Reconocimiento Continuo de Movimiento con Edge Impulse en Wio Terminal usando el Acelerómetro Integrado
En este tutorial, usarás aprendizaje automático para construir un sistema de reconocimiento de gestos que funcione en Wio Terminal. Esta es una tarea difícil de resolver usando programación basada en reglas, ya que las personas no realizan gestos exactamente de la misma manera cada vez. Pero el aprendizaje automático puede manejar estas variaciones con facilidad. Aprenderás cómo recopilar datos de alta frecuencia de sensores reales, usar procesamiento de señales para limpiar datos, construir un clasificador de red neuronal, y cómo desplegar tu modelo de vuelta a un dispositivo. Al final de este tutorial tendrás una comprensión sólida de la aplicación de aprendizaje automático en dispositivos embebidos usando Edge Impulse.
También hay una versión en video de este tutorial:
1. Prerrequisitos
Para este tutorial necesitarás un dispositivo compatible. Sigue primero el tutorial Wio Terminal Edge Impulse antes de continuar con lo siguiente.
Además de Wio Terminal, aquí hay otros dispositivos compatibles.
Si tu dispositivo está conectado bajo Dispositivos en el estudio puedes proceder:
Edge Impulse puede ingerir datos de cualquier dispositivo - incluyendo dispositivos embebidos que ya tengas en producción. Consulta la documentación del servicio de Ingesta para más información.
2. Recopilando tus primeros datos
Con tu dispositivo conectado podemos recopilar algunos datos. En el estudio ve a la pestaña Adquisición de datos. Este es el lugar donde se almacenan todos tus datos en bruto, y - si tu dispositivo está conectado a la API de gestión remota - donde puedes comenzar a muestrear nuevos datos.
Bajo Grabar nuevos datos, selecciona tu dispositivo, establece la etiqueta como idle, la longitud de muestra a 5000, el sensor a Built-in accelerometer y la frecuencia a 62.5Hz. Esto indica que quieres grabar datos durante 10 segundos, y etiquetar los datos grabados como idle. Puedes editar estas etiquetas más tarde si es necesario.
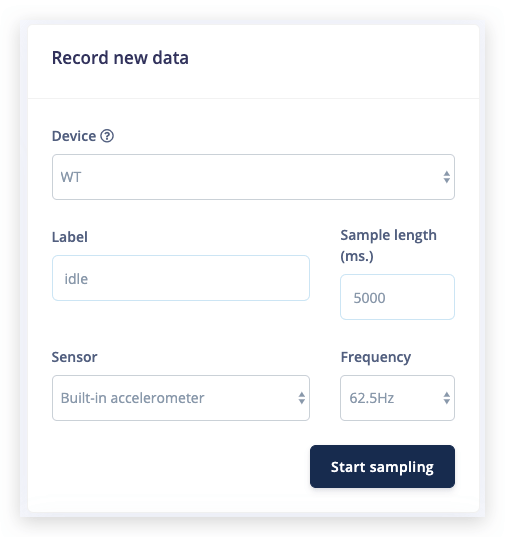
Después de hacer clic en Iniciar muestreo mueve tu dispositivo hacia arriba y hacia abajo en un movimiento continuo. En aproximadamente doce segundos el dispositivo debería completar el muestreo y subir el archivo de vuelta a Edge Impulse. Verás aparecer una nueva línea bajo 'Datos recopilados' en el estudio. Cuando hagas clic en ella ahora verás los datos en bruto graficados. Como el acelerómetro en la placa de desarrollo tiene tres ejes notarás tres líneas diferentes, una para cada eje.
Es importante hacer movimientos continuos ya que más tarde dividiremos los datos en ventanas más pequeñas.
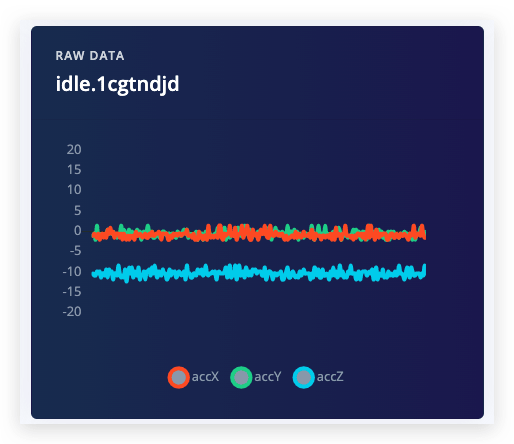
El aprendizaje automático funciona mejor con muchos datos, así que una sola muestra no será suficiente. Ahora es el momento de comenzar a construir tu propio conjunto de datos. Por ejemplo, usa las siguientes tres clases, y graba alrededor de 3 minutos de datos por clase:
- Idle - simplemente reposando en tu escritorio mientras trabajas.
