Ajuste fino de GR00T N1.7 para reBot Arm y despliegue en Jetson Thor
Introducción
Este wiki explica cómo ajustar finamente NVIDIA Isaac GR00T N1.7 para el reBot Arm B601 DM y desplegarlo en reComputer Robotics J601 usando aceleración TensorRT.
NVIDIA GR00T N1.7 marca un gran salto adelante en la evolución de la inteligencia encarnada como un modelo base de última generación, de extremo a extremo, de Visión‑Lenguaje‑Acción (VLA). Cierra sin problemas la brecha entre percepción y ejecución, permitiendo que los robots transformen entradas visuales complejas e indicaciones verbales directamente en maniobras físicas en el mundo real. Impulsado por el nuevo modelo de visión‑lenguaje Cosmos Reason2-2B, GR00T N1.7 alcanza un nivel sin precedentes de conciencia del entorno, mientras que su decodificador de acciones de última generación DiT (Diffusion Transformer) ofrece una generación de acciones ultra fluida y una solidez absoluta frente a perturbaciones del mundo real.

Requisitos de hardware
- reComputer Robotics J601 con NVIDIA Jetson Thor (JetPack 7.x instalado)
- reBot Arm B601 DM
- Star Arm 102 para reBot Arm B601‑DM Leader
- Adaptador USB-a-CAN
- Cámara USB x2
- Fuente de alimentación y cable USB para el brazo robótico
Conexión de hardware
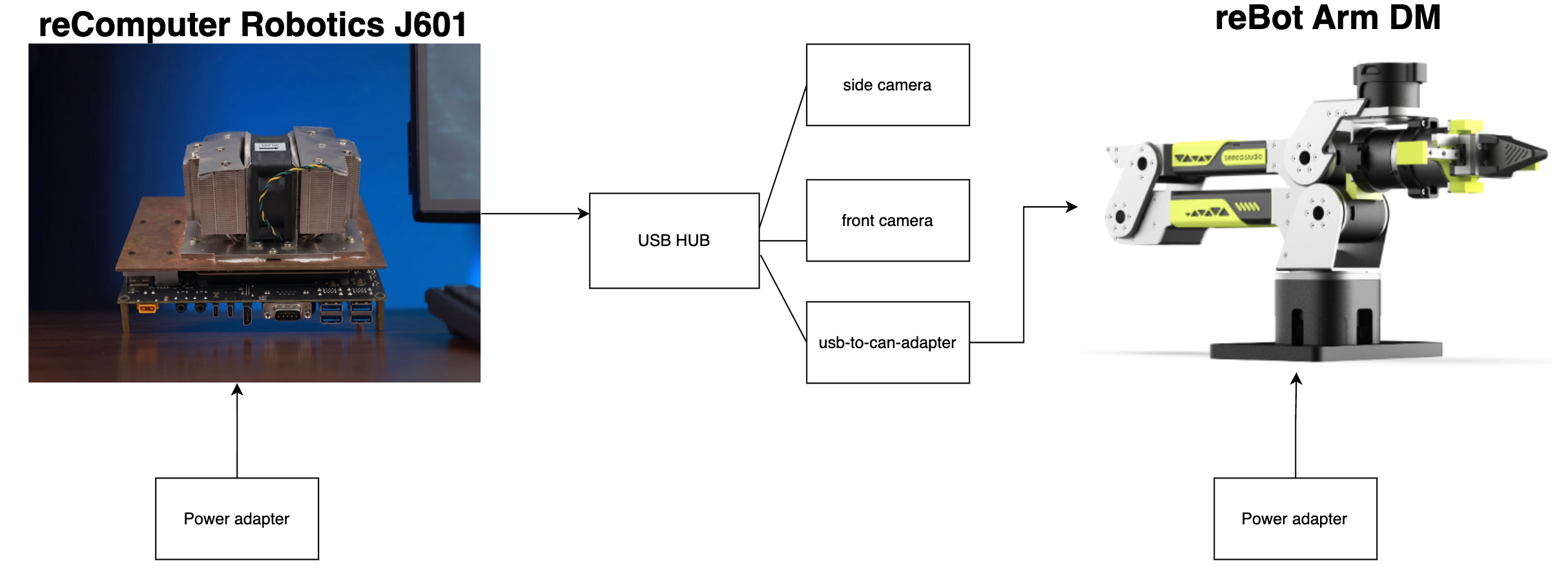
Recopilación de datos
Si quieres desplegar tu propio modelo VLA, primero necesitamos recopilar un conjunto de datos adecuado para nuestra tarea para ajustar finamente el modelo, de modo que pueda adaptarse a nuestra tarea de agarre. Puedes consultar este wiki para la configuración del entorno y la recopilación de datos.
Ajuste fino del modelo
Preparar el entorno de Python
En el servidor de ajuste fino (x86 con GPU), clona el repositorio y configura el entorno:
sudo apt install git-lfs && git lfs install
git clone --recurse-submodules https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T
sudo apt-get update && sudo apt-get install -y ffmpeg
uv sync --python 3.10
cd /examples/SO100/
uv pip install -e .
