PyCuVSLAM con reComputer

Introducción
PyCuVSLAM es el wrapper de Python de la biblioteca de odometría visual y SLAM acelerada por GPU cuVSLAM de NVIDIA. Soporta modos monocular, estéreo, RGB-D, multicámara y visual-inercial (IMU), proporcionando una API simple de Python que puede interfaz directamente con flujos de cámara y generar poses de cámara en tiempo real, puntos de mapa e información de cierre de bucle. La optimización CUDA subyacente permite inferencia SLAM de alta precisión y baja latencia tanto en dispositivos PC como Jetson, haciéndolo adecuado para navegación robótica, posicionamiento de drones y aplicaciones de percepción 3D. Este wiki proporcionará instrucciones sobre cómo desplegar pycuvslam en reComputer.

Prerrequisitos
- reComputer con Jetpack 6.2 preinstalado
- Cámara RGB
- Cámara RGB-D (Orbbec Gemini2 recomendada)
- Entorno ROS2 Humble instalado
Instalación
Paso 1. Clonar el Repositorio PyCuVSLAM
git clone https://github.com/NVlabs/pycuvslam.git
cd pycuvslam
Paso 2. Instalar Git LFS
sudo apt-get install git-lfs
Paso 3. Instalar el Paquete PyCuVSLAM
Para dispositivos Jetson (arquitectura ARM64):
# For Jetson devices
pip install -e bin/aarch64
Para PC Ubuntu (arquitectura x86_64):
# For Ubuntu PC
pip install -e bin/x86_64
Paso 4. Instalar Dependencias Requeridas
# Install required packages
pip install -r examples/requirements.txt
Odometría Visual Monocular
Configuración del Dataset
Paso 1. Descargar el dataset EuRoC MH_01_easy:
mkdir -p examples/euroc/dataset
wget http://robotics.ethz.ch/~asl-datasets/ijrr_euroc_mav_dataset/machine_hall/MH_01_easy/MH_01_easy.zip -O examples/euroc/dataset/MH_01_easy.zip
unzip examples/euroc/dataset/MH_01_easy.zip -d examples/euroc/dataset
rm examples/euroc/dataset/MH_01_easy.zip
Paso 2. Copiar los archivos de calibración:
cp examples/euroc/sensor_cam0.yaml examples/euroc/dataset/mav0/cam0/sensor_recalibrated.yaml
cp examples/euroc/sensor_cam1.yaml examples/euroc/dataset/mav0/cam1/sensor_recalibrated.yaml
cp examples/euroc/sensor_imu0.yaml examples/euroc/dataset/mav0/imu0/sensor_recalibrated.yaml
Calibración de Cámara
El paquete v4l2_camera actúa como un puente entre la API Linux Video4Linux2 (V4L2) y los tópicos ROS 2, publicando mensajes de imagen e información de cámara que pueden ser fácilmente utilizados en pipelines de calibración.
Paso 1. Instalar el Paquete de Calibración de Cámara:
# Install Camera Calibration Package
sudo apt install ros-humble-camera-calibration
# v4l2_camera is the official ROS2 maintained node that can directly publish USB camera images
sudo apt install ros-${ROS_DISTRO}-v4l2-camera
Paso 2. lanzar el nodo de cámara:
# Launch camera node
ros2 run v4l2_camera v4l2_camera_node
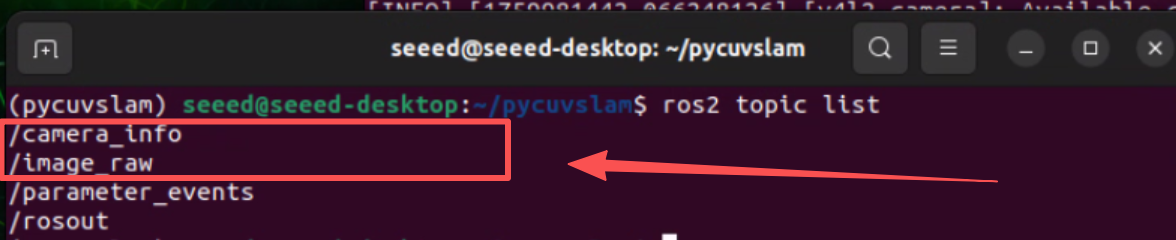
Los tópicos predeterminados publicados son:
/image_raw- Imagen cruda de la cámara/camera- Información de la cámara
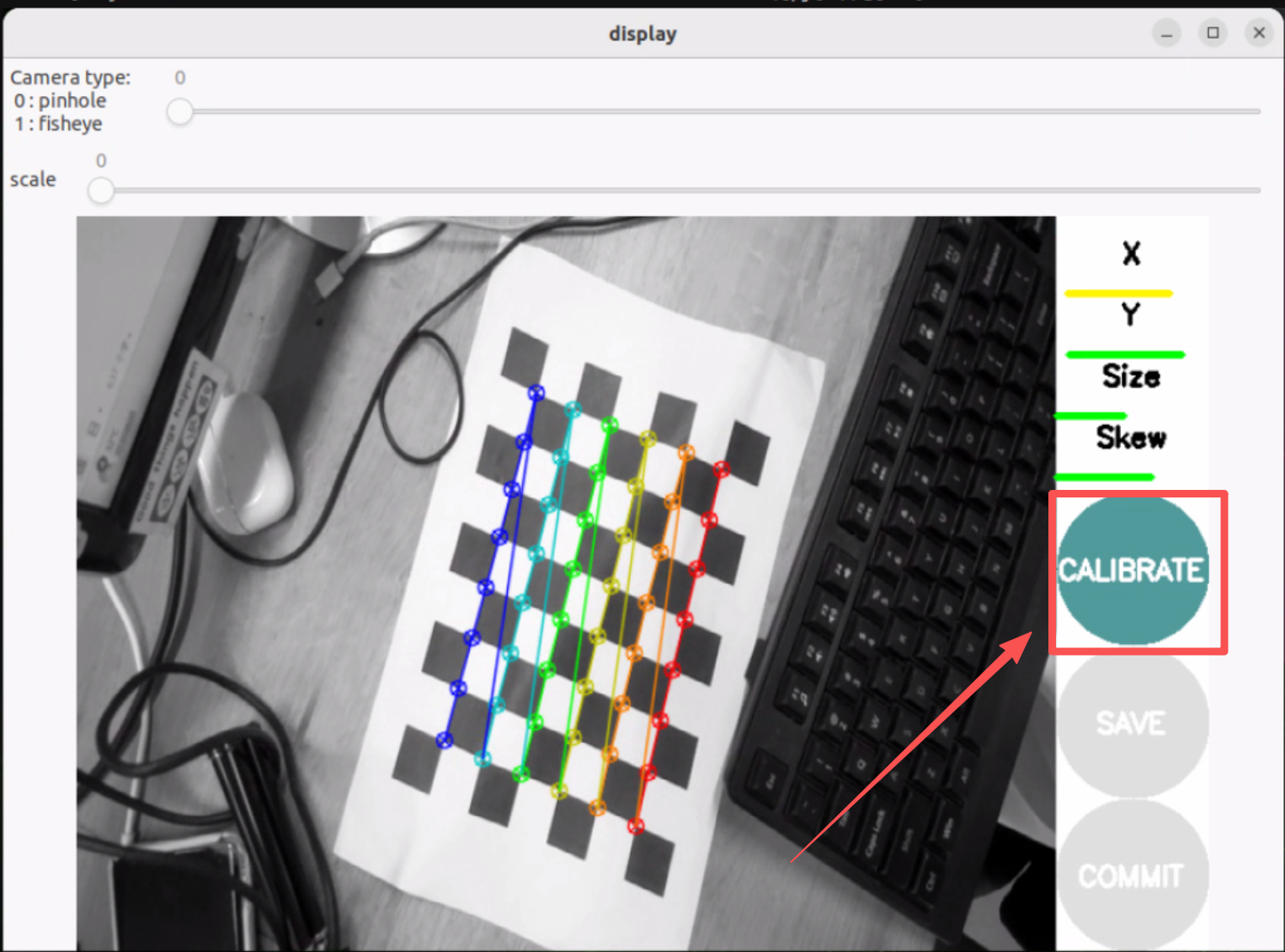
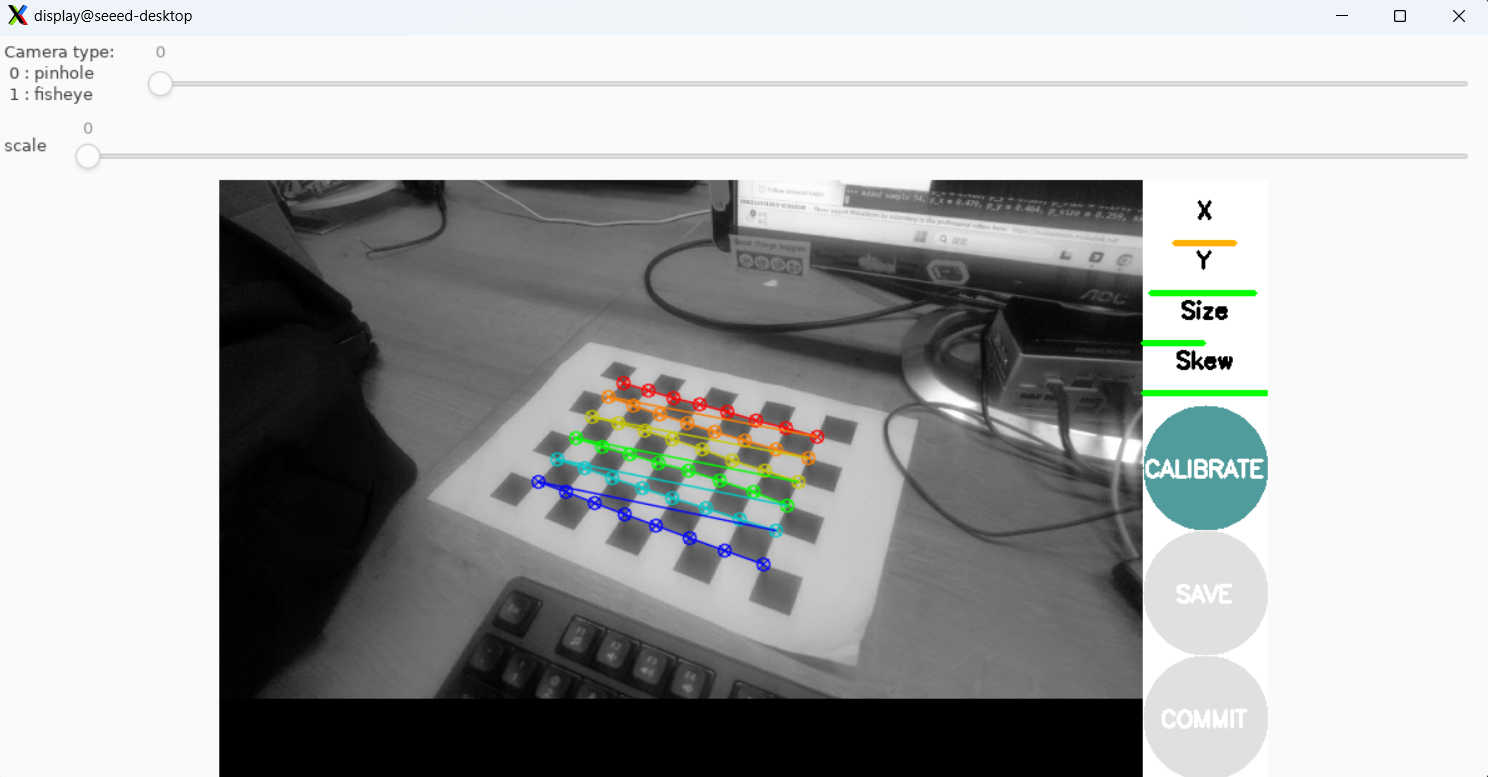
Paso 3. Ejecutar calibración de cámara:
# In another terminal
ros2 run camera_calibration cameracalibrator \
--size 8x6 --square 0.025 \
--ros-args --remap image:=/image_raw --remap camera:=/camera
--size 8x6se refiere al número de esquinas internas (8×6 = 48 esquinas para una cuadrícula de 9×7)--square 0.025se refiere al tamaño del cuadrado en metros (25mm)- Mueve la cámara alrededor para capturar imágenes desde diferentes ángulos hasta que el botón
CALIBRATEse ilumine
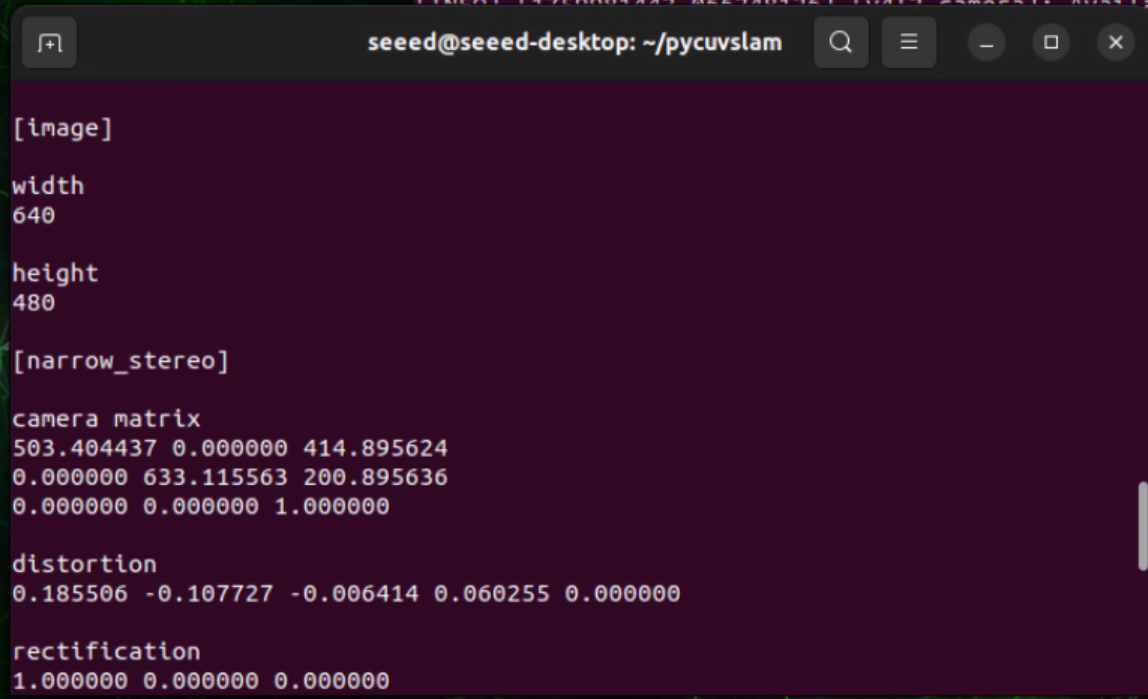
Después de una calibración exitosa, obtendrás parámetros de cámara en el terminal similares a:
Ejecutar el ejemplo
mono_slam.py
#
# Copyright (c) 2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
#
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
# property and proprietary rights in and to this material, related
# documentation and any modifications thereto. Any use, reproduction,
# disclosure or distribution of this material and related documentation
# without an express license agreement from NVIDIA CORPORATION or
# its affiliates is strictly prohibited.
#
"""
Real-time Monocular Visual SLAM using webcam/USB camera
This script demonstrates how to use cuVSLAM for real-time monocular SLAM with live camera feed.
"""
import argparse
import time
from typing import List, Optional
import os
import cv2
import numpy as np
import rerun as rr
import rerun.blueprint as rrb
import yaml
import cuvslam
def color_from_id(identifier):
"""Generate pseudo-random color from integer identifier for visualization."""
return [
(identifier * 17) % 256,
(identifier * 31) % 256,
(identifier * 47) % 256
]
def load_camera_config(config_path: str) -> dict:
"""
Load camera configuration from YAML file.
Args:
config_path: Path to YAML configuration file
Returns:
Dictionary containing camera parameters
"""
if not os.path.exists(config_path):
raise FileNotFoundError(f"Config file not found: {config_path}")
with open(config_path, 'r') as f:
config = yaml.safe_load(f)
return config
def create_camera_rig(
width: int,
height: int,
fx: Optional[float] = None,
fy: Optional[float] = None,
cx: Optional[float] = None,
cy: Optional[float] = None,
distortion_coeffs: Optional[List[float]] = None
) -> cuvslam.Rig:
"""
Create a monocular camera rig with specified parameters.
Args:
width: Image width in pixels
height: Image height in pixels
