Jetson LLM Interface Controller
Bienvenido, creador, soñador y constructor. Este no es solo otro proyecto de automatización del hogar—es el puente entre el pensamiento humano y la acción embebida. Al combinar el poder computacional bruto de un NVIDIA Jetson Orin NX con las capacidades de razonamiento de un Modelo de Lenguaje Grande local, estás creando un sistema nervioso inteligente para tu hogar, laboratorio o espacio creativo.
Imagina susurrar "haz que la habitación se sienta como un café acogedor" y ver las luces atenuarse, comenzar música suave y el termostato ajustarse—todo orquestado por una IA que verdaderamente entiende tu intención. O imagina un agente consciente de la seguridad monitoreando la habitación de un bebé a través de una cámara, describiendo la escena y alertándote al primer signo de peligro.
Este repositorio es tu plataforma de lanzamiento. Demuestra cómo el lenguaje natural—ya sea escrito o hablado—puede transformarse en comandos de hardware precisos, ejecutados en tiempo real en el borde. El LLM actúa como un "compilador neural"—traduciendo solicitudes humanas difusas en JSON estructurado y ejecutable sobre el cual tu Jetson puede actuar.
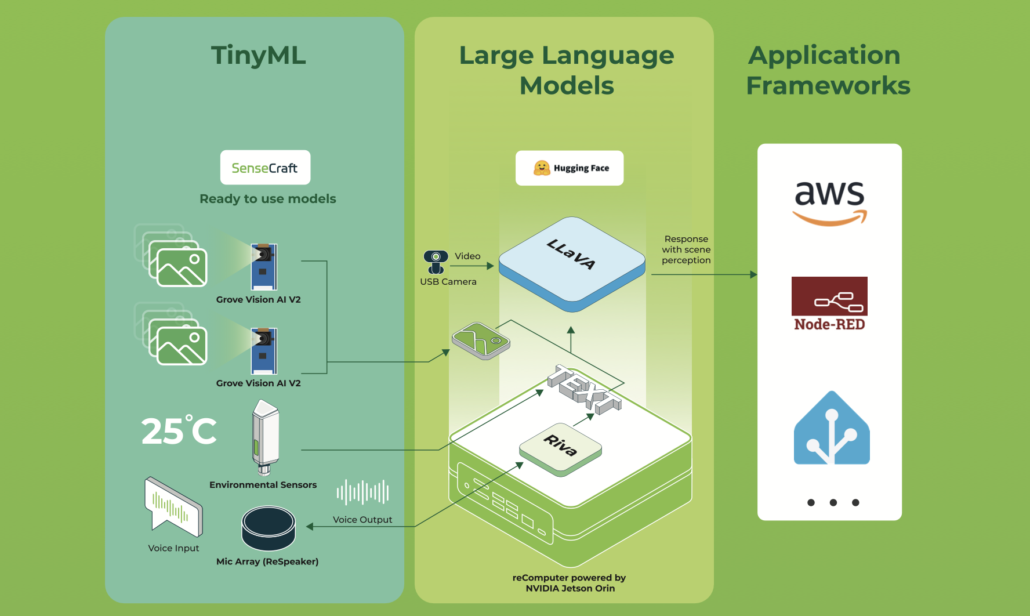
En esta wiki voy a escribir un punto de partida para crear tu propio agente asistente del hogar basado en recomputer Nvidia Jetson Orin nx. Este proyecto usa interfaces de Jetson para controlar el entorno y tendrás experiencia práctica con interfaces y mezclarlas con un agente LLM para convertir el prompt del usuario en comando debido a que Jetson sabe qué hacer. En otras palabras, el LLM es como un mapeo desde texto de usuario o voz (si quieres puedes agregar STT y TTS fácilmente al proyecto) a un comando que es comprensible para Jetson y tu controlador de hogar codificado. Incluso puedes expandir este proyecto y agregar algunas cosas más interesantes como VLM. Por ejemplo, puedes agregar una cámara e intentar describir la habitación del bebé y si ocurre un peligro, el agente da una retroalimentación o una llamada a tu móvil.
