Estación meteorológica inteligente Wio Terminal Tensorflow Lite Micro con BME280
En este proyecto vamos a usar Wio Terminal y Tensorflow Lite para Microcontroladores para crear una estación meteorológica inteligente, capaz de predecir el tiempo y las precipitaciones para las próximas 24 horas basándose en datos locales del sensor ambiental BME280.

¡Para más detalles y visuales, mira el video correspondiente!
Aprenderás cómo aplicar técnicas de optimización de modelos, que permitirán no solo ejecutar una red neuronal convolucional de tamaño mediano, sino también tener esta elegante GUI y conexión WiFi funcionando al mismo tiempo durante días y meses seguidos.

Este es el resultado final, puedes ver que hay valores actuales de temperatura, humedad y presión atmosférica mostrados en la pantalla, junto con el nombre de la ciudad, el tipo de clima predicho y la probabilidad de precipitación predicha – y en la parte inferior de la pantalla hay un campo de salida de registro, que puedes fácilmente reutilizar para mostrar información de clima extremo u otra información relevante. Aunque se ve bien y útil como está, hay muchas cosas que puedes agregar tú mismo – por ejemplo la salida de noticias/tweets mencionada anteriormente en la pantalla o usar el modo de sueño profundo para conservar energía y hacerlo alimentado por batería, etc.
En este proyecto estaremos tratando con datos de series temporales, como hicimos múltiples veces antes - la única gran diferencia esta vez es que el período de tiempo es mucho mayor para la predicción del tiempo. Vamos a tomar una medición cada hora y realizar predicción en 24 horas de datos. También, ya que vamos a predecir el tipo de clima promedio para las próximas 24 horas, adicionalmente predeciremos una probabilidad de precipitación para las próximas 24 horas, con el mismo modelo. Para hacer eso utilizaremos la API Funcional de Keras y un modelo de múltiples salidas.
Dentro del modelo de múltiples salidas va a haber "un tronco", común para ambas salidas, que va a "ramificarse" hacia dos salidas diferentes. El beneficio principal de usar un modelo de múltiples salidas comparado con dos modelos independientes aquí es que los datos y características aprendidas usadas para predecir el tipo de clima y la probabilidad de precipitación están altamente relacionados.
Si estás haciendo este proyecto en Windows, lo primero que necesitarás hacer es descargar la versión nocturna del IDE de Arduino, ya que la versión estable actual 1.18.3 no compilará sketches con muchas dependencias de librerías (el problema es que el comando del enlazador durante la compilación excede la longitud máxima en Windows).
Segundo, necesitas asegurarte de tener la versión 1.8.2 de las definiciones de placa Seeed SAMD en el IDE de Arduino.
Finalmente, ya que estamos usando una red neuronal convolucional y la construimos con la API de Keras, contiene una operación no soportada por la versión estable actual de Tensorflow Micro. Navegando por los issues de Tensorflow en Github encontré que hay una solicitud de extracción para agregar esta operación (EXPAND_DIMS) a la lista de operaciones disponibles, pero no fue fusionada al master al momento de hacer este video. Puedes hacer git clone del repositorio de Tensorflow, cambiar a la rama PR y compilar la librería de Arduino ejecutando ./tensorflow/lite/micro/tools/ci_build/test_arduino.sh en una máquina Linux – la librería resultante se puede encontrar en tensorflow/lite/micro/tools/make/gen/arduino_x86_64/prj/tensorflow_lite.zip. Alternativamente, puedes descargar la librería ya compilada desde el repositorio Github de este proyecto y colocarla en tu carpeta de librerías de sketches de Arduino – ¡solo asegúrate de tener solo una librería de Tensorflow lite a la vez!
