¡GPT-OSS Ejecutándose en Vivo en reComputer Jetson!
Introducción
Esto es mucho más que un simple ejercicio de portabilidad técnica: es una exploración de lo que es posible en el borde. En este artículo, demostraré cómo un modelo de lenguaje grande de código abierto de 20B parámetros cobra vida en dispositivos de borde como el Nvidia Jetson Orin Nx.

La serie NVIDIA Jetson se destaca como una plataforma de computación de borde premier, reconocida por su excepcional eficiencia energética y factor de forma compacto. Mientras tanto, GPT-OSS-20B representa la vanguardia de los modelos de lenguaje grandes de código abierto disponibles gratuitamente. Su convergencia no solo muestra el potencial sin explotar de los dispositivos de borde, sino que también pionera nuevas posibilidades para aplicaciones de IA sin conexión.
Prerrequisitos
- reComputer Super J4012
En esta wiki, lograremos las siguientes tareas usando el reComputer Super J4012, pero también puedes intentar usar otros dispositivos Jetson.

Los pasos siguientes involucrarán configurar múltiples entornos de Python en el Jetson. Recomendamos instalar Conda en el dispositivo Jetson:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
Instalar llama.cpp
Primero, necesitamos instalar el motor de inferencia llama.cpp en el Jetson. Por favor ejecuta los siguientes comandos en la ventana de terminal del Jetson.
sudo apt update
sudo apt install -y build-essential cmake git
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --parallel
Después de la compilación, todos los archivos ejecutables para llama.cpp se generarán en build/bin.
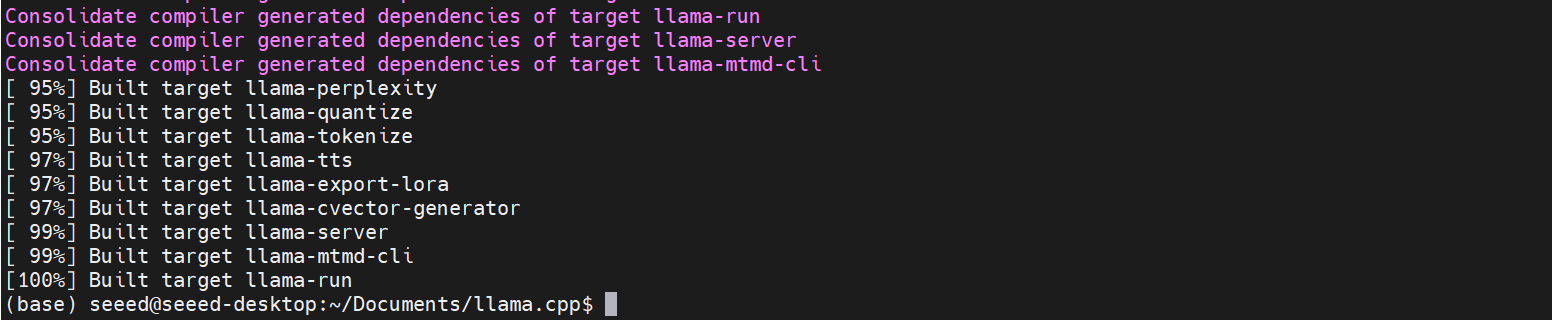
El proceso de construcción típicamente toma alrededor de 2 horas.
Preparar el Modelo GPT-OSS
Paso 1. Descarga el GPT-OSS-20B desde Huggingface y súbelo al Jetson.

Paso 2. Instala las dependencias requeridas para la conversión del modelo.
conda create -n gpt-oss python=3.10
conda activate gpt-oss
cd /home/seeed/Documents/llama.cpp # cd `ruta_de_llama.cpp`
pip install .
