Seeed&高擎双足机器人强化学习Hackathon
介绍
欢迎来到 Seeed 具身智能 Hackathon,一场面向未来的具身智能实战体验,即将开启!本篇文章将会引导您亲手操控双足机器人"小π",从零开始体验具身智能的完整开发流程:搭建 Isaacgym 仿真环境、训练控制策略、完成 sim2sim 验证,最终实现 sim2real 强化学习部署,把你的智能算法真正"装进"机器人的身体!

环境配置
为保障具身智能算法训练与硬件部署的流畅性,参赛者需预先配置符合以下技术规范的开发环境。本活动推荐采用NVIDIA生态链开发方案,确保仿真训练与实体机器人间的算力一致性。
硬件准备
- 算力平台:
- GPU:NVIDIA RTX 20系列以上 (注意: 不能使用50系列nvidia 显卡)
- 显存:大于 6GB
- 内存:大于 16GB
- 操作系统:Ubuntu 20.04/22.04
已下硬件将由活动举办方提供。
- 小π机器人 + 备用电池
- 120w Type-C 充电适配器
- USB 转网口线缆
- 路由器
运行环境配置
步骤1. 安装 NVIDIA 驱动
请在 ubuntu 计算平台的终端中使用 nvidia-smi 命令测试 Nvidia 启动是否正常安装。
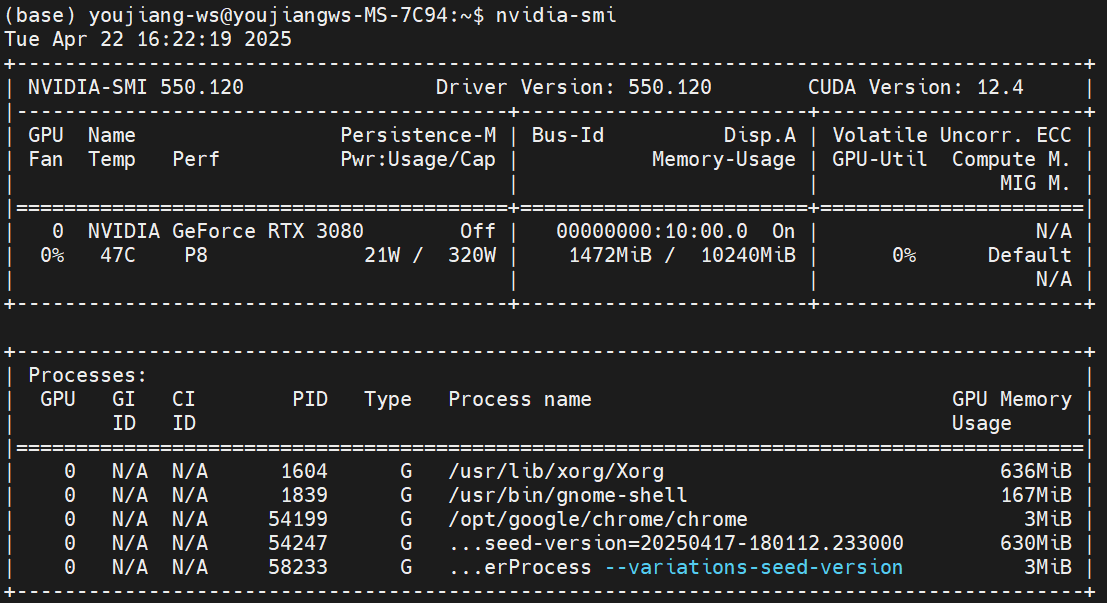
如果没有报错并返回类似上图中的内容则证明你的设备中已经安装了 NVIDIA 驱动,可以跳转到步骤2,否则,请参考下面的命令安装 Nvidia 驱动。
sudo apt update
sudo apt install nvidia-driver-535
sudo reboot #安装完成后,重启系统
nvidia-smi #验证查看
步骤2. 安装Miniconda
安装并使用 conda 是为了方便管理 Python 环境和包,可创建相互隔离的虚拟环境,避免不同项目间依赖冲突,如果你的电脑中已经安装了conda相关软件,可以直接跳转到 步骤3,否则,请在终端中运行下面的命令安装 Miniconda:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
source ~/.bashrc
conda --version

步骤3. 创建 conda 虚拟环境
请使用下面的终端命令创建并激活虚拟环境:
conda create --name pi python=3.8
conda activate pi
如果虚拟环境成功激活,您的终端用户标识之前应该出现 (pi) 的标识。
步骤4. 安装 Isaac gym
- 下载并解压 Isaacgym 代码。
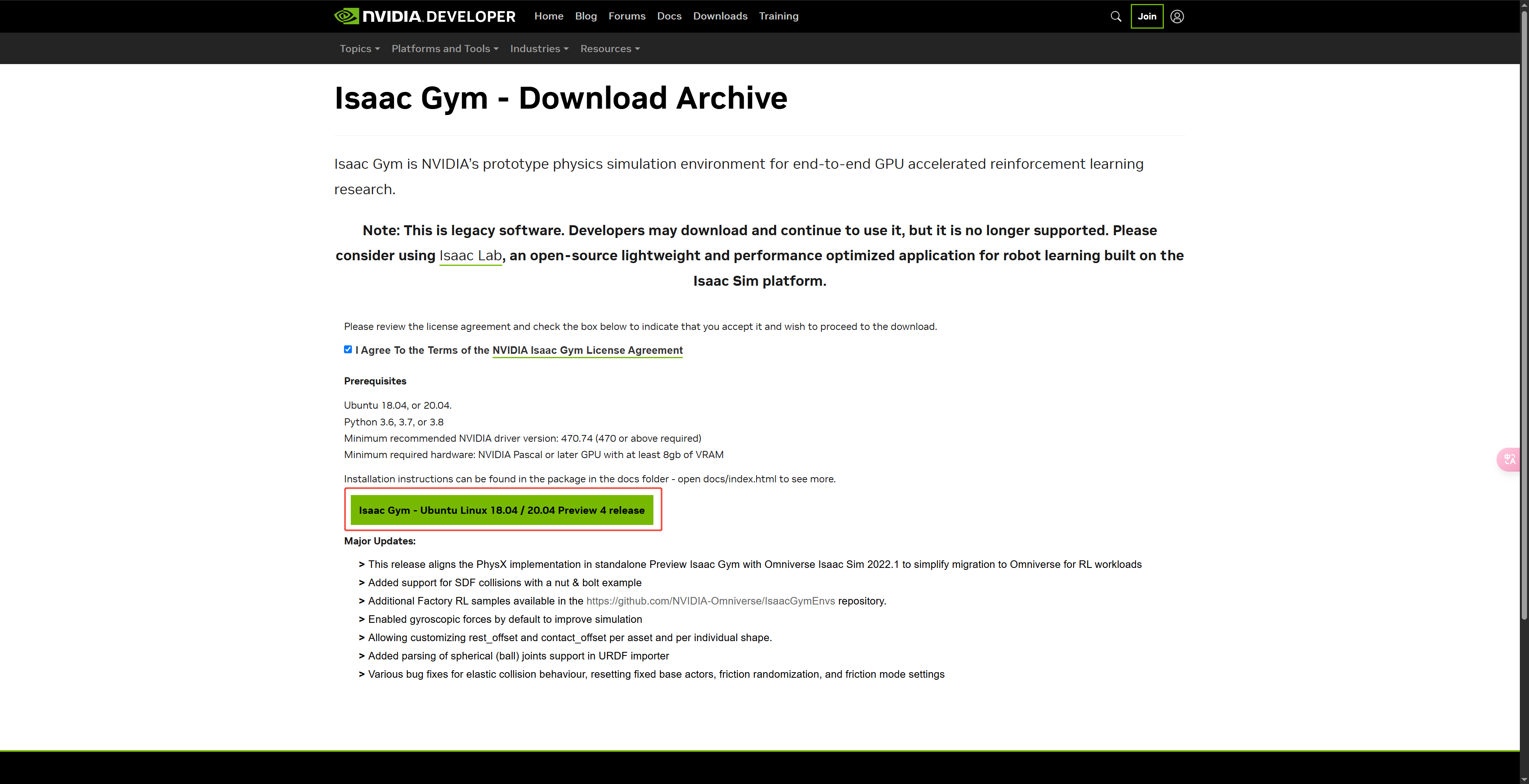
虽然 Nvidia Isaac Gym 下载页面中没有包含 ubuntu 22.04,但是在我们的测试中 ubuntu 22.04 也可以正常运行 Isaac Gym。
- 在虚拟环境中安装pytorch等依赖
conda install pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia
conda install numpy=1.23
- 安装 Isaac Gym
cd <path_to_isaacgym>/IsaacGym_Preview_4_Package/isaacgym/python
pip install -e .
- 验证 Isaac 是否安装成功
cd <path_to_isaacgym>/IsaacGym_Preview_4_Package/isaacgym/python/examples
python 1080_balls_of_solitude.py
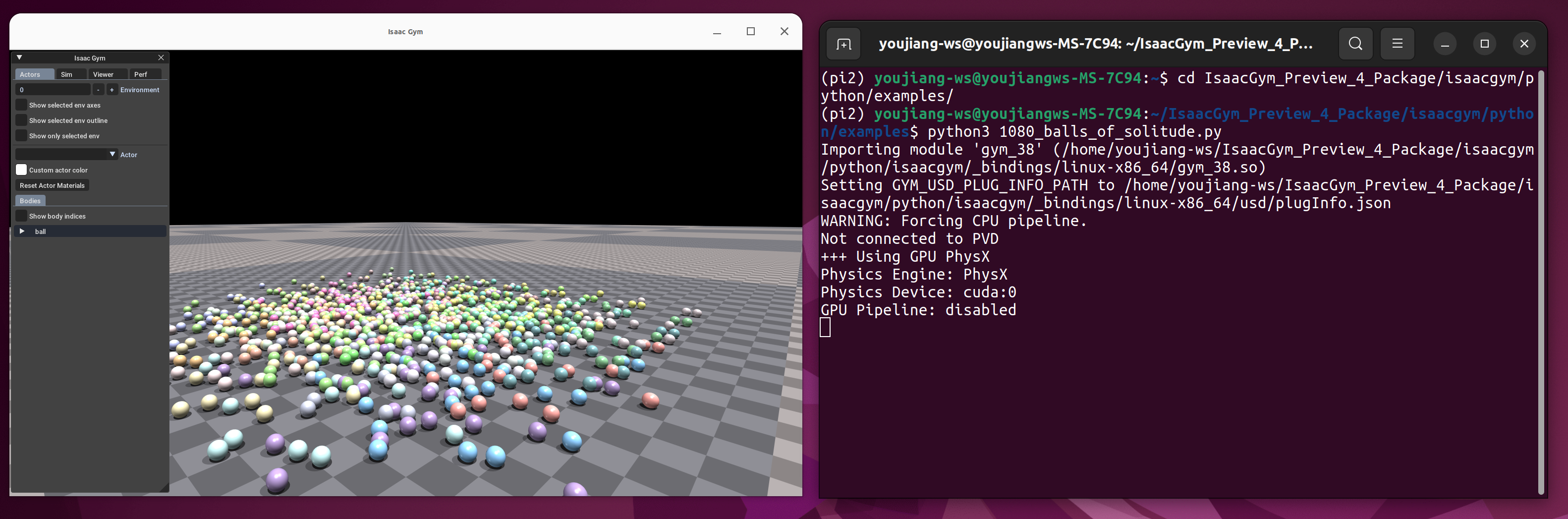
运行 python 脚本时可能会出现报错:
ImportError: libpython3.8.so.1.0: cannot open shared object file: No such file or dire
你可以通过下面的命令解决该问题,
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/home/youjiang-ws/anaconda3/envs/pi/lib
请注意,需要将 ${LD_LIBRARY_PATH}: 后面的路径替换成你自己的路径。
步骤5. 安装小pi运行环境
git clone https://github.com/HighTorque-Robotics/livelybot_pi_rl_baseline.git
cd livelybot_pi_rl_baseline
pip install -e .