Conversión del conjunto de datos
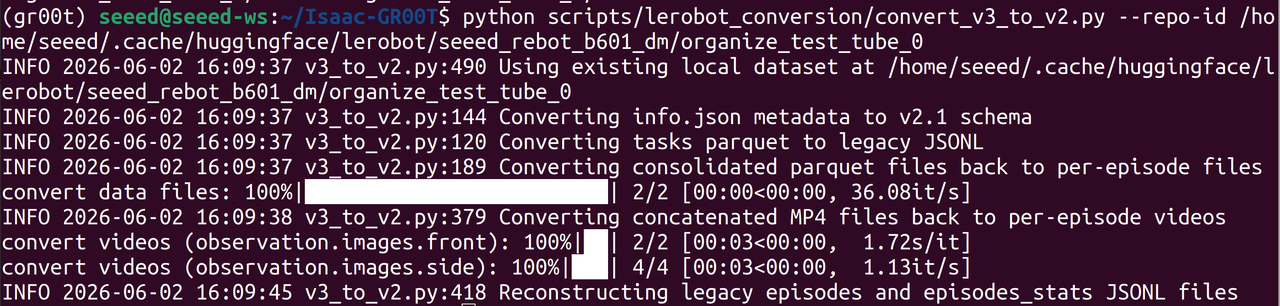
El conjunto de datos recopilado mediante el framework LeRobot está en formato v3.0, mientras que GR00T requiere v2.0. Ejecuta el script de conversión incluido en el repositorio Isaac-GR00T:
cd <path-to-isaac-gr00t>
uv run --project scripts/lerobot_conversion \
python scripts/lerobot_conversion/convert_v3_to_v2.py \
--repo-id /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/organize_test_tube
Por favor, sustituye la ruta del archivo por la ruta de tu propio conjunto de datos.
Después de la ejecución, el conjunto de datos de LeRobot recopilado previamente se degradará del formato v3.0 al formato v2.0.
Luego copia el siguiente archivo modality.json en la carpeta meta del conjunto de datos convertido:
modality.json (haz clic para expandir)
{
"state": {
"single_arm": {
"start": 0,
"end": 6
},
"gripper": {
"start": 6,
"end": 7
}
},
"action": {
"single_arm": {
"start": 0,
"end": 6
},
"gripper": {
"start": 6,
"end": 7
}
},
"video": {
"front": {
"original_key": "observation.images.front"
},
"side": {
"original_key": "observation.images.side"
}
},
"annotation": {
"human.task_description": {
"original_key": "task_index"
}
}
}
Ajustar finamente GR00T N1.7
Una vez que el conjunto de datos esté listo, ejecuta el script de ajuste fino:
cd <path-to-isaac-gr00t>
uv pip uninstall deepspeed
export MAX_STEPS=10000
export SAVE_STEPS=5000
bash examples/finetune.sh \
--base-model-path nvidia/GR00T-N1.7-3B \
--dataset-path /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/organize_test_tube_0 \
--modality-config-path examples/SO100/so100_config.py \
--embodiment-tag NEW_EMBODIMENT \
--output-dir ~/output
Por favor, sustituye la ruta del archivo por las rutas de tu propio conjunto de datos y del directorio de salida.
Dado que nuestro conjunto de datos de entrenamiento es relativamente pequeño, puedes reducir el número de pasos de entrenamiento para ahorrar recursos de cómputo.
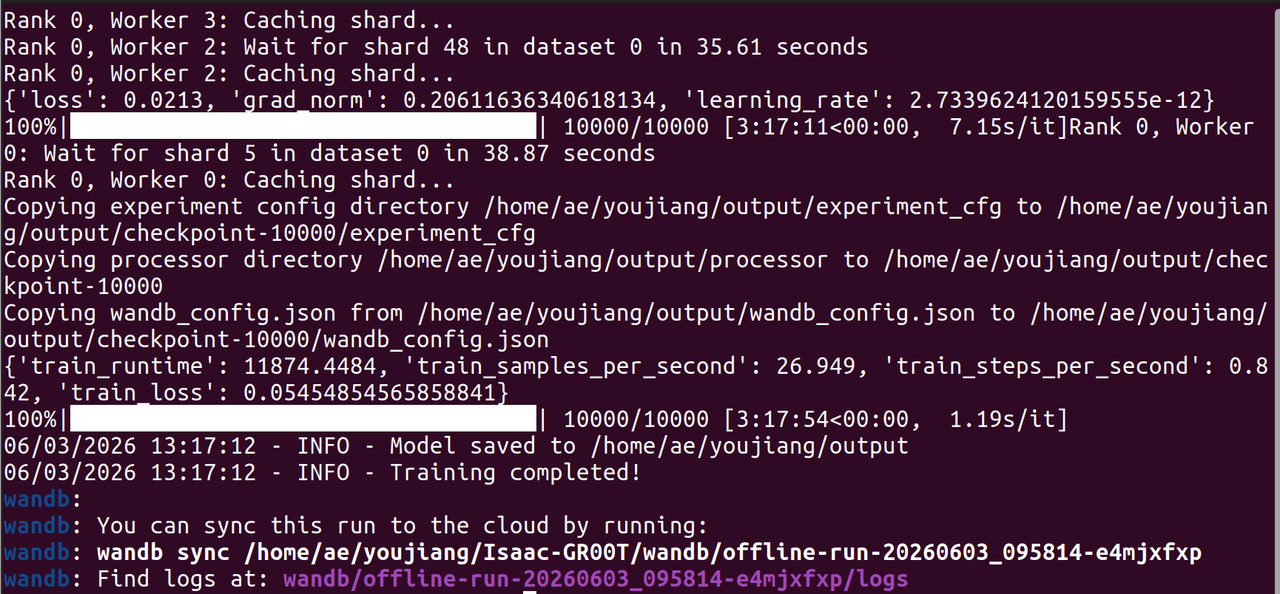
Una vez finalizado el entrenamiento, podrás encontrar los archivos del modelo GR00T N1.7 ajustado finamente en el directorio --output-dir.