Entendiendo los datos
Todo comienza con los datos, por supuesto. Para este tutorial utilizaremos un conjunto de datos meteorológicos fácilmente disponible de Kaggle, Historical Hourly Weather Data 2012-2017. La sede de Seeed EDU está ubicada en Shenzhen, una ciudad en el sur de China – y esa ciudad está ausente del conjunto de datos, así que elegimos una ciudad que está ubicada en una latitud similar y también tiene un clima subtropical – Miami.
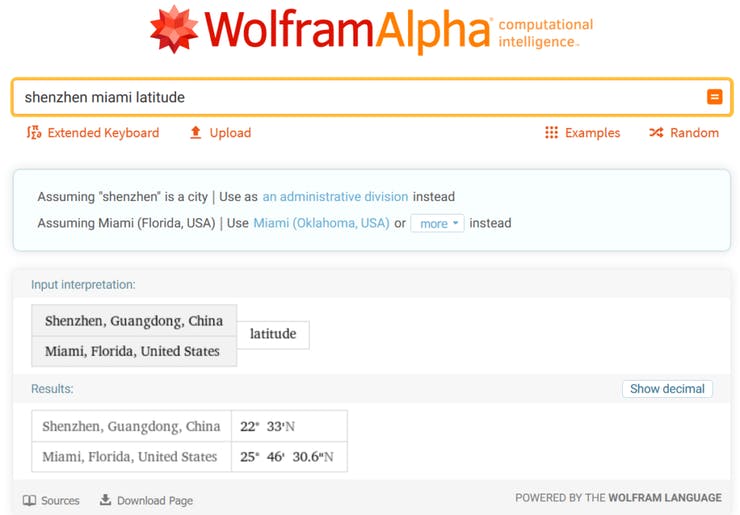
Necesitarás elegir una ciudad que al menos se parezca al clima donde vives – no hace falta decir que el modelo entrenado con datos de Miami y luego desplegado en Chicago en invierno no va a generar predicciones correctas.
Construyendo un modelo de aprendizaje automático
Para el procesamiento de datos y el paso de entrenamiento del modelo, abramos Jupyter Notebook que puedes encontrar en los materiales del curso. La forma más fácil de ejecutar este notebook es subirlo a Google Colab, ya que ya tiene todos los paquetes instalados y listos para ejecutar.
Alternativamente puedes ejecutar el notebook localmente - para hacer eso primero instala todas las dependencias requeridas en el entorno virtual ejecutando
pip install -r requirements.txt
con el entorno virtual de ml que creaste anteriormente activado. Luego ejecuta el comando jupyter notebook en el mismo entorno, lo cual abrirá el servidor de notebook en tu navegador predeterminado. Los Jupyter Notebooks son una excelente manera de explorar y presentar datos, ya que permiten tener tanto texto como código ejecutable en el mismo entorno. El flujo de trabajo general se explica en las secciones de texto del Notebook.
Desplegando en Wio Terminal
El modelo que entrenaste en el último paso fue convertido a un arreglo de bytes, que contiene la estructura del modelo y los pesos y ahora puede ser cargado en Wio Terminal junto con código C++.
Tensorflow Lite para Microcontroladores incluye un Intérprete de modelo, que está diseñado para ser ligero y rápido. El intérprete usa un ordenamiento de grafo estático y un asignador de memoria personalizado (menos dinámico) para asegurar una latencia mínima de carga, inicialización y ejecución. Los datos colocados en los buffers de entrada se alimentan al grafo del modelo y luego, después de que la inferencia termina, los resultados se colocan en el buffer de salida. Para reducir el tamaño del modelo y disminuir el tiempo de inferencia, realizamos dos optimizaciones importantes: • Realizar cuantización de enteros completos, cambiando los pesos del modelo, entradas y salidas de números de punto flotante de 32 bits (cada uno ocupando 32 bits de memoria) a números enteros de 8 bits (cada uno ocupando solo 8 bits), reduciendo así el tamaño por un factor de 4.
