Desplegar YOLOv8 en NVIDIA Jetson usando TensorRT
Esta guía wiki explica cómo desplegar un modelo YOLOv8 en la plataforma NVIDIA Jetson y realizar inferencia usando TensorRT. Aquí usamos TensorRT para maximizar el rendimiento de inferencia en la plataforma Jetson.
Se introducirán diferentes tareas de visión por computadora como:
- Detección de Objetos
- Segmentación de Imágenes
- Clasificación de Imágenes
- Estimación de Pose
- Seguimiento de Objetos

Prerrequisitos
- PC Host Ubuntu (nativo o VM usando VMware Workstation Player)
- reComputer Jetson o cualquier otro dispositivo NVIDIA Jetson ejecutando JetPack 5.1.1 o superior
Esta wiki ha sido probada y verificada en un reComputer J4012 y reComputer Industrial J4012[https://www.seeedstudio.com/reComputer-Industrial-J4012-p-5684.html] alimentado por el módulo NVIDIA Jetson orin NX 16GB
Flashear JetPack a Jetson
Ahora necesitas asegurarte de que el dispositivo Jetson esté flasheado con un sistema JetPack. Puedes usar NVIDIA SDK Manager o línea de comandos para flashear JetPack al dispositivo.
Para las guías de flasheo de dispositivos Seeed alimentados por Jetson, consulta los siguientes enlaces:
- reComputer J1010 | J101
- reComputer J2021 | J202
- reComputer J1020 | A206
- reComputer J4012 | J401
- A203 Carrier Board
- A205 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
Asegúrate de flashear la versión 5.1.1 de JetPack porque esa es la versión que hemos verificado para esta wiki
¡Desplegar YOLOV8 a Jetson en Una Línea de Código!
Después de flashear el dispositivo Jetson con JetPack, simplemente puedes ejecutar los siguientes comandos para ejecutar modelos YOLOv8. Esto primero descargará e instalará los paquetes necesarios, dependencias, configurará el entorno y descargará modelos preentrenados de YOLOv8 para realizar tareas de detección de objetos, segmentación de imágenes, estimación de pose y clasificación de imágenes!
wget files.seeedstudio.com/YOLOv8-Jetson.py && python YOLOv8-Jetson.py
El código fuente del script anterior se puede encontrar aquí
Usar modelos pre-entrenados
La forma más rápida de comenzar con YOLOv8 es usar modelos pre-entrenados proporcionados por YOLOv8. Sin embargo, estos son modelos PyTorch y por lo tanto solo utilizarán la CPU al hacer inferencia en el Jetson. Si quieres el mejor rendimiento de estos modelos en el Jetson mientras se ejecutan en la GPU, puedes exportar los modelos PyTorch a TensorRT siguiendo esta sección del wiki.
- Detección de Objetos
- Clasificación de Imágenes
- Segmentación de Imágenes
- Estimación de Pose
- Seguimiento de Objetos
YOLOv8 ofrece 5 pesos de modelos PyTorch pre-entrenados para detección de objetos, entrenados en el conjunto de datos COCO con tamaño de imagen de entrada de 640x640. Puedes encontrarlos a continuación
| Modelo | tamaño (píxeles) | mAPval 50-95 | Velocidad CPU ONNX (ms) | Velocidad A100 TensorRT (ms) | parámetros (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
Referencia: https://docs.ultralytics.com/tasks/detect
Puedes elegir y descargar tu modelo deseado de la tabla anterior y ejecutar el siguiente comando para ejecutar inferencia en una imagen
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' show=True
Aquí para el modelo, puedes cambiar a yolov8s.pt, yolov8m.pt, yolov8l.pt, yolov8x.pt y descargará el modelo pre-entrenado relevante
También puedes conectar una cámara web y ejecutar el siguiente comando
yolo detect predict model=yolov8n.pt source='0' show=True
Si encuentras algún error al ejecutar los comandos anteriores, intenta añadir "device=0" al final del comando

Lo anterior se ejecuta en un reComputer J4012/ reComputer Industrial J4012 y utiliza el modelo YOLOv8s entrenado con entrada de 640x640 y usa precisión TensorRT FP16.
YOLOv8 ofrece 5 pesos de modelo PyTorch preentrenados para clasificación de imágenes, entrenados en ImageNet con tamaño de imagen de entrada de 224x224. Puedes encontrarlos a continuación
| Modelo | tamaño (píxeles) | acc top1 | acc top5 | Velocidad CPU ONNX (ms) | Velocidad A100 TensorRT (ms) | params (M) | FLOPs (B) en 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
Referencia: https://docs.ultralytics.com/tasks/classify
Puedes elegir tu modelo deseado y ejecutar el comando siguiente para ejecutar inferencia en una imagen
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' show=True
Aquí para el modelo, puedes cambiar a yolov8s-cls.pt, yolov8m-cls.pt, yolov8l-cls.pt, yolov8x-cls.pt y descargará el modelo preentrenado relevante
También puedes conectar una cámara web y ejecutar el siguiente comando
yolo classify predict model=yolov8n-cls.pt source='0' show=True
Si encuentras algún error al ejecutar los comandos anteriores, intenta añadir "device=0" al final del comando
(actualización con inferencia 224)
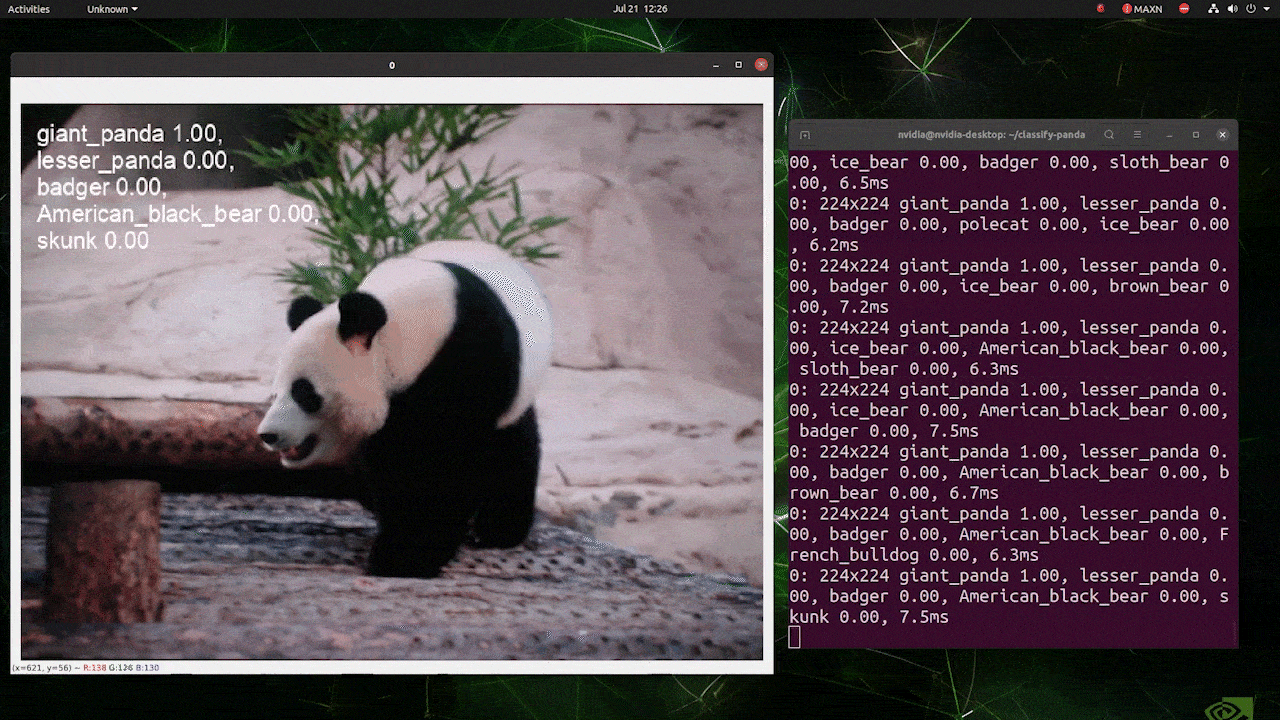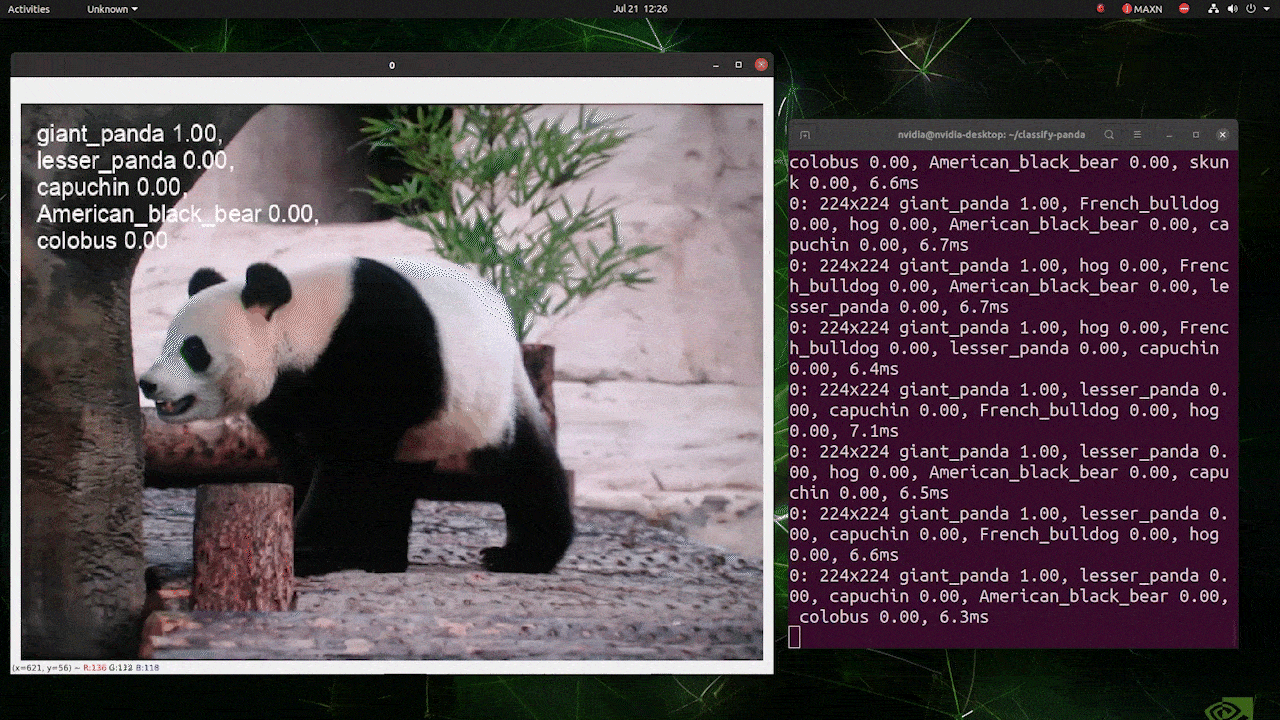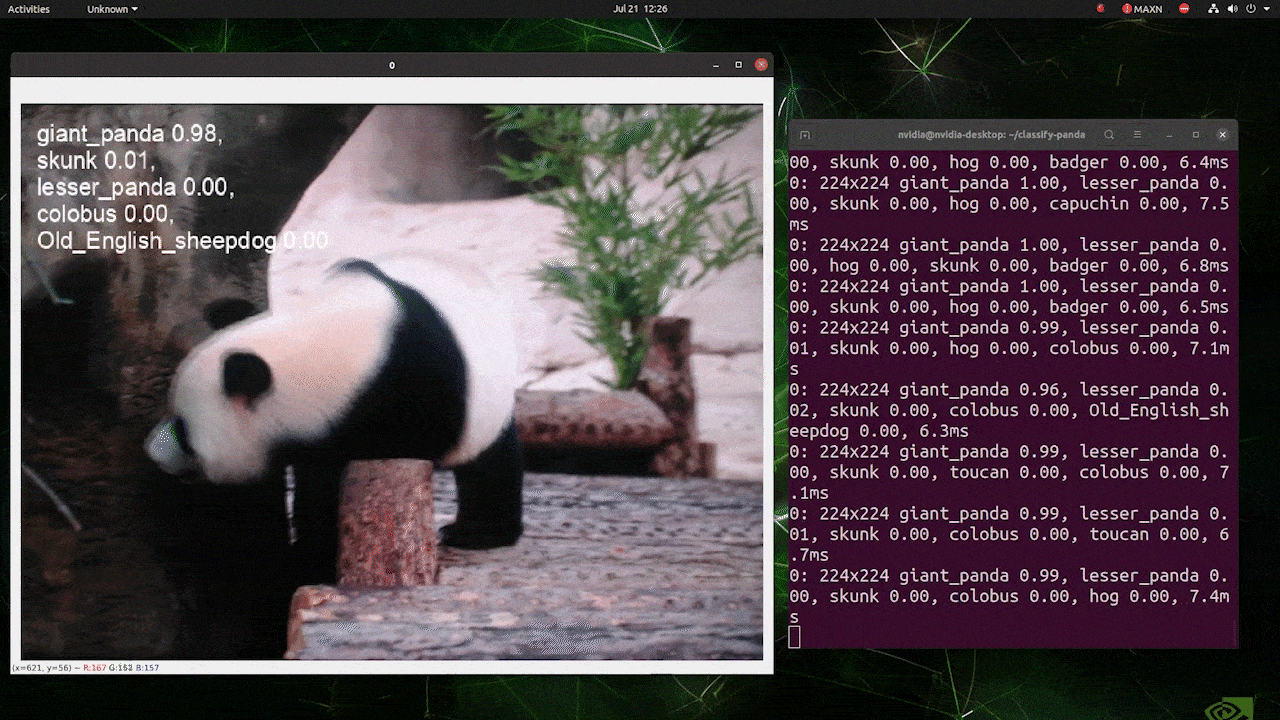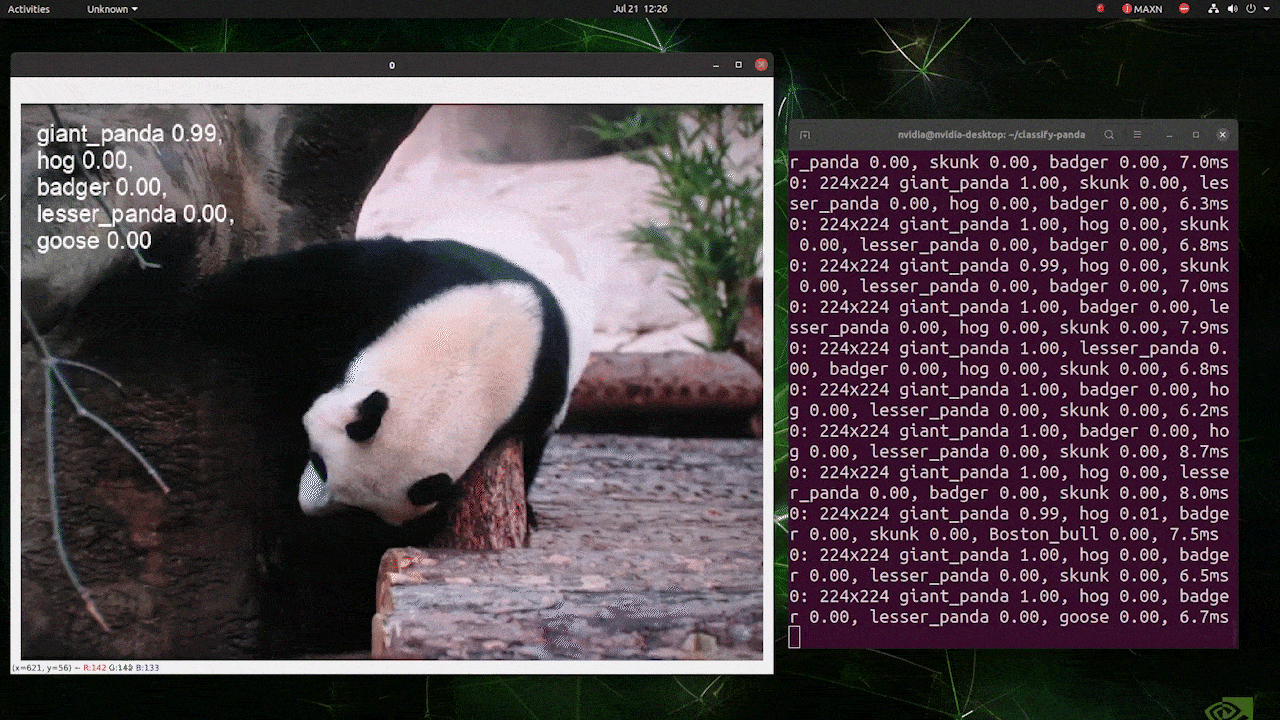
Lo anterior se ejecuta en un reComputer J4012/ reComputer Industrial J4012 y utiliza el modelo YOLOv8s-cls entrenado con entrada de 224x224 y usa precisión FP16 de TensorRT. Además, asegúrate de pasar el argumento imgsz=224 dentro del comando de inferencia con exportaciones de TensorRT porque el motor de inferencia acepta tamaño de imagen 640 por defecto cuando se usan modelos de TensorRT.
