Desplegar TensorRT Edge-LLM en Jetpack6.2
¿Qué es TensorRT Edge-LLM?
TensorRT Edge-LLM es el runtime de inferencia en C++ de alto rendimiento de NVIDIA para Modelos de Lenguaje Grandes (LLMs) y Modelos Visión-Lenguaje (VLMs) en plataformas embebidas. Permite el despliegue eficiente de modelos de lenguaje de última generación en dispositivos con recursos limitados como las plataformas NVIDIA Jetson y NVIDIA DRIVE.
TensorRT Edge-LLM es compatible con una amplia gama de modelos de última generación:
-
Modelos de Lenguaje Grandes: Llama 3.x, Qwen 2/2.5/3, DeepSeek-R1 Distilled
-
Modelos Visión-Lenguaje: Qwen2/2.5/3-VL, InternVL3-1B-hf, InternVL3-2B-hf, Phi-4-Multimodal
-
Cuantización: FP16, FP8 (SM89+), INT4 AWQ/GPTQ, NVFP4 (SM100+)
Para la lista completa de modelos compatibles, requisitos de precisión y compatibilidad de plataforma, consulta Supported Models.https://nvidia.github.io/TensorRT-Edge-LLM/0.6.0/user_guide/getting_started/supported-models.html
TensorRT Edge-LLM está diseñado principalmente para la pila de software JetPack 7.x. Sin embargo, NVIDIA documenta oficialmente la compatibilidad con JetPack 6.2 a través de una versión compatible dedicada. Esta guía describe el flujo de trabajo de despliegue y el proceso de validación para TensorRT Edge-LLM en JetPack 6.2.
Para sistemas con JetPack 6.2, TensorRT Edge-LLM v0.6.0 es la versión recomendada y validada.
El flujo de trabajo de despliegue consta de dos etapas:
-
Preparación del modelo en un host Linux x86
En una estación de trabajo Linux x86 equipada con una GPU NVIDIA, el modelo de lenguaje grande (LLM) de destino se cuantiza y se exporta al formato ONNX utilizando la cadena de herramientas de TensorRT Edge-LLM.
-
Generación del motor en Jetson
El modelo ONNX exportado se transfiere al dispositivo Jetson, donde TensorRT Edge-LLM genera un motor de inferencia TensorRT optimizado para el despliegue y la ejecución en tiempo de ejecución.
Parte 1: Preparación del modelo (host x86 con GPU)
El pipeline de exportación en Python convierte y cuantiza modelos. Esto debe ejecutarse en un sistema Linux x86 con una GPU NVIDIA.
Requisitos del sistema
-
Plataforma: sistema Linux x86-64
-
SO recomendado: Ubuntu 22.04, 24.04
-
GPU: GPU NVIDIA con Compute Capability 8.0+ (Ampere o más reciente)
-
CUDA: 12.x o 13.x
-
Python: 3.10+
Requisitos de memoria(Dependiendo del tamaño del modelo que quieras desplegar.)
Memoria de GPU (VRAM):
-
Regla general: ~2-3x el tamaño del modelo para la mayoría de las operaciones, ~5-6x el tamaño del modelo para la exportación ONNX en FP8
-
Modelos pequeños (0.6B-3B): 8-16GB
-
Modelos grandes (7B-8B): 20-48GB
-
Modelos muy grandes (13B+): 48GB+
Memoria de CPU (RAM):
-
Regla general: ~2-3x el tamaño del modelo para la mayoría de las operaciones, ~18-20x el tamaño del modelo para la exportación ONNX en FP8
-
Modelos pequeños (0.6B-3B): 8-16GB (48GB+ para la exportación ONNX en FP8)
-
Modelos grandes (7B-8B): 20-48GB (128GB+ para la exportación ONNX en FP8)
-
Modelos muy grandes (13B+): 48GB+
Nota: La exportación ONNX en FP8 actualmente requiere una memoria de CPU significativamente mayor (hasta 20x el tamaño del modelo) y de GPU (hasta 6x el tamaño del modelo) debido al procesamiento interno. Este es un problema conocido y se está optimizando activamente.