训练代理
调整训练参数
pai_config.py
以下是对pai_config.py中相关代码的参数的中文注释。环境相关配置由于跟机器人结构耦合,因此无法修改。**可以根据需求修改pd控制器、仿真等参数,**训练后查看效果
pai_config.py
class PaiCfg(LeggedRobotCfg):
class env(LeggedRobotCfg.env):
# --- 环境配置 ---
# 更改观测维度相关设置
frame_stack = 15 # 状态观测帧叠加数量 (用于捕捉时序信息)
c_frame_stack = 3 # 特权观测帧叠加数量
num_single_obs = 47 # 单帧状态观测的维度
num_observations = int(frame_stack * (num_single_obs)) # 总的状态观测维度 = 叠加数 * 单帧维度
single_num_privileged_obs = 73 # 单帧特权观测的维度
num_privileged_obs = int(c_frame_stack * (single_num_privileged_obs)) # 总的特权观测维度 (用于 Critic 或特殊训练)
num_actions = 12 # 动作空间维度 (通常是关节数量)
num_envs = 4096 # 并行环境的数量
episode_length_s = 12 # 单个回合(episode)的最大时长(秒)
use_ref_actions = False # 是否使用参考动作 (通常用于模仿学习)
class safety:
# --- 安全相关设置 ---
# 安全系数(用于限制计算或应用中的值,例如软限制的阈值比例)
pos_limit = 1.0 # 位置限制因子 (比例)
vel_limit = 1.0 # 速度限制因子 (比例)
torque_limit = 0.85 # 力矩限制因子 (比例)
class asset(LeggedRobotCfg.asset):
# --- 机器人资源配置 ---
# URDF 文件路径 (使用环境变量或相对路径)
file = "{LEGGED_GYM_ROOT_DIR}/resources/robots/pi_12dof_release_v1/urdf/pi_12dof_release_v1_rl.urdf"
name = "Pai" # 机器人名称
foot_name = "ankle_roll" # 足部连杆名称标识 (用于接触检测)
knee_name = "calf" # 膝部连杆名称标识 (可能用于奖励或检测)
# 当这些连杆接触时终止回合
terminate_after_contacts_on = ["base_link"]
# 当这些连杆接触时施加惩罚
penalize_contacts_on = ["base_link"]
self_collisions = 0 # 自碰撞设置 (0: 开启, 1: 关闭)
flip_visual_attachments = False # 是否翻转可视化附件 (如果模型视觉部分方向错误)
replace_cylinder_with_capsule = False # 是否将圆柱体碰撞体替换为胶囊体 (可能更稳定)
fix_base_link = False # 是否固定基座连杆 (False表示可自由移动,用于行走)
class terrain(LeggedRobotCfg.terrain):
# --- 地形配置 ---
mesh_type = "plane" # 地形网格类型 ('plane': 平面, 'trimesh': 三角网格)
# mesh_type = 'trimesh'
curriculum = False # 是否启用课程学习 (逐步增加地形难度)
# --- 仅在崎岖地形 ('rough' 或 'trimesh') 时相关的参数 ---
measure_heights = False # 是否在观测中包含地形高度测量
static_friction = 0.6 # 地面静摩擦系数
dynamic_friction = 0.6 # 地面动摩擦系数
terrain_length = 8.0 # 地形长度 (米)
terrain_width = 8.0 # 地形宽度 (米)
num_rows = 20 # 地形网格行数 (用于生成高度图)
num_cols = 20 # 地形网格列数 (用于生成高度图)
max_init_terrain_level = 10 # 课程学习的初始地形难度级别
# 定义不同类型地形的比例 [平面, 障碍物, 均匀随机, 上坡, 下坡, 上楼梯, 下楼梯]
terrain_proportions = [0.2, 0.2, 0.4, 0.1, 0.1, 0, 0]
restitution = 0.0 # 地面恢复系数 (反弹程度, 0表示无反弹)
class noise:
# --- 噪声配置 (添加到观测值中,模拟传感器噪声) ---
add_noise = True # 是否添加噪声
noise_level = 0.6 # 全局噪声缩放系数 (乘以其他噪声尺度)
class noise_scales:
# --- 不同观测量的噪声尺度 (标准差) ---
dof_pos = 0.05 # 关节位置噪声
dof_vel = 0.5 # 关节速度噪声
ang_vel = 0.1 # 角速度噪声
lin_vel = 0.05 # 线速度噪声
quat = 0.03 # 四元数 (姿态) 噪声
height_measurements = 0.1 # 地形高度测量噪声
class init_state(LeggedRobotCfg.init_state):
# --- 机器人初始状态配置 ---
pos = [0.0, 0.0, 0.3453] # 初始基座位置 [x, y, z] (米)
# rot = [0., 0.27154693695611287, 0., 0.962425197628238] # 初始基座旋转 (四元数 w, x, y, z) - 这里被注释掉了
default_joint_angles = { # 默认关节角度 [rad] (当输入动作 action = 0.0 时的目标角度)
"r_hip_pitch_joint": 0.0, # 右髋关节俯仰
"r_hip_roll_joint": 0.0, # 右髋关节翻滚
"r_thigh_joint": 0.0, # 右大腿关节
"r_calf_joint": 0.0, # 右小腿关节
"r_ankle_pitch_joint": 0.0, # 右脚踝俯仰
"r_ankle_roll_joint": 0.0, # 右脚踝翻滚
"l_hip_pitch_joint": 0.0, # 左髋关节俯仰
"l_hip_roll_joint": 0.0, # 左髋关节翻滚
"l_thigh_joint": 0.0, # 左大腿关节
"l_calf_joint": 0.0, # 左小腿关节
"l_ankle_pitch_joint": 0.0, # 左脚踝俯仰
"l_ankle_roll_joint": 0.0, # 左脚踝翻滚
}
class control(LeggedRobotCfg.control):
# --- 控制参数配置 ---
# PD 控制器参数:
stiffness = { # 刚度 (P增益) [N*m/rad]
"hip_pitch_joint": 40.0,
"hip_roll_joint": 20.0,
"thigh_joint": 20.0,
"calf_joint": 40.0,
"ankle_pitch_joint": 40.0,
"ankle_roll_joint": 20.0,
}
damping = { # 阻尼 (D增益) [N*m*s/rad]
"hip_pitch_joint": 0.6,
"hip_roll_joint": 0.4,
"thigh_joint": 0.4,
"calf_joint": 0.6,
"ankle_pitch_joint": 0.6,
"ankle_roll_joint": 0.4,
}
# 动作缩放: target angle = actionScale * action + defaultAngle
action_scale = 0.25 # 策略网络输出动作的缩放因子
# action_scale = 0.5
# 控制频率抽取: 每个策略决策时间步 (policy DT) 内执行的物理仿真的控制动作更新次数 (@ sim DT)
# decimation = 10 # 仿真步长0.001s, decimation=10 -> 控制频率 1000/10 = 100Hz
decimation = 20 # 仿真步长0.001s, decimation=20 -> 控制频率 1000/20 = 50Hz
class sim(LeggedRobotCfg.sim):
# --- 仿真参数配置 ---
dt = 0.001 # 物理仿真步长时间 (秒), 对应 1000 Hz
substeps = 1 # 每个仿真步长(dt)内的物理子步数
up_axis = 1 # 指定哪个轴是向上的 (0: y轴向上, 1: z轴向上)
class physx(LeggedRobotCfg.sim.physx):
# --- PhysX 引擎特定参数 ---
num_threads = 30 # PhysX 使用的工作线程数
solver_type = 1 # 求解器类型 (0: PGS - 稳定但慢, 1: TGS - 快但可能不稳定)
num_position_iterations = 4 # 位置求解迭代次数
num_velocity_iterations = 0 # 速度求解迭代次数 (TGS通常设为0)
contact_offset = 0.01 # 接触偏移 [米] (在此距离内开始计算接触)
rest_offset = 0.0 # 静止偏移 [米] (接触稳定后的距离)
bounce_threshold_velocity = 0.1 # 触发反弹的最小速度阈值 [米/秒]
max_depenetration_velocity = 1.0 # 最大允许的反穿透速度
max_gpu_contact_pairs = 2**23 # GPU上允许的最大接触对数量 (影响显存)
default_buffer_size_multiplier = 5 # 内部缓冲区大小乘数
# 接触收集模式 (0: 从不, 1: 仅最后一个子步, 2: 所有子步)
contact_collection = 2
class domain_rand:
# --- 领域随机化配置 (用于 Sim2Real) ---
randomize_friction = True # 是否随机化摩擦系数
friction_range = [0.1, 2.0] # 摩擦系数随机化范围 [最小值, 最大值]
randomize_base_mass = True # 是否随机化基座质量
added_mass_range = [-1.0, 1.0] # 基座附加质量的范围 [最小值, 最大值] (公斤)
push_robots = True # 是否对机器人施加随机推力
push_interval_s = 4 # 施加推力的时间间隔 (秒)
max_push_vel_xy = 0.2 # XY平面最大推力脉冲产生的速度变化 [米/秒]
max_push_ang_vel = 0.4 # 最大推力脉冲产生的角速度变化 [弧度/秒]
dynamic_randomization = 0.02 # 动态随机化参数 (可能用于调整随机化强度或频率)
class commands(LeggedRobotCfg.commands):
# --- 指令配置 (机器人需要跟随的目标) ---
# 指令向量内容: 线速度x, 线速度y, 角速度yaw, 朝向角 (在朝向模式下,角速度yaw会根据朝向误差重新计算)
num_commands = 4 # 指令向量的维度
resampling_time = 8.0 # 指令重新采样的时间间隔 [秒]
heading_command = True # 如果为True: 根据朝向误差计算目标角速度指令
class ranges:
# --- 指令值的范围 ---
lin_vel_x = [-0.3, 0.6] # x轴线速度目标范围 [最小值, 最大值] [米/秒]
lin_vel_y = [-0.3, 0.3] # y轴线速度目标范围 [最小值, 最大值] [米/秒]
ang_vel_yaw = [-0.3, 0.3] # z轴角速度目标范围 [最小值, 最大值] [弧度/秒]
heading = [-3.14, 3.14] # 朝向角目标范围 [弧度]
class rewards:
# --- 奖励函数配置 ---
base_height_target = 0.3453 # 目标基座高度 (米)
min_dist = 0.15 # 最小距离阈值 (可能用于足间或膝间距奖励) (米)
max_dist = 0.2 # 最大距离阈值 (可能用于足间或膝间距奖励) (米)
# --- 用于LLM参数调整的一些设置? (注释原文如此) ---
target_joint_pos_scale = 0.08 # 目标关节位置奖励的缩放因子? (弧度)
target_feet_height = 0.02 # 目标足部抬起高度 (用于奖励?) (米)
cycle_time = 0.4 # 步态周期时间 (秒) (用于相位相关奖励?)
