Reconocimiento de Escenas de Audio con Wio Terminal Edge Impulse usando Micrófono Integrado
En este proyecto aprenderemos cómo entrenar y desplegar un clasificador de escenas de audio con Wio Terminal y Edge Impulse. ¡Para más detalles y tutorial en video, mira el video correspondiente!
Procesamiento de sonido en computadoras
La clasificación de escenas de audio es una tarea donde el modelo de aprendizaje automático necesita predecir una clase para un segmento de audio, por ejemplo, "un bebé llorando", "una tos", "un perro ladrando", etc.
El sonido es una vibración que se propaga (o viaja) como una onda acústica, a través de un medio de transmisión como un gas, líquido o sólido.

La fuente del sonido empuja las moléculas del medio circundante, estas empujan las moléculas junto a ellas y así sucesivamente. Cuando llegan a otro objeto también vibra ligeramente – usamos ese principio en el micrófono. La membrana del micrófono es empujada hacia adentro por las moléculas del medio y luego regresa a su posición original.
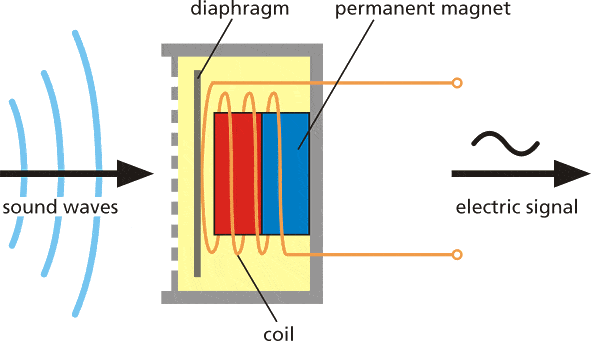
Eso genera corriente alterna en el circuito, donde el voltaje es proporcional a la amplitud del sonido – mientras más fuerte el sonido, más empuja la membrana, generando así mayor voltaje. Luego leemos este voltaje con un convertidor analógico-digital y grabamos a intervalos iguales – el número de veces que tomamos medición del sonido en un segundo se llama frecuencia de muestreo, por ejemplo una frecuencia de muestreo de 8000 Hz es tomar medición 8000 veces por segundo. La frecuencia de muestreo obviamente importa mucho para la calidad del sonido – si muestreamos muy lento podríamos perder partes importantes. Los números usados para grabar sonido digitalmente también importan – mientras mayor sea el rango de un número usado, más "matices" podemos preservar del sonido original. Eso se llama profundidad de bits de audio – podrías haber escuchado términos como sonido de 8 bits y sonido de 16 bits. Bueno, es exactamente lo que dice – para sonido de 8 bits se usan enteros de 8 bits sin signo, que tienen rango de 0 a 255. Para sonido de 16 bits se usan enteros de 16 bits con signo, así que eso es -32768 a 32767. Muy bien, así que al final tenemos una cadena de números, con números más grandes correspondiendo a partes fuertes del sonido y podemos visualizarlo así - esto es 1 segundo de sonido de disparo grabado a 8000 Hz de frecuencia en profundidad de 8 bits (0-255).

Sin embargo, no podemos hacer mucho con esta representación de sonido cruda – sí, podemos cortar y pegar las partes o hacerlo más silencioso o más fuerte, pero para analizar el sonido, es, bueno, demasiado crudo. Aquí es donde entran la transformada de Fourier, la escala Mel, espectrogramas y coeficientes cepstrum. Para el propósito de este proyecto, definiremos la transformada de Fourier como una transformada matemática, que nos permite descomponer una señal en sus frecuencias individuales y la amplitud de la frecuencia.
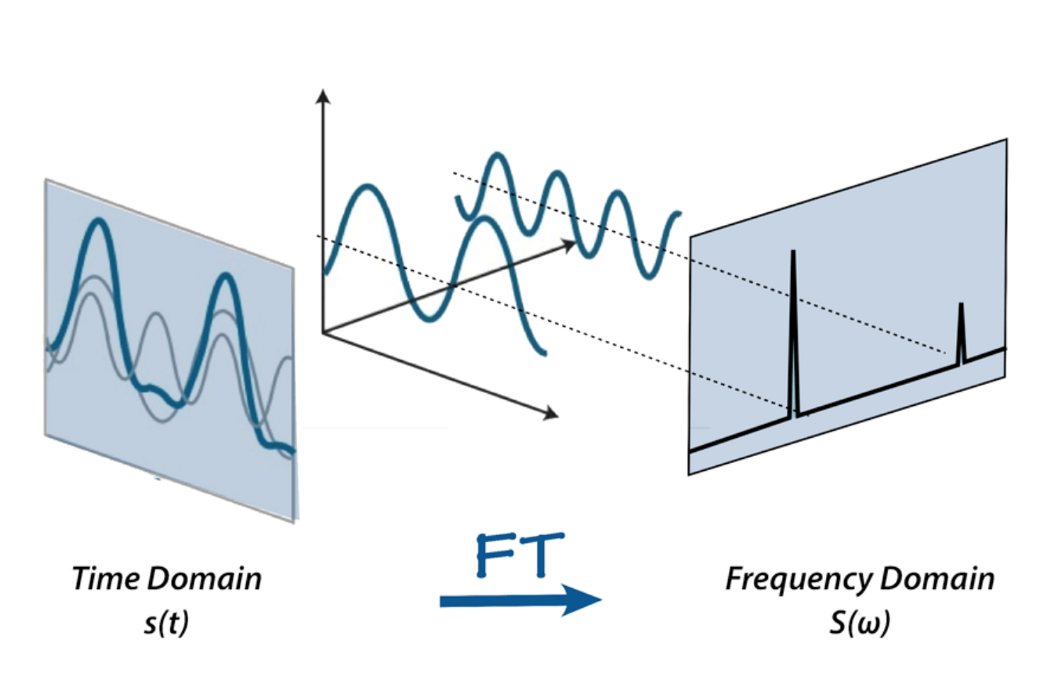
O, si te gustaría usar una metáfora – dado el batido, produce la receta.
