Detección de Objetos Few-Shot con YOLOv5 y Roboflow
Introducción
YOLO es uno de los algoritmos de detección de objetos más famosos disponibles. Solo necesita pocas muestras para el entrenamiento, mientras proporciona tiempos de entrenamiento más rápidos y alta precisión. Demostraremos estas características una por una en este wiki, mientras explicamos el pipeline completo de aprendizaje automático paso a paso donde recopilas datos, los etiquetas, los entrenas y finalmente detectas objetos usando los datos entrenados ejecutando el modelo entrenado en un dispositivo edge como la plataforma NVIDIA Jetson. Además, compararemos la diferencia entre usar conjuntos de datos personalizados y conjuntos de datos públicos.
¿Qué es YOLOv5?
YOLO es una abreviatura del término 'You Only Look Once'. Es un algoritmo que detecta y reconoce varios objetos en una imagen en tiempo real. Ultralytics YOLOv5 es la última versión de YOLO y ahora está basada en el framework PyTorch.

¿Qué es la detección de objetos few-shot?
Tradicionalmente, si quieres entrenar un modelo de aprendizaje automático, usarías un conjunto de datos público como el conjunto de datos Pascal VOC 2012 que consiste en alrededor de 17112 imágenes. Sin embargo, usaremos transfer learning para realizar detección de objetos few-shot con YOLOv5 que necesita solo muy pocas muestras de entrenamiento. Demostraremos esto en este wiki.
Hardware soportado
YOLOv5 es soportado por el siguiente hardware:
-
Kits de Desarrollo Oficiales por NVIDIA:
- NVIDIA® Jetson Nano Developer Kit
- NVIDIA® Jetson Xavier NX Developer Kit
- NVIDIA® Jetson AGX Xavier Developer Kit
- NVIDIA® Jetson TX2 Developer Kit
-
SoMs Oficiales por NVIDIA:
- NVIDIA® Jetson Nano module
- NVIDIA® Jetson Xavier NX module
- NVIDIA® Jetson TX2 NX module
- NVIDIA® Jetson TX2 module
- NVIDIA® Jetson AGX Xavier module
-
Placas Carrier por Seeed:
- Jetson Mate
- Jetson SUB Mini PC
- Jetson Xavier AGX H01 Kit
- A203 Carrier Board
- A203 (Version 2) Carrier Board
- A205 Carrier Board
- A206 Carrier Board
Prerrequisitos
-
Cualquiera de los dispositivos Jetson anteriores ejecutando la última JetPack v4.6.1 con todos los componentes SDK instalados (consulta este wiki como referencia para la instalación)
-
PC Host
- El entrenamiento local necesita una PC Linux (preferiblemente Ubuntu)
- El entrenamiento en la nube se puede realizar desde una PC con cualquier SO
Comenzando
¡Ejecutar tu primer proyecto de detección de objetos en un dispositivo edge como la plataforma Jetson simplemente involucra 4 pasos principales!
-
Recopilar conjunto de datos o usar conjunto de datos disponible públicamente
- Recopilar conjunto de datos manualmente
- Usar conjunto de datos disponible públicamente
-
Anotar conjunto de datos usando Roboflow
-
Entrenar en PC local o nube
- Entrenar en PC local (Linux)
- Entrenar en Google Colab
-
Inferencia en dispositivo Jetson
Recopilar conjunto de datos o usar conjunto de datos disponible públicamente
El primer paso de un proyecto de detección de objetos es obtener datos para el entrenamiento. ¡Puedes descargar conjuntos de datos disponibles públicamente o crear tu propio conjunto de datos! Usualmente los conjuntos de datos públicos se utilizan para propósitos educativos y de investigación. Sin embargo, si quieres construir proyectos específicos de detección de objetos donde los conjuntos de datos públicos no tienen los objetos que quieres detectar, podrías querer construir tu propio conjunto de datos.
Recopilar conjunto de datos manualmente
Se recomienda que primero grabes un video del objeto que quieres reconocer. Tienes que asegurarte de cubrir todos los ángulos (360 grados) del objeto, colocar el objeto en diferentes entornos, diferentes condiciones de iluminación y diferentes condiciones climáticas. El video total que grabamos tiene 9 minutos de duración donde 4.5 minutos son para flores y los 4.5 minutos restantes son para hojas. La grabación se puede desglosar de la siguiente manera:

- mañana clima normal
- mañana clima ventoso
- mañana clima lluvioso
- mediodía clima normal
- mediodía clima ventoso
- mediodía clima lluvioso
- tarde clima normal
- tarde clima ventoso
- tarde clima lluvioso
Nota: Más adelante, convertiremos este video en una serie de imágenes para formar el conjunto de datos para el entrenamiento.
Usar conjunto de datos disponible públicamente
Puedes descargar varios conjuntos de datos disponibles públicamente como el conjunto de datos COCO, conjunto de datos Pascal VOC y muchos más. Roboflow Universe es una plataforma recomendada que proporciona una amplia gama de conjuntos de datos y tiene más de 90,000 conjuntos de datos con más de 66 millones de imágenes disponibles para construir modelos de visión por computadora. También, puedes simplemente buscar conjuntos de datos de código abierto en Google y elegir de una variedad de conjuntos de datos disponibles.
Anotar conjunto de datos usando Roboflow
A continuación procederemos a anotar el conjunto de datos que tenemos. Anotar significa simplemente dibujar cajas rectangulares alrededor de cada objeto que queremos detectar y asignarles etiquetas. Explicaremos cómo hacer esto usando Roboflow.
Roboflow es una herramienta de anotación basada en línea. Aquí podemos importar directamente el video que grabamos antes en Roboflow y será exportado como una serie de imágenes. Esta herramienta es muy conveniente porque nos permitirá distribuir el conjunto de datos en "entrenamiento, validación y prueba". También esta herramienta nos permitirá añadir procesamiento adicional a estas imágenes después de etiquetarlas. Además, puede exportar fácilmente el conjunto de datos etiquetado al formato YOLOV5 PyTorch que es exactamente lo que necesitamos!
-
Paso 1. Haz clic aquí para registrarte en una cuenta de Roboflow
-
Paso 2. Haz clic en Create New Project para iniciar nuestro proyecto
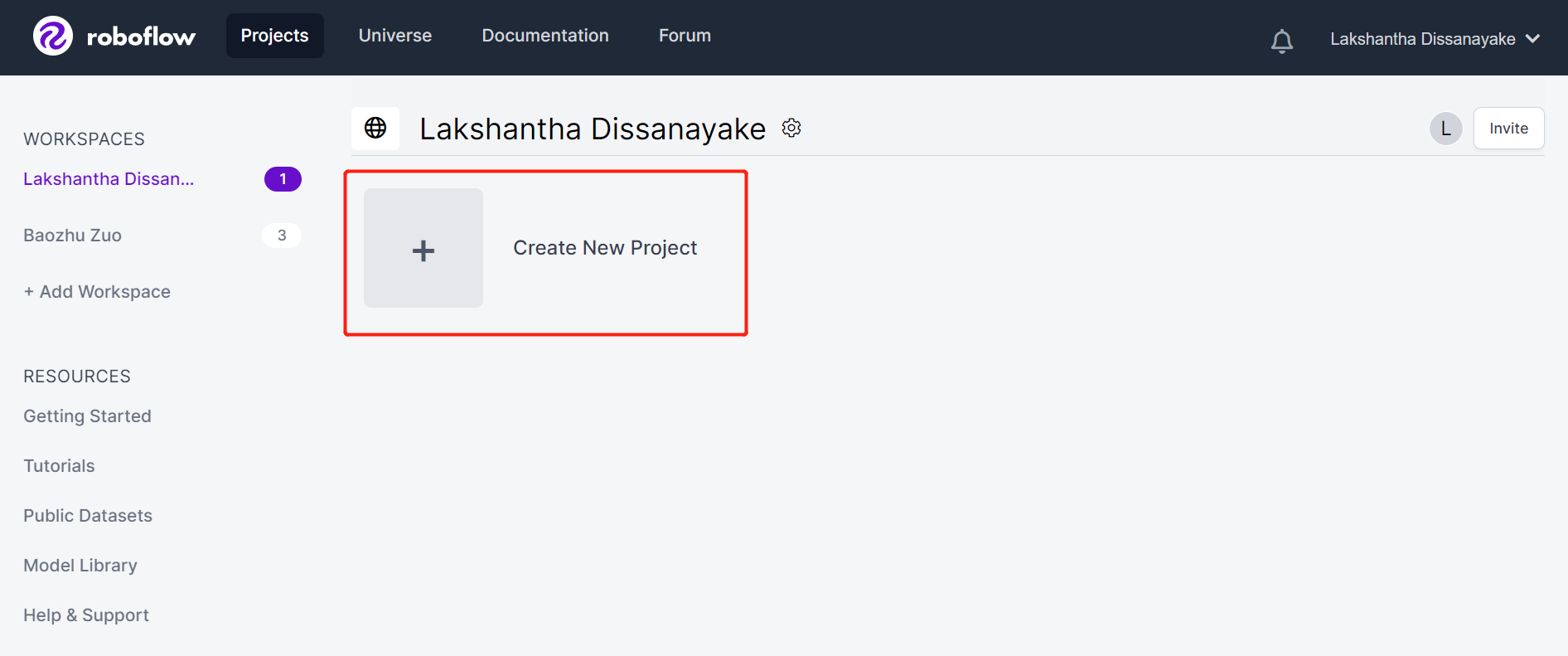
- Paso 3. Completa Project Name, mantén la License (CC BY 4.0) y Project type (Object Detection (Bounding Box)) como predeterminados. Bajo la columna What will your model predict?, completa un nombre de grupo de anotación. Por ejemplo, en nuestro caso elegimos plants. Este nombre debe resaltar todas las clases de tu conjunto de datos. Finalmente, haz clic en Create Public Project.
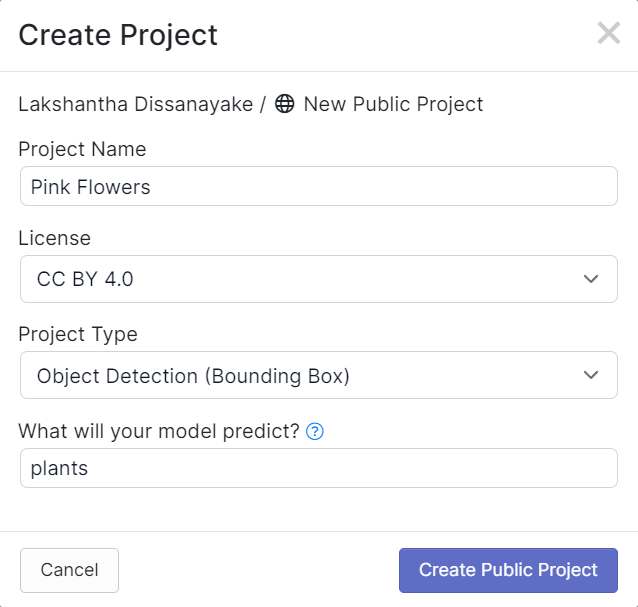
- Paso 4. Arrastra y suelta el video que grabaste antes
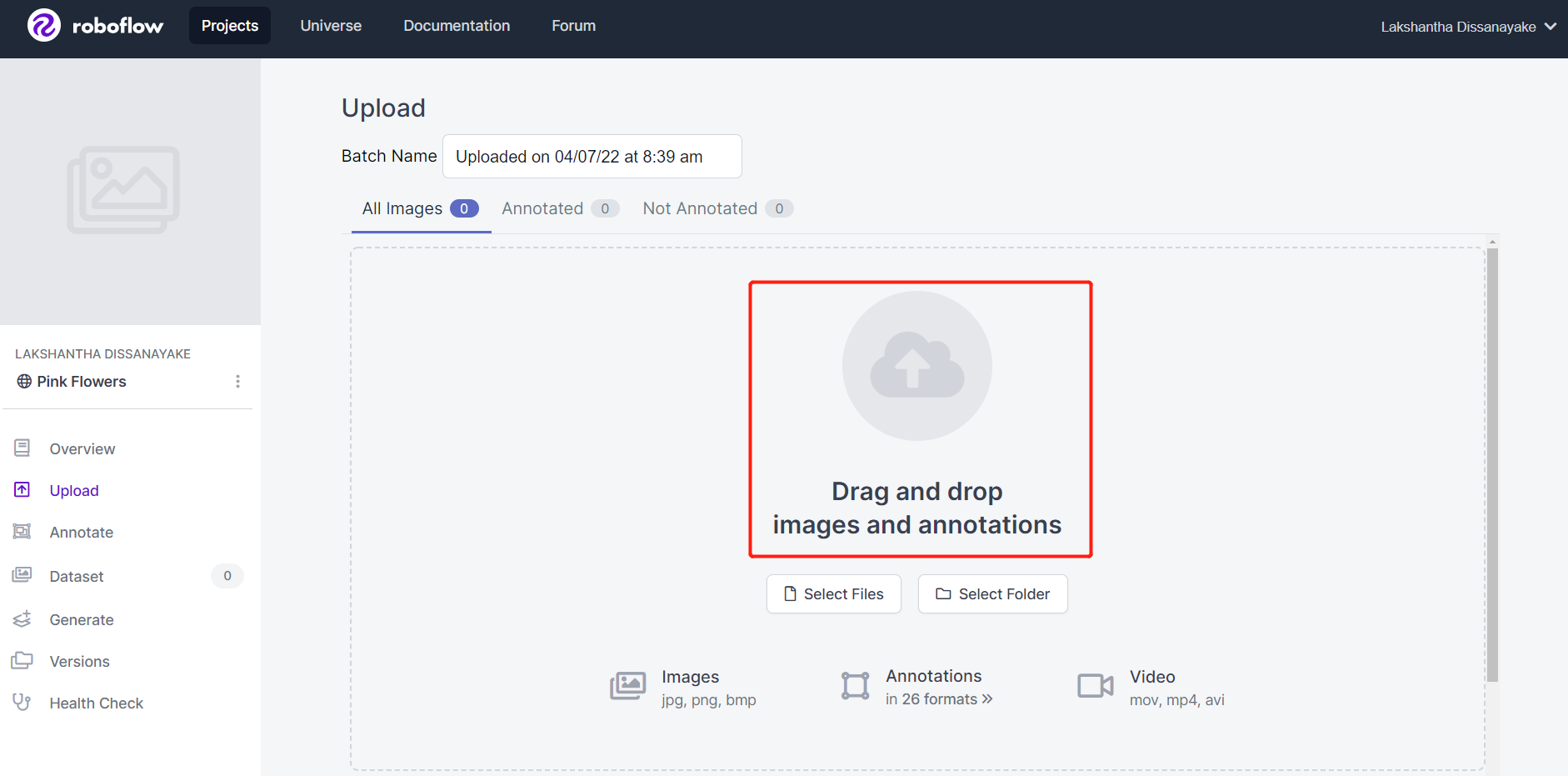
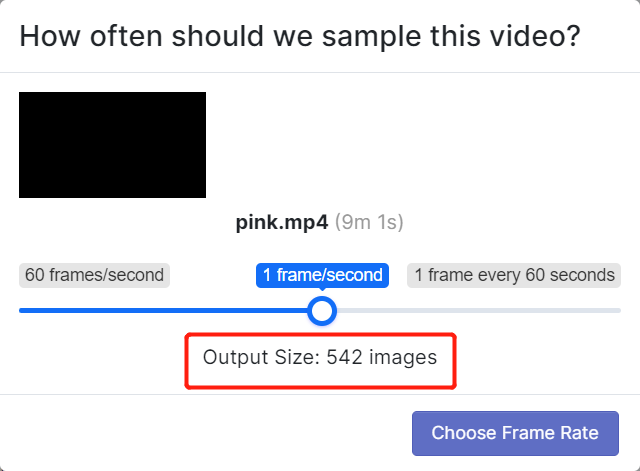
- Paso 5. Elige una velocidad de fotogramas para que el video sea dividido en una serie de imágenes. Aquí usaremos la velocidad de fotogramas predeterminada que es 1 fotograma/segundo y esto generará 542 imágenes en total. Una vez que selecciones una velocidad de fotogramas deslizando el control deslizante, haz clic en Choose Frame Rate. Tomará unos segundos a unos minutos (dependiendo de la duración del video) terminar este proceso.
- Paso 6. Después de que las imágenes sean procesadas, haz clic en Finish Uploading. Espera pacientemente hasta que las imágenes sean subidas.
- Paso 7. Después de que las imágenes sean subidas, haz clic en Assign Images
- Paso 8. Selecciona una imagen, dibuja una caja rectangular alrededor de una flor, elige la etiqueta como pink flower y presiona ENTER
- Paso 9. Repite lo mismo para las flores restantes
- Paso 10. Dibuja una caja rectangular alrededor de una hoja, elige la etiqueta como leaf y presiona ENTER
- Paso 11. Repite lo mismo para las hojas restantes
Nota: Trata de etiquetar todos los objetos que veas dentro de la imagen. Si solo una parte del objeto es visible, trata de etiquetarla también.
