Introducción a Jetson-Claw en Orin Nano / NX 8GB
Este wiki explica paso a paso una configuración práctica inicial de Jetson-Claw para Jetson Orin Nano 8GB y Jetson Orin NX 8GB. Toda la pila se ejecuta localmente en Jetson: instalamos nanobot, ampliamos el espacio de swap para una carga de modelos más segura, compilamos llama.cpp con CUDA, descargamos un modelo GGUF Qwen3.5 4B, cambiamos nanobot a un backend local llama.cpp y, por último, conectamos el bot a Feishu para que puedas controlarlo desde el chat.
En comparación con un despliegue OpenClaw más grande, nanobot se adapta mejor a esta configuración de entrada de Jetson-Claw porque es mucho más ligero, arranca más rápido, es más fácil de leer y modificar, y ya es compatible con Feishu además de backends locales compatibles con OpenAI. En un Jetson de 8 GB, esa menor sobrecarga en tiempo de ejecución deja más espacio para el propio modelo local. Si más adelante necesitas un ecosistema de plugins más grande o un flujo de trabajo más pesado con varios componentes, siempre puedes pasar a OpenClaw.
Qué vas a construir
- Un asistente de IA local y ligero basado en
nanobot - Un servidor HTTP
llama.cppcompatible con OpenAI ejecutándose en Jetson - Un modelo local GGUF
Qwen3.5 4B - Un bot de Jetson conectado a Feishu que puede controlarse desde chats privados o menciones en grupos
Requisitos previos
- 1 x Jetson Orin Nano 8GB o Jetson Orin NX 8GB
- JetPack 6.x ya instalado
- Conexión a Internet para descargar paquetes y modelos
- Se recomiendan al menos 20 GB de almacenamiento libre
Esta guía utiliza reComputer Super J3011 como la plataforma Jetson de referencia:

nanobot actualmente requiere Python 3.11 o superior, por lo que esta guía utiliza un entorno Miniconda en lugar del Python del sistema por defecto en Jetson.
Paso 1. Instalar nanobot
Primero instala las dependencias del sistema y Miniconda:
sudo apt update
sudo apt install -y git curl wget build-essential cmake libcurl4-openssl-dev python3-pip
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
Crea un entorno limpio de Python 3.11 e instala nanobot:
conda create -y -n jetson-claw python=3.11
conda activate jetson-claw
pip install -U pip
pip install nanobot-ai
Inicializa el directorio de ejecución:
nanobot onboard
Tras la inicialización, el archivo principal de configuración se encuentra en:
~/.nanobot/config.json
nanobot está inspirado en OpenClaw, pero para Orin Nano / NX 8GB suele ser el mejor punto de partida: menos consumo de memoria, arranque más rápido y menos componentes que depurar.
Paso 2. Aumentar el espacio de Swap
Ejecutar un modelo local de 4B en un Jetson de 8 GB es mucho más estable con swap adicional. Esto ayuda durante la carga del modelo, la compilación y la inferencia con contexto largo.
sudo fallocate -l 8G /var/swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /var/swapfile
sudo swapon /var/swapfile
echo '/var/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
swapon --show
Si planeas experimentar con tamaños de contexto mayores u otros modelos, puedes aumentar aún más el swap.
Paso 3. Compilar llama.cpp con CUDA
Configura las rutas de CUDA:
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Clona y compila llama.cpp:
git clone https://github.com/ggml-org/llama.cpp.git ~/llama.cpp
cd ~/llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build --parallel
Tras la compilación, los ejecutables principales se colocarán en:
~/llama.cpp/build/bin
Puedes confirmar rápidamente que el binario del servidor está listo con:
~/llama.cpp/build/bin/llama-server --help
Paso 4. Descargar los pesos GGUF de Qwen3.5 4B
Esta guía utiliza una cuantización GGUF Q4_K_M porque es un equilibrio práctico entre uso de memoria y calidad de respuesta para dispositivos Jetson de 8 GB.
