Comenzando con Roboflow Inference en Dispositivos NVIDIA® Jetson
Esta guía wiki explica cómo desplegar fácilmente modelos de IA usando el servidor de inferencia de Roboflow ejecutándose en dispositivos NVIDIA Jetson. ¡Aquí usaremos Roboflow Universe para seleccionar un modelo ya entrenado, desplegar el modelo al dispositivo Jetson y realizar inferencia en una transmisión de webcam en vivo!
Roboflow Inference es la forma más fácil de usar y desplegar modelos de visión por computadora, proporcionando una API HTTP de Roboflow utilizada para ejecutar inferencia. Roboflow inference soporta:
- Detección de objetos
- Segmentación de imágenes
- Clasificación de imágenes
y modelos fundamentales como CLIP y SAM.
Prerrequisitos
- PC Host Ubuntu (nativo o VM usando VMware Workstation Player)
- reComputer Jetson o cualquier otro dispositivo NVIDIA Jetson
Esta wiki ha sido probada y verificada en un reComputer J4012 y reComputer Industrial J4012 alimentado por el módulo NVIDIA Jetson Orin NX 16GB
Flashear JetPack a Jetson
Ahora necesitas asegurarte de que el dispositivo Jetson esté flasheado con un sistema JetPack. Puedes usar NVIDIA SDK Manager o línea de comandos para flashear JetPack al dispositivo.
Para las guías de flasheo de dispositivos Seeed alimentados por Jetson, por favor consulta los siguientes enlaces:
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 Carrier Board
- A205 Carrier Board
- A206 Carrier Board
- A603 Carrier Board
- A607 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
- reComputer Indsutrial
- reServer Industrial
Asegúrate de flashear la versión 5.1.1 de JetPack porque esa es la versión que hemos verificado para esta wiki