- Paso 12. Continúa anotando todas las imágenes en el conjunto de datos
Roboflow tiene una característica llamada Label Assist donde puede predecir las etiquetas de antemano para que tu etiquetado sea mucho más rápido. Sin embargo, no funcionará con todos los tipos de objetos, sino con un tipo seleccionado de objetos. Para activar esta característica, simplemente necesitas presionar el botón Label Assist, seleccionar un modelo, seleccionar las clases y navegar a través de las imágenes para ver las etiquetas predichas con cajas delimitadoras
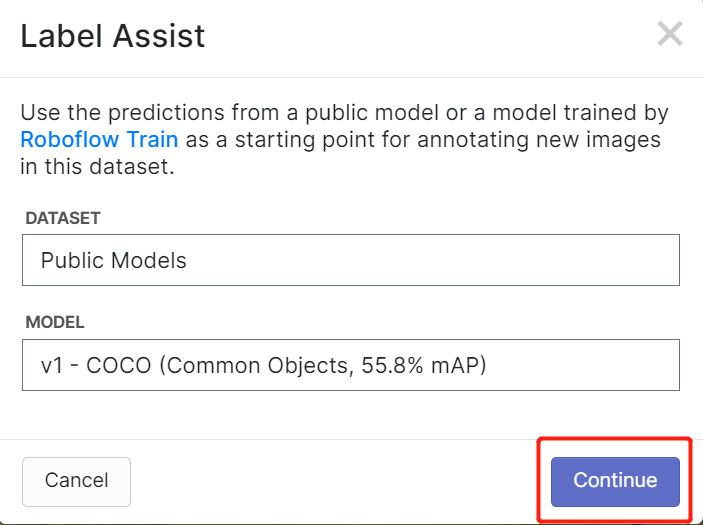
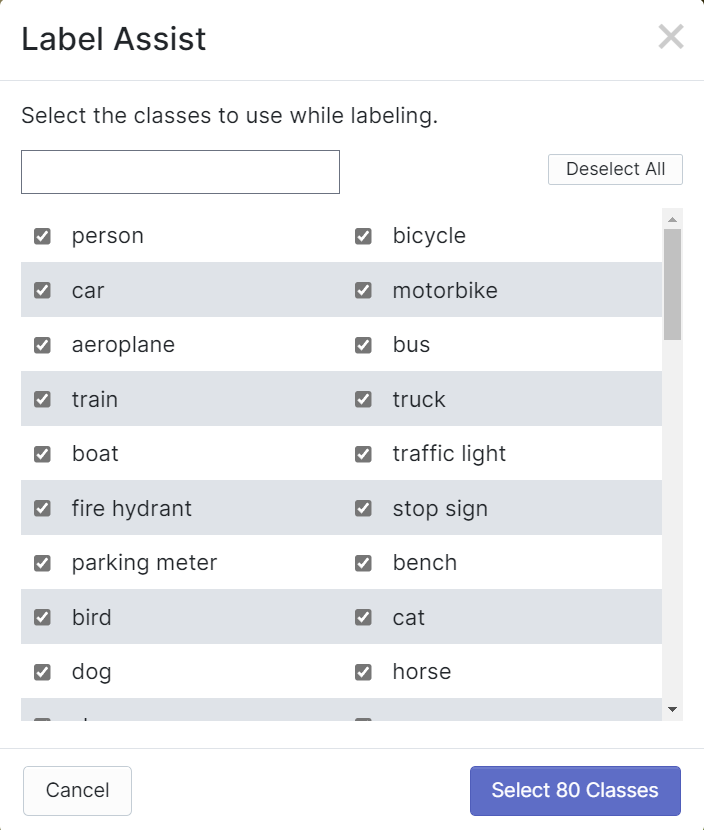
Como puedes ver arriba, solo puede ayudar a predecir anotaciones para las 80 clases mencionadas. Si tus imágenes no contienen las clases de objetos de arriba, no puedes usar la función de asistencia de etiquetado.
- Paso 13. Una vez que el etiquetado esté terminado, haz clic en Add images to Dataset

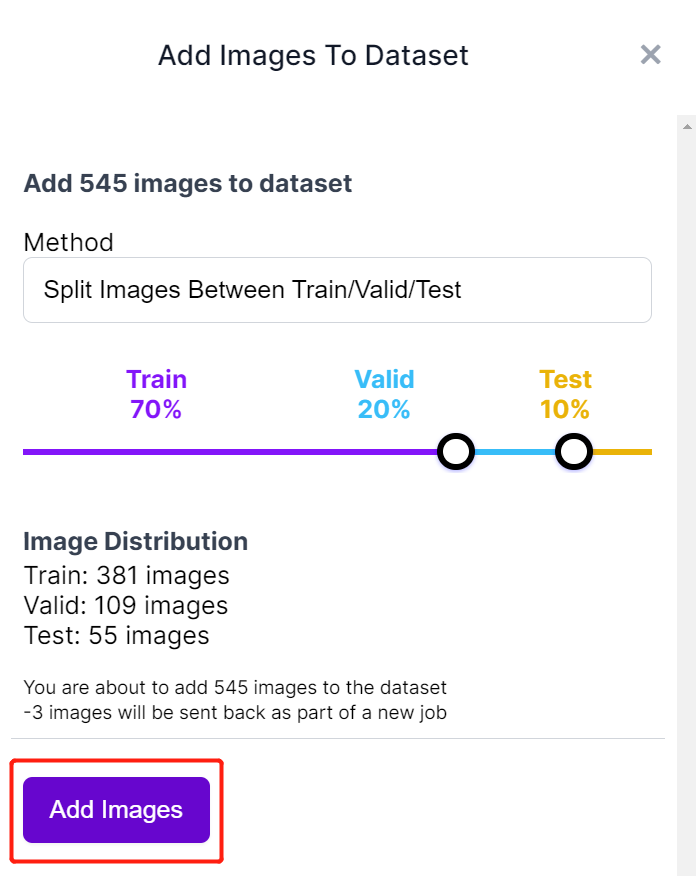
- Paso 14. A continuación dividiremos las imágenes entre "Train, Valid y Test". Mantén los porcentajes predeterminados para la distribución y haz clic en Add Images
- Paso 15. Haz clic en Generate New Version

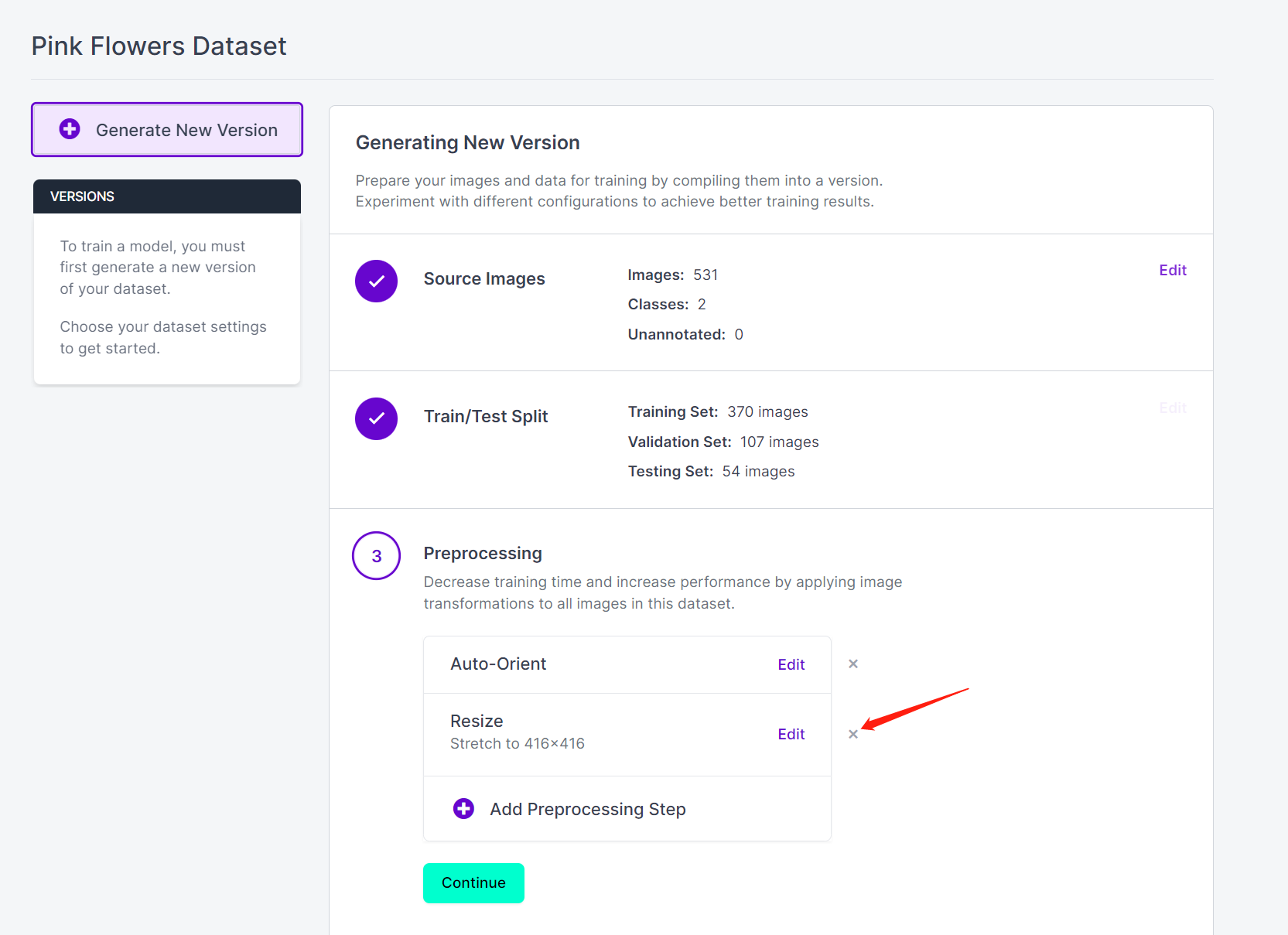
- Paso 16. Ahora puedes agregar Preprocessing y Augmentation si lo prefieres. Aquí eliminaremos la opción Resize y mantendremos los tamaños de imagen originales
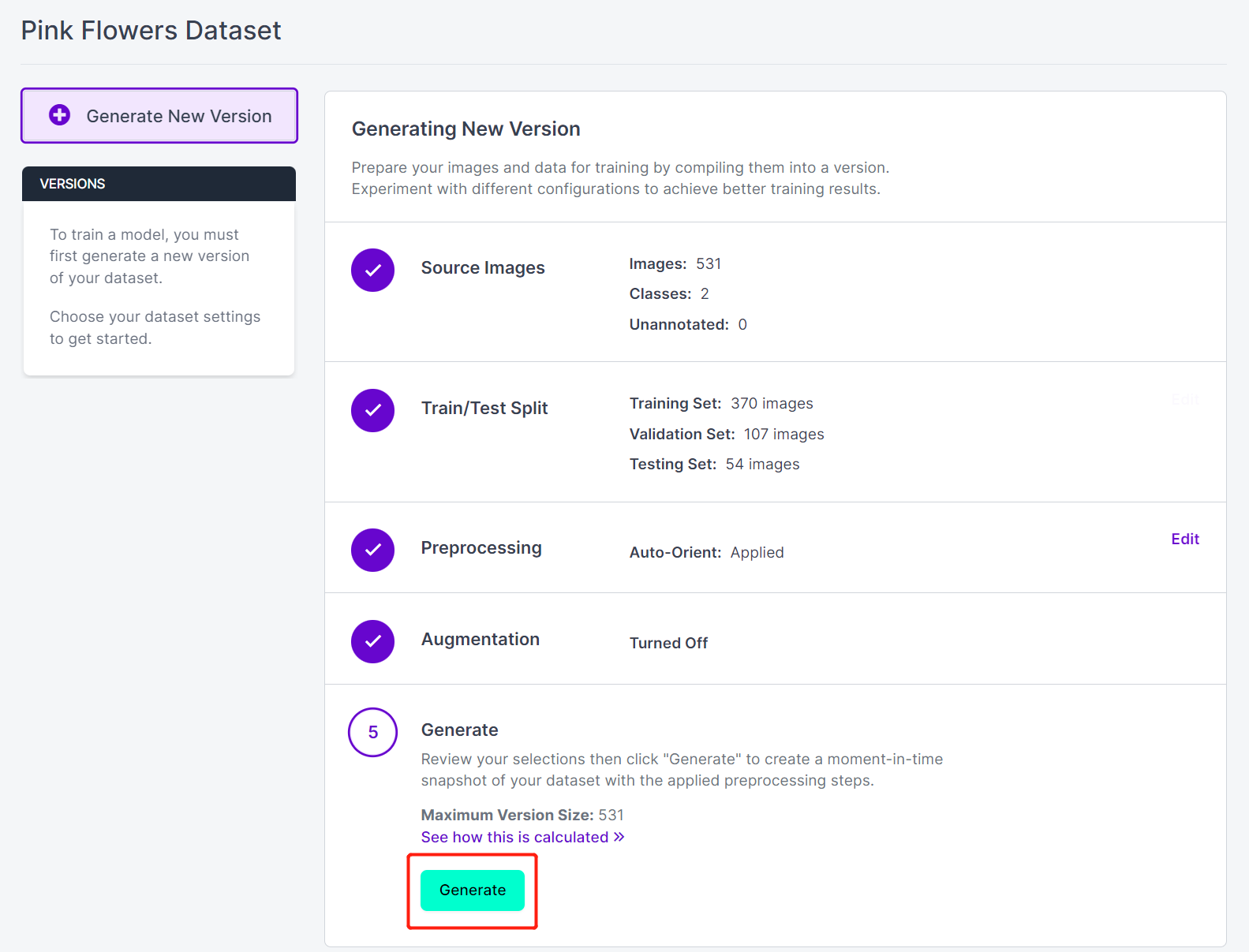
- Paso 17. A continuación, procede con los valores predeterminados restantes y haz clic en Generate
- Paso 18. Haz clic en Export
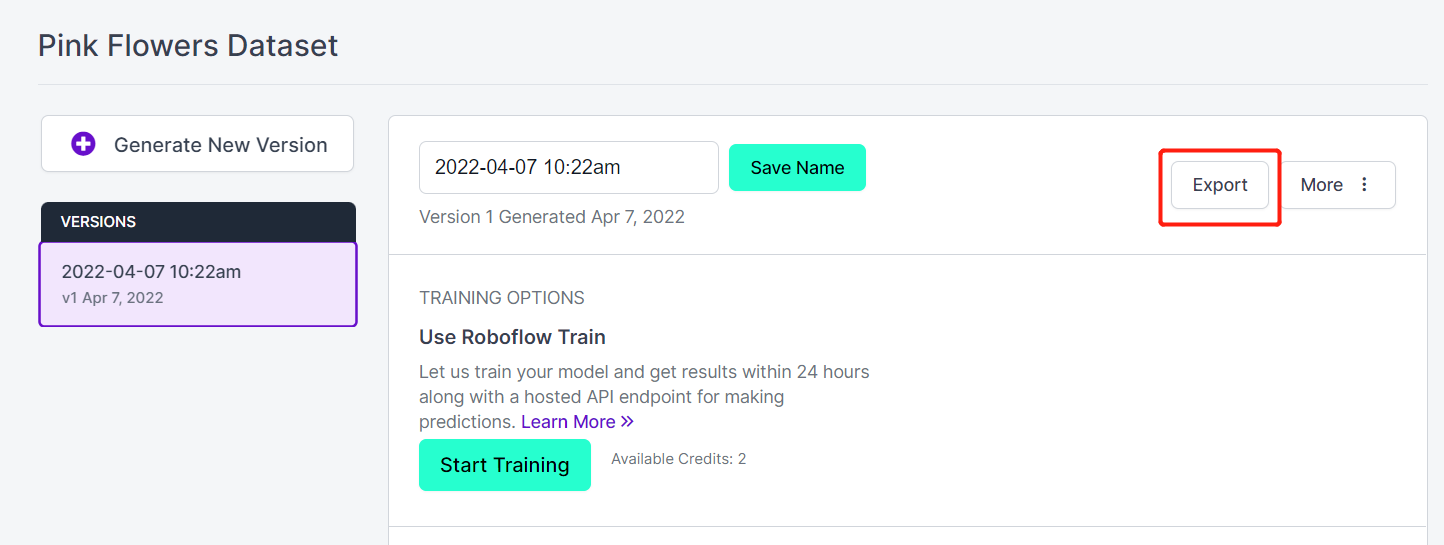
- Paso 19. Selecciona download zip to computer, bajo "Select a Format" elige YOLO v5 PyTorch y haz clic en Continue
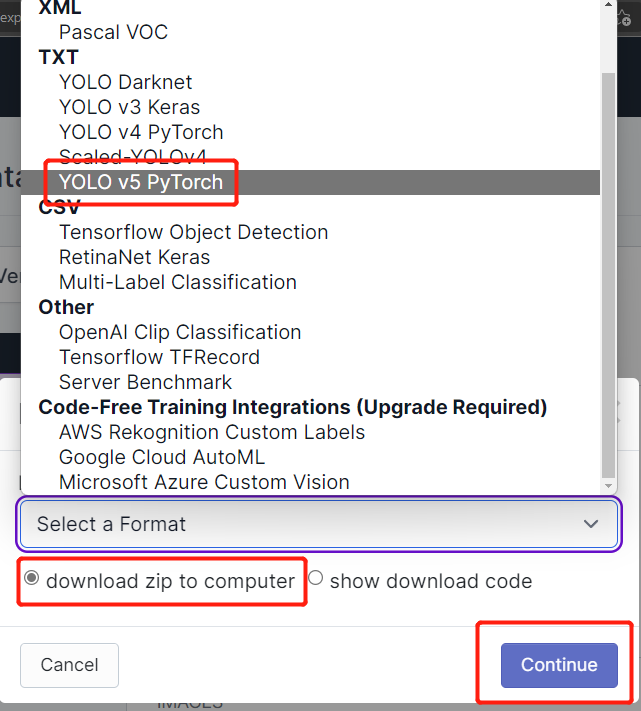
- Paso 20. Después de eso, se descargará un archivo .zip a tu computadora. Necesitaremos este archivo .zip más tarde para nuestro entrenamiento.
Entrenar en PC local o en la nube
Después de terminar con la anotación del conjunto de datos, necesitamos entrenar el conjunto de datos. Para el entrenamiento introduciremos dos métodos. Un método será basado en línea (Google Colab) y el otro método será basado en PC local (Linux).
Para el entrenamiento en Google Colab, usaremos dos métodos. En el primer método, usaremos Ultralytics HUB para subir el conjunto de datos, configurar el entrenamiento en Colab, monitorear el entrenamiento y obtener el modelo entrenado. En el segundo método, obtendremos el conjunto de datos de Roboflow a través de la api de Roboflow, entrenaremos y descargaremos el modelo desde Colab.
Usar Google Colab con Ultralytics HUB
Ultralytics HUB es una plataforma donde puedes entrenar tus modelos sin tener que conocer una sola línea de código. ¡Simplemente sube tus datos a Ultralytics HUB, entrena tu modelo y despliégalo en el mundo real! Es rápido, simple y fácil de usar. ¡Cualquiera puede empezar!