Despliegue en Jetson
Adquisición de permisos
Para descargar modelos y conjuntos de datos desde Hugging Face, primero debes conceder acceso a los repositorios necesarios.
Instala la CLI de Hugging Face e inicia sesión:
uv tool install -U "huggingface_hub[cli]"
# Log in to your Hugging Face account and input your token
hf auth login
Visita el siguiente enlace para obtener permiso de descarga para el modelo requerido: 🔗 https://huggingface.co/nvidia/Cosmos-Reason2-2B
Clonar el repositorio
# Install git-lfs
sudo apt install git-lfs && git lfs install
# Clone the repository
git clone --recurse-submodules https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T
git submodule update --init --recursive
Configuración de Docker (recomendado)
Thor utiliza CUDA 13 y Python 3.12, que requieren una pila de dependencias diferente a la de x86 u Orin. Probado con JetPack 7.1. Hay dos formas de ejecutar en Thor: Docker (recomendado) o bare metal.
Compila el contenedor de Thor desde la raíz del repositorio:
cd docker && sudo bash build.sh --profile=thor
Descarga el modelo ajustado finamente (ejecutar una vez, en el host):
uv run hf download nvidia/GR00T-N1.7-LIBERO \
--include "libero_10/config.json" \
"libero_10/embodiment_id.json" \
"libero_10/model-*.safetensors" \
"libero_10/model.safetensors.index.json" \
"libero_10/processor_config.json" \
"libero_10/statistics.json" \
--local-dir checkpoints/GR00T-N1.7-LIBERO
Inicia una sesión interactiva de Docker (recomendado para trabajo TRT de varios pasos):
# Add Docker to the user group
sudo usermod -aG docker $USER
docker run -it --rm --runtime nvidia --gpus all \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--network host \
-v "$(pwd)":/workspace/repo \
-v "${HF_HOME:-${HOME}/.cache/huggingface}":/root/.cache/huggingface \
-w /workspace/repo \
-e HF_TOKEN="${HF_TOKEN:-}" \
gr00t-thor \
bash
Configuración bare metal
Si prefieres no usar Docker, puedes instalar las dependencias directamente:
bash scripts/deployment/thor/install_deps.sh
# In each new shell
source .venv/bin/activate
source scripts/activate_thor.sh
Verificar el entorno
Puedes ejecutar inferencia con PyTorch para verificar que el entorno esté configurado correctamente.
Antes de ejecutar el script, debes iniciar sesión en tu cuenta de Hugging Face con antelación e introducir tu token.
# Run inference on demo trajectories using PyTorch (no TRT setup needed):
uv run python scripts/deployment/standalone_inference_script.py \
--model-path checkpoints/GR00T-N1.7-LIBERO/libero_10 \
--dataset-path demo_data/libero_demo \
--embodiment-tag LIBERO_PANDA \
--traj-ids 0 1 2 3 4 \
--inference-mode pytorch \
--action-horizon 8
Conversión del formato del conjunto de datos
GR00T solo admite conjuntos de datos en el formato LeRobot v2.1. Sin embargo, el formato de conjunto de datos utilizado al recopilar datos con el framework LeRobot es v3.0. Para exportar el modelo acelerado TensorRT en Jetson, es necesario convertir el formato del conjunto de datos al mismo formato utilizado durante el entrenamiento de GR00T.
Coloca el siguiente script de conversión como scripts/convert_v3_to_v2.py en el repositorio Isaac-GR00T:
convert_v3_to_v2.py (haz clic para expandir)
#!/usr/bin/env python3
"""
LeRobot v3.0 to v2.1 Format Converter for Seeed REBOT-B601-DM Dataset
Converts a LeRobot v3.0 dataset to v2.1 format compatible with GR00T's
LeRobotEpisodeLoader.
