Introducción a Edge Impulse con Wio Terminal

Edge Impulse permite a los desarrolladores crear la próxima generación de soluciones de dispositivos inteligentes con Machine Learning embebido. El Machine Learning en el borde permitirá el uso valioso del 99% de los datos de sensores que se descartan hoy en día debido a restricciones de costo, ancho de banda o energía.
Ahora, Wio Terminal es oficialmente compatible con Edge Impulse. ¡Veamos cómo comenzar con Wio Terminal y el Machine Learning en el borde!
Instalación de dependencias
Para configurar Wio Terminal en Edge Impulse, necesitarás instalar el siguiente software:
- Node.js v12 o superior.
- Arduino CLI
- La CLI de Edge Impulse y un monitor serie. Instala abriendo el símbolo del sistema o terminal y ejecuta:
npm install -g edge-impulse-cli
¿Problemas con la instalación del CLI? Por favor consulta Instalación y solución de problemas para más referencia.
Conectando a Edge Impulse
Con todo el software en su lugar es hora de conectar la placa de desarrollo a Edge Impulse.
1. Conecta la placa de desarrollo a tu computadora
Conecta Wio Terminal a tu computadora. Entra al modo bootloader deslizando el interruptor de encendido dos veces rápidamente. Para más referencia, por favor también consulta aquí.

Una unidad externa llamada Arduino debería aparecer en tu PC. Arrastra los archivos de firmware uf2 de Edge Impulse descargados a la unidad Arduino. ¡Ahora, Edge Impulse está cargado en Seeeduino Wio Terminal!
NOTA: Aquí está el código fuente de Wio Terminal Edge Impulse, también puedes construir el firmware desde aquí.
2. Configurando Claves
Desde un símbolo del sistema o terminal ejecuta:
edge-impulse-daemon
NOTA: Al conectar a un nuevo dispositivo, ejecuta edge-impulse-daemon --clean para eliminar el caché previo.
3. Verificando que el dispositivo está conectado
¡Eso es todo! Tu dispositivo ahora está conectado a Edge Impulse. Para verificar esto, ve a tu proyecto de Edge Impulse, y haz clic en Devices. El dispositivo aparecerá listado aquí.
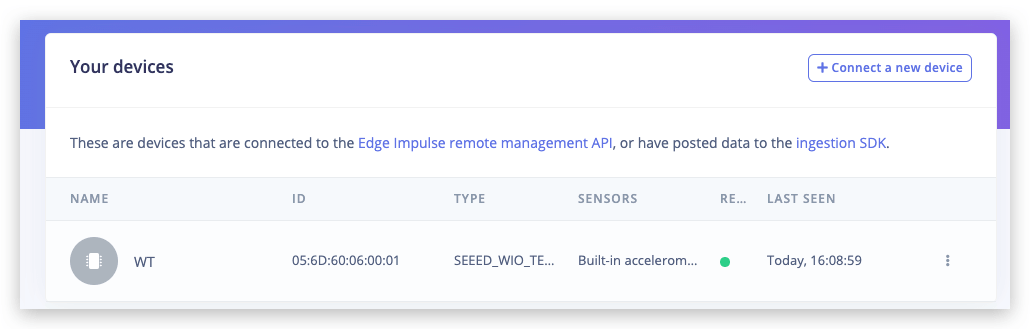
Para tu primer proyecto, vamos a entrenar y desplegar rápidamente una red neuronal simple para clasificar gestos de piedra-papel-tijeras con solo un sensor de luz. ¡Para más detalles y tutorial en video, mira el video correspondiente!
Adquisición de datos de entrenamiento
Ve a la pestaña Data acquisition. Establece la longitud de muestra a aproximadamente 10000 ms o 10 segundos y crea 10 muestras para cada gesto, agitando la mano en las proximidades del Wio terminal.

Este es un conjunto de datos pequeño, pero también tenemos una red neuronal diminuta, por lo que el underfitting es más probable que el overfitting en este caso particular.
Underfitting: Se dice que un modelo estadístico o un algoritmo de aprendizaje automático tiene underfitting cuando no puede capturar la tendencia subyacente de los datos, lo que ocurre (entre otros casos) cuando el tamaño del modelo es demasiado pequeño para desarrollar una regla general para datos que tienen gran variedad y cantidad de ruido.
Overfitting: Se dice que un modelo estadístico está sobreajustado, cuando comienza a aprender del ruido y entradas de datos inexactas en nuestro conjunto de datos. Eso ocurre cuando tienes un modelo grande y un conjunto de datos relativamente pequeño - el modelo puede simplemente aprender "de memoria" todos los puntos de datos sin generalizar.
Al recopilar muestras es importante proporcionar diversidad para que el modelo pueda generalizar mejor, por ejemplo tener muestras con diferente dirección, velocidad y distancia del sensor. En general, la red solo puede aprender de los datos presentes en el conjunto de datos – así que si las únicas muestras que tienes son gestos siendo movidos de izquierda a derecha sobre el sensor, no deberías esperar que el modelo entrenado sea capaz de reconocer gestos siendo movidos de derecha a izquierda o arriba y abajo.
Construyendo un modelo de aprendizaje automático
Después de que recopilaste las muestras es hora de diseñar un "impulse". Impulse aquí es la palabra que Edge Impulse usa para denotar el procesamiento de datos – pipeline de entrenamiento. Presiona en Create Impulse y establece Window length a 1000 ms. y Window length increase a 50 ms.