Instalación
-
Clonar el repositorio
git clone https://github.com/NVIDIA/TensorRT-Edge-LLM.git
cd TensorRT-Edge-LLM
git submodule update --init --recursive -
Instalar el paquete de Python
Se recomienda usar un entorno virtual:
python3 -m venv venv
source venv/bin/activateLuego simplemente instala el software:
pip3 install . -
Verificar la instalación
tensorrt-edgellm-export-llm --help
tensorrt-edgellm-quantize-llm --help
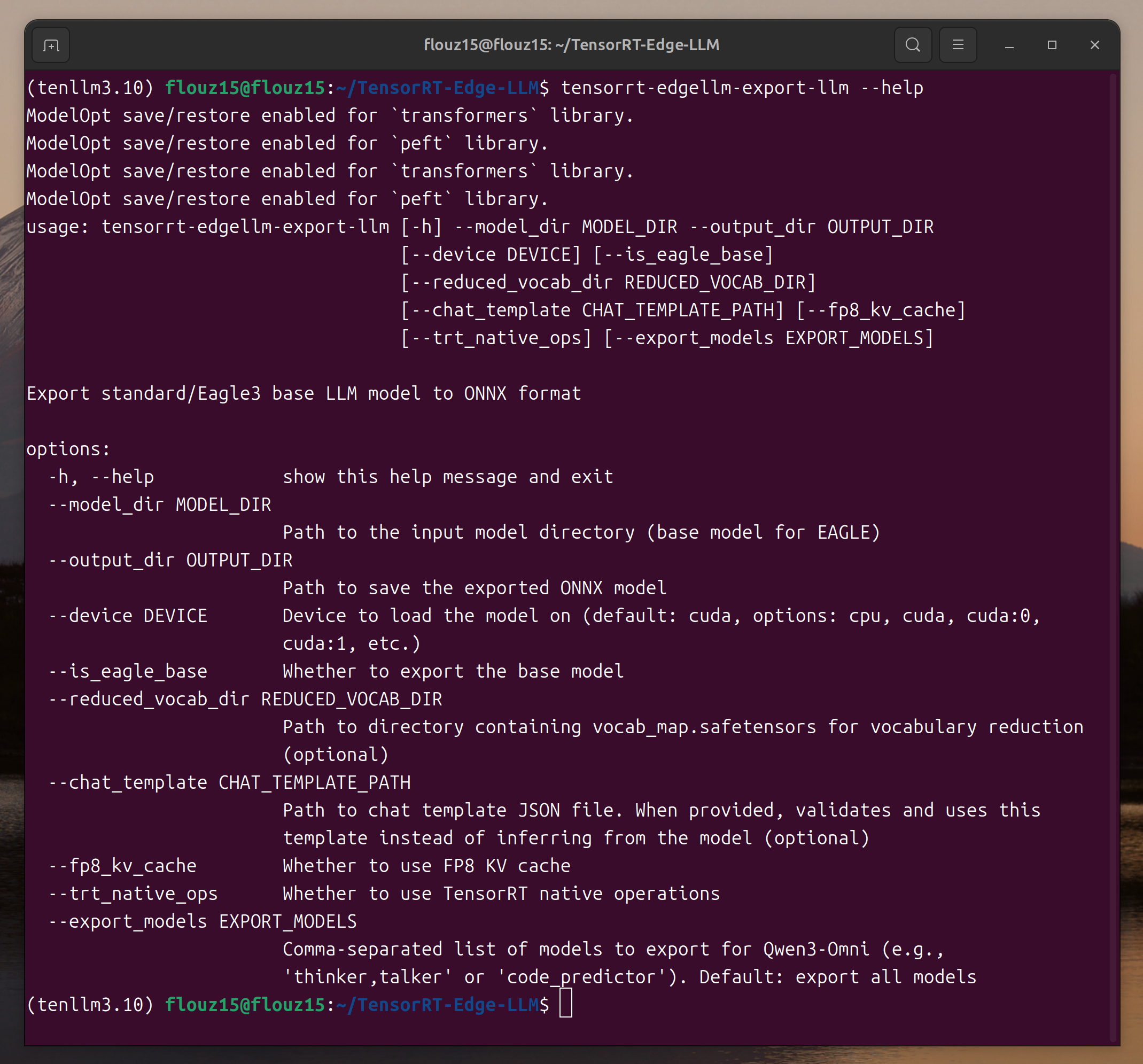
Si se muestra la descripción de los parámetros, TensorRT Edge-LLM se ha instalado correctamente.