-
Paso 1. Visita este enlace para registrarte para una cuenta gratuita de Ultralytics HUB
-
Paso 2. Ingresa tus credenciales y regístrate con email o regístrate directamente con una cuenta de Google, GitHub o Apple
Después de iniciar sesión en Ultralytics HUB, verás el panel de control como sigue
-
Paso 3. Extrae el archivo zip que descargamos antes de Roboflow y pon todos los archivos incluidos dentro de una nueva carpeta
-
Paso 4. Asegúrate de que tu yaml del conjunto de datos y carpeta raíz (la carpeta que creamos antes) compartan el mismo nombre. Por ejemplo, si nombras tu archivo yaml como pinkflowers.yaml, la carpeta raíz debería llamarse pinkflowers.
-
Paso 5. Abre el archivo pinkflowers.yaml y edita los directorios train y val como sigue
train: train/images
val: valid/images
- Paso 6. Comprime la carpeta raíz como un .zip y nómbrala igual que la carpeta raíz (pinkflowers.zip en este ejemplo)
Ahora hemos preparado el conjunto de datos que está listo para ser subido a Ultalytics HUB.
- Paso 7. Haz clic en la pestaña Datasets y haz clic en Upload Dataset
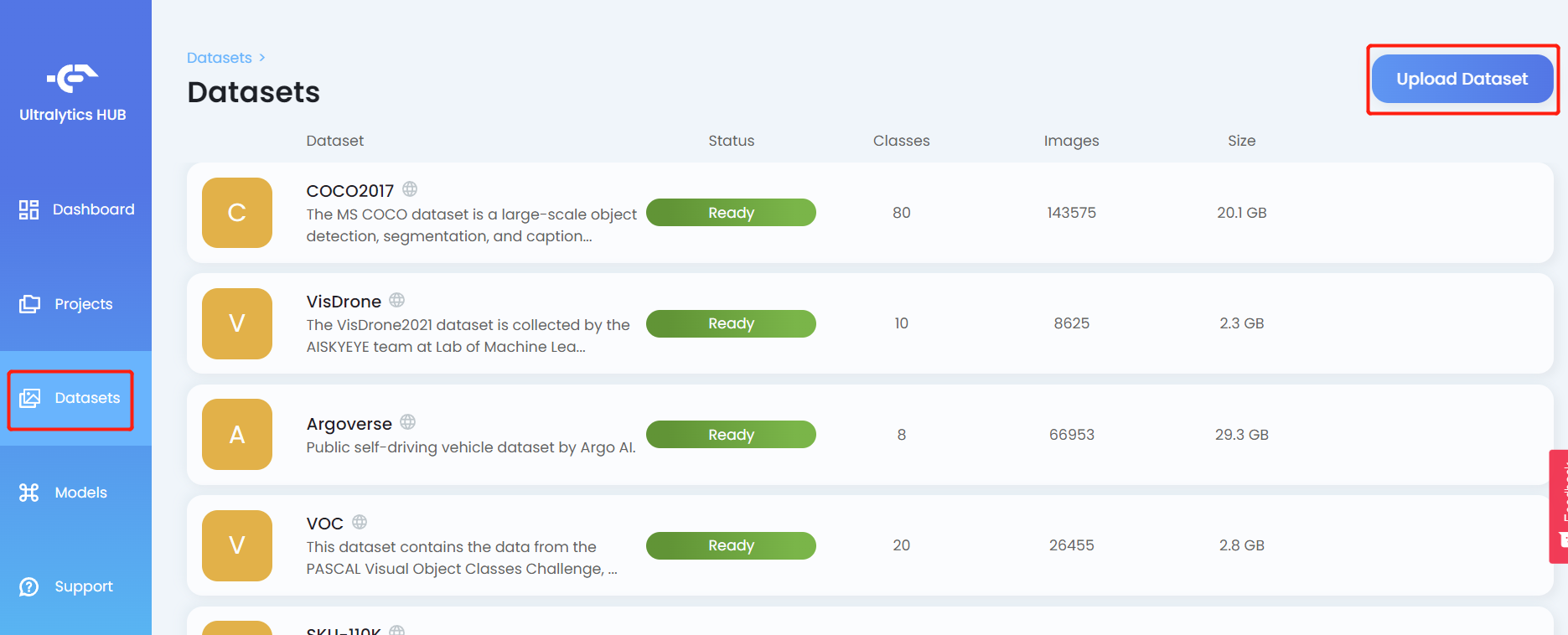
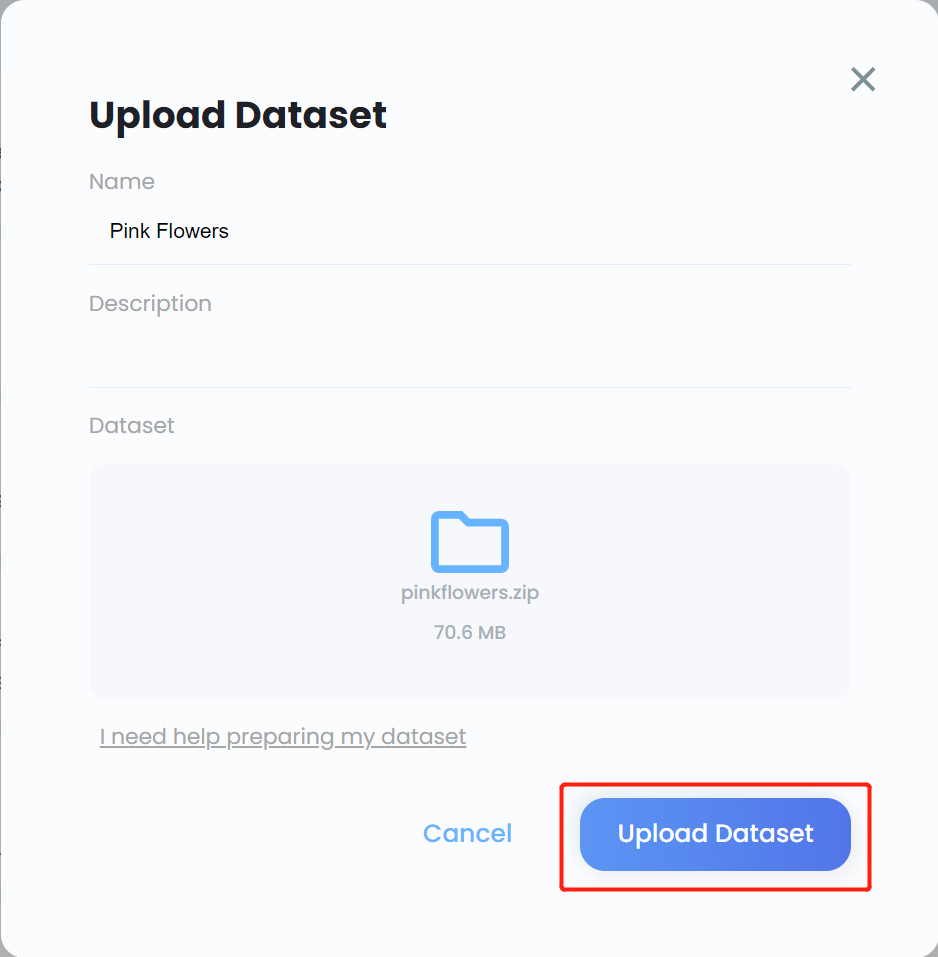
- Paso 8. Ingresa un Name para el conjunto de datos, ingresa una Description si es necesario, arrastra y suelta el archivo .zip que creamos antes bajo el campo Dataset y haz clic en Upload Dataset
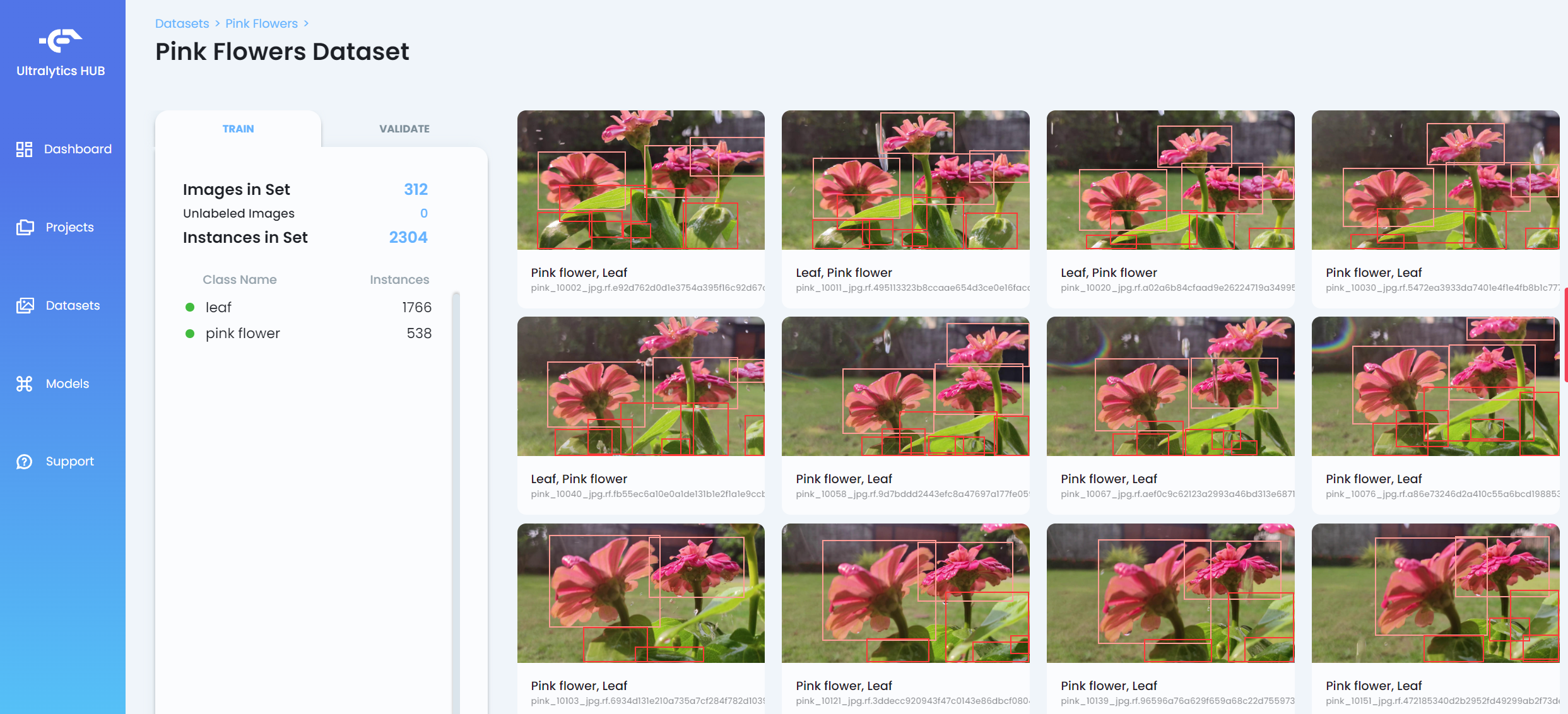
- Paso 9. Después de que el conjunto de datos sea subido, haz clic en el conjunto de datos para ver más información sobre el conjunto de datos
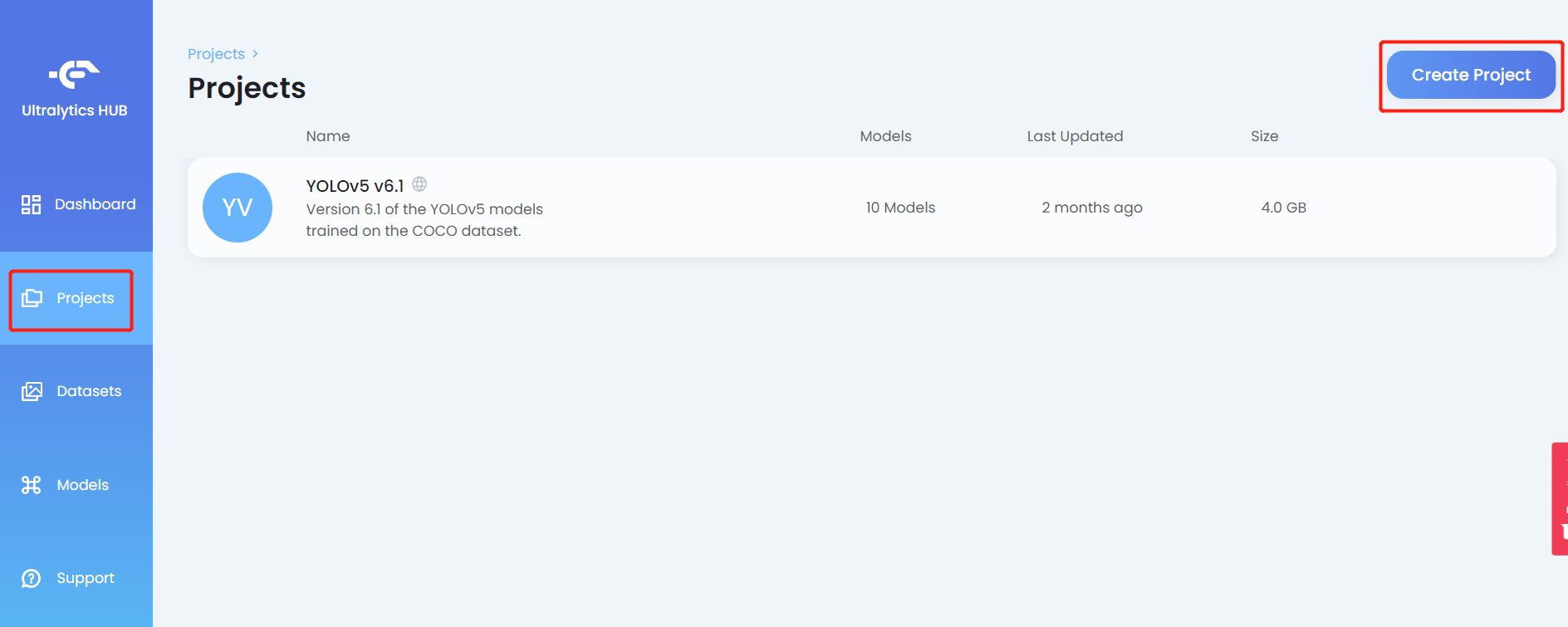
- Paso 10. Haz clic en la pestaña Projects y haz clic en Create Project
- Paso 11. Ingresa un Name para el proyecto, ingresa una Description si es necesario, agrega una cover image si es necesario, y haz clic en Create Project
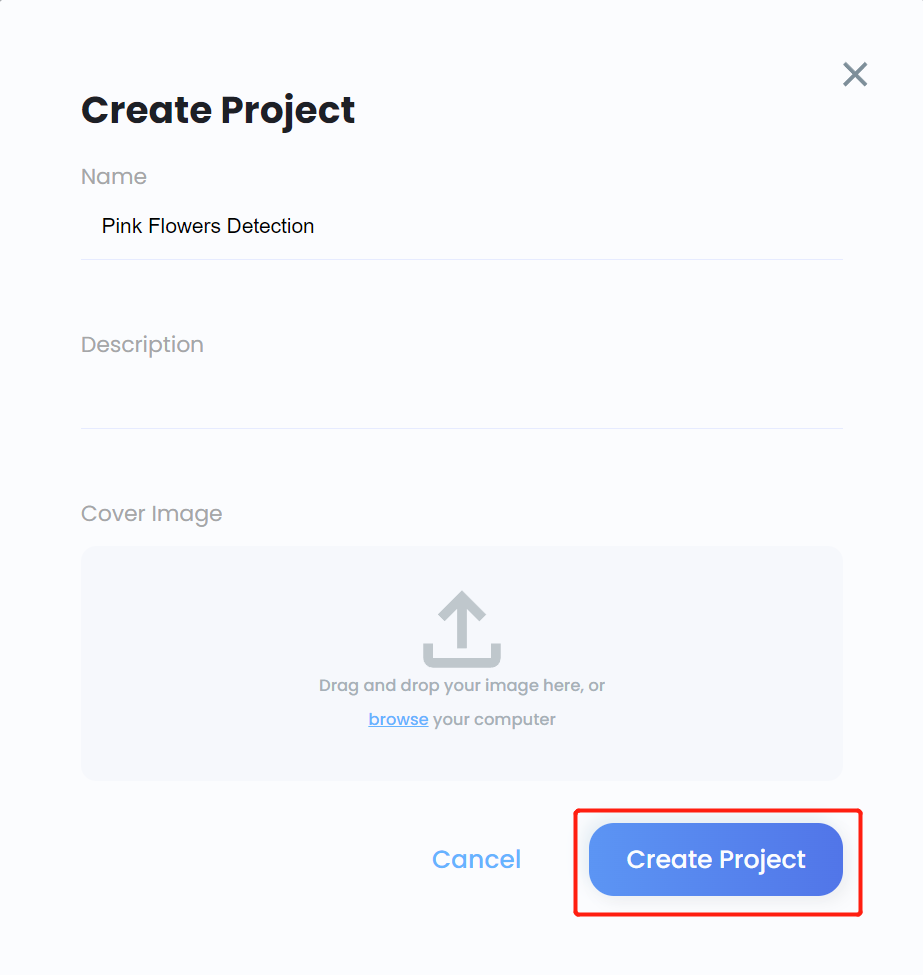
- Paso 12. Ingresa al proyecto recién creado y haz clic en Create Model

- Paso 13. Ingresa un Model name, elige YOLOv5n como el modelo preentrenado, y haz clic en Next
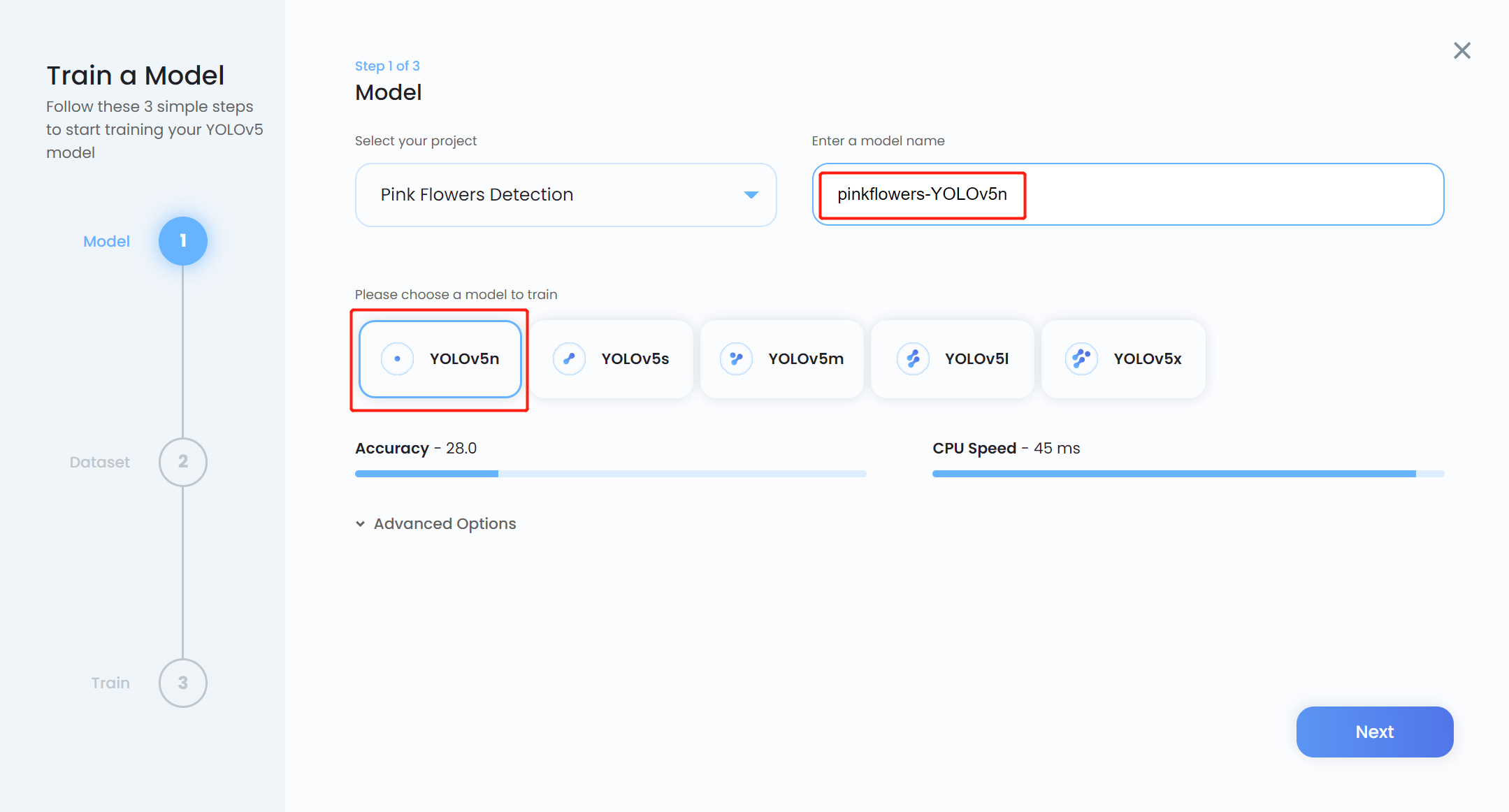
Nota: Usualmente YOLOv5n6 es preferido como el modelo preentrenado porque es adecuado para ser usado en dispositivos edge como la plataforma Jetson. Sin embargo, Ultralytics HUB aún no tiene soporte para él. Así que usamos YOLOv5n que es un modelo ligeramente similar.
