Desplegar YOLOv8 en NVIDIA Jetson usando TensorRT y DeepStream SDK Support
Esta guía explica cómo desplegar un modelo de IA entrenado en la plataforma NVIDIA Jetson y realizar inferencia usando TensorRT y DeepStream SDK. Aquí usamos TensorRT para maximizar el rendimiento de inferencia en la plataforma Jetson.

Prerrequisitos
- PC Host Ubuntu (nativo o VM usando VMware Workstation Player)
- reComputer Jetson o cualquier otro dispositivo NVIDIA Jetson ejecutando JetPack 4.6 o superior
Versión de DeepStream Correspondiente a la Versión de JetPack
Para que YOLOv8 funcione junto con DeepStream, estamos usando este repositorio DeepStram-YOLO y soporta diferentes versiones de DeepStream. Así que asegúrate de usar la versión correcta de JetPack según la versión correcta de DeepStream.
| Versión de DeepStream | Versión de JetPack |
|---|---|
| 6.2 | 5.1.1 |
| 5.1 | |
| 6.1.1 | 5.0.2 |
| 6.1 | 5.0.1 DP |
| 6.0.1 | 4.6.3 |
| 4.6.2 | |
| 4.6.1 | |
| 6.0 | 4.6 |
Para verificar esta wiki, hemos instalado DeepStream SDK 6.2 en un sistema JetPack 5.1.1 ejecutándose en reComputer J4012.
Flashear JetPack a Jetson
Ahora necesitas asegurarte de que el dispositivo Jetson esté flasheado con un sistema JetPack incluyendo componentes SDK como CUDA, TensorRT, cuDNN y más. Puedes usar NVIDIA SDK Manager o línea de comandos para flashear JetPack al dispositivo.
Para las guías de flasheo de dispositivos Seeed con tecnología Jetson, por favor consulta los siguientes enlaces:
- reComputer J1010 | J101
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 Carrier Board
- A205 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
Instalar DeepStream
Hay múltiples formas de instalar DeepStream en el dispositivo Jetson. Puedes seguir esta guía para aprender más. Sin embargo, te recomendamos instalar DeepStream a través del SDK Manager porque puede garantizar una instalación exitosa y fácil.
Si instalas DeepStream usando el SDK manager, necesitas ejecutar los siguientes comandos que son dependencias adicionales para DeepStream, después de que el sistema arranque
sudo apt install \
libssl1.1 \
libgstreamer1.0-0 \
gstreamer1.0-tools \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly \
gstreamer1.0-libav \
libgstreamer-plugins-base1.0-dev \
libgstrtspserver-1.0-0 \
libjansson4 \
libyaml-cpp-dev
Instalar Paquetes Necesarios
- Paso 1. Accede a la terminal del dispositivo Jetson, instala pip y actualízalo
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- Paso 2. Clona el siguiente repositorio
git clone https://github.com/ultralytics/ultralytics.git
- Paso 3. Abre requirements.txt
cd ultralytics
vi requirements.txt
- Paso 4. Edita las siguientes líneas. Aquí necesitas presionar
iprimero para entrar al modo de edición. PresionaESC, luego escribe:wqpara guardar y salir
# torch>=1.7.0
# torchvision>=0.8.1
Nota: torch y torchvision se excluyen por ahora porque se instalarán más tarde.
- Paso 5. Instala los paquetes necesarios
pip3 install -r requirements.txt
Si el instalador se queja sobre el paquete python-dateutil desactualizado, actualízalo con
pip3 install python-dateutil --upgrade
Instalar PyTorch y Torchvision
No podemos instalar PyTorch y Torchvision desde pip porque no son compatibles para ejecutarse en la plataforma Jetson que está basada en arquitectura ARM aarch64. Por lo tanto necesitamos instalar manualmente la rueda pip de PyTorch pre-construida y compilar/instalar Torchvision desde el código fuente.
Visita esta página para acceder a todos los enlaces de PyTorch y Torchvision.
Aquí hay algunas de las versiones soportadas por JetPack 5.0 y superiores.
PyTorch v1.11.0
Soportado por JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) con Python 3.8
file_name: torch-1.11.0-cp38-cp38-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/ssf2v7pf5i245fk4i0q926hy4imzs2ph.whl
PyTorch v1.12.0
Soportado por JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) con Python 3.8
file_name: torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Paso 1. Instala torch según tu versión de JetPack en el siguiente formato
wget <URL> -O <file_name>
pip3 install <file_name>
Por ejemplo, aquí estamos ejecutando JP5.0.2 y por lo tanto elegimos PyTorch v1.12.0
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl -O torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
pip3 install torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Paso 2. Instala torchvision dependiendo de la versión de PyTorch que hayas instalado. Por ejemplo, elegimos PyTorch v1.12.0, lo que significa que necesitamos elegir Torchvision v0.13.0
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.13.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
Aquí hay una lista de la versión correspondiente de torchvision que necesitas instalar según la versión de PyTorch:
- PyTorch v1.11 - torchvision v0.12.0
- PyTorch v1.12 - torchvision v0.13.0
Si quieres una lista más detallada, por favor revisa este enlace.
Configuración de DeepStream para YOLOv8
- Paso 1. Clona el siguiente repositorio
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- Paso 2. Cambia el repositorio al siguiente commit
cd DeepStream-Yolo
git checkout 68f762d5bdeae7ac3458529bfe6fed72714336ca
- Paso 3. Copia gen_wts_yoloV8.py desde DeepStream-Yolo/utils al directorio ultralytics
cp utils/gen_wts_yoloV8.py ~/ultralytics
- Paso 4. Dentro del repositorio ultralytics, descarga el archivo pt desde YOLOv8 releases (ejemplo para YOLOv8s)
wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt
NOTA: Puedes usar tu modelo personalizado, pero es importante mantener la referencia del modelo YOLO (yolov8_) en tus nombres de archivo cfg y weights/wts para generar el motor correctamente.
- Paso 5. Genera los archivos cfg, wts y labels.txt (si está disponible) (ejemplo para YOLOv8s)
python3 gen_wts_yoloV8.py -w yolov8s.pt
Nota: Para cambiar el tamaño de inferencia (por defecto: 640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Ejemplo para 1280:
-s 1280
o
-s 1280 1280
- Paso 6. Copia los archivos generados cfg, wts y labels.txt (si se generó) a la carpeta DeepStream-Yolo
cp yolov8s.cfg ~/DeepStream-Yolo
cp yolov8s.wts ~/DeepStream-Yolo
cp labels.txt ~/DeepStream-Yolo
- Paso 7. Abre la carpeta DeepStream-Yolo y compila la biblioteca
cd ~/DeepStream-Yolo
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # para DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # para DeepStream 6.0.1 / 6.0
- Paso 8. Edita el archivo config_infer_primary_yoloV8.txt según tu modelo (ejemplo para YOLOv8s con 80 clases)
[property]
...
custom-network-config=yolov8s.cfg
model-file=yolov8s.wts
...
num-detected-classes=80
...