Accede a más de 50,000 Modelos en Roboflow Universe
Roboflow ofrece más de 50,000 modelos de IA listos para usar para que todos puedan comenzar con el despliegue de visión por computadora de la manera más rápida. Puedes explorarlos todos en Roboflow Universe. Roboflow Universe también ofrece más de 200,000 conjuntos de datos donde puedes usar estos conjuntos de datos para entrenar un modelo en los servidores en la nube de Roboflow o traer tu propio conjunto de datos, usar la herramienta de anotación de imágenes en línea de Roboflow y comenzar a entrenar.
-
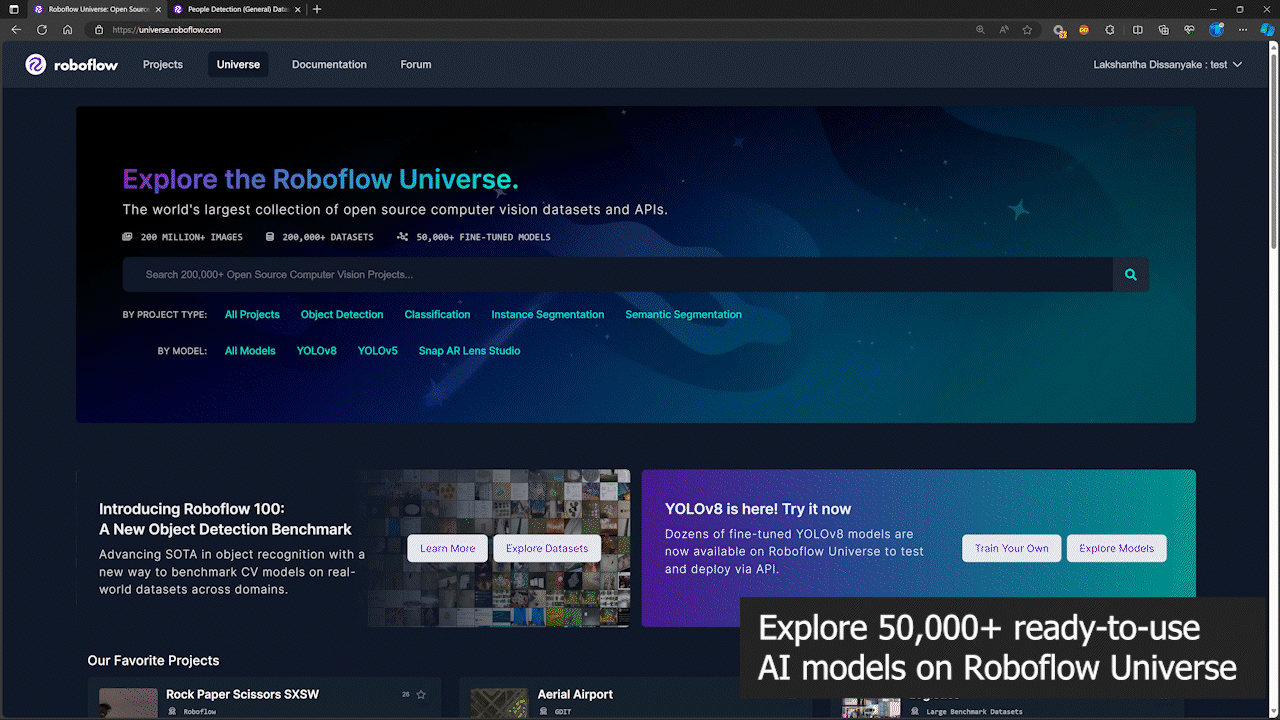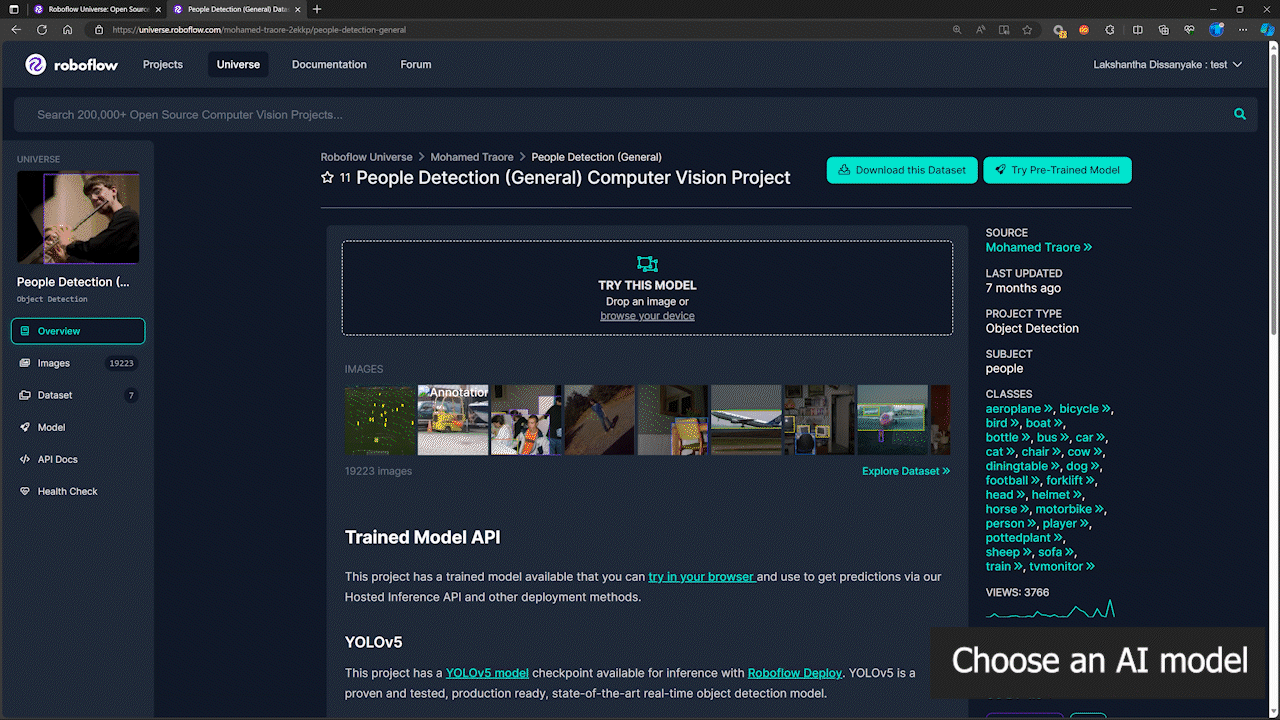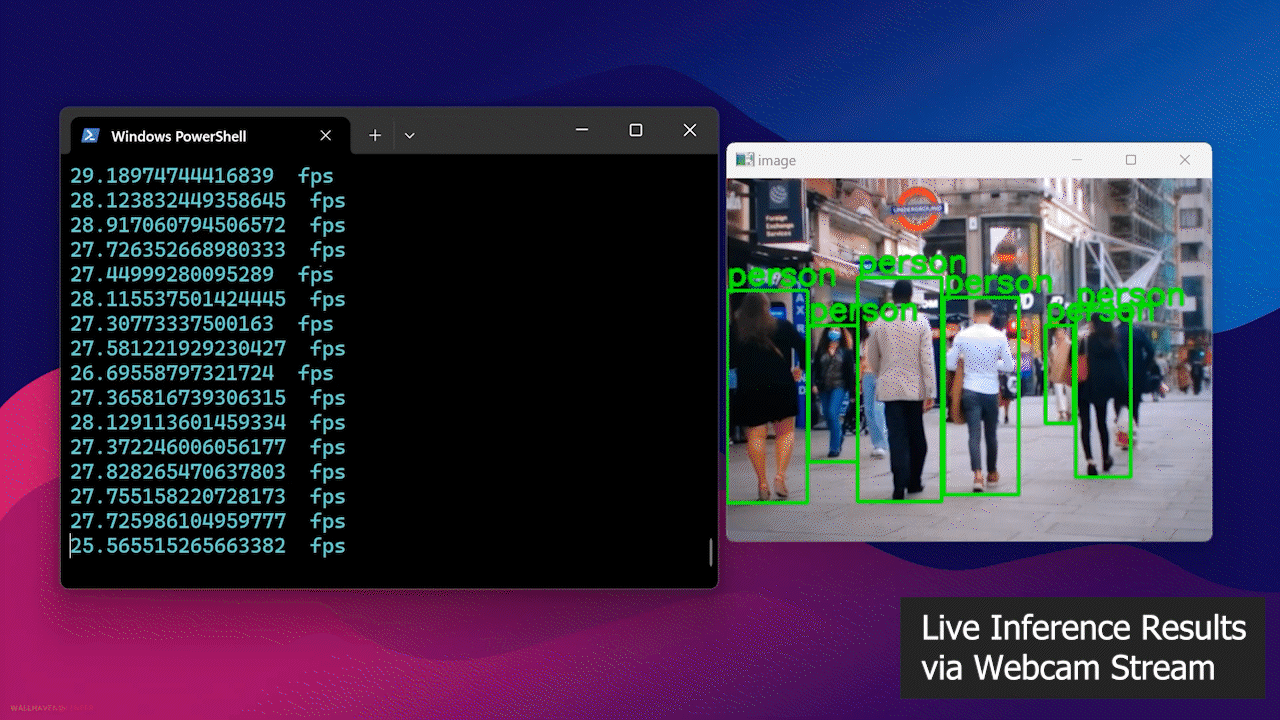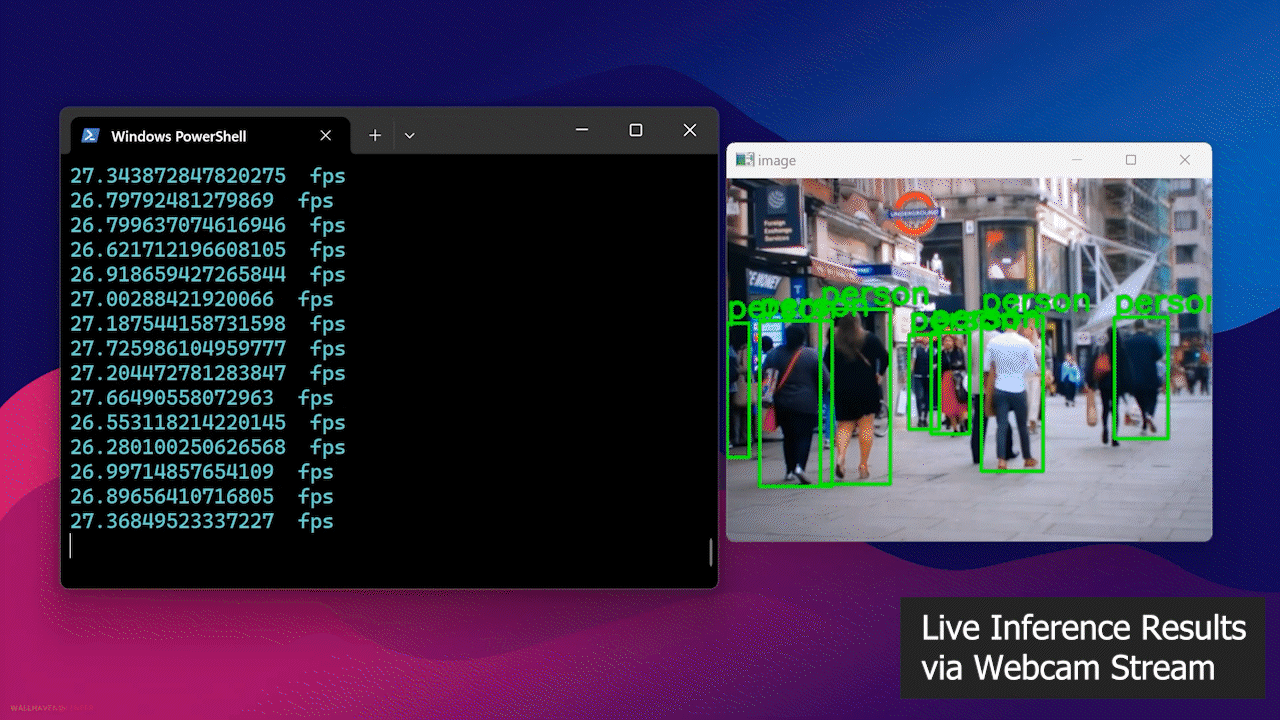
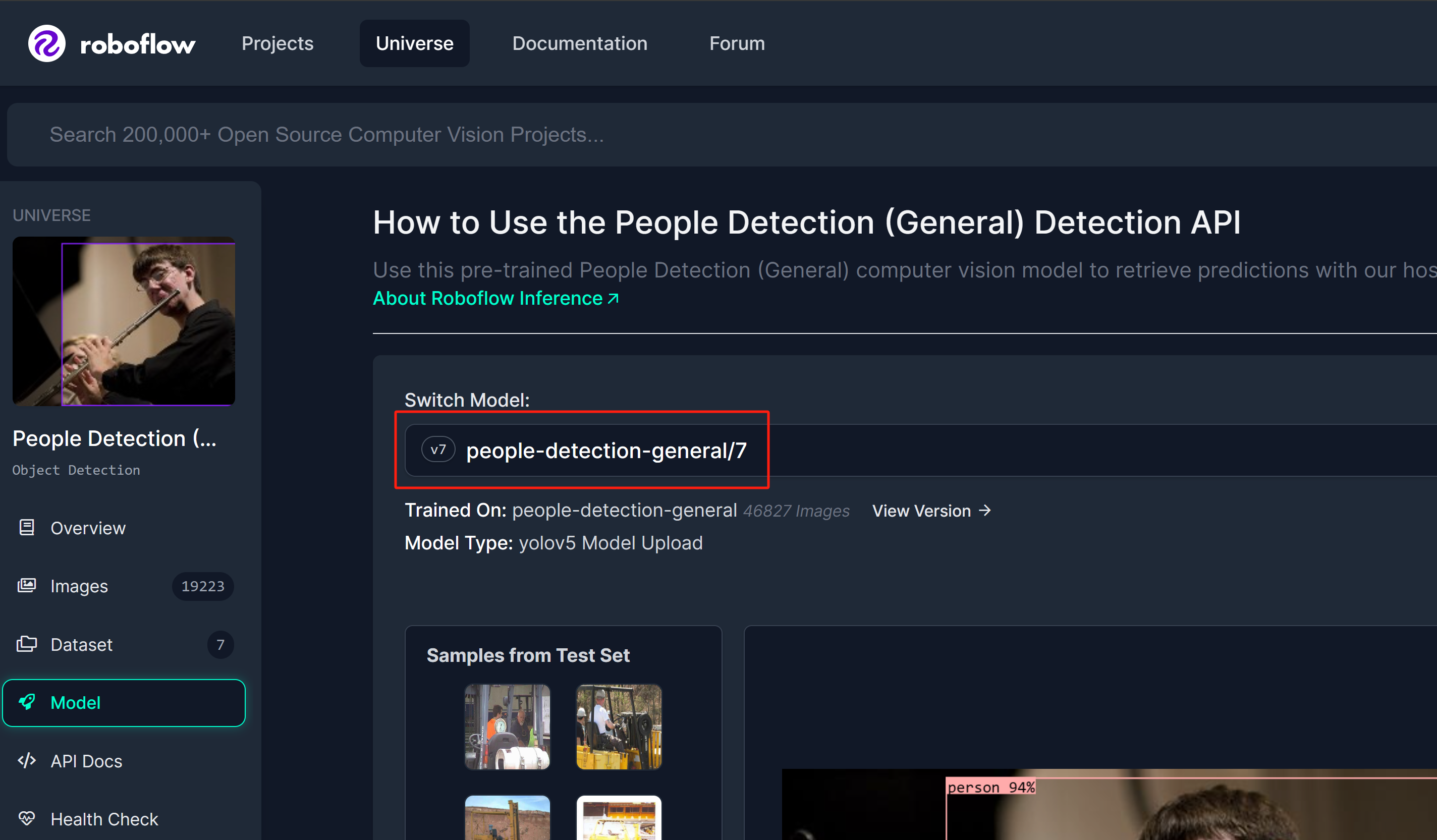
