Cómo ejecutar un LLM local de texto a imagen en reComputer
Introducción
Un modelo de texto a imagen es un tipo de modelo de inteligencia artificial (IA) que genera imágenes a partir de una descripción textual. Estos modelos toman entrada textual, como oraciones o párrafos que describen una escena y producen una imagen basada en esa descripción.
Estos modelos se entrenan en grandes conjuntos de datos que contienen pares de descripciones de texto e imágenes correspondientes, aprendiendo a entender las relaciones entre la información textual y visual.
Los modelos de texto a imagen han logrado un progreso significativo en los últimos años, pero generar imágenes de alta calidad y diversas que coincidan con precisión con las descripciones textuales sigue siendo una tarea desafiante en la investigación de IA.
Descripción general
En este tutorial, vamos a explorar varias formas de desplegar y ejecutar un LLM local de texto a imagen:
- Crear el entorno virtual (tanto TensorFlow como PyTorch)
- 1.1. Crear un ejemplo con Keras Stable Diffusion
- 1.2. Crear un ejemplo usando uno de los modelos disponibles en Hugging Face
- 1.3. Crear una pequeña API de Python que usaremos para generar imágenes llamando a la API tanto para Keras como para Hugging Face
- Usar un contenedor de Nvidia.
Solución de problemas
Antes de comenzar, aquí hay algunos pasos que podemos tomar para tener más memoria disponible.
-
Deshabilitar la GUI del escritorio. Podemos usar el Jetson a través de SSH. Podemos ahorrar alrededor de ~800MB de memoria.
-
Deshabilitar ZRAM y usar Swap.
Puedes encontrar estos consejos en el Nvidia Jetson AI Lab y cómo implementarlos.
Requisitos
Para este tutorial, vamos a necesitar un Nvidia Jetson Orin NX 16GB.

Y vamos a necesitar asegurarnos de que TensorFlow y PyTorch estén instalados - pero voy a cubrir eso aquí.
Paso 1 - Crear los entornos virtuales
Keras puede usar TensorFlow o PyTorch como backends. Hugging Face usará principalmente PyTorch
Vamos a instalar TensorFlow y PyTorch.
Las instrucciones sobre cómo instalar TensorFlow y PyTorch para el Jetson Orin NX están en el sitio web de Nvidia.
Podemos instalar TensorFlow y PyTorch globalmente o en un entorno virtual. Vamos a usar un entorno virtual.
Al usar un entorno virtual no corremos el riesgo de mezclar proyectos o versiones de paquetes.
Esta es la mejor manera, aunque el sitio de Nvidia prefiere el método global.
TensorFlow
Crear el entorno virtual (estoy usando el nombre kerasStableEnvironment porque lo voy a usar para el ejemplo de keras. Usa otro nombre si quieres.)
sudo apt install python3.8-venv
python -m venv kerasStableEnvironment
Después de crearlo, activa el entorno virtual
source kerasStableEnvironment/bin/activate
Cuando esté activo, verás el nombre antes del prompt

Ingresa al entorno virtual
cd kerasStableEnvironment
Actualizar PIP e instalar algunas dependencias
pip install -U pip
pip install -U numpy grpcio absl-py py-cpuinfo psutil portpicker six mock requests gast h5py astor termcolor protobuf keras-applications keras-preprocessing wrapt google-pasta setuptools testresources
Instalar TensorFlow para Jetpack 5.1.1
Para encontrar qué versión de JetPack tenemos, ejecuta el siguiente comando:
dpkg -l | grep -i jetpack
y el resultado debería mostrar la versión de jetpack:

pip install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v511 tensorflow==2.12.0+nv23.05
Si tienes otra versión de JetPack, consulta el Sitio web de Nvidia para obtener la URL correcta.
Ahora, vamos a verificar la instalación de TensorFlow
python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
Esta línea debería devolver lo siguiente:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
PyTorch
Instalemos algunas dependencias
sudo apt install libopenblas-dev
Ahora, instala PyTorch para JetPack 5.1.1
pip install --no-cache https://developer.download.nvidia.com/compute/redist/jp/v511/pytorch/torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
Para verificar la instalación y si CUDA está disponible
python -c "import torch; print(torch.cuda.is_available())"
Debería devolver True
Ahora que tenemos tanto TensorFlow como PyTorch instalados, vamos a instalar Keras y crear una imagen
1.1 Keras
Después de instalar PyTorch y Tensorflow, ahora estamos listos para comenzar a crear imágenes a partir de indicaciones de texto. Asegúrate de que aún estés en el entorno virtual.
KerasCV tiene una implementación (junto con varias otras) del modelo texto-a-imagen de Stability.ai, Stable Diffusion.
Al usar la implementación de KerasCV, podemos usar algunas de las ventajas de rendimiento, como la compilación XLA y el soporte de precisión mixta.
Puedes leer más en el sitio web de Keras
Instala keras y las dependencias. Vamos con estas versiones porque funcionan con las versiones de TensorFlow (o PyTorch) que tenemos instaladas.
pip install keras-cv==0.5.1
pip install keras==2.12.0
pip install Pillow
Abre tu editor preferido y escribe el siguiente ejemplo
vi generate_image.py
import keras_cv
import keras
from PIL import Image
keras.mixed_precision.set_global_policy("mixed_float16")
model = keras_cv.models.StableDiffusion (
img_width=512, # we can choose another size, but has to be a mutiple of 128
img_height=512, # the same above
jit_compile=True
)
prompt = "a cute magical flying dog, fantasy art, golden color, high quality, highly detailed, elegant, sharp focus, concept art, character concepts, digital painting, mystery, adventure"
image = model.text_to_image (prompt,
num_steps = 25, #image quality
batch_size = 1 # how many images to generate at once
)
Image.fromarray(image[0]).save("keras_generate_image.png")
Mientras se ejecuta el script, aquí hay algunas estadísticas
Y después de un tiempo, aquí está el resultado

Paso 1.2 - Hugging Face
Hugging Face es como el Github para el Aprendizaje Automático. Permite a los desarrolladores construir, desplegar, compartir y entrenar sus modelos de ML.
Hugging Face también es conocido por su biblioteca de Python Transformers, que facilita el proceso de descargar y entrenar modelos de ML.
Usemos algunos de los modelos disponibles. Ve a Hugging Face y elige ver los modelos.
En el lado izquierdo, tienes filtros que nos permiten elegir qué tipo de modelos queremos ver.
Hay muchos modelos disponibles, pero nos vamos a concentrar en los modelos de texto a imagen.
Entorno virtual
Crea un Entorno Virtual, como hicimos arriba, para que podamos usar Hugging Face sin alterar las versiones de paquetes o instalar paquetes que no necesitamos.
python -m venv huggingfaceTesting
source huggingfaceTesting/bin/activate
Después de crear el entorno virtual, vamos a ingresar a él. Instala PyTorch usando las instrucciones anteriores.
cd huggingfaceTesting
Modelo
Hugging Face tiene muchos modelos de texto a imagen. Aunque teóricamente deberían funcionar con nuestro Jetson, no lo hacen.
stable-diffusion-v1-5
Voy a probar el stable-diffusion-v1-5 de Runaway.
En la tarjeta del modelo, tienen toda la información necesaria para trabajar con el modelo.

Vamos a usar la biblioteca diffusers de Hugging Face. Dentro del entorno virtual (y con él activado) instala las dependencias.
pip install diffusers transformers accelerate
Ahora que tenemos todas las dependencias instaladas, probemos el modelo. Usando tu editor favorito, copia el siguiente código (también disponible en la página de la tarjeta del modelo):
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a master jedi cat in star wars holding a lightsaber, wearing a jedi cloak hood, dramatic, cinematic lighting"
image = pipe(prompt).images[0]
image.save("cat_jedi.png")
Probemos el modelo.
python stableDiffusion.py
Recuerda: Esto ocupa mucho espacio. Los puntos de control del modelo se están descargando. Esto se hará solo una vez.

