Introducción a Jetson Mate

Jetson Mate es una placa portadora que puede instalar hasta 4 SoMs Nvidia Jetson Nano/NX. Hay un switch gigabit de 5 puertos integrado que permite a los 4 SoMs comunicarse entre sí. Los 3 SoMs periféricos pueden encenderse o apagarse por separado. Con un cargador PD de 2 puertos de 65W para SoMs Jetson Nano o un cargador PD de 2 puertos de 90W para SoMs Jetson NX, y un cable ethernet, los desarrolladores pueden construir fácilmente su propio clúster Jetson.
Características
- Fácil de construir y configurar
- Potente y compacto
- Viene con una carcasa dedicada y ventilador
Especificaciones
| Especificación | -- |
|---|---|
| Alimentación | 65w PD |
| Dimensiones | 110mm x 110mm |
| Switch Integrado | Microchip KSZ9896CTXC |
Descripción del Hardware
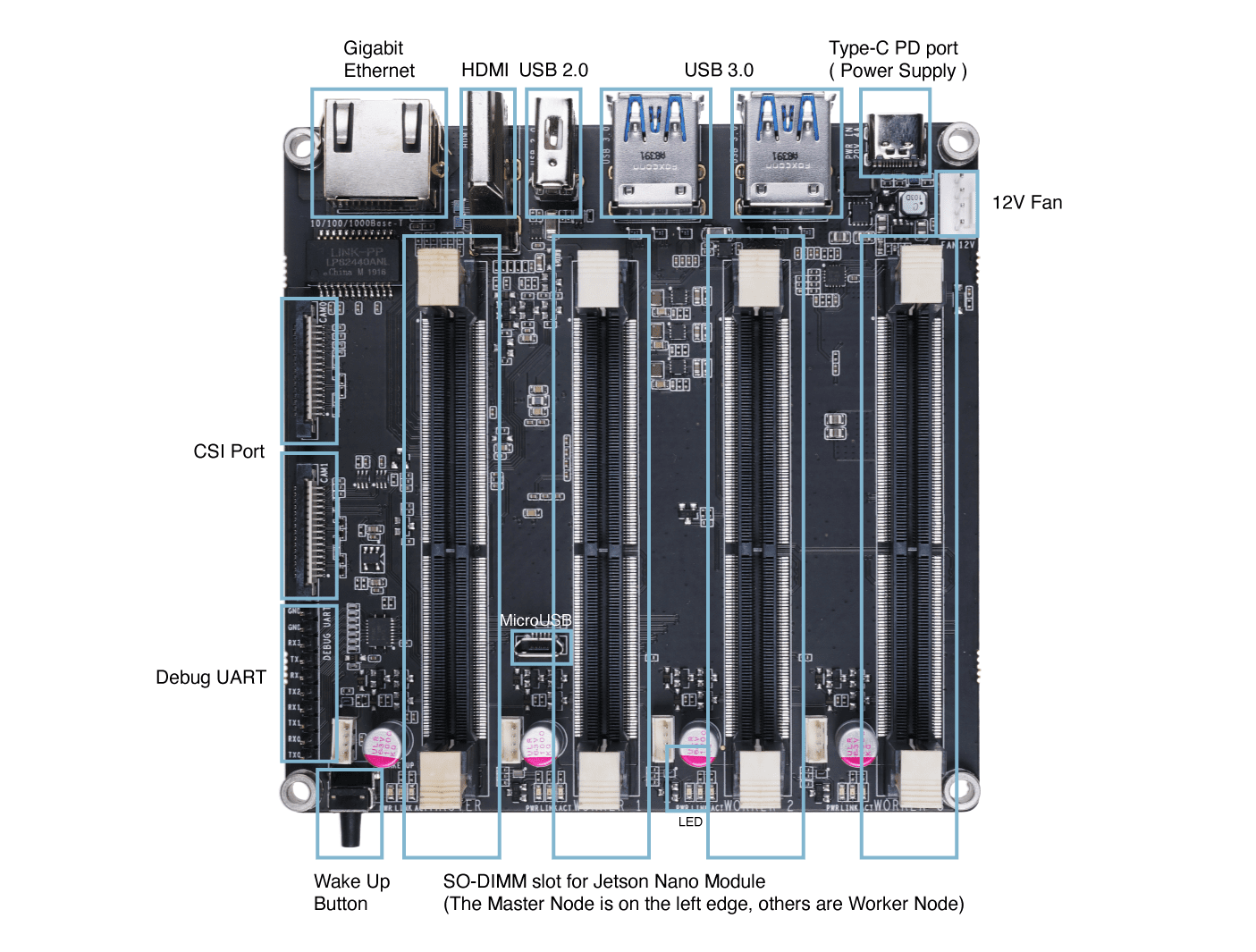