- Paso 9. Edita el archivo deepstream_app_config.txt
...
[primary-gie]
...
config-file=config_infer_primary_yoloV8.txt
- Paso 10. Cambia la fuente de video en el archivo deepstream_app_config.txt. Aquí se carga un archivo de video por defecto como puedes ver a continuación
...
[source0]
...
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
Ejecutar la Inferencia
deepstream-app -c deepstream_app_config.txt
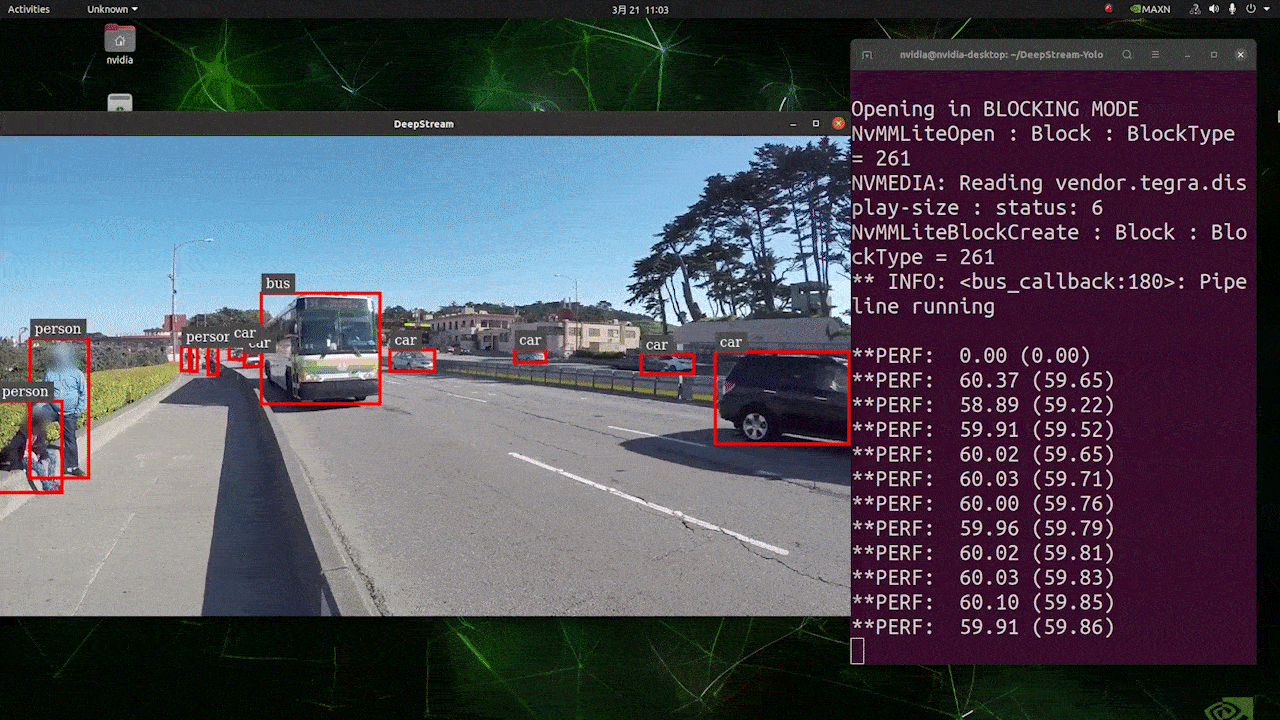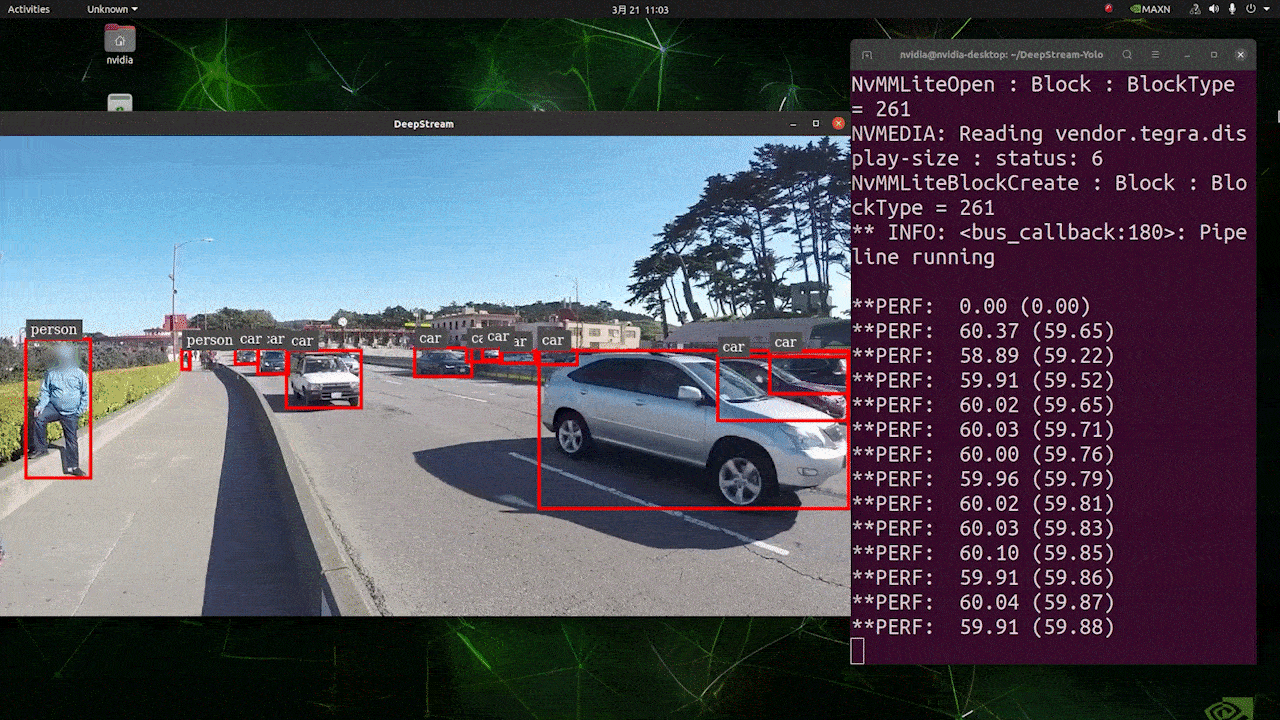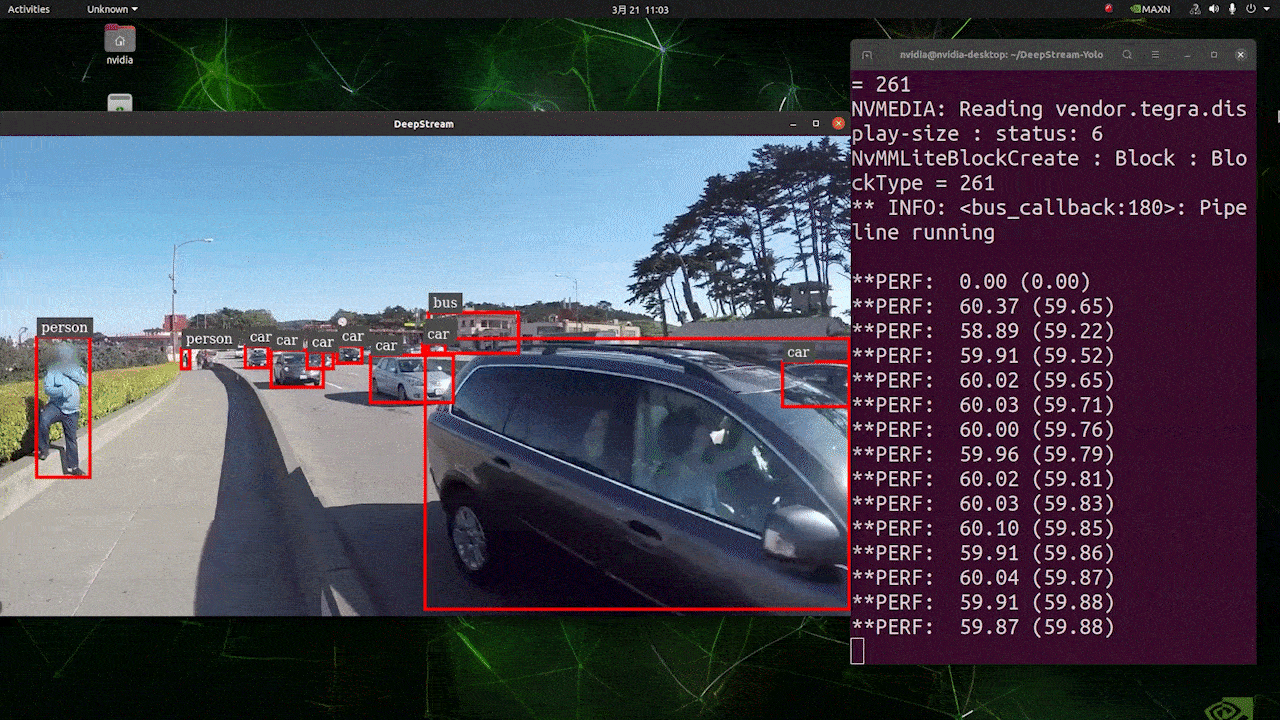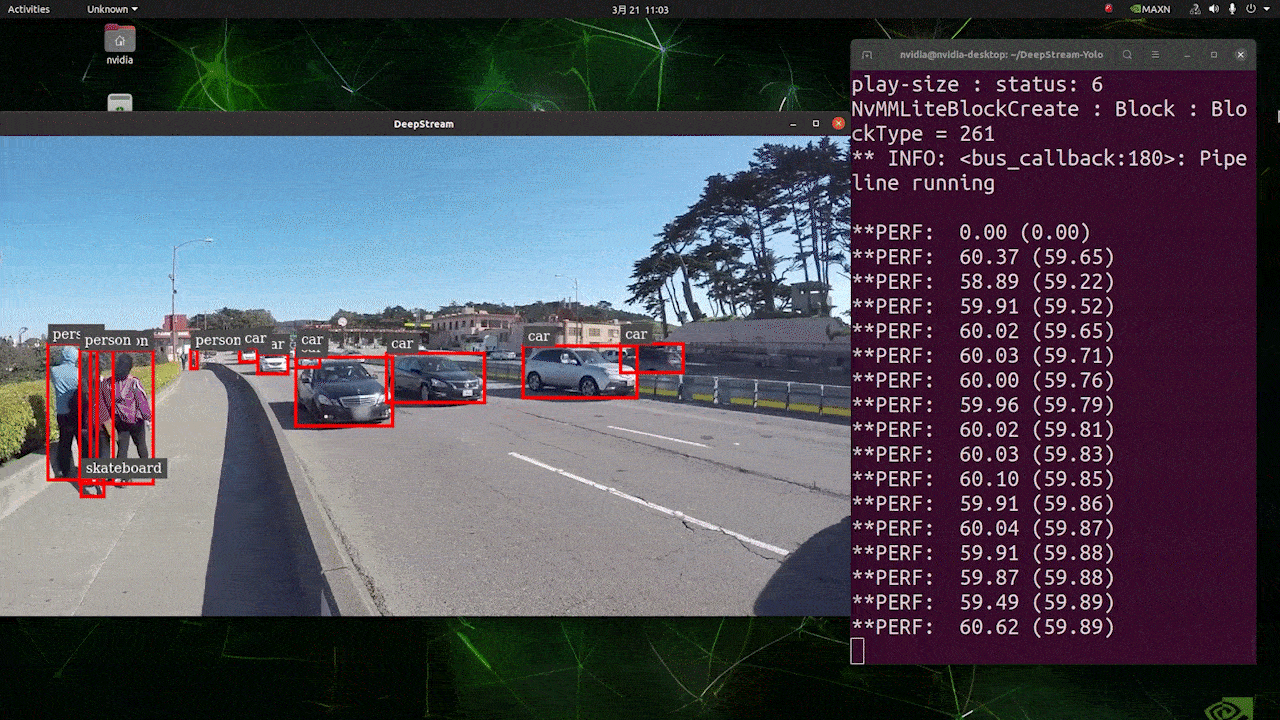
El resultado anterior se ejecuta en Jetson AGX Orin 32GB H01 Kit con FP32 y YOLOv8s 640x640. Podemos ver que los FPS están alrededor de 60 y ese no es el FPS real porque cuando configuramos type=2 bajo [sink0] en el archivo deepstream_app_config.txt, los FPS están limitados a los fps del monitor y el monitor que usamos para esta prueba es un monitor de 60Hz. Sin embargo, si cambias este valor a type=1, podrás obtener los FPS máximos, pero no habrá salida de detección en vivo.
Para la misma fuente de video y el mismo modelo usado anteriormente, después de cambiar type=1 bajo [sink0], se puede obtener el siguiente resultado.