Paso 3. Ejecuta el proceso de conversión del modelo.
python convert_hf_to_gguf.py --outfile /home/seeed/Downloads/gpt-oss /home/seeed/Documents/gpt-oss-gguf/
# python convert_hf_to_gguf.py --outfile <ruta_del_modelo_entrada> <ruta_del_modelo_salida>
Paso 4. Cuantización del Modelo.
./build/bin/llama-quantize /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf /home/seeed/Documents/gpt-oss-gguf-Q4/Gpt-Oss-32x2.4B-Q4.gguf Q4_K
# ./build/bin/llama-quantize <ruta_del_modelo_f16_gguf> <ruta_del_modelo_salida> <método_cuantización>
Lanzar GPT-OSS con llama.cpp
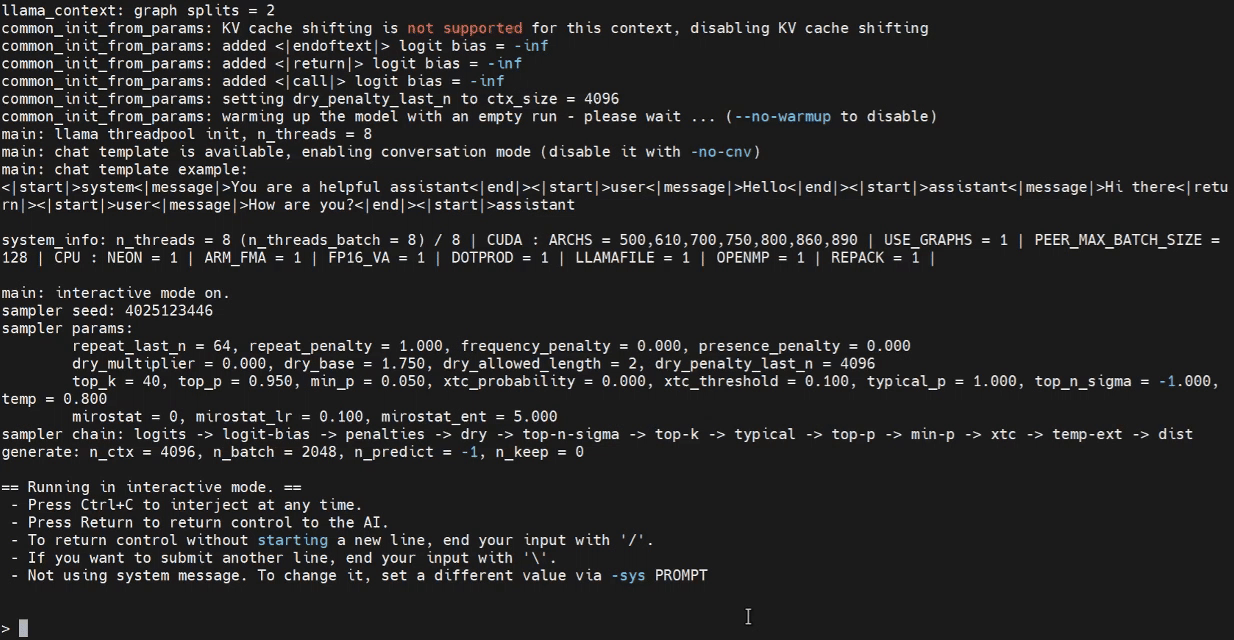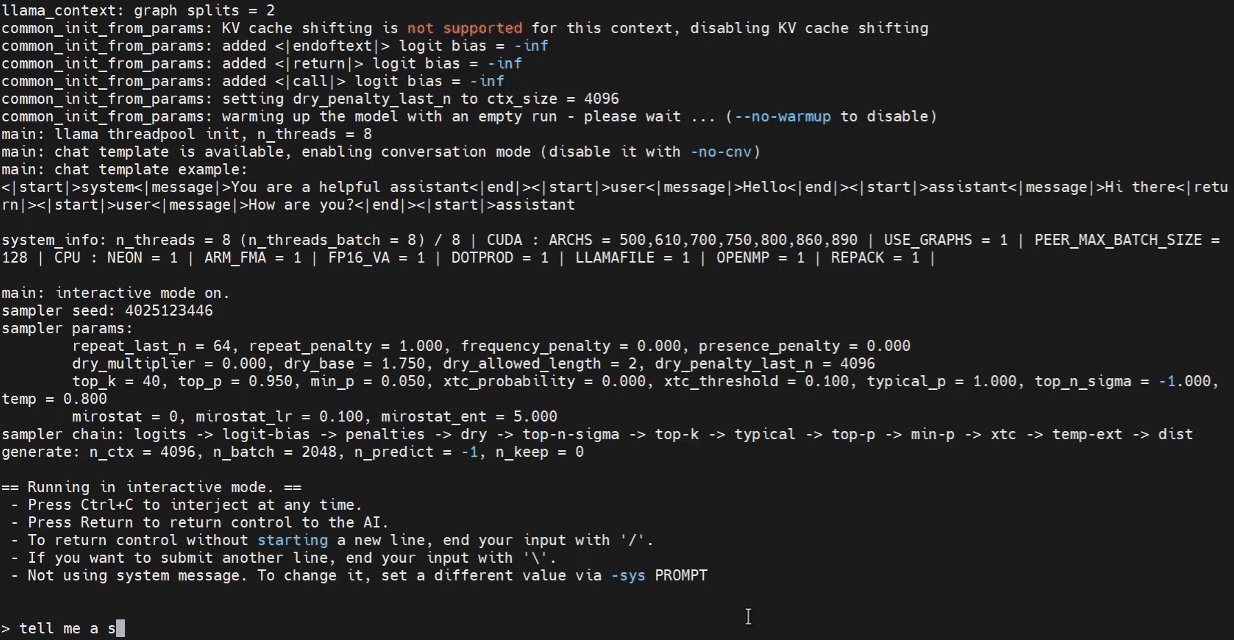