Primeros Pasos
!!!Note En esta guía, Ubuntu 18.04 LTS está instalado en la PC anfitriona. Actualmente el flasheo del SO usando NVIDIA SDK Manager no es compatible con Ubuntu 20.04. Así que asegúrate de usar Ubuntu 18.04 o 16.04. También si estás ejecutando Ubuntu en una máquina virtual, se recomienda usar VMware Workstation Player ya que lo hemos probado. No se recomienda usar Oracle VM VirtualBox, ya que falla al flashear el SO.
Hardware Necesario
- Jetson Mate
- Módulo(s) Jetson Nano/ NX
- Cable Micro - USB
- Adaptador de carga de 65W o 90W con cable USB Type-C
- PC anfitriona con Ubuntu 18.04 o 16.04 instalado
Configuración del Hardware
- Paso 1. Inserta un módulo Jetson Nano/ NX en el Nodo Maestro

- Paso 2. Conecta un cable micro-USB desde Jetson Mate a la PC

- Paso 3. Conecta un jumper entre los pines BOOT y GND para el modo de recuperación

-
Paso 4. Conecta Jetson Mate a un adaptador de alimentación y enciende Jetson Mate presionando el botón WAKE
-
Paso 5. Retira el jumper después de que Jetson Mate se encienda
-
Paso 6. Abre una ventana de terminal en la PC anfitriona y ejecuta lo siguiente
lsusb

Si la salida incluye 0955:7f21 NVidia Corp., Jetson Mate ha entrado en modo de recuperación
Configuración de Software
Si estás usando módulos con tarjeta micro-SD del Kit de Desarrollador, sugerimos que instales y configures el sistema siguiendo esta guía para Jetson Nano, esta guía para Jetson Nano 2GB y esta guía para Jetson Xavier NX
Si estás usando módulos con almacenamiento eMMC, por favor usa el SDK Manager oficial de NVIDIA y sigue los pasos a continuación
- Paso 1. Descarga NVIDIA SDK Manager haciendo clic aquí
Nota: Elige la versión relevante según el SO de la PC anfitriona. Elegimos Ubuntu aquí porque la PC anfitriona usada en esta guía está ejecutando Ubuntu 18.04

-
Paso 2. Crea una cuenta o inicia sesión en NVIDIA Developer Program Membership
-
Paso 3. Instala NVIDIA SDK Manager
Nota: Haz doble clic en el archivo descargado para instalarlo
- Paso 4. Abre NVIDIA SDK Manager y notarás que detecta automáticamente el módulo Jetson Nano/ NX conectado

-
Paso 5. Selecciona el módulo conectado
-
Paso 6. En la ventana de configuración, desmarca Host Machine.