Paso 1: Usaremos un modelo de detección de personas de Roboflow Universe como referencia
-
Paso 2: Aquí el nombre del modelo seguirá el formato "nombre_modelo/versión". En este caso, es people-detection-general/7. Usaremos este nombre de modelo más adelante en esta wiki cuando comencemos la inferencia.
Obtener Clave API de Roboflow
Ahora necesitamos obtener una clave API de Roboflow para que funcione el servidor de inferencia de Roboflow.
-
Paso 1: Regístrate para una nueva cuenta de Roboflow ingresando tus credenciales
-
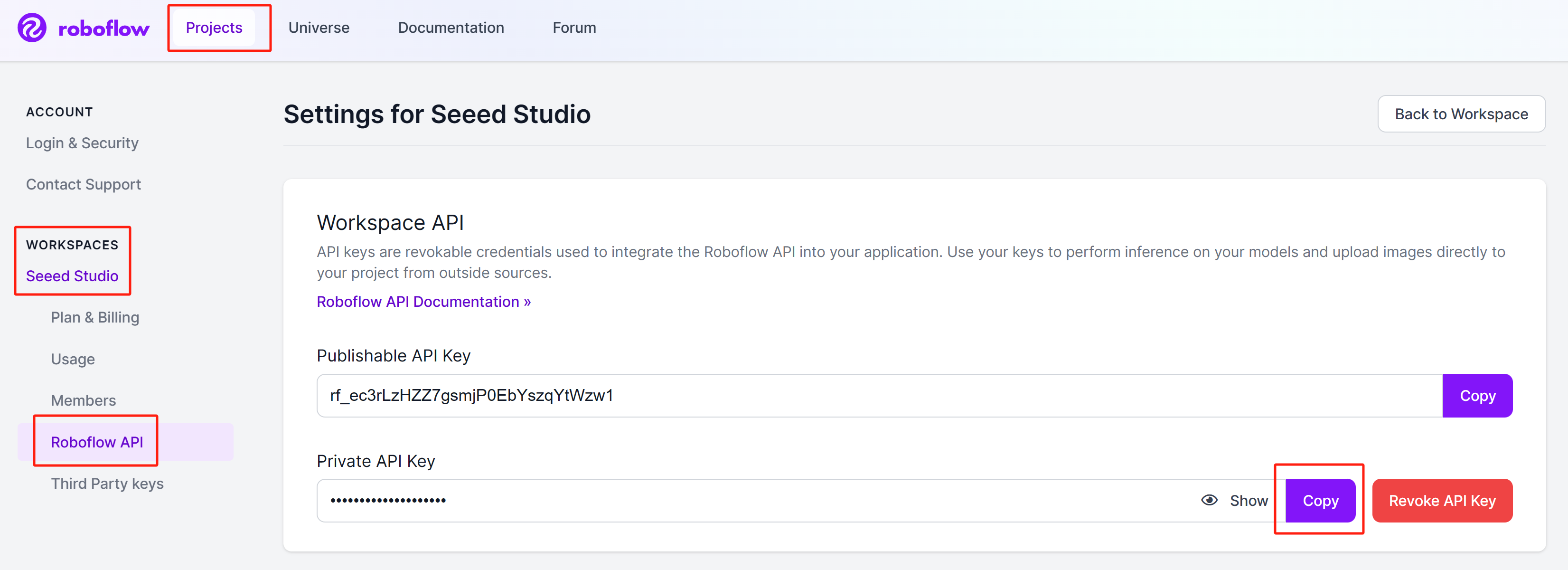
Paso 2: Inicia sesión en la cuenta, navega a
Projects > Workspaces > <nombre_de_tu_workspace> > Roboflow API, y haz clic en Copy junto a la sección "Private API Key"
Guarda esta clave privada porque la necesitaremos más adelante.