Instala la CLI de Hugging Face:
conda activate jetson-claw
pip install -U "huggingface_hub[cli]"
mkdir -p ~/llama.cpp/models/Qwen3.5-4B-GGUF
Luego abre la página del modelo de abajo y descarga el archivo GGUF Q4_K_M en ~/llama.cpp/models/Qwen3.5-4B-GGUF/:
Elige el archivo Qwen3.5-4B.Q4_K_M.gguf en la página de Hugging Face:
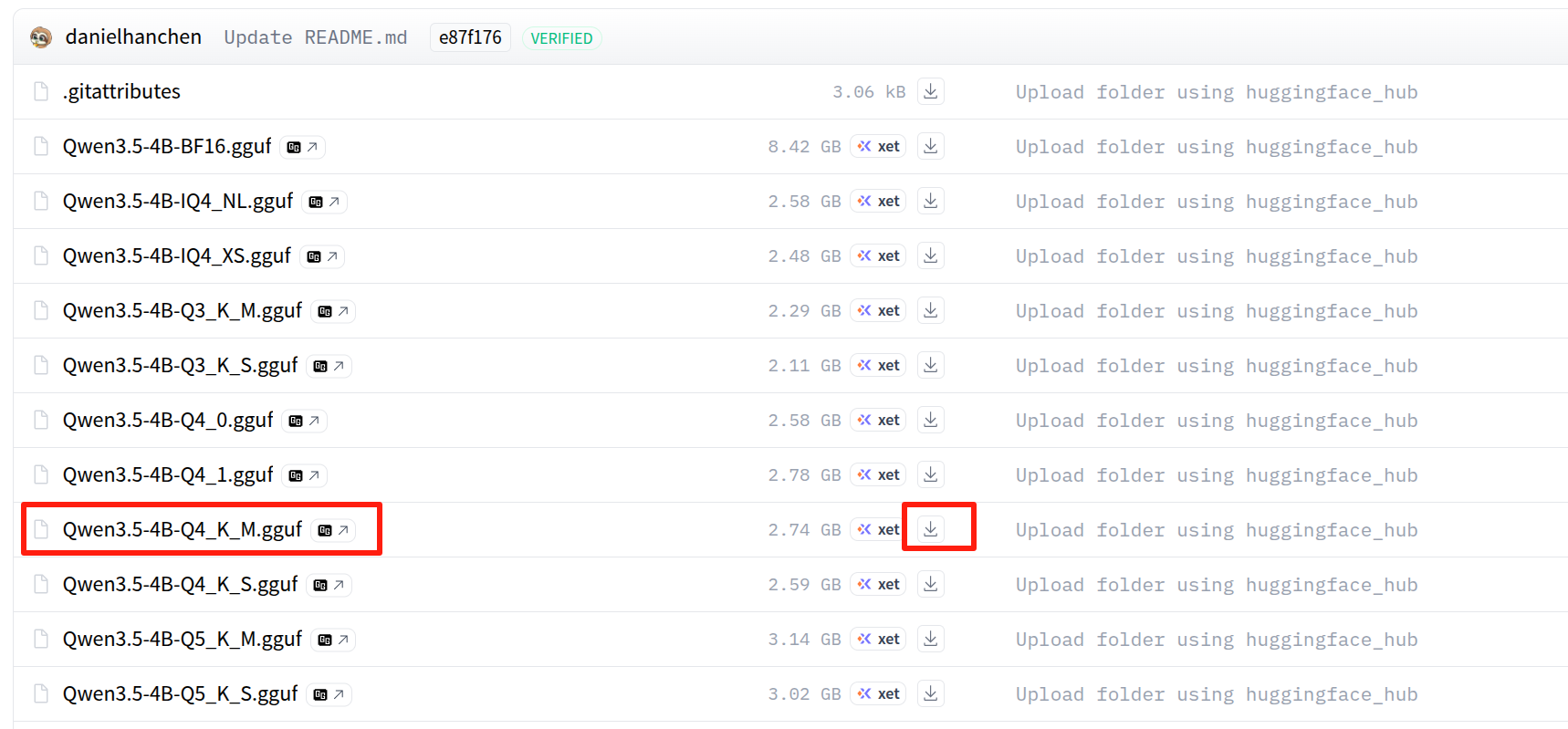
Si el repositorio utiliza el mismo nombre de archivo que el ejemplo de esta guía, también puedes descargarlo con:
huggingface-cli download \
unsloth/Qwen3.5-4B-GGUF \
Qwen3.5-4B.Q4_K_M.gguf \
--local-dir ~/llama.cpp/models/Qwen3.5-4B-GGUF
Si tu archivo tiene un nombre diferente, solo actualiza la ruta en el comando de inicio de más abajo. En el ejemplo de aquí, asumimos que el archivo del modelo es:
~/llama.cpp/models/Qwen3.5-4B-GGUF/Qwen3.5-4B.Q4_K_M.gguf
Paso 5. Iniciar llama.cpp como backend local
Inicia el servidor local de API compatible con OpenAI:
conda activate jetson-claw
cd ~/llama.cpp
./build/bin/llama-server \
-m ~/llama.cpp/models/Qwen3.5-4B-GGUF/Qwen3.5-4B.Q4_K_M.gguf \
--alias qwen3.5-4b-local \
-t 6 \
-c 40960 \
--n-gpu-layers 40 \
--reasoning off \
--reasoning-format none \
--host 127.0.0.1 \
--port 8080
Notas sobre los parámetros recomendados:
--alias qwen3.5-4b-local: asigna al modelo local un nombre de modelo de API limpio parananobot-t 6: usa un número moderado de hilos de CPU en dispositivos Jetson de entrada-c 40960: proporciona una ventana de contexto grande, pero puedes reducirla si la memoria es limitada--n-gpu-layers 40: descarga tantas capas como sea práctico a la GPU del Jetson--reasoning off: mantiene la salida más simple y reduce la sobrecarga innecesaria para una configuración inicial
