Primeros pasos con los brazos robóticos SO-ARM100 y SO-ARM101 con LeRobot
Introducción
El SO-10xARM es un proyecto de brazo robótico totalmente de código abierto lanzado por TheRobotStudio. Incluye el brazo seguidor y el brazo robótico líder, y también proporciona archivos detallados de impresión 3D y guías de operación. LeRobot se compromete a proporcionar modelos, conjuntos de datos y herramientas para robótica en el mundo real en PyTorch. Su objetivo es reducir la barrera de entrada a la robótica, permitiendo que todos contribuyan y se beneficien del intercambio de conjuntos de datos y modelos preentrenados. LeRobot integra metodologías de vanguardia validadas para aplicaciones en el mundo real, centrándose en el aprendizaje por imitación. Ha proporcionado un conjunto de modelos preentrenados, conjuntos de datos con demostraciones recopiladas por humanos y entornos de simulación, lo que permite a los usuarios comenzar sin necesidad de ensamblar robots. En las próximas semanas, la intención es aumentar el soporte para robótica en el mundo real en los robots más rentables y competentes disponibles actualmente.
Introducción a los proyectos
El kit de robot inteligente SO-ARM10x y reComputer Jetson AI combina a la perfección el control de brazo robótico de alta precisión con una potente plataforma de computación de IA, proporcionando una solución integral de desarrollo robótico. Este kit se basa en la plataforma Jetson Orin o AGX Orin, combinada con el brazo robótico SO-ARM10x y el framework de IA LeRobot, ofreciendo a los usuarios un sistema robótico inteligente aplicable a múltiples escenarios como educación, investigación y automatización industrial. Este wiki proporciona el tutorial de ensamblaje y depuración para la SO ARM10x y permite la recopilación de datos y el entrenamiento dentro del framework Lerobot.

Características principales
- Código abierto y bajo costo: Es una solución de brazo robótico de código abierto y bajo costo de TheRobotStudio
- Integración con LeRobot: Diseñado para la integración con la plataforma LeRobot
- Abundantes recursos de aprendizaje: Proporciona completos recursos de aprendizaje de código abierto como guías de ensamblaje y calibración, y tutoriales para pruebas, recopilación de datos, entrenamiento y despliegue para ayudar a los usuarios a comenzar rápidamente y desarrollar aplicaciones robóticas.
- Compatible con Nvidia: Despliega este kit de brazo con reComputer Mini J4012 Orin NX 16 GB.
- Aplicación en múltiples escenarios: Es aplicable a campos como educación, investigación científica, producción automatizada y robótica, ayudando a los usuarios a lograr operaciones robóticas eficientes y precisas en diversas tareas complejas.
Novedades:
- Optimización del cableado: En comparación con SO-ARM100, SO-ARM101 presenta un cableado mejorado que evita los problemas de desconexión observados anteriormente en la articulación 3. El nuevo diseño de cableado tampoco limita el rango de movimiento de las articulaciones.
- Diferentes relaciones de engranajes para el brazo líder: El brazo líder ahora utiliza motores con relaciones de engranajes optimizadas, mejorando el rendimiento y eliminando la necesidad de cajas de engranajes externas.
- Soporte de nuevas funciones: El brazo líder ahora puede seguir al brazo seguidor en tiempo real, lo cual es crucial para la próxima política de aprendizaje, donde una persona puede intervenir y corregir las acciones del robot.
Seeed Studio solo es responsable de la calidad del hardware en sí. Los tutoriales se actualizan estrictamente de acuerdo con la documentación oficial. Si encuentras problemas de software o dependencias de entorno que no puedan resolverse, además de consultar la sección de Preguntas Frecuentes (FAQ) al final de este tutorial, informa el problema de inmediato en la plataforma LeRobot o en el canal de Discord de LeRobot.
Especificaciones
| Tipo | SO-ARM100 | SO-ARM101 | ||
|---|---|---|---|---|
| Arm Kit | Arm Kit Pro | Arm Kit | Arm Kit Pro | |
| Brazo líder | 12x motores ST-3215- C001 (7.4V) con relación de engranajes 1:345 para todas las articulaciones | 12x motores ST-3215-C018/ST-3215-C047 (12V) con relación de engranajes 1:345 para todas las articulaciones | 1x motor ST-3215- C001 (7.4V) con relación de engranajes 1:345 solo para la articulación 2 | |
| Brazo seguidor | Igual que SO-ARM100 | |||
| Fuente de alimentación | 5.5 mm × 2.1 mm DC 5 V 4 A | 5.5 mm × 2.1 mm DC 12 V 2 A | 5.5 mm × 2.1 mm DC 5 V 4 A | 5.5 mm × 2.1 mm DC 12 V 2 A (Brazo seguidor) |
| Sensor de ángulo | Codificador magnético de 12 bits | |||
| Temperatura de funcionamiento recomendada | 0 °C a 40 °C | |||
| Comunicación | UART | |||
| Método de control | PC | |||
Si compras la versión Arm Kit, ambas fuentes de alimentación son de 5V. Si compras la versión Arm Kit Pro, utiliza la fuente de alimentación de 5V para la calibración y cada paso del brazo robótico líder, y la fuente de alimentación de 12V para la calibración y cada paso del brazo robótico seguidor.
Lista de materiales (BOM)
| Parte | Cantidad | Incluido |
|---|---|---|
| Servo Motos | 12 | ✅ |
| Placa de control de motor | 2 | ✅ |
| Cable USB-C 2 pcs | 1 | ✅ |
| Fuente de alimentación2 | 2 | ✅ |
| Abrazadera de mesa | 4 | ✅ |
| Piezas impresas en 3D del brazo | 1 | Opción |
Entorno inicial del sistema
Para Ubuntu x86:
- Ubuntu 22.04
- CUDA 12+
- Python 3.10
- Torch 2.6+
Para Jetson Orin:
- Jetson JetPack 6.0 y 6.1, no compatible con 6.1
- Python 3.10
- Torch 2.3+
Tabla de contenidos
H. Registrar el conjunto de datos
I. Visualizar el conjunto de datos
Guía de impresión 3D
Tras la actualización oficial de SO101, SO100 dejará de recibir soporte y los archivos fuente se eliminarán según lo indicado oficialmente, pero los archivos fuente aún pueden encontrarse en nuestro Makerworld. Sin embargo, para los usuarios que hayan comprado previamente SO100, los tutoriales y métodos de instalación siguen siendo compatibles. La impresión de SO101 es totalmente compatible con la instalación del kit de motor de SO100.
Paso 1: Elegir una impresora
Los archivos STL proporcionados están listos para imprimirse en muchas impresoras FDM. A continuación se muestran los ajustes probados y sugeridos, aunque otros también pueden funcionar.
- Material: PLA+
- Diámetro de la boquilla y precisión: boquilla de 0.4mm de diámetro con altura de capa de 0.2mm o boquilla de 0.6mm con altura de capa de 0.4mm.
- Densidad de relleno: 15%
Paso 2: Configurar la impresora
- Asegúrate de que la impresora esté calibrada y que el nivel de la cama esté correctamente ajustado siguiendo las instrucciones específicas de la impresora.
- Limpia la cama de impresión, asegurándote de que esté libre de polvo o grasa. Si limpias la cama con agua u otro líquido, sécala.
- Si tu impresora lo recomienda, utiliza un pegamento en barra estándar y aplica una capa fina y uniforme de pegamento en toda el área de impresión de la cama. Evita los grumos o una aplicación desigual.
- Carga el filamento de la impresora siguiendo las instrucciones específicas de la impresora.
- Asegúrate de que la configuración de la impresora coincida con la sugerida arriba (la mayoría de las impresoras tienen múltiples configuraciones, así que elige las que más se acerquen).
- Configura soportes en todas partes, pero ignora las pendientes mayores de 45 grados respecto a la horizontal.
- No debe haber soportes en los orificios de los tornillos con ejes horizontales.
Paso 3: Imprimir las piezas
Todas las piezas para el líder o el seguidor están preparadas para una fácil impresión 3D en un único archivo, correctamente orientadas con z hacia arriba para minimizar los soportes.
-
Para camas de impresión de 220mmx220mm (como la Ender), imprime estos archivos:
-
Para camas de impresión de 205mm x 250mm (como la Prusa/Up):
Instalar LeRobot
Entornos como pytorch y torchvision deben instalarse en función de tu versión de CUDA.
- Instalar Miniconda: Para Jetson:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
O, para X86 Ubuntu 22.04:
mkdir -p ~/miniconda3
cd miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
source ~/miniconda3/bin/activate
conda init --all
- Crea y activa un entorno conda nuevo para lerobot
conda create -y -n lerobot python=3.10 && conda activate lerobot
- Clonar Lerobot:
git clone https://github.com/Seeed-Projects/lerobot.git ~/lerobot
- Cuando uses miniconda, instala ffmpeg en tu entorno:
conda install ffmpeg -c conda-forge
Esto normalmente instala ffmpeg 7.X para tu plataforma compilado con el codificador libsvtav1. Si libsvtav1 no es compatible (comprueba los codificadores compatibles con ffmpeg -encoders), puedes:
- [En cualquier plataforma] Instalar explícitamente ffmpeg 7.X usando:
conda install ffmpeg=7.1.1 -c conda-forge
- [Solo en Linux] Instalar las dependencias de compilación de ffmpeg y compilar ffmpeg desde el código fuente con libsvtav1, y asegurarte de usar el binario de ffmpeg correspondiente a tu instalación con which ffmpeg.
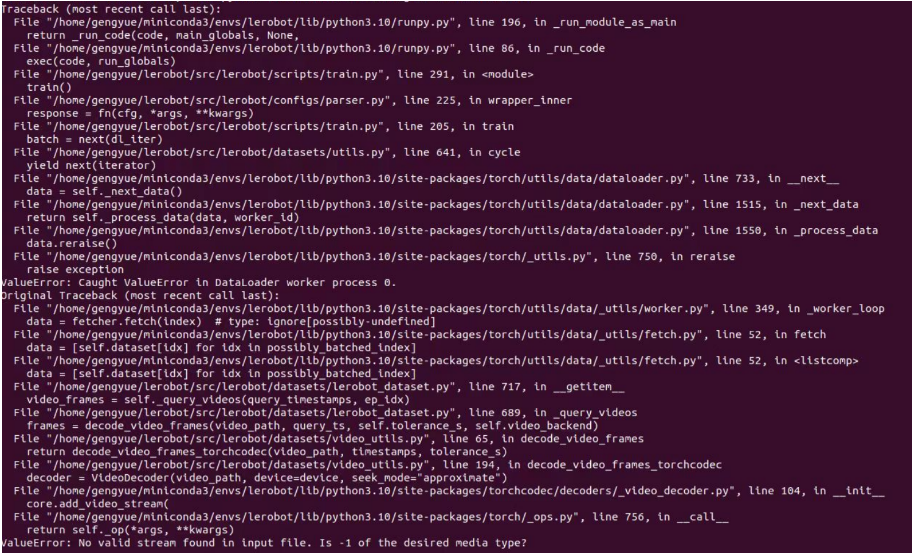
Si encuentras un error como este, también puedes usar este comando.
- Instalar LeRobot con dependencias para los motores feetech:
cd ~/lerobot && pip install -e ".[feetech]"
Para dispositivos Jetson Jetpack 6.0+ (asegúrate de instalar Pytorch-gpu y Torchvision desde el paso 5 antes de ejecutar este paso):
conda install -y -c conda-forge "opencv>=4.10.0.84" # Install OpenCV and other dependencies through conda, this step is only for Jetson Jetpack 6.0+
conda remove opencv # Uninstall OpenCV
pip3 install opencv-python==4.10.0.84 # Then install opencv-python via pip3
conda install -y -c conda-forge ffmpeg
conda uninstall numpy
pip3 install numpy==1.26.0 # This should match torchvision
- Comprobar Pytorch y Torchvision
Dado que instalar el entorno lerobot mediante pip desinstalará las versiones originales de Pytorch y Torchvision e instalará las versiones de CPU de Pytorch y Torchvision, necesitas realizar una comprobación en Python.
import torch
print(torch.cuda.is_available())
Si el resultado impreso es False, necesitas reinstalar Pytorch y Torchvision según el tutorial del sitio web oficial.
Si estás usando un dispositivo Jetson, instala Pytorch y Torchvision según este tutorial.
