Cómo Entrenar y Desplegar YOLOv8 en reComputer
Introducción
Ante desafíos cada vez más complejos y dinámicos, la aplicación de la inteligencia artificial proporciona nuevas vías para resolver problemas y ha hecho contribuciones significativas al desarrollo sostenible de la sociedad global y la mejora de la calidad de vida de las personas. Típicamente, antes de desplegar algoritmos de inteligencia artificial, el diseño y entrenamiento de modelos de IA tiene lugar en servidores de computación de alto rendimiento. Una vez que el entrenamiento del modelo está completo, se exporta a dispositivos de computación de borde para inferencia en el borde. De hecho, todos estos procesos pueden ocurrir directamente en dispositivos de computación de borde. Específicamente, tareas como preparar conjuntos de datos, entrenar redes neuronales, validar redes neuronales y desplegar modelos pueden realizarse en dispositivos de borde. Esto no solo garantiza la seguridad de los datos sino que también ahorra costos asociados con la compra de dispositivos adicionales.

En este documento, entrenamos y desplegamos un modelo de detección de objetos para escenas de tráfico en el reComputer J4012. Este documento utiliza el algoritmo de detección de objetos YOLOv8 como ejemplo y proporciona una visión detallada de todo el proceso. Tenga en cuenta que todas las operaciones descritas a continuación tienen lugar en el dispositivo de computación de borde Jetson, asegurándose de que el dispositivo Jetson tenga un sistema operativo instalado que sea JetPack 5.0 o superior.
Conjunto de Datos
El proceso de aprendizaje automático implica encontrar patrones dentro de datos dados y luego usar una función para capturar estos patrones. Por lo tanto, la calidad del conjunto de datos afecta directamente el rendimiento del modelo. En términos generales, cuanto mejor sea la calidad y cantidad de los datos de entrenamiento, mejor será el modelo entrenado. Por lo tanto, la preparación del conjunto de datos es crucial.
Existen varios métodos para recopilar conjuntos de datos de entrenamiento. Aquí, se introducen dos métodos: 1. Descargar conjuntos de datos públicos de código abierto pre-anotados. 2. Recopilar y anotar datos de entrenamiento. Finalmente, consolidar todos los datos para prepararse para la fase de entrenamiento posterior.
Descargar conjuntos de datos públicos
Los conjuntos de datos públicos son recursos de datos estandarizados compartidos ampliamente utilizados en investigación de aprendizaje automático e inteligencia artificial. Proporcionan a los investigadores puntos de referencia estándar para evaluar el rendimiento de algoritmos, fomentando la innovación y colaboración en el campo. Estos conjuntos de datos impulsan a la comunidad de IA hacia una dirección más abierta, innovadora y sostenible.
Hay muchas plataformas donde puede descargar conjuntos de datos de forma gratuita, como Roboflow, Kaggle, y más. Aquí, descargamos un conjunto de datos anotado relacionado con escenas de tráfico, Traffic Detection Project, de Kaggle.
La estructura de archivos después de la extracción es la siguiente:
archive
├── data.yaml
├── README.dataset.txt
├── README.roboflow.txt
├── test
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.jpg
│ │ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.txt
│ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.txt
│ ├── ...
├── train
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.jpg
│ │ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.txt
│ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.txt
│ ├── ...
└── valid
├── images
│ ├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.jpg
│ ├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.jpg
│ ├── ...
└── labels
├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.txt
├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.txt
├──...
Cada imagen tiene un archivo de texto correspondiente que contiene la información de anotación completa para esa imagen. El archivo data.json registra las ubicaciones de los conjuntos de entrenamiento, prueba y validación, y necesita modificar las rutas:
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 5
names: ['bicycle', 'bus', 'car', 'motorbike', 'person']
Recopilación y anotación de datos
Cuando los conjuntos de datos públicos no pueden satisfacer los requisitos del usuario, es necesario considerar recopilar y crear conjuntos de datos personalizados adaptados a necesidades específicas. Esto se puede lograr recopilando, anotando y organizando datos relevantes. Para fines de demostración, capturé y guardé tres imágenes de YouTube , e intento usar Label Studio para anotar las imágenes.
