Wio Terminal Tensorflow Lite Micro Reconocimiento de voz en MCU – Voz-a-Intención
Un enfoque tradicional para usar la voz para el control de dispositivos/cumplimiento de solicitudes del usuario es primero, transcribir la voz a texto y luego analizar el texto a los comandos/consultas en formato adecuado. Aunque este enfoque ofrece mucha flexibilidad en términos de vocabulario y/o escenarios de aplicación, una combinación de modelo de reconocimiento de voz y analizador dedicado no es adecuada para los recursos limitados de los microcontroladores.
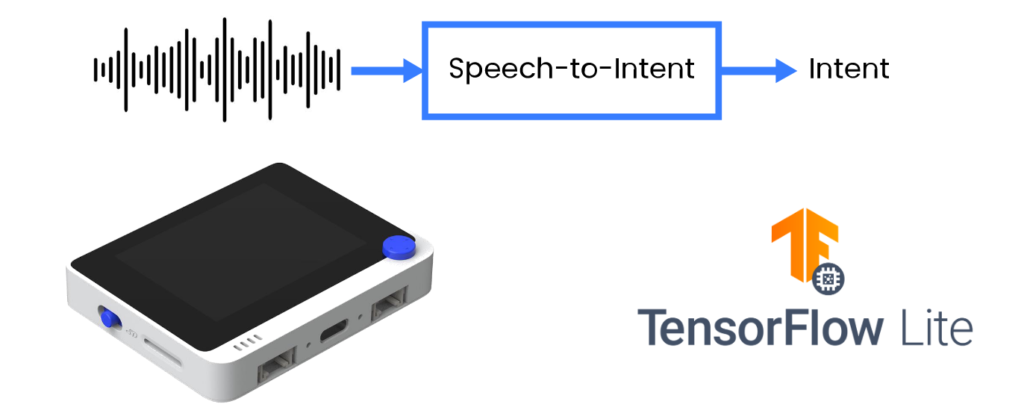
Fuente: Wio Terminal, Picovoice, Tensorflow Lite
En este proyecto vamos a emplear un método más eficiente y analizar directamente las expresiones del usuario en salida accionable en forma de intención/ranuras. Compartiremos técnicas para entrenar un modelo de voz-a-intención de dominio específico y desplegarlo en una placa de desarrollo basada en Cortex M4F con micrófono incorporado, Wio Terminal de Seeed Studio.
¡Para más detalles y visuales, mira el video correspondiente!
Hay diferentes tipos de tareas de reconocimiento de voz – podemos dividirlas aproximadamente en tres grupos:
- Reconocimiento de voz continua de vocabulario amplio (LVCSR)
- Detección de palabras clave
- Voz-a-Intención
La detección de palabras clave funciona bien en microcontroladores, es bastante fácil de entrenar con variedad de herramientas de código abierto sin código disponibles, por ejemplo Edge Impulse, pero no puede manejar bien vocabularios grandes.
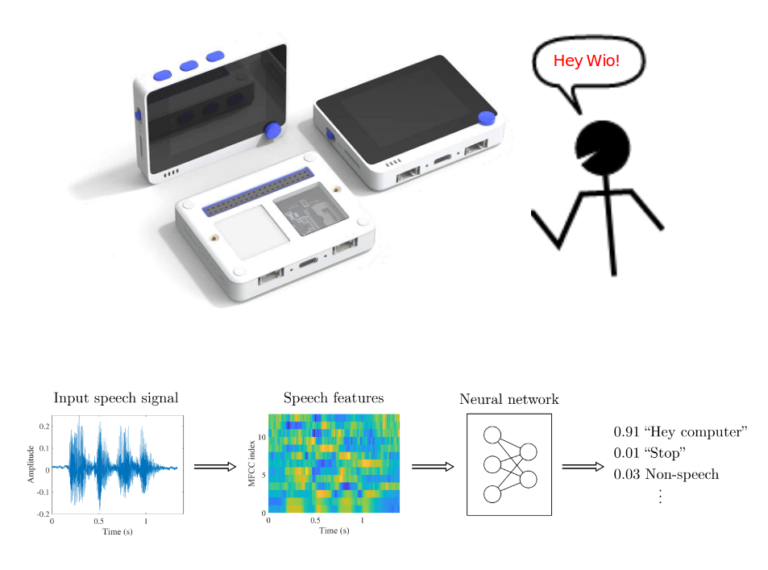
Si quisiéramos tener un dispositivo que haga una acción útil basada en entrada de voz, necesitamos combinar el modelo LVCSR y un analizador de lenguaje natural basado en texto – este enfoque es robusto y algo más fácil de implementar, dada la abundancia de motores ASR disponibles públicamente, pero no es adecuado para ejecutarse incluso en SBCs, y mucho menos en microcontroladores.