- Wave - agitando el dispositivo de izquierda a derecha.
- Circle - dibujando círculos.
Asegúrate de realizar variaciones en los movimientos. Por ejemplo, haz movimientos tanto lentos como rápidos y varía la orientación de la placa. Nunca sabrás cómo usará el dispositivo tu usuario. Es mejor recopilar muestras de ~10 segundos cada una.
3. Diseñando un impulso
Con el conjunto de entrenamiento en su lugar puedes diseñar un impulso. Un impulso toma los datos en bruto, los divide en ventanas más pequeñas, usa bloques de procesamiento de señales para extraer características, y luego usa un bloque de aprendizaje para clasificar nuevos datos. Los bloques de procesamiento de señales siempre devuelven los mismos valores para la misma entrada y se usan para hacer que los datos en bruto sean más fáciles de procesar, mientras que los bloques de aprendizaje aprenden de experiencias pasadas.
Para este tutorial usaremos el bloque de procesamiento de señales 'Spectral analysis'. Este bloque aplica un filtro, realiza análisis espectral en la señal, y extrae datos de frecuencia y potencia espectral. Luego usaremos un bloque de aprendizaje 'Neural Network', que toma estas características espectrales y aprende a distinguir entre las tres clases (idle, circle, wave).
En el estudio ve a Create impulse, establece el tamaño de ventana a 2000 (puedes hacer clic en el texto 2000 ms. para ingresar un valor exacto), el incremento de ventana a 80, y añade los bloques Spectral Analysis y Neural Network (Keras). Luego haz clic en Save impulse.
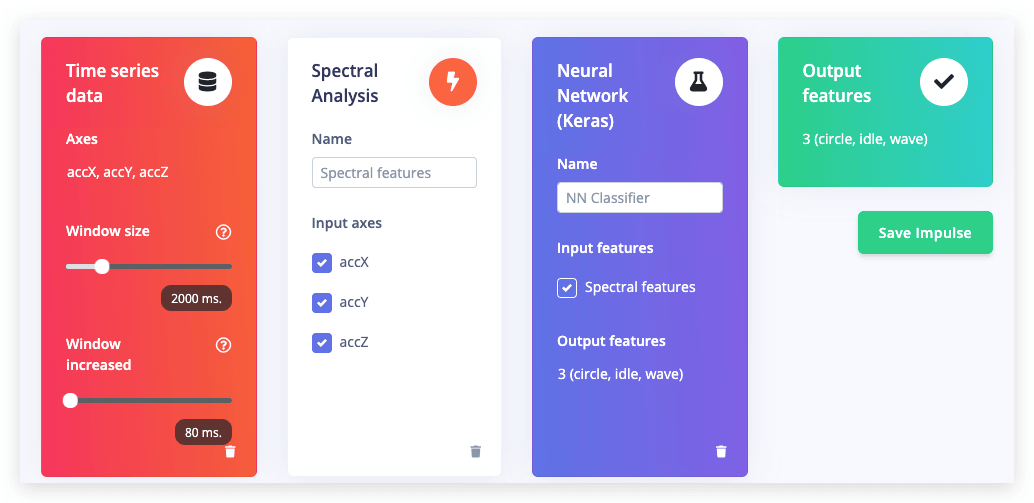
Configurando el bloque de análisis espectral
Para configurar tu bloque de procesamiento de señales, haz clic en Spectral features en el menú de la izquierda. Esto te mostrará los datos en bruto en la parte superior de la pantalla (puedes seleccionar otros archivos a través del menú desplegable), y los resultados del procesamiento de señales a través de gráficos en la derecha. Para el bloque de características espectrales verás los siguientes gráficos:
- After filter - la señal después de aplicar un filtro pasa-bajos. Esto eliminará el ruido.
- Frequency domain - la frecuencia a la cual la señal se repite (ej. hacer un movimiento de onda por segundo mostrará un pico a 1 Hz).