Paso 1. Recopilar datos en bruto:

Paso 2. Instalar y ejecutar la herramienta de anotación:
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
sudo chmod a+rw /var/run/docker.sock
mkdir label_studio_data
sudo chmod -R 776 label_studio_data
docker run -it -p 8080:8080 -v $(pwd)/label_studio_data:/label-studio/data heartexlabs/label-studio:latest
Paso 3. Crear un nuevo proyecto y completar la anotación según las indicaciones: Documentación de Referencia de Label Studio
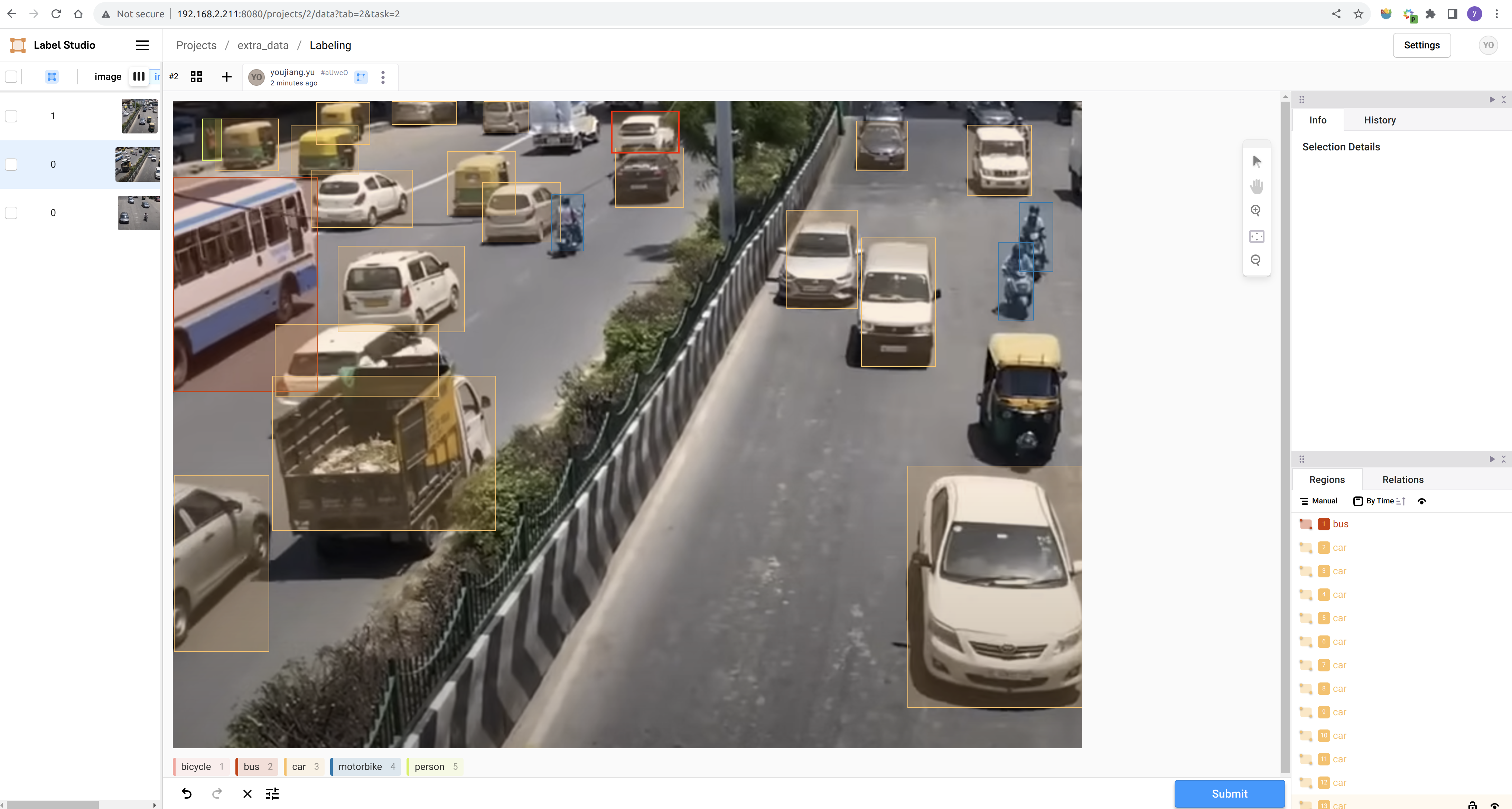
Después de completar la anotación, puedes exportar el conjunto de datos en formato YOLO y organizar los datos anotados junto con los datos descargados. El enfoque más simple es copiar todas las imágenes a la carpeta train/images del conjunto de datos público y los archivos de texto de anotación generados a la carpeta train/labels del conjunto de datos público.