Después de un tiempo, aquí está el resultado

SDXL-Turbo
Aquí hay otro modelo que podemos probar. SDXL Turbo de Stability AI. Copia el siguiente código
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "full body, cat dressed as a Viking, with weapon in his paws, battle coloring, glow hyper-detail, hyper-realism, cinematic"
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
image.save("sdxl-turbo.png")
Este prompt fue tomado de un artículo de Medium escrito por Daria Wind
Este es realmente rápido generando una imagen. Toma casi 30s, desde ejecutar el script hasta que termina. Aquí está el resultado

También podemos probar otros modelos, como modelos entrenados específicamente para anime o cyberpunk.
Habrá algunos modelos que no funcionarán. Puede ser debido a varios factores - memoria, CPUs disponibles o incluso memoria Swap.
Paso 1.3 - Crear una pequeña API
Ahora vamos a crear una pequeña API con Flask para usar para generar una imagen dado un prompt y devolverla al llamador.
Imagina que tienes el Jetson ejecutándose y quieres poder generar una imagen llamando a una API - tu LLM personal de imagen-a-texto.
Ya hay proyectos que hacen esto (como el que vamos a ver más tarde), pero nada supera hacerlo tú mismo.
Vamos a crear un nuevo Entorno Virtual
python -m venv imageAPIGenerator
Activa el entorno y entra en él
source imageAPIGenerator/bin/activate
cd imageAPIGenerator
Vamos a usar Flask para esto. Flask es un framework de aplicaciones web escrito en Python. Es lo suficientemente pequeño para nuestro propósito.
Instala Flask.
pip install Flask
Después de instalarlo, vamos a instalar todas las otras dependencias que necesitamos. Solo con fines de demostración, vamos a usar Keras, porque tiene las menores dependencias.
Instala TensorFlow. Sigue las instrucciones anteriores. A continuación, instala Keras.
pip install keras-cv==0.5.1
pip install keras==2.12.0
pip install Pillow
Ahora, comencemos a escribir nuestra aplicación.
vi app.py
Para aquellos que no saben qué es Flask o qué hace, probemos con un pequeño ejemplo.
from flask import Flask
app = Flask (__name__)
@app.route("/generate_image")
def generate_image_api():
return "<h2>Hello World !</h2>"
if __name__ == "__main__":
app.run(host='',port=8080)
Para ejecutar, ejecuta el script de python:
python app.py
Deberías ver lo siguiente:

Ahora, abre un navegador e intenta acceder a tu dispositivo Jetson con el puerto 8080.


Lo que hicimos fue importar la clase Flask
import Flask
A continuación creamos una instancia de la clase Flask
app = Flask(__name__)
A continuación creamos un decorador de ruta para decirle a Flask qué URL activará nuestra función
@app.route("/generate_image")
Cuando se usa generate_image en la URL, activaremos nuestra función
def generate_image_api():
return "<h2>Hello World !</h2>"
También podemos usar curl para acceder a nuestra API
curl http://192.168.2.230:8080/generate_image

Ahora que sabemos cómo crear una API, profundicemos en ello y escribámosla.
vi app.py
Y pega el código
from flask import Flask, request, send_file
import random, string
import keras_cv
import keras
from PIL import Image
#define APP
app = Flask (__name__)
#option for keras
keras.mixed_precision.set_global_policy("mixed_float16")
# generate custom filename
def generate_random_string(size):
"""Generate a random string of specified size."""
return ''.join(random.choices(string.ascii_letters + string.digits, k=size))
"""
This is the function that will generate the image
and save it using a random created filename
"""
def generate_image(prompt):
model = keras_cv.models.StableDiffusion (
img_width=512, # we can choose another size, but has to be a mutiple of 128
img_height=512, # the same above
jit_compile=True
)
image = model.text_to_image (prompt,
num_steps = 25,
batch_size = 1
)
# image filename
filename = generate_random_string(10) + ".png"
Image.fromarray(image[0]).save(filename)
return filename # return filename to send it to client
#define routes
# Use this to get the prompt. we're going to receive it using GET
@app.route("/generate_image", methods=["GET"])
def generate_image_api():
# get the prompt
prompt = request.args.get("prompt")
if not prompt:
# let's define a default prompt
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image_name = generate_image(prompt)
return send_file(image_name, mimetype='image/png')
if __name__ == "__main__":
app.run(host='0.0.0.0',port=8080)
RECUERDA: Este no es código listo para Internet. No tenemos ninguna medida de seguridad en absoluto.
Vamos a ejecutarlo.
En un navegador, escribe la URL http://jetsonIP:8080/generate_image y espera.
Si no le damos un prompt, usará el predeterminado que hemos establecido.
En la CLI, puedes ver la imagen siendo generada