# 如果为True, 负的总奖励会被裁剪到零 (避免过早终止问题)
only_positive_rewards = True
# 追踪奖励 = exp(-error^2 / sigma^2) 或类似形式, sigma 控制奖励的敏感度
tracking_sigma_ang = 0.1 # 角速度追踪奖励的 sigma
tracking_sigma_lin = 0.1 # 线速度追踪奖励的 sigma
max_contact_force = 100 # 惩罚超过此值的接触力 [牛顿]
class scales:
# --- 各项奖励/惩罚的权重系数 ---
# -- 参考运动追踪 (可能用于模仿学习) --
joint_pos = 1.6 # 关节位置追踪奖励权重
feet_clearance = 5.0 # 足部离地高度/障碍物穿越奖励权重
feet_contact_number = 1.2 # 足部接触数量奖励权重 (鼓励特定接触模式?)
# -- 步态相关 --
feet_air_time = 1.0 # 足部滞空时间奖励权重 (鼓励动态步态)
foot_slip = -0.05 # 足部滑动惩罚权重
feet_distance = 0.16 # 足间距奖励/惩罚权重 (维持特定距离)
knee_distance = 0.16 # 膝间距奖励/惩罚权重 (避免碰撞)
# -- 接触相关 --
feet_contact_forces = -0.001 # 足部接触力惩罚权重 (惩罚过大冲击)
# -- 速度追踪 --
tracking_lin_vel = 10 # 线速度追踪奖励权重
tracking_ang_vel = 20 # 角速度追踪奖励权重
vel_mismatch_exp = 0.5 # 非期望速度惩罚权重 (z轴线速度, x/y轴角速度)
low_speed = 0.05 # 低速惩罚/奖励权重 (可能用于鼓励移动)
track_vel_hard = 0.2 # 硬性速度追踪奖励权重 (可能是在特定条件下?)
# -- 基座姿态与位置 --
default_hip_roll_joint_pos = 4 # 维持默认髋关节翻滚角度的奖励权重
default_thigh_joint_pos = 1.0 # 维持默认大腿关节角度的奖励权重
default_ankle_roll_pos = 0.5 # 维持默认脚踝翻滚角度的奖励权重
orientation = 0.5 # 维持基座水平姿态的奖励权重
base_height = 0.5 # 维持基座高度的奖励权重
base_acc = 0.2 # 基座加速度惩罚权重 (鼓励平稳)
# -- 能量与平滑性 --
action_smoothness = -0.002 # 动作平滑性惩罚权重 (相邻动作变化)
torques = -1e-5 # 关节力矩惩罚权重 (节能)
dof_vel = -5e-5 # 关节速度惩罚权重 (鼓励低速平稳?)
dof_acc = -1e-8 # 关节加速度惩罚权重 (平滑)
collision = -1.0 # 碰撞惩罚权重
# -- 终止相关 --
termination = 1.0 # 回合正常结束时的奖励权重 (区别于因错误终止)
class normalization:
# --- 观测值和动作的归一化/裁剪配置 ---
class obs_scales:
# --- 观测值缩放因子 (obs_norm = obs * scale) ---
lin_vel = 2.0 # 线速度观测缩放
ang_vel = 1.0 # 角速度观测缩放
dof_pos = 1.0 # 关节位置观测缩放
dof_vel = 0.05 # 关节速度观测缩放
quat = 1.0 # 四元数观测缩放
height_measurements = 5.0 # 地形高度观测缩放
clip_observations = 18.0 # 观测值的裁剪范围 [-clip, clip]
clip_actions = 18.0 # 动作值的裁剪范围 [-clip, clip]
class PaiCfgPPO(LeggedRobotCfgPPO):
# --- PPO 算法特定配置 ---
seed = 5 # 随机种子
runner_class_name = "OnPolicyRunner" # 使用的运行器类名 (可能还有其他如 DWLOnPolicyRunner)
class policy:
# --- 策略网络配置 ---
init_noise_std = 1.0 # 初始动作噪声标准差 (用于探索)
actor_hidden_dims = [512, 256, 128] # Actor 网络隐藏层维度
critic_hidden_dims = [768, 256, 128] # Critic 网络隐藏层维度 (可以与 Actor 不同)
class algorithm(LeggedRobotCfgPPO.algorithm):
# --- PPO 算法超参数 ---
entropy_coef = 0.001 # 熵项系数 (鼓励探索)
learning_rate = 1e-5 # 学习率
num_learning_epochs = 2 # 每个训练迭代中,使用同一批数据进行学习的轮数
gamma = 0.994 # 折扣因子 (Discount factor)
lam = 0.9 # GAE (Generalized Advantage Estimation) 中的 lambda 参数
num_mini_batches = 4 # 每个 Epoch 中 Mini-batch 的数量
class runner:
# --- 训练运行器配置 ---
policy_class_name = "ActorCritic" # 使用的策略网络类名
algorithm_class_name = "PPO" # 使用的算法类名
num_steps_per_env = 24 # 每个环境在一个训练迭代中收集的步数
max_iterations = 10001 # 最大训练迭代次数 (策略更新次数)
# --- 日志记录 ---
save_interval = 100 # 模型保存的时间间隔 (每 N 次迭代检查一次)
experiment_name = "Pai_ppo" # 实验名称 (用于日志文件夹)
run_name = "v1" # 运行名称 (用于日志文件夹内的子目录)
# --- 加载与恢复训练 ---
resume = False # 是否从之前的 checkpoint 恢复训练
load_run = -1 # 要加载的运行序号 (-1 表示加载最新的运行)
checkpoint = -1 # 要加载的模型 checkpoint 序号 (-1 表示加载最新的模型)
resume_path = None # 恢复训练的路径 (通常由 load_run 和 checkpoint 自动生成)
pai_env.py
以下是对pai_env.py代码中相关代码的中文注释,其中“_reward”开头的是各种奖励函数定义,可以修改pai_config.py中的class rewards中对应的系数来改变奖励惩罚的权重:
pai_env.py
from isaacgym.torch_utils import * # 导入 Isaac Gym PyTorch 工具函数
from isaacgym import gymtorch, gymapi # 导入 Isaac Gym 核心库
import torch # 导入 PyTorch
from humanoid.envs import LeggedRobot # 导入基础 LeggedRobot 环境类
from humanoid.envs.pai.pai_config import PaiCfg # 导入 Pai 机器人的特定配置
from humanoid.utils.terrain import HumanoidTerrain # 导入人形机器人地形类
# from collections import deque # 导入双端队列(当前未启用)
def get_euler_xyz_tensor(quat):
"""将四元数张量转换为欧拉角(XYZ顺序)张量"""
r, p, w = get_euler_xyz(quat) # 调用 Isaac Gym 的工具函数获取 roll, pitch, yaw
# 将 r, p, w 堆叠到维度 1
euler_xyz = torch.stack((r, p, w), dim=1)
# 将大于 pi 的角度减去 2*pi,使范围在 [-pi, pi]
euler_xyz[euler_xyz > np.pi] -= 2 * np.pi
return euler_xyz
class PaiFreeEnv(LeggedRobot):
"""
PaiFreeEnv 是一个为足式机器人定义的自定义环境类。
Args:
cfg (PaiCfg): 足式机器人的配置对象。
sim_params: 仿真的参数。
physics_engine: 仿真中使用的物理引擎。
sim_device: 仿真使用的设备 ('cpu' 或 'cuda:N')。
headless: 指示仿真是否应在无头模式下运行的标志。
Attributes:
last_feet_z (float): 上一时刻足部的 z 坐标。
feet_height (torch.Tensor): 表示足部高度的张量。
sim (gymtorch.GymSim): 仿真对象。
terrain (HumanoidTerrain): 地形对象。
up_axis_idx (int): 代表向上轴的索引。
command_input (torch.Tensor): 表示指令输入的张量。
privileged_obs_buf (torch.Tensor): 表示特权观测缓冲区的张量。
obs_buf (torch.Tensor): 表示观测缓冲区的张量。
obs_history (collections.deque): 包含观测历史的双端队列。
critic_history (collections.deque): 包含 Critic 观测历史的双端队列。
Methods:
_push_robots(): 随机推动机器人(通过设置随机的基座速度)。
_get_phase(): 计算步态周期的相位。
_get_gait_phase(): 计算步态相位(触地/摆动)。
compute_ref_state(): 计算参考状态。
create_sim(): 创建仿真、地形和环境。
_get_noise_scale_vec(cfg): 设置用于缩放添加到观测值的噪声的向量。
step(actions): 使用给定的动作执行一个仿真步骤。
compute_observations(): 计算观测值。
reset_idx(env_ids): 为指定的环境 ID 重置环境。
"""
def __init__(
self, cfg: PaiCfg, sim_params, physics_engine, sim_device, headless
):
"""环境初始化函数"""
# 调用父类 LeggedRobot 的初始化函数
super().__init__(cfg, sim_params, physics_engine, sim_device, headless)
# 初始化上一时刻足部 Z 坐标
self.last_feet_z = 0.05
# 初始化足部高度缓冲区
self.feet_height = torch.zeros((self.num_envs, 2), device=self.device) # 假设是双足机器人或关注两个足部
# 重置所有环境
self.reset_idx(torch.tensor(range(self.num_envs), device=self.device))
# 计算初始观测值
self.compute_observations()
def _push_robots(self):
"""随机推动机器人。通过设置一个随机化的基座速度来模拟一个冲量。"""
max_vel = self.cfg.domain_rand.max_push_vel_xy # 获取配置中定义的最大 XY 平面推力速度
max_push_angular = self.cfg.domain_rand.max_push_ang_vel # 获取配置中定义的最大角速度推力
# 生成随机的 XY 平面推力速度
self.rand_push_force[:, :2] = torch_rand_float(
-max_vel, max_vel, (self.num_envs, 2), device=self.device
) # 线速度 x/y
# 将随机速度应用到机器人的根状态张量 (线速度部分)
self.root_states[:, 7:9] = self.rand_push_force[:, :2]
# 生成随机的角速度推力
self.rand_push_torque = torch_rand_float(
-max_push_angular, max_push_angular, (self.num_envs, 3), device=self.device
)
# 将随机角速度应用到机器人的根状态张量 (角速度部分)
self.root_states[:, 10:13] = self.rand_push_torque
# 使用 Isaac Gym API 将更新后的根状态张量设置回仿真器
self.gym.set_actor_root_state_tensor(
self.sim, gymtorch.unwrap_tensor(self.root_states)
)
def check_termination(self):
"""检查环境是否需要重置 (判断回合是否终止)"""
# 检查终止接触:如果指定用于终止的连杆(如基座)接触力过大,则重置
self.reset_buf = torch.any(
torch.norm(
self.contact_forces[:, self.termination_contact_indices, :], dim=-1 # 计算终止连杆上的接触力范数
)
> 1.0, # 如果范数大于 1.0
dim=1, # 沿着环境维度检查是否至少有一个连杆满足条件
)
# 检查超时:如果当前回合长度超过最大回合长度,则重置
self.time_out_buf = (
self.episode_length_buf > self.max_episode_length
) # 超时不算作失败终止 (通常没有负奖励)
# 检查姿态:如果基座的投影重力向量在 X 或 Y 方向的分量过大(表示倾斜过大),则重置
self.reset_buf |= torch.any(
torch.abs(self.projected_gravity[:, 0:1]) > 0.8, dim=1 # 检查 Roll 方向倾斜
)
self.reset_buf |= torch.any(
torch.abs(self.projected_gravity[:, 1:2]) > 0.8, dim=1 # 检查 Pitch 方向倾斜
)