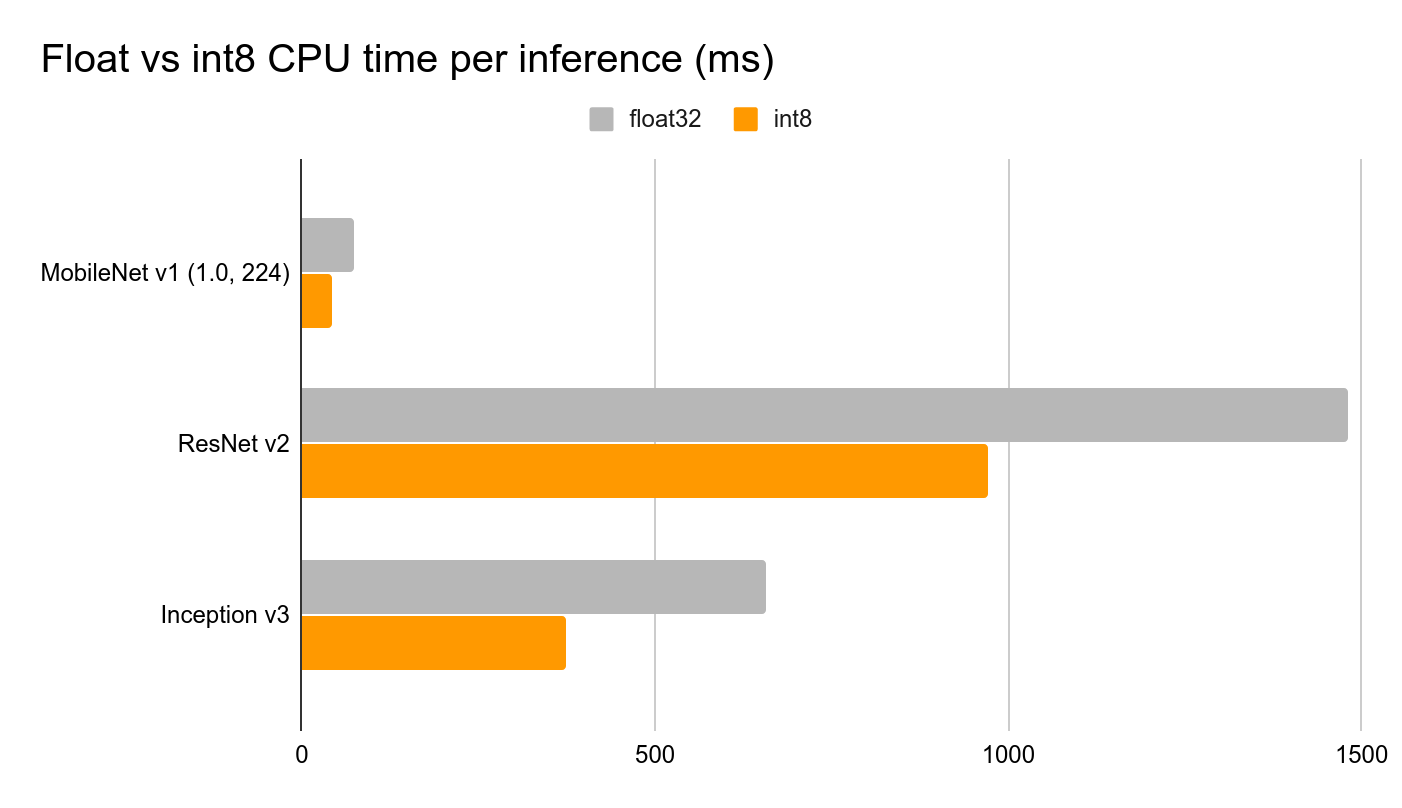
• Usar micro_mutable_op_resolver y especificar las operaciones que tenemos en la red neuronal, para compilar nuestro código solo con las operaciones necesarias para ejecutar el modelo, en oposición a usar all_ops_resolver, que incluye todas las operaciones soportadas por el intérprete actual de Tensorflow Lite para Microcontroladores.
