Entrena y Despliega Tu Propio Modelo de IA en SenseCAP A1101
Descripción General
En esta wiki, te enseñaremos cómo entrenar tu propio modelo de IA para tu aplicación específica y luego desplegarlo fácilmente en el SenseCAP A1101 - Sensor de Visión IA LoRaWAN. ¡Comencemos!
Nuestro firmware actual del dispositivo es compatible con EI. Si compraste el dispositivo después del 30 de marzo de 2023, necesitas flashear el dispositivo de vuelta al firmware predeterminado para seguir esta wiki.
Introducción al hardware
Utilizaremos principalmente el SenseCAP A1101 - Sensor de Visión IA LoRaWAN a lo largo de esta wiki. Así que primero, familiaricémonos con este hardware.
SenseCAP A1101 - Sensor de Visión IA LoRaWAN combina la tecnología de IA TinyML y la transmisión de largo alcance LoRaWAN para habilitar una solución de dispositivo de IA de bajo consumo y alto rendimiento para uso exterior. Este sensor cuenta con la solución de visión de IA de alto rendimiento y bajo consumo de Himax que soporta el framework Google TensorFlow Lite y múltiples plataformas de IA TinyML. Diferentes modelos pueden implementar diferentes funciones de IA, por ejemplo, detección de plagas, conteo de personas, reconocimiento de objetos. Los usuarios pueden adoptar modelos proporcionados por Seeed, generar sus propios modelos a través de herramientas de entrenamiento de IA, o adquirir modelos comerciales desplegables de los proveedores de modelos socios de Seeed.

Introducción al software
Utilizaremos las siguientes tecnologías de software en esta wiki
- Roboflow - para anotar
- YOLOv5 - para entrenar
- TensorFlow Lite - para inferencia

¿Qué es Roboflow?
Roboflow es una herramienta de anotación basada en línea. Esta herramienta te permite anotar fácilmente todas tus imágenes, añadir procesamiento adicional a estas imágenes y exportar el conjunto de datos etiquetado en diferentes formatos como YOLOV5 PyTorch, Pascal VOC, ¡y más! Roboflow también tiene conjuntos de datos públicos disponibles para los usuarios.
¿Qué es YOLOv5?
YOLO es una abreviación del término 'You Only Look Once' (Solo Miras Una Vez). Es un algoritmo que detecta y reconoce varios objetos en una imagen en tiempo real. Ultralytics YOLOv5 es la versión de YOLO basada en el framework PyTorch.
¿Qué es TensorFlow Lite?
TensorFlow Lite es un framework de aprendizaje profundo multiplataforma, listo para producción y de código abierto que convierte un modelo pre-entrenado en TensorFlow a un formato especial que puede ser optimizado para velocidad o almacenamiento. El modelo de formato especial puede ser desplegado en dispositivos edge como móviles usando Android o iOS o dispositivos embebidos basados en Linux como Raspberry Pi o Microcontroladores para hacer la inferencia en el Edge.
Estructura del Wiki
Este wiki se dividirá en tres secciones principales
- Entrena tu propio modelo de IA con un conjunto de datos público
- Entrena tu propio modelo de IA con tu propio conjunto de datos
- Despliega el modelo de IA entrenado en SenseCAP A1101
La primera sección será la forma más rápida de construir tu propio modelo de IA con el menor número de pasos. La segunda sección tomará algo de tiempo y esfuerzo para construir tu propio modelo de IA, pero definitivamente valdrá la pena el conocimiento. La tercera sección sobre el despliegue del modelo de IA se puede hacer después de la primera o segunda sección.
Así que hay dos formas de seguir este wiki:
Sin embargo, recomendamos seguir la primera forma al principio y luego pasar a la segunda forma.
1. Entrena tu propio modelo de IA con un conjunto de datos público
El primer paso de un proyecto de detección de objetos es obtener datos para el entrenamiento. ¡Puedes descargar conjuntos de datos disponibles públicamente o crear tu propio conjunto de datos!
Pero ¿cuál es la forma más rápida y fácil de comenzar con la detección de objetos? Bueno... Usar conjuntos de datos públicos puede ahorrarte mucho tiempo que de otra manera gastarías recolectando datos por ti mismo y anotándolos. Estos conjuntos de datos públicos ya están anotados listos para usar, dándote más tiempo para enfocarte en tus aplicaciones de visión de IA.
Preparación del hardware
- SenseCAP A1101 - Sensor de Visión IA LoRaWAN
- Cable USB Type-C
- Windows/ Linux/ Mac con acceso a internet
Preparación del software
- No es necesario preparar software adicional
Usar conjunto de datos anotado disponible públicamente
Puedes descargar varios conjuntos de datos disponibles públicamente como el conjunto de datos COCO, conjunto de datos Pascal VOC y muchos más. Roboflow Universe es una plataforma recomendada que proporciona una amplia gama de conjuntos de datos y tiene más de 90,000 conjuntos de datos con más de 66 millones de imágenes disponibles para construir modelos de visión por computadora. También, puedes simplemente buscar conjuntos de datos de código abierto en Google y elegir de una variedad de conjuntos de datos disponibles.
-
Paso 1. Visita esta URL para acceder a un conjunto de datos de Detección de Manzanas disponible públicamente en Roboflow Universe
-
Paso 2. Haz clic en Create Account para crear una cuenta de Roboflow
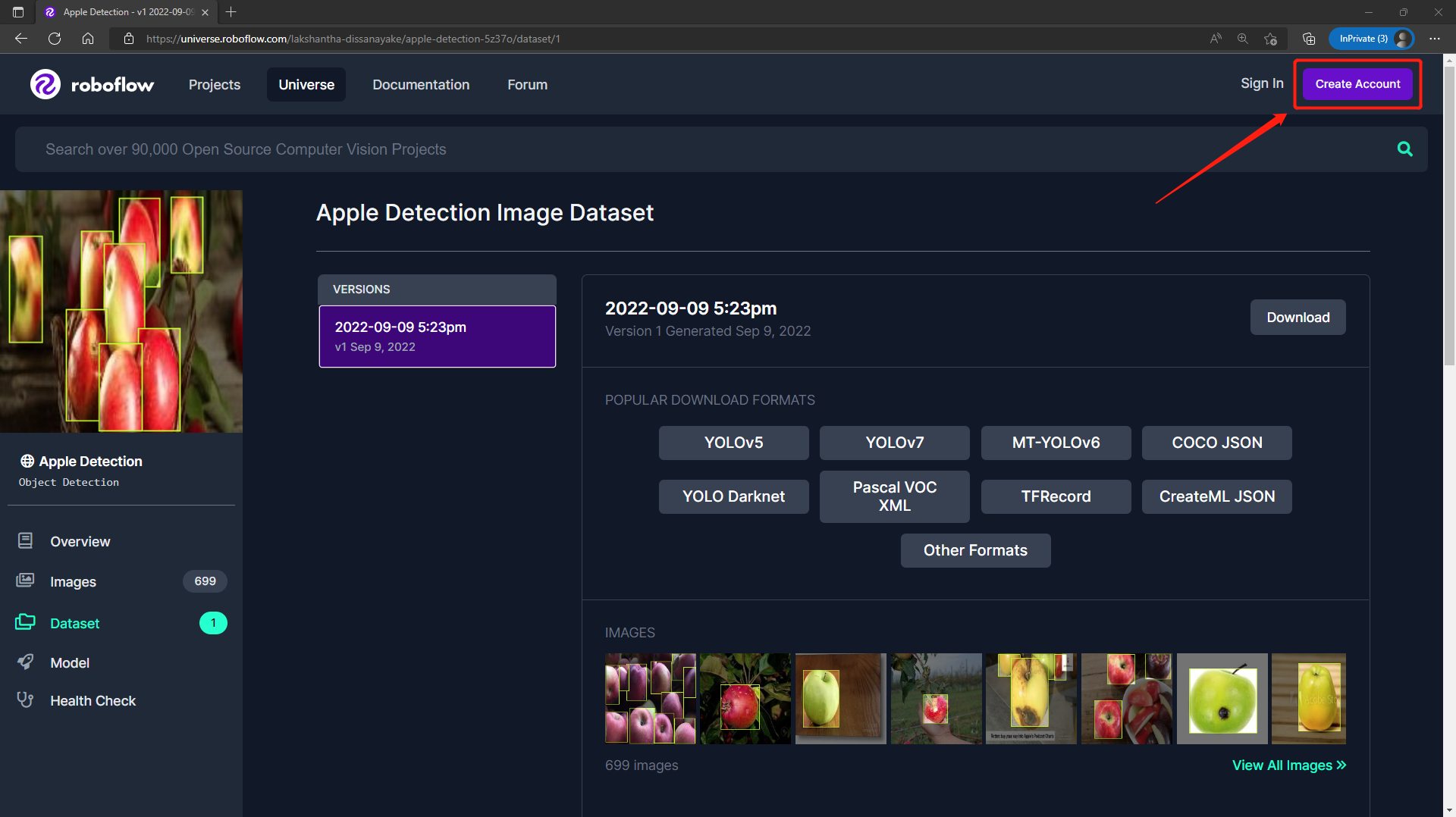
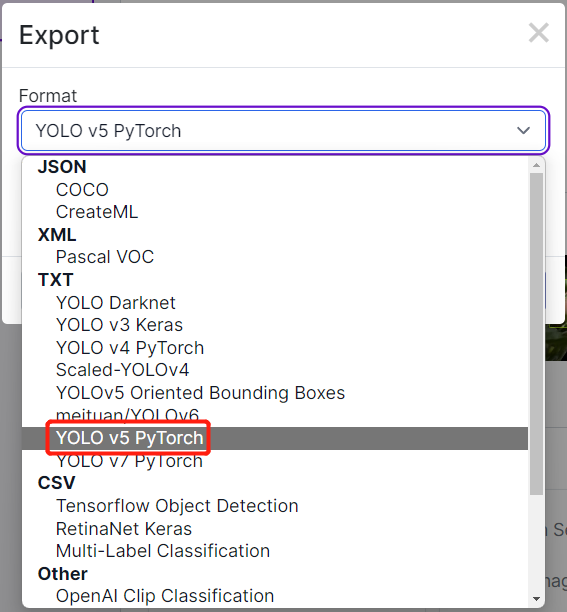
- Paso 3. Haz clic en Download, selecciona YOLO v5 PyTorch como el Format, haz clic en show download code y haz clic en Continue
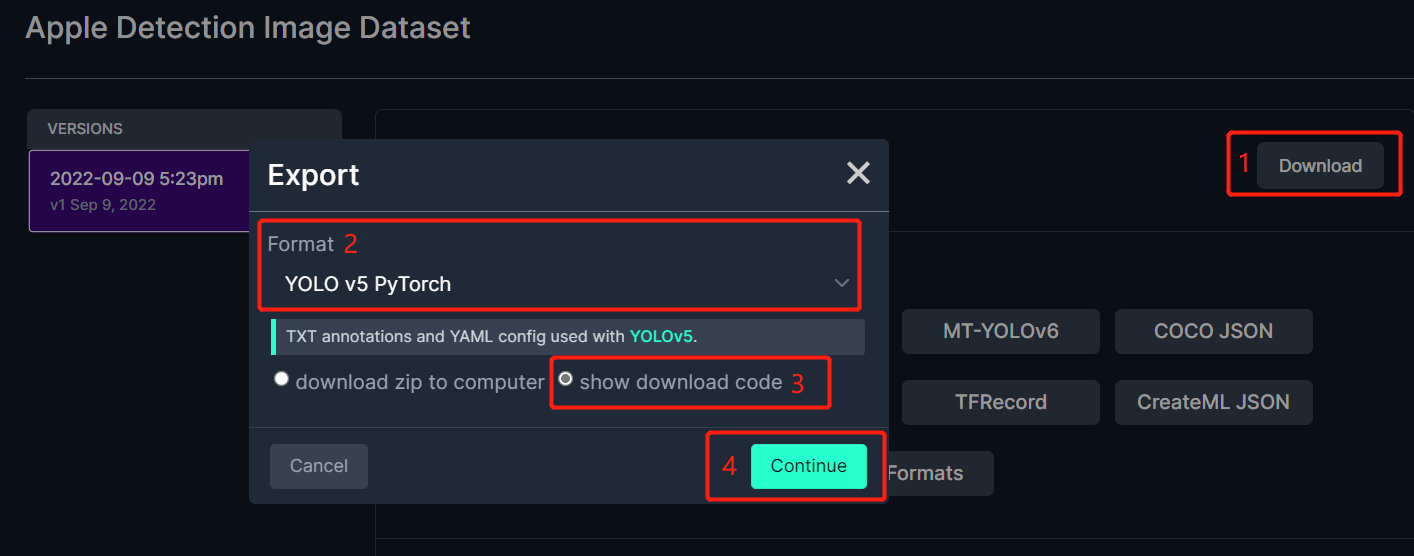
Esto generará un fragmento de código que usaremos más tarde dentro del entrenamiento de Google Colab. Así que por favor mantén esta ventana abierta en segundo plano.