YOLOv8 ofrece 5 pesos de modelo PyTorch preentrenados para segmentación de imágenes, entrenados en el conjunto de datos COCO con tamaño de imagen de entrada 640x640. Puedes encontrarlos a continuación
| Modelo | tamaño (píxeles) | mAPbox 50-95 | mAPmask 50-95 | Velocidad CPU ONNX (ms) | Velocidad A100 TensorRT (ms) | parámetros (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
Referencia: https://docs.ultralytics.com/tasks/segment
Puedes elegir tu modelo deseado y ejecutar el comando siguiente para ejecutar inferencia en una imagen
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' show=True
Aquí para el modelo, puedes cambiar a yolov8s-seg.pt, yolov8m-seg.pt, yolov8l-seg.pt, yolov8x-seg.pt y descargará el modelo preentrenado relevante
También puedes conectar una cámara web y ejecutar el siguiente comando
yolo segment predict model=yolov8n-seg.pt source='0' show=True
Si encuentras algún error al ejecutar los comandos anteriores, intenta añadir "device=0" al final del comando

Lo anterior se ejecuta en un reComputer J4012/ reComputer Industrial J4012 y utiliza el modelo YOLOv8s-seg entrenado con entrada de 640x640 y usa precisión TensorRT FP16.
YOLOv8 ofrece 6 pesos de modelo PyTorch preentrenados para estimación de pose, entrenados en el conjunto de datos COCO keypoints con tamaño de imagen de entrada de 640x640. Puedes encontrarlos a continuación
| Modelo | tamaño (píxeles) | mAPpose 50-95 | mAPpose 50 | Velocidad CPU ONNX (ms) | Velocidad A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-pose | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-pose | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-pose | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-pose | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-pose | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
Referencia: https://docs.ultralytics.com/tasks/pose
Puedes elegir tu modelo deseado y ejecutar el comando siguiente para ejecutar inferencia en una imagen
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg'
Aquí para el modelo, puedes cambiar a yolov8s-pose.pt, yolov8m-pose.pt, yolov8l-pose.pt, yolov8x-pose.pt, yolov8x-pose-p6 y descargará el modelo pre-entrenado relevante
También puedes conectar una cámara web y ejecutar el siguiente comando
yolo pose predict model=yolov8n-pose.pt source='0'
Si encuentras algún error al ejecutar los comandos anteriores, intenta añadir "device=0" al final del comando

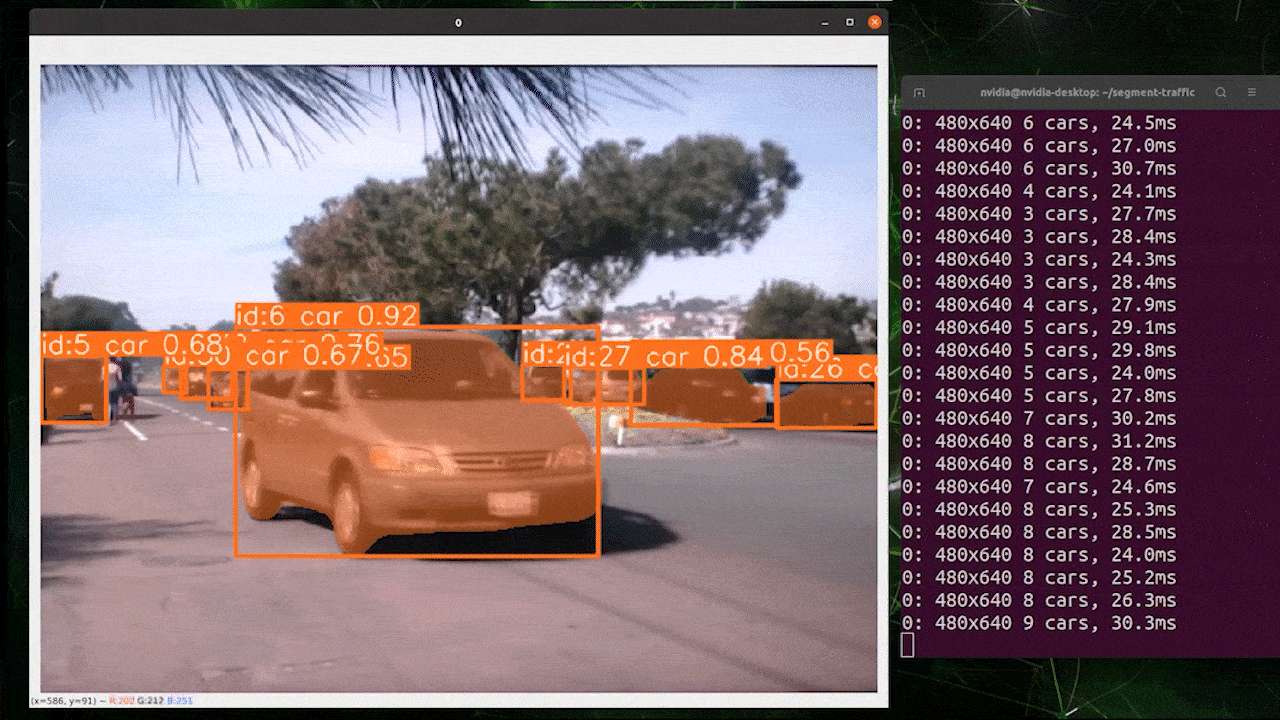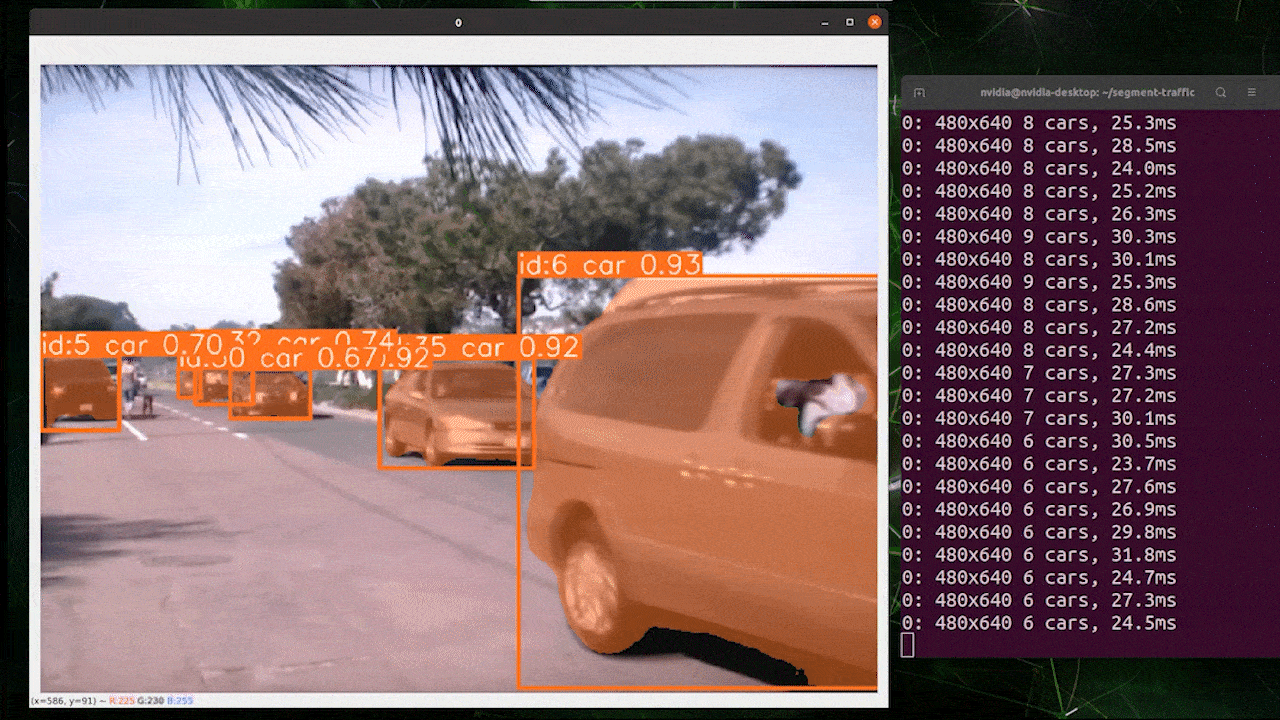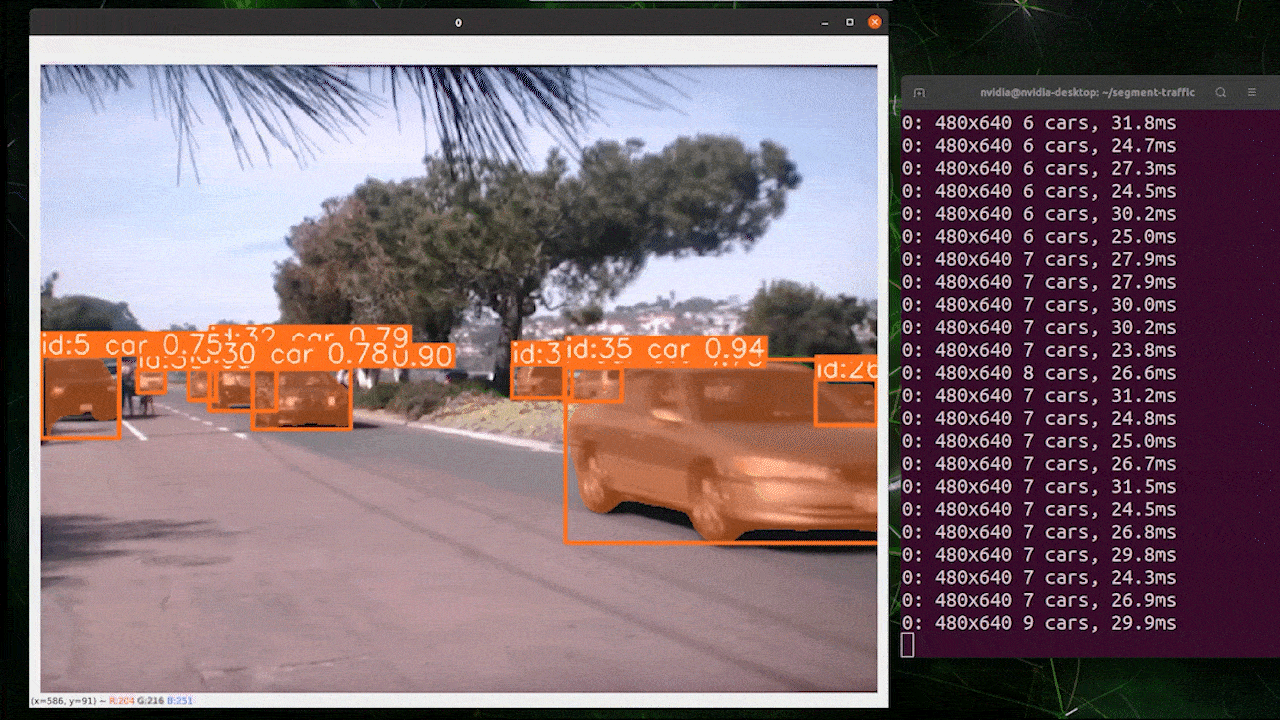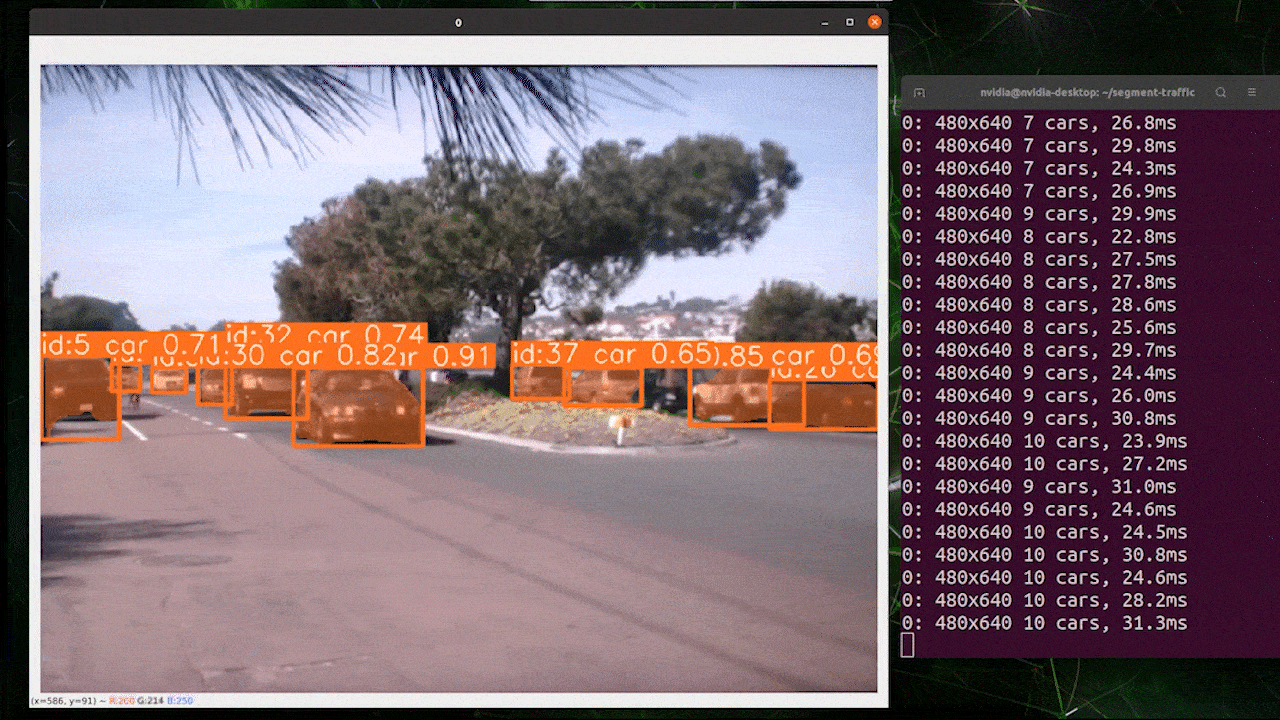
El seguimiento de objetos es una tarea que implica identificar la ubicación y clase de los objetos, luego asignar un ID único a esa detección en flujos de video.
Básicamente, la salida del seguimiento de objetos es la misma que la detección de objetos con un ID de objeto añadido.
Referencia: https://docs.ultralytics.com/modes/track
Puedes elegir tu modelo deseado basado en detección de objetos/segmentación de imágenes y ejecutar el siguiente comando para ejecutar inferencia en un video
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc"
Aquí para el modelo, puedes cambiar a yolov8n.pt, yolov8s.pt, yolov8m.pt, yolov8l.pt, yolov8x.pt, yolov8n-seg.pt, yolov8s-seg.pt, yolov8m-seg.pt, yolov8l-seg.pt, yolov8x-seg.pt, y descargará el modelo pre-entrenado relevante
También puedes conectar una cámara web y ejecutar el siguiente comando
yolo track model=yolov8n.pt source="0"
Si encuentras algún error al ejecutar los comandos anteriores, intenta añadir "device=0" al final del comando

Usar TensorRT para Mejorar la Velocidad de Inferencia
Como mencionamos antes, si quieres mejorar la velocidad de inferencia en el Jetson ejecutando modelos YOLOv8, primero necesitas convertir los modelos PyTorch originales a modelos TensorRT.
Sigue los pasos a continuación para convertir modelos PyTorch YOLOv8 a modelos TensorRT.