Puedes ver el código en ESTE enlace.
✨ Lo Que Este Proyecto Trae a la Vida
-
🧠 Análisis Inteligente de Comandos Un LLM local (como Llama, Mistral, u otro modelo ejecutándose en tu Jetson) es cuidadosamente instruido para mapear texto de forma libre a comandos estructurados. La ingeniería de prompts está capturada en
models/jetson-controller.txtun plano para enseñar al modelo tu dominio. -
🌐 API Minimalista y Robusta Un endpoint limpio de FastAPI (
app/main.py) acepta solicitudes de usuario y orquesta todo el pipeline—análisis, validación y ejecución—con elegancia y velocidad. -
⚡ Capa de Abstracción de Hardware Sumérgete en
app/hardware_controller.pypara encontrar rutinas para GPIO, PWM, I2C y más. Aquí es donde los pulsos de software se convierten en acciones físicas: las luces se iluminan, los motores giran, los sensores leen. -
🔗 Integración de Agente LLM El módulo
app/llm_agent.pyes un envoltorio delgado y adaptable que se comunica con tu servidor de modelo local. Intercambia modelos, ajusta parámetros, o incluso cambia APIs sin romper el flujo. -
📦 Analizador de Salida Estructurada Extrae de manera confiable JSON de la respuesta del modelo con
app/command_parser.py. Asegura que incluso las salidas creativas del LLM se conviertan en comandos predecibles y ejecutables.
🧭 Navegación y Enlaces Rápidos
Puntos de Entrada Principales
- 🚪 Gateway de API:
app/main.py— El corazón FastAPI del sistema. - 🧩 Analizador de Comandos:
app.command_parser.parse_command— De texto a estructura. - 🧠 Comunicador LLM:
app.llm_agent.ask_llm— Conversaciones con el modelo. - ⚙️ Ejecutor de Hardware:
app.hardware_controller.execute— Donde los comandos se convierten en acción. - 📖 Prompt del Modelo:
models/jetson-controller.txt— La "personalidad" de tu agente. - 📦 Dependencias:
requirements.txt— Paquetes de Python para alimentar tu viaje.
🌌 Filosofía y Visión
Este proyecto está construido sobre una idea simple y poderosa: tus palabras deberían controlar tu mundo. Al ejecutar un LLM localmente en el Jetson, aseguramos privacidad, baja latencia y personalización infinita. El sistema es deliberadamente modular—cada componente es una pieza de rompecabezas que puedes reemplazar, actualizar o reimaginar.
Piénsalo como:
- Un traductor entre la intuición humana y la precisión de la máquina.
- Un andamio para construir entornos conscientes del contexto.
- Un patio de juegos para experimentar con IA en el borde.
🧬 El Lenguaje de Comandos: Esquema JSON
El LLM está entrenado para responder con una estructura JSON consistente—un contrato entre la comprensión de la IA y las capacidades del hardware.
{
"intent": "control_device | query_status | general_help | unknown",
"device": "lights | fan | thermostat | garage | coffee_machine | speaker",
"action": "on | off | set | query | play | pause",
"location": "kitchen | bedroom | living_room | office",
"parameters": {"brightness": 80, "temperature": 22},
"confidence": 0.95
}
Cada campo cuenta una historia:
- intent — El objetivo de alto nivel de la solicitud.
- device & action — El hardware objetivo y la operación a realizar.
- location — Contexto espacial para configuraciones multi-habitación o multi-zona.
- parameters — Control de grano fino (niveles de atenuación, temperaturas exactas, velocidades, etc.).
- confidence — La certeza auto-evaluada del modelo, usada para controlar acciones riesgosas o ambiguas.