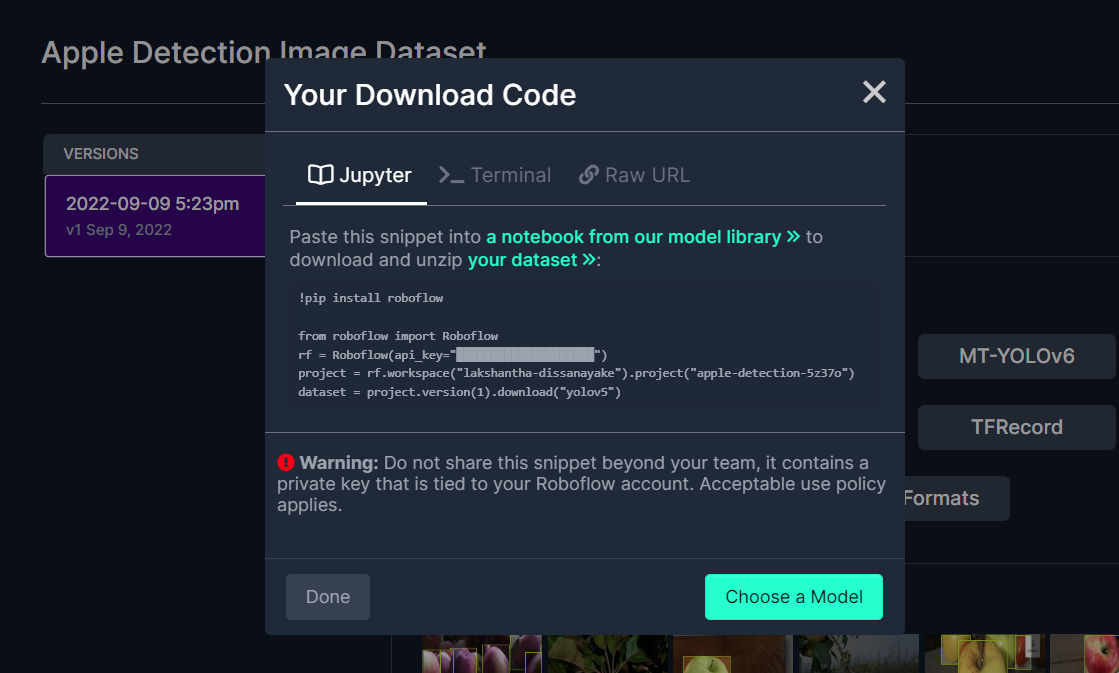
Entrenar usando YOLOv5 en Google Colab
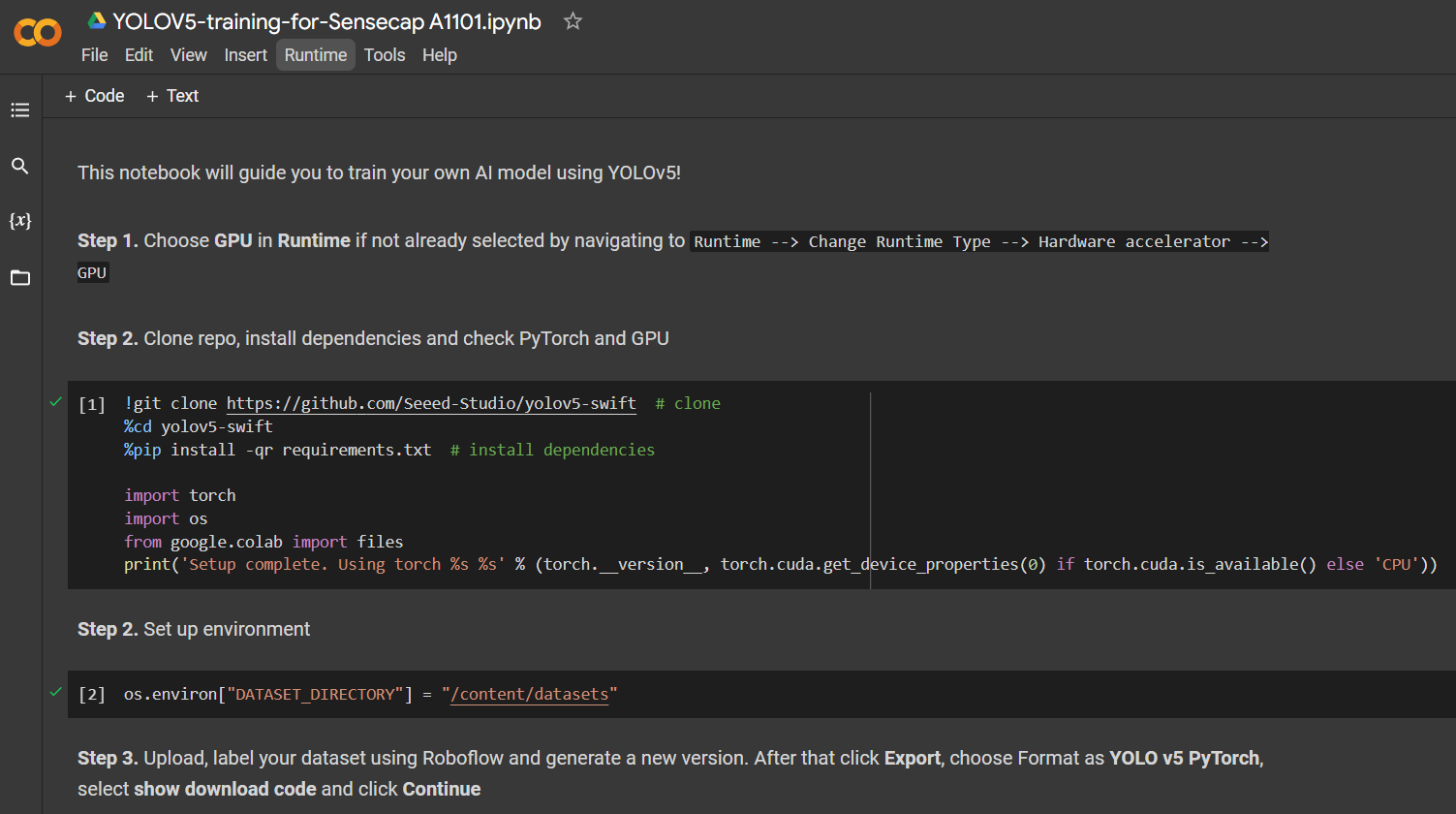
Después de haber elegido un conjunto de datos público, necesitamos entrenar el conjunto de datos. Aquí usamos un entorno de Google Colaboratory para realizar el entrenamiento en la nube. Además, usamos la api de Roboflow dentro de Colab para descargar fácilmente nuestro conjunto de datos.
Haz clic aquí para abrir un espacio de trabajo de Google Colab ya preparado, revisa los pasos mencionados en el espacio de trabajo y ejecuta las celdas de código una por una.
Nota: En Google Colab, en la celda de código bajo Step 4, puedes copiar directamente el fragmento de código de Roboflow como se mencionó anteriormente
Te guiará a través de lo siguiente:
- Configurar un entorno para el entrenamiento
- Descargar un conjunto de datos
- Realizar el entrenamiento
- Descargar el modelo entrenado
Para un conjunto de datos de detección de manzanas con 699 imágenes, tomó alrededor de 7 minutos terminar el proceso de entrenamiento en Google Colab ejecutándose en GPU NVIDIA Tesla T4 con 16GB de memoria GPU.
Si seguiste el proyecto de Colab anterior, sabes que puedes cargar 4 modelos al dispositivo todos a la vez. Sin embargo, ten en cuenta que solo un modelo puede ser cargado a la vez. Esto puede ser especificado por el usuario y se explicará más adelante en este wiki.
Despliegue e inferencia
Si quieres saltar directamente a la sección 3 que explica cómo desplegar el modelo de IA entrenado en SenseCAP A1101 y realizar inferencia, haz clic aquí.
2. Entrena tu propio modelo de IA con tu propio conjunto de datos
Si quieres construir proyectos específicos de detección de objetos donde los conjuntos de datos públicos no tienen los objetos que quieres detectar, es posible que quieras construir tu propio conjunto de datos. Cuando registres datos para tu propio conjunto de datos, tienes que asegurarte de cubrir todos los ángulos (360 grados) del objeto, colocar el objeto en diferentes entornos, diferentes condiciones de iluminación y diferentes condiciones climáticas. Después de registrar tu propio conjunto de datos, también tienes que anotar las imágenes en el conjunto de datos. Todos estos pasos se cubrirán en esta sección.
Aunque hay diferentes métodos de recolección de datos como usar la cámara de un teléfono móvil, la mejor manera de recolectar datos es usar la cámara integrada en el SenseCAP A1101. Esto es porque los colores, la calidad de imagen y otros detalles serán similares cuando realicemos inferencia en el SenseCAP A1101, lo que hace que la detección general sea más precisa.
Preparación del hardware
- SenseCAP A1101 - Sensor de IA de Visión LoRaWAN
- Cable USB Type-C
- Windows/ Linux/ Mac con acceso a internet
Preparación del software
Ahora configuremos el software. La configuración del software para Windows, Linux e Intel Mac será la misma, mientras que para M1/M2 Mac será diferente.
Windows, Linux, Intel Mac
-
Paso 1. Asegúrate de que Python ya esté instalado en la computadora. Si no, visita esta página para descargar e instalar la última versión de Python
-
Paso 2. Instala la siguiente dependencia
pip3 install libusb1
M1/ M2 Mac
- Paso 1. Instalar Homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- Paso 2. Instalar conda
brew install conda
- Paso 3. Descargar libusb
wget https://conda.anaconda.org/conda-forge/osx-arm64/libusb-1.0.26-h1c322ee_100.tar.bz2
- Paso 4. Instalar libusb
conda install libusb-1.0.26-h1c322ee_100.tar.bz2
Necesitas asegurarte de que tu versión de BootLoader sea mayor a 2.0.0 antes de poder cambiar el firmware para hacer lo siguiente. Si no estás seguro, por favor verifica la versión del BootLoader siguiendo los pasos mencionados en esta sección, y si la versión es menor a 2.0.0, por favor actualiza el BootLoader siguiendo los pasos mencionados en esta sección
Recopilar conjunto de datos
- Paso 1. Conecta SenseCAP A1101 a la PC usando un cable USB Type-C

- Paso 2. Haz doble clic en el botón de arranque para entrar en modo de arranque

Después de esto verás una nueva unidad de almacenamiento mostrada en tu explorador de archivos como SENSECAP
- Paso 3. Arrastra y suelta este archivo .uf2 a la unidad SENSECAP
Tan pronto como el uf2 termine de copiarse en la unidad, la unidad desaparecerá. Esto significa que el uf2 ha sido cargado exitosamente al módulo.
-
Paso 4. Copia y pega este script de Python dentro de un archivo recién creado llamado capture_images_script.py en tu PC
-
Paso 5. Ejecuta el script de Python para comenzar a capturar imágenes
python3 capture_images_script.py
Por defecto, capturará una imagen cada 300ms. Si quieres cambiar esto, puedes ejecutar el script en este formato
python3 capture_images_script.py --interval <time_in_ms>
Por ejemplo, para capturar una imagen cada segundo
python3 capture_images_script.py --interval 1000
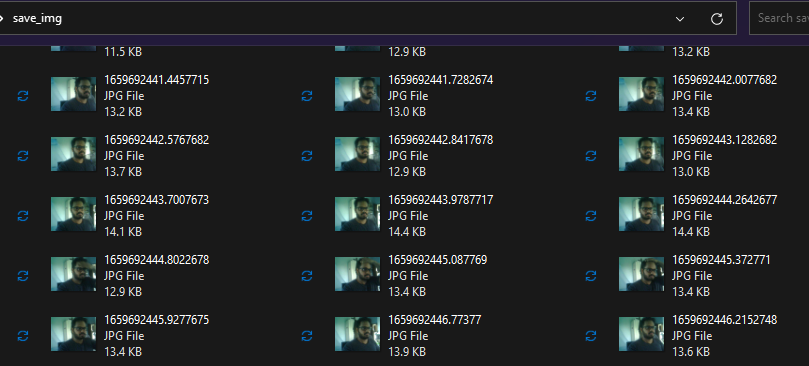
Después de ejecutar el script anterior, el SenseCAP A1101 comenzará a capturar imágenes de las cámaras integradas de forma continua y las guardará todas dentro de una carpeta llamada save_img
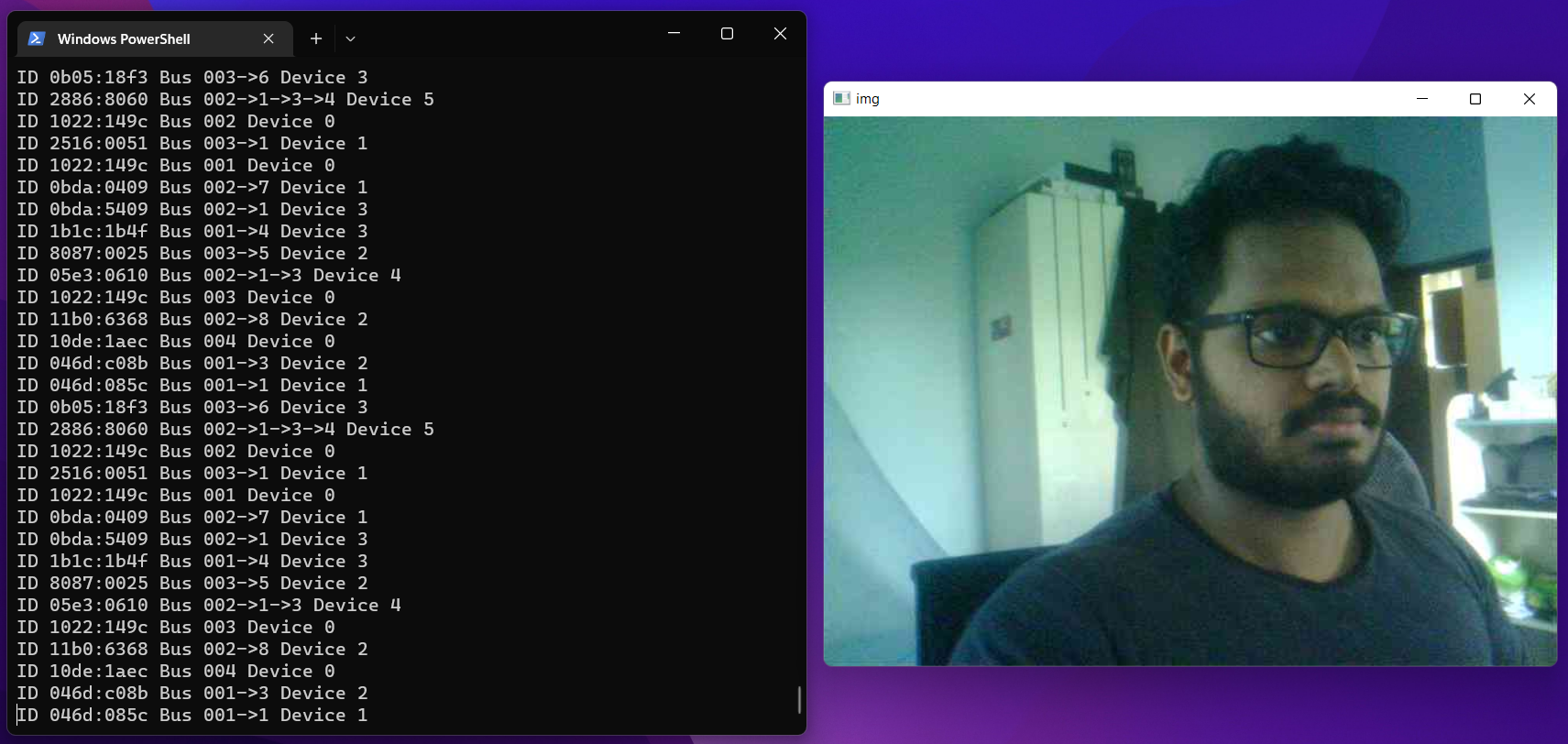
Además, abrirá una ventana de vista previa mientras está grabando
Después de haber capturado suficientes imágenes, haz clic en la ventana del terminal y presiona las siguientes combinaciones de teclas para detener el proceso de captura
- Windows: Ctrl + Break
- Linux: Ctrl + Shift + \
- Mac: CMD + Shift + \
Cambiar el firmware del dispositivo después de la recolección de imágenes
Después de haber terminado de grabar imágenes para el conjunto de datos, necesitas asegurarte de cambiar el firmware dentro del SenseCAP A1101 de vuelta al original, para que puedas cargar nuevamente modelos de detección de objetos para la detección. Veamos los pasos ahora.