Esto funciona para las cuatro tareas de visión por computadora que hemos mencionado antes
- Paso 1. Ejecuta el comando de exportación especificando la ruta del modelo
yolo export model=<path_to_pt_file> format=engine device=0
Por ejemplo:
yolo export model=yolov8n.pt format=engine device=0
Si encuentras un error sobre cmake, puedes ignorarlo. Por favor ten paciencia hasta que la exportación de TensorRT termine. Puede tomar unos minutos
Después de que el archivo del modelo TensorRT (.engine) sea creado, verás la salida como sigue
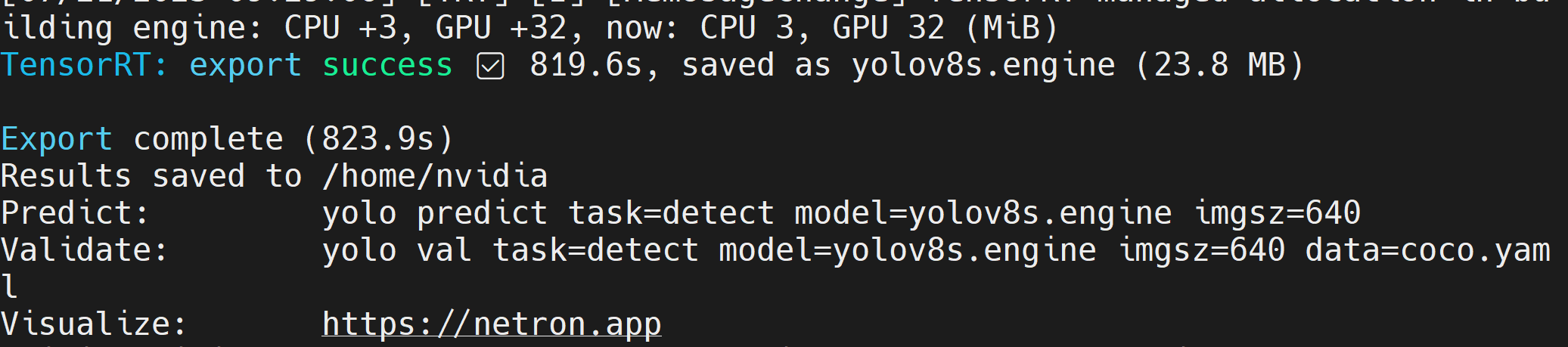
- Paso 2. Si quieres pasar argumentos adicionales, puedes hacerlo siguiendo la tabla de abajo
| Clave | Valor | Descripción |
|---|---|---|
| imgsz | 640 | Tamaño de imagen como escalar o lista (h, w), ej. (640, 480) |
| half | False | Cuantización FP16 |
| dynamic | False | Ejes dinámicos |
| simplify | False | Simplificar modelo |
| workspace | 4 | Tamaño del espacio de trabajo (GB) |
Por ejemplo, si quieres convertir tu modelo PyTorch en un modelo TensorRT con cuantización FP16, ejecuta como
yolo export model=yolov8n.pt format=engine half=True device=0
Una vez que el modelo se exporta exitosamente, puedes reemplazar directamente este modelo con el argumento model= dentro del comando predict de yolo al ejecutar las 4 tareas de detección, clasificación, segmentación y estimación de pose.
Por ejemplo, con detección de objetos:
yolo detect predict model=yolov8n.engine source='0' show=True
Trae Tu Propio Modelo de IA
Recolección y Etiquetado de Datos
Si tienes una aplicación de IA específica y quieres traer tu propio modelo de IA que sea adecuado para tu aplicación, puedes recopilar tu propio conjunto de datos, etiquetarlos y luego entrenar usando YOLOv8.
Si no quieres recopilar datos por ti mismo, también puedes elegir conjuntos de datos públicos que están fácilmente disponibles. Puedes descargar una serie de conjuntos de datos disponibles públicamente como el conjunto de datos COCO, conjunto de datos Pascal VOC y muchos más. Roboflow Universe es una plataforma recomendada que proporciona