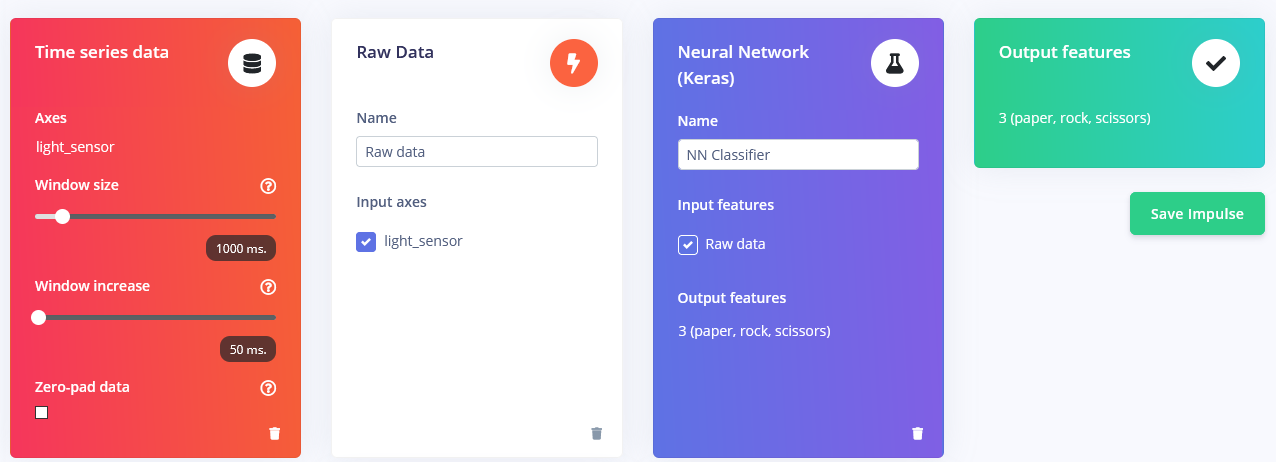
Estas configuraciones significan que cada vez que se realiza una inferencia vamos a tomar mediciones del sensor durante 1000 ms. - cuántas mediciones va a tomar tu dispositivo depende de la frecuencia. Durante la recopilación de datos estableciste la frecuencia de muestreo a 40 Hz, o 40 veces por 1 segundo. Así que, para resumir, tu dispositivo va a recopilar 40 muestras de datos dentro de una ventana de tiempo de 1000 ms. y luego tomar estos valores, preprocesarlos y alimentarlos a la red neuronal para obtener el resultado de inferencia. Por supuesto usamos el mismo tamaño de ventana durante el entrenamiento. Para este proyecto de prueba de concepto, vamos a probar tres bloques de preprocesamiento diferentes con parámetros por defecto (excepto por añadir escalado) – Bloque Flatten, que toma y calcula Promedio, Mín, Máx y otras funciones de datos en bruto dentro de la ventana de tiempo.
Bloque Spectral Features, que extrae las características de frecuencia y potencia de una señal a lo largo del tiempo.