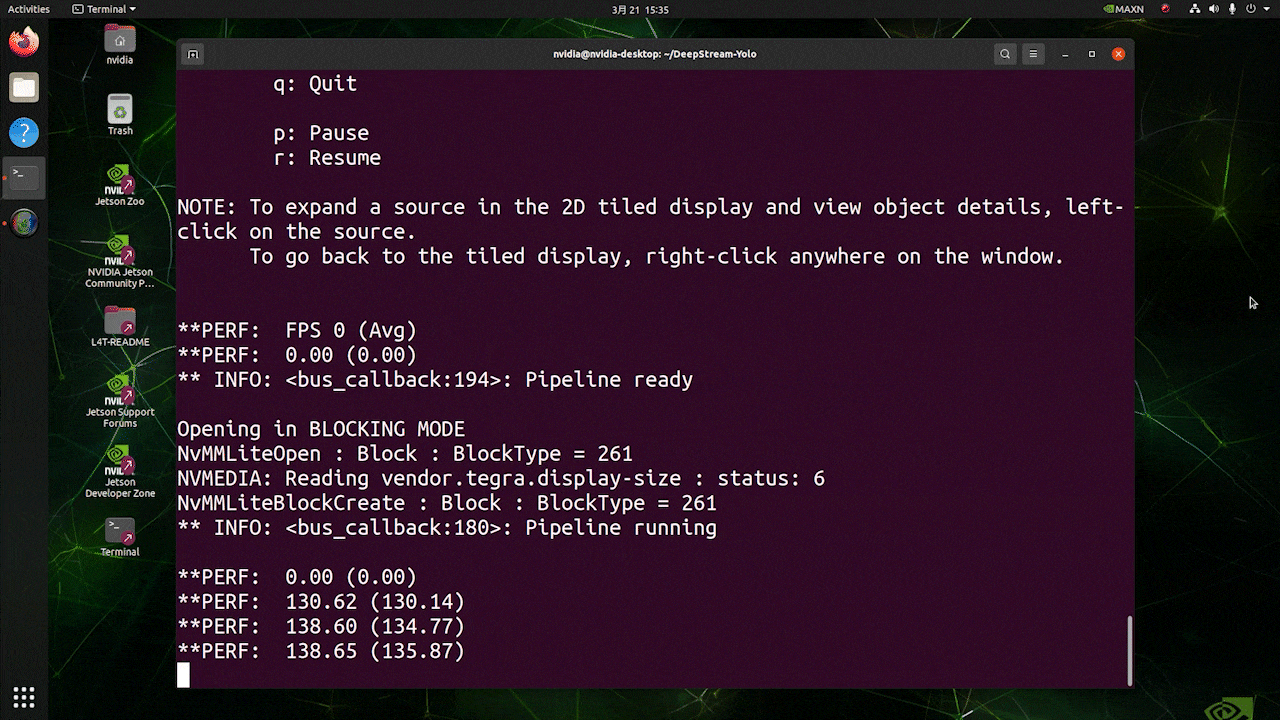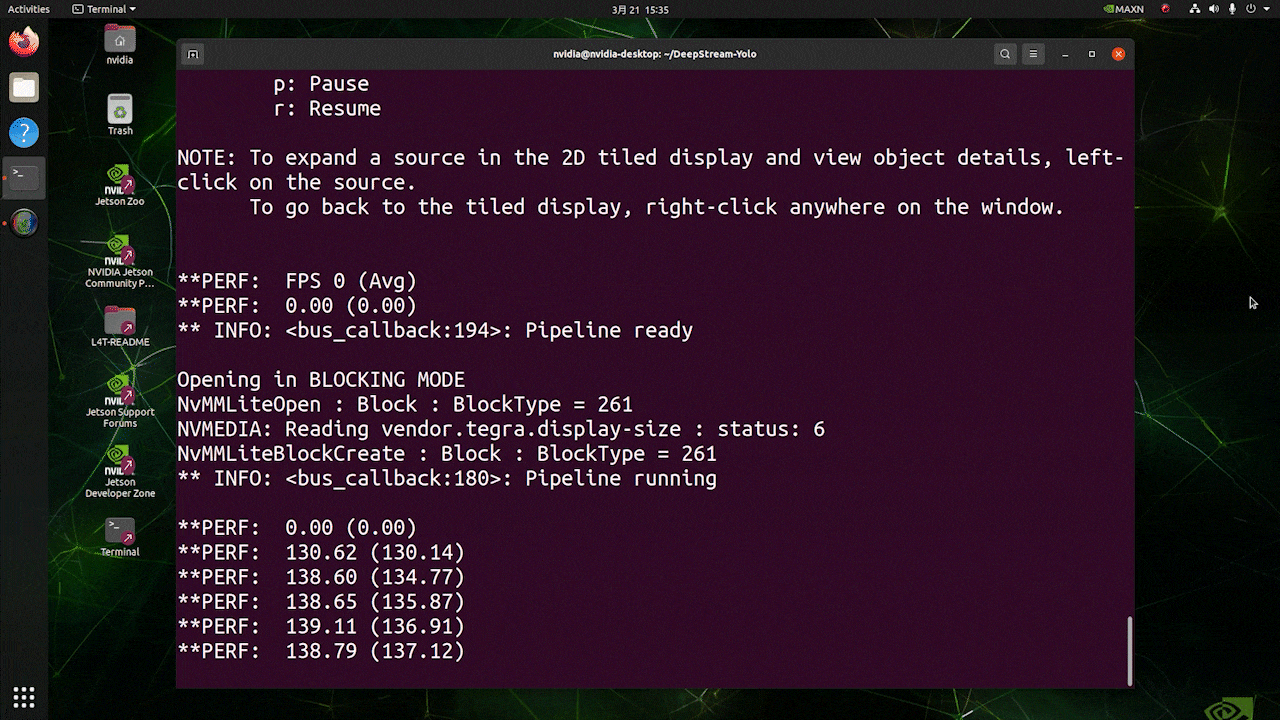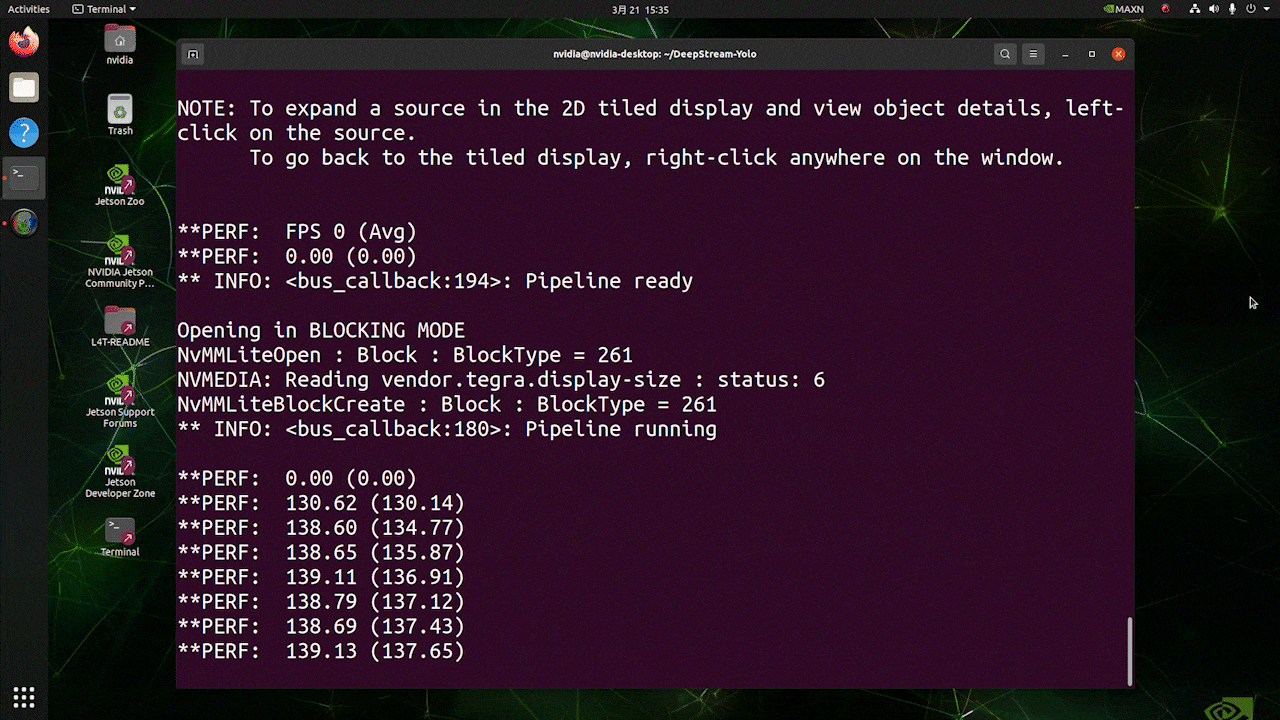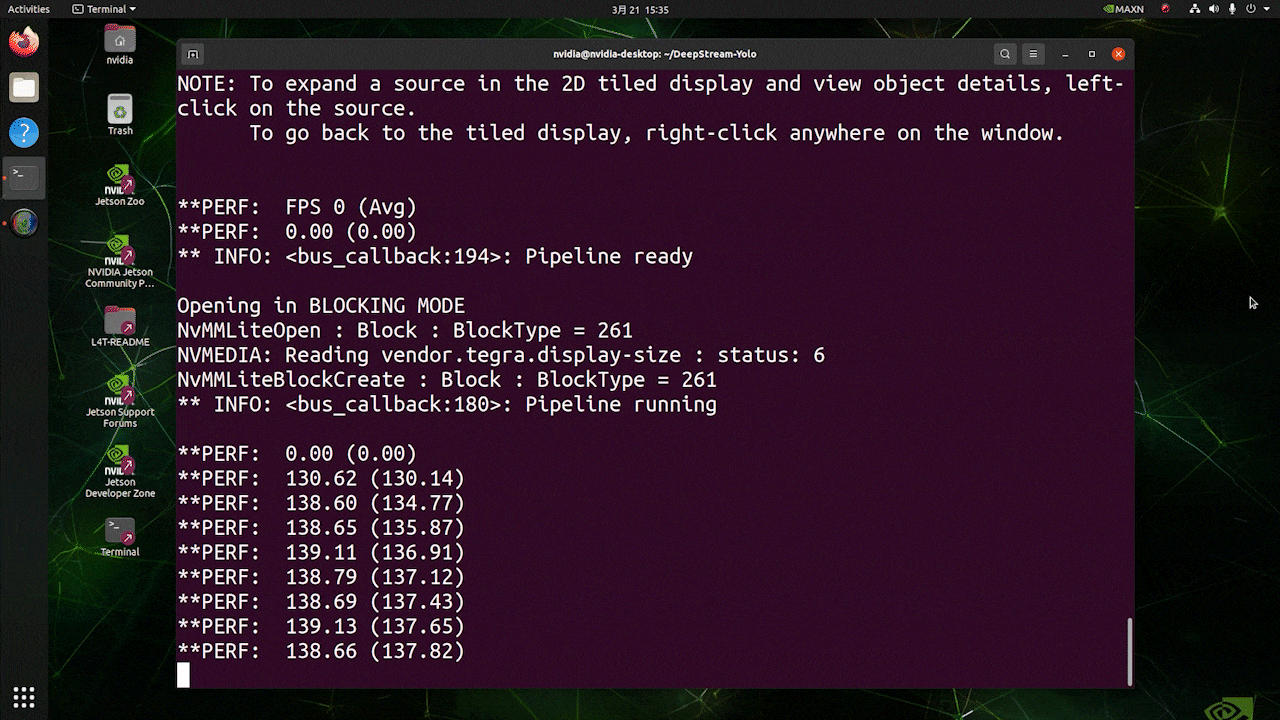
Como puedes ver, podemos obtener unos fps de aproximadamente 139 que se relaciona con el valor real de fps.
Calibración INT8
Si quieres usar precisión INT8 para inferencia, necesitas seguir los pasos a continuación
- Paso 1. Instalar OpenCV
sudo apt-get install libopencv-dev
- Paso 2. Compilar/recompilar la biblioteca nvdsinfer_custom_impl_Yolo con soporte OpenCV
cd ~/DeepStream-Yolo
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # para DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # para DeepStream 6.0.1 / 6.0
-
Paso 3. Para el dataset COCO, descargar el val2017, extraer, y mover a la carpeta DeepStream-Yolo
-
Paso 4. Crear un nuevo directorio para las imágenes de calibración
mkdir calibration
- Paso 5. Ejecutar lo siguiente para seleccionar 1000 imágenes aleatorias del dataset COCO para ejecutar la calibración
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
Nota: NVIDIA recomienda al menos 500 imágenes para obtener una buena precisión. En este ejemplo, se eligen 1000 imágenes para obtener mejor precisión (más imágenes = más precisión). Valores más altos de INT8_CALIB_BATCH_SIZE resultarán en más precisión y velocidad de calibración más rápida. Configúralo según la memoria de tu GPU. Puedes configurarlo desde head -1000. Por ejemplo, para 2000 imágenes, head -2000. Este proceso puede tomar mucho tiempo.
- Paso 6. Crear el archivo calibration.txt con todas las imágenes seleccionadas
realpath calibration/*jpg > calibration.txt
- Paso 7. Configurar variables de entorno
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- Paso 8. Actualizar el archivo config_infer_primary_yoloV8.txt
De
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
A
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
-
Paso 9. Antes de ejecutar la inferencia, configurar type=2 bajo [sink0] en el archivo deepstream_app_config.txt como se mencionó antes para obtener el rendimiento máximo de fps.