Nota: Aquí DeepStream SDK también está desmarcado. Pero si planeas instalarlo también, puedes marcarlo. Sin embargo, los 16GB en el módulo eMMC no serán suficientes para instalar este SDK.
-
Paso 7. Haz clic en CONTINUE TO STEP 02
-
Paso 8. Revisa los componentes requeridos y marca I accept the terms and conditions of the license agreements

Nota: Si solo quieres instalar el Jetson OS, puedes desmarcar Jetson SDK Components
-
Paso 9. Haz clic en CONTINUE TO STEP 03
-
Paso 10. Una vez que aparezca el siguiente mensaje de error, haz clic en Create

- Paso 11. Inicia la descarga y flasheo

- Paso 12. Después de que termine la descarga y flasheo del SO, verás la siguiente salida

-
Paso 13. Apaga Jetson Mate
-
Paso 14. Abre una ventana de terminal en la PC anfitriona e instala minicom que es una aplicación de terminal serie
sudo apt update
sudo apt install minicom
Nota: Usaremos esta aplicación para establecer una conexión serie entre la PC anfitriona y Jetson Mate
- Paso 15. Enciende Jetson Mate mientras aún está conectado a la PC a través del cable micro-USB, ingresa lo siguiente para identificar el puerto serie conectado
dmesg | grep tty

Nota: Aquí el nombre del puerto es ttyACM0
- Paso 16. Conectar a Jetson Mate usando minicom
sudo minicom -b 9600 -D /dev/ttyACM0
Nota: -b es la velocidad de baudios y -D es el dispositivo
- Paso 17. Realiza la configuración inicial para Jetson OS

- Paso 18. Después de que termine la configuración, regresa a la ventana de SDK Manager, ingresa el nombre de usuario y contraseña establecidos para Jetson Mate y haz clic en Install

Nota: Usa el nombre de usuario y contraseña establecidos en la configuración inicial
Ahora comenzará a descargar e instalar los componentes del SDK

Verás la siguiente salida cuando el SDK manager haya descargado e instalado exitosamente los componentes necesarios

