llama.cpp Distribuido en reComputer Jetson (Modo RPC)

Ejecutar modelos de lenguaje grandes (LLMs) en dispositivos edge como NVIDIA Jetson puede ser desafiante debido a las limitaciones de memoria y cómputo. Esta guía demuestra cómo distribuir la inferencia de LLM a través de múltiples dispositivos reComputer Jetson usando el backend RPC de llama.cpp, habilitando escalado horizontal para cargas de trabajo más exigentes.
Prerrequisitos
- Dos dispositivos reComputer Jetson con JetPack 6.x+ instalado y controladores CUDA funcionando correctamente
- Ambos dispositivos en la misma red local, capaces de hacer
pingentre sí - Máquina local (cliente) con ≥ 64 GB RAM, nodo remoto con ≥ 32 GB RAM
1. Clonar Código Fuente
Paso 1. Clonar el repositorio llama.cpp:
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
2. Instalar Dependencias de Compilación
Paso 1. Actualizar lista de paquetes e instalar dependencias requeridas:
sudo apt update
sudo apt install -y build-essential cmake git libcurl4-openssl-dev python3-pip
3. Compilar con Backend RPC + CUDA
Paso 1. Configurar CMake con soporte RPC y CUDA:
cmake -B build \
-DGGML_CUDA=ON \
-DGGML_RPC=ON \
-DCMAKE_BUILD_TYPE=Release
Paso 2. Compilar con trabajos paralelos:
cmake --build build --parallel # Multi-core parallel compilation
4. Instalar Herramientas de Conversión Python
Paso 1. Instalar el paquete Python en modo desarrollo:
pip3 install -e .
5. Descargar y Convertir Modelo
Este ejemplo usa TinyLlama-1.1B-Chat-v1.0:
Enlace del modelo: https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
Descarga estos archivos y colócalos en una carpeta TinyLlama-1.1B-Chat-v1.0 creada por ti.
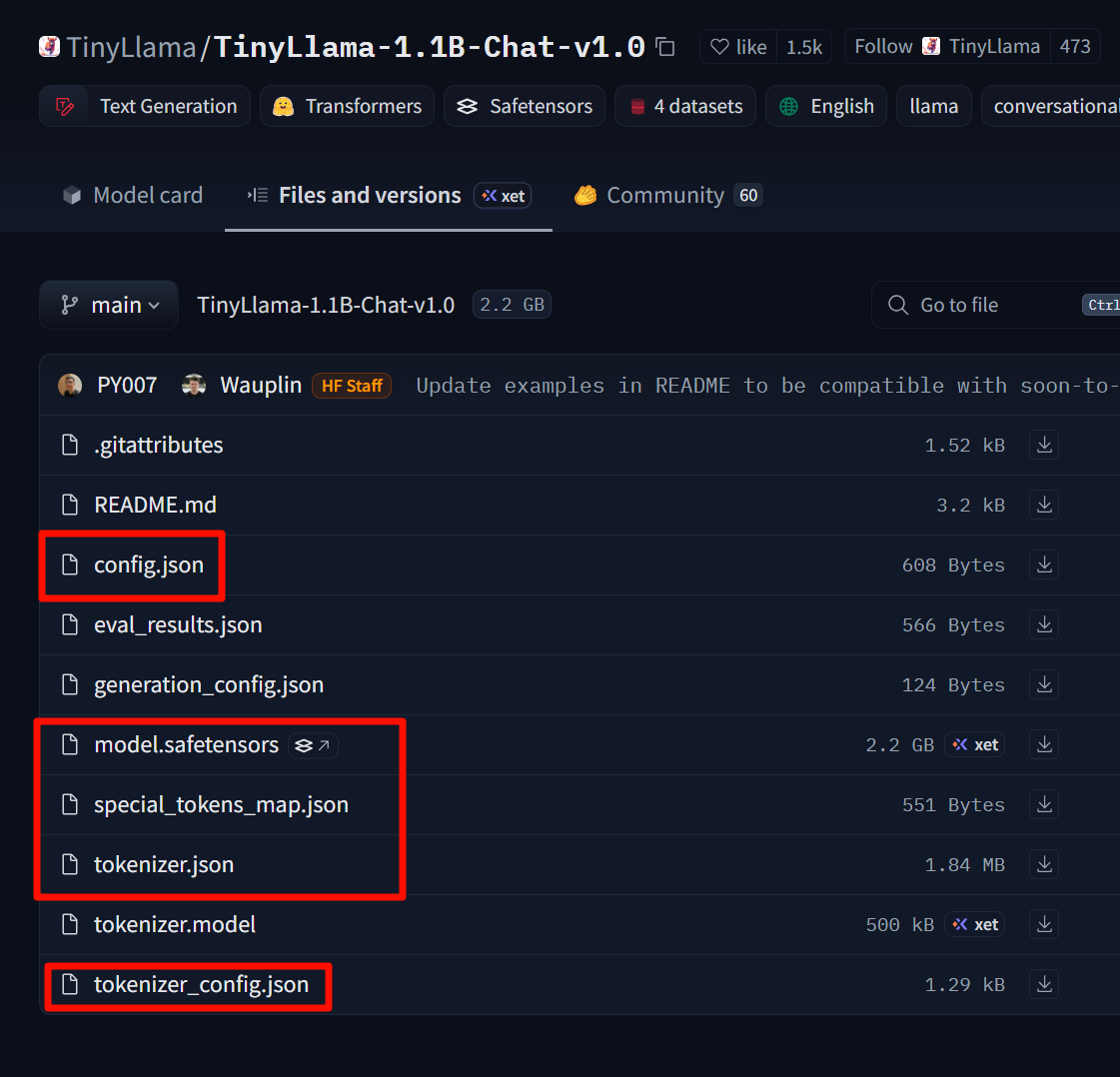
Paso 1. Convertir el modelo de Hugging Face al formato GGUF:
# Assuming the model is already downloaded to ~/TinyLlama-1.1B-Chat-v1.0 using git-lfs or huggingface-cli
python3 convert_hf_to_gguf.py \
--outfile ~/TinyLlama-1.1B.gguf \
~/TinyLlama-1.1B-Chat-v1.0
6. Verificar Inferencia de Una Sola Máquina
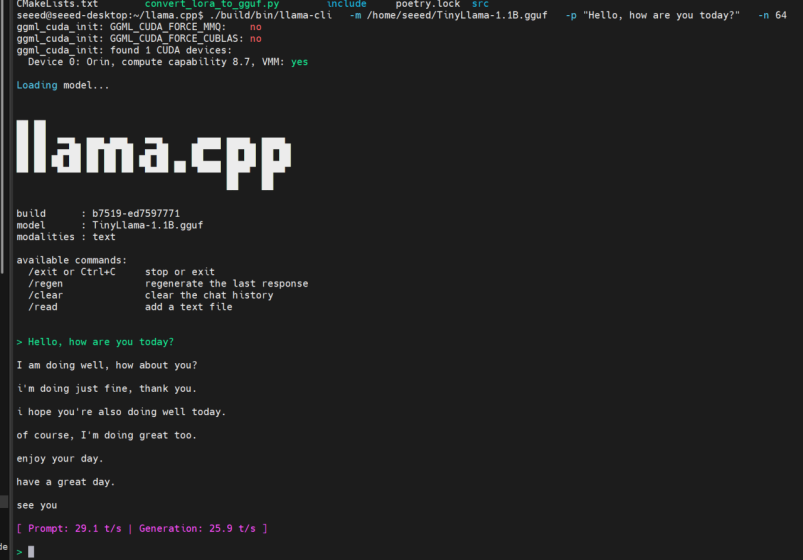
Paso 1. Probar el modelo con un prompt simple:
./build/bin/llama-cli \
-m ~/TinyLlama-1.1B.gguf \
-p "Hello, how are you today?" \
-n 64
Si recibes una respuesta, el modelo está funcionando correctamente.