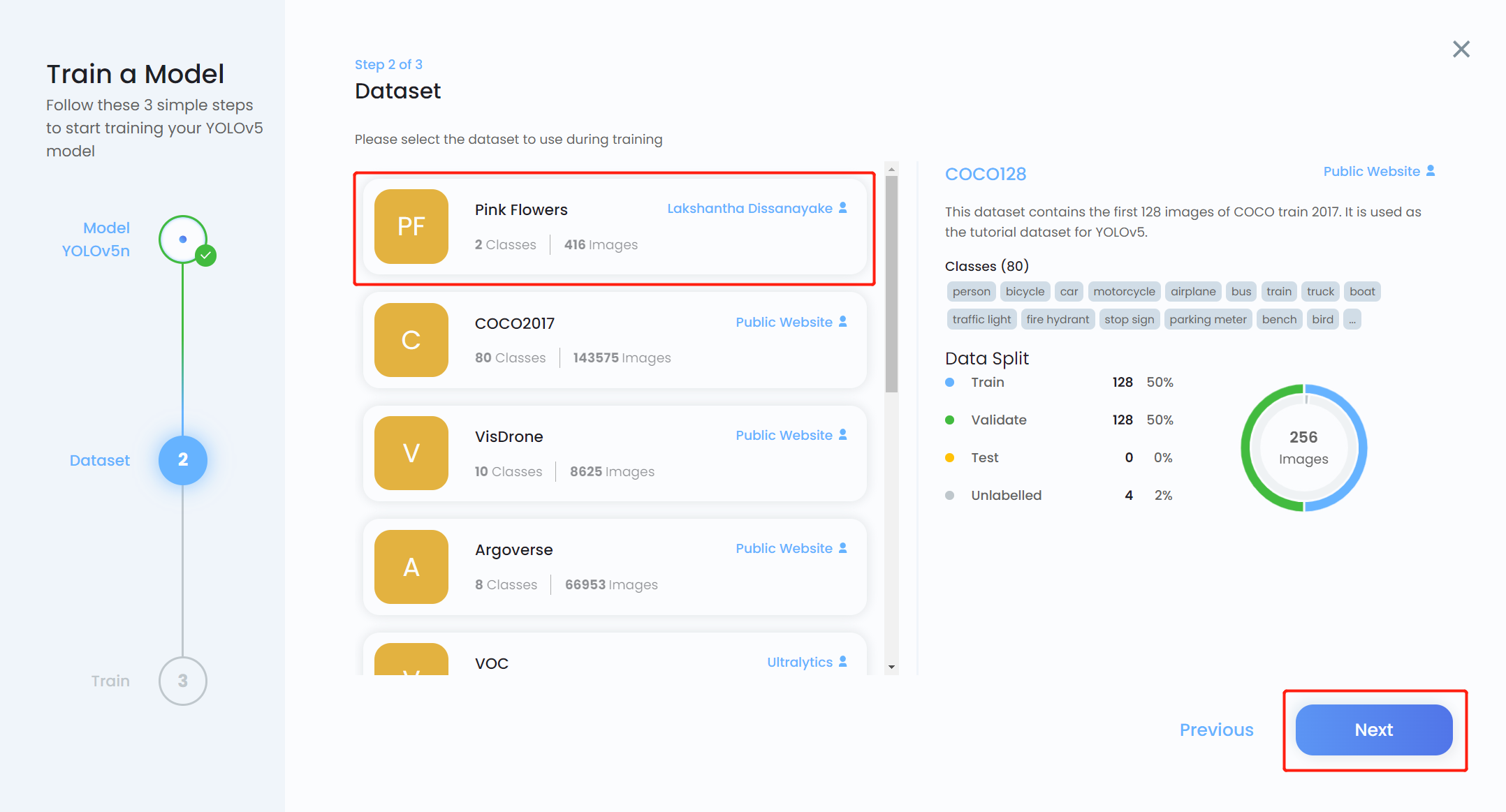
- Paso 14. Elige el conjunto de datos que subimos antes y haz clic en Next
- Paso 15. Elige Google Colab como plataforma de entrenamiento y haz clic en el menú desplegable Advanced Options. Aquí podemos cambiar algunas configuraciones para el entrenamiento. Por ejemplo, cambiaremos el número de épocas de 300 a 100 y mantendremos las otras configuraciones como están. Haz clic en Save
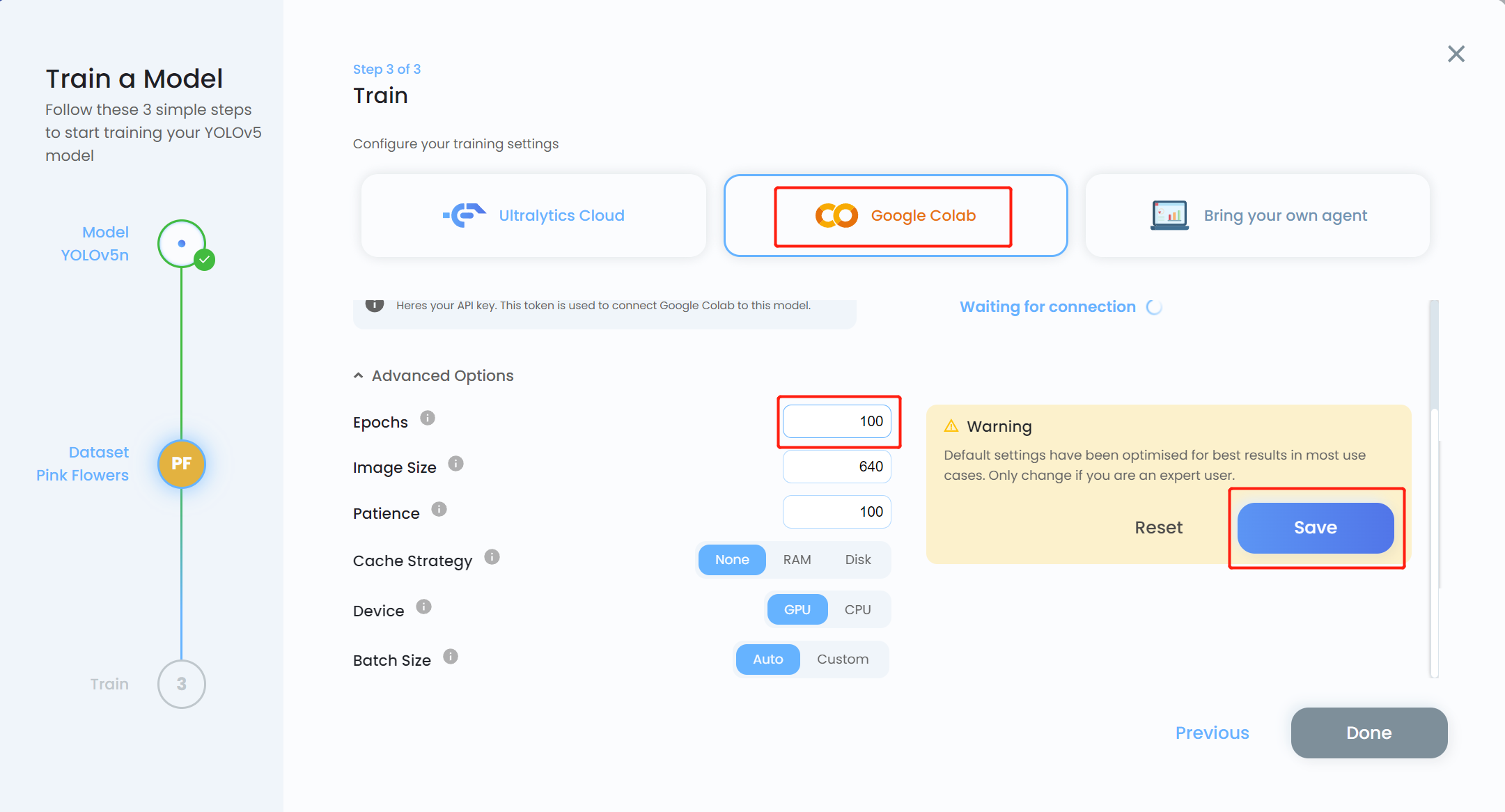
Nota: También puedes elegir Bring your own agent si planeas realizar entrenamiento local
- Paso 16. Copia la API key y haz clic en Open Colab
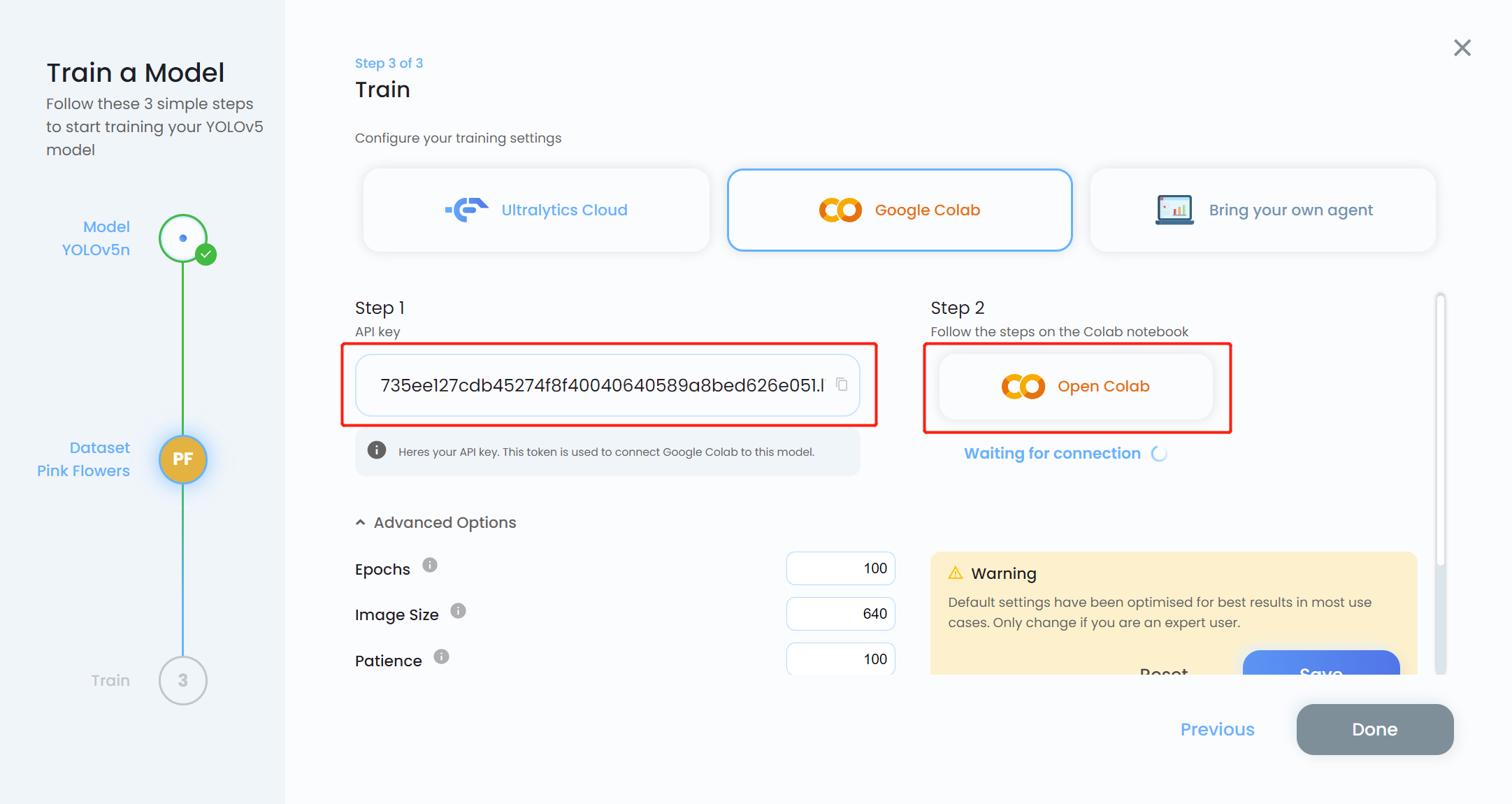
- Paso 17. Reemplaza MODEL_KEY con la API key que copiamos antes
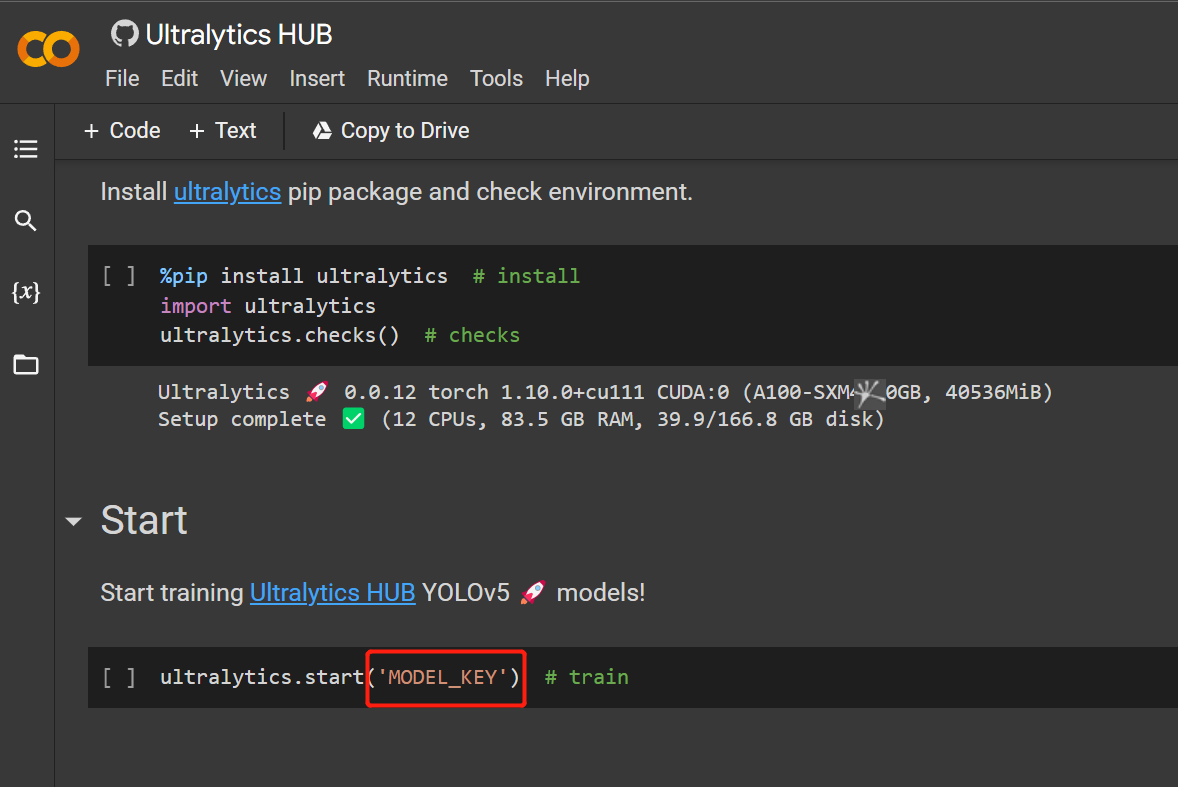
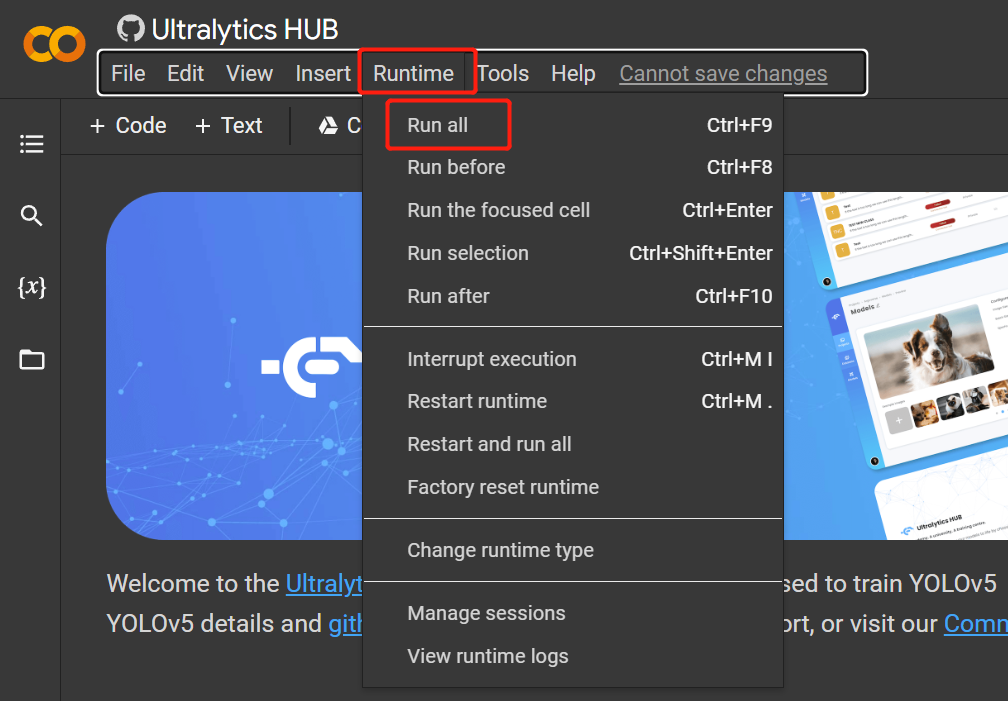
- Paso 18. Haz clic en
Runtime > Rull Allpara ejecutar todas las celdas de código e iniciar el proceso de entrenamiento
- Paso 19. Regresa a Ultralytics HUB y haz clic en Done cuando se vuelva azul. También verás que Colab se muestra como Connected.