- Paso 19. Flashea todos los módulos Jetson Nano/ NX restantes que tengas
Nota: Todos los módulos solo pueden ser flasheados cuando están instalados en el nodo maestro. Por lo tanto, debes flashear y configurar los módulos uno por uno en el nodo maestro.
Lanzar el Clúster
- Paso 1. Conecta un cable Ethernet del router al Jetson Mate
Nota: Asegúrate de que la PC y el Jetson Mate estén conectados al mismo router
- Paso 2. Ingresa al Jetson Mate usando minicom como se explicó antes, mientras el micro-USB está conectado a la PC anfitriona y escribe lo siguiente para obtener las direcciones IP de los módulos conectados al Jetson Mate
ifconfig
- Paso 3. Escribe lo siguiente en la terminal de la PC anfitriona para establecer una conexión SSH
Nota: Reemplaza user con tu nombre de usuario de Jetson Nano/ NX y 192.xxx.xx.xx con tu dirección IP de Jetson Nano/ NX
Nota: También puedes conectarte a los nodos reemplazando la dirección IP por su nombre de host
Construir un clúster de Kubernetes con Jetson Mate
Kubernetes es un sistema de orquestación de contenedores de nivel empresarial diseñado desde el inicio para ser nativo de la nube. Ha crecido hasta convertirse en la plataforma de contenedores de nube de facto, continuando expandiéndose mientras ha adoptado nuevas tecnologías, incluyendo virtualización nativa de contenedores y computación sin servidor.
Kubernetes gestiona contenedores y más, desde micro-escala en el borde hasta escala masiva, tanto en entornos de nube pública como privada. Es una elección perfecta para un proyecto de "nube privada en casa", proporcionando tanto orquestación robusta de contenedores como la oportunidad de aprender sobre una tecnología tan demandada y tan completamente integrada en la nube que su nombre es prácticamente sinónimo de "computación en la nube."
En este tutorial, usamos un maestro y tres trabajadores. En los siguientes pasos, indicaremos en negrita si el software se ejecuta en master o en worker, o en worker and master.
configurar Docker
worker and master, Necesitamos configurar el tiempo de ejecución de docker para usar "nvidia" como predeterminado.
modificar el archivo /etc/docker/daemon.json
{
"default-runtime" : "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
Reinicia el daemon de Docker:
sudo systemctl daemon-reload && sudo systemctl restart docker
Valida el runtime predeterminado de Docker como NVIDIA:
sudo docker info | grep -i runtime
Aquí está el resultado de muestra:
Runtimes: nvidia runc
Default Runtime: nvidia
Instalando Kubernetes
worker y master, Instalar kubelet, kubeadm y kubectl:
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
# Add the Kubernetes repo
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt update && sudo apt install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
Deshabilita el swap, tienes que desactivar esto cada vez que reinicies.
sudo swapoff -a
Compila deviceQuery, que usaremos en los siguientes pasos.
cd /usr/local/cuda/samples/1_Utilities/deviceQuery && sudo make
cd
Configurar Kubernetes
master, Inicializar el clúster:
sudo kubeadm init --pod-network-cidr=10.244.0.0/16
La salida te muestra comandos para ejecutar para desplegar una red de pods al clúster, así como comandos para unirse al clúster. Si todo es exitoso, deberías ver algo similar a esto al final de la salida:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
Usando las instrucciones de salida, ejecuta los siguientes comandos:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Instala un complemento de red de pods en el nodo del plano de control. Usa calico como complemento de red de pods:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Si estás en China, sigue esto en su lugar:
kubectl apply -f https://gitee.com/wj204811/wj204811/raw/master/kube-flannel.yml
Asegúrate de que todos los pods estén funcionando:
kubectl get pods --all-namespaces
