Convertir y Cuantificar Modelos de IA

La herramienta de conversión de modelos de IA de reCamera actualmente soporta frameworks como PyTorch, ONNX, TFLite, y Caffe. Los modelos de otros frameworks necesitan ser convertidos al formato ONNX. Para instrucciones sobre cómo convertir modelos de otras arquitecturas de aprendizaje profundo a ONNX, puedes consultar el sitio web oficial de ONNX: https://github.com/onnx/tutorials.
El diagrama de flujo para desplegar modelos de IA en reCamera se muestra a continuación.
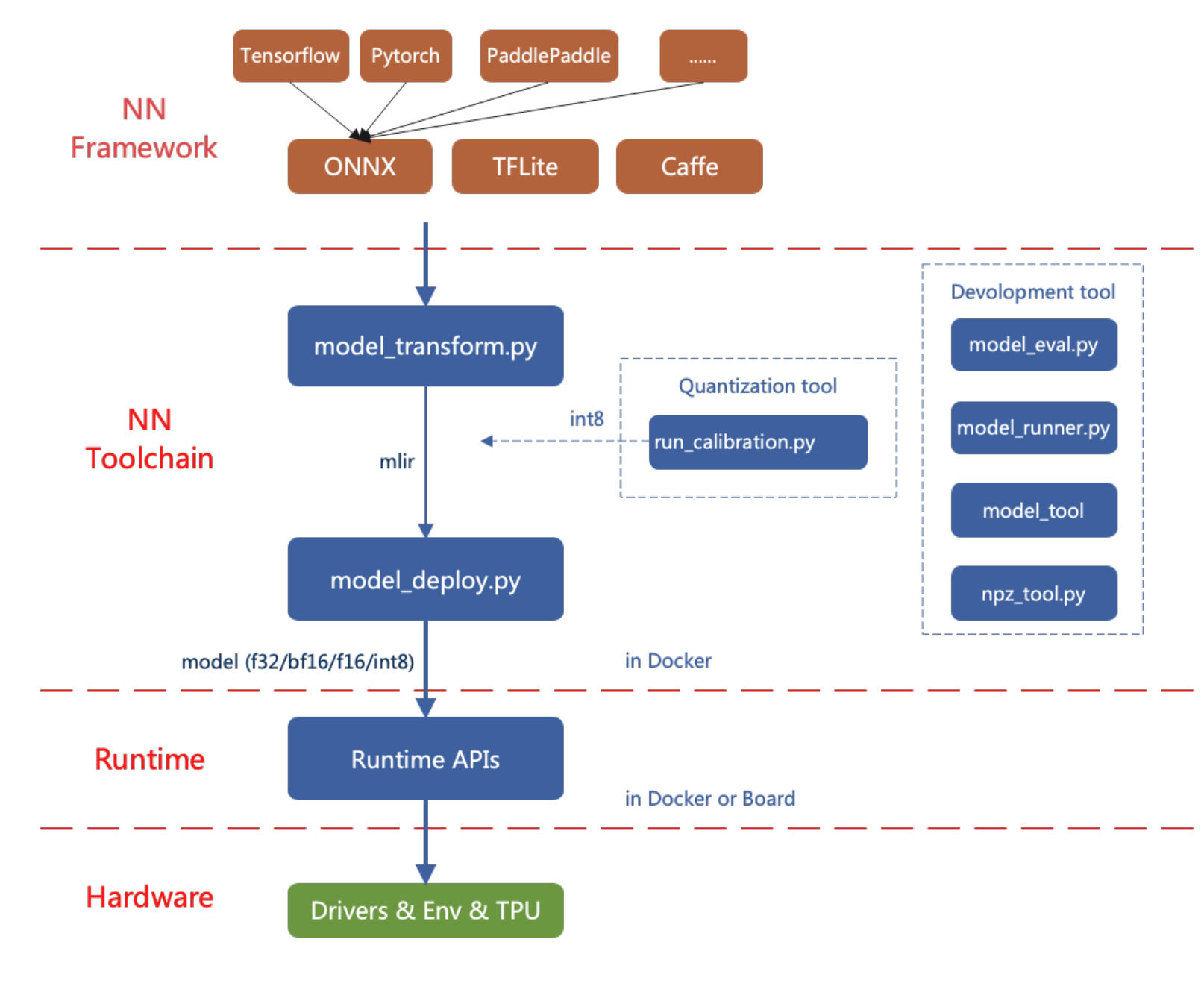
Este artículo introduce cómo usar la herramienta de conversión de modelos de IA de reCamera a través de ejemplos simples.
Configurar el entorno de trabajo
Método 1: Instalación en una Imagen de Docker (recomendado)
Descarga la imagen requerida desde DockerHub (haz clic aquí) y recomendamos usar la versión 3.1:
docker pull sophgo/tpuc_dev:v3.1
Si estás usando Docker por primera vez, puedes ejecutar los siguientes comandos para la instalación y configuración (solo necesario para la configuración inicial):
sudo apt install docker.io
sudo systemctl start docker
sudo systemctl enable docker
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker
Luego crea un contenedor en el directorio actual de la siguiente manera:
docker run --privileged --name MyName -v $PWD:/workspace -it sophgo/tpuc_dev:v3.1
** Reemplaza "MyName" con el nombre deseado para tu contenedor*
Usa pip para instalar tpu_mlir dentro del contenedor Docker, igual que en el Método 1:
pip install tpu_mlir[all]==1.7
Método 2: Instalación Local
Primero verifica si el entorno del sistema actual cumple con:
Si no se cumple o la instalación falla, elige el Método 2 para instalar la herramienta de conversión de modelos.
Instala tpu_mlir usando pip:
pip install tpu_mlir==1.7
Las dependencias requeridas por tpu_mlir varían al manejar modelos de diferentes frameworks. Para archivos de modelo generados por ONNX o Torch, instala las dependencias adicionales usando el siguiente comando:
pip install tpu_mlir[onnx]==1.7
pip install tpu_mlir[torch]==1.7
Actualmente, se admiten cinco configuraciones: onnx, torch, tensorflow, caffe y paddle. O puedes usar el siguiente comando para instalar todas las dependencias:
pip install tpu_mlir[all]==1.7
Cuando el archivo tpu_mlir-{version}.whl ya existe localmente, también puedes usar el siguiente comando para instalarlo:
pip install path/to/tpu_mlir-{version}.whl[all]
Convertir y Cuantizar Modelos de IA al Formato cvimodel
Preparando el ONNX
reCamera ya ha adaptado la serie YOLO para inferencia local. Por lo tanto, esta sección usa yolo11n.onnx como ejemplo para demostrar cómo convertir un modelo ONNX al cvimodel.