-
Paso 10. Ejecutar la inferencia
deepstream-app -c deepstream_app_config.txt
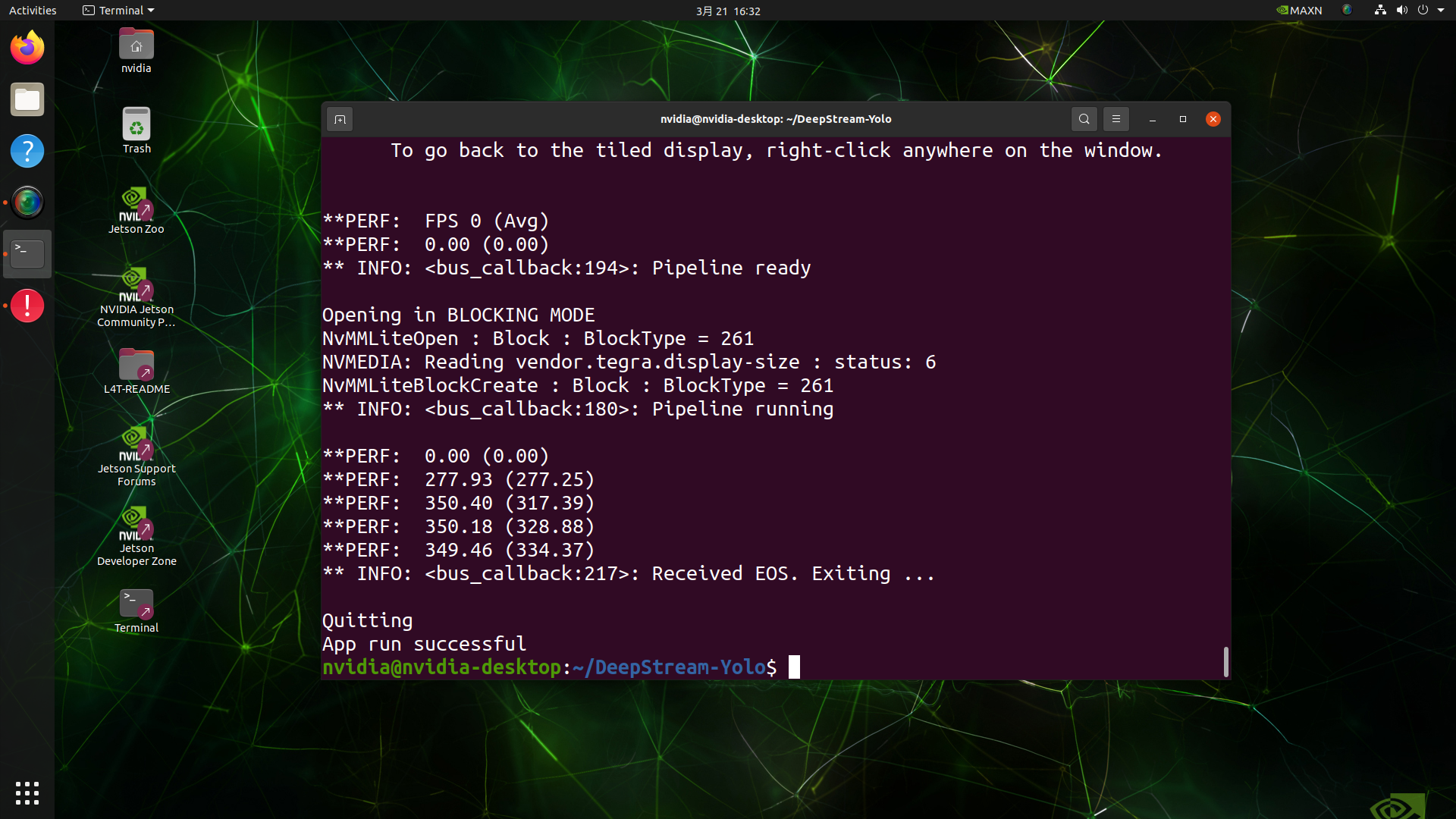
¡Aquí obtenemos un valor de FPS de aproximadamente 350!
Configuración Multistream
NVIDIA DeepStream te permite configurar fácilmente múltiples streams en un solo archivo de configuración para construir aplicaciones de análisis de video multistream. Demostraremos más adelante en este wiki cómo los modelos con alto rendimiento de FPS pueden realmente ayudar con aplicaciones multistream junto con algunos benchmarks.
Aquí tomaremos 9 streams como ejemplo. Estaremos cambiando el archivo deepstream_app_config.txt.
- Paso 1. Dentro de la sección [tiled-display], cambiar las filas y columnas a 3 y 3 para que podamos tener una cuadrícula de 3x3 con 9 streams
[tiled-display]
rows=3
columns=3
- Paso 2. Dentro de la sección [source0], configurar num-sources=9 y agregar más uri. Aquí simplemente duplicaremos el archivo de video de ejemplo actual 8 veces para completar 9 streams en total. Sin embargo, puedes cambiar a diferentes streams de video según tu aplicación
[source0]
enable=1
type=3
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
num-sources=9
Ahora si ejecutas la aplicación nuevamente con el comando deepstream-app -c deepstream_app_config.txt, verás la siguiente salida
Herramienta trtexec
Incluida en el directorio de muestras hay una herramienta de línea de comandos llamada trtexec. trtexec es una herramienta para usar TensorRT sin tener que desarrollar tu propia aplicación. La herramienta trtexec tiene tres propósitos principales:
- Hacer benchmarks de redes con datos de entrada aleatorios o proporcionados por el usuario.
- Generar motores serializados a partir de modelos.
- Generar una caché de tiempo serializada desde el constructor.
Aquí podemos usar la herramienta trtexec para hacer benchmarks rápidamente de los modelos con diferentes parámetros. Pero primero, necesitas tener un modelo onnx y podemos generar este modelo onnx usando ultralytics yolov8.