-
Paso 1. Entra en modo Boot en el SenseCAP A1101 como se explicó anteriormente
-
Paso 2. Arrastra y suelta este archivo .uf2 a la unidad SENSECAP según tu dispositivo
Tan pronto como el uf2 termine de copiarse en la unidad, la unidad desaparecerá. Esto significa que el uf2 se ha subido exitosamente al módulo.
Anotar conjunto de datos usando Roboflow
Si usas tu propio conjunto de datos, necesitarás anotar todas las imágenes en tu conjunto de datos. Anotar significa simplemente dibujar cajas rectangulares alrededor de cada objeto que queremos detectar y asignarles etiquetas. Explicaremos cómo hacer esto usando Roboflow.
Roboflow es una herramienta de anotación basada en línea. Aquí podemos importar directamente las grabaciones de video que hemos grabado en Roboflow y se exportarán como una serie de imágenes. Esta herramienta es muy conveniente porque nos permitirá distribuir el conjunto de datos en "entrenamiento, validación y prueba". También esta herramienta nos permitirá añadir procesamiento adicional a estas imágenes después de etiquetarlas. Además, puede exportar fácilmente el conjunto de datos etiquetado al formato YOLOV5 PyTorch que es exactamente lo que necesitamos!
Para este wiki, usaremos un conjunto de datos con imágenes que contienen manzanas para que podamos detectar manzanas más tarde y también hacer conteo.
-
Paso 1. Haz clic aquí para registrarte en una cuenta de Roboflow
-
Paso 2. Haz clic en Create New Project para comenzar nuestro proyecto
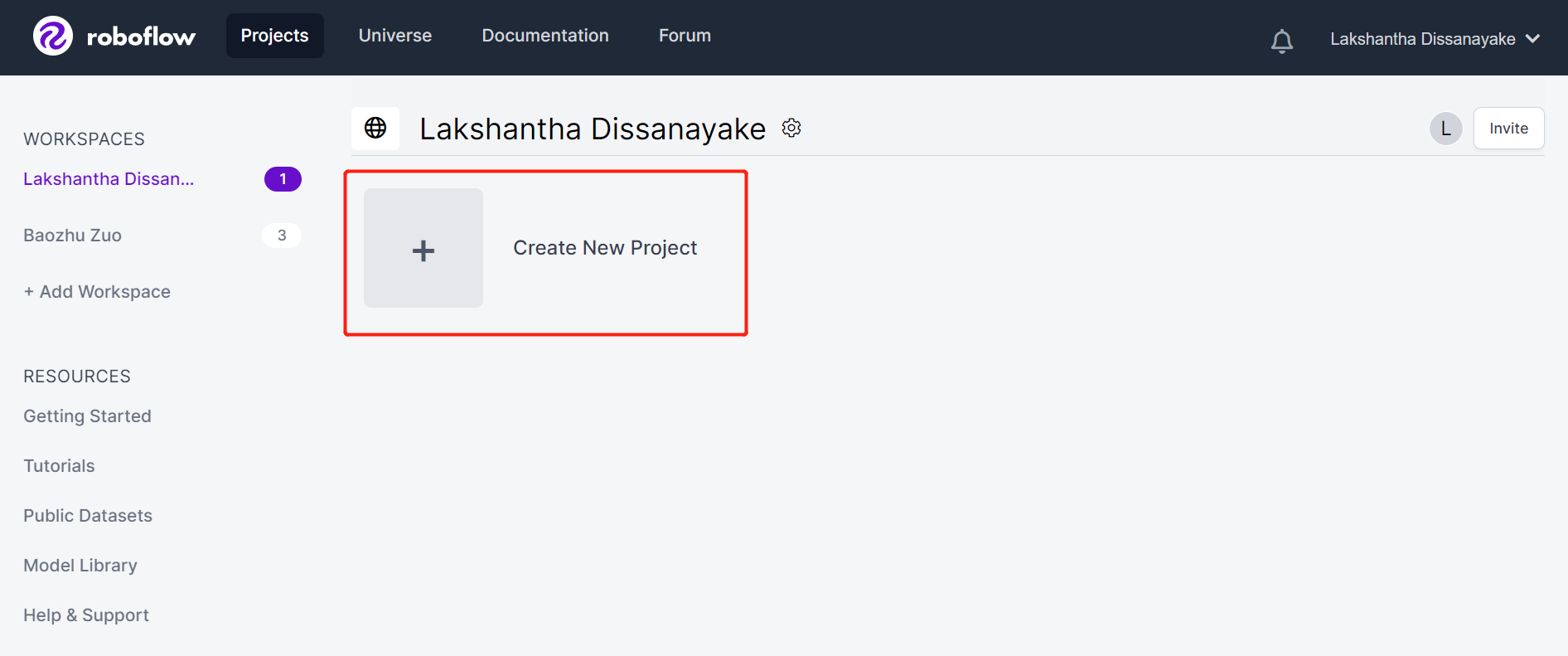
- Paso 3. Completa el Project Name, mantén la License (CC BY 4.0) y Project type (Object Detection (Bounding Box)) como predeterminados. Bajo la columna What will your model predict?, completa un nombre de grupo de anotación. Por ejemplo, en nuestro caso elegimos apples. Este nombre debe resaltar todas las clases de tu conjunto de datos. Finalmente, haz clic en Create Public Project.
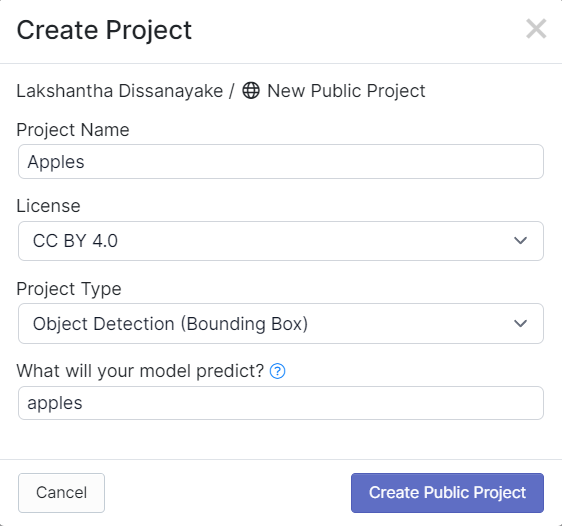
- Paso 4. Arrastra y suelta las imágenes que has capturado usando el SenseCAP A1101
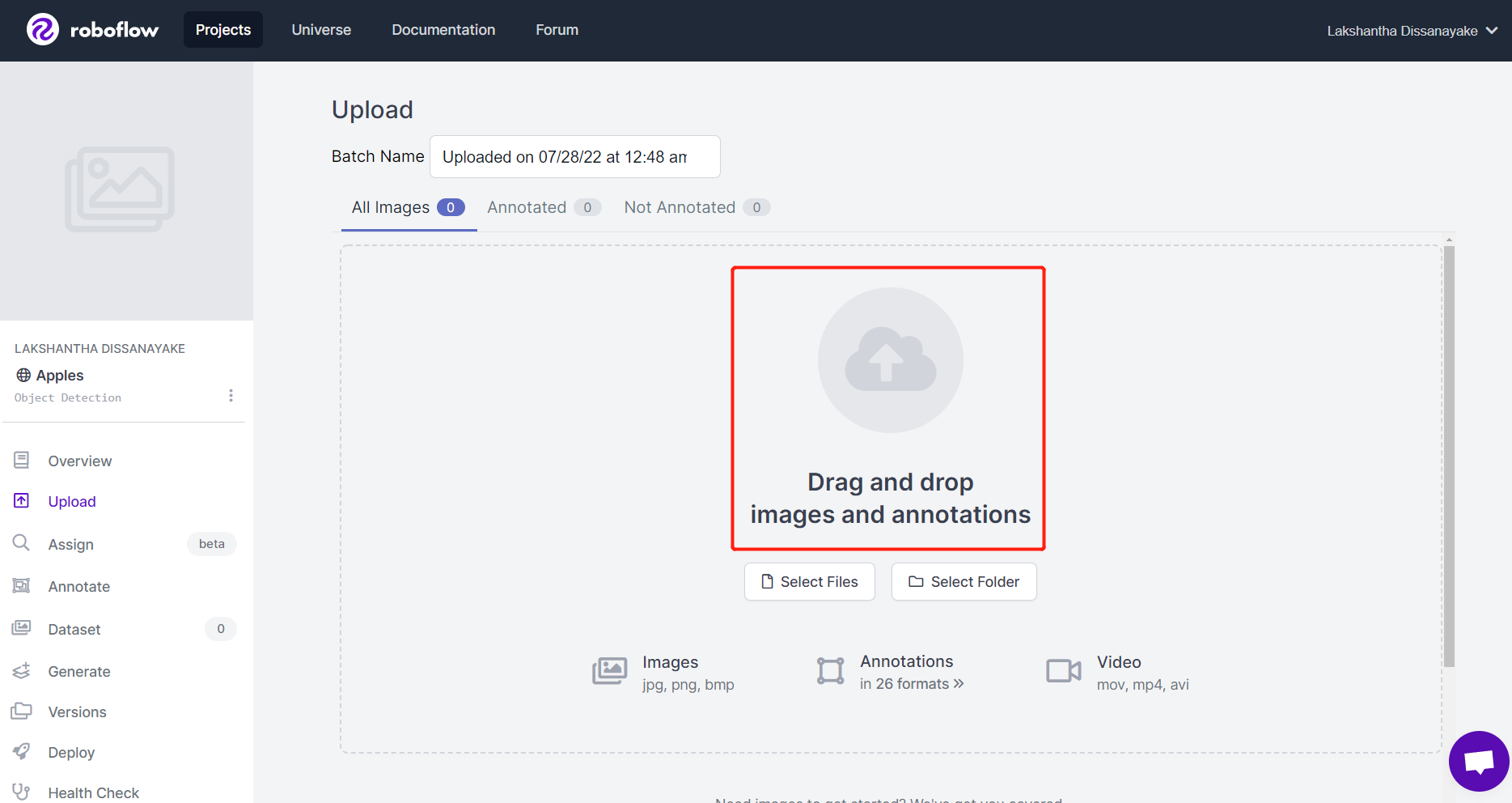
- Paso 5. Después de que las imágenes sean procesadas, haz clic en Finish Uploading. Espera pacientemente hasta que las imágenes sean subidas.