Ejecutando el Servidor de Inferencia de Roboflow
Puedes comenzar con Roboflow inference en NVIDIA Jetson de 3 maneras diferentes.
- Usando paquete pip - Usar el paquete pip será la forma más rápida de comenzar, sin embargo necesitarás instalar componentes SDK (CUDA, cuDNN, TensorRT) junto con JetPack.
- Usando Docker hub - Usar Docker hub será un poco lento porque primero descargará una imagen de Docker que es de alrededor de 19GB. sin embargo no necesitas instalar componentes SDK porque la imagen de Docker ya los tendrá.
- Usando construcción local de Docker - Usar construcción local de Docker es una extensión del método de Docker hub donde puedes cambiar el código fuente para la imagen de Docker según tu aplicación deseada (como habilitar precisión de TensorRT con INT8).
Antes de continuar con la ejecución del servidor de inferencia de Roboflow, necesitas obtener un modelo de IA para hacer inferencia, y una clave API de Roboflow. Primero revisaremos eso.
- pip Package
- Docker Hub
- Local Docker Build
Usando paquete pip
- Paso 1: Si solo flasheas el dispositivo Jetson con Jetson L4T, necesitas instalar primero los componentes SDK
sudo apt update
sudo apt install nvidia-jetpack -y
- Paso 2: Ejecuta los siguientes comandos en la terminal para instalar el paquete pip del servidor de inferencia de Roboflow
sudo apt update
sudo apt install python3-pip -y
pip install inference-gpu
Paso 3: Ejecuta lo siguiente y reemplaza con tu Clave de API Privada de Roboflow que obtuviste anteriormente
export ROBOFLOW_API_KEY=your_key_here
- Paso 4: Conecta una cámara web al dispositivo Jetson y ejecuta el siguiente script de Python para ejecutar un modelo de detección de personas de código abierto en tu transmisión de cámara web
webcam.py
import cv2
import inference
import supervision as sv
annotator = sv.BoxAnnotator()
