Detección de Cuchillos: Un Modelo de Detección de Objetos desplegado en Triton Inference Server basado en reComputer
El control de seguridad es una alarma de seguridad para la consideración de los pasajeros y los sectores de transporte, manteniendo el peligro alejado, aplicándose usualmente en aeropuertos, estaciones de ferrocarril, estaciones de metro, etc. En el campo de inspección de seguridad existente, las máquinas de inspección de seguridad se despliegan en los pasillos de entrada del transporte público. En general, requiere que múltiples dispositivos trabajen al mismo tiempo.
Sin embargo, el rendimiento de detección de artículos prohibidos en imágenes de rayos X aún no es ideal debido a la superposición de objetos detectados durante la inspección de seguridad. Para este asunto, basado en el módulo de des-oclusión en el Triton Interface Server, desplegar un algoritmo de detección de artículos prohibidos en las imágenes de rayos X puede realizar una mejor manera.
Por lo tanto, gracias a Yanlu Wei, Renshuai Tao et al., proporcionamos este proyecto fundamental donde vamos a desplegar un modelo de Deep Learning en reComputer J1010 que podría detectar artículos prohibidos (cuchillos) con la Raspberry Pi y el reComputer J1010 donde usamos un reComputer J1010 como nuestro servidor de inferencia y dos Raspberry Pi para simular máquinas de inspección de seguridad enviando imágenes. El reComputer 1020, reComputer J2011, reComputer J2012 y Nvidia Jetson AGX Xavier son todos compatibles.
Comenzando
Triton Inference Server proporciona una solución de inferencia en la nube y en el borde, optimizada tanto para CPUs como GPUs. Triton soporta un protocolo HTTP/REST y GRPC que permite a clientes remotos solicitar inferencia para cualquier modelo siendo gestionado por el servidor. Aquí vamos a usar Triton (Triton Inference Server) como nuestro servidor local que desplegará el modelo de detección.
Hardware
Hardware Requerido
En este proyecto los dispositivos requeridos se muestran a continuación:
- Raspberry Pi 4B*2
- reComputer J1010
- Pantalla HDMI, ratón y teclado
- PC
Configuración de Hardware
