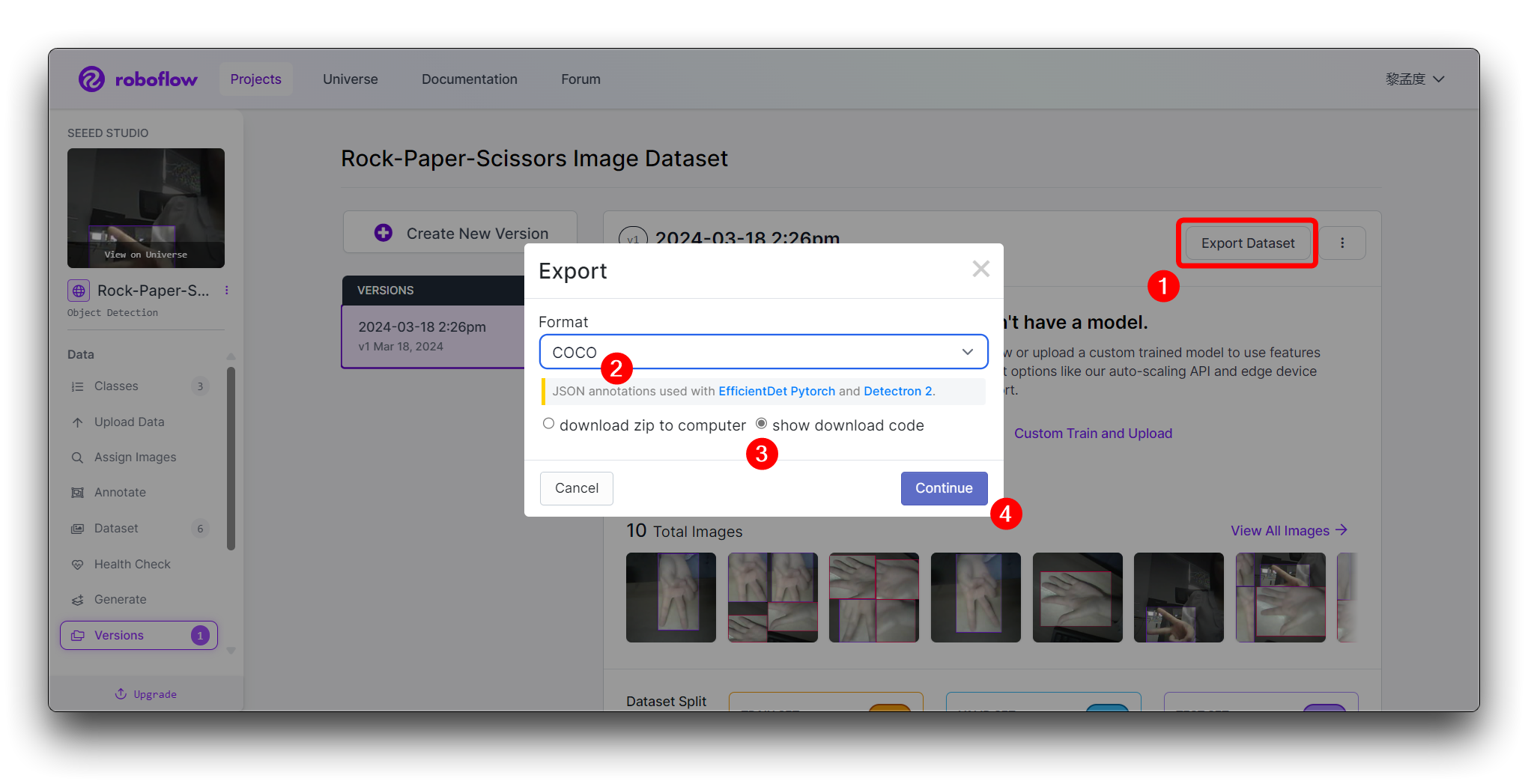
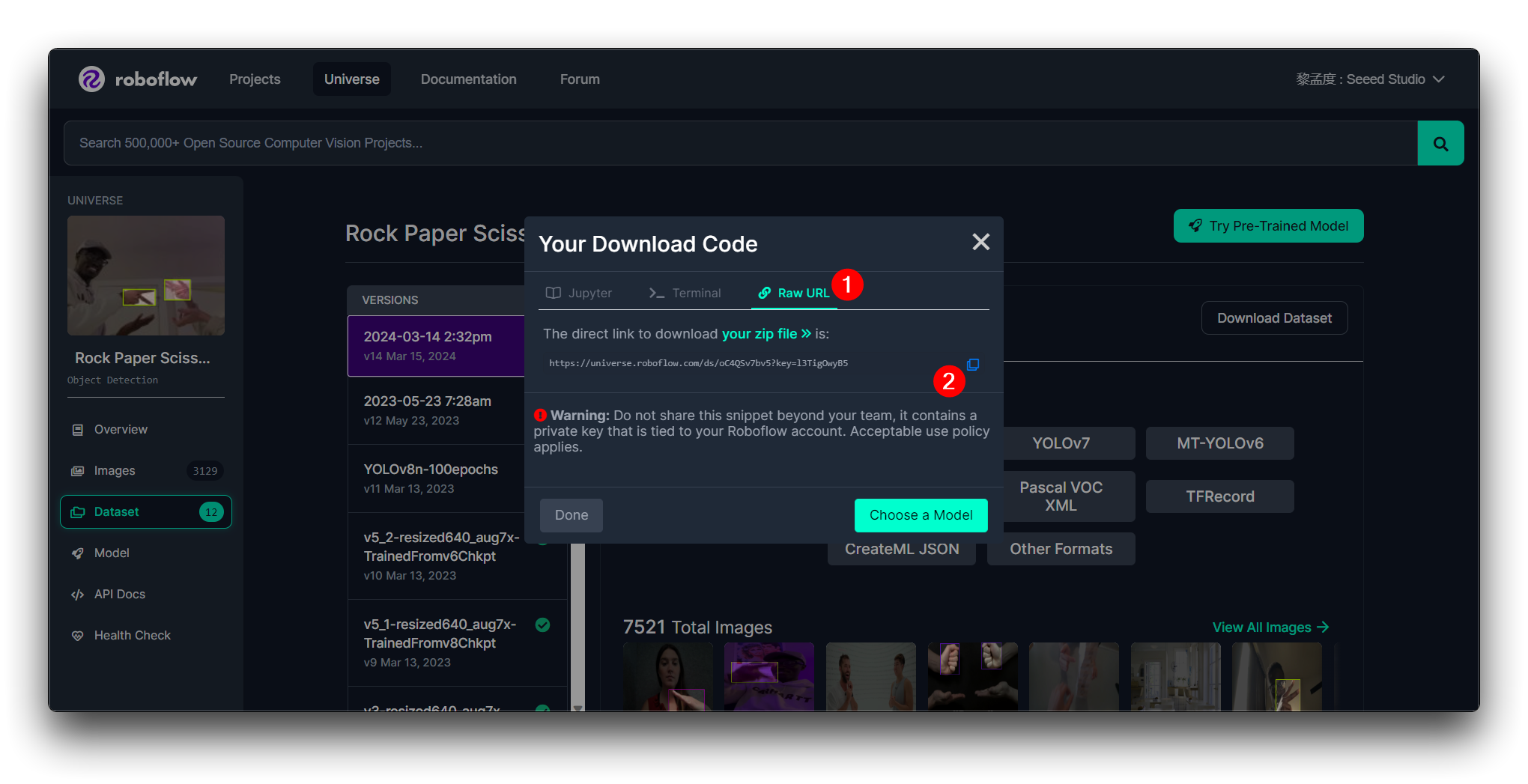
点击 Continue,然后您将获得此模型的原始 URL。请保存它,我们稍后在模型训练步骤中会使用这个链接。
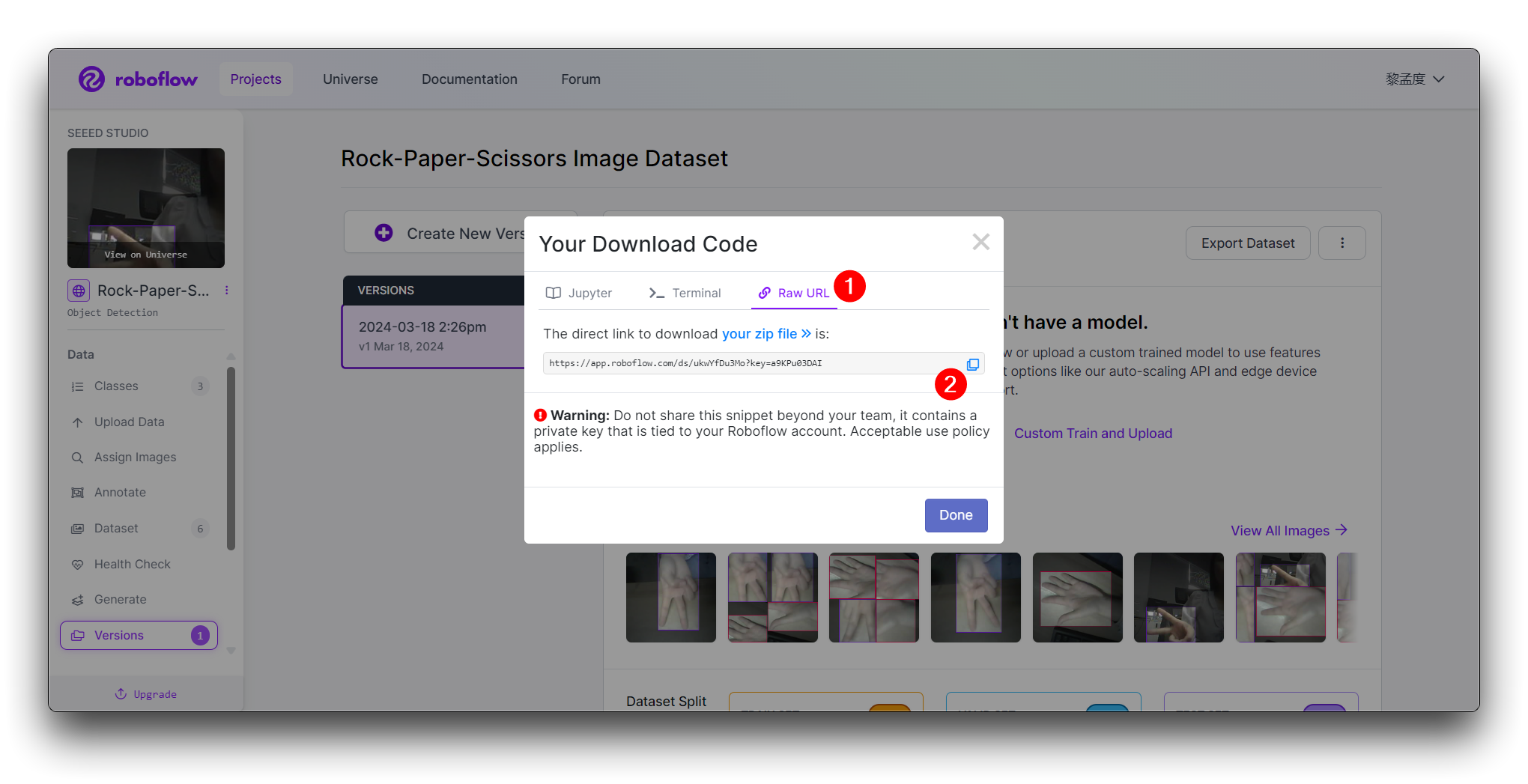
恭喜!您已成功使用 Roboflow 上传、标注并导出了石头剪刀布手势检测模型的数据集。数据集准备就绪后,您可以继续使用 Google Colab 等平台训练机器学习模型。
记住保持数据集的多样性和良好的标注质量,以提高未来模型的准确性。祝您模型训练顺利,享受使用 AI 的力量进行手势分类的乐趣!