una amplia gama de conjuntos de datos y tiene más de 90,000 conjuntos de datos con más de 66 millones de imágenes disponibles para construir modelos de visión por computadora. Además, puedes simplemente buscar conjuntos de datos de código abierto en Google y elegir entre una variedad de conjuntos de datos disponibles.
Si tienes tu propio conjunto de datos y quieres anotar las imágenes, te recomendamos usar la herramienta de anotación proporcionada por Roboflow. Por favor sigue esta parte del wiki para aprender más sobre ello. También puedes seguir esta guía de Roboflow sobre anotación.
Entrenamiento
Aquí tenemos 3 métodos para entrenar un modelo.
-
La primera forma sería usar Ultralytics HUB. Puedes integrar fácilmente Roboflow en Ultralytics HUB para que todos tus proyectos de Roboflow estén fácilmente disponibles para entrenamiento. Aquí ofrece un cuaderno de Google Colab para iniciar fácilmente el proceso de entrenamiento y también ver el progreso del entrenamiento en tiempo real.
-
La segunda forma sería usar un espacio de trabajo de Google Colab creado por nosotros para hacer el proceso de entrenamiento más fácil. Aquí usamos la API de Roboflow para descargar el conjunto de datos del proyecto de Roboflow.
-
La tercera forma sería usar una PC local para el proceso de entrenamiento. Aquí necesitas asegurarte de tener una GPU lo suficientemente potente y también necesitas descargar manualmente el conjunto de datos.
- Ultralytics HUB + Roboflow + Google Colab
- Roboflow + Google Colab
- Roboflow + PC Local
Aquí usamos Ultralytics HUB para cargar el proyecto de Roboflow y luego entrenar en Google Colab.
-
Paso 1. Visita esta URL y regístrate para una cuenta de Ultralytics
-
Paso 2. Una vez que inicies sesión con la cuenta recién creada, serás recibido con el siguiente panel de control
-
Paso 3. Visita esta URL y regístrate para una cuenta de Roboflow
-
Paso 4. Una vez que inicies sesión con la cuenta recién creada, serás recibido con el siguiente panel de control
-