Dos Raspberry Pi y reComputer deben estar encendidos y todos ellos deben estar bajo la misma internet. En este proyecto, usamos dos Raspberry pi para simular el trabajo de la máquina de seguridad ya que las máquinas de inspección de seguridad son usadas por múltiples dispositivos en la mayoría de instancias. Por lo tanto, ambos
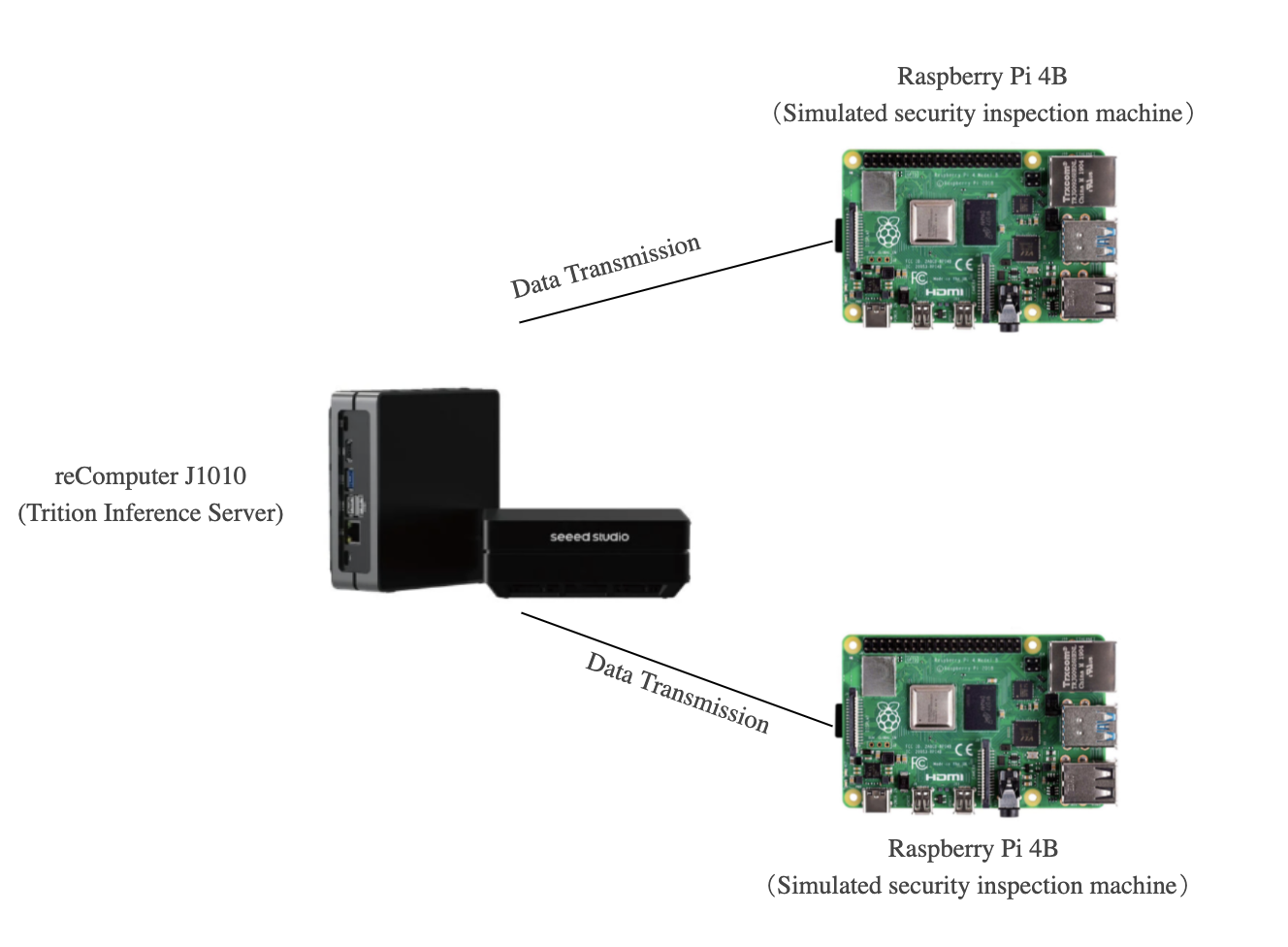
Solo una Raspberry Pi también podría aplicarse a este proyecto. Sin embargo, la demostración de detección simultánea de cuchillos en dos dispositivos podría ofrecer mejores capacidades de agrupamiento dinámico del Triton Inference Server. En la siguiente instrucción, te introduciremos cómo configurar el software en Raspberry Pi y reComputer J1010.
Software
Aquí usamos dataset de imágenes de rayos X como nuestros datos de entrada que serán colocados en la Raspberry Pi. Después de eso, reComputer enviará los resultados de inferencia procesados a la Raspberry Pi. Al final, la Raspberry Pi completará el trabajo final y mostrará en la pantalla, es decir, la última capa del modelo de inferencia será desplegada en la Raspberry Pi.
Configurar Raspberry Pi
Aquí te mostraremos cómo configurar los softwares requeridos en Raspberry Pi, incluyendo
Paso 1. Instalar el sistema Raspbian Buster y configuración básica desde el sitio web oficial. En este proyecto, usamos RASPBERRY PI OS(64 bit) como nuestro sistema operativo.
Paso 2. Configurar el puerto SSH de Raspberry Pi (opcional).
Antes de desplegar el entorno, podemos abrir el puerto SSH de Raspberry Pi y llamarlo remotamente usando la interfaz SSH en la PC.
Aviso: asegúrate de que la PC y Raspberry Pi estén bajo la misma LAN.
Paso 3. Configurar el entorno Python.
Necesitamos desplegar los entornos requeridos para el modelo de inferencia como Python, PyTorch, Tritonclient, y TorchVision. y visualización de imágenes como OpenCV en la Raspberry Pi. Proporcionamos las instrucciones a continuación:
Python
Podemos ejecutar python –V y asegurar que la versión de Python es 3.9.2. Necesitamos instalar PyTorch, Torchclient y TorchVision que las versiones que necesitamos corresponden a la versión de Python 3.9.2. Puedes referirte a aquí para descargar e instalar.
PyTorch
Si la versión de Python es correcta. Ahora podemos instalar Pytorch.
Aviso: Antes de instalar Pytorch, tenemos que verificar la versión de Raspbian.