Hay una tercera forma, conversión directa de voz a intención analizada, basada en vocabulario de dominio específico. Tomemos una lavadora inteligente o luces inteligentes como ejemplo. El modelo de Voz-a-Intención al procesar la expresión "Ciclo normal con centrifugado bajo" produciría una intención analizada, por ejemplo
{ Intent: washClothes },
{ Slots: cycle: normal,
spin: low,
water: default }
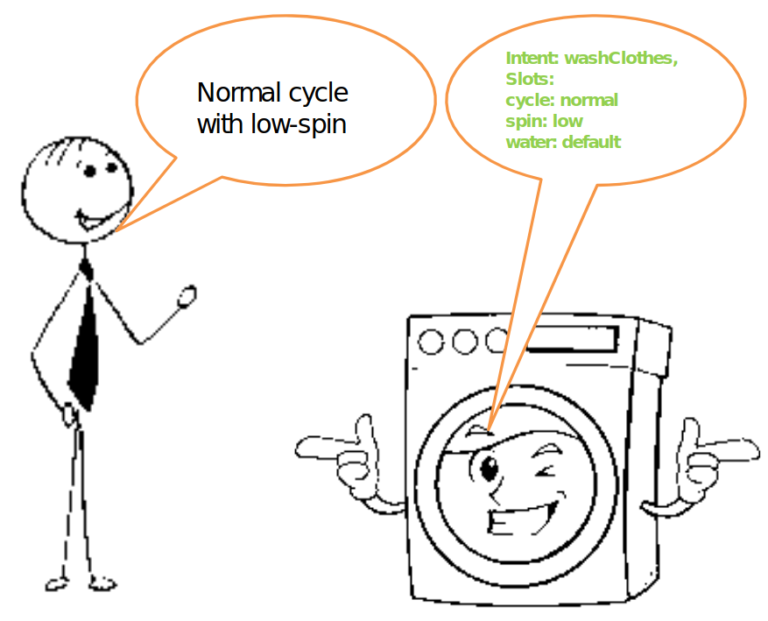
Y esto es realmente todo lo que necesitamos para poder controlar dicha lavadora inteligente con voz.
Speech-to-Intent está bien representado en la investigación, pero carece de implementaciones de código abierto ampliamente disponibles adecuadas para microcontroladores. Listo para producción, no de código abierto:
- Picovoice
- Fluent.ai
Listo para producción, FOSS, no adecuado para microcontroladores:
- Speechbrain.io
Para el entrenamiento del modelo puedes usar ya sea un Jupyter Notebook que preparamos o scripts de entrenamiento del repositorio de Github (encuéntralos en la sección Referencia al final del artículo). Jupyter Notebook contiene una implementación de modelo de referencia muy básica y también tiene explicación para cada celda.