En este punto, hemos obtenido los datos de entrenamiento a través de dos métodos diferentes y los hemos integrado. Si deseas datos de entrenamiento de mayor calidad, hay muchos pasos adicionales a considerar, como la limpieza de datos, el equilibrio de clases, y más. Dado que nuestra tarea es relativamente simple, omitiremos estos pasos por ahora y procederemos con el entrenamiento usando los datos obtenidos anteriormente.
Modelo
En esta sección, descargaremos el código fuente de YOLOv8 en reComputer y configuraremos el entorno de ejecución.
Paso 1. Usa el siguiente comando para descargar el código fuente:
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
Paso 2. Abre requirements.txt y modifica el contenido relevante:
# Usa el comando `vi` para abrir el archivo
vi requirements.txt
# Presiona `a` para entrar al modo de edición, y modifica el siguiente contenido:
torch>=1.7.0 --> # torch>=1.7.0
torchvision>=0.8.1 --> # torchvision>=0.8.1
# Presiona `ESC` para salir del modo de edición, y finalmente ingresa `:wq` para guardar y salir del archivo.
Paso 3. Ejecuta los siguientes comandos para descargar las dependencias requeridas para YOLO e instalar YOLOv8:
pip3 install -e .
cd ..
Paso 4. Instala la versión Jetson de PyTorch:
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.cn/compute/redist/jp/v512/pytorch/torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl -O torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
Paso 5. Instala la torchvision correspondiente:
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.16.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
cd ..
Paso 6. Usa el siguiente comando para asegurar que YOLO se haya instalado exitosamente:
yolo detect predict model=yolov8s.pt source='https://ultralytics.com/images/bus.jpg'
Entrenar
El entrenamiento del modelo es el proceso de actualizar los pesos del modelo. Al entrenar el modelo, los algoritmos de aprendizaje automático pueden aprender de los datos para reconocer patrones y relaciones, permitiendo predicciones y decisiones sobre nuevos datos.
Paso 1. Crear un script de Python para el entrenamiento:
vi train.py