Configurar los motores
- SO101
El proceso de calibración e inicialización del servo para el SO-ARM101 es el mismo que el del SO-ARM100 tanto en método como en código. Sin embargo, ten en cuenta que las relaciones de engranajes de las tres primeras articulaciones del brazo líder SO-ARM101 difieren de las del SO-ARM100, por lo que es importante distinguirlas y calibrarlas cuidadosamente.
Para configurar los motores, asigna un adaptador de bus servo y 6 motores para tu brazo líder, y de forma similar el otro adaptador de bus servo y 6 motores para el brazo seguidor. Es conveniente etiquetarlos y escribir en cada motor si es para el seguidor F o para el líder L y su ID de 1 a 6. Usamos F1–F6 para representar las articulaciones 1 a 6 del Brazo Seguidor, y L1–L6 para representar las articulaciones 1 a 6 del Brazo Líder. El modelo de servo correspondiente, las asignaciones de articulaciones y los detalles de la relación de engranajes son los siguientes:
| Modelo de servo | Relación de engranajes | Articulaciones correspondientes |
|---|---|---|
| ST-3215-C044(7.4V) | 1:191 | L1 |
| ST-3215-C001(7.4V) | 1:345 | L2 |
| ST-3215-C044(7.4V) | 1:191 | L3 |
| ST-3215-C046(7.4V) | 1:147 | L4–L6 |
| ST-3215-C001(7.4V) / C018(12V) / C047(12V) | 1:345 | F1–F6 |
Ahora debes conectar la fuente de alimentación de 5V o 12V al bus de motores. 5V para los motores STS3215 de 7.4V y 12V para los motores STS3215 de 12V. Ten en cuenta que el brazo líder siempre usa los motores de 7.4V, así que asegúrate de conectar la fuente de alimentación correcta si tienes motores de 12V y 7.4V, ¡de lo contrario podrías quemar tus motores! Ahora, conecta el bus de motores a tu ordenador mediante USB. Ten en cuenta que el USB no proporciona alimentación, y tanto la fuente de alimentación como el USB deben estar conectados.

Los siguientes son los pasos de calibración del código, calibra con el servo de cableado de referencia en la imagen de arriba
Encontrar los puertos USB asociados a tus brazos Para encontrar los puertos correctos para cada brazo, ejecuta el script de utilidad dos veces:
lerobot-find-port
Ejemplo de salida:
Finding all available ports for the MotorBus.
['/dev/ttyACM0', '/dev/ttyACM1']
Remove the usb cable from your MotorsBus and press Enter when done.
[...Disconnect corresponding leader or follower arm and press Enter...]
The port of this MotorsBus is /dev/ttyACM1
Reconnect the USB cable.
Recuerda retirar el USB, de lo contrario la interfaz no será detectada.
Ejemplo de salida al identificar el puerto del brazo seguidor (por ejemplo, /dev/tty.usbmodem575E0031751 en Mac, o posiblemente /dev/ttyACM0 en Linux):
Ejemplo de salida al identificar el puerto del brazo líder (por ejemplo, /dev/tty.usbmodem575E0032081, o posiblemente /dev/ttyACM1 en Linux):
Es posible que necesites dar acceso a los puertos USB ejecutando:
sudo chmod 666 /dev/ttyACM0
sudo chmod 666 /dev/ttyACM1
Configura tus motores
Utiliza una fuente de alimentación de 5V para calibrar los motores del Líder (ST-3215-C046, C044, 001).
| Calibración de la articulación 6 del Brazo Líder | Calibración de la articulación 5 del Brazo Líder | Calibración de la articulación 4 del Brazo Líder | Calibración de la articulación 3 del Brazo Líder | Calibración de la articulación 2 del Brazo Líder | Calibración de la articulación 1 del Brazo Líder |
|---|---|---|---|---|---|
 |  |  |  |  |  |
Si compras la versión Arm Kit (ST-3215-C001), utiliza una fuente de alimentación de 5V. Si compras la versión Arm Kit Pro, utiliza una fuente de alimentación de 12V para calibrar el servo (ST-3215-C047/ST-3215-C018).
| Calibración de la articulación 6 del Brazo Seguidor | Calibración de la articulación 5 del Brazo Seguidor | Calibración de la articulación 4 del Brazo Seguidor | Calibración de la articulación 3 del Brazo Seguidor | Calibración de la articulación 2 del Brazo Seguidor | Calibración de la articulación 1 del Brazo Seguidor |
|---|---|---|---|---|---|
 |  |  |  |  |  |
Nuevamente, asegúrate de que los IDs de las articulaciones de los servos y las relaciones de engranajes correspondan estrictamente a las del SO-ARM101.
Conecta el cable USB desde tu ordenador y la fuente de alimentación a la placa controladora del brazo seguidor. Luego, ejecuta el siguiente comando.
lerobot-setup-motors \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 # <- paste here the port found at previous step
Deberías ver la siguiente instrucción.
Connect the controller board to the 'gripper' motor only and press enter.
Según se indica, conecta el motor de la garra. Asegúrate de que sea el único motor conectado a la placa y de que el propio motor aún no esté encadenado en serie con ningún otro motor. Al pulsar [Enter], el script configurará automáticamente el id y la velocidad en baudios de ese motor.
A continuación deberías ver el siguiente mensaje:
'gripper' motor id set to 6
Seguido de la siguiente instrucción:
Connect the controller board to the 'wrist_roll' motor only and press enter.
Puedes desconectar el cable de 3 pines de la placa controladora, pero puedes dejarlo conectado al motor de la garra en el otro extremo, ya que ya estará en el lugar correcto. Ahora, conecta otro cable de 3 pines al motor de giro de muñeca y conéctalo a la placa controladora. Como con el motor anterior, asegúrate de que sea el único motor conectado a la placa y de que el propio motor no esté conectado a ningún otro.
Repite la operación para cada motor según se indique.
Comprueba el cableado en cada paso antes de pulsar Enter. Por ejemplo, el cable de la fuente de alimentación podría desconectarse mientras manipulas la placa.
Cuando termines, el script simplemente finalizará, momento en el cual los motores estarán listos para usarse. Ahora puedes conectar el cable de 3 pines de cada motor al siguiente, y el cable del primer motor (el “giro de hombro” con id=1) a la placa controladora, que ahora puede fijarse a la base del brazo.
Realiza los mismos pasos para el brazo líder.
lerobot-setup-motors \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM0 # <- paste here the port found at previous step
Ensamblaje
- El proceso de ensamblaje de doble brazo del SO-ARM101 es el mismo que el del SO-ARM100. Las únicas diferencias son la adición de clips para cables en el SO-ARM101 y las diferentes relaciones de engranajes de los servos de las articulaciones en el Brazo Líder. Por lo tanto, tanto el SO100 como el SO101 pueden instalarse haciendo referencia al siguiente contenido.
- Antes del ensamblaje, vuelve a comprobar el modelo de tu motor y la relación de reducción. Si has comprado el SO100, puedes ignorar este paso. Si has comprado el SO101, consulta la siguiente tabla para distinguir F1 a F6 y L1 a L6.
| Modelo de servo | Relación de engranajes | Articulaciones correspondientes |
|---|---|---|
| ST-3215-C044(7.4V) | 1:191 | L1 |
| ST-3215-C001(7.4V) | 1:345 | L2 |
| ST-3215-C044(7.4V) | 1:191 | L3 |
| ST-3215-C046(7.4V) | 1:147 | L4–L6 |
| ST-3215-C001(7.4V) / C018(12V) / C047(12V) | 1:345 | F1–F6 |
Si compraste el SO101 Arm Kit Standard Edition, todas las fuentes de alimentación son de 5V. Si compraste el SO101 Arm Kit Pro Edition, el Brazo Líder debe calibrarse y operarse en cada paso utilizando una fuente de alimentación de 5V, mientras que el Brazo Seguidor debe calibrarse y operarse en cada paso utilizando una fuente de alimentación de 12V.
Ensamblar Brazo Líder
| Paso 1 | Paso 2 | Paso 3 | Paso 4 | Paso 5 | Paso 6 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| Paso 7 | Paso 8 | Paso 9 | Paso 10 | Paso 11 | Paso 12 |
 |  |  |  |  |  |
| Paso 13 | Paso 14 | Paso 15 | Paso 16 | Paso 17 | Paso 18 |
 |  |  |  |  |  |
| Paso 19 | Paso 20 | ||||
 |  |
Ensamblar Brazo Seguidor
- Los pasos para ensamblar el Brazo Seguidor son, en general, los mismos que para el Brazo Líder. La única diferencia radica en el método de instalación del efector final (garra y empuñadura) después del Paso 12.
| Paso 1 | Paso 2 | Paso 3 | Paso 4 | Paso 5 | Paso 6 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| Paso 7 | Paso 8 | Paso 9 | Paso 10 | Paso 11 | Paso 12 |
 |  |  |  |  |  |
| Paso 13 | Paso 14 | Paso 15 | Paso 16 | Paso 17 | |
 |  |  |  |  |
Calibración
Los códigos de SO100 y SO101 son compatibles. Los usuarios de SO100 pueden utilizar directamente los parámetros y el código de SO101 para la operación.
Si compraste el SO101 Arm Kit Standard Edition, todas las fuentes de alimentación son de 5V. Si compraste el SO101 Arm Kit Pro Edition, el Brazo Líder debe calibrarse y operarse en cada paso utilizando una fuente de alimentación de 5V, mientras que el Brazo Seguidor debe calibrarse y operarse en cada paso utilizando una fuente de alimentación de 12V.
A continuación, debes conectar la fuente de alimentación y el cable de datos a tu robot SO-10x para la calibración, a fin de garantizar que los brazos líder y seguidor tengan los mismos valores de posición cuando estén en la misma posición física. Esta calibración es esencial porque permite que una red neuronal entrenada en un robot SO-10x funcione en otro. Si necesitas recalibrar el brazo robótico, elimina los archivos en ~/.cache/huggingface/lerobot/calibration/robots o ~/.cache/huggingface/lerobot/calibration/teleoperators y vuelve a calibrar el brazo robótico. De lo contrario, aparecerá un mensaje de error. La información de calibración del brazo robótico se almacenará en los archivos JSON de este directorio.
En PC (Linux) y dispositivos Jetson, el primer dispositivo USB que conectas normalmente se asigna a ttyACM0, y el segundo se asigna a ttyACM1. Verifica dos veces qué puerto está asignado al líder y al seguidor antes de ejecutar los comandos.
Calibración manual del brazo seguidor
Conecta las interfaces de los 6 servomotores del robot mediante un cable de 3 pines y conecta el servomotor del chasis a la placa de accionamiento de servos, luego ejecuta el siguiente comando o ejemplo de API para calibrar el brazo robótico:
Primero se otorgan los permisos de la interfaz
sudo chmod 666 /dev/ttyACM*
Luego calibra el brazo seguidor
lerobot-calibrate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \# <- The port of your robot
--robot.id=my_awesome_follower_arm # <- Give the robot a unique name
El siguiente video muestra cómo realizar la calibración. Primero debes mover el robot a la posición en la que todas las articulaciones estén en el centro de sus rangos. Luego, después de presionar Enter, debes mover cada articulación a lo largo de todo su rango de movimiento.
Calibración manual del brazo líder
Realiza los mismos pasos para calibrar el brazo líder, ejecuta el siguiente comando o ejemplo de API:
lerobot-calibrate \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \# <- The port of your robot
--teleop.id=my_awesome_leader_arm # <- Give the robot a unique name
(Opcional) Calibración de posición media con la herramienta rápida Seeed Studio SoARM
Al calibrar o ejecutar el robot, si ves errores como:
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)
Esto generalmente significa que la posición actual / el desplazamiento de cero de un servomotor es anormal, lo que hace que el ángulo leído exceda el rango esperado. En ese caso, puedes usar la herramienta SoARM de Seeed Studio para hacer una calibración de posición media (escribir la posición actual en el valor medio 2048), y luego repetir la calibración de todo el brazo.