Si el servidor no se inicia debido a presión de memoria, intenta reducir primero -c a 16384 y luego bajar --n-gpu-layers.
En otra terminal, verifica la API:
curl http://127.0.0.1:8080/v1/models
Paso 6. Configurar nanobot para usar llama.cpp
Abre el archivo de configuración:
nano ~/.nanobot/config.json
Luego fusiona las siguientes secciones en tu configuración:
{
"agents": {
"defaults": {
"workspace": "~/.nanobot/workspace",
"model": "qwen3.5-4b-local",
"provider": "custom",
"maxTokens": 8192,
"contextWindowTokens": 40960,
"temperature": 0.1,
"maxToolIterations": 40,
"reasoningEffort": null
}
},
"channels": {
"sendProgress": true,
"sendToolHints": false,
"feishu": {
"enabled": true,
"appId": "cli_xxx",
"appSecret": "xxx",
"encryptKey": "",
"verificationToken": "",
"allowFrom": ["*"],
"reactEmoji": "THUMBSUP",
"groupPolicy": "mention",
"replyToMessage": false
}
},
"providers": {
"custom": {
"apiKey": "no-key",
"apiBase": "http://127.0.0.1:8080/v1",
"extraHeaders": null
}
},
"gateway": {
"host": "0.0.0.0",
"port": 18790
}
}
Por qué esto funciona:
provider: "custom"indica ananobotque use cualquier backend compatible con OpenAIapiBase: "http://127.0.0.1:8080/v1"apunta alllama-serverlocalmodel: "qwen3.5-4b-local"coincide con el valor de--aliasusado al iniciarllama.cpp
Para pruebas rápidas, allowFrom: ["*"] es conveniente. Para uso en producción, sustitúyelo por tu propio open_id de Feishu después de la validación.
Paso 7. Conectar Feishu a nanobot
Crea una aplicación de Feishu en la Plataforma Abierta de Feishu:
- Abre https://open.feishu.cn/app
- Crea o abre tu aplicación de bot
- Copia el App ID y el App Secret
- Pégalos en
channels.feishu.appIdychannels.feishu.appSecret
Para el modo de Conexión Larga, encryptKey y verificationToken pueden dejarse vacíos.