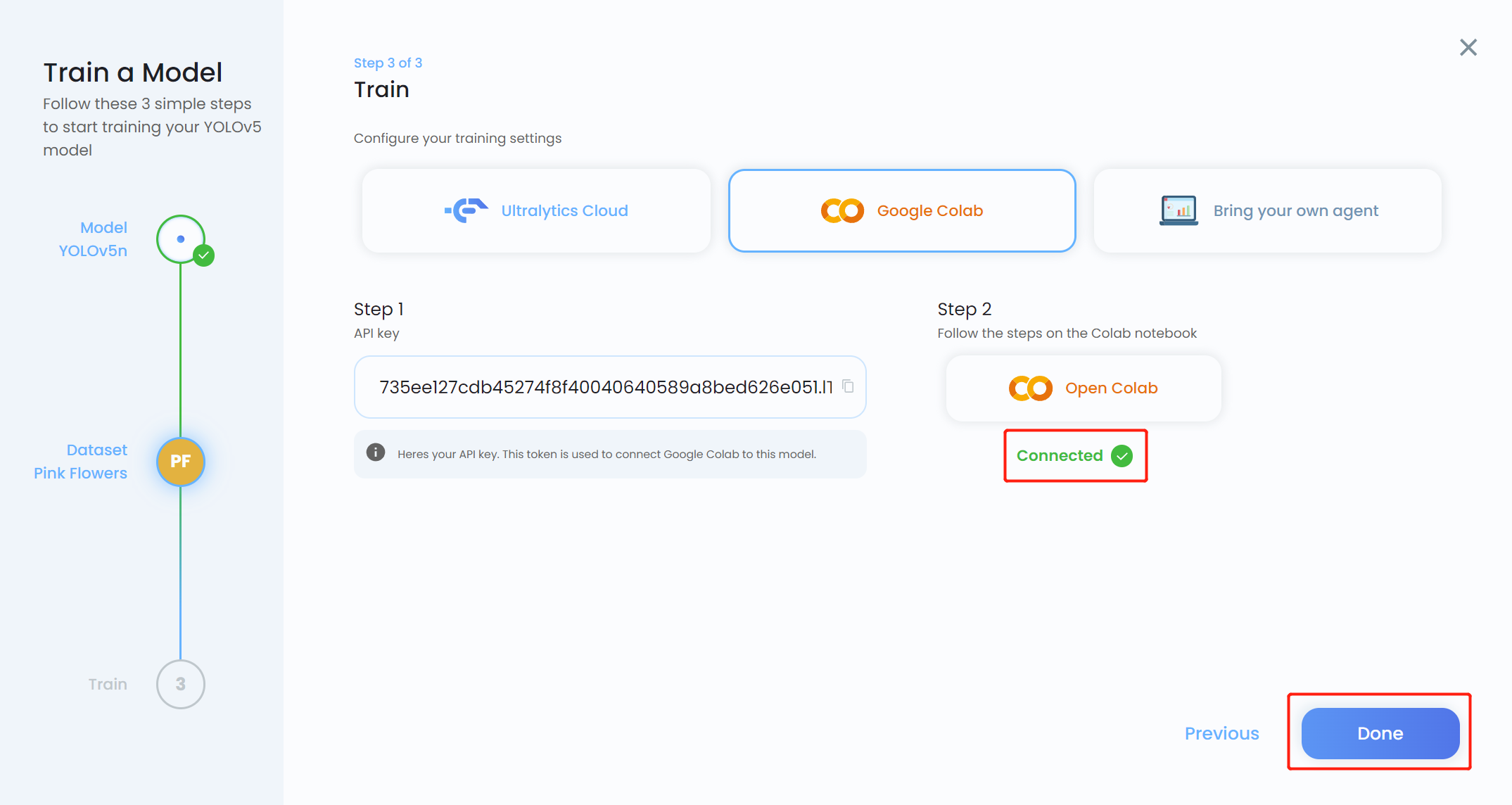
Ahora verás el progreso del entrenamiento en el HUB
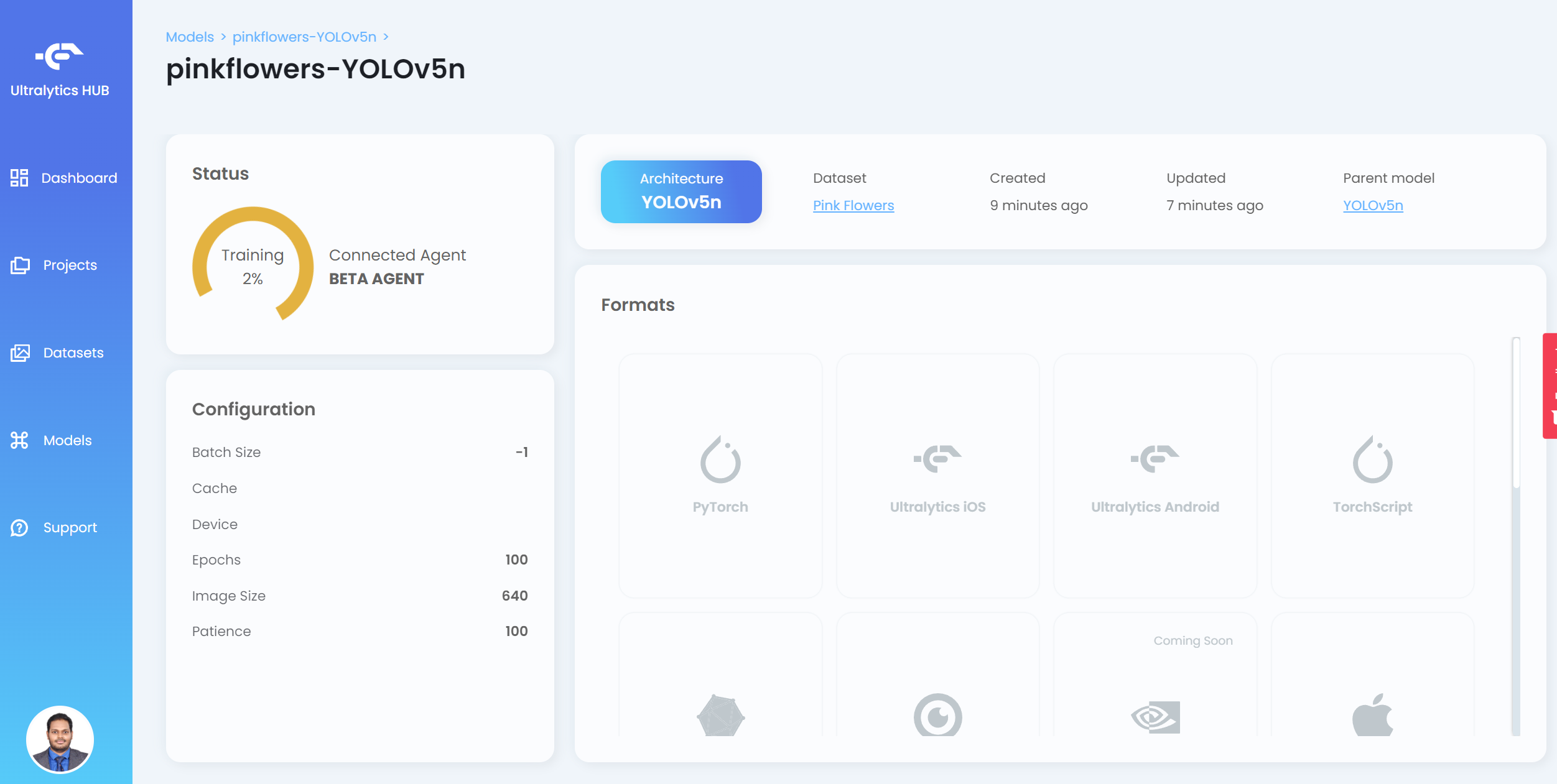
- Paso 20. Después de que termine el entrenamiento, haz clic en PyTorch para descargar el modelo entrenado en formato PyTorch. PyTorch es el formato que necesitamos para realizar inferencia en el dispositivo Jetson
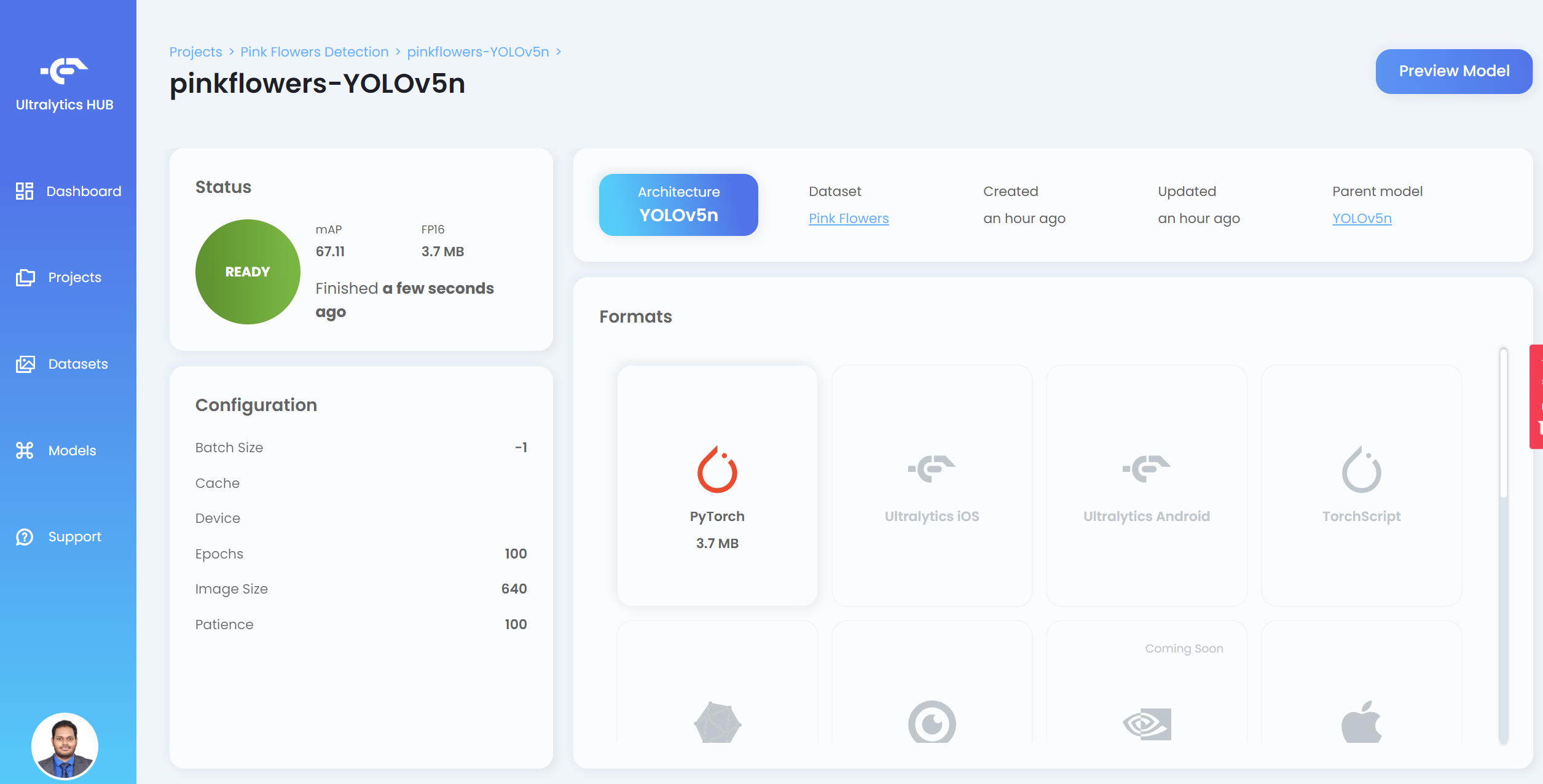
Nota: También puedes exportar a otros formatos que se muestran bajo Formats
Si regresas a Google Colab, puedes ver más detalles como sigue:
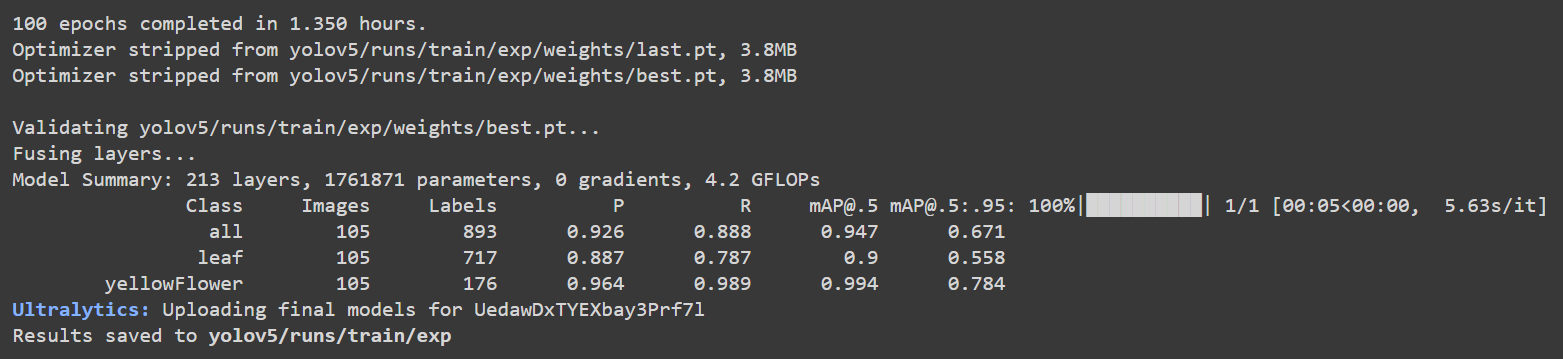
Aquí la precisión [email protected] es aproximadamente 90% y 99.4% para hoja y flor respectivamente, mientras que la precisión total [email protected] es aproximadamente 94.7%.
Usar Google Colab con api de Roboflow
Aquí usamos un entorno de Google Colaboratory para realizar entrenamiento en la nube. Además, usamos la api de Roboflow dentro de Colab para descargar fácilmente nuestro conjunto de datos.
- Paso 1. Haz clic aquí para abrir un espacio de trabajo de Google Colab ya preparado y sigue los pasos mencionados en el espacio de trabajo
Después de que termine el entrenamiento, verás una salida como sigue:
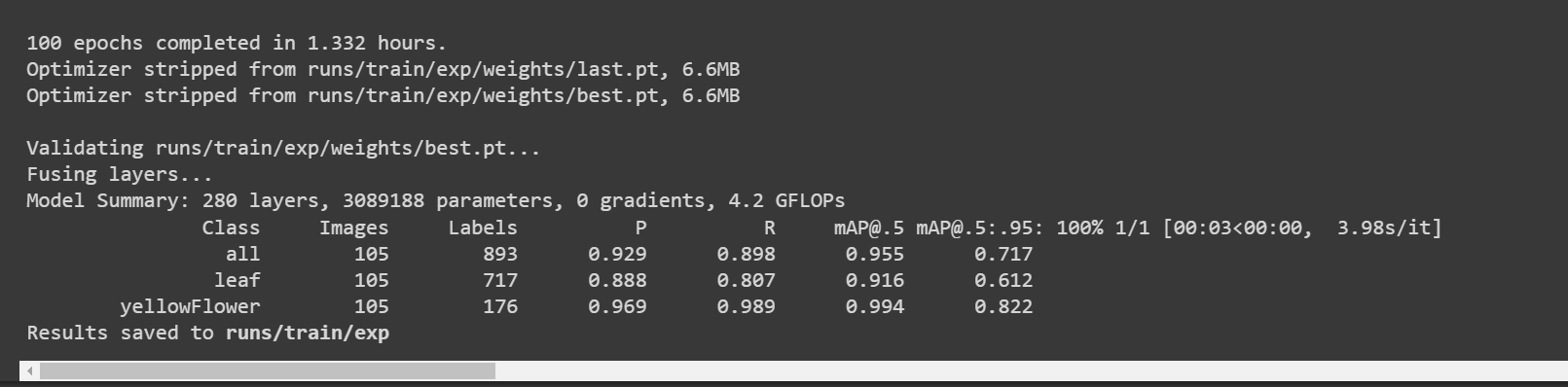
Aquí la precisión [email protected] es aproximadamente 91.6% y 99.4% para hoja y flor respectivamente, mientras que la precisión total [email protected] es aproximadamente 95.5%.