Hay mucho material en Internet sobre la transformada de Fourier, por ejemplo este artículo de betterexplained.com y un video de 3Blue1Gray – échales un vistazo para encontrar más sobre FFT.
Así es como se ve nuestro sonido después de aplicar la transformada de Fourier – las barras más altas corresponden a frecuencias de mayor amplitud.

¡Eso es genial! Ahora podemos hacer cosas más interesantes con la señal de audio – por ejemplo eliminar las frecuencias menos importantes para comprimir el archivo de audio o remover el ruido o tal vez el sonido de la voz, etc. Pero aún no es lo suficientemente bueno para reconocimiento de audio y habla – al hacer la transformada de Fourier perdemos toda la información del dominio del tiempo, lo cual no es bueno para señales no periódicas, como el habla humana. Sin embargo, somos galletas inteligentes y simplemente tomamos la transformada de Fourier múltiples veces en la muestra de señal, esencialmente cortándola y luego cosiendo los datos de múltiples transformadas de Fourier de vuelta juntos en forma de espectrograma.
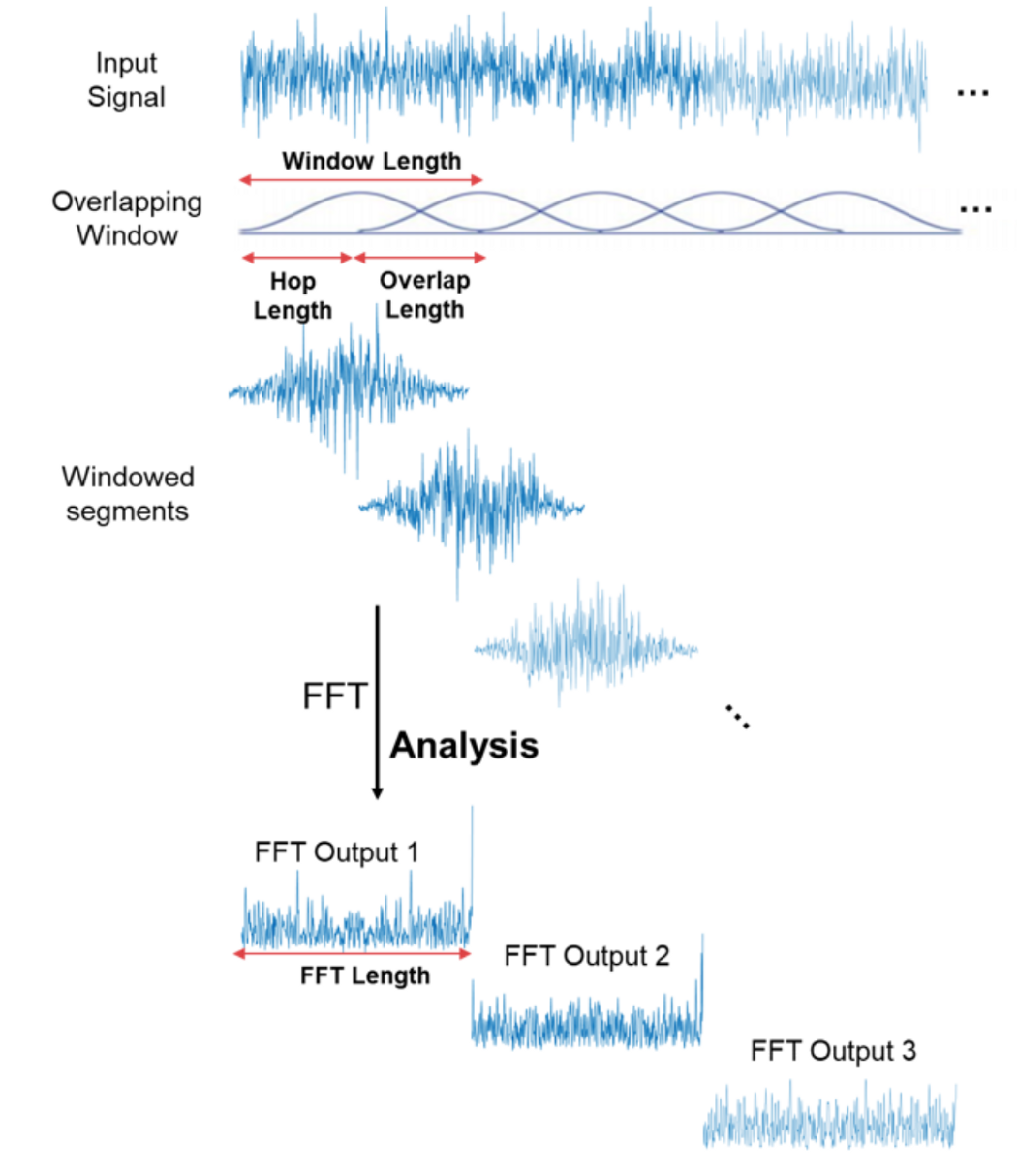
Aquí el eje x es el tiempo, el eje y es la frecuencia y la amplitud de una frecuencia se expresa a través de un color, los colores más brillantes corresponden a mayor amplitud.