Paso 5. Crea un nuevo espacio de trabajo y crea un nuevo proyecto bajo el espacio de trabajo siguiendo esta guía del wiki que hemos preparado. También puedes revisar aquí para aprender más de la documentación oficial de Roboflow.
-
Paso 6. Una vez que tengas un par de proyectos dentro de tu espacio de trabajo, se verá como abajo
- Paso 7. Ve a Settings y haz clic en Roboflow API
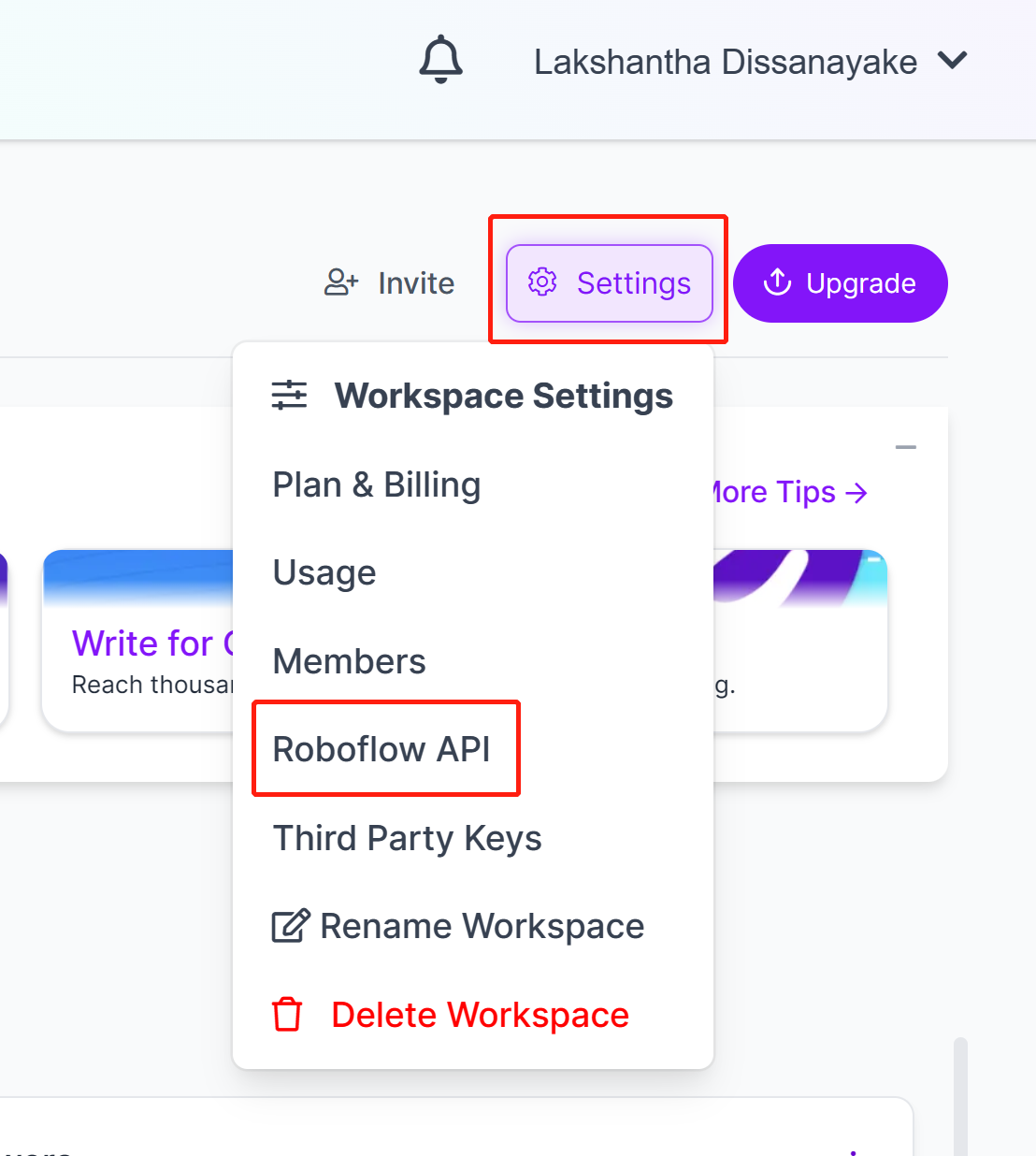
- Paso 8. Haz clic en el botón copy para copiar la Private API Key
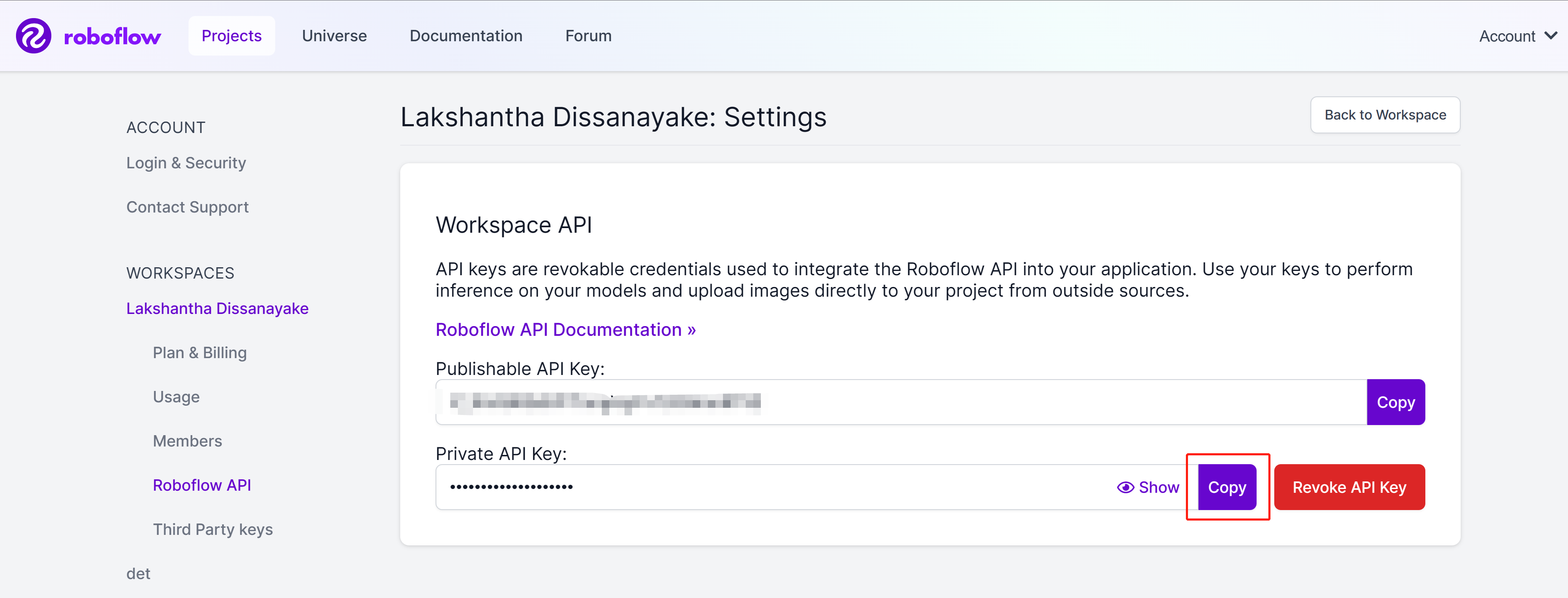
- Paso 9. Regresa al panel de control de Ultralytics HUB, haz clic en Integrations, pega la API Key que copiamos antes en la columna vacía y haz clic en Add
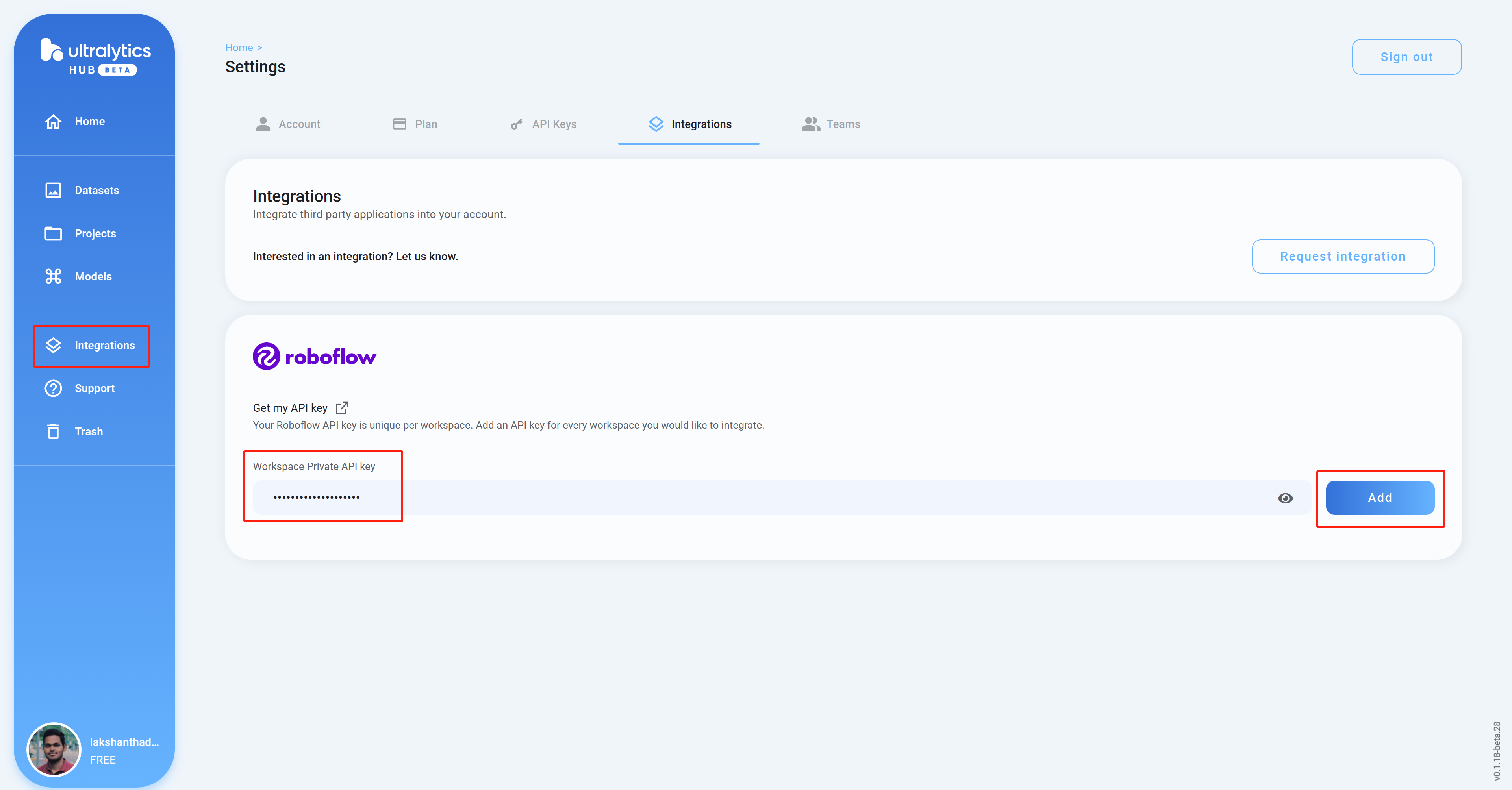
- Paso 10 Si ves el nombre de tu espacio de trabajo listado, eso significa que la integración fue exitosa
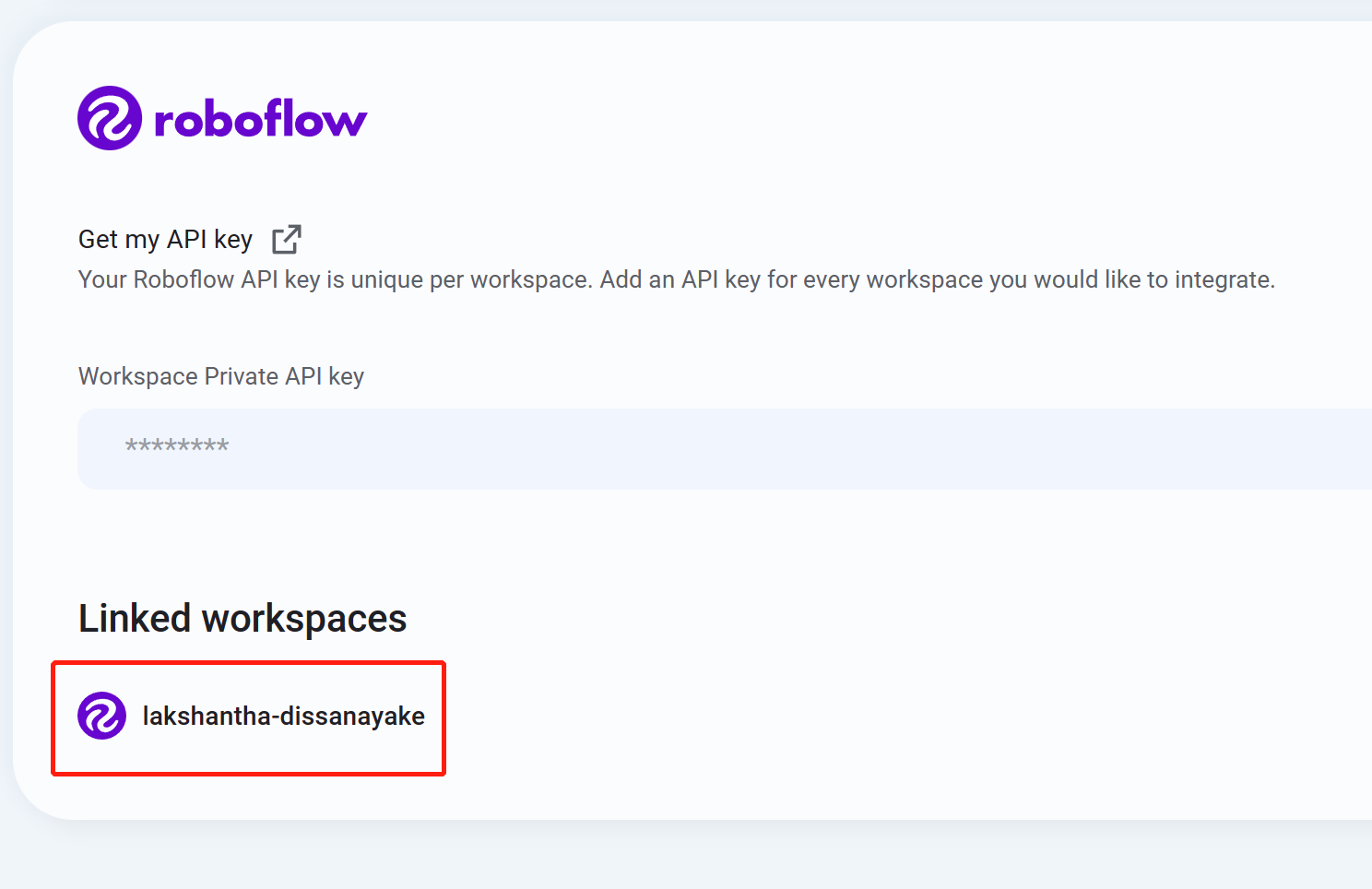
- Paso 11 Navega a Datasets y verás todos tus proyectos de Roboflow aquí
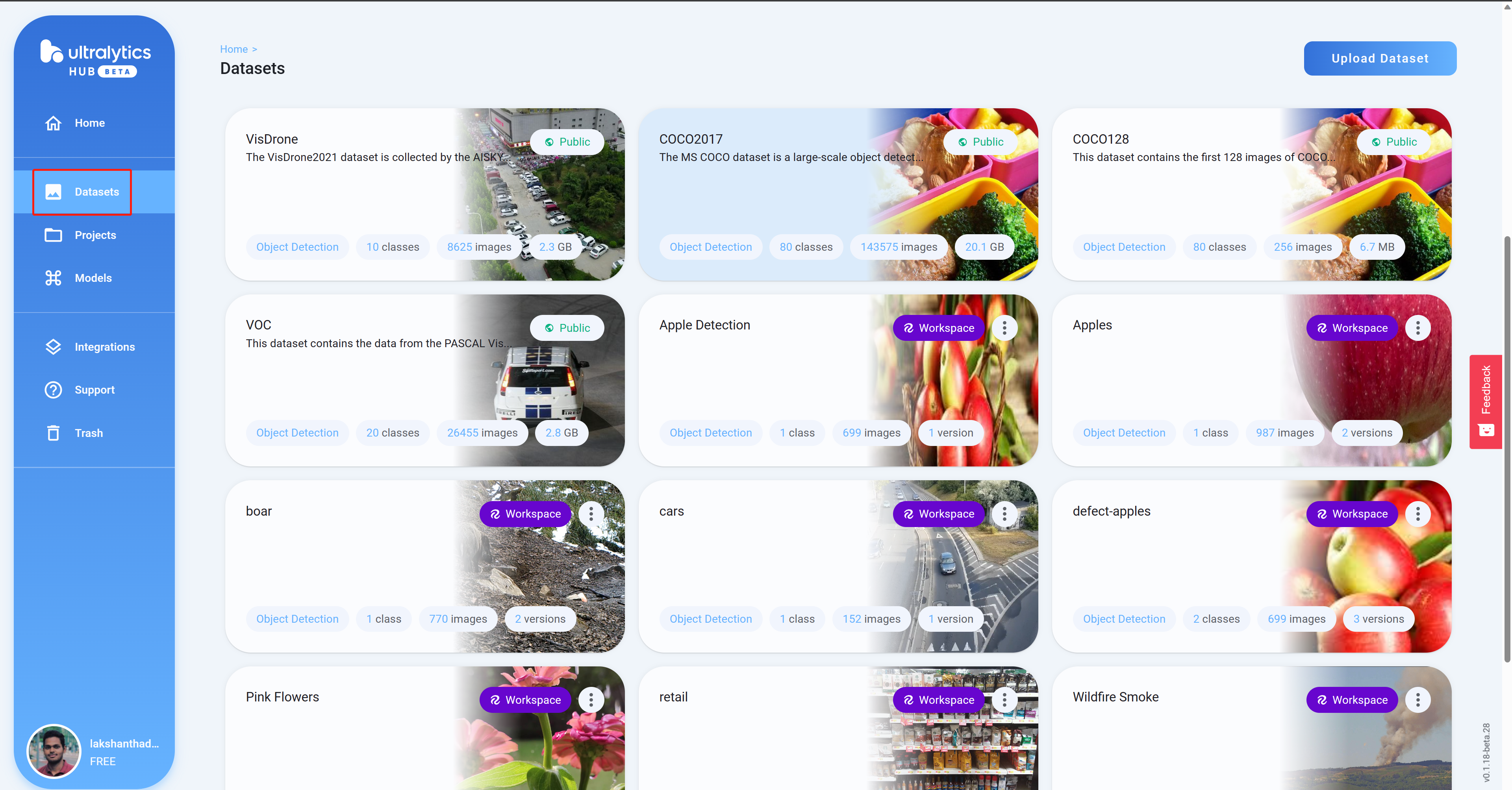
- Paso 12 Haz clic en un proyecto para revisar más sobre el conjunto de datos. Aquí he seleccionado un conjunto de datos que puede detectar manzanas sanas y dañadas
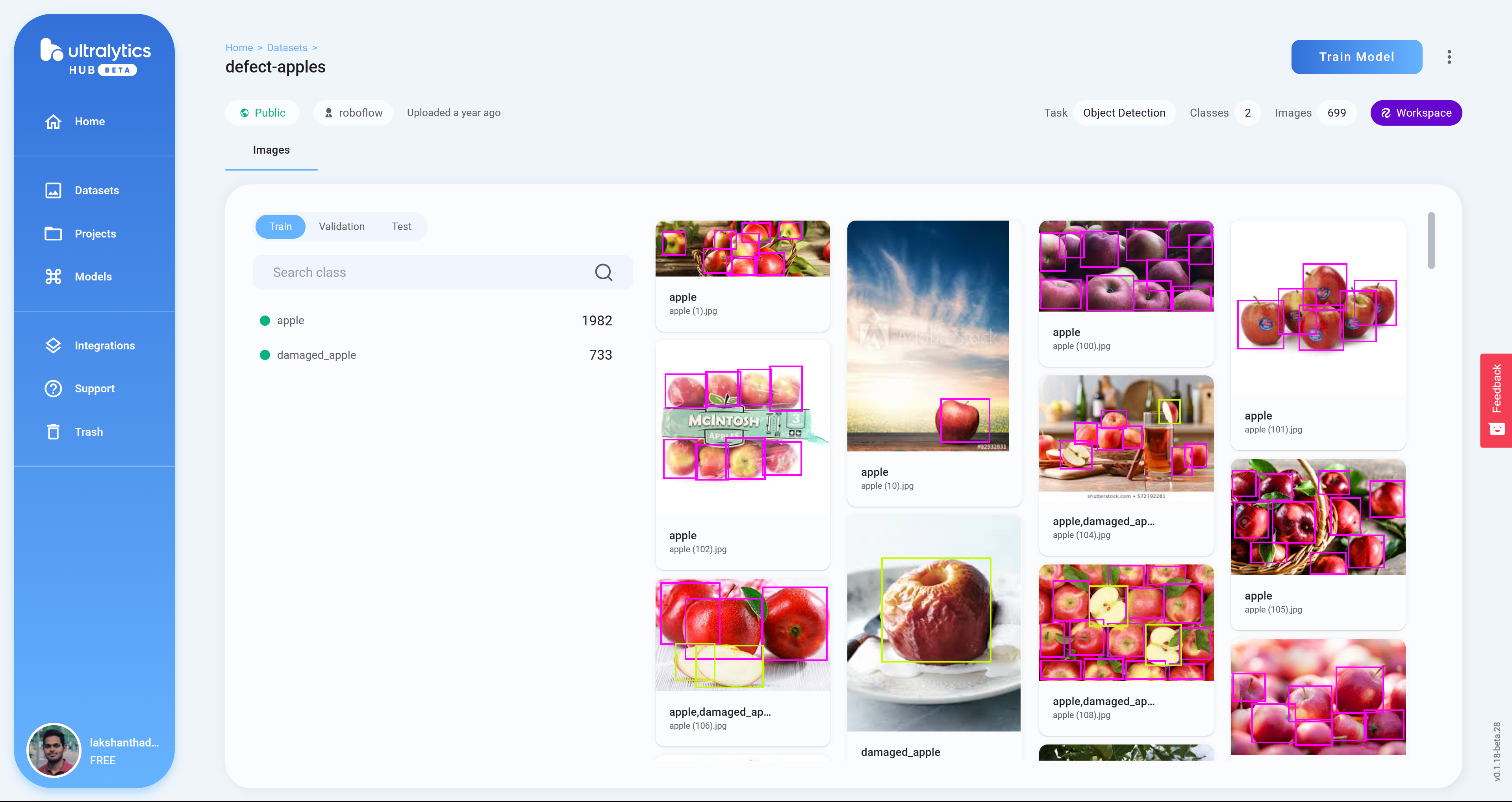
- Paso 13 Haz clic en Train Model
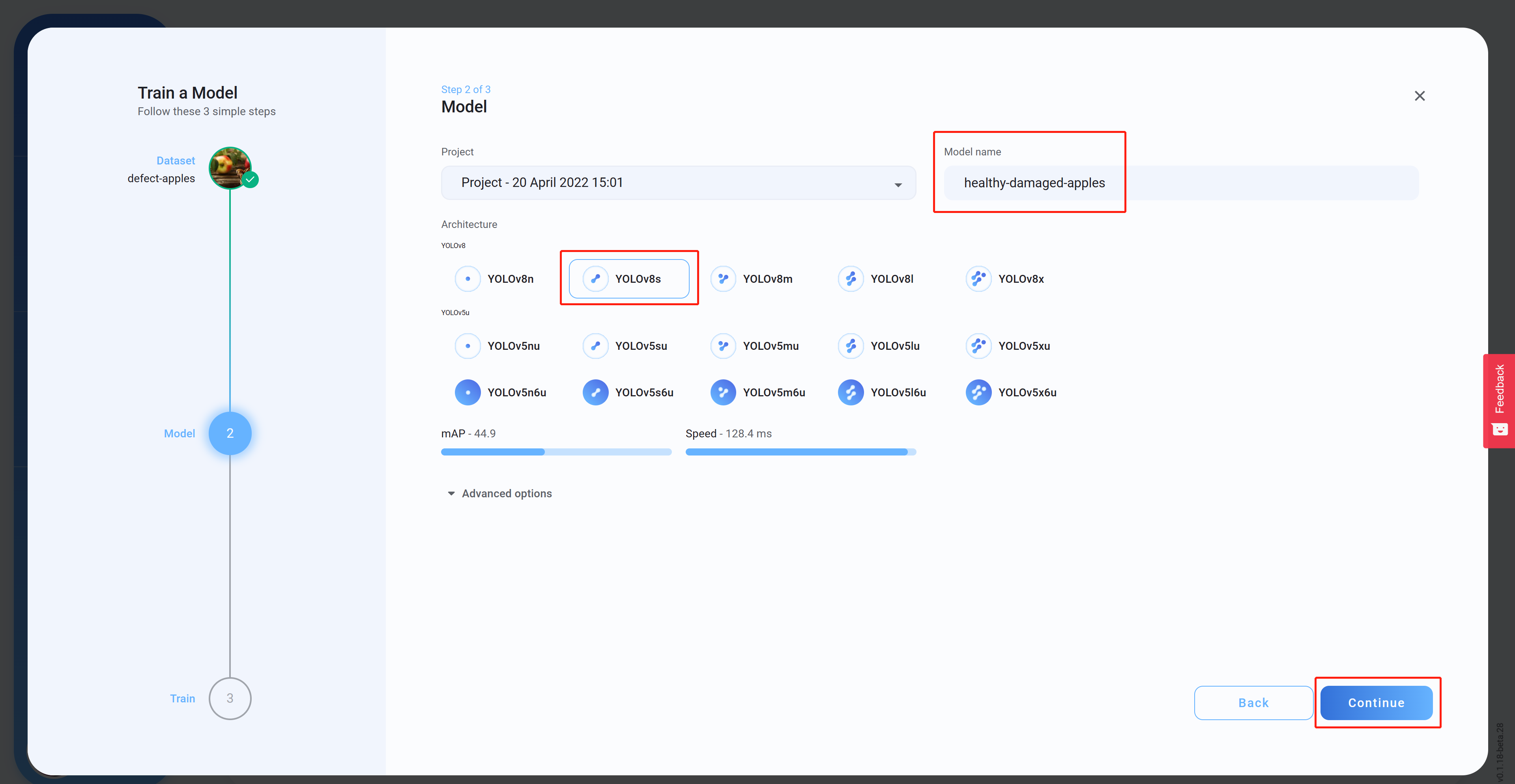
- Paso 14 Selecciona la Architecture, establece un Model name (opcional) y luego haz clic en Continue. Aquí hemos seleccionado YOLOv8s como la arquitectura del modelo
- Paso 15 Bajo Advanced options, configura los ajustes según tu preferencia, copia y pega el código de Colab (esto se pegará más tarde en el espacio de trabajo de Colab) y luego haz clic en Open Google Colab
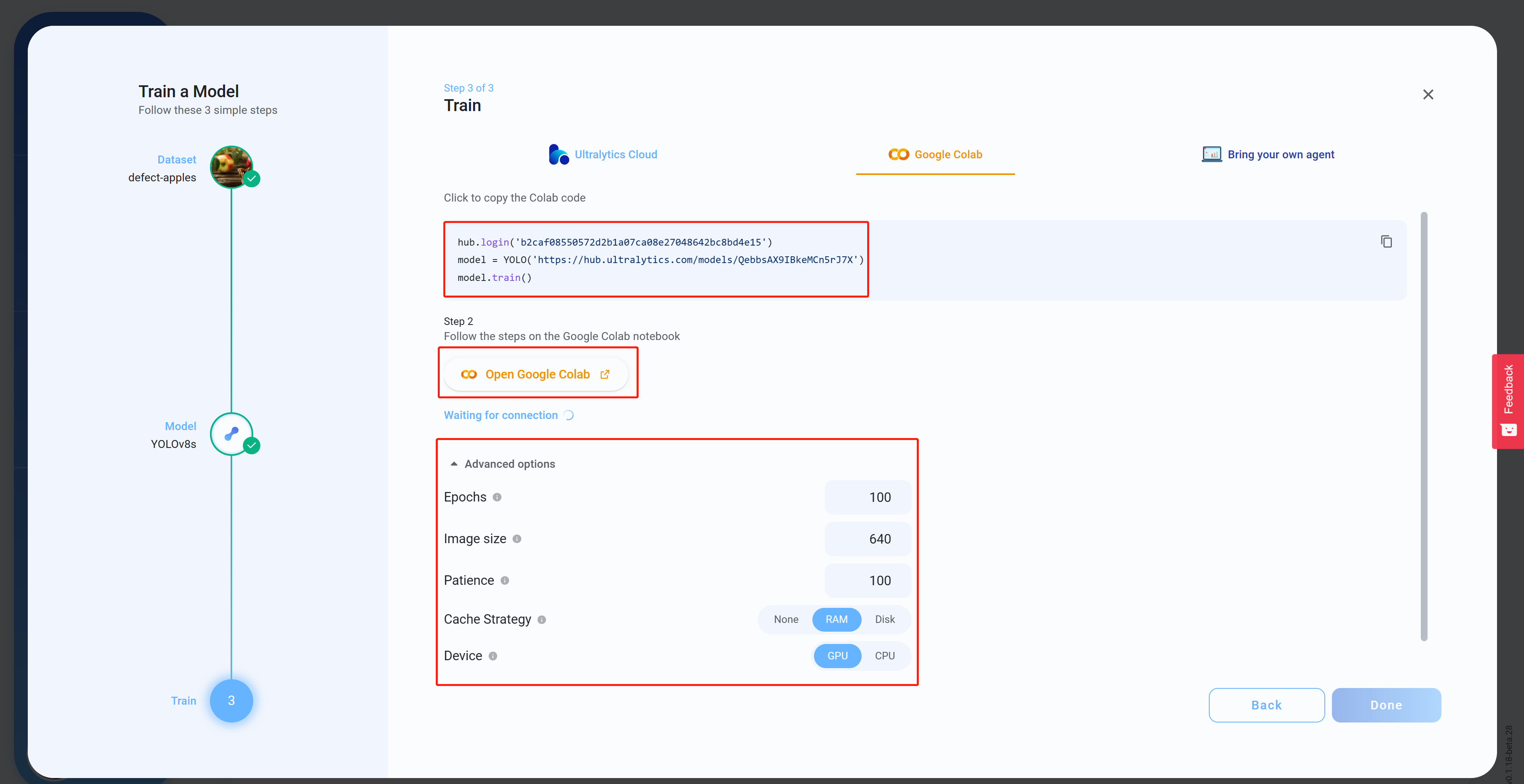
- Paso 16 Inicia sesión en tu cuenta de Google si no has iniciado sesión ya
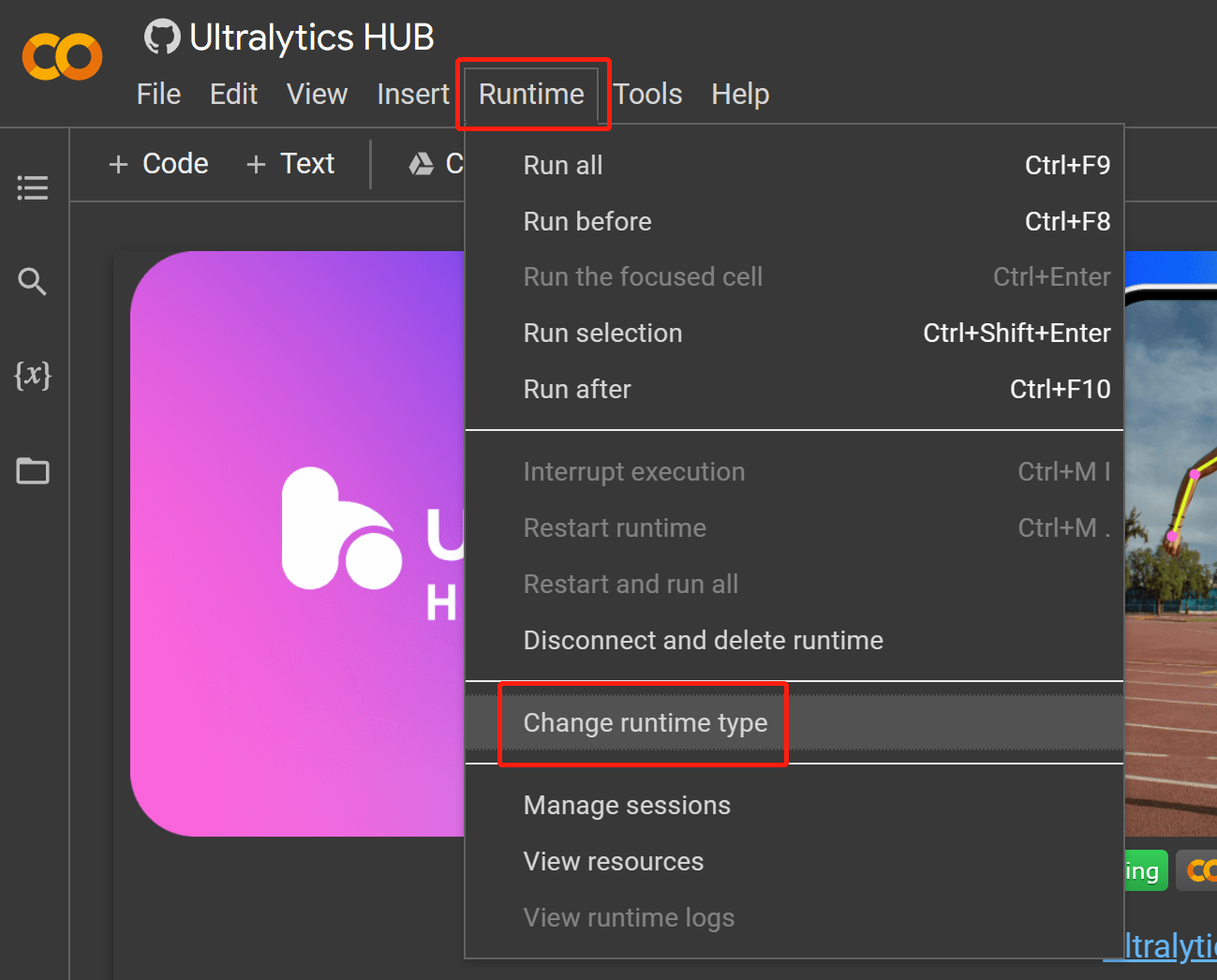
- Paso 17 Navega a
Runtime > Change runtime type
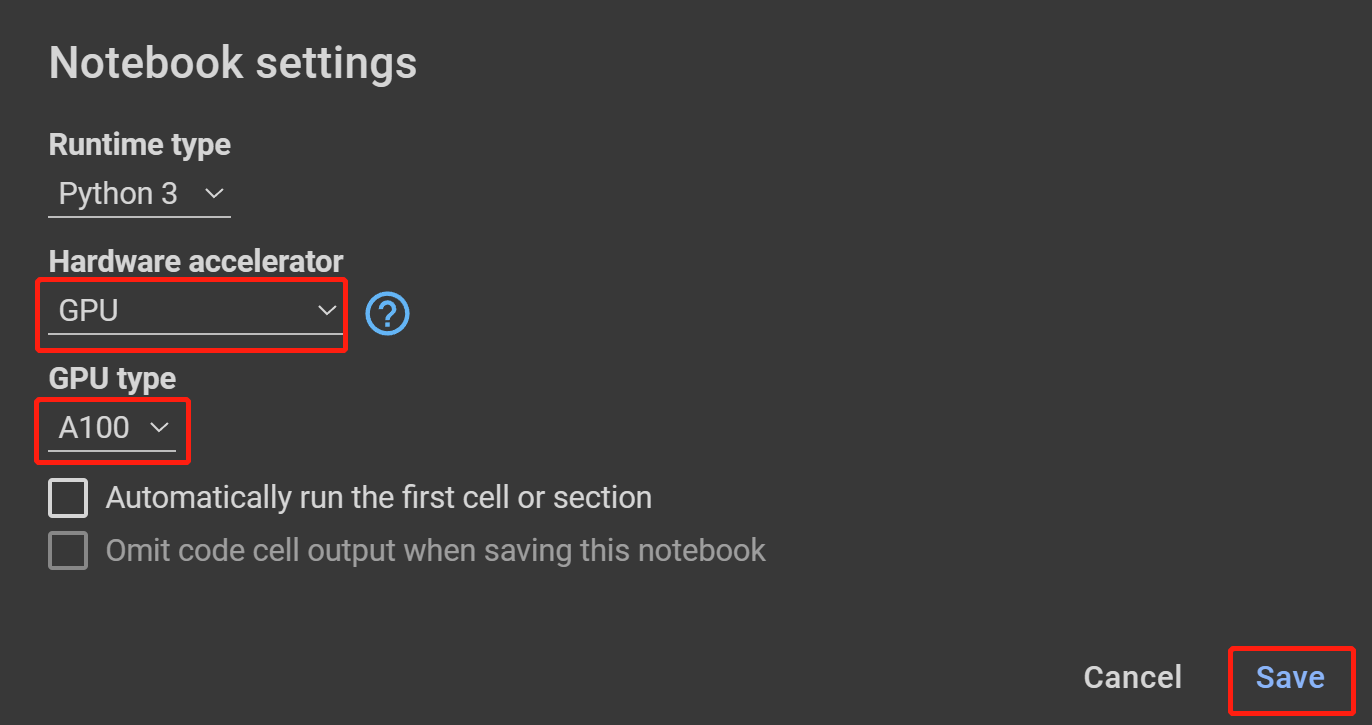
- Paso 18 Selecciona GPU bajo Hardware accelerator, el más alto disponible bajo GPU type y haz clic en Save
- Paso 19 Haz clic en Connect
- Paso 20 Haz clic en el botón RAM, Disk para revisar el uso de recursos de hardware
- Paso 21 Haz clic en el botón Play para ejecutar la primera celda de código