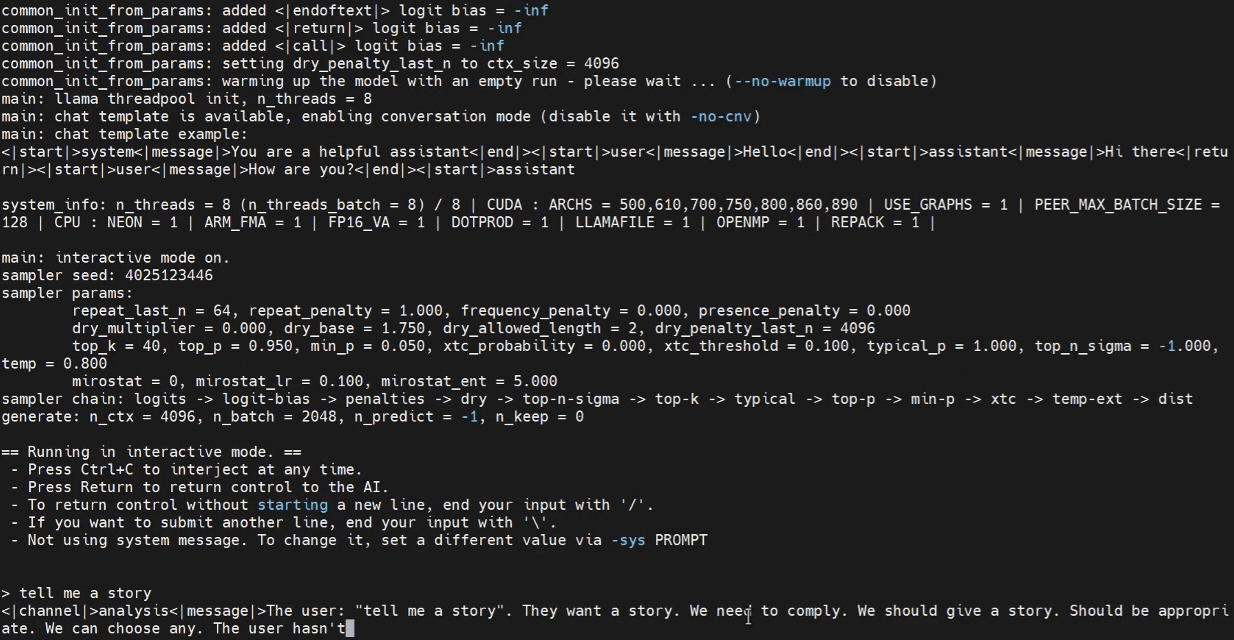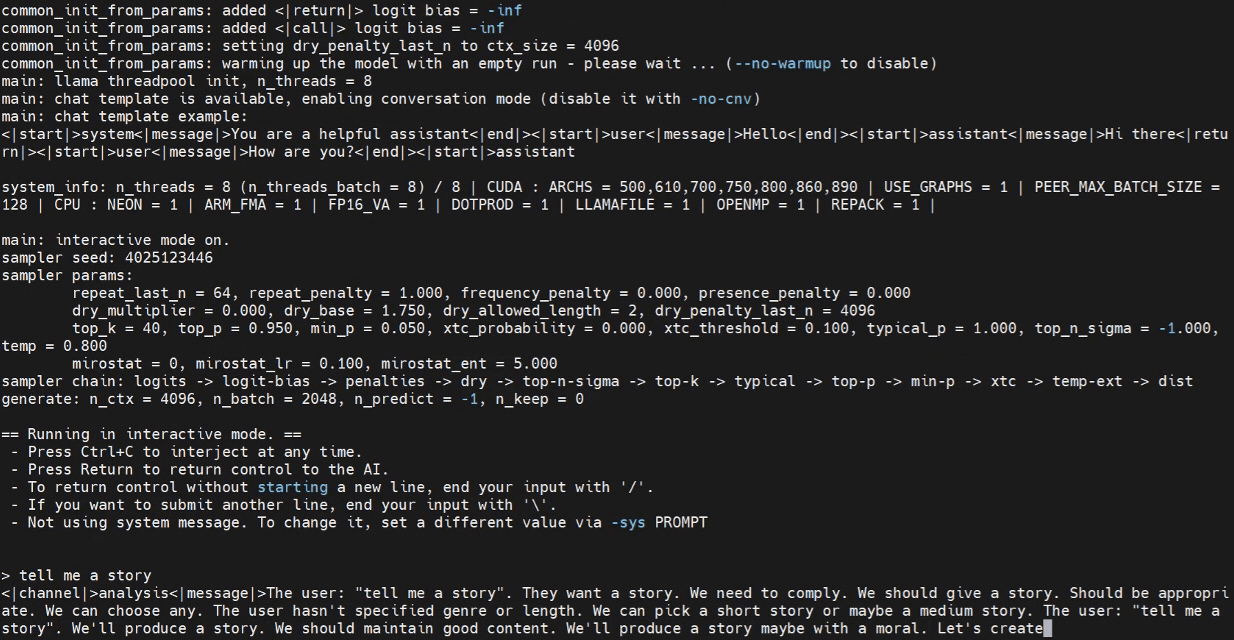
Ahora podemos intentar lanzar el programa de inferencia en la terminal del Jetson.
./build/bin/llama-cli -m /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf -ngl 40
Por favor reemplaza la ruta del modelo según sea necesario.