fx: Focal length in x (pixels). If None, estimated from image width
fy: Focal length in y (pixels). If None, estimated from image width
cx: Principal point x coordinate. If None, set to width/2
cy: Principal point y coordinate. If None, set to height/2
distortion_coeffs: Distortion coefficients [k1, k2, p1, p2, k3]. If None, assumes pinhole
Returns:
cuvslam.Rig object configured for monocular tracking
"""
# Default camera parameters if not provided
# Estimate focal length based on typical webcam FOV (~60-70 degrees)
if fx is None:
fx = width * 0.9 # Approximate focal length
if fy is None:
fy = width * 0.9
if cx is None:
cx = width / 2.0
if cy is None:
cy = height / 2.0
# Create camera object
cam = cuvslam.Camera()
cam.focal = (fx, fy)
cam.principal = (cx, cy)
cam.size = (width, height)
# Set distortion model
if distortion_coeffs is not None:
# Brown-Conrady distortion model
cam.distortion = cuvslam.Distortion(
cuvslam.Distortion.Model.Brown,
distortion_coeffs
)
else:
# Pinhole camera (no distortion)
cam.distortion = cuvslam.Distortion(cuvslam.Distortion.Model.Pinhole)
# For monocular camera, set identity transform (camera is at rig origin)
cam.rig_from_camera = cuvslam.Pose(
rotation=[0, 0, 0, 1], # Identity quaternion (w, x, y, z)
translation=[0, 0, 0] # Zero translation
)
# Create rig with single camera
rig = cuvslam.Rig()
rig.cameras = [cam]
return rig
def setup_visualizer():
"""Initialize rerun visualizer with monocular SLAM layout."""
rr.init("Monocular SLAM Visualizer", spawn=True)
# Setup coordinate basis - cuVSLAM uses right-hand system with
# X-right, Y-down, Z-forward
rr.log("world", rr.ViewCoordinates.RIGHT_HAND_Y_DOWN, static=True)
# Setup visualization layout
rr.send_blueprint(
rrb.Blueprint(
rrb.TimePanel(state="collapsed"),
rrb.Horizontal(
column_shares=[0.5, 0.5],
contents=[
rrb.Vertical(contents=[
rrb.Spatial2DView(
origin='world/camera',
name="Camera Feed with Features"
),
]),
rrb.Spatial3DView(
origin='world',
name="3D Trajectory"
)
]
)
)
)
def main():
"""Main function for real-time monocular SLAM."""
parser = argparse.ArgumentParser(description='Real-time Monocular Visual SLAM')
parser.add_argument(
'--config',
type=str,
default=None,
help='Path to camera config YAML file (overrides individual parameters)'
)
parser.add_argument(
'--camera',
type=int,
default=0,
help='Camera device ID (default: 0 for /dev/video0)'
)
parser.add_argument(
'--width',
type=int,
default=640,
help='Camera frame width (default: 640)'
)
parser.add_argument(
'--height',
type=int,
default=480,
help='Camera frame height (default: 480)'
)
parser.add_argument(
'--fps',
type=int,
default=30,
help='Camera FPS (default: 30)'
)
parser.add_argument(
'--fx',
type=float,
default=None,
help='Focal length x (pixels). If not provided, will be estimated'
)
parser.add_argument(
'--fy',
type=float,
default=None,
help='Focal length y (pixels). If not provided, will be estimated'
)
parser.add_argument(
'--cx',
type=float,
default=None,
help='Principal point x. If not provided, will be image_width/2'
)
parser.add_argument(
'--cy',
type=float,
default=None,
help='Principal point y. If not provided, will be image_height/2'
)
parser.add_argument(
'--distortion',
type=float,
nargs=5,
default=None,
metavar=('k1', 'k2', 'p1', 'p2', 'k3'),
help='Distortion coefficients: k1 k2 p1 p2 k3 (Brown-Conrady model)'
)
parser.add_argument(
'--grayscale',
action='store_true',
help='Convert frames to grayscale (recommended for better performance)'
)
parser.add_argument(
'--undistort',
action='store_true',
help='Undistort images before tracking (recommended if you have distortion coefficients)'
)
parser.add_argument(
'--show-debug',
action='store_true',
help='Show debug information and feature count'
)
parser.add_argument(
'--detect-stationary',
action='store_true',
help='Enable stationary detection to suppress drift when camera is still'
)
parser.add_argument(
'--min-features',
type=int,
default=50,
help='Minimum number of features required for tracking (default: 50)'
)
parser.add_argument(
'--quality-threshold',
type=float,
default=0.01,
help='Quality threshold for feature detection (default: 0.01)'
)
parser.add_argument(
'--show-opencv',
action='store_true',
help='Show OpenCV window with features (in addition to Rerun)'
)
args = parser.parse_args()
# Load camera config from file if provided
fx, fy, cx, cy, distortion_coeffs = None, None, None, None, None
if args.config:
print(f"Loading camera config from: {args.config}")
config = load_camera_config(args.config)
# Extract parameters from config
if 'image' in config:
args.width = config['image'].get('width', args.width)
args.height = config['image'].get('height', args.height)
if 'camera_matrix' in config:
fx = config['camera_matrix'].get('fx')
fy = config['camera_matrix'].get('fy')
cx = config['camera_matrix'].get('cx')
cy = config['camera_matrix'].get('cy')
if 'distortion_coefficients' in config:
dist = config['distortion_coefficients']
distortion_coeffs = [
dist.get('k1', 0.0),
dist.get('k2', 0.0),
dist.get('p1', 0.0),
dist.get('p2', 0.0),
dist.get('k3', 0.0)
]
print(f"Config loaded: {args.width}x{args.height}, fx={fx}, fy={fy}, cx={cx}, cy={cy}")
else:
# Use command line arguments
fx = args.fx
fy = args.fy
cx = args.cx
cy = args.cy
distortion_coeffs = args.distortion
# Open camera
print(f"Opening camera {args.camera}...")