Y en el navegador, después de un rato, podemos ver la imagen
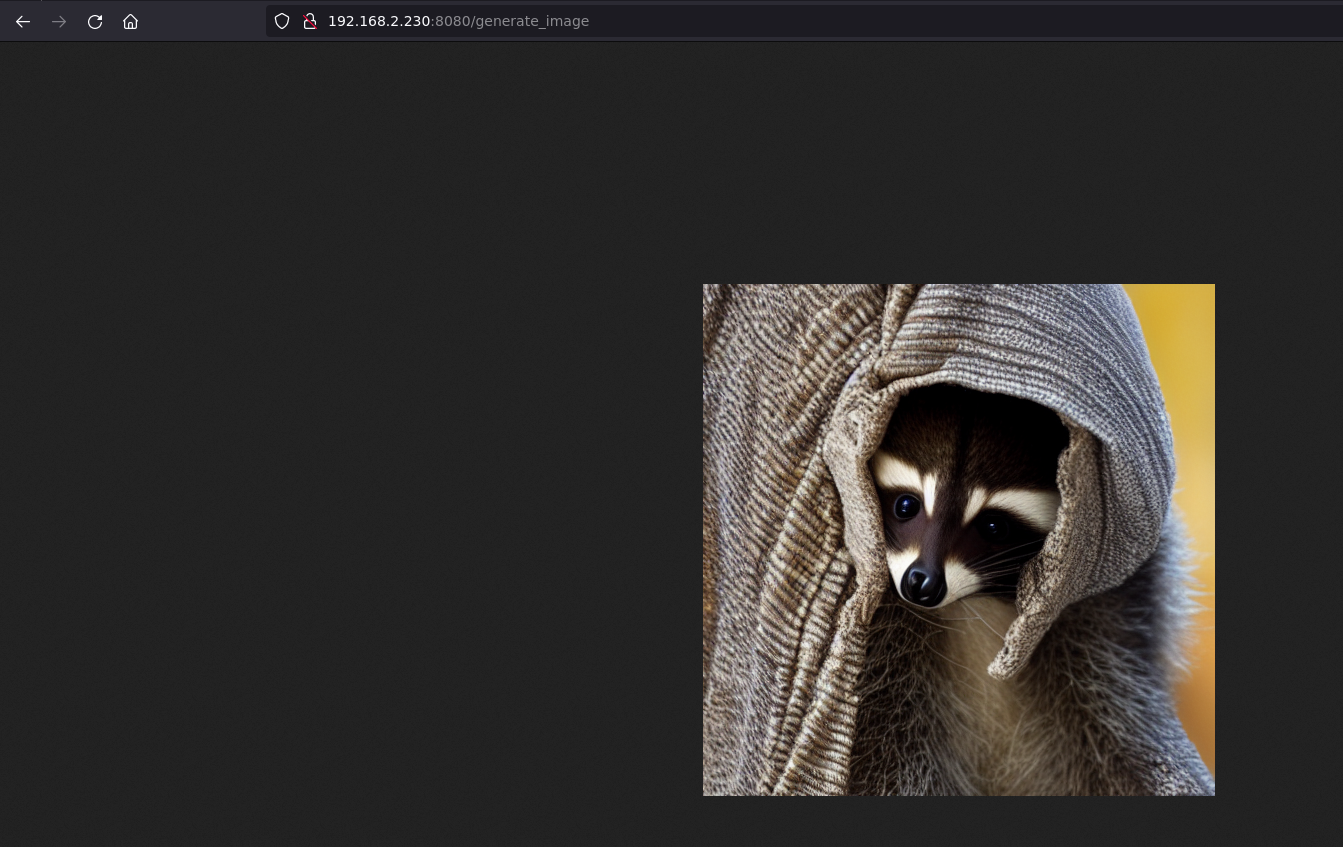
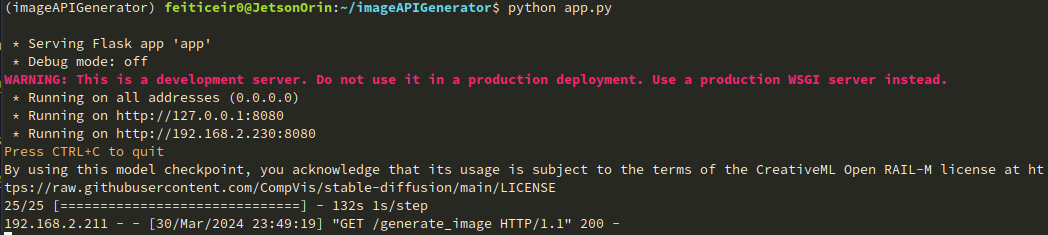
También podemos ver que la imagen ha sido enviada
También podemos usar curl para obtener la imagen y guardarla.
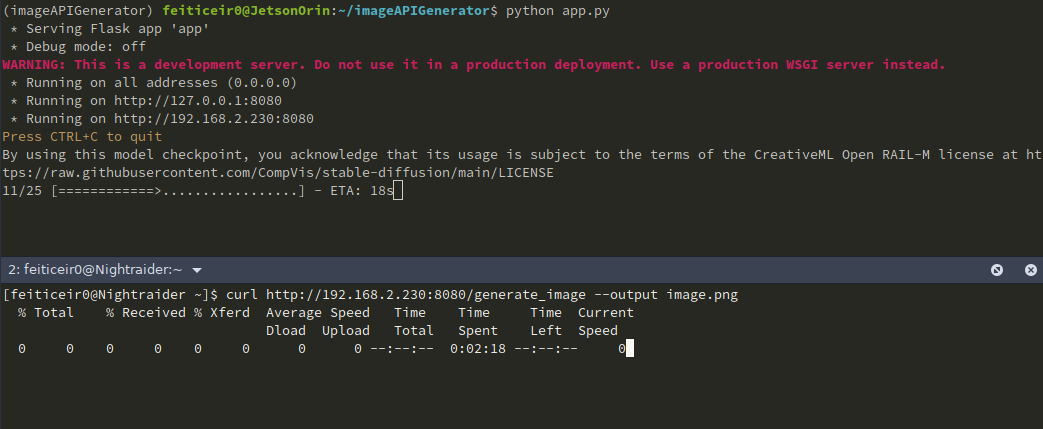
Si queremos darle un prompt (como deberíamos), la URL se verá como http://jetsonIP:8080/generate_image?prompt=<tu_prompt>
Podemos expandir este ejemplo para construir una página mejor, como tener algunas cajas de texto para entrada del usuario, un fondo bonito, etc. Pero eso es para otro proyecto.
Paso 2 - Nvidia LLM
Stable Diffusion v1.5
Podemos usar el proyecto Jetson Containers para ejecutar stable-diffusion-webui usando AUTOMATIC1111. El proyecto Jetson Containers es dirigido por Dusty Franklin, un empleado de NVIDIA.
NVIDIA tiene el proyecto NVIDIA Jetson Generative AI Lab que tiene muchos tutoriales sobre Aprendizaje Automático.
Vamos a usar el tutorial de Stable Diffusion para esto.
Vamos a clonar el repositorio de github, entrar al repositorio e instalar dependencias
git clone https://github.com/dusty-nv/jetson-containers
cd jetson-containers/
sudo apt update; sudo apt install -y python3-pip
pip3 install -r requirements.txt
Ahora que tenemos todo lo que necesitamos, ejecutemos el contenedor con el stable-diffusion-webui autotag
./run.sh $(./autotag stable-diffusion-webui)
Comenzará a ejecutar el contenedor.
Después de un tiempo, dirá que hay un contenedor compatible y si queremos proceder.
Found compatible container dustynv/stable-diffusion-webui:r35.3.1 (2024-02-02, 7.3GB) - would you like to pull it? [Y/n]
Comenzará a descargar el contenedor.
Después de terminar, descargará el modelo y ejecutará el servidor en el puerto 7860.
Aquí para mí no funcionó al principio. No aparecía ningún checkpoint para elegir, sin importar cuántas veces presionara el botón de actualizar.