- Spectral power - la cantidad de potencia que se aplicó a la señal en cada frecuencia.
Un buen bloque de procesamiento de señales producirá resultados similares para datos similares. Si mueves la ventana deslizante (en el gráfico de datos en bruto) alrededor, los gráficos deberían permanecer similares. También, cuando cambies a otro archivo con la misma etiqueta, deberías ver gráficos similares, incluso si la orientación del dispositivo era diferente.
Una vez que estés satisfecho con el resultado, haz clic en Save parameters. Esto te enviará a la pantalla Feature generation. Aquí:
- Dividirás todos los datos en bruto en ventanas (basado en el tamaño de ventana y el incremento de ventana).
- Aplicarás el bloque de características espectrales en todas estas ventanas.
Haz clic en Generate features para iniciar el proceso.
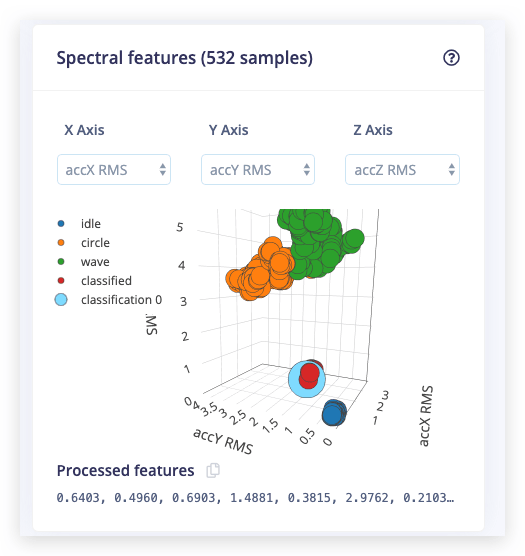
Después se cargará el Feature explorer. Este es un gráfico de todas las características extraídas contra todas las ventanas generadas. Puedes usar este gráfico para comparar tu conjunto de datos completo. Por ejemplo, graficando la altura del primer pico en el eje X contra la potencia espectral entre 0.5 Hz y 1 Hz en el eje Y. Una buena regla general es que si puedes separar visualmente los datos en varios ejes, entonces el modelo de aprendizaje automático también podrá hacerlo.
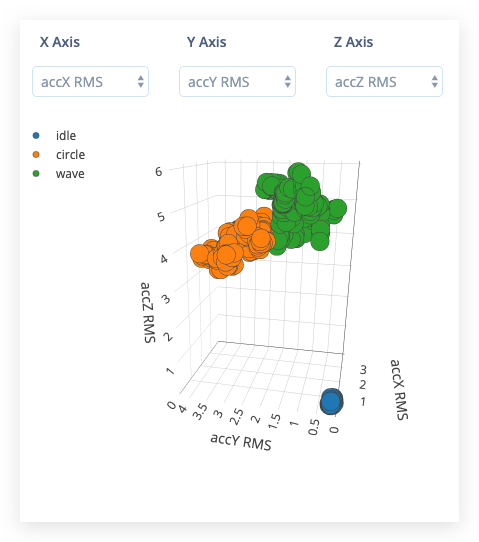
Configurando la red neuronal
Con todos los datos procesados es hora de comenzar a entrenar una red neuronal. Las redes neuronales son un conjunto de algoritmos, modelados vagamente según el cerebro humano, que están diseñados para reconocer patrones. La red que estamos entrenando aquí tomará los datos de procesamiento de señales como entrada, e intentará mapear esto a una de las tres clases.
Entonces, ¿cómo sabe una red neuronal qué predecir? Una red neuronal consiste en capas de neuronas, todas interconectadas, y cada conexión tiene un peso. Una de esas neuronas en la capa de entrada sería la altura del primer pico del eje X (del bloque de procesamiento de señales); y una de esas neuronas en la capa de salida sería wave (una de las clases). Al definir la red neuronal todas estas conexiones se inicializan aleatoriamente, y por lo tanto la red neuronal hará predicciones aleatorias. Durante el entrenamiento entonces tomamos todos los datos en bruto, pedimos a la red que haga una predicción, y luego hacemos pequeñas alteraciones a los pesos dependiendo del resultado (por esto es importante etiquetar los datos en bruto).
