GPT-OSS Running Live on reComputer Jetson!
Introduction
This is far more than a simple technical porting exercise - it's an exploration of what's possible at the edge. In this article, I'll demonstrate how a 20B-parameter open-source large language model comes to life on edge devices like Nvidia Jetson Orin Nx.

The NVIDIA Jetson series stands as a premier edge computing platform, renowned for its exceptional power efficiency and compact form factor. Meanwhile, GPT-OSS-20B represents the cutting edge of freely available open-source large language models. Their convergence not only showcases the untapped potential of edge devices, but also pioneers new possibilities for offline AI applications.
Prerequisites
- reComputer Super J4012
In this wiki, we will accomplish the following tasks using the reComputer Super J4012, but you can also try using other Jetson devices.

The subsequent steps will involve setting up multiple Python environments on the Jetson. We recommend installing Conda on Jetson device:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
Install llama.cpp
First, we need to install the llama.cpp inference engine on the Jetson. Please execute the following commands in the terminal window of the Jetson.
sudo apt update
sudo apt install -y build-essential cmake git
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --parallel
After compilation, all executable files for llama.cpp will be generated in build/bin.
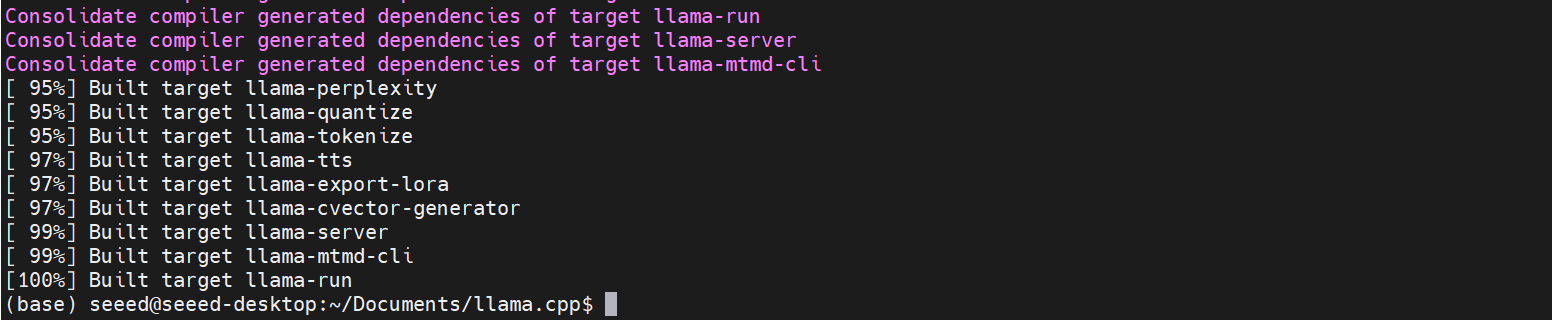
The build process typically takes around 2 hours.
Prepare GPT-OSS Model
Step1. Download the GPT-OSS-20B from Huggingface and upload to Jetson.

Step2. Install the required dependencies for model conversion.
conda create -n gpt-oss python=3.10
conda activate gpt-oss
cd /home/seeed/Documents/llama.cpp # cd `path_of_llama.cpp`
pip install .
Step3. Run the model conversion process.
python convert_hf_to_gguf.py --outfile /home/seeed/Downloads/gpt-oss /home/seeed/Documents/gpt-oss-gguf/
# python convert_hf_to_gguf.py --outfile <path_of_input_model> <path_of_output_model>
Step4. Model Quantization.