cap = cv2.VideoCapture(args.camera)
if not cap.isOpened():
print(f"Error: Cannot open camera {args.camera}")
return
# Set camera properties
cap.set(cv2.CAP_PROP_FRAME_WIDTH, args.width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, args.height)
cap.set(cv2.CAP_PROP_FPS, args.fps)
# Get actual camera properties (may differ from requested)
actual_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
actual_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
actual_fps = cap.get(cv2.CAP_PROP_FPS)
print(f"Camera initialized: {actual_width}x{actual_height} @ {actual_fps} FPS")
# Create camera rig
rig = create_camera_rig(
width=actual_width,
height=actual_height,
fx=fx,
fy=fy,
cx=cx,
cy=cy,
distortion_coeffs=distortion_coeffs
)
print(f"Camera intrinsics:")
print(f" Focal length: ({rig.cameras[0].focal[0]:.2f}, {rig.cameras[0].focal[1]:.2f})")
print(f" Principal point: ({rig.cameras[0].principal[0]:.2f}, {rig.cameras[0].principal[1]:.2f})")
print(f" Resolution: {rig.cameras[0].size}")
if distortion_coeffs:
print(f" Distortion: {distortion_coeffs}")
# Configure tracker for monocular mode
# Note: Monocular SLAM cannot estimate absolute scale, only relative motion
# Optimized parameters for better accuracy and reduced drift
cfg = cuvslam.Tracker.OdometryConfig(
async_sba=True, # Enable async bundle adjustment for better optimization
enable_observations_export=True,
enable_final_landmarks_export=False, # Disable for performance
horizontal_stereo_camera=False,
odometry_mode=cuvslam.Tracker.OdometryMode.Mono,
use_gpu=True, # Use GPU acceleration
use_motion_model=True, # Use motion model for prediction
enable_landmarks_export=False # Disable for performance
)
# Initialize tracker
tracker = cuvslam.Tracker(rig, cfg)
print(f"cuVSLAM Tracker initialized with odometry mode: Monocular")
print("Note: Monocular SLAM provides rotation and relative translation (scale is arbitrary)")
# Setup visualizer
setup_visualizer()
# Tracking variables
frame_id = 0
trajectory = []
start_time = time.time()
failed_frames = 0
# Monocular SLAM initialization state
is_initialized = False
initialization_frames = 0
min_init_frames = 30 # Need at least 30 frames with good features to initialize
# Stationary detection
stationary_threshold = 0.001 # Very small threshold for monocular (scale is arbitrary)
stationary_count = 0
last_position = None
is_stationary = False
# Motion quality tracking
low_feature_count = 0
motion_warnings = []
print("\nStarting real-time SLAM...")
print("=" * 60)
print("📌 Monocular SLAM Usage Tips:")
print(" 1. Move camera slowly during initialization (first 30 frames)")
print(" 2. Avoid rapid rotation or translation")
print(" 3. Ensure scene has rich texture features")
print(" 4. Keep lighting stable")
print(" 5. Note: Monocular SLAM cannot estimate real scale")
print("=" * 60)
print("\nPress 'q' to quit, 's' to save trajectory\n")
try:
while True:
# Capture frame
ret, frame = cap.read()
if not ret:
print("Error: Failed to capture frame")
break
# Convert to grayscale if requested
if args.grayscale:
if len(frame.shape) == 3:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
else:
# cuVSLAM expects BGR format, OpenCV uses BGR by default
pass
# Generate timestamp (nanoseconds)
# Use monotonic time to avoid issues with system clock changes
timestamp_ns = int((time.time() - start_time) * 1e9)
# Track frame
# For monocular, pass single image in a list
odom_pose_estimate, _ = tracker.track(timestamp_ns, [frame])
# Check if tracking succeeded
if odom_pose_estimate.world_from_rig is None:
failed_frames += 1
if frame_id % 10 == 0 or frame_id < 50:
print(f"⚠️ Warning: Frame {frame_id} tracking failed")
frame_id += 1
continue
# Get current pose and observations
odom_pose = odom_pose_estimate.world_from_rig.pose
current_observations = tracker.get_last_observations(0)
num_features = len(current_observations)
# Check feature count quality
if num_features < args.min_features:
low_feature_count += 1
if low_feature_count % 10 == 1:
print(f"⚠️ Insufficient features: {num_features} < {args.min_features} (suggest improving lighting or scene texture)")
else:
low_feature_count = 0
# Monocular initialization phase
if not is_initialized:
initialization_frames += 1
if initialization_frames >= min_init_frames and num_features >= args.min_features:
is_initialized = True
print(f"✅ Monocular SLAM initialization complete! Processed {initialization_frames} frames")
print(f" Starting normal tracking, current features: {num_features}")
elif initialization_frames % 10 == 0:
print(f"⏳ Initializing... {initialization_frames}/{min_init_frames} frames, features: {num_features}")
# Get position for drift detection
current_position = np.array(odom_pose.translation)
# Stationary detection (for monocular, after initialization)
if args.detect_stationary and is_initialized and last_position is not None:
position_change = np.linalg.norm(current_position - last_position)
if position_change < stationary_threshold:
stationary_count += 1
if stationary_count > 30: # 30 frames still
is_stationary = True
else:
stationary_count = 0
is_stationary = False
# Suppress drift when stationary
if is_stationary and len(trajectory) > 0:
current_position = last_position
last_position = current_position.copy()
trajectory.append(current_position)
# Visualize with rerun
rr.set_time_sequence("frame", frame_id)
# Log trajectory (only if initialized to avoid noisy initial trajectory)
if is_initialized and len(trajectory) > 1:
# Smooth trajectory for visualization (reduce jitter)
if len(trajectory) > 5:
# Use last N points for smoother visualization
smoothed_traj = trajectory[-min(len(trajectory), 500):]
rr.log("world/trajectory", rr.LineStrips3D(smoothed_traj), static=True)
else:
rr.log("world/trajectory", rr.LineStrips3D(trajectory), static=True)
# Log camera pose
rr.log(
"world/camera",
rr.Transform3D(
translation=odom_pose.translation,
quaternion=odom_pose.rotation
),
rr.Arrows3D(
vectors=np.eye(3) * 0.2,
colors=[[255, 0, 0], [0, 255, 0], [0, 0, 255]] # RGB for XYZ
)
)
# Log observations on camera image
points = np.array([[obs.u, obs.v] for obs in current_observations])
colors = np.array([color_from_id(obs.id) for obs in current_observations])
# Prepare image for visualization
if args.grayscale and len(frame.shape) == 2:
# Convert grayscale to RGB for visualization
vis_frame = cv2.cvtColor(frame, cv2.COLOR_GRAY2RGB)
elif not args.grayscale and len(frame.shape) == 3:
# Convert BGR to RGB for visualization
vis_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
else:
vis_frame = frame
rr.log(
"world/camera/observations",
rr.Points2D(positions=points, colors=colors, radii=5.0),
rr.Image(vis_frame).compress(jpeg_quality=80)
)
# Display FPS and feature count
if frame_id % 30 == 0 and is_initialized:
elapsed = time.time() - start_time
fps = frame_id / elapsed if elapsed > 0 else 0
# Status indicators
feature_status = "🔴 LOW" if num_features < args.min_features else "🟡 OK" if num_features < 100 else "🟢 GOOD"
motion_status = "🛑 Stationary" if is_stationary else "🚀 Moving"
status_line = f"📊 Frame {frame_id}: {num_features} features {feature_status}, {fps:.1f} FPS"
if args.detect_stationary:
status_line += f" | {motion_status}"
print(status_line)
print(f" 📍 Relative position: [{current_position[0]:.3f}, {current_position[1]:.3f}, {current_position[2]:.3f}] (arbitrary scale)")
if failed_frames > 0:
print(f" ⚠️ Cumulative failed frames: {failed_frames}")
frame_id += 1
# Optional: Display frame in OpenCV window for debugging
if args.show_opencv:
# Draw features on frame
display_frame = vis_frame.copy()
for obs in current_observations:
pt = (int(obs.u), int(obs.v))
cv2.circle(display_frame, pt, 2, (0, 255, 0), -1)
# Add status text
status_text = f"Frame: {frame_id}"
if is_initialized:
status_text += f" | Features: {num_features}"
if args.detect_stationary and is_stationary:
status_text += " | STATIONARY"
else:
status_text += f" | INIT: {initialization_frames}/{min_init_frames}"
cv2.putText(display_frame, status_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.imshow('Monocular SLAM', display_frame)
key = cv2.waitKey(1)
if key == ord('q'):
break
elif key == ord('s'):
# Save trajectory
if len(trajectory) > 0:
np.savetxt('trajectory_mono.txt', np.array(trajectory),
fmt='%.6f', delimiter=',')
print(f"✅ Trajectory saved: trajectory_mono.txt ({len(trajectory)} poses)")
except KeyboardInterrupt:
print("\nInterrupted by user")
finally:
# Cleanup
print("\n" + "="*60)
print("Monocular SLAM Session Summary")
print("="*60)
print(f"Total processed frames: {frame_id}")
print(f"Successful tracking: {len(trajectory)} poses")
print(f"Failed frames: {failed_frames}")
print(f"Initialization status: {'✅ Complete' if is_initialized else '❌ Incomplete'}")
if frame_id > 0:
success_rate = (len(trajectory) / frame_id) * 100
print(f"Success rate: {success_rate:.1f}%")
# Motion quality statistics
if low_feature_count > 0:
print(f"\n⚠️ Tracking quality warnings:")
print(f" Low feature frames: {low_feature_count}")
# Save trajectory
if len(trajectory) > 0:
trajectory_array = np.array(trajectory)
np.savetxt('trajectory_mono.txt', trajectory_array,
fmt='%.6f', delimiter=',',
header='x,y,z (arbitrary scale)')
print(f"\n✅ Trajectory saved to trajectory_mono.txt ({len(trajectory)} poses)")
# Calculate trajectory statistics
if len(trajectory) > 1:
distances = np.diff(trajectory_array, axis=0)
total_distance = np.sum(np.linalg.norm(distances, axis=1))
print(f" Total distance traveled: {total_distance:.2f} (arbitrary units)")
else:
print("\n⚠️ No trajectory data to save")
cap.release()
cv2.destroyAllWindows()
print("\nCamera released, exiting...")