1) Clonar la herramienta desde GitHub e instalar dependencias
git clone https://github.com/Seeed-Projects/Seeed_RoboController.git
cd Seeed_RoboController
pip install -r requirements.txt
2) Calibración de posición media y verificación
Ubicación de los scripts:
src/tools/servo_middle_calibration.py: calibración de posición media (escribe la posición actual como 2048)src/tools/servo_disable.py: desactivar el par del servomotor (más fácil girar las articulaciones a mano)src/tools/servo_center_test.py: mover a 2048 para verificar el resultado de la calibración
Ejecuta en orden (los comandos te pedirán interactivamente que selecciones un puerto):
- (Opcional) Desactiva el par para ajustar las articulaciones manualmente:
python -m src.tools.servo_disable
- Realiza la calibración de posición media (establece la posición actual en 2048):
python -m src.tools.servo_middle_calibration
- Verifica: mueve el servomotor a 2048 y comprueba si vuelve a la posición media esperada:
python -m src.tools.servo_center_test
Después de la calibración de posición media, vuelve a los pasos de lerobot-calibrate anteriores y repite la calibración de todo el brazo.
Teleoperar
Teleoperación simple Entonces ya estás listo para teleoperar tu robot. Ejecuta este script sencillo (no se conectará ni mostrará las cámaras):
Ten en cuenta que el id asociado a un robot se utiliza para almacenar el archivo de calibración. Es importante usar el mismo id al teleoperar, grabar y evaluar cuando uses la misma configuración.
sudo chmod 666 /dev/ttyACM*
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm
El comando de teleoperación hará automáticamente lo siguiente:
- Identificar cualquier calibración faltante e iniciar el procedimiento de calibración.
- Conectar el robot y el dispositivo de teleoperación e iniciar la teleoperación.
Añadir cámaras
If using the Orbbec Gemini2 Depth Camera

- 🚀 Paso 1: Instalar el entorno de dependencias del SDK de Orbbec
-
Clona el repositorio
pyorbbeccd ~/
git clone https://github.com/orbbec/pyorbbecsdk.git -
Descarga e instala el archivo .whl correspondiente para el SDK
Ve a pyorbbecsdk Releases,
selecciona e instala según tu versión de Python. Por ejemplo:pip install pyorbbecsdk-x.x.x-cp310-cp310-linux_x86_64.whl -
Instala las dependencias en el directorio
pyorbbeccd ~/pyorbbecsdk
pip install -r requirements.txtFuerza la degradación de la versión de
numpya1.26.0pip install numpy==1.26.0
Se pueden ignorar los mensajes de error en rojo.
- Clona el SDK de Orbbec en el directorio
~/lerobot/src/lerobot/cameras
cd ~/lerobot/src/lerobot/cameras
git clone https://github.com/ZhuYaoHui1998/orbbec.git
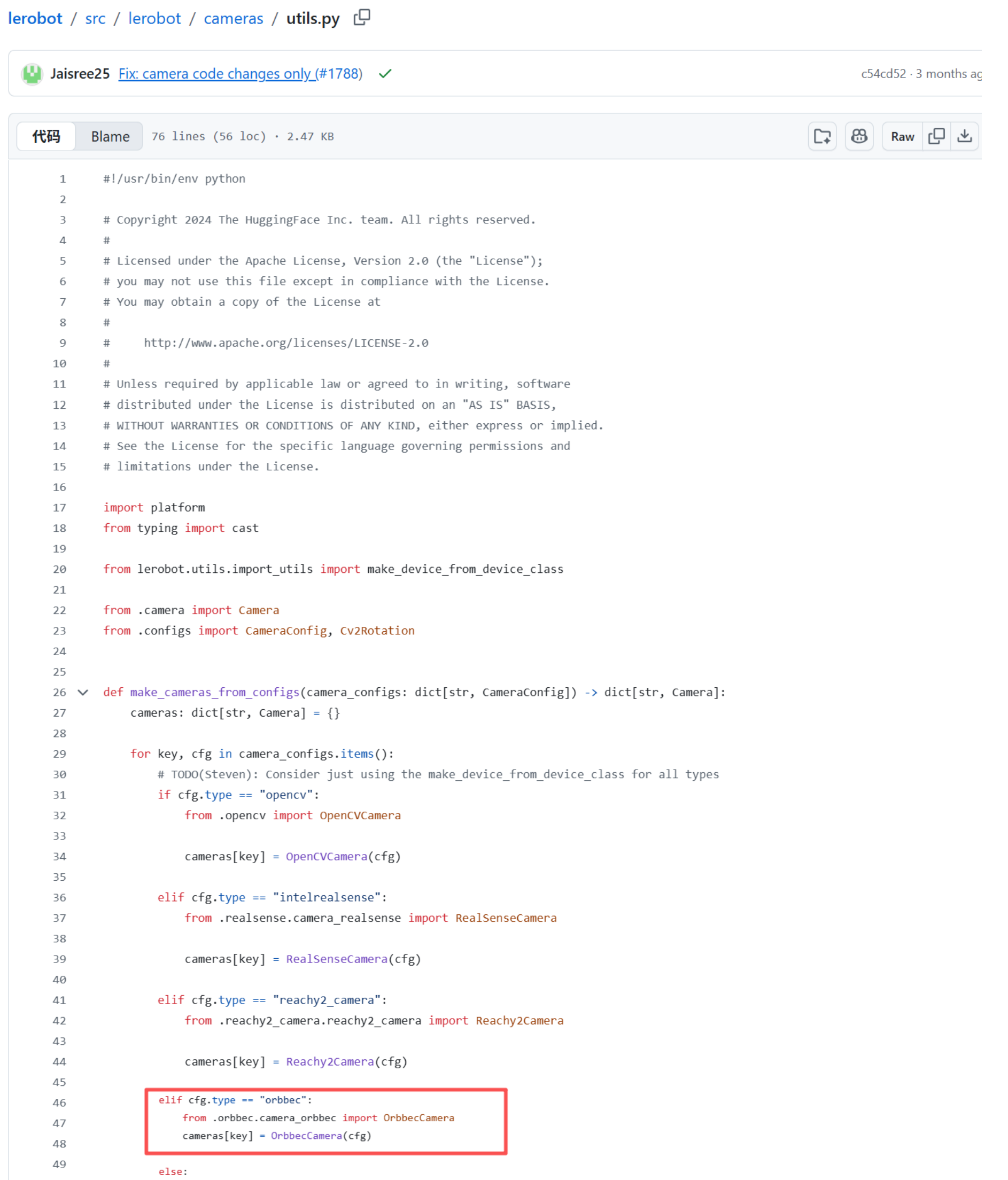
- Modificar utils.py y init.py
- Busca
utils.pyen el directorio~/lerobot/src/lerobot/camerasy añade el siguiente código aproximadamente en la línea 45:
elif cfg.type == "orbbec":
from .orbbec.camera_orbbec import OrbbecCamera
cameras[key] = OrbbecCamera(cfg)
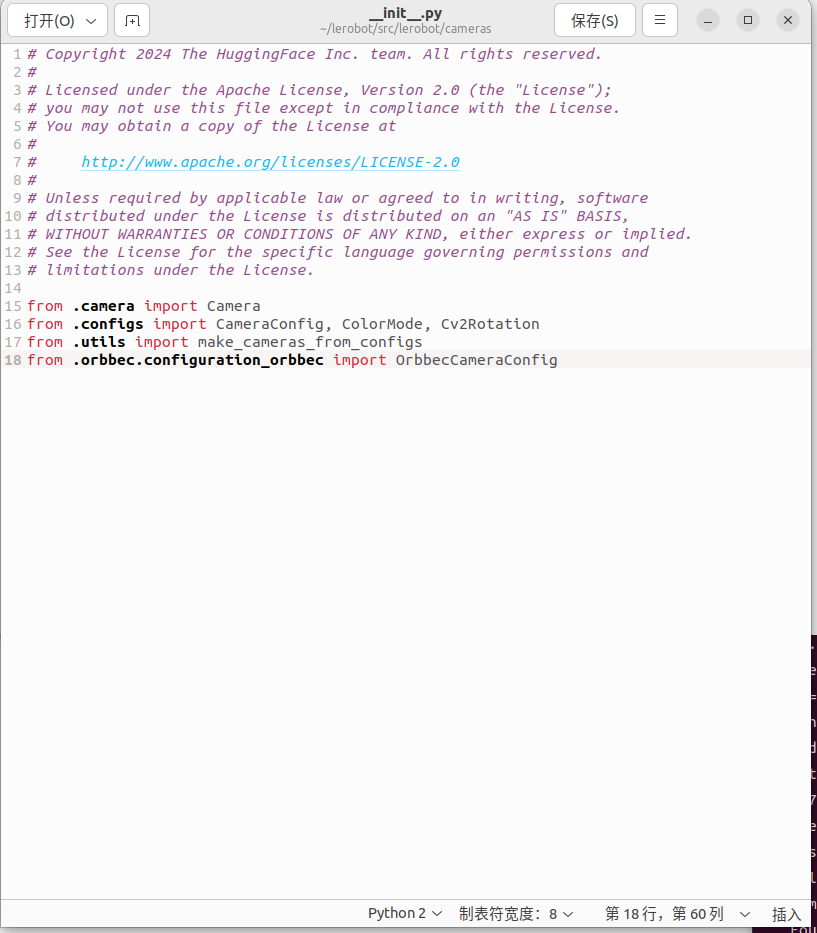
- Busca
__init__.pyen el directorio~/lerobot/src/lerobot/camerasy añade el siguiente código en la línea 18:
from .orbbec.configuration_orbbec import OrbbecCameraConfig
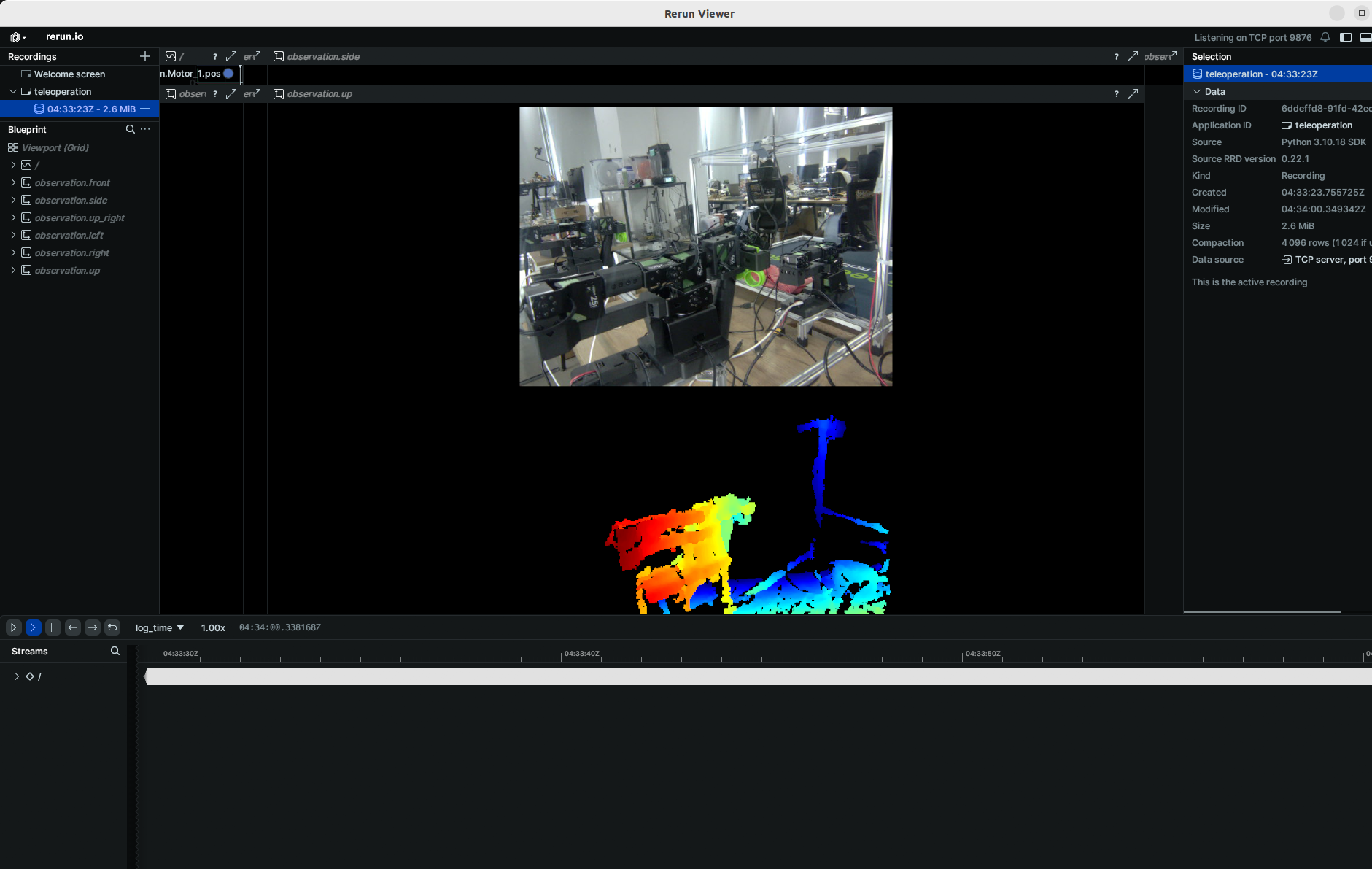
- 🚀 Paso 2: Llamada de función y ejemplos
En todos los ejemplos siguientes, reemplaza so101_follower con el modelo real del brazo robótico que estés usando (por ejemplo, so100 / so101).