De esta manera, después de muchas iteraciones, la red neuronal aprende; y eventualmente se volverá mucho mejor prediciendo nuevos datos. Probemos esto haciendo clic en NN Classifier en el menú.
Establece Number of training cycles a 1. Esto limitará el entrenamiento a una sola iteración. Y luego haz clic en Start training.
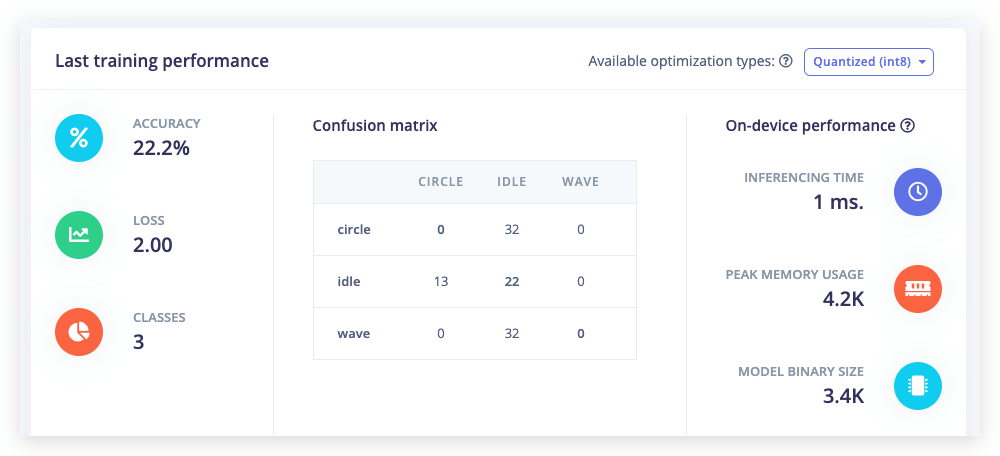
Ahora cambia Number of training cycles a 2 y verás que el rendimiento mejora. Finalmente, cambia Number of training cycles a 100 o más y deja que termine el entrenamiento. ¡Acabas de entrenar tu primera red neuronal!
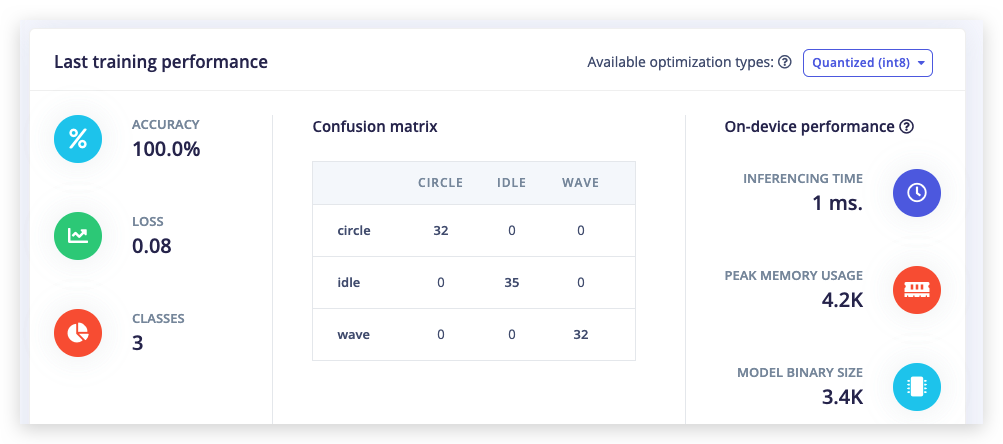
Podrías terminar con una precisión del 100% después de entrenar por 100 ciclos de entrenamiento. Esto no es necesariamente algo bueno, ya que podría ser una señal de que la red neuronal está demasiado ajustada para el conjunto de prueba específico y podría funcionar mal con nuevos datos (sobreajuste). La mejor manera de reducir esto es añadiendo más datos o reduciendo la tasa de aprendizaje.
4. Clasificando nuevos datos
A partir de las estadísticas del paso anterior sabemos que el modelo funciona contra nuestros datos de entrenamiento, pero ¿qué tan bien funcionaría la red con nuevos datos? Haz clic en Live classification en el menú para averiguarlo. Tu dispositivo debería (al igual que en el paso 2) mostrarse como en línea bajo Classify new data. Establece el Sample length en 5000 (5 segundos), haz clic en Start sampling y comienza a hacer movimientos. Después obtendrás un informe completo sobre lo que la red pensó que hiciste.