Usage:
python convert_v3_to_v2.py \
--input /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test \
--output /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test_v2
The converter:
1. Reads episodes from meta/episodes/chunk-*/file-*.parquet
2. Splits data parquet into per-episode parquet files (v2.1 naming)
3. Extracts video clips per episode from v3.0 continuous MP4 files
4. Generates meta/modality.json, meta/tasks.jsonl, meta/episodes.jsonl
"""
import argparse
import json
import os
import shutil
import subprocess
from pathlib import Path
import pandas as pd
def _val(x):
"""Convert pyarrow/pandas scalar to native Python value."""
if hasattr(x, "item"):
return x.item()
elif hasattr(x, "tolist"):
return x.tolist()
return x
# ============================================================================
# 1. meta/modality.json
# ============================================================================
MODALITY_JSON = {
"video": {
"down_size": {
"type": "video",
"original_key": "observation.images.down_size"
},
"up_side": {
"type": "video",
"original_key": "observation.images.up_side"
}
},
"state": {
"single_arm": {
"start": 0,
"end": 6,
"original_key": "observation.state"
},
"gripper": {
"start": 6,
"end": 7,
"original_key": "observation.state"
}
},
"action": {
"single_arm": {
"start": 0,
"end": 6,
"original_key": "action"
},
"gripper": {
"start": 6,
"end": 7,
"original_key": "action"
}
},
"annotation": {
"language.language_instruction": {
"original_key": "task_index"
}
}
}
# ============================================================================
# 2. Convert tasks.parquet -> tasks.jsonl
# ============================================================================
def convert_tasks(input_dir: Path, output_dir: Path):
"""Convert tasks.parquet to tasks.jsonl."""
eps_dir = input_dir / "meta" / "episodes"
task_text = "unknown"
for chunk_dir in sorted(eps_dir.iterdir()):
if chunk_dir.is_dir():
for pf in sorted(chunk_dir.glob("*.parquet")):
df_eps = pd.read_parquet(pf, engine="pyarrow")
for _, row in df_eps.iterrows():
tasks_val = row.get("tasks", None)
if tasks_val is not None:
if hasattr(tasks_val, "tolist"):
tasks_val = tasks_val.tolist()
if isinstance(tasks_val, (list, tuple)) and len(tasks_val) > 0:
task_text = str(tasks_val[0])
break
if task_text != "unknown":
break
if task_text != "unknown":
break
tasks_path = input_dir / "meta" / "tasks.parquet"
df_tasks = pd.read_parquet(tasks_path, engine="pyarrow")
tasks = []
for _, row in df_tasks.iterrows():
ti_val = row["task_index"]
ti = int(ti_val.item()) if hasattr(ti_val, "item") else int(ti_val)
tasks.append({"task_index": ti, "task": task_text})
tasks_path_out = output_dir / "meta" / "tasks.jsonl"
with open(tasks_path_out, "w") as f:
for t in tasks:
f.write(json.dumps(t) + "\n")
print(f" Created tasks.jsonl ({len(tasks)} tasks)")
# ============================================================================
# 3. Convert episodes -> episodes.jsonl
# ============================================================================
def convert_episodes(input_dir: Path, output_dir: Path):
"""Convert episodes parquet files to episodes.jsonl."""
eps_dir = input_dir / "meta" / "episodes"
all_eps = []
for chunk_dir in sorted(eps_dir.iterdir()):
if chunk_dir.is_dir():
for pf in sorted(chunk_dir.glob("*.parquet")):
df = pd.read_parquet(pf, engine="pyarrow")
for _, row in df.iterrows():
def get(v):
val = row[v]
if hasattr(val, "tolist"):
val = val.tolist()
return val
tasks_val = get("tasks")
if isinstance(tasks_val, (list, tuple)) and len(tasks_val) > 0:
tasks_str = [str(tasks_val[0])]
else:
tasks_str = ["unknown"]
ep = {
"episode_index": int(get("episode_index")),
"length": int(get("length")),
"tasks": tasks_str,
}
all_eps.append(ep)
all_eps.sort(key=lambda x: x["episode_index"])
eps_path_out = output_dir / "meta" / "episodes.jsonl"
with open(eps_path_out, "w") as f:
for ep in all_eps:
f.write(json.dumps(ep) + "\n")
print(f" Created episodes.jsonl ({len(all_eps)} episodes)")
# ============================================================================
# 4. Split data parquet -> per-episode parquet files (v2.1 naming)
# ============================================================================
def convert_data_parquet(input_dir: Path, output_dir: Path):
"""
Split combined data parquet files into per-episode parquet files.