y bloque Raw data, que como podrías haber adivinado simplemente alimenta datos en bruto al bloque de aprendizaje NN (opcionalmente normalizando los datos).
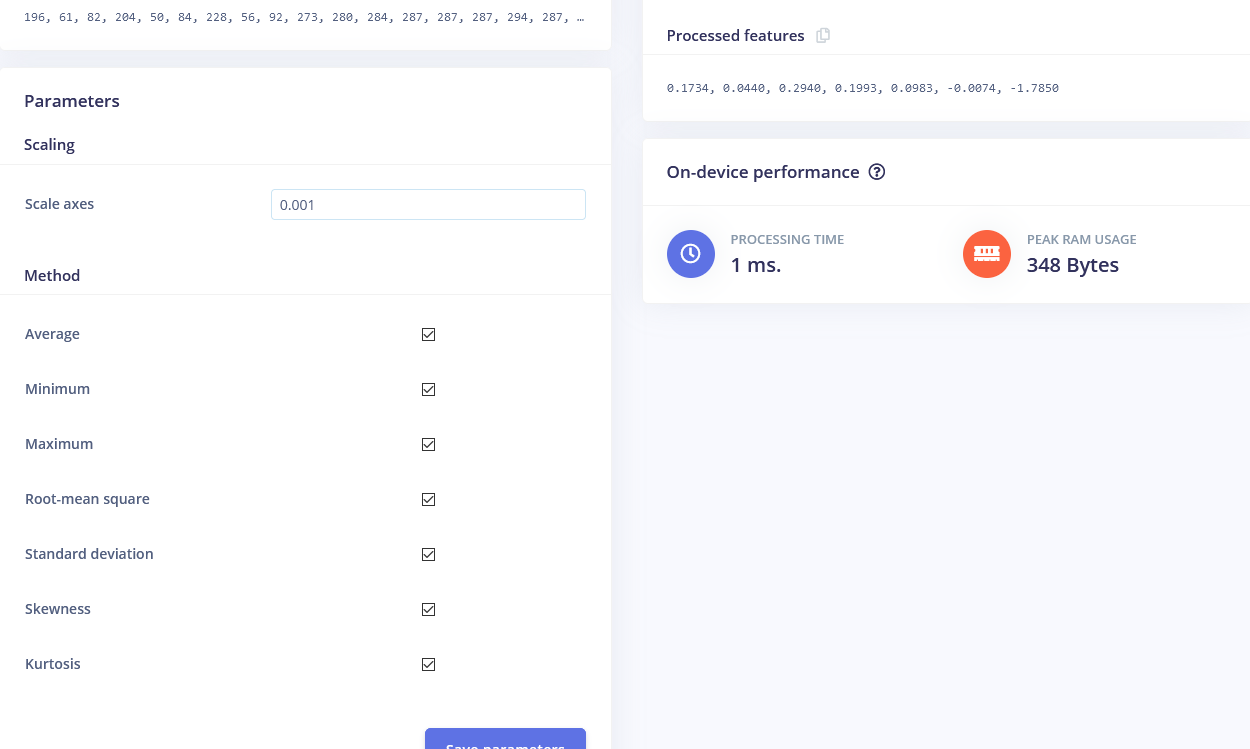
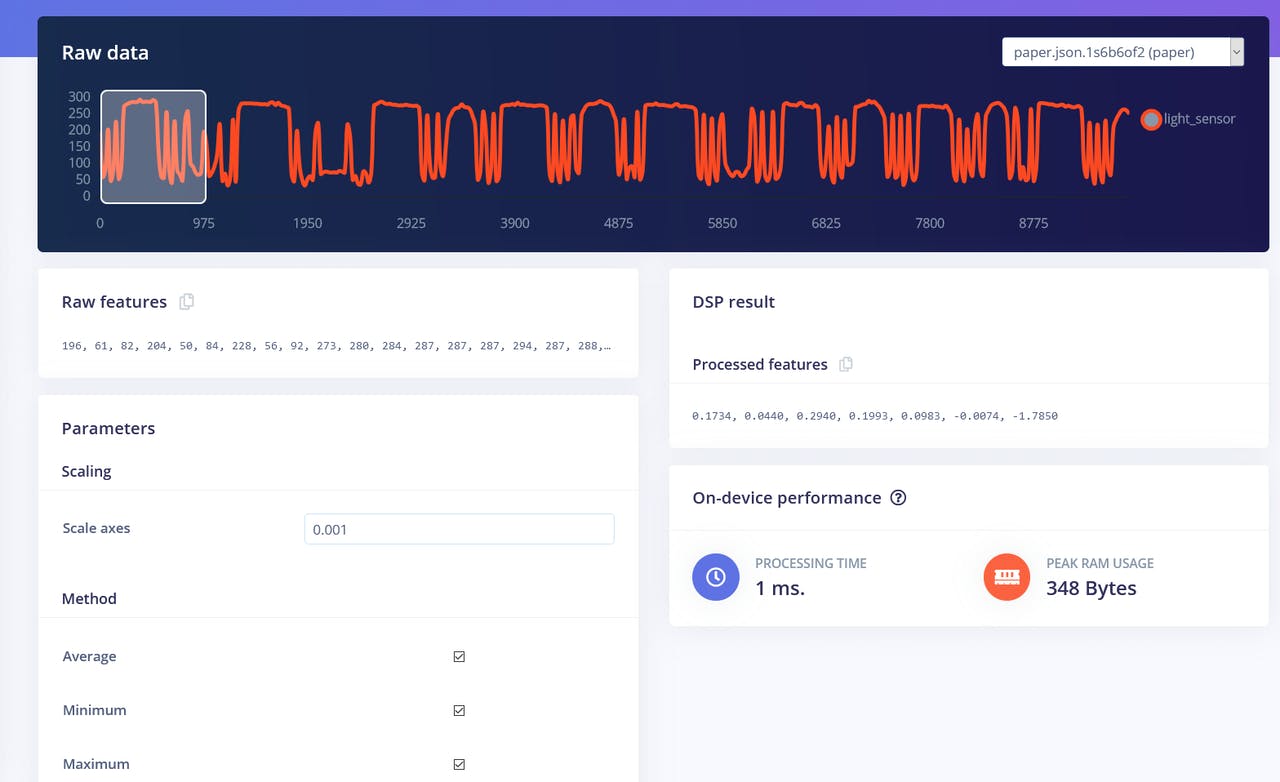
Comenzaremos con el bloque Flatten. Añade este bloque y luego añade Neural Network (Keras) como bloque de aprendizaje, marca Flatten como características de entrada y haz clic en Save Impulse. Ve a la siguiente pestaña, que tiene el nombre del bloque de procesamiento que has elegido - Flatten. Ahí ingresa 0.001 en scaling y deja los otros parámetros iguales. Presiona en Save parameters y luego Generate features.
La visualización de características es una herramienta particularmente útil en la interfaz web de Edge Impulse, ya que permite a los usuarios obtener información gráfica sobre cómo se ven los datos después del preprocesamiento. Por ejemplo, estos son los datos después del bloque de procesamiento Flatten:
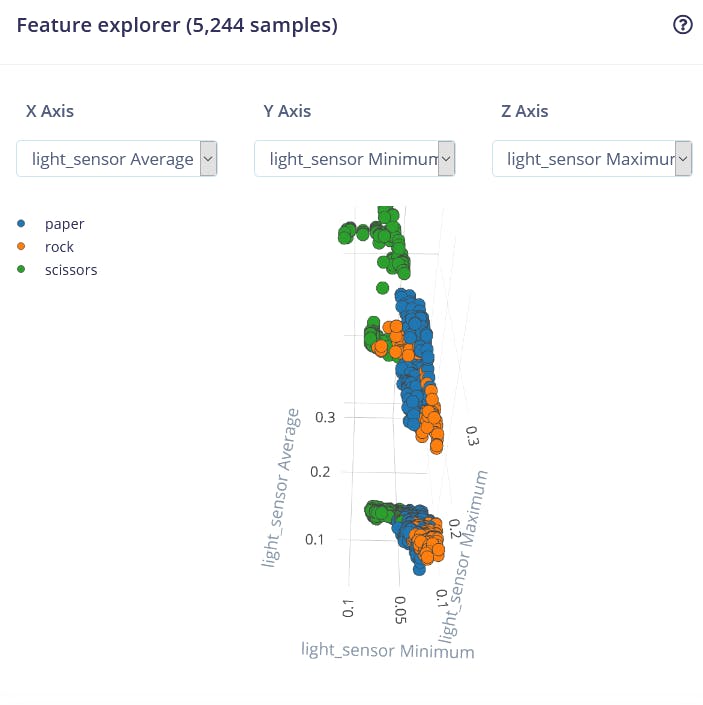
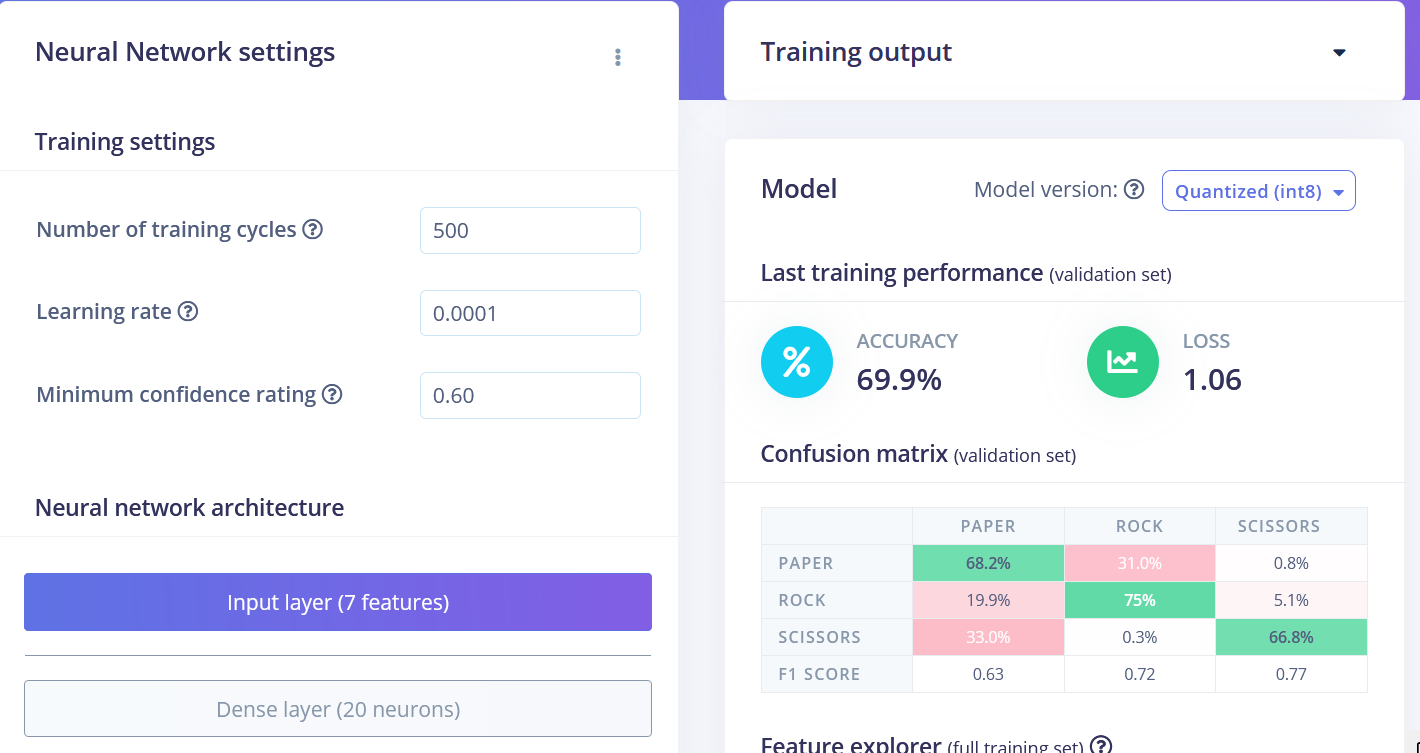