# --- 其他可选的终止条件(当前被注释掉)---
# 检查角速度过大
# self.reset_buf |= torch.any(
# torch.norm(self.base_ang_vel, dim=-1, keepdim=True) > 15.0, dim=1
# )
# 检查线速度过大
# self.reset_buf |= torch.any(
# torch.norm(self.base_lin_vel, dim=-1, keepdim=True) > 25.0, dim=1
# )
# 检查特定关节(如大腿)角度超限
# self.reset_buf |= torch.any(torch.abs(self.dof_pos[:, 2:3]) > 0.3, dim=1)
# self.reset_buf |= torch.any(torch.abs(self.dof_pos[:, 8:9]) > 0.3, dim=1)
# 检查特定关节(如髋关节翻滚)角度超限
# self.reset_buf |= torch.any(torch.abs(self.dof_pos[:, 1:2]) > 0.1, dim=1)
# self.reset_buf |= torch.any(torch.abs(self.dof_pos[:, 7:8]) > 0.1, dim=1)
# 检查特定关节(如脚踝翻滚)角度超限
# self.reset_buf |= torch.any(torch.abs(self.dof_pos[:, 5:6]) > 0.15, dim=1)
# self.reset_buf |= torch.any(torch.abs(self.dof_pos[:, 11:12]) > 0.15, dim=1)
# 检查基座高度过低 (例如 < 0.3 米)
self.reset_buf |= torch.any(self.base_pos[:, 2:3] < 0.3, dim=1)
# 将超时也加入重置标志
self.reset_buf |= self.time_out_buf
def _get_phase(self):
"""计算步态周期相位"""
cycle_time = self.cfg.rewards.cycle_time # 获取配置中定义的步态周期时间
# 相位 = (当前回合已进行时间 / 周期时间) 取模 1 (隐式)
phase = self.episode_length_buf * self.dt / cycle_time
return phase
def _get_gait_phase(self):
"""计算步态相位(触地/摆动状态)"""
# 返回一个浮点数掩码: 1 表示支撑相 (stance), 0 表示摆动相 (swing)
phase = self._get_phase() # 获取当前相位
# 计算相位的正弦值,并加入随机的半周期偏移以增加多样性
sin_pos = torch.sin(2 * torch.pi * phase + self.random_half_phase[0])
# 添加双支撑阶段 (当相位接近 0 或 pi 时)
stance_mask = torch.zeros((self.num_envs, 2), device=self.device) # 初始化为全 0 (摆动)
# 左脚支撑相: 当 sin_pos >= 0
stance_mask[:, 0] = sin_pos >= 0
# 右脚支撑相: 当 sin_pos < 0
stance_mask[:, 1] = sin_pos < 0
# 双支撑阶段: 当 sin_pos 的绝对值小于某个阈值 (如 0.1) 时,双脚都视为支撑
stance_mask[torch.abs(sin_pos) < 0.1] = 1
return stance_mask
def compute_ref_state(self):
"""计算参考状态 (例如用于模仿学习或特定奖励计算)"""
phase = self._get_phase() # 获取当前相位
# 计算相位的正弦值,并加入随机半周期偏移
sin_pos = torch.sin(2 * torch.pi * phase + self.random_half_phase[0])
sin_pos_l = sin_pos.clone() # 左腿相位信号
sin_pos_r = sin_pos.clone() # 右腿相位信号
# 初始化参考关节位置为零
self.ref_dof_pos = torch.zeros_like(self.dof_pos)
# 获取配置中定义的目标关节位置缩放因子
scale_1 = self.cfg.rewards.target_joint_pos_scale
scale_2 = 2 * scale_1 # 另一个缩放因子
# 左脚支撑相时,关节位置设置为 0 (或默认值)
sin_pos_l[sin_pos_l > 0] = 0 # 将大于 0 的值设为 0
# 根据相位信号设置左腿部分关节的参考位置
self.ref_dof_pos[:, 0] = sin_pos_l * scale_1 # 例如: 左髋关节俯仰
self.ref_dof_pos[:, 3] = -sin_pos_l * scale_2 # 例如: 左小腿关节
self.ref_dof_pos[:, 4] = sin_pos_l * scale_1 # 例如: 左脚踝俯仰
# 右脚支撑相时,关节位置设置为 0 (或默认值)
sin_pos_r[sin_pos_r < 0] = 0 # 将小于 0 的值设为 0
# 根据相位信号设置右腿部分关节的参考位置
self.ref_dof_pos[:, 6] = -sin_pos_r * scale_1 # 例如: 右髋关节俯仰
self.ref_dof_pos[:, 9] = sin_pos_r * scale_2 # 例如: 右小腿关节
self.ref_dof_pos[:, 10] = -sin_pos_r * scale_1# 例如: 右脚踝俯仰
# 在双支撑阶段,所有参考位置设为 0
self.ref_dof_pos[torch.abs(sin_pos) < 0.1] = 0
# 计算参考动作 (简单地乘以 2,具体含义取决于控制策略)
self.ref_action = 2 * self.ref_dof_pos
def create_sim(self):
"""创建仿真、地形和环境"""
self.up_axis_idx = 2 # 设置向上轴为 Z 轴 (索引为 2)
# 使用 Isaac Gym API 创建仿真实例
self.sim = self.gym.create_sim(
self.sim_device_id, # 仿真设备 ID
self.graphics_device_id, # 图形设备 ID
self.physics_engine, # 使用的物理引擎
self.sim_params, # 仿真参数
)
mesh_type = self.cfg.terrain.mesh_type # 获取配置中指定的地形类型
# 如果地形类型是 'heightfield' 或 'trimesh'
if mesh_type in ["heightfield", "trimesh"]:
# 创建 HumanoidTerrain 地形对象
self.terrain = HumanoidTerrain(self.cfg.terrain, self.num_envs)
# 如果地形类型是 'plane'
if mesh_type == "plane":
# 创建一个简单的地面平面
self._create_ground_plane()
# 如果地形类型是 'heightfield'
elif mesh_type == "heightfield":
# 创建高度场地形
self._create_heightfield()
# 如果地形类型是 'trimesh'
elif mesh_type == "trimesh":
# 创建三角网格地形
self._create_trimesh()
# 如果地形类型是其他无法识别的值
elif mesh_type is not None:
raise ValueError(
"无法识别的地形网格类型。允许的类型为 [None, plane, heightfield, trimesh]"
)
# 创建所有并行的环境实例
self._create_envs()
def _get_noise_scale_vec(self, cfg):
"""设置用于缩放添加到观测值的噪声的向量。
[注意]: 当改变观测结构时必须进行调整。
Args:
cfg (Dict): 环境配置文件
Returns:
[torch.Tensor]: 用于乘以 [-1, 1] 均匀分布的尺度向量
"""
# 初始化噪声尺度向量为零,维度与单帧观测维度相同
noise_vec = torch.zeros(self.cfg.env.num_single_obs, device=self.device)
self.add_noise = self.cfg.noise.add_noise # 获取是否添加噪声的标志
noise_scales = self.cfg.noise.noise_scales # 获取配置中定义的噪声尺度
# --- 根据观测向量的结构设置噪声尺度 ---
# [0:5] 对应指令 (通常不加噪声)
noise_vec[0:5] = 0.0
# [5:17] 对应关节位置 (乘以关节位置噪声尺度和观测缩放尺度)
noise_vec[5:17] = noise_scales.dof_pos * self.obs_scales.dof_pos
# [17:29] 对应关节速度 (乘以关节速度噪声尺度和观测缩放尺度)
noise_vec[17:29] = noise_scales.dof_vel * self.obs_scales.dof_vel
# [29:41] 对应上一时刻动作 (通常不加噪声)
noise_vec[29:41] = 0.0
# [41:44] 对应基座角速度 (乘以角速度噪声尺度和观测缩放尺度)
noise_vec[41:44] = noise_scales.ang_vel * self.obs_scales.ang_vel
# [44:47] 对应基座姿态 (欧拉角) (乘以姿态噪声尺度和观测缩放尺度)
noise_vec[44:47] = noise_scales.quat * self.obs_scales.quat
return noise_vec
def step(self, actions):
"""执行一个仿真步骤"""
# 如果配置了使用参考动作 (例如模仿学习)
if self.cfg.env.use_ref_actions:
actions += self.ref_action # 将网络输出的动作与参考动作相加
# --- 动态随机化 ---
# 生成随机延迟因子
delay = torch.rand((self.num_envs, 1), device=self.device)
# 对当前动作和上一时刻动作进行加权平均,模拟延迟
actions = (1 - delay) * actions + delay * self.actions
# 添加与动作本身成比例的随机噪声,模拟执行器或控制噪声
actions += (
self.cfg.domain_rand.dynamic_randomization # 获取动态随机化强度因子
* torch.randn_like(actions) # 生成标准正态分布噪声
* actions # 乘以动作本身
)
# 调用父类的 step 函数,执行物理仿真、奖励计算等
return super().step(actions)
def compute_observations(self):
"""计算观测值"""
# print("feet_indices", self.feet_indices) # 调试信息:打印足部索引
# print(self.root_states[:, 2][0]) # 调试信息:打印第一个环境的基座 Z 坐标
phase = self._get_phase() # 计算步态相位
self.compute_ref_state() # 计算参考状态 (关节位置等)
# 计算相位相关的正弦和余弦值,用于观测
sin_pos = torch.sin(2 * torch.pi * phase + self.random_half_phase[0]).unsqueeze(1)
cos_pos = torch.cos(2 * torch.pi * phase + self.random_half_phase[0]).unsqueeze(1)
# 获取步态相位掩码 (支撑/摆动)
stance_mask = self._get_gait_phase()
# 获取接触掩码 (足部接触力是否大于阈值)
contact_mask = self.contact_forces[:, self.feet_indices, 2] > 5.0
# --- 构建指令输入部分观测 ---
self.command_input = torch.cat(
(sin_pos, cos_pos, self.commands[:, :3] * self.commands_scale), dim=1
) # 包含相位信息和速度指令 (5维)
# --- 获取关节状态观测 ---
# 归一化的相对关节位置 (当前位置 - 默认位置) * 缩放因子
q = (self.dof_pos - self.default_dof_pos) * self.obs_scales.dof_pos
# 归一化的关节速度
dq = self.dof_vel * self.obs_scales.dof_vel
# 计算当前关节位置与参考关节位置的差值
diff = self.dof_pos - self.ref_dof_pos
# --- 构建特权观测缓冲区 (包含仿真内部信息,用于 Critic) ---
self.privileged_obs_buf = torch.cat(
(
self.command_input, # 指令输入 (5维)
(self.dof_pos - self.default_joint_pd_target) # 相对关节位置(相对于PD目标?) (12维)
* self.obs_scales.dof_pos,
self.dof_vel * self.obs_scales.dof_vel, # 关节速度 (12维)
self.actions, # 上一时刻的动作 (12维)
diff, # 关节位置与参考位置的差值 (12维)
self.base_lin_vel * self.obs_scales.lin_vel, # 基座线速度 (3维)
self.base_ang_vel * self.obs_scales.ang_vel, # 基座角速度 (3维)
self.base_euler_xyz * self.obs_scales.quat, # 基座欧拉角 (3维)
self.rand_push_force[:, :2], # 施加的随机推力 (XY) (2维) -> 注释写3维? 需确认
self.rand_push_torque, # 施加的随机力矩 (3维)
self.env_frictions, # 环境摩擦系数 (1维)
self.body_mass / 30.0, # 归一化的身体质量 (1维)