Ejecuta el comando a continuación para instalar Pytorch:
# obtener un nuevo comienzo
sudo apt-get update
sudo apt-get upgrade
# instalar las dependencias
sudo apt-get install python3-pip libjpeg-dev libopenblas-dev libopenmpi-dev libomp-dev
# arriba de 58.3.0 obtienes problemas de versión
sudo -H pip3 install setuptools==58.3.0
sudo -H pip3 install Cython
# instalar gdown para descargar desde Google drive
sudo -H pip3 install gdown
# Buster OS
# descargar el wheel
gdown https://drive.google.com/uc?id=1gAxP9q94pMeHQ1XOvLHqjEcmgyxjlY_R
# instalar PyTorch 1.11.0
sudo -H pip3 install torch-1.11.0a0+gitbc2c6ed-cp39-cp39-linux_aarch64.whl
# limpiar
rm torch-1.11.0a0+gitbc2c6ed-cp39-cp39m-linux_aarch64.whl
Después de una instalación exitosa, podemos verificar PyTorch con los siguientes comandos después de iniciar python:
import torch as tr
print(tr.__version__)
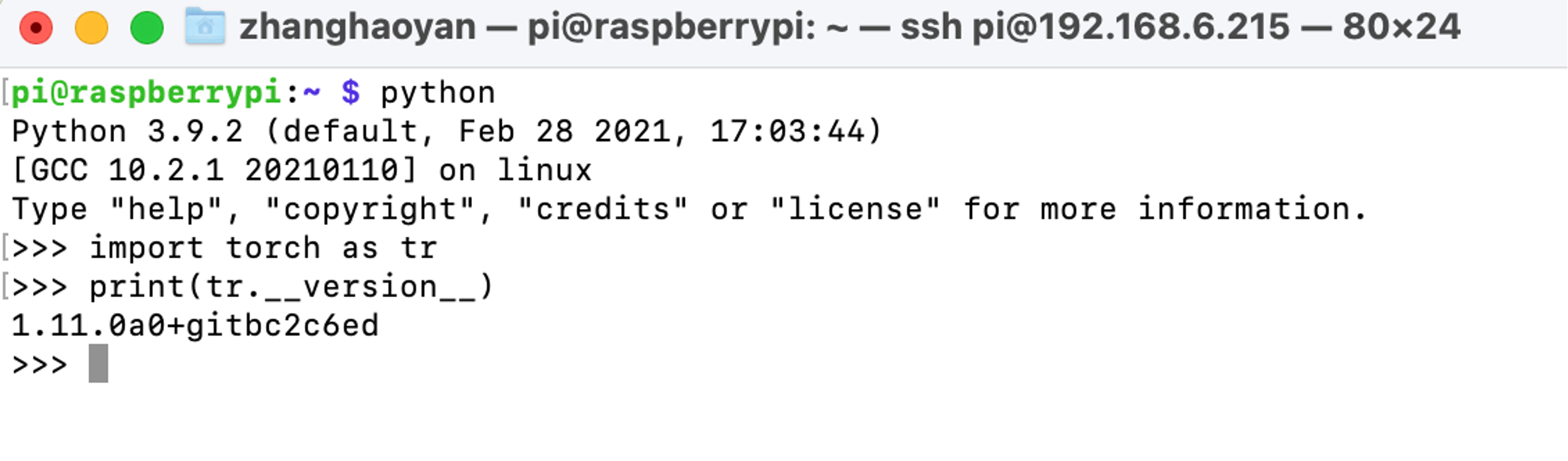