Una vez que el entrenamiento del modelo esté terminado, crea un sketch vacío y guárdalo. Luego copia el modelo que entrenaste a la carpeta del sketch y vuelve a abrir el sketch. Cambia el nombre de la variable del modelo y la longitud del modelo a algo más corto. Luego usa el código de wio_terminal_tfmicro_weather_prediction_static.ino, que puedes encontrar en los materiales del curso para pruebas.
Repasemos los pasos principales que tenemos en el código C++ Incluimos los encabezados para la biblioteca de Tensorflow y el archivo con el flatbuffer del modelo
#include <TensorFlowLite.h>
//#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/micro/all_ops_resolver.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/system_setup.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "model_Conv1D.h"
Observa cómo tengo micro_mutable_op_resolver.h comentado y all_ops_resolver.h habilitado – el encabezado all_ops_resolver.h compila todas las operaciones actualmente presentes en Tensorflow Micro y es conveniente para pruebas, pero una vez que termines las pruebas es mucho mejor cambiar a micro_mutable_op_resolver.h para ahorrar memoria del dispositivo – hace una gran diferencia. A continuación definimos los punteros para el reportador de errores, modelo, tensores de entrada y salida e intérprete. Observa cómo nuestro modelo tiene dos salidas – una para la cantidad de precipitación y otra para el tipo de clima. También definimos la arena de tensores, que puedes pensar como un tablero de trabajo, que contiene los arreglos de entrada, salida e intermedios – el tamaño requerido dependerá del modelo que estés usando, y puede necesitar ser determinado por experimentación.
// Globals, used for compatibility with Arduino-style sketches.
namespace {
tflite::ErrorReporter* error_reporter = nullptr;
const tflite::Model* model = nullptr;
tflite::MicroInterpreter* interpreter = nullptr;
TfLiteTensor* input = nullptr;
TfLiteTensor* output_type = nullptr;
TfLiteTensor* output_precip = nullptr;
constexpr int kTensorArenaSize = 1024*25;
uint8_t tensor_arena[kTensorArenaSize];
} // namespace
Luego, en la función de configuración, hay más código repetitivo, como instanciar el reportador de errores, el resolvedor de operaciones, el intérprete, mapear el modelo, asignar tensores y finalmente verificar las formas de los tensores después de la asignación. Aquí es cuando el código podría lanzar un error durante la ejecución, si algunas de las operaciones del modelo no son compatibles con la versión actual de la biblioteca Tensorflow Micro. En caso de que tengas operaciones no compatibles, puedes cambiar la arquitectura del modelo o agregar el soporte para el operador tú mismo, generalmente portándolo desde Tensorflow Lite.
void setup() {
Serial.begin(115200);
while (!Serial) {delay(10);}
// Set up logging. Google style is to avoid globals or statics because of
// lifetime uncertainty, but since this has a trivial destructor it's okay.
// NOLINTNEXTLINE(runtime-global-variables)
static tflite::MicroErrorReporter micro_error_reporter;
error_reporter = µ_error_reporter;
// Map the model into a usable data structure. This doesn't involve any
// copying or parsing, it's a very lightweight operation.
model = tflite::GetModel(Conv1D_tflite);
if (model->version() != TFLITE_SCHEMA_VERSION) {
TF_LITE_REPORT_ERROR(error_reporter,
"Model provided is schema version %d not equal "
"to supported version %d.",
model->version(), TFLITE_SCHEMA_VERSION);
return;
}
// This pulls in all the operation implementations we need.
// NOLINTNEXTLINE(runtime-global-variables)
//static tflite::MicroMutableOpResolver<1> resolver;
static tflite::AllOpsResolver resolver;
// Build an interpreter to run the model with.
static tflite::MicroInterpreter static_interpreter(model, resolver, tensor_arena, kTensorArenaSize, error_reporter);
interpreter = &static_interpreter;
// Allocate memory from the tensor_arena for the model's tensors.