- Paso 2. Bajo la pestaña Files, si navegas a
runs/train/exp/weights, verás un archivo llamado best.pt. Este es el modelo generado del entrenamiento. Descarga este archivo y cópialo a tu dispositivo Jetson porque este es el modelo que vamos a usar más tarde para inferencia en el dispositivo Jetson.
Usar PC local
Aquí puedes usar una PC con un SO Linux para entrenamiento. Hemos usado una PC Ubuntu 20.04 para este wiki.
- Paso 1. Clona el repositorio YOLOv5 e instala requirements.txt en un entorno Python>=3.7.0
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
- Paso 2. Copia y pega el archivo .zip que descargamos antes de Roboflow en el directorio yolov5 y extráelo
# ejemplo
cp ~/Downloads/pink-flowers.v1i.yolov5pytorch.zip ~/yolov5
unzip pink-flowers.v1i.yolov5pytorch.zip
- Paso 3. Abre el archivo data.yaml y edita los directorios train y val como sigue
train: train/images
val: valid/images
- Paso 4. Ejecuta lo siguiente para iniciar el entrenamiento
python3 train.py --data data.yaml --img-size 640 --batch-size -1 --epoch 100 --weights yolov5n6.pt
Dado que nuestro conjunto de datos es relativamente pequeño (~500 imágenes), se espera que el aprendizaje por transferencia produzca mejores resultados que entrenar desde cero. Nuestro modelo fue inicializado con pesos de un modelo COCO preentrenado, pasando el nombre del modelo (yolov5n6) al argumento 'weights'. Aquí usamos yolov5n6 porque es ideal para dispositivos edge. Aquí el tamaño de imagen está configurado a 640x640. Usamos batch-size como -1 porque eso determinará automáticamente el mejor tamaño de lote. Sin embargo, si hay un error que dice "GPU memory not enough", elige el tamaño de lote como 32, o incluso 16. También puedes cambiar epoch según tu preferencia.
Después de que termine el entrenamiento, verás una salida como sigue:

Aquí la precisión [email protected] es aproximadamente 90.6% y 99.4% para hoja y flor respectivamente, mientras que la precisión total [email protected] es aproximadamente 95%.
- Paso 5. Si navegas a
runs/train/exp/weights, verás un archivo llamado best.pt. Este es el modelo generado del entrenamiento. Copia y pega este archivo a tu dispositivo Jetson porque este es el modelo que vamos a usar más tarde para inferencia en el dispositivo Jetson.

Inferencia en dispositivo Jetson
Usando TensorRT
Ahora usaremos un dispositivo Jetson para realizar inferencia (detectar objetos) en imágenes con la ayuda del modelo generado de nuestro entrenamiento anterior. Aquí usaremos NVIDIA TensorRT para aumentar el rendimiento de inferencia en la plataforma Jetson
- Paso 1. Accede a la terminal del dispositivo Jetson, instala pip y actualízalo
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- Paso 2. Clona el siguiente repositorio
git clone https://github.com/ultralytics/yolov5
- Paso 3. Abre requirements.txt
cd yolov5
vi requirements.txt
- Paso 4. Edita las siguientes líneas. Aquí necesitas presionar i primero para entrar al modo de edición. Presiona ESC, luego escribe :wq para guardar y salir
matplotlib==3.2.2
numpy==1.19.4
# torch>=1.7.0
# torchvision>=0.8.1
Nota: Incluimos versiones fijas para matplotlib y numpy para asegurar que no haya errores al ejecutar YOLOv5 más tarde. Además, torch y torchvision se excluyen por ahora porque se instalarán más tarde.
- Paso 5. instala la siguiente dependencia
sudo apt install -y libfreetype6-dev
- Paso 6. Instala los paquetes necesarios
pip3 install -r requirements.txt
- Paso 7. Instala torch
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- Paso 8. Instala torchvision
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
- Paso 9. Clona el siguiente repositorio
cd ~
git clone https://github.com/wang-xinyu/tensorrtx
-
Paso 10. Copia el archivo best.pt del entrenamiento anterior al directorio yolov5
-
Paso 11. Copia gen_wts.py de tensorrtx/yolov5 al directorio yolov5
cp tensorrtx/yolov5/gen_wts.py yolov5
- Paso 12. Genera el archivo .wts desde PyTorch con .pt
cd yolov5
python3 gen_wts.py -w best.pt -o best.wts
- Paso 13. Navega a tensorrtx/yolov5
cd ~
cd tensorrtx/yolov5
- Paso 14. Abre yololayer.h con el editor de texto vi
vi yololayer.h
- Paso 15. Cambia CLASS_NUM al número de clases para las que tu modelo está entrenado. En nuestro ejemplo, es 2
CLASS_NUM = 2
- Paso 16. Crea un nuevo directorio build y navega dentro
mkdir build
cd build
- Paso 17. Copia el archivo best.wts generado previamente a este directorio build
cp ~/yolov5/best.wts .
- Paso 18. Compílalo
cmake ..
make
- Paso 19. Serializa el modelo
sudo ./yolov5 -s [.wts] [.engine] [n/s/m/l/x/n6/s6/m6/l6/x6 or c/c6 gd gw]
#ejemplo
sudo ./yolov5 -s best.wts best.engine n6
Aquí usamos n6 porque eso se recomienda para dispositivos edge como la plataforma NVIDIA Jetson. Sin embargo, si usas Ultralytics HUB para configurar el entrenamiento, solo puedes usar n porque n6 aún no está soportado por el HUB.
-
Paso 20. Copia las imágenes en las que quieres que el modelo detecte a una nueva carpeta como tensorrtx/yolov5/images
-
Paso 21. Deserializa y ejecuta inferencia en las imágenes como sigue
sudo ./yolov5 -d best.engine images
A continuación se muestra una comparación del tiempo de inferencia ejecutándose en Jetson Nano vs Jetson Xavier NX.
Jetson Nano
Aquí la cuantización está configurada a FP16
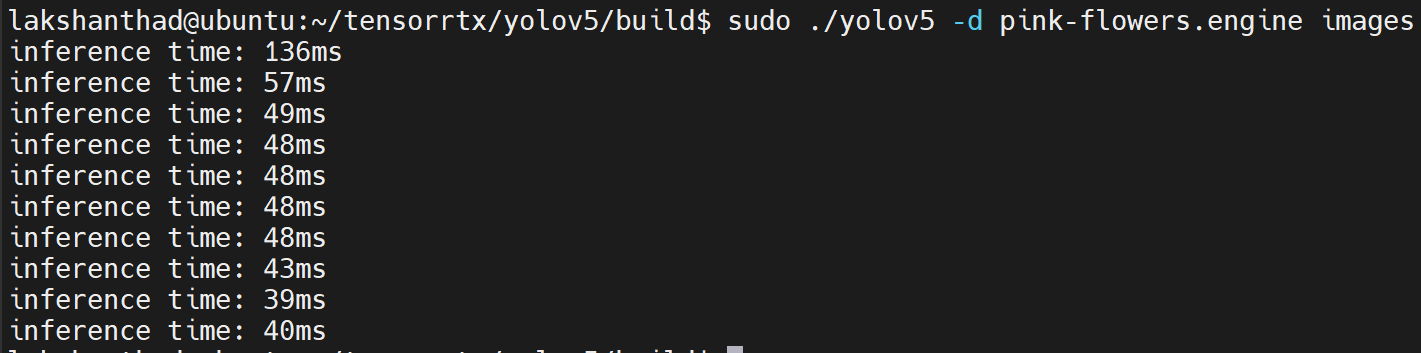
De los resultados anteriores, podemos tomar el promedio como aproximadamente 47ms. Convirtiendo este valor a fotogramas por segundo: 1000/47 = 21.2766 = 21fps.
Jetson Xavier NX
Aquí la cuantización está configurada a FP16
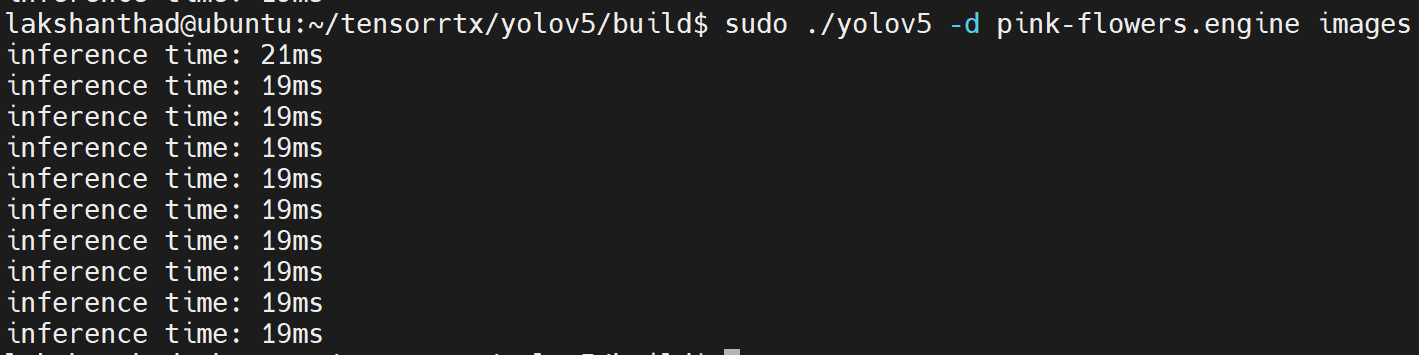
De los resultados anteriores, podemos tomar el promedio como aproximadamente 20ms. Convirtiendo este valor a fotogramas por segundo: 1000/20 = 50fps.
Además, las imágenes de salida serán como sigue con los objetos detectados:


Usando TensorRT y DeepStream SDK
Aquí usaremos NVIDIA TensorRT junto con NVIDIA DeepStream SDK para realizar inferencia en un video
- Paso 1. Asegúrate de haber instalado correctamente todos los Componentes SDK y DeepStream SDK en el dispositivo Jetson. (consulta este wiki como referencia para la instalación)
Nota: Se recomienda usar NVIDIA SDK Manager para instalar todos los componentes SDK y DeepStream SDK
- Paso 2. Accede a la terminal del dispositivo Jetson, instala pip y actualízalo
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- Paso 3. Clona el siguiente repositorio
git clone https://github.com/ultralytics/yolov5
- Paso 4. Abre requirements.txt
cd yolov5
vi requirements.txt
- Paso 5. Edita las siguientes líneas. Aquí necesitas presionar i primero para entrar al modo de edición. Presiona ESC, luego escribe :wq para guardar y salir
matplotlib==3.2.2
numpy==1.19.4
# torch>=1.7.0
# torchvision>=0.8.1
Nota: Incluimos versiones fijas para matplotlib y numpy para asegurar que no haya errores al ejecutar YOLOv5 más tarde. Además, torch y torchvision se excluyen por ahora porque se instalarán más tarde.
- Paso 6. instala la siguiente dependencia
sudo apt install -y libfreetype6-dev
- Paso 7. Instala los paquetes necesarios
pip3 install -r requirements.txt
- Paso 8. Instala torch
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- Paso 9. Instalar torchvision
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
- Paso 10. Clonar el siguiente repositorio
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- Paso 11. Copiar gen_wts_yoloV5.py desde DeepStream-Yolo/utils al directorio yolov5
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5
- Paso 12. Dentro del repositorio yolov5, descargar el archivo pt desde las versiones de YOLOv5 (ejemplo para YOLOv5s 6.1)
cd yolov5
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
- Paso 13. Generar los archivos cfg y wts
python3 gen_wts_yoloV5.py -w yolov5s.pt
Nota: Para cambiar el tamaño de inferencia (por defecto: 640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Ejemplo para 1280:
-s 1280
o
-s 1280 1280
- Paso 14. Copiar los archivos cfg y wts generados a la carpeta DeepStream-Yolo
cp yolov5s.cfg ~/DeepStream-Yolo
cp yolov5s.wts ~/DeepStream-Yolo
- Paso 15. Abrir la carpeta DeepStream-Yolo y compilar la biblioteca
cd ~/DeepStream-Yolo
# Para DeepStream 6.1
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo
# Para DeepStream 6.0.1 / 6.0
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo
- Paso 16. Editar el archivo config_infer_primary_yoloV5.txt según tu modelo
[property]
...
custom-network-config=yolov5s.cfg
model-file=yolov5s.wts
...
- Paso 17. Editar el archivo deepstream_app_config
...
[primary-gie]
...