训练数据集导出模型
步骤 1. 访问 Colab Notebook
您可以在 SenseCraft Model Assistant 的 Wiki 上找到不同类型的模型 Google Colab 代码文件。如果您不知道应该选择哪个代码,可以根据您的模型类别(目标检测或图像分类)选择其中任何一个。
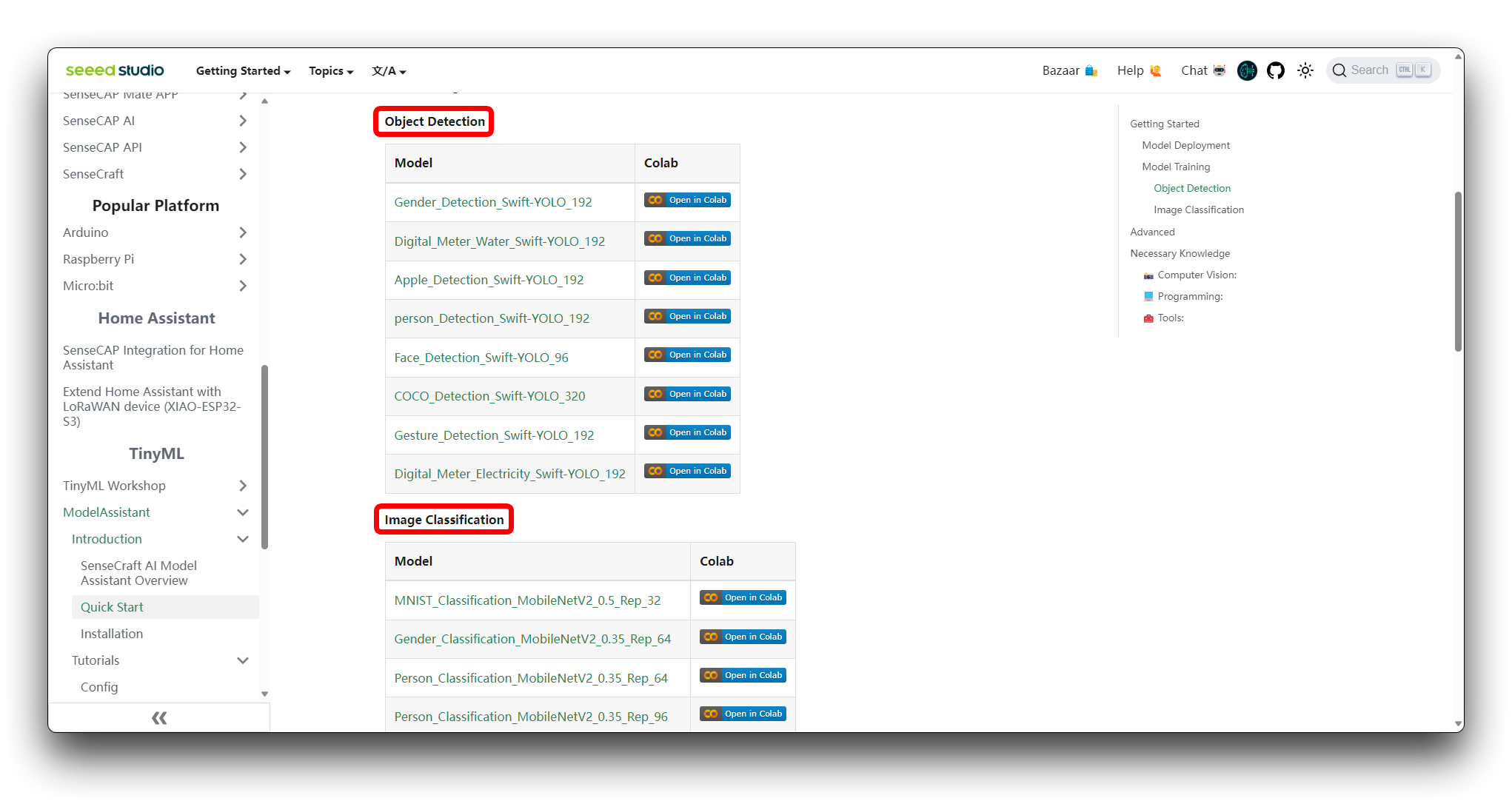
如果您尚未登录 Google 账户,请登录以访问 Google Colab 的完整功能。
点击"Connect"为您的 Colab 会话分配资源。

步骤 2. 添加您的 Roboflow 数据集
在正式逐步运行代码块之前,我们需要修改代码内容,以便代码可以使用我们准备的数据集。我们必须提供一个 URL 来直接将数据集下载到 Colab 文件系统中。
请在代码中找到 Download the dataset 部分。您将看到以下示例程序。
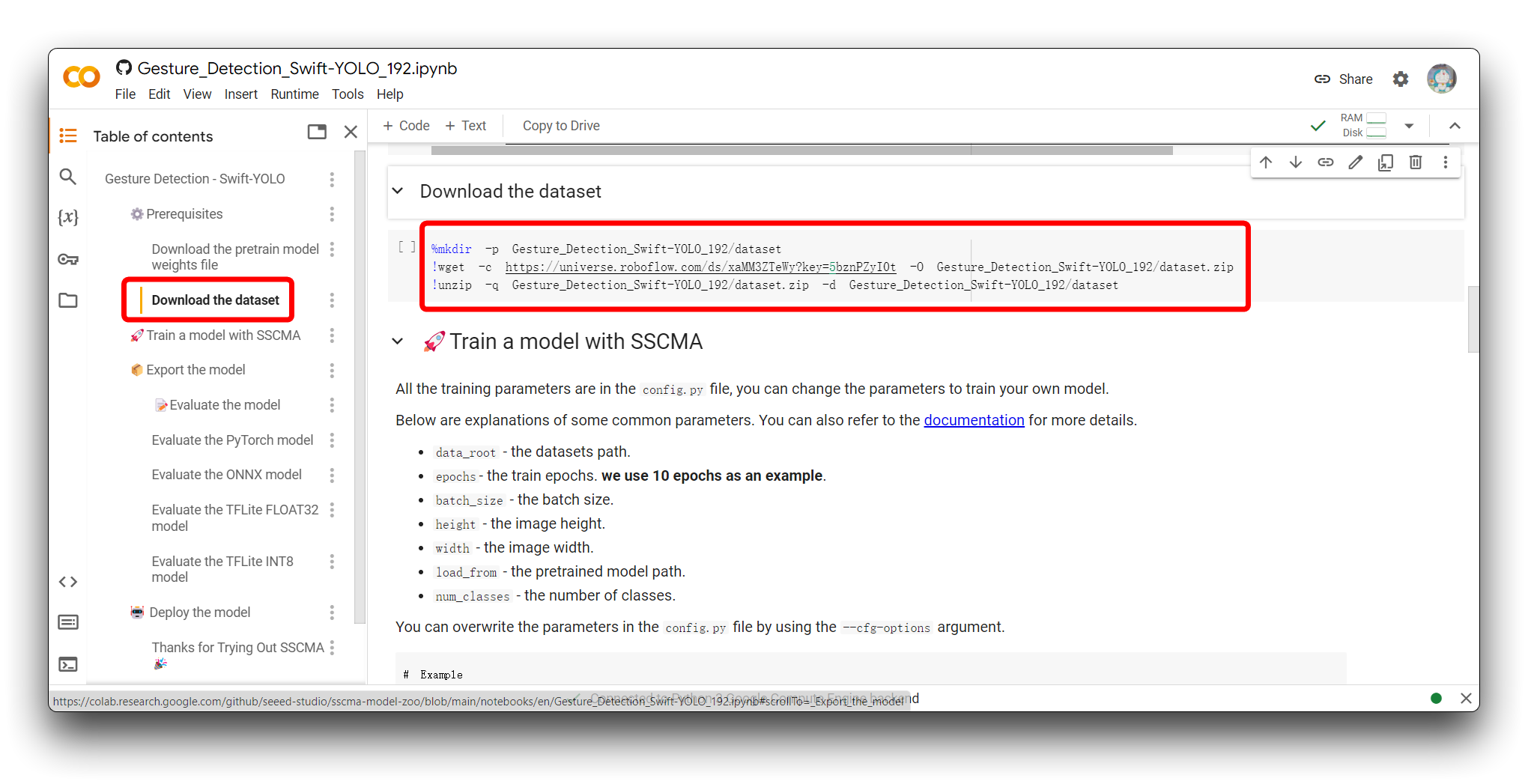
%mkdir -p Gesture_Detection_Swift-YOLO_192/dataset
!wget -c https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t -O Gesture_Detection_Swift-YOLO_192/dataset.zip
!unzip -q Gesture_Detection_Swift-YOLO_192/dataset.zip -d Gesture_Detection_Swift-YOLO_192/dataset
这段代码用于创建目录、从 Roboflow 下载数据集,并在 Google Colab 环境中将其解压到新创建的目录中。以下是每行代码的详细说明:
-
%mkdir -p Gesture_Detection_Swift-YOLO_192/dataset:- 这行代码创建一个名为
Gesture_Detection_Swift-YOLO_192的新目录和一个名为dataset的子目录。-p标志确保如果目录已存在,命令不会返回错误,并创建任何必要的父目录。
- 这行代码创建一个名为
-
!wget -c https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t -O Gesture_Detection_Swift-YOLO_192/dataset.zip:- 这行代码使用
wget(一个命令行工具)从提供的 Roboflow URL 下载数据集。-c标志允许在下载中断时恢复下载。-O标志指定下载文件的输出位置和文件名,在这种情况下是Gesture_Detection_Swift-YOLO_192/dataset.zip。
- 这行代码使用
-