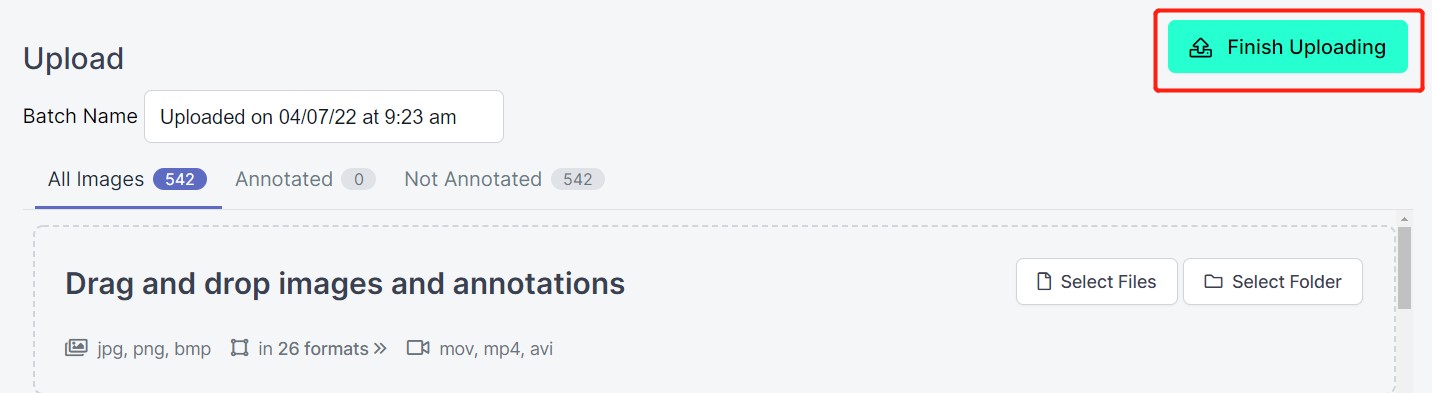
- Paso 6. Después de que las imágenes sean subidas, haz clic en Assign Images
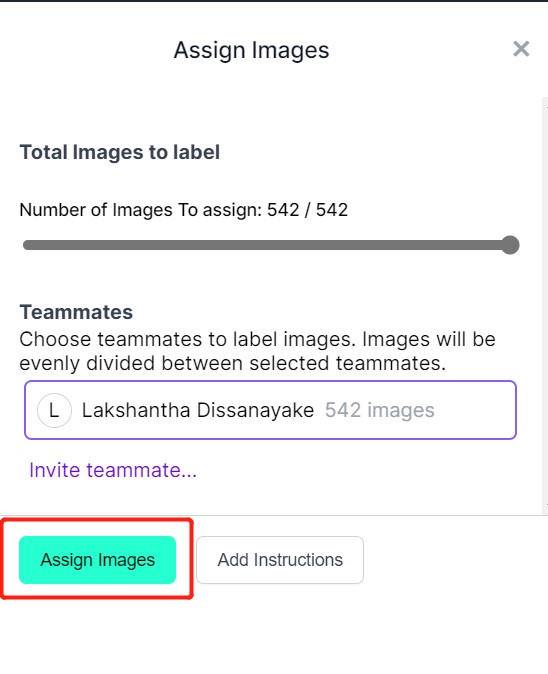
- Paso 7. Selecciona una imagen, dibuja una caja rectangular alrededor de una manzana, elige la etiqueta como apple y presiona ENTER
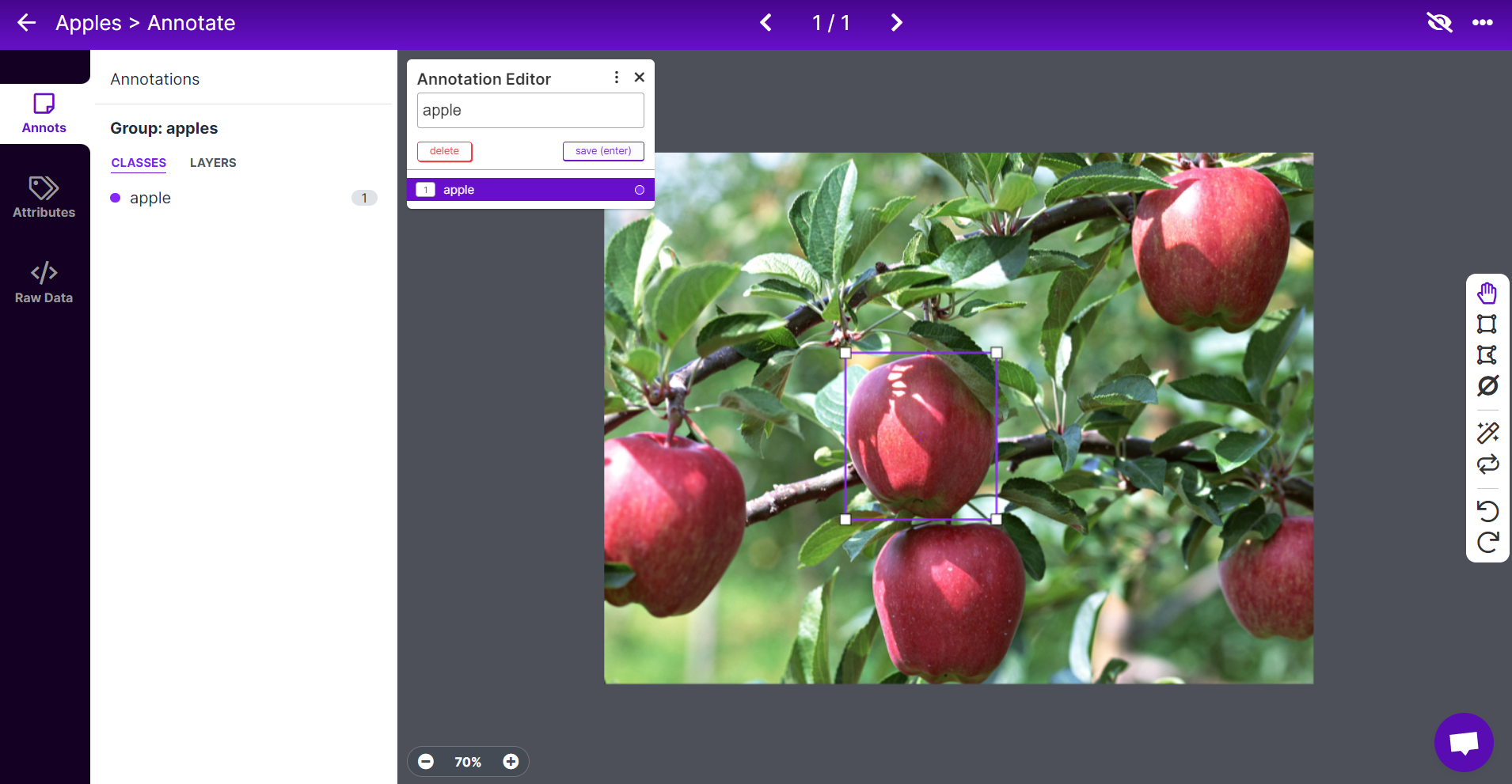
- Paso 8. Repite lo mismo para las manzanas restantes
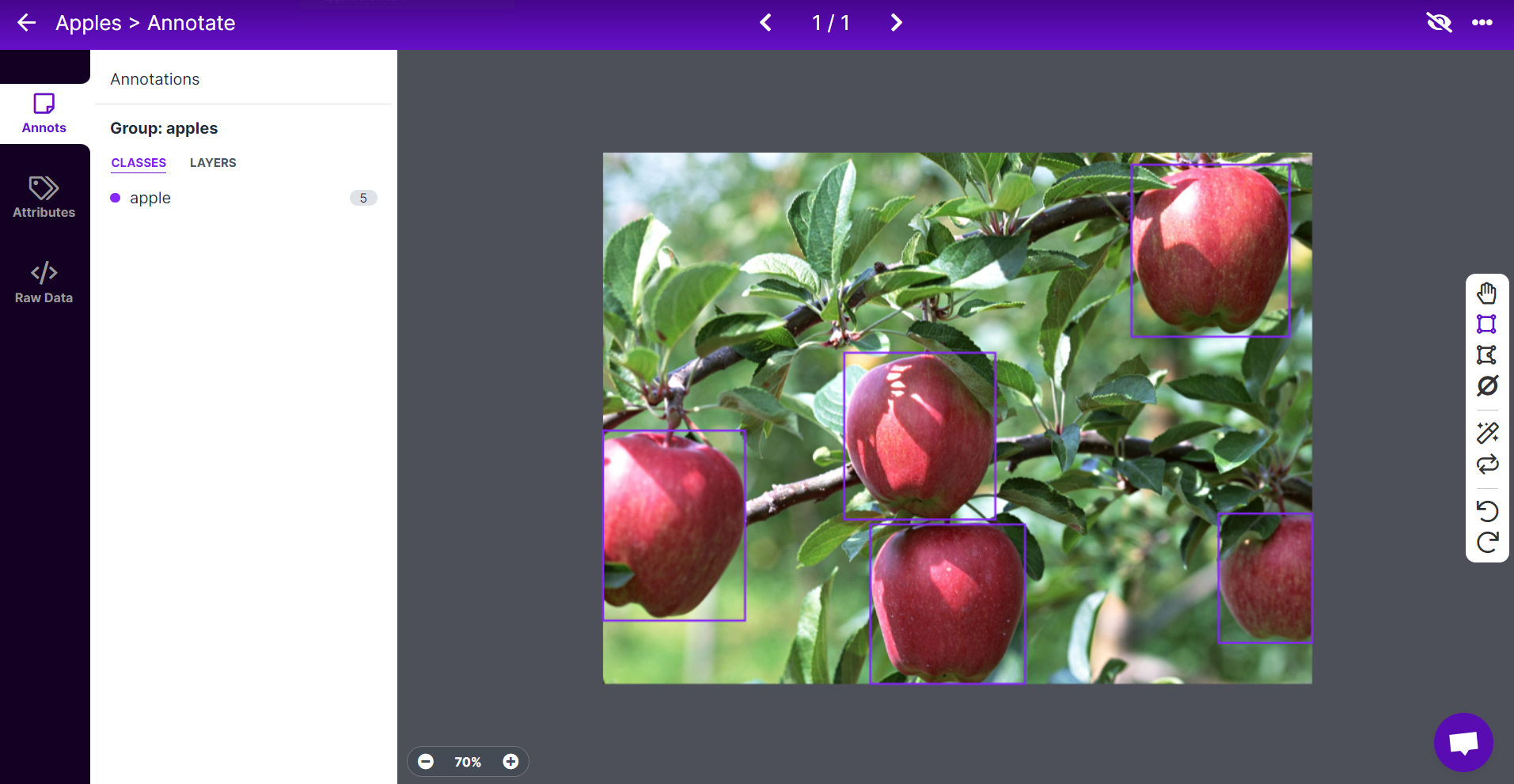
Nota: Trata de etiquetar todas las manzanas que veas dentro de la imagen. Si solo una parte de una manzana es visible, trata de etiquetarla también.
- Paso 9. Continúa anotando todas las imágenes en el conjunto de datos
Roboflow tiene una característica llamada Label Assist donde puede predecir las etiquetas de antemano para que tu etiquetado sea mucho más rápido. Sin embargo, no funcionará con todos los tipos de objetos, sino con un tipo seleccionado de objetos. Para activar esta característica, simplemente necesitas presionar el botón Label Assist, seleccionar un modelo, seleccionar las clases y navegar a través de las imágenes para ver las etiquetas predichas con cajas delimitadoras
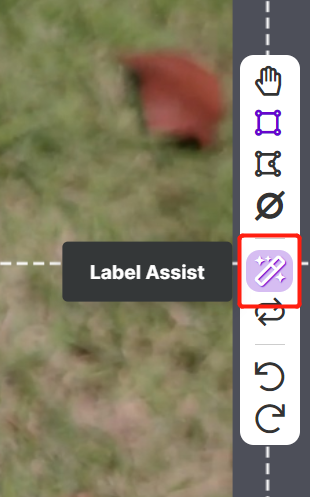
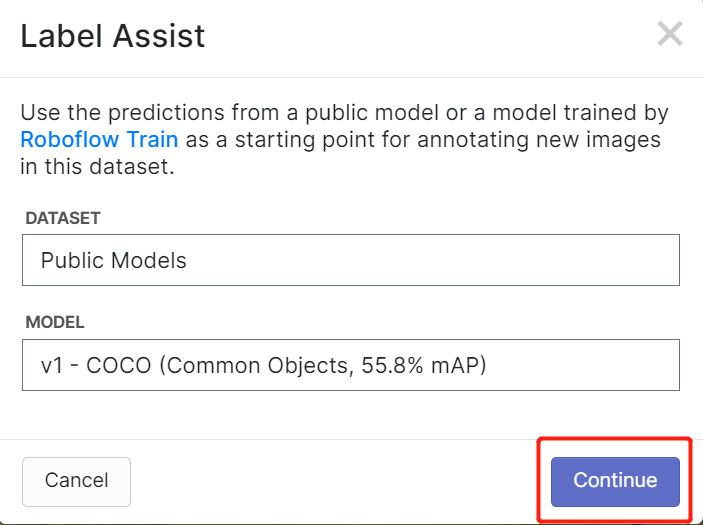
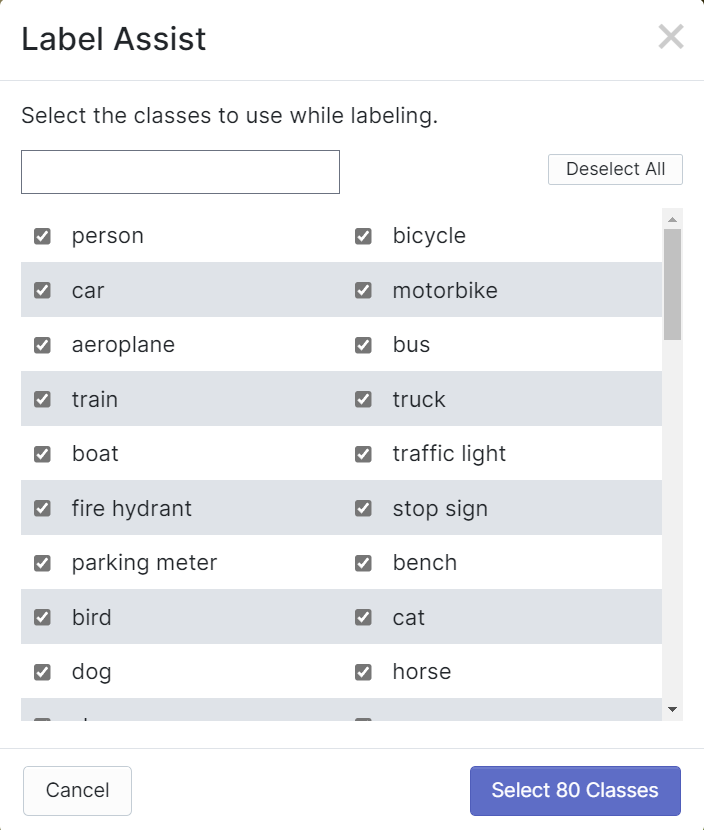
Como puedes ver arriba, solo puede ayudar a predecir anotaciones para las 80 clases mencionadas. Si tus imágenes no contienen las clases de objetos de arriba, no puedes usar la característica de asistencia de etiquetas.