¡Muy bien! ¿Podemos hacer reconocimiento de sonido ahora? ¡No! ¡Sí! ¡Tal vez! El espectrograma normal contiene demasiada información si solo nos importa reconocer sonidos que el oído humano puede escuchar. Los estudios han mostrado que los humanos no perciben las frecuencias en una escala lineal. Somos mejores detectando diferencias en frecuencias más bajas que en frecuencias más altas. Por ejemplo, podemos fácilmente distinguir la diferencia entre 500 y 1000 Hz, pero difícilmente podremos distinguir una diferencia entre 10000 y 10500 Hz, aunque la distancia entre los dos pares sea la misma. En 1937, Stevens, Volkmann, y Newmann propusieron una unidad de tono tal que distancias iguales en tono sonaran igualmente distantes al oyente. Esto se llama la escala mel.
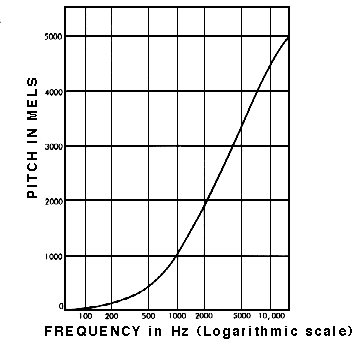
Un espectrograma mel es un espectrograma donde las frecuencias se convierten a la escala mel.

Hay más pasos involucrados para reconocer el habla – por ejemplo, coeficientes de cepstrum, que mencionamos anteriormente – los discutiremos en proyectos posteriores. Es hora de finalmente comenzar con la implementación práctica.
Adquisición de datos de entrenamiento
La señal de audio necesita ser muestreada a una tasa de muestreo muy alta, 8000 Hz o, idealmente, 16000 Hz. La herramienta Edge Impulse Data Forwarder es demasiado lenta para manejar esta tasa de muestreo, por lo que necesitaremos usar firmware dedicado de recolección de datos para obtener los datos para este proyecto. Descarga una nueva versión del firmware de Wio Terminal Edge Impulse con soporte de micrófono y flashéalo a tu dispositivo, como se describe en la página Comenzando con Edge Impulse. Después de eso, crea un nuevo proyecto en la plataforma Edge Impulse, lanza el servicio de ingesta edge-impulse
edge-impulse-daemon
Si has usado edge-impulse-daemon antes, necesitarás añadir --clean al comando anterior para limpiar los datos del proyecto.
Luego inicia sesión con tus credenciales y elige un proyecto que acabas de crear. Ve a la pestaña Data Acquisition y puedes comenzar a obtener muestras de datos.
Tendremos tres clases de datos:
• background
• coughing
• crying
Graba 10 muestras para cada clase, 5000 milisegundos de duración cada una. Puedes grabar los sonidos reproducidos desde los altavoces de la computadora (excepto para la clase background), pero si tienes la oportunidad de grabar sonidos reales, eso sería aún mejor.
Para la clase background graba sonidos que no deberían clasificarse como tos o llanto, por ejemplo, personas hablando, sin sonidos, aire acondicionado/ventilador y así sucesivamente.

30 muestras es terriblemente pequeño, así que también vamos a subir algunos datos más. Simplemente descarga los sonidos de Internet, remuestréalos a 16000 Hz y guárdalos en formato .wav con este script convertidor
import librosa
import sys
import soundfile as sf
input_filename = sys.argv[1]
output_filename = sys.argv[2]
data, samplerate = librosa.load(input_filename, sr=16000)
print(data.shape, samplerate)
sf.write(output_filename, data, samplerate, subtype='PCM_16')
Copia el código y pégalo en un documento de texto (usa Notepad++, IDLE IDE u otro IDE adecuado. No uses el Bloc de notas predeterminado de Windows).
Guarda el documento como converter.py y luego desde el entorno de Anaconda ejecuta
python converter.py name-of-the-downloaded-file class_name.number.wav

Puedes encontrar archivos de sonido de ejemplo ya convertidos al formato correcto en el repositorio de Github para este proyecto. Luego divide todas las muestras de sonido para dejar solo las partes "interesantes" – haz esto para cada clase, excepto para el fondo.
Después de que se complete la recolección de datos, es hora de elegir bloques de procesamiento y definir nuestro modelo de red neuronal.
Construyendo un modelo de aprendizaje automático
Entre los bloques de procesamiento vemos tres opciones familiares – a saber Raw, Spectral Analysis, que es esencialmente la transformada de Fourier de la señal, Spectrogram y MFE (Mel-Frequency Energy banks) – ¡que corresponden a las cuatro etapas de procesamiento de audio que describimos anteriormente!