!unzip -q Gesture_Detection_Swift-YOLO_192/dataset.zip -d Gesture_Detection_Swift-YOLO_192/dataset:- 这行代码使用
unzip命令将dataset.zip文件的内容提取到之前创建的dataset目录中。-q标志以静默模式运行unzip命令,抑制大部分输出消息。
- 这行代码使用
要为您自己的 Roboflow 模型链接自定义此代码:
-
将
Gesture_Detection_Swift-YOLO_192替换为您想要存储数据集的所需目录名称。 -
将 Roboflow 数据集 URL(
https://universe.roboflow.com/ds/xaMM3ZTeWy?key=5bznPZyI0t)替换为您导出数据集的链接(这是我们在标记数据集的最后一步中获得的原始 URL)。如果需要访问权限,请确保包含 key 参数。 -
如有必要,调整
wget命令中的输出文件名(-O your_directory/your_filename.zip)。 -
确保
unzip命令中的输出目录与您创建的目录匹配,文件名与您在wget命令中设置的文件名匹配。
如果您更改文件夹目录 Gesture_Detection_Swift-YOLO_192 的名称,请注意您需要对更改前代码中使用的其他目录名称进行相应更改,否则可能会出现错误!
步骤 3. 调整模型参数
下一步是调整模型的输入参数。请跳转到使用 SSCMA 训练模型部分,您将看到以下代码片段。
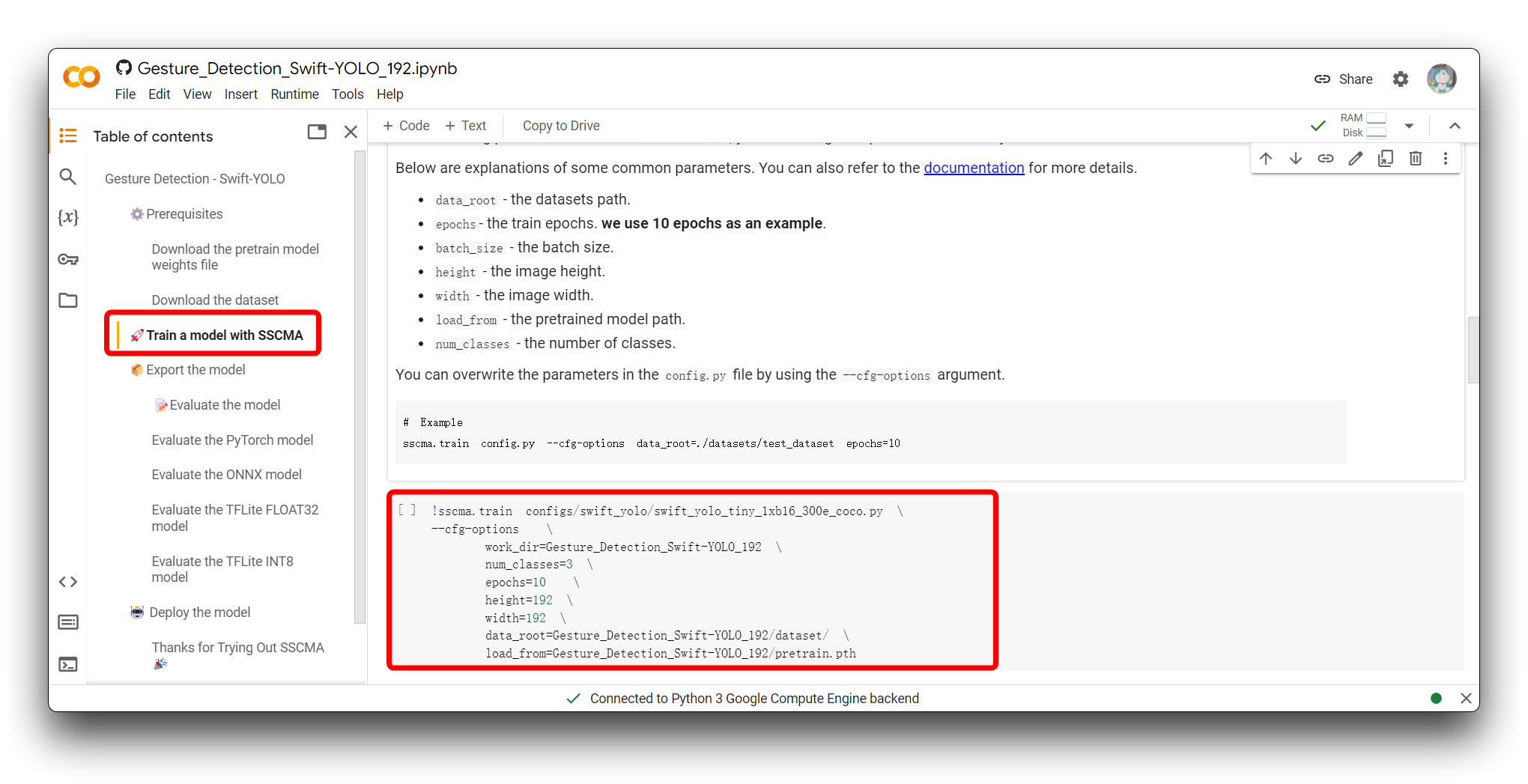
!sscma.train configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py \
--cfg-options \
work_dir=Gesture_Detection_Swift-YOLO_192 \
num_classes=3 \
epochs=10 \
height=192 \
width=192 \
data_root=Gesture_Detection_Swift-YOLO_192/dataset/ \
load_from=Gesture_Detection_Swift-YOLO_192/pretrain.pth
这个命令用于启动机器学习模型的训练过程,特别是使用 SSCMA(Seeed Studio SenseCraft Model Assistant)框架的 YOLO(You Only Look Once)模型。该命令包含各种选项来配置训练过程。以下是每个部分的作用:
-
!sscma.train是在 SSCMA 框架内启动训练的命令。 -
configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py指定训练的配置文件,其中包括模型架构、训练计划、数据增强策略等设置。 -