Presiona a para entrar al modo de edición, y modifica el siguiente contenido:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8s.pt')
# Train the model
results = model.train(
data='/home/nvidia/Everything_Happens_Locally/Dataset/data.yaml',
batch=8, epochs=100, imgsz=640, save_period=5
)
Presiona ESC para salir del modo de edición, y finalmente ingresa :wq para guardar y salir del archivo.
El método YOLO.train() tiene muchos parámetros de configuración; por favor consulta la
documentación
para más detalles. Adicionalmente, puedes usar un enfoque CLI más simplificado para iniciar el entrenamiento basado en tus requerimientos específicos.
Paso 2. Iniciar el entrenamiento con el siguiente comando:
python3 train.py
Luego viene el largo proceso de espera. Considerando la posibilidad de cerrar la ventana de conexión remota durante la espera, este tutorial usa el Tmux multiplexor de terminal. Por lo tanto, la interfaz que veo durante el proceso se ve así:
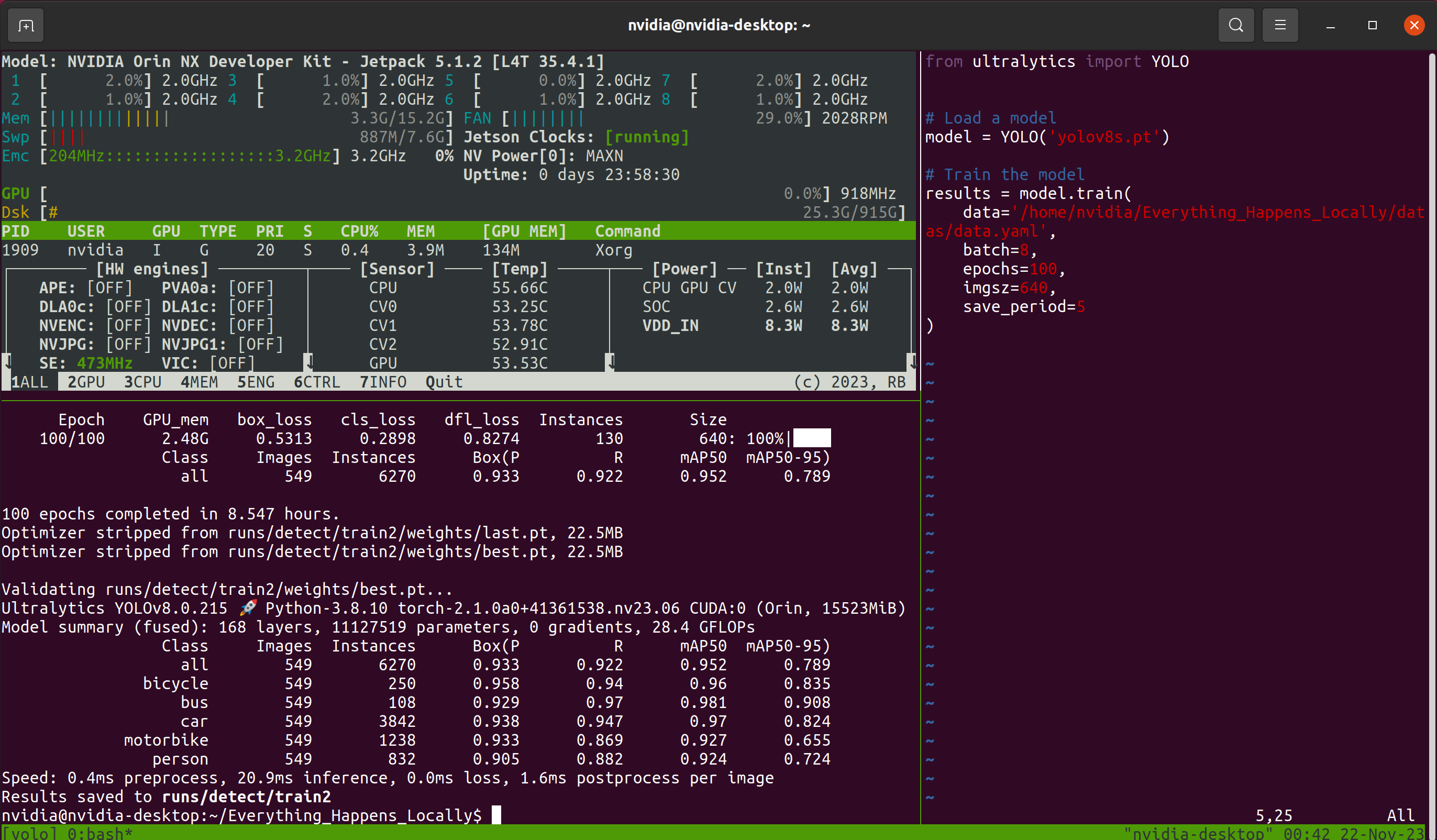
Tmux es opcional; siempre y cuando el modelo esté entrenando normalmente. Después de que el programa de entrenamiento termine, puedes encontrar los archivos de pesos del modelo guardados durante el proceso de entrenamiento en la carpeta designada:

Validación
El proceso de validación involucra usar una porción de los datos para validar la confiabilidad del modelo. Este proceso ayuda a asegurar que el modelo pueda realizar tareas de manera precisa y robusta en aplicaciones del mundo real. Si examinas de cerca la información de salida durante el proceso de entrenamiento, notarás que muchas validaciones están intercaladas a lo largo del entrenamiento. Esta sección no analizará el significado de cada métrica de evaluación sino que analizará la usabilidad del modelo examinando los resultados de predicción.
Paso 1. Usar el modelo entrenado para inferir en una imagen específica:
yolo detect predict \
model='./runs/detect/train2/weights/best.pt' \
source='./datas/test/images/ant_sales-2615_png_jpg.rf.0ceaf2af2a89d4080000f35af44d1b03.jpg' \
save=True show=False
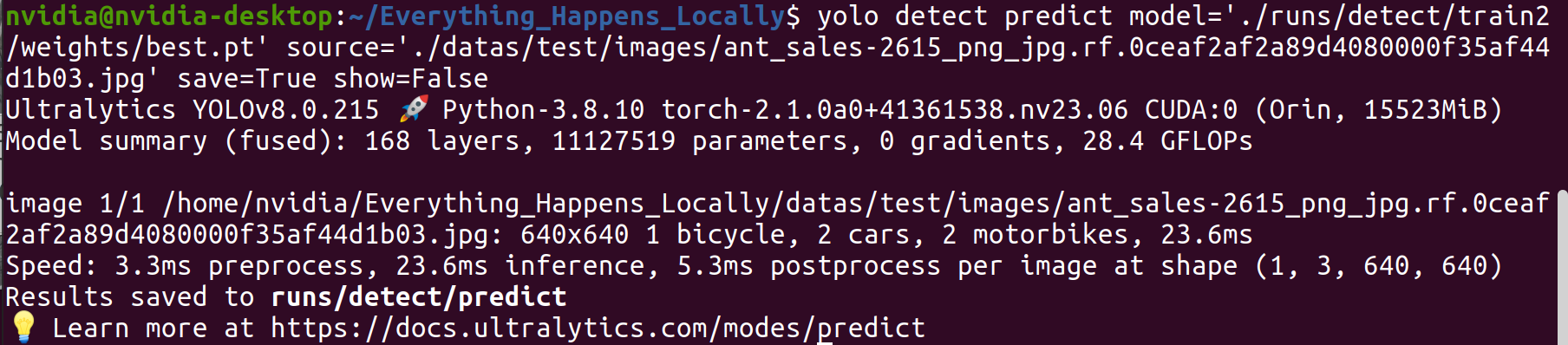
Paso 2. Examinar los resultados de inferencia.
