Interacción de voz con IA con reCamera
Introducción
Este proyecto demuestra una forma de interactuar con reCamera mediante lenguaje natural. Después de que el razonamiento visual activa la grabación de audio, reCamera envía la grabación al servidor, la procesa a través de la canalización completa de STT (Speech-to-Text) → LLM (Large Language Model Reasoning) → TTS (Text-to-Speech) y la voz sintetizada se devuelve a reCamera para su reproducción, lo que permite una conversación en lenguaje natural.
¿Alguna vez has querido una cámara que no solo pueda "ver", sino también "entender" y "hablar"? A través de la arquitectura de este proyecto, utilizando el micrófono y el altavoz de la reCamera, el dispositivo deja de ser solo una herramienta visual para convertirse en un asistente inteligente capaz de mantener conversaciones naturales. Esto incluye, entre otros, los siguientes escenarios:
-
Asistente inteligente de control de acceso: Instala reCamera en la entrada, donde los visitantes pueden completar el registro de identidad, dejar mensajes u obtener indicaciones solo mediante la voz, sin necesidad de una pantalla interactiva adicional.
-
Compañero de inspección de seguridad en fábrica: En entornos industriales, cuando las manos de los trabajadores están ocupadas, pueden activar la interacción por voz mediante gestos para preguntar al asistente de IA sobre el estado del equipo, manuales de operación o para informar anomalías.
-
Interacción asistida para accesibilidad: Proporciona un punto de entrada de control por voz para usuarios con discapacidad visual o movilidad reducida, permitiendo la conversación en lenguaje natural con el dispositivo mediante simples gestos para obtener información del entorno o enviar comandos.
-
Guía educativa y de exposiciones: En museos o salas de exposiciones, los visitantes pueden activar la interacción por voz mediante gestos para preguntar al asistente de IA sobre la información de las exhibiciones y recibir visitas guiadas personalizadas.
Video de demostración
Arquitectura del sistema
Todo el sistema se completa de forma colaborativa por dos partes: lado reCamera y lado servidor PC. La arquitectura es la siguiente:
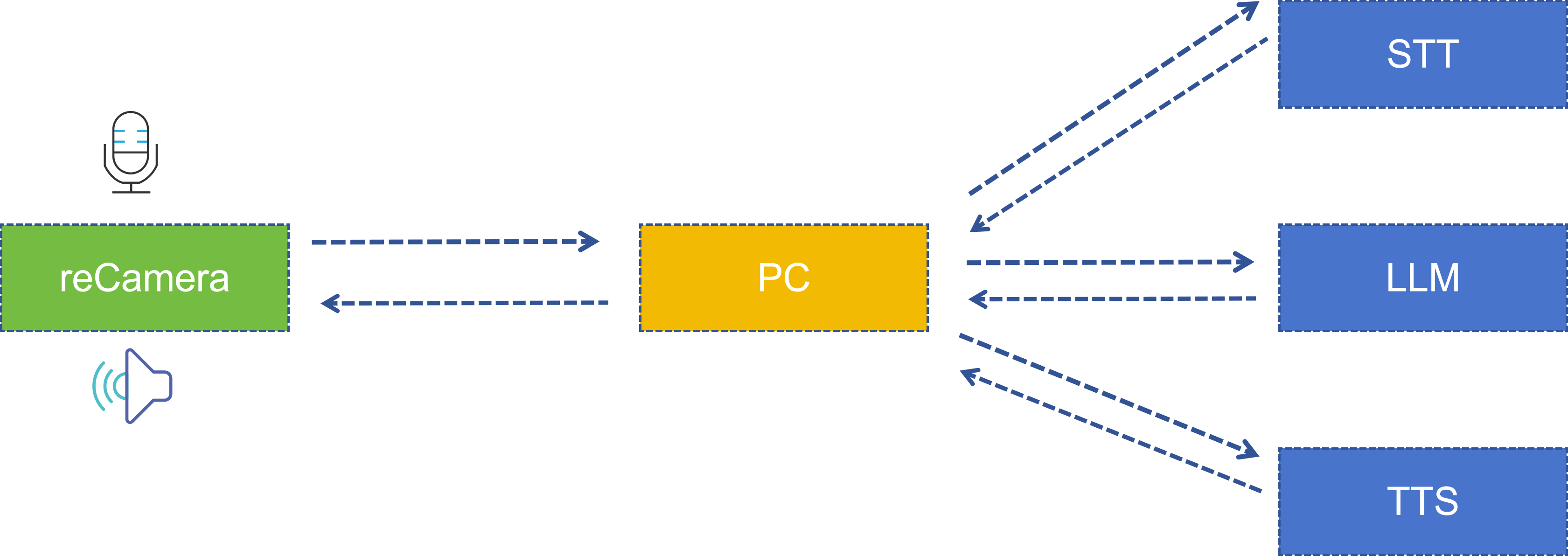
| Etapa | Ubicación de ejecución | Tecnología/Modelo utilizado | Descripción |
|---|---|---|---|
| Detección de pose | reCamera | YOLO11n Pose | Detecta 17 puntos clave del cuerpo humano |
| Juicio de pose | reCamera (Función de Node-RED) | Lógica personalizada | Compara las distancias de los puntos clave del hombro y del codo |
| Grabación/Reproducción | reCamera | arecord / aplay | PCM mono de 16 kHz |
| Reconocimiento de voz (STT) | Servidor PC | iFlytek Speech Dictation API | Audio a texto |
| Razonamiento de gran modelo (LLM) | Servidor PC | Spark Large Model Spark Lite | Genera respuestas inteligentes |
| Texto a voz (TTS) | Servidor PC | iFlytek Speech Synthesis API | Texto a audio |
Preparación de hardware
Para ejecutar esta demostración, necesitas el siguiente hardware:
- Un dispositivo reCamera (compatible con todas las variantes de reCamera)
- Un ordenador PC (para ejecutar el servicio de procesamiento de voz, debe estar en la misma LAN que reCamera)
Puedes elegir cualquier versión de reCamera según tus necesidades de despliegue:
- reCamera 2002 Serie (Wi-Fi)
- reCamera Gimbal
- reCamera HQ PoE (Ethernet + PoE)
Nota: La versión PoE no admite Wi-Fi y debe conectarse a la misma red local a través de un switch compatible con PoE.