config-file=config_infer_primary_yoloV5.txt
- Paso 18. Ejecutar la inferencia
deepstream-app -c deepstream_app_config.txt
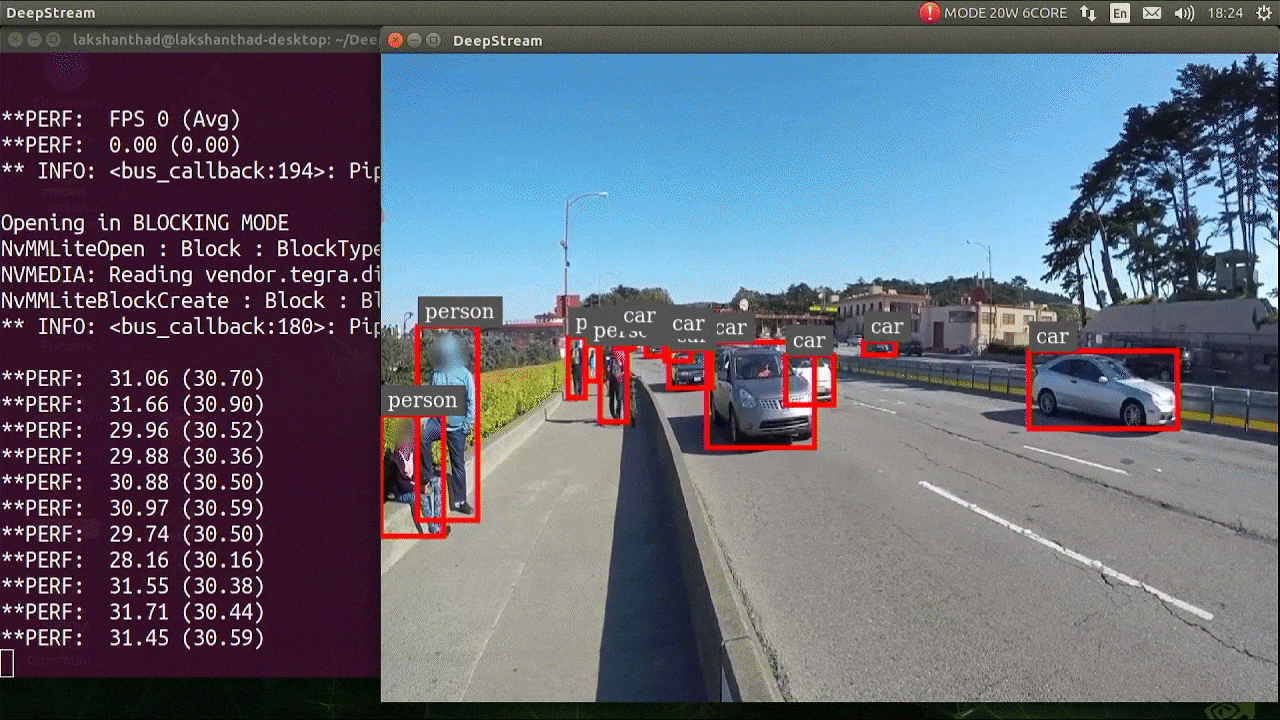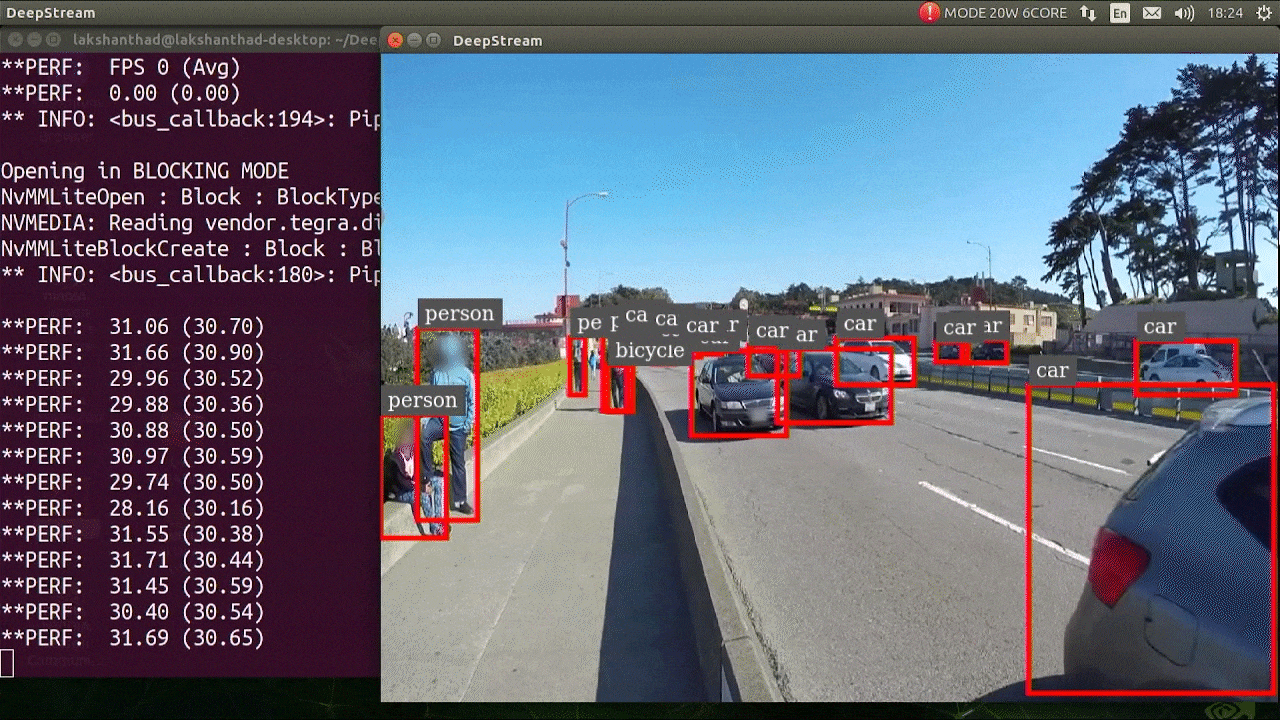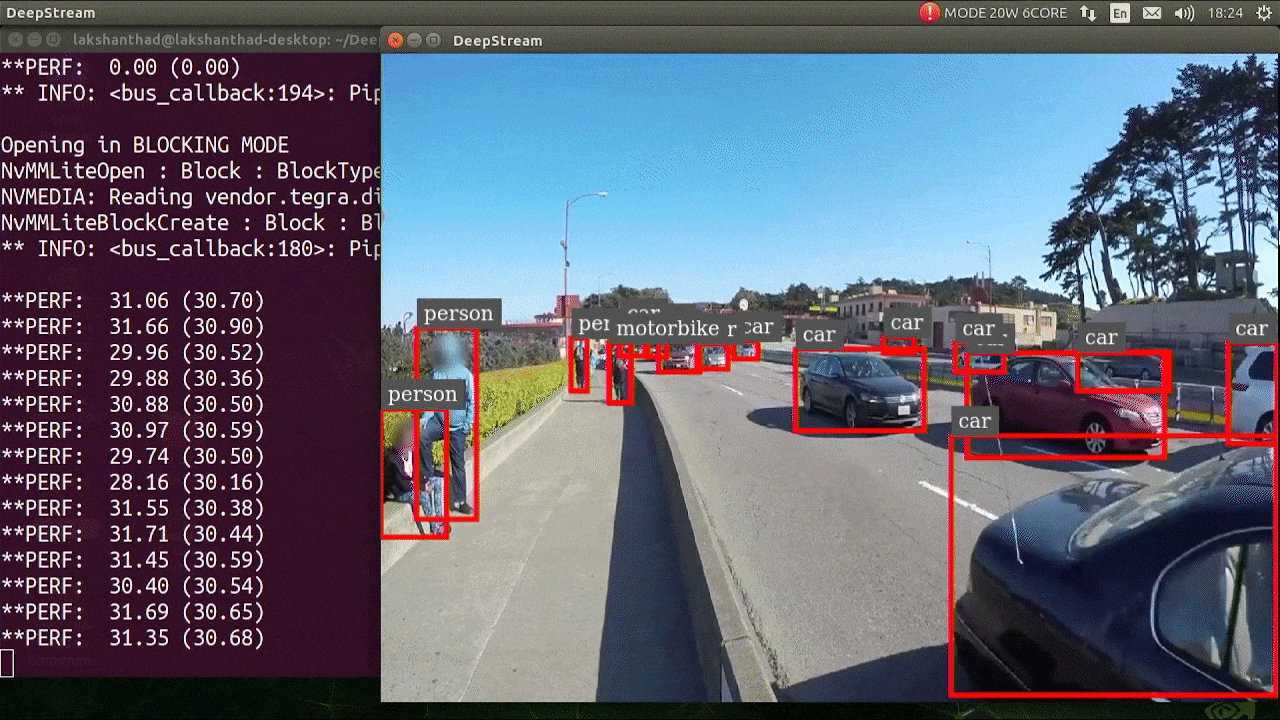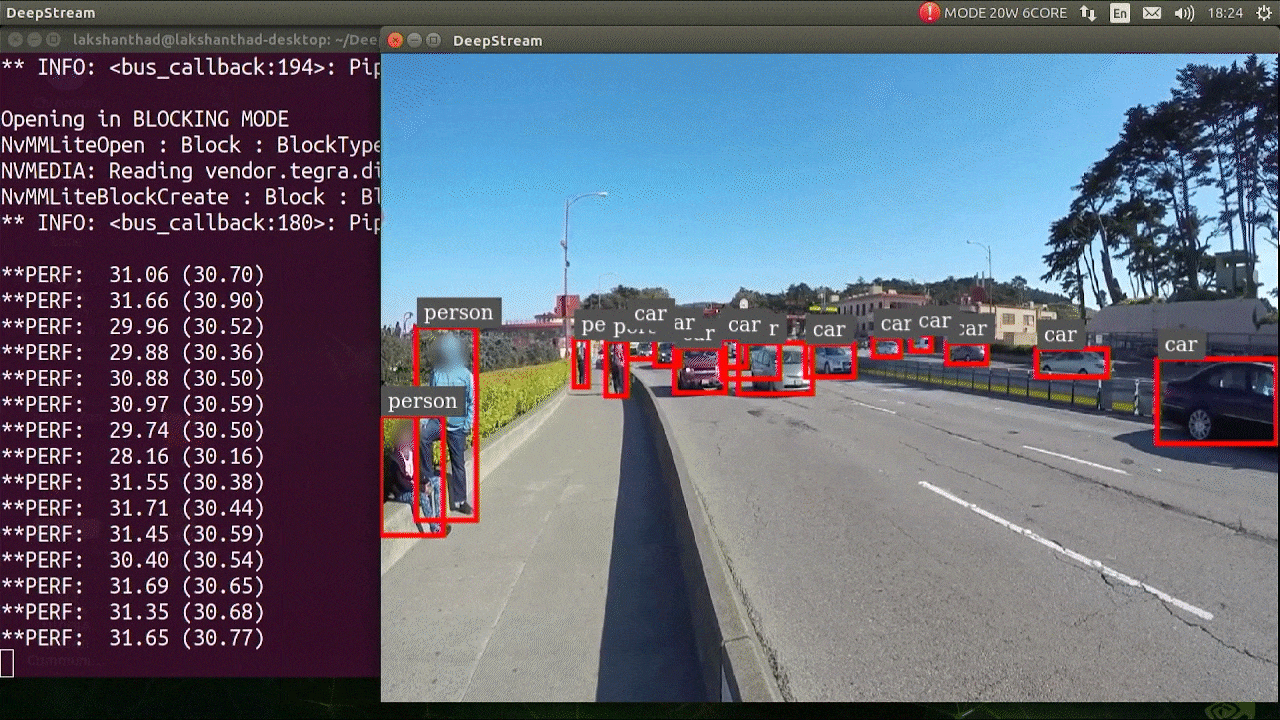
El resultado anterior se ejecuta en Jetson Xavier NX con FP32 y YOLOv5s 640x640. Podemos ver que los FPS están alrededor de 30.
Calibración INT8
Si quieres usar precisión INT8 para la inferencia, necesitas seguir los pasos a continuación
- Paso 1. Instalar OpenCV
sudo apt-get install libopencv-dev
- Paso 2. Compilar/recompilar la biblioteca nvdsinfer_custom_impl_Yolo con soporte para OpenCV
cd ~/DeepStream-Yolo
# Para DeepStream 6.1
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo
# Para DeepStream 6.0.1 / 6.0
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo
-
Paso 3. Para el conjunto de datos COCO, descargar val2017, extraer y mover a la carpeta DeepStream-Yolo
-
Paso 4. Crear un nuevo directorio para las imágenes de calibración
mkdir calibration
- Paso 5. Ejecutar lo siguiente para seleccionar 1000 imágenes aleatorias del conjunto de datos COCO para ejecutar la calibración
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
Nota: NVIDIA recomienda al menos 500 imágenes para obtener una buena precisión. En este ejemplo, se eligen 1000 imágenes para obtener mejor precisión (más imágenes = más precisión). Valores más altos de INT8_CALIB_BATCH_SIZE resultarán en más precisión y velocidad de calibración más rápida. Configúralo según tu memoria GPU. Puedes configurarlo desde head -1000. Por ejemplo, para 2000 imágenes, head -2000. Este proceso puede tomar mucho tiempo.
- Paso 6. Crear el archivo calibration.txt con todas las imágenes seleccionadas
realpath calibration/*jpg > calibration.txt
- Paso 7. Configurar variables de entorno
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- Paso 8. Actualizar el archivo config_infer_primary_yoloV5.txt
De
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
A
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
- Paso 9. Ejecutar la inferencia
deepstream-app -c deepstream_app_config.txt
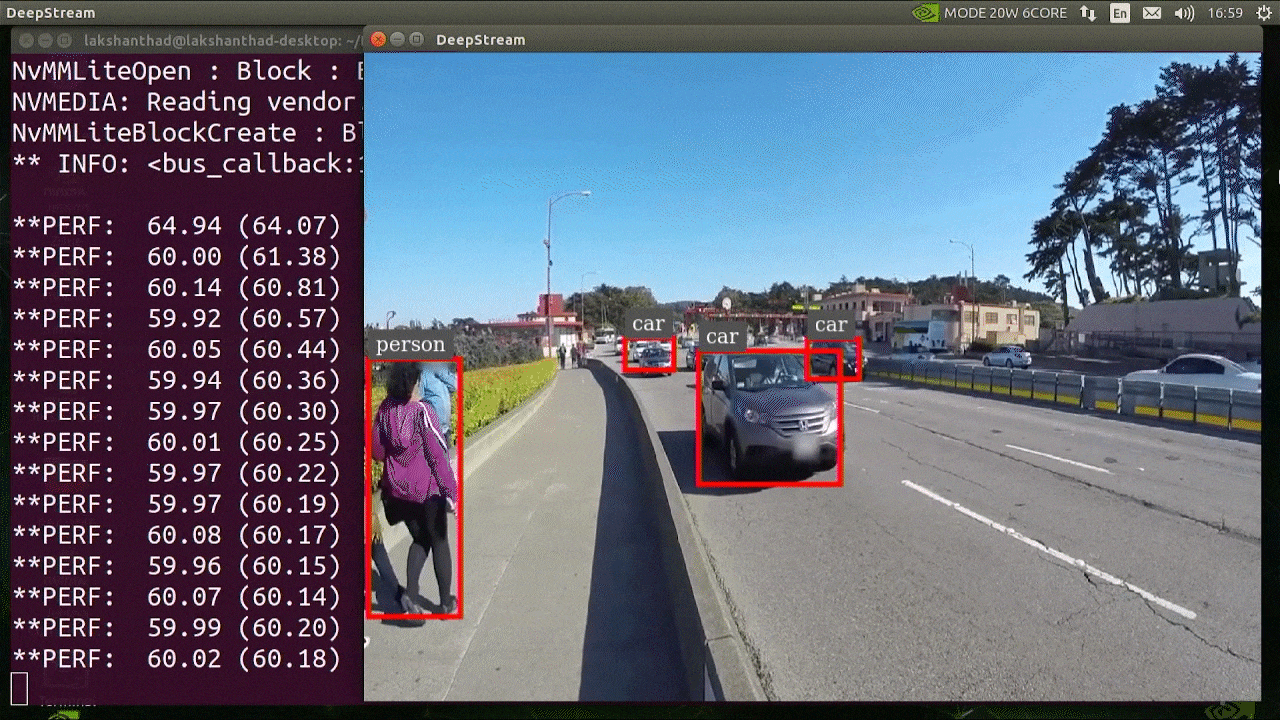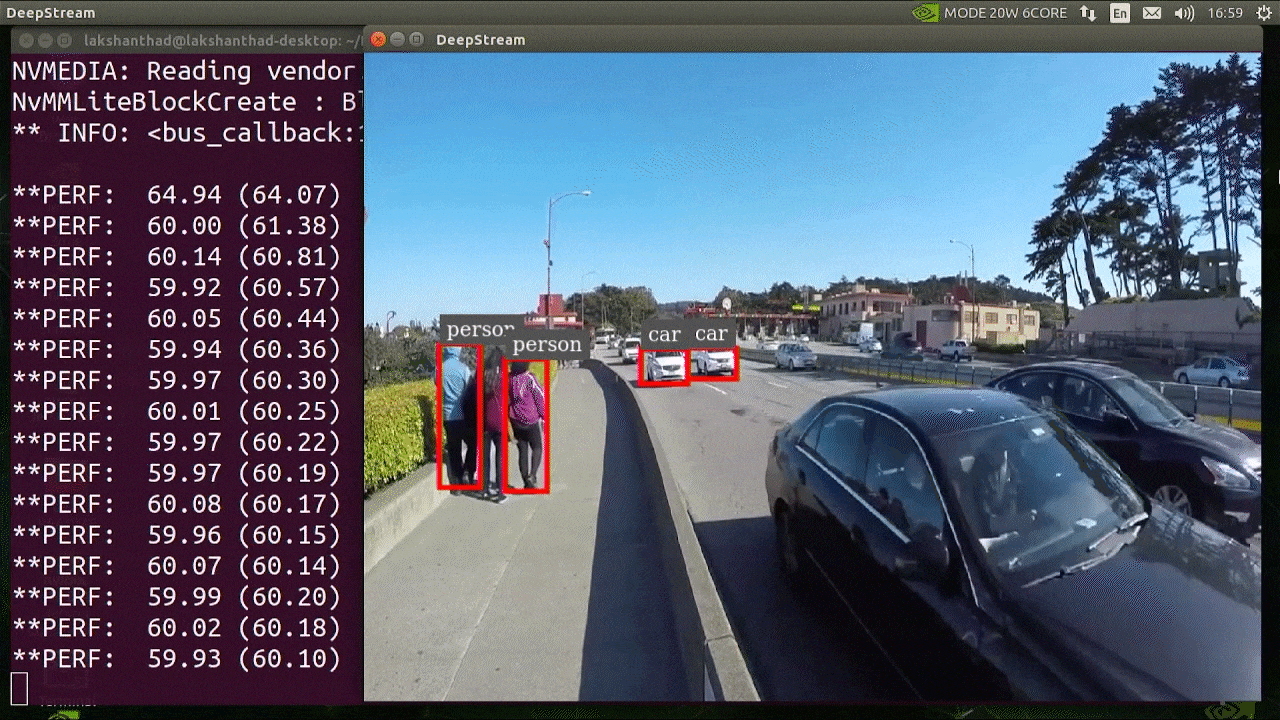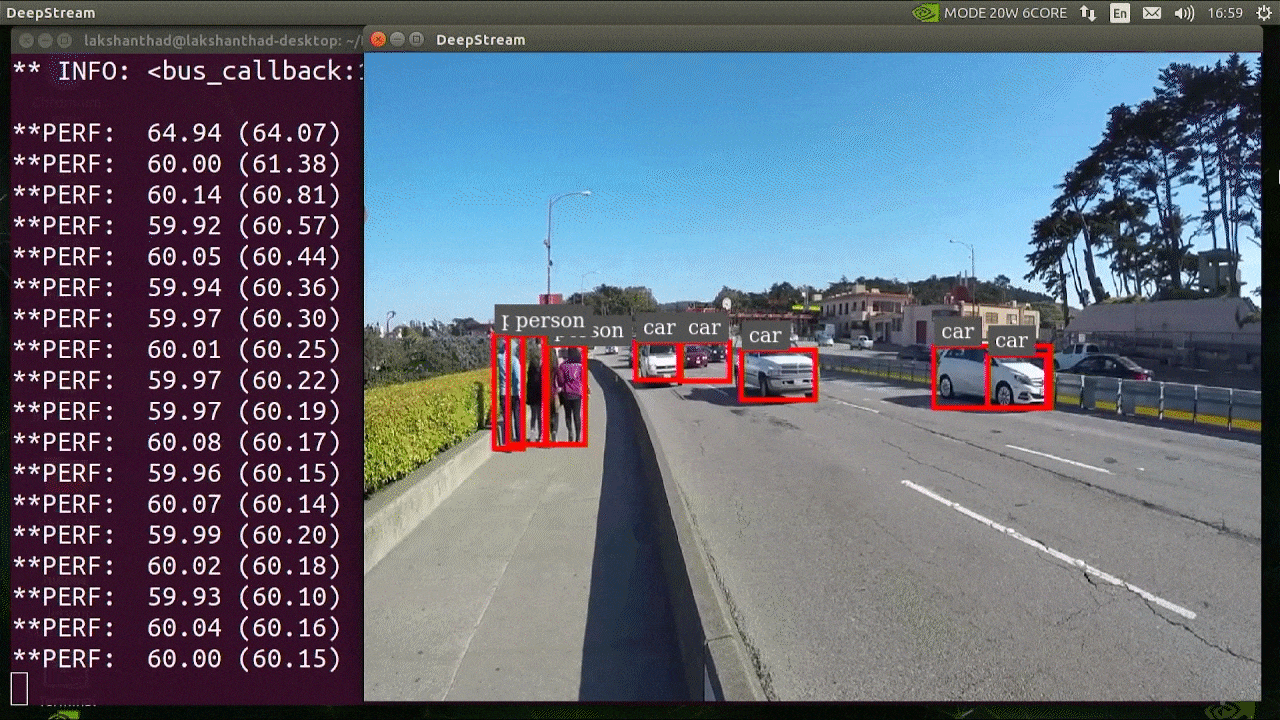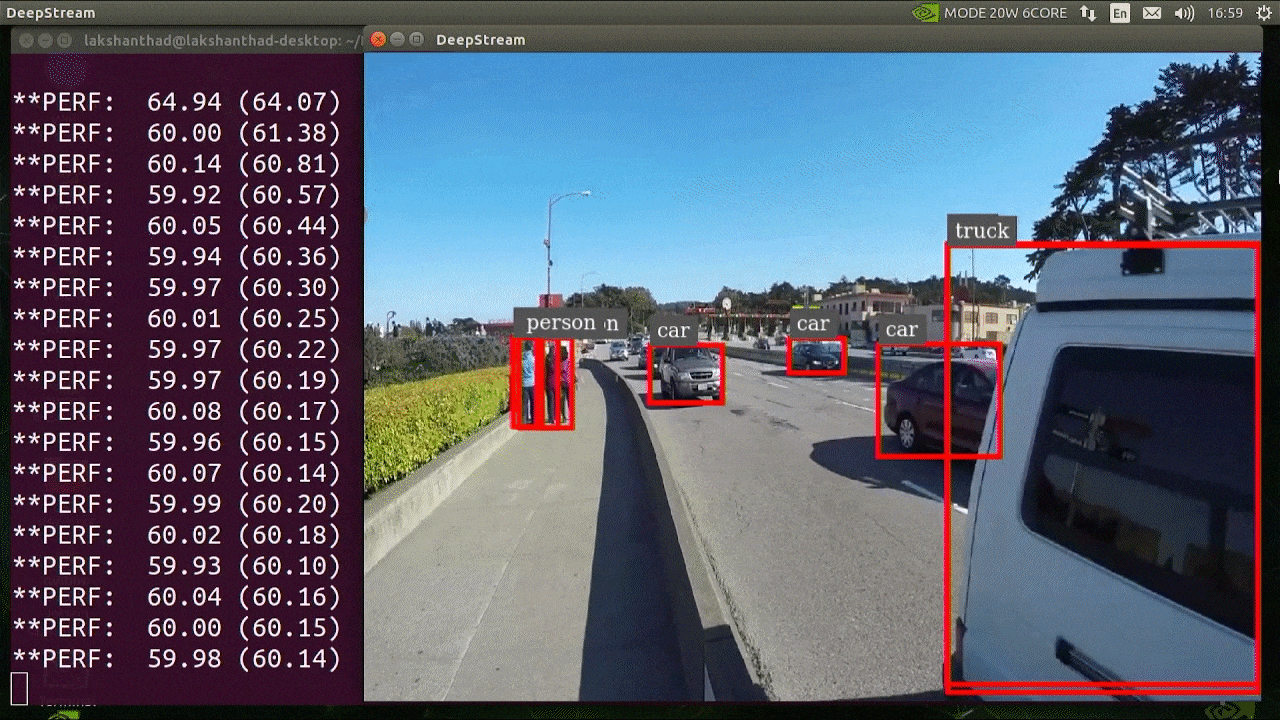
El resultado anterior se ejecuta en Jetson Xavier NX con INT8 y YOLOv5s 640x640. Podemos ver que los FPS están alrededor de 60.