Podemos ver que los puntos de datos para diferentes clases están aproximadamente divididos, pero hay mucha superposición entre rock y otras clases, lo que causará problemas y baja precisión para estas dos clases. Después de que generaste e inspeccionaste las características, ve a la pestaña NN CLassifier. Entrena una red completamente conectada simple con 2 capas ocultas, 20 y 10 neuronas en cada capa oculta durante 500 épocas con una tasa de aprendizaje de 1e-4. Después de que el entrenamiento termine vas a ver los resultados de prueba en la matriz de confusión, similar a esta:
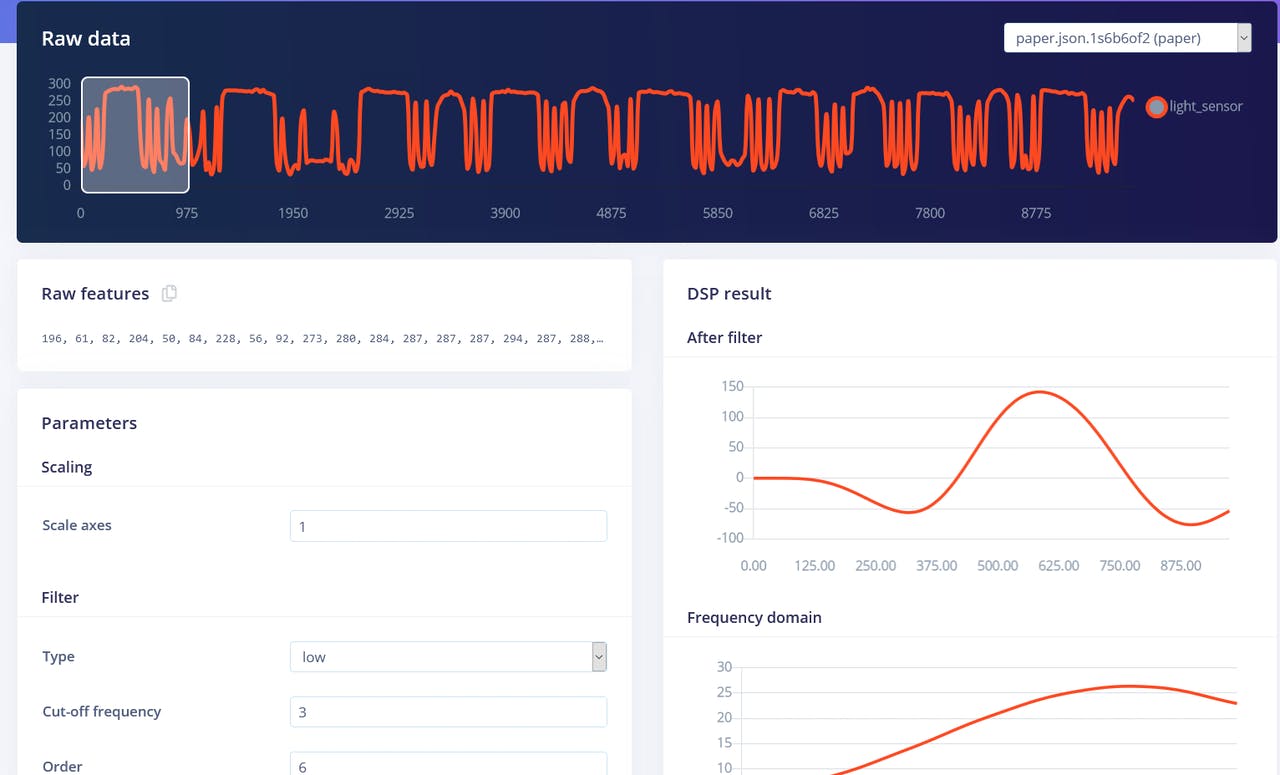
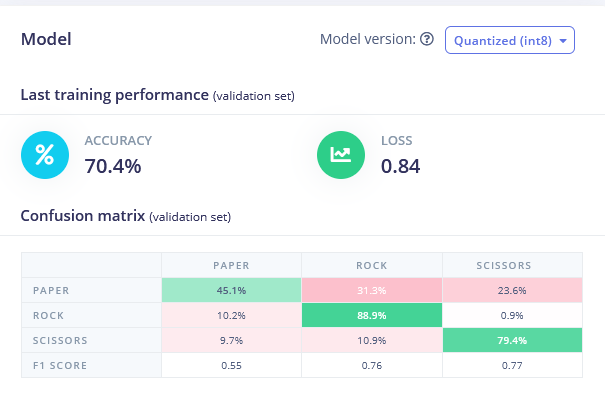
Regresa a la pestaña Create Impulse, elimina el bloque Flatten y elige el bloque Spectral Features, genera las características (¡recuerda establecer scaling a 0.001!) y entrena la Red neuronal en los datos de Spectral features. Deberías ver una ligera mejora.
Tanto los bloques Flatten como Spectral Features en realidad no son los mejores métodos de procesamiento para la tarea de reconocimiento de gestos piedra-papel-tijeras. Si pensamos en ello, para clasificar gestos de