--cfg-options允许您使用命令行中提供的配置覆盖.py文件中指定的默认配置。 -
work_dir=Gesture_Detection_Swift-YOLO_192设置存储训练输出(如日志和保存的模型检查点)的目录。 -
num_classes=3指定模型应该训练识别的类别数量。这取决于您拥有的标签数量,例如石头、剪刀、布应该是三个标签。 -
epochs=10设置要运行的训练周期(epochs)数量。推荐值在 50 到 100 之间。 -
height=192和width=192设置模型期望的输入图像的高度和宽度。
我们不建议您在 Colab 代码中更改图像大小,因为这个值是我们验证过的更合适的数据集大小,它是大小、准确性和推理速度的组合。如果您使用的数据集不是这个大小,并且您可能想要考虑更改图像大小以确保准确性,那么请不要超过 240x240。
-
data_root=Gesture_Detection_Swift-YOLO_192/dataset/定义训练数据所在目录的路径。 -
load_from=Gesture_Detection_Swift-YOLO_192/pretrain.pth提供预训练模型检查点文件的路径,训练应该从该文件恢复或将其用作迁移学习的起点。
要为您自己的训练自定义此命令,您需要:
-
如果您有自定义配置文件,请将
configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py替换为您自己配置文件的路径。 -
将
work_dir更改为您希望保存训练输出的目录。 -
更新
num_classes以匹配您自己数据集中的类别数量。这取决于您拥有的标签数量,例如石头、剪刀、布应该是三个标签。 -
将
epochs调整为您模型所需的训练轮数。推荐值在 50 到 100 之间。 -
设置
height和width以匹配您模型输入图像的尺寸。 -
将
data_root更改为指向您数据集的根目录。 -
如果您有不同的预训练模型文件,请相应地更新
load_from路径。
步骤 4. 运行 Google Colab 代码
运行代码块的方法是点击代码块左上角的播放按钮。
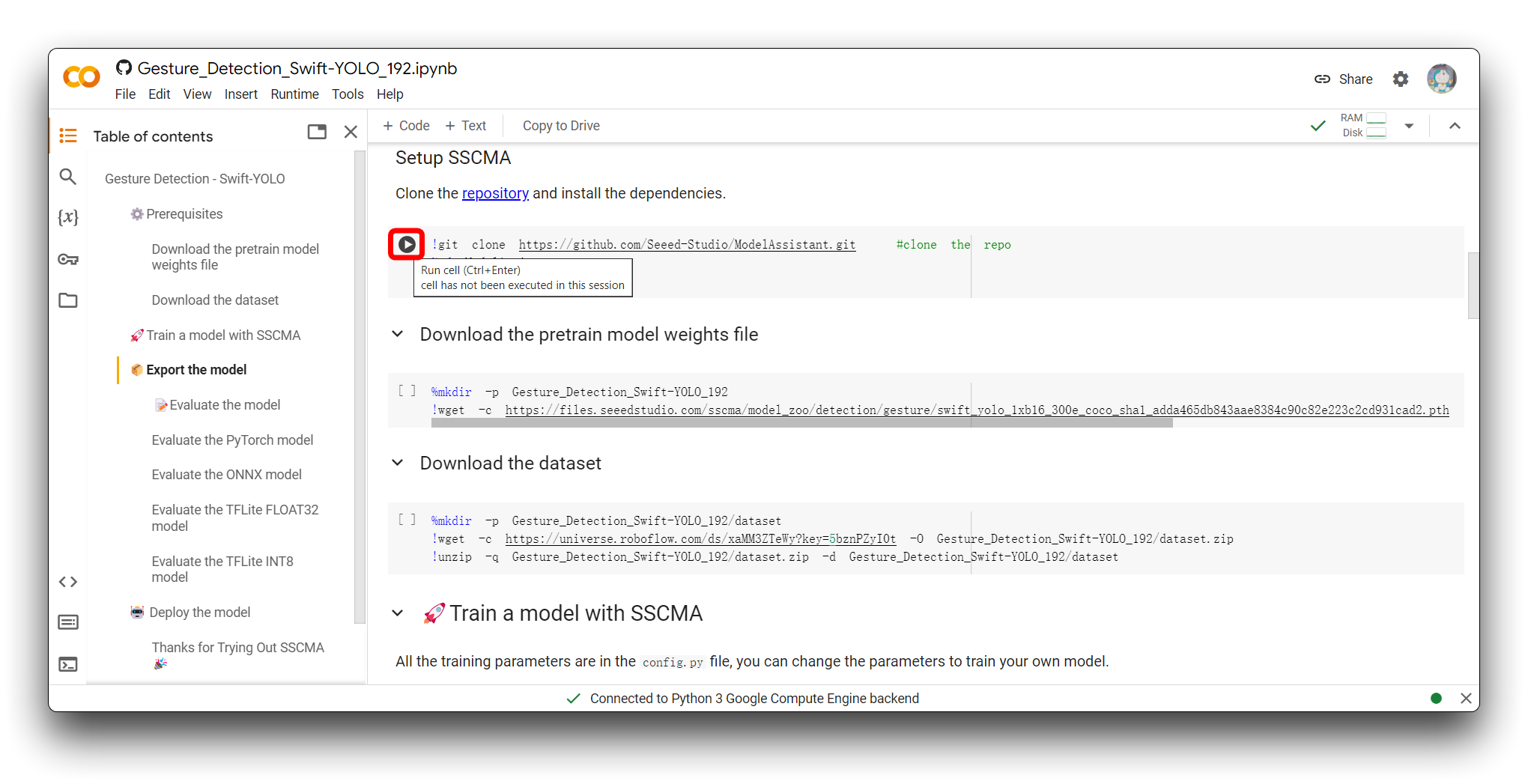
点击按钮后代码块将被执行,如果一切顺利,您将看到代码块执行完成的标志——块左侧出现勾号符号。如图所示是第一个代码块执行完成后的效果。
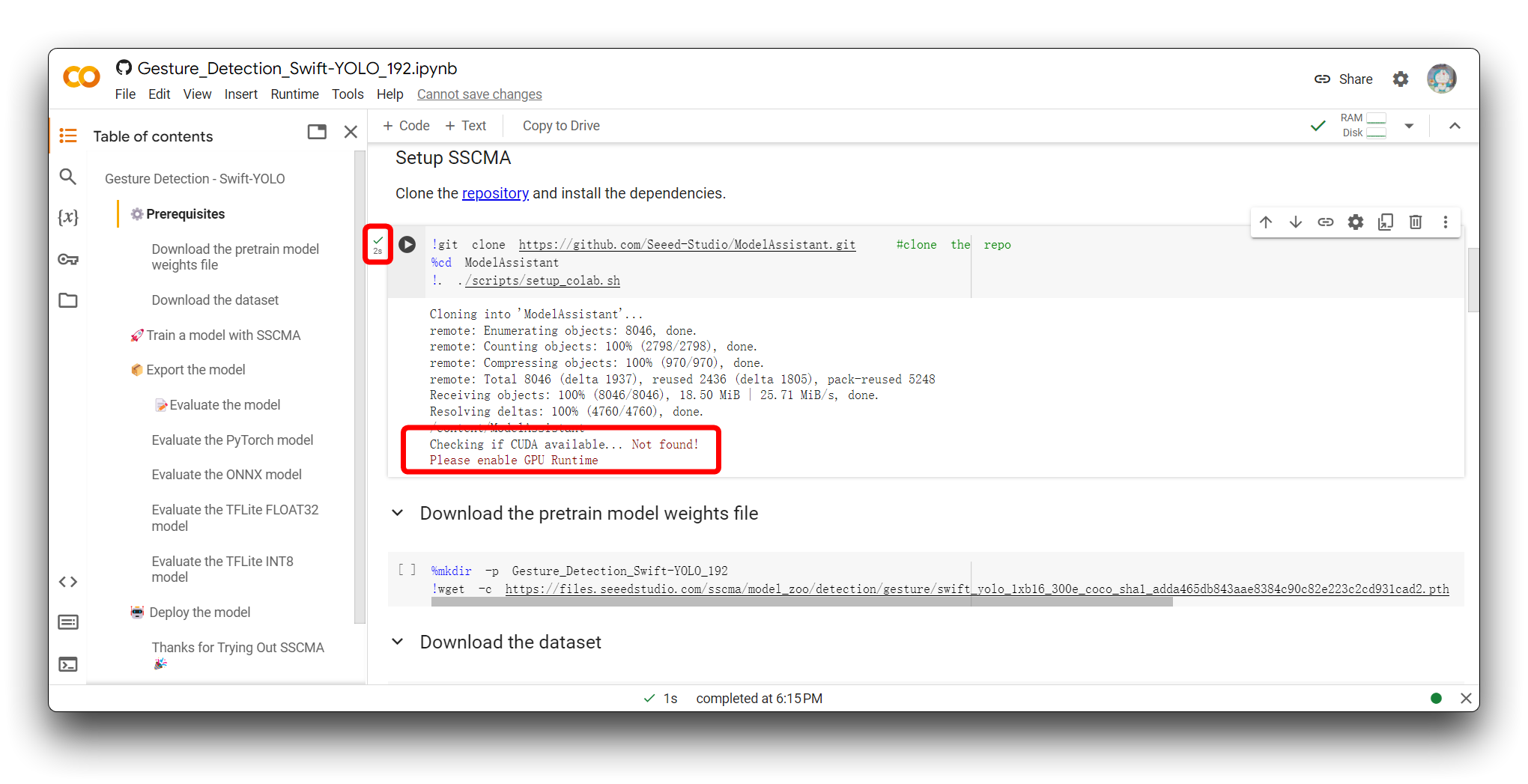
如果您遇到与我在上图中相同的错误消息,请检查您是否使用的是 T4 GPU,请不要在此项目中使用 CPU。
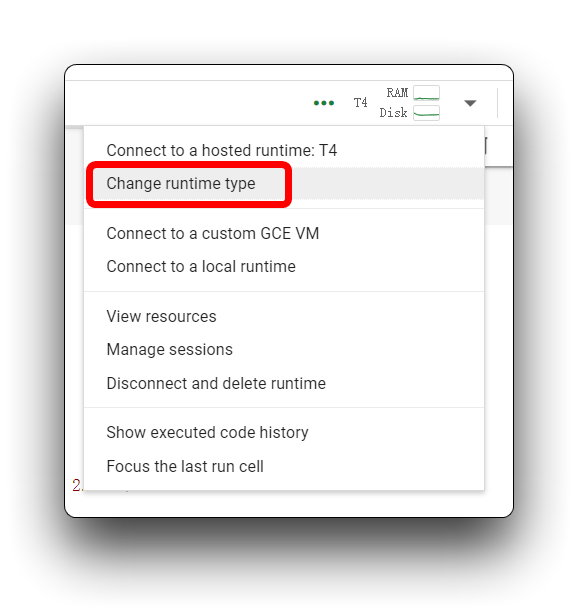
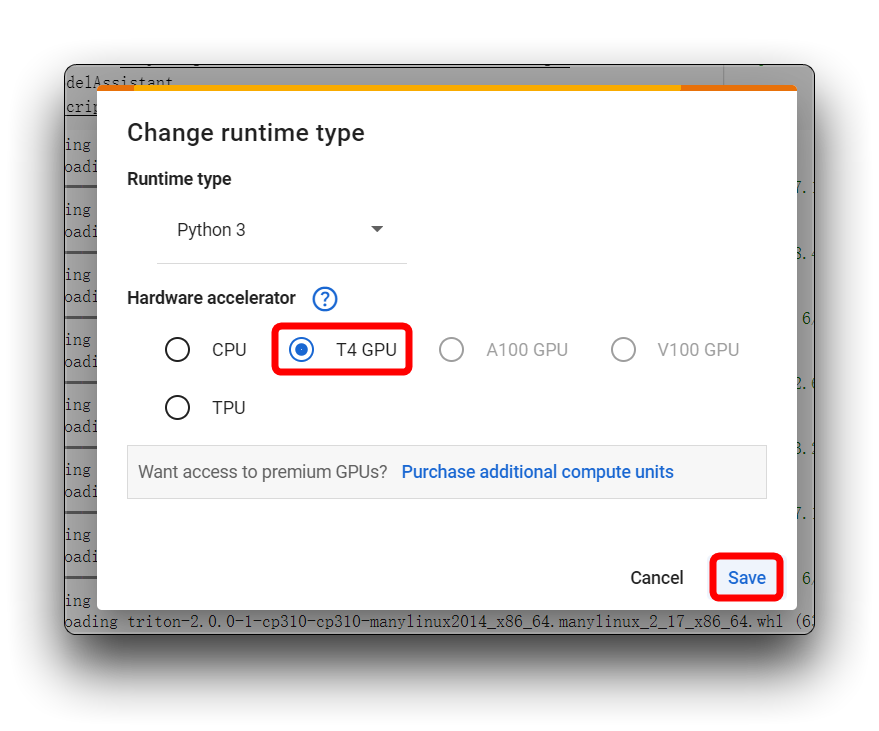