- Paso 1. Construir ONNX usando:
yolo mode=export model=yolov8s.pt format=onnx
- Paso 1. Construir archivo de motor usando trtexec como sigue:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<ruta_al_archivo_onnx> --saveEngine=<ruta_para_guardar_archivo_motor>
Por ejemplo:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine
Esto mostrará resultados de rendimiento como sigue junto con un archivo .engine generado. Por defecto convertirá ONNX a un archivo optimizado de TensorRT en precisión FP32 y puedes ver la salida como sigue
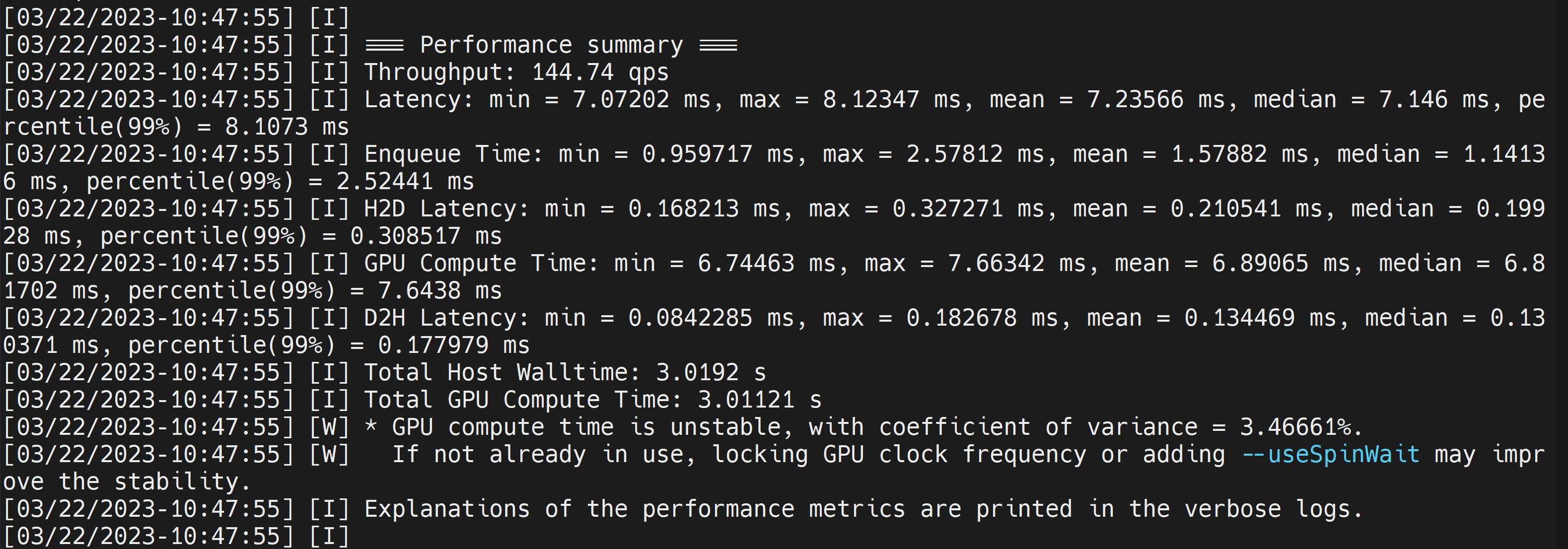
Aquí podemos tomar la latencia media como 7.2ms que se traduce a 139FPS. Este es el mismo rendimiento que obtuvimos en la demostración anterior de DeepStream.
Sin embargo, si quieres precisión INT8 que ofrece mejor rendimiento, puedes ejecutar el comando anterior como sigue
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
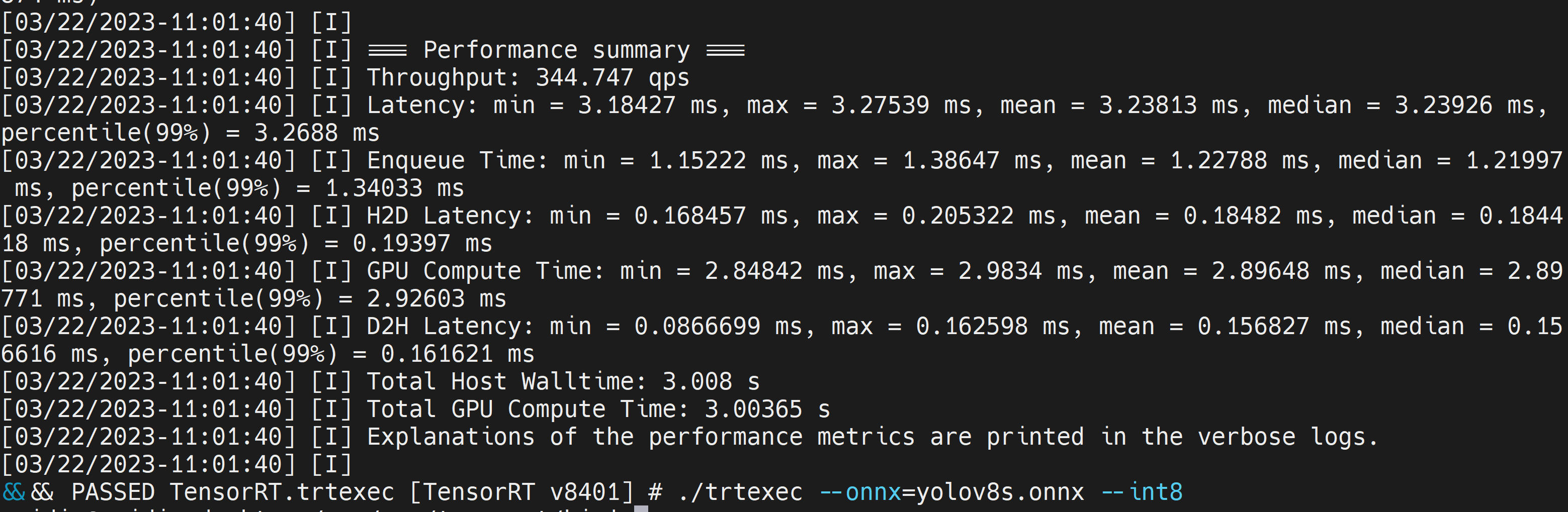
Aquí podemos tomar la latencia media como 3.2ms que se traduce a 313FPS.