El cvimodel es el formato de modelo de IA utilizado para inferencia local en reCamera.
El método para convertir y cuantizar modelos PyTorch, TFLite, y Caffe es el mismo que en esta sección.
Aquí está el enlace de descarga para yolo11n.onnx. Puedes hacer clic en el enlace para descargar el modelo y copiarlo a tu Workspace para uso posterior.
Descargar el modelo: Descargar yolo11n.onnx Este archivo ONNX puede ser usado directamente para los ejemplos en las siguientes secciones sin necesidad de modificar la versión IR o la versión Opset.
Actualmente, ONNX en este wiki está basado en IR versión 8 y Opset versión 17. Si tu archivo ONNX es convertido desde un ejemplo por Ultralytics después de diciembre 2024, puede en procesos posteriores debido a una versión superior.
Puedes ver la información del archivo ONNX usando Netron:
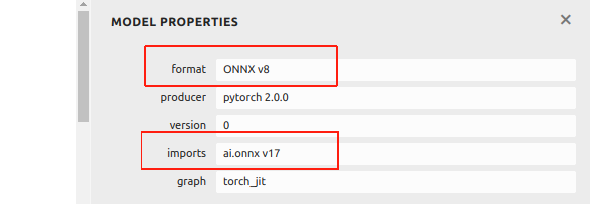
Si tu archivo ONNX es superior a IR v8 y Opset v17, , proporcionamos un ejemplo aquí para ayudarte a degradarlo. Primero, instalando onnx vía pip:
pip install onnx
Descarga el programa para modificar la versión del archivo ONNX desde GitHub:
git clone https://github.com/jjjadand/ONNX_Downgrade.git
cd ONNX_Downgrade/
Ejecuta el script proporcionando las rutas de los archivos del modelo de entrada y salida como argumentos de línea de comandos:
python downgrade_onnx.py <input_model_path> <output_model_path> --target_ir_version <IR_version> --target_opset_version <Opset_version>
<input_model_path>: La ruta al modelo ONNX original que deseas degradar.<output_model_path>: La ruta donde se guardará el modelo degradado.- --target_ir_version
<IR_version>: Opcional. La versión IR objetivo a la cual degradar. Por defecto es 8. - --target_opset_version
<Opset_version>: Opcional. La versión Opset objetivo a la cual degradar. Por defecto es 17.
Por ejemplo, usando Versiones por Defecto (IR v8, Opset v17):
python downgrade_onnx.py model_v12.onnx model_v8.onnx
Esto cargará model_v12.onnx, lo degradará a la versión IR 8, establecerá la versión opset 17, validará, y guardará el nuevo modelo como model_v8.onnx.
Usando Versiones Personalizadas (IR v9, Opset v11):
python downgrade_onnx.py model_v12.onnx model_v9.onnx --target_ir_version 9 --target_opset_version 11
Esto cargará model_v12.onnx, lo degradará a la versión IR 9, establecerá la versión opset 11, validará y guardará el nuevo modelo como model_v9.onnx.
- Para evitar errores, recomendamos usar ONNX con IR v8 y Opset v17.
Preparando el Espacio de Trabajo
Crea el directorio model_yolo11n al mismo nivel que tpu-mlir. Los archivos de imagen suelen ser parte del conjunto de datos de entrenamiento del modelo, utilizados para calibración durante el proceso de cuantización posterior.
Ingresa el siguiente comando en la terminal:
git clone -b v1.7 --depth 1 https://github.com/sophgo/tpu-mlir.git
cd tpu-mlir
source ./envsetup.sh
./build.sh
mkdir model_yolo11n && cd model_yolo11n
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir Workspace && cd Workspace
Después de obtener un archivo ONNX utilizable, colócalo en el directorio Workspace que creaste. La estructura del directorio es la siguiente:
model_yolo11n
├── COCO2017
├── image
└── Workspace
└──yolo11n.onnx
Los pasos siguientes se llevarán a cabo en tu Workspace.
ONNX a MLIR
La conversión de ONNX a MLIR es un paso intermedio en el proceso de transformación del modelo. Antes de obtener un modelo adecuado para inferencia en reCamera, necesitas primero convertir el modelo ONNX al formato MLIR. Este archivo MLIR sirve como puente para generar el modelo final optimizado para el motor de inferencia de reCamera.
Si la entrada es una imagen, necesitamos conocer el preprocesamiento del modelo antes de transferirlo. Si
el modelo usa archivos npz preprocesados como entrada, no es necesario considerar preprocesamiento. El
proceso de preprocesamiento se formula de la siguiente manera ( x representa la entrada):
y = (x − mean) × scale
El rango de normalización de yolo11 es [0, 1], y la imagen del yolo11 oficial es RGB. Cada valor será multiplicado por 1/255, respectivamente
correspondiendo a 0.0, 0.0, 0.0 y 0.0039216, 0.0039216, 0.0039216 cuando se convierte en mean
y scale. Los parámetros para mean y scale difieren dependiendo del modelo, ya que están determinados por el método de normalización usado para cada modelo específico.
Puedes consultar el siguiente comando de conversión de modelo en terminal:
model_transform \
--model_name yolo11n \
--model_def yolo11n.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../image/dog.jpg \
--test_result yolo11n_top_outputs.npz \
--mlir yolo11n.mlir
Después de convertir a un archivo mlir, se generará un archivo ${model_name}_in_f32.npz, que
es el archivo de entrada para los modelos posteriores.
Con respecto a la selección del parámetro --output_names, la conversión del modelo YOLO11 en este ejemplo no elige la salida final llamada output0. En su lugar, selecciona las seis salidas antes del head del modelo como parámetro. Puedes importar el archivo ONNX en Netron para ver la estructura del modelo.