stance_mask, # 步态相位掩码 (2维)
contact_mask, # 接触掩码 (2维)
# 总维度: 5+12+12+12+12+3+3+3+2+3+1+1+2+2 = 73 (与配置相符 single_num_privileged_obs)
),
dim=-1,
)
# --- 构建标准观测缓冲区 (用于 Actor) ---
obs_buf = torch.cat(
(
self.command_input, # 指令输入 (5维)
q, # 归一化相对关节位置 (12维)
dq, # 归一化关节速度 (12维)
self.actions, # 上一时刻动作 (12维)
self.base_ang_vel * self.obs_scales.ang_vel, # 基座角速度 (3维)
self.base_euler_xyz * self.obs_scales.quat, # 基座欧拉角 (3维)
# 总维度: 5 + 12 + 12 + 12 + 3 + 3 = 47 (与配置相符 num_single_obs)
),
dim=-1,
)
# 如果配置了测量地形高度
if self.cfg.terrain.measure_heights:
# 计算归一化的地形高度观测值
heights = (
torch.clip(
self.root_states[:, 2].unsqueeze(1) - 0.5 - self.measured_heights, # (基座高度 - 0.5 - 地形高度)
-1, # 裁剪范围
1.0,
)
* self.obs_scales.height_measurements # 乘以缩放因子
)
# 将高度信息附加到特权观测缓冲区 (也可能附加到标准观测缓冲区,取决于具体实现)
self.privileged_obs_buf = torch.cat((self.obs_buf, heights), dim=-1) # 这里是附加到 obs_buf? 可能是笔误,应为 privileged_obs_buf
# 如果配置了添加噪声
if self.add_noise:
# 在当前观测值上添加高斯噪声,并使用噪声尺度向量进行缩放
obs_now = (
obs_buf.clone()
+ torch.randn_like(obs_buf) # 生成同形状标准正态分布噪声
* self.noise_scale_vec # 乘以各维度的噪声尺度
* self.cfg.noise.noise_level # 乘以全局噪声等级
)
else:
# 不添加噪声,直接使用原始观测值
obs_now = obs_buf.clone()
# --- 使用历史观测帧 (Frame Stack) ---
# 将当前观测帧添加到历史队列
self.obs_history.append(obs_now)
# 将当前特权观测帧添加到历史队列
self.critic_history.append(self.privileged_obs_buf)
# 将历史观测帧堆叠起来 (N, T, K), N=环境数, T=历史帧数, K=单帧维度
obs_buf_all = torch.stack(
[self.obs_history[i] for i in range(self.obs_history.maxlen)], dim=1
)
# 将堆叠后的观测历史展平成 (N, T*K),作为最终的观测缓冲区 (用于 Actor)
self.obs_buf = obs_buf_all.reshape(self.num_envs, -1)
# 将历史特权观测帧堆叠起来,作为最终的特权观测缓冲区 (用于 Critic)
self.privileged_obs_buf = torch.cat(
[self.critic_history[i] for i in range(self.cfg.env.c_frame_stack)], dim=1 # 使用配置中定义的 c_frame_stack 数量
)
def reset_idx(self, env_ids):
"""重置指定 ID 的环境"""
# 调用父类的 reset_idx 方法,处理基础的重置逻辑 (如设置初始状态)
super().reset_idx(env_ids)
# 清空这些环境的观测历史记录 (乘以 0)
for i in range(self.obs_history.maxlen):
self.obs_history[i][env_ids] *= 0
# 清空这些环境的 Critic 观测历史记录 (乘以 0)
for i in range(self.critic_history.maxlen):
self.critic_history[i][env_ids] *= 0
# ================================================ 奖励函数 ================================================== #
def _reward_joint_pos(self):
"""
根据当前关节位置和目标关节位置之间的差异计算奖励。
(此函数似乎只关注部分特定关节: 0, 3, 4, 6, 9, 10)
"""
selected_columns = [0, 3, 4, 6, 9, 10] # 选择要计算奖励的关节索引
# 计算选中关节的当前位置与参考位置的差值
diff = (self.dof_pos - self.ref_dof_pos)[:, selected_columns]
# 使用指数函数计算奖励,差值越大奖励越小;同时减去一个线性惩罚项(带截断)
r = torch.exp(-2 * torch.norm(diff, dim=1)) - 0.2 * torch.norm(
diff, dim=1
).clamp(0, 0.5)
return r
def _reward_feet_distance(self):
"""
根据足部之间的距离计算奖励。惩罚足部靠得太近或太远的情况。
"""
# 获取足部 XY 坐标
foot_pos = self.rigid_state[:, self.feet_indices, :2]
# 计算双脚之间的距离
foot_dist = torch.norm(foot_pos[:, 0, :] - foot_pos[:, 1, :], dim=1)
fd = self.cfg.rewards.min_dist # 获取配置中的最小距离阈值
max_df = self.cfg.rewards.max_dist # 获取配置中的最大距离阈值
# 计算距离小于最小阈值的惩罚项 (指数形式)
d_min = torch.clamp(foot_dist - fd, -0.5, 0.0) # 负数表示小于阈值
# 计算距离大于最大阈值的惩罚项 (指数形式)
d_max = torch.clamp(foot_dist - max_df, 0, 0.5) # 正数表示大于阈值
# 结合两个惩罚项计算奖励
return (
torch.exp(-torch.abs(d_min) * 100) + torch.exp(-torch.abs(d_max) * 100)
) / 2
def _reward_knee_distance(self):
"""
根据人形机器人膝盖之间的距离计算奖励。
(逻辑类似足间距奖励,但可能使用不同的阈值)
"""
# 获取膝盖 XY 坐标
foot_pos = self.rigid_state[:, self.knee_indices, :2] # 使用膝盖索引
# 计算膝盖之间的距离
foot_dist = torch.norm(foot_pos[:, 0, :] - foot_pos[:, 1, :], dim=1)
fd = self.cfg.rewards.min_dist # 最小距离阈值
max_df = self.cfg.rewards.max_dist * 2.0 # 最大距离阈值 (这里是足部最大距离的2倍?)
# 计算距离小于最小阈值的惩罚项
d_min = torch.clamp(foot_dist - fd, -0.5, 0.0)
# 计算距离大于最大阈值的惩罚项
d_max = torch.clamp(foot_dist - max_df, 0, 0.5)
# 结合两个惩罚项计算奖励
return (
torch.exp(-torch.abs(d_min) * 100) + torch.exp(-torch.abs(d_max) * 100)
) / 2
def _reward_foot_slip(self):
"""
计算最小化足部滑动的奖励。奖励基于接触力和足部速度。
使用接触阈值来判断足部是否与地面接触。
足部速度通过接触条件进行缩放(只惩罚接触时的滑动)。
"""
# 判断足部是否接触地面 (接触力大于阈值)
contact = self.contact_forces[:, self.feet_indices, 2] > 5.0
# 计算足部 XY 平面速度的范数 (速率)
foot_speed_norm = torch.norm(
self.rigid_state[:, self.feet_indices, 10:12], dim=2 # [:, :, 10:12] 对应线速度 vy, vz? 需确认索引含义
)
# 计算滑动惩罚 (速度的平方根)
rew = torch.sqrt(foot_speed_norm)
# 只在接触时考虑滑动惩罚
rew *= contact
# 对双脚的滑动惩罚求和
return torch.sum(rew, dim=1)
def _reward_feet_air_time(self):
"""
计算足部滞空时间的奖励,鼓励更长的步幅。
通过检查离空后首次接触地面来实现。
滞空时间在奖励计算中被限制在一个最大值。
"""
# 获取当前接触状态
contact = self.contact_forces[:, self.feet_indices, 2] > 5.0
# 获取期望的步态相位 (支撑/摆动)
stance_mask = self._get_gait_phase()
# 结合当前接触、期望相位和上一时刻接触状态,判断是否处于有效的接触/支撑状态
# (逻辑比较复杂,可能用于过滤掉短暂的接触或相位不匹配的情况)
self.contact_filt = torch.logical_or(
torch.logical_or(contact, stance_mask), self.last_contacts
)
# 更新上一时刻接触状态
self.last_contacts = contact
# 判断是否是首次接触 (从滞空状态转为接触/支撑状态)
first_contact = (self.feet_air_time > 0.0) * self.contact_filt
# 累积滞空时间
self.feet_air_time += self.dt
# 计算本次滞空时间的奖励 (限制最大值,且只在首次接触时计算)
air_time = self.feet_air_time.clamp(0, 0.5) * first_contact
# 如果脚处于接触/支撑状态,则重置滞空时间计数器
self.feet_air_time *= ~self.contact_filt
# 对双脚的滞空时间奖励求和
return air_time.sum(dim=1)
def _reward_feet_contact_number(self):
"""
根据足部接触数量与步态相位的一致性计算奖励。
根据足部接触是否符合预期的步态相位给予奖励或惩罚。
"""
# 获取接触状态
contact = self.contact_forces[:, self.feet_indices, 2] > 5.0
# 获取期望的步态相位 (支撑/摆动)
stance_mask = self._get_gait_phase()
# 如果接触状态与期望相位一致,奖励为 1,否则惩罚为 -0.3
reward = torch.where(contact == stance_mask, 1, -0.3)
# 对双脚的奖励/惩罚取平均值
return torch.mean(reward, dim=1)
def _reward_orientation(self):
"""
计算维持基座水平姿态的奖励。
使用基座欧拉角和投影重力向量来惩罚与期望姿态的偏差。
"""
# 根据欧拉角计算姿态偏差奖励 (惩罚 roll 和 pitch)
quat_mismatch = torch.exp(
-torch.sum(torch.abs(self.base_euler_xyz[:, :2]), dim=1) * 10 # 指数衰减,偏差越大奖励越小
)
# 根据投影重力向量计算姿态偏差奖励 (惩罚 XY 方向的分量)
orientation = torch.exp(-torch.norm(self.projected_gravity[:, :2], dim=1) * 20) # 指数衰减
# 结合两种计算方式
return (quat_mismatch + orientation) / 2.0
def _reward_feet_contact_forces(self):
"""
计算使接触力保持在指定范围内的奖励。惩罚过高的足部接触力。
"""
# 计算接触力范数超过最大允许接触力的部分,并进行裁剪
penalty = torch.sum(
(
torch.norm(self.contact_forces[:, self.feet_indices, :], dim=-1) # 计算接触力范数
- self.cfg.rewards.max_contact_force # 减去最大允许力
).clip(0, 400), # 将结果裁剪到 [0, 400] 范围 (只惩罚超出的部分)
dim=1, # 对双脚求和
)
# 返回的是惩罚值,因为奖励函数通常越大越好,所以实际应用时会乘以负的权重
return penalty
def _reward_default_hip_roll_joint_pos(self):
"""
计算使关节位置接近默认位置的奖励,重点惩罚 Yaw 和 Roll 方向的偏差。
(函数名似乎只提到了 hip roll,但代码计算了多个关节)
"""
selected_columns = [1, 5, 7, 11] # 选择髋关节和脚踝的翻滚关节索引
_yaw_roll = self.dof_pos[:, selected_columns] # 获取这些关节的当前位置
yaw_roll = torch.norm(_yaw_roll, dim=1) # 计算这些关节位置的范数 (综合偏差)
yaw_roll = torch.clamp(yaw_roll, 0, 50) # 限制最大偏差值
# 使用指数函数计算奖励,偏差越大奖励越小
return torch.exp(-yaw_roll / 0.1) # 0.1 控制衰减速度
def _reward_default_thigh_joint_pos(self):
"""计算维持默认大腿关节位置的奖励"""
selected_columns = [2, 8] # 选择大腿关节索引
_yaw_roll = self.dof_pos[:, selected_columns] # 获取大腿关节位置