Hemos añadido el hiperparámetro focus_area. Dado que los datos de profundidad que están demasiado lejos no tienen sentido para el brazo robótico (no puede alcanzar ni agarrar objetos), los datos de profundidad menores o mayores que focus_area se mostrarán en negro. El focus_area predeterminado es (20, 600).
Actualmente, la única resolución compatible es ancho: 640, alto: 880.
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ up: {type: orbbec, width: 640, height: 880, fps: 30, focus_area:[60,300]}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
Para tareas posteriores como recopilación de datos, entrenamiento y evaluación, el proceso es el mismo que para los comandos RGB normales. Solo necesitas reemplazar la parte correspondiente en el comando RGB normal por:
--robot.cameras="{ up: {type: orbbec, width: 640, height: 880, fps: 30, focus_area:[60,300]}}" \
También puedes añadir posteriormente una cámara RGB monocular adicional.
Los códigos de SO100 y SO101 son compatibles. Los usuarios de SO100 pueden utilizar directamente los parámetros y el código de SO101 para la operación.
Para instanciar una cámara, necesitas un identificador de cámara. Este identificador puede cambiar si reinicias tu ordenador o vuelves a conectar tu cámara, un comportamiento que depende principalmente de tu sistema operativo.
Para encontrar los índices de las cámaras conectadas a tu sistema, ejecuta el siguiente script:
lerobot-find-cameras opencv # or realsense for Intel Realsense cameras
El terminal imprimirá la siguiente información.
--- Detected Cameras ---
Camera #0:
Name: OpenCV Camera @ 0
Type: OpenCV
Id: 0
Backend api: AVFOUNDATION
Default stream profile:
Format: 16.0
Width: 1920
Height: 1080
Fps: 15.0
--------------------
(more cameras ...)
Puedes encontrar las imágenes tomadas por cada cámara en el directorio outputs/captured_images.
Al usar cámaras Intel RealSense en , podrías obtener este error: , esto se puede resolver ejecutando el mismo comando con permisos. Ten en cuenta que usar cámaras RealSense en es inestable.macOSError finding RealSense cameras: failed to set power statesudomacOS.
Entonces podrás mostrar las cámaras en tu ordenador mientras teleoperas ejecutando el siguiente código. Esto es útil para preparar tu configuración antes de grabar tu primer conjunto de datos.
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
Si tienes más cámaras, puedes cambiar --robot.cameras para añadir cámaras. Debes tener en cuenta el formato de index_or_path, que viene determinado por el último dígito del ID de la cámara que se obtiene con python -m lerobot.find_cameras opencv.
Las imágenes en formato fourcc: "MJPG" están comprimidas. Puedes probar resoluciones más altas y también puedes intentar el formato YUYV. Sin embargo, este último reducirá la resolución de la imagen y los FPS, lo que provocará retrasos en el funcionamiento del brazo robótico. Actualmente, con el formato MJPG, se pueden soportar 3 cámaras a una resolución de 1920*1080 manteniendo 30FPS. Aun así, no se recomienda conectar 2 cámaras a un ordenador a través del mismo HUB USB.
Por ejemplo, quieres añadir una cámara lateral:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
Las imágenes en formato fourcc: "MJPG" están comprimidas. Puedes probar resoluciones más altas y también puedes intentar el formato YUYV. Sin embargo, este último reducirá la resolución de la imagen y los FPS, lo que provocará retrasos en el funcionamiento del brazo robótico. Actualmente, con el formato MJPG, se pueden soportar 3 cámaras a una resolución de 1920*1080 manteniendo 30FPS. Aun así, no se recomienda conectar 2 cámaras a un ordenador a través del mismo HUB USB.
Si encuentras un error como este.
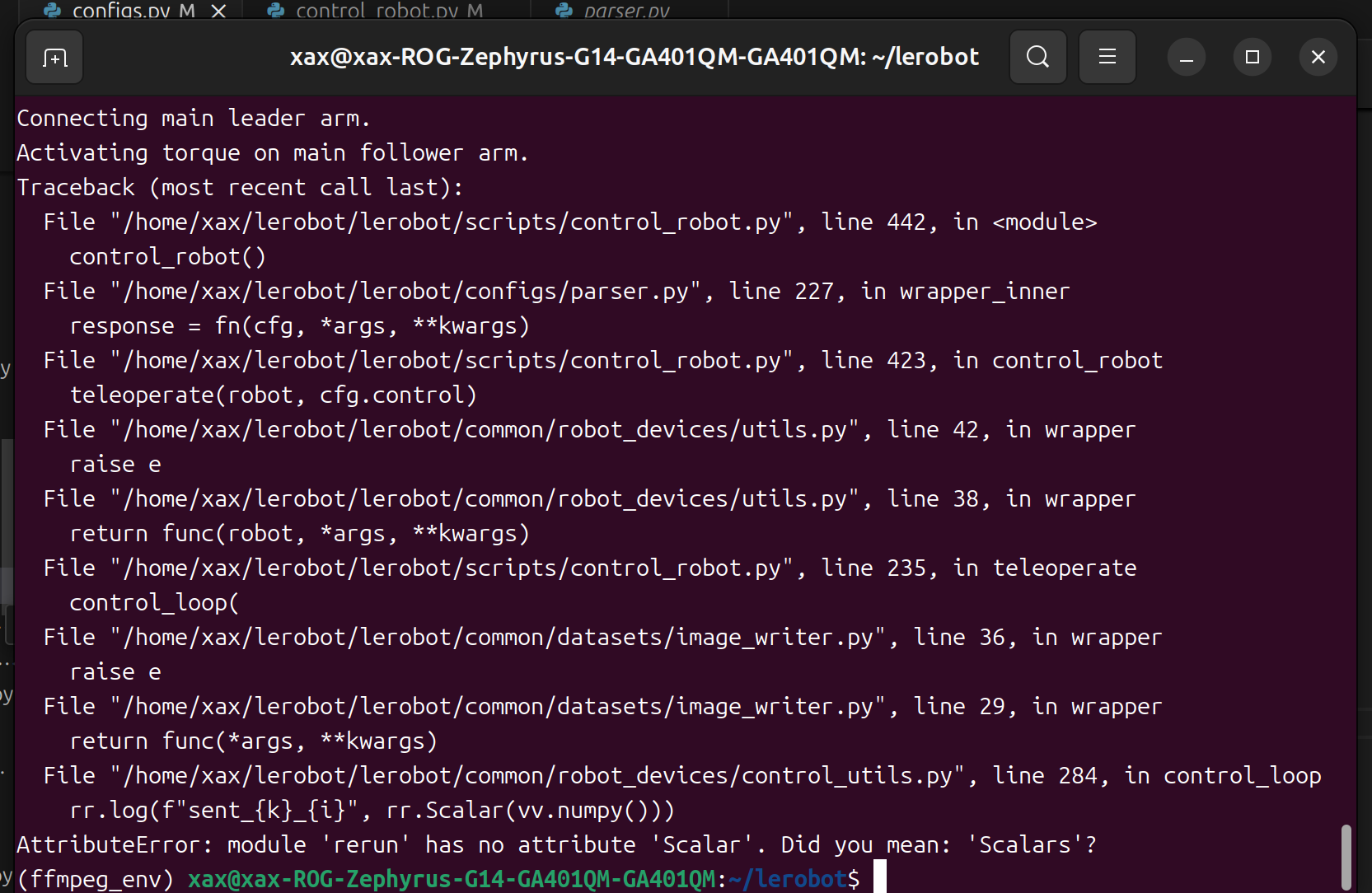
Puedes hacer un downgrade de la versión de rerun para resolver el problema.
pip3 install rerun-sdk==0.23
Registrar el conjunto de datos
- Si quieres guardar el conjunto de datos localmente, puedes ejecutarlo directamente:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=seeedstudio123/test \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black cube" \
--dataset.push_to_hub=false \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=30
Entre ellos, repo_id se puede modificar de forma personalizada, y push_to_hub=false. Finalmente, el conjunto de datos se guardará en el directorio ~/.cache/huggingface/lerobot de la carpeta de inicio, donde se creará la carpeta seeedstudio123/test mencionada anteriormente.
- Si quieres usar las funciones del hub de Hugging Face para subir tu conjunto de datos y no lo has hecho antes, asegúrate de haber iniciado sesión usando un token con permisos de escritura, que se puede generar desde los ajustes de Hugging Face:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential
Guarda el nombre de tu repositorio de Hugging Face en una variable para ejecutar estos comandos:
HF_USER=$(huggingface-cli whoami | head -n 1)
echo $HF_USER
Graba 5 episodios y sube tu conjunto de datos al hub:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=${HF_USER}/record-test \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black cube" \
--dataset.push_to_hub=true \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=30
Verás aparecer muchas líneas como esta:
INFO 2024-08-10 15:02:58 ol_robot.py:219 dt:33.34 (30.0hz) dtRlead: 5.06 (197.5hz) dtWfoll: 0.25 (3963.7hz) dtRfoll: 6.22 (160.7hz) dtRlaptop: 32.57 (30.7hz) dtRphone: 33.84 (29.5hz)
Función de grabación
La función record proporciona un conjunto de herramientas para capturar y gestionar datos durante el funcionamiento del robot.
1. Almacenamiento de datos
- Los datos se almacenan usando el formato
LeRobotDatasety se guardan en disco durante la grabación. - De forma predeterminada, el conjunto de datos se envía a tu página de Hugging Face después de la grabación.
- Para desactivar la subida, usa:
--dataset.push_to_hub=False
2. Puntos de control y reanudación
- Los puntos de control se crean automáticamente durante la grabación.
- Para reanudar después de una interrupción, vuelve a ejecutar el mismo comando con:
--resume=true
⚠️ Nota crítica: Al reanudar, establece --dataset.num_episodes en el número de episodios adicionales que se van a grabar (no en el número total de episodios objetivo del conjunto de datos).
- Para empezar a grabar desde cero, elimina manualmente el directorio del conjunto de datos.
3. Parámetros de grabación
Configura el flujo de grabación de datos usando argumentos de línea de comandos:
| Parámetro | Descripción | Predeterminado |
|---|---|---|
| --dataset.episode_time_s | Duración por episodio de datos (segundos) | 60 |
| --dataset.reset_time_s | Tiempo de reinicio del entorno después de cada episodio (segundos) | 60 |
| --dataset.num_episodes | Número total de episodios a grabar | 50 |
4. Controles de teclado durante la grabación
Controla el flujo de grabación de datos usando atajos de teclado:
| Tecla | Acción |
|---|---|
| → (Flecha derecha) | Detener anticipadamente el episodio actual/reiniciar; pasar al siguiente. |
| ← (Flecha izquierda) | Cancelar el episodio actual; volver a grabarlo. |
| ESC | Detener la sesión inmediatamente, codificar los vídeos y subir el conjunto de datos. |
Si el teclado no funciona, puede que necesites instalar otra versión de pynput.
pip install pynput==1.6.8
Consejos para recopilar datos
- Sugerencia de tarea: Agarra objetos en diferentes ubicaciones y colócalos en un contenedor.
- Escala: Graba ≥50 episodios (10 episodios por ubicación).
- Consistencia:
- Mantén las cámaras fijas.
- Mantén un comportamiento de agarre idéntico.
- Asegúrate de que los objetos manipulados sean visibles en las imágenes de las cámaras.
- Progresión:
- Comienza con agarres fiables antes de añadir variaciones (nuevas ubicaciones, técnicas, ajustes de cámara).
- Evita aumentar la complejidad demasiado rápido para prevenir fallos.
💡 Regla general: Deberías ser capaz de realizar la tarea tú mismo solo mirando las imágenes de la cámara.
Si quieres profundizar más en este tema importante, puedes consultar la entrada de blog que escribimos sobre qué hace que un conjunto de datos sea bueno.