Inferencia con WebUI (Opcional)
Si quieres acceder al modelo a través de una interfaz UI, puedes instalar OpenWebUI en el Jetson para lograr esto. Abre una nueva terminal en Jetson e ingresa el siguiente comando:
conda create -n open-webui python=3.11
conda activate open-webui
pip install open-webui
open-webui serve
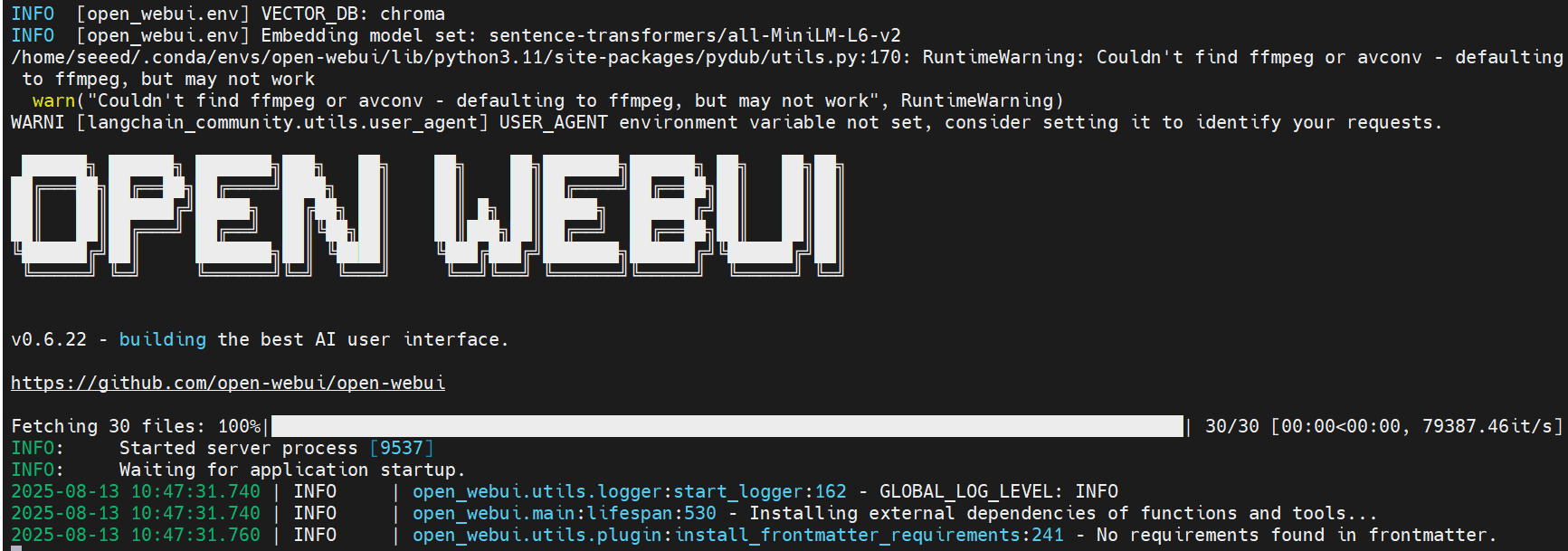
Lanzar OpenWebUI instalará dependencias y descargará modelos —— por favor ten paciencia.
Una vez que la configuración esté completa, deberías ver logs similares a estos en la terminal.
Luego, abre tu navegador y navega a http://<ip-del-jetson>:8080 para lanzar Open WebUI.