- Paso 10. Una vez que el etiquetado esté terminado, haz clic en Add images to Dataset

- Paso 11. A continuación dividiremos las imágenes entre "Train, Valid y Test". Mantén los porcentajes predeterminados para la distribución y haz clic en Add Images
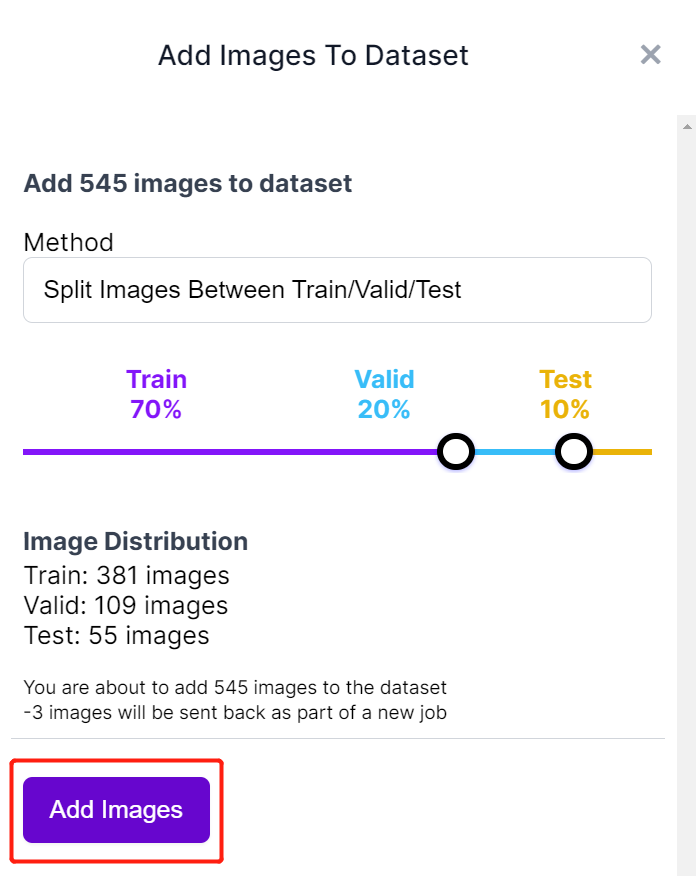
- Paso 12. Haz clic en Generate New Version

- Paso 13. Ahora puedes añadir Preprocessing y Augmentation si prefieres. Aquí cambiaremos la opción Resize a 192x192
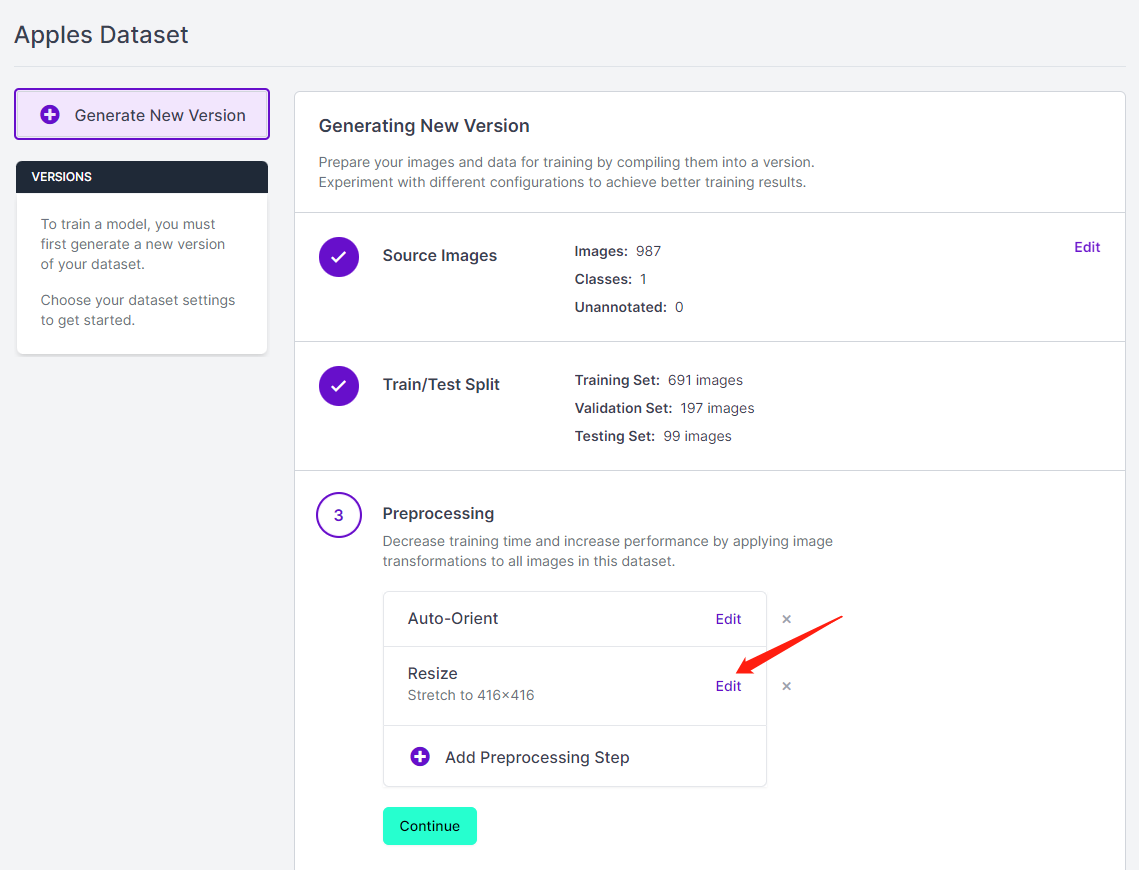
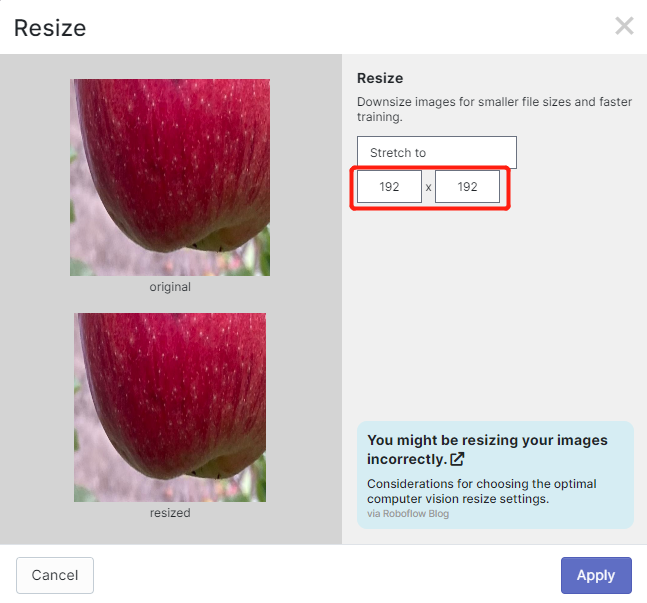
Aquí cambiamos el tamaño de la imagen a 192x192 porque usaremos ese tamaño para el entrenamiento y el entrenamiento será más rápido. De lo contrario, tendrá que convertir todas las imágenes a 192x192 durante el proceso de entrenamiento, lo que consume más recursos de CPU y hace que el proceso de entrenamiento sea más lento.
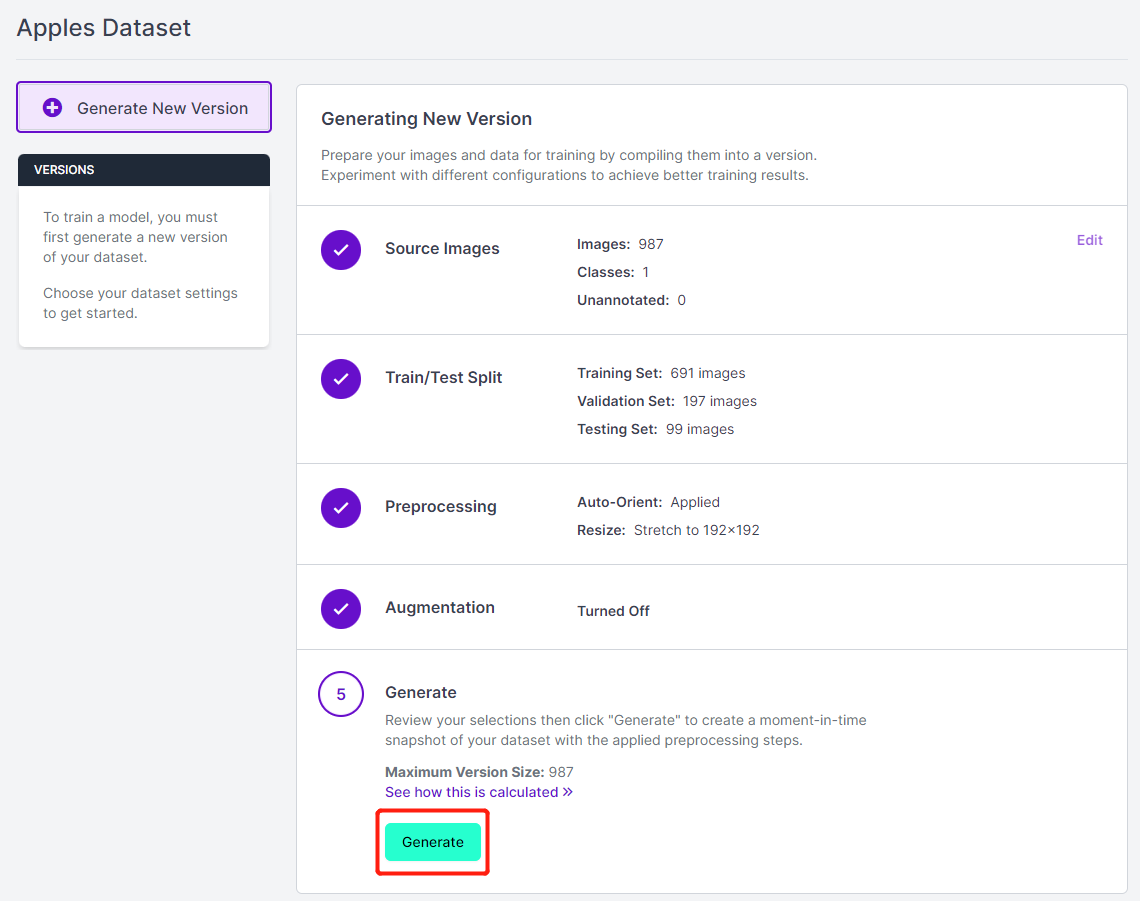
- Paso 14. A continuación, procede con los valores predeterminados restantes y haz clic en Generate
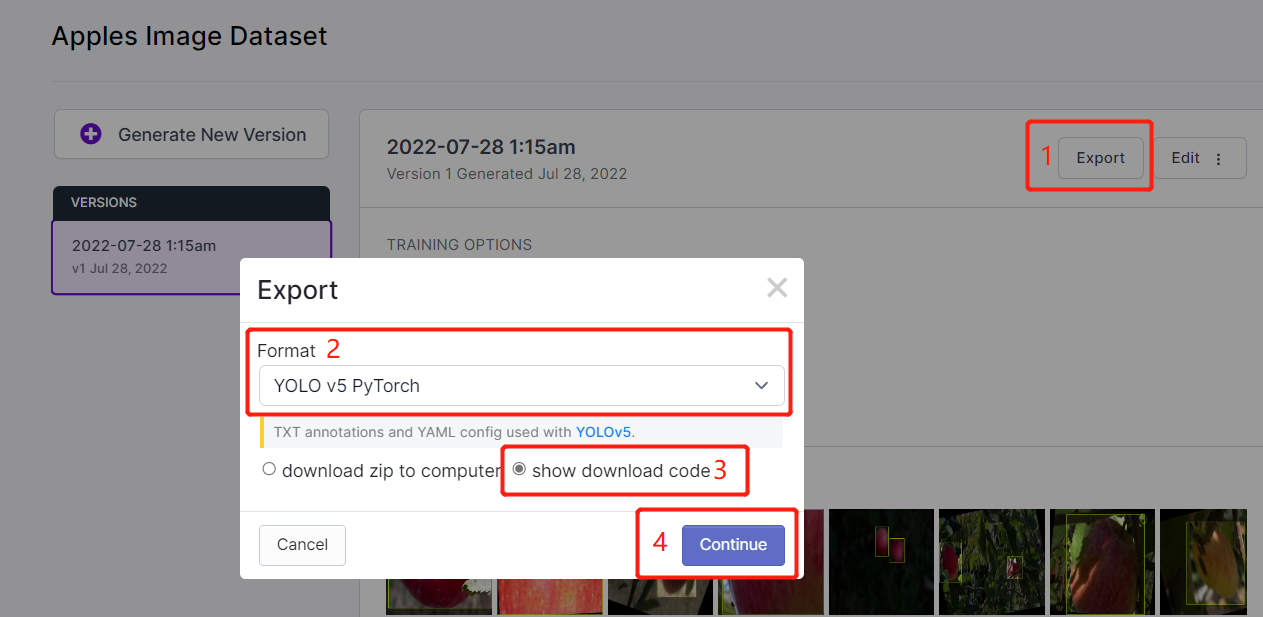
- Paso 15. Haz clic en Export, selecciona Format como YOLO v5 PyTorch, selecciona show download code y haz clic en Continue
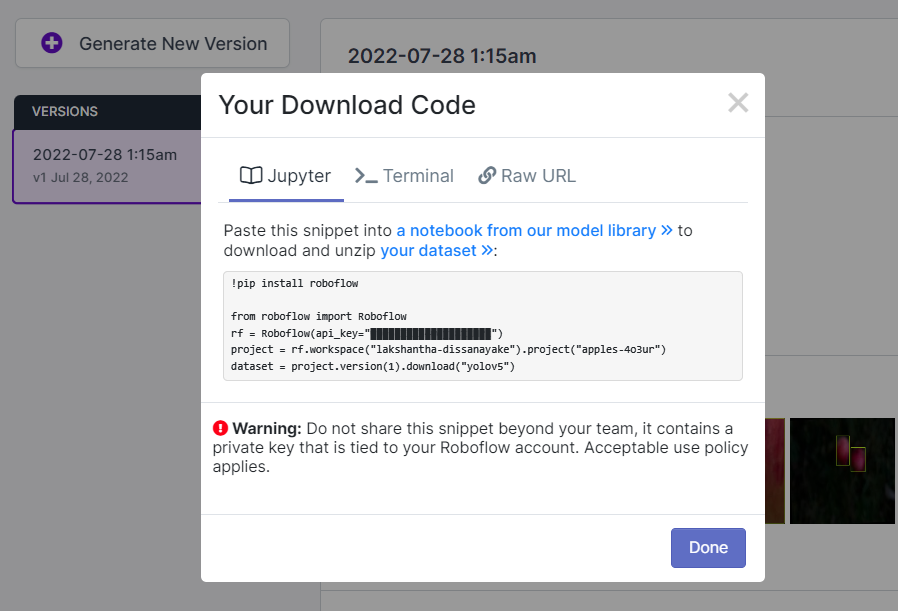
Esto generará un fragmento de código que usaremos más tarde dentro del entrenamiento de Google Colab. Así que por favor mantén esta ventana abierta en segundo plano.