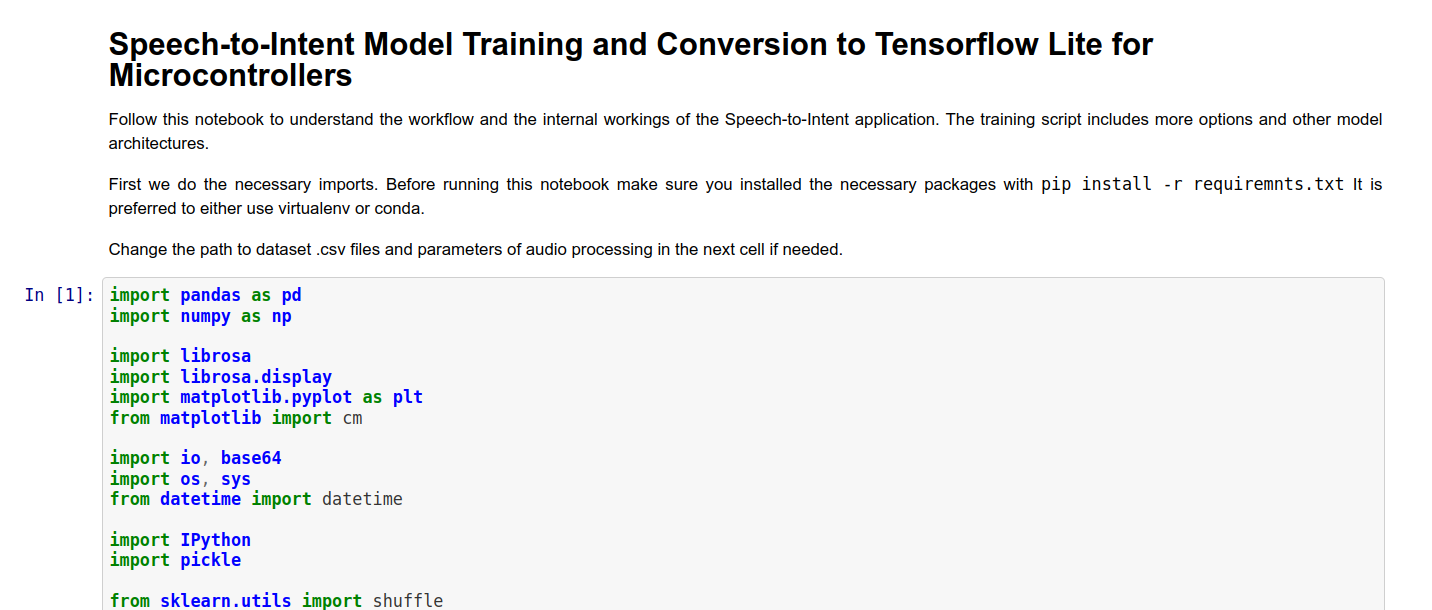
Después de que el modelo esté entrenado, cópialo a la carpeta con código para Wio Terminal y cambia el nombre del modelo en la línea 106 por el nombre de tu modelo. Repasemos las piezas más importantes del código. Puede dividirse aproximadamente en tres partes:
- adquisición de audio
- cálculo de MFCC
- inferencia en características MFCC
Adquisición de audio

Para grabar sonido para procesamiento con el micrófono integrado de Wio Terminal usamos la función DMA ADC del MCU Cortex M4F. DMA significa acceso directo a memoria y es exactamente lo que dice en la etiqueta – una parte específica del MCU llamada DMAC o Control de Acceso Directo a Memoria se configura de antemano para "canalizar" los datos de una ubicación (por ejemplo, memoria interna, SPI, I2C, ADC u otra interfaz) a otra. De esta manera la transferencia puede ocurrir sin mucha participación del MCU, aparte de la configuración inicial. Establecemos la fuente y el destino para la transferencia aquí
descriptor.descaddr = (uint32_t)&descriptor_section[1]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_0 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_0 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[0], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
descriptor.descaddr = (uint32_t)&descriptor_section[0]; // Set up a circular descriptor
descriptor.srcaddr = (uint32_t)&ADC1->RESULT.reg; // Take the result from the ADC0 RESULT register
descriptor.dstaddr = (uint32_t)adc_buf_1 + sizeof(uint16_t) * ADC_BUF_LEN; // Place it in the adc_buf_1 array
descriptor.btcnt = ADC_BUF_LEN; // Beat count
descriptor.btctrl = DMAC_BTCTRL_BEATSIZE_HWORD | // Beat size is HWORD (16-bits)
DMAC_BTCTRL_DSTINC | // Increment the destination address
DMAC_BTCTRL_VALID | // Descriptor is valid
DMAC_BTCTRL_BLOCKACT_SUSPEND; // Suspend DMAC channel 0 after block transfer
memcpy(&descriptor_section[1], &descriptor, sizeof(descriptor)); // Copy the descriptor to the descriptor section
Como especificamos con el parámetro DMAC_BTCTRL_BLOCKACT_SUSPEND; en el descriptor DMA, el Canal DMA debería suspenderse después de una transferencia de bloque completa. Luego procedemos a configurar una ISR (Rutina de Servicio de Interrupción) activada con el temporizador TC5:
// Configure Timer/Counter 5
GCLK->PCHCTRL[TC5_GCLK_ID].reg = GCLK_PCHCTRL_CHEN | // Enable perhipheral channel for TC5
GCLK_PCHCTRL_GEN_GCLK1; // Connect generic clock 0 at 48MHz
TC5->COUNT16.WAVE.reg = TC_WAVE_WAVEGEN_MFRQ; // Set TC5 to Match Frequency(MFRQ) mode
TC5->COUNT16.CC[0].reg = 3000 - 1; // Set the trigger to 16 kHz: (4Mhz / 16000) - 1
while (TC5->COUNT16.SYNCBUSY.bit.CC0); // Wait for synchronization
// Start Timer/Counter 5
TC5->COUNT16.CTRLA.bit.ENABLE = 1; // Enable the TC5 timer