Exportar y cuantizar
Usemos Qwen3-0.6B como un ejemplo ligero:
Nota: Los comandos reales pueden variar dependiendo de tu estructura de carpetas específica.
# Set up workspace directory
export WORKSPACE_DIR=$HOME/tensorrt-edgellm-workspace
export MODEL_NAME=Qwen3-0.6B
mkdir -p $WORKSPACE_DIR
cd $WORKSPACE_DIR
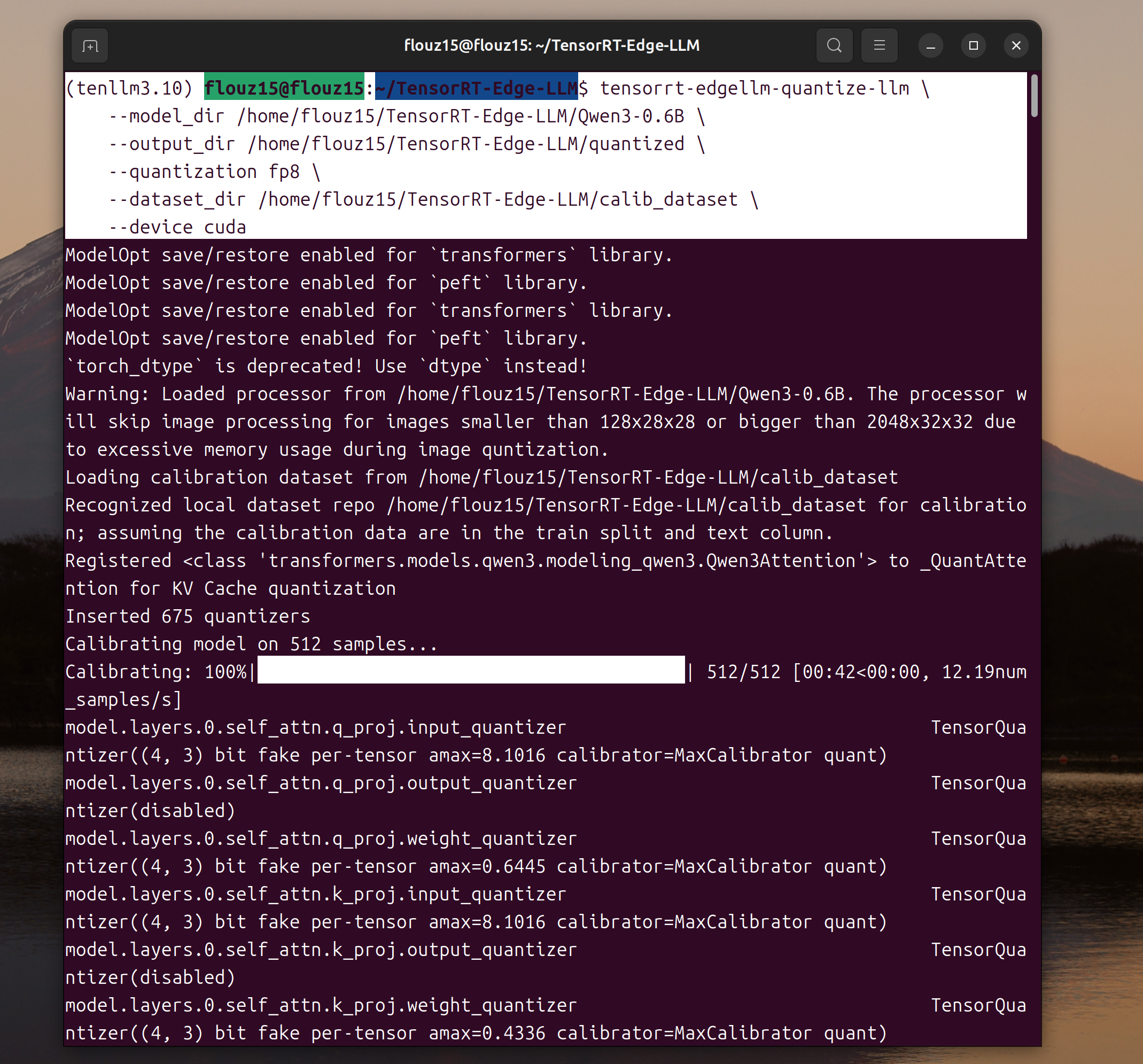
# Step 1: Quantize to FP8 (downloads model automatically)
tensorrt-edgellm-quantize-llm \
--model_dir Qwen/Qwen3-0.6B \
--output_dir $MODEL_NAME/quantized \
--quantization fp8
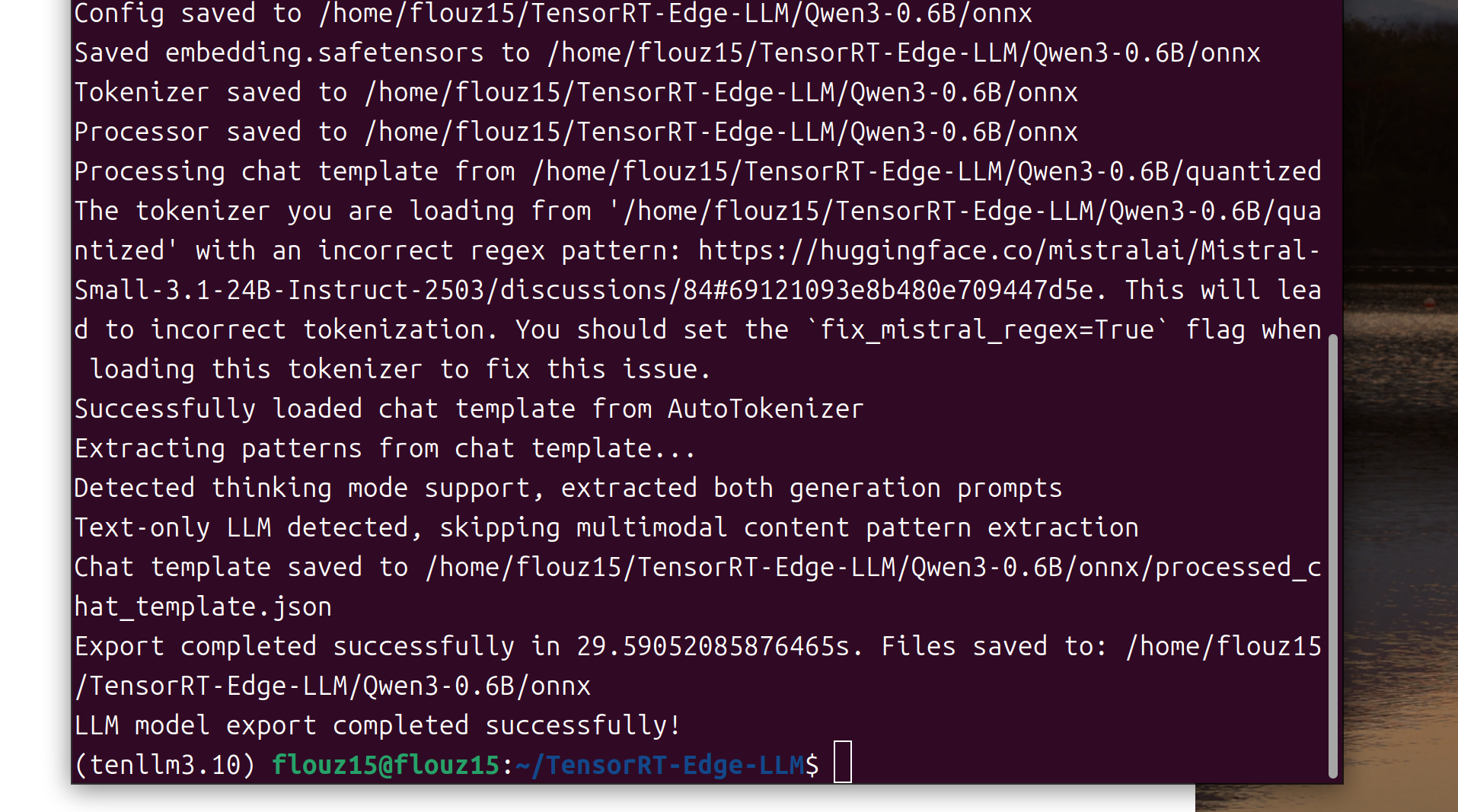