Si no puedes encontrar tus credenciales más tarde, ve a:
- Plataforma Abierta de Feishu
- Tu aplicación
Credentials & Basic Info
Importar permisos de Feishu
Para que el manejo de archivos, imágenes y mensajes enriquecidos funcione correctamente, importa el siguiente conjunto de permisos en:
- Plataforma Abierta de Feishu
- Tu aplicación
Permission ManagementBulk Import
{
"scopes": {
"tenant": [
"aily:file:read",
"aily:file:write",
"application:application.app_message_stats.overview:readonly",
"application:application:self_manage",
"application:bot.menu:write",
"cardkit:card:write",
"contact:user.employee_id:readonly",
"corehr:file:download",
"docs:document.content:read",
"event:ip_list",
"im:chat",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.members:bot_access",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:message:readonly",
"im:message:send_as_bot",
"im:resource",
"sheets:spreadsheet",
"wiki:wiki:readonly"
],
"user": [
"aily:file:read",
"aily:file:write",
"im:chat.access_event.bot_p2p_chat:read"
]
}
}
Después de importar los permisos:
- Crea una nueva versión de la app
- Publica la versión de la app
De lo contrario, es posible que los permisos recién añadidos no surtan efecto.
Paso 8. Iniciar nanobot y probar el control desde Feishu
Mantén llama-server ejecutándose en una terminal y luego inicia nanobot en otra:
conda activate jetson-claw
nanobot gateway
Comprobaciones útiles:
nanobot status
nanobot channels status
Ahora envía un mensaje al bot desde Feishu:
- En un chat privado, envía un mensaje directo
- En un chat de grupo, menciona al bot si mantienes
groupPolicy: "mention"
Si usaste allowFrom: ["*"], el bot debería responder inmediatamente. Si más tarde quieres restringir el acceso, envía primero un mensaje, revisa los registros de nanobot para encontrar tu open_id, y reemplaza ["*"] con ese valor.
Opcional: Añadir una habilidad de ejemplo de Jetson-Claw
Si quieres convertir esta configuración inicial en una demostración de Jetson-Claw más útil, puedes añadir un conjunto de habilidades de ejemplo:
git clone https://github.com/jjjadand/JetsonClaw-SKILLS.git ~/JetsonClaw-SKILLS
mkdir -p ~/.nanobot/workspace/skills
cp -r ~/JetsonClaw-SKILLS/person-detection ~/.nanobot/workspace/skills/
Luego reinicia nanobot gateway, conecta una cámara USB a Jetson y pídele al bot en Feishu que compruebe si hay una persona visible delante de la cámara.
Ejemplo de flujo de monitorización en Feishu
Después de instalar la habilidad, puedes enviar una solicitud desde la app de Feishu para pedir a Jetson-Claw que revise la señal de la cámara:
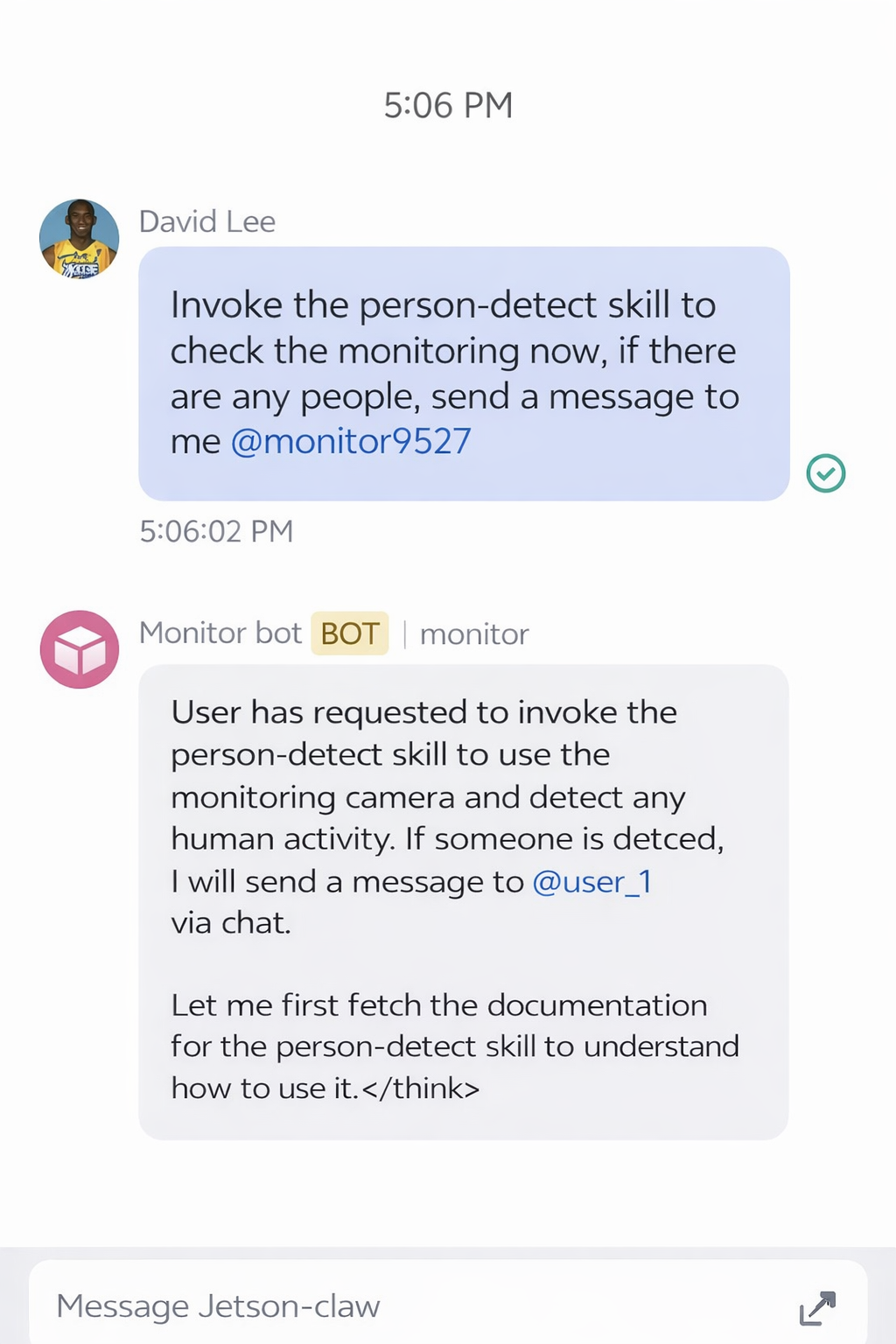
Si no se detecta ninguna persona, el resultado de la monitorización puede verse así:
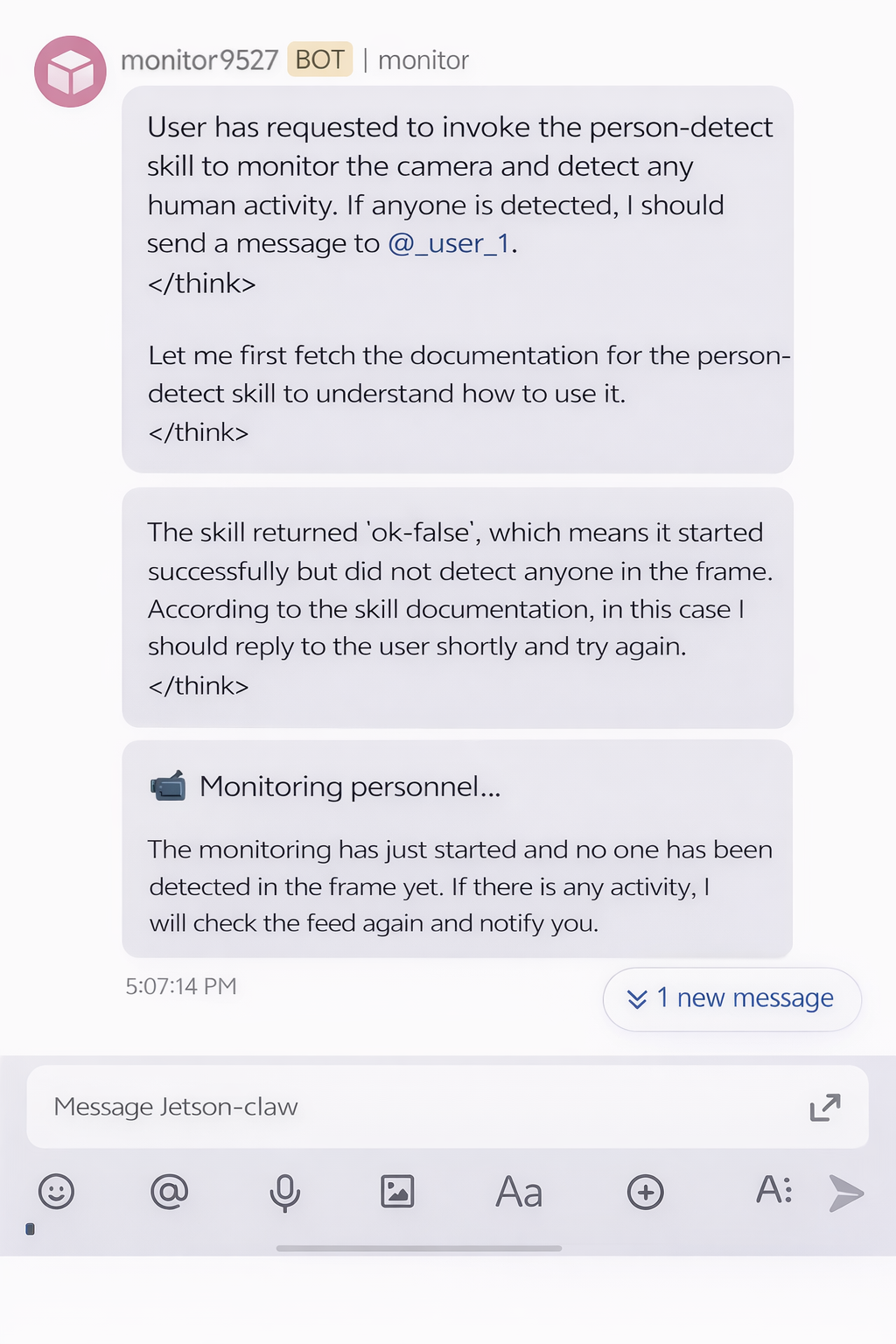
Si se detecta una persona, Jetson-Claw puede devolver una alerta a través de Feishu:
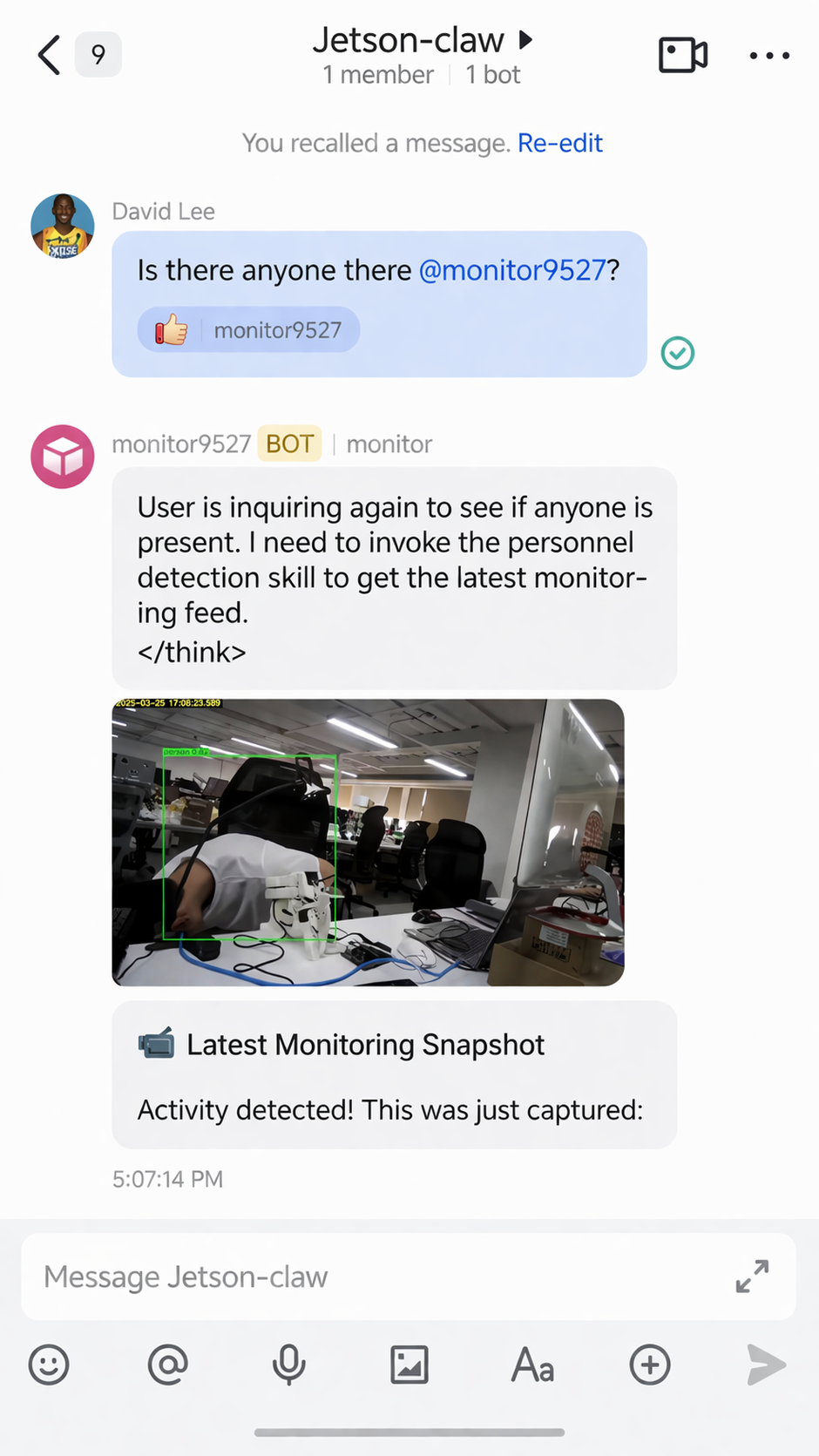
La habilidad de monitorización también puede enviar de vuelta la imagen del resultado capturado:

Solución de problemas
nanobotno se instala: asegúrate de estar dentro de un entorno de Python 3.11llama-serverse cierra durante la carga del modelo: aumenta la memoria de intercambio (swap) o reduce-c- El bot de Feishu no responde: verifica el App ID, App Secret, los permisos importados y la versión publicada de la app
- Los mensajes de grupo no activan el bot: comprueba
groupPolicyy asegúrate de mencionar al bot - Las respuestas son lentas: reduce el tamaño del contexto, disminuye el uso concurrente o utiliza una cuantización más pequeña
Referencias
- https://github.com/HKUDS/nanobot
- https://github.com/ggml-org/llama.cpp
- https://huggingface.co/unsloth/Qwen3.5-4B-GGUF/tree/main
- https://open.feishu.cn/app
- https://github.com/jjjadand/JetsonClaw-SKILLS
- https://wiki.seeedstudio.com/es/local_openclaw_on_recomputer_jetson/
Soporte técnico y debate sobre productos
Gracias por elegir nuestros productos. Estamos aquí para ofrecerte diferentes tipos de soporte y garantizar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para adaptarnos a diferentes preferencias y necesidades.