Descubrí que tenía el 100% del espacio ocupado.
feiticeir0@JetsonOrin:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p1 79G 79G 0 100% /
none 7,4G 0 7,4G 0% /dev
tmpfs 7,6G 0 7,6G 0% /dev/shm
tmpfs 1,6G 19M 1,5G 2% /run
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,6G 0 7,6G 0% /sys/fs/cgroup
/dev/loop0 162M 162M 0 100% /snap/chromium/2797
/dev/loop2 128K 128K 0 100% /snap/bare/5
/dev/loop1 70M 70M 0 100% /snap/core22/1125
/dev/loop3 65M 65M 0 100% /snap/cups/1025
/dev/loop4 92M 92M 0 100% /snap/gtk-common-themes/1535
/dev/loop6 162M 162M 0 100% /snap/chromium/2807
/dev/loop5 483M 483M 0 100% /snap/gnome-42-2204/174
/dev/loop7 35M 35M 0 100% /snap/snapd/21185
tmpfs 1,6G 4,0K 1,6G 1% /run/user/1000
He estado probando otros modelos y ocuparon todo el espacio. Si esto te sucede, simplemente ve a tu directorio home, al directorio cache oculto y elimina el directorio huggingface.
cd ~/.cache
rm -rf huggingface
Ahora deberías tener espacio disponible. O simplemente consigue una nueva unidad, con más espacio. :)
Ahora el modelo se está descargando.