v3.0: data/chunk-000/file-000.parquet contains ALL episodes' data
v2.1: data/chunk-000/episode_000000.parquet (one per episode)
"""
data_dir = input_dir / "data"
output_data = output_dir / "data"
eps_dir = input_dir / "meta" / "episodes"
ep_data_map = {}
for chunk_dir in sorted(eps_dir.iterdir()):
if chunk_dir.is_dir():
for pf in sorted(chunk_dir.glob("*.parquet")):
df_eps = pd.read_parquet(pf, engine="pyarrow")
for _, erow in df_eps.iterrows():
ei = int(_val(erow["episode_index"]))
dci = int(_val(erow["data/chunk_index"]))
dfi = int(_val(erow["data/file_index"]))
ep_data_map[ei] = (dci, dfi)
chunk_files = {}
for chunk_dir in sorted(data_dir.iterdir()):
if not chunk_dir.is_dir():
continue
chunk_idx = int(chunk_dir.name.split("-")[1])
files = {}
for pf in sorted(chunk_dir.glob("*.parquet")):
file_idx = int(pf.stem.split("-")[1])
files[file_idx] = pf
chunk_files[chunk_idx] = files
for chunk_idx, files in sorted(chunk_files.items()):
output_chunk = output_data / f"chunk-{chunk_idx:03d}"
output_chunk.mkdir(parents=True, exist_ok=True)
ep_chunks = {}
for ep_idx, (dci, dfi) in sorted(ep_data_map.items()):
if dci == chunk_idx:
ep_chunks[ep_idx] = files[dfi]
for ep_idx, parquet_path in sorted(ep_chunks.items()):
df = pd.read_parquet(parquet_path, engine="pyarrow")
ep_rows = df[df["episode_index"] == ep_idx]
cols_to_keep = [c for c in ep_rows.columns if c in ("action", "observation.state", "task_index")]
ep_rows = ep_rows[cols_to_keep].reset_index(drop=True)
out_name = f"episode_{ep_idx:06d}.parquet"
out_path = output_chunk / out_name
ep_rows.to_parquet(out_path, engine="pyarrow", index=False)
total_eps = len(list(output_data.glob("chunk-*/episode_*.parquet")))
print(f" Converted data: {total_eps} episode parquet files")
# ============================================================================
# 5. Extract video clips per episode
# ============================================================================
def convert_videos(input_dir: Path, output_dir: Path):
"""
Extract per-episode video clips from v3.0 continuous MP4 files.
v3.0: videos/{cam}/chunk-{chunk:03d}/file-{file:03d}.mp4 (continuous, multi-episode)
v2.1: videos/{cam}/chunk-{chunk:03d}/episode_{ep:06d}.mp4 (one per episode)
"""
videos_dir = input_dir / "videos"
output_videos = output_dir / "videos"
camera_keys = [
"observation.images.down_size",
"observation.images.up_side",
]
eps_dir = input_dir / "meta" / "episodes"
ep_video_map = {}
for chunk_dir in sorted(eps_dir.iterdir()):
if chunk_dir.is_dir():
for pf in sorted(chunk_dir.glob("*.parquet")):
df_eps = pd.read_parquet(pf, engine="pyarrow")
for _, row in df_eps.iterrows():
ei = int(_val(row["episode_index"]))
ep_video_map[ei] = {}
for cam in camera_keys:
ep_video_map[ei][cam] = {
"chunk": int(_val(row[f"videos/{cam}/chunk_index"])),
"file": int(_val(row[f"videos/{cam}/file_index"])),
"from_ts": float(_val(row[f"videos/{cam}/from_timestamp"])),
"to_ts": float(_val(row[f"videos/{cam}/to_timestamp"])),
}
all_tasks = [(ep_idx, cam) for ep_idx, cam_data in sorted(ep_video_map.items()) for cam in camera_keys]
total = len(all_tasks)
done = 0
errors = 0
for ep_idx, cam in all_tasks:
vinfo = ep_video_map[ep_idx][cam]
src_name = f"file-{vinfo['file']:03d}.mp4"
src = videos_dir / cam / f"chunk-{vinfo['chunk']:03d}" / src_name
dest = output_videos / cam / f"chunk-{vinfo['chunk']:03d}" / f"episode_{ep_idx:06d}.mp4"
dest.parent.mkdir(parents=True, exist_ok=True)
if dest.exists():
done += 1
print(f"\r Extracting clips: {done}/{total} (errors: {errors})", end="", flush=True)
continue
duration = vinfo["to_ts"] - vinfo["from_ts"]
start = vinfo["from_ts"]
cmd = [
"ffmpeg", "-y",
"-ss", str(start),
"-i", str(src),
"-t", str(duration),
"-c:v", "libx264",
"-crf", "18",
"-preset", "fast",
"-an",
str(dest),
]
result = subprocess.run(cmd, capture_output=True, text=True)
done += 1
if result.returncode != 0:
errors += 1
print(f"\n ERROR ep{ep_idx} {cam}: {result.stderr[-300:]}")
print(f"\r Extracting clips: {done}/{total} (errors: {errors})", end="", flush=True)
print()
print(f" Extracted {total - errors} video clips ({len(ep_video_map)} episodes x {len(camera_keys)} cameras)")
# ============================================================================
# 6. Generate v2.1 info.json
# ============================================================================
def convert_info_json(input_dir: Path, output_dir: Path):
"""Update info.json for v2.1 format."""