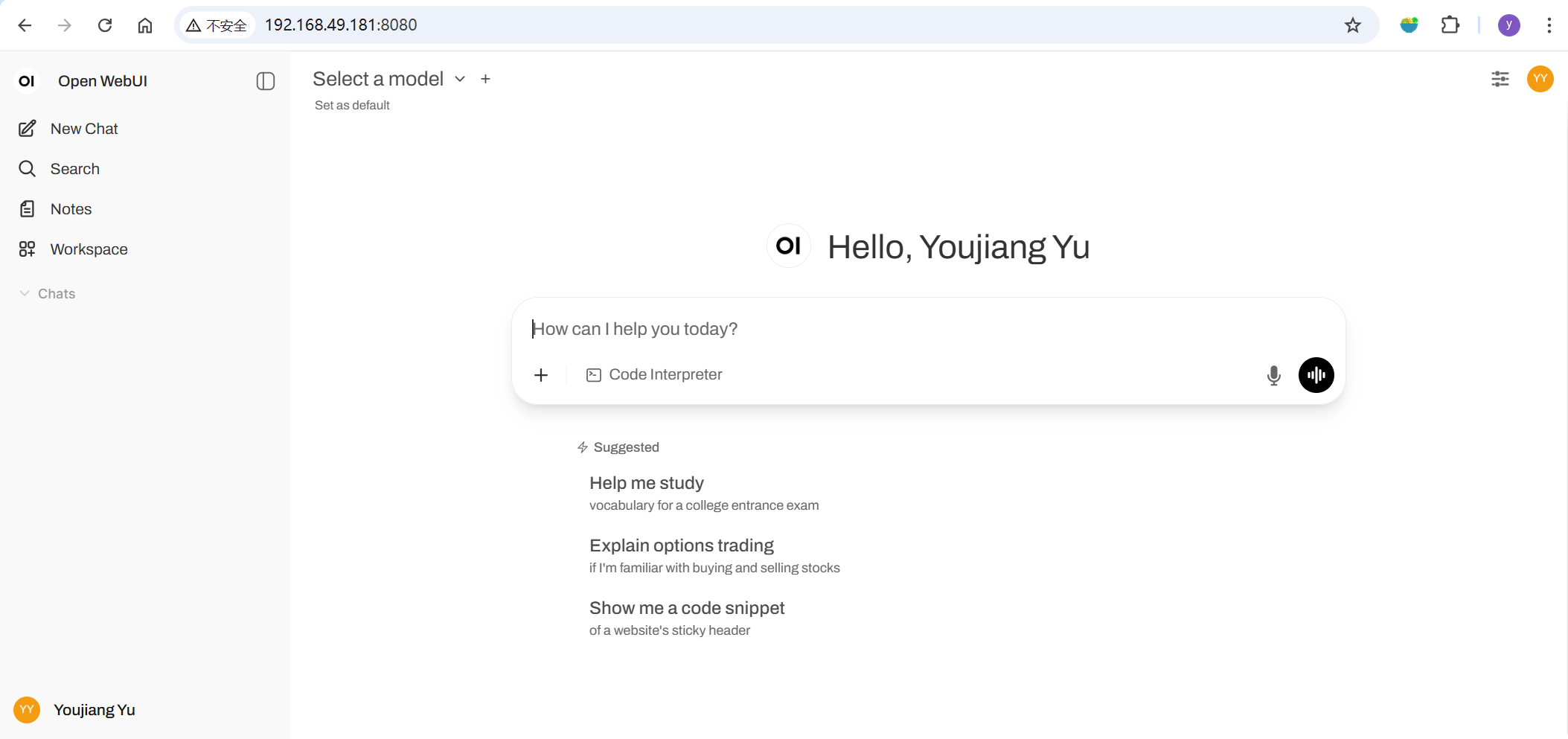
Si estás abriendo esto por primera vez, por favor sigue las instrucciones para configurar tu cuenta.
Ve a ⚙️ Configuración de Administrador → Conexiones → Conexiones OpenAI para establecer la url como: http://127.0.0.1:8081. Una vez guardado, ¡Open WebUI comenzará a usar tu servidor local Llama.cpp como backend!
Demostración del Efecto
Finalmente, demostraré el rendimiento real de inferencia del modelo GPT-OSS-20B en un NVIDIA Jetson Orin NX a través de una demostración en video.
Referencias
- https://hyd.ai/2025/03/07/llamacpp-on-jetson-orin-agx/
- https://docs.openwebui.com/getting-started/quick-start/starting-with-llama-cpp
- https://github.com/open-webui/open-webui
- https://huggingface.co/openai/gpt-oss-20b
- https://www.seeedstudio.com/tag/nvidia.html
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para proporcionarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para atender diferentes preferencias y necesidades.