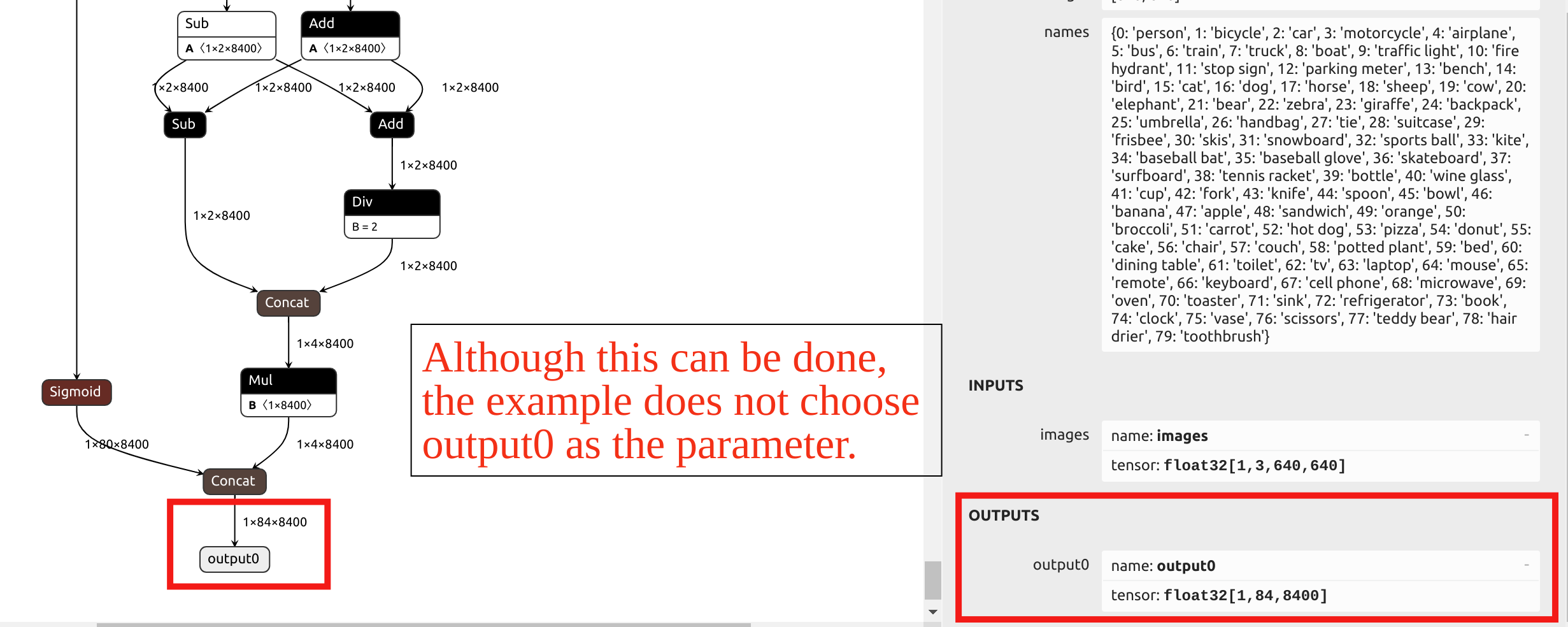
Los operadores en el head de YOLO tienen una precisión muy baja después de la cuantización INT8. Si se eligiera output0 al final como parámetro, se requeriría cuantización de precisión mixta.
Dado que las secciones posteriores de este artículo proporcionarán ejemplos de cuantización de precisión mixta, y esta sección usa una sola precisión de cuantización para el ejemplo, se eligen las salidas antes del head como parámetros. Al visualizar el modelo ONNX en Netron, puedes ver las posiciones de los seis nombres de salida:
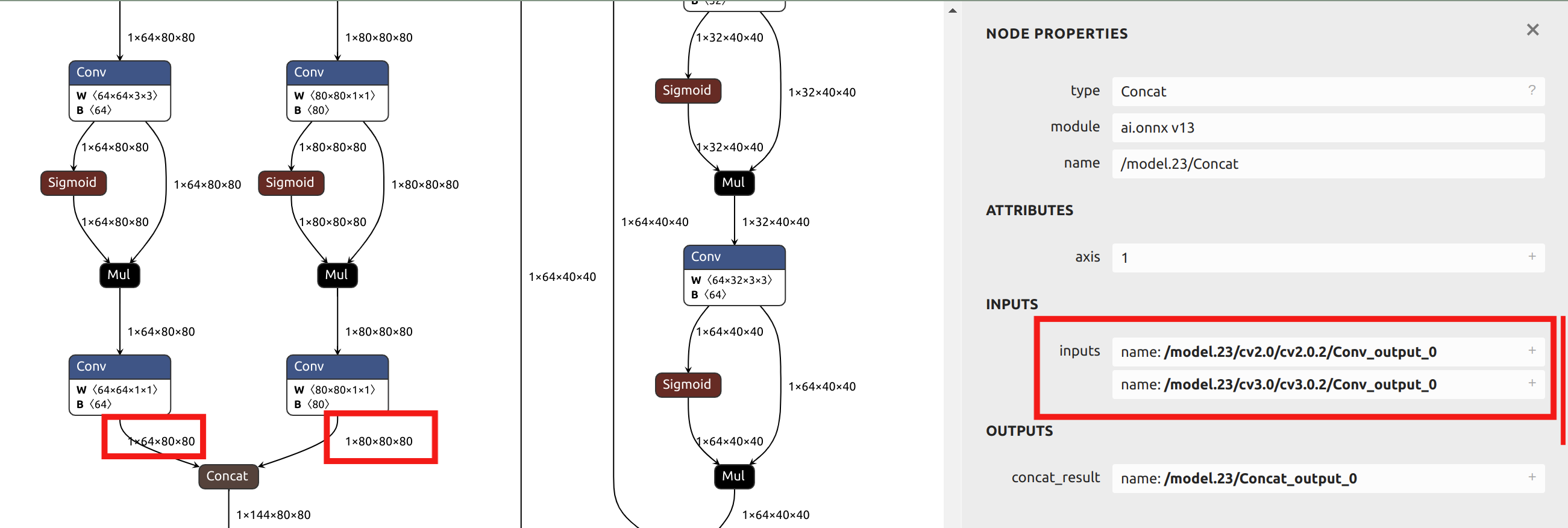
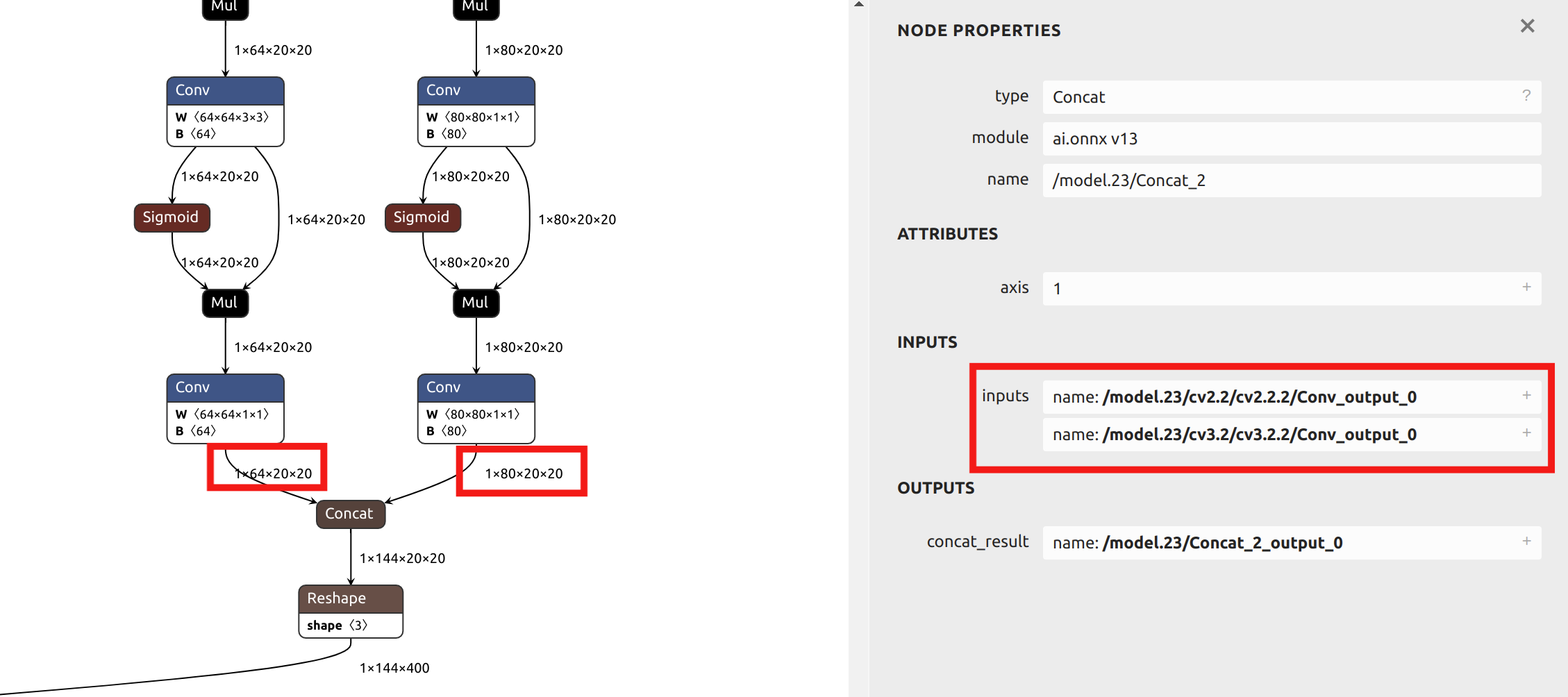
Descripción de los Parámetros Principales para model_transform:
| Nombre del Parámetro | ¿Requerido? | Descripción |
|---|---|---|
| model_name | Sí | Especificar el nombre del modelo. |
| model_def | Sí | Especificar el archivo de definición del modelo, como '.onnx', '.tflite', o '.prototxt'. |
| input_shapes | No | Especificar la forma de entrada, por ejemplo, [[1,3,640,640]]. Un arreglo bidimensional que puede soportar múltiples entradas. |
| input_types | No | Especificar los tipos de entrada, como int32. Usar comas para separar múltiples entradas. Por defecto es float32. |
| resize_dims | No | Especificar las dimensiones a las cuales la imagen original debe ser redimensionada. Si no se especifica, será redimensionada al tamaño de entrada del modelo. |
| keep_aspect_ratio | No | Si mantener la relación de aspecto al redimensionar. Por defecto es false; si es true, se usará relleno con ceros para las áreas faltantes. |
| mean | No | Valor medio para cada canal de la imagen. Por defecto es 0,0,0,0. |