print("="*60)
if __name__ == "__main__":
main()
Ejecuta el script de ejemplo:
python mono_slam.py --config /path/to/your/Camera parameters yaml file
Necesitas modificar /path/to/your/Camera parameters yaml file al archivo yaml donde están guardados los parámetros de tu cámara. El contenido del archivo yaml es el siguiente: camera.yaml
# Monocular Camera Calibration Configuration File
# Image parameters
image:
width: 640
height: 480
# Camera intrinsic matrix (3x3)
# Format: [fx, 0, cx; 0, fy, cy; 0, 0, 1]
camera_matrix:
fx: 503.404437 # Focal length in X direction
fy: 633.115563 # Focal length in Y direction
cx: 414.895624 # Principal point X coordinate
cy: 200.895636 # Principal point Y coordinate
# Distortion coefficients (Brown-Conrady model)
# Format: [k1, k2, p1, p2, k3]
distortion_coefficients:
k1: 0.185506 # Radial distortion coefficient 1
k2: -0.107727 # Radial distortion coefficient 2
p1: -0.006414 # Tangential distortion coefficient 1
p2: 0.060255 # Tangential distortion coefficient 2
k3: 0.000000 # Radial distortion coefficient 3
# Monocular SLAM optimization suggestions
slam_optimization:
# Recommended minimum number of features
min_features: 80
# Recommended camera movement speed (relative)
max_motion_per_frame: 0.1
# Initialization recommendations
initialization:
min_frames: 30
slow_motion: true
rich_texture: true
Odometría Visual Monocular-Profundidad
Calibración de Cámara
La Odometría Visual Monocular-Profundidad requiere correspondencia píxel a píxel entre las imágenes de cámara y profundidad. La Orbbec Gemini 2 es una cámara 3D IR estéreo de luz estructurada / estéreo activo que proporciona salidas tanto de profundidad como RGB (color). Una de sus características clave es la alineación acelerada por hardware de profundidad a color (D2C, depth → color), lo que significa que el mapa de profundidad y la imagen RGB están alineados espacialmente a nivel de píxel antes de que los datos lleguen a tu computadora host. Esto reduce la carga computacional en tu procesador host y simplifica la fusión de profundidad + color para aplicaciones como reconstrucción 3D, SLAM, detección de objetos con profundidad, etc.
Paso 1. Instala el Driver ROS2 de Orbbec:
mkdir -p ~/ros2_ws/src
cd ~/ros2_ws/src
git clone https://github.com/orbbec/OrbbecSDK_ROS2.git
# Install dependencies
sudo apt install libgflags-dev nlohmann-json3-dev \
ros-$ROS_DISTRO-image-transport ros-${ROS_DISTRO}-image-transport-plugins \
ros-${ROS_DISTRO}-compressed-image-transport ros-$ROS_DISTRO-image-publisher \
ros-$ROS_DISTRO-camera-info-manager ros-$ROS_DISTRO-diagnostic-updater \
ros-$ROS_DISTRO-diagnostic-msgs ros-$ROS_DISTRO-statistics-msgs \
ros-$ROS_DISTRO-backward-ros libdw-dev
pip install catkin_pkg empy==3.3.4 lark-parser
# Install udev rules
cd ~/ros2_ws/src/OrbbecSDK_ROS2/orbbec_camera/scripts
sudo bash install_udev_rules.sh
sudo udevadm control --reload-rules && sudo udevadm trigger
# Build
cd ~/ros2_ws/
colcon build --event-handlers console_direct+ --cmake-args -DCMAKE_BUILD_TYPE=Release
colcon build --packages-select orbbec_camera_msgs
# Source and launch
source ./install/setup.bash
ros2 launch orbbec_camera gemini2.launch.py
Puedes verificar si el nodo de la cámara puede iniciarse normalmente observando si el tópico de datos de la cámara se publica normalmente.
Paso 2. Ejecuta la calibración de cámara RGB-D:
ros2 run camera_calibration cameracalibrator --size 8x6 --square 0.025 \
--ros-args --remap image:=/camera/color/image_raw --remap camera:=/camera/color
Para cámaras RGB-D, obtendrás parámetros para las cámaras:
[image]
width: 1280
height: 720
[narrow_stereo]
camera matrix:
690.546721 0.000000 684.064868
0.000000 683.586452 370.939099
0.000000 0.000000 1.000000
distortion:
-0.010482 -0.019797 0.001294 0.021572 0.000000
rectification:
1.000000 0.000000 0.000000
0.000000 1.000000 0.000000
0.000000 0.000000 1.000000
projection:
654.569214 0.000000 734.393949 0.000000
0.000000 690.282776 371.706832 0.000000
0.000000 0.000000 1.000000 0.000000
Paso 3. Obtén las Extrínsecas de Profundidad a Color
ros2 launch orbbec_camera gemini2.launch.py
ros2 topic echo /camera/depth_to_color
Lee la matriz de rotación y el vector de traslación del tópico ROS2 desde el sistema de coordenadas de la cámara de profundidad al sistema de coordenadas de la cámara de color:
# Depth camera to color camera coordinate system transformation
rotation:
- 0.9999980330467224
- 0.0005175529513508081
- 0.0019138390198349953
- -0.0005151802906766534
- 0.9999991059303284
- -0.0012400292325764894
- -0.0019144790712743998
- 0.001239040750078857
- 0.9999973773956299
translation:
- -0.013858354568481446
- 0.0001548745185136795
- -0.00187313711643219
Paso 4. Configura el SDK de Python de Gemini 2
#install pybind11
pip install pybind11
#clone the repository
git clone https://github.com/orbbec/pyorbbecsdk.git
#Install the necessary packages
cd pyorbbecsdk
pip install -r requirements.txt
mkdir build && cd build
#Build the project
cmake \
-Dpybind11_DIR=`pybind11-config --cmakedir` \
-DPython3_EXECUTABLE=/usr/bin/python3.10 \
-DPython3_INCLUDE_DIR=/usr/include/python3.10 \
-DPython3_LIBRARY=/usr/lib/aarch64-linux-gnu/libpython3.10.so \
..
make -j4
sudo make install
cd ..