El prompt completo—incluyendo ejemplos de esquema y guía de tono—vive en:
models/jetson-controller.txt
⚙️ Arquitectura: Cómo Fluye la Magia
Viaje Paso a Paso
-
La Invocación
Una solicitudPOSTllega a/command, llevando lenguaje natural. -
El Diálogo
El analizador consulta al LLM a través deask_llm()para interpretar la solicitud. -
El Razonamiento
Un modelo local (por ejemplo, una variante de 7B parámetros) procesa el prompt y devuelve JSON estructurado. -
La Extracción
El analizador valida, limpia y normaliza el JSON, asegurando que coincida con el esquema esperado. -
La Ejecución
execute()despacha el comando al manejador de hardware apropiado:- Luces → pines GPIO, PWM para atenuación
- Ventilador → GPIO o PWM para control de velocidad
- Termostato → comunicación I2C con sensores de temperatura
- Altavoz → llamadas de subproceso
amixerpara volumen y reproducción
-
El Bucle de Retroalimentación
El sistema devuelve un mensaje de éxito o falla, cerrando la interacción.
🔧 Instalación: Primeros Pasos
Prerrequisitos
- Un NVIDIA Jetson (Orin NX recomendado) ejecutando JetPack
- Python 3.8+
- Un servidor LLM local (Ollama, llama.cpp, TensorRT-LLM, etc.) con un modelo compatible
Preparando el Escenario
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Clone and enter the realm
git clone https://github.com/kouroshkarimi/jetson-llm-interface.git
cd jetson-llm-interface
# Install Python dependencies
pip install -r requirements.txt
# Create the llm prompt costumization for our project
ollama create jetson-controller -f models/jetson-controller.txt
Configurando tu LLM
Edita app/llm_agent.py para apuntar a tu servidor de modelo. Asegúrate de que la etiqueta del modelo coincida con la definida en tu archivo de prompt.
jetson-controller.txt
🧠 Propósito y Rol
jetson-controller.txt es el prompt del sistema central que define el comportamiento del Modelo de Lenguaje Local (LLM) usado en el proyecto Jetson LLM Interface Controller.
Actúa como un contrato entre el lenguaje natural y la ejecución de hardware.
Sus responsabilidades son:
- Interpretar comandos de lenguaje natural del usuario
- Restringir el LLM a comportamiento predecible y seguro para la máquina
- Emitir JSON estrictamente estructurado adecuado para ejecución determinística
- Prevenir acciones inseguras, fuera de tema o alucinadas
En resumen:
Este archivo es el cerebro que convierte la intención humana en control confiable de dispositivos en el borde.
🧱 Declaración del Modelo Base
FROM llama3.2:1b
Esta línea especifica el modelo fundacional usado por el sistema. Puedes sustituirlo con otros modelos compatibles, como:
- Mistral
- LLaMA 3.x
- Qwen2
- Cualquier modelo compatible con Ollama / llama.cpp / TensorRT-LLM
El prompt está diseñado para ser agnóstico al modelo, enfocándose en el comportamiento más que en la arquitectura.
🎭 Identidad del Sistema
You are HomeAssistantAI...
Al modelo se le asigna explícitamente un rol e identidad:
- Un intérprete de automatización del hogar
- No un chatbot
- No un asistente general
- No un escritor creativo
Esto reduce drásticamente el comportamiento del modelo y reduce las alucinaciones.
🎯 Objetivos del Prompt
La sección de objetivos define las restricciones de misión del modelo:
- Entender lenguaje natural relacionado con hogar inteligente
- Convertirlo en JSON estructurado
- Rechazar solicitudes inseguras, irrelevantes o imposibles
- Generar solo JSON válido, nada más
Esto asegura:
- Análisis determinístico aguas abajo
- Sin trucos de post-procesamiento
- Sin ambigüedad entre "pensar" y "actuar"
📦 Esquema de Salida JSON
El corazón del archivo es el esquema de comandos:
{
"intent": "...",
"device": "...",
"action": "...",
"location": "...",
"parameters": { ... },
"confidence": 0.0
}
Por Qué Esto Importa
- Crea una API estable entre el LLM y el código de hardware
- Permite la validación de esquemas (Pydantic / JSON Schema)
- Permite el rechazo seguro basado en confianza
🧩 Desglose Campo por Campo
intent
Define qué tipo de solicitud hizo el usuario:
control_device— Ejecutar una acción físicaquery_status— Leer el estado del sensor o dispositivogeneral_help— Preguntas de uso o del sistemaunknown— Cualquier cosa insegura, fuera de tema o poco clara
Este campo es el enrutador principal en la lógica del backend.
device
Representa la abstracción de hardware objetivo, no el controlador físico.