TfLiteStatus allocate_status = interpreter->AllocateTensors();
if (allocate_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "AllocateTensors() failed");
return;
}
// Obtain pointers to the model's input and output tensors.
input = interpreter->input(0);
output_type = interpreter->output(1);
output_precip = interpreter->output(0);
Serial.println(input->dims->size);
Serial.println(input->dims->data[1]);
Serial.println(input->dims->data[2]);
Serial.println(input->type);
Serial.println(output_type->dims->size);
Serial.println(output_type->dims->data[1]);
Serial.println(output_type->type);
Serial.println(output_precip->dims->size);
Serial.println(output_precip->dims->data[1]);
Serial.println(output_precip->type);
}
Finalmente, en la función loop definimos un marcador de posición para valores INT8 cuantizados y un arreglo con valores float, que puedes copiar y pegar desde el notebook de Colab para comparar la inferencia del modelo en el dispositivo vs. en Colab.
void loop() {
int8_t x_quantized[72];
float x[72] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0};
Cuantizamos los valores float a INT8 en un bucle for y los colocamos en el tensor de entrada uno por uno:
for (byte i = 0; i < 72; i = i + 1) {
input->data.int8[i] = x[i] / input->params.scale + input->params.zero_point;
}
Luego se realiza la inferencia mediante el intérprete de Tensorflow Micro y si no se reportan errores, los valores se colocan en los tensores de salida.
// Run inference, and report any error
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed");
return;
}
Similar a la entrada, la salida del modelo también está cuantizada, por lo que necesitamos realizar la operación inversa y convertirla de INT8 a float.
// Obtain the quantized output from model's output tensor
float y_type[4];
// Dequantize the output from integer to floating-point
int8_t y_precip_q = output_precip->data.int8[0];
Serial.println(y_precip_q);
float y_precip = (y_precip_q - output_precip->params.zero_point) * output_precip->params.scale;
Serial.print("Precip: ");
Serial.print(y_precip);
Serial.print("\t");
Serial.print("Type: ");
for (byte i = 0; i < 4; i = i + 1) {
y_type[i] = (output_type->data.int8[i] - output_type->params.zero_point) * output_type->params.scale;
Serial.print(y_type[i]);
Serial.print(" ");
}
Serial.print("\n");
}
Verifica y compara los valores para el mismo punto de datos, deberían ser iguales para el modelo cuantizado de Tensorflow Lite en el notebook de Colab y el modelo de Tensorflow Micro ejecutándose en tu Wio Terminal.

Interfaz LVGL y WiFi
Ahora el siguiente paso es convertirlo de una demostración en un proyecto realmente útil. Abre el sketch wio_terminal_tfmicro_weather_prediction_static.ino de los materiales del curso y echa un vistazo a su contenido.

El código está dividido en sketch principal, get_historical_data y partes de GUI. Dado que nuestro modelo requiere los datos de las últimas 24 horas, necesitaríamos esperar 24 horas para realizar la primera inferencia, lo cual es mucho – para resolver este problema obtenemos el clima de las últimas 24 horas desde la API de openweathermap.com y podemos realizar la primera inferencia inmediatamente después de que el dispositivo se inicie y luego reemplazar los valores en el buffer circular con temperatura, humedad y presión del sensor BME280 conectado al socket I2C Grove del Wio Terminal. Para la GUI usamos LVGL, una Biblioteca de Gráficos Pequeña y Versátil.

Compila y sube el código, asegúrate de cambiar las credenciales de WiFi, tu ubicación y la clave API de openweathermap.com en el sketch antes de subirlo. Después de la subida, el dispositivo se conectará a Internet, obtendrá los datos de las últimas 24 horas para tu ubicación y realizará la primera inferencia. Luego esperará 1 hora antes de obtener los valores del sensor BME280 conectado al Wio Terminal - si no hay sensor conectado, el programa no se inicializará.