7. Operación RPC Distribuida
7.1 Ejemplo de Topología de Hardware
| Dispositivo | RAM | Rol | IP |
|---|---|---|---|
| Máquina A | 64 GB | Cliente + Servidor Local | 192.168.100.2 |
| Máquina B | 32 GB | Servidor Remoto | 192.168.100.1 |
7.2 Iniciar Servidor RPC Remoto (Máquina B)
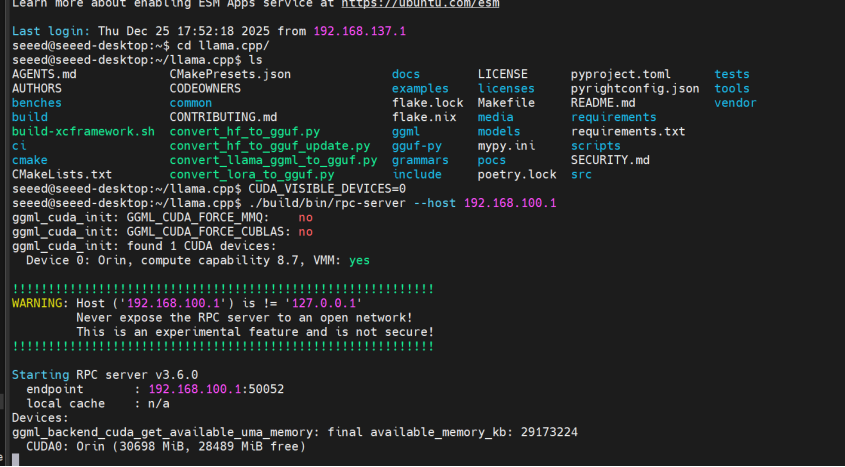
Paso 1. Conectarse a la máquina remota e iniciar el servidor RPC:
ssh [email protected]
cd ~/llama.cpp
CUDA_VISIBLE_DEVICES=0 ./build/bin/rpc-server --host 192.168.100.1
El servidor usa por defecto el puerto 50052. Para personalizar, añade -p <puerto>.
7.3 Iniciar Servidor RPC Local (Máquina A)
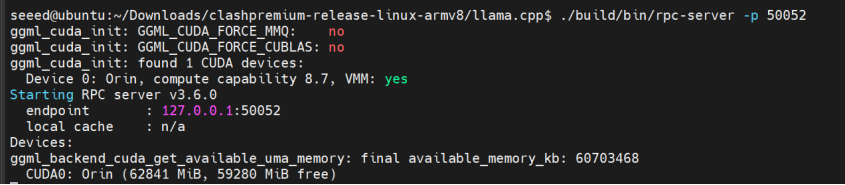
Paso 1. Iniciar el servidor RPC local:
cd ~/llama.cpp
CUDA_VISIBLE_DEVICES=0 ./build/bin/rpc-server -p 50052
7.4 Inferencia Conjunta (Carga Multi-nodo)
Paso 1. Ejecutar inferencia usando tanto servidores RPC locales como remotos:
./build/bin/llama-cli \
-m ~/TinyLlama-1.1B.gguf \
-p "Hello, my name is" \
-n 64 \
--rpc 192.168.100.1:50052,127.0.0.1:50052 \
-ngl 99
-ngl 99 descarga el 99% de las capas a GPUs (tanto nodos RPC como GPU local).
Si quieres ejecutar solo localmente, elimina la dirección remota de --rpc:
--rpc 127.0.0.1:50052