Solución de problemas
Problema específico de Linux:
Si las teclas Flecha derecha/Flecha izquierda/ESC no responden durante la grabación:
- Verifica que la variable de entorno
$DISPLAYesté configurada (consulta las limitaciones de pynput).
Visualizar el conjunto de datos
Los códigos de SO100 y SO101 son compatibles. Los usuarios de SO100 pueden utilizar directamente los parámetros y el código de SO101 para la operación.
Si subiste tu conjunto de datos al hub con --control.push_to_hub=true, puedes visualizar tu conjunto de datos en línea copiando y pegando tu repo id proporcionado por:
echo ${HF_USER}/so101_test
Si no lo subiste con --dataset.push_to_hub=false, también puedes visualizarlo localmente con:
lerobot-dataset-viz \
--repo-id ${HF_USER}/so101_test \
Si lo subes con --dataset.push_to_hub=false, también puedes visualizarlo localmente con:
lerobot-dataset-viz \
--repo-id seeed_123/so101_test \
Aquí, seeed_123 es el nombre personalizado de repo_id definido al recopilar datos.
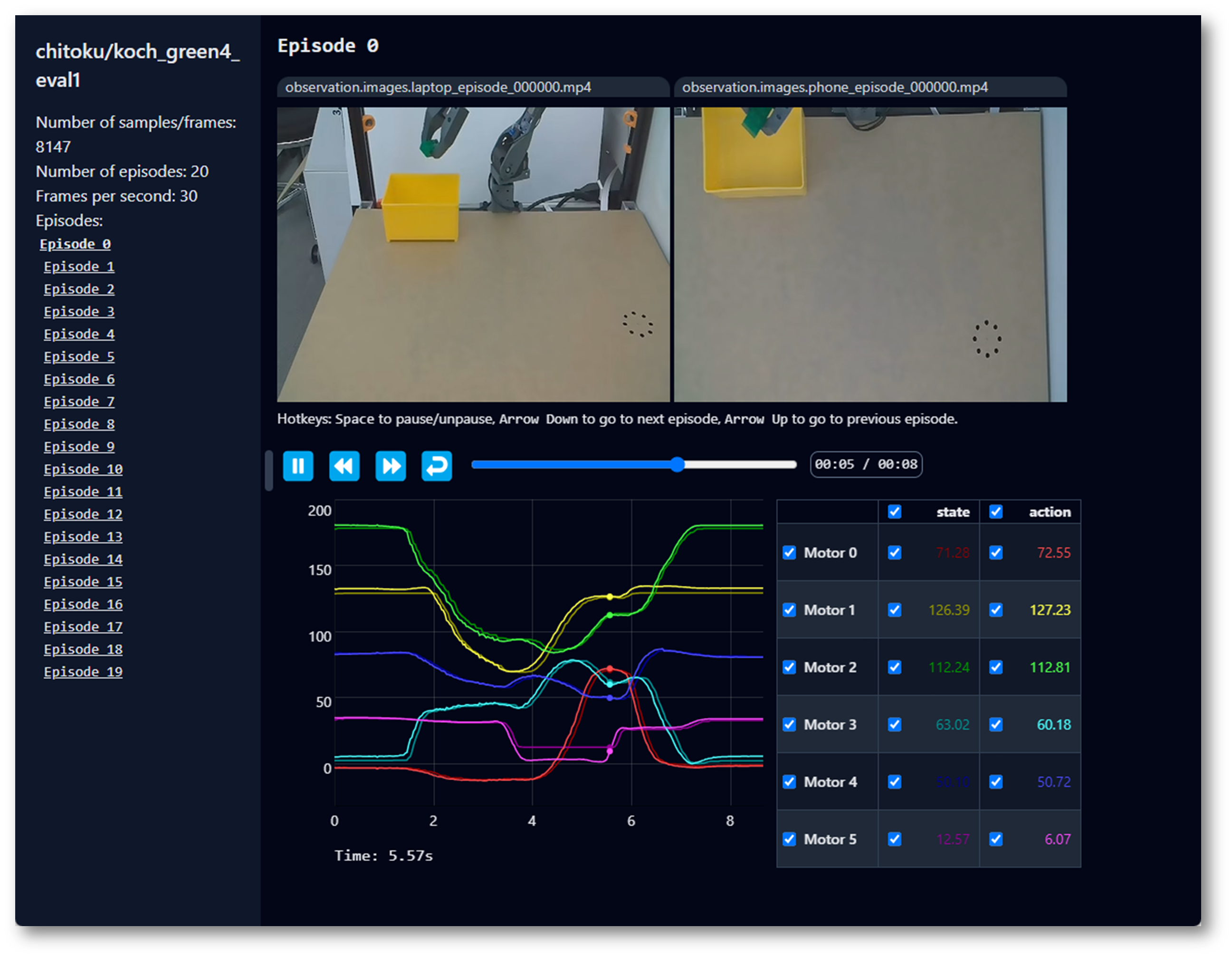
Reproducir un episodio
Los códigos de SO100 y SO101 son compatibles. Los usuarios de SO100 pueden utilizar directamente los parámetros y el código de SO101 para la operación.
Una función útil es replay, que te permite reproducir cualquier episodio que hayas grabado o episodios de cualquier conjunto de datos disponible. Esta función te ayuda a probar la repetibilidad de las acciones de tu robot y evaluar la transferibilidad entre robots del mismo modelo.
Puedes reproducir el primer episodio en tu robot con el siguiente comando o con el ejemplo de la API:
lerobot-replay \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--dataset.repo_id=${HF_USER}/record-test \
--dataset.episode=0
Tu robot debería reproducir movimientos similares a los que grabaste.
Entrenar y evaluar
ACT
Consulta ACT
Para entrenar una política para controlar tu robot, utiliza el script lerobot-train.
Entrenar
lerobot-train \
--dataset.repo_id=${HF_USER}/so101_test \
--policy.type=act \
--output_dir=outputs/train/act_so101_test \
--job_name=act_so101_test \
--policy.device=cuda \
--wandb.enable=false \
--steps=300000
Si quieres entrenar con un conjunto de datos local, asegúrate de que el repo_id coincida con el utilizado durante la recopilación de datos y añade --policy.push_to_hub=False.
lerobot-train \
--dataset.repo_id=seeedstudio123/test \
--policy.type=act \
--output_dir=outputs/train/act_so101_test \
--job_name=act_so101_test \
--policy.device=cuda \
--wandb.enable=false \
--policy.push_to_hub=false\
--steps=300000
Vamos a explicarlo:
- Especificación del conjunto de datos: Proporcionamos el conjunto de datos mediante el parámetro
--dataset.repo_id=${HF_USER}/so101_test. - Pasos de entrenamiento: Modificamos el número de pasos de entrenamiento usando
--steps=300000. El algoritmo usa por defecto 800000 pasos, y puedes ajustarlo en función de la dificultad de tu tarea y observando la pérdida durante el entrenamiento. - Tipo de política: Proporcionamos la política con
policy.type=act. Del mismo modo, puedes cambiar entre políticas como [act,diffusion,pi0,pi0fast,pi0fast,sac,smolvla], lo que cargará la configuración desdeconfiguration_act.py. Es importante destacar que esta política se adaptará automáticamente a los estados de los motores, las acciones de los motores y el número de cámaras de tu robot (por ejemplo,laptopyphone), ya que esta información ya está almacenada en tu conjunto de datos. - Selección de dispositivo: Proporcionamos
policy.device=cudaporque estamos entrenando en una GPU Nvidia, pero puedes usarpolicy.device=mpspara entrenar en Apple Silicon. - Herramienta de visualización: Proporcionamos
wandb.enable=truepara visualizar las gráficas de entrenamiento usando Weights and Biases. Esto es opcional, pero si lo utilizas, asegúrate de haber iniciado sesión ejecutandowandb login.
Evaluar
Los códigos SO100 y SO101 son compatibles. Los usuarios de SO100 pueden utilizar directamente los parámetros y el código de SO101 para la operación.
Puedes usar la función record de lerobot/record.py pero con un checkpoint de política como entrada. Por ejemplo, ejecuta este comando para registrar 10 episodios de evaluación:
lerobot-record \
--robot.type=so100_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ up: {type: opencv, index_or_path: /dev/video10, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: intelrealsense, serial_number_or_name: 233522074606, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=${HF_USER}/eval_so100 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=${HF_USER}/my_policy
como:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/train/act_so101_test/checkpoints/last/pretrained_model
-
El parámetro
--policy.pathindica la ruta al archivo de pesos de los resultados de tu entrenamiento de política (por ejemplo,outputs/train/act_so101_test/checkpoints/last/pretrained_model). Si subes el archivo de pesos del resultado del entrenamiento del modelo a Hub, también puedes usar el repositorio del modelo (por ejemplo,${HF_USER}/act_so100_test). -
El nombre del conjunto de datos
dataset.repo_idcomienza coneval_. Esta operación registrará por separado vídeos y datos durante la evaluación, que se guardarán en la carpeta que comienza coneval_, comoseeed/eval_test123. -
Si encuentras
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'durante la fase de evaluación, elimina primero la carpeta que comienza coneval_y luego ejecuta de nuevo el programa. -
Cuando te encuentres con
mean is infinity. You should either initialize with stats as an argument or use a pretrained model, ten en cuenta que palabras clave como front y side en el parámetro--robot.camerasdeben ser estrictamente coherentes con las utilizadas al recopilar el conjunto de datos.
SmolVLA
SmolVLA es el modelo base ligero de robótica de Hugging Face. Diseñado para un ajuste fino sencillo en conjuntos de datos de LeRobot, ¡ayuda a acelerar tu desarrollo!
Configura tu entorno
Instala las dependencias de SmolVLA ejecutando:
pip install -e ".[smolvla]"
Ajusta finamente SmolVLA con tus datos
Usa smolvla_base, nuestro modelo preentrenado de 450M, y ajústalo finamente con tus datos. Entrenar el modelo durante 20k pasos llevará aproximadamente ~4 horas en una sola GPU A100. Debes ajustar el número de pasos en función del rendimiento y de tu caso de uso.
Si no tienes un dispositivo GPU, puedes entrenar usando nuestro cuaderno en Google Colab.
Pasa tu conjunto de datos al script de entrenamiento usando --dataset.repo_id. Si quieres probar tu instalación, ejecuta el siguiente comando donde usamos uno de los conjuntos de datos que recopilamos para el artículo de SmolVLA.
lerobot-train \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=${HF_USER}/mydataset \
--batch_size=64 \
--steps=20000 \
--output_dir=outputs/train/my_smolvla \
--job_name=my_smolvla_training \
--policy.device=cuda \
--wandb.enable=true
Puedes empezar con un tamaño de lote pequeño e incrementarlo gradualmente, si la GPU lo permite, siempre que los tiempos de carga sigan siendo cortos.
El ajuste fino es un arte. Para una visión completa de las opciones de ajuste fino, ejecuta
lerobot-train --help
Evalúa el modelo ajustado finamente y ejecútalo en tiempo real
De forma similar a cuando se graba un episodio, se recomienda que hayas iniciado sesión en HuggingFace Hub. Puedes seguir los pasos correspondientes: Grabar un conjunto de datos. Una vez que hayas iniciado sesión, puedes ejecutar inferencia en tu configuración haciendo:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \ # <- Use your port
--robot.id=my_blue_follower_arm \ # <- Use your robot id
--robot.cameras="{ front: {type: opencv, index_or_path: 8, width: 640, height: 480, fps: 30, fourcc: "MJPG"}}" \ # <- Use your cameras
--dataset.single_task="Grasp a lego block and put it in the bin." \ # <- Use the same task description you used in your dataset recording
--dataset.repo_id=${HF_USER}/eval_DATASET_NAME_test \ # <- This will be the dataset name on HF Hub
--dataset.episode_time_s=50 \
--dataset.num_episodes=10 \
# <- Teleop optional if you want to teleoperate in between episodes \
# --teleop.type=so100_leader \
# --teleop.port=/dev/ttyACM0 \
# --teleop.id=my_red_leader_arm \
--policy.path=HF_USER/FINETUNE_MODEL_NAME # <- Use your fine-tuned model
Según tu configuración de evaluación, puedes configurar la duración y el número de episodios que se van a registrar para tu conjunto de evaluación.