Entrenar usando YOLOv5 en Google Colab
Después de terminar con la anotación del conjunto de datos, necesitamos entrenar el conjunto de datos. Ve a esta parte que explica cómo entrenar un modelo de IA usando YOLOv5 ejecutándose en Google Colab.
3. Desplegar el modelo entrenado y realizar inferencia
Ahora moveremos el model-1.uf2 que obtuvimos al final del entrenamiento al SenseCAP A1101.
-
Paso 1. Instala la última versión de Google Chrome o Microsoft Edge browser y ábrelo
-
Paso 2. Conecta el SenseCAP A1101 a tu PC mediante un cable USB Type-C
- Paso 3. Haz doble clic en el botón de arranque del SenseCAP A1101 para entrar en modo de almacenamiento masivo
Después de esto, verás una nueva unidad de almacenamiento mostrada en tu explorador de archivos como SENSECAP
- Paso 4. Arrastra y suelta el archivo model-1.uf2 a la unidad SENSECAP
Tan pronto como el uf2 termine de copiarse en la unidad, la unidad desaparecerá. Esto significa que el uf2 se ha subido exitosamente al módulo.
Nota: Si tienes 4 archivos de modelo listos, puedes arrastrar y soltar cada modelo uno por uno. Suelta el primer modelo, espera hasta que termine de copiarse, entra en modo de arranque nuevamente, suelta el segundo modelo y así sucesivamente. Si solo has cargado un modelo (con índice 1) en el SenseCAP A1101, cargará ese modelo.
-
Paso 5. Abre la SenseCAP Mate App. Si no la tienes, descárgala e instálala en tu teléfono móvil según tu sistema operativo
-
Paso 6. Abre la aplicación, en la pantalla Config, selecciona Vision AI Sensor

- Paso 7. Mantén presionado el botón de configuración del SenseCap A1101 durante 3 segundos para entrar en modo de emparejamiento bluetooth

- Paso 8. Haz clic en Setup y comenzará a escanear dispositivos SenseCAP A1101 cercanos
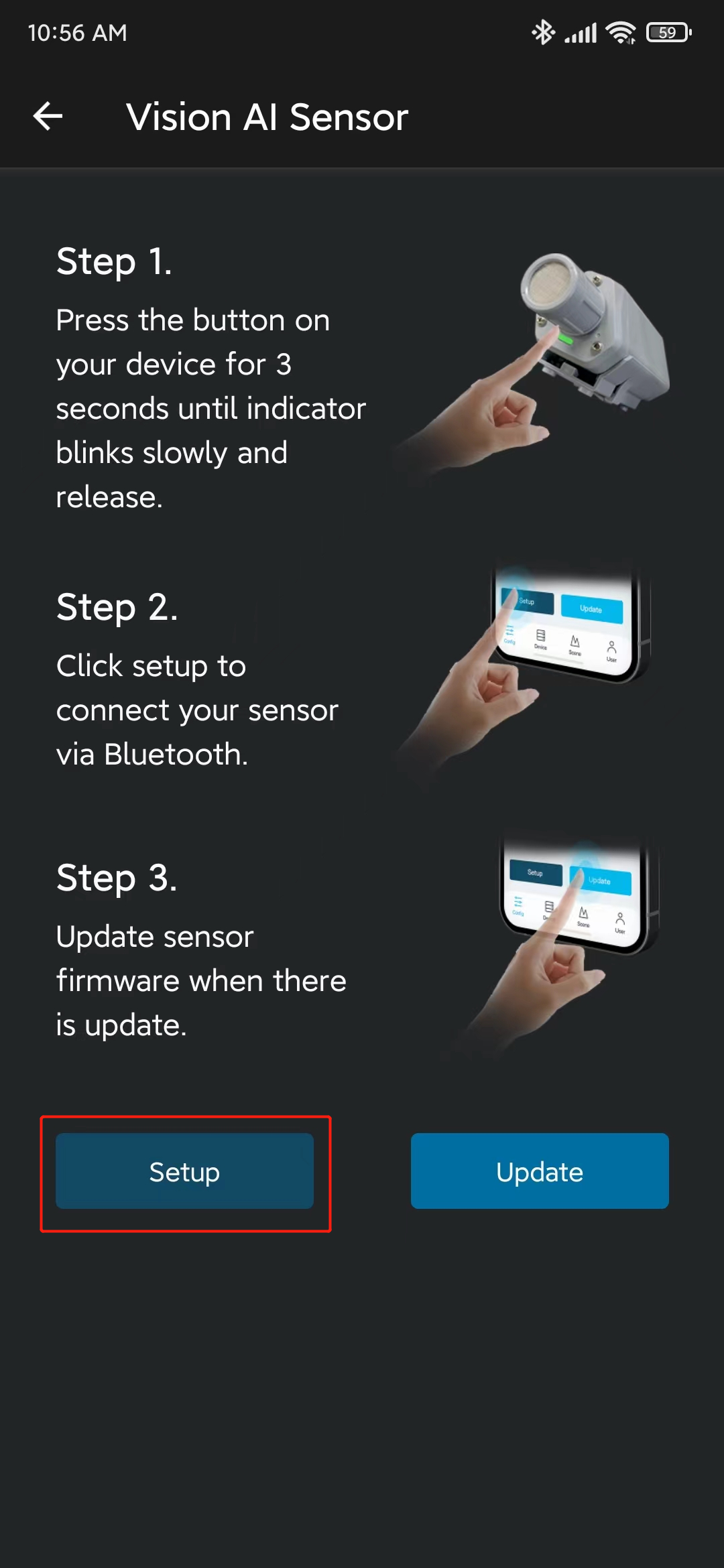
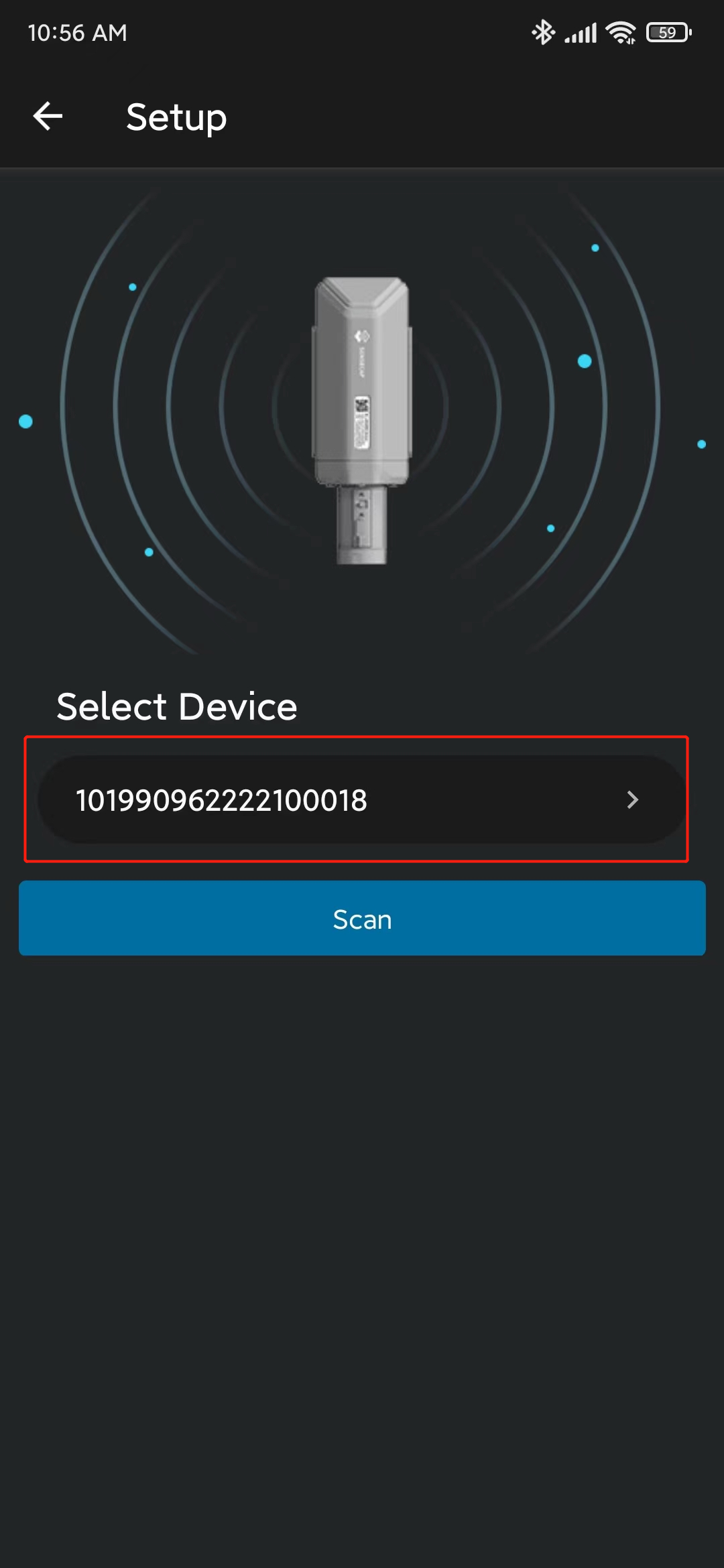
- Paso 9. Haz clic en el dispositivo encontrado
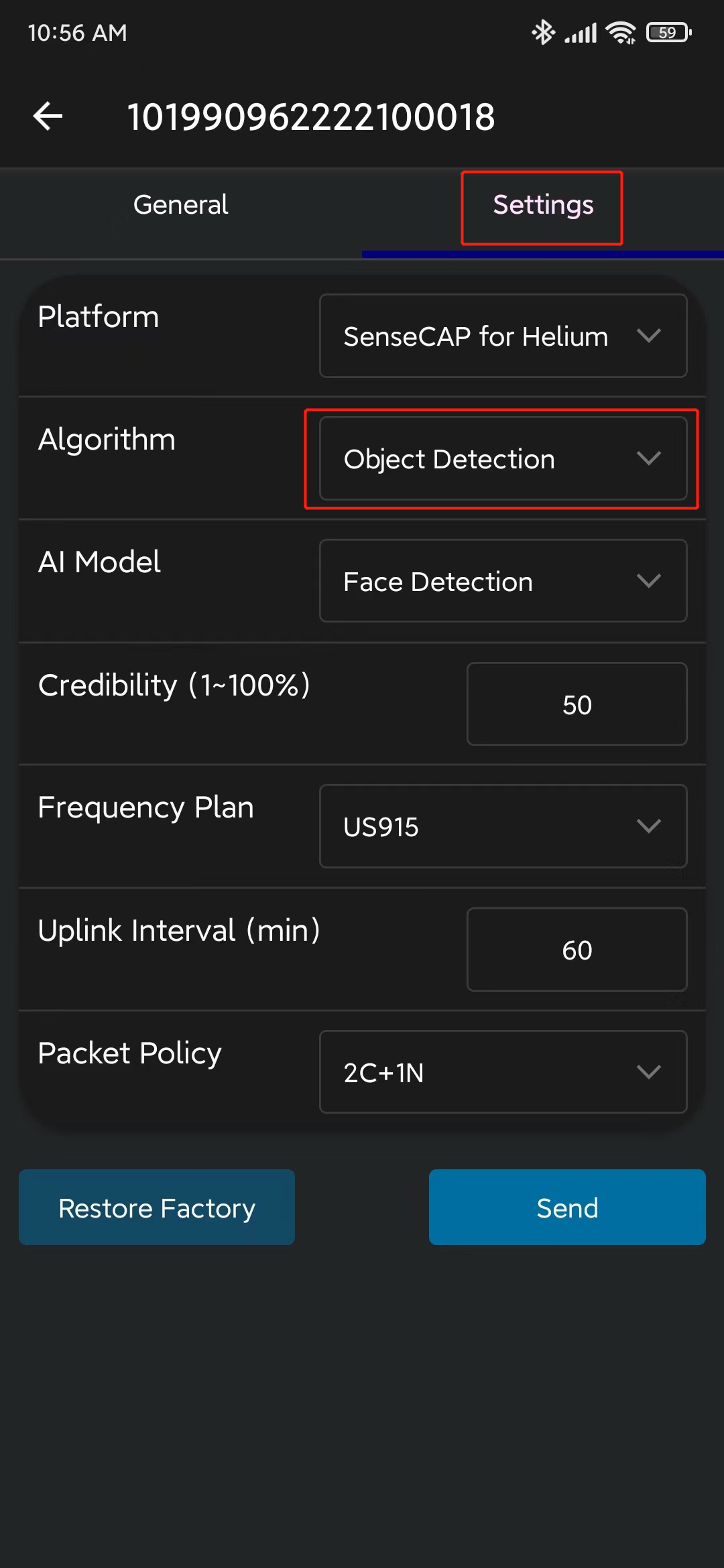
- Paso 10. Ve a Settings y asegúrate de que Object Detection esté seleccionado. Si no, selecciónalo y haz clic en Send
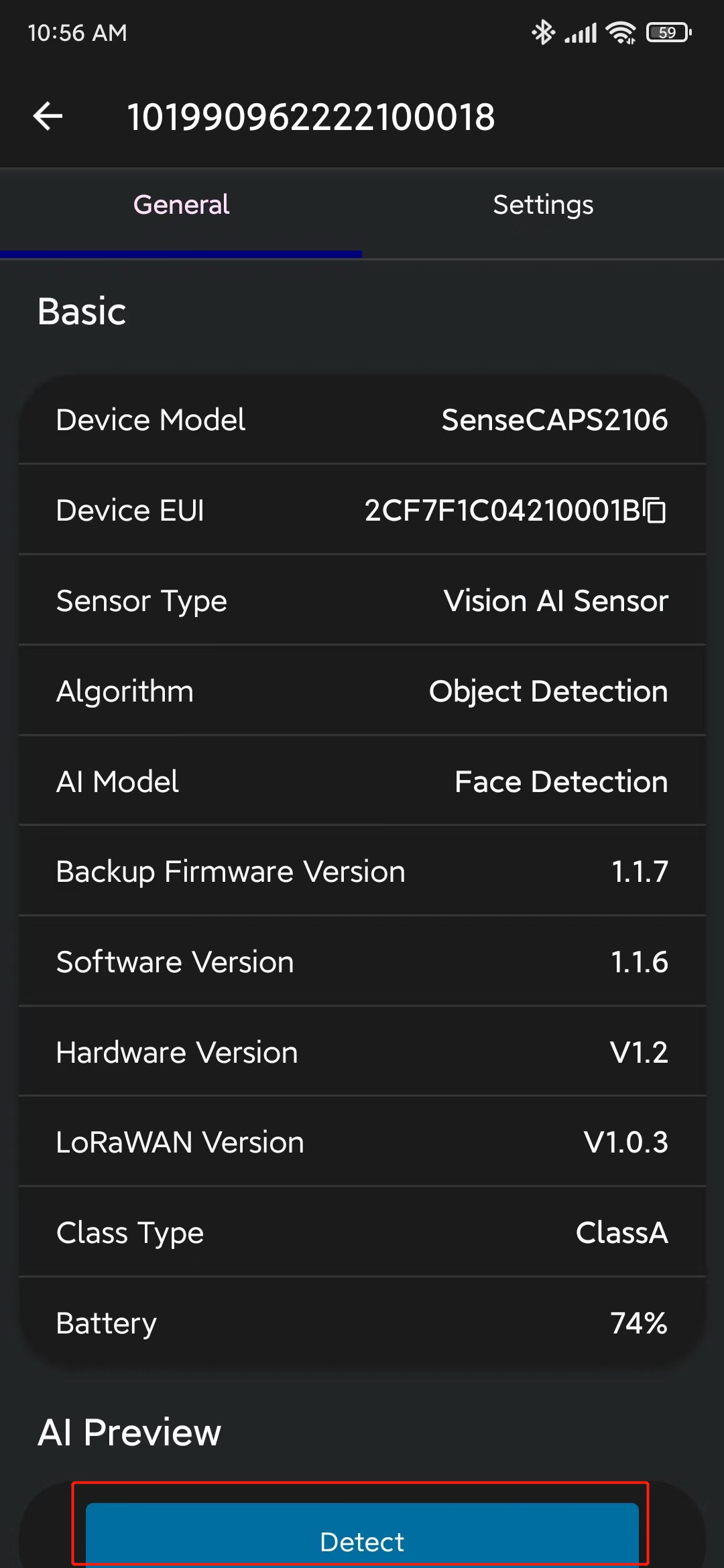
- Paso 11. Ve a General y haz clic en Detect
- Paso 12. Haz clic aquí para abrir una ventana de vista previa del flujo de la cámara

- Paso 13. Haz clic en el botón Connect. Entonces verás una ventana emergente en el navegador. Selecciona SenseCAP Vision AI - Paired y haz clic en Connect
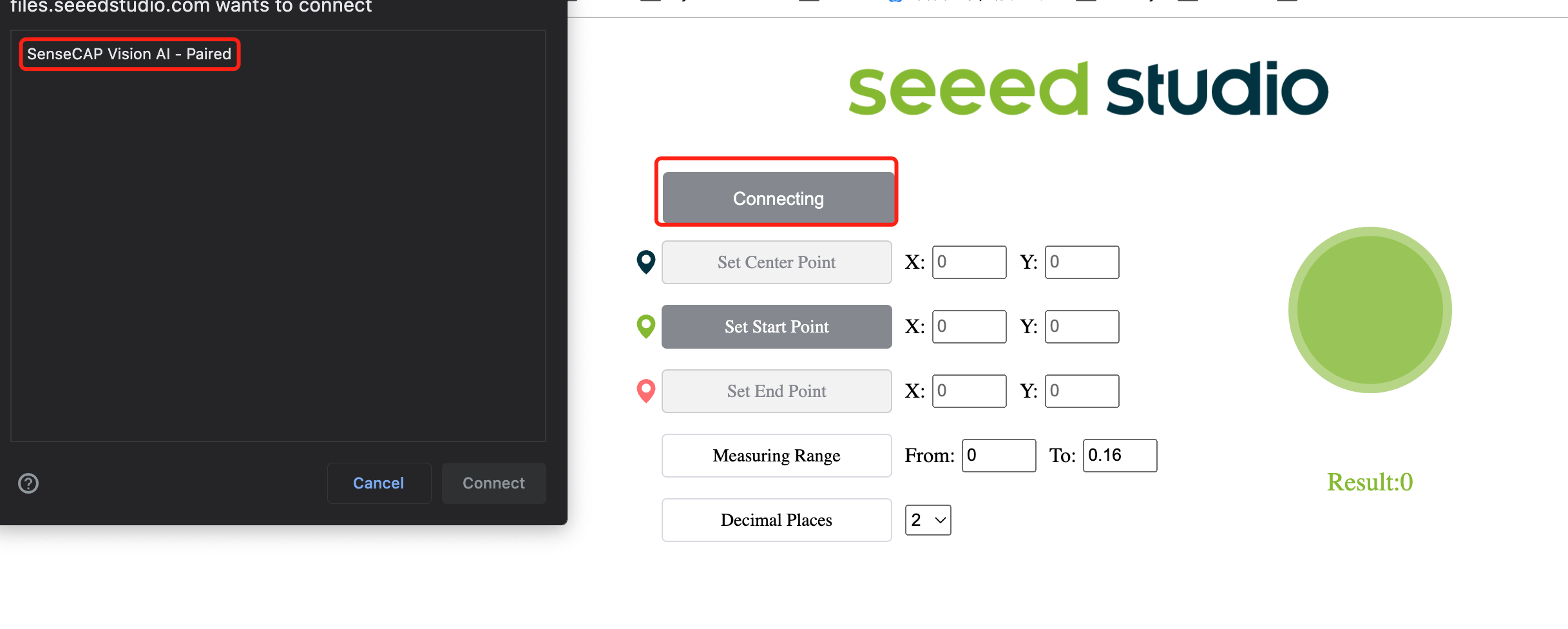
- Paso 14. ¡Ve los resultados de inferencia en tiempo real usando la ventana de vista previa!

Como puedes ver arriba, las manzanas están siendo detectadas con cajas delimitadoras alrededor de ellas. Aquí "0" corresponde a cada detección de la misma clase. Si tienes múltiples clases, se nombrarán como 0,1,2,3,4 y así sucesivamente. ¡También se muestra la puntuación de confianza para cada manzana detectada (0.8 y 0.84 en la demostración anterior)!