./build/bin/llama-quantize /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf /home/seeed/Documents/gpt-oss-gguf-Q4/Gpt-Oss-32x2.4B-Q4.gguf Q4_K
# ./build/bin/llama-quantize <path_of_f16_gguf_model> <path_of_output_model> <quantization_method>
Launch GPT-OSS by llama.cpp
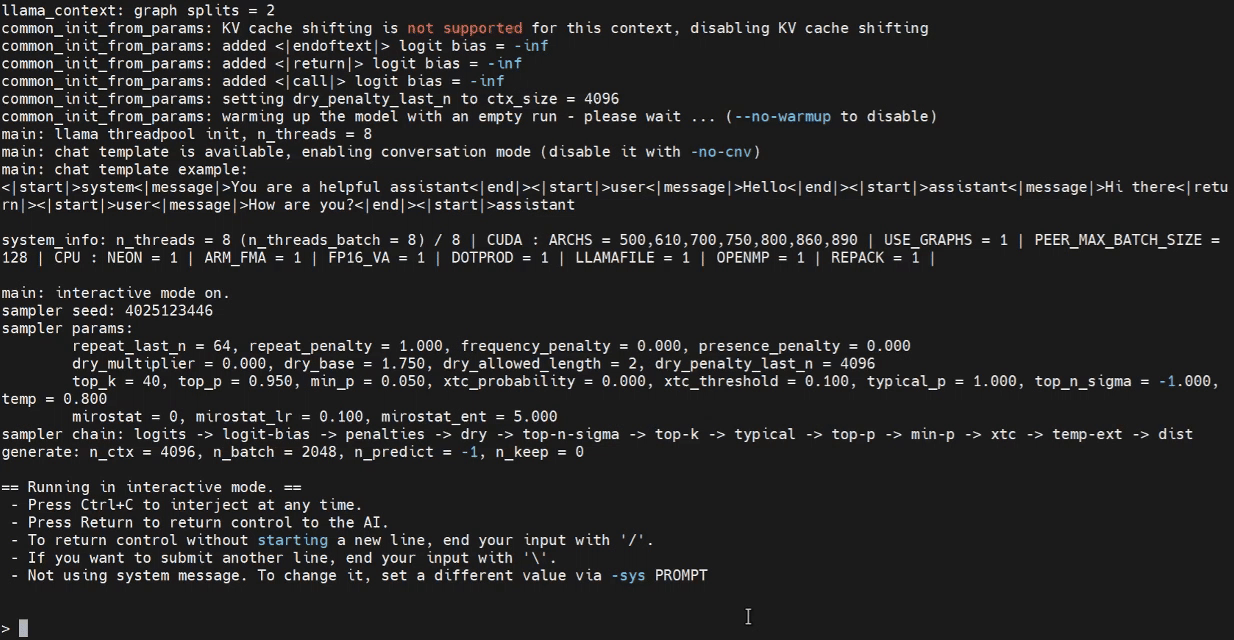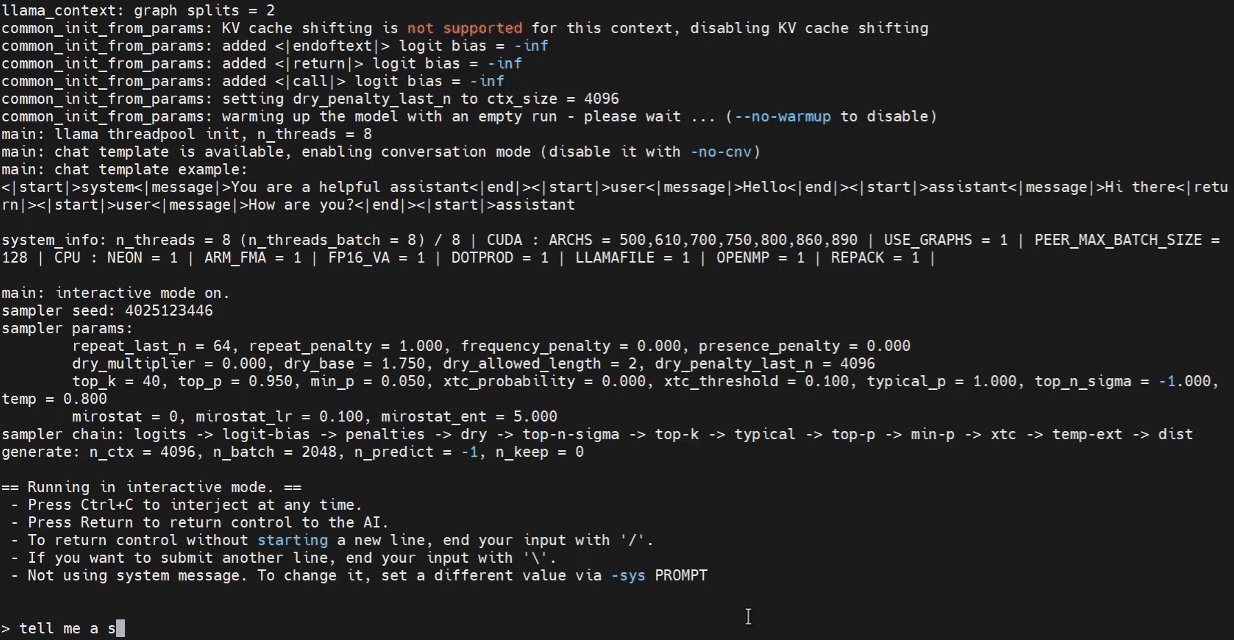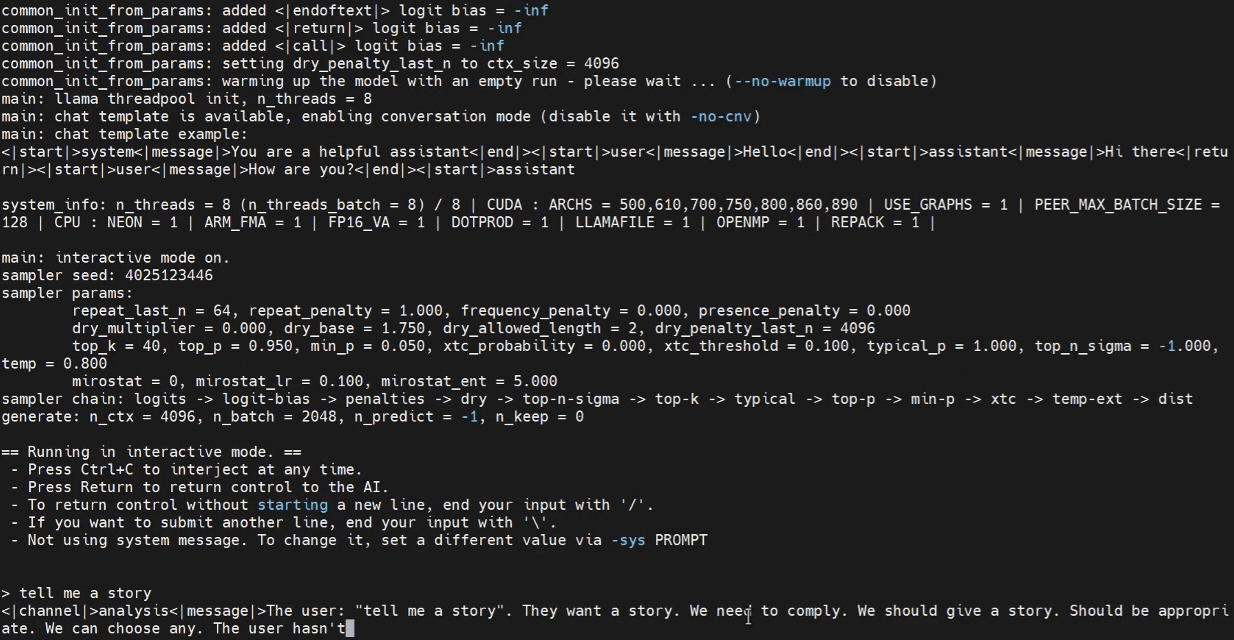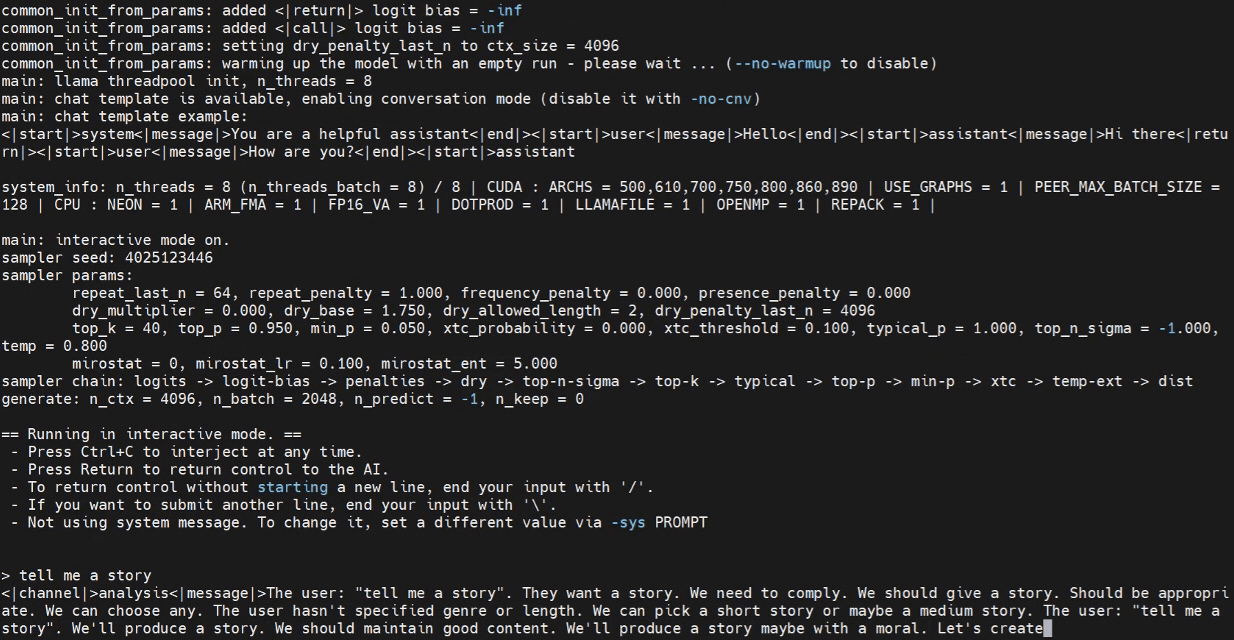
Now we can attempt to launch the inference program in the Jetson terminal.
./build/bin/llama-cli -m /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf -ngl 40
Please replace the model path as needed.
Inference with WebUI (Optional)
If you want to access the model through a UI interface, you can install OpenWebUI on the Jetson to achieve this. Open a new terminal in Jetson and enter the following command:
conda create -n open-webui python=3.11
conda activate open-webui
pip install open-webui
open-webui serve
Launching OpenWebUI will install dependencies and download models —— please be patient.
Once the setup is complete, you should see logs similar to this in the terminal.
Then, open your browser and navigate to http://<ip-of-jetson>:8080 to launch Open WebUI.