# Step 2: Export to ONNX
tensorrt-edgellm-export-llm \
--model_dir $MODEL_NAME/quantized \
--output_dir $MODEL_NAME/onnx
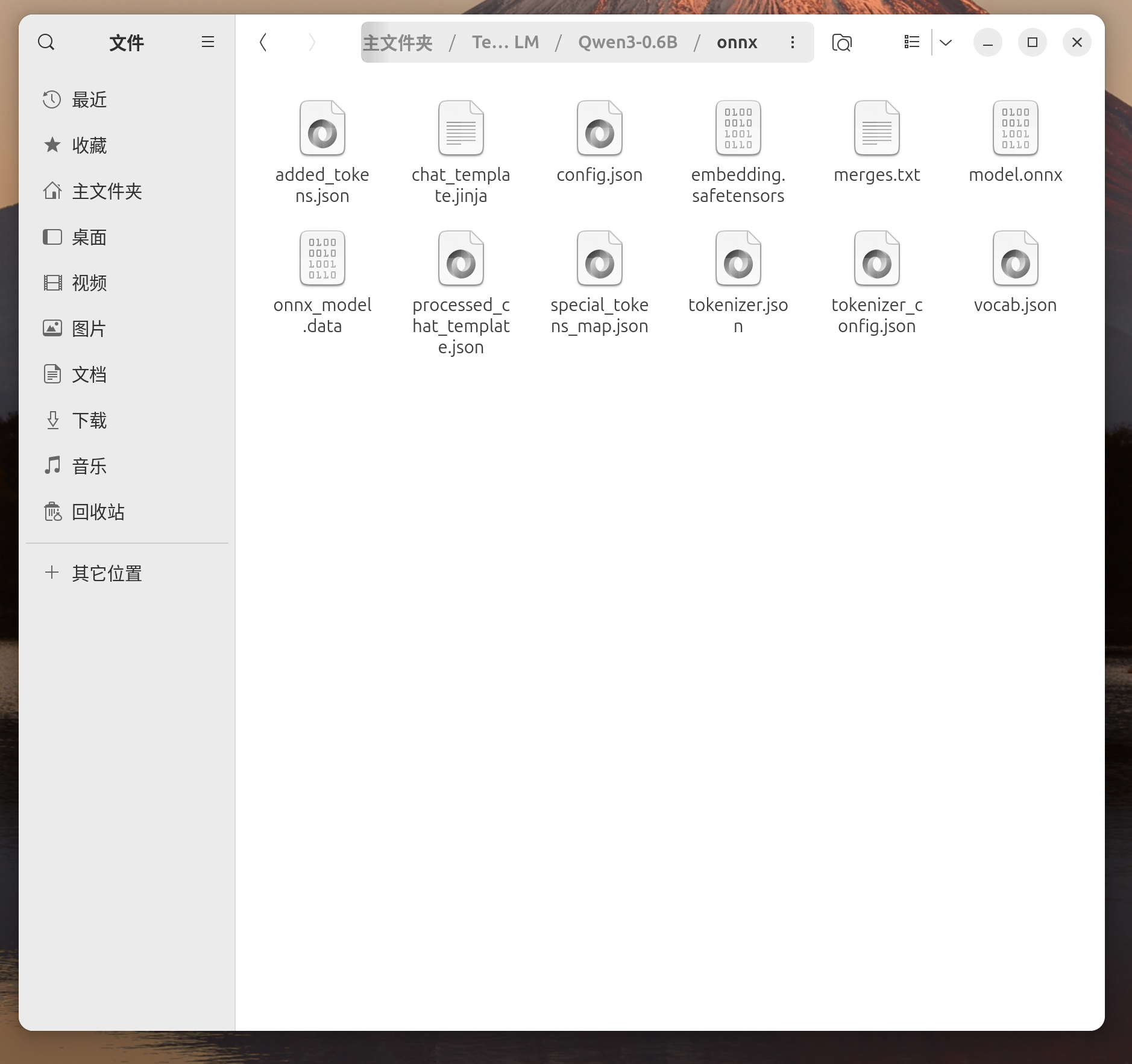
Parte 2: Generación del motor (dispositivo Jetson de borde)
El runtime en C++ construye y ejecuta modelos en el dispositivo de borde de destino. Esto debe compilarse en o para la plataforma de destino.
Requisitos del sistema
Plataforma de destino:
-
NVIDIA Jetson Orin NX SUPER 16GB
-
JetPack 6.2
-
Espacio en disco: 20~50GB para archivos ONNX y motores TensorRT
Instalar y compilar
-