inference.Stream(
source="webcam",
model=" people-detection-general/7",
output_channel_order="BGR",
use_main_thread=True,
on_prediction=lambda predictions, image: (
print(predictions),
cv2.imshow(
"Prediction",
annotator.annotate(
scene=image,
detections=sv.Detections.from_roboflow(predictions)
)
),
cv2.waitKey(1)
)
)
Finalmente, verás el resultado como sigue
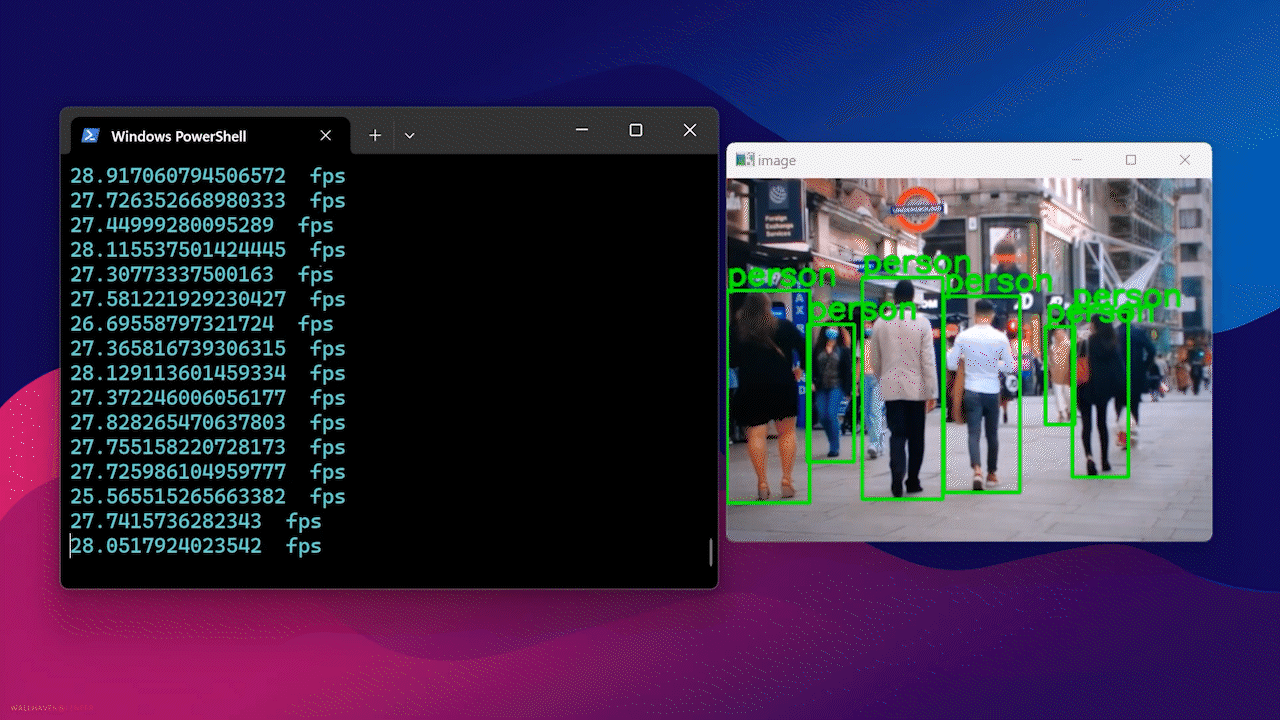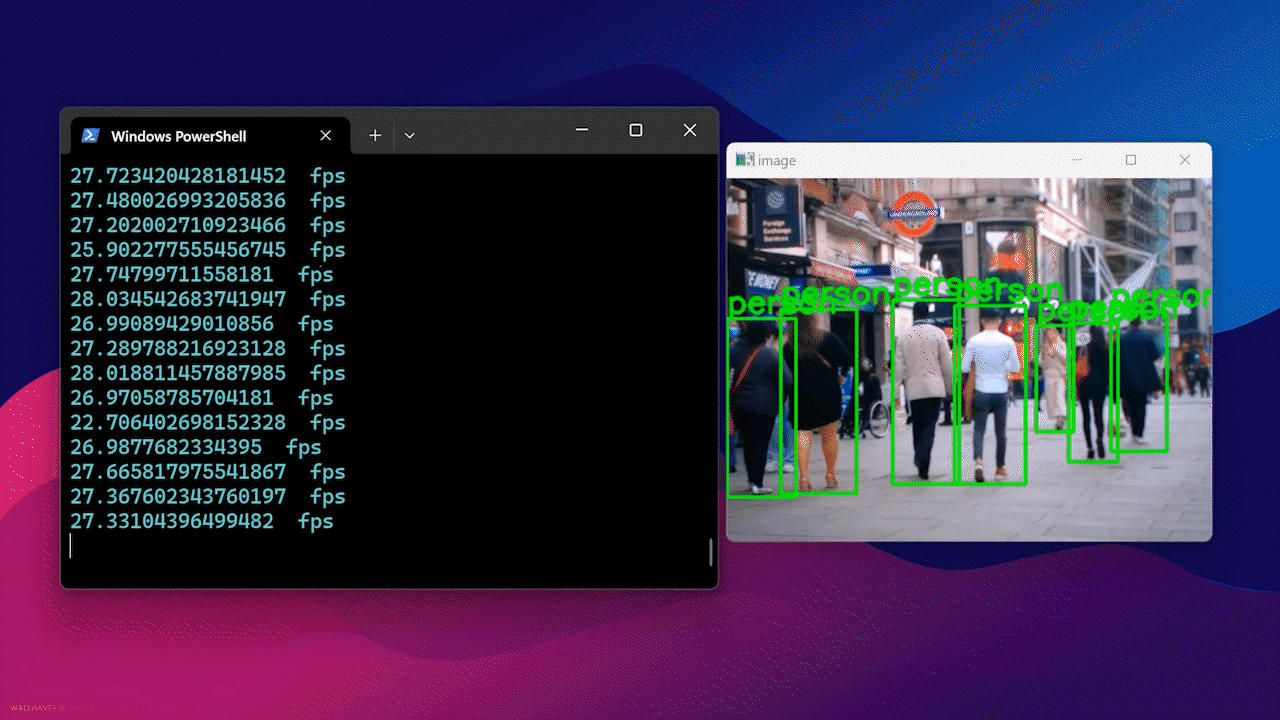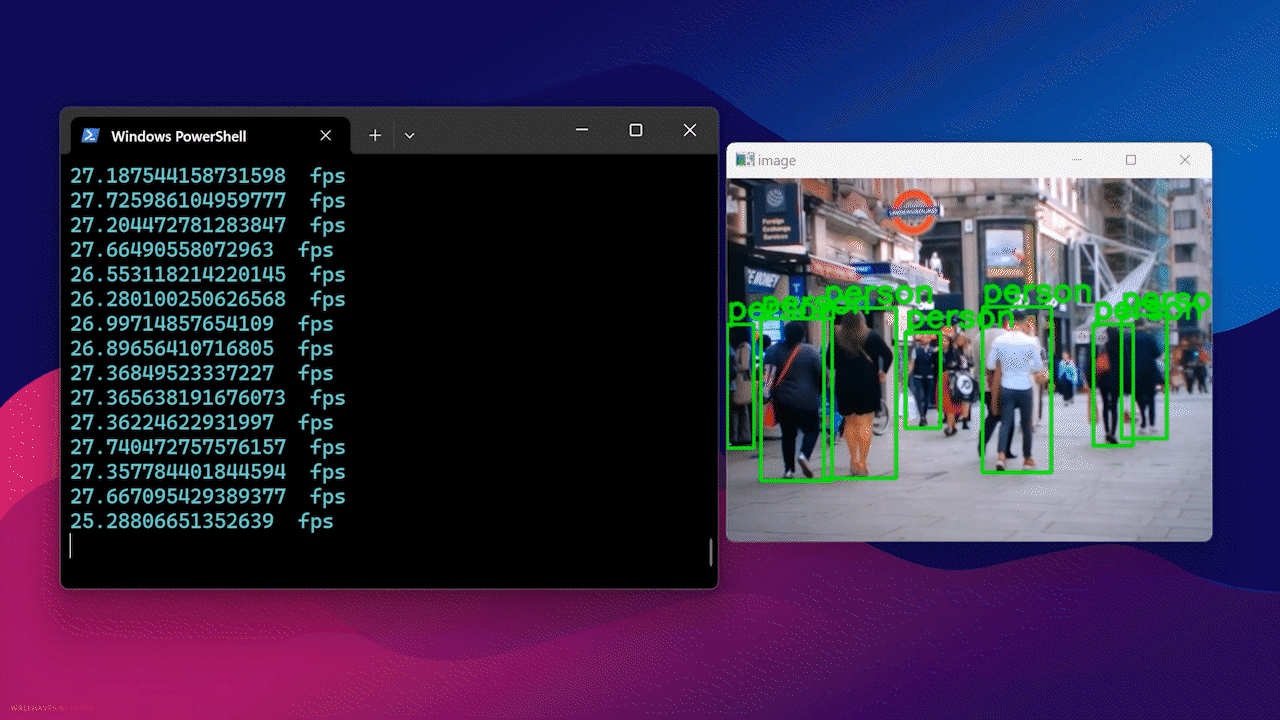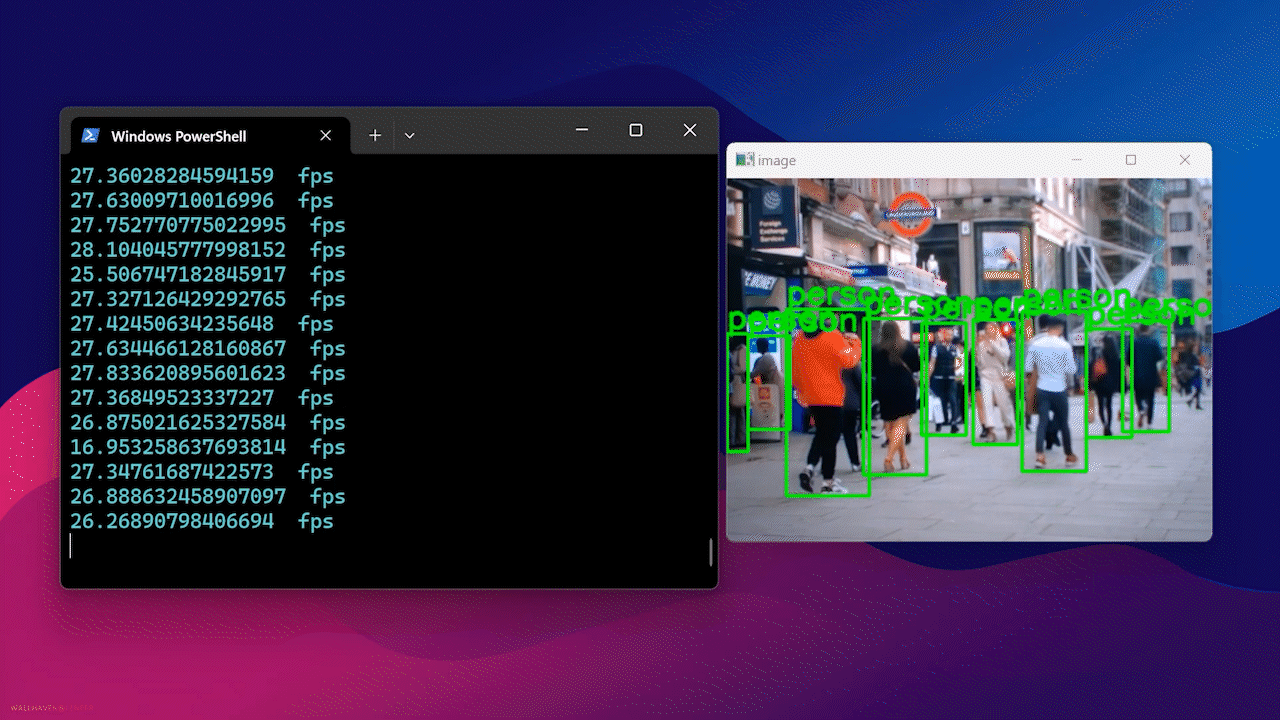
Usando Docker Hub
Para usar este método, es suficiente con flashear el dispositivo con Jetson L4T. Esto utiliza una arquitectura cliente-servidor donde el servidor de inferencia de Roboflow se ejecutará en un puerto de red específico en el Jetson y podrás acceder a este servidor de inferencia usando cualquier PC en la misma red o incluso usar el Jetson como servidor y cliente a la vez.