De los resultados de detección, se puede observar que el modelo entrenado logra el rendimiento de detección esperado.

Despliegue
El despliegue es el proceso de aplicar un modelo de aprendizaje automático o aprendizaje profundo entrenado a escenarios del mundo real. El contenido introducido anteriormente ha validado la viabilidad del modelo, pero no ha considerado la eficiencia de inferencia del modelo. En la fase de despliegue, es necesario encontrar un equilibrio entre la precisión de detección y la eficiencia. El motor de inferencia TensorRT puede ser utilizado para mejorar la velocidad de inferencia del modelo.
Paso 1. Para demostrar visualmente el contraste entre los modelos ligeros y originales, crea un nuevo archivo inference.py usando la herramienta vi para implementar la inferencia de archivos de video. Puedes reemplazar el modelo de inferencia y el video de entrada modificando las líneas 8 y 9. La entrada en este documento es un video que grabé con mi teléfono.
from ultralytics import YOLO
import os
import cv2
import time
import datetime
model = YOLO("/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt")
cap = cv2.VideoCapture('./sample_video.mp4')
save_dir = os.path.join('runs/inference_test', datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S'))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
output = cv2.VideoWriter(os.path.join(save_dir, 'result.mp4'), fourcc, fps, size)
while cap.isOpened():
success, frame = cap.read()
if success:
start_time = time.time()
results = model(frame)
annotated_frame = results[0].plot()
total_time = time.time() - start_time
fps = 1/total_time
cv2.rectangle(annotated_frame, (20, 20), (200, 60), (55, 104, 0), -1)
cv2.putText(annotated_frame, f'FPS: {round(fps, 2)}', (30, 50), 0, 0.9, (255, 255, 255), thickness=2, lineType=cv2.LINE_AA)
print(f'FPS: {fps}')
cv2.imshow("YOLOv8 Inference", annotated_frame)
output.write(annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cv2.destroyAllWindows()
cap.release()
output.release()
Paso 2. Ejecuta el siguiente comando y registra la velocidad de inferencia antes de la cuantización del modelo:
python3 inference.py

El resultado indica que la velocidad de inferencia del modelo antes de la cuantización es 21.9 FPS
Paso 3. Genera el modelo cuantizado:
pip3 install onnx
yolo export model=/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt format=engine half=True device=0
Después de que el programa se complete (aproximadamente 10-20 minutos), se generará un archivo .engine en el mismo directorio que el modelo de entrada. Este archivo es el modelo cuantizado.

Paso 4. Prueba la velocidad de inferencia usando el modelo cuantizado.
Aquí, necesitas modificar el contenido de la línea 8 en el script creado en el Paso 1.
model = YOLO(<ruta al .pt>) --> model = YOLO(<ruta al .engine>)
Luego, vuelve a ejecutar el comando de inferencia:
python3 inference.py

Desde la perspectiva de la eficiencia de inferencia, el modelo cuantizado muestra una mejora significativa en la velocidad de inferencia.
Resumen
Este artículo proporciona a los lectores una guía completa que cubre varios aspectos desde la recolección de datos y entrenamiento de modelos hasta el despliegue. Importante, todos los procesos ocurren en reComputer, eliminando la necesidad de GPUs adicionales de los usuarios.
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarle diferentes tipos de soporte para asegurar que su experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.