- Paso 22 Pega la celda de código que copiamos de Ultralytics HUB antes bajo la sección Start y ejecútala para comenzar el entrenamiento
- Paso 23 Ahora si regresas a Ultralytics HUB, verás el mensaje Connected. Haz clic en Done
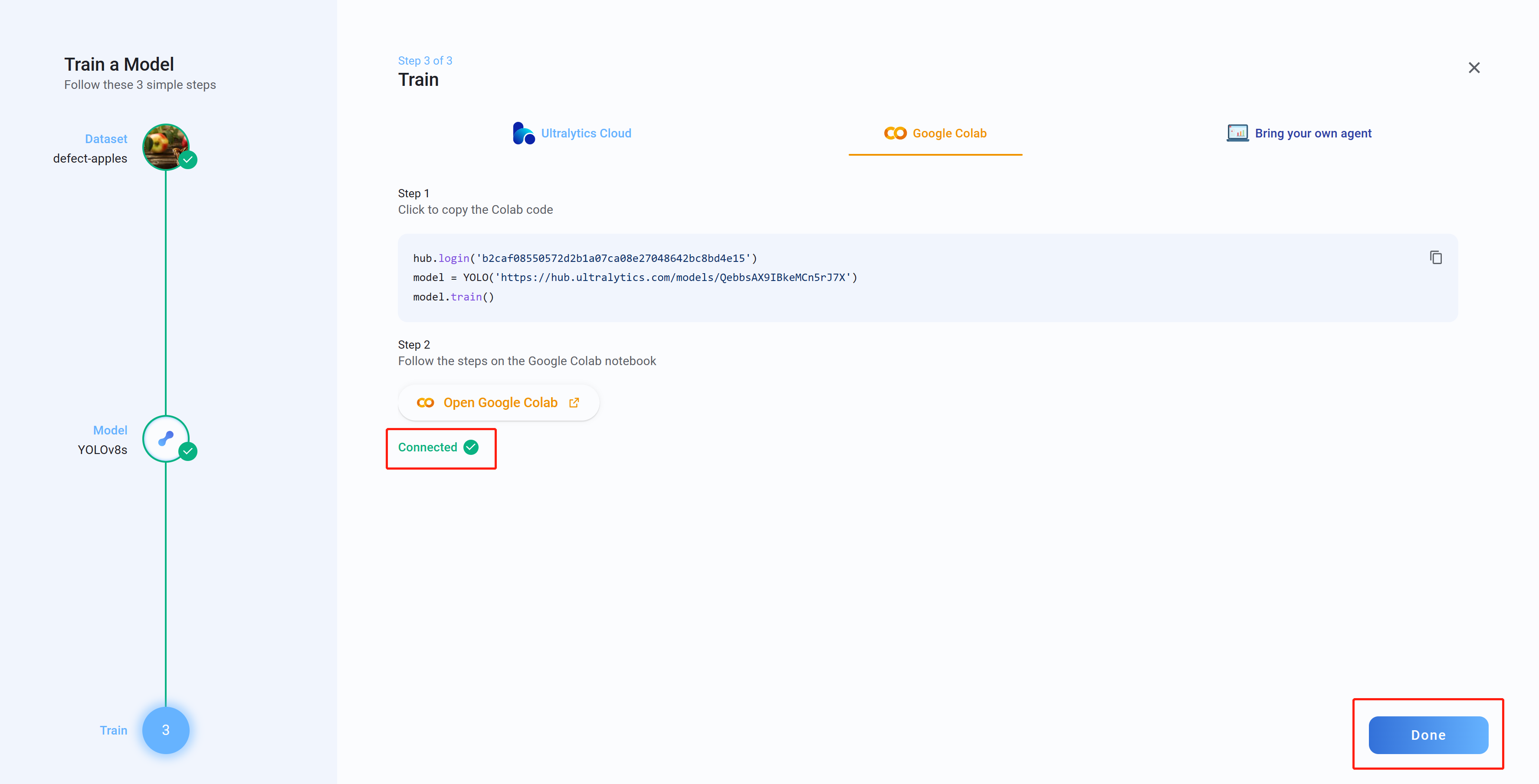
- Paso 24 Aquí verás Box Loss, Class Loss y Object Loss en tiempo real mientras el modelo se entrena en Google Colab
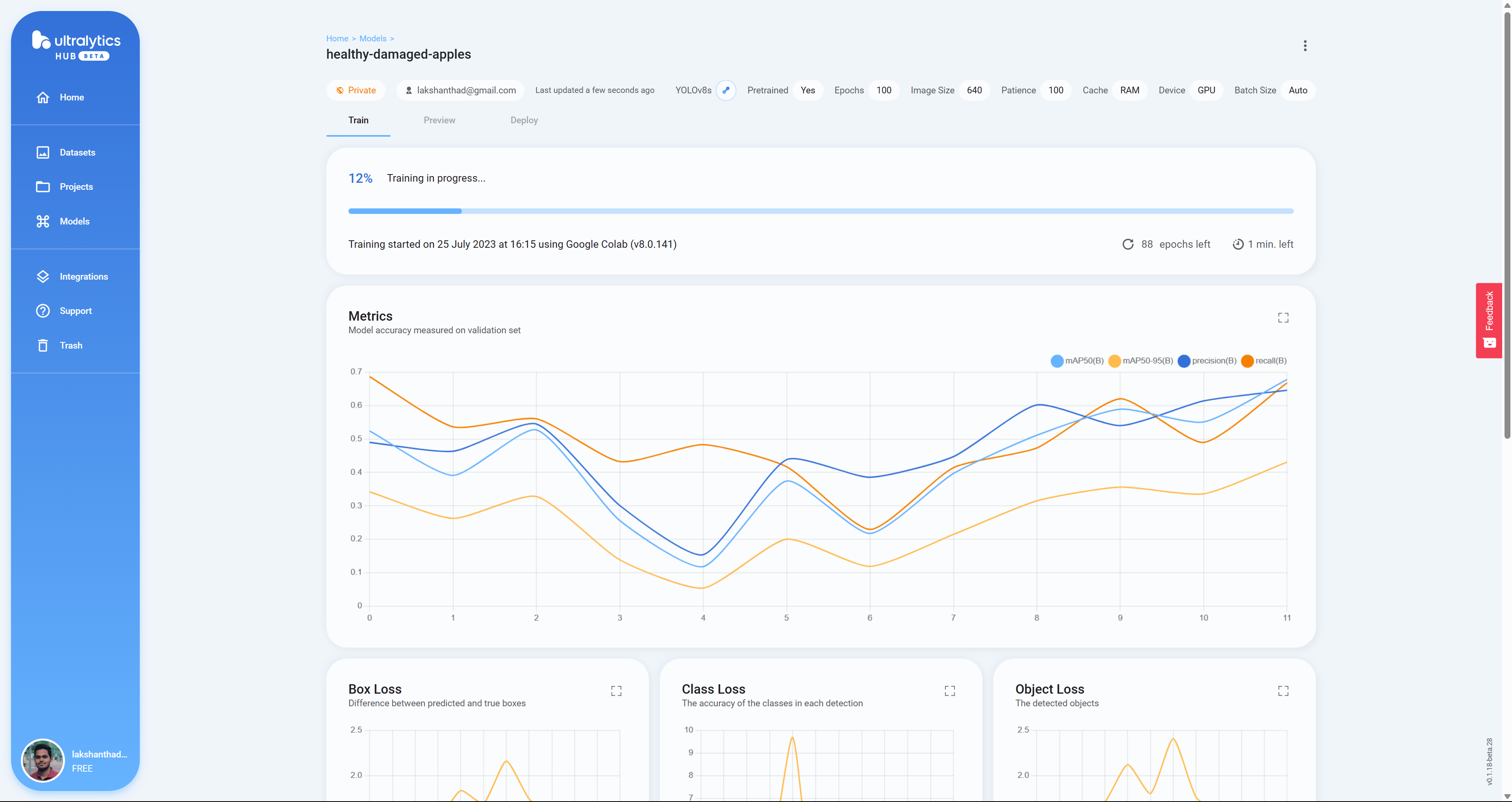
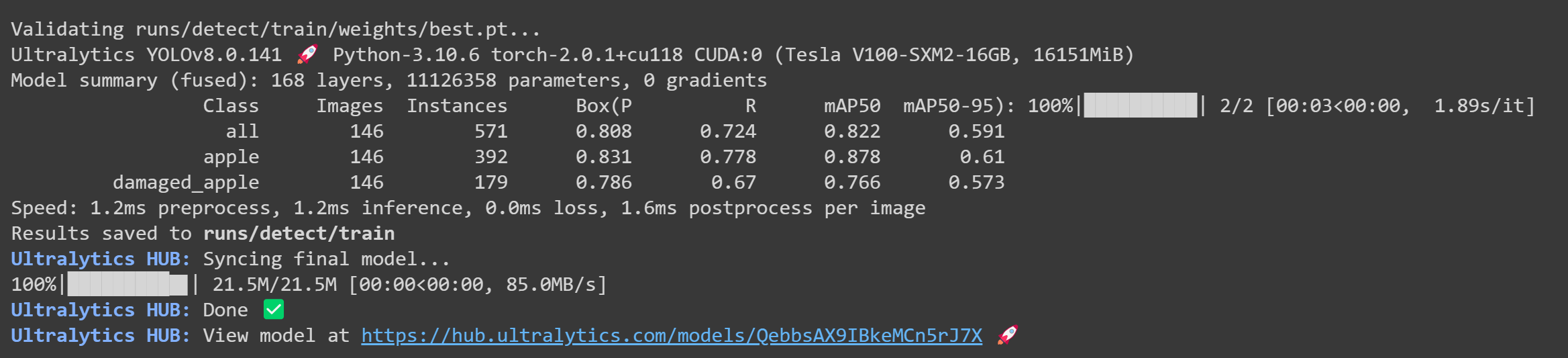
- Paso 25 Después de que termine el entrenamiento, verás la siguiente salida en Google Colab
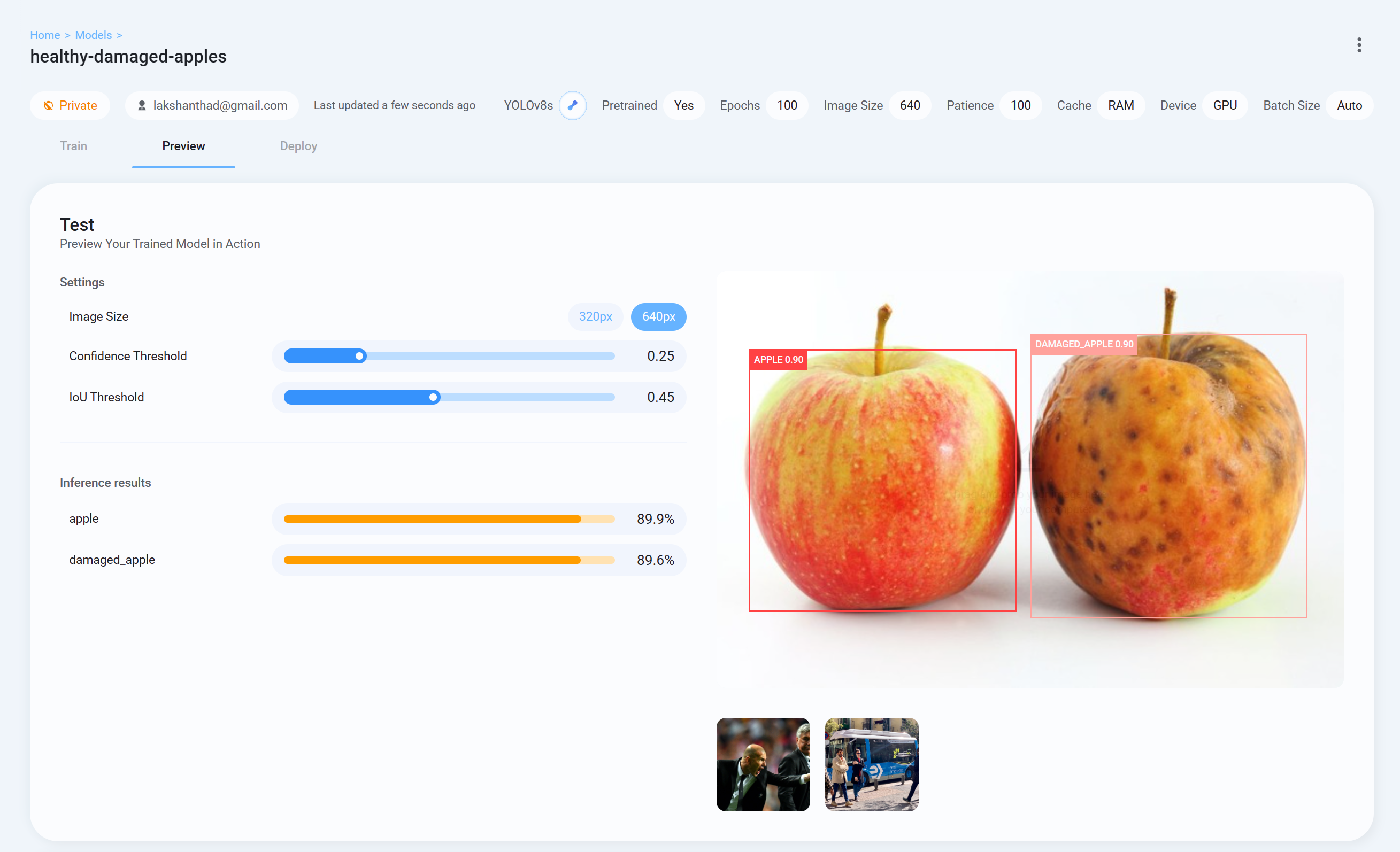
- Paso 26 Ahora regresa a Ultralytics HUB, ve a la pestaña Preview y sube una imagen de prueba para verificar cómo está funcionando el modelo entrenado
- Paso 26 Finalmente ve a la pestaña Deploy y descarga el modelo entrenado en el formato que prefieras para hacer inferencia con YOLOv8. Aquí hemos elegido PyTorch.
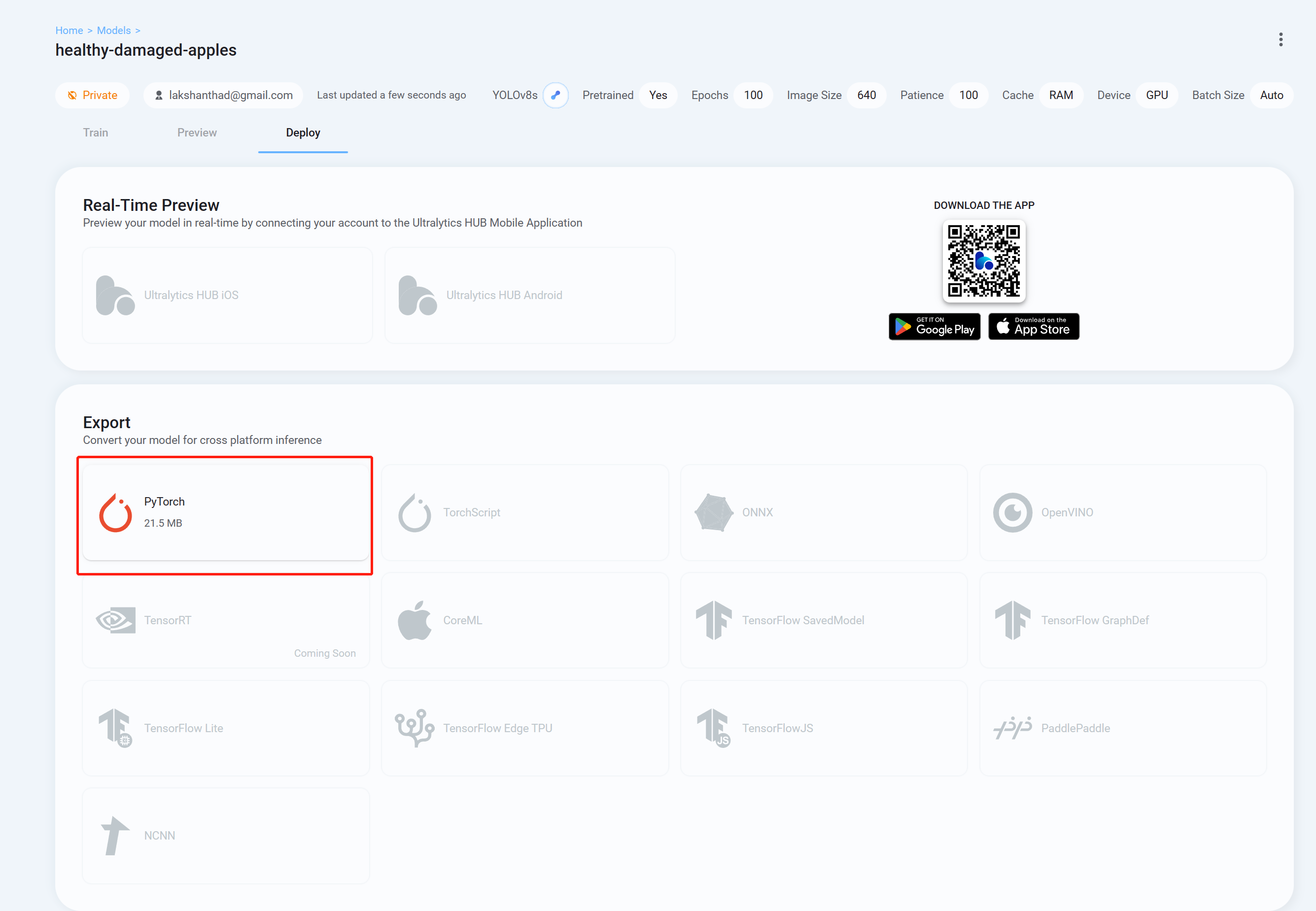
Ahora puedes usar este modelo descargado con las tareas que hemos explicado en este wiki anteriormente. Solo necesitas reemplazar el archivo del modelo con tu modelo.
Por ejemplo:
yolo detect predict model=<your_model.pt> source='0' show=True
Aquí utilizamos un entorno de Google Colaboratory para realizar el entrenamiento en la nube. Además, utilizamos la API de Roboflow dentro de Colab para descargar fácilmente nuestro conjunto de datos.
- Paso 1. Haz clic aquí para abrir un espacio de trabajo de Google Colab ya preparado y sigue los pasos mencionados en el espacio de trabajo
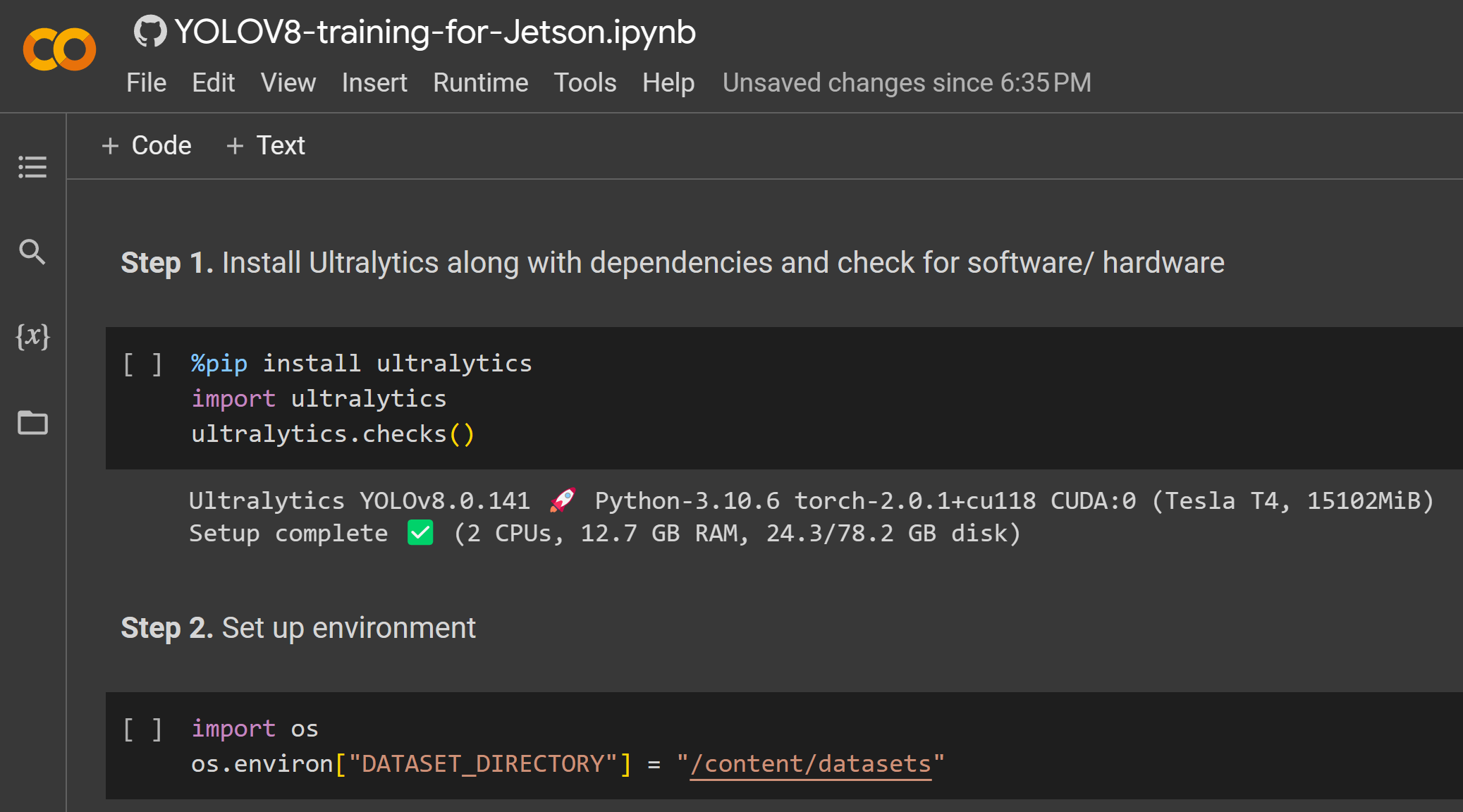
Después de que el entrenamiento haya terminado, verás una salida como la siguiente:
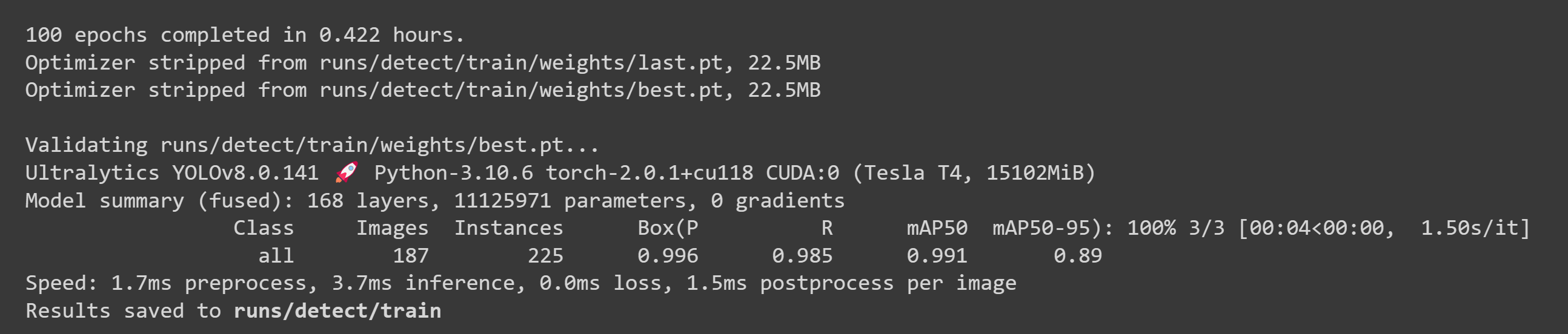
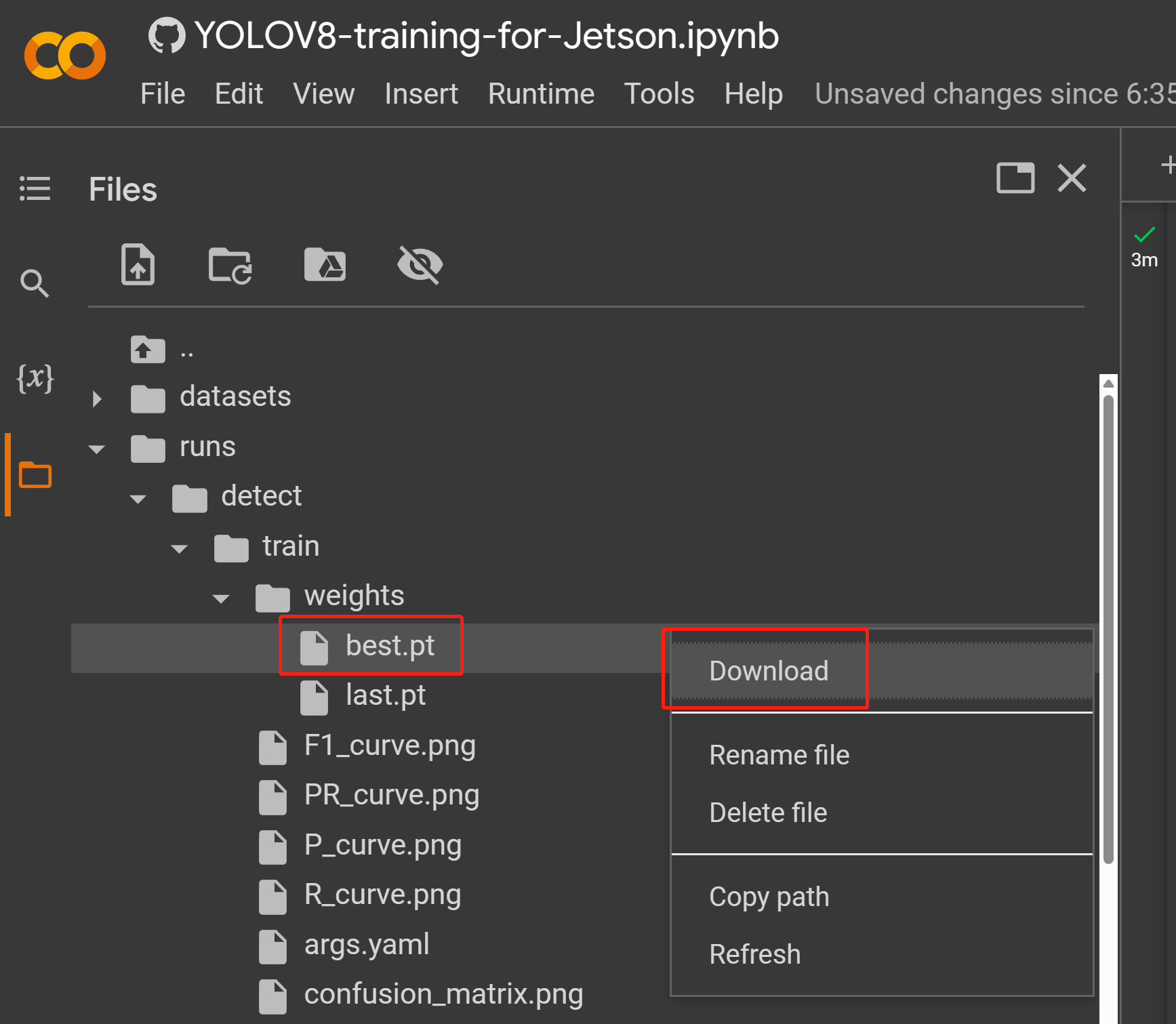
- Paso 2. En la pestaña Files, si navegas a
runs/train/exp/weights, verás un archivo llamado best.pt. Este es el modelo generado del entrenamiento. Descarga este archivo y cópialo a tu dispositivo Jetson porque este es el modelo que vamos a usar más tarde para la inferencia en el dispositivo Jetson.