Instalar dependencias del sistema (en el dispositivo de borde)
sudo apt update
sudo apt install -y \
cmake \
build-essential \
git -
Verificar la instalación de CUDA y TensorRT
Después de instalar JetPack, TensorRT debería estar instalado en /usr
Comprobar la versión de CUDA
nvcc --version # Should show CUDA 12.6 -
Clonar el repositorio (en el dispositivo de borde)
cd ~
git clone https://github.com/NVIDIA/TensorRT-Edge-LLM.git
cd TensorRT-Edge-LLM
git submodule update --init --recursive -
Configurar la compilación
En tu dispositivo Jetson Thor, configura la compilación con el siguiente comando:
mkdir build
cd build
cmake .. \
-DCMAKE_BUILD_TYPE=Release \
-DTRT_PACKAGE_DIR=/usr \
-DCMAKE_TOOLCHAIN_FILE=cmake/aarch64_linux_toolchain.cmake \
-DEMBEDDED_TARGET=jetson-orin -
Compilar el proyecto
make -j$(nproc)Tiempo de compilación: ~1-2 minutos dependiendo del hardware.
Verificar la compilación
# Test C++ examples
./examples/llm/llm_build --help
./examples/llm/llm_inference --help
Compilar el motor TensorRT
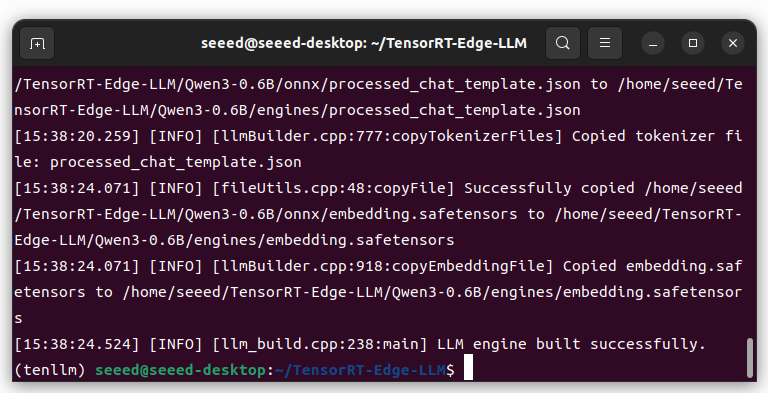
Copia el directorio del modelo ONNX generado en el PC host al dispositivo Jetson.