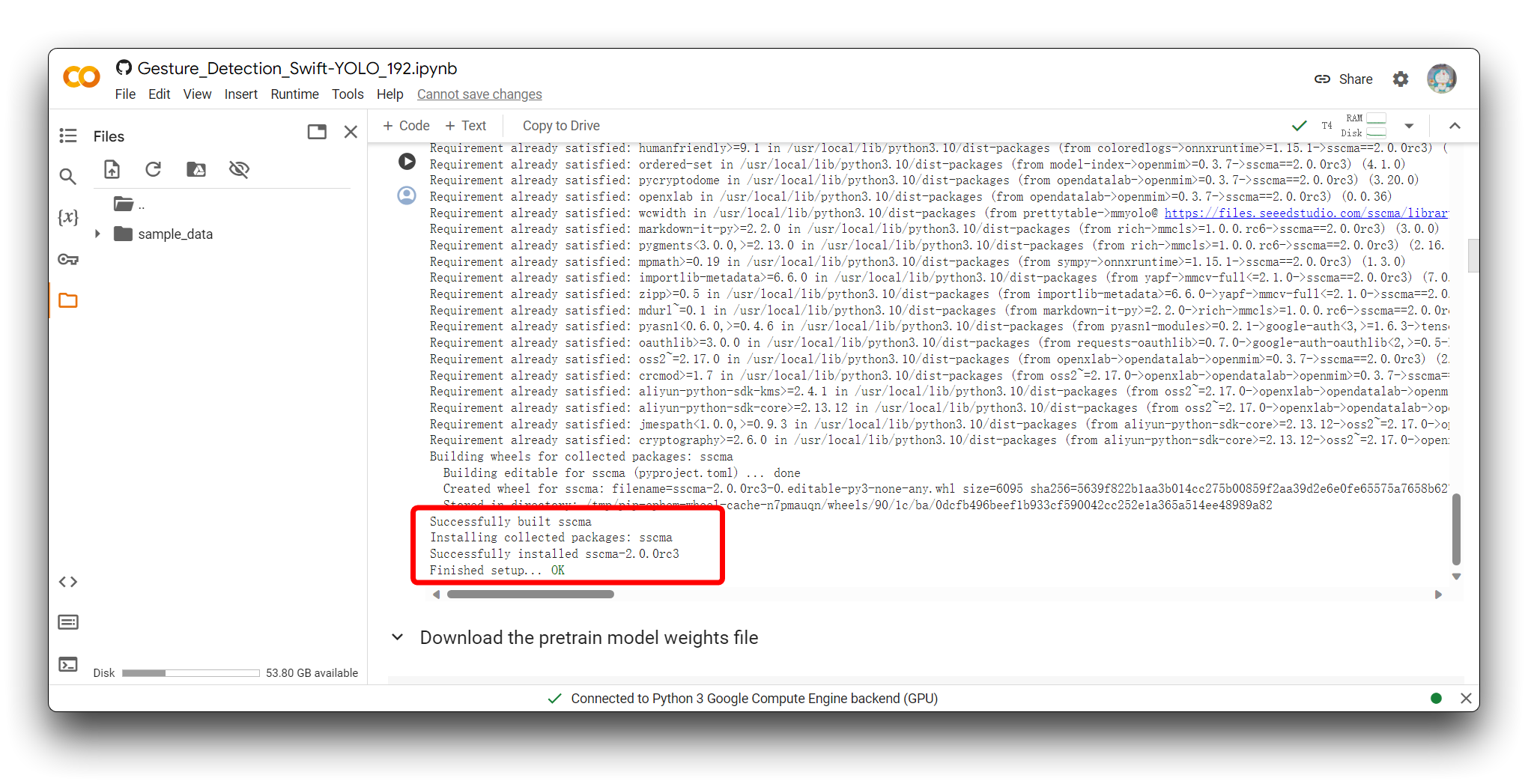
然后,重新执行代码块。对于第一个代码块,如果一切顺利,您将看到如下所示的结果。
接下来,执行从 Download the pretrain model weights file 到 Export the model 的所有代码块。请确保每个代码块都没有错误。
代码中出现的警告可以忽略。
步骤 5. 评估模型
当您到达 Evaluate the model 部分时,您可以选择执行 Evaluate the TFLite INT8 model 代码块。
评估 TFLite INT8 模型涉及针对单独的测试数据集测试量化模型的预测以衡量其准确性和性能指标,评估量化对模型精度的影响,以及分析其推理速度和资源使用情况以确保满足边缘设备的部署约束。
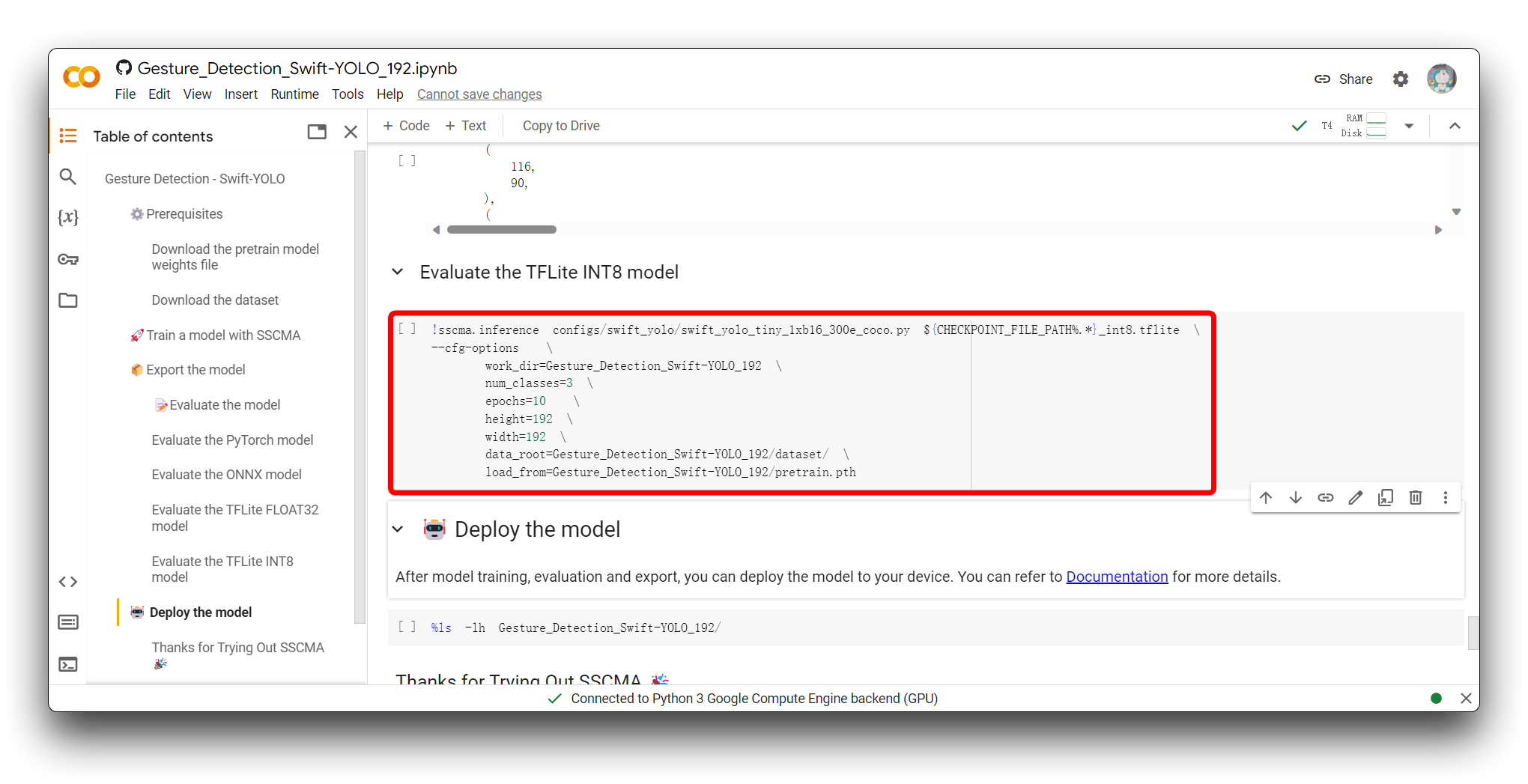
以下代码片段是我执行此代码块后结果的有效部分。
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.450
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.929
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.361
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.474
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.456
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.515
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.536
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.537
03/19 01:38:43 - mmengine - INFO - bbox_mAP_copypaste: 0.450 0.929 0.361 -1.000 0.474 0.456
{'coco/bbox_mAP': 0.45, 'coco/bbox_mAP_50': 0.929, 'coco/bbox_mAP_75': 0.361, 'coco/bbox_mAP_s': -1.0, 'coco/bbox_mAP_m': 0.474, 'coco/bbox_mAP_l': 0.456}
FPS: 128.350449 fram/s
评估结果包括一系列平均精度(AP)和平均召回率(AR)指标,这些指标针对不同的交并比(IoU)阈值和目标尺寸进行计算,通常用于评估目标检测模型的性能。
-