while (TC5->COUNT16.SYNCBUSY.bit.ENABLE); // Wait for synchronization
El ISR llamará a una función específica en intervalos de tiempo igualmente espaciados, controlados por el temporizador TC5. Echemos un vistazo a esa función.
/**
* Interrupt Service Routine (ISR) for DMAC 1
*/
void DMAC_1_Handler() {
static uint8_t count = 0;
// Check if DMAC channel 1 has been suspended (SUSP)
if (DMAC->Channel[1].CHINTFLAG.bit.SUSP) {
// Debug: make pin high before copying buffer
#ifdef DEBUG
digitalWrite(debug_pin, HIGH);
#endif
// Restart DMAC on channel 1 and clear SUSP interrupt flag
DMAC->Channel[1].CHCTRLB.reg = DMAC_CHCTRLB_CMD_RESUME;
DMAC->Channel[1].CHINTFLAG.bit.SUSP = 1;
// See which buffer has filled up, and dump results into large buffer
if (count) {
audio_rec_callback(adc_buf_0, ADC_BUF_LEN);
} else {
audio_rec_callback(adc_buf_1, ADC_BUF_LEN);
}
// Flip to next buffer
count = (count + 1) % 2;
// Debug: make pin low after copying buffer
#ifdef DEBUG
digitalWrite(debug_pin, LOW);
#endif
}
}
La función ISR llamada DMAC1_Handler() verifica si el Canal 1 de DMAC fue suspendido – lo cual ocurre cuando un bloque de información ha terminado de grabarse. Si fue así, llama a una función definida por el usuario audio_rec_callback(), donde copiamos el contenido del búfer DMA ADC lleno en un búfer (posiblemente) más grande usado para calcular características MFCC. Opcionalmente también aplicamos algún post-procesamiento de sonido en este paso.
Cálculo de MFCC
La extracción de características MFCC para coincidir con el código TensorFlow MFCC Op está tomada del repositorio ARM para Búsqueda de Palabras Clave en Microcontroladores ARM. Puedes encontrar el código original aquí.
La mayor parte del trabajo relacionado con el cálculo de características MFCC ocurre dentro del método mfcc_compute(const int16_t audio_data, float mfcc_out) de la clase MFCC. El método recibe un puntero a datos de audio, en nuestro caso 320 puntos de datos de sonido y un puntero a una posición específica en el arreglo de valores de salida MFCC. Para una porción de tiempo realizamos las siguientes operaciones:
Normalizar los datos a -1,1 y rellenarlos (en nuestro caso el relleno no ocurre, ya que los datos de audio siempre tienen el tamaño exacto necesario para calcular una porción de características MFCC):
//TensorFlow way of normalizing .wav data to (-1,1)
for (i = 0; i < frame_len; i++) {
frame[i] = (float)audio_data[i]/(1<<15);
}
//Fill up remaining with zeros
memset(&frame[frame_len], 0, sizeof(float) * (frame_len_padded-frame_len));
Calcula RFTT o Transformada Rápida de Fourier Real con la función de la biblioteca ARM Math:
//Compute FFT
arm_rfft_fast_f32(rfft, frame, buffer, 0);
Convierte los valores al espectro de potencia:
//frame is stored as [real0, realN/2-1, real1, im1, real2, im2, ...]