En tu Jetson:
# Set up workspace directory
export WORKSPACE_DIR=$HOME/tensorrt-edgellm-workspace
export MODEL_NAME=Qwen3-0.6B
cd ~/TensorRT-Edge-LLM
# Build engine
./build/examples/llm/llm_build \
--onnxDir $WORKSPACE_DIR/$MODEL_NAME/onnx \
--engineDir $WORKSPACE_DIR/$MODEL_NAME/engines \
--maxBatchSize 1 \
--maxInputLen 1024 \
--maxKVCacheCapacity 4096
Ejecutar la inferencia
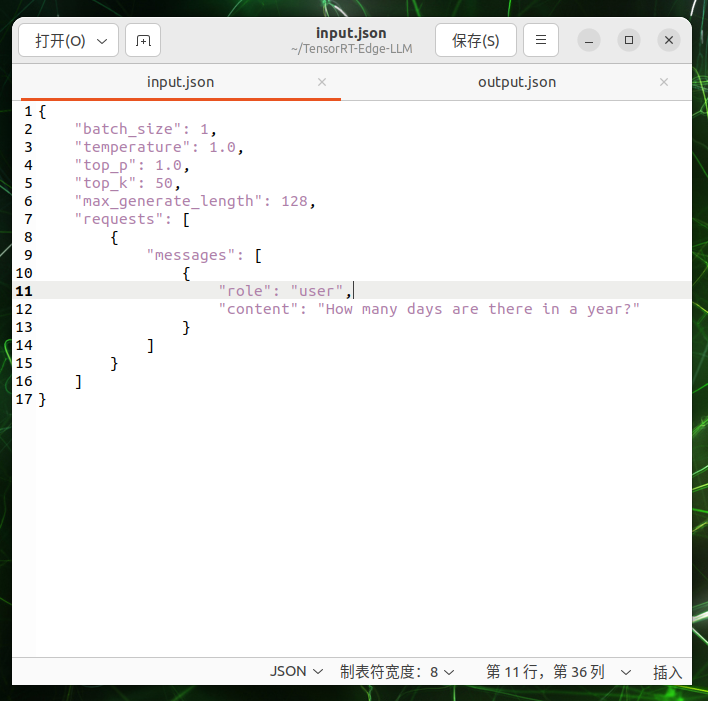
Crea un archivo de entrada con una pregunta de ejemplo:
cat > $WORKSPACE_DIR/input.json << 'EOF'
{
"batch_size": 1,
"temperature": 1.0,
"top_p": 1.0,
"top_k": 50,
"max_generate_length": 128,
"requests": [
{
"messages": [
{
"role": "user",
"content": "What is the capital of United States?"
}
]
}
]
}
EOF
"content"is the input to the LLM.Run engine:
cd ~/TensorRT-Edge-LLM
./build/examples/llm/llm_inference \
--engineDir $WORKSPACE_DIR/$MODEL_NAME/engines \
--inputFile $WORKSPACE_DIR/input.json \
--outputFile $WORKSPACE_DIR/output.json
Verifica la salida:
# View the model response
cat $WORKSPACE_DIR/output.json
Deberías ver una respuesta JSON con la respuesta del modelo, similar a:
{
"responses": [
{
"text": "The capital of the United States is Washington, D.C.",
"finish_reason": "stop"
}
]
}
¡Éxito! 🎉 ¡Has ejecutado correctamente la inferencia de LLM en tu dispositivo de borde!
Soporte técnico y debate sobre el producto
Gracias por elegir nuestros productos. Estamos aquí para ofrecerte diferentes tipos de soporte y garantizar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para adaptarnos a diferentes preferencias y necesidades.