Entiendo las reglas. Estoy listo para traducir el documento técnico en Markdown que proporciones. Por favor, comparte el contenido y procederé con la traducción completa siguiendo todas las especificaciones de formato que has detallado.
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-flannel-ds-arm64-gz28t 1/1 Running 0 2m8s
kube-system coredns-5c98db65d4-d4kgh 1/1 Running 0 9m8s
kube-system coredns-5c98db65d4-h6x8m 1/1 Running 0 9m8s
kube-system etcd-#yourhost 1/1 Running 0 8m25s
kube-system kube-apiserver-#yourhost 1/1 Running 0 8m7s
kube-system kube-controller-manager-#yourhost 1/1 Running 0 8m3s
kube-system kube-proxy-6sh42 1/1 Running 0 9m7s
kube-system kube-scheduler-#yourhost 1/1 Running 0 8m26s
worker, Une los nodos de cómputo al clúster, ahora es momento de agregar nodos de cómputo al clúster. Unir los nodos de cómputo es simplemente cuestión de ejecutar el comando kubeadm join proporcionado al final del comando kube init ejecutado para inicializar el nodo del Plano de Control. Para los otros Jetson nano que quieras unir a tu clúster, inicia sesión en el host y ejecuta el comando:
the cluster - your tokens and ca-cert-hash will vary
$ sudo kubeadm join 192.168.2.114:6443 --token zqqoy7.9oi8dpkfmqkop2p5 \
--discovery-token-ca-cert-hash sha256:71270ea137214422221319c1bdb9ba6d4b76abfa2506753703ed654a90c4982b
master, una vez que hayas completado el proceso de unión en cada nodo, deberías poder ver los nuevos nodos en la salida de kubectl get nodes:
kubectl get nodes
Aquí está la salida de ejemplo:
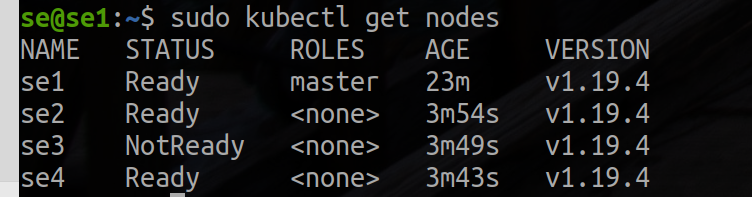
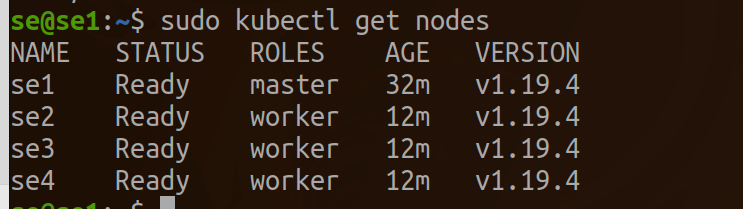
etiqueta como nodo para el trabajador.
kubectl label node se2 node-role.kubernetes.io/worker=worker
kubectl label node se3 node-role.kubernetes.io/worker=worker
kubectl label node se4 node-role.kubernetes.io/worker=worker
Validando una instalación exitosa de EGX 2.0
worker y master, Para validar que la pila EGX funciona como se espera, sigue estos pasos para crear un archivo yaml de pod. Si el comando get pods muestra el estado del pod como completado, la instalación ha sido exitosa. También puedes verificar la ejecución exitosa del archivo cuda-samples.yaml verificando que la salida muestre Result=PASS. Crea un archivo yaml de pod, añade el siguiente contenido a él, y guárdalo como samples.yaml:
nano cuda-samples.yaml
Añade el siguiente contenido y guárdalo como cuda-samples.yaml:
apiVersion: v1
kind: Pod
metadata:
name: nvidia-l4t-base
spec:
restartPolicy: OnFailure
containers:
- name: nvidia-l4t-base
image: "nvcr.io/nvidia/l4t-base:r32.4.2"
args:
- /usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery
Crear un pod GPU de ejemplo:
sudo kubectl apply -f cuda-samples.yaml
Verifica si se creó el pod de muestras:
kubectl get pods
Valida los logs de muestra del pod para soportar las librerías CUDA:
kubectl logs nvidia-l4t-base
Aquí está la salida de ejemplo:
/usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Xavier"
CUDA Driver Version / Runtime Version 10.2 / 10.2
CUDA Capability Major/Minor version number: 7.2
Total amount of global memory: 7764 MBytes (8140709888 bytes)
( 6) Multiprocessors, ( 64) CUDA Cores/MP: 384 CUDA Cores
GPU Max Clock rate: 1109 MHz (1.11 GHz)
Memory Clock rate: 1109 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: Yes
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.2, NumDevs = 1
Result = PASS
Configurar Jupyter en Kubernetes
worker y master, Añade el siguiente contenido y guárdalo como jupyter.yaml:
nano jupyter.yaml
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: cluster-deployment
spec:
selector:
matchLabels:
app: cluster
replicas: 3 # tells deployment to run 3 pods matching the template
template:
metadata:
labels:
app: cluster
spec:
containers:
- name: nginx
image: helmuthva/jetson-nano-jupyter:latest
ports:
- containerPort: 8888
Crear un pod GPU de jupyter:
kubectl apply -f jupyter.yml
Verifica si el pod de jupyter fue creado y está ejecutándose:
kubectl get pod
Crear un Balanceador de Carga Externo
kubectl expose deployment cluster-deployment --port=8888 --type=LoadBalancer