info_path = input_dir / "meta" / "info.json"
with open(info_path) as f:
info = json.load(f)
info["data_path"] = "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet"
info["video_path"] = "videos/{video_key}/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.mp4"
for key in ["data_files_size_in_mb", "video_files_size_in_mb", "splits"]:
info.pop(key, None)
info_path_out = output_dir / "meta" / "info.json"
with open(info_path_out, "w") as f:
json.dump(info, f, indent=2)
print(f" Created info.json")
# ============================================================================
# Main
# ============================================================================
def main():
parser = argparse.ArgumentParser(description="Convert LeRobot v3.0 dataset to v2.1 format")
parser.add_argument("--input", type=str, required=True, help="Input v3.0 dataset path")
parser.add_argument("--output", type=str, required=True, help="Output v2.1 dataset path")
args = parser.parse_args()
input_dir = Path(args.input)
output_dir = Path(args.output)
print(f"\nConverting LeRobot v3.0 -> v2.1")
print(f" Input: {input_dir}")
print(f" Output: {output_dir}")
(output_dir / "meta").mkdir(parents=True, exist_ok=True)
print("\n[1/6] Creating meta/modality.json...")
with open(output_dir / "meta" / "modality.json", "w") as f:
json.dump(MODALITY_JSON, f, indent=2)
print(" Created modality.json")
print("\n[2/6] Creating meta/tasks.jsonl...")
convert_tasks(input_dir, output_dir)
print("\n[3/6] Creating meta/episodes.jsonl...")
convert_episodes(input_dir, output_dir)
print("\n[4/6] Converting data parquet files...")
convert_data_parquet(input_dir, output_dir)
print("\n[5/6] Extracting video clips...")
convert_videos(input_dir, output_dir)
print("\n[6/6] Creating meta/info.json...")
convert_info_json(input_dir, output_dir)
print("\n[Done] Copying meta/stats.json...")
shutil.copy(input_dir / "meta" / "stats.json", output_dir / "meta" / "stats.json")
print(" Copied stats.json")
print(f"\nConversion complete: {output_dir}")
if __name__ == "__main__":
main()
Ejecuta el script de conversión, por ejemplo:
python3 scripts/convert_v3_to_v2.py \
--input /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test \
--output /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test_v2
Exportar el modelo como motor TensorRT
Después de verificar el entorno y preparar el conjunto de datos, puedes exportar el modelo ajustado finamente a un motor TensorRT para inferencia acelerada en Jetson Thor.
cd Isaac-GR00T/
source .venv/bin/activate
source scripts/activate_thor.sh
python3 scripts/deployment/build_trt_pipeline.py \
--model-path /path/to/your/finetuned_model \
--dataset-path /home/seeed/.cache/huggingface/lerobot/seeed_rebot_b601_dm/test_v2 \
--embodiment-tag NEW_EMBODIMENT \
--output-dir ./seeed_rebot_b601_dm_deployment \
--precision bf16 \
--batch-size 1 \
--steps export,build
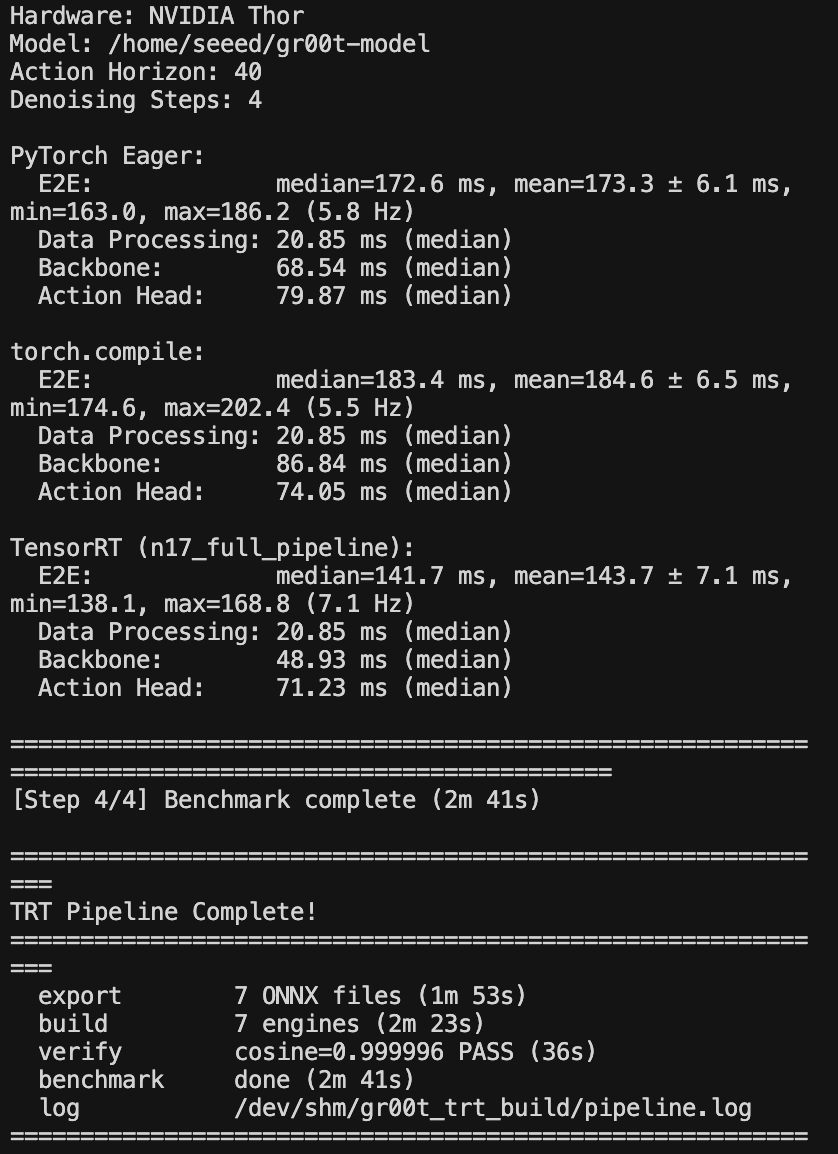
Recibirás un archivo de modelo acelerado y optimizado en formato de motor, así como el archivo ONNX convertido intermedio mientras esperas.