| reCamera 2002 Serie | reCamera Gimbal | reCamera HQ PoE |
|---|---|---|
 |  |  |
Configuración de la demostración
Paso 1: Configurar reCamera
Primero, sigue la guía oficial de inicio rápido para completar la configuración básica de reCamera: reCamera Getting Started
Después de completar la configuración inicial, asegúrate de que el dispositivo esté encendido y correctamente conectado a la red. Luego, accede a la dirección 192.168.42.1 a través de un navegador para iniciar sesión en reCamera y entrar en el espacio de trabajo de Node-RED.
Si puedes acceder correctamente a la interfaz de flujo de trabajo de Node-RED como se muestra a continuación, la configuración está completa.

Paso 2: Importar el flujo de trabajo de Node-RED
Esta demostración proporciona un archivo de flujo de trabajo preconfigurado con todos los nodos y conexiones necesarios para el asistente de voz inteligente ya configurados. Debes seguir los pasos a continuación para realizar algunas configuraciones y ejecutar correctamente este proyecto.
Crea una nueva aplicación, luego descarga el archivo de flujo de trabajo AI Voice Assistant desde la plataforma SenseCraft AI e impórtalo directamente en reCamera. Para los tutoriales de SenseCraft AI, consulta el enlace Access SenseCraft AI reCamera Dashboard.
Si puedes acceder correctamente a la interfaz de flujo de trabajo de Node-RED como se muestra a continuación, el flujo de trabajo se ha importado correctamente.
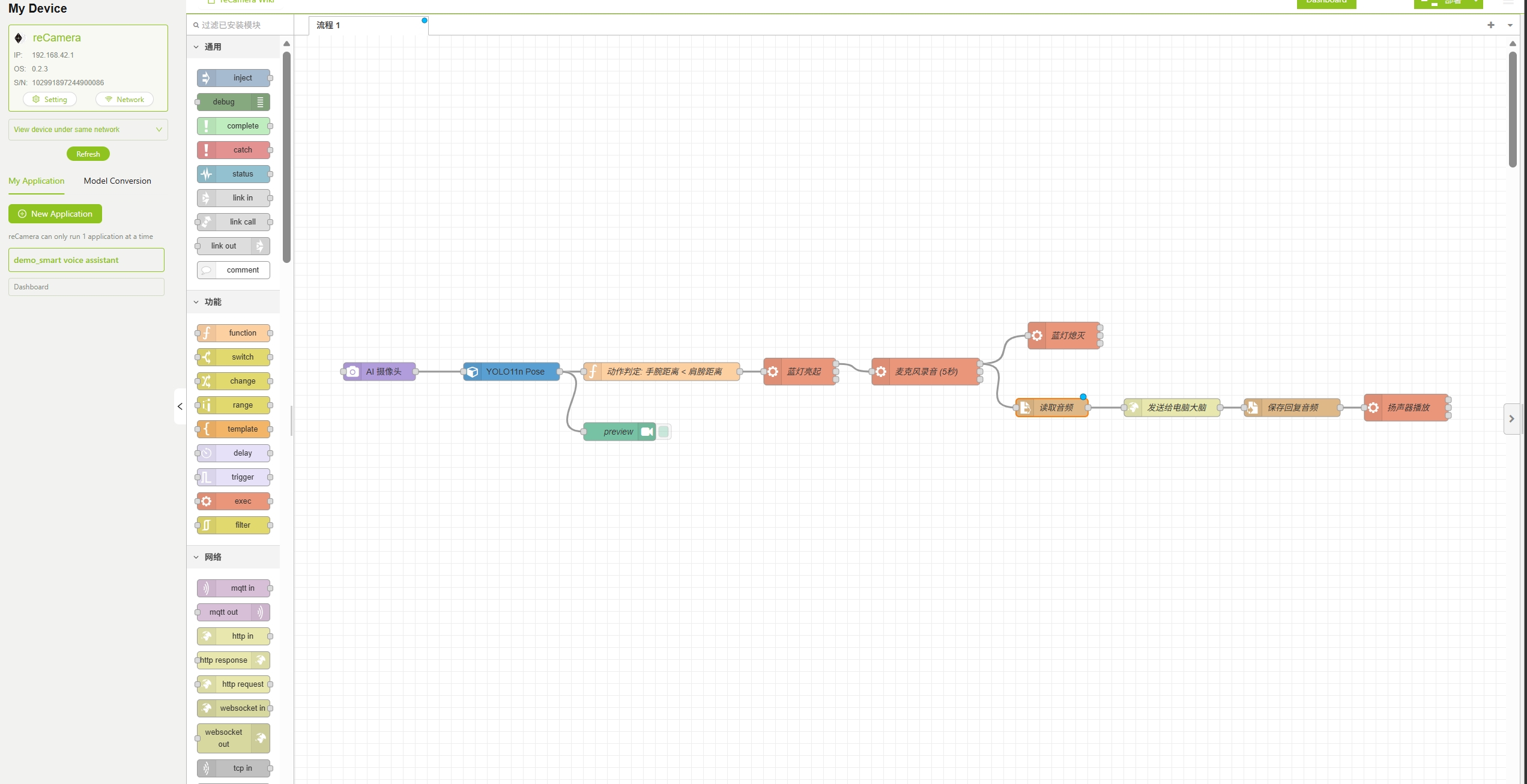
Paso 3: Configurar los parámetros del flujo de trabajo
Después de importar el flujo de trabajo, debes modificar los parámetros en las secciones 3.1 a 3.5 que aparecen a continuación de acuerdo con tu entorno de red real y la configuración del sistema.