piedra-papel-tijeras solo necesitamos contar cuántas veces y por cuánto tiempo el sensor de luz ha recibido valores "más bajos de lo normal". Si es una vez relativamente larga – entonces es rock (puño pasando sobre los sensores). Si es dos veces, entonces es scissors. Cualquier cosa más que eso es paper. Suena fácil, pero preservar los datos de series temporales es realmente importante para que la red neuronal sea capaz de aprender esta relación en los puntos de datos. Tanto los bloques de procesamiento Flatten como Spectral Features eliminan la relación temporal dentro de cada ventana – el bloque Flatten simplemente convierte los valores en bruto, que están inicialmente en secuencia a valores de Promedio, Mín, Máx, etc. calculados en todos los valores en la ventana de tiempo, independientemente de su orden. El bloque Spectral Features extrae las características de frecuencia y potencia y la razón por la que no funcionó tan bien para esta tarea particular es probablemente, que la duración de cada gesto es demasiado corta. Entonces, la manera de lograr el mejor rendimiento es usar el bloque Raw data, que preservará los datos de series temporales. Echa un vistazo al proyecto de muestra donde usamos Raw data y red Convolutional 1D, un tipo de red más especializada, comparada con completamente conectada. ¡Pudimos lograr 92.4% de precisión en los mismos datos!
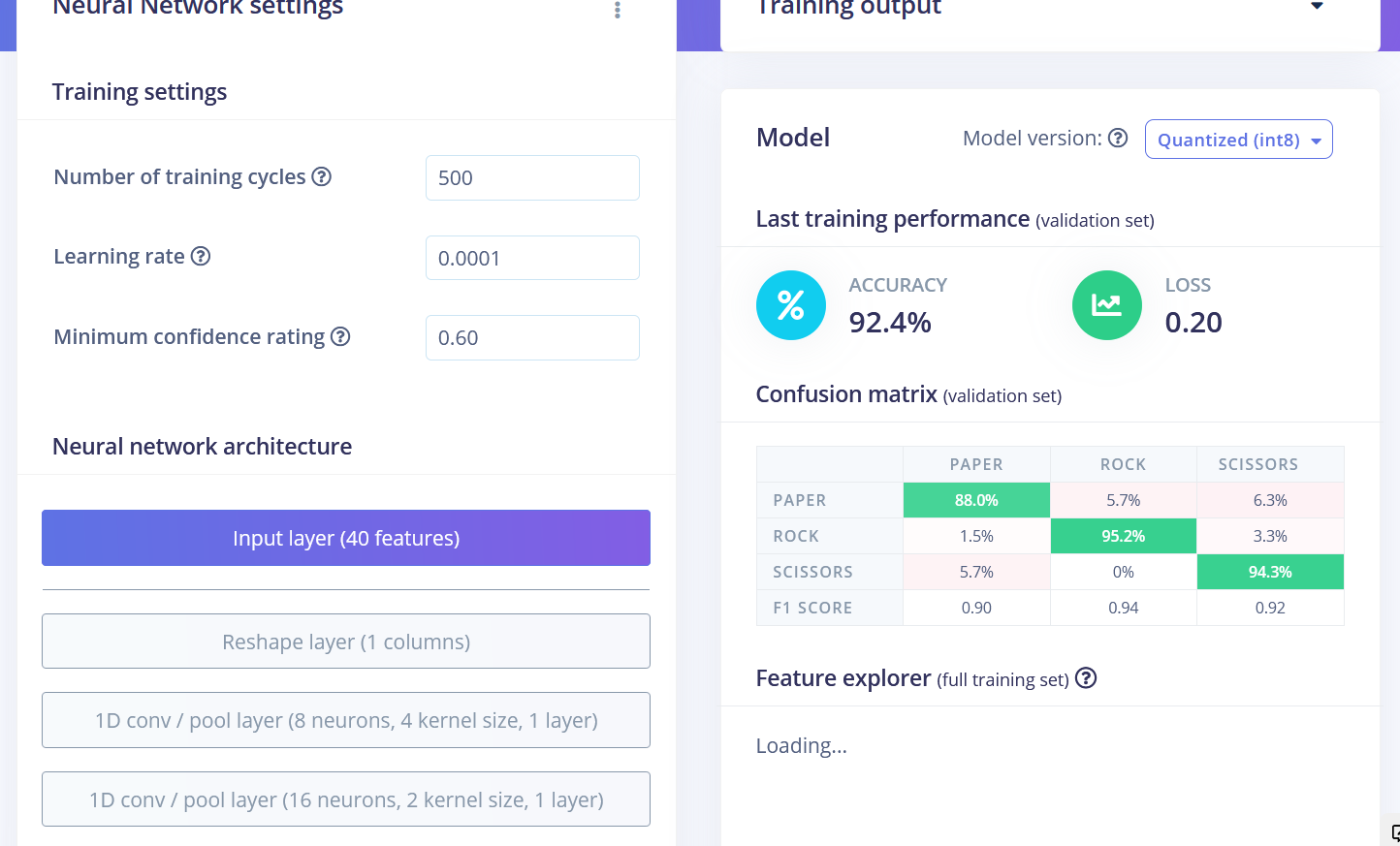
Los resultados finales después del entrenamiento fueron
• Flatten FC 69.9 % de precisión
• Spectral Features FC 70.4 % de precisión
• Raw Data Conv1D 92.4 % de precisión
Después del entrenamiento puedes probar el modelo usando la pestaña Live classification, que recopilará una muestra de datos del dispositivo y la clasificará con el modelo alojado en Edge Impulse. Probamos con tres gestos diferentes y vemos que la precisión es satisfactoria en lo que respecta a la prueba de concepto.
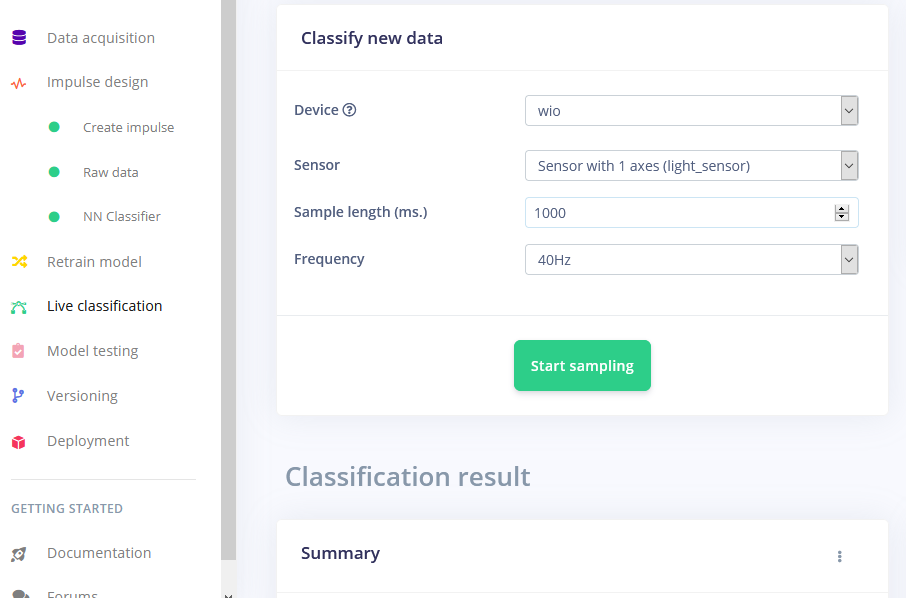
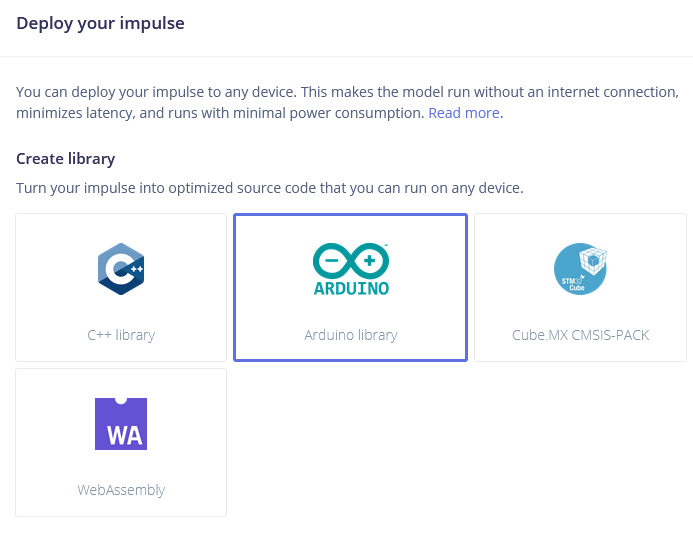
Desplegando en Wio Terminal
El siguiente paso es el despliegue en el dispositivo. Después de hacer clic en la pestaña Deployment, elige la librería de Arduino y descárgala.