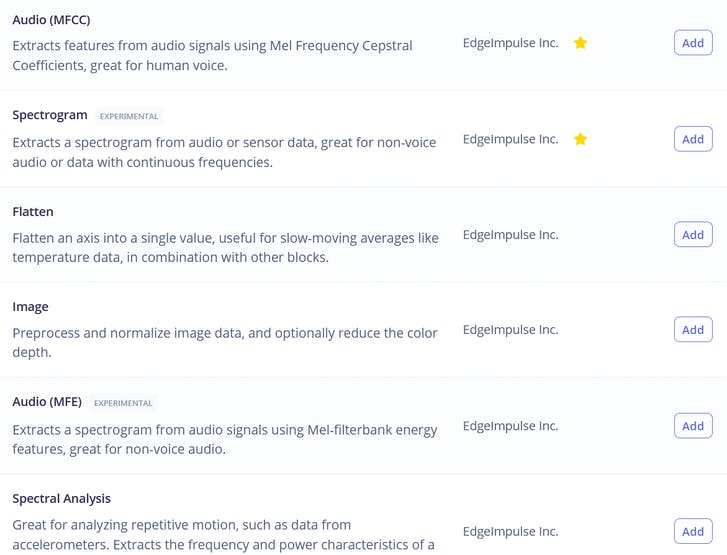
Si te gusta experimentar, puedes intentar usar todas ellas en tus datos, excepto quizás Raw, que tendrá demasiados datos para nuestra red neuronal relativamente pequeña. Para el propósito de esta lección simplemente iremos con la mejor opción para esta tarea, que es MFE o Mel-Frequency Energy banks. Después de calcular las características, ve a la pestaña NN classifier y elige una arquitectura de modelo adecuada. Las dos opciones que tenemos son usar 1D Conv y 2D Conv. Ambas funcionarán, pero si es posible, siempre deberíamos optar por un modelo más pequeño, ya que querremos desplegarlo en un dispositivo embebido. Al escribir los materiales para este curso ejecutamos 4 experimentos diferentes, 1D Conv/2D Conv con características MFE y MFCC y los resultados para ellos están en esta tabla.

El mejor modelo fue la red 1D Conv con bloque de procesamiento MFE. Al ajustar los parámetros de MFE (específicamente aumentando el stride a 0.02 y disminuyendo la frecuencia baja a 0) hemos logrado una precisión del 89.4% en el conjunto de datos de validación.
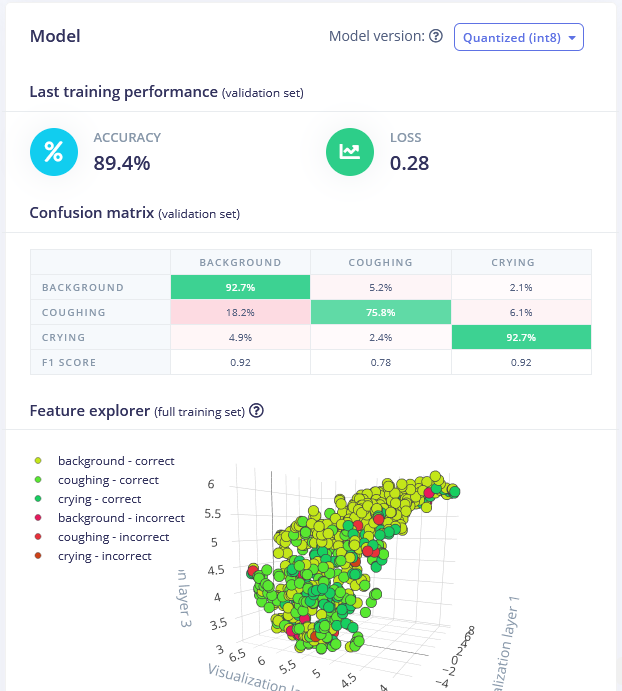
Puedes encontrar el modelo entrenado aquí y probarlo tú mismo. Aunque es bueno distinguiendo sonidos de llanto del fondo, la precisión de detección de sonidos de tos es un poco baja y podría requerir obtener más muestras.
Desplegando en Wio Terminal
Después de que tenemos nuestro modelo y estamos satisfechos con su precisión en el entrenamiento, podemos probarlo en nuevos datos en la pestaña Live classification y luego Desplegarlo en Wio terminal. Lo descargaremos como biblioteca de Arduino, lo pondremos en la carpeta de bibliotecas de Arduino y abriremos Examples -> nombre de tu proyecto -> nano_33_ble_sense_microphone_continuous. La demostración está basada en Arduino Nano 33 BLE y usa la biblioteca PDM. Para Wio Terminal nos basaremos en el controlador DMA o Direct Memory Access para obtener muestras del ADC (Analog to Digital Converter) y guardarlas en el buffer de inferencia sin involucrar al MCU.
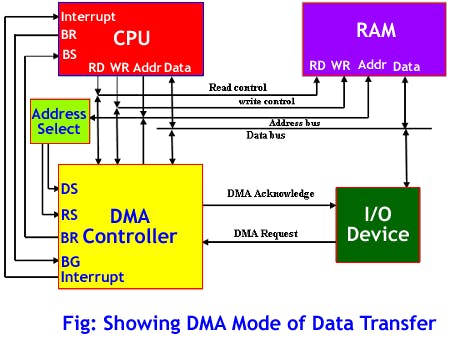
Eso nos permitirá recolectar las muestras de sonido y realizar inferencia al mismo tiempo. Hay bastantes cambios que necesitamos hacer para cambiar la recolección de datos de sonido de la biblioteca PDM a DMA, si te sientes un poco perdido durante la explicación, echa un vistazo al código de muestra completo, que puedes encontrar en los materiales del curso. Elimina la biblioteca PDM del sketch
#include <PDM.h>
Añade la estructura del descriptor DMA y otras constantes de configuración justo después de la última declaración include
// Settings
#define DEBUG 1 // Enable pin pulse during ISR
enum {ADC_BUF_LEN = 4096}; // Size of one of the DMA double buffers
static const int debug_pin = 1; // Toggles each DAC ISR (if DEBUG is set to 1)
// DMAC descriptor structure
typedef struct {
uint16_t btctrl;
uint16_t btcnt;
uint32_t srcaddr;
uint32_t dstaddr;
uint32_t descaddr;
} dmacdescriptor;
Luego, justo antes de la función setup, crea variables para arrays de buffer, variables volátiles para pasar los valores entre la callback ISR y el código principal y también un filtro Butterworth de paso alto, que aplicaremos a la señal para eliminar la mayor parte del componente DC en la señal del micrófono.