Ahora puedes usar este modelo descargado con las tareas que hemos explicado en este wiki anteriormente. Solo necesitas reemplazar el archivo del modelo con tu modelo.
Por ejemplo:
yolo detect predict model=<your_model.pt> source='0' show=True
Aquí puedes usar una PC con un SO Linux para el entrenamiento. Hemos usado una PC Ubuntu 20.04 para este wiki.
- Paso 1. Instala pip si no tienes pip en tu sistema
sudo apt install python3-pip -y
- Paso 2. Instalar Ultralytics junto con las dependencias
pip install ultralytics
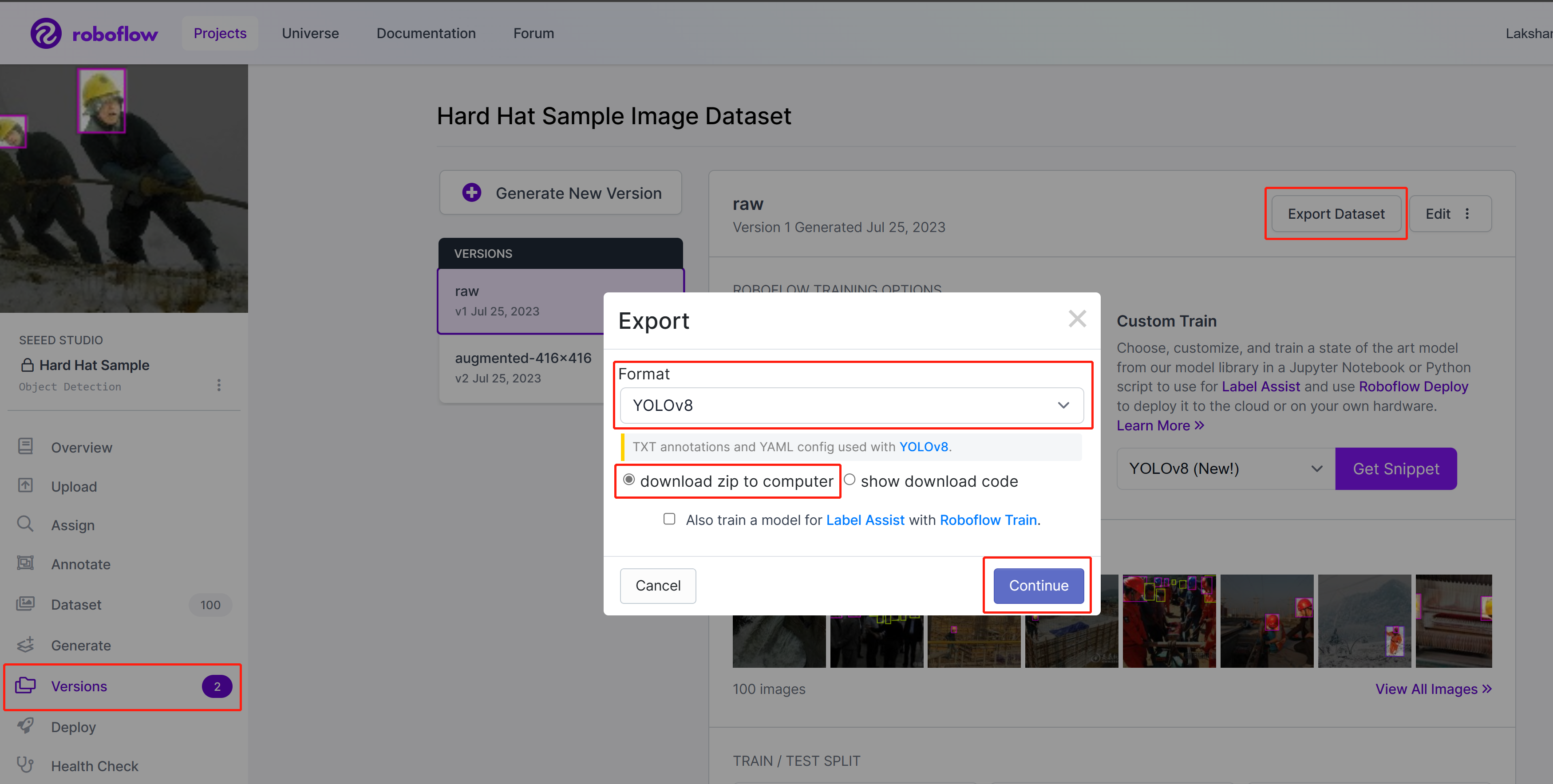
- Paso 3. En Roboflow, dentro de tu proyecto, ve a Versions, selecciona Export Dataset, selecciona Format como YOLOv8, elige download zip to computer y haz clic en Continue
-
Paso 4. Extrae el archivo zip descargado
-
Paso 5. Ejecuta lo siguiente para comenzar el entrenamiento. Aquí necesitas reemplazar path_to_yaml con la ubicación del archivo .yaml que está dentro del archivo zip extraído anteriormente
yolo train data=<path_to_yaml> model=yolov8s.pt epochs=100 imgsz=640 batch=-1
Aquí el tamaño de imagen se establece en 640x640. Usamos batch-size como -1 porque eso determinará automáticamente el mejor tamaño de lote. También puedes cambiar epoch según tu preferencia. Aquí puedes cambiar el modelo pre-entrenado a cualquier modelo de detección, segmentación, clasificación o pose.
Después de que el entrenamiento esté terminado, verás una salida como la siguiente:
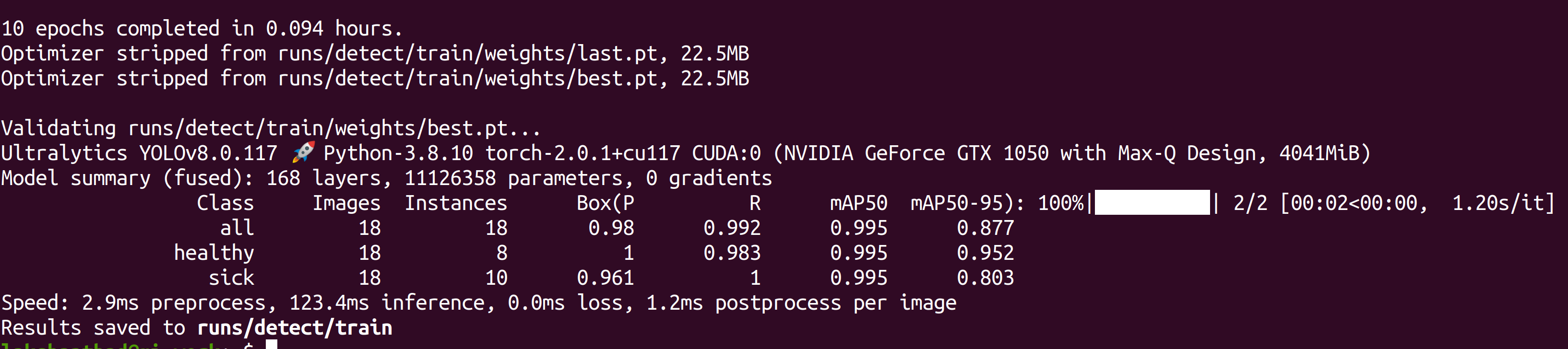
- Paso 6. Bajo runs/detect/train/weights, verás un archivo llamado best.pt. Este es el modelo generado del entrenamiento. Descarga este archivo y cópialo a tu dispositivo Jetson porque este es el modelo que vamos a usar más tarde para inferencia en el dispositivo Jetson.

Ahora puedes usar este modelo descargado con las tareas que hemos explicado en este wiki antes. Solo necesitas reemplazar el archivo del modelo con tu modelo.
Por ejemplo:
yolo detect predict model=<your_model.pt> source='0' show=True
Benchmarks de Rendimiento
Preparación
Hemos realizado benchmarks de rendimiento para todas las tareas de visión por computadora soportadas por YOLOv8 ejecutándose en reComputer J4012/ reComputer Industrial J4012 alimentado por el módulo NVIDIA Jetson Orin NX 16GB.
Incluido en el directorio de muestras hay una herramienta de línea de comandos llamada trtexec. trtexec es una herramienta para usar TensorRT sin tener que desarrollar tu propia aplicación. La herramienta trtexec tiene tres propósitos principales:
- Hacer benchmarks de redes con datos de entrada aleatorios o proporcionados por el usuario.
- Generar motores serializados a partir de modelos.
- Generar una caché de tiempo serializada desde el constructor.
Aquí podemos usar la herramienta trtexec para hacer benchmarks rápidamente de los modelos con diferentes parámetros. Pero primero que nada, necesitas tener un modelo onnx y podemos generar este modelo onnx usando ultralytics yolov8.
- Paso 1. Construir ONNX usando:
yolo mode=export model=yolov8s.pt format=onnx
- Paso 2. Construye el archivo del motor usando trtexec de la siguiente manera:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
Por ejemplo:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine
Esto generará resultados de rendimiento como se muestra a continuación junto con un archivo .engine generado. Por defecto convertirá ONNX a un archivo optimizado TensorRT en precisión FP32 y puedes ver la salida como sigue
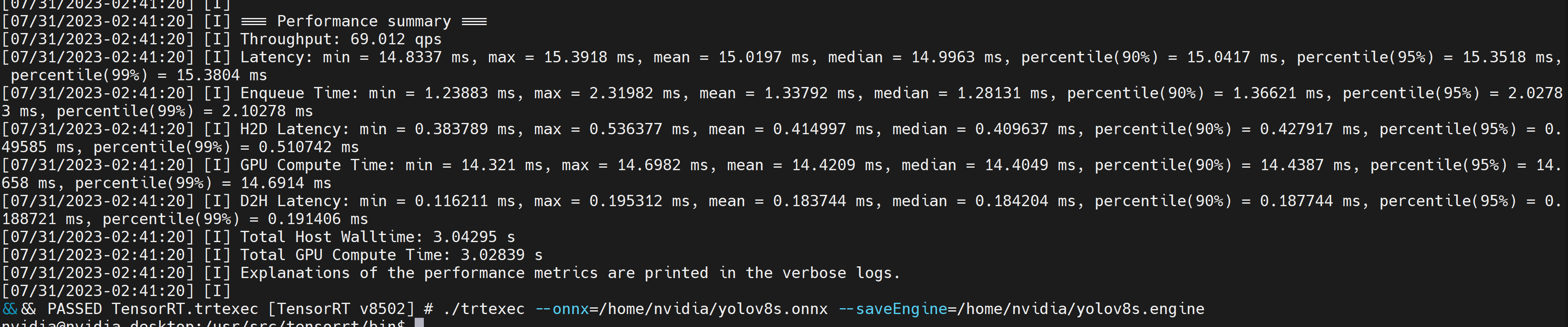
Si quieres precisión FP16 que ofrece mejor rendimiento que FP32, puedes ejecutar el comando anterior como sigue
./trtexec --onnx=/home/nvidia/yolov8s.onnx --fp16 --saveEngine=/home/nvidia/yolov8s.engine
Sin embargo, si deseas precisión INT8 que ofrece mejor rendimiento que FP16, puedes ejecutar el comando anterior de la siguiente manera
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
Resultados
A continuación resumimos los resultados que obtenemos de las cuatro tareas de visión por computadora ejecutándose en reComputer J4012/ reComputer Industrial J4012.