LIBERO
LIBERO es un benchmark diseñado para estudiar el aprendizaje continuo de robots. La idea es que los robots no solo se preentrenarán una vez en una fábrica, sino que necesitarán seguir aprendiendo y adaptándose junto con sus usuarios humanos a lo largo del tiempo. Esta adaptación continua se denomina aprendizaje continuo en la toma de decisiones (LLDM), y es un paso clave hacia la construcción de robots que se conviertan en ayudantes verdaderamente personalizados.
Evaluación con LIBERO
En LeRobot, portamos LIBERO a nuestro framework y lo usamos principalmente para evaluar SmolVLA, nuestro modelo ligero de Visión-Lenguaje-Acción.
LIBERO es ahora parte de nuestra simulación con evaluación múltiple, lo que significa que puedes evaluar tus políticas en un único conjunto de tareas o en múltiples conjuntos a la vez con solo una bandera.
Para instalar LIBERO, después de seguir las instrucciones oficiales de LeRobot, simplemente ejecuta: pip install -e ".[libero]"
Evaluación de un solo conjunto
Evalúa una política en un conjunto LIBERO:
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_object \
--eval.batch_size=2 \
--eval.n_episodes=3
--env.taskselecciona el conjunto (libero_object,libero_spatial, etc.).--eval.batch_sizecontrola cuántos entornos se ejecutan en paralelo.--eval.n_episodesestablece cuántos episodios se ejecutan en total.
Evaluación de múltiples conjuntos
Evalúa una política en múltiples conjuntos a la vez:
lerobot-eval \
--policy.path="your-policy-id" \
--env.type=libero \
--env.task=libero_object,libero_spatial \
--eval.batch_size=1 \
--eval.n_episodes=2
- Pasa una lista separada por comas a
--env.taskpara la evaluación de múltiples conjuntos.
Ejemplo de comando de entrenamiento
lerobot-train \
--policy.type=smolvla \
--policy.repo_id=${HF_USER}/libero-test \
--dataset.repo_id=HuggingFaceVLA/libero \
--env.type=libero \
--env.task=libero_10 \
--output_dir=./outputs/ \
--steps=100000 \
--batch_size=4 \
--eval.batch_size=1 \
--eval.n_episodes=1 \
--eval_freq=1000 \
Nota sobre el renderizado
LeRobot utiliza MuJoCo para la simulación. Debes configurar el backend de renderizado antes del entrenamiento o la evaluación:
export MUJOCO_GL=egl→ para servidores sin pantalla (por ejemplo, HPC, nube)
Pi0
Consulta Pi0
pip install -e ".[pi]"
Entrenar
lerobot-train \
--policy.type=pi0 \
--dataset.repo_id=seeed/eval_test123 \
--job_name=pi0_training \
--output_dir=outputs/pi0_training \
--policy.pretrained_path=lerobot/pi0_base \
--policy.compile_model=true \
--policy.gradient_checkpointing=true \
--policy.dtype=bfloat16 \
--steps=20000 \
--policy.device=cuda \
--batch_size=32 \
--wandb.enable=false
Evaluar
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30,fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/pi0_training/checkpoints/last/pretrained_model
Pi0.5
Consulta Pi0.5
pip install -e ".[pi]"
Entrenar
lerobot-train \
--dataset.repo_id=seeed/eval_test123 \
--policy.type=pi05 \
--output_dir=outputs/pi05_training \
--job_name=pi05_training \
--policy.pretrained_path=lerobot/pi05_base \
--policy.compile_model=true \
--policy.gradient_checkpointing=true \
--wandb.enable=false \
--policy.dtype=bfloat16 \
--steps=3000 \
--policy.device=cuda \
--batch_size=32
Evaluar
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30, fourcc: "MJPG"}, side: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30,fourcc: "MJPG"}}" \
--robot.id=my_awesome_follower_arm \
--display_data=false \
--dataset.repo_id=seeed/eval_test123 \
--dataset.single_task="Put lego brick into the transparent box" \
--policy.path=outputs/pi05_training/checkpoints/last/pretrained_model
GR00T N1.5
Consulta la documentación oficial: GR00T N1.5.
GR00T N1.5 es un modelo base abierto de NVIDIA para un razonamiento robótico y aprendizaje de habilidades más generales. Es un modelo multi-cuerpo: puede tomar entradas multimodales como lenguaje e imágenes, y ejecutar tareas de manipulación en diferentes entornos.
En LeRobot, la clave es establecer el tipo de política a --policy.type=groot. Ten en cuenta que GR00T N1.5 tiene requisitos de entorno más altos (depende de FlashAttention y requiere una GPU CUDA). Se recomienda primero hacer que ACT / Pi0 funcionen de extremo a extremo y luego probar GR00T.
Instalación (importante)
Según la documentación oficial actual, GR00T N1.5 requiere flash-attn y solo puede utilizarse en hardware compatible con CUDA.
Orden recomendado:
- Prepara primero tu entorno base (Python, CUDA, controladores, etc.). No instales aún
lerobot. - Instala PyTorch para tu versión de CUDA (las diferentes versiones de CUDA pueden requerir un
--index-urldistinto; sigue la página de instalación de PyTorch).
pip install "torch>=2.2.1,<2.8.0" "torchvision>=0.21.0,<0.23.0"
- Instala las dependencias de compilación para
flash-attn, luego instalaflash-attnen sí.
pip install ninja "packaging>=24.2,<26.0"
pip install "flash-attn>=2.5.9,<3.0.0" --no-build-isolation
python -c "import flash_attn; print(f'Flash Attention {flash_attn.__version__} imported successfully')"
- Instala LeRobot con las dependencias opcionales de
groot(lerobot[groot]).
pip install "lerobot[groot]"
Si la instalación de flash-attn falla, normalmente se debe a (1) una incompatibilidad entre PyTorch y CUDA, (2) dependencias de compilación que faltan o (3) un entorno demasiado nuevo/demasiado antiguo. Primero contrasta la documentación oficial de GR00T y las instrucciones de instalación de PyTorch.
Entrenamiento (fine-tuning)
La documentación oficial proporciona un ejemplo multi-GPU con accelerate launch --multi_gpu .... Si solo tienes una GPU, aún puedes empezar haciendo que funcione primero una ejecución de un solo proceso (la compatibilidad/argumentos exactos dependen de la documentación oficial).
accelerate launch \
--multi_gpu \
--num_processes=$NUM_GPUS \
$(which lerobot-train) \
--output_dir=$OUTPUT_DIR \
--save_checkpoint=true \
--batch_size=$BATCH_SIZE \
--steps=$NUM_STEPS \
--save_freq=$SAVE_FREQ \
--log_freq=$LOG_FREQ \
--policy.push_to_hub=true \
--policy.type=groot \
--policy.repo_id=$REPO_ID \
--policy.tune_diffusion_model=false \
--dataset.repo_id=$DATASET_ID \
--wandb.enable=true \
--wandb.disable_artifact=true \
--job_name=$JOB_NAME
Validación en el robot (evaluación)
Después del entrenamiento, puedes evaluar y registrar repeticiones con lerobot-record como con otras políticas. La documentación oficial incluye un ejemplo bimanual; los usuarios de SO101 de un solo brazo no necesitan argumentos del tipo left_arm_port/right_arm_port.
lerobot-record \
--robot.type=bi_so_follower \
--robot.left_arm_port=/dev/ttyACM1 \
--robot.right_arm_port=/dev/ttyACM0 \
--robot.id=bimanual_follower \
--robot.cameras='{ right: {"type": "opencv", "index_or_path": 0, "width": 640, "height": 480, "fps": 30}, left: {"type": "opencv", "index_or_path": 2, "width": 640, "height": 480, "fps": 30}, top: {"type": "opencv", "index_or_path": 4, "width": 640, "height": 480, "fps": 30} }' \
--display_data=true \
--dataset.repo_id=${HF_USER}/eval_groot_bimanual \
--dataset.num_episodes=10 \
--dataset.single_task="Grab and handover the red cube to the other arm" \
--policy.path=${HF_USER}/groot-bimanual \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=10
Licencia: Apache 2.0 (igual que el repositorio original de GR00T).
(Opcional) Fine-tuning eficiente en parámetros (PEFT)
PEFT (Parameter-Efficient Fine-Tuning) es una familia de métodos y herramientas que ayudan a que un modelo grande preentrenado se adapte a nuevas tareas sin actualizar todos los parámetros. Para políticas LeRobot preentrenadas (por ejemplo, SmolVLA, Pi0), a menudo puedes entrenar solo un pequeño conjunto de parámetros “adaptadores” (por ejemplo, LoRA) para reducir el uso de VRAM y el coste de entrenamiento, manteniendo un rendimiento cercano al del fine-tuning completo.
Instalar
Después de instalar LeRobot con las dependencias opcionales de peft, puedes usar argumentos relacionados con PEFT en el entrenamiento.
pip install -e ".[peft]"
pip install "lerobot[peft]"
Más conceptos y métodos: 🤗 Documentación de PEFT.
Ejemplo: hacer fine-tuning de SmolVLA con LoRA (subtarea LIBERO libero_spatial)
Este ejemplo hace fine-tuning de lerobot/smolvla_base con LoRA en el conjunto de datos HuggingFaceVLA/libero. Los nombres de los argumentos dependen de la versión de LeRobot; se recomienda también consultar lerobot-train --help.
lerobot-train \
--policy.path=lerobot/smolvla_base \
--policy.repo_id=${HF_USER}/my_libero_smolvla_peft \
--dataset.repo_id=HuggingFaceVLA/libero \
--env.type=libero \
--env.task=libero_spatial \
--output_dir=outputs/train/my_libero_smolvla_peft \
--job_name=my_libero_smolvla_peft \
--policy.device=cuda \
--steps=10000 \
--batch_size=32 \
--optimizer.lr=1e-3 \
--peft.method_type=LORA \
--peft.r=64
Argumentos clave de PEFT
--peft.method_type: Selecciona el método PEFT. LoRA (Low-Rank Adapter) es una de las opciones más comunes.--peft.r: Rango de LoRA. Un rango más alto suele aumentar la capacidad, pero también incrementa el número de parámetros y el uso de VRAM.
Elegir en qué capas/módulos inyectar LoRA (opcional)
Por defecto, PEFT suele inyectar LoRA en las capas de proyección más importantes (por ejemplo, q_proj, v_proj de atención) y también puede cubrir proyecciones de estado/acción. Si quieres personalizarlo, usa --peft.target_modules.
Patrones comunes:
- Proporcionar una lista de sufijos de nombres de módulo (ejemplo):
--peft.target_modules="['q_proj', 'v_proj']"
- Proporcionar una expresión regular (ejemplo; ajústala a los nombres de módulo reales del modelo):
--peft.target_modules='(model\\.vlm_with_expert\\.lm_expert\\..*\\.(down|gate|up)_proj|.*\\.(state_proj|action_in_proj|action_out_proj|action_time_mlp_in|action_time_mlp_out))'
Entrenar completamente algunos módulos (opcional)
Si quieres que algunos módulos se entrenen completamente (en lugar de solo inyectar LoRA), usa --peft.full_training_modules. Por ejemplo, entrenar completamente solo state_proj:
--peft.full_training_modules="['state_proj']"
Sugerencia de tasa de aprendizaje (regla general)
Las tasas de aprendizaje de LoRA suelen ser ~10× más altas que en el fine-tuning completo. Por ejemplo, si el fine-tuning completo usa comúnmente 1e-4, LoRA puede empezar en 1e-3. Si utilizas un programador de tasa de aprendizaje, la tasa de aprendizaje final suele estar alrededor de 1e-4 como referencia.
(Opcional) Entrenamiento multi-GPU con Accelerate
Pasos de entrenamiento
Método 1: usar flags de la CLI.
- Instala
accelerateen tu entorno delerobot.
pip install accelerate
- Lanza el entrenamiento multi-GPU con
accelerate launchy las flags--multi_gpuy--num_processes.
accelerate launch \
--multi_gpu \
--num_processes=2 \
$(which lerobot-train) \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=act \
--policy.repo_id=${HF_USER}/my_trained_policy \
--output_dir=outputs/train/act_multi_gpu \
--job_name=act_multi_gpu \
--wandb.enable=true
Flags clave de accelerate:
--multi_gpu: Habilita el entrenamiento multi-GPU.--num_processes: Número de GPUs a usar (normalmente igual al número de GPUs disponibles en la máquina).--mixed_precision=fp16: Usa precisión mixta fp16 (si tu hardware lo soporta, también puedes usar bf16).