3.1 Nodo Model
El nodo Model en el flujo de trabajo incluye varios modelos preentrenados. Aquí puedes seleccionar y configurar varios parámetros del modelo. Esta demostración utiliza el modelo YOLO11n Pose para detectar poses humanas.
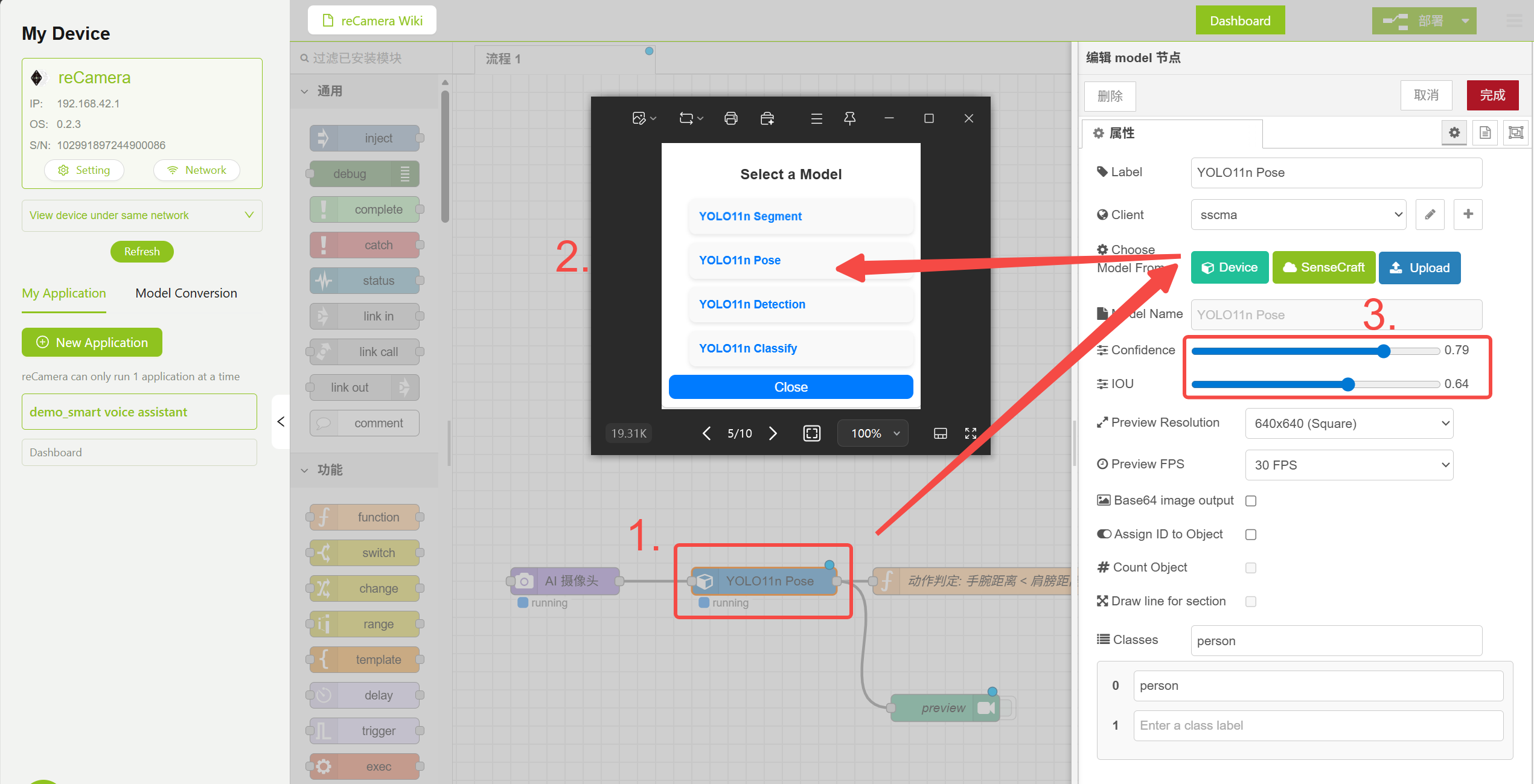
Configuración del nodo Model
3.2 Nodo Model — Lógica de juicio de pose
El nodo Function contiene la lógica de juicio de pose que determina si se debe activar la interacción por voz comparando la distancia del punto clave del hombro con la distancia del punto clave del codo. Puedes ajustar los parámetros de Confidence e IOU en el nodo Model para reducir falsos positivos, o modificar el código lógico en el nodo Function que se muestra a continuación para implementar funciones adicionales.