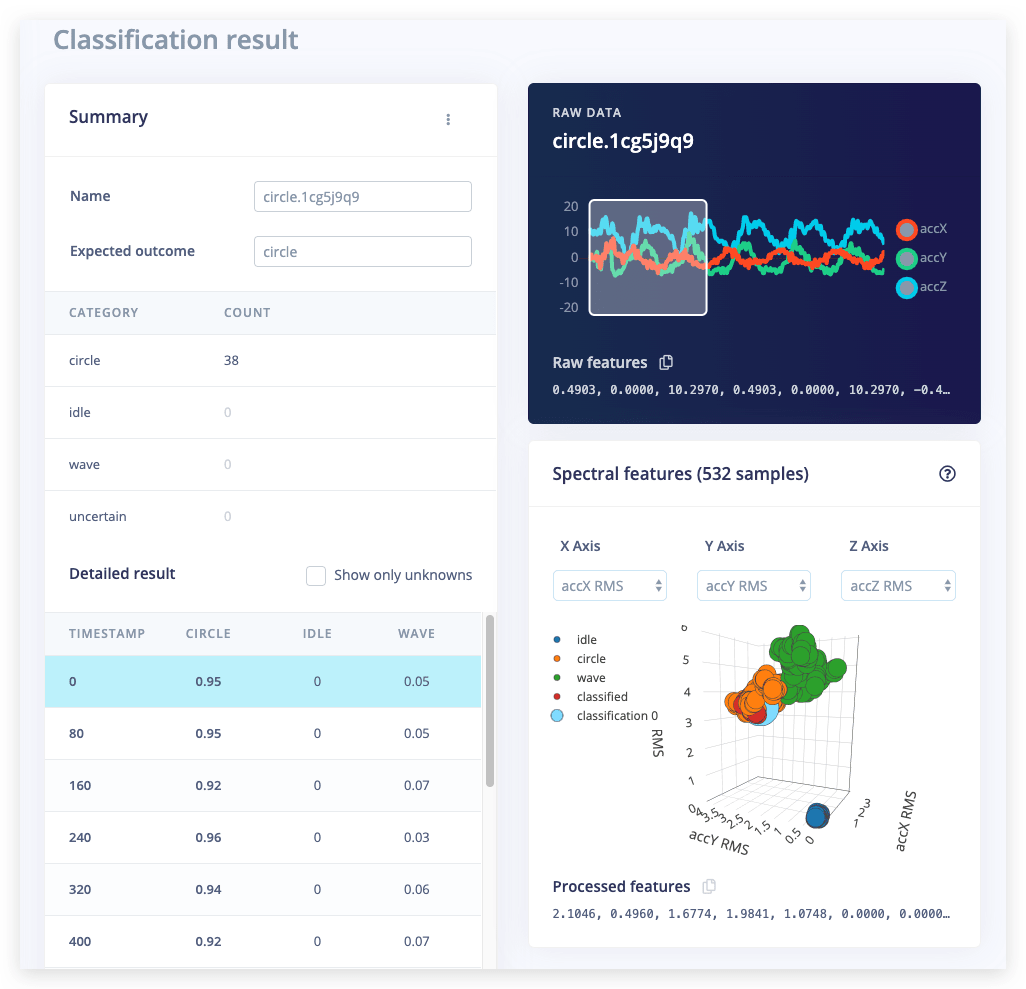
Si la red funcionó muy bien, ¡fantástico! Pero ¿qué pasa si funcionó mal? Podría haber una variedad de razones, pero las más comunes son:
- No hay suficientes datos. Las redes neuronales necesitan aprender patrones en conjuntos de datos, y mientras más datos, mejor.
- Los datos no se parecen a otros datos que la red ha visto antes. Esto es común cuando alguien usa el dispositivo de una manera que no agregaste al conjunto de prueba. Puedes agregar el archivo actual al conjunto de prueba haciendo clic, luego seleccionando Move to training set. Asegúrate de actualizar la etiqueta bajo
Data acquisitionantes del entrenamiento. - El modelo no ha sido entrenado lo suficiente. Aumenta el número de épocas a
200y ve si el rendimiento mejora (el archivo clasificado se almacena, y puedes cargarlo a través deClassify existing validation sample). - El modelo está sobreajustado y por lo tanto funciona mal con nuevos datos. Intenta reducir la tasa de aprendizaje o agregar más datos.