Ten en cuenta: bf16 requiere compatibilidad de hardware y no está disponible en todas las GPU.
| Precisión | Compatibilidad de hardware |
|---|---|
| fp16 | Compatible con casi todas las GPU de NVIDIA |
| bf16 | Solo compatible con algunas GPU más recientes (Ampere y posteriores) |
Si tu GPU no es compatible con bf16, elige fp16 en la configuración de Accelerate o especifica fp16 explícitamente.
Método 2: Usa un archivo de configuración de accelerate (opcional).
Si entrenas con múltiples GPU con frecuencia, puedes guardar la configuración para evitar escribir repetidamente las mismas banderas.
accelerate config guarda tu configuración de hardware (número de GPU, precisión mixta, etc.) en un archivo de configuración, de modo que no tengas que volver a introducir esas opciones cuando ejecutes accelerate launch más tarde. No cambia la lógica de entrenamiento de LeRobot; solo reduce las entradas repetitivas en la CLI.
Si solo usas varias GPU ocasionalmente (o es tu primera vez), omitir esto está perfectamente bien.
En la configuración interactiva, para el escenario común de “una sola máquina + múltiples GPU”, las opciones típicas son:
- Entorno de cómputo: Esta máquina
- Número de máquinas: 1
- Número de procesos: Número de GPU que quieres usar
- IDs de GPU a usar: pulsa Enter (usar todas las GPU)
- Precisión mixta: se prefiere fp16; elige bf16 solo si sabes que tu GPU lo admite
accelerate config
accelerate launch $(which lerobot-train) \
--dataset.repo_id=${HF_USER}/my_dataset \
--policy.type=act \
--policy.repo_id=${HF_USER}/my_trained_policy \
--output_dir=outputs/train/act_multi_gpu \
--job_name=act_multi_gpu \
--wandb.enable=true
Cómo el uso de múltiples GPU afecta a los hiperparámetros (y cómo ajustarlos)
LeRobot no ajusta automáticamente la tasa de aprendizaje ni los pasos de entrenamiento en función del número de GPU, para evitar cambiar silenciosamente el comportamiento del entrenamiento. Esto es diferente de algunos otros frameworks de entrenamiento distribuido.
Si quieres ajustar los hiperparámetros para múltiples GPU, un enfoque común es:
- Pasos: el tamaño de lote efectivo aumenta (batch_size × num_gpus), por lo que puedes reducir los pasos aproximadamente de forma proporcional a
1 / num_gpuspara mantener un número total similar de muestras vistas.
accelerate launch --num_processes=2 $(which lerobot-train) \
--batch_size=8 \
--steps=50000 \
--dataset.repo_id=lerobot/pusht \
--policy=act
- Tasa de aprendizaje: dado que cada paso usa más muestras, a menudo puedes escalar la tasa de aprendizaje linealmente con el número de GPU: new_lr = single_gpu_lr × num_gpus
accelerate launch --num_processes=2 $(which lerobot-train) \
--optimizer.lr=2e-4 \
--dataset.repo_id=lerobot/pusht \
--policy=act
Estas no son reglas estrictas; son heurísticas comunes. Si no estás seguro, también puedes mantener la tasa de aprendizaje y los pasos sin cambios siempre que el entrenamiento siga siendo estable.
Para configuración avanzada y resolución de problemas, consulta la documentación de Accelerate: Accelerate.
(Opcional) Inferencia asíncrona
Cuando la inferencia asíncrona no está habilitada, el flujo de control de LeRobot puede entenderse como inferencia secuencial / síncrona convencional: la política primero predice un segmento de acciones, luego ejecuta ese segmento y solo después espera la siguiente predicción.
Para modelos más grandes, esto puede hacer que el robot haga una pausa notable mientras espera el siguiente bloque de acciones.
El objetivo de la inferencia asíncrona es permitir que el robot ejecute el bloque de acciones actual mientras calcula por adelantado el siguiente, reduciendo así el tiempo de inactividad y mejorando la capacidad de respuesta.
La inferencia asíncrona es aplicable a las políticas compatibles con LeRobot, incluidas las políticas de acciones basadas en bloques como ACT, OpenVLA, Pi0 y SmolVLA.
Dado que la inferencia está desacoplada del control real, la inferencia asíncrona también ayuda a aprovechar máquinas con mayores recursos de cómputo para realizar la inferencia del robot.
Puedes leer más sobre inferencia asíncrona en el blog de Hugging Face
Primero presentemos algunos conceptos básicos:
-
Cliente: se conecta al brazo robótico y a las cámaras, recopila datos de observación (como imágenes y poses del robot), envía estas observaciones al servidor y recibe los bloques de acciones devueltos por el servidor y los ejecuta en orden.
-
Servidor: el dispositivo que proporciona recursos de cómputo. Recibe datos de la cámara y del brazo robótico, realiza la inferencia (es decir, el cómputo) para producir bloques de acciones y los envía de vuelta al cliente. Puede ser el mismo dispositivo conectado al brazo robótico y a las cámaras, otro ordenador en la misma red local o un servidor en la nube alquilado en Internet.
-
Bloque de acciones: una secuencia de comandos de acción del brazo robótico obtenida mediante la inferencia de la política en el lado del servidor.
Tres escenarios de despliegue para la inferencia asíncrona
- Despliegue en una sola máquina
El robot, las cámaras, el cliente y el servidor están todos en el mismo dispositivo.
Este es el caso más sencillo: el servidor puede escuchar en 127.0.0.1 y el cliente también puede conectarse a 127.0.0.1:port. El ejemplo de comando en la documentación oficial es para este escenario.
- Despliegue en LAN
El robot y las cámaras están conectados a un dispositivo ligero, mientras que el servidor de políticas se ejecuta en otra máquina de alto cómputo en la misma red local.
En este caso, el servidor debe escuchar en una dirección accesible por otras máquinas, y el cliente también debe conectarse a la IP de la LAN del servidor, en lugar de 127.0.0.1.
- Despliegue entre redes / en la nube
El servidor de políticas se ejecuta en un host en la nube accesible públicamente, y el cliente se conecta a él a través de Internet pública.
Este enfoque puede aprovechar la GPU más potente del host en la nube. Cuando las condiciones de red son buenas, el tiempo de ida y vuelta de la red (latencia de red) a veces puede ser relativamente pequeño en comparación con el tiempo de inferencia, pero esto depende de tu entorno de red real.
Nota de seguridad: la canalización de inferencia asíncrona de LeRobot tiene un riesgo relacionado con gRPC sin autenticación + deserialización con pickle. Si hay información o servicios importantes en el servidor, no se recomienda exponer el servicio directamente a Internet en un despliegue público. Un enfoque más seguro es usar VPN o túneles SSH, o al menos restringir las IP de origen permitidas en el grupo de seguridad a la IP pública de tu propio cliente.
Introducción al despliegue de inferencia asíncrona
Paso 1: Configuración del entorno
Primero, usa pip para instalar las dependencias adicionales necesarias para la inferencia asíncrona. Tanto el cliente como el servidor deben tener lerobot instalado junto con las dependencias extra:
pip install -e ".[async]"
Paso 2: Configuración y comprobaciones de red
- Problemas de proxy
Si tu terminal actual está configurado para usar un proxy y la conexión se comporta de forma anómala, puedes desactivar temporalmente las variables de entorno del proxy:
unset http_proxy https_proxy ftp_proxy all_proxy HTTP_PROXY HTTPS_PROXY FTP_PROXY ALL_PROXY
Nota: el comando anterior solo afecta a la sesión de terminal actual. Si abres otra ventana de terminal, necesitas ejecutarlo de nuevo.
- Abrir el puerto en el firewall / grupo de seguridad
Despliegue en una sola máquina: normalmente se puede omitir.
Despliegue en LAN: necesitas abrir el puerto de escucha en el lado del servidor.
Ejemplo para abrir el puerto de escucha en una configuración de LAN (ejecutar en el lado del servidor):
sudo ufw allow 8080/tcp
Despliegue en la nube: necesitas abrir este puerto en el grupo de seguridad del servidor en la nube, y se recomienda restringir las IP de origen tanto como sea posible.
Si estás ejecutando en un servidor en la nube:
Abre el puerto 8080 en el grupo de seguridad de la consola de gestión del servidor, o usa otro puerto que ya esté abierto. Las diferentes plataformas de servicios en la nube manejan esto de manera diferente; consulta la documentación de tu proveedor de nube.
- Confirmar la dirección IP
Este paso se puede omitir para el despliegue en una sola máquina (la dirección IP para una sola máquina siempre es 127.0.0.1).
Si se trata de un despliegue en LAN:
Necesitas confirmar y recordar la dirección IP de la LAN del lado del servidor. Cuando el cliente se conecte, lo que debe rellenarse es la IP de la LAN de la máquina que ejecuta policy_server, no la IP propia del cliente.
Linux / Jetson / Raspberry Pi:
hostname -I
Si se muestran varias direcciones, generalmente elige la que corresponde a la interfaz de red de la LAN actual, por ejemplo 192.168.x.x.
También puedes usar:
ip addr
para ver el campo inet bajo la interfaz de red actualmente conectada.
Windows:
ipconfig
Busca un campo como Dirección IPv4 . . . . . . . . . . . : 192.168.14.140; esa es la dirección IP de la LAN de esa máquina.
macOS:
ifconfig
Busca el campo inet correspondiente a la interfaz de red actualmente conectada; esa es la dirección IP de la LAN.
Necesitamos recordar la dirección IP de la LAN del lado del servidor. Usaremos <LAN IP address> para referirnos a ella.
Si se trata de un despliegue en un servidor en la nube:
Busca la IP pública en el panel de control del servidor. Normalmente se llama de una de las siguientes maneras:
Public IPv4
External IP
Public IP address
EIP
Public IP
Necesitamos recordar la dirección IP pública. Usaremos<server public IP>para referirnos a ella.
- Prueba de conexión
Despliegue en una sola máquina: este paso se puede omitir
Despliegue en LAN / nube: se recomienda probar desde el lado del cliente si el puerto del servidor es accesible. Los ejemplos de prueba son los siguientes:
Ejemplo de LAN: ejecutar en el lado del cliente
nc -vz <LAN IP address> 8080
Ejemplo en la nube: ejecutar en el lado del cliente
nc -vz <server public IP> 8080
Paso 3: Iniciar el servicio
Escenario A: Despliegue en una sola máquina
Inicia el servicio local en una terminal:
python -m lerobot.async_inference.policy_server \
--host=127.0.0.1 \
--port=8080
Después de que se inicie correctamente, debes mantener esta terminal abierta. Necesitarás abrir una nueva terminal para ejecutar otros comandos.
Escenario B: Despliegue en LAN
Ejecutar en el lado del servidor:
python -m lerobot.async_inference.policy_server \
--host=0.0.0.0 \
--port=8080
En este caso, cuando el cliente se conecta, --server_address debe ser la dirección IP de la LAN del servidor, es decir, <LAN IP address>:8080.
Escenario C: Implementación en servidor en la nube
Ejecutar en el lado del servidor:
python -m lerobot.async_inference.policy_server \
--host=0.0.0.0 \
--port=8080
En este caso, cuando el cliente se conecta, --server_address debe ser la dirección IP pública del servidor, es decir, <server public IP>:8080.
Paso 4: Elegir parámetros de inferencia
Ejecutar en el lado del cliente:
python -m lerobot.async_inference.robot_client \
--server_address=<ip address>:8080 \
--robot.type=so100_follower \
--robot.port=/dev/tty.usbmodem585A0076841 \
--robot.id=follower_so100 \
--robot.cameras="{ laptop: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}, phone: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \
--task="dummy" \
--policy_type=your_policy_type \
--pretrained_name_or_path=user/model \
--policy_device=cuda \
--actions_per_chunk=50 \
--chunk_size_threshold=0.5 \
--aggregate_fn_name=weighted_average \
--debug_visualize_queue_size=True
Explicación de parámetros:
--server_address
Especifica la dirección y el puerto del servidor de políticas. <ip address> debe sustituirse por 127.0.0.1 (máquina local), <LAN IP address> (LAN), o <server public IP> (servidor en la nube).
--robot.type, --robot.port, --robot.id, --robot.cameras
Parámetros del dispositivo de hardware. Deben mantenerse coherentes con los parámetros usados durante la recopilación del conjunto de datos.
--task
La descripción de la tarea. Las políticas de visión y lenguaje como SmolVLA pueden determinar el objetivo de la acción basándose en el texto de la tarea.