Resultados de benchmark
La siguiente tabla resume cómo funcionan diferentes modelos en Jetson Xavier NX.
| Nombre del Modelo | Precisión | Tamaño de Inferencia | Tiempo de Inferencia (ms) | FPS |
|---|---|---|---|---|
| YOLOv5s | FP32 | 320x320 | 16.66 | 60 |
| FP32 | 640x640 | 33.33 | 30 | |
| INT8 | 640x640 | 16.66 | 60 | |
| YOLOv5n | FP32 | 640x640 | 16.66 | 60 |
Comparación entre usar conjuntos de datos públicos y conjuntos de datos personalizados
Ahora compararemos la diferencia entre el número de muestras de entrenamiento y el tiempo de entrenamiento al usar conjuntos de datos públicos y sus propios conjuntos de datos personalizados
Número de muestras de entrenamiento
Conjunto de datos personalizado
En este wiki, recopilamos nuestro conjunto de datos de plantas como un video primero y luego convertimos el video en una serie de imágenes usando Roboflow. Aquí obtuvimos 542 imágenes, lo cual es un conjunto de datos muy pequeño cuando se compara con conjuntos de datos públicos.
Conjunto de datos público
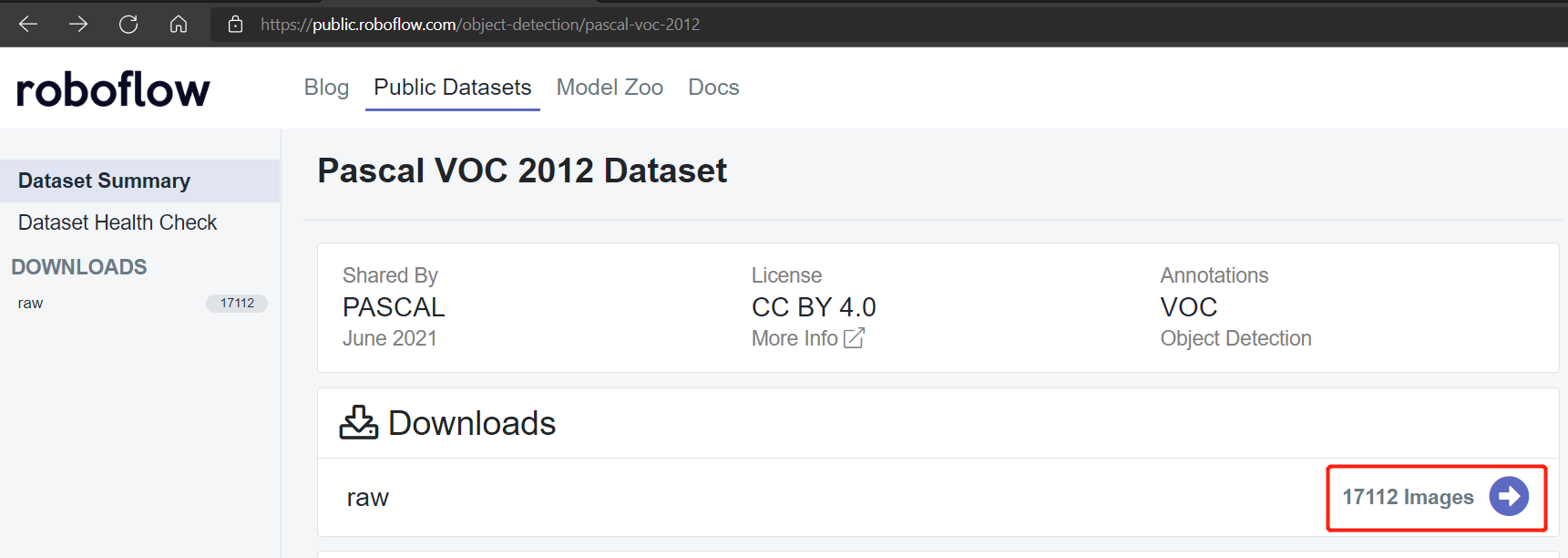
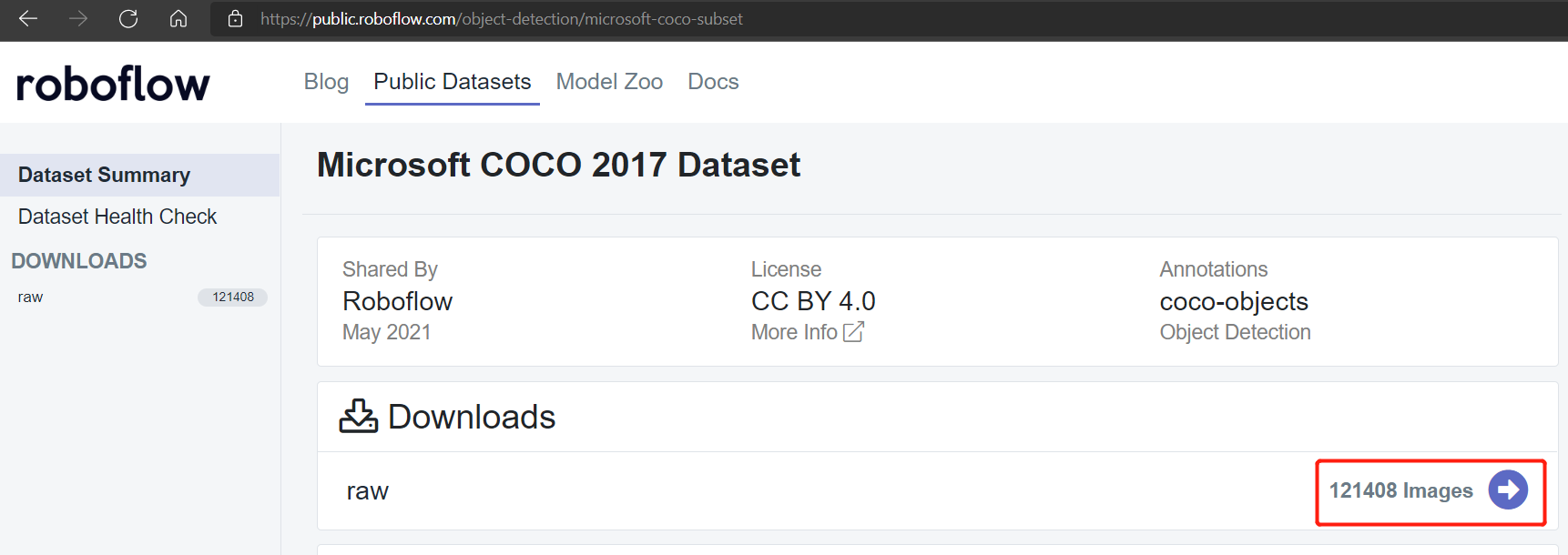
Los conjuntos de datos públicos como Pascal VOC 2012 y Microsoft COCO 2017 tienen alrededor de 17112 y 121408 imágenes respectivamente.
Conjunto de datos Pascal VOC 2012
Conjunto de datos Microsoft COCO 2017
Tiempo de entrenamiento
Entrenamiento local
El entrenamiento se realizó en una tarjeta gráfica NVIDIA GeForce GTX 1660 Super con 6GB de memoria
Conjunto de datos personalizado con entrenamiento local
Conjunto de datos de 540 imágenes
Según el entrenamiento local que realizamos antes para las plantas, obtuvimos los siguientes resultados
Aquí tomó solo 2.2 horas ejecutar 100 épocas. Esto es comparativamente más rápido que entrenar usando conjuntos de datos públicos.
Conjunto de datos de 240 imágenes
Redujimos el conjunto de datos a 240 imágenes y realizamos el entrenamiento nuevamente y obtuvimos los siguientes resultados

Aquí tomó solo aproximadamente 1 hora ejecutar 100 épocas. Esto es comparativamente más rápido que entrenar usando conjuntos de datos públicos.
Conjunto de datos Pascal VOC 2012 con entrenamiento local
Usamos un conjunto de datos Pascal VOC 2012 para el entrenamiento en este escenario mientras manteníamos los mismos parámetros de entrenamiento. Encontramos que estaba tomando aproximadamente 50 minutos (0.846 horas * 60) ejecutar 1 época, y por lo tanto detuvimos el entrenamiento en 1 época.

Si calculamos el tiempo de entrenamiento para 100 épocas, tomaría aproximadamente 50 * 100 minutos = 5000 minutos = 83 horas, lo cual es mucho más largo que el tiempo de entrenamiento para el conjunto de datos personalizado.
Conjunto de datos Microsoft COCO 2017 con entrenamiento local
Usamos un conjunto de datos Microsoft COCO 2017 para el entrenamiento en este escenario mientras manteníamos los mismos parámetros de entrenamiento. Encontramos que se estimaba que tomaría aproximadamente 7.5 horas ejecutar 1 época, y por lo tanto detuvimos el entrenamiento antes de que terminara 1 época.

Si calculamos el tiempo de entrenamiento para 100 épocas, tomaría aproximadamente 7.5 horas * 100 = 750 horas, lo cual es mucho más largo que el tiempo de entrenamiento para el conjunto de datos personalizado.
Entrenamiento en Google Colab
El entrenamiento se realizó en una tarjeta gráfica NVIDIA Tesla K80 con 12GB de memoria
Conjunto de datos personalizado
Conjunto de datos de 540 imágenes
Según el entrenamiento en Google Colab que realizamos antes para las plantas con 540 imágenes, obtuvimos los siguientes resultados
Aquí tomó solo aproximadamente 1.3 horas ejecutar 100 épocas. Esto también es comparativamente más rápido que entrenar usando conjuntos de datos públicos.
Conjunto de datos de 240 imágenes
Redujimos el conjunto de datos a 240 imágenes y realizamos el entrenamiento nuevamente y obtuvimos los siguientes resultados
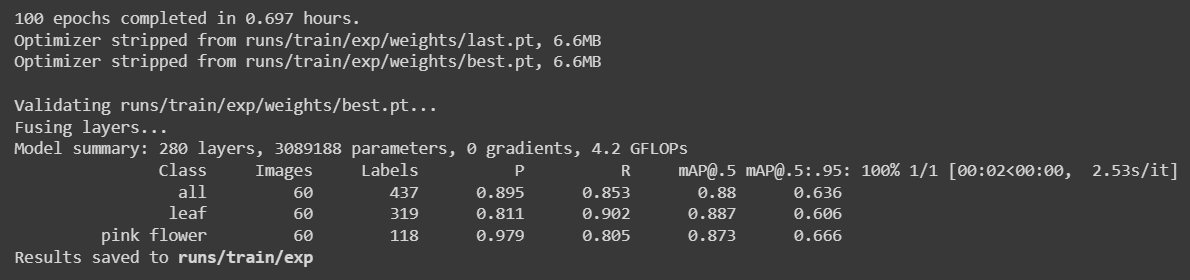
Aquí tomó solo aproximadamente 42 minutos (0.697 horas * 60) ejecutar 100 épocas. Esto es comparativamente más rápido que entrenar usando conjuntos de datos públicos.
Conjunto de datos Pascal VOC 2012 con entrenamiento en Google Colab
Usamos un conjunto de datos Pascal VOC 2012 para el entrenamiento en este escenario mientras manteníamos los mismos parámetros de entrenamiento. Encontramos que estaba tomando aproximadamente 9 minutos (0.148 horas * 60) ejecutar 1 época, y por lo tanto detuvimos el entrenamiento en 1 época.
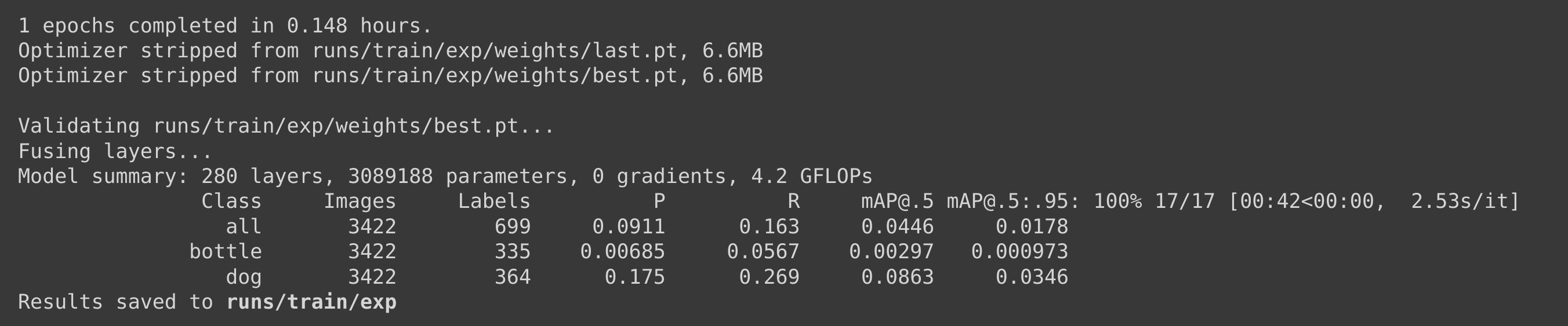
Si calculamos el tiempo de entrenamiento para 100 épocas, tomaría aproximadamente 9 * 100 minutos = 900 minutos = 15 horas, lo cual es mucho más largo que el tiempo de entrenamiento para el conjunto de datos personalizado.
Conjunto de datos Microsoft COCO 2017 con entrenamiento en Google Colab
Usamos un conjunto de datos Microsoft COCO 2017 para el entrenamiento en este escenario mientras manteníamos los mismos parámetros de entrenamiento. Encontramos que se estimaba que tomaría aproximadamente 1.25 horas ejecutar 1 época, y por lo tanto detuvimos el entrenamiento antes de que terminara 1 época.

Si calculamos el tiempo de entrenamiento para 100 épocas, tomaría aproximadamente 1.25 horas * 100 = 125 horas, lo cual es mucho más largo que el tiempo de entrenamiento para el conjunto de datos personalizado.
Resumen del número de muestras de entrenamiento y tiempo de entrenamiento
| Conjunto de datos | Número de muestras de entrenamiento | Tiempo de entrenamiento en PC local (GTX 1660 Super) | Tiempo de entrenamiento en Google Colab (NVIDIA Tesla K80) |
|---|---|---|---|
| Personalizado | 542 | 2.2 horas | 1.3 horas |
| 240 | 1 hora | 42 minutos | |
| Pascal VOC 2012 | 17112 | 83 horas | 15 horas |
| Microsoft COCO 2017 | 121408 | 750 horas | 125 horas |
Comparación de checkpoints preentrenados
Puedes aprender más sobre los checkpoints preentrenados en la tabla a continuación. Aquí hemos destacado nuestro escenario cuando se entrenó con Google Colab y la inferencia se realizó en Jetson Nano y Jetson Xavier NX con YOLOv5n6 como el checkpoint preentrenado.
| Model | size (pixels) | mAPval 0.5:0.95 | mAPval 0.5 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | Speed Jetson Nano FP16 (ms) | Speed Jetson Xavier NX FP16 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 | ||
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 | ||
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 | ||
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 | ||
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 | ||
| YOLOv5n6 | 640 | 71.7 | 95.5 | 153 | 8.1 | 2.1 | 47 | 20 | 3.1 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 | ||
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 | ||
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 | ||
| YOLOv5x6 + [TTA] | 1280 1536 | 55.0 55.8 | 72.7 72.7 | 3136 - | 26.2 - | 19.4 - | 140.7 - | 209.8 - |
Referencia: YOLOv5 GitHub
Aplicaciones adicionales
Dado que todos los pasos que explicamos anteriormente son comunes para cualquier tipo de aplicación de detección de objetos, ¡solo necesitas cambiar el conjunto de datos por tu propia aplicación de detección de objetos!
Detección de señales de tráfico
Aquí usamos el conjunto de datos de señales de tráfico de Roboflow y realizamos inferencia en NVIDIA Jetson!

Detección de humo de incendios forestales
Aquí usamos el conjunto de datos de humo de incendios forestales de Roboflow y realizamos inferencia en NVIDIA Jetson!

Recursos
-
[Página Web] Documentación de YOLOv5
-
[Página Web] Ultralytics HUB
-
[Página Web] Documentación de Roboflow
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.