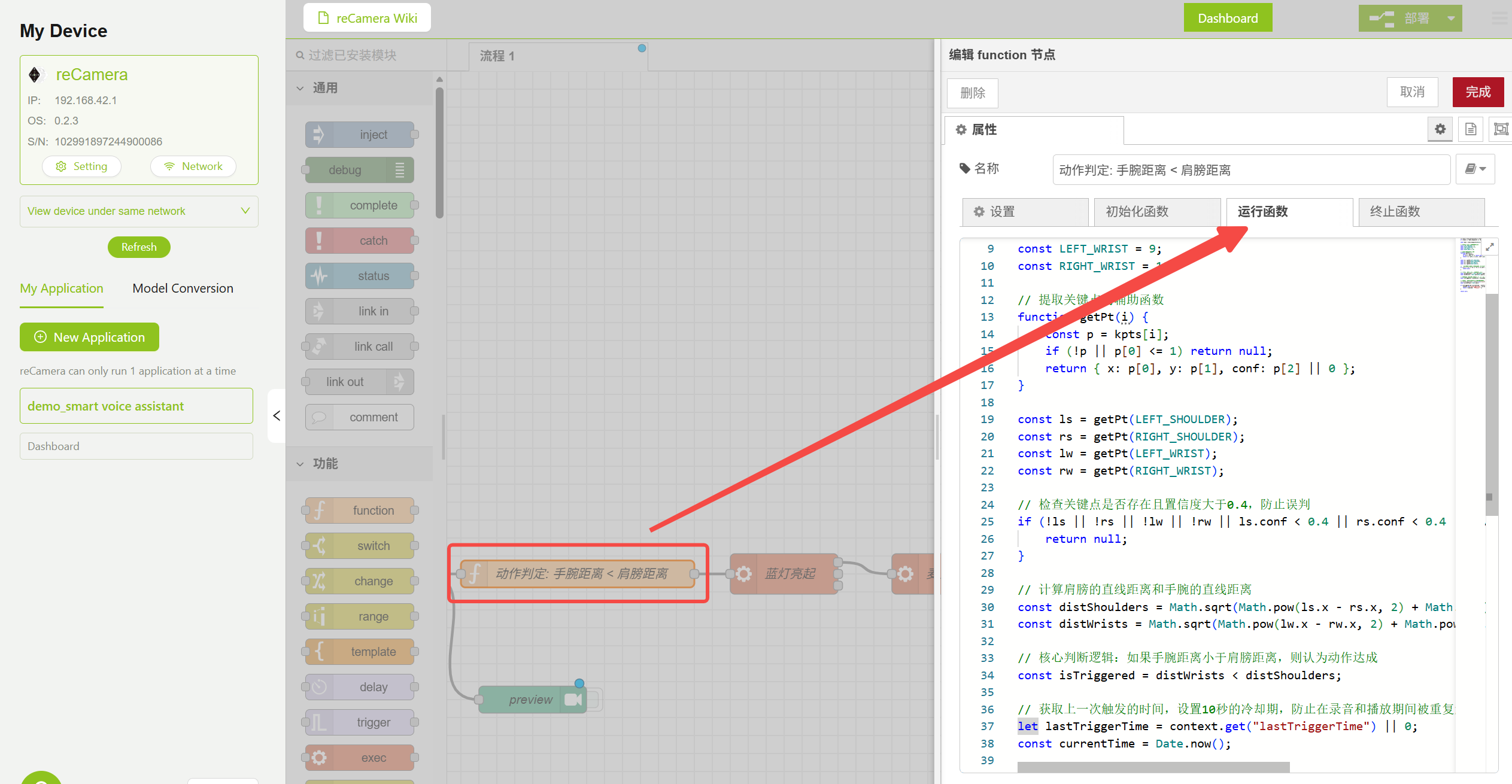
Configuración del nodo Function de juicio de pose
3.3 Nodo Exec — Control de LED y grabación
El flujo de trabajo utiliza nodos Exec para ejecutar comandos del sistema para controlar el LED y la grabación. Haz doble clic en el nodo correspondiente y modifica la contraseña root de reCamera según tu configuración real:
echo "your_Password" | sudo -S sh -c 'echo 1 > /sys/class/leds/blue/brightness'
- Encender y apagar el LED azul (indica que la grabación ha comenzado)
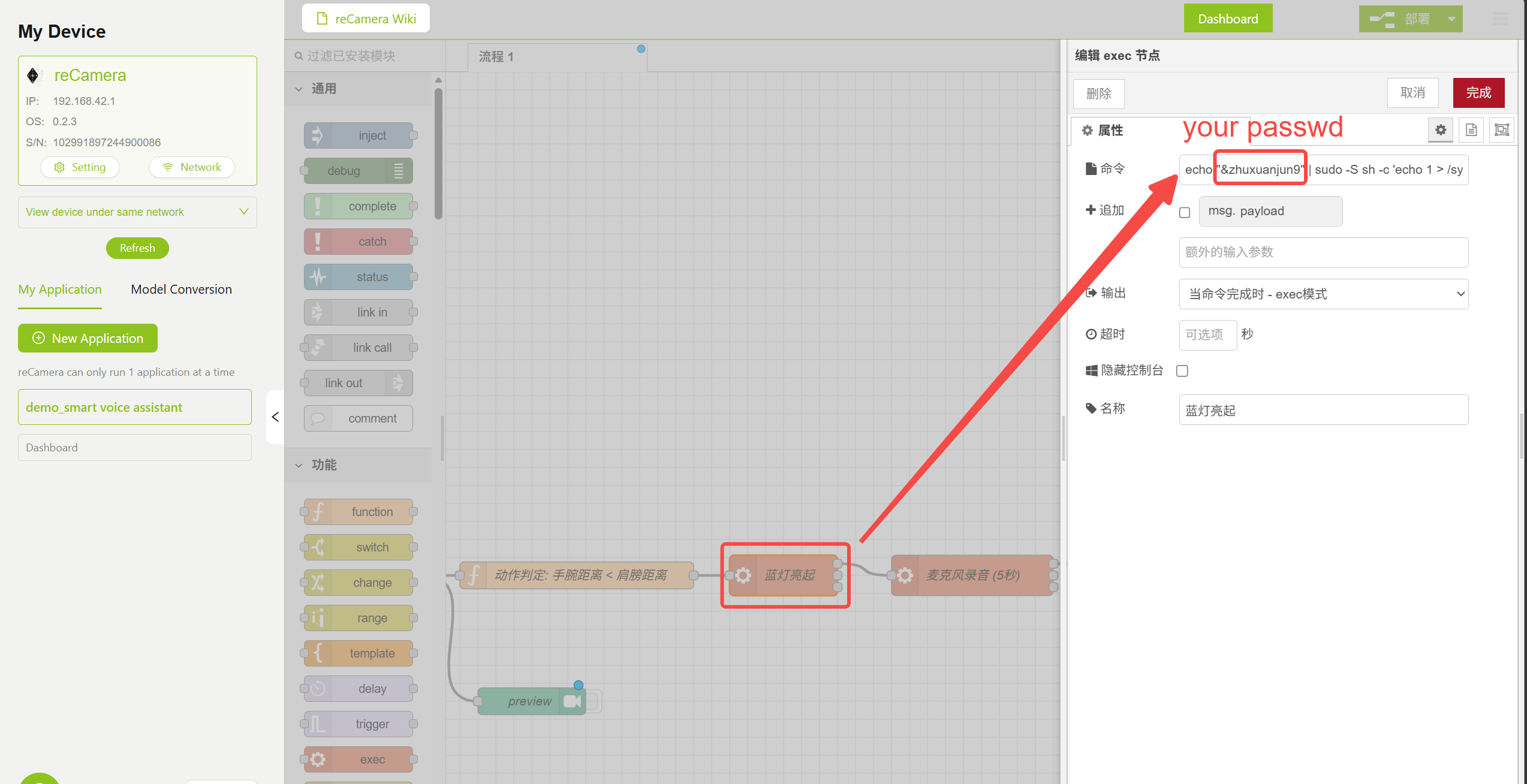