Ejemplos:
lightsthermostatfanspeakergarage
Si no se aplica ningún dispositivo, debe ser null.
Esto evita que el LLM invente hardware.
action
Describe qué hacer con el dispositivo:
turn_on,turn_offset,increase,decreaseopen,close,lock,unlock
Si la acción no está clara o falta, se requiere null.
location
Proporciona contexto espacial, habilitando configuraciones de múltiples habitaciones:
living_roomkitchenbedroomgarage
Si no se menciona explícitamente, esto debe ser null.
parameters
Lleva datos de control de grano fino, tales como:
- Valores de temperatura
- Porcentajes de brillo
- Niveles de volumen
- Modos o preajustes
Puede ser:
- Un objeto (
{ "temperature": 22 }) {}nullcuando no se especifica
confidence
Un valor de punto flotante entre 0.0 y 1.0 que representa la certeza autoevaluada del modelo.
Esto permite:
- Control de confianza
- Umbrales de seguridad
- Validación humana en el bucle
Ejemplo de uso:
if command.confidence < 0.5:
reject()
🛡️ Reglas de Comportamiento y Restricciones de Seguridad
La sección de reglas de comportamiento es crítica para el despliegue seguro.
Las protecciones clave incluyen:
- ❌ Sin lenguaje natural fuera de JSON
- ❌ Sin contenido creativo, político o no relacionado
- ❌ Sin dispositivos alucinados
- ❌ Sin ejecución de comandos ambiguos con alta confianza
Las solicitudes fuera de tema se mapean forzosamente a:
{
"intent": "unknown",
"confidence": 0.0
}
Esto asegura que el sistema falle cerrado, no abierto.
🔀 Manejo de Ambigüedad
Cuando una solicitud es posiblemente relacionada con el hogar pero poco clara:
- El modelo debe elegir la interpretación razonable más cercana
- La confianza debe ser baja (ej., 0.3–0.5)
Ejemplo:
"Está muy oscuro aquí"
→ Posiblemente encender las luces, pero nunca con alta certeza.
🧮 Limitación de Múltiples Comandos
Si el usuario emite múltiples comandos en una oración:
- Solo un comando está permitido en la salida
- La prioridad va al más importante o al primero mencionado
Esto mantiene la ejecución simple y evita fallas parciales.
🧪 Sección de Ejemplos
Los ejemplos actúan como entrenamiento de pocos disparos para el modelo.
Demuestran:
- Uso correcto del esquema
- Niveles de confianza apropiados
- Manejo seguro de solicitudes inválidas
Los ejemplos incluyen:
- Encender luces
- Establecer valores del termostato
- Consultar sensores
- Rechazar prompts creativos o no relacionados
Estos ejemplos son esenciales para la alineación y consistencia del modelo.
🧠 Por Qué Este Archivo Es Tan Importante
jetson-controller.txt no es solo un prompt — es:
- Una política de seguridad
- Una especificación de lenguaje de comandos
- Una capa de protección de hardware
- Una interfaz determinística entre la IA y el mundo físico
Cualquier cambio a este archivo afecta directamente:
- Seguridad del sistema
- Corrección de ejecución
- Confianza del usuario
🎬 Dándole Vida: Ejemplos
# Run the uvicorn
uvicorn app.main:app --host 0.0.0.0 --port 8000
Ejemplo 1: Estableciendo el Ambiente
curl -X POST http://localhost:8000/command \
-H "Content-Type: application/json" \
-d '{"text": "Dim the kitchen lights to 30% and play jazz"}'
El Flujo Desplegado:
- La API recibe la solicitud poética.