int32_t half_dim = frame_len_padded/2;
float first_energy = buffer[0] * buffer[0],
last_energy = buffer[1] * buffer[1]; // handle this special case
for (i = 1; i < half_dim; i++) {
float real = buffer[i*2], im = buffer[i*2 + 1];
buffer[i] = real*real + im*im;
}
buffer[0] = first_energy;
buffer[half_dim] = last_energy;
Luego aplica bancos de filtros Mel a las raíces cuadradas de los datos guardados en el buffer en el último paso. Los bancos de filtros Mel se crean cuando se instancia la clase MFCC, dentro del método create_mel_fbank(). El número de bancos de filtros, las frecuencias mínima y máxima son especificadas por el usuario de antemano – y es muy importante mantenerlas consistentes entre el script de entrenamiento y el código de inferencia, de lo contrario habrá una caída significativa en la precisión.
float sqrt_data;
//Apply mel filterbanks
for (bin = 0; bin < NUM_FBANK_BINS; bin++) {
j = 0;
float mel_energy = 0;
int32_t first_index = fbank_filter_first[bin];
int32_t last_index = fbank_filter_last[bin];
for (i = first_index; i <= last_index; i++) {
arm_sqrt_f32(buffer[i],&sqrt_data);
mel_energy += (sqrt_data) * mel_fbank[bin][j++];
}
mel_energies[bin] = mel_energy;
//avoid log of zero
if (mel_energy == 0.0)
mel_energies[bin] = FLT_MIN;
}
Finalmente tomamos la transformada discreta del coseno del array de energías Mel y la escribimos al array de salida de características MFCC. En el script original también se realizaba una cuantización en este paso, pero opté por usar el procedimiento de cuantización del ejemplo de Tensorflow Lite para Microcontroladores en su lugar.
Inferencia en características MFCC
Una vez que todo el audio dentro de una muestra (3 segundos) es procesado y convertido a características MFCC, convertimos todo el array de características MFCC de valores FLOAT32 a INT8 y lo alimentamos a la red neuronal. El proceso de inicialización e inferencia de TensorFlow Lite para Microcontroladores ya fue descrito en uno de mis artículos anteriores, así que no lo repetiré aquí.
Antes de compilar el sketch asegúrate de tener todas las librerías necesarias instaladas y que las definiciones de placas Seeed SAMD sean al menos versión 1.8.2 – eso es muy importante para que la librería TensorFlow Lite compile sin errores. Compila y sube el sketch – si tienes el parámetro DEBUG configurado como false, el código comenzará a ejecutarse inmediatamente y todo lo que necesitas hacer es presionar el botón C en la parte superior del Wio Terminal y decir una de las oraciones del dataset. Los resultados se mostrarán tanto en la pantalla como en la salida del monitor Serial si el Wio Terminal está conectado a la computadora.
Aunque este curso está basado en Wio Terminal, ya que es muy adecuado para explorar Aprendizaje Automático Embebido, definitivamente es posible implementarlo en otros dispositivos. Lo más fácil sería portar el código a otro MCU Cortex M4F, como el Nano33 BLE Sense – eso solo requeriría ajustar para un micrófono diferente. Portar a otros MCUs ARM también debería ser bastante trivial.

Portar a otras arquitecturas, por ejemplo ESP32 o K210 u otras requeriría re-implementar los cálculos MFCC, ya que usan funciones específicas de ARM de CMSIS-DSP.
Hay múltiples mejoras que se pueden hacer a las arquitecturas básicas de redes neuronales en el proyecto. Estas mejoras son:
- pre-entrenamiento del modelo
- seq2seq, LSTM, atención
- filtros entrenables
- AutoML, datos sintéticos
¡Echa un vistazo a esta charla de TinyML sobre este tema para descubrir más al respecto y encontrar enlaces a los papers!
Te animamos a hacer fork del repositorio de código, intentar entrenar en tu propio dataset y quizás intentar implementar arquitecturas más avanzadas o técnicas de entrenamiento de modelos. Si lo haces, ¡no dudes en mencionarme aquí o hacer un PR en Github!