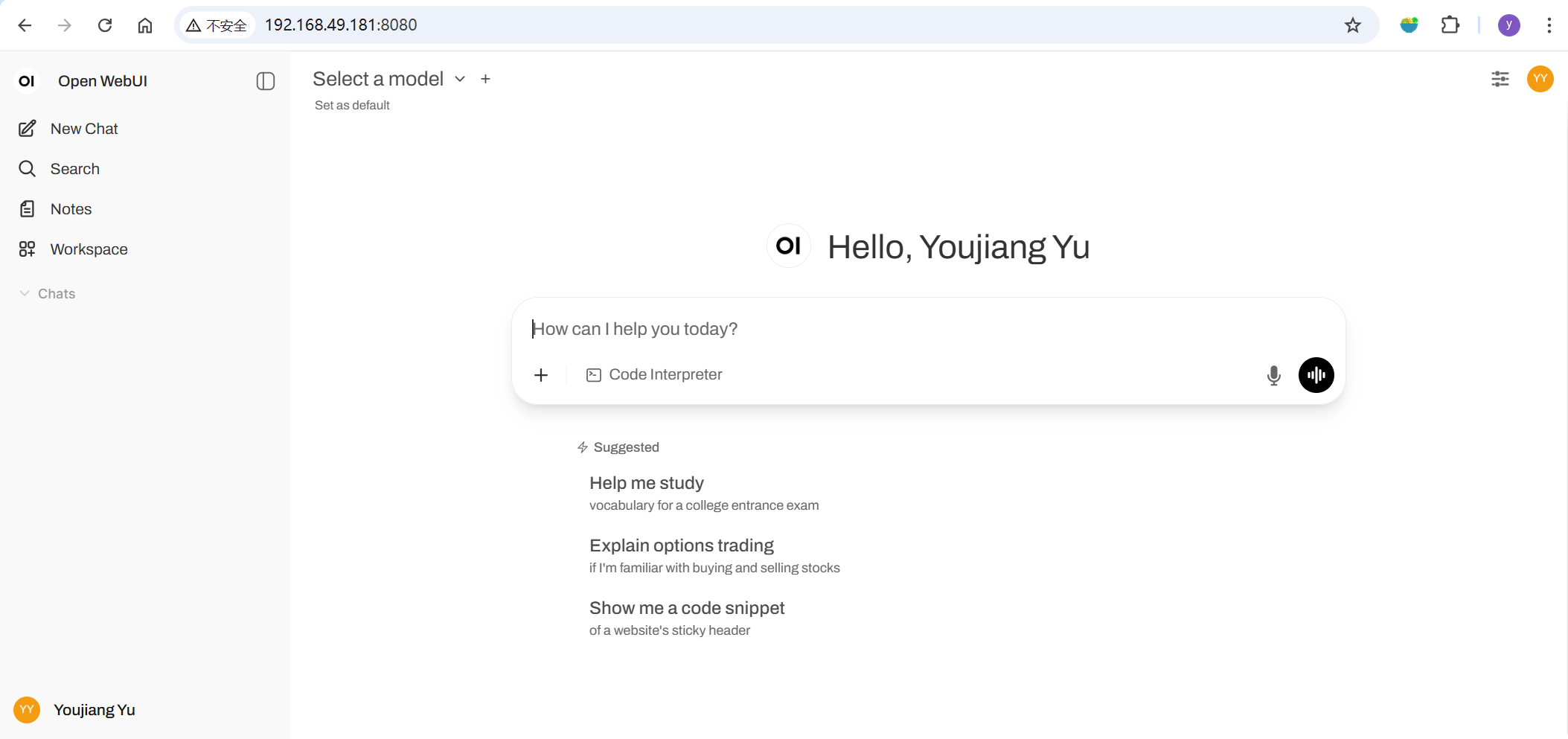
If you're opening this for the first time, please follow the instructions to set up your account.
Go to ⚙️ Admin Settings → Connections → OpenAI Connections to set the url as : http://127.0.0.1:8081. Once saved, Open WebUI will begin using your local Llama.cpp server as a backend!
Effect Demonstration
Finally, I will demonstrate the actual inference performance of the GPT-OSS-20B model on an NVIDIA Jetson Orin NX through a video demonstration.
References
- https://hyd.ai/2025/03/07/llamacpp-on-jetson-orin-agx/
- https://docs.openwebui.com/getting-started/quick-start/starting-with-llama-cpp
- https://github.com/open-webui/open-webui
- https://huggingface.co/openai/gpt-oss-20b
- https://www.seeedstudio.com/tag/nvidia.html
Tech Support & Product Discussion
Thank you for choosing our products! We are here to provide you with different support to ensure that your experience with our products is as smooth as possible. We offer several communication channels to cater to different preferences and needs.