Contenido adicional
Si te sientes más aventurero, ¡puedes continuar siguiendo el resto del wiki!
¿Puedo entrenar un modelo de IA en mi PC?
También puedes usar tu propia PC para entrenar un modelo de detección de objetos. Sin embargo, el rendimiento del entrenamiento dependerá del hardware que tengas. También necesitas tener una PC con un sistema operativo Linux para el entrenamiento. Hemos usado una PC Ubuntu 20.04 para este wiki.
- Paso 1. Clona el repositorio yolov5-swift e instala requirements.txt en un entorno Python>=3.7.0
git clone https://github.com/Seeed-Studio/yolov5-swift
cd yolov5-swift
pip install -r requirements.txt
- Paso 2. Si seguiste los pasos de esta wiki anteriormente, podrías recordar que exportamos el conjunto de datos después de anotar en Robolflow. También en Roboflow Universe, descargamos el conjunto de datos. En ambos métodos, había una ventana como la de abajo donde pregunta qué tipo de formato descargar para el conjunto de datos. Así que ahora, por favor selecciona download zip to computer, bajo Format elige YOLO v5 PyTorch y haz clic en Continue
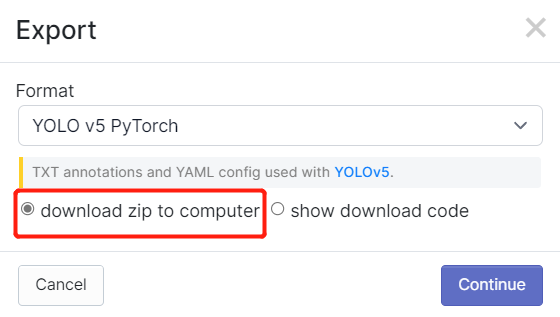
Después de eso, un archivo .zip se descargará a tu computadora
- Paso 3. Copia y pega el archivo .zip que descargamos en el directorio yolov5-swift y extráelo
# example
cp ~/Downloads/Apples.v1i.yolov5pytorch.zip ~/yolov5-swift
unzip Apples.v1i.yolov5pytorch.zip
- Paso 4. Abre el archivo data.yaml y edita los directorios train y val como se muestra a continuación
train: train/images
val: valid/images
- Paso 5. Descargar un modelo preentrenado adecuado para nuestro entrenamiento
sudo apt install wget
wget https://github.com/Seeed-Studio/yolov5-swift/releases/download/v0.1.0-alpha/yolov5n6-xiao.pt
- Paso 6. Ejecuta lo siguiente para comenzar el entrenamiento
Aquí, podemos pasar varios argumentos:
- img: define el tamaño de imagen de entrada
- batch: determina el tamaño del lote
- epochs: define el número de épocas de entrenamiento
- data: establece la ruta a nuestro archivo yaml
- cfg: especifica nuestra configuración del modelo
- weights: especifica una ruta personalizada a los pesos
- name: nombres de resultados
- nosave: solo guarda el checkpoint final
- cache: almacena en caché las imágenes para un entrenamiento más rápido
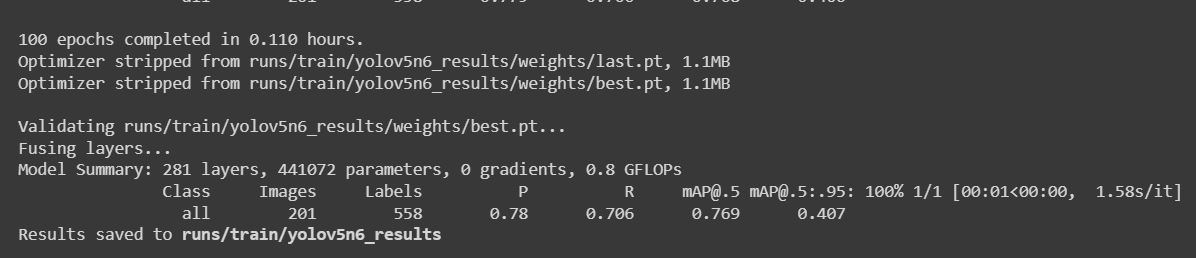
python3 train.py --img 192 --batch 64 --epochs 100 --data data.yaml --cfg yolov5n6-xiao.yaml --weights yolov5n6-xiao.pt --name yolov5n6_results --cache
Para un conjunto de datos de detección de manzanas con 987 imágenes, tomó alrededor de 30 minutos completar el proceso de entrenamiento en una PC local ejecutándose en GPU NVIDIA GeForce GTX 1660 Super con 6GB de memoria GPU.