Aviso: Las ruedas de PyTorch para Raspberry Pi 4 se pueden encontrar en https://github.com/Qengineering/PyTorch-Raspberry-Pi-64-OS
Tritonclient
Podemos ejecutar pip3 install tritonclient[all] para descargar Tritonclient.
TorchVision
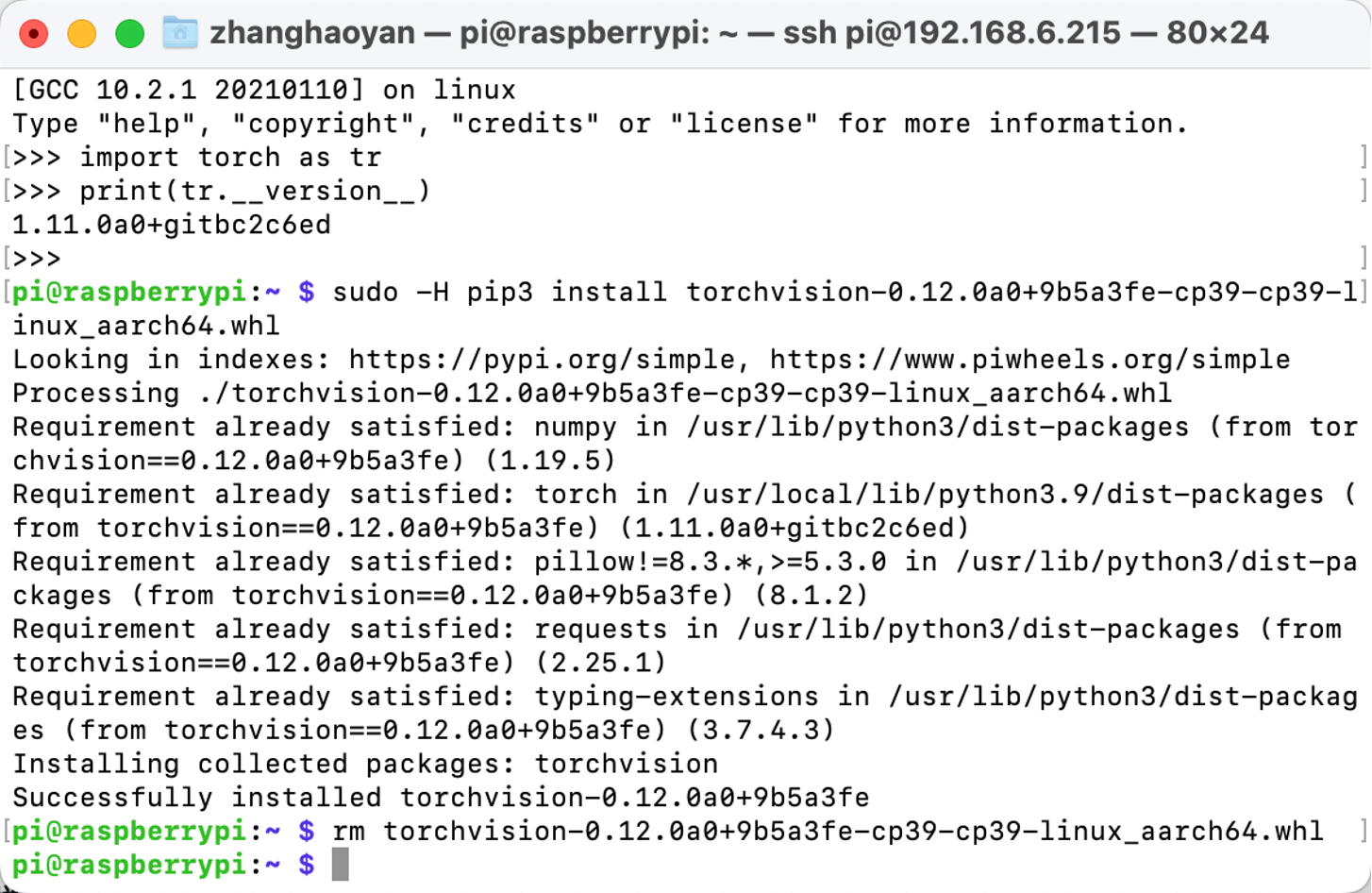
Después de que Pytorch fue instalado, podemos pasar a la instalación de Torchvision. Aquí están los comandos:
# descargar la rueda
gdown https://drive.google.com/uc?id=1oDsJEHoVNEXe53S9f1zEzx9UZCFWbExh
# instalar torchvision 0.12.0
sudo -H pip3 install torchvision-0.12.0a0+9b5a3fe-cp39-cp39-linux_aarch64.whl
# limpiar
rm torchvision-0.12.0a0+9b5a3fe-cp39-cp39-linux_aarch64.whl
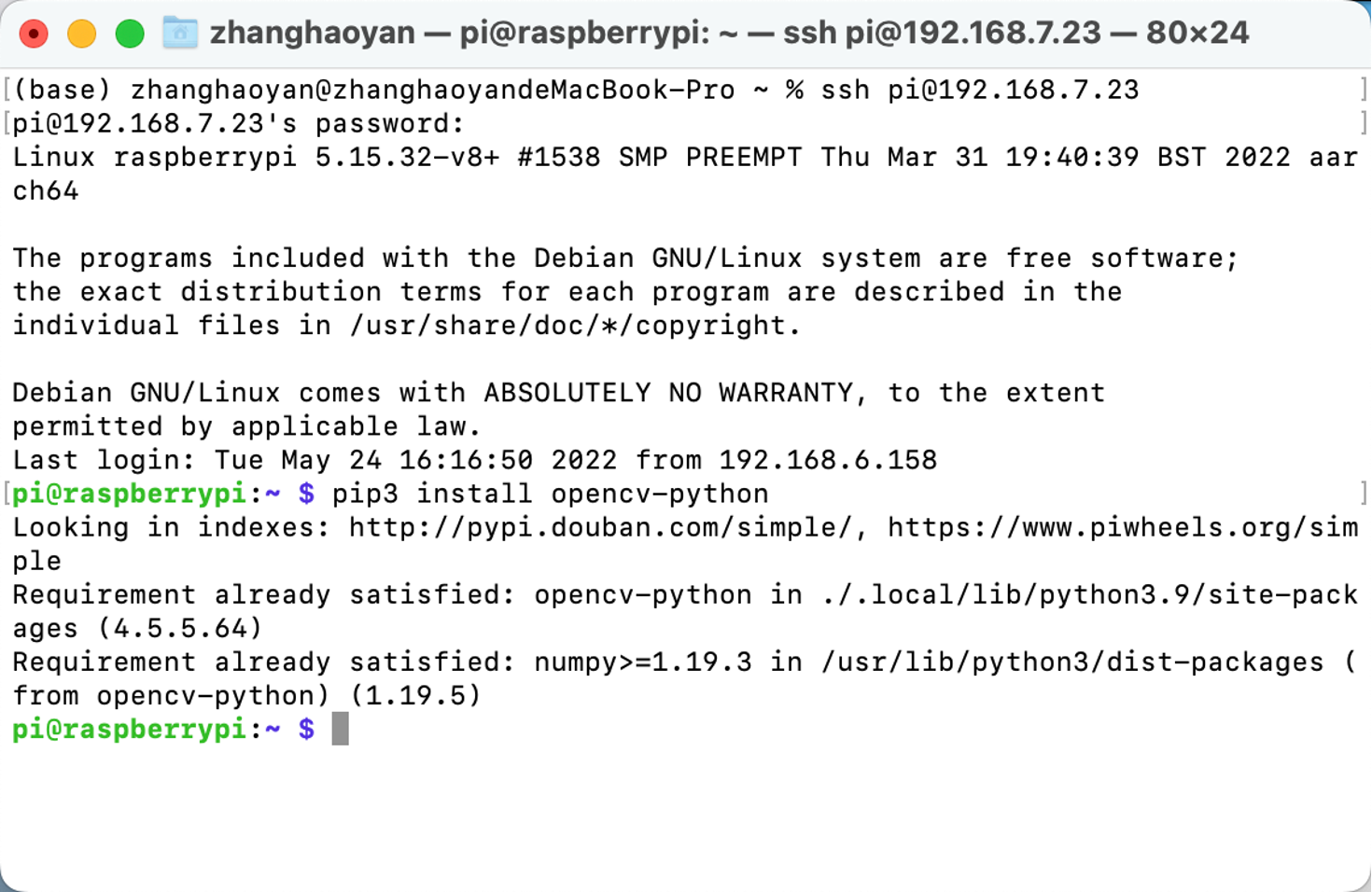
OpenCV
Podemos ejecutar directamente pip3 install opencv-python para instalar OpenCV:
Configurar reComputer J1010
En este proyecto, desplegaremos Triton Inference Server en el reComputer J1010. Para mejorar la interactividad y conveniencia de despliegue del modelo entrenado, convertiremos el modelo al formato ONXX.