// Globals - DMA and ADC
volatile uint8_t recording = 0;
volatile boolean results0Ready = false;
volatile boolean results1Ready = false;
uint16_t adc_buf_0[ADC_BUF_LEN]; // ADC results array 0
uint16_t adc_buf_1[ADC_BUF_LEN]; // ADC results array 1
volatile dmacdescriptor wrb[DMAC_CH_NUM] __attribute__ ((aligned (16))); // Write-back DMAC descriptors
dmacdescriptor descriptor_section[DMAC_CH_NUM] __attribute__ ((aligned (16))); // DMAC channel descriptors
dmacdescriptor descriptor __attribute__ ((aligned (16))); // Place holder descriptor
//High pass butterworth filter order=1 alpha1=0.0125
class FilterBuHp1
{
public:
FilterBuHp1()
{
v[0]=0.0;
}
private:
float v[2];
public:
float step(float x) //class II
{
v[0] = v[1];
v[1] = (9.621952458291035404e-1f * x)
+ (0.92439049165820696974f * v[0]);
return
(v[1] - v[0]);
}
};
FilterBuHp1 filter;
Añade tres bloques de código después de eso: el primero es una función de callback, llamada por ISR (Rutina de Servicio de Interrupción) cada vez que uno de los dos buffers se llena. Dentro de esa función leemos elementos del buffer de grabación (el que se acaba de llenar), los procesamos y los colocamos en un buffer de inferencia.
/*******************************************************************************
* Interrupt Service Routines (ISRs)
*/
/**
* @brief Copy sample data in selected buf and signal ready when buffer is full
*
* @param[in] *buf Pointer to source buffer
* @param[in] buf_len Number of samples to copy from buffer
*/
static void audio_rec_callback(uint16_t *buf, uint32_t buf_len) {
static uint32_t idx = 0;
// Copy samples from DMA buffer to inference buffer
if (recording) {
for (uint32_t i = 0; i < buf_len; i++) {
// Convert 12-bit unsigned ADC value to 16-bit PCM (signed) audio value
inference.buffers[inference.buf_select][inference.buf_count++] = filter.step(((int16_t)buf[i] - 1024) * 16);
// Swap double buffer if necessary
if (inference.buf_count >= inference.n_samples) {
inference.buf_select ^= 1;
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
}
El siguiente bloque contiene la propia ISR - es ejecutada por un temporizador en cierto período de tiempo, dentro de esa función verificamos si el canal 1 de DMAC ha sido suspendido - si ha sido suspendido significa que uno de los búferes para datos del micrófono se ha llenado y necesitamos copiar los datos de él, cambiar a otro búfer y reiniciar el ADC DMAC.
/**
* Interrupt Service Routine (ISR) for DMAC 1
*/
void DMAC_1_Handler() {
static uint8_t count = 0;
// Check if DMAC channel 1 has been suspended (SUSP)
if (DMAC->Channel[1].CHINTFLAG.bit.SUSP) {
// Debug: make pin high before copying buffer
#if DEBUG
digitalWrite(debug_pin, HIGH);
#endif
// Restart DMAC on channel 1 and clear SUSP interrupt flag
DMAC->Channel[1].CHCTRLB.reg = DMAC_CHCTRLB_CMD_RESUME;
DMAC->Channel[1].CHINTFLAG.bit.SUSP = 1;
// See which buffer has filled up, and dump results into large buffer
if (count) {
audio_rec_callback(adc_buf_0, ADC_BUF_LEN);
} else {
audio_rec_callback(adc_buf_1, ADC_BUF_LEN);
}
// Flip to next buffer
count = (count + 1) % 2;
// Debug: make pin low after copying buffer
#if DEBUG
digitalWrite(debug_pin, LOW);
#endif
}
}
El siguiente bloque contiene datos de configuración para ADC DMAC y temporizador que controla ISR (Rutina de Servicio de Interrupción)
// Configure DMA to sample from ADC at regular interval
void config_dma_adc() {
// Configure DMA to sample from ADC at a regular interval (triggered by timer/counter)
DMAC->BASEADDR.reg = (uint32_t)descriptor_section; // Specify the location of the descriptors
DMAC->WRBADDR.reg = (uint32_t)wrb; // Specify the location of the write back descriptors
DMAC->CTRL.reg = DMAC_CTRL_DMAENABLE | DMAC_CTRL_LVLEN(0xf); // Enable the DMAC peripheral
DMAC->Channel[1].CHCTRLA.reg = DMAC_CHCTRLA_TRIGSRC(TC5_DMAC_ID_OVF) | // Set DMAC to trigger on TC5 timer overflow
DMAC_CHCTRLA_TRIGACT_BURST; // DMAC burst transfer