Si siguió el proyecto de Colab anterior, sabe que puede cargar 4 modelos al dispositivo todos a la vez. Sin embargo, tenga en cuenta que solo un modelo puede cargarse a la vez. Esto puede ser especificado por el usuario y se explicará más adelante en este wiki.
- Paso 7. Si navega a
runs/train/exp/weights, verá un archivo llamado best.pt. Este es el modelo generado del entrenamiento.

- Paso 8. Exporte el modelo entrenado a TensorFlow Lite
python3 export.py --data {dataset.location}/data.yaml --weights runs/train/yolov5n6_results/weights/best.pt --imgsz 192 --int8 --include tflite
- Paso 9. Convertir TensorFlow Lite a un archivo UF2
UF2 es un formato de archivo, desarrollado por Microsoft. Seeed usa este formato para convertir .tflite a .uf2, permitiendo que los archivos tflite se almacenen en los dispositivos AIoT lanzados por Seeed. Actualmente los dispositivos de Seeed soportan hasta 4 modelos, cada modelo (.tflite) es menor a 1M .
Puedes especificar el modelo a ser colocado en el índice correspondiente con -t.
Por ejemplo:
-t 1: índice 1-t 2: índice 2
# Place the model to index 1
python3 uf2conv.py -f GROVEAI -t 1 -c runs//train/yolov5n6_results//weights/best-int8.tflite -o model-1.uf2
Aunque puedes cargar 4 modelos al dispositivo de una vez, ten en cuenta que solo un modelo puede cargarse a la vez. Esto puede ser especificado por el usuario y se explicará más adelante en esta wiki.
- Paso 10. Ahora se generará un archivo llamado model-1.uf2. ¡Este es el archivo que cargaremos en el Módulo SenseCAP A1101 para realizar la inferencia!
Verificar Versión del BootLoader
- Haz doble clic en el botón BOOT y espera a que se monte la unidad extraíble
- Abre INFO_UF2.TXT en la unidad extraíble

Actualizar BootLoader
Si tu SenseCAP A1101 no es reconocido por tu computadora y se comporta como si no tuviera número de puerto, entonces puede que necesites actualizar el BootLoader.
- Paso 1. Descarga el archivo
.bindel BootLoader en la PC con Windows.
Por favor descarga la versión más reciente del archivo BootLoader en el enlace de abajo. El nombre del BootLoader es usualmente tinyuf2-sensecap_vision_ai_vx.x.x.bin.
Este es el firmware que controla el chip BL702 que construye la conexión entre la computadora y el chip Himax. La versión más reciente del BootLoader ahora ha solucionado el problema de que Vision AI no pueda ser reconocido por Mac y Linux.
- Paso 2. Descarga y abre el software BLDevCube.exe, selecciona BL702/704/706, y luego haz clic en Finish.

- Paso 3. Haz clic en View, elige MCU primero. Ve a Image file, haz clic en Browse y selecciona el firmware que acabas de descargar.
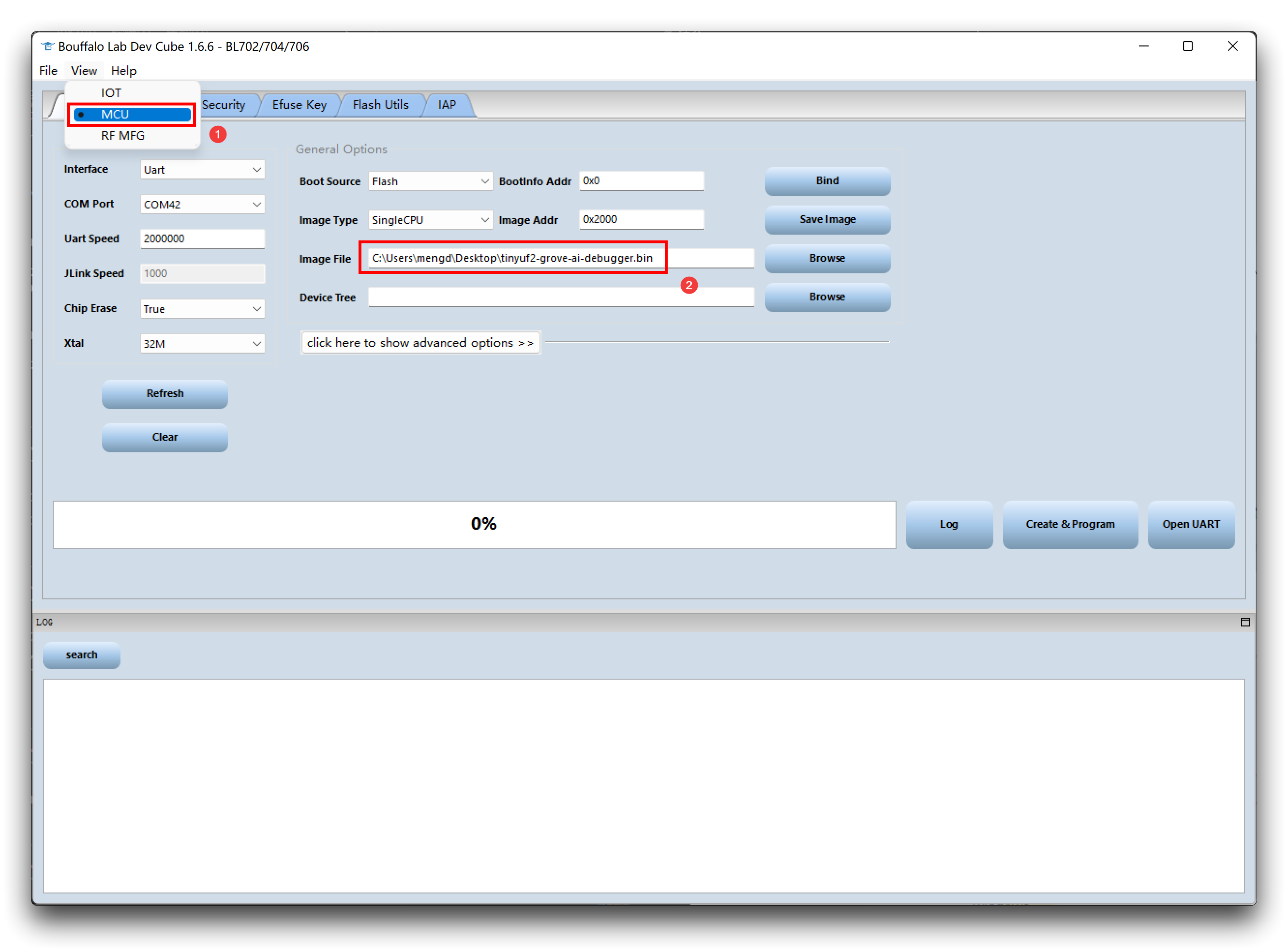
-
Paso 4. Asegúrate de que no haya otros dispositivos conectados a la PC. Luego mantén presionado el botón Boot en el módulo, conéctalo a la PC.
-
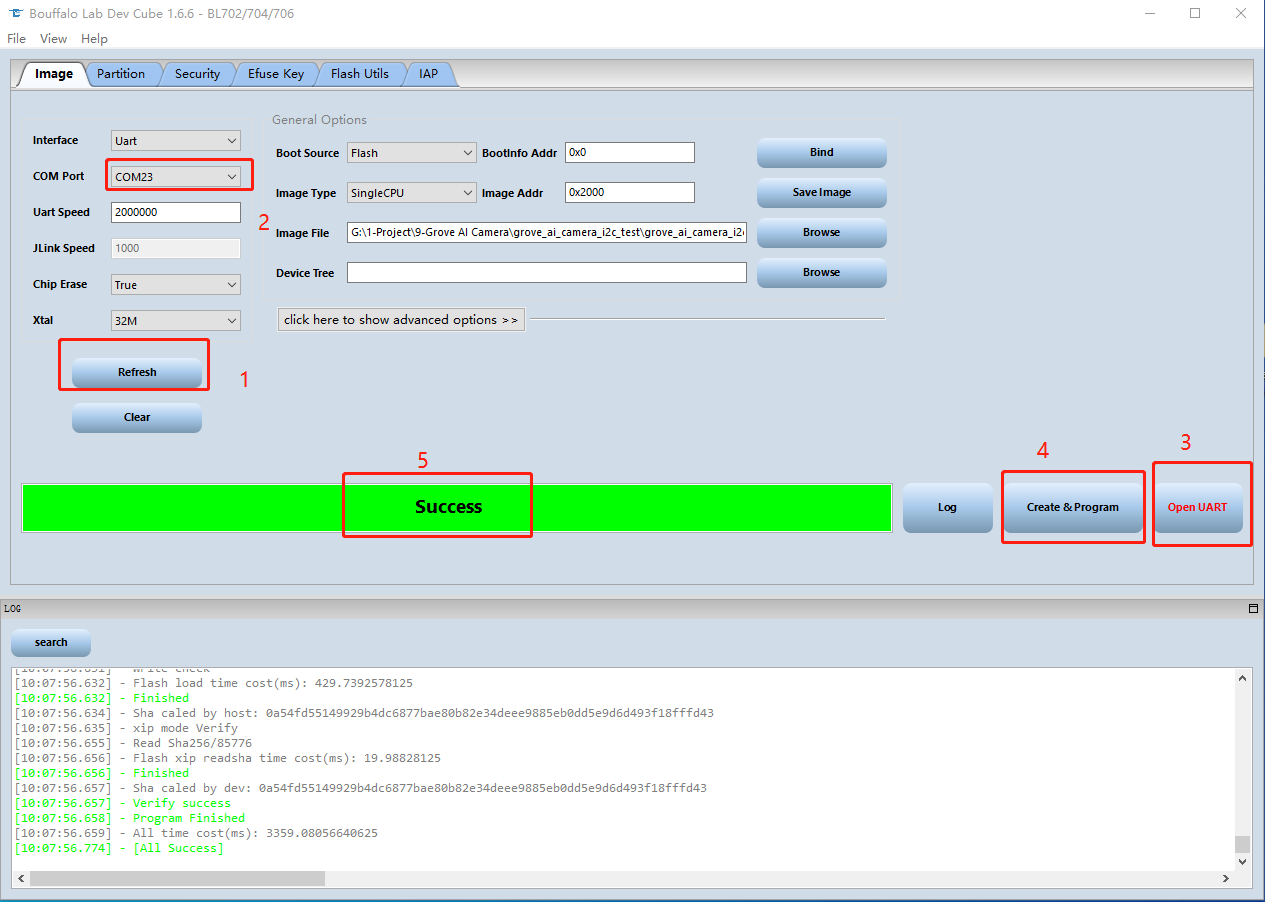
Paso 5. Regresa al software BLDevCube en la PC, haz clic en Refresh y elige un puerto apropiado. Luego haz clic en Open UART y establece Chip Erase en True, después haz clic en Create&Program, espera a que el proceso termine.
Recursos
-
[Página Web] Documentación de YOLOv5
-
[Página Web] Ultralytics HUB
-
[Página Web] Documentación de Roboflow
-
[Página Web] Documentación de TensorFlow Lite
-
[PDF] Especificación del Sensor de IA de Visión LoRaWAN SenseCAP A1101
-
[PDF] Guía del Usuario del Sensor de IA de Visión LoRaWAN SenseCAP A1101
-
[PDF] Preguntas Frecuentes para el Sensor de IA de Visión LoRaWAN SenseCAP A1101
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarle diferentes tipos de soporte para asegurar que su experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.