Paso 1. Instalar Jetpack 4.6.1 en reComputer J1010.
Paso 2. Crear una nueva carpeta "opi/1" en "home/server/docs/examples/model_repository ". y luego descargar el model.onnx entrenado y convertido y ponerlo en la carpeta "1".
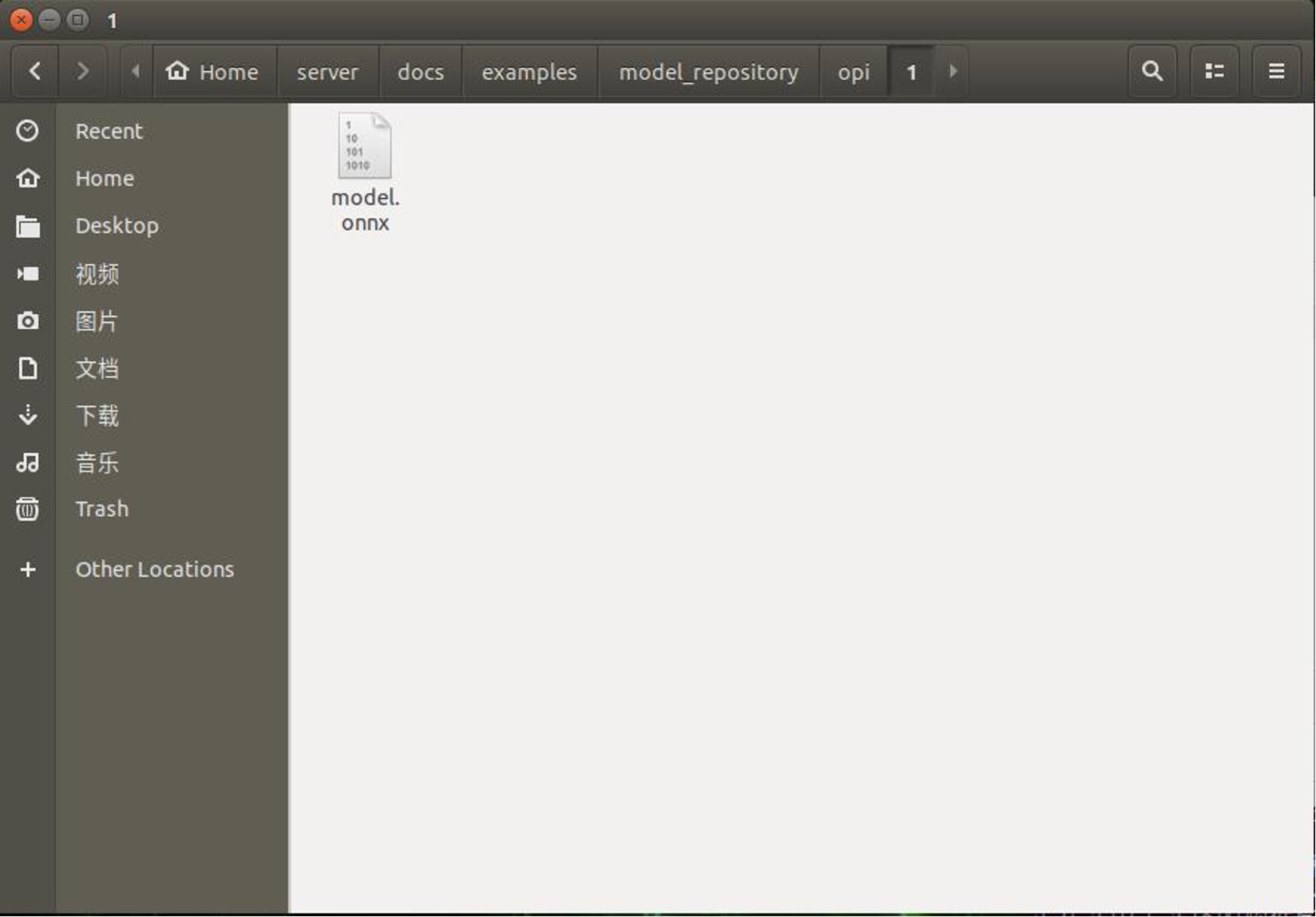
Si necesitas otro servidor general, puedes ejecutar los siguientes pasos.