--policy_type
Sustituye esto por el nombre específico de la política, por ejemplo:
-
smolvla
-
act
-
--pretrained_name_or_path
Este valor debe sustituirse por la ruta del modelo en el lado del servidor, o una ruta de modelo en Hugging Face.
--policy_device
Especifica el dispositivo de inferencia utilizado en el lado del servidor.
Puede ser cuda, mps o cpu.
--actions_per_chunk=50
Especifica cuántas acciones se generan en cada inferencia.
Cuanto mayor sea este valor:
Ventaja: el búfer de acciones es más abundante, por lo que es menos probable que se agote Desventaja: el horizonte de predicción es más largo, por lo que el error de control puede acumularse de forma más notable
--chunk_size_threshold=0.5
Especifica cuándo solicitar el siguiente bloque de acciones al servidor.
Este es un umbral, normalmente en el rango de 0 a 1.
Se puede entender como: cuando la proporción restante de la cola de acciones actual cae por debajo de este umbral, el cliente enviará por adelantado una nueva observación y solicitará el siguiente bloque de acciones.
Configurar aquí el valor 0.5 significa:
cuando el bloque de acciones actual se ha consumido aproximadamente a la mitad
el cliente comienza a solicitar el siguiente bloque de acciones
Cuanto mayor sea este valor, con más frecuencia se enviarán solicitudes y más receptivo será el sistema, pero también aumentará la carga en el servidor.
Cuanto menor sea este valor, más se acercará el comportamiento a la inferencia síncrona.
--aggregate_fn_name=weighted_average
Especifica el método de agregación para intervalos de acciones superpuestos.
En la inferencia asíncrona, cuando el bloque de acciones antiguo aún no se ha ejecutado por completo, es posible que el nuevo bloque de acciones ya haya llegado.
En ese caso, los dos bloques se superponen en parte del intervalo de tiempo, y se necesita una función de agregación para combinarlos en la acción final ejecutada.
El significado de weighted_average es:
usar un promedio ponderado para fusionar la parte superpuesta.
Esto normalmente hace que el cambio de acciones sea más suave y reduce los cambios bruscos.
--debug_visualize_queue_size=True
Indica si se visualiza el tamaño de la cola de acciones en tiempo de ejecución.
Cuando está activado, te permite ver de forma más directa si la cola toca el fondo con frecuencia, lo que te ayuda a ajustar actions_per_chunk y chunk_size_threshold.
Paso 5: Ajustar parámetros según el comportamiento del robot
En la inferencia asíncrona, hay dos parámetros adicionales que necesitan ajuste y que no existen en la inferencia síncrona:
Parámetro Valor inicial sugerido Descripción
actions_per_chunk 50 Cuántas acciones genera la política de una sola vez. Valores típicos: 10–50.
chunk_size_threshold 0.5 Cuando la proporción restante de la cola de acciones es ≤ chunk_size_threshold, el cliente envía una nueva solicitud de bloque de acciones. El rango de valores es [0, 1].
Cuando --debug_visualize_queue_size=True, el cambio en el tamaño de la cola de acciones se representará gráficamente en tiempo de ejecución.
Lo que la inferencia asíncrona necesita equilibrar es: la velocidad a la que el servidor genera bloques de acciones debe ser mayor o igual que la velocidad a la que el cliente consume bloques de acciones. De lo contrario, la cola de acciones se vaciará y el robot comenzará a tartamudear de nuevo (esto puede verse como la curva tocando el fondo en la visualización de la cola).
La velocidad a la que el servidor genera bloques de acciones se ve afectada por factores como el tamaño del modelo, el tipo de dispositivo, la VRAM / memoria y la potencia de cálculo de la GPU.
La velocidad a la que el cliente consume bloques de acciones se ve afectada por los fps de ejecución configurados.
Si la cola se vacía con frecuencia, necesitas aumentar actions_per_chunk, aumentar chunk_size_threshold o reducir los fps.
Si la curva de la cola fluctúa con frecuencia pero las acciones restantes en la cola siempre son suficientes, puedes disminuir chunk_size_threshold de forma adecuada.
En general:
el rango empírico de actions_per_chunk es 10–50
el rango empírico de chunk_size_threshold es 0.5–0.7; al ajustar, se recomienda comenzar desde 0.5 e incrementarlo gradualmente
Si encuentras el siguiente error:
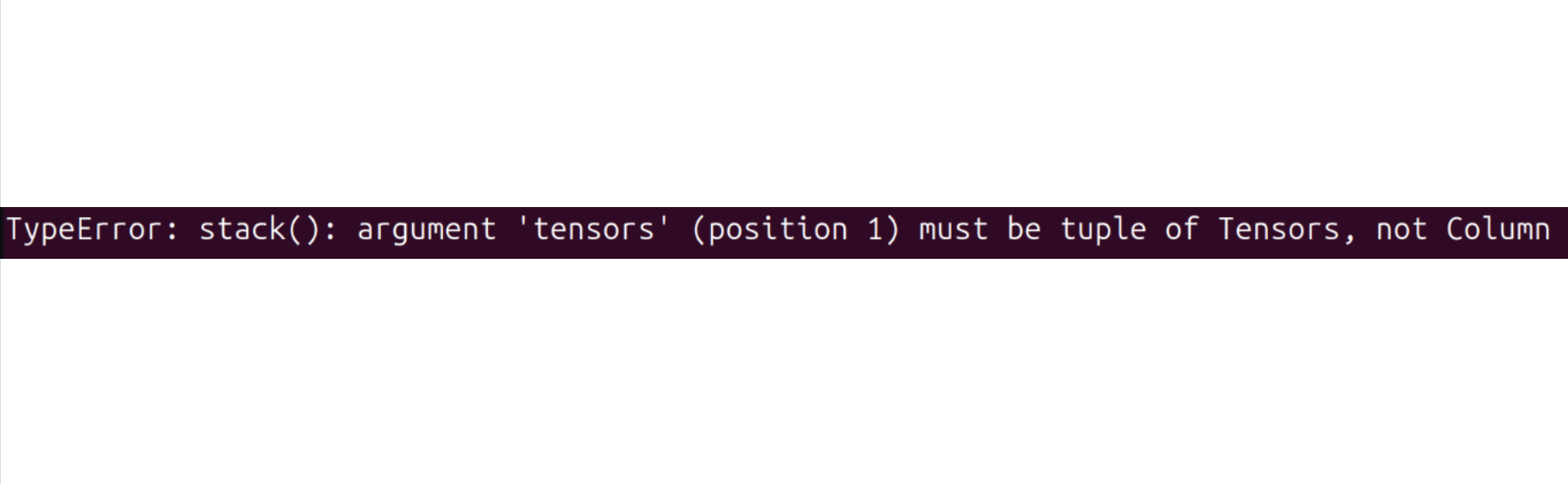
Intenta ejecutar el siguiente comando para resolverlo:
pip install datasets==2.19
El entrenamiento debería tardar varias horas. Encontrarás checkpoints en outputs/train/act_so100_test/checkpoints.
Para reanudar el entrenamiento desde un checkpoint, a continuación se muestra un comando de ejemplo para reanudar desde el checkpoint last de la política act_so101_test:
lerobot-train \
--config_path=outputs/train/act_so101_test/checkpoints/last/pretrained_model/train_config.json \
--resume=true
Subir checkpoints de la política
Una vez finalizado el entrenamiento, sube el último checkpoint con:
huggingface-cli upload ${HF_USER}/act_so101_test \
outputs/train/act_so101_test/checkpoints/last/pretrained_model
También puedes subir checkpoints intermedios con:
CKPT=010000
huggingface-cli upload ${HF_USER}/act_so101_test${CKPT} \
outputs/train/act_so101_test/checkpoints/${CKPT}/pretrained_model
Preguntas frecuentes (FAQ)
-
Si estás siguiendo esta documentación/tutorial, por favor haz git clone del repositorio de GitHub recomendado
https://github.com/Seeed-Projects/lerobot.git. El repositorio recomendado en esta documentación es una versión estable verificada; el repositorio oficial de Lerobot se actualiza continuamente a la última versión, lo que puede causar problemas imprevistos como diferentes versiones de conjuntos de datos, diferentes comandos, etc. -
Si encuentras el siguiente error al calibrar los IDs de los servos:
`Motor ‘gripper’ was not found, Make sure it is connected`Por favor, comprueba cuidadosamente si el cable de comunicación está correctamente conectado al servo y si la fuente de alimentación proporciona el voltaje correcto.
-
Si encuentras:
Could not connect on port "/dev/ttyACM0"Y puedes ver que ACM0 existe al ejecutar
ls /dev/ttyACM*, significa que olvidaste otorgar permisos al puerto serie. Introducesudo chmod 666 /dev/ttyACM*en la terminal para solucionarlo. -
Si encuentras:
No valid stream found in input file. Is -1 of the desired media type?Por favor, instala ffmpeg 7.1.1 usando
conda install ffmpeg=7.1.1 -c conda-forge.
-
Si encuentras:
ConnectionError: Failed to sync read 'Present_Position' on ids=[1,2,3,4,5,6] after 1 tries. [TxRxResult] There is no status packet!Necesitas comprobar si el brazo robótico en el puerto correspondiente está encendido y si los cables de datos de los servos de bus están sueltos o desconectados. Si la luz de un servo no está encendida, significa que el cable del servo anterior está suelto.
-
Si encuentras el siguiente error al calibrar el brazo robótico:
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)Apaga y reinicia el brazo robótico y luego intenta calibrar de nuevo. Este método también se puede usar si el ángulo MAX alcanza un valor de decenas de miles durante la calibración. Si esto no funciona, necesitas recalibrar los servos correspondientes, incluyendo la calibración del punto medio y la escritura del ID.
-
Si encuentras durante la fase de evaluación:
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'Por favor, elimina primero la carpeta que comienza con
eval_y luego ejecuta el programa de nuevo. -
Si encuentras durante la fase de evaluación:
`mean` is infinity. You should either initialize with `stats` as an argument or use a pretrained modelTen en cuenta que palabras clave como "front" y "side" en el parámetro
--robot.camerasdeben ser estrictamente coherentes con las utilizadas al recopilar el conjunto de datos. -
Si has reparado o reemplazado partes del brazo robótico, por favor elimina completamente los archivos bajo
~/.cache/huggingface/lerobot/calibration/robotso~/.cache/huggingface/lerobot/calibration/teleoperatorsy recalibra el brazo robótico. De lo contrario, pueden aparecer mensajes de error, ya que la información de calibración se almacena en archivos JSON en estos directorios. -
Entrenar ACT con 50 conjuntos de datos lleva aproximadamente 6 horas en un portátil con una RTX 3060 (8GB), y alrededor de 2–3 horas en ordenadores con GPUs RTX 4090 o A100.
-
Durante la recopilación de datos, asegúrate de que la posición de la cámara, el ángulo y la iluminación ambiental sean estables. Reduce la cantidad de fondo inestable y de peatones capturados por la cámara, ya que cambios excesivos en el entorno de despliegue pueden hacer que el brazo robótico no pueda agarrar correctamente.
-
Para el comando de recopilación de datos, asegúrate de que el parámetro
num-episodesesté configurado para recopilar suficientes datos. No pauses manualmente a mitad de camino, ya que la media y la varianza de los datos se calculan solo después de que la recopilación de datos se haya completado, lo cual es necesario para el entrenamiento. -
Si el programa indica que no puede leer datos de imagen desde la cámara USB, asegúrate de que la cámara USB no esté conectada a través de un hub. La cámara USB debe estar conectada directamente al dispositivo para garantizar una alta velocidad de transmisión de imágenes.
-
Si encuentras un bug como
AttributeError: module 'rerun' has no attribute 'scalar'. Did you mean: 'scalars'?, puedes degradar la versión de rerun para resolver el problema.
pip3 install rerun-sdk==0.23
Si encuentras problemas de software o de dependencias del entorno que no se puedan resolver, además de revisar la sección de Preguntas Frecuentes al final de este tutorial, informa el problema de inmediato en la plataforma LeRobot o en el canal de Discord de LeRobot.
Cita
Proyecto TheRobotStudio: SO-ARM10x
Proyecto Huggingface: Lerobot
Dnsty: Jetson Containers
Soporte técnico y debate sobre el producto
Gracias por elegir nuestros productos. Estamos aquí para ofrecerte diferentes tipos de soporte y garantizar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para adaptarnos a diferentes preferencias y necesidades.