AP@[IoU=0.50:0.95 | area=all | maxDets=100] = 0.450
- 这个分数是模型在IoU阈值从0.50到0.95范围内(以0.05递增)的平均精度。AP为0.450表明您的模型在这个范围内具有中等精度。这是COCO数据集常用的关键指标。
-
AP@[IoU=0.50 | area=all | maxDets=100] = 0.929
- 在IoU阈值为0.50时,模型达到了0.929的高平均精度,表明它在较宽松的匹配标准下能够非常准确地检测目标。
-
AP@[IoU=0.75 | area=all | maxDets=100] = 0.361
- 在更严格的IoU阈值0.75下,模型的平均精度下降到0.361,表明在更严格的匹配标准下性能有所下降。
-
AP@[IoU=0.50:0.95 | area=small/medium/large | maxDets=100]
- 不同尺寸目标的AP分数有所不同。然而,小目标的AP为-1.000,这可能表明缺乏小目标的评估数据或模型在小目标检测上性能较差。中等和大目标的AP分数分别为0.474和0.456,表明模型对中等和大目标的检测相对较好。
-
AR@[IoU=0.50:0.95 | area=all | maxDets=1/10/100]
- 不同
maxDets值的平均召回率相当一致,范围从0.515到0.529,表明模型能够可靠地检索到大部分真正的正例实例。
- 不同
-
FPS: 128.350449 fram/s
- 模型在推理过程中以大约128.35帧每秒的非常快的速度处理图像,表明具有实时或近实时应用的潜力。
总体而言,模型在IoU为0.50时表现优异,在IoU为0.75时表现中等。它在中等和大目标检测上表现更好,但在检测小目标方面可能存在问题。此外,模型推理速度很快,适合需要快速处理的场景。如果在应用中检测小目标至关重要,我们可能需要进一步优化模型或收集更多小目标数据来提高性能。
步骤6. 下载导出的模型文件
在导出模型部分之后,您将获得各种格式的模型文件,这些文件默认存储在ModelAssistant文件夹中。在本教程中,存储目录是Gesture_Detection_Swift_YOLO_192。
有时Google Colab不会自动刷新文件夹的内容。在这种情况下,您可能需要通过点击左上角的刷新图标来刷新文件目录。
在上述目录中,.tflite模型文件可用于XIAO ESP32S3和Grove Vision AI V2。对于XIAO ESP32S3 Sense,请确保选择使用xxx_int8.tflite格式的模型文件。XIAO ESP32S3 Sense无法使用其他格式。
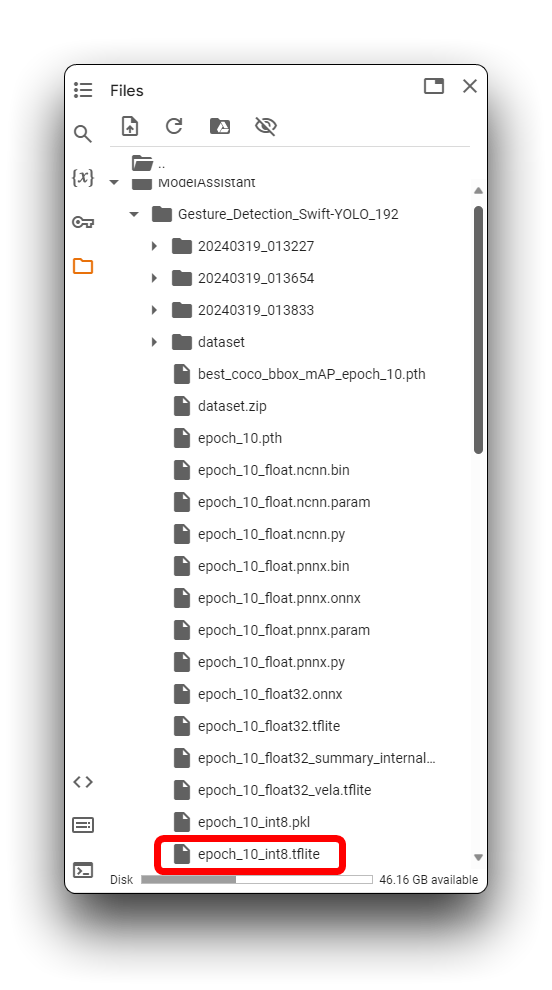
找到模型文件后,请尽快将它们下载到您的计算机本地,如果您长时间处于空闲状态,Google Colab可能会清空您的存储目录!