Y tenemos un checkpoint
Abre tu navegador y dirígete a la dirección IP de tu Jetson y el puerto para ejecutar la interfaz web de Stable Diffusion de AUTOMATIC1111
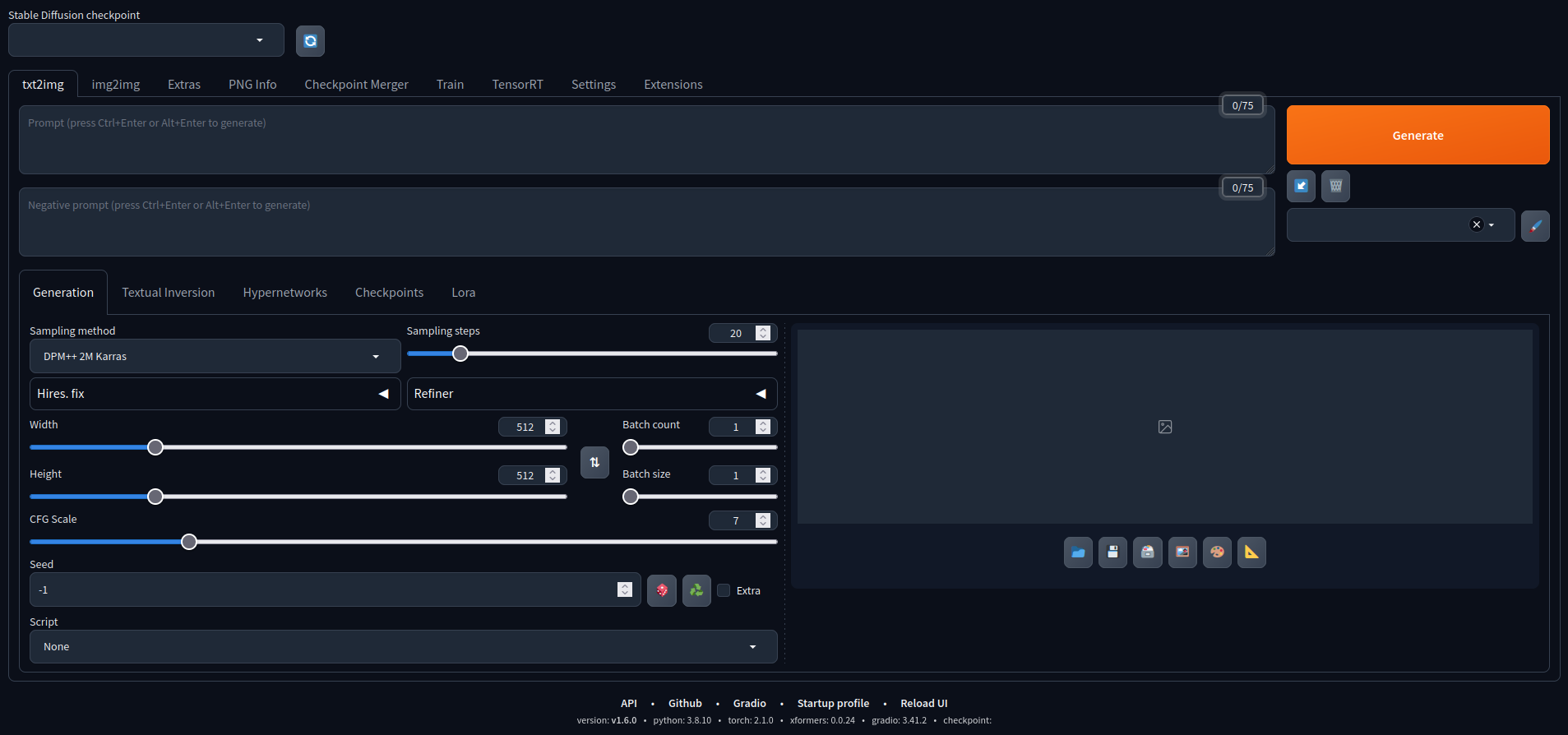
Ahora podemos jugar con él. Aquí hay algunas imágenes creadas con el modelo predeterminado.
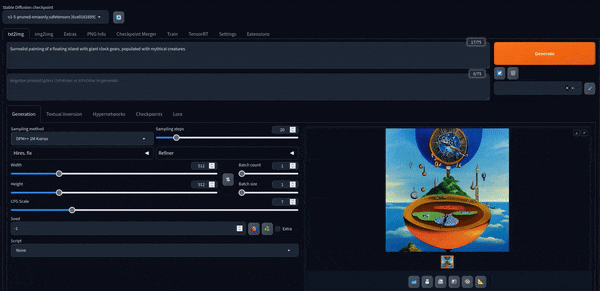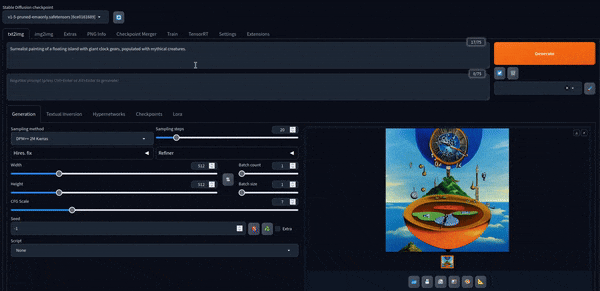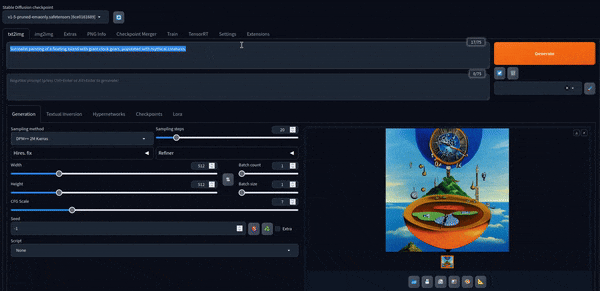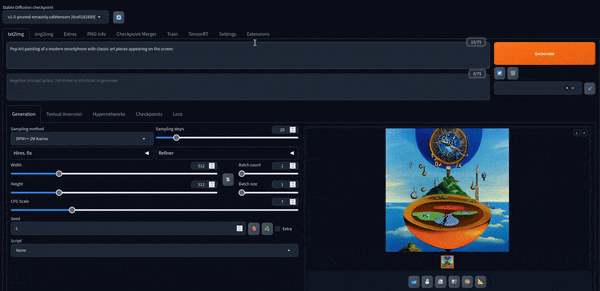
Stable Diffusion XL
AUTOMATIC1111 soporta otros modelos. Probemos con Stable Diffusion XL. Tiene 6.6 mil millones de parámetros.
Para añadir otro modelo, y para que sea más fácil descargarlo, definamos algunas variables, cambiemos permisos y descarguemos los modelos. Este es un ejemplo del Tutorial de NVIDIA.
CONTAINERS_DIR=<where_jetson-containers_is_located>
MODEL_DIR=$CONTAINERS_DIR/data/models/stable-diffusion/models/Stable-diffusion/
sudo chown -R $USER $MODEL_DIR
Ahora, descarga el modelo
wget -P $MODEL_DIR https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
wget -P $MODEL_DIR https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors
Con los modelos descargados, actualicemos el menú desplegable de checkpoints si tienes el contenedor ejecutándose, o lanza el contenedor nuevamente.
Ahora tenemos dos modelos más disponibles para nosotros.
Este es un ejemplo generado con el modelo XL, con el siguiente prompt:
Un Retrato, modelo de moda usando ropa futurista, en un ambiente de azotea cyberpunk, con un fondo de ciudad iluminada con neón, retroiluminado por el resplandor vibrante de la ciudad, fotografía de moda