| scale | No | Valor de escala para cada canal de la imagen. Por defecto es 1.0,1.0,1.0. |
| pixel_format | No | Tipo de imagen, que puede ser uno de 'rgb', 'bgr', 'gray', o 'rgbd'. Por defecto es 'bgr'. |
| channel_format | No | Tipo de canal para entrada de imagen, que puede ser 'nhwc' o 'nchw'. Para entradas que no son imágenes, usar 'none'. Por defecto es 'nchw'. |
| output_names | No | Especificar nombres de salida. Si no se especifica, se usan los nombres de salida por defecto del modelo. |
| test_input | No | Especificar un archivo de entrada para validación, como una imagen, archivo npy, o npz. Si no se especifica, no se realiza validación de precisión. |
| test_result | No | Especificar el archivo de salida para el resultado de validación. |
| excepts | No | Especificar capas de red a excluir de la validación, separadas por comas. |
| mlir | Sí | Especificar el nombre y ruta del archivo MLIR de salida. |
MLIR a cvimodel F16
Si deseas convertir de mlir a cvimodel con precisión F16, puedes ingresar el siguiente comando de referencia en la terminal:
model_deploy \
--mlir yolo11n.mlir \
--quant_input \
--quantize F16 \
--customization_format RGB_PACKED \
--processor cv181x \
--test_input ../image/dog.jpg \
--test_reference yolo11n_top_outputs.npz \
--fuse_preprocess \
--tolerance 0.99,0.9 \
--model yolo11n_1684x_f16.cvimodel
Después de una conversión exitosa, obtendrás un archivo cvimodel de precisión FP16 que puede ser usado directamente para inferencia. Si necesitas un archivo cvimodel de precisión INT8 o de precisión mixta, por favor consulta el contenido en las secciones posteriores del siguiente artículo.