Inferencia en Jetson Thor
Este capítulo explica cómo realizar inferencia en Jetson usando el modelo GR00T N1.7 que ha sido ajustado finamente y acelerado con TensorRT.
Iniciar el servicio de inferencia
Utiliza el siguiente script para iniciar el servicio del modelo. Se han realizado pequeñas modificaciones al script original para admitir la inferencia del modelo de motor TensorRT.
run_gr00t_server.py (haz clic para expandir)
# SPDX-FileCopyrightText: Copyright (c) 2026 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
import importlib
import json
import os
from pathlib import Path
import sys
from gr00t.data.embodiment_tags import EmbodimentTag
from gr00t.data.types import ModalityConfig
from gr00t.policy.gr00t_policy import Gr00tPolicy
from gr00t.policy.replay_policy import ReplayPolicy
from gr00t.policy.server_client import PolicyServer
import tyro
DEFAULT_MODEL_SERVER_PORT = 5555
@dataclass
class ServerConfig:
"""Configuration for running the GR00T inference server."""
# Gr00t policy configs
model_path: str | None = None
"""Path to the model checkpoint directory"""
embodiment_tag: str = "new_embodiment"
"""Embodiment tag (name or value, case-insensitive). Run with --help to see known tags."""
device: str = "cuda"
"""Device to run the model on"""
# Replay policy configs
dataset_path: str | None = None
"""Path to the dataset for replay trajectory"""
modality_config_path: str | None = None
"""Path to the modality configuration file"""
execution_horizon: int | None = None
"""Policy execution horizon during inference. Required when --dataset-path is set (ReplayPolicy)."""
# Server configs
host: str = "0.0.0.0"
"""Host address for the server"""
port: int = DEFAULT_MODEL_SERVER_PORT
"""Port number for the server"""
strict: bool = True
"""Whether to enforce strict input and output validation"""
use_sim_policy_wrapper: bool = False
"""Whether to use the sim policy wrapper"""
# TensorRT inference configs
trt_engine_path: str = ""
"""Path to directory containing TensorRT engine files. If set, uses TRT inference instead of PyTorch."""
trt_mode: str = "n17_full_pipeline"
"""TRT mode: 'n17_full_pipeline', 'vit_llm_only', 'action_head', or 'dit_only'."""
def main(config: ServerConfig):
config.embodiment_tag = EmbodimentTag.resolve(config.embodiment_tag)
print("Starting GR00T inference server...")
print(f" Embodiment tag: {config.embodiment_tag}")
print(f" Model path: {config.model_path}")
print(f" Device: {config.device}")
print(f" Host: {config.host}")
print(f" Port: {config.port}")
if config.trt_engine_path:
print(f" TRT engines: {config.trt_engine_path}")
print(f" TRT mode: {config.trt_mode}")
# Create and start the server
if config.model_path is not None:
if config.model_path.startswith("/") and not os.path.exists(config.model_path):
raise FileNotFoundError(f"Model path {config.model_path} does not exist")
policy = Gr00tPolicy(
embodiment_tag=config.embodiment_tag,
model_path=config.model_path,
device=config.device,
strict=config.strict,
)
# Replace PyTorch modules with TensorRT engines if requested
if config.trt_engine_path:
deploy_dir = str(Path(__file__).resolve().parents[2] / "scripts" / "deployment")
if deploy_dir not in sys.path:
sys.path.insert(0, deploy_dir)
from trt_model_forward import setup_tensorrt_engines
setup_tensorrt_engines(policy, config.trt_engine_path, mode=config.trt_mode)
print(f" TensorRT engines loaded in '{config.trt_mode}' mode")
elif config.dataset_path is not None:
if config.execution_horizon is None:
raise ValueError(
"--execution-horizon is required when --dataset-path is set "
"(ReplayPolicy needs a positive integer to advance episodes)."