- La arquitectura de la red neuronal no es una gran opción para tus datos. Juega con el número de capas y neuronas y ve si el rendimiento mejora.
Como puedes ver, todavía hay mucho ensayo y error al construir redes neuronales, pero esperamos que las visualizaciones ayuden mucho. También puedes ejecutar la red contra el conjunto completo de validación a través de Model validation. ¡Piensa en la página de validación del modelo como un conjunto de pruebas unitarias para tu modelo!
Con un modelo funcional en su lugar podemos mirar lugares donde nuestro impulso actual funciona mal...
5. Detección de anomalías
Las redes neuronales son geniales, pero tienen un gran defecto. Son terribles para lidiar con datos que nunca han visto antes (como un nuevo gesto). Las redes neuronales no pueden juzgar esto, ya que solo están conscientes de los datos de entrenamiento. Si les das algo diferente a cualquier cosa que hayan visto antes, aún clasificarán como una de las tres clases.
Veamos cómo funciona esto en la práctica. Ve a Live classification y graba algunos datos nuevos, pero ahora agita vívidamente tu dispositivo. Echa un vistazo y ve cómo la red predecirá algo sin importar qué.
Entonces... ¿cómo podemos hacerlo mejor? Si miras el explorador de características en los ejes accX RMS, accY RMS y accZ RMS, deberías poder separar visualmente los datos clasificados de los datos de entrenamiento. Podemos usar esto a nuestro favor entrenando una nueva (segunda) red que crea grupos alrededor de datos que hemos visto antes, y compara los datos entrantes contra estos grupos. Si la distancia de un grupo es demasiado grande puedes marcar la muestra como una anomalía, y no confiar en la red neuronal.
Para agregar este bloque ve a Create impulse, haz clic en Add learning block, y selecciona K-means Anomaly Detection. Luego haz clic en Save impulse.
Para configurar el modelo de agrupamiento haz clic en Anomaly detection en el menú. Aquí necesitamos especificar:
- El número de grupos. Aquí usa
32. - Los ejes que queremos seleccionar durante el agrupamiento. Como podemos separar visualmente los datos en los ejes accX RMS, accY RMS y accZ RMS, selecciona esos.
Haz clic en Start training para generar los grupos. Puedes cargar muestras de validación existentes en el explorador de anomalías con el menú desplegable.
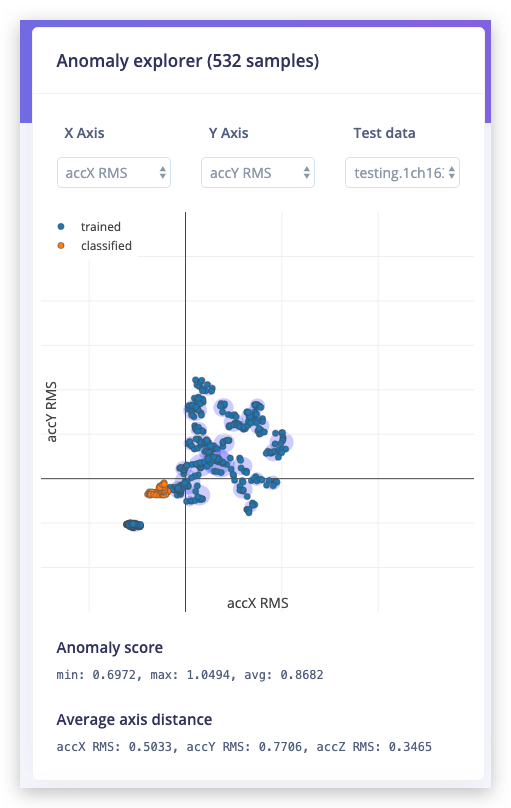
Grupos conocidos en azul, los datos de agitación en naranja. Está claramente fuera de cualquier grupo conocido y por lo tanto puede ser etiquetado como una anomalía.
El explorador de anomalías solo grafica dos ejes a la vez. Bajo average axis distance ves qué tan lejos de cada eje está la muestra de validación. Usa los menús desplegables para cambiar ejes.