descriptor.descaddr = (uint32_t)&descriptor_section[1]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_0 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_0 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[0], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
descriptor.descaddr = (uint32_t)&descriptor_section[0]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_1 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_1 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[1], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
// Configure NVIC
NVIC_SetPriority(DMAC_1_IRQn, 0); // Set the Nested Vector Interrupt Controller (NVIC) priority for DMAC1 to 0 (highest)
NVIC_EnableIRQ(DMAC_1_IRQn); // Connect DMAC1 to Nested Vector Interrupt Controller (NVIC)
// Activate the suspend (SUSP) interrupt on DMAC channel 1
DMAC->Channel[1].CHINTENSET.reg = DMAC_CHINTENSET_SUSP;
// Configure ADC
ADC1->INPUTCTRL.bit.MUXPOS = ADC_INPUTCTRL_MUXPOS_AIN12_Val; // Set the analog input to ADC0/AIN2 (PB08 - A4 on Metro M4)
while(ADC1->SYNCBUSY.bit.INPUTCTRL); // Wait for synchronization
ADC1->SAMPCTRL.bit.SAMPLEN = 0x00; // Set max Sampling Time Length to half divided ADC clock pulse (2.66us)
while(ADC1->SYNCBUSY.bit.SAMPCTRL); // Wait for synchronization
ADC1->CTRLA.reg = ADC_CTRLA_PRESCALER_DIV128; // Divide Clock ADC GCLK by 128 (48MHz/128 = 375kHz)
ADC1->CTRLB.reg = ADC_CTRLB_RESSEL_12BIT | // Set ADC resolution to 12 bits
ADC_CTRLB_FREERUN; // Set ADC to free run mode
while(ADC1->SYNCBUSY.bit.CTRLB); // Wait for synchronization
ADC1->CTRLA.bit.ENABLE = 1; // Enable the ADC
while(ADC1->SYNCBUSY.bit.ENABLE); // Wait for synchronization
ADC1->SWTRIG.bit.START = 1; // Initiate a software trigger to start an ADC conversion
while(ADC1->SYNCBUSY.bit.SWTRIG); // Wait for synchronization
// Enable DMA channel 1
DMAC->Channel[1].CHCTRLA.bit.ENABLE = 1;
// Configure Timer/Counter 5
GCLK->PCHCTRL[TC5_GCLK_ID].reg = GCLK_PCHCTRL_CHEN | // Enable perhipheral channel for TC5
GCLK_PCHCTRL_GEN_GCLK1; // Connect generic clock 0 at 48MHz
TC5->COUNT16.WAVE.reg = TC_WAVE_WAVEGEN_MFRQ; // Set TC5 to Match Frequency (MFRQ) mode
TC5->COUNT16.CC[0].reg = 3000 - 1; // Set the trigger to 16 kHz: (4Mhz / 16000) - 1
while (TC5->COUNT16.SYNCBUSY.bit.CC0); // Wait for synchronization
// Start Timer/Counter 5
TC5->COUNT16.CTRLA.bit.ENABLE = 1; // Enable the TC5 timer
while (TC5->COUNT16.SYNCBUSY.bit.ENABLE); // Wait for synchronization
}
Agrega la condición de depuración en la parte superior de la función de configuración:
// Configure pin to toggle on DMA interrupt
#if DEBUG
pinMode(debug_pin, OUTPUT);
#endif
Luego en la función setup, después de run_classifier_init(); añade el siguiente código que crea buffers de inferencia, configura DMA e inicia la grabación estableciendo la variable global volátil recording a 1.
// Create double buffer for inference
inference.buffers[0] = (int16_t *)malloc(EI_CLASSIFIER_SLICE_SIZE * sizeof(int16_t));
if (inference.buffers[0] == NULL) {
ei_printf("ERROR: Failed to create inference buffer 0");
return;
}
inference.buffers[1] = (int16_t *)malloc(EI_CLASSIFIER_SLICE_SIZE *
sizeof(int16_t));
if (inference.buffers[1] == NULL) {
ei_printf("ERROR: Failed to create inference buffer 1");
free(inference.buffers[0]);
return;
}
// Set inference parameters
inference.buf_select = 0;
inference.buf_count = 0;
inference.n_samples = EI_CLASSIFIER_SLICE_SIZE;
inference.buf_ready = 0;
// Configure DMA to sample from ADC at 16kHz (start sampling immediately)
config_dma_adc();
// Start recording to inference buffers
recording = 1;
}
Elimina PDM.end(); y free(sampleBuffer); de la función microphone_inference_end(void) y también las funciones microphone_inference_start(uint32_t n_samples) y pdm_data_ready_inference_callback(void), ya que no las estamos usando.
Después de compilar y subir el código, abre el Monitor Serie y verás las probabilidades para cada clase impresas. ¡Reproduce algunos sonidos o tose en el Wio Terminal para verificar la precisión!