Descripción de los Parámetros Principales para model_deploy:
| Nombre del Parámetro | ¿Requerido? | Descripción |
|---|---|---|
| mlir | Sí | Archivo MLIR |
| quantize | Sí | Tipo de cuantización (F32/F16/BF16/INT8) |
| processor | Sí | Depende de la plataforma que se esté utilizando. La versión 2024 de reCamera selecciona "cv181x" como parámetro. |
| calibration_table | No | La ruta de la tabla de calibración. Requerida cuando es cuantización INT8 |
| tolerance | No | Tolerancia para la similitud mínima entre los resultados de inferencia de MLIR cuantizado y MLIR fp32 |
| test_input | No | El archivo de entrada para validación, que puede ser una imagen, npy o npz. No se realizará validación si no se especifica |
| test_reference | No | Datos de referencia para validar la tolerancia de mlir (en formato npz). Es el resultado de cada operador |
| compare_all | No | Comparar todos los tensores, si se establece |
| excepts | No | Nombres de las capas de red que necesitan ser excluidas de la validación. Separados por coma |
| op_divide | No | Intentar dividir la operación más grande en múltiples operaciones más pequeñas para lograr el propósito de ahorro de memoria ion, adecuado para algunos modelos específicos |
| model | Sí | Nombre del archivo de modelo de salida (incluyendo ruta) |
| skip_validation | No | Omitir la verificación de corrección de cvimodel para aumentar la eficiencia de despliegue; la verificación de cvimodel está activada por defecto |
Después de la compilación, se genera un archivo llamado yolo11n_1684x_f16.cvimodel. El modelo cuantizado puede tener una ligera pérdida en precisión, pero será más ligero y tendrá una velocidad de inferencia más rápida.
MLIR a cvimodel INT8
Generación de tabla de calibración
Antes de convertir al modelo INT8, necesitas ejecutar la calibración para obtener la tabla de calibración.
El número de datos de entrada es de aproximadamente 100 a 1000 según la situación.
Luego usa la tabla de calibración para generar un cvimodel simétrico o asimétrico. Generalmente no se recomienda usar el simétrico si el simétrico ya cumple con los requisitos, porque el rendimiento del modelo asimétrico será ligeramente peor que el modelo simétrico.
Aquí hay un ejemplo de las 100 imágenes existentes de COCO2017 para realizar la calibración:
run_calibration \
yolo11n.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolo11n_calib_table
Después de ejecutar el comando anterior, se generará un archivo llamado yolo11n_calib_table, que
se utiliza como archivo de entrada para la compilación posterior del modelo INT8.
Descripción de los Parámetros Principales para run_calibration:
| Parámetro | ¿Requerido? | Descripción |
|---|---|---|
| N/A | Sí | Especificar el archivo MLIR |
| dataset | No | Especificar el directorio de muestras de entrada, donde la ruta contiene las imágenes correspondientes, archivos npz o npy |
| data_list | No | Especificar la lista de muestras; se debe seleccionar dataset o data_list |
| input_num | No | Especificar el número de muestras de calibración; si se establece en 0, se utilizan todas las muestras |
| tune_num | No | Especificar el número de muestras de ajuste; por defecto es 10 |
| histogram_bin_num | No | Número de bins para el histograma; por defecto es 2048 |
| o | Sí | Generar el archivo de tabla de calibración |
Compilar a cvimodel cuantizado simétrico INT8
Después de obtener el archivo yolo11n_cali_table, ejecute el siguiente comando para convertirlo en un modelo cuantizado simétrico INT8:
model_deploy \
--mlir yolo11n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo11n_calib_table \
--test_input ../image/dog.jpg \
--test_reference yolo11n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo11n_1684x_int8_sym.cvimodel
Después de la compilación, se genera un archivo llamado yolo11n_1684x_int8_sym.cvimodel. El modelo cuantizado a INT8 es más ligero y tiene una velocidad de inferencia más rápida en comparación con los modelos cuantizados a F16/BF16.
Prueba Rápida
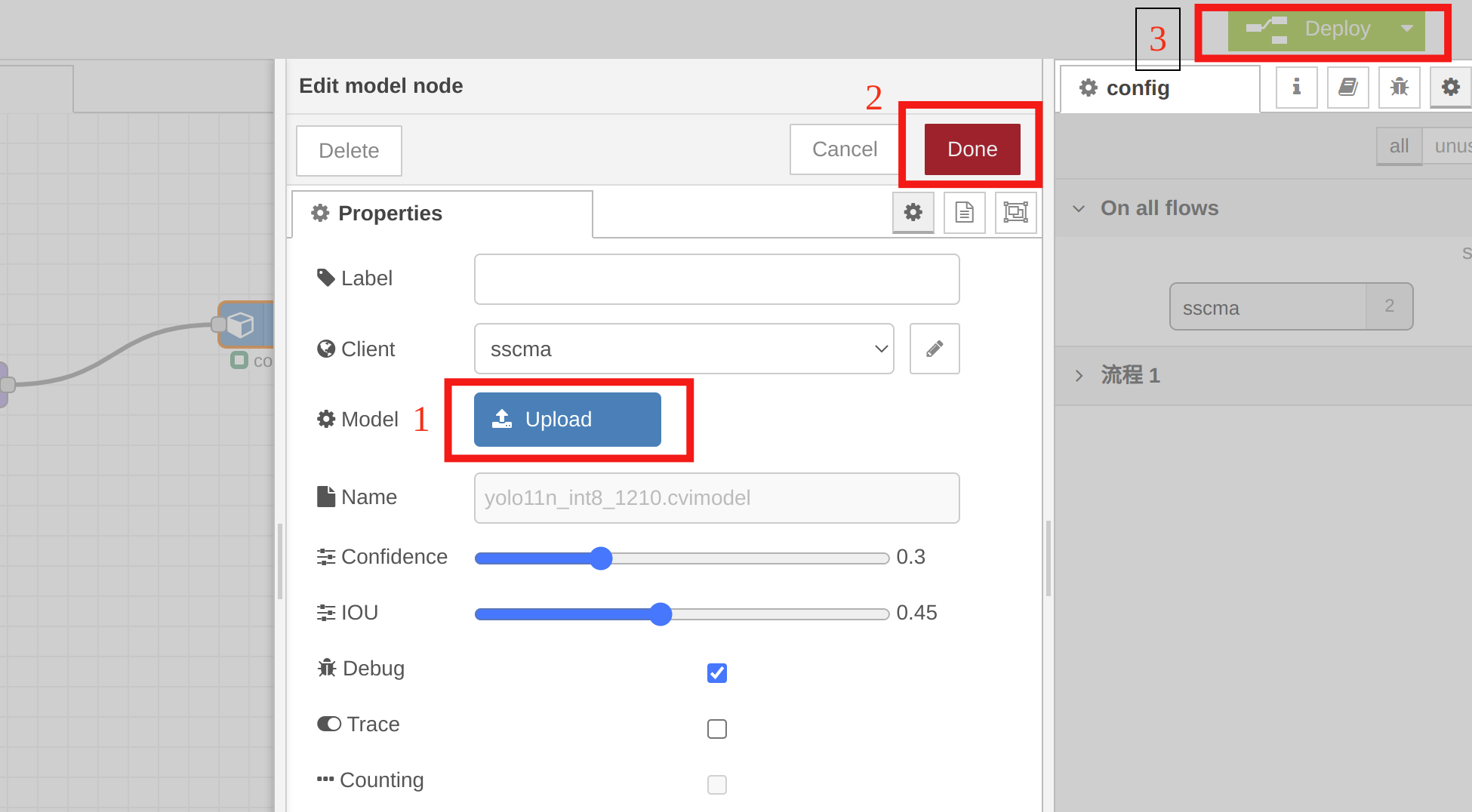
Puedes usar Node-RED en reCamera para visualización y verificar rápidamente el yolo11n_1684x_int8_sym.cvimodel convertido. Simplemente configura algunos nodos, como se muestra en el video de ejemplo a continuación:
Necesitas seleccionar el yolo11n_1684x_int8_sym.cvimodel en el nodo model para verificación rápida. Haz doble clic en el nodo del modelo, haz clic en "Upload" para importar el modelo cuantizado, luego haz clic en "Done", y finalmente haz clic en "Deploy".