#apply the python SDK
pip install wheel
python setup.py bdist_wheel
pip install dist/*.whl
#Configure udev_rules
export PYTHONPATH=$PYTHONPATH:$(pwd)/install/lib/
sudo bash ./scripts/install_udev_rules.sh
sudo udevadm control --reload-rules && sudo udevadm trigger
Ejecutar el ejemplo
rgbd_slam.py
#
# Copyright (c) 2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
#
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
# property and proprietary rights in and to this material, related
# documentation and any modifications thereto. Any use, reproduction,
# disclosure or distribution of this material and related documentation
# without an express license agreement from NVIDIA CORPORATION or
# its affiliates is strictly prohibited.
#
"""
Orbbec Gemini 2 Depth Camera RGBD Visual SLAM
This script demonstrates how to use cuVSLAM with Orbbec Gemini 2 camera for RGBD SLAM
"""
# Import system libraries
import sys
import time
from typing import List, Optional, Tuple
import argparse
# Import computer vision and numerical computing libraries
import cv2 # OpenCV - image processing
import numpy as np # NumPy - numerical computing
import yaml # YAML - configuration file parsing
# Import Orbbec camera SDK
from pyorbbecsdk import *
# Import NVIDIA cuVSLAM library
import cuvslam as vslam
# Add realsense folder to system path for importing visualizers
import os
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), 'examples', 'realsense')))
# Add cuvslam to system path
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), 'bin', 'aarch64')))
from visualizer import RerunVisualizer
# ==================== Constant Definitions ====================
WARMUP_FRAMES = 30 # Warmup frames - SLAM system needs some frames to initialize (reduced for faster startup)
IMAGE_JITTER_THRESHOLD_MS = 200 * 1e6 # Image jitter threshold (nanoseconds) - increased threshold for better tolerance
NUM_VIZ_CAMERAS = 2 # Number of visualization cameras - for displaying color and depth images
DEPTH_SCALE_FACTOR = 1000.0 # Depth scale factor - convert millimeters to meters (Gemini 2 depth unit is millimeters)
FRAME_WAIT_TIMEOUT_MS = 100 # Frame wait timeout (milliseconds) - reduced timeout for better responsiveness
def simple_frame_to_bgr(frame) -> Optional[np.ndarray]:
"""
Convert Orbbec frame to BGR format numpy array
Args:
frame: Orbbec camera frame object
Returns:
Optional[np.ndarray]: BGR format image array, returns None if conversion fails
"""
# Get frame width and height
width = frame.get_width()
height = frame.get_height()
# Create numpy array from frame data
data = np.frombuffer(frame.get_data(), dtype=np.uint8)
# Check if data size is correct (should be width * height * 3 bytes)
if data.size != width * height * 3:
return None
# Reshape 1D array to 3D image array (height, width, 3)
image = data.reshape((height, width, 3))
# Convert RGB format to BGR format (OpenCV uses BGR)
return cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
def create_depth_visualization(depth_data: np.ndarray) -> np.ndarray:
"""
Create depth image visualization effect (similar to test_camera.py)
Args:
depth_data: Depth data array (unit: millimeters)
Returns:
np.ndarray: Colored depth visualization image
"""
# Set depth range (millimeters) - filter out too close and too far points
# Adjusted range for better depth point coverage
min_depth = 100 # Minimum depth 100mm (reduced from 150mm)
max_depth = 3000 # Maximum depth 3000mm (increased from 2000mm)
# Limit depth values to specified range
depth_clipped = np.clip(depth_data, min_depth, max_depth)
# Invert depth values (close points appear bright, far points appear dark)
depth_inverted = max_depth - depth_clipped
# Normalize depth values to 0-255 range
depth_normalized = cv2.normalize(depth_inverted, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)
# Apply MAGMA color mapping (red-yellow-white gradient)
depth_vis = cv2.applyColorMap(depth_normalized, cv2.COLORMAP_MAGMA)
return depth_vis
def get_gemini2_camera_intrinsics(color_profile) -> dict:
"""
Extract camera intrinsics from Orbbec Gemini 2 color stream configuration
Args:
color_profile: Orbbec color stream configuration object
Returns:
dict: Dictionary containing camera intrinsics
- fx, fy: Focal length (pixels)
- cx, cy: Principal point coordinates (pixels)
- width, height: Image resolution
"""
# Get camera intrinsics
intrinsics = color_profile.get_intrinsic()
# Return intrinsics dictionary
return {
'fx': intrinsics.fx, # X direction focal length
'fy': intrinsics.fy, # Y direction focal length
'cx': intrinsics.cx, # X direction principal point
'cy': intrinsics.cy, # Y direction principal point
'width': intrinsics.width, # Image width
'height': intrinsics.height # Image height
}
def create_gemini2_rig(intrinsics: dict, distortion_coeffs: Optional[List[float]] = None) -> vslam.Rig:
"""
Create cuVSLAM Rig object for Orbbec Gemini 2 camera
Args:
intrinsics: Camera intrinsics dictionary
distortion_coeffs: Distortion coefficients list [k1, k2, p1, p2, k3]
Returns:
vslam.Rig: cuVSLAM Rig object containing camera configuration
"""
# Create camera object
cam = vslam.Camera()
# Set camera intrinsics
cam.focal = (intrinsics['fx'], intrinsics['fy']) # Focal length
cam.principal = (intrinsics['cx'], intrinsics['cy']) # Principal point
cam.size = (intrinsics['width'], intrinsics['height']) # Image size
# Set distortion model
if distortion_coeffs is not None and any(abs(coeff) > 1e-6 for coeff in distortion_coeffs):
# Use RadialTangential distortion model (cuVSLAM supported distortion model)
try:
cam.distortion = vslam.Distortion(vslam.Distortion.Model.RadialTangential)
cam.distortion.coeffs = distortion_coeffs
print(f"Using distortion correction: {distortion_coeffs}")
except AttributeError:
# If RadialTangential is not available, try other models
try:
cam.distortion = vslam.Distortion(vslam.Distortion.Model.Radial)
cam.distortion.coeffs = distortion_coeffs[:2] # Only use first two radial distortion coefficients
print(f"Using radial distortion correction: {distortion_coeffs[:2]}")
except AttributeError:
# If none are supported, use pinhole model
cam.distortion = vslam.Distortion(vslam.Distortion.Model.Pinhole)
print("Distortion model not supported, using pinhole model (no distortion)")
else:
# Using pinhole model (no distortion)
cam.distortion = vslam.Distortion(vslam.Distortion.Model.Pinhole)
print("Using pinhole model (no distortion)")
# Camera pose in Rig coordinate system (camera located at Rig origin)
cam.rig_from_camera = vslam.Pose(
rotation=[0, 0, 0, 1], # Unit quaternion (w, x, y, z)
translation=[0, 0, 0] # Zero translation
)
# Create Rig containing single camera
rig = vslam.Rig()
rig.cameras = [cam]
return rig
def setup_gemini2_pipeline(target_width: Optional[int] = None, target_height: Optional[int] = None) -> Tuple[Pipeline, Config, dict]:
"""
Setup Orbbec Gemini 2 camera pipeline and get camera intrinsics
Args:
target_width: Target image width(None means use default/highest resolution)
target_height: Target image height(None means use default/highest resolution)
Returns:
Tuple[Pipeline, Config, dict]:
- Pipeline: Orbbec camera pipeline object
- Config: Camera configuration object
- dict: Camera intrinsics dictionary
"""
# Create camera configuration and pipeline objects
config = Config()
pipeline = Pipeline()
# Get color stream configuration - Use same method as test_camera.py
color_profile_list = pipeline.get_stream_profile_list(OBSensorType.COLOR_SENSOR)
color_profile = None
# If resolution is specified, find matching configuration
if target_width is not None and target_height is not None:
print(f"Looking for resolution {target_width}x{target_height} RGB configuration...")
for cp in color_profile_list:
if cp.get_format() == OBFormat.RGB:
if cp.get_width() == target_width and cp.get_height() == target_height:
color_profile = cp
print(f"✅ Found matching resolution configuration: {target_width}x{target_height}")
break
if color_profile is None:
print(f"⚠️ No exact matching resolution found {target_width}x{target_height}")
print("Available RGB resolutions:")
for cp in color_profile_list:
if cp.get_format() == OBFormat.RGB:
print(f" - {cp.get_width()}x{cp.get_height()}")
print("Will use default resolution...")
# If specified resolution not found, use default RGB configuration
if color_profile is None:
for cp in color_profile_list:
if cp.get_format() == OBFormat.RGB:
color_profile = cp
break
if color_profile is None:
print("Error: No RGB format color stream configuration found")
sys.exit(-1)
# Get depth stream configuration aligned with color stream - Use hardware D2C alignment
hw_d2c_profile_list = pipeline.get_d2c_depth_profile_list(color_profile, OBAlignMode.HW_MODE)
if len(hw_d2c_profile_list) == 0:
print("Error: No D2C aligned depth stream configuration found")
sys.exit(-1)
hw_d2c_profile = hw_d2c_profile_list[0]
# Enable stream configuration
config.enable_stream(hw_d2c_profile) # Enable depth stream
config.enable_stream(color_profile) # Enable color stream
config.set_align_mode(OBAlignMode.HW_MODE) # Set hardware alignment mode
pipeline.enable_frame_sync() # Enable frame synchronization
# Start pipeline
pipeline.start(config)
# Get initial frame to extract intrinsics - With retry mechanism
print("Getting initial frame to extract intrinsics...")
frames = None
for attempt in range(10): # Try up to 10 times
frames = pipeline.wait_for_frames(100)
if frames is not None:
color_frame = frames.get_color_frame()
if color_frame is not None:
print(f"Attempt{attempt + 1}successfully obtained initial frame")
break
print(f"Attempt{attempt + 1}attempt: No valid frame obtained, retrying...")
if frames is None:
print("Error: Unable to get frames from camera after 10 attempts")
sys.exit(-1)
color_frame = frames.get_color_frame()
if color_frame is None:
print("Error: Unable to get color frame")
sys.exit(-1)
# Extract camera intrinsics
intrinsics = get_gemini2_camera_intrinsics(color_profile)
# Print camera intrinsics information
print(f"Gemini 2 camera intrinsics:")
print(f" Resolution: {intrinsics['width']}x{intrinsics['height']}")
print(f" Focal length: ({intrinsics['fx']:.2f}, {intrinsics['fy']:.2f})")
print(f" Principal point: ({intrinsics['cx']:.2f}, {intrinsics['cy']:.2f})")
return pipeline, config, intrinsics
def load_camera_config(config_path: str) -> dict:
"""
Load camera configuration from YAML file
Args:
config_path: Configuration file path
Returns:
dict: Camera configuration dictionary
Exceptions:
FileNotFoundError: Thrown when configuration file does not exist
"""
# Check if configuration file exists
if not os.path.exists(config_path):
raise FileNotFoundError(f"Configuration file not found: {config_path}")
# Read and parse YAML configuration file
with open(config_path, 'r') as f:
config = yaml.safe_load(f)
return config
def apply_depth_to_color_transform(depth_data: np.ndarray, transform: dict) -> np.ndarray:
"""
Apply depth camera to color camera transformation (if needed)
Args:
depth_data: Original depth data
transform: Depth to color transformation parameters
Returns:
np.ndarray: Transformed depth data
"""
# Currently Orbbec SDK has handled D2C alignment,So this is mainly for completeness
# If additional transformation processing is needed in the future,Can be implemented here
return depth_data
def validate_depth_color_alignment(color_image: np.ndarray, depth_data: np.ndarray) -> bool:
"""
Validate depth and color image alignment quality
Args:
color_image: Color image
depth_data: Depth data
Returns:
bool: Whether alignment quality is good
"""
# Check if image size matches
if color_image.shape[:2] != depth_data.shape:
print(f"Warning: Depth and color image size mismatch - Color: {color_image.shape[:2]}, Depth: {depth_data.shape}")
return False
# Check validity of depth data
valid_depth_ratio = np.sum(depth_data > 0) / depth_data.size
if valid_depth_ratio < 0.15: # If valid depth points less than 15% (reduced threshold)
print(f"Warning: Valid depth point ratio too low: {valid_depth_ratio:.2%}")
return False
return True
def suggest_performance_optimizations(avg_fps: float, valid_depth_ratio: float, frame_interval_ms: float) -> List[str]:
"""
Suggest performance optimizations based on current metrics
Args:
avg_fps: Average FPS
valid_depth_ratio: Ratio of valid depth points
frame_interval_ms: Average frame interval in milliseconds
Returns:
List[str]: List of optimization suggestions
"""
suggestions = []
if avg_fps < 15:
suggestions.append("🚀 Try --resolution 640x480 for maximum FPS improvement")
suggestions.append("⚡ Use --fast-depth for faster depth processing")
suggestions.append("🔧 Use --viz-skip-frames 3 to reduce visualization overhead")
if valid_depth_ratio < 0.3:
suggestions.append("📏 Improve lighting conditions for better depth sensing")
suggestions.append("🎯 Ensure objects are within 0.5-5 meters range")
suggestions.append("💡 Avoid reflective surfaces that affect depth perception")
if frame_interval_ms > 100:
suggestions.append("⏱️ Use --use-hardware-timestamp for better timing accuracy")
suggestions.append("🔄 Try --disable-observations to reduce processing load")
suggestions.append("🖥️ Close other applications to free up system resources")
return suggestions
def enhance_depth_quality(depth_data: np.ndarray, fast_mode: bool = True) -> np.ndarray:
"""
Enhance depth data quality
Args:
depth_data: Original depth data
fast_mode: Fast mode(Use smaller filter kernel to improve performance)
Returns:
np.ndarray: Enhanced depth data
"""
if fast_mode:
# Fast mode: Only use 3x3 median filter, significantly improve performance
depth_enhanced = cv2.medianBlur(depth_data.astype(np.uint16), 3)
else:
# Complete mode: Use larger filter kernel, better quality but slower speed
# Apply median filter to remove noise
depth_enhanced = cv2.medianBlur(depth_data.astype(np.uint16), 5)
# For depth data, use Gaussian filter instead of bilateral filter(Because bilateral filter does not support uint16)
# First convert to float32 for filtering, then convert back to uint16
depth_float = depth_enhanced.astype(np.float32)
depth_filtered = cv2.GaussianBlur(depth_float, (5, 5), 1.0)
depth_enhanced = depth_filtered.astype(np.uint16)
return depth_enhanced
def main() -> None:
"""
Functions:
1. Parse command line arguments
2. Setup camera pipeline
3. Initialize SLAM tracker
4. Run real-time tracking loop
5. Save trajectory data
"""
# Create command line argument parser
parser = argparse.ArgumentParser(description='Orbbec Gemini 2 RGBD Visual SLAM')
# Add command line arguments
parser.add_argument(
'--config',
type=str,
default=None,
help='Camera configuration YAML file path(Use calibration parameters if provided)'
)
parser.add_argument(
'--undistort',
action='store_true',
help='Use calibration parameters for distortion correction'
)
parser.add_argument(
'--no-viz',
action='store_true',
help='Disable visualization(Useful when Rerun server is not available)'
)
parser.add_argument(
'--enable-distortion',
action='store_true',
help='Enable distortion correction(Use distortion coefficients from calibration file)'
)
parser.add_argument(
'--enhance-depth',
action='store_true',
help='Enable depth data quality enhancement(Filtering and noise removal)'
)
parser.add_argument(
'--viz-skip-frames',
type=int,
default=1,
help='Visualization skip frames(For example: 2 means visualize every other frame to improve performance)'
)
parser.add_argument(
'--fast-depth',
action='store_true',
help='Use fast depth enhancement mode (3x3 filter instead of 5x5+Gaussian, improve performance)'
)
parser.add_argument(
'--disable-observations',
action='store_true',
help='Disable observation export(Maximize performance, but visualization will not show feature points)'
)
parser.add_argument(
'--resolution',
type=str,
default=None,
help='Camera resolution (Format: WIDTHxHEIGHT, For example: 640x480, 1280x720)。Common: 640x480(Fastest), 1280x720(Balanced), 1920x1080(Default)'
)
parser.add_argument(
'--list-resolutions',
action='store_true',
help='List all supported resolutions and exit'
)
parser.add_argument(
'--use-hardware-timestamp',
action='store_true',
help='Use camera hardware timestamp instead of system timestamp(Improve time accuracy)'
)
parser.add_argument(
'--diagnose-timestamps',
action='store_true',
help='Enable timestamp diagnosis mode(Display detailed frame interval statistics)'
)
parser.add_argument(
'--camera-timeout',
type=int,
default=FRAME_WAIT_TIMEOUT_MS,
help=f'Camera frame wait timeout(milliseconds),Default: {FRAME_WAIT_TIMEOUT_MS}ms'
)
parser.add_argument(
'--detect-stationary',
action='store_true',
help='Enable stationary detection(Suppress pose updates when camera is stationary, reduce drift)'
)
# Parse command line arguments
args = parser.parse_args()
# If user wants to list all supported resolutions
if args.list_resolutions:
print("Querying supported resolutions...")
try:
from pyorbbecsdk import Pipeline, OBSensorType, OBFormat
pipeline = Pipeline()
color_profile_list = pipeline.get_stream_profile_list(OBSensorType.COLOR_SENSOR)
print("\nSupported RGB resolutions:")
print("-" * 40)
resolutions = []
for cp in color_profile_list:
if cp.get_format() == OBFormat.RGB:
width = cp.get_width()
height = cp.get_height()
res_str = f"{width}x{height}"
if res_str not in resolutions:
resolutions.append(res_str)
# Add performance suggestions
if width <= 640:
perf = "🚀 Fastest"
elif width <= 1280:
perf = "⚡ Fast"
elif width <= 1920:
perf = "⚖️ Balanced"
else:
perf = "🐢 Slower"
print(f" {res_str:15s} {perf}")
print("-" * 40)
print(f"\nUsage: --resolution WIDTHxHEIGHT")
print(f"Example: python {sys.argv[0]} --resolution 640x480")
except Exception as e:
print(f"Error: Unable to query resolution - {e}")
sys.exit(0)
# Parse resolution parameters
target_width = None
target_height = None
if args.resolution:
try:
width_str, height_str = args.resolution.split('x')
target_width = int(width_str)
target_height = int(height_str)
print(f"Will use resolution: {target_width}x{target_height}")
except ValueError:
print(f"Error: Invalid resolution format '{args.resolution}'")
print(f"Correct format: WIDTHxHEIGHT (For example: 640x480)")
sys.exit(-1)
# Print program title
print("="*60)
print("Orbbec Gemini 2 RGBD Visual SLAM")
print("="*60)
# TrySetup camera pipeline(With retry mechanism)
pipeline = None
config = None
intrinsics = None
# Try up to 3 times to setup camera pipeline
for attempt in range(3):
try:
print(f"Trying to setup camera pipeline(Attempt{attempt + 1}/3attempt)...")
pipeline, config, intrinsics = setup_gemini2_pipeline(target_width, target_height)
print("✅ Camera pipeline setup successful!")
break
except Exception as e:
print(f"❌ Attempt{attempt + 1}attemptfailed: {e}")
if attempt < 2:
print("2seconds later retry...")
time.sleep(2)
else:
print("All attempts failed。Please check:")
print("1. Camera is properly connected")
print("2. No other applications are using the camera")
print("3. USB permissions are correct")
sys.exit(-1)
# If configuration file is provided, load calibration configuration
calibrated_intrinsics = None
distortion_coeffs = None
depth_to_color_transform = None
if args.config:
print(f"Loading calibration configuration from path: {args.config}")
calib_config = load_camera_config(args.config)
# Use calibration values to override intrinsics
calibrated_intrinsics = {
'fx': calib_config['camera_matrix']['fx'], # Calibrated X direction focal length
'fy': calib_config['camera_matrix']['fy'], # Calibrated Y direction focal length
'cx': calib_config['camera_matrix']['cx'], # Calibrated X direction principal point
'cy': calib_config['camera_matrix']['cy'], # Calibrated Y direction principal point
'width': calib_config['image']['width'], # Image width during calibration
'height': calib_config['image']['height'] # Image height during calibration
}
# Load distortion coefficients(Only when distortion correction is enabled)
if args.enable_distortion and 'distortion_coefficients' in calib_config:
distortion_coeffs = [
calib_config['distortion_coefficients']['k1'],
calib_config['distortion_coefficients']['k2'],
calib_config['distortion_coefficients']['p1'],
calib_config['distortion_coefficients']['p2'],
calib_config['distortion_coefficients']['k3']
]
print(f"Distortion correction enabled")
else:
distortion_coeffs = None
if not args.enable_distortion:
print(f"Distortion correction disabled(Use --enable-distortion Enable)")
# Load depth camera to color camera transformation parameters
if 'depth_to_color_transform' in calib_config:
depth_to_color_transform = calib_config['depth_to_color_transform']
print(f"Using calibrated intrinsics:")
print(f" Resolution: {calibrated_intrinsics['width']}x{calibrated_intrinsics['height']}")
print(f" Focal length: ({calibrated_intrinsics['fx']:.2f}, {calibrated_intrinsics['fy']:.2f})")
print(f" Principal point: ({calibrated_intrinsics['cx']:.2f}, {calibrated_intrinsics['cy']:.2f})")
if distortion_coeffs:
print(f" Distortion coefficients: {distortion_coeffs}")
if depth_to_color_transform:
print(f" Depth-color transformation: Loaded")
# Create camera Rig(Use calibration values if calibrated intrinsics available)
# But maintain actual camera resolution for image processing
if calibrated_intrinsics:
# Use calibrated intrinsics but maintain actual camera resolution
final_intrinsics = calibrated_intrinsics.copy()
final_intrinsics['width'] = intrinsics['width'] # Use actual camera width
final_intrinsics['height'] = intrinsics['height'] # Use actual camera height
# Scale focal length and principal point proportionally
scale_x = intrinsics['width'] / calibrated_intrinsics['width']
scale_y = intrinsics['height'] / calibrated_intrinsics['height']
final_intrinsics['fx'] *= scale_x # Scale X direction focal length
final_intrinsics['fy'] *= scale_y # Scale Y direction focal length
final_intrinsics['cx'] *= scale_x # Scale X direction principal point
final_intrinsics['cy'] *= scale_y # Scale Y direction principal point
print(f"Intrinsics scaled for actual resolution:")
print(f" Resolution: {final_intrinsics['width']}x{final_intrinsics['height']}")
print(f" Focal length: ({final_intrinsics['fx']:.2f}, {final_intrinsics['fy']:.2f})")
print(f" Principal point: ({final_intrinsics['cx']:.2f}, {final_intrinsics['cy']:.2f})")
# Create Rig, use calibrated intrinsics and distortion coefficients
rig = create_gemini2_rig(final_intrinsics, distortion_coeffs)
else:
# If no calibration file, use camera default intrinsics
rig = create_gemini2_rig(intrinsics)
# Configure RGBD settings
rgbd_settings = vslam.Tracker.OdometryRGBDSettings()
rgbd_settings.depth_scale_factor = DEPTH_SCALE_FACTOR # Convert millimeters to meters
rgbd_settings.depth_camera_id = 0 # Depth camera ID(First camera)
rgbd_settings.enable_depth_stereo_tracking = False # Disable depth stereo tracking
# If depth to color transformation parameters exist, can be applied here
if depth_to_color_transform:
print("Depth-color transformation parameters loaded, will be used to optimize RGBD alignment")
# Configure tracker - use supported parameters(Optimize performance)
cfg = vslam.Tracker.OdometryConfig(
async_sba=True, # Enable async bundle adjustment(Improve performance)
enable_final_landmarks_export=False, # Disable final landmark export(Improve performance)
odometry_mode=vslam.Tracker.OdometryMode.RGBD, # Set to RGBD odometry mode
rgbd_settings=rgbd_settings, # Apply RGBD settings
use_gpu=True, # Use GPU acceleration
use_motion_model=True, # Use motion model(Improve tracking stability)
use_denoising=False, # Disable denoising(We have our own depth enhancement, save computation)
enable_observations_export=not args.disable_observations, # Observation export(For visualizing feature points)
enable_landmarks_export=False # Disable landmark export(Improve performance)
)
# Initialize tracker and visualizer
tracker = vslam.Tracker(rig, cfg) # Create SLAM tracker
# Create visualizer(Optional, only supports Rerun visualization)
visualizer = None
if not args.no_viz:
# Try to use Rerun visualizer
try:
visualizer = RerunVisualizer(num_viz_cameras=NUM_VIZ_CAMERAS)
print("✅ Rerun visualizer initialization successful")
except Exception as e:
print(f"⚠️ Rerun visualizer initialization failed: {e}")
print("Continue running, but no visualization interface...")