Abrir una nueva Terminal y ejecutar
git clone https://github.com/triton-inference-server/server
cd ~/server/docs/examples
sh fetch_models.sh
Paso 3. Instalar la versión de Triton para JetPack 4.6.1 y se proporciona en el archivo tar adjunto: tritonserver2.21.0-jetpack5.0.tgz.
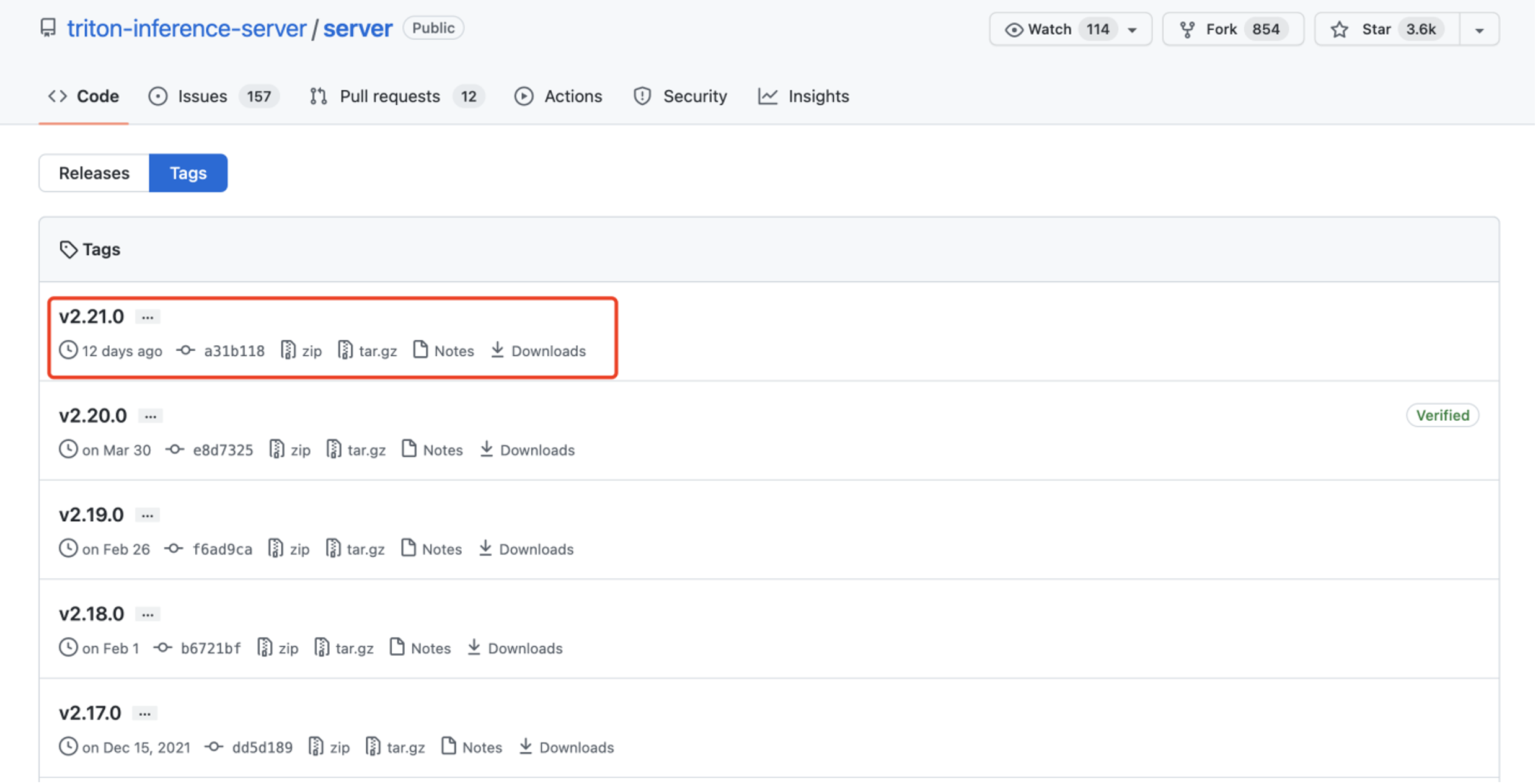
El archivo tar aquí contiene el ejecutable del servidor Triton y las bibliotecas compartidas incluyendo las bibliotecas cliente de C++ y Python y ejemplos. Para más información sobre cómo instalar y usar Triton en JetPack puedes consultar aquí.