Podemos ver los resultados de inferencia del modelo cuantizado INT8 en el nodo preview. El cvimodel obtenido a través de métodos correctos de conversión y cuantización sigue siendo confiable:
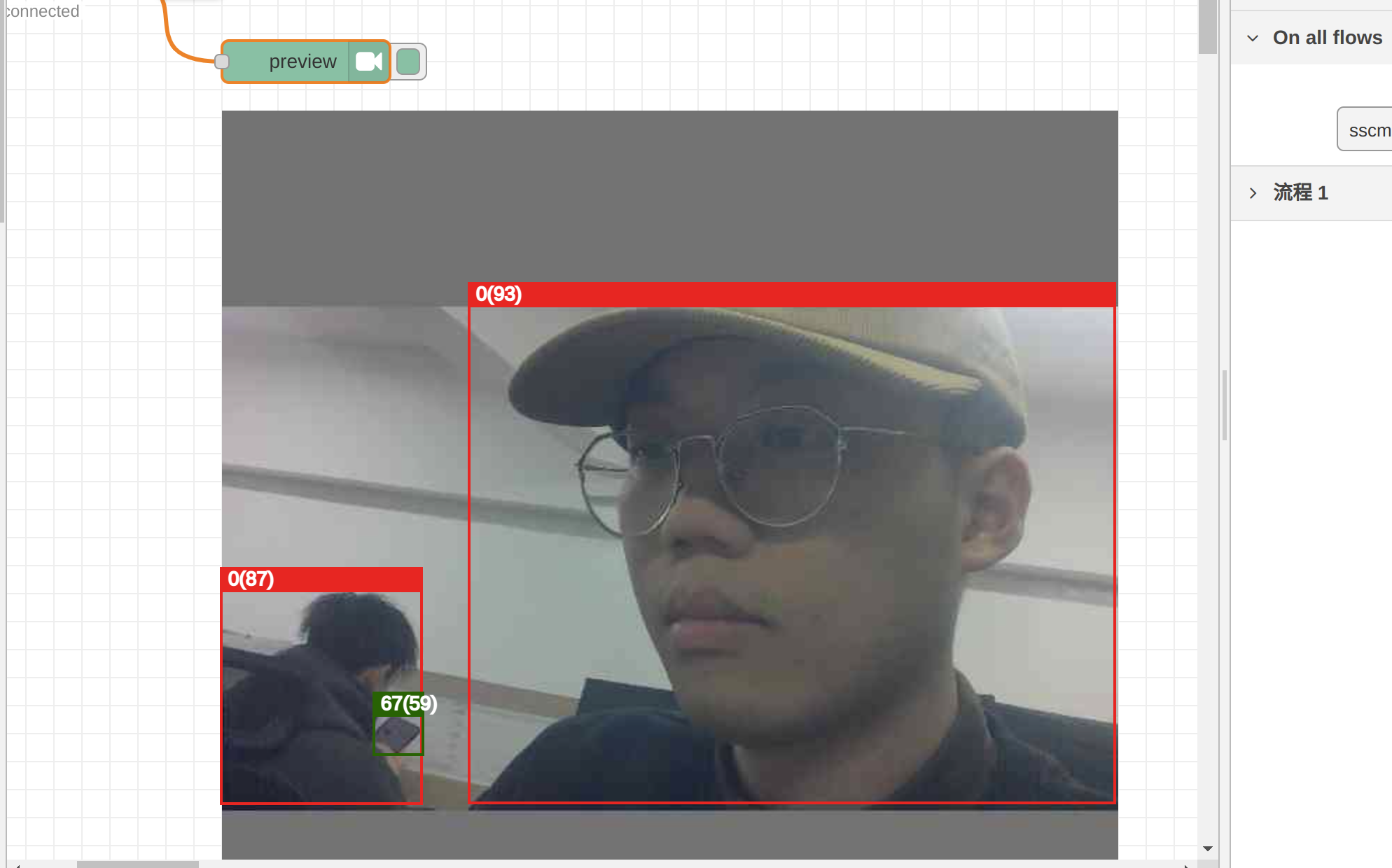
Actualmente, Node-RED de reCamera solo soporta pruebas de vista previa para un número limitado de modelos. En el futuro, adaptaremos más modelos. Si importas un modelo personalizado a Node-RED o no estableces el tensor de salida especificado como se muestra en nuestro ejemplo, el backend de Node-RED no soporta pruebas de vista previa, incluso si tu cvimodel es correcto.
Lanzaremos tutoriales sobre preprocesamiento y postprocesamiento para varios modelos, para que puedas escribir tu propio código para inferir tu cvimodel personalizado.
Cuantización de Precisión Mixta
Cuando la precisión de ciertas capas en un modelo se ve fácilmente afectada por la cuantización, pero aún necesitamos una velocidad de inferencia más rápida, una cuantización de precisión única puede ya no ser adecuada. En tales casos, la cuantización de precisión mixta puede abordar mejor la situación. Para las capas que son más sensibles a la cuantización, podemos elegir cuantización F16/BF16, mientras que para las capas con pérdida mínima de precisión, podemos usar INT8.