Resultados de Benchmark de YOLOv8
Hemos realizado benchmarks de rendimiento para diferentes modelos YOLOv8 ejecutándose en reComputer J4012, AGX Orin 32GB H01 Kit y reComputer J2021
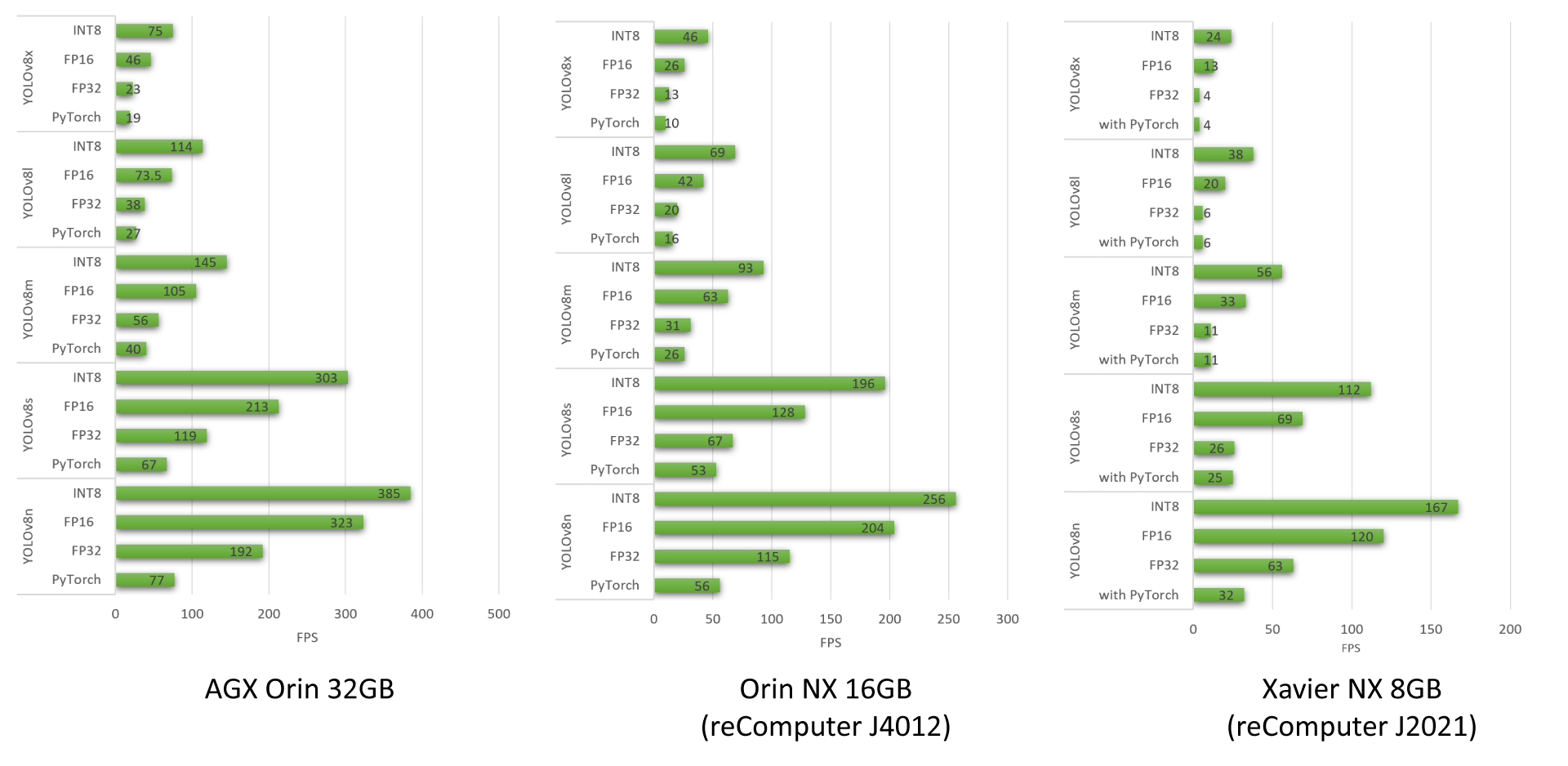
Para aprender sobre más benchmarks de rendimiento que hemos realizado usando modelos YOLOv8, por favor revisa nuestro blog.
Benchmarks de Modelo Multistream
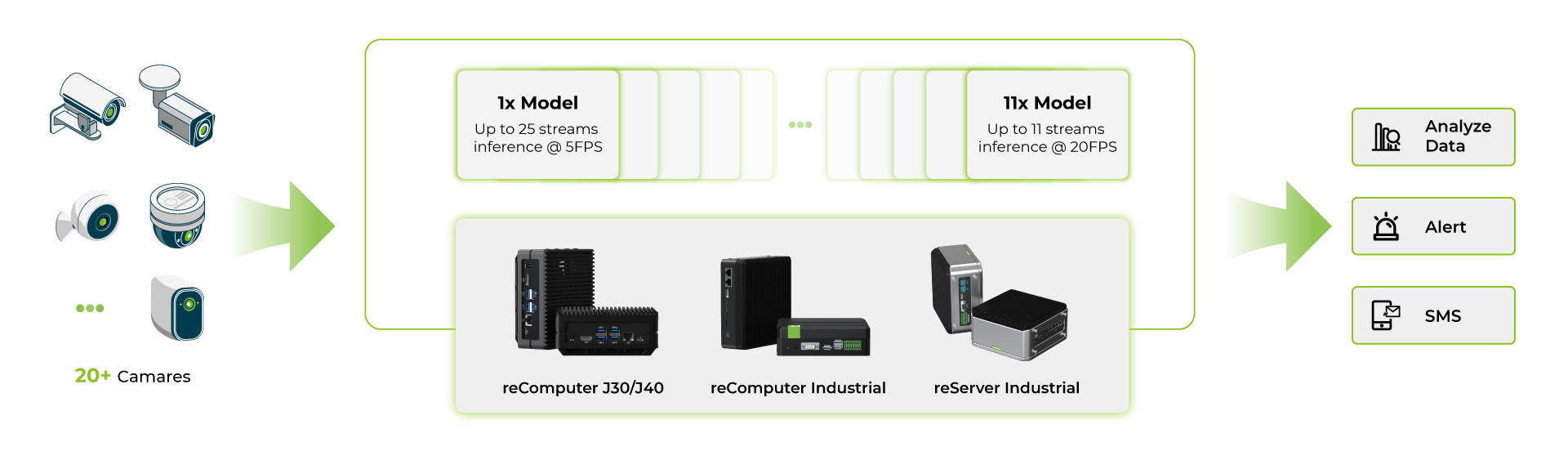
Después de ejecutar varias aplicaciones deepstream en productos de la serie reComputer Jetson Orin, hemos realizado benchmarks con los modelos YOLOv8s.
- Primero, hemos usado un solo modelo de IA y ejecutado múltiples streams en el mismo modelo de IA
- Segundo, hemos usado múltiples modelos de IA y ejecutado múltiples streams en múltiples modelos de IA
Todos estos benchmarks se realizan bajo las siguientes condiciones:
- YOLOv8s entrada de imagen 640x640
- Deshabilitar UI
- Activar modo de máxima potencia y máximo rendimiento
De estos benchmarks, podemos ver que para el dispositivo Orin NX 16GB de gama más alta con un solo modelo YOLOv8s en INT8, puedes usar alrededor de 40 cámaras a aproximadamente 5fps y con múltiples modelos YOLOv8s en INT8 para cada stream, puedes usar alrededor de 11 cámaras a aproximadamente 15fps. Para aplicaciones multi modelo, el número de cámaras es menor debido a las limitaciones de RAM en el dispositivo y cada modelo ocupa una cantidad sustancial de RAM.
En resumen, cuando se opera un dispositivo edge con modelo YOLOv8 únicamente sin aplicaciones ejecutándose, el Jetson Orin Nano 8GB puede soportar 4-6 streams, mientras que el Jetson Orin NX 16GB puede manejar 16-18 streams a máxima capacidad. Sin embargo, estos números pueden disminuir cuando los recursos de RAM se utilizan en aplicaciones del mundo real. Por lo tanto, es recomendable usar estas cifras como guías y realizar tus propias pruebas bajo tus condiciones específicas.
Recursos
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarle diferentes tipos de soporte para asegurar que su experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.