Paso 4. Ejecutar el siguiente comando:
mkdir ~/TritonServer && tar -xzvf tritonserver2.19.0-jetpack4.6.1.tgz -C ~/TritonServer
cd ~/TritonServer/bin
./tritonserver --model-repository=/home/seeed/server/docs/examples/model_repository --backend-directory=/home/seeed/TritonServer/backends --strict-model-config=false --min-supported-compute-capability=5.3
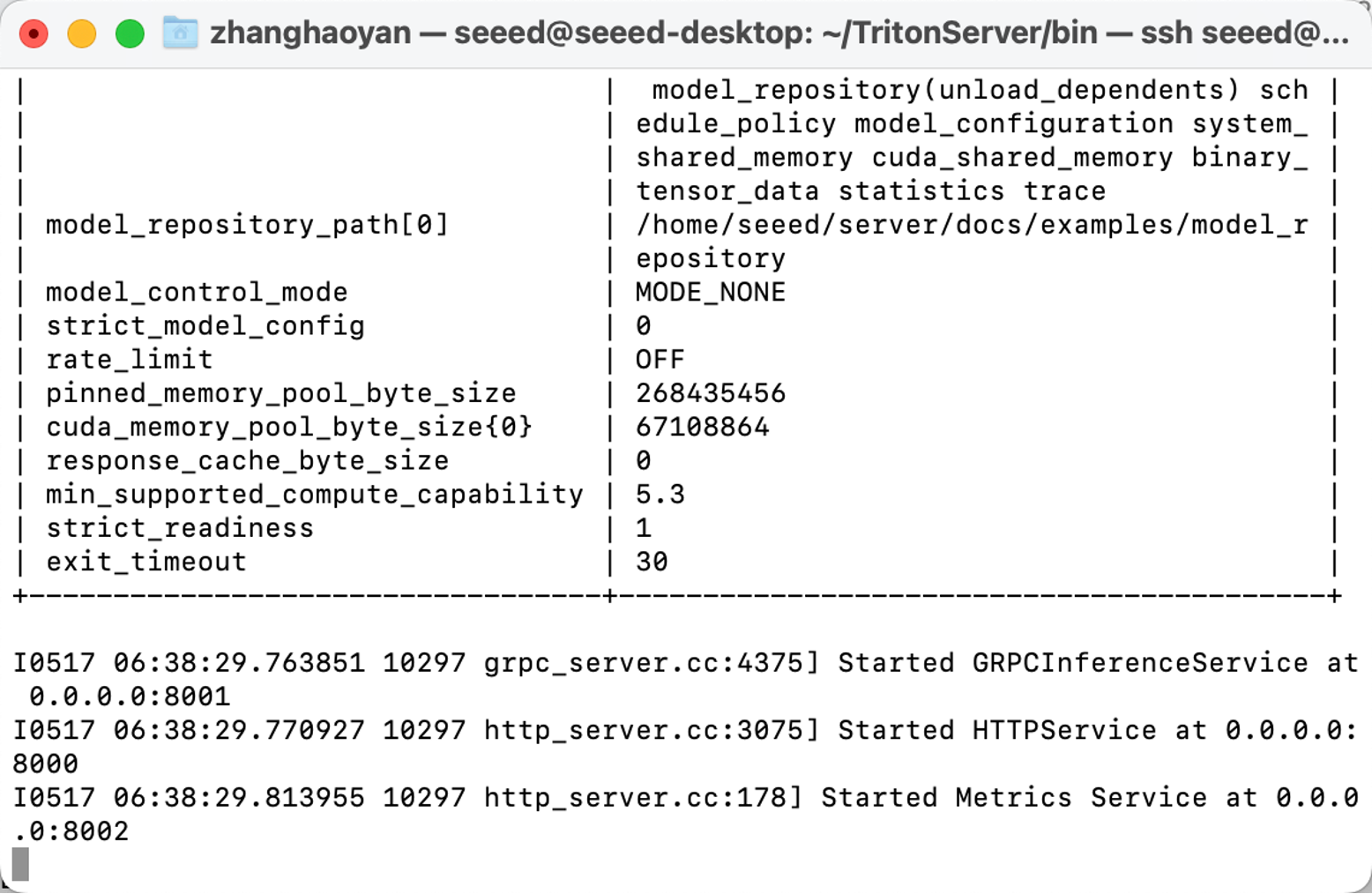
Ahora, hemos configurado todos los preparativos.
Operando el Programa
Dado que todos los entornos requeridos están desplegados, podemos ejecutar nuestro proyecto siguiendo los siguientes pasos.
Paso 1. Descargar modelo y archivos relacionados.
- Clonar módulo desde GitHub.