A continuación, usaremos yolov5s.onnx como ejemplo para demostrar cómo convertir y cuantizar rápidamente el modelo en un cvimodel de precisión mixta. Antes de leer esta sección, asegúrate de haber revisado las secciones anteriores del artículo, ya que las operaciones en esta sección se basan en el contenido cubierto anteriormente.
Aquí está el enlace de descarga para yolov5s.onnx. Puedes hacer clic en el enlace para descargar el modelo y copiarlo a tu espacio de trabajo para uso posterior.
Descargar el modelo: Descargar yolov5s.onnx
Después de descargar el modelo, por favor colócalo en tu workspace para los siguientes pasos.
mkdir model_yolov5s && cd model_yolov5s
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir workspace && cd workspace
El primer paso sigue siendo convertir el modelo al archivo .mlir. Debido a que la pérdida de precisión en la cabeza de YOLO es mínima cuando se usa cuantización de precisión mixta, a diferencia del enfoque anterior, elegiremos el nombre de salida final al final en lugar de las salidas antes de la cabeza en el parámetro --output_names. Visualiza el ONNx en Netron:
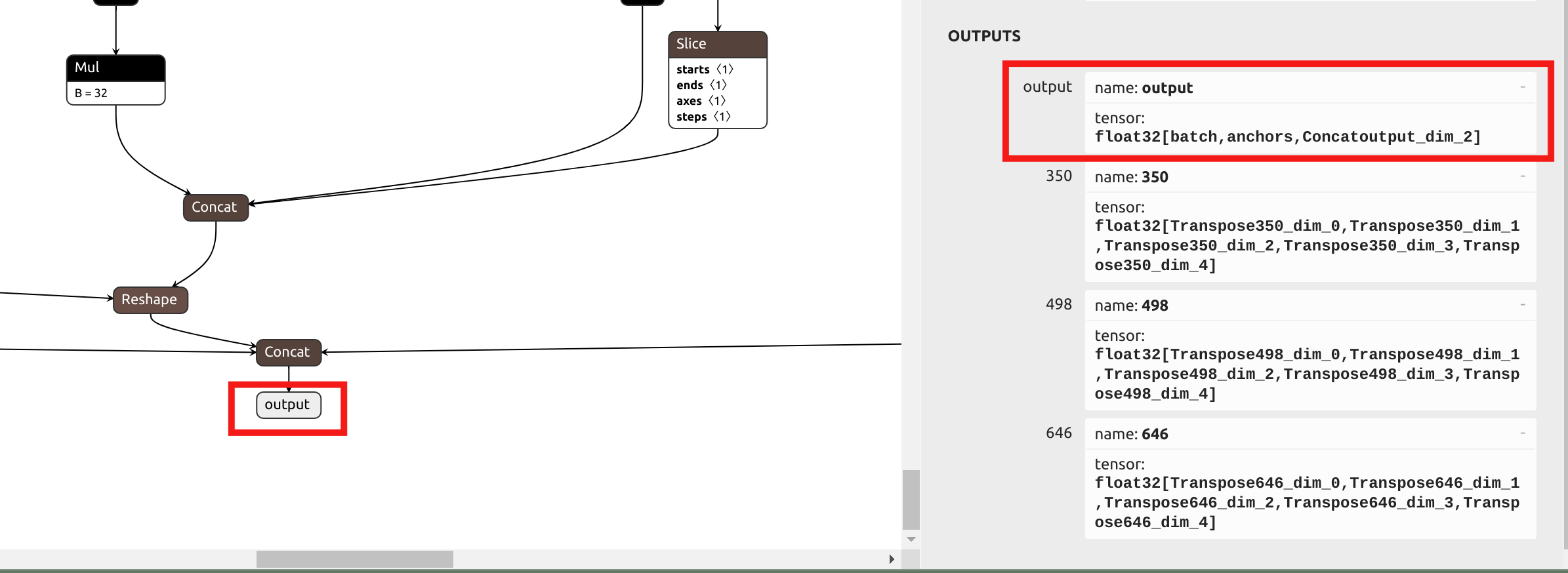
Dado que los parámetros de normalización de yolov5 son los mismos que los de yolo11, podemos obtener el siguiente comando para model_transform:
model_transform \
--model_name yolov5s \
--model_def yolov5s.onnx \
--input_shapes [[1,3,640,640]] \
--mean 0.0,0.0,0.0 \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names output \
--test_input ../image/dog.jpg \
--test_result yolov5s_top_outputs.npz \
--mlir yolov5s.mlir
Luego también necesitamos generar la tabla de calibración, y este paso es el mismo que en la sección anterior:
run_calibration \
yolov5s.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolov5s_calib_table
A diferencia de la sección donde convertimos el modelo yolo11 cuantizado simétrico int8, antes de ejecutar model_deploy, necesitamos generar una tabla de cuantización de precisión mixta. El comando de referencia es el siguiente:
run_qtable \
yolov5s.mlir \
--dataset ../COCO2017 \
--calibration_table yolov5s_calib_table \
--processor cv181x \
--min_layer_cos 0.99 \
--expected_cos 0.999 \
-o yolov5s_qtable
La descripción de parámetros para run_qtable se muestra en la tabla a continuación:
| Parámetro | ¿Requerido? | Descripción |
|---|---|---|
| N/A | Sí | Especificar el archivo MLIR |
| dataset | No | Especificar el directorio de muestras de entrada, que contiene archivos de imágenes, npz o npy |
| data_list | No | Especificar la lista de muestras; se debe seleccionar dataset o data_list |
| calibration_table | Sí | Tabla de calibración de entrada |
| processor | Sí | Depende de la plataforma que se esté utilizando. La versión 2024 de reCamera selecciona "cv181x" como parámetro. |
| fp_type | No | Especificar el tipo de precisión de punto flotante para precisión mixta, soporta auto, F16, F32, BF16; por defecto es auto |
| input_num | No | Especificar el número de muestras de entrada; por defecto es 10 |
| expected_cos | No | Especificar la similitud coseno mínima esperada para la capa de salida final de la red; por defecto es 0.99 |
| min_layer_cos | No | Especificar la similitud coseno mínima para la salida de cada capa; valores por debajo de este umbral usarán computación de punto flotante; por defecto es 0.99 |
| debug_cmd | No | Especificar cadena de comando de depuración para uso de desarrollo; por defecto está vacío |
| global_compare_layers | No | Especificar las capas a reemplazar para la comparación de salida final, ej., 'layer1,layer2' o 'layer1:0.3,layer2:0.7' |
| loss_table | No | Especificar el nombre del archivo para guardar los valores de pérdida de todas las capas cuantizadas a tipos de punto flotante; por defecto es full_loss_table.txt |
Después de que la capa predecesora de cada capa se convierte al modo de punto flotante correspondiente basado en su cos, se verifica el valor cos calculado para esa capa. Si el cos sigue siendo menor que el parámetro min_layer_cos, la capa actual y sus capas sucesoras directas se configurarán para usar operaciones de punto flotante.
run_qtable recalcula el cos de la salida de toda la red después de configurar cada par de capas adyacentes para usar computación de punto flotante. Si el cos excede el parámetro expected_cos especificado, la búsqueda termina. Por lo tanto, establecer un expected_cos más grande resultará en que se intenten más capas para operaciones de punto flotante.