Configuración de parámetros del nodo Turn On LED
3.4 Nodo HTTP Request — Dirección de envío de audio
Busca el nodo HTTP Request en el flujo de trabajo y modifica la URL a la dirección de tu servidor PC. Para ello debes completar primero el Paso 4 y ejecutar server.py, luego rellenar la dirección en la posición correspondiente que se muestra a continuación.
http://<PC_IP_ADDRESS>:5000/interact
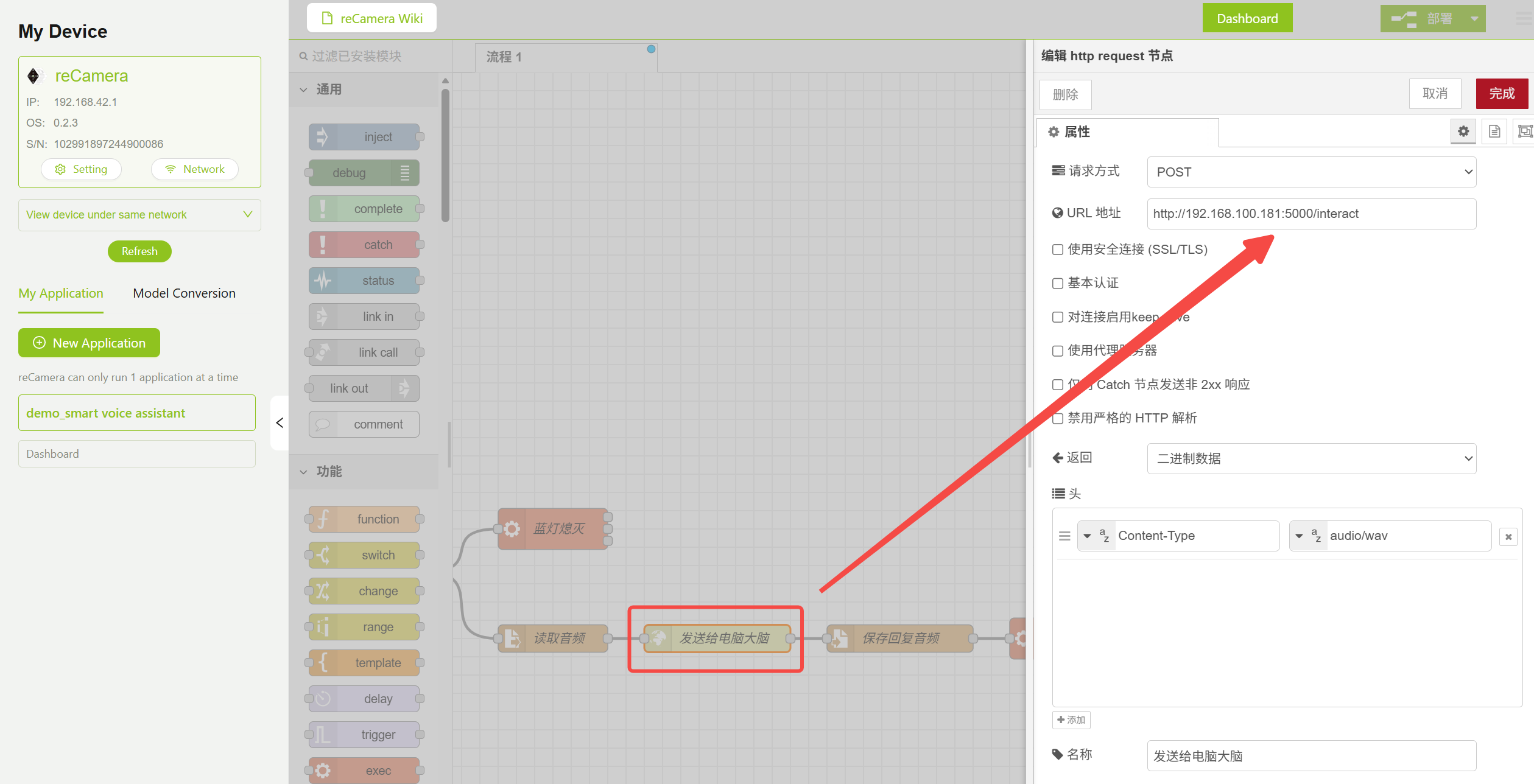
Configuración de parámetros del nodo HTTP Request
3.5 Nodo Exec — Reproducción de audio