Extrae el archivo y colócalo en tu carpeta de librerías de Arduino. Abre Arduino IDE y elige el sketch static buffer (ubicado en File -> Examples -> nombre de tu proyecto -> static_buffer), que ya tiene todo el código base para la clasificación con tu modelo en su lugar. ¡Genial!
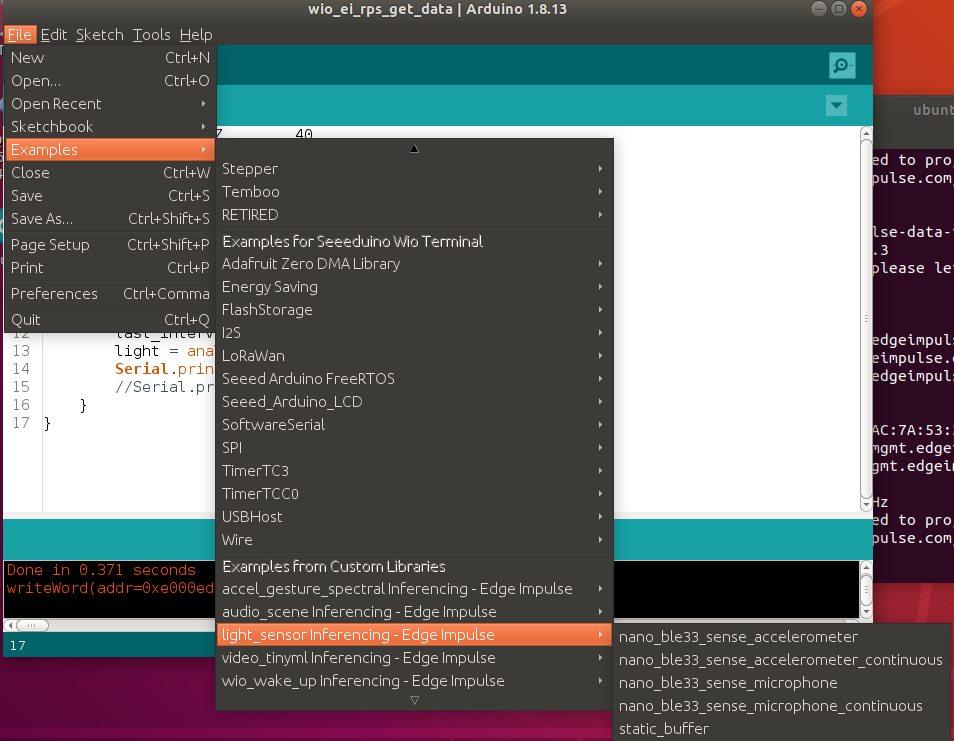
Lo único que necesitamos completar es la adquisición de datos en el dispositivo. Usaremos un simple bucle for con delay para tener en cuenta la frecuencia (si recuerdas, teníamos un delay de 25 ms cuando recopilábamos datos para el conjunto de datos de entrenamiento).
int raw_feature_get_data(size_t offset, size_t length, float *out_ptr) {
float features[40];
for (byte i = 0; i < 40; i = i + 1)
{
features[i]=analogRead(WIO_LIGHT);
delay(25);