visualizer = None
# Print tracker initialization information
print(f"\ncuVSLAM tracker initialized, odometry mode: RGBD")
print(f"Depth scale factor: {DEPTH_SCALE_FACTOR} (Millimeters to meters)")
# Print performance optimization configuration
print(f"\n⚡ Performance configuration:")
print(f" Resolution: {intrinsics['width']}x{intrinsics['height']}")
print(f" Camera timeout: {args.camera_timeout}ms")
print(f" Timestamp mode: {'Hardware timestamp' if args.use_hardware_timestamp else 'System timestamp'}")
print(f" Timestamp diagnosis: {'Enabled (detailed mode)' if args.diagnose_timestamps else 'Disabled'}")
print(f" Visualization skip frames: Every {args.viz_skip_frames} frames")
if args.enhance_depth:
depth_mode = "Fast mode (3x3)" if args.fast_depth else "Complete mode (5x5+Gaussian)"
print(f" Depth enhancement: Enabled [{depth_mode}]")
else:
print(f" Depth enhancement: Disabled")
print(f" Distortion correction: {'Enabled' if (args.enable_distortion and distortion_coeffs) else 'Disabled'}")
print(f" Visualizer: Rerun")
print(f" Observation export: {'Disabled (maximum performance)' if args.disable_observations else 'Enabled'}")
print(f" Stationary detection: {'Enabled (suppress drift)' if args.detect_stationary else 'Disabled'}")
if args.viz_skip_frames == 1 and not args.disable_observations and args.resolution is None:
print(f"\n💡 Performance optimization tips:")
print(f" If frame rate is low, try the following options(From low to high impact):")
print(f" --resolution 640x480 # Reduce resolution (maximum improvement!)")
print(f" --viz-skip-frames 3 # Visualize every 3 frames (slight improvement)")
print(f" --fast-depth # Use fast depth enhancement (medium improvement)")
print(f" --disable-observations # Disable feature point export(Significant improvement)")
print(f" --no-viz # Completely disable visualization (maximum improvement)")
print(f"\n 💡 Use --list-resolutions to view all supported resolutions")
# Tracking variable initialization
frame_id = 0 # Frame counter
prev_timestamp: Optional[int] = None # Previous frame timestamp
trajectory: List[np.ndarray] = [] # Trajectory point list(Position only)
pose_data: List[dict] = [] # Complete pose data list(Position + rotation)
start_time = time.time() # Start time
frame_drop_warnings = 0 # Frame loss warning counter
# Timestamp diagnosis statistics
timestamp_intervals = [] # Timestamp interval list(For statistics)
hardware_timestamp_base = None # Hardware timestamp baseline
last_frame_time = time.time() # Previous frame system time(For calculating actual FPS)
# Stationary detection
stationary_threshold = 0.001 # 1mm position change threshold
stationary_count = 0 # Consecutive stationary frames
last_position = None # Previous frame position
is_stationary = False # Currently stationary
# Performance monitoring
performance_monitor = {
'frame_times': [],
'processing_times': [],
'fps_history': [],
'last_optimization': 0
}
# Print start information and usage tips
print("\n" + "="*60)
print("Starting RGBD SLAM...")
print("="*60)
print("\n💡 Better tracking effect tips:")
print(" 1. Ensure color camera has good lighting conditions")
print(" 2. Avoid reflective surfaces affecting depth perception")
print(" 3. Move camera slowly and smoothly")
print(" 4. Keep objects within 0.5-5 meters for best depth quality")
print("\nPress Ctrl+C to stop and save trajectory\n")
try:
# Main tracking loop
while True:
# Record frame acquisition start time
frame_acquire_start = time.time()
# Wait for frame data(Use configured timeout time)
frames = pipeline.wait_for_frames(args.camera_timeout)
if frames is None:
continue # If no frames obtained, continue next loop
# Get color frames and depth frames
color_frame = frames.get_color_frame()
depth_frame = frames.get_depth_frame()
# If any frame is empty, skip this frame(Silently skip, similar to test_camera.py)
if color_frame is None or depth_frame is None:
continue
# Convert frames to numpy array(Same method as test_camera.py)
color_image = simple_frame_to_bgr(color_frame)
if color_image is None:
continue # If conversion fails, silently skip this frame
# Get depth data(Same method as test_camera.py)
depth_height = depth_frame.get_height() # Depth image height
depth_width = depth_frame.get_width() # Depth image width
depth_data = np.frombuffer(depth_frame.get_data(), dtype=np.uint16).reshape((depth_height, depth_width))
# Validate depth-color alignment quality
if not validate_depth_color_alignment(color_image, depth_data):
continue # If alignment quality is poor, skip this frame
# Enhance depth data quality(If enabled)
if args.enhance_depth:
depth_data = enhance_depth_quality(depth_data, fast_mode=args.fast_depth)
# Apply depth to color transformation(If configured)
if depth_to_color_transform:
depth_data = apply_depth_to_color_transform(depth_data, depth_to_color_transform)
# Generate timestamp(nanoseconds)
if args.use_hardware_timestamp:
# Try to use camera hardware timestamp
try:
# Get color frame hardware timestamp(microseconds)
hw_timestamp_us = color_frame.get_timestamp()
# Initialize hardware timestamp baseline
if hardware_timestamp_base is None:
hardware_timestamp_base = hw_timestamp_us
# Convert to relative timestamp(nanoseconds)
timestamp_ns = int((hw_timestamp_us - hardware_timestamp_base) * 1000)
except Exception as e:
# If hardware timestamp unavailable, fallback to system time
if frame_id == 0:
print(f"⚠️ Hardware timestamp unavailable, using system time: {e}")
timestamp_ns = int((time.time() - start_time) * 1e9)
else:
# UseSystem timestamp
timestamp_ns = int((time.time() - start_time) * 1e9)
# Calculate actual frame interval(For FPS statistics)
current_frame_time = time.time()
actual_frame_interval_ms = (current_frame_time - last_frame_time) * 1000
last_frame_time = current_frame_time
# Check timestamp difference with previous frame
if prev_timestamp is not None:
timestamp_diff = timestamp_ns - prev_timestamp
timestamp_intervals.append(timestamp_diff / 1e6) # Save interval(milliseconds)
# Diagnosis mode: display detailed information
if args.diagnose_timestamps and frame_id > WARMUP_FRAMES:
print(f"[frames {frame_id}] Timestamp interval: {timestamp_diff/1e6:.2f}ms, "
f"Actual interval: {actual_frame_interval_ms:.2f}ms, "
f"Real-time FPS: {1000/actual_frame_interval_ms:.1f}")
# Normal mode: only warn when exceeding threshold
if timestamp_diff > IMAGE_JITTER_THRESHOLD_MS:
frame_drop_warnings += 1
# Only display every 10 warnings to reduce information redundancy
if frame_drop_warnings % 10 == 1:
print(
f"⚠️ Timestamp interval too large: {timestamp_diff/1e6:.2f} ms "
f"(Threshold: {IMAGE_JITTER_THRESHOLD_MS/1e6:.2f} ms) "
f"[Actual FPS: {1000/actual_frame_interval_ms:.1f}] "
f"(#{frame_drop_warnings} times)"
)
frame_id += 1 # Increment frame counter
# Warmup specified number of frames
if frame_id > WARMUP_FRAMES:
# Prepare images for tracking
images = [color_image] # Color image list
depths = [depth_data] # Depth image list
# Track current frame
odom_pose_estimate, _ = tracker.track(
timestamp_ns, images=images, depths=depths
)
# Check if tracking succeeded
if odom_pose_estimate.world_from_rig is None:
print(f"Warning: Tracking frame {frame_id} failed")
continue
# Get current pose and observation data
odom_pose = odom_pose_estimate.world_from_rig.pose
current_position = np.array(odom_pose.translation)
# Stationary detection
if args.detect_stationary and last_position is not None:
position_change = np.linalg.norm(current_position - last_position)
if position_change < stationary_threshold:
stationary_count += 1
if stationary_count > 30: # Consecutive 30 frames stationary
is_stationary = True
else:
stationary_count = 0
is_stationary = False
# If stationary detected, use first position(Suppress drift)
if is_stationary and len(trajectory) > 0:
# Use recent stable position instead of drifted position
current_position = last_position
last_position = current_position.copy()