El audio devuelto se reproduce mediante el comando aplay. Debes especificar los parámetros de audio correctos para que coincidan con el formato de salida del modelo TTS (16 kHz, mono, 16 bits):
aplay -D hw:1,0 -f S16_LE -c 1 -r 16000 /tmp/reply.wav
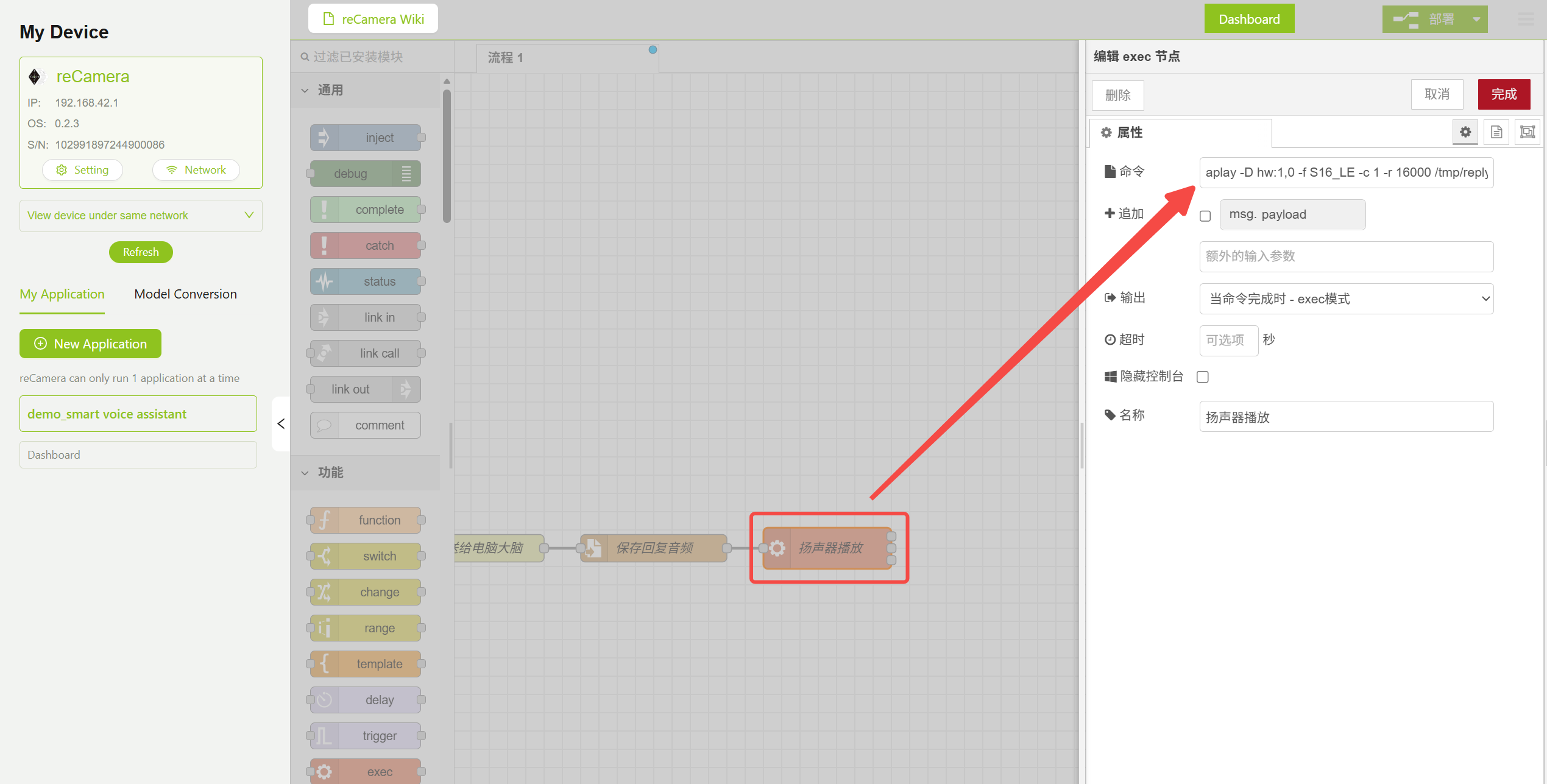
Configuración de parámetros del nodo de reproducción de audio
Paso 4: Desplegar el servicio de procesamiento de voz en el PC
El servicio de procesamiento de voz se ejecuta en el PC y es responsable de completar toda la canalización de procesamiento de voz STT → LLM → TTS.