)
if config.execution_horizon <= 0:
raise ValueError(
f"--execution-horizon must be positive; got {config.execution_horizon}."
)
modality_configs: dict[str, ModalityConfig] | None = None
if config.modality_config_path is not None:
config_path = Path(config.modality_config_path)
if config_path.suffix == ".py":
sys.path.append(str(config_path.parent))
importlib.import_module(config_path.stem)
print(f"Loaded modality config: {config_path}")
elif config_path.suffix == ".json":
with open(config.modality_config_path, "r") as f:
raw = json.load(f)
modality_configs = {k: ModalityConfig(**v) for k, v in raw.items()}
else:
raise ValueError(
f"Unsupported modality config format: {config_path.suffix}. Use .py or .json"
)
if modality_configs is None:
from gr00t.configs.data.embodiment_configs import MODALITY_CONFIGS
modality_configs = MODALITY_CONFIGS.get(config.embodiment_tag.value)
if modality_configs is None:
raise ValueError(
f"No built-in modality config for embodiment tag "
f"'{config.embodiment_tag.name}' (value='{config.embodiment_tag.value}'). "
f"Available tags: {sorted(MODALITY_CONFIGS.keys())}. "
f"Please provide --modality-config-path (JSON or .py) "
f"when using this tag with ReplayPolicy."
)
policy = ReplayPolicy(
dataset_path=config.dataset_path,
modality_configs=modality_configs,
execution_horizon=config.execution_horizon,
strict=config.strict,
)
else:
raise ValueError("Either model_path or dataset_path must be provided")
# Apply sim policy wrapper if needed
if config.use_sim_policy_wrapper:
from gr00t.policy.gr00t_policy import Gr00tSimPolicyWrapper
policy = Gr00tSimPolicyWrapper(policy)
server = PolicyServer(
policy=policy,
host=config.host,
port=config.port,
)
print(f"\n✓ Server ready — listening on {config.host}:{config.port}\n")
try:
server.run()
except KeyboardInterrupt:
print("\nShutting down server...")
if __name__ == "__main__":
config = tyro.cli(ServerConfig)
main(config)
Ejecuta el servidor de inferencia con el motor TensorRT:
python gr00t/eval/run_gr00t_server.py \
--model-path /home/seeed/checkpoint-10000/ \
--embodiment-tag NEW_EMBODIMENT \
--trt-engine-path /dev/shm/gr00t_trt_build/engines \
--trt-mode n17_full_pipeline
Asegúrate de reemplazar la ruta del modelo con la ruta de tu propio checkpoint de modelo ajustado finamente.
Ejecución en robot real
Aquí, utiliza el entorno LeRobot para iniciar el brazo robótico y realizar la tarea.
cd /path/to/lerobot
source .venv/bin/activate
cd Isaac-GR00T/gr00t/eval/real_robot
git clone https://github.com/zibochen6/rebot-arm-dm.git
uv pip install -e .
uv pip install --no-deps -e ../../../../
Inicia el brazo robótico:
python eval_rebot_arm_dm.py \
--robot.type=seeed_b601_dm_follower \
--robot.id=b601_dm_follower \
--robot.port=/dev/ttyACM0 \
--robot.can_adapter=damiao \
--robot.cameras='{ front: {type: opencv, index_or_path: /dev/video0, width: 640, height: 480, fps: 30}, side: {type: opencv, index_or_path: /dev/video2, width: 640, height: 480, fps: 30}}' \
--policy_host=localhost \
--policy_port=5555 \
--lang_instruction="Grab markers and place into pen holder." \
--action_smoothing_alpha=0.05 \
--action_smoothing_max_delta=20.0 \
--action_smoothing_gripper_alpha=0.1
La primera ejecución puede informar un fallo al encontrar el archivo de calibración para el brazo robótico. Esto se debe a que el archivo de calibración generado al usar LeRobot para verificar el reBot Arm tiene el nombre follower1.json, mientras que el programa está buscando b601_dm_follower.json. Cambia el nombre del archivo de calibración para resolver el problema:
mv ~/.cache/huggingface/lerobot/calibration/robots/seeed_b601_dm_follower/follower1.json \
~/.cache/huggingface/lerobot/calibration/robots/seeed_b601_dm_follower/b601_dm_follower.json
Referencias
- 🔗 https://developer.nvidia.com/embedded/jetpack
- 🔗 https://github.com/NVIDIA/Isaac-GR00T/tree/main
- 🔗 https://huggingface.co/nvidia/GR00T-N1.7-LIBERO
Soporte técnico y debate sobre el producto
Gracias por elegir nuestros productos. Estamos aquí para ofrecerte diferentes tipos de soporte y garantizar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para adaptarnos a distintas preferencias y necesidades.