trajectory.append(current_position) # Add position to trajectory
# Store complete pose data
# cuVSLAM's odom_pose.rotation is in [x, y, z, w] order.
# Convert and store as [w, x, y, z] for consistent usage elsewhere.
raw_quat = odom_pose.rotation # [x, y, z, w]
qx, qy, qz, qw = raw_quat
quat_wxyz = [qw, qx, qy, qz]
pose_data.append({
'frame_id': frame_id, # framesID
'timestamp': timestamp_ns, # Timestamp
'position': current_position, # Position [x, y, z]
'rotation_quat': quat_wxyz, # Rotation quaternion [w, x, y, z]
'stationary': is_stationary if args.detect_stationary else False # Stationary flag
})
# Extract position and rotation information
position = odom_pose.translation # Position vector [x, y, z]
# cuVSLAM returns quaternion in [x, y, z, w] order. Map to w,x,y,z for calculations.
rotation_quat = odom_pose.rotation # Quaternion [x, y, z, w]
qx, qy, qz, qw = rotation_quat
# Convert quaternion to Euler angles(Roll, pitch, yaw)
import math
w, x, y, z = qw, qx, qy, qz # Quaternion components in w,x,y,z order
# Roll (rotation around X axis)
sinr_cosp = 2 * (w * x + y * z)
cosr_cosp = 1 - 2 * (x * x + y * y)
roll = math.atan2(sinr_cosp, cosr_cosp)
# Pitch (rotation around Y axis)
sinp = 2 * (w * y - z * x)
if abs(sinp) >= 1:
pitch = math.copysign(math.pi / 2, sinp) # If out of range, use 90 degrees
else:
pitch = math.asin(sinp)
# Yaw (rotation around Z axis)
siny_cosp = 2 * (w * z + x * y)
cosy_cosp = 1 - 2 * (y * y + z * z)
yaw = math.atan2(siny_cosp, cosy_cosp)
# Convert to degrees
roll_deg = math.degrees(roll) # Roll angle (degrees)
pitch_deg = math.degrees(pitch) # Pitch angle (degrees)
yaw_deg = math.degrees(yaw) # Yaw angle (degrees)
# Get observation data for visualization (if observation export is enabled)
observations = [] if args.disable_observations else tracker.get_last_observations(0)
# Store current timestamp for next iteration
prev_timestamp = timestamp_ns
# Visualize results (if enabled, only supports Rerun visualizer)
# Use frame skipping to reduce visualization overhead for better performance
if visualizer is not None and frame_id % args.viz_skip_frames == 0:
try:
# Rerun visualizer call(Consistent with run_rgbd.py)
# For RGBD, we only have one camera, so copy images and observation data
# Create depth visualization for second view
depth_vis = create_depth_visualization(depth_data)
visualizer.visualize_frame(
frame_id=frame_id, # framesID
images=[images[0], depth_vis], # Color image and depth visualization
pose=odom_pose, # Current pose
observations_main_cam=[observations, observations], # Main camera observation data
trajectory=trajectory, # Trajectory
timestamp=timestamp_ns # Timestamp
)
except Exception as e:
# If visualization fails, silently continue running
if frame_id % 100 == 0: # Print warning every 100 frames
print(f"⚠️ Visualization error: {e}")
# Display status every 60 frames(Reduce print frequency to improve performance)
if frame_id % 60 == 0:
elapsed = time.time() - start_time # Elapsed time
fps = frame_id / elapsed if elapsed > 0 else 0 # Calculate FPS
num_features = len(observations) # Number of feature points
# Calculate valid depth ratio
valid_depth_ratio = np.sum(depth_data > 0) / depth_data.size
# Calculate average frame interval
avg_interval_ms = np.mean(timestamp_intervals[-60:]) if len(timestamp_intervals) > 0 else 0
# Feature quality indicator
feature_status = "🔴 LOW" if num_features < 30 else "🟡 OK" if num_features < 80 else "🟢 GOOD"
# Stationary status indicator
motion_status = "🛑 Stationary" if is_stationary else "🚀 Moving"
# Print detailed status information
status_line = f"📊 frames {frame_id}: {num_features} feature points {feature_status}, {fps:.1f} FPS"
if args.detect_stationary:
status_line += f" | {motion_status}"
print(status_line)
print(f" 📍 Position (XYZ): [{position[0]:.3f}, {position[1]:.3f}, {position[2]:.3f}] meters")
print(f" 🔄 Rotation (RPY): Roll={roll_deg:.1f}°, Pitch={pitch_deg:.1f}°, Yaw={yaw_deg:.1f}°")
print(f" 🧭 Quaternion: w={w:.3f}, x={x:.3f}, y={y:.3f}, z={z:.3f}")
print(f" 📏 Depth coverage: {valid_depth_ratio:.1%} | Avg interval: {avg_interval_ms:.1f}ms")
# Show performance suggestions if needed
if fps < 15 or valid_depth_ratio < 0.3 or avg_interval_ms > 100:
suggestions = suggest_performance_optimizations(fps, valid_depth_ratio, avg_interval_ms)
if suggestions:
print(f" 💡 Performance tips:")
for suggestion in suggestions[:3]: # Show top 3 suggestions
print(f" {suggestion}")
print()
else:
# During warmup, only show progress
if frame_id % 10 == 0:
print(f"⏳ Warming up... frames {frame_id}/{WARMUP_FRAMES}")
except KeyboardInterrupt:
print("\nUser interrupted program")
finally:
# Cleanup and summary
print("\n" + "="*60)
print("RGBD SLAM session summary")
print("="*60)
print(f"Total processed frames: {frame_id}")
print(f"Successful tracking: {len(trajectory)} poses")
print(f"Frame loss warnings: {frame_drop_warnings}")
if frame_id > WARMUP_FRAMES:
success_rate = (len(trajectory) / (frame_id - WARMUP_FRAMES)) * 100
print(f"Success rate: {success_rate:.1f}%")
# Timestamp statistics
if len(timestamp_intervals) > 0:
import statistics
avg_interval = statistics.mean(timestamp_intervals)
min_interval = min(timestamp_intervals)
max_interval = max(timestamp_intervals)
median_interval = statistics.median(timestamp_intervals)
stdev_interval = statistics.stdev(timestamp_intervals) if len(timestamp_intervals) > 1 else 0
print(f"\n📊 Timestamp interval statistics:")
print(f" Average interval: {avg_interval:.2f} ms ({1000/avg_interval:.1f} FPS)")
print(f" Median interval: {median_interval:.2f} ms ({1000/median_interval:.1f} FPS)")
print(f" Minimum interval: {min_interval:.2f} ms ({1000/min_interval:.1f} FPS)")
print(f" Maximum interval: {max_interval:.2f} ms ({1000/max_interval:.1f} FPS)")
print(f" Standard deviation: {stdev_interval:.2f} ms")
print(f" Interval jitter: {(stdev_interval/avg_interval*100):.1f}%")
# Analyze problems
if avg_interval > 100:
print(f"\n⚠️ Timestamp analysis:")
print(f" Average frame interval ({avg_interval:.1f}ms) Large, possible reasons:")
print(f" 1. Slow processing speed(Try reducing resolution --resolution 640x480)")
print(f" 2. Low camera frame rate(Check camera configuration)")
print(f" 3. High CPU/GPU load(Close other programs)")
if stdev_interval / avg_interval > 0.3:
print(f"\n⚠️ Large timestamp jitter ({stdev_interval/avg_interval*100:.1f}%),Possible reasons:")
print(f" 1. Unstable system load")
print(f" 2. Insufficient USB bandwidth")
print(f" 3. Large visualization overhead(Try --viz-skip-frames or --no-viz)")
if args.use_hardware_timestamp:
print(f"\n✅ Hardware timestamp used")
else:
print(f"\n💡 Tip: Use --use-hardware-timestamp may improve time accuracy")
# Save trajectory and pose data
if len(trajectory) > 0:
# Save simple trajectory(Position only)
trajectory_array = np.array(trajectory)
np.savetxt('trajectory_gemini2_rgbd.txt', trajectory_array,
fmt='%.6f', delimiter=',',
header='x,y,z (meters)')
# Save complete pose data(Position + rotation)
with open('pose_data_gemini2_rgbd.txt', 'w') as f:
f.write('# Frame_ID, Timestamp(ns), X(m), Y(m), Z(m), Qw, Qx, Qy, Qz\n')
for pose in pose_data:
pos = pose['position']
quat = pose['rotation_quat']
f.write(f"{pose['frame_id']}, {pose['timestamp']}, "
f"{pos[0]:.6f}, {pos[1]:.6f}, {pos[2]:.6f}, "
f"{quat[0]:.6f}, {quat[1]:.6f}, {quat[2]:.6f}, {quat[3]:.6f}\n")
print(f"\n✅ Data saved:")
print(f" 📍 Trajectory: trajectory_gemini2_rgbd.txt ({len(trajectory)} poses)")
print(f" 🎯 Complete pose: pose_data_gemini2_rgbd.txt ({len(pose_data)} poses)")
# Calculate trajectory statistics
if len(trajectory) > 1:
distances = np.diff(trajectory_array, axis=0)
total_distance = np.sum(np.linalg.norm(distances, axis=1))
print(f" 📏 Total distance traveled: {total_distance:.2f} meters")
else:
print("\n⚠️ No trajectory data to save")
# Stop camera pipeline and visualizer
try:
pipeline.stop()
print("\nCamera released, program exiting...")
except Exception as e:
print(f"\nWarning: Error stopping camera pipeline: {e}")
finally:
# Close visualizer
if visualizer is not None and hasattr(visualizer, 'close'):
try:
visualizer.close()
except Exception as e:
print(f"Error closing visualizer: {e}")
print("="*60)
# Program entry point
if __name__ == "__main__":
main()
python rgbd_slam.py --config ./gemini2_calibrated_config.yaml --resolution 1280x720 --enable-distortion --enhance-depth --fast-depth
el archivo yaml es el siguiente:
gemini2_calibrated_config.yaml
# Gemini 2 Camera Calibration Configuration File
image:
width: 1280
height: 720
# Camera intrinsic matrix (updated calibration parameters)
# [fx 0 cx]
# [ 0 fy cy]
# [ 0 0 1]
camera_matrix:
fx: 690.546721
fy: 683.586452
cx: 684.064868
cy: 370.939099
# Distortion coefficients (Brown-Conrady model) - updated calibration parameters
# [k1, k2, p1, p2, k3]
distortion_coefficients:
k1: -0.010482
k2: -0.019797
p1: 0.001294
p2: 0.021572
k3: 0.000000
# Projection matrix (for reference)
projection_matrix:
- [675.994629, 0.000000, 740.107685, 0.000000]
- [0.000000, 698.293884, 396.362314, 0.000000]
- [0.000000, 0.000000, 1.000000, 0.000000]
# Depth camera to color camera transformation parameters (from ROS2 topics)
# Used for depth-color alignment in RGBD SLAM
depth_to_color_transform:
# Rotation matrix (3x3)
rotation:
- [0.9999980330467224, 0.0005175529513508081, 0.0019138390198349953]
- [-0.0005151802906766534, 0.9999991059303284, -0.0012400292325764894]
- [-0.0019144790712743998, 0.001239040750078857, 0.9999973773956299]
# Translation vector (3x1)
translation:
- -0.013858354568481446
- 0.0001548745185136795
- -0.00187313711643219
Recursos
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarle diferentes tipos de soporte para asegurar que su experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.