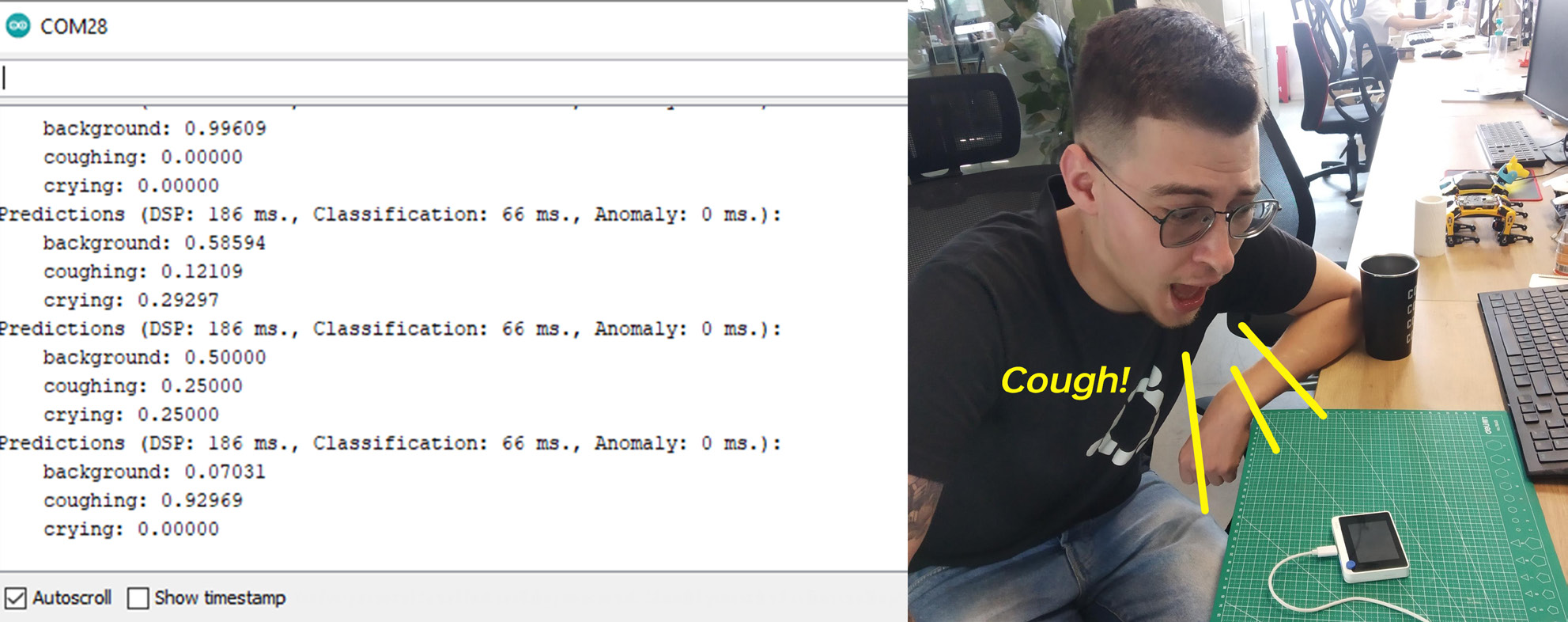
Integración con Blynk
Dado que WioTerminal puede conectarse a Internet, podemos tomar esta demostración simple y convertirla en una aplicación IoT real con Blynk.
Blynk es una plataforma que te permite construir rápidamente interfaces para controlar y monitorear tus proyectos de hardware desde tus dispositivos iOS y Android. En este caso usaremos Blink para enviar notificaciones push a nuestro smartphone si Wio Terminal detecta cualquier sonido del que deberíamos preocuparnos. Para comenzar con Blink, descarga la aplicación, registra una nueva cuenta y crea un nuevo proyecto. Añade un elemento de notificación push y presiona el botón de reproducir.

Luego asegúrate de haber configurado las librerías WiFi y firmware de Wio Terminal, según la guía aquí. Descarga la librería Blynk como se describe en ese tutorial.
Luego prueba tu configuración compilando y subiendo el ejemplo simple de botón push – asegúrate de cambiar el SSID WiFi, contraseña y tu token API de Blynk, que puedes obtener en la aplicación.
#define BLYNK_PRINT Serial
#include <rpcWiFi.h>
#include <WiFiClient.h>
#include <BlynkSimpleWioTerminal.h>
char auth[] = "token";