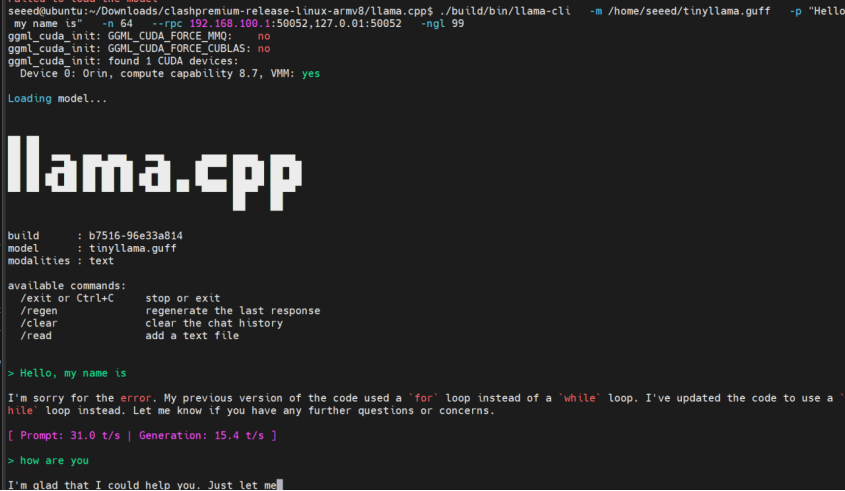
8. Comparación de Rendimiento
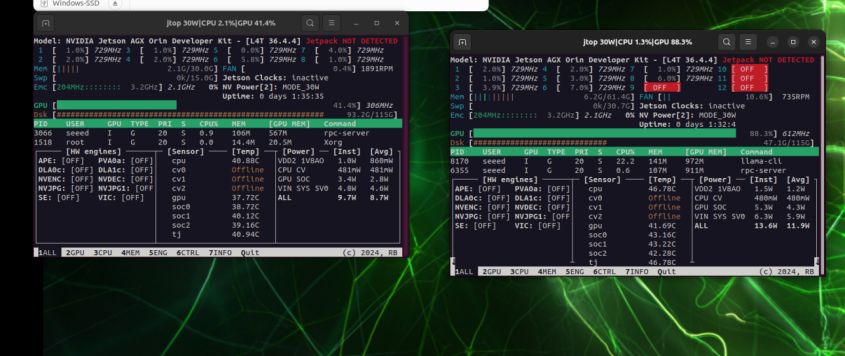
Izquierda: Utilización de GPU en 192.168.100.1; Derecha: Utilización de GPU en 192.168.100.2
Cuando se ejecuta solo localmente, la presión de GPU se concentra en una sola tarjeta
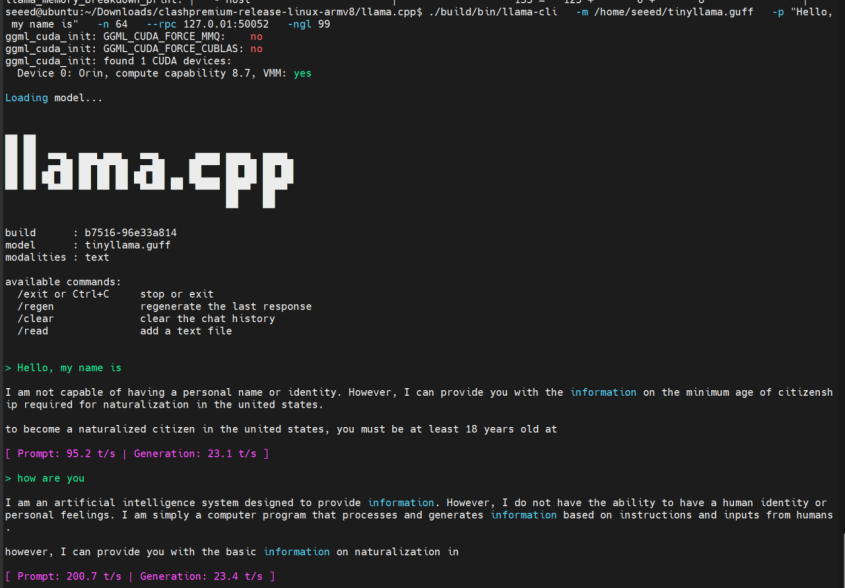
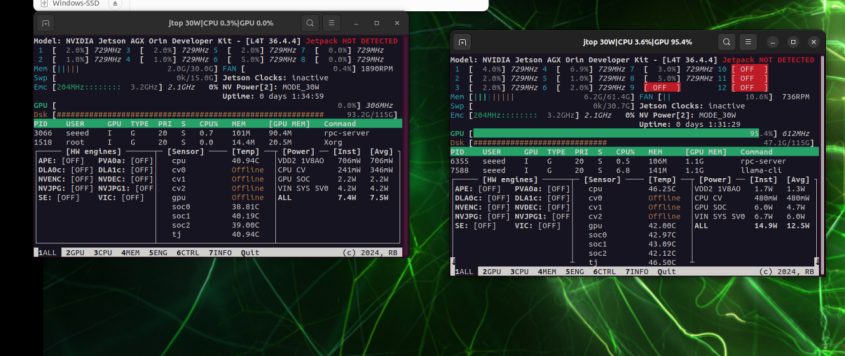
9. Solución de Problemas
| Problema | Solución |
|---|---|
| Fallo al iniciar rpc-server | Verificar si el puerto está ocupado o el firewall está bloqueando 50052/tcp |
| Velocidad de inferencia más lenta | Modelo demasiado pequeño, latencia de red > beneficio de cómputo; probar modelo más grande o modo Unix-socket |
| Error de memoria insuficiente | Reducir valor -ngl para descargar menos capas a GPU, o mantener algunas capas en CPU |
Con esta configuración, ahora puedes lograr "escalado horizontal" para inferencia de LLM a través de múltiples dispositivos Jetson usando el backend RPC de llama.cpp. Para mayor rendimiento, puedes añadir más nodos RPC o cuantizar aún más el modelo a formatos como q4_0 o q5_k_m.
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para atender diferentes preferencias y necesidades.