通过这里执行的步骤,我们已经成功导出了可以被XIAO ESP32S3支持的模型文件,接下来让我们将模型部署到设备上。
通过 SenseCraft Model Assistant 上传模型
步骤 7. 将自定义模型上传到 XIAO ESP32S3
接下来,我们来到 Model Assistant 页面。
请在选择 XIAO ESP32S3 后连接设备,然后在页面底部选择 Upload Custom AI Model。
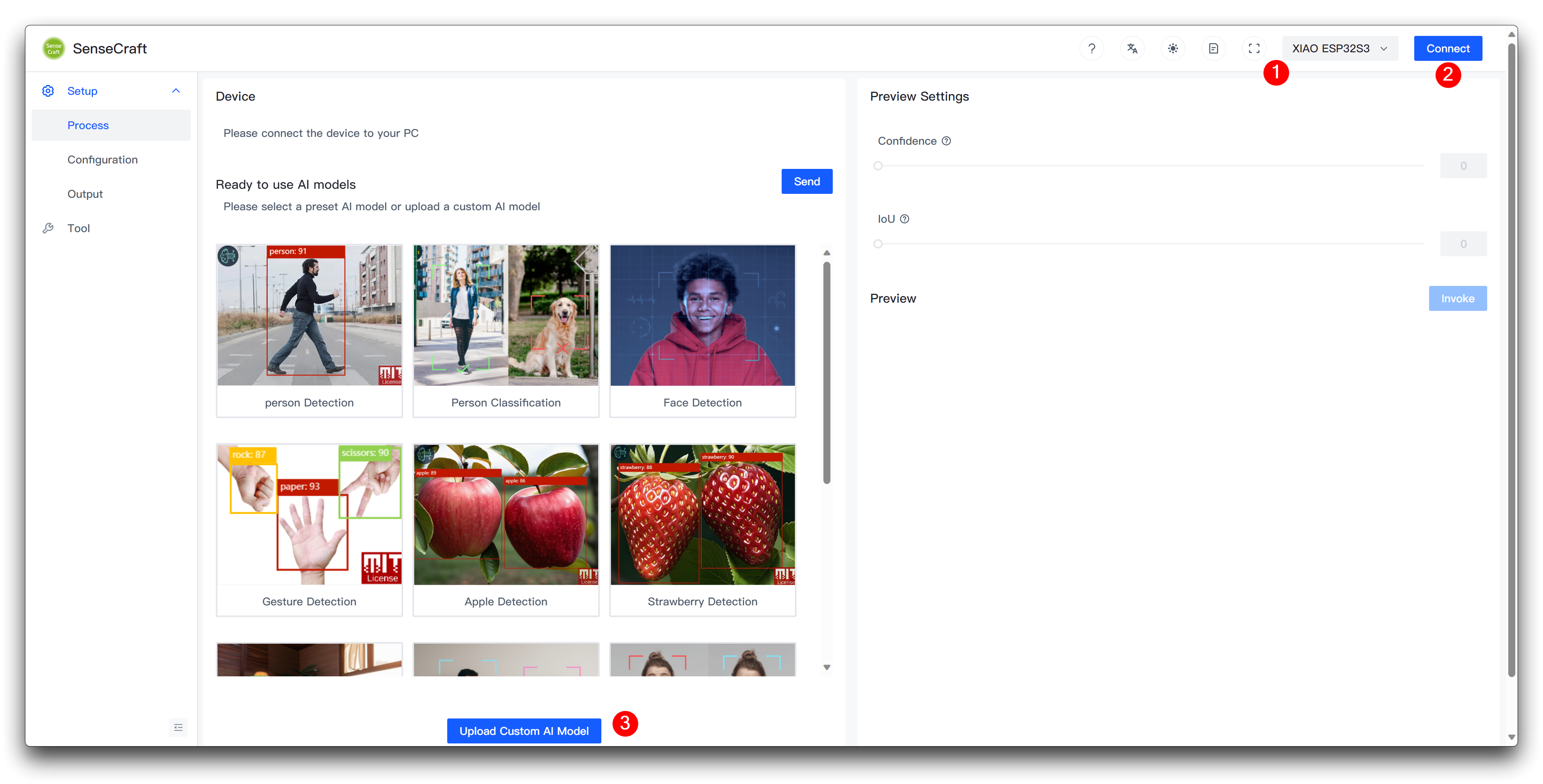
然后您需要准备模型名称、模型文件和标签。我想在这里重点说明标签 ID 这个元素是如何确定的。
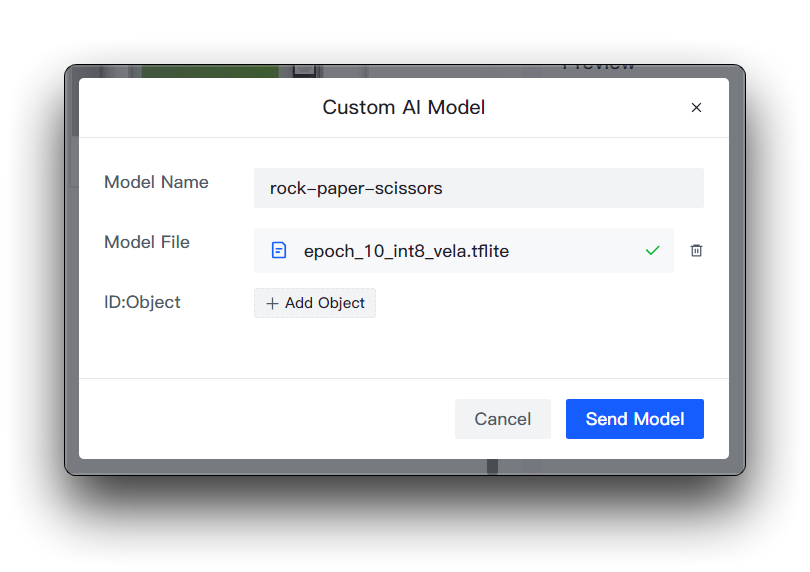
如果您直接下载 Roboflow 的数据集
如果您直接下载了 Roboflow 的数据集,那么您可以在 Health Check 页面查看不同的类别及其顺序。只需按照这里输入的顺序安装即可。
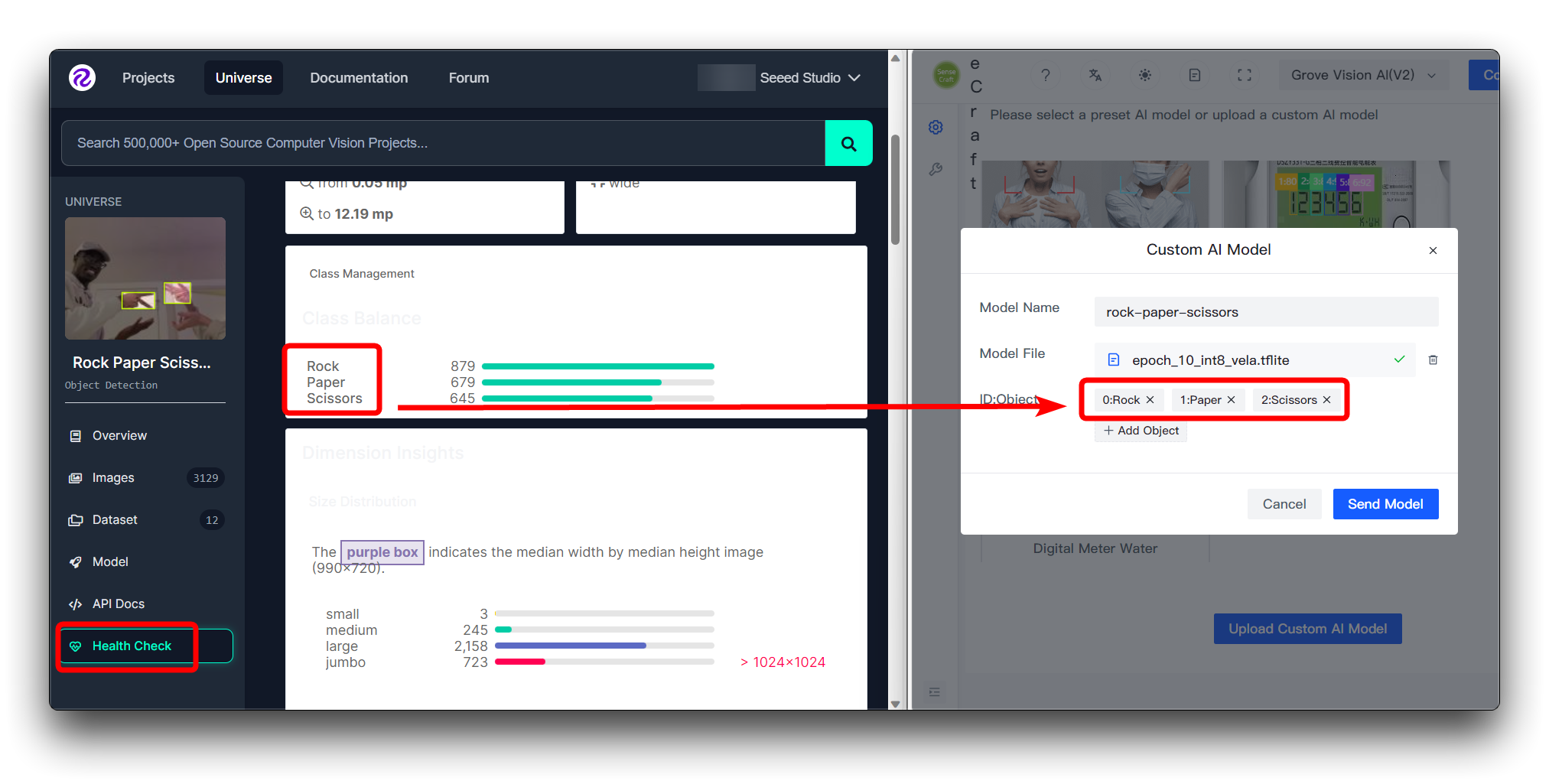
您不需要在 ID:Object 中填写数字,只需直接填写类别名称,图像上类别前面的数字和冒号是自动添加的。
如果您使用自定义数据集
如果您使用自定义数据集,那么您可以在 Health Check 页面查看不同的类别及其顺序。只需按照这里输入的顺序安装即可。
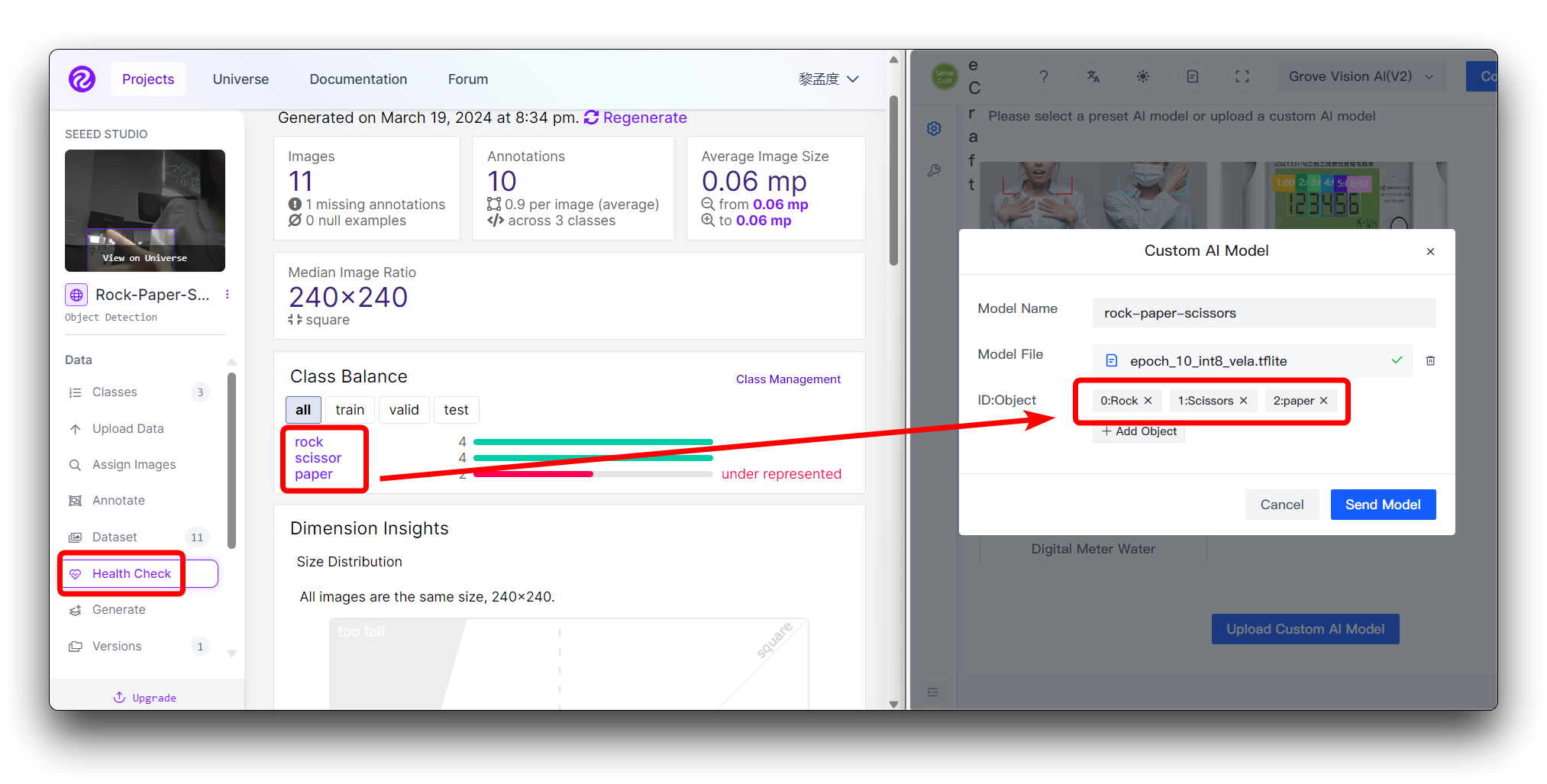
您不需要在 ID:Object 中填写数字,只需直接填写类别名称,图像上类别前面的数字和冒号是自动添加的。
然后点击右下角的 Send Model。这可能需要大约 3 到 5 分钟左右。如果一切顺利,那么您可以在上方的 Model Name 和 Preview 窗口中看到您的模型结果。
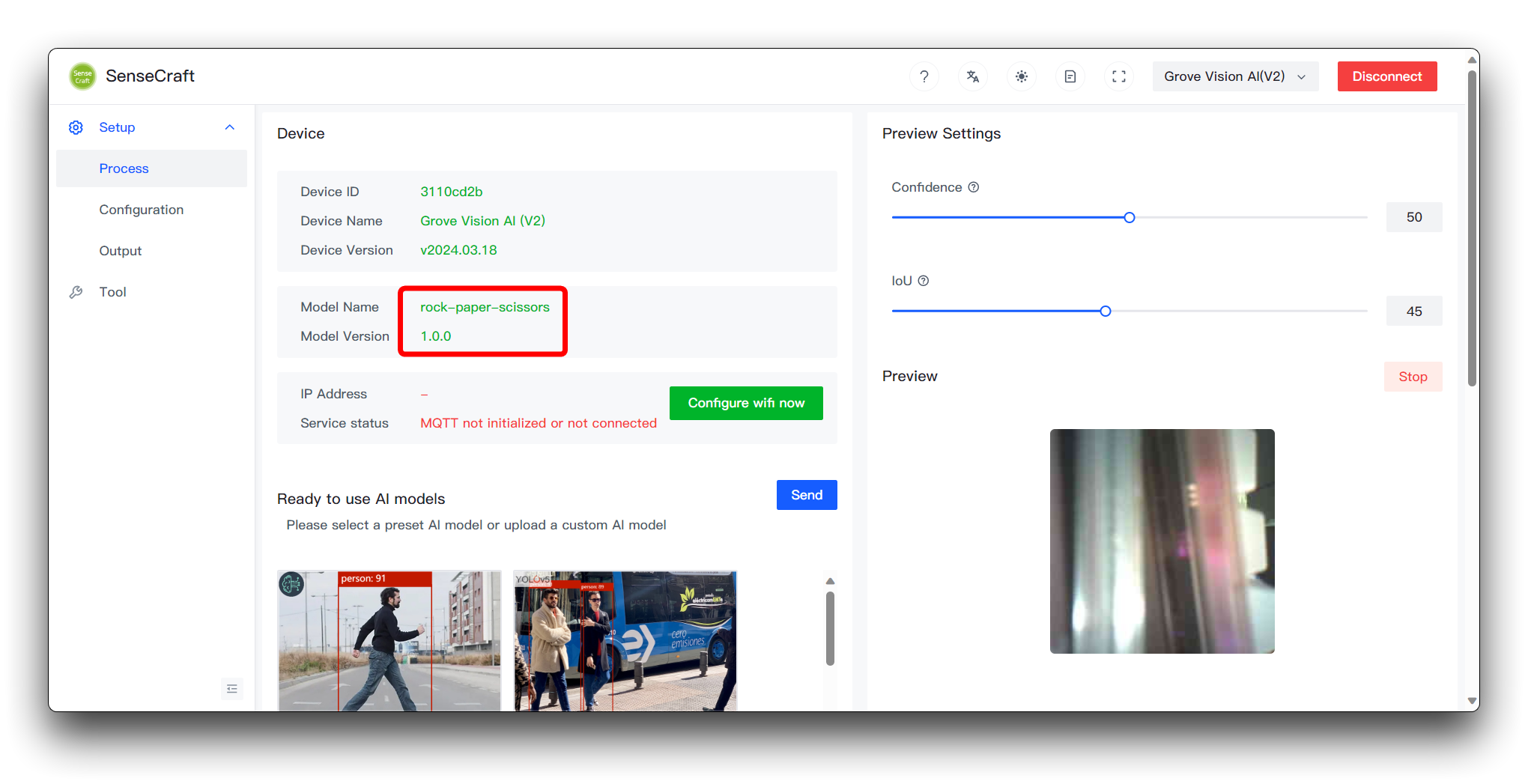
做到这一步,恭喜您,您已经能够成功训练和部署自己的模型了。