4.1 Requisitos previos
Asegúrate de que el siguiente entorno esté instalado en tu PC:
- Python 3.8+
- Administrador de paquetes pip
4.2 Obtén el código e instala las dependencias
Obtén el código Python del lado del servidor para el Asistente de Voz con IA desde el repositorio. Después de descargar el código del proyecto a tu PC, entra en el directorio del servicio e instala las dependencias de Python:
cd server/
pip install -r requirements.txt
Las dependencias principales incluyen:
| Paquete | Propósito |
|---|---|
| Flask | Framework de servicio HTTP |
| websocket-client | Comunicación con la API de iFlytek |
| certifi | Verificación de certificados SSL |
| pydub | Procesamiento de audio |
4.3 Configurar claves de API
Antes de ejecutar el servicio, debes configurar las claves de API de iFlytek. Ve a la Plataforma Abierta de iFlytek para registrar una cuenta y activar los siguientes tres servicios:
| Servicio | Propósito | Enlace de activación |
|---|---|---|
| Speech Dictation (STT) | Convertir el habla del usuario en texto | iFlytek Speech Dictation |
| Spark Large Model (LLM) | Generar respuestas inteligentes basadas en texto | iFlytek Spark Large Model |
| Speech Synthesis (TTS) | Convertir el texto de respuesta en voz | iFlytek Speech Synthesis |
Después de la activación, rellena tus claves de API en server.py:
# 1. STT Speech Recognition Configuration
STT_APPID = "your_APPID"
STT_APISecret = "your_APISecret"
STT_APIKey = "your_APIKey"
# 2. TTS Speech Synthesis Configuration
TTS_APPID = "your_APPID"
TTS_APISecret = "your_APISecret"
TTS_APIKey = "your_APIKey"
# 3. LLM Spark Large Model Configuration (Spark Lite)
LLM_APPID = "your_APPID"
LLM_APISecret = "your_APISecret"
LLM_APIKey = "your_APIKey"
Esta demo utiliza el modelo Spark Lite (gratuito). También puedes cambiar a una versión de modelo más avanzada según sea necesario, o usar modelos grandes de otros proveedores.
4.4 Iniciar el servicio
python server.py

Registro de inicio del servidor
Después de que el servicio se inicie, esperará solicitudes de audio desde reCamera. Asegúrate de que el firewall del PC permita conexiones entrantes en el puerto 5000 y de que el PC y la reCamera estén en la misma LAN.Paso 5: Ejecutar la demostración
- Asegúrate de que
server.pyen el PC esté iniciado y en ejecución - Haz clic en Deploy en Node-RED para desplegar el flujo de trabajo
- Ponte frente a la reCamera y haz un gesto de brazos cruzados (la distancia entre hombros debe ser menor que la distancia entre codos)
- El LED azul de la reCamera se enciende, indicando que la grabación ha comenzado
- Di tu pregunta al micrófono
- Después de que el LED azul se apague, la reCamera envía el audio al servidor y reproduce la respuesta después de recibirla.