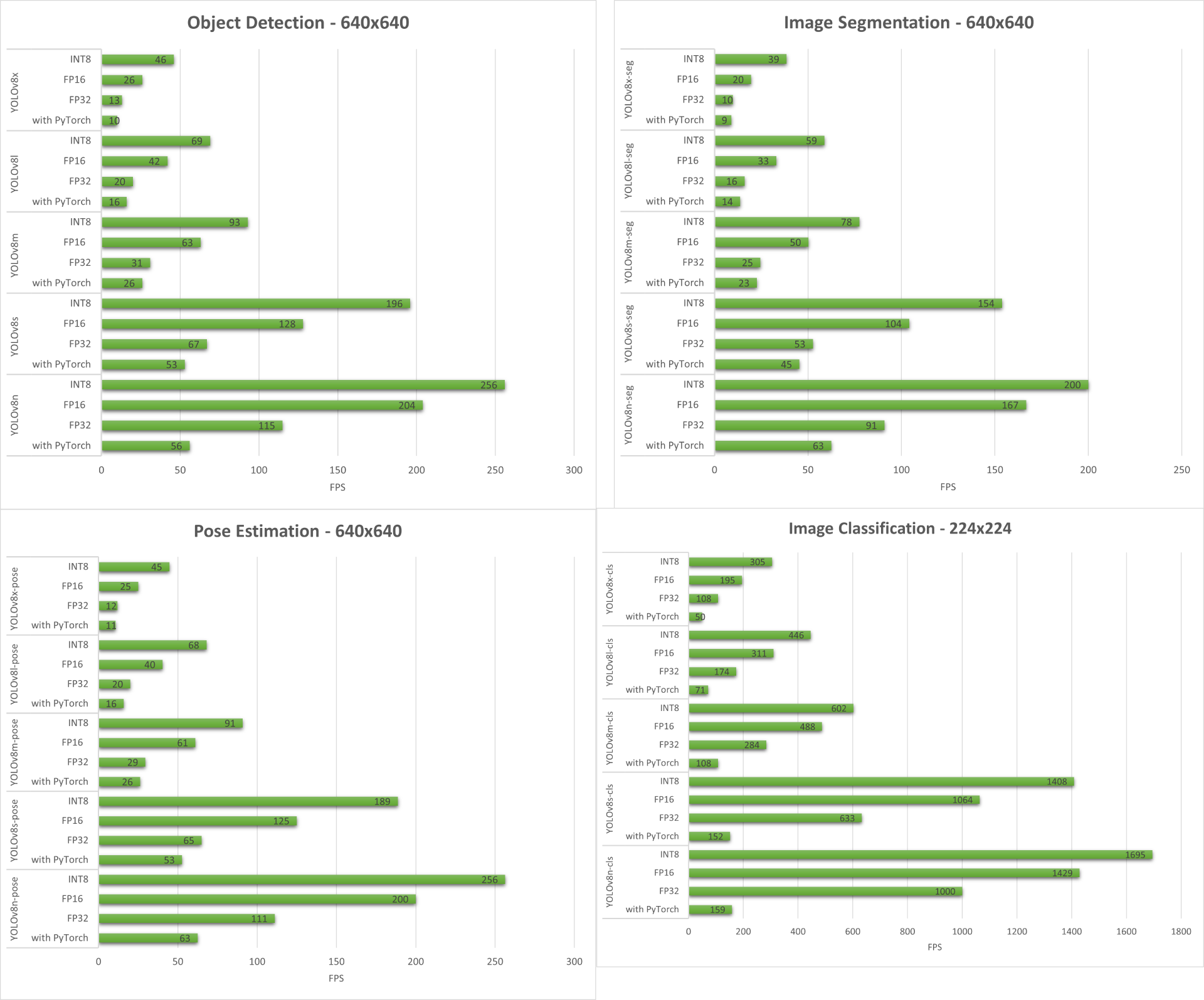
Demo Adicional: Detector y Contador de Ejercicios con YOLOv8
Hemos construido una aplicación demo de estimación de pose para detección y conteo de ejercicios con YOLOv8 usando el modelo YOLOv8-Pose. Puedes revisar el proyecto aquí para aprender más sobre esta demo y desplegarla en tu propio dispositivo Jetson!
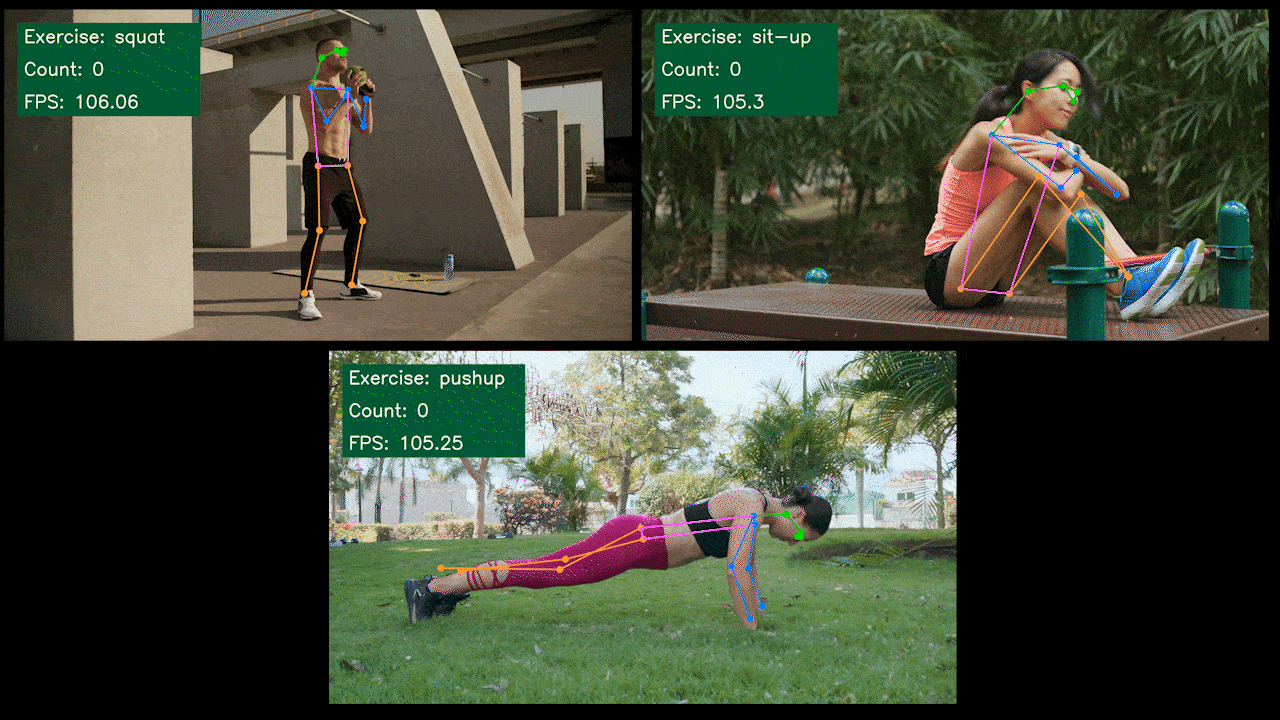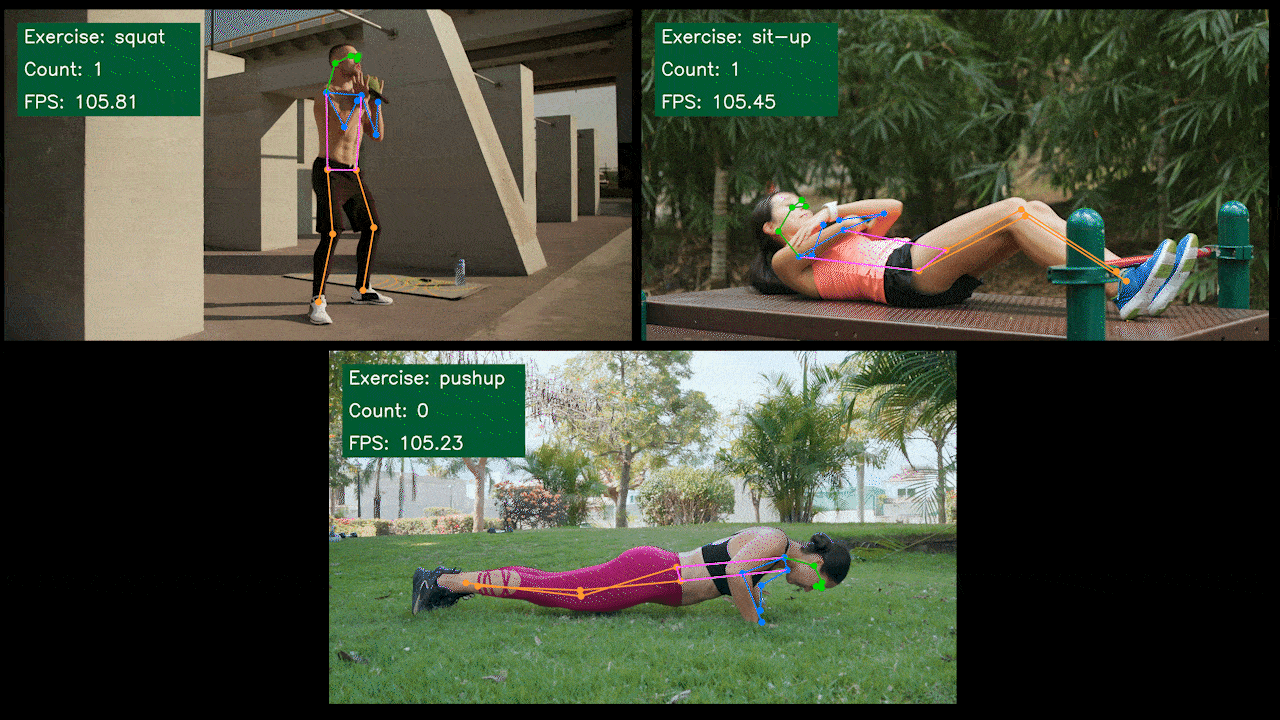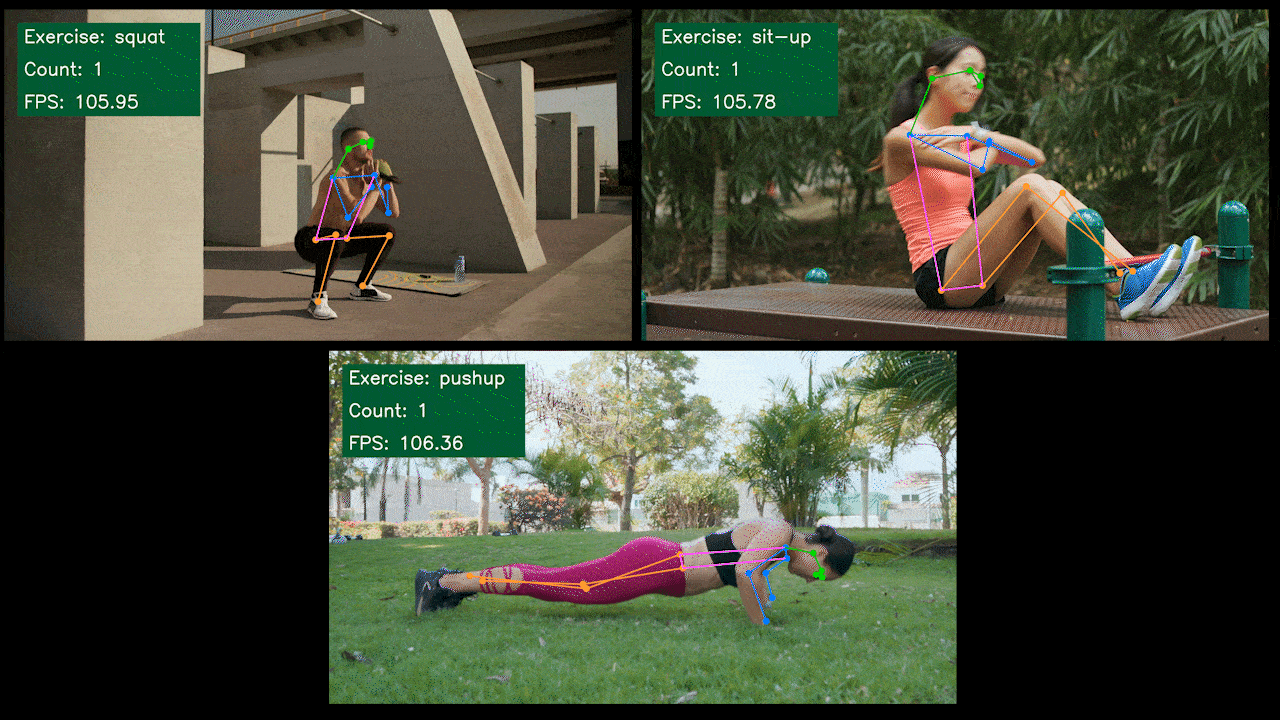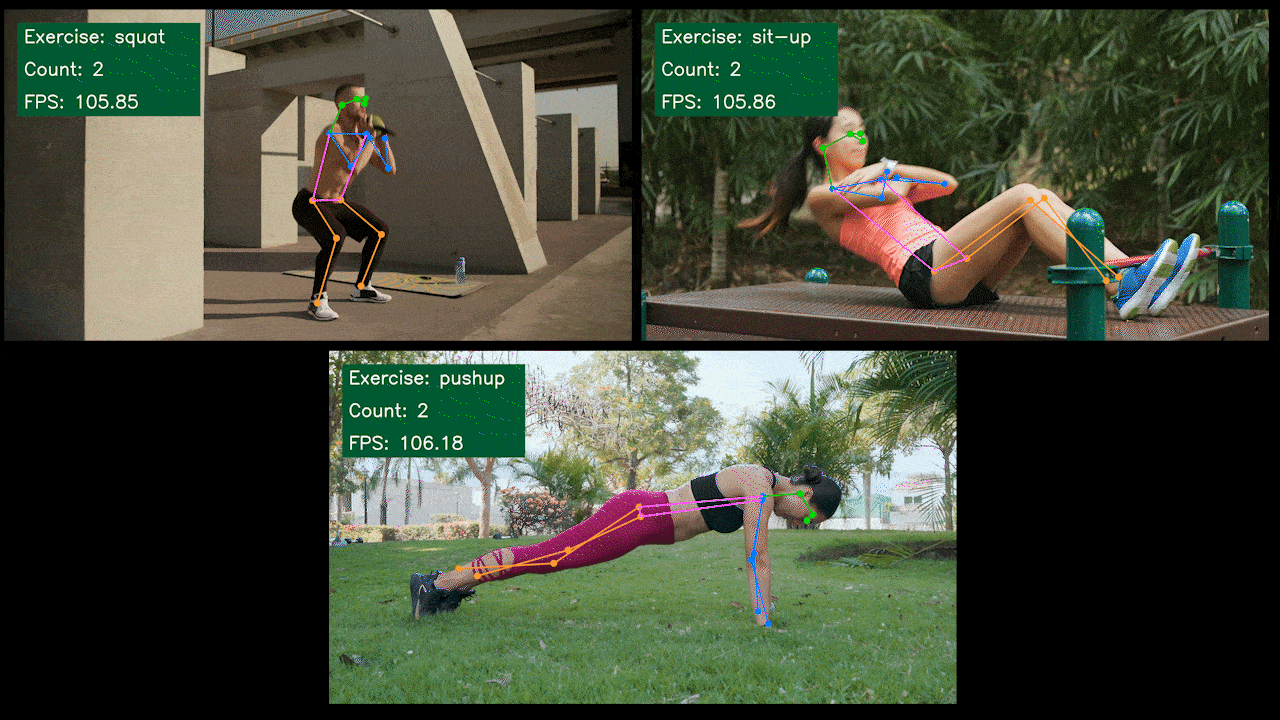
Configuración Manual de YOLOv8 para NVIDIA Jetson
Si el script de una línea que mencionamos anteriormente tiene algunos errores, puedes seguir los pasos a continuación uno por uno para preparar el dispositivo Jetson con YOLOv8.
Instalar el Paquete Ultralytics
- Paso 1. Accede a la terminal del dispositivo Jetson, instala pip y actualízalo
sudo apt update
sudo apt install -y python3-pip -y
pip3 install --upgrade pip
- Paso 2. Instalar el paquete Ultralytics
pip3 install ultralytics
- Paso 3. Actualizar la versión de numpy a la más reciente
pip3 install numpy -U
- Paso 4. Reinicia el dispositivo
sudo reboot
Desinstalar Torch y Torchvision
La instalación de ultralytics anterior instalará Torch y Torchvision. Sin embargo, estos 2 paquetes instalados a través de pip no son compatibles para ejecutarse en la plataforma Jetson que está basada en arquitectura ARM aarch64. Por lo tanto, necesitamos instalar manualmente la rueda pip de PyTorch pre-construida y compilar/instalar Torchvision desde el código fuente.
pip3 uninstall torch torchvision
Instalar PyTorch y Torchvision
Visita esta página para acceder a todos los enlaces de PyTorch y Torchvision.
Aquí tienes algunas de las versiones compatibles con JetPack 5.0 y superior.
PyTorch v2.0.0
Compatible con JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) con Python 3.8
nombre_archivo: torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl
PyTorch v1.13.0
Compatible con JetPack 5.0 (L4T R34.1) / JetPack 5.0.2 (L4T R35.1) / JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1) con Python 3.8
nombre_archivo: torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v502/pytorch/torch-1.13.0a0+d0d6b1f2.nv22.10-cp38-cp38-linux_aarch64.whl
- Paso 1. Instala torch según tu versión de JetPack en el siguiente formato pip3
wget <URL> -O <file_name>
pip3 install <file_name>
Por ejemplo, aquí estamos ejecutando JP5.1.1 y por lo tanto elegimos PyTorch v2.0.0
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl -O torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
- Paso 2. Instala torchvision dependiendo de la versión de PyTorch que hayas instalado. Por ejemplo, elegimos PyTorch v2.0.0, lo que significa que necesitamos elegir Torchvision v0.15.2
sudo apt install -y libjpeg-dev zlib1g-dev
git clone https://github.com/pytorch/vision torchvision
cd torchvision
git checkout v0.15.2
python3 setup.py install --user
Aquí tienes una lista de las versiones correspondientes de torchvision que necesitas instalar según la versión de PyTorch:
- PyTorch v2.0.0 - torchvision v0.15
- PyTorch v1.13.0 - torchvision v0.14
Si quieres una lista más detallada, por favor consulta este enlace.
Instalar ONNX y Degradar Numpy
Esto solo es necesario si quieres convertir los modelos de PyTorch a TensorRT
- Paso 1. Instala ONNX que es un requisito
pip3 install onnx
- Paso 2. Degradar a una versión inferior de Numpy para corregir un error
pip3 install numpy==1.20.3
Recursos
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarle diferentes tipos de soporte para asegurar que su experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.