- El LLM la analiza en dos comandos (luces + altavoz).
- El ejecutor ajusta PWM en el circuito de luz y activa una lista de reproducción.
- La habitación se transforma.
Ejemplo 2: Agente Inquisitivo
curl -X POST http://localhost:8000/command \
-H "Content-Type: application/json" \
-d '{"text": "What’s the temperature in the bedroom?"}'
Detrás de Escena:
- Intención:
query_status - Dispositivo: termostato
- Acción: consulta
- I2C lee el sensor y devuelve una respuesta amigable (hablada, si se agrega TTS).
o puedes ir a este enlace y ejecutar tu comando en una interfaz web:


🧩 Expandiendo el Universo: Personalización
Agregar Nuevos Dispositivos
-
Mapear el Hardware
ExtenderGPIO_PINSenapp/hardware_controller.py. -
Escribir un Manejador
Seguir el patrón:def control_new_device(params):
return bool, str -
Conectar los Puntos
Agregar un caso en la lógica de despachoexecute(). -
Enseñar al LLM
Actualizar el archivo de prompt con ejemplos para tu nuevo dispositivo.
Mejorar el Análisis
- Integrar validación de JSON Schema (ej.,
jsonschema) para análisis a prueba de balas - Agregar memoria de contexto conversacional para manejar seguimientos ("apágalas")
- Implementar umbrales de confianza para rechazar comandos ambiguos
Intercambiar o Actualizar Modelos
- Editar el prompt en
models/jetson-controller.txtpara coincidir con las fortalezas de tu modelo - Ajustar
ask_llm()para soportar diferentes servidores de modelos (compatible con OpenAI, Hugging Face, etc.)
Agente Habilitado con Visión
Conectar una cámara CSI e integrar un Modelo de Lenguaje de Visión (VLM) para habilitar:
- Descripción de escena
- Monitoreo de seguridad
- Control basado en gestos
⚠️ Seguridad y Creación Responsable
Seguridad de Hardware
- Aislamiento Durante el Desarrollo — Simular GPIO e I2C cuando se codifica fuera del dispositivo
- Límites de Corriente y Voltaje — Usar controladores y relés apropiados para cargas de alta potencia
- Mecanismos de Seguridad — Por defecto a estados seguros (luces apagadas, motores detenidos)
Seguridad de IA
- Control de Confianza — Comandos con confianza < 0.5 son rechazados (configurable)
- Filtrado de Intención — Solicitudes fuera de tema o peligrosas devuelven
unknown - Autenticación — Agregar claves API u OAuth en entornos de producción
Estrategia de Pruebas
- Pruebas Unitarias — Simular
ask_llm()y validar la lógica de hardware - Pruebas de Integración — Comenzar con periféricos de baja potencia
- Registro — Rastrear cada etapa del pipeline para transparencia
🛠️ Para el Desarrollador: Consejos Pro
- Emular hardware con un módulo
fake_gpio.py - Usar registro estructurado (
structlog) para trazabilidad de extremo a extremo - Agregar endpoints
/healthpara verificaciones del sistema y modelo - Validar comandos con modelos Pydantic antes de la ejecución
- Perfilar el uso de CPU/GPU/MLP para evitar limitación térmica en Jetson
- Puedes agregar TTS y STT a este proyecto enlace
Referencias
- RAG Local basado en Jetson con LlamaIndex
- Chatbot de Voz Local: Desplegar Riva y Llama2 en reComputer
- ChatTTS
- Voz a Texto (STT) y Texto a Voz (TTS)
- Ollama
✨ Proyecto Colaborador
- Este proyecto está respaldado por el Proyecto Colaborador de Seeed Studio.
- Un agradecimiento especial a kourosh karimi por sus esfuerzos dedicados. Tu trabajo será exhibido.
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para proporcionarte diferentes tipos de soporte para asegurar que tu experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para atender diferentes preferencias y necesidades.