}
memcpy(out_ptr, features + offset, length * sizeof(float));
return 0;
}
Ciertamente hay mejores formas de implementar esto, por ejemplo un buffer de datos del sensor, que nos permitiría realizar inferencia más a menudo. Pero llegaremos a eso en artículos posteriores de esta serie.
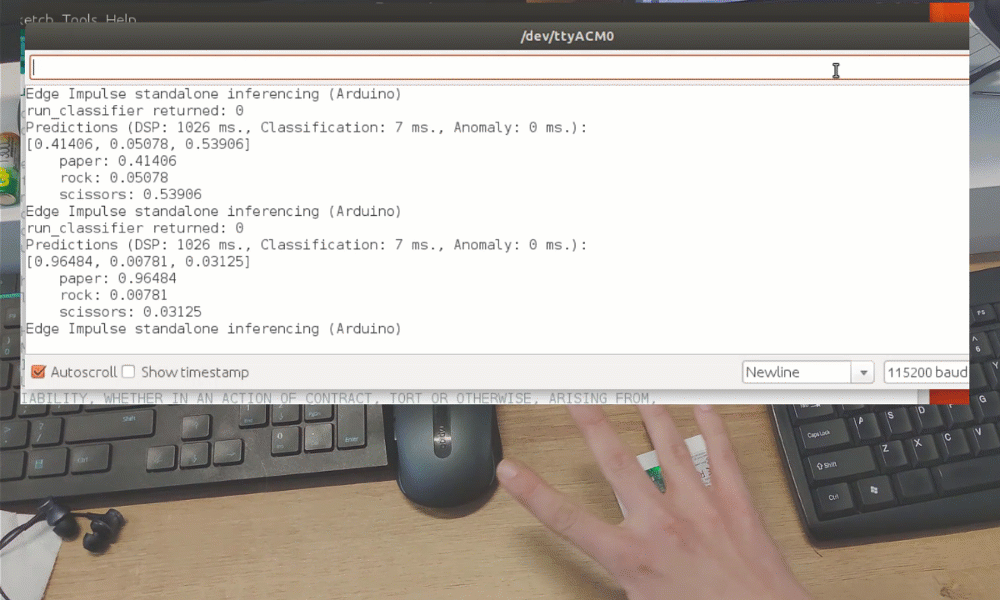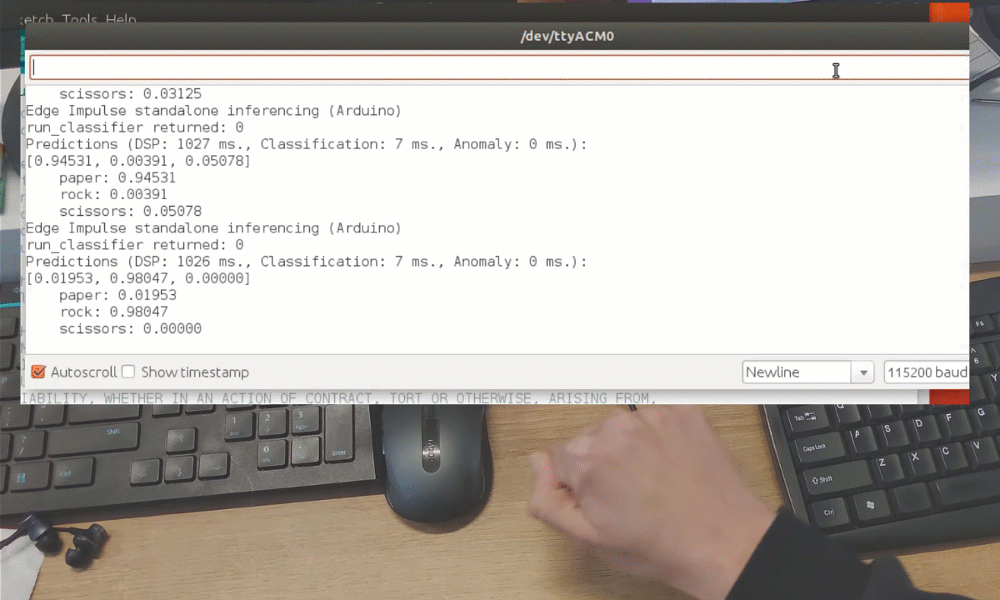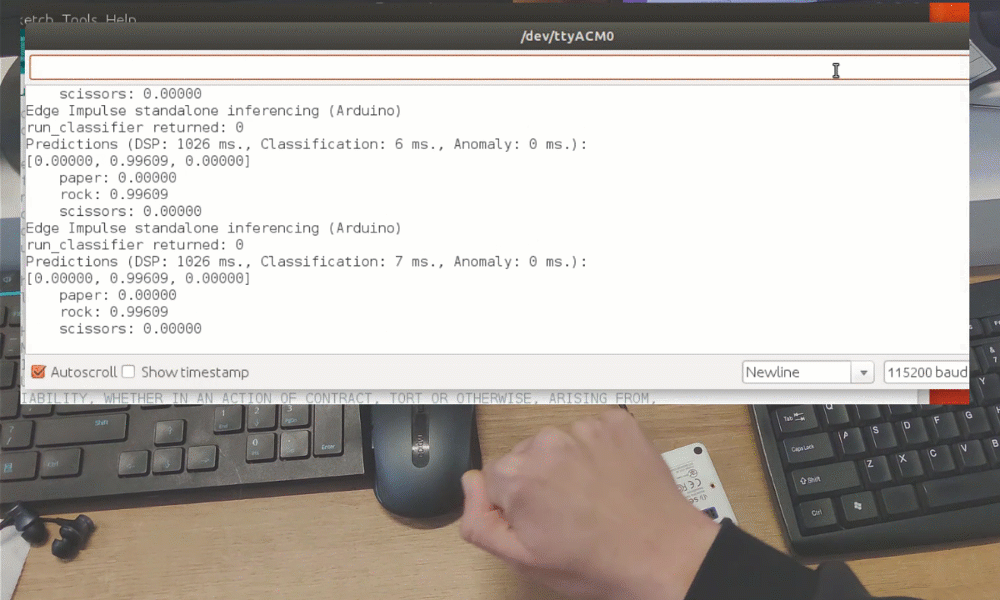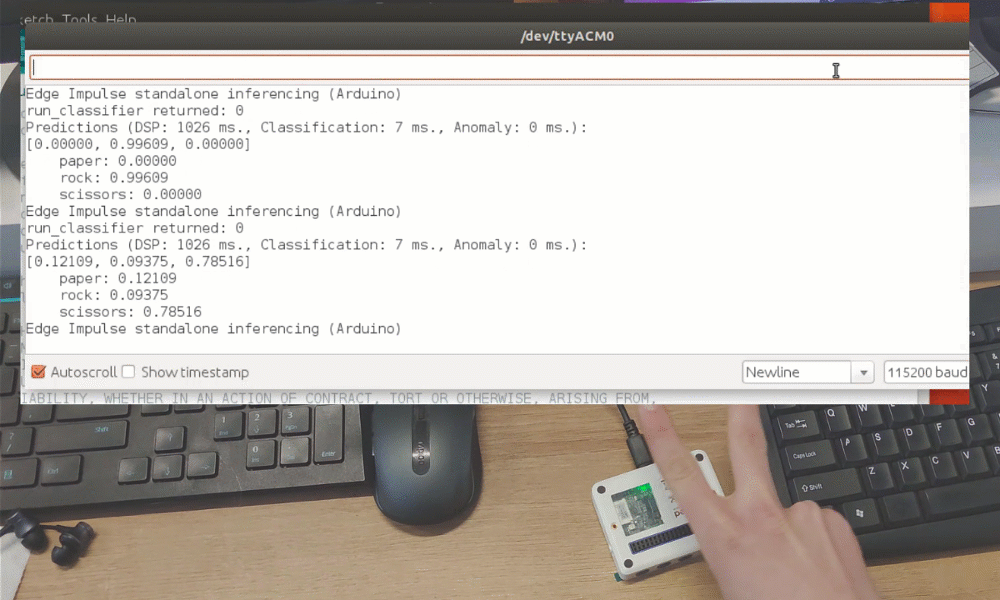
Aunque fue solo una demostración de prueba de concepto, realmente muestra que TinyML está preparado para algo grande. Probablemente sabías que es posible reconocer gestos con un sensor de cámara, incluso si la imagen se reduce mucho en escala. ¡Pero reconocer gestos con solo 1 píxel es un nivel completamente diferente!