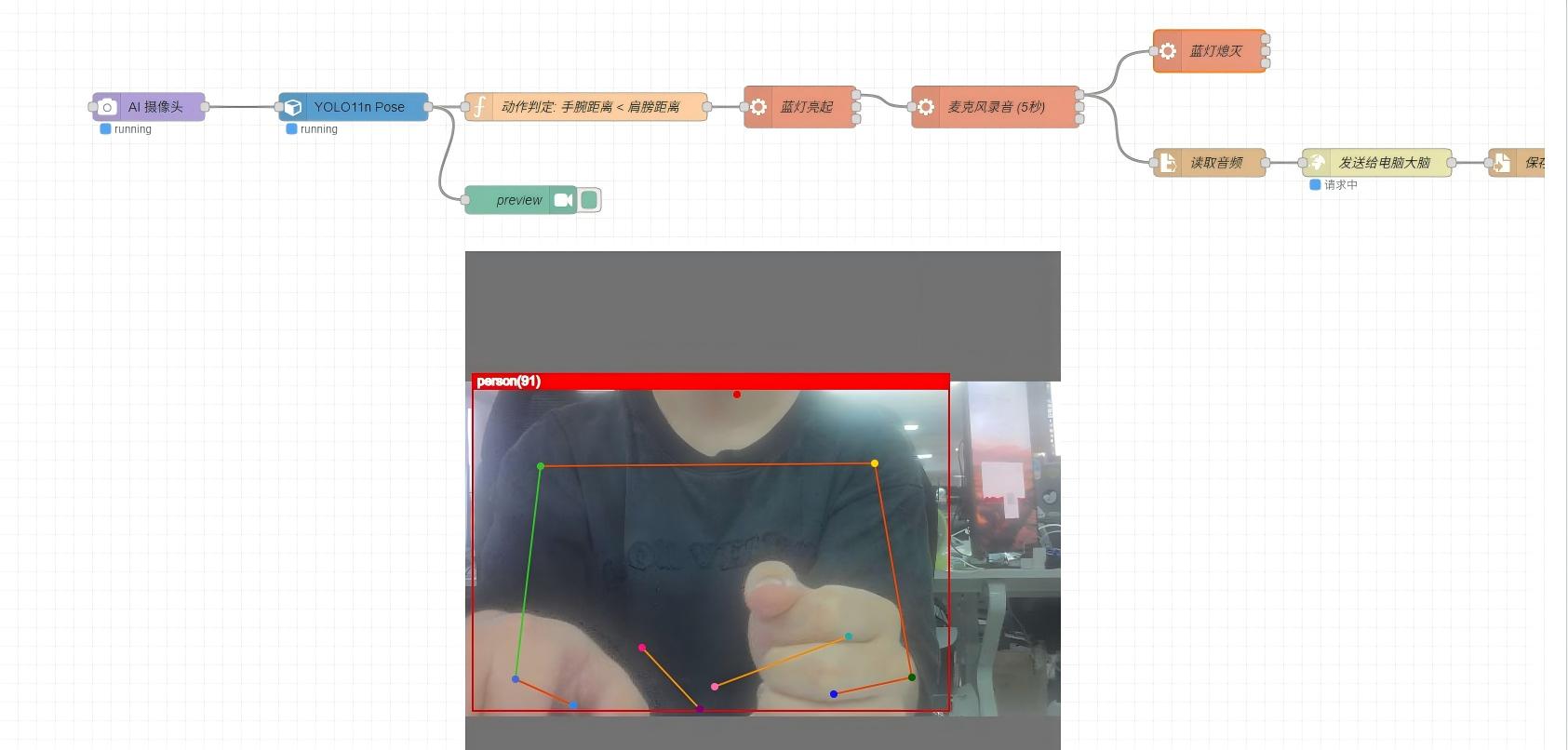
Activación del flujo de conversación por voz
Received reCamera audio,length:160044 bytes
User said:Hi,who are you?
LLM is thinking……
LLM reply:Hi,I′m the voice assistant on your smart camera reCamera.I'm here to help you with any questions or concerns you may have.
Generating speech……
Speech delivered! Waiting for next interaction.
192.168.4.53--[11/Jun/2026 16:38:14]"POST /interact HTTP/1.1" 200 -

Registro del servidor
Detalles del flujo de trabajo
La lógica de alto nivel de todo el flujo de trabajo es la siguiente:
-
Entrada de video y detección de pose La cámara captura continuamente fotogramas de video, y el modelo de estimación de pose YOLO11 detecta los puntos clave del cuerpo humano (17 puntos clave en total, incluidos hombros, codos, muñecas, etc.).
-
Juicio de activación por gesto El nodo Function calcula la distancia entre los puntos clave de los hombros izquierdo y derecho y la distancia entre los puntos clave de los codos izquierdo y derecho. Cuando distancia entre hombros < distancia entre codos, se determina como un gesto de activación (es decir, pose de brazos cruzados).
-
Proceso de grabación Después de la activación: encender el LED azul → grabar audio → apagar el LED azul.
-
Procesamiento de audio y generación de diálogo Después de que la grabación se complete, los datos de audio se envían por POST al servicio Flask del PC mediante una solicitud HTTP, ejecutando:
- STT: la API de Speech Dictation de iFlytek convierte el audio en texto
- LLM: Spark Large Model (Spark Lite) genera respuestas inteligentes basadas en la entrada del usuario
- TTS: la API de Speech Synthesis de iFlytek convierte el texto de respuesta en audio
-
Reproducción de audio El PC devuelve audio WAV, y la reCamera reproduce la voz de respuesta mediante el comando
aplay.
Notas
- El intervalo de grabación actual está configurado en 10 segundos. Si el tiempo de procesamiento STT → LLM → TTS excede este intervalo, múltiples activaciones pueden causar congestión en la canalización. Se recomienda controlar el número de palabras de la respuesta del LLM (la indicación del sistema actual lo limita a 50 palabras o menos) para reducir el tiempo de procesamiento.
- Si la congestión hace que la CPU deje de responder, puedes ajustar el atributo Confidence en el nodo Model para reducir falsos positivos y controlar la frecuencia de activación.
- Al reproducir el audio devuelto usando
aplay, especifica los parámetros correctos (-f S16_LE -c 1 -r 16000), de lo contrario la reproducción puede no funcionar correctamente. Consulta el audio generado por TTS para conocer los parámetros específicos.
Soporte técnico y debate sobre el producto
Gracias por elegir nuestros productos. Si necesitas orientación sobre objetivos de personalización específicos o quieres ampliar aún más el flujo de trabajo, no dudes en contactarnos. Estamos aquí para ofrecerte distintos niveles de soporte y garantizar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para adaptarnos a diferentes preferencias y necesidades.