Configuración del Servidor - Jetson
Ejecuta lo siguiente para descargar y ejecutar el contenedor Docker del servidor de inferencia de Roboflow
sudo docker run --network=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1
Si ves la siguiente salida, el servidor de inferencia se ha iniciado exitosamente

Configuración del Cliente - Jetson/ PC
- Paso 1: Instala los paquetes necesarios
sudo apt update
sudo apt install python3-pip -y
git clone https://github.com/roboflow/roboflow-api-snippets
cd Python/webcam
pip install -r requirements.txt
-
Paso 2: Crea un archivo roboflow_config.json en el mismo directorio incluyendo tu clave API de Roboflow, nombre del modelo. Puedes consultar el archivo de muestra roboflow_config.sample.json incluido dentro de este repositorio de GitHub
-
Paso 3: En el mismo dispositivo en una ventana de terminal diferente o en otra PC en la misma red que el Jetson, ejecuta el siguiente script de Python para ejecutar un modelo de detección de personas de código abierto en tu transmisión de cámara web
python infer-simple.py
Usando Construcción Local Docker
Configuración del Servidor - Jetson
Para usar este método, es suficiente flashear el dispositivo con Jetson L4T. Esto utiliza una arquitectura cliente-servidor donde el servidor de inferencia de Roboflow se ejecutará en un puerto de red específico en el Jetson y podrás acceder a este servidor de inferencia usando cualquier PC en la misma red o incluso usar el Jetson mismo como servidor y cliente a la vez.
- Paso 1: Clona el repositorio del servidor de inferencia de Roboflow
git clone https://github.com/roboflow/inference
- Paso 2: Ingresa al directorio "inference" y comienza a compilar tu propia imagen de Docker
cd inference
sudo docker build \
-f docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1 \
-t roboflow/roboflow-inference-server-jetson-5.1.1:seeed1 .
Aquí el texto después de "-t" es el nombre del contenedor que estamos construyendo. Puedes darle cualquier nombre.
- Paso 3: Ejecuta el siguiente comando para verificar si la imagen de Docker que compilamos está listada
sudo docker ps

- Paso 4: Inicia un contenedor Docker basado en la imagen Docker que acabas de construir
docker run --privileged --net=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1:seeed1
Si ves la siguiente salida, el servidor de inferencia se ha iniciado exitosamente

Configuración del Cliente - Jetson/ PC
Ejecuta el siguiente script de Python para ejecutar un modelo de detección de personas de código abierto en tu transmisión de cámara web webcam.py
import cv2
import base64
import requests
import time
upload_url = ("http://<ip_address_of_jetson>:9001/"
"people-detection-general/7"
"?api_key=xxxxxxxx"
"&stroke=5")
video = cv2.VideoCapture(0)
while True:
start = time.time()
ret, img = video.read()
if ret:
# Resize (while maintaining the aspect ratio) to improve speed and save bandwidth
height, width, channels = img.shape
scale = 416 / max(height, width)
img = cv2.resize(img, (round(scale * width), round(scale * height)))
# Encode image to base64 string
retval, buffer = cv2.imencode('.jpg', img)
img_str = base64.b64encode(buffer)
# Get prediction from Roboflow Infer API
resp = requests.post(upload_url, data=img_str, headers={
"Content-Type": "application/x-www-form-urlencoded"
}, stream=True)
resp = resp.json()
for bbox in resp["predictions"]:
img = cv2.rectangle(
img,
(int(bbox['x']-(bbox['width']/2)), int(bbox['y']-(bbox['height']/2))),
(int(bbox['x']+(bbox['width']/2)), int(bbox['y']+(bbox['height']/2))),
(0, 255, 0),
2)
cv2.putText(
img, f"{bbox['class']}",
(int(bbox['x']-(bbox['width']/2)), int(bbox['y']-(bbox['height']/2)-5)),
0, 0.9,
(0, 255, 0), thickness=2, lineType=cv2.LINE_AA
)
cv2.imshow('image', img)
print((1/(time.time()-start)), " fps")
if cv2.waitKey(1) == ord('q'):
break
video.release()
cv2.destroyAllWindows()
Tenga en cuenta que los elementos que deben incluirse en la upload_url en el script son:
- Dirección IP del servidor de inferencia de roboflow
- El modelo que desea ejecutar
- Clave API de roboflow
El modelo se puede seleccionar en el universo de roboflow
Habilitar TensorRT
Por defecto, el servidor de inferencia de Roboflow está usando el tiempo de ejecución CUDA. Sin embargo, si desea cambiar al tiempo de ejecución TensorRT para aumentar la velocidad de inferencia, puede agregar lo siguiente dentro del archivo "inference/docker/dockerfiles /Dockerfile.onnx.jetson.5.1.1" y construir la imagen Docker
ENV ONNXRUNTIME_EXECUTION_PROVIDERS=TensorrtExecutionProvider
Aprende más
Roboflow ofrece documentación muy detallada y completa. Por lo tanto, es altamente recomendable revisarla aquí.
Soporte Técnico y Discusión del Producto
¡Gracias por elegir nuestros productos! Estamos aquí para brindarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.