模型的通用协议和应用
在上传自定义模型的过程中,除了我们可以可视化上传的模型文件外,还有设备的固件需要传输到设备。在设备的固件中,有一套既定的通信协议,规定了模型结果输出的格式,以及用户可以对模型做什么。
由于篇幅问题,我们不会在这个 wiki 中展开这些协议的具体内容,我们将通过 Github 上的文档详细介绍这一部分。如果您对更深入的开发感兴趣,请前往这里。
故障排除
1. 如果我按照步骤操作,但模型结果不够理想怎么办?
如果您的模型识别准确率不理想,您可以从以下几个方面进行诊断和改进:
-
数据质量和数量
- 问题:数据集可能太小或缺乏多样性,或者标注中可能存在不准确之处。
- 解决方案:增加训练数据的大小和多样性,并执行数据清理以纠正任何标注错误。
-
训练过程
- 问题:训练时间可能不足,或者学习率设置不当,导致模型无法有效学习。
- 解决方案:增加训练轮数,调整学习率和其他超参数,并实施早停以避免过拟合。
-
类别不平衡
- 问题:某些类别的样本数量明显多于其他类别,导致模型偏向于多数类别。
- 解决方案:使用类别权重,对少数类别进行过采样,或对多数类别进行欠采样以平衡数据。
通过全面分析和实施有针对性的改进,您可以逐步提高模型的准确率。记住在每次修改后使用验证集测试模型性能,以确保改进的有效性。
2. 为什么我按照 Wiki 中的步骤操作后,在 SenseCraft 部署中看到 Invoke failed 消息?
如果您遇到 Invoke failed,那么您训练的模型不符合设备使用要求。请关注以下几个方面。
- 请检查您是否修改了 Colab 的图像大小。默认压缩大小为 192x192,Grove Vision AI V2 要求图像大小压缩为正方形,请不要使用非正方形大小进行压缩。同时不要使用过大的尺寸 (建议不超过 240x240)。
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。