6. Desplegando de vuelta al dispositivo
Con el impulso diseñado, entrenado y verificado puedes desplegar este modelo de vuelta a tu dispositivo. Esto hace que el modelo funcione sin una conexión a internet, minimiza la latencia y funciona con un consumo mínimo de energía. Edge Impulse puede empaquetar el impulso completo - incluyendo el código de procesamiento de señales, los pesos de la red neuronal y el código de clasificación - en una sola biblioteca de C++ que puedes incluir en tu software embebido.
Después de hacer clic en la pestaña Deployment, elige la biblioteca de Arduino y descárgala. Extrae el archivo y colócalo en tu carpeta de bibliotecas de Arduino. Abre Arduino IDE y elige Examples-> nombre de tu proyecto Inferencing Edge Impulse - > sketch nano_ble33_sense_accelerometer. Nuestra placa es similar al Arduino Nano BLE33 Sense, pero usa un acelerómetro diferente (LIS3DHTR en lugar de LSM9DS1), así que necesitaremos cambiar la sección de adquisición de datos en consecuencia. Además, dado que Wio Terminal tiene una pantalla LCD, vamos a mostrar el nombre de la clase detectada si el valor de confianza de esta clase está por encima del umbral. Primero cambia el encabezado
#include <Arduino_LSM9DS1.h>
a
#include"LIS3DHTR.h"
#include"TFT_eSPI.h"
LIS3DHTR<TwoWire> lis;
TFT_eSPI tft;
Luego cambia la inicialización en la función setup
if (!IMU.begin()) {
ei_printf("Failed to initialize IMU!\r\n");
}
else {
ei_printf("IMU initialized\r\n");
}
a
tft.begin();
tft.setRotation(3);
tft.fillScreen(TFT_WHITE);
lis.begin(Wire1);
if (!lis.available()) {
Serial.println("Failed to initialize IMU!");
while (1);
}
else {
ei_printf("IMU initialized\r\n");
}
lis.setOutputDataRate(LIS3DHTR_DATARATE_100HZ); // Setting output data rage to 25Hz, can be set up tp 5kHz
lis.setFullScaleRange(LIS3DHTR_RANGE_16G); // Setting scale range to 2g, select from 2,4,8,16g
Realizamos la recolección de datos y la inferencia dentro de la función loop, aquí es donde necesitamos cambiar la adquisición de datos con LSM9DS1 por la función de adquisición de datos para LIS3DHTR
IMU.readAcceleration(buffer[ix], buffer[ix + 1], buffer[ix + 2]);
a
lis.getAcceleration(&buffer[ix], &buffer[ix + 1], &buffer[ix + 2]);
Y luego para mostrar el nombre de la clase en la pantalla LCD, después de
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: %.3f\n", result.anomaly);
#endif
añade el siguiente bloque de código, en el cual verificamos los valores de confianza de cada clase y si uno de ellos es mayor que el umbral, cambiamos el color de la pantalla y mostramos el nombre de esa clase.
if (result.classification[1].value > 0.7) {
tft.fillScreen(TFT_PURPLE);
tft.setFreeFont(&FreeSansBoldOblique12pt7b);
tft.drawString("Wave", 20, 80);
delay(1000);
tft.fillScreen(TFT_WHITE);
}
if (result.classification[2].value > 0.7) {
tft.fillScreen(TFT_RED);
tft.setFreeFont(&FreeSansBoldOblique12pt7b);
tft.drawString("Circle", 20, 80);
delay(1000);
tft.fillScreen(TFT_WHITE);
}
Luego compila y carga - abre el monitor serie y realiza uno de los gestos! Podrás ver los resultados de inferencia mostrados en el monitor Serie y también en la pantalla LCD.
7. Conclusión
El aprendizaje automático es un campo súper interesante: te permite construir sistemas complejos que aprenden de experiencias pasadas, encuentran automáticamente patrones en datos de sensores, y buscan anomalías sin programar explícitamente las cosas. Creemos que hay una gran oportunidad para el aprendizaje automático en sistemas embebidos. Hay enormes cantidades de datos de sensores que se recopilan actualmente, pero el 99% de estos datos se descartan debido a restricciones de costo, ancho de banda o energía.
Edge Impulse te ayuda a desbloquear estos datos. Al procesar datos directamente en el dispositivo ya no tienes que enviar datos en bruto a la nube, sino que puedes sacar conclusiones directamente donde importa. ¡No podemos esperar a ver lo que construirás!