Abrir una nueva Terminal y ejecutar:.
git clone https://github.com/LemonCANDY42/Seeed_SMG_AIOT.git
cd Seeed_SMG_AIOT/
git clone https://github.com/LemonCANDY42/OPIXray.git
- Crear una nueva carpeta "weights" para almacenar el peso entrenado de este algoritmo "DOAM.pth". Descargar el archivo de peso y ejecutar:
cd OPIXray/DOAMmkdir weights
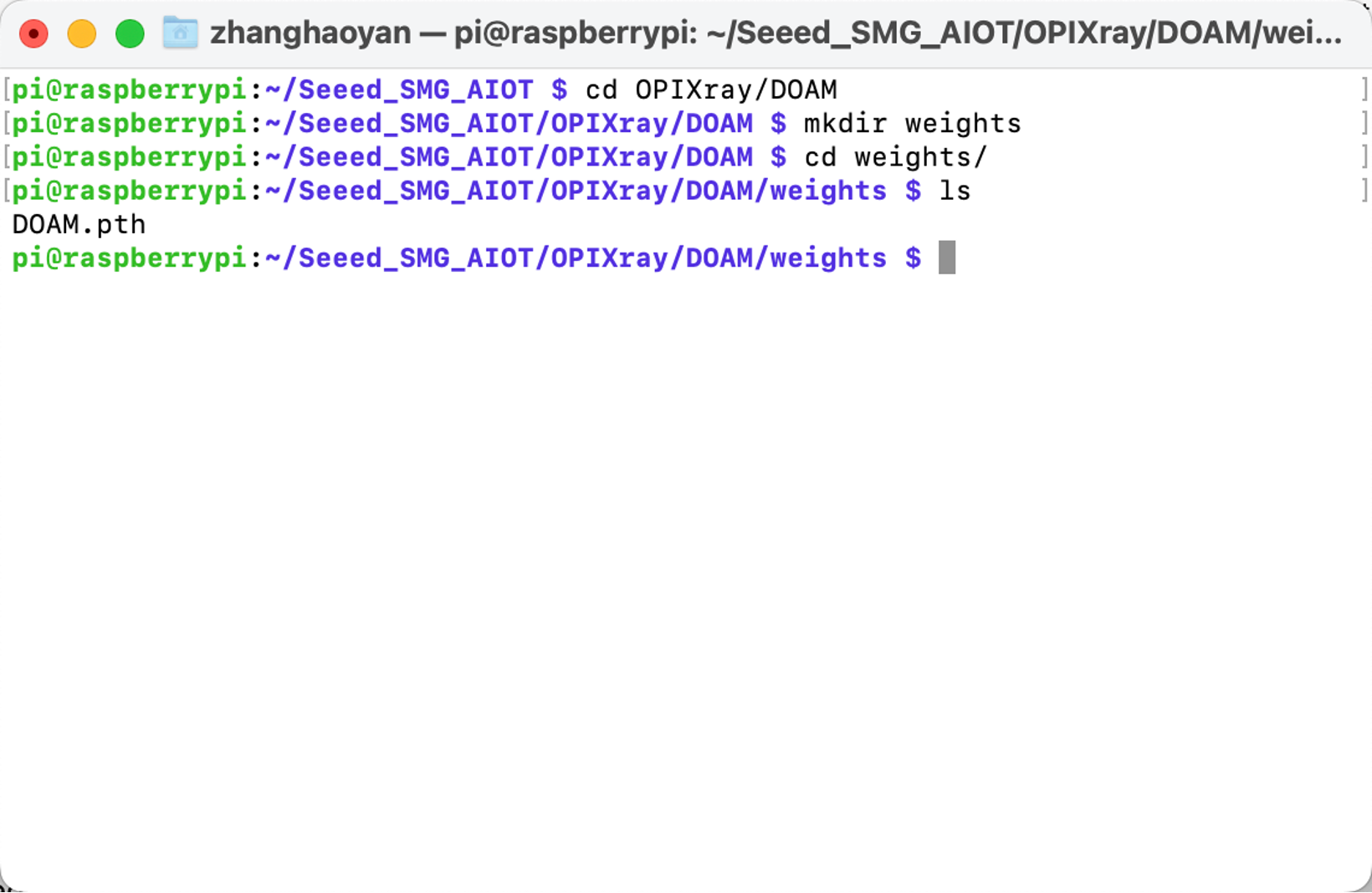
- Crear una nueva carpeta "Dataset" para almacenar el conjunto de datos de imágenes Xray.
Paso 2. Ejecutando modelo de inferencia.
Ejecutar python OPIXray_grpc_image_client.py -u 192.168.8.230:8001 -m opi Dataset
El resultado se mostrará como la figura a continuación:

Solución de Problemas
Cuando inicies el servidor Triton, puedes encontrar los siguientes errores:
- si hay error con libb64.so.0d, ejecutar:
sudo apt-get install libb64-0d
- si hay error con libre2.so.2, ejecutar:
sudo apt-get install libre2-dev
- si error: creating server: Internal - failed to load all models, ejecutar:
--exit-on-error=false
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para proporcionarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para atender diferentes preferencias y necesidades.