Aquí puedes ver que el clúster jupyter tiene acceso externo en el puerto 31262. Así que usamos http://se1.local:31262 para visitar jupyter.
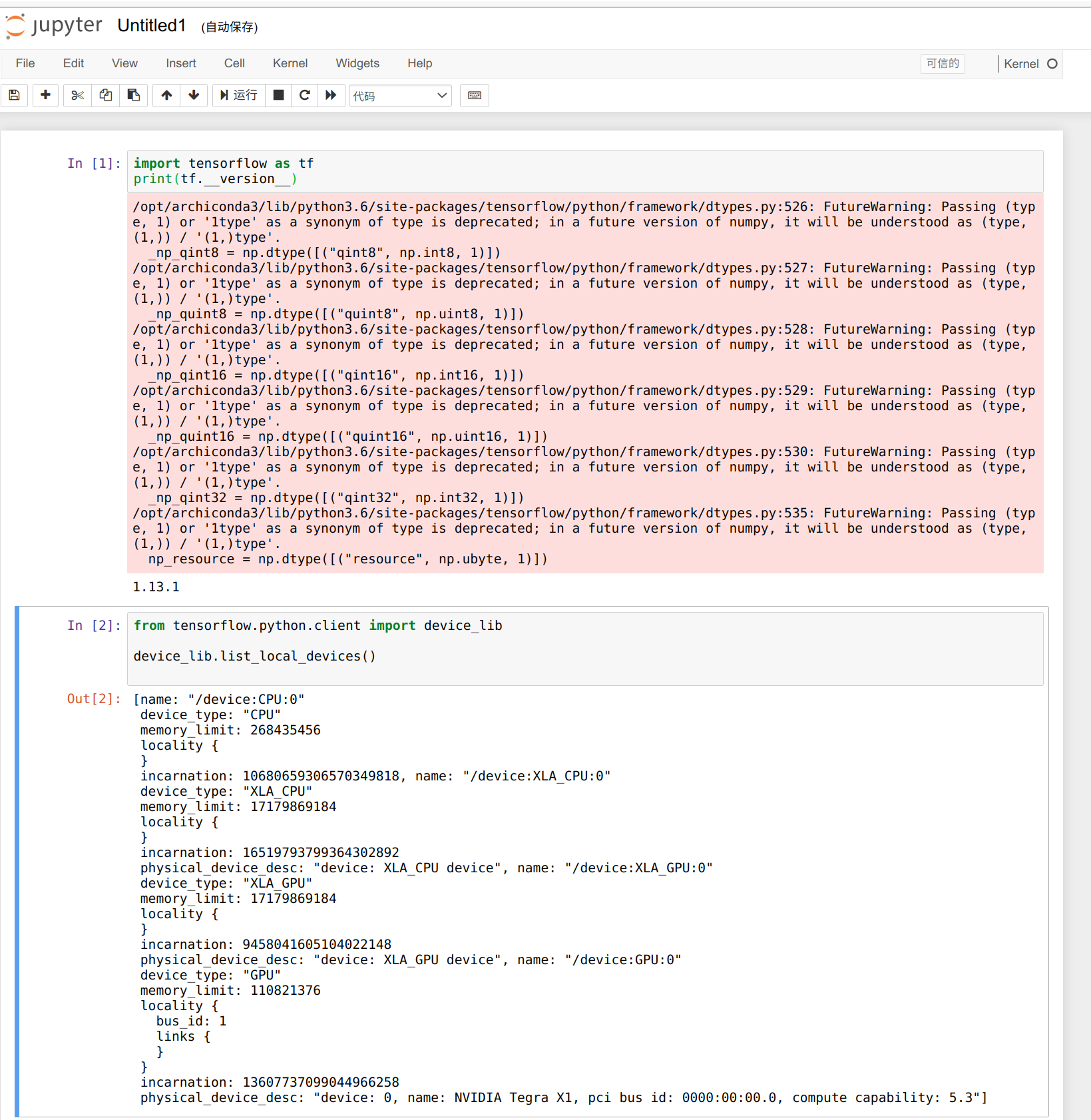
Podemos usar el siguiente código para verificar el número de GPUs disponibles, solo tenemos 3 workers, y el número de GPUs disponibles es 3.
from tensorflow.python.client import device_lib
def get_available_gpus():
local_device_protos = device_lib.list_local_devices()
return [x.name for x in local_device_protos if x.device_type == 'GPU']
get_available_gpus()
Muy bien, aquí está tu espectáculo.
Recursos
- [PDF] Esquemas de Jetson Mate
- [PDF] PCB Superior de Jetson Mate
- [PDF] PCB Inferior de Jetson Mate
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarle diferentes tipos de soporte para asegurar que su experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.