Finalmente, ejecuta model_deploy para obtener el cvimodel de precisión mixta:
model_deploy \
--mlir yolov5s.mlir \
--quantize INT8 \
--quantize_table yolov5s_qtable \
--calibration_table yolov5s_calib_table \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--processor cv181x \
--model yolov5s_mix-precision.cvimodel
Después de obtener yolov5s_mix-precision.cvimodel, podemos usar model_tool para ver información detallada sobre el modelo:
model_tool --info yolov5s_mix-precision.cvimodel
La información clave como TensorMap y WeightMap se imprimirá en el terminal:
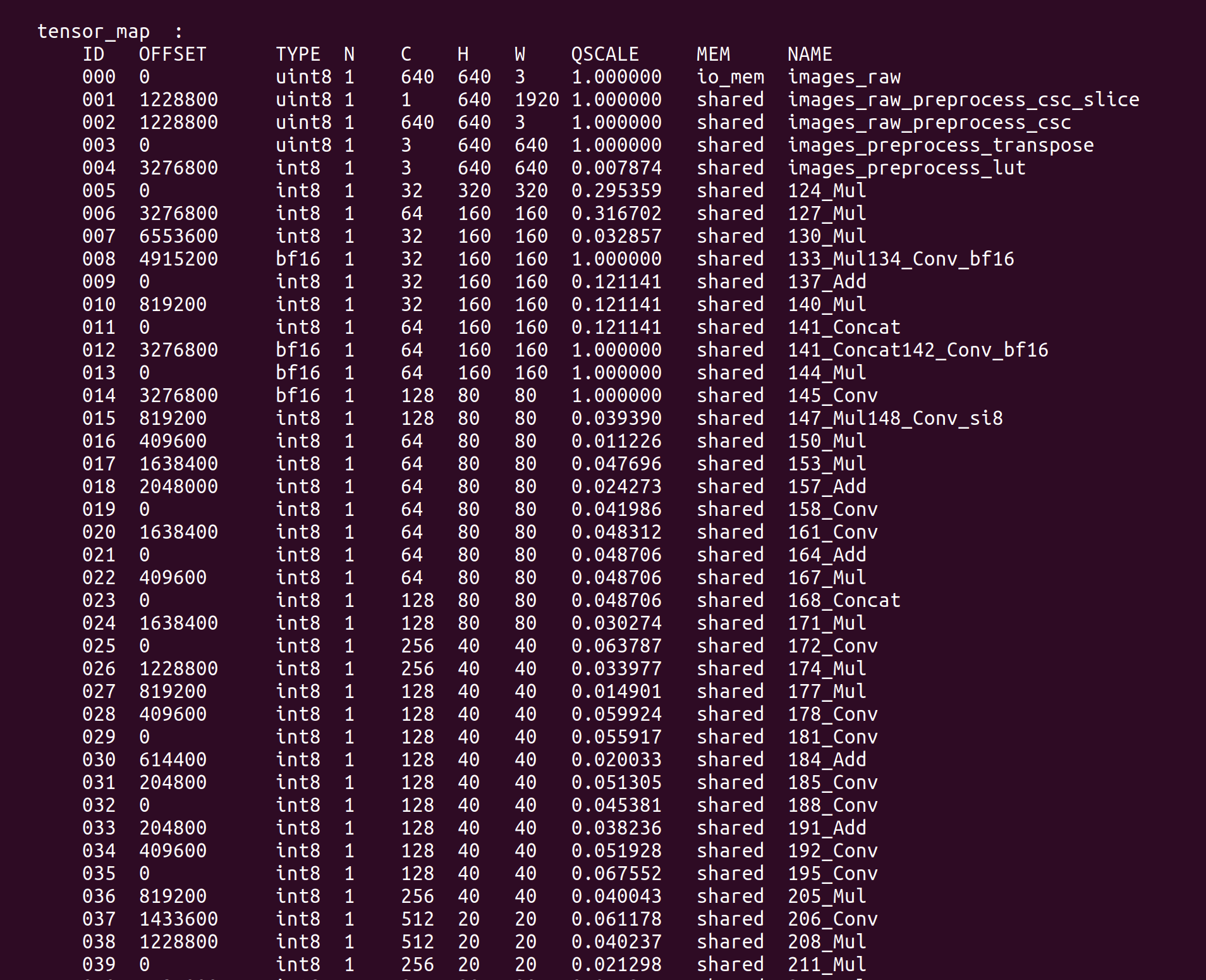
Podemos ejecutar un ejemplo en reCamera para verificar el modelo YOLOv5 cuantizado de precisión mixta. Descarga el ejemplo de prueba compilado:
git clone https://github.com/jjjadand/yolov5_Test_reCamera.git
Copia los ejemplos compilados y yolov5s_mix-precision.cvimodel usando software como FileZilla a reCamera. (Puedes revisar Primeros pasos con reCamera)
Después de que la copia esté completa, ejecuta el comando en la terminal de recamera:
cp /path/to/yolov5s_mix-precision.cvimodel /path/to/yolov5_Test_reCamera/solutions/sscma-model/build/
cd yolov5_Test_reCamera/solutions/sscma-model/build/
sudo ./sscma-model yolov5s_mix-precision.cvimodel Dog.jpg Out.jpg
Vista previa de Out.jog, los resultados de inferencia del modelo yolov5 cuantizado con mixed-precision son los siguientes:

Recursos
Soporte Técnico y Discusión de Productos
¡Gracias por elegir nuestros productos! Estamos aquí para brindarle diferentes tipos de soporte para asegurar que su experiencia con nuestros productos sea lo más fluida posible. Ofrecemos varios canales de comunicación para satisfacer diferentes preferencias y necesidades.