Pruébalo. Recuerda que puede no funcionar con algunas opciones seleccionadas.
Añadiendo otros modelos
También podemos añadir muchos más modelos. Además de Hugging Face, Civitai es otro hub con más modelos para elegir. Civitai tiene algunos modelos NSFW, así que considérate advertido.
Selecciona el que quieras, descarga los checkpoints y colócalos en el directorio de modelos
/home/<user>/<jetson-containers-location>/data/models/stable-diffusion/models/Stable-diffusion/
Voy a descargar y probar un modelo llamado DreamShaper XL.
Recuerda que algunos modelos pueden no funcionar.
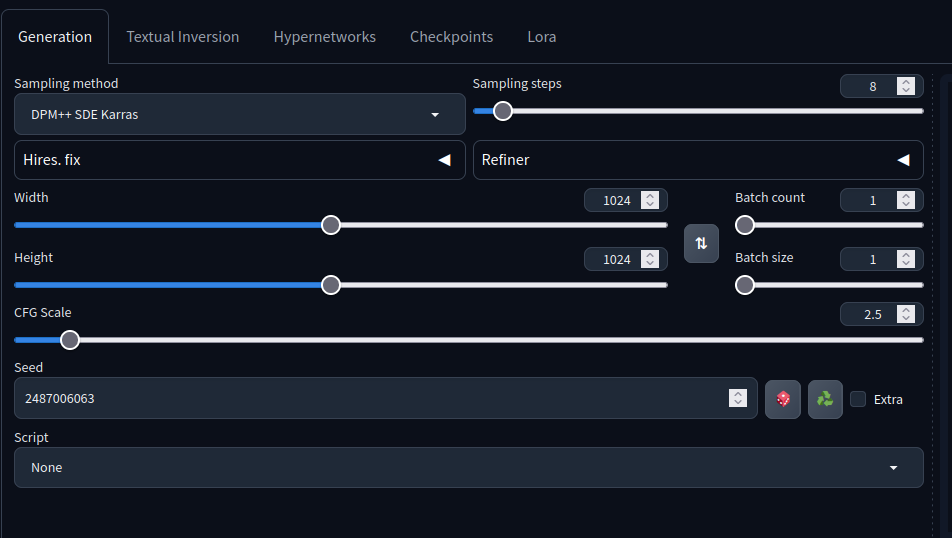
Necesitas jugar con la configuración y leer la tarjeta del modelo para saber qué configuraciones pueden funcionar mejor (si es que funcionan).
Por ejemplo, esta tarjeta del modelo dice que los pasos de muestreo deberían ser 4-8, el método de muestreo debería ser DPM++ SDE Karras, etc...
Descarga el checkpoint del modelo y añádelo al directorio anterior.
Después de actualizar, deberías tener el modelo listo para seleccionar. Al seleccionar, AUTOMATIC1111 optimizará el modelo.
Si se cierra o aparece un error, consigue más espacio. Me estaba pasando y después de conseguir más espacio, todo funcionó.
Usando el siguiente prompt
holding a staff, orbstaff
<lora:orbstaff:0.60>, ,(by Gabriel Isak and Adam Elsheimer:1.20), (by Jon Whitcomb and Bayard Wu and Malcolm Liepke0.80),8k , professional fashion shot
de esta imagen, sin el prompt negativo, obtuve el siguiente resultado

con estas configuraciones:
¿Recuerdas el prompt anterior para la chica cyberpunk usando el modelo Stable Diffusion XL?
Aquí hay una nueva imagen, con el mismo prompt, generada con DreamShaper XL con las mismas configuraciones anteriores

Como puedes ver, se pueden crear imágenes maravillosas, siempre que sepas los parámetros que ajustar. :)
He aprendido que las imágenes más grandes tienden a producir mejores resultados.
Espero que hayas aprendido cómo generar imágenes usando el Nvidia Jetson NX 16GB y cómo usarlo como servidor para generar imágenes bajo demanda.
✨ Proyecto de Colaborador
- Este proyecto está respaldado por el Proyecto de Colaborador de Seeed Studio.
- Gracias a los esfuerzos de Bruno y tu trabajo será exhibido.
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para atender diferentes preferencias y necesidades.