char ssid[] = "ssid";
char pass[] = "password";
void checkPin()
{
int isButtonPressed = !digitalRead(WIO_KEY_A);
if (isButtonPressed) {
Serial.println("Button is pressed.");
Blynk.notify("Yaaay... button is pressed!");
}
}
void setup()
{
Serial.begin(115200);
Blynk.begin(auth, ssid, pass);
pinMode(WIO_KEY_A, INPUT_PULLUP);
}
void loop()
{
Blynk.run();
checkPin();
}
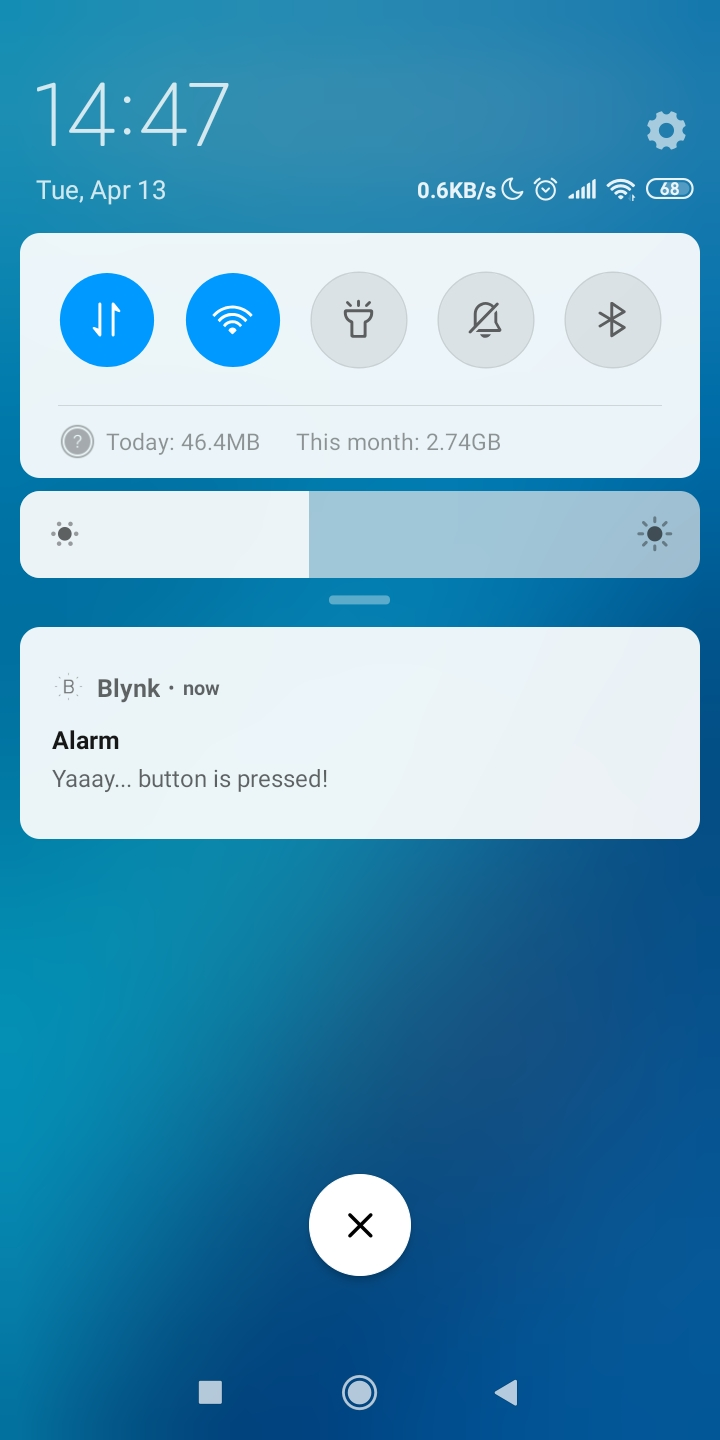
Si el código compila y la prueba es exitosa (presionar el botón superior izquierdo en Wio Terminal hace que aparezca una notificación push en tu teléfono), entonces puedes pasar a la siguiente etapa.
Vamos a mover todo el código de inferencia de la red neuronal a una función separada y llamarla en la función loop() justo después de Blynk.run(). Similar a lo que hicimos antes, verificamos las probabilidades de predicción de la red neuronal y si son más altas que el umbral para una cierta clase, llamamos a la función Blynk.notify(), que como podrías haber adivinado envía una notificación a tu dispositivo móvil.
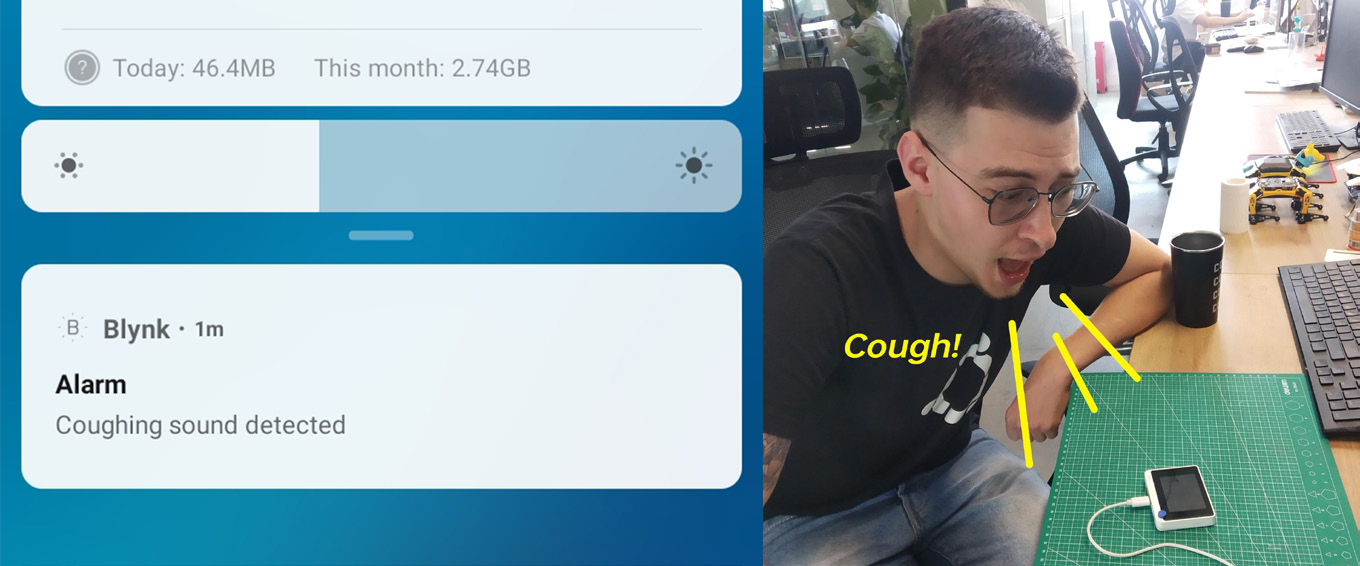
Encuentra el código completo para inferencia NN + notificación Blynk en el repositorio Github para este proyecto.