yaw_roll = torch.norm(_yaw_roll, dim=1) # 计算偏差范数
yaw_roll = torch.clamp(yaw_roll, 0, 50) # 限制最大偏差
# 使用指数函数计算奖励
return torch.exp(-yaw_roll / 0.1)
def _reward_base_height(self):
"""
根据机器人基座高度计算奖励。惩罚与目标基座高度的偏差。
奖励是根据机器人基座与其接触地面的足部平均高度之间的高度差计算的。
"""
stance_mask = self._get_gait_phase() # 获取支撑相掩码
# 计算支撑脚的平均 Z 坐标 (只考虑支撑脚)
measured_heights = torch.sum(
self.rigid_state[:, self.feet_indices, 2] * stance_mask, dim=1 # 足部 Z 坐标 * 支撑掩码
) / torch.sum(stance_mask, dim=1) # 除以支撑脚数量
# 计算基座相对于支撑脚的实际高度 (减去一个偏移量 0.05)
base_height = self.root_states[:, 2] - (measured_heights - 0.05)
# 计算与目标基座高度的偏差,并使用指数函数计算奖励
return torch.exp(
-torch.abs(base_height - self.cfg.rewards.base_height_target) * 50 # 指数衰减,偏差越大奖励越小
)
def _reward_base_acc(self):
"""
根据基座的加速度计算奖励。惩罚机器人基座的高加速度,鼓励更平滑的运动。
"""
# 计算基座加速度 (用上一时刻速度 - 当前速度近似)
root_acc = self.last_root_vel - self.root_states[:, 7:13] # [:, 7:13] 包含线速度和角速度
# 计算加速度范数,并使用指数函数计算奖励 (加速度越大奖励越小)
rew = torch.exp(-torch.norm(root_acc, dim=1) * 3) # 3 控制衰减速度
return rew
def _reward_vel_mismatch_exp(self):
"""
根据机器人线速度和角速度的不匹配程度计算奖励。
通过惩罚大的偏差来鼓励机器人保持稳定的速度。
(主要惩罚 Z 轴线速度和 XY 轴角速度)
"""
# 计算 Z 轴线速度的惩罚 (指数形式)
lin_mismatch = torch.exp(-torch.square(self.base_lin_vel[:, 2]) * 10)
# 计算 XY 轴角速度的惩罚 (指数形式)
ang_mismatch = torch.exp(-torch.norm(self.base_ang_vel[:, :2], dim=1) * 5.0)
# 结合线速度和角速度的惩罚
c_update = (lin_mismatch + ang_mismatch) / 2.0
return c_update
def _reward_track_vel_hard(self):
"""
计算精确跟踪线速度和角速度指令的奖励。
惩罚与指定线速度和角速度目标的偏差。
(与 _reward_tracking_* 类似,但计算方式和权重可能不同)
"""
# 计算线速度(XY)跟踪误差范数
lin_vel_error = torch.norm(
self.commands[:, :2] - self.base_lin_vel[:, :2], dim=1
)
# 计算线速度跟踪奖励 (指数形式)
lin_vel_error_exp = torch.exp(-lin_vel_error * 10)
# 计算角速度(Yaw)跟踪误差绝对值
ang_vel_error = torch.abs(self.commands[:, 2] - self.base_ang_vel[:, 2])
# 计算角速度跟踪奖励 (指数形式)
ang_vel_error_exp = torch.exp(-ang_vel_error * 10)
# 计算一个线性的误差惩罚项
linear_error = 0.2 * (lin_vel_error + ang_vel_error)
# 结合指数奖励和线性惩罚
return (lin_vel_error_exp + ang_vel_error_exp) / 2.0 - linear_error
def _reward_tracking_lin_vel(self):
"""
跟踪 XY 轴上的线速度指令。
根据机器人线速度与指令值的匹配程度计算奖励。
(考虑了指令速度大小的影响,指令越大,容忍的绝对误差越大)
"""
# 计算线速度误差
error = self.commands[:, :2] - self.base_lin_vel[:, :2]
# 根据指令速度大小调整误差 (指令速度越大,误差权重越小)
error *= 1.0 / (1.0 + torch.abs(self.commands[:, :2]))
# 使用负平方指数函数计算奖励,并对 XY 轴求平均
rew = self._neg_sqrd_exp(error, a=self.cfg.rewards.tracking_sigma_lin).sum(dim=1)/2
return rew
def _reward_tracking_ang_vel(self):
"""
跟踪 Yaw 轴的角速度指令。
根据机器人角速度与指令 Yaw 值的匹配程度计算奖励。
(考虑了指令速度大小的影响)
"""
# 计算角速度误差
error = self.commands[:, 2] - self.base_ang_vel[:, 2]
# 根据指令速度大小调整误差
error *= 1.0 / (1.0 + torch.abs(self.commands[:, 2]))
# 使用负平方指数函数计算奖励
rew = self._neg_sqrd_exp(error, a=self.cfg.rewards.tracking_sigma_ang)
# print(rew.size()) # 调试信息
return rew
def _reward_feet_clearance(self):
"""
根据运动过程中摆动腿离地间隙计算奖励。
鼓励在步态的摆动阶段适当抬起脚。
"""
# 计算足部接触掩码
contact = self.contact_forces[:, self.feet_indices, 2] > 0.1
# 获取足部(或关联连杆)的 Z 坐标,并减去偏移量得到相对高度
feet_z = (
# self.rigid_state[:, self.feet_indices, 2] # 直接用足部 Z 坐标
# +
self.rigid_state[:, self.feet_indices - 1, 2] # 使用足部索引减 1 的连杆 Z 坐标?
) - 0.05063 # 减去一个固定偏移
# 计算 Z 坐标的变化量
delta_z = feet_z - self.last_feet_z
# 累积足部高度变化
self.feet_height += delta_z
# 更新上一时刻足部 Z 坐标
self.last_feet_z = feet_z
# 获取摆动相掩码 (1 表示摆动)
swing_mask = 1 - self._get_gait_phase()
# 如果足部高度接近目标抬起高度,则给予奖励
rew_pos = (
torch.abs(self.feet_height - self.cfg.rewards.target_feet_height) < 0.01
)
# 只在摆动相时计算奖励,并对双脚求和
rew_pos = torch.sum(rew_pos * swing_mask, dim=1)
# 如果脚接触地面,则重置累积的足部高度
self.feet_height *= ~contact
return rew_pos
def _reward_low_speed(self):
"""
根据机器人速度与指令速度的关系奖励或惩罚机器人。
检查机器人是否移动过慢、过快或以期望速度移动,
以及移动方向是否与指令匹配。
(主要关注 X 轴线速度)
"""
# 计算当前速度和指令速度的绝对值
absolute_speed = torch.abs(self.base_lin_vel[:, 0])
absolute_command = torch.abs(self.commands[:, 0])
# 定义速度标准
speed_too_low = absolute_speed < 0.5 * absolute_command # 速度低于指令的 50%
speed_too_high = absolute_speed > 1.2 * absolute_command # 速度高于指令的 120%
speed_desired = ~(speed_too_low | speed_too_high) # 速度在期望范围内
# 检查速度方向与指令方向是否不匹配
sign_mismatch = torch.sign(self.base_lin_vel[:, 0]) != torch.sign(
self.commands[:, 0]
)
# 初始化奖励张量
reward = torch.zeros_like(self.base_lin_vel[:, 0])
# 根据条件分配奖励
reward[speed_too_low] = -1.0 # 速度过慢:惩罚
reward[speed_too_high] = 0.0 # 速度过快:中性 (不惩罚也不奖励?)
reward[speed_desired] = 1.2 # 速度合适:奖励
reward[sign_mismatch] = -2.0 # 方向不匹配:最高优先级惩罚
# 只有当指令速度大于某个阈值时才应用此奖励/惩罚
return reward * (self.commands[:, 0].abs() > 0.1)
def _reward_torques(self):
"""
惩罚机器人关节中使用的高力矩。鼓励通过最小化电机施加的力来实现高效运动。
"""
# 计算所有关节力矩的平方和
return torch.sum(torch.square(self.torques), dim=1)
def _reward_dof_vel(self):
"""
惩罚机器人自由度(DOF)上的高速度。鼓励更平滑、更可控的运动。
"""
# 计算所有关节速度的平方和
return torch.sum(torch.square(self.dof_vel), dim=1)
def _reward_dof_acc(self):
"""
惩罚机器人自由度(DOF)上的高加速度。这对于确保平滑稳定的运动、
减少机器人机械部件的磨损非常重要。
"""
# 计算关节加速度的平方和 (用差分近似)
return torch.sum(
torch.square((self.last_dof_vel - self.dof_vel) / self.dt), dim=1
)
def _reward_collision(self):
"""
惩罚机器人与环境的碰撞,特别关注选定的身体部位。
鼓励机器人避免与物体或表面的不期望接触。
"""
# 计算被指定为需要惩罚接触的连杆上的接触力范数,如果大于阈值则计为 1,然后求和
return torch.sum(
1.0
* (
torch.norm(
self.contact_forces[:, self.penalised_contact_indices, :], dim=-1 # 计算接触力范数
)
> 0.1 # 判断是否大于阈值
),
dim=1, # 对所有受惩罚连杆求和
)
def _reward_action_smoothness(self):
"""
通过惩罚连续动作之间的巨大差异来鼓励机器人动作的平滑性。
这对于实现流畅运动和减少机械应力非常重要。
"""
# 惩罚一阶差分 (动作变化率)
term_1 = torch.sum(torch.square(self.last_actions - self.actions), dim=1)
# 惩罚二阶差分 (动作加速度)
term_2 = torch.sum(
torch.square(self.actions + self.last_last_actions - 2 * self.last_actions),
dim=1,
)
# 惩罚动作本身的幅度 (鼓励小动作?)
term_3 = 0.05 * torch.sum(torch.abs(self.actions), dim=1)
# 结合三项惩罚
return term_1 + term_2 + term_3
def _reward_default_ankle_roll_pos(self):
"""根据足部姿态计算奖励,惩罚足部翻滚和俯仰角度偏差"""
# 获取左脚和右脚的姿态四元数
e_1 = get_euler_xyz_tensor(self.rigid_state[:, self.feet_indices[0], 3:7]) # 左脚欧拉角
e_2 = get_euler_xyz_tensor(self.rigid_state[:, self.feet_indices[1], 3:7]) # 右脚欧拉角
# 计算 Roll 方向偏差奖励
feet_eular_0 = torch.abs(e_1[:, 0]) # 左脚 Roll 角度绝对值
feet_eular_1 = torch.abs(e_2[:, 0]) # 右脚 Roll 角度绝对值
rew = torch.exp(-((feet_eular_0 + feet_eular_1) / 2) / 0.1) # 指数衰减,偏差越大奖励越小
# 计算 Pitch 方向偏差奖励
feet_eular_0 = torch.abs(e_1[:, 1]) # 左脚 Pitch 角度绝对值
feet_eular_1 = torch.abs(e_2[:, 1]) # 右脚 Pitch 角度绝对值
rew += torch.exp(-((feet_eular_0 + feet_eular_1) / 2) / 0.1) # 累加 Pitch 方向奖励
# 返回 Roll 和 Pitch 方向奖励的平均值
return rew / 2
def _reward_termination(self):
"""计算回合终止时的奖励/惩罚"""
# 如果回合是因为错误条件终止 (reset_buf=True 且不是因为超时 time_out_buf=False)
# 则给予 -1.0 的惩罚
return -(self.reset_buf * ~self.time_out_buf).float()
# * ######################### 辅助函数 ############################## * #
def _neg_exp(self, x, a=1):
""" 负指数函数的简写助手 e^(-x/a)
a: x 的范围或衰减因子
"""
return torch.exp(-(x/a)/a) # 这里似乎应该是 torch.exp(-x/a) ?
def _neg_sqrd_exp(self, x, a=1):
""" 负平方指数函数的简写助手 e^(-(x/a)^2)
a: x 的范围或衰减因子
"""
return torch.exp(-torch.square(x/a)/a) # 这里似乎应该是 torch.exp(-torch.square(x/a)) 或 torch.exp(-torch.square(x)/a) ? 需确认原意
修改步态并可视化
为了方便演示,本文使用飞的岛up主开源的步态可视化工具
步骤1. 加载镜像(找工作人员)
docker load -i ubuntu20_pino_cro.tar
步骤2. 运行 docker
sudo docker run -it \
-v .:/data \
--device=/dev/dri \
--group-add video \
--volume=/tmp/.X11-unix:/tmp/.X11-unix \
--env="DISPLAY=$DISPLAY" \
--env="QT_X11_NO_MITSHM=1" \
--name=pinU20 \
ubuntu20_pino_cro:v0 /bin/bash
步骤3. 在主机开启运行显示
在主机上,运行xhost +local:$(whoami)来运行显示
步骤4. 安装依赖
容器中如果要用mujoco之类的,需要在容器中安装
apt-get install libglfw3 libglfw3-dev
apt-get install libx11-dev libxcursor-dev
apt-get install libx11-dev libxcursor-dev libxinerama-dev
步骤5. (Optional) pinocchio 使用
如果用pinocchio的c++编写一些程序
find_package(Eigen3 REQUIRED)
INCLUDE_DIRECTORIES(${EIGEN3_INCLUDE_DIR})
set(LIBPINOCCHIO_INC_DIR "/opt/openrobots/include")
set(LIBPINOCCHIO_LINK_DIR "/opt/openrobots/lib")
include_directories(${LIBPINOCCHIO_INC_DIR})
link_directories( ${LIBPINOCCHIO_LINK_DIR})
##新的
target_link_libraries(ctl PUBLIC pinocchio_default pinocchio_parsers pinocchio_collision )
##老的
##target_link_libraries(ctl PUBLIC pinocchio )
步骤6. 运行可视化脚本
可以利用Cursor等工具来修改实现自定义步态,以下代码是模拟“立定跳远”:
viewer.py
import os
import sys
import time
import numpy as np
import math
sys.path.append("/opt/openrobots/lib/python3.8/site-packages")
from pinocchio import visualize
import pinocchio
import example_robot_data
import crocoddyl
from pinocchio.robot_wrapper import RobotWrapper
# 设置路径和 URDF 文件
current_directory = os.getcwd()
modelPath = os.path.join(current_directory, "robot_description")
URDF_FILENAME = "icub/robots/pi/pi_12dof_release_v1_rl.urdf"
print("Pinocchio 版本:", pinocchio.__version__)
# 加载机器人模型(使用自由飞行基座)
rh5_robot = RobotWrapper.BuildFromURDF(
os.path.join(modelPath, URDF_FILENAME), [modelPath],
pinocchio.JointModelFreeFlyer()
)
rmodel = rh5_robot.model
# 定义展示中需要显示的关键帧(例如左右后足)
rightFoot = 'r_foot_rear'
leftFoot = 'l_foot_rear'
display = crocoddyl.MeshcatDisplay(rh5_robot, frameNames=[rightFoot, leftFoot])
# 设置初始配置(7个基础自由度 + 12个关节)
q = pinocchio.utils.zero(rmodel.nq)
# 设置基础的四元数为单位(无旋转)和初始高度
q[3:7] = [0, 0, 0, 1]
initialHeight = 0.5848
q[2] = initialHeight
# 将12个关节初始置零
q[7:19] = 0
display.display([q])
time.sleep(1) # 初始姿态显示一秒
# ----------------------------
# 引入 compute_ref_state 控制逻辑
# ----------------------------
# 参数设置
cycle_time = 1 # 步态周期,单位:秒
scale_1 = 0.5 # 参考关节位置缩放因子
scale_2 = 2 * scale_1 # 左右腿关节之间的比例
phase_offset = 0.0 # 相位偏移(可根据需要调整)
start_time = time.time()
while True:
current_time = time.time()
elapsed = current_time - start_time
# 计算周期相位(归一化到 [0,1))
phase = (elapsed % cycle_time) / cycle_time
# 计算正弦信号
sin_pos = np.sin(2 * np.pi * phase + phase_offset)
# 对于髋部(或其他控制关节),可保持原有的正弦映射:
hip_angle = sin_pos * scale_1
# 对于膝关节,采用优化的函数确保始终为非负:
# 当 sin_pos >= 0 时,(abs(sin_pos)-sin_pos)/2 = 0,膝关节参考角度为0(完全伸直)
# 当 sin_pos < 0 时,该表达式等于 (-sin_pos),即膝关节屈曲角度 = -sin_pos * scale_2
knee_angle = scale_2 * (abs(sin_pos) - sin_pos) / 2
# 定义一个12维的关节参考向量(假设左右腿的关节排列顺序如下)
ref_joints = np.zeros(12)
# 左腿:假设控制关节为索引 0(髋部)、3(膝关节)、4(踝部或其他)
ref_joints[0] = hip_angle
ref_joints[3] = knee_angle
ref_joints[4] = hip_angle # 可根据需要调整
# 右腿:假设控制关节为索引 6(髋部)、9(膝关节)、10(踝部或其他)
ref_joints[6] = hip_angle
ref_joints[9] = knee_angle
ref_joints[10] = hip_angle
# 可选:在 |sin_pos| 较小(接近0)时归零以模拟双支撑阶段
if abs(sin_pos) < 0.1:
for idx in [0, 3, 4, 6, 9, 10]:
ref_joints[idx] = 0.0
# 更新机器人配置中的关节部分(假设关节部分在 q[7:19])
q[7:19] = ref_joints
# 更新显示
display.display([q])
time.sleep(0.05) # 控制刷新率
步骤7. 查看效果
通过修改参数来实现不同的步态或腿部动作,运行后可以查看最终的效果:
训练代理并仿真验证
训练代理
首先运行play.py脚本,这样在”/logs/exported/“目录下会生成”policy_1.pt“策略权重
python humanoid/scripts/play.py --task=pai_ppo --load_run=Mar12_10-23-45_v2 --checkpoint -1 --run_name=v2
Sim2Sim 仿真
运行sim2sim.py在mujoco中进行仿真:
python scripts/sim2sim.py --load_model /path/to/logs/Pai_ppo/exported/policies/policy_1.pt

模型部署
步骤1. 登入机器
机器人开机
- 启动电池: 短按电池按钮一次;在短按后的一秒内,长按电池按钮, 持续时间需超过1秒。
- 模组通电:短按下开关按钮即可打开关节模组电源,打开后开关灯光亮起
- 主控通电: 长按电源按键3秒以上随后放开即可,打开时开关灯光亮起((约20s后即可配对手柄))
一定要按照上面的顺序依次打开
电池开关按钮
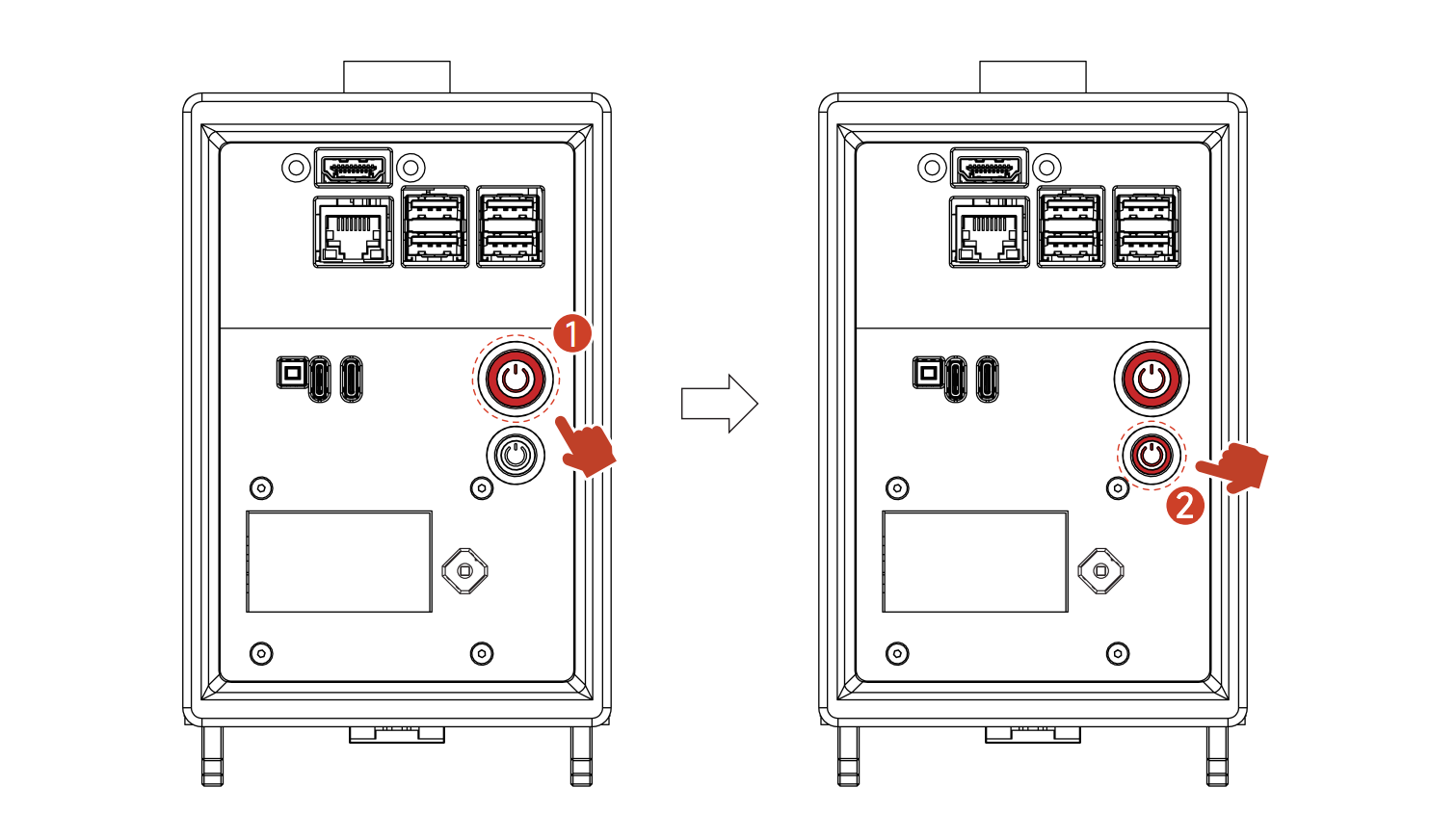
1号为 模组电源开关,2号为主控电源开关
详细信息请参考这里。
接入网络
使用usb 转网口接入网络,路由器后台找到IP ,开发电脑需要和机器人处于同一网络
使用ssh工具登入, 用户名:nvidia, 密码:nvidia
步骤2. 部署 Policy
- 把 policy 放在这个文件夹次文件夹 /home/nvidia/Desktop/sim2real_master-series_structure_pi/src/custom_config/policy/
- 修改 /home/nvidia/Desktop/sim2real_master-series_structure_pi/src/custom_config/config.yaml 文件的 policy_name
- 重启服务:
sudo systemctl restart sim2real.service
如果在训练电脑修改了 pai_config.py 文件, 需要把对应修改的同步到jetson上 custom_config/config.yaml 文件上.
步骤3. 运行和使用
- 用手柄切换到custom 模式, LCD 将显示CUSTOM
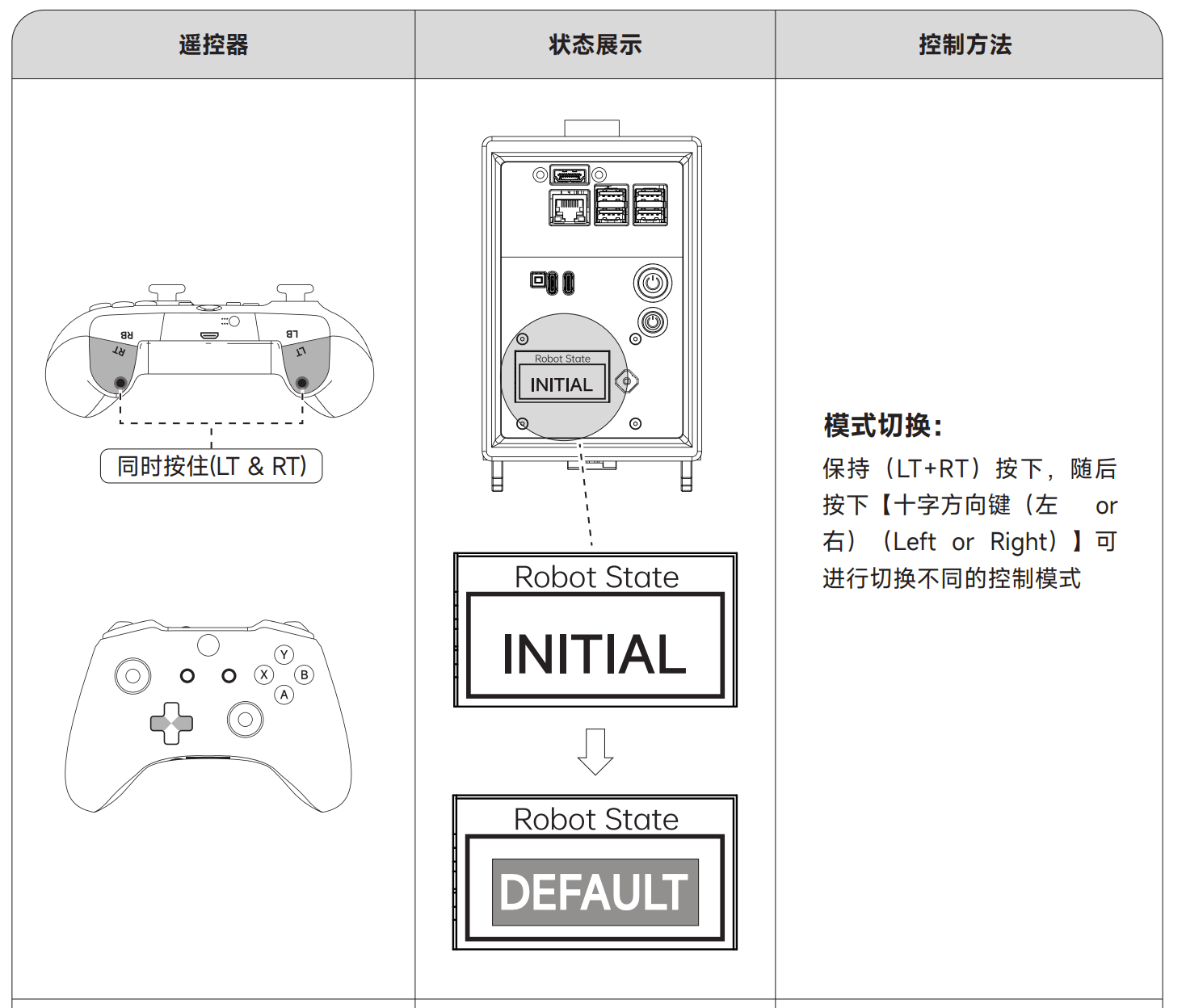
当已经选中一个模式时, 需要退出当前模式 保持(LT+RT)按下,随后 按下(B)键
- 使用
- 左摇杆(LS ⊥),按下即可 使机器人缓慢站起
- 按下(LB)时机器人可以原 地踏步,再次按下即可暂停
FAQ
Q1: 验证IsaacGym是否安装成功时出现报错 [Error] [carb] Failed to acquire interface: xxx。
你的电脑中可能安装有 Isaac Lab 或者其他仿真软件,你需要删除其他仿真软件后重新安装 IsaacGym。
Q2: 如何开始训练?
在仓库根目录下,通常运行类似 python legged_gym/scripts/train.py --task=Pi 的命令。--task=Pi 指定了使用哪个环境配置(对应 https://pi_config.py )。查看 train.py 的参数或仓库 README 获取更详细的训练选项。
Q3: 训练好的模型保存在哪里?
模型和训练日志通常保存在仓库根目录下的 logs/<experiment_name>/<run_name>/ 文件夹中。其中 <experiment_name> 通常对应环境名称(如 PiRough),<run_name> 包含日期和时间戳。策略模型文件通常以 .pt 结尾。
Q4: 如何可视化训练好的策略?
运行类似 python legged_gym/scripts/play.py --task=Pi --checkpoint=logs/<experiment_name>/<run_name>/model_<iteration_number>.pt 的命令。你需要将 --checkpoint 指向你想要加载的模型文件。
Q5: 训练速度很慢怎么办?
- 检查 GPU 使用情况: 确保 train.py 配置为使用 GPU (--sim_device=cuda, --rl_device=cuda) 并且 GPU 被充分利用。
- 增加 num_envs: 如果 GPU 显存允许,增加并行环境数量可以加速数据收集。
- 减少网络复杂度: 如果修改了策略网络结构,过于复杂的网络会减慢训练。
- 检查物理引擎: 确保使用的是 PhysX (--physics_engine=physx)。
Q6: 机器人在仿真中一开始就摔倒/行为怪异怎么办?
- 检查初始姿态: 查看 pi_config.py 中 asset.default_joint_angles 是否合理。
- 检查 PD 参数: asset.stiffness 和 asset.damping 是否设置得过低或过高?
- 检查奖励函数: 是否有某个惩罚项过大导致机器人不敢动?或者缺乏必要的奖励项(如维持姿态、高度)?
- 检查观测值归一化: normalization.obs_scales 是否合理?不正确的归一化会误导策略。
- 检查 URDF: 模型的碰撞体、关节限制是否正确?
Q7: 如何修改训练的地形?
在 pi_config.py 中修改 terrain 部分的参数。
- mesh_type: 选择地形类型 (plane, rough, trimesh)。plane 是平地,rough 是程序生成的崎岖地形,trimesh 可以加载自定义的三角网格模型。
- 修改 terrain_proportions 来控制不同类型地形出现的比例。
- 调整与选定地形类型相关的参数(如 measure_heights, static_friction, dynamic_friction, restitution, rough_terrain_params 等)
Q8: 奖励函数中的各项权重应该设为多少?
没有固定的“最佳”权重,它们高度依赖于具体的任务目标、机器人特性和环境。这是一个需要反复试验和调整的过程。建议:
- 从默认配置或类似工作的论文/代码库中获取初始值。
- 理解每个奖励项的物理意义。
- 小幅度调整权重,观察行为变化。
- 利用 TensorBoard 查看各项奖励的具体数值,判断是否符合预期。
Q9: Sim2Sim 迁移失败,机器人不稳定或行走方式差异很大,可能是什么原因?
这是 Sim2Sim 的核心挑战,常见原因包括:
- 仿真模型不准确: 质量、惯量、质心、电机特性(PD增益)、摩擦、延迟等与真实机器人差异过大。需要进行系统辨识和模型校准。
- 领域随机化不足或过度: DR 没有覆盖到真实世界与仿真的关键差异,或者 DR 范围过大导致策略过于保守。
- 状态估计不准: 真实机器人上的状态估计(特别是基座姿态和速度)有误差。
- 传感器噪声/延迟: 真实传感器的噪声和延迟未在仿真中充分模拟。
- 底层控制器差异: 真实机器人上的 PD 控制器性能、响应速度与仿真不符。需要仔细调整实机 PD 增益。
- 未建模的动力学: 仿真中忽略了某些物理效应(如电机发热、柔性部件、线缆影响等)。
Q10: 如何在观测 (Observation) 中加入新的传感器信息(比如足底接触力传感器)?
这需要修改代码:
- 修改环境代码: 在 legged_gym/envs/pi/pi.py (或类似文件) 中: 增加 num_observations 的值。
- 在 _get_observations 函数中,获取新的传感器数据(可能需要修改仿真接口或物理引擎交互部分来读取接触力)。
- 将新的传感器数据添加到观测向量 obs 中。
- 修改配置: 在 pi_config.py 中更新 env.num_observations 的值。
- 可能需要更新归一化参数: 在 normalization.obs_scales 中为新的观测值添加合适的缩放因子。
- 重新训练策略。
Q11: 我可以修改使用的强化学习算法吗? legged_gym 默认深度集成了 rsl_rl 库,主要使用 PPO 算法。替换为其他 RL 算法(如 SAC)通常需要较多的代码修改和集成工作,涉及到与环境的交互方式、数据收集和策略更新逻辑的对接。对于不熟悉框架底层实现的用户来说,这可能比较困难。建议首先充分利用 PPO 及其可调参数。
参考文档
技术支持与产品讨论
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您使用我们产品的体验尽可能顺